一种基于CycleGAN的语音识别模型的防御方法及装置与流程
本发明属于深度学习算法及信息安全研究领域,具体涉及一种基于cyclegan的语音识别模型的防御方法。
背景技术:
随着技术的不断发展,语音识别技术正在越来越多的被人们使用。语音识别技术带来了极大的便利性,简化了人与机器之间的通信,省略了中间键盘输入和手写的步骤,有着丰富的应用场景。在智能化家电领域,有语音控制的家电设备,人们用语音就可以控制家里的所有语音设备;在国防领域,自动语音识别系统通过语音命令提供选定的驾驶舱控制,为飞行员带来了方便;在医疗领域,利用语音识别技术帮助有显著发声障碍的患者的语言表达;在自动驾驶领域,可以利用语音控制车载设备,甚至可以控制汽车的行驶。
近些年来,深度学习的应用给语音识别系统带来了极为便捷的训练步骤,并且大幅度的提高了语音识别模型的识别精度,2017年,微软语音识别系统错误率由5.9%降低到5.1%,可达到专业速记员的水平;国内语音识别行业的佼佼者科大讯飞的语音听写准确率则达到了95%,表现优良。虽然深度学习带来了便捷的训练步骤也提高了模型的识别精度,但是深度学习也给语音识别系统带来了潜在的风险。最近的研究表明,深度神经网络容易受到对输入数据进行细微扰动形式的对抗攻击。这种做法会导致模型输出不正确的预测结果,在一些场景下会造成一些严重的事故。如在自动驾驶领域,若语音识别系统被外加的细微扰动所攻击,汽车将会错误的识别乘客的指令,如将“stop”识别为“go”,这给自动驾驶系统带来了极大的安全隐患,极有可能引发交通事故,造成人员的伤亡。
已有的语音识别攻击方法主要分为白盒和黑盒攻击。白盒攻击是攻击者已知模型内部参数的情况下进行的,如利用快速梯度符号法(fgsm),通过反向传播计算模型关于噪声的梯度,不断迭代生成对抗样本。黑盒攻击是攻击者在未知模型内部参数的情况下进行的,利用一些寻优算法,如利用遗传算法(ga),粒子群算法(pso)不断优化所需要添加的扰动,迭代生成对抗样本。由此可以利用白盒或黑盒攻击方法,对语音识别模型进行攻击,使生成的对抗样本能够被识别为目标短语。
基于以上语音识别模型易被攻击的问题,研究一种利用cyclegan作为语音识别系统的前端,将其集成到语音识别模型中,对输入语音识别系统的语音进行处理,对于对抗样本进行去噪操作,而保留正常的语音,使语音识别系统达到抵御对抗样本攻击的效果具有重要的意义和实践价值。
技术实现要素:
针对目前语音识别系统存在识别精度不高,容易受到对抗样本攻击的安全性问题,本发明提供了一种基于cyclegan的语音识别模型的防御方法,该方法可以提高语音识别模型的识别精度,并可以使语音识别模型的能够抵御对抗样本的攻击,提高语音识别模型的安全性及鲁棒性。
本发明的技术方案为:
一种基于cyclegan的语音识别模型的防御方法,包括如下步骤:
s1生成用于cyclegan模型训练的数据集,所述的数据集包括对抗样本数据集和正常语音数据集,将所述数据集划分为训练集和测试集;
s2搭建cyclegan模型,所述的cyclegan模型由两组gan模型以对偶的形式构成;
一组gan模型将对抗样本传递给生成器ga~b滤除噪音,由判别器db判别是否为正常语音,然后将滤除噪音后的语音传递给生成器gb~a添加噪音;
另一组gan模型将正常语音传递给生成器gb~a添加噪音,由判别器da判别是否为对抗样本,然后将添加噪音后的语音传递给生成器ga~b滤除噪音;
s3构建cyclegan模型的损失函数lcyclegan;所述损失函数lcyclegan由ladv、lcyc和lid组成,如式(2)所示,
lcyclegan=ladv+λlcyc+λidlid(2);
其中,所述λ和λid为缩放因子,ladv为对抗性损失函数,lcyc为循环一致损失函数,lid为身份映射损失函数;
s4利用训练集对cyclegan模型进行训练,训练完成后,用测试集进行测试,统计经过cyclegan模型处理后的对抗样本的失效率,若失效率达不到预设标准,则更改cyclegan模型参数继续训练模型,直到失效率达到预设标准;
s5将失效率达到预设标准的cyclegan模型中的生成器ga~b集成到语音识别模型中,以抵御对抗样本的攻击。
构建cyclegan模型的损失函数,该损失函数l由三个部分构成,ladv,lcyc和lid,lady损用来实现两个尘成器的功能以及判别器和生成器性能的提升;lcyc用来保证生成器的多样性;lid用来保留语音信息,即让生成器只对对抗样本进行处理,而尽量不影响正常的语音。
公式(3)为一般的gan模型的损失函数,若仅使用公式(3),由于使用的是非平行的数据集,那么生成器很可能将数据集a映射为数据集b中的某一句话造成损失函数失效,因此引入公式(4),保证两个生成器的多样性,由于公式(3)和(4)都没有考虑生成器对语音中的语义信息,若公式(2)中未加入公式(5),则生成器ga~b可能会有滤噪声过渡造成语义信息丢失,因此引入公式(5)保证语音不会被过渡处理。
本发明还提供了基于上述防御方法的装置,包括计算机存储器、计算机处理器以及存储在所述计算机存储器中并可在所述计算机处理器上执行的计算机程序,所述计算机处理器执行所述计算机程序时实现上述基于cyclegan的语音识别模型的防御方法。
与现有技术相比,本发明具有如下有益效果:
(1)本发明所述防御方法使用的cyclegan模型及其损失函数,一方面可以使用非平行的语料库进行训练,另一方面避免了生成器将对抗样本映射为正常语音中的一条语音而造成的损失函数失效的问题。
(2)针对可能存在的对语音识别模型的白盒或黑盒的攻击,本发明利用对抗样本数据集和正常语音数据集对cyclegan模型进行训练,使cyclegan模型能够在不影响正常样本的前提下对对抗样本进行降噪操作,使cyclegan模型成为语音识别系统的前端,集成到语音识别模型中,使语音识别模型的识别准确率得到提升,并能抵御对抗样本的攻击。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动前提下,还可以根据这些附图获得其他附图。
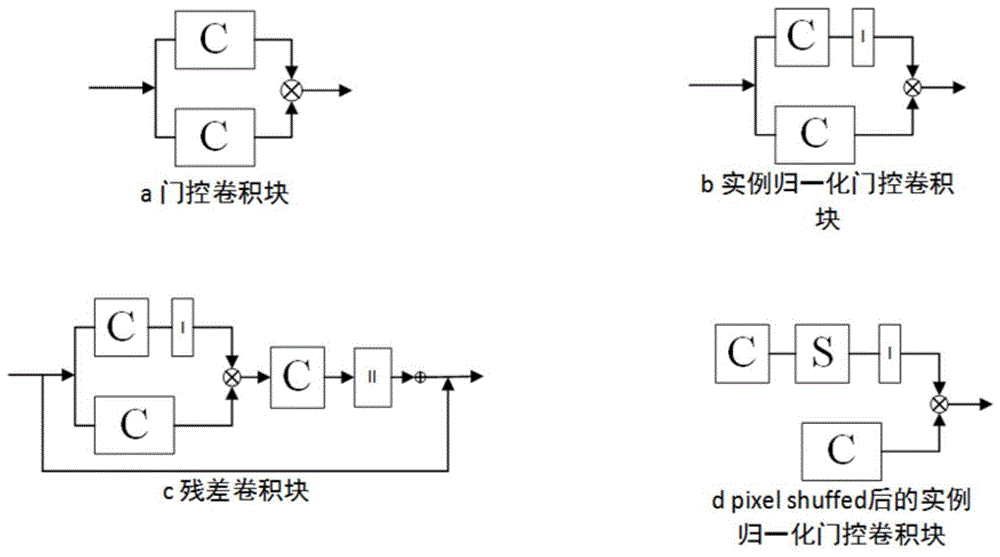
图1为本发明所述四个不同卷积块的组成。
其中,a是门控卷积块,b是实例归一化门控卷积块,c是残差卷积块,d是pixelshuffed后的实例归一化门控卷积块。
图2为本发明所述cyclegan模型的两个生成器的组成。
图3为本发明所述cyclegan模型的两个生成器的组成。
其中,图2、图3中gatedc表示门控卷积块,i-gatedc表示实例归一化门控卷积块,res-c表示残差卷积块,si-gatedc表示pixelshuffed后的实例归一化门控卷积块。
图4为本发明cyclegan模型及其损失函数。
其中,图4中a表示对抗样本数据集,b表示正常语音数据集,fb表示经过过滤噪声后生成的正常样本,fa表示经过添加噪声后生成的对抗样本,ga~b用来滤除对抗样本中的噪声,gb~a用来往正常样本中添加噪声,判别器da用来判别音频是否为带噪语音,判别器db用来判别音频是否为正常语音;laadv为ga~b与db构成的对抗网络的对抗性损失函数,lbadv为gb~a与da构成的对抗网络的对抗性损失函数;lacyc为ga~b与gb~a构成的对抗网络的循环一致损失函数,lbcyc为gb~a与ga~b构成的对抗网络的循环一致损失函数。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不限定本发明的保护范围。
本发明提供的一种基于cyclegan的语音识别模型的防御方法,具体包括以下步骤:
s1生成用于cyclegan模型训练的数据集,所述的数据集包括对抗样本数据集和正常语音数据集,将所述数据集划分为训练集和测试集。
s11初始化遗传算法的损失函数如式(1)所示:
l=lctc(x,t)(1);
其中,lctc表示ctc损失函数用于衡量对抗样本经语音识别模型转录的结果与目标短语的相近程度,x表示迭代过程中的最优样本,t表示设置的目标短语;设定种群大小设为100,精英数量为10,迭代次数为3000;
s12通过复制原始样本将样本数量扩大至设定的种群大小,给个体添加随机噪声进行变异,在变异后,攻击语音识别模型,根据公式(1)选择损失函数较小的10个样本作为精英群体,根据公式(1),从精英群体中挑选100次,组成父辈1,再挑选100次组成父辈2;
s13通过从父辈1和父辈2中各取一半的样本进行交义变异来生成子代,根据公式(1)选择最优样本;
s14判断迭代次数是否达到3000或最优样本的转录结果是否为目标短语,若是,则该样本就为对抗样本数据集,若否,将该最优样本作为下一次迭代的原始样本,回到步骤s12;
s15选择librispeech、voxforge、timit、chime或ted-lium语音数据集作为正常语音数据集;
s16将对抗样本数据集与正常语音数据集组合在一起形成用于cyclegan模型训练的数据集;按照比例划分为训练集和测试集。
s2搭建cyclegan模型,所述的cyclegan模型由两组gan模型以对偶的形式构成;
一组gan模型将对抗样本传递给生成器ga~b滤除噪音,由判别器db判别是否为正常语音,然后将滤除噪音后的语音传递给生成器gb~a添加噪音;
另一组gan模型将正常语音传递给生成器gb~a添加噪音,由判别器da判别是否为对抗样本,然后将添加噪音后的语音传递给生成器ga~b滤除噪音。
s21搭建cyclegan模型的两个生成器ga~b和gb~a,所述生成器ga~b和生成器gb~a的结构相同,均由12个卷积块组成,依次为1个门控卷积块,2个实例归一化门控卷积块,6个残差卷积块,2个pixelshuffed后的实例归一化门控卷积块以及1个卷积层。
本实施例中的生成器如图2所示。
s22搭建cyclegan模型的两个判别器da和db,所述的判别器da和判别器db的结构相同,均由6个卷积块组成,依次为1个门控卷积块,3个实例归一化门控卷积块,1个全连接层和1个sigmoid函数。
本实施例中的判别器如图3所示。
s3构建cyclegan模型的损失函数lcyclegan;所述损失函数lcyclegan由ladv、lcyc和lid组成,如式(2)所示,
lcyclegan=ladv+λlcyc+λidlid(2);
其中,所述λ和λid为缩放因子,ladv为对抗性损失函数,lcyc为循环一致损失函数,lid为身份映射损失函数。
所述的ladv计算公式如式(3)所示,
其中,所述laadv为ga~b与db构成的对抗网络的对抗性损失函数,lbadv为gb~a与da构成的对抗网络的对抗性损失函数;a为对抗样本数据集中的语音,b为正常语音数据集中的语音;da()为判断输入是否为对抗样本的判别器,db()为输入是否为正常语音的判别器;gb~a()为添加噪音的生成器,ga~b()为滤除噪音的生成器,e表示期望。
所述的lcyc计算公式如式(4)所示,
lcyc=lacyc+lbcyc
=ea||gb~a(ga~b(a))-a||1+eb||ga~b(gb~a(b))-b||1(4);
其中,所述lacyc为ga~b与gb~a构成的对抗网络的循环一致损失函数,lbcyc为gb~a与ga~b构成的对抗网络的循环一致损失函数;||||1表示11范数。
所述的lid计算公式如式(5)所示,
lid=ea||gb~a(a)-a||1+eb||ga~b(b)-b||1(5)。
s4利用训练集对cyclegan模型进行训练直到损失函数不再减小,训练完成后,用测试集进行测试,统计经过cyclegan模型生成器ga~b处理后的对抗样本攻击语音识别模型的失效率,若失效率达不到预设标准,则更改cyclegan模型参数继续训练模型,直到失效率达到预设标准。
s5将失效率达到预设标准的cyclegan模型中的生成器ga~b集成到语音识别模型中,以抵御对抗样本的攻击。
本发明还提供了基于上述防御方法的装置,包括计算机存储器、计算机处理器以及存储在所述计算机存储器中并可在所述计算机处理器上执行的计算机程序,所述计算机处理器执行所述计算机程序时实现上述基于cyclegan的语音识别模型的防御方法。
由于该防御装置中以及计算机存储器存储的计算机程序主要用于实现上述的一种面向语音识别系统黑盒攻击模型的防御方法,因此其作用于上述防御方法的作用相对应,此处不再赘述。
以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的最优选实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!