家居环境下的录音重放检测方法与流程
本发明涉及声纹识别技术领域,具体的说,是一种家居环境下的录音重放检测方法。
背景技术:
在生物识别技术领域,声纹识别系统因安全性较高,语料获取较为方便,在生活领域、金融领域以及司法领域得到了广泛应用。声纹识别技术不断发展的同时,各种仿冒语音对声纹系统的攻击也日趋严峻。仿冒语音大致分为两种:逻辑性攻击和物理攻击。逻辑性攻击包括合成语音和转换语音,物理攻击包括录音重放攻击。在过去的几年中,研究人员对仿冒语音的检测主要集中在合成语音和转换语音的上,一定程度上忽视了回放语音对声纹识别系统的攻击。事实上,由于回放语音是通过真实声音直接录音得到的,因此比合成语音和转换语音更具有威胁性。其次,回放语音相较于其他仿冒语音获取更为方便,仅仅需要一部录音设备就可以完成为仿冒者提供了便利。同时近些年高保真设备的普及化和便携化,更是极大的提升了回放语音对声纹识别系统的威胁。因此,需要一种对录音重放检测方法,以区分真人说话以及录音回放。现有技术中通过目标用户的预留训练语音建立用户信道模型,利用最大期望算法训练模型。依据用户信道模型计算待识别语音的信任度打分,将信任度打分与设定的阈值比较,若信任度打分小于设定阈值,则认定待识别语音存在重放,返回待识别语音,认证失败,反之,则通过重放检测,即待识别语音认证成功,通过计算待识别语音在所述用户信道模型上的信任度打分,从而避免了闯入者重放攻击的问题。但其特征提取较为复杂,需要预留目标用户的信道。实际家居环境下,语料收集与特征处理难以平衡。在模型训练方面,如果语料库非常大,即使运用最大期望算法优化,收敛速度也较慢,在实际操作中往往采用限制对角协方差矩阵的方法,加快收敛,但这样做会损失模型的精度。
技术实现要素:
本发明的目的在于提供一种家居环境下的录音重放检测方法,用于解决现有技术中通过目标用户的预留训练语音建立用户信道模型,利用最大期望算法训练模型,依据用户信道模型计算待识别语音的信任度打分的方法,特征提取较为复杂,需要预留目标用户的信道、模型训练算法存在收敛速度较慢或者会损失模型的精度的问题。
本发明通过下述技术方案解决上述问题:
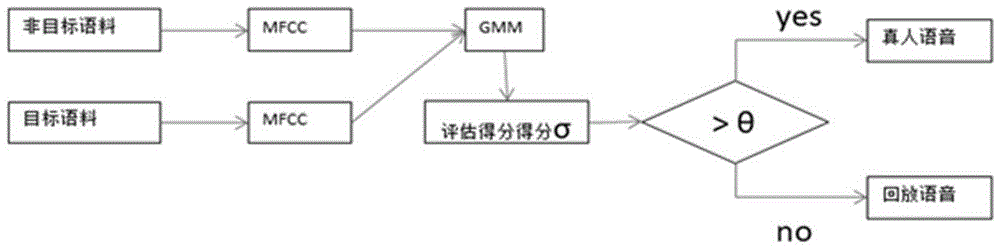
一种家居环境下的录音重放检测方法,包括:
步骤s100:收集不同用户的语音数据,分别组成测试样本集和训练样本集,所述训练样本集包括原始语音和回放语音;
步骤s200:提取训练样本集和测试样本集语音的mfcc特征;
步骤s300:采用训练样本集中的原始语音训练原始语音的gmm模型,记作λt;采用训练样本集中的回放语音训练回放语音的gmm模型,记作λf;
步骤s400:将测试样本集的mfcc特征分别在原始语音的gmm模型和回放语音的gmm模型进行测试,得到评估得分σ;
步骤s500:根据评估得分σ与阈值θ的比较结果,将评估得分σ大于阈值θ的语音判定为真人语音,将评估得分σ小于或等于阈值θ的语音判定为回放语音。
进一步地,所述步骤s300中训练原始语音的gmm模型以及训练回放语音的gmm模型均采用随机变分推断,具体流程为:
步骤s310:初始化gmm模型参数λ,设置步长ρ_t;
步骤s320:从训练样本集中随机选取一个数据x_t;
步骤s330:采用近似模型的概率分布函数优化局部变分参数:φ_t=e[η(x_t)];
步骤s340:采用近似概率分布函数的参数优化全局变分参数:λ_=e_φ[η(x_t)];
步骤s350:更新当前变分参数:λ_t=(1-ρ_t)λ_(t-1)+ρ_t*λ_;
循环步骤s320-步骤s350,直到所有的数据训练完成。
训练数据集较大时,采用最大期望算法训练模型较不容易收敛。而一般的变分推断,由于要遍历所有数据,亦无法在较大规模的数据集上使用。随机变分推断可以很好的解决上述问题。本发明采用随机变分推断,优化混合高斯模型(gmm模型)的参数,提高了模型训练速度,同时保障了精度。
进一步地,所述步骤s400中的评估得分σ由以下函数执行:
σ=sigmoid(log(p(x|λt)/p(x|λf)))
其中,x为训练样本集中的数据,sigmoid函数用于将似然比归一化到(0,1)区间,函数p为gmm模型的输出分数。直接使用后验概率的分数似然比,会导致分数分布较分散,不易给出最后的评估阈值的设定方案。本发明使用sigmoid函数将似然比归一化到(0,1)区间,在最后设定阈值时提供了较直观的解释。
步骤s500中根据阈值θ处的虚警率pfa(θ)和漏警率pmiss(θ),其中虚警率pfa(θ)反映被判定为原始语音的样本中,有多少个是回放语音,漏警率pmiss(θ)反映有多少个原始语音被判定为回放语音。pfa(θ)和pmiss(θ)分别是关于θ的单调递减和单调递增的函数。通过调节阈值θ的取值可以调节虚警率pfa(θ)和漏警率pmiss(θ)。若使得虚警率降低,则漏警率就会变大;反之若降低漏警率,则虚警率就会相应的提升。因此对于阈值的选择,可根据实际情况进行调节。如果在高安全性在训练阶段,则可以通过调节阈值使得虚警率最小,以提高安全性。若用于诸如考勤等低安全性领域,则可以适当降低阈值以提另一高漏警率,以兼顾易用性。在家居环境下,阈值可适度降低,以保证更好的使用体验。
本发明与现有技术相比,具有以下优点及有益效果:
本发明采用随机变分推断,优化混合高斯模型(gmm模型)的参数,提高了模型训练速度,同时保障了精度。
附图说明
图1为本发明的流程图。
具体实施方式
下面结合实施例对本发明作进一步地详细说明,但本发明的实施方式不限于此。
实施例1:
结合附图1所示,一种家居环境下的录音重放检测方法,包括:
步骤s100:收集不同用户的语音数据(非目标语料和目标语料,分别用于测试模型和训练模型),分别组成测试样本集和训练样本集,所述训练样本集包括原始语音和回放语音;
步骤s200:提取训练样本集和测试样本集语音的mfcc特征;
步骤s300:采用训练样本集中的原始语音训练原始语音的gmm模型,记作λt;采用训练样本集中的回放语音训练回放语音的gmm模型,记作λf;
训练模型采用随机变分推断,具体流程为:
步骤s310:初始化gmm模型参数λ,设置步长ρ_t;
步骤s320:从训练样本集中随机选取一个数据x_t;
步骤s330:采用近似模型的概率分布函数优化局部变分参数:φ_t=e[η(x_t)];
步骤s340:采用近似概率分布函数的参数优化全局变分参数:λ_=e_φ[η(x_t)];
步骤s350:更新当前变分参数:λ_t=(1-ρ_t)λ_(t-1)+ρ_t*λ_;
将优化后的参数代入gmm模型;
循环步骤s320-步骤s350,直到所有的数据训练完成;
步骤s400:将测试样本集的mfcc特征分别在原始语音的gmm模型和回放语音的gmm模型进行测试,得到评估得分σ;评估得分σ由以下函数执行:
σ=sigmoid(log(p(x|λt)/p(x|λf)))
其中,x为训练样本集中的数据,sigmoid函数用于将似然比归一化到(0,1)区间,函数p为gmm模型的输出分数;
步骤s500:根据评估得分σ与阈值θ的比较结果,将评估得分σ大于阈值θ的语音判定为真人语音,将评估得分σ小于或等于阈值θ的语音判定为回放语音。
根据阈值θ处的虚警率pfa(θ)和漏警率pmiss(θ),其中虚警率pfa(θ)反映被判定为原始语音的样本中,有多少个是回放语音,漏警率pmiss(θ)反映有多少个原始语音被判定为回放语音。pfa(θ)和pmiss(θ)分别是关于θ的单调递减和单调递增的函数。通过调节阈值θ的取值可以调节虚警率pfa(θ)和漏警率pmiss(θ)。若使得虚警率降低,则漏警率就会变大;反之若降低漏警率,则虚警率就会相应的提升。因此对于阈值的选择,可根据实际情况进行调节。如果在高安全性在训练阶段,则可以通过调节阈值使得虚警率最小,以提高安全性。若用于诸如考勤等低安全性领域,则可以适当降低阈值以提另一高漏警率,以兼顾易用性。在家居环境下,阈值可适度降低,以保证更好的使用体验。
尽管这里参照本发明的解释性实施例对本发明进行了描述,上述实施例仅为本发明较佳的实施方式,本发明的实施方式并不受上述实施例的限制,应该理解,本领域技术人员可以设计出很多其他的修改和实施方式,这些修改和实施方式将落在本申请公开的原则范围和精神之内。
- 还没有人留言评论。精彩留言会获得点赞!