一种智能语音交互机器人的制作方法
本发明涉及机器人领域,尤其是语音交互机器人领域,具体为一种智能语音交互机器人。本发明通过对机器人的结构进行改进,提供一种全新的智能语音交互机器人,其采用类似熊猫外形的结构设计,并通过对内部结构进行改进,有效解决了现有语音交互机器人所存在的语音仅能单独输入或输出的问题,对于推动语音交互机器人的发展,推动机器人语音交互技术的进步,具有重要的意义。
背景技术:
语音作为人类所特有的能力,是人类之间交流及获取外界信息资源的重要的工具和渠道,对于人类文明的发展具有重要的意义。语音识别技术作为人机交互分支的重要组成,是人机交互的重要接口,对于人工智能的发展具有重要的实际意义。语音识别技术经过数十年的发展,已经取得了显著的进步,逐步开始从实验室慢慢走向市场。目前,针对特定说话人的语音识别系统已经有较高的识别精度,并被广泛应用于工业、家电、通信、汽车电子、医疗、家庭服务和消费电子类产品等领域。
近年来,随着语音识别技术在机器人控制中的应用,机器人的应用领域不断扩大。同时,国内外关于基于语音识别的机器人控制技术的研究也取得了一定的进展。例如,国内有白琳在基于语音识别的机器人控制技术的研究中对语音特征参数提取方法进行了改进,将传统的mfcc特征参数与共振峰参数相结合,提出了新的语音特征参数提取方法。
目前,现有的语音交互产品大多基于专用的语音识别芯片,其内核为单片机或数字信号中央处理器,其实质是将麦克风输入的声音信号采样编码,再通过内部处理器与其事先录制好的语音信息匹配,再将相应的语音信息通过片内的模块经过外置的扬声器输出。例如,中国专利cn201620720668.8公开了一种具有语音交互功能的机器人系统,其包括由机器人头部、机器人身部和底座组成的机器人,所述机器人身部内设有一pcb板,所述pcb板连接有一单片机,所述单片机连接有一信号发射电路,所述机器人头部设有图像采集传感器和语音接收器,所述信号发射电路与所述语音接收器、图像采集传感器相连,所述信号发射电路与移动终端相连,所述单片机还连接有一信号接收电路和语音播放器,所述信号接收电路分别与移动终端和语音播放器相连,所述信号发射电路、信号接收电路均连接有一滤波器,所述机器人身部包括机器人手臂、显示装置和输入按钮,所述输入按钮与所述显示装置相连,其能实现语音交互的功能。
然而,申请人研究发现,现有的语音识别机器人具有较好的单向识别能力,但双向语音识别能力较弱,主要有如下两方面的问题:
1)机器人在移动过程中,由于步进电机等设备的基底噪声干扰,会给语音交互机器人带来不可预知的结果;
2)当机器人在说话,或者播放音乐时,即使用户发出指令,机器人也难以对用户发出的指令进行识别,双向语音识别能力几乎丧失,这也是目前现有的机器人主要采用问答方式进行控制的主要原因。
基于现有语音交互机器人所存在的上述缺陷,人机交互的友好性和安全性不能得到保障,违背了机器人的三定律。为此,迫切需要一种新的装置,以解决上述问题。
技术实现要素:
本发明的发明目的在于:针对目前现有的语音智能交互机器人仅能采用一问一答的方式进行控制,人机交互的友好性和安全性不能得到保障的问题,提供一种智能语音交互机器人。本发明的机器人通过对其结构的改进,能有效进行双向语音识别,突破现有技术所存在的缺陷。另一方面,基于机器人内部结构的改进,机器人在移动过程中,由于步进电机等设备的基底噪声干扰,所导致的语音交互问题,得到有效解决。本发明能够实现人与机器人的双向互动交流,有效提升人机交互的友好性,具有显著的进步意义。
为了实现上述目的,本发明采用如下技术方案:
一种智能语音交互机器人,包括底部支撑架、驱动机构、第一腔体、第二腔体、控制系统,所述驱动机构设置在底部支撑架上且驱动机构通过底部支撑架能带动机器人运动,所述第一腔体、第二腔体相连构成机器人主体,所述机器人主体设置在底部支撑架上;
所述第二腔体上对称设置有两个第三腔体,所述第一腔体、第二腔体、第三腔体分别为中空结构;
所述第一腔体的空腔内设置有第一支撑架,所述第一支撑架与底部支撑架相连,所述第一腔体侧壁上分别设置有第一语音播放装置、第一空腔,所述第一腔体下方设置有第一隔音板,所述第一腔体的第一空腔内从下至上依次设置有上隔音抽屉、下隔音抽屉且第一支撑架能够分别为上隔音抽屉、下隔音抽屉提供支撑,所述第一隔音板位于底部支撑架与下隔音抽屉之间;
所述第一腔体与第二腔体之间设置有第二隔音板,所述第三腔体上分别设置有第三语音播放装置、与第三语音播放装置相配合的喇叭孔、语音识别装置,所述第三腔体呈球形,所述第三语音播放装置为两个且分别设置在第三腔体上,所述喇叭孔为若干个且喇叭孔呈扇形环带状,所述语音识别装置位于第三语音播放装置之间;
所述控制系统分别与第一语音播放装置、第三语音播放装置、语音识别装置相连。
所述机器人主体下方设置有若干个散热孔。
若干个散热孔构成矩形设置于主体下方。
所述第一腔体上还设置有凹槽,所述凹槽内设置有与控制系统相连的信号接收器、扶手中的一种或多种。
所述信号接收器设置在第一支撑架上。
还包括与控制系统相连的显示器,所述显示器设置在第二腔体的侧壁上,所述显示器位于两个第三腔体之间且语音识别装置设置在显示器下方。
所述显示器与水平面之间的夹角为15~90°。
所述上隔音抽屉、下隔音抽屉之间设置有第三隔音板。
所述语音识别装置位于第三语音播放装置之间的中线上。
还包括摄像头跟随机构、避障机构,所述摄像头跟随机构、避障机构分别设置在机器人主体上且摄像头跟随机构、避障机构分别与控制系统相连,所述控制系统能够接受、处理摄像头跟随机构传输的图像信号以及避障机构所检测的位置信号,进而控制驱动机构的动作。
还包括与控制系统相连的导航机构。
用于前述智能语音交互机器人交互系统的方法,包括如下步骤:
(一)判断语音输入类型
1)判断语音输入类型,若为输入输出双向识别系统,则执行步骤(二),若为输入单向识别系统,则执行步骤(三);
(二)预定义输入输出双向识别系统;
2)预定义语音输出表,并根据预定义语音输出表采集语音播放装置组成输出样本集和输出测试集;
3)预定义语音词汇表,并根据该语音词汇表采集语音样本数据组成输入样本集和输入测试集;
4)分别对输出样本集内的n个语音样本、输入样本集内的m个语音样本全排列,得到n!m!个排列;分别将每一个排列输入训练系统中,得到一个训练好的语音矢量中心;最后求出n!m!个语音矢量中心的平均矢量和方差参数,得到最终的语音训练模板;其中,n、m为大于1的整数;
5)同时使用输出测试集、输入测试集中的语音样本作为待测语音进行测试,得到不同语音样本下的鲁棒性程度,包括每个语音样本的正确识别率和语音样本平均正确识别率;
6)按照语音样本正确识别率的大小对语音样本进行排序,选择单词正确识别率大于平均正确识别率的语音样本组成双向候选词汇表;
7)针对双向候选词汇表,再次使用步骤4)训练语音模板,得到各个语音模板的平均矢量μ1和平均方差σ1;
8)当待测语音输入时,计算待测语音与各语音模板的匹配距离,选择最小匹配距离对应的语音模板为识别结果;
9)输出待测语音的识别结果;
(三)预定义输入单向识别系统;
10)对步骤3)内输入样本集内的m个语音样本全排列,得到m!个排列;分别将每一个排列输入训练系统中,得到一个训练好的语音矢量中心;最后求出m!个语音矢量中心的平均矢量和方差参数,得到最终的语音训练模板;其中,m为大于1的整数;
11)使用输入测试集中的语音样本作为待测语音进行测试,得到相应语音样本的鲁棒性程度,包括每个语音样本的正确识别率和语音样本平均正确识别率;
12)按照语音样本正确识别率的大小对语音样本进行排序,选择单词正确识别率大于平均正确识别率的语音样本组成单向候选词汇表;
13)针对单向候选词汇表,再次使用步骤10)训练语音模板,得到各个语音模板的平均矢量μ2和平均方差σ2;
14)当待测语音输入时,计算待测语音与各语音模板的匹配距离,选择最小匹配距离对应的语音模板为识别结果;
15)输出待测语音的识别结果。
在现有结构中,主要是采用一问一答的方式进行控制,这主要是由于机器人自身的输出会对语音识别效果产生极大影响的问题。目前,通用采用对芯片进行改进的方式,以解决前述问题。而发明中,通过对机器人的整体结构进行改进,有效减少语音输出对语音输入的干扰,进而达到语音输入输出双向交互的目的。
该结构包括底部支撑架、驱动机构、第一腔体、第二腔体、控制系统;其中,底部支撑架为其他部件提供支撑,驱动机构与底部支撑架相连,驱动机构带动底部支撑架及其上的其他部件运动。驱动机构包括一组主动轮、从动轮,主动轮分别与控制系统相连。本发明中,从动轮可以为万向轮,主动轮为两个且分别通过电机带动主动轮转动。进一步,主动轮可以为麦克拉姆轮,主动轮、从动轮呈等腰三角形分布。
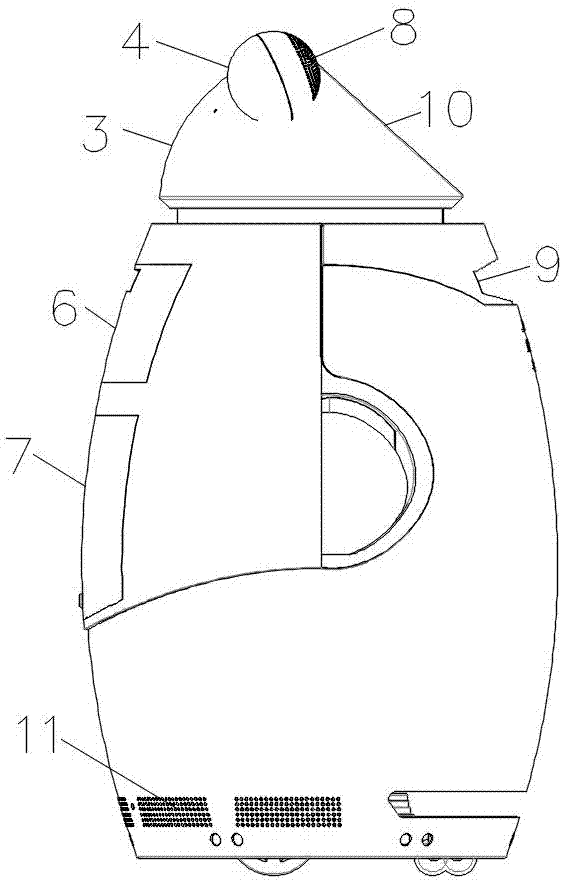
第一腔体、第二腔体相连,构成机器人主体,第一腔体、第二腔体从下至上依次设置;并且,第二腔体上对称设置有两个第三腔体,第一腔体、第二腔体、第三腔体分别为中空结构,第三腔体呈球形。第一腔体大于第二腔体,第二腔体大于第三腔体。采用该结构,形成下大上小、上部有两个耳朵的熊猫形态的智能机器人。
第一腔体侧壁上分别设置有第一语音播放装置、第一开口,第一腔体的空腔内设置有第一支撑架,第一支撑架为第一腔体内的其他部件提供支撑。通过第一语音播放装置,能够实现机器人的语音输出。
本发明中,在第一腔体的空腔内从下至上依次设置有上隔音抽屉、下隔音抽屉,通过上隔音抽屉、下隔音抽屉起到隔音、减震的作用。第一腔体下方设置有第一隔音板,第一隔音板位于底部支撑架与下隔音抽屉之间,第一腔体与第二腔体之间设置有第二隔音板。第三腔体上分别设置有第三语音播放装置、与第三语音播放装置相配合的喇叭孔、语音识别装置,第三语音播放装置为两个且分别设置在第三腔体上,喇叭孔呈扇形环带状分布,语音识别装置位于两个第三语音播放装置之间,优选为中线上。
申请人分析后认为,现有迎宾类、家用小型拟人或仿动物形态智能机器人无法实现语音双向输入输出的问题在于,机器人自身的结构上;现有迎宾类、家用小型拟人或仿动物形态智能机器人采用单独的腔体结构,其内部会形成一个巨大的音腔,音腔会严重影响语音识别的效果。为此,本发明在结构上进行了如下几方面的改进:1)将现有技术中单独的腔体结构改进为第一腔体、第二腔体两个单独的腔体,2)在第一腔体与第二腔体之间设置有第二隔音板,阻断第一腔体音腔对识别装置的影响,3)并将第一腔体的空腔内从下至上依次设置上隔音抽屉、下隔音抽屉,通过上隔音抽屉、下隔音抽屉的设置,一方面有利于用户物品等的放置,起到置物的作用,另一方面则能破坏第一腔体原有的音腔,尽可能减少第一语音播放装置对语音识别装置的影响;4)第三语音播放装置对称设置在第三腔体上,喇叭孔呈扇形环带状,采用该方式,第三语音播放装置形成一个对称的语音输出,极大降低第三语音播放装置对于语音识别装置的影响。基于上述结构的改进,本发明能够实现机器人的语音输出与用户的语音输入的双向互动,极大提高用户的双向语音识别效率,有效解决现有技术所存在的问题和缺陷。
进一步,机器人主体下方设置有若干个散热孔;通过散热孔能够有效散发机器人内部的热量,保证机器人的正常运行。
进一步,第一腔体上还设置有凹槽,所述凹槽内设置有与控制系统相连的信号接收器、扶手中的一种或多种。采用该方式,用户可以通过扶手对机器人进行操作;用户除直接使用语音之另外,可以通过信号接收器,向机器人发送相应的控制指令。
进一步,还包括与控制系统相连的显示器,显示器设置在第二腔体的侧壁上,显示器位于两个第三语音播放装置之间且语音识别装置设置在显示器下方。采用该方式,显示器形成类似熊猫的可爱的脸,第三腔体则形成熊猫的耳朵,给人以更好的亲近感,增强用户交互的友好性。
进一步,显示器与水平面之间的夹角为15~90°。采用该方式,能够便于用户对显示器的观看。
进一步,为了提高隔音效果,本发明在上隔音抽屉、下隔音抽屉之间设置有第三隔音板,以进一步降低第一语音播放装置对语音识别装置的影响。
进一步,还包括摄像头跟随机构、避障机构,摄像头跟随机构、避障机构分别设置在机器人主体上且摄像头跟随机构、避障机构分别与控制系统相连,控制系统能够接受、处理摄像头跟随机构传输的图像信号以及避障机构所检测的位置信号,进而控制驱动机构的动作。采用该方式,本发明的机器人通过摄像头跟随机构识别用户的运动轨迹,并将图像信息传递给控制系统;同时,避障机构将所检测的位置信号传递给控制系统;控制系统接受、处理摄像头跟随机构传输的图像信号以及避障机构所检测的位置信号,并控制驱动机构的动作,实现对用户的智能跟随。
进一步,还包括与控制系统相连的导航机构。通过导航机构,本发明能够为用户提供导航指导;同时,基于导航机构,本发明也能够自动运动到设定的位置。
本发明还提供基于前述智能语音交互机器人的交互系统的实现方法,该方法中,针对不同的语音情景进行判断,并基于判断的结果,执行相应的识别操作。该方法中,采用单独的语音识别装置,即可实现对语音的识别处理,而无需采用多个语音识别装置,进行语音降噪处理。同时,该方法不依赖于特定的说明者,通过对语音输出表、语音词汇表的定义,并依靠语音训练模板等后续处理,使得本发明在抗噪声和与说话人无关方面得以改进,弱化了不同说话人的个性信息。另一方面,基于本发明的方法,可以用于在线联网识别,也能实现无网离线识别,识别率高,识别效果好。
采用该方法,能够有效修正识别结果,实现单向语音输入和双向语音输入输出,且在单向语音输入和双向语音输入输出中,均具有较好的识别效果。经实际测试,本发明的识别精度能达到95%以上,有效实现了说话人与机器人双向语音输入输出的双向进行,使得说话人与机器人之间的友好性和互动性得到极大增强,具有显著的进步意义。
附图说明
本发明将通过例子并参照附图的方式说明,其中:
图1为实施例1中装置的侧视图。
图2为实施例1中装置的后视图。
图中标记:1为驱动机构,2为第一腔体,3为第二腔体,4为第三腔体,6为上隔音抽屉,7为下隔音抽屉,8为喇叭孔,9为信号接收器,10为显示器,11为散热孔。
具体实施方式
本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。
本说明书中公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换。即,除非特别叙述,每个特征只是一系列等效或类似特征中的一个例子而已。
实施例1
本实施例的智能语音交互机器人包括底部支撑架、驱动机构、第一腔体、第二腔体、控制系统。其中,驱动机构设置在底部支撑架上,第一腔体、第二腔体相连构成机器人主体,机器人主体设置在底部支撑架上。第二腔体上对称设置有两个第三腔体,第一腔体、第二腔体、第三腔体分别为中空结构。
本实施例中,驱动机构包括一个从动轮和两个主动轮、两个与主动轮相连的驱动电机。采用该结构,驱动机构能够带动机器人相对地面进行移动。
同时,第一腔体的空腔内设置有第一支撑架,第一支撑架与底部支撑架相连,第一腔体侧壁上分别设置有第一语音播放装置、第一空腔,第一腔体下方设置有位于底部支撑架与下隔音抽屉之间的第一隔音板,第一腔体的第一空腔内从下至上依次设置有上隔音抽屉、下隔音抽屉,第一支撑架能够分别为上隔音抽屉、下隔音抽屉提供支撑。
本实施例中,第一腔体与第二腔体之间设置有第二隔音板,第三腔体上分别设置有第三语音播放装置、与第三语音播放装置相配合的喇叭孔、语音识别装置,第三腔体呈球形,第三语音播放装置为两个且分别设置在第三腔体上,喇叭孔为若干个且喇叭孔呈扇形环带状(如图所示),语音识别装置位于第三语音播放装置之间。
本实施例中,驱动电机、第一语音播放装置、第三语音播放装置、语音识别装置分别与控制系统相连。
本实施例中,第一腔体下方还设置有若干个散热孔,散热孔呈矩形布置;第一腔体上还设置有凹槽,凹槽内设置有与控制系统相连的信号接收器;第二腔体的侧壁上还设置与控制系统相连的显示器,显示器位于两个第三腔体之间,语音识别装置位于显示器下方。本实施例中,显示器与水平面之间的夹角为45°,语音识别装置位于两个第三语音播放装置之间的中线上。
本实施例中,还包括摄像头跟随机构、避障机构、导航机构,摄像头跟随机构、避障机构分别设置在机器人主体上。摄像头跟随机构、避障机构、导航机构分别与控制系统相连,控制系统能够接受、处理摄像头跟随机构传输的图像信号以及避障机构所检测的位置信号,进而控制驱动机构的动作。
采用该方式,本实施例的机器人通过摄像头跟随机构识别用户的运动轨迹,并将图像信息传递给控制系统;同时,避障机构将所检测的位置信号传递给控制系统;控制系统接受、处理摄像头跟随机构传输的图像信号以及避障机构所检测的位置信号,并控制驱动机构的动作,实现对用户的智能跟随。而基于导航机构,控制系统能够控制本实施例的机器人自动运动到设定位置。
本实施例中,采用讯飞语音识别接口进行语音识别,双向语音输入输出识别精确度达到88%以上,单向语音输入识别精度达95%左右,具有较好的效果。
实施例2
以实施例1的装置为基础,本实施例提供一种不同的语音交互系统的实现方法,其包括如下步骤:
(一)判断语音输入类型
1)判断语音输入类型,若为输入输出双向识别系统,则执行步骤(二),若为输入单向识别系统,则执行步骤(三);
(二)预定义输入输出双向识别系统;
2)预定义语音输出表,并根据预定义语音输出表采集语音播放装置组成输出样本集和输出测试集;
3)预定义语音词汇表,并根据该语音词汇表采集语音样本数据组成输入样本集和输入测试集;
4)分别对输出样本集内的n个语音样本、输入样本集内的m个语音样本全排列,得到n!m!个排列;分别将每一个排列输入训练系统中,得到一个训练好的语音矢量中心;最后求出n!m!个语音矢量中心的平均矢量和方差参数,得到最终的语音训练模板;其中,n、m为大于1的整数;
5)同时使用输出测试集、输入测试集中的语音样本作为待测语音进行测试,得到不同语音样本下的鲁棒性程度,包括每个语音样本的正确识别率和语音样本平均正确识别率;
6)按照语音样本正确识别率的大小对语音样本进行排序,选择单词正确识别率大于平均正确识别率的语音样本组成双向候选词汇表;
7)针对双向候选词汇表,再次使用步骤4)训练语音模板,得到各个语音模板的平均矢量μ1和平均方差σ1;
8)当待测语音输入时,计算待测语音与各语音模板的匹配距离,选择最小匹配距离对应的语音模板为识别结果;
9)输出待测语音的识别结果;
(三)预定义输入单向识别系统;
10)对步骤3)内输入样本集内的m个语音样本全排列,得到m!个排列;分别将每一个排列输入训练系统中,得到一个训练好的语音矢量中心;最后求出m!个语音矢量中心的平均矢量和方差参数,得到最终的语音训练模板;其中,m为大于1的整数;
11)使用输入测试集中的语音样本作为待测语音进行测试,得到相应语音样本的鲁棒性程度,包括每个语音样本的正确识别率和语音样本平均正确识别率;
12)按照语音样本正确识别率的大小对语音样本进行排序,选择单词正确识别率大于平均正确识别率的语音样本组成单向候选词汇表;
13)针对单向候选词汇表,再次使用步骤10)训练语音模板,得到各个语音模板的平均矢量μ2和平均方差σ2;
14)当待测语音输入时,计算待测语音与各语音模板的匹配距离,选择最小匹配距离对应的语音模板为识别结果;
15)输出待测语音的识别结果。
本实施例中,双向语音输入输出识别精确度达到95%以上,单向语音输入识别精度达97%左右,具有较好的效果。
本发明并不局限于前述的具体实施方式。本发明扩展到任何在本说明书中披露的新特征或任何新的组合,以及披露的任一新的方法或过程的步骤或任何新的组合。
- 还没有人留言评论。精彩留言会获得点赞!