基于方言背景的语音识别方法及相关设备与流程
本申请涉及人工智能技术领域,尤其涉及一种基于方言背景的语音识别方法及相关设备。
背景技术:
贷款是银行或其他金融机构按一定利率和必须归还等条件出借货币资金的一种信用活动形式。广义的贷款指贷款、贴现、透支等出贷资金的总称。银行通过贷款的方式将所集中的货币和货币资金投放出去,可以满足社会扩大再生产对补充资金的需要,促进经济的发展,同时,银行也可以由此取得贷款利息收入,增加银行自身的积累。然而,贷款安全问题是商业银行面临的首要问题。
对于贷款安全问题,目前各个银行普遍开始采用语音识别的方式对贷款人的身份进行核实,以防止贷款过程中的欺诈行为。但是基于方言背景的语音分析还不成熟。由于我国幅员辽阔,各地的方言存在着很大的差异,在进行语音识别时,无法准确的根据用户的语音分析出其方言特征,从而无法对用户的身份进行有效识别。
技术实现要素:
有鉴于此,有必要针对各地的方言存在着很大的差异,在进行语音识别时,无法准确的根据用户的语音对用户的身份进行有效识别的问题,提供一种基于方言背景的语音识别方法及相关设备。
一种基于方言背景的语音识别方法,包括:
采集若干地方的方言信息数据,对所述方言信息数据按照地域进行分类存储,生成方言信息数据库;
获取目标对象的音频数据,从所述音频数据中提取多个特征词语的实际发音,将每一所述特征词语的实际发音的声波进行矢量化处理,生成矢量集a;
从所述方言信息数据库中提取n个不同地域的方言信息数据,分别从每一地域的方言信息数据中提取与所述特征词语字形相同的词语对应的方言发音,将各所述方言发音矢量化,得到各所述方言发音对应的矢量值,将各所述方言发音对应的矢量值分别进行汇总,生成n个方言矢量集;
将所述矢量集a与所述n个方言矢量集中的每一个矢量集分别进行比较,得到所述目标对象语音中的方言地理特征,其中,所述方言地理特征包括第一籍贯信息和第一居住地信息;
获取所述目标对象提供的户籍信息,所述户籍信息包括第二籍贯信息和第二居住地信息,判断所述方言地理特征和所述户籍信息是否一致。
在其中一个可能的实施例中,所述采集若干地方的方言信息数据,对所述方言信息数据按照地域进行分类存储,生成方言信息数据库,包括:
通过网络爬虫的方式从现有各网络平台中获取若干地方的所述方言信息数据;
将所述方言信息数据按照地域进行分类并打包,生成多个地域的方言信息数据包,对各地域的所述方言信息数据包使用不同的标记符号进行标记;
将标记好的所述方言信息数据包存储于不同的位置,生成方言信息数据库。
在其中一个可能的实施例中,所述获取所述目标对象提供的户籍信息,所述户籍信息包括第二籍贯信息和第二居住地信息,判断所述方言地理特征和所述户籍信息是否一致,包括:
提取所述方言地理特征中所述目标对象的地域地点文字信息和所述籍贯信息的籍贯地点文字信息以及所述居住地信息的居住地点文字信息;
将所述地域地点文字信息分别与所述籍贯地点文字信息、所述居住地点文字信息进行比较,判断所述地域地点文字信息与所述籍贯地点文字信息或者所述居住地点文字信息是否一致。
在其中一个可能的实施例中,所所述获取目标对象的音频数据,从所述音频数据中提取多个特征词语的实际发音,将每一所述特征词语的实际发音的声波进行矢量化处理,生成矢量集a,包括:
从视频通话中提取所述目标对象的音频数据,从所述音频数据中提取音轨;
从所述音轨中截取多个所述特征词语的实际发音对应的声波,对每一所述声波进行降噪处理;
对降噪处理后的每一所述声波按照预设的频率和预设的长度分别截取成若干帧片段;
分别将每一所述声波对应的若干所述帧片段转化为一矢量值,汇总所有所述矢量值,生成所述矢量集a。
在其中一个可能的实施例中,所述将所述矢量集a与所述n个方言矢量集中的每一个矢量集分别进行比较,得到所述目标对象语音中的方言地理特征,包括:
从所述n个矢量集中选取其中一个矢量集作为矢量集b,将所述矢量集a中的每一矢量分别与所述矢量集b中对应的矢量进行比较,得到比较结果;
将所述比较结果与预设的误差阈值进行比较,若所述比较结果小于所述误差阈值,则得出所述目标对象的方言地理特征为所述矢量集b对应的所述方言信息数据所属的方言地理特征,若所述比较结果大于所述阈值,则从所述n个矢量集中再选取一个矢量集与所述矢量集a进行比较,直到得出所述目标对象的方言地理特征。
在其中一个可能的实施例中,所述将所述地域地点文字信息分别与所述籍贯地点文字信息、所述居住地点文字信息进行比较,判断所述地域地点文字信息与所述籍贯地点文字信息或者所述居住地点文字信息是否一致,包括:
按照预设的字符长度和高度在所述地域地点文字信息、所述籍贯地点文字信息以及所述居住地点文字信息中分别建立若干相同的矩形区域;
比较所述地域地点文字信息和所述籍贯地点文字信息相同位置上的所述矩形区域的像素值,若每一相同位置上的像素值均相同,则所述地域地点文字信息与所述籍贯地点文字信息一致,否则,不一致;
比较所述地域地点文字信息和所述居住地点文字信息相同位置上的所述矩形区域的像素值,若每一相同位置上的像素值均相同,则所述地域地点文字信息与所述居住地点文字信息一致,否则,不一致。
一种基于方言背景的语音识别装置,包括如下模块:
采集模块,设置为采集若干地方的方言信息数据,对所述方言信息数据按照地域进行分类存储,生成方言信息数据库;
矢量集a生成模块,设置为获取目标对象的音频数据,从所述音频数据中提取多个特征词语的实际发音,将每一所述特征词语的实际发音的声波进行矢量化处理,生成矢量集a;
方言矢量集生成模块,设置为从所述方言信息数据库中提取n个不同地域的方言信息数据,分别从每一地域的方言信息数据中提取与所述特征词语字形相同的词语对应的方言发音,将各所述方言发音矢量化,得到各所述方言发音对应的矢量值,将各所述方言发音对应的矢量值分别进行汇总,生成n个方言矢量集;
比较模块,设置为将所述矢量集a与所述n个方言矢量集中的每一个矢量集分别进行比较,得到所述目标对象语音中的方言地理特征,其中,所述方言地理特征包括第一籍贯信息和第一居住地信息;
判断模块,设置为获取所述目标对象提供的户籍信息,所述户籍信息包括第二籍贯信息和第二居住地信息,判断所述方言地理特征和所述户籍信息是否一致。
在其中一个可能的实施例中,所述采集模块还用于:
通过网络爬虫的方式从现有各网络平台中获取若干地方的所述方言信息数据;将所述方言信息数据按照地域进行分类并打包,生成多个地域的方言信息数据包,对各地域的所述方言信息数据包使用不同的标记符号进行标记;将标记好的所述方言信息数据包存储于不同的位置,生成方言信息数据库。
基于相同的构思,本申请提出了一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器中存储有计算机可读指令,所述计算机可读指令被一个或多个所述处理器执行时,使得一个或多个所述处理器执行上述基于方言背景的语音识别方法的步骤。
基于相同的构思,本申请提出了一种存储介质,所述存储介质可被处理器读写,所述存储介质存储有计算机可读指令,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个所述处理器执行上述基于方言背景的语音识别方法的步骤。
与现有技术相比,本申请中,通过授信审核视频通话中的音频数据分析其语音中带有的方言特征,有效的对用户的语音进行识别,从而扩大了贷款业务流程中欺诈信息的获取维度和分析维度,增加了判断贷款申请人是否涉嫌欺诈的判断方向,进一步增强了贷款机构的反欺诈能力,提高了贷款机构的放贷安全。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。
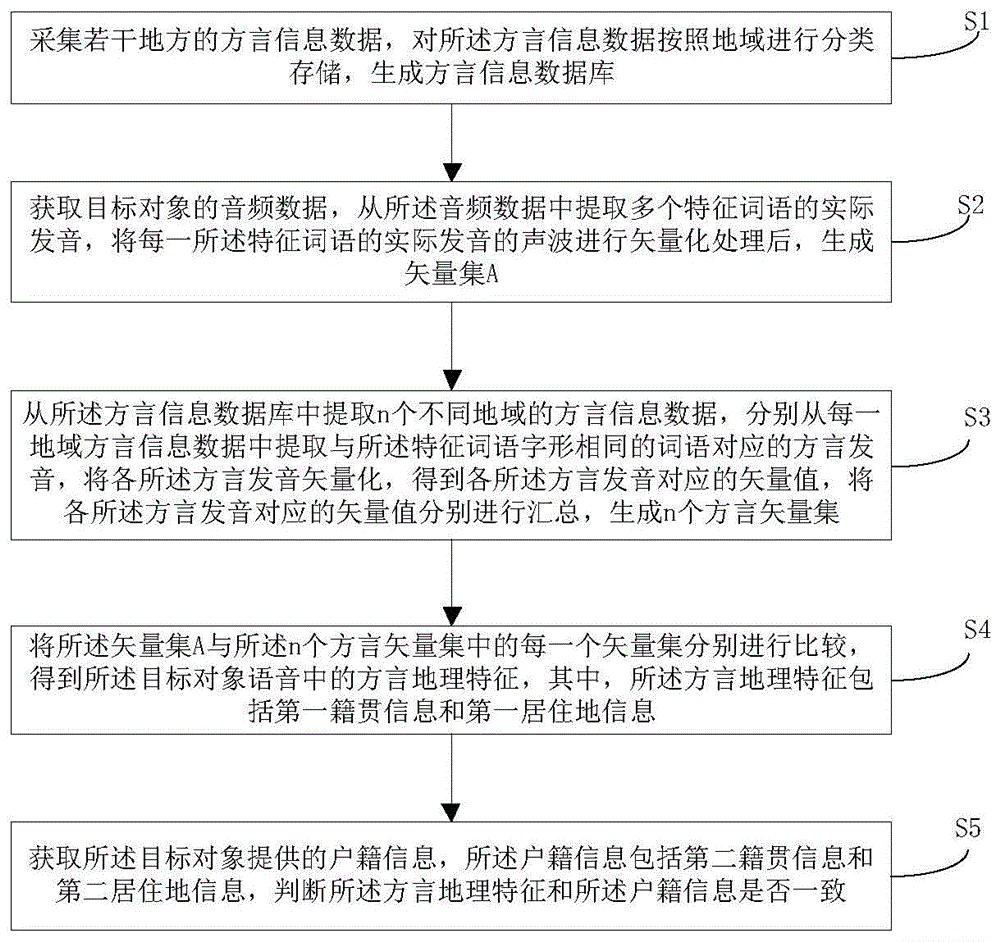
图1为本申请实施例中的一种基于方言背景的语音识别方法的整体流程图;
图2为本申请实施例中的一种基于方言背景的语音识别方法中的判断信息欺诈过程的示意图;
图3为本申请实施例中的一种基于方言背景的语音识别装置的结构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本发明的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。
图1为本申请实施例中的一种基于方言背景的语音识别方法的整体流程图,如图1所示,一种基于方言背景的语音识别方法,包括:
步骤s1,采集若干地方的方言信息数据,对所述方言信息数据按照地域进行分类存储,生成方言信息数据库。
本步骤执行时,采集地方方言信息数据的方式有多种,可以从现有各网络平台中获取若干地方的所述方言信息数据,也可以去各地收集所述方言信息数据。所述方言信息数据包括方言的语音音频数据和方言的文字数据。采集到的方言信息数据数量比较庞大,所以需要建立方言信息数据库,且需要将这些方言信息数据按地域的不同进行分类,具体的,可以按照县的级别进行分类。分好类之后,将所述方言信息数据按照地域级别进行打包,生成多个地域的方言信息数据包,再对每一个方言信息数据包使用不同的标记符号进行标记,并将标记好的所述方言信息数据包存储于不同的位置,这样就建立了一个方言信息数据库。
步骤s2,获取目标对象的音频数据,从所述音频数据中提取多个特征词语的实际发音,将每一所述特征词语的实际发音的声波进行矢量化处理,生成矢量集a。
本步骤执行时,首先,在授信审核视频通话时,就从视频通话中提取的目标对象的音频数据,再从所述音频数据中提取所述目标对象的说的若干词语的发音,将每一所述词语的发音的声波均矢量化,生成矢量集a。
步骤s3,从所述方言信息数据库中提取n个不同地域的方言信息数据,分别从每一地域的方言信息数据中提取与所述特征词语字形相同的词语对应的方言发音,将各所述方言发音矢量化,得到各所述方言发音对应的矢量值,将各所述方言发音对应的矢量值分别进行汇总,生成n个方言矢量集。
本步骤执行时,在将方言发音矢量化时,可以建立一个二维坐标系,以接收声波的接收器作为二维坐标系的原点,根据声波的传输方向和分贝大小确定不同方言发音的音高和方向。对于不同的地域,每个字的发音是不一样的,比如“吃”在北方发“chi”,而在南方部分地区发“qia”,二者的音高存在着显著差异。
步骤s4,将所述矢量集a与所述n个方言矢量集中的每一个矢量集分别进行比较,得到所述目标对象语音中的方言地理特征,其中,所述方言地理特征包括第一籍贯信息和第一居住地信息。
本步骤执行时,从所述n个方言矢量集中选取其中一个矢量集作为矢量集b,将所述矢量集a中的每一矢量分别与所述矢量集b中对应的矢量进行比较,得到比较结果;将所述比较结果与预设的误差阈值进行比较,若所述比较结果小于所述误差阈值,则得出所述贷款申请人的方言地理特征为所述矢量集b对应的所述方言信息数据所属的方言地理特征,若所述比较结果大于所述阈值,则从所述n个矢量集中再选取一个矢量集与所述矢量集a进行比较,直到得出所述申请人的方言地理特征。
步骤s5,获取所述目标对象提供的户籍信息,所述户籍信息包括第二籍贯信息和第二居住地信息,判断所述方言地理特征和所述户籍信息是否一致。
本实施例,通过授信审核视频通话中目标对象的音频数据分析其语音中带有的方言特征,扩大了贷款业务流程中欺诈信息的获取维度和分析维度,增加了判断贷款申请人是否涉嫌欺诈的判断方向,进一步增强了贷款机构的反欺诈能力,提高了贷款机构的放贷安全。
在一个实施例中,所述步骤s1,采集若干地方的方言信息数据,对所述方言信息数据按照地域进行分类存储,生成方言信息数据库,包括:
通过网络爬虫的方式从现有各网络平台中获取若干地方的所述方言信息数据;
本步骤中,与方言相关的文献和记载都非常详实,这部分信息极易从现有各网络平台中获取。较佳地,还可以去各地收集所述方言信息数据,让当地人用当地方言说指定的话,对这些进行录音。
其中,所述方言信息数据包括方言的语音数据和方言的文字数据。具体的,方言信息数据包括方言的音调类型、语法特征、语气助词、分布区域等。其中,音调类型包括:阴平阳平、阴上阳上、阴去阳去、阴入阳入。音调占比包括平、上、去、入,四种音调的占比。古汉语学习中都会学习使动用法、为动用法和意动用法。而动词的使动用法是非常突出的地域特征标志。在长期方言环境中,即使发音很标准,但这种动词的使用方法还是会受到长期方言环境的影响,不同地方的使动用法不尽相同。这些信息都是维护进方言信息数据库的。还有语气助词的使用也是比较明显的方言特征。
将所述方言信息数据按照地域进行分类并打包,生成多个地域的方言信息数据包,对各地域的所述方言信息数据包使用不同的标记符号进行标记;
本步骤中,由于采集到的方言信息数据数量比较庞大,所以需要将这些方言信息数据按地方进行分类。分类的依据可以按照地域的级别分,具体的,可以按照县的级别划分,也可以按照乡镇的级别划分,更精准地,可以按照村的级别进行分类,按村的级别分类的话,后续分析可能会更精确。分好类之后,将所述方言信息数据按照县或乡镇或村的级别进行打包,生成多个县或乡镇或村的方言信息数据包,再对每一个方言信息数据包使用不同的标记符号进行标记。
将标记好的所述方言信息数据包存储于不同的位置,生成方言信息数据库。
本实施例,通过授信审核视频通话中的音频数据分析其语音中带有的方言特征,有效的对用户的语音进行识别,从而扩大了贷款业务流程中欺诈信息的获取维度和分析维度,增加了判断贷款申请人是否涉嫌欺诈的判断方向,进一步增强了贷款机构的反欺诈能力,提高了贷款机构的放贷安全。
在一个实施例中,图2为本申请实施例中的一种基于方言背景的语音识别方法中的判断信息欺诈过程的示意图,如图2所示,所述步骤s5,获取所述目标对象提供的户籍信息,所述户籍信息包括第二籍贯信息和第二居住地信息,判断所述方言地理特征和所述户籍信息是否一致,包括:
步骤s501,提取所述方言地理特征中所述目标对象的地域地点文字信息和所述籍贯信息的籍贯地点文字信息以及所述居住地信息的居住地点文字信息。
本步骤中,在提取所述贷款申请人的地域地点文字信息、籍贯信息的籍贯地点文字信息以及所述居住地信息的居住地点文字信息时,都要提取其中的地方名字的全称。
步骤s502,将所述地域地点文字信息分别与所述籍贯地点文字信息、所述居住地点文字信息进行比较,判断所述地域地点文字信息与所述籍贯地点文字信息或者所述居住地点文字信息是否一致。
本步骤中,将三者进行比较时,可以将三者均转化为词向量从而计算它们之间的汉明距离或余弦值从而得出比较结果,还可以建立矩形区域,比较相同位置上的矩形区域的像素值从而得出比较结果。
在一个实施例中,所述获取目标对象的音频数据,从所述音频数据中提取多个特征词语的实际发音,将每一所述特征词语的实际发音的声波进行矢量化处理,生成矢量集a,包括:
从视频通话中提取所述目标对象的音频数据,从所述音频数据中提取音轨;
本步骤执行时,从所述贷款授信审核视频通话中提取所述目标对象的音频数据,提取的音频数据是数字化的,从所述音频数据中去除无用片段和杂音片段就得到了该音频数据的音轨。
从所述音轨中截取多个所述特征词语的实际发音对应的声波,对每一所述声波进行降噪处理;
本步骤中,截取若干词语的实际发音对应的音轨时,截取词语的长度是一致的,按照每个词语的发音在音轨上截取相应长度的音轨,从而获得每个词语发音对应的声波。之后,还要对每一段声波进行降噪处理,以获得不含杂音的纯净的声波。
对降噪处理后的每一所述声波按照预设的频率和预设的长度分别截取成若干帧片段;
本步骤中,截取声波时,是按照固定的长度和固定的频率截取的,为了保证截取的片段的连贯性,使用的是时间窗函数去截取的,就是前后两个帧片段都会有相同的部分。
分别将每一所述声波对应的若干所述帧片段转化为一矢量值,汇总所有所述矢量值,生成所述矢量集a。
本实施例,对音轨和声波均进行去杂音处理,提高了后续比较的准确性。
在一个实施例中,所述将所述矢量集a与所述n个方言矢量集中的每一个矢量集分别进行比较,得到所述目标对象语音中的方言地理特征,包括:
从所述n个矢量集中选取其中一个矢量集作为矢量集b,将所述矢量集a中的每一矢量分别与所述矢量集b中对应的矢量进行比较,得到比较结果;
将所述比较结果与预设的误差阈值进行比较,若所述比较结果小于所述误差阈值,则得出所述目标对象的方言地理特征为所述矢量集b对应的所述方言信息数据所属的方言地理特征,若所述比较结果大于所述阈值,则从所述n个矢量集中再选取一个矢量集与所述矢量集a进行比较,直到得出所述目标对象的方言地理特征。
在一个实施例中,所述将所述地域地点文字信息分别与所述籍贯地点文字信息、所述居住地点文字信息进行比较,判断所述地域地点文字信息与所述籍贯地点文字信息或者所述居住地点文字信息是否一致,包括:
按照预设的字符长度和高度在所述地域地点文字信息、所述籍贯地点文字信息以及所述居住地点文字信息中分别建立若干相同的矩形区域;
比较所述地域地点文字信息和所述籍贯地点文字信息相同位置上的所述矩形区域的像素值,若每一相同位置上的像素值均相同,则所述地域地点文字信息与所述籍贯地点文字信息一致,否则,不一致;
比较所述地域地点文字信息和所述居住地点文字信息相同位置上的所述矩形区域的像素值,若每一相同位置上的像素值均相同,则所述地域地点文字信息与所述居住地点文字信息一致,否则,不一致。
本实施例,通过建立矩形区域,比较矩形区域的像素值,从而得到比较结果,提高了比较的准确率。
在一个实施例中,提出一种基于方言背景的语音识别装置,如图3所示,包括以下模块:
采集模块,设置为采集若干地方的方言信息数据,对所述方言信息数据按照地域进行分类存储,生成方言信息数据库;
矢量集a生成模块,设置为获取目标对象的音频数据,从所述音频数据中提取多个特征词语的实际发音,将每一所述特征词语的实际发音的声波进行矢量化处理,生成矢量集a;
方言矢量集生成模块,设置为从所述方言信息数据库中提取n个不同地域的方言信息数据,分别从每一地域的方言信息数据中提取与所述特征词语字形相同的词语对应的方言发音,将各所述方言发音矢量化,得到各所述方言发音对应的矢量值,将各所述方言发音对应的矢量值分别进行汇总,生成n个方言矢量集;
比较模块,设置为将所述矢量集a与所述n个方言矢量集中的每一个矢量集分别进行比较,得到所述目标对象语音中的方言地理特征,其中,所述方言地理特征包括第一籍贯信息和第一居住地信息;
判断模块,设置为获取所述目标对象提供的户籍信息,所述户籍信息包括第二籍贯信息和第二居住地信息,判断所述方言地理特征和所述户籍信息是否一致。
在一个实施例中,所述采集模块还用于:
通过网络爬虫的方式从现有各网络平台中获取若干地方的所述方言信息数据;将所述方言信息数据按照地域进行分类并打包,生成多个地域的方言信息数据包,对各地域的所述方言信息数据包使用不同的标记符号进行标记;将标记好的所述方言信息数据包存储于不同的位置,生成方言信息数据库。
在一个实施例中,提出一种计算机设备,所述计算机设备包括存储器和处理器,存储器中存储有计算机可读指令,计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行计算机可读指令时实现上述各实施例中所述的基于方言背景的语音识别方法的步骤。
在一个实施例中,提出一种存储介质,所述存储介质可被处理器读写,所述存储介质存储有计算机可读指令,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行上述各实施例中所述的基于方言背景的语音识别方法的步骤。其中,所述存储介质可以为非易失性存储介质。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(rom,readonlymemory)、随机存取存储器(ram,randomaccessmemory)、磁盘或光盘等。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明一些示例性实施例,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!