一种基于GMM模型的语音激活检测方法与流程
本发明属于音频处理技术领域,尤其涉及voip通讯过程的音频处理技术。
背景技术:
随着voip及视频会议技术的不断发展创新,voip、视频会议已成为公司日常工作沟通和交流的重要手段,因此长时间的视频会议,语音会议司空见惯。在会议间隙不免可能会有长时间的资料整理,录入,调试等工作,这段时间没有人说话,但是由于与会者离voip终端较近,会导致对端听到键盘敲击声,纸张翻阅,或者其他的的较大的噪声,对对端造成干扰。为了避免上述尴尬的发生,本发明提出一种语音激活检测方法,其对语音通话中特定噪声检测并做相应处理,当有人重新说话时,则开启正常通话模式。
现有的语音激活检测方法,大多只能区别比较小的背景噪音与语音,对于键盘敲击等特定的较大的噪声,则无法判别。本发明提出基于对语音信号和特定噪声分别用gmm(gaussianmixturemodel,高斯混合模型)训练模型并用于检测区别语音信号与特定噪声的语音激活检测方法。
技术实现要素:
本发明的目的在于提供一种基于gmm模型的语音激活检测方法,为了实现在voip通话过程中在无人说话时对特定的噪声信号进行噪声处理,以减少通话间隙长时间无人说话时,一些噪声对对端与会者造成干扰。
为了实现上述发明目的,本发明一种基于gmm模型的语音激活检测方法,主要包括以下操作:数据训练:建立训练样本库和用em核心算法分别训练语音信号gmm模型、噪声信号gmm模型;数据测试:对实时通话进行检测,包括:分帧处理、特征提取、概率计算;数据判断:根据语音信号概率
优选的,该数据训练进一步包括:步骤1-a:收集语音信号样本集
优选的,该数据测试包括:步骤2-a:对测试信号
优选的,语音信号概率
优选的,语音帧信号集
优选的,语音特征集
优选的,数据训练还包括:提取训练特征操作,记
优选的,对
优选的,数据测试包括:步骤2-a:对测试信号
优选的,数据判断包括:根据
本发明提供的方案在会议通话过程中,有效监测通话信号为噪声信号还是语音信号,从而对无效噪声信号进行相应处理。
本发明提供的技术方案对特定噪声信号进行采集,提取特征集,并用gmm训练特定噪声模型参数集,从而用于对实时信号计算其为噪声信号的概率,对特定噪声信号的训练,能够有针对性的处理目标噪声信号,如敲击声,脚步声等。
本发明提供的技术方案对语音信号提取特征集,并用gmm训练语音模型参数集,用于对实时信号计算其为语音信号的概率,从而保证在无人说话的消噪状态到有人说话时恢复正常通话状态的准确切换。
本发明先用噪声信号及语音信号预先训练gmm模型参数,再对实时通话信号进行检测判别其为噪声信号还是语音信号时对提取的信号特征,根据预先训练的gmm模型参数分别计算其为噪声的概率还是语音的概率,计算复杂度低,保证实时性。
附图说明
图1为本发明具体实施例中gmm模型参数训练框图。
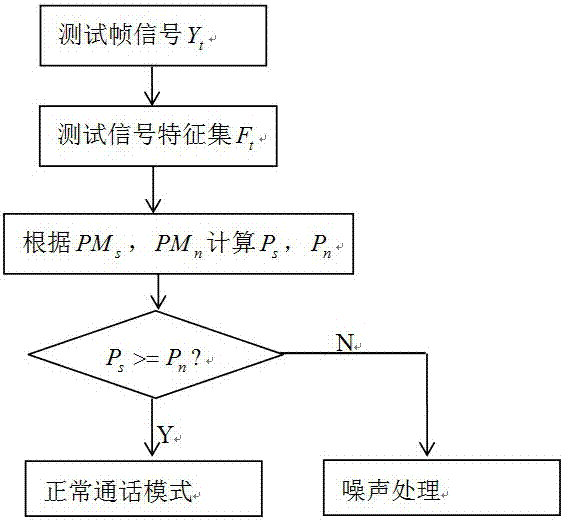
图2为本发明具体实施例中测试帧信号测试框图。
具体实施方式
发明的基本原理:本发明采用gmm对特定噪声和语音分别训练模型参数,用于实时检测voip通话信号为特定噪声信号还是语音信号,如果为噪声信号则做相应处理,为语音信号则为正常通话状态。用于gmm训练和检测的语音信号的特征集为语音基音频率特征与时域特征的结合。
为了更清楚地说明本发明实例的技术方案,下面将结合示例图对本发明的具体实施例进行详细的介绍,下面的描述仅仅是本发明的一些实施例。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些实施例获得本发明的其他实施方式。
本发明实施例提供了一种对voip终端采集信号判断其为噪声还是语音信号并做相应处理,从而实现在无人说话时,针对性的处理会议室如敲击声,键盘声,脚步声等噪声,避免与会者在对端无人说话时,受其噪声干扰。
本发明实施例提供的基于gmm对特定噪声训练模型的语音激活检测方法分为训练部分和检测部分。训练部分对特定噪声信号训练gmm噪声模型参数集,对语音信号训练gmm语音模型参数集。
图1为本发明具体实施例中gmm模型参数训练框图。如图1所示,本发明的训练部分主要内容包括:
步骤s110:收集语音信号样本集
步骤s120:对语音信号样本集
步骤s130:对语音帧信号
其中,
步骤s140:对
图2为本发明具体实施例中测试帧信号测试框图。由该图所示,本发明的测试部分主要内容包括:
步骤s210:对测试信号分帧处理,该测试帧信号记为
步骤s220:对
其中,
步骤s230:根据
步骤s240:根据
步骤s250:根据步骤s240判决结果,对判别为语音信号的帧信号保持正常通话模式,对判别为噪声信号的帧信号则进行噪声处理模式。
此时,训练过程具体实施方案如下所述:
首先是对于训练部分,主要包括建立训练样本库和用em核心算法分别训练语音信号gmm模型、噪声信号gmm模型。
步骤s310:收集语音信号样本库。通过网络下载及自己录制获得一定数量的语音信号音频文件,将这些文件用音频编辑软件进行整理,获得语音样本集
步骤s320:对语音信号样本集
步骤s330:对
3-a记
3-b对语音帧信号
步骤s340对信号特征集集合用em为核心算法的gmm模型训练,得到语音信号gmm模型参数集
4-a.对
4-b.对
4-c.对
4-d.对
步骤4-c,4-d中
本发明的测试部分主要为:
步骤s410:以10ms为一帧长对测试信号时域采样点进行读取,得到测试帧信号,记为
步骤s420:对
步骤s430:用多维高斯概率密度计算公式,根据
步骤s440:根据
步骤s450:根据步骤s440判决结果,对判别为语音信号的帧信号保持正常通话模式,对判别为噪声信号的帧信号则进行相应处理。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!