一种基于贝叶斯推理的码元改写信息隐藏检测方法及系统与流程
本发明涉及信息安全和机器学习技术领域,特别涉及一种基于贝叶斯推理的码元改写信息隐藏检测方法及系统。
背景技术:
随着带宽的持续增长以及网络融合趋势的增强,基于网络数据通信的网络流媒体服务得到了空前的发展,网络压缩语音码流成为隐蔽通信常用载体之一。它给人们的生活和工作带来便利的同时,也给犯罪分子带来了可乘之机。对于敏感机构而言,需要对机构中的语音码流进行评估审查,确定是否存在隐蔽通信信道进行秘密信息的外泄。信息隐藏检测技术作为隐蔽通信的对抗技术,能够有效的监控网络压缩语音码流中的隐蔽通信,实现对敏感机构中的语音码流信息隐藏检测。
在压缩语音中进行信息隐藏之后,都会对码元造成不同程度的改写。现有的压缩语音信息隐藏检测方法绝大部分是在解码过程中进行的,即针对某种编码过程的信息隐藏进行检测,如线性预测编码、开环基音预测、码本搜索等;还有小部分是针对特定的信息隐藏方法直接分析压缩语音码流,该类方法针对单一码元分别进行分析,以效果最好的码元检测结果为最终检测结果。现有的码元改写信息隐藏检测方法都只能针对特定的信息隐藏方法进行检测,目前尚未有能适合任意码元改写的检测方法。在实际应用过程中,很难获取到压缩语音中使用的是何种信息隐藏方法,因此,研究一种通用的码元改写信息隐藏检测方法很有必要。
技术实现要素:
本发明的目的在于提出一种通用的码元改写信息隐藏检测方法,该方法首先分析压缩语音各个码元自身取值统计特征,计算得到码元分布熵,选取分布熵较小的码元作为隐写敏感码元;接着以同类隐写敏感码元帧内取值和相邻帧间取值关系构建码元关联网络;然后以马尔科夫转移概率为关联指数对码元关联网络进行剪枝,得到码元强关联网络;最后基于码元强关联网络构建码元贝叶斯网络分类器,并使用dirichlet分布作为先验分布学习网络参数,从而实现对码元改写的信息隐藏检测。
为了实现上述目的,本发明提供了一种基于贝叶斯推理的码元改写信息隐藏检测方法,所述方法包括以下步骤:
步骤1)在训练样本中根据压缩语音码元取值分布熵选取隐写敏感码元,由此构建码元强关联网络;基于码元强关联网络构建码元贝叶斯网络分类器,并使用dirichlet分布作为先验分布学习码元贝叶斯网络分类器的参数;
步骤2)根据码元贝叶斯网络分类器和训练样本计算隐写指数阈值jthr;
步骤3)对于一段未知类型的压缩语音,计算其隐写指数j0,若j0≥jthr,判定该语音段为未隐写语音段;若j0<jthr,判定该语音段为隐写语音段。
作为上述方法的一种改进,所述步骤1)具体包括:
步骤s1)根据训练样本计算压缩语音码元取值分布熵,选取分布熵小于阈值的码元作为隐写敏感码元;
步骤s2)以隐写敏感码元帧内取值和相邻帧间取值关系构建码元关联网络,以马尔科夫转移概率为关联指数对码元关联网络进行剪枝,得到码元强关联网络;
步骤s3)基于码元强关联网络构建码元贝叶斯网络分类器,并使用dirichlet分布作为先验分布学习码元贝叶斯网络分类器的参数。
作为上述方法的一种改进,所述步骤s1)具体包括:
步骤s1-1)计算压缩语音码元取值分布,记第k个码元的取值范围为[0,rk],其取值概率分布为
步骤s1-2)根据码元取值概率分布计算各个码元取值分布熵,第k个码元的分布熵ek计算如下:
步骤s1-3)选取分布熵小于阈值ethr的码元作为隐写敏感码元。
作为上述方法的一种改进,所述步骤s2)具体包括:
步骤s2-1)根据步骤s1-3)得到的隐写敏感码元构建码元关联网络,记为有向图d=(v,e),定义如下:
v={vi[k],i∈{0,1,2,...}}
e={<vu[p],vv[q]>,vu[p],vv[q]∈v,v-u∈{0,1}}
其中,v为有向图中的顶点构成的集合,每个顶点对应一个隐写敏感码元vi[k],vi[k]表示第i帧中的第k个码元;其中e为有向图中的有向边构成的集合,<vu[p],vv[q]>表示由顶点vu[p]指向vv[q]的有向边,且vu[p]和vv[q]为取值范围相同的同类码元,即rp=rq;当v-u=0时,表示帧内关联边;当v-u=1时,表示帧间关联边;
步骤s2-2)根据步骤s2-1)得到的码元关联网络,计算每条边对应的码元取值转移概率矩阵rpq,如下:
其中pi,j,i=0,1,...,rp,j=0,1,...,rq,rp=rq表示第p个码元取值为i,第q个码元取值为j时的转移概率;
步骤s2-3)根据步骤s2-2)得到的转移概率矩阵rpq计算关联指数repq,计算公式如下:
repq表示两个码元取值相同时的转移概率之和;
步骤s2-4)根据步骤s2-3)得到的关联指数repq,去掉关联指数repq小于阈值rethr的关联边,得到码元强关联网络d′=(v′,e′),记v′中包含n个顶点,为v′=v1,v2,...,vn。
作为上述方法的一种改进,所述步骤s3)具体包括:
步骤s3-1)根据步骤s2-4)得到的码元强关联网络,构建码元贝叶斯网络分类器,其网络节点随机变量记为u={x0,x1,…,xm},m为节点的总个数;随机变量相应的取值记为u={u0,u1,…,um};
步骤s3-2)根据步骤s3-1)得到的码元贝叶斯网络分类器,使用dirichlet分布作为先验分布学习码元贝叶斯网络分类器的参数。
作为上述方法的一种改进,所述步骤s3-1)具体包括:
步骤s3-1-1)以压缩语音帧类别作为码元贝叶斯网络分类器的根节点x0,帧类别为:未隐写和隐写;
步骤s3-1-2)根据步骤s2-4)得到的码元强关联网络,将顶点v′中每个码元取值范围分为多个取值集合;其中,对于取值范围大于255的码元,利用训练样本计算码元取值直方图,将码元取值直方图按降序排列,将排序后的取值均匀划分为256个取值集合;对于取值范围小于或者等于255的码元,每个取值为一个集合;以码元取值集合作为子节点x1,x2,...,xn,构成由x0→x1,x0→x2,...,x0→xn的n条有向边,节点xi取值对应码元vi的一个取值集合;
步骤s3-1-3)根据步骤s2-4)得到的码元强关联网络,若存在帧内关联边<vi[p],vi[q]>,则增加子节点
步骤s3-1-4)根据步骤s2-4)得到的码元强关联网络,若存在相邻帧间关联边<vi[p],vi+1[p]>,则增加子节点
作为上述方法的一种改进,所述步骤s3-2)具体包括:
步骤s3-2-1)根据步骤s3-1)得到的码元贝叶斯网络分类器,记随机变量xi共有ki个取值,xi的取值概率为
θijk=p(xi=xik|pa(xi)=pa(xi)j)
初始化随机变量xi取值先验分布π(θij)为dirichlet分布,即:
其中γ(·)为gamma函数,αijk为超参数,初始值根据经验设定;
步骤s3-2-2)根据步骤s3-2-1)得到的xi取值先验分布π(θij),统计样本χ中满足xi=xik且pa(xi)=pa(xi)j的个数为βijk,由于后验分布π(θ|χ)也服从dirichlet分布,则π(θij|χ)表示为:
步骤s3-2-3)根据步骤s3-2-2)得到的后验分布π(θij|χ),采用最大似然估计方法计算码元贝叶斯网络分类器每个参数
作为上述方法的一种改进,所述步骤2)具体包括:
步骤2-1)根据步骤s3)得到的码元贝叶斯网络分类器,利用子节点x1,…,xm的取值及相应的节点参数来推理父节点x0的取值后验概率,即语音帧的类别,其中为未隐写帧的后验概率计算为:
为隐写帧的后验概率计算为:
步骤2-2)根据步骤2-1)得到的语音帧类别后验概率,计算语音段的隐写指数jx;
记一段包含t帧的语音段第i帧为未隐写帧的概率为pui,为隐写帧的概率为psi,则jx表示为:
步骤2-3)根据步骤2-2)得到的语音段隐写指数jx,根据训练样本计算隐写指数阈值jthr;
设训练样本包含l段语音,记训练样本在未隐写情况下的隐写指数为ju={ju1,ju2,…,jul},在隐写情况下的隐写指数为js={js1,js2,…,jsl},则jthr由下式得到:
其中,cnt(ju:juj≥jx)表示未隐写指数ju中满足juj≥jx的个数,即未隐写情况下判定正确的语音数;cnt(js:jsj<jx)表示隐写指数js中满足jsj<jx的个数。
一种基于贝叶斯推理的码元改写信息隐藏检测系统,包括存储器、处理器和存储在存储器上的并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现上述方法的步骤。
本发明的方法优点在于:
1、本发明的方法中的贝叶斯网络分类器是基于隐写敏感码元强关联网络构建的,能确保贝叶斯网络结构能充分体现隐写对码元自身、同类码元帧间、同一码元帧间关联的影响;
2、本发明的方法以dirichlet分布作为先验分布,结合样本数据对先验分布修正,有效地提高了参数学习的精度,从而得到更准确的隐写检测结果;
3、本发明的方法以码流中的码元作为分析对象,不需要进行解码,可以达到实时隐写检测的效果。
附图说明
图1是本发明的基于贝叶斯推理的码元改写信息隐藏检测方法的流程示意图;
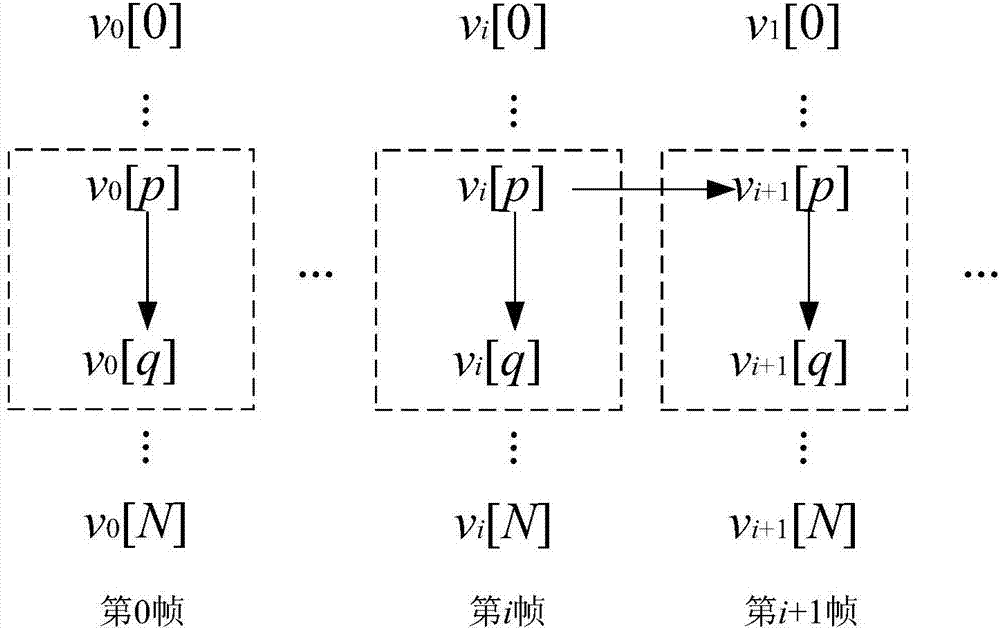
图2是本发明的码元强关联网络示意图;
图3是本发明的码元贝叶斯网络分类器示意图。
具体实施方式
现结合附图和具体实施例对本发明做进一步的描述。
如图1所示,一种基于贝叶斯推理的码元改写信息隐藏检测方法,所述方法包括以下步骤:
步骤s1)根据训练样本计算压缩语音码元取值分布熵,选取分布熵小于阈值的码元作为隐写敏感码元;具体包括:
步骤s1-1)计算压缩语音码元取值分布,记第k个码元的取值范围为[0,rk],其取值概率分布为
步骤s1-2)根据码元取值概率分布计算各个码元取值分布熵,第k个码元的分布熵ek计算如下:
步骤s1-3)选取分布熵小于阈值ethr的码元作为隐写敏感码元;
步骤s2)以隐写敏感码元帧内取值和相邻帧间取值关系构建码元关联网络,以马尔科夫转移概率为关联指数对码元关联网络进行剪枝,得到码元强关联网络;如
图2所示;所述步骤s2)具体包括:
步骤s2-1)根据步骤s1-3)得到的隐写敏感码元构建码元关联网络,记为有向图d=(v,e),定义如下:
v={vi[k],i∈{0,1,2,...}}
e={<vu[p],vv[q]>,vu[p],vv[q]∈v,v-u∈{0,1}}
其中v为有向图中的顶点构成的集合,每个顶点对应一个隐写敏感码元vi[k],vi[k]表示第i帧中的第k个码元。其中e为有向图中的有向边构成的集合,<vu[p],vv[q]>表示由顶点vu[p]指向vv[q]的有向边,且vu[p]和vv[q]为取值范围相同的同类码元,即rp=rq;当v-u=0时,表示帧内关联边;当v-u=1时,表示帧间关联边。
步骤s2-2)根据步骤s2-1)得到的码元关联网络,计算每条边对应的码元取值转移概率矩阵rpq,如下:
其中pi,j(i=0,1,...,rp,j=0,1,...,rq,rp=rq)表示第p个码元取值为i,第q个码元取值为j时的转移概率。
步骤s2-3)根据步骤s2-2)得到的转移概率矩阵rpq计算关联指数repq,计算公式如下:
repq表示两个码元p和q取值相同时的转移概率之和。
步骤s2-4)根据步骤s2-3)得到的关联指数repq,去掉关联指数repq小于阈值rethr的关联边,得到码元强关联网络d′=(v′,e′),记v′中包含n个顶点,为v′=v1,v2,...,vn,如图2所示;
步骤s3)基于码元强关联网络构建码元贝叶斯网络分类器,并使用dirichlet分布作为先验分布学习网络参数;具体包括:
步骤s3-1)根据步骤s2-4)得到的码元强关联网络,构建码元贝叶斯网络分类器;具体包括:
如图3所示;贝叶斯网络节点随机变量记为u={x0,x1,…,xm},随机变量相应的取值记为u={u0,u1,…,um};
步骤s3-1-1)以压缩语音帧类别作为贝叶斯网络分类器的根节点x0,帧类别为:未隐写(记为0)和隐写(记为1)两种;
步骤s3-1-2)根据步骤s2-4)得到的码元强关联网络,将顶点v′中每个码元取值范围分为多个取值集合;其中,对于取值范围大于255的码元,利用训练样本计算码元取值直方图,将码元取值直方图按降序排列,将排序后的取值均匀划分为256个取值集合;对于取值范围小于或者等于255的码元,每个取值为一个集合;以码元取值集合作为子节点x1,x2,...,xn,构成由x0→x1,x0→x2,...,x0→xn的n条有向边,节点xi取值对应码元vi的一个取值集合;
步骤s3-1-3)根据步骤s2-4)得到的码元强关联网络,若存在帧内关联边,如图2中虚线框内的<vi[p],vi[q]>,则增加子节点
步骤s3-1-4)根据步骤s2-4)得到的码元强关联网络,若存在相邻帧间关联边,图2中<vi[p],vi+1[p]>,则增加子节点
步骤s3-2)根据步骤s3-1)得到的贝叶斯网络分类器,使用dirichlet分布作为先验分布计算网络分类器的参数;具体包括:
步骤s3-2-1)根据步骤s3-1)得到的码元贝叶斯网络分类器,记随机变量xi共有ki个取值,xi的取值概率为
θijk=p(xi=xik|pa(xi)=pa(xi)j)
初始化随机变量xi取值先验分布π(θij)为dirichlet分布,即:
其中γ(·)为gamma函数,αijk为超参数,初始值根据经验设定;
步骤s3-2-2)根据步骤s3-2-1)得到的xi取值先验分布π(θij),统计样本χ中满足xi=xik且pa(xi)=pa(xi)j的个数为βijk,由于后验分布π(θ|χ)也服从dirichlet分布,则π(θ|χ)可表示为:
步骤s3-2-3)根据步骤s3-2-2)得到的后验分布π(θ|χ),采用最大似然估计方法计算每个网络分类器的参数
步骤s4)运用码元贝叶斯网络分类器,对未知类型的压缩语音进行隐写检测;具体包括:
步骤s4-1)根据步骤s3)得到的贝叶斯网络分类器,利用子节点x1,…,xm的取值及相应的节点参数来推理父节点x0的取值后验概率,即语音帧的类别,其中为未隐写帧的后验概率计算为:
为隐写帧的后验概率计算为:
步骤s4-2)根据步骤s4-1)得到的语音帧类别后验概率,计算语音段的隐写指数jx;
记一段包含n帧的语音段第i帧为未隐写帧的概率为pui,为隐写帧的概率为psi,则jx表示为:
步骤s4-3)根据步骤s4-2)得到的语音段隐写指数jx,根据训练样本计算隐写指数阈值jthr;
设训练样本包含m段语音,记训练样本在未隐写情况下的隐写指数为ju={ju1,ju2,…,jum},在隐写情况下的隐写指数为js={js1,js2,…,jsm},则jthr由下式得到:
其中cnt(ju:juj≥jx)表示未隐写指数ju中满足juj≥jx的个数,即未隐写情况下判定正确的语音数;cnt(js:jsj<jx)表示隐写指数js中满足jsj<jx的个数。
步骤s4-4)根据步骤s4-3)得到的隐写指数阈值jthr,给定一段未知类型的压缩语音,计算其隐写指数j0,若j0≥jthr,判定该语音段为未隐写语音段;若j0<jthr,判定该语音段为隐写语音段。
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!