语音识别方法及装置与流程
本申请涉及语音识别技术领域,尤其涉及一种语音识别方法及装置。
背景技术:
随着语音识别技术的发展,出现了可以将音频转换成文字的语音识别引擎。其中,语音合成引擎包括在线语音识别引擎和离线语音识别引擎。
现有技术中,为了在不同网络状况下都能顺利进行语音识别,出现了综合使用在线语音识别引擎和离线语音识别引擎进行语音识别的方法。具体为:在用户输入音频信息后,客户端将用户输入的音频信息同时发送至离线语音识别引擎和在线语音识别引擎。在预定时间内,若客户端接收到在线语音识别引擎返回的文字信息,则使用在线语音识别引擎进行语音识别;否则,使用离线语音识别引擎进行语音识别。
上述语音识别方法中,在用户输入音频信息后,需要等待预定时间,才能确定所使用的语音合成引擎,导致语音识别的实时性较差。
技术实现要素:
本申请的多个方面提供一种语音识别方法及装置,用以提高语音识别的实时性。
本申请实施例提供一种语音识别方法,包括:
响应于用户在语音识别客户端的音频输入界面上输入音频信息的操作,获取预先根据所述语音识别客户端与在线语音识别引擎之间的网络状况确定的语音识别引擎指示信息;
发送所述音频信息至所述语音识别引擎指示信息所指示的语音识别引擎,以通过所述语音识别引擎指示信息所指示的语音识别引擎识别所述音频信息。
可选地,在响应于用户在语音识别客户端的音频输入界面上输入音频信息的操作之前,所述方法还包括:
响应于进入所述音频输入界面或者开启所述语音识别客户端的操作,侦测所述语音识别客户端与所述在线语音识别引擎之间的网络状况;
根据侦测到所述语音识别客户端与所述在线语音识别引擎之间的网络状况,确定所述语音识别引擎指示信息。
可选地,在响应于进入所述音频输入界面或者开启所述语音识别客户端的操作之前,所述方法还包括:
响应于所述用户的侦测配置请求,展示网络设置界面,以供所述用户配置侦测周期以及侦测网址;
响应于所述用户在所述网络设置界面上的设置操作,获取所述用户配置的所述侦测周期以及所述侦测网址。
可选地,响应于进入所述音频输入界面或者开启所述语音识别客户端的操作,侦测所述语音识别客户端与所述在线语音识别引擎之间的网络状况,包括:
响应于进入所述音频输入界面或者开启所述语音识别客户端的操作,按照所述侦测周期,周期性地向所述侦测网址对应的所述在线语音识别引擎发送侦测请求;
根据所述在线语音识别引擎对所述侦测请求的响应情况,确定所述语音识别客户端与所述在线语音识别引擎之间的网络状况。
可选地,根据侦测到所述语音识别客户端与所述在线语音识别引擎之间的网络状况,确定所述语音识别引擎指示信息,包括:
若所述语音识别客户端与所述在线语音识别引擎之间的网络状况满足设定的网络要求,确定指示所述在线语音识别引擎的语音识别引擎指示信息;
若所述语音识别客户端与所述在线语音识别引擎之间的网络状况不满足设定的网络要求,确定指示离线语音识别引擎的语音识别引擎指示信息。
可选地,在根据侦测到所述语音识别客户端与所述在线语音识别引擎之间的网络状况,确定所述语音识别引擎指示信息之后,所述方法还包括:
保存所述语音识别引擎指示信息至本地内存;
所述响应于用户在语音识别客户端提供的音频输入界面上输入音频信息的操作,获取预先根据所述语音识别客户端与在线语音识别引擎之间的网络状况确定的语音识别引擎指示信息,包括:
响应于所述用户在所述音频输入界面上输入音频信息的操作,从所述本地内存,获取最近一次保存的所述语音识别引擎指示信息。
可选地,所述方法还包括:
在所述语音识别引擎指示信息所指示的语音识别引擎识别所述音频信息的过程中,侦测所述语音识别客户端与在线语音识别引擎之间的网络状况;
当所述语音识别客户端与在线语音识别引擎之间的网络状况发生变化时,更新所述语音识别引擎指示信息。
可选地,所述方法还包括:
响应于退出所述音频输入界面或关闭所述语音识别客户端的操作,停止侦测所述语音识别客户端与在线语音识别引擎之间的网络状况。
本申请实施例还提供一种语音识别装置,包括:
第一获取模块,用于响应于用户在语音识别客户端的音频输入界面上输入音频信息的操作,获取预先根据所述语音识别客户端与在线语音识别引擎之间的网络状况确定的语音识别引擎指示信息;
发送模块,用于发送所述音频信息至所述语音识别引擎指示信息所指示的语音识别引擎,以通过所述语音识别引擎指示信息所指示的语音识别引擎识别所述音频信息。
可选地,所述装置还包括:
侦测模块,用于响应于进入所述音频输入界面或者开启所述语音识别客户端的操作,侦测所述语音识别客户端与所述在线语音识别引擎之间的网络状况;
确定模块,用于根据侦测到所述语音识别客户端与所述在线语音识别引擎之间的网络状况,确定所述语音识别引擎指示信息。
在本申请实施例中,在用户执行输入音频信息的操作之前,预先根据网络状况确定语音识别引擎指示信息;进而在用户执行输入音频信息的操作时,可以立即获取到语音识别引擎指示信息,并确定可用的语音识别引擎;进一步可以在用户输入音频信息之后,立即通过确定的语音识别引擎进行语音识别,从而提高了语音识别的实时性,减少时间的浪费。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1为本申请一实施例提供的语音识别方法的流程示意图;
图2为本申请又一实施例提供的语音识别方法的流程示意图;
图3为本申请又一实施例提供的语音识别装置的模块结构图;
图4为本申请又一实施例提供的语音识别装置的模块结构图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请具体实施例及相应的附图对本申请技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
以下结合附图,详细说明本申请各实施例提供的技术方案。
图1为本申请一实施例提供的语音识别方法的流程示意图。如图1所示,该方法包括以下步骤:
s101:响应于用户在语音识别客户端的音频输入界面上输入音频信息的操作,获取预先根据语音识别客户端与在线语音识别引擎之间的网络状况确定的语音识别引擎指示信息。
s102:发送音频信息至语音识别引擎指示信息所指示的语音识别引擎,以通过语音识别引擎指示信息所指示的语音识别引擎识别音频信息。
当用户有音频识别的需求时,可以将待识别的音频信息输入至语音识别客户端,再由语音识别客户端将接收到的音频信息发送至语音识别引擎进行语音识别。
对于语音识别客户端来说,一般会提供一音频输入界面,用户可以在音频输入界面上执行输入音频信息的操作。
可选地,在音频输入界面上可以设置一音频输入控件,用户可以通过触发音频输入控件,执行音频信息的输入。例如,音频输入控件可以为麦克风图标控件,用户可以通过触控麦克风图标控件,输入音频信息。
接着,为了在用户输入音频信息后,能够立即确定语音识别引擎,本实施例预先确定出语音识别引擎指示信息,进而可响应于用户在音频输入界面上输入音频信息的操作,获取预先确定的语音识别引擎指示信息,从而基于该语音识别引擎指示信息确定用于对用户输入的音频信息进行语音识别的语音识别引擎。其中,语音识别引擎指示信息是预先根据语音识别客户端与在线语音识别引擎之间的网络状况确定的。为方便描述,在下述实施例中语音识别客户端与在线语音识别引擎之间的网络状况简称为网络状况。
可选地,语音识别引擎指示信息包括指示在线语音识别引擎的指示信息以及指示离线语音识别引擎的指示信息。
可选地,若网络状况可以供在线语音识别引擎进行语音识别,则确定指示在线语音识别引擎的指示信息;若网络状况不可以供在线语音识别引擎进行语音识别,则确定指示离线语音识别引擎的指示信息。接着,可以根据语音识别引擎指示信息确定在线语音识别引擎或者离线语音识别引擎。
然后,语音识别客户端可以发送音频信息至语音识别引擎指示信息所指示的语音识别引擎。语音识别引擎在接收到音频信息后,对音频信息进行识别。
语音识别引擎完成语音识别后,可以将识别结果返回至语音识别客户端,由语音识别客户端展示给用户。
本实施例中,通过预先根据网络状况确定语音识别引擎指示信息,进而在用户执行输入音频信息的操作时,可以立即获取到语音识别引擎指示信息,并确定可用的语音识别引擎;进一步地,在用户输入音频信息之后,可立即通过确定的语音识别引擎进行语音识别,从而提高了语音识别的实时性。
在上述实施例或下述实施例中,在响应于用户在语音识别客户端的音频输入界面上输入音频信息的操作之前,可预先通过网络状况确定语音识别引擎指示信息。
可选地,可以响应于进入音频输入界面或者开启语音识别客户端的操作,侦测语音识别客户端与在线语音识别引擎之间的网络状况,并根据侦测到语音识别客户端与在线语音识别引擎之间的网络状况,确定语音识别引擎指示信息。
当用户有语音识别的需求时,首先需要开启语音识别客户端。在开启语音识别客户端后,语音识别客户端展示的页面可能是音频输入界面,也可能不是音频输入界面。若开启语音识别客户端时,语音识别客户端展示的页面不是音频输入界面,还需要再进入音频输入界面。随后,在音频输入界面上,通过触发音频输入控件输入音频信息。
基于上述的分析,当用户进入音频输入界面或者开启语音识别客户端时,意味着用户将要执行音频信息的输入操作。此时,可以响应于进入音频输入界面或者开启语音识别客户端的操作,侦测语音识别客户端与在线语音识别引擎之间的网络状况。进而根据侦测到语音识别客户端与在线语音识别引擎之间的网络状况,确定语音识别引擎指示信息。待用户输入音频信息时,可以直接获取已确定的语音识别引擎指示信息,据此及时地确定语音识别所需的语音识别引擎。
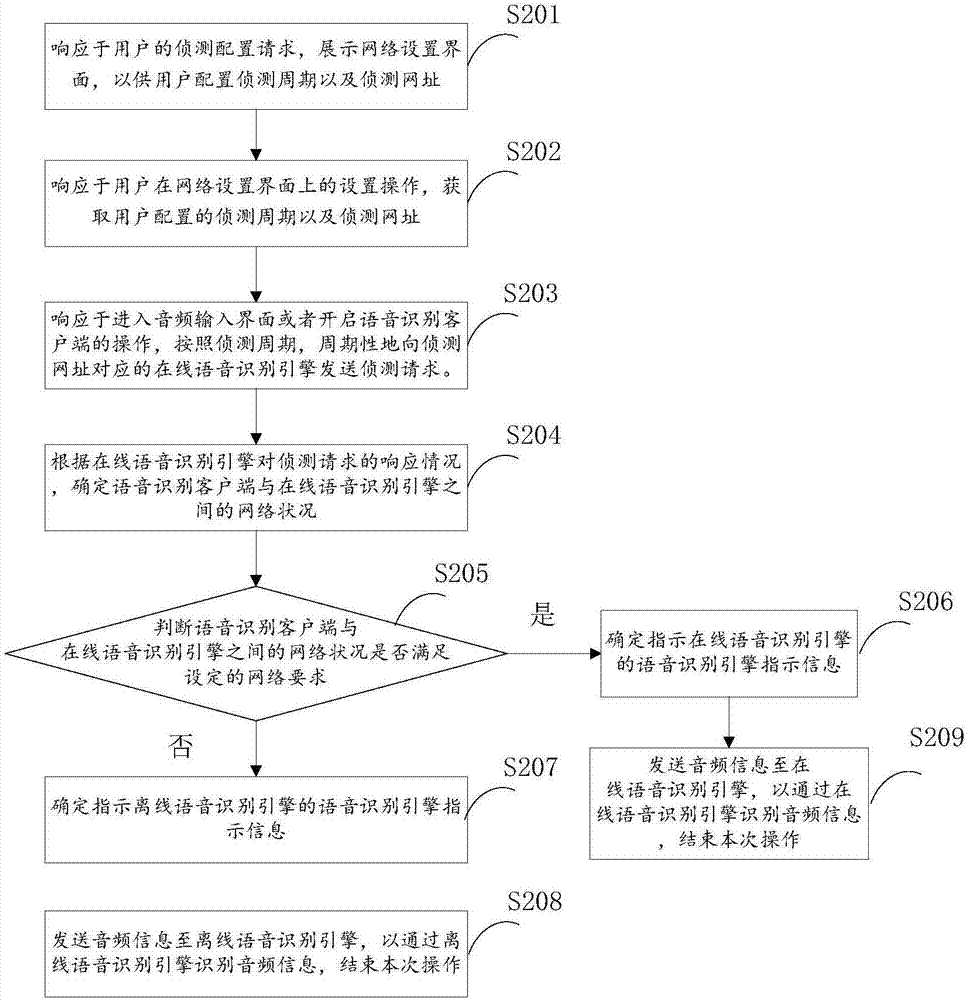
图2为本申请又一实施例提供的语音识别方法的流程示意图。如图2所示,包括以下步骤。
s201:响应于用户的侦测配置请求,展示网络设置界面,以供用户配置侦测周期以及侦测网址。
s202:响应于用户在网络设置界面上的设置操作,获取用户配置的侦测周期以及侦测网址。
s203:响应于进入音频输入界面或者开启语音识别客户端的操作,按照侦测周期,周期性地向侦测网址对应的在线语音识别引擎发送侦测请求。
s204:根据在线语音识别引擎对侦测请求的响应情况,确定语音识别客户端与在线语音识别引擎之间的网络状况。
s205:判断语音识别客户端与在线语音识别引擎之间的网络状况是否满足设定的网络要求。若是,跳转到步骤s206;若否,跳转到步骤s207。
s206:确定指示在线语音识别引擎的语音识别引擎指示信息,并跳转到步骤s209。
s207:确定指示离线语音识别引擎的语音识别引擎指示信息,继续执行步骤s208。
s208:发送音频信息至指示离线语音识别引擎的语音识别引擎指示信息所指示的离线语音识别引擎,以通过所述离线语音识别引擎识别音频信息,结束本次操作。
s209:发送音频信息至指示在线语音识别引擎的语音识别引擎指示信息所指示的在线语音识别引擎,以通过所述在线语音识别引擎识别音频信息,结束本次操作。
由于侦测网络状况的操作需要一定的时长,为了在用户输入音频信息时,能够立即获取语音识别引擎指示信息,可选地,可以响应于进入音频输入界面或者开启所述语音识别客户端的操作,即开始侦测网络状况。基于此,可以在进入音频输入界面或者开启语音识别客户端之前,预先配置好侦测网络状况所需的参数。可选地,侦测网络状况所需的参数可包括但不限于:侦测周期和侦测网址。
基于此,在用户进入音频输入界面或者开启语音识别客户端之前,可预先设置侦测周期与侦测网址。可选地,用户可以向语音识别客户端发送侦测配置请求;语音识别客户端可以响应于用户的侦测配置请求,向用户展示网络设置界面,以供用户配置侦测周期以及侦测网址(即步骤s201)。
其中,侦测网址为语音识别客户端发送侦测请求的网址。本实施例中的侦测网址可包括ip地址和/或域名地址,例如域名地址可以是www.baidu.com,ip地址可以是61.135.169.121等。为了成功侦测语音识别客户端与在线语音识别引擎之间的网络状况,侦测网址应为在线语音识别引擎所在的ip地址和/或域名地址,或者在语音识别客户端与在线语音识别引擎的通讯链路上的中转服务器的ip地址和/或域名地址。
侦测周期为语音识别客户端发送侦测请求的周期,例如1s、2s等。其中,侦测请求为语音识别客户端向侦测网址对应的服务器发送的请求信号。
可选地,在网络设置界面上可以预先提供侦测周期和侦测网址的选项,或者提供侦测周期和侦测网址的输入框,以供用户选择或输入侦测周期和侦测网址。
在用户在网络设置界面上设置完侦测周期和侦测网址后,语音识别客户端可响应于用户在网络设置界面上的设置操作,获取用户配置的侦测周期以及侦测网址(即步骤s202)。
可选地,在用户在网络设置界面上设置完成后,可进行提交操作或保存操作,例如触发提交控件或保存控件。语音识别客户端可响应于用户在网络设置界面上的提交操作或保存操作,获取用户设置的侦测周期以及侦测网址。
用户不必每次在进入音频输入界面或开启语音识别客户端前,都设置一次侦测周期以及侦测网址。可选地,在获取到用户设置的侦测周期以及侦测网址后,可将侦测周期以及侦测网址保存在本地内存,在用户下次有语音识别的需求时,可不必发送侦测配置请求,语音识别客户端可直接从本地内存中获取早前设置好的侦测网址和侦测周期。
在获取到侦测网址和侦测周期后,语音识别客户端可侦测网络状况。可选地,响应于进入音频输入界面或者开启语音识别客户端的操作,按照侦测周期,周期性地向侦测网址对应的在线语音识别引擎发送侦测请求(即步骤s203)。接着,根据在线语音识别引擎对侦测请求的响应情况,确定语音识别客户端与在线语音识别引擎之间的网络状况(即步骤s204)。
可选地,为了尽快获取根据网络状况确定的语音识别引擎指示信息,可以响应于用户进入音频输入界面或者开启语音识别客户端的操作,即刻向侦测网址对应的在线语音识别引擎发送侦测请求,随后,按照侦测周期发送侦测请求。
可选地,本实施例可使用超文本传输协议(hypertexttransferprotocol,简称http)侦测网络状况。
http协议采用请求/响应模型。语音识别客户端向侦测网址对应的在线语音识别引擎发送一个请求报文,在线语音识别引擎回复一个响应本文。
例如,在浏览器地址栏键入侦测网址url,按下回车键后,浏览器会与侦测网址url对应的在线语音识别引擎建立连接。接着,浏览器发送读取文件的http请求,即侦测请求,至在线语音搜索引擎;在线语音识别引擎对浏览器的http请求作出响应,并把对应的html响应报文发送给浏览器,进而浏览器可显示接收到的html响应报文。
根据html响应报文的返回时间和内容,在线语音识别引擎对http请求的响应情况,包括以下三种情况:
第一种响应情况:在指定时间内没有返回html报文。可能浏览器并未与侦测网址url对应的在线语音识别引擎成功建立连接,造成没有html响应报文;或者由于网络堵塞造成html响应报文的返回时间超过指定时间。
第二种响应情况:html响应报文的返回时间未超过指定时间,但是html响应报文的内容不是表示请求正常的httpresponse200ok。例如,html响应报文的内容为403forbidden、notfound。
第三种响应情况:html响应报文的返回时间未超过指定时间,且html响应报文的内容为表示请求正常的httpresponse200ok。
在线语音识别引擎对侦测请求的响应情况不同,确定的网络状况不同。基于此,可以将指定时间和httpresponse200ok的html响应报文内容作为设定的网络要求,进而判断语音识别客户端与在线语音识别引擎之间的网络状况是否满足设定的网络要求(即步骤s205)。
显然,对于第一种响应情况和第二种响应情况来说,所确定的网络状况不满足设定的网络要求;对于第三种响应情况来说,所确定的网络状况满足设定的网络要求。
可选地,若语音识别客户端与在线语音识别引擎之间的网络状况满足设定的网络要求,意味着根据此时的网络状况可以通过在线语音识别引擎进行语音识别,则确定指示在线语音识别引擎的语音识别引擎指示信息(即步骤s206)。继而,发送音频信息至指示在线语音识别引擎的语音识别引擎指示信息所指示的在线语音识别引擎,以通过所述在线语音识别引擎识别音频信息,结束本次操作(即步骤s209)。
若语音识别客户端与在线语音识别引擎之间的网络状况不满足设定的网络要求,意味着根据此时的网络状况不可以通过在线语音识别引擎进行语音识别,则确定指示离线语音识别引擎的语音识别引擎指示信息(即步骤s207)。继而,发送音频信息至指示离线语音识别引擎的语音识别引擎指示信息所指示的离线语音识别引擎,以通过所述离线语音识别引擎识别音频信息,结束本次操作(即步骤s208)。
可选地,在确定语音识别引擎指示信息之后,发送音频信息至对应的语音识别引擎之前,还包括开启麦克风装置;并通过麦克风装置接收用户在音频输入界面上输入的音频信息。然后再将用户输入的音频信息发送至对应的语音识别引擎。
可选地,语音识别引擎可将接收到的音频信息分成多个音频片段。继而,以音频片段为单位,每识别完一个音频片段后,就将该音频片段的识别结果,如一段文字,返回至语音识别客户端。接着再执行下一个音频片段的识别,直到识别完该音频信息分成的所有音频片段。基于此,语音识别客户端可以向用户展示一段一段的识别结果。
在确定语音识别引擎指示信息之后,为了方便语音识别客户端获取语音识别引擎指示信息,可选地,可以在确定语音识别引擎指示信息之后,保存语音识别引擎指示信息至本地内存。
在实际应用中,语音识别引擎指示信息可以具体实现为一语音识别引擎变量,例如menginetype。若网络状况满足设定的网络要求,可将变量menginetype赋值为cloud,用于指示在线语音识别引擎;若网络状况不满足设定的网络要求,可将变量menginetype赋值为local,用于指示离线语音识别引擎。
基于此,响应于用户在语音识别客户端提供的音频输入界面上输入音频信息的操作,获取预先根据语音识别客户端与在线语音识别引擎之间的网络状况确定的语音识别引擎指示信息,包括:响应于用户在音频输入界面上输入音频信息的操作,从本地内存,获取最近一次保存的语音识别引擎指示信息。
其中,最近一次保存的语音识别引擎指示信息是根据最近时刻的网络状况确定的,最近时刻的网络状况与进行语音识别时的网络状况在很大概率上相同,因此有利于成功通过确定的语音识别引擎进行语音识别。可选地,语音识别引擎指示信息可以具体实现为最近一次被赋值的语音识别引擎变量,如cloud或者local。
在一些情况下,用户会一次性将音频信息输入至语音识别客户端,之后,在音频输入界面上不再输入音频信息。在另一些情况下,用户需要多次输入音频信息,例如在聊天场景中,用户会多次输入聊天语音。这种情况下,若在用户输入音频信息后,网络状况发生了改变;在用户下次输入音频信息时,获取的仍是上一次输入音频信息时所获取的语音识别引擎指示信息是不合适的。
基于上述的分析,在语音识别引擎指示信息所指示的语音识别引擎识别音频信息的过程中,可继续侦测语音识别客户端与在线语音识别引擎之间的网络状况。当语音识别客户端与在线语音识别引擎之间的网络状况发生变化时,更新语音识别引擎指示信息。那么,在用户在下一次输入音频信息时,可获取更新后的语音识别引擎指示信息。
其中,网络状况发生变化的情况包括网络状况由满足设定的网络要求变化为不满足设定的网络要求,或者网络状况由不满足设定的网络要求变化为满足设定的网络要求。
基于此,更新语音识别引擎指示信息包括将当前的指示在线语音识别引擎的语音识别引擎指示信息更新为指示离线语音识别引擎的语音识别引擎指示信息,例如,将“cloud”更新为“local”。或者,将当前的指示离线语音识别引擎的语音识别引擎指示信息更新为指示在线语音识别引擎的语音识别引擎指示信息,例如,将“local”更新为“cloud”。
在用户退出音频输入界面或关闭语音识别客户端时,意味着用户不再输入音频信息,可不必侦测网络状况。基于此,语音识别客户端可以响应于退出音频输入界面或关闭语音识别客户端的操作,停止侦测语音识别客户端与在线语音识别引擎之间的网络状况。
本申请实施例还提供一种语音识别装置300,如图3所示,包括第一获取模块301和发送模块302。
第一获取模块301,用于响应于用户在语音识别客户端的音频输入界面上输入音频信息的操作,获取预先根据所述语音识别客户端与在线语音识别引擎之间的网络状况确定的语音识别引擎指示信息。
发送模块302,用于发送所述音频信息至第一获取模块401获取的语音识别引擎指示信息所指示的语音识别引擎,以通过所述语音识别引擎指示信息所指示的语音识别引擎识别所述音频信息。
本实施例中,通过预先根据网络状况确定语音识别引擎指示信息,进而在用户执行输入音频信息的操作时,可以立即获取到语音识别引擎指示信息,并进一步确定可用的语音识别引擎;从而在用户输入音频信息之后,可立即通过确定的语音识别引擎进行语音识别,从而提高了语音识别的实时性。
可选地,如图4所示,语音识别装置300还包括侦测模块303和确定模块304。
侦测模块303,用于响应于进入所述音频输入界面或者开启所述语音识别客户端的操作,侦测所述语音识别客户端与所述在线语音识别引擎之间的网络状况。
确定模块304,用于根据侦测模块303侦测到的所述语音识别客户端与所述在线语音识别引擎之间的网络状况,确定所述语音识别引擎指示信息。
可选地,如图4所示,语音识别装置300还包括展示模块305和第二获取模块306。
展示模块305,具体用于在响应于进入所述音频输入界面或者开启所述语音识别客户端的操作前,响应于所述用户的侦测配置请求,展示网络设置界面,以供所述用户配置侦测周期以及侦测网址。
第二获取模块306,用于响应于所述用户在展示模块305展示的网络设置界面上的设置操作,获取所述用户配置的所述侦测周期以及所述侦测网址。
可选地,侦测模块303在响应于进入所述音频输入界面或者开启所述语音识别客户端的操作,侦测所述语音识别客户端与所述在线语音识别引擎之间的网络状况时,具体还用于:响应于进入所述音频输入界面或者开启所述语音识别客户端的操作,按照所述侦测周期,周期性地向所述侦测网址对应的所述在线语音识别引擎发送侦测请求。
基于此,确定模块304还用于根据所述在线语音识别引擎对所述侦测请求的响应情况,确定所述语音识别客户端与所述在线语音识别引擎之间的网络状况。
可选地,在确定模块304根据侦测到所述语音识别客户端与所述在线语音识别引擎之间的网络状况,确定所述语音识别引擎指示信息时,具体还用于:若所述语音识别客户端与所述在线语音识别引擎之间的网络状况满足设定的网络要求,确定指示所述在线语音识别引擎的语音识别引擎指示信息;若所述语音识别客户端与所述在线语音识别引擎之间的网络状况不满足设定的网络要求,确定指示离线语音识别引擎的语音识别引擎指示信息。
可选地,语音识别装置300还包括保存模块,用于在根据侦测到所述语音识别客户端与所述在线语音识别引擎之间的网络状况,确定所述语音识别引擎指示信息之后,保存所述语音识别引擎指示信息至本地内存。
基于此,第一获取模块301在响应于用户在语音识别客户端提供的音频输入界面上输入音频信息的操作,获取预先根据所述语音识别客户端与在线语音识别引擎之间的网络状况确定的语音识别引擎指示信息时,具体还用于:
响应于所述用户在所述音频输入界面上输入音频信息的操作,从所述本地内存,获取最近一次保存的所述语音识别引擎指示信息。
可选地,侦测模块303还用于:在所述语音识别引擎指示信息所指示的语音识别引擎识别所述音频信息的过程中,侦测所述语音识别客户端与在线语音识别引擎之间的网络状况。
基于此,保存模块还用于当所述语音识别客户端与在线语音识别引擎之间的网络状况发生变化时,更新所述语音识别引擎指示信息。
可选地,侦测模块303还用于:响应于退出所述音频输入界面或关闭所述语音识别客户端的操作,停止侦测所述语音识别客户端与在线语音识别引擎之间的网络状况。
以上仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!