基于注意力机制和卷积神经网络的语音抑郁症识别方法与流程
本发明涉及语音处理,机器学习和深度学习领域,尤其是涉及基于注意力机制和卷积神经网络的语音抑郁症识别方法。
背景技术:
抑郁症是一种最常见的情绪障碍,往往表现出情绪低落,态度消极,自我责备等负面状态。抑郁症不仅会对自身造成伤害,对日常生活,社会工作,人际关系等产生很大的影响。但现阶段,抑郁症的诊断还是依靠医生的主观判断为主,一些评价量表为辅助手段,因此抑郁症很难被准确诊断,使得抑郁症患者难以得到基本的治疗。如何让计算机通过语音信号自动分析和判别说话人的抑郁症的严重程度,即语音的抑郁症识别,成为了研究热点。能够找到客观准确、简便高效、非侵入、低廉的自动检测抑郁症的方法对抑郁症的就诊率和治愈率有很大的提高作用,对医学领域也有重要的贡献。
目前,对语音的抑郁症识别的研究主要是从语音信号中提取与抑郁症相关基础的低级特征(llds),比如基频(f0)、共振峰、梅尔频谱系数(mfcc)等。然后用分类器对这些提取的特征进行分类,分类器包括支持向量机(svm),随机森林(rf),高斯混合模型(gmm)等。但存在的问题是上述特征提取过程提取的是低级手动提取的语音特征,没有提取语音信号中更深层次的特征,因此并不能充分表示语音数据。随着深度学习的发展,卷积神经网络在图像特征提取中体现出了优异的性能。有研究者在语音抑郁症识别方面也尝试去用卷积神经网络来自动提取语音中和抑郁症相关的更深层次特征,取得了一定的研究进展。
这些方法都通过分割语音,得到语音片段,然后将语音频谱图输入到神经网络中,自动提取与抑郁症相关的深层次特征,最后进行决策分类。但是,存在的问题是,并不是所以的语音片段都包含与抑郁症相关的特征,比如静音段,沉默段。这些语音片段并没有与抑郁症相关的特征,但是训练时,将分类标签和整句的标签设为一样,都是抑郁症标签,这使得分类的准确率大大的降低。
注意力机制(attentionmechanism)在机器翻译,图像字幕匹配等方面表现出显著的性能。注意力模型能够使神经网络关注最相关的信息,比如在语音特征中,使和神经网络关注和抑郁症最相关的信息,忽略不相关的特征,这很好的解决了不相关的特征在训练神经网络过程中的影响。目前,在语音的抑郁症识别领域,还未见采用注意力机制和卷积神经网络结合来识别抑郁症的方法。本发明就是利用注意力机制和卷积神经网络实现语音的抑郁症识别。
技术实现要素:
本发明的目的就是为了解决上述现有语音的抑郁症识别技术的不足,提供一种基于注意力机制和卷积神经网络的语音抑郁症识别方法,用于实现根据语音来自动检测抑郁症,提高抑郁症识别的准确率。
本发明解决上述技术问题所采用的技术方案为:
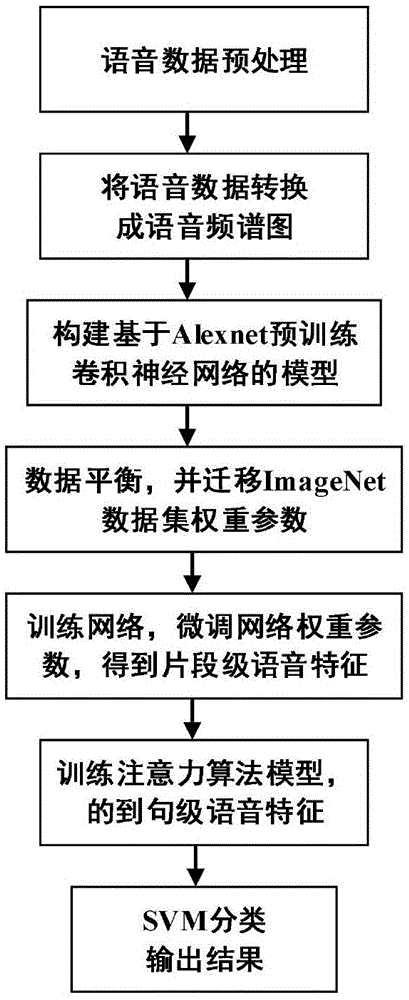
一种基于注意力机制和卷积神经网络的语音抑郁症识别方法,通过语音数据的预处理、提取语音频谱图、构建深度卷积神经网络(dcnn)预训练模型得到片段级特征、用注意力机制算法得到句级特征、svm模型分类输出结果;
该方法包含的具体步骤如下:
步骤1、语音数据的预处理,包括:
将语音抑郁症识别的语音数据集中的所有语音样本,分为训练集、验证集和测试集三部分。分析所有语音样本的语音数据,从提问方式的语音样本中挑选出10句最长的句子,去掉提问者的语音,只保留被试者的语音数据。最后对每个语音样本的10个句子进行标定标签,标定和原语音样本相同的标签。从而产生语音抑郁症识别的样本;
步骤2、提取语音频谱图,包括:
对每个语音样本的10个句子,按窗口大小分割语音数据,从而对每个片段提取rgb三通道的语音频谱图。然后堆叠三通道的频谱图,调整频谱图的尺寸大小,作为卷积神经网络的输入;
步骤3、构建深度卷积神经网络,包括:
构建深度卷积神经网络,对网络进行预训练,然后将语音频谱图输入到卷积神经网络中,进行权值的微调,从而提取语音频谱图中更深层的特征,即得到每个语音分割片段的语音特征;
步骤4、注意力机制算法提取语音的句级特征,包括:
通过卷积神经网络得到了每个片段的语音特征,然后融合一个句子的所有片段特征,填充到相同长度,并用attention模型对得到的融合特征进行权值调整,最后训练attention模型,得到语音的句级特征。
步骤5、svm模型分类输出结果,包括:
构建svm分类器模型,然后用得到的句级特征进行训练,最后输出语音的抑郁症识别结果。
步骤1中所述的语音数据集,采用的是avec2017比赛子项目的数据库。数据库包含了189个被试者,包含107个训练集、35个验证集和47个测试集。该数据库的语音数据采集的过程是虚拟机器人ellie通过访谈的方式提问被试者问题,记录其语音对话,每个个体的语音长度从7-35min不等。
步骤1中所述的在每个语音样本中挑选10个最长的句子,一方面为了去除和抑郁症不相关问题的语音数据,比如访谈交谈过程的客套问题;另一方面为了扩充样本集,增强模型训练,提高模型的适应能力。挑选最长的10个句子其提问的问题都是和抑郁症比较相关的问题,比如:你最近睡眠质量怎么样,你最近是否有被诊断为抑郁症,最近令你烦恼的事情是什么等问题。之后去除提问者的语音数据,只提取对应回答者的回答语音,作为一个新的样本,依据的是提问者的语音对抑郁症识别毫无相关,只需提取被试者的语音数据。
步骤1中所述的标签标定每个语音样本中10个句子的标签都是和原语音样本的标签一致,即原语音样本的标签如果是抑郁症,则对应的10个句子都是抑郁症标签,这等于将原来的数据集扩充了10倍数据,能够更好的训练网络。
步骤2中所述语音频谱图的提取过程,包含如下步骤:
2-1.对每条语音数据进行预加重;
2-2.将预加重后的语音信号进行分帧;
2-3.对分帧后的语音信号进行加窗处理;
2-4.将加窗后的波形信号进行快速傅里叶变换;
2-5.最后将语音数据转换为rgb三通道的语音频谱图。
步骤2中所述的rgb三通道的语音频谱图,三个通道分别为static、delta,、deltadelta。其中static是上述过程后得到的原始语音频谱图,delta是通过static求解其一阶回归系数得到,deltadelta是通过static求解其二阶回归系数得到。
步骤2中所述调整语音频谱图大小,是由于输入到卷积神经网络的尺寸是固定的,需要调整频谱图的大小使其适合卷积神经网络的输入。本发明选择64个梅尔滤波器,频率从20~8000hz。语音分割段的长度选择64帧,则分割段的长度为10ms×63+25ms=655ms。最后得到64×64像素的语音频谱图,由于dcnn的输入固定为227×227,因此需要调整频谱图的大小以适应dcnn的输入。通过双线性插值的方法,将输出得到的64×64×3像素的频谱图调整为227×227×3像素大小。
步骤3中所述的dcnn卷积神经网络用到的是alexnet网络模型。alexnet包括5层卷积层、2层全连接层和1层softmax分类层。第1层卷积层后和第5层卷积层后面分别有1层池化层,池化层选择最大池化(maxpooling),全连接层后设有dropout层,用于防止训练数据不平衡出现过拟合现象,softmax层用于训练时的分类,本发明中分为2类,即抑郁症和非抑郁症。
步骤3中所述的预训练和权值微调过程,其步骤包括:
3-1.首先采用重复采样方法对语音的抑郁症数据集进行数据平衡,使抑郁症和非抑郁症的语音片段数据大致做到相等。
3-2.迁移在imagenet数据集上预训练alexnet网络模型的权重参数,固定前5层卷积层的权重参数,使在网络训练时前5层的权重参数不变,只调整之后2层全连接层的参数;
3-3.用平衡好的语音数据集训练alexnet神经网络,微调后2层全连接层的权值参数。在网络微调训练过程中,经softmax激活函数判断是否是抑郁症。
3-4.训练完后去除softmax层,然后连接上步骤4中的attention算法模块。训练后续模块和测试时将dcnn的权值参数固定。
步骤4中所述的融合一个句子的所有片段级语音特征是将一个句子的所有片段级语音特征按时间序列拼接成一个矩阵。由于每个句子的长度不相同,因此每个句子分割的片段数是不同的,因此矩阵的长度是不同的。本发明将填充补0到相同长度的特征矩阵。依据的是,attention算法对抑郁症相关的特征片段赋予很高的权值,对于不相关的特征赋予很小或者0的权值,这样填充0的部分等于和抑郁症不相关,权值设为0,因此填充0到相同长度不影响整个识别结果。
步骤4中所述的注意力机制算法,其方法可以表述如下:
式中,t为每一时段帧的编号,t为一个句子中帧的总数量,τ指某一帧的序号。yt为经过卷积神经网络输出的片段级特征,u为注意力参数向量,两者进行内积操作。αt可以解释为对最终整句语音的抑郁症表达所贡献的权值分数。
将得到的权值分数进行加权平均,z为得到的句级特征表示:
步骤中所述的训练attention模型的过程实际是训练权重矩阵的过程,权值分数αt和融合得到的片段级特征yt进行内积操作得到最后的句级特征。
步骤中所述svm分类输出结果的过程,包括构建svm分类模型和训练模型两个过程。首先构建svm分类器模型,然后用步骤4得到的句级特征进行训练,最后输出语音的抑郁症识别结果。
步骤5中所述的svm分类过程,在语音的抑郁症识别测试中,采用10倍交叉验证的技术,即所有语音数据平分为10份,9份数据用于训练,剩下1份数据用于测试,这样的过程重复10次得到的平均值作为最终的识别结果。
与现有技术相比,本发明的有益效果在于:
(1)本发明充分考虑了每个个体语音数据的长度不同以及和语音片段和抑郁症之间的相关性,利用attention算法进行权值调整,使和抑郁症相关的特征更加凸显,分配更大的权值;和抑郁症不相关的特征分配更小的权值或设置为0,提高了识别的准确率。
(2)本发明方法使用语谱图和预训练的深度卷积神经网络,同时对语音数据进行数据平衡,提高了网络训练的速度,同时提高了识别准确率。
附图说明
图1为本发明方法的流程示意图。
图2为本发明总体实现的网络示意图
图3为本发明alexnet卷积神经网络训练模型和权值微调过程图。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
图1为本发明的方法流程图,主要包括五个过程:语音数据的预处理、提取语音频谱图、构建深度卷积神经网络预训练模型得到片段级特征、注意力机制算法得到句级特征、svm模型分类输出结果。
一、语音数据的预处理
本发明选择一个语音抑郁症识别比赛的数据库avec2017–dsc(见文献:ringevalf,schullerb,valstarm,etal.summaryforavec2017:real-lifedepressionandaffectchallengeandworkshop[c]//acmonmultimediaconference.acm,2017:1963-1964)。该数据库包含了189个被试者,包含107个训练集,35个验证集,47个测试集。采集的语音数据的过程是虚拟机器人ellie通过访谈方式提问被试者,记录其语音对话,每个个体的语音长度从7-35min不等。语音预处理过程表述如下:
首先,对每个个体的语音对话进行了分析,选择了和抑郁症识别最为相关并且长度最长的10句对话。挑选最长的10个句子其提问的问题都是和抑郁症比较相关的问题,比如:你最近睡眠质量怎么样,你最近是否有被诊断为抑郁症,最近令你烦恼的事情是什么等问题。在这些问题中,抑郁症个体和非抑郁症个体在语音表述上有一定的差别。比如:抑郁症个人在回答令人烦恼的事情时,回答的语音特点明显和正常人不相同,往往情绪更加低沉失落。然后去掉提问者的语音,只挑选出被试者回答的语音数据。最后对这些语音数据标定标签,10句话的标签和原样本的标签一致,这样就得到了预处理后的语音样本数据集。
二、提取语音频谱图
语音频谱图提取过程,包含如下步骤:
1)对每条语音数据进行预加重。预加重的目的是提升高频部分,使信号的频谱变得平坦,同时消除发生过程中声带和嘴唇的影响,补偿语音信号高频部分。预加重处理的传递函数公式为:
h(z)=1-μz-1
其中z为语音信号波形,μ为预加重系数,μ的取值一般去0.9-1,本发明μ取0.97;
2)将预加重后的语音波形信号进行分帧。分帧的每帧长度大概在20ms~30ms,这里选择每一帧的长度为25ms,为了避免相邻两帧的变化过大,因此会让两相邻帧之间有一段重叠区域,加上帧移可以更好的与实际的语音波形信号相接近,本发明帧移选择为10ms。
3)对分帧后的语音数据进行加窗处理。需要对分帧后的语音波形信号每一帧乘以汉明窗,以增加帧左端和右端的连续性。同时避免在后续快速傅里叶变换中发生高频部分泄漏的情况。汉明窗口公式可以表述为:
式中,a为汉明窗口系数,不同的a会产生不同的汉明窗,一般取0.46。
4)将加窗后的数据进行快速傅里叶变换。其公式为:
其中s(t)为加窗后的语音波形信号,t为汉明窗的长度,h(t)为汉明窗函数,fft为快速傅里叶变换函数。
5)最后将语音数据转换为rgb三通道的语音频谱图。三个通道分别为static,delta,deltadelta。其中static是上述过程后得到的原始语音频谱图,delta是通过static求解其一阶回归系数得到,deltadelta是通过static求解其二阶回归系数得到。本发明选择64个梅尔滤波器,频率从20~8000hz,语音分割段的长度选择64帧,则分割段的长度为10ms×63+25ms=655ms。如图2所示,最后得到64×64像素的语音频谱图,由于dcnn的输入固定为227×227,因此需要调整频谱图的大小以适应dcnn的输入。堆叠三个通道的语音频谱图,通过双线性插值的方法,将输出得到的64×64×3像素的频谱图调整为227×227×3像素大小的频谱图,从而得到本发明输入到alexnet卷积神经网络中的语音频谱图。
三、构建预训练模型,提取语音片段级特征
提取语音片段级包括如下步骤:
1)构建alexnet深度卷积神经网络模型。该网络有5层卷积层和2层全连接层构成。如图3所示,卷积神经网络由c1、p1、c2、p2、c3、c4、c5、p5、fc6、fc7和softmax构成。c表示卷积层,p表示池化层,fc表示全连接层,softmax用于训练微调时的分类。具体的网络结构参数设置为:卷积层c1的卷积核大小为11×11×96,步长为4×4;池化层p1的池化窗口大小为3×3,步长为2×2,填充方式为大小为2的零填充;卷积层c2的卷积核大小为5×5×256,步长为1×1;池化层p2的池化窗口大小为3×3,步长为2×2,填充方式为大小为1的零填充;卷积层c3的卷积核大小为3×3×384,步长为1×1;卷积层c4的卷积核大小为3×3×384,步长为1×1;卷积层c5的卷积核大小为3×3×256,步长为1×1;池化层p5的池化窗口大小为3×3,步长为2×2,填充方式为大小为1的零填充;全连接层fc6和fc7都包含4096个神经元。
使用relu函数作为卷积和池化的激活函数,池化操作均选用最大池化方式,以减小计算复杂度。全连接层后设有dropout层用于防止训练数据不平衡出现过拟合现象,dropout率设置为0.5。使用随机梯度下降法(sgd)计算损失函数,学习率为0.001,动量为0.9。
2)平衡语音数据集。由于样本中抑郁症的个体和非抑郁症的个体的数量有较大差别,需要对样本进行平衡。本发明选择用重复采样方法对语音的抑郁症数据集进行数据平衡,使抑郁症和非抑郁症的语音片段数大致相等。
3)迁移在imagenet数据集上预训练的alexnet网络的权重参数。用迁移的权重参数初始化上述构建的深度卷积神经网络部分权重参数。迁移学习能够加快网络的训练,提高网络的泛化能力。由于imagenet的图片和语音频谱图的差别较大,且语音频谱具有一定的特性,因此在训练时固定前5层卷积层的权重参数,使在网络训练时前5层的权重参数不变,只调整之后2层全连接层的参数。
4)用平衡好的数据集训练alexnet神经网络,微调后2层全连接层的权值参数。在网络微调训练过程中,经softmax激活函数判断是否是抑郁症。训练完后去除softmax层,然后连接上步骤(4)中的attention算法模块。训练后续模块和测试时将dcnn的权值参数固定。
这样经过alexnet网络就自动提取了语音的片段级特征。由于句子的长度是不同的,因此句子之间的片段数是不等的,因此采用步骤(4)中的注意力机制算法,减小和抑郁症不相关的片段特征的影响,凸显和抑郁症相关的特征。
四、注意力算法得到句级特征
1)首先融合一个句子的所有片段级语音特征是将一个句子的所有片段级语音特征按时间序列拼接成一个矩阵。由于每个句子的长度不相同,因此每个句子分割的片段数是不同的,因此矩阵的长度是不同的。本发明将填充补0到相同长度的特征矩阵。依据的是,attention算法对抑郁症相关的特征片段赋予很高的权值,对于不相关的特征赋予很小或者0的权值,这样填充0的部分等于和抑郁症不相关,权值设为0,因此填充0到相同长度不影响整个识别结果。
2)其次构建attention算法模型,所述的注意力机制算法,其方法可以表述如下:
式中,t为每一时段帧的编号,yt为经过卷积神经网络的输出,u为注意力参数向量,两者进行内积操作。αt可以解释为对最终整句语音的抑郁症表达所贡献的权值分数。
将得到的权值进行加权平均,z为得到句级的特征表示:
3)最后,训练attention模型。训练attention模型实际是训练权重矩阵的过程,权重αt和融合得到的片段级特征yt进行内积操作得到最后的句级特征。这样得到了每个句子的句级特征表示,也就是输入到svm模型的特征。
五、svm分类
对得到的句级特征进行分类,分类模型选择svm分类器。首先构建svm分类器模型,然后用得到的句级特征样本进行训练,最后输出语音的抑郁症识别结果。在语音的抑郁症识别测试中,采用10倍交叉验证的技术,即所有语音数据平分为10份,9份数据用于训练,剩下1份数据用于测试,这样的过程重复10次得到的平均值作为最终的识别结果。
现在对本实施例尝试的结果进行分析和说明:
本发明方案利用imagenet数据集预训练好的alexnet模型提取片段级的语音特征,并用attention算法对片段级特征进行权值调整,使和抑郁症相关的片段特征权值更高,减小和抑郁症不相关或者无关的特征权值,提高了语音的抑郁症识别的准确率。用预训练的alexnet模型有一定的泛化能力,提高了了网络训练的速度,一定程度上提高了网络的识别准确率。本实验的评价指标是均方根误差(rmse)和平均绝对误差(mae),只用语音数据得到的基线标准:rmse=7.78,mae=5.72。本实验测试的结果:rmse=6.24,mae=5.02,实验结果误差小于基线标准,证明了本技术方案的有效性,同时实验结果优于其他文献采用传统的提取语音基础llds特征的方法。attention算法进一步提高了语音抑郁症识别的准确率,没有采用attention机制的结果rmse=6.76,mae=5.43,验证了attention算法的有效性和适用性,提高了最后的识别准确率。
- 还没有人留言评论。精彩留言会获得点赞!