一种语音端点检测的方法和装置与流程
本申请涉及语音信号处理技术,特别涉及一种语音端点检测的方法和装置。
背景技术:
端点检测是指通过准确识别一段语音信号中的起始点和结束点,区分出语音信号和噪音信号的过程,是语音分析、语音合成和语音识别等领域中的一个重要环节。端点检测通过识别并去除噪音段数据,节省数据处理时间,提升语音识别的精度,在实际应用中具有重要的研究意义。
现有的端点检测方法主要包括基于能量和过零率、mel倒频谱系数、信息熵、hmm和小波变换等分析方法。
小波变换(wavlettransform)作为一种重要的时频分析方法,其性能要优于傅里叶变换。它具有同时在时域和频域表征信号局部化能力,通过在不同的尺度因子s上计算连续域或离散域语音信号的小波变换系数,然后多次分解具有低频小波系数,根据小波系数阈值或小波系数方差判断语音信号所属的类别。
连续小波变换计算公式为
小波基函数为
其中,x(t)为语音信号,ψ(t)为连续小波变换函数,尺度因子为s,位置因子为τ。因此小波变换具有一定的瞬时性、抗噪性和多分辨率,能够处理非线性、非平稳的语音信号,是语音端点检测中比较有代表性的方法。
现有的小波变换算法主要依赖于阈值和低频小波系数进行语音端点检测,对不同语音信号和噪音信号的适应性,起伏变化比较大,对于某些信号可能检测准确性较高,而对于某些信号的检测准确性又较低,同时,对语音信号起始点的识别准确度也较差。
技术实现要素:
本申请提供一种语音端点的检测方法和装置,能够提高语音信号检测的抗噪能力和适应能力,同时实现起止点的准确检测。
为实现上述目的,本申请采用如下技术方案:
一种语音端点的检测方法,包括:
将待检测的语音信号进行小波变换,在不同尺度因子下将同一语音信号经小波变换后分别得到高频和低频小波系数集,并分别计算高频系数对应的熵向量和低频系数对应的熵向量;
将所述高频系数对应的熵向量和所述低频系数对应的熵向量分别输入预先训练生成的第一blstm神经网络和第二blstm神经网络进行深度学习,得到高频系数对应的隐藏层向量和低频系数对应的隐藏层向量,并将所述高频系数对应的隐藏层向量和所述低频系数对应的隐藏层向量,分别进行cnn处理;
利用高频系数对应的cnn处理结果,计算每帧语音信号属于噪音段的第一概率;利用低频系数对应的cnn处理结果,计算每帧语音信号属于语音段的第二概率;
根据所述第一概率和所述第二概率的比较,确定每帧语音信号所属的类别,并根据所有帧语音信号所属的类别确定语音端点。
较佳地,训练所述blstm神经网络的方式包括:
将用于训练的语音信号根据特性划分成多个语音段和噪声段,其中,语音段长度在预设的长度范围内,并将不符合要求的语音信号片段删除;将各语音段和噪音段内的信号分别以帧为单位对应标记为语音和噪音,并将所述标记作为相应帧的实际标记;
将所述各语音段和所述各噪音段进行小波变换,在不同尺度因子下将同一语音信号经小波变换后分别得到高频和低频小波系数集,并分别计算高频系数对应的熵向量和低频系数对应的熵向量;将所述高频系数对应的熵向量和所述低频系数对应的熵向量分别输入当前第一blstm神经网络和当前第二blstm神经网络进行深度学习,将高频系数对应的隐藏层向量和低频系数对应的隐藏层向量,分别进行cnn处理;
利用高频系数对应的cnn处理结果,计算各帧语音信号属于噪音段的第一概率;利用低频系数对应的cnn处理结果,计算各帧语音信号属于语音段的第二概率;
根据所述第一概率和所述第二概率的比较,确定相应帧语音信号属于语音段还是噪音段,并将其作为帧语音信号的预测标记;将每帧语音信号对应的预测标记与实际标记进行比较,并反向传播更新当前第一blstm神经网络的参数和当前第二blstm神经网络的参数,直到预测标记的准确性达到设定要求,停止训练。
较佳地,所述第一blstm神经网络和所述第二blstm神经网络相互独立。
一种语音端点的检测装置,包括:小波变换单元、第一熵计算单元、第二熵计算单元、第一blstm神经网络处理单元、第二blstm神经网络、第一cnn单元、第二cnn单元、分类单元和检测单元;
所述小波变换单元,用于将待检测的语音信号进行小波变换,将变换后得到的小波系数分成高频系数集和低频系数集,分别输入所述第一熵计算单元和所述第二熵计算单元;
所述第一熵计算单元,用于计算高频系数对应的熵向量,并输出给所述第一blstm神经网络处理单元;
所述第二熵计算单元,用于计算低频系数对应的熵向量,并输出给所述第二blstm神经网络处理单元;
所述第一blstm神经网络处理单元,用于利用训练生成的第一blstm神经网络对输入的高频系数对应的熵向量进行深度学习,得到高频系数对应的隐藏层向量输出给所述第一cnn单元;
所述第二blstm神经网络处理单元,用于利用训练生成的第二blstm神经网络对输入的低频系数对应的熵向量进行深度学习,得到低频系数对应的隐藏层向量输出给所述第二cnn单元;
所述第一cnn单元,用于对所述高频系数对应的隐藏层向量进行cnn处理,并利用该处理结果计算每帧语音信号属于噪音段的第一概率;
所述第二cnn单元,用于对所述低频系数对应的隐藏层向量进行cnn处理,并利用该处理结果计算每帧语音信号属于语音段的第二概率;
所述分类单元,用于根据所述第一概率和所述第二概率的比较,确定每帧语音信号所属的类别;
所述检测单元,用于根据所有帧语音信号所属的类别确定语音端点。
较佳地,进一步包括训练单元;
所述小波变换单元,还用于对将用于训练的语音信号根据特性划分成多个语音段和噪声段,并对所述语音段和噪声段进行小波变换,将变换后得到的小波系数分成高频系数集和低频系数集,分别输入所述第一熵计算单元和所述第二熵计算单元;其中,语音段长度在预设的长度范围内,并将不符合要求的语音信号片段删除;
所述训练单元,用于将各所述语音段和各所述噪音段内的信号分别以帧为单位对应标记为语音和噪音,并将所述标记作为相应帧的实际标记;将所述分类单元确定出的各所述语音段和各所述噪音段内每帧的标记与相应帧的实际标记进行比较,并反向传播更新当前第一blstm、当前第一cnn神经网络的参数和当前第二blstm、当前第二cnn神经网络的参数,直到预测标记的准确性达到设定要求,停止训练。
由上述技术方案可见,本申请中,将待检测的语音信号进行小波变换,将变换后得到的小波系数分成高频系数集和低频系数集,并分别计算高频系数对应的熵向量和低频系数对应的熵向量;将高频系数对应的熵向量和所述低频系数对应的熵向量分别输入预先训练生成的第一blstm神经网络和第二blstm神经网络进行深度学习,得到高频系数对应的隐藏层向量和低频系数对应的隐藏层向量,并将高频系数对应的隐藏层向量和低频系数对应的隐藏层向量,分别进行cnn处理;利用高频系数对应的cnn处理结果,计算每帧语音信号属于噪音段的第一概率;利用低频系数对应的cnn处理结果,计算每帧语音信号属于语音段的第二概率;根据第一概率和第二概率的比较,确定每帧语音信号所属的类别,并根据所有帧语音信号所属的类别确定语音端点。通过上述小波变换和blstm神经网络的结合,能够提高语音信号检测的抗噪能力和适应能力,同时实现起止点的准确检测。
附图说明
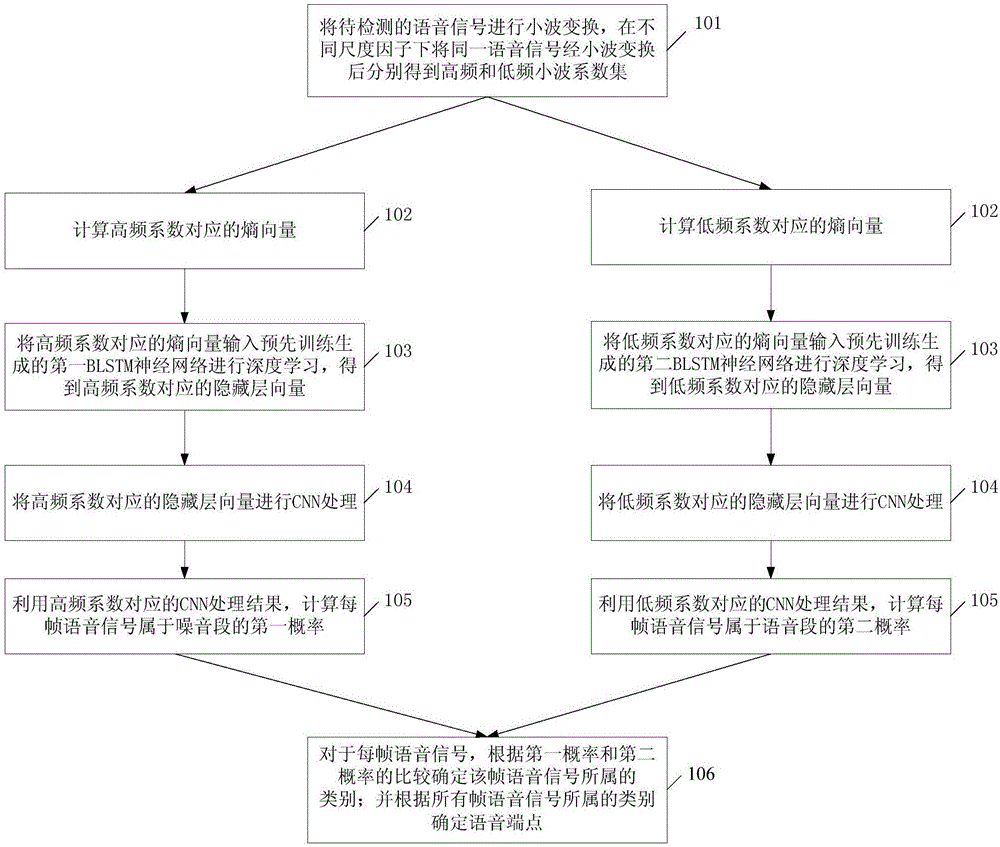
图1为本申请中语音端点检测方法的基本流程示意图;
图2为本申请中语音端点检测装置的基本结构示意图。
具体实施方式
为了使本申请的目的、技术手段和优点更加清楚明白,以下结合附图对本申请做进一步详细说明。
本申请引入循环神经网络,将高、低频语音信号进行端点检测,利用blstm从前后两个方向学习语音信号的特征和非线性关系,并采用softmax概率比较方式克服固定阈值的缺点,增强小波变换对不同语音信号和噪音信号的适应能力。
图1为本申请中语音端点检测方法的基本流程示意图。如图1所示,本申请中的检测方法包括:
步骤101,将待检测的语音信号进行小波变换,将变换后得到的小波系数分成高频系数集和低频系数集。
本申请对语音信号进行连续小波分解,以抽取语音信号不同时频域的波形特征;然后,分别在不同尺度因子上经小波变换形成高频和低频两个不同的小波系数集:coefficientsetshigh-fre,coefficientsetslow-fre。进行小波变换时采用的小波基可以根据实际需要进行选择,优选地,采用daubechies小波基函数。
步骤102,分别计算高频系数对应的熵向量和低频系数对应的熵向量。
针对步骤101的高频系数集和低频系数集,通过信息熵计算熵向量,得到高频系数对应的熵向量entropyvectorhigh-fre和低频系数对应的熵向量entropyvectorlow-fre。
信息熵计算公式为
其中,x=x1,x2,x3,...xn是一帧高频或低频系数,p(xi)是高频或低频系数xi的频率,近似于概率。
步骤103,将高频系数对应的熵向量和低频系数对应的熵向量分别输入预先训练生成的第一blstm神经网络和第二blstm神经网络进行深度学习,得到高频系数对应的隐藏层向量和低频系数对应的隐藏层向量。
双向循环神经网络blstm为双向长短期记忆网络,基于自循环权重机制,从两个平行相反的lstm层,以相同的网络结构抽取语音信号的特征。本申请中,基于熵向量从前后两个方向学习语音信号特征和非线性关系,可以通过时间向前移动的子rnn状态h(t)和向后移动的子rnn状态g(t),允许输入单元o(t)计算同时依赖于过去和未来且对时刻t的输入值最敏感的表示,以实现语音信号的特征强化。
具体地,本申请中采用梯度下降sgd算法。
lstm自循环更新机制为
自循环权重fi(t)计算公式为
外部输入门单元gi(t)计算公式为
其中,x(t)是当前输入向量,ht是当前隐藏层向量,bf、uf、wf分别是lstm网络中的偏置、输入权重和遗忘门循环权重。
其中,当前输入向量x(t)就是高频或低频系数对应的熵向量,隐藏层向量ht是经过blstm神经网络处理后的输出,即高频系数对应的隐藏层向量和低频系数对应的隐藏层向量。
另外,在具体处理中用到的第一blstm神经网络、第二blstm神经网络是通过预先的训练生成的。训练过程的目的就是调整blstm和cnn神经网络中的权重参数,以使blstm神经网络与小波变换、cnn和softmax概率结合,可以实现对音频帧的准确分类。其中,第一blstm、第一cnn神经网络和第二blstm、第二cnn神经网络相互独立,采用自己一套独立的参数。
具体神经网络的训练过程与图1中的检测过程类似,具体将在后面的内容中进行介绍。本步骤中,将高频系数对应的熵向量输入第一blstm神经网络,将低频系数对应的熵向量输入第二blstm神经网络,blstm神经网络的具体处理与现有方式相同,这里就不再赘述。
步骤104,将高频系数对应的隐藏层向量和低频系数对应的隐藏层向量分别进行cnn处理。
通过接收blstm网络的隐藏层输出,利用卷积网络进行卷积、池化操作,进行降维,同时,在一定程度上还可以进一步进行特征强化。
步骤105,利用高频系数对应的cnn处理结果,采用softmax计算每帧语音信号属于噪音段的第一概率;利用低频系数对应的cnn处理结果,采用softmax计算每帧语音信号属于语音段的第二概率。
本申请中,采用softmax概率比较来判定每帧语音信号是噪音还是语音。
一般地,如果一段语音信号为噪音,那么这段语音信号的能量往往集中在高频部分;如果一段语音信号为语音,那么这段语音信号的能量往往集中在低频部分。基于此,本申请将同一段音频信号在不同尺度因子下经小波变换分别形成高频和低频信号的小波系数集,对高低频小波系数集分别进行处理,以对应确定目标音频帧是噪音和语音的概率。
步骤106,对于每帧语音信号,根据第一概率和第二概率的比较确定该帧语音信号所属的类别;并根据所有帧语音信号所属的类别确定语音端点。
如步骤105中所述,第一概率代表某帧语音信号属于噪音的概率,第二概率代表某帧语音信号属于语音的概率,对于某帧语音信号,通过比较该帧的第一概率和第二概率即可以确定该帧是语音还是噪音。
最后,根据所有帧语音信号所属的类别就可以确定语音端点。
至此,本申请中的语音端点检测方法流程结束。
如前所述,对于网络的训练过程与图1所示的流程类似,具体包括:
1)将用于训练的已知语音信号根据特性划分成多个语音段和噪声段,其中,语音段长度在预设的长度范围内,并将不符合要求的语音信号片段删除;通常,通话语音的长度大概在4s~6s,基于此,优选地,语音段长度最长可以为4s,并将过短的语音片段删除;
2)将各语音段和噪音段内的信号分别以帧为单位对应标记为语音(可以利用s或1表示)和噪音(可以利用n或0表示),并将相应的标记作为相应帧的实际标记,用于后续和预测标记进行比较,以更新blstm和cnn网络的权重参数;
3)将步骤1)得到的各语音段和各噪音段进行小波变换,对每段音频信号经小波变换后分别得到分成高频和低频小波系数集,并分别计算高频系数对应的熵向量和低频系数对应的熵向量;将高频系数对应的熵向量和所述低频系数对应的熵向量分别输入当前第一blstm神经网络和当前第二blstm神经网络进行深度学习,将高频系数对应的隐藏层向量和低频系数对应的隐藏层向量,分别进行cnn处理;利用高频系数对应的cnn处理结果,计算各帧语音信号属于噪音段的第一概率;利用低频系数对应的cnn处理结果,计算各帧语音信号属于语音段的第二概率;这里的处理与图1中步骤101~105相同;
4)根据第一概率和第二概率的比较,确定相应帧语音信号属于语音段还是噪音段,并将其作为帧语音信号的预测标记;将每帧语音信号对应的预测标记与实际标记进行比较,并反向传播更新当前第一blstm神经网络的参数和当前第二blstm神经网络的参数,直到预测标记的准确性达到设定要求即可停止训练。
由上述可见,训练过程与实际识别过程相比,增加了循环更新网络参数的处理,直到标记预测的准确率达到要求。也正是通过上述循环往复进行的过程,找到最合适的网络参数,以保证每帧语音信号类别判定的准确性。
上述即为本申请中语音端点检测方法的具体实现。本申请还提供了一种语音端点检测装置,可以用于实施上述方法。图2为本申请中语音端点检测装置的基本结构示意图。如图2所示,该装置包括:小波变换单元、第一熵计算单元、第二熵计算单元、第一blstm神经网络处理单元、第二blstm神经网络、第一cnn单元、第二cnn单元、分类单元和检测单元。
其中,小波变换单元,用于将待检测的语音信号进行小波变换,在不同尺度因子下将同一语音信号经小波变换后分别得到高频和低频小波系数集,分别输入第一熵计算单元和第二熵计算单元。
第一熵计算单元,用于计算高频系数对应的熵向量,并输出给所述第一blstm神经网络处理单元。第二熵计算单元,用于计算低频系数对应的熵向量,并输出给所述第二blstm神经网络处理单元。
第一blstm神经网络处理单元,用于利用训练生成的第一blstm神经网络对输入的高频系数对应的熵向量进行深度学习,得到高频系数对应的隐藏层向量输出给第一cnn单元。第二blstm神经网络处理单元,用于利用训练生成的第二blstm神经网络对输入的低频系数对应的熵向量进行深度学习,得到低频系数对应的隐藏层向量输出给第二cnn单元。
第一cnn单元,用于对高频系数对应的隐藏层向量进行cnn处理,并利用该处理结果计算每帧语音信号属于噪音段的第一概率。第二cnn单元,用于对低频系数对应的隐藏层向量进行cnn处理,并利用该处理结果计算每帧语音信号属于语音段的第二概率。
分类单元,用于根据第一概率和第二概率的比较,确定每帧语音信号所属的类别。检测单元,用于根据所有帧语音信号所属的类别确定语音端点。
为实现网络的训练过程,优选地,图2所示的装置还可以进一步包括训练单元。
在训练过程中,小波变换单元,还用于对将用于训练的语音信号根据特性划分成多个语音段和噪声段,并对语音段和噪声段进行小波变换,将变换后得到的小波系数分成高频系数集和低频系数集,分别输入第一熵计算单元和第二熵计算单元;其中,语音段长度在预设的长度范围内,并将不符合要求的语音信号片段删除。
训练单元,用于将各语音段和各噪音段内的信号分别以帧为单位对应标记为语音和噪音,并将所述标记作为相应帧的实际标记;将分类单元确定出的各语音段和各噪音段内每帧的标记与相应帧的实际标记进行比较,并反向传播更新当前第一blstm、第一cnn神经网络的参数和当前第二blstm、第二cnn神经网络的参数,直到预测标记的准确性达到设定要求,停止训练。
上述即为本申请中语音端点的检测方法和装置,通过本申请的处理,能够提高语音信号检测的自适应能力、抗噪能力和鲁棒性等特征,帮助小波变换提升语音端点检测的准确度性能。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!