一种基于中文语音OpenSmile和双向LSTM的端到端情绪识别方法与流程
本发明涉及基于语音的情绪识别方法技术领域,尤其是涉及一种基于中文语音opensmile和双向lstm的端到端情绪识别方法。
背景技术:
随着人工智能技术的发展,计算机已经成为人类的亲密伙伴。它可以帮助我们检索知识、规划城市、预测金融走势、保障生产安全,甚至陪我们下棋、打电子游戏。对于如此亲密的“生活伴侣”,我们自然希望计算机能知情识趣,而不是冷冰冰的机器。为了让计算机拥有感情,研究者从图象、文字、语音等各个方面展开了大量研究,到目前为止,至少在感知层次,机器已经能分清好赖话,看懂好赖脸了。
和说话人识别和语种识别相比,语音情绪识别更加困难。主要原因包括两个方面。首先,“情绪”一词的定义非常模糊,事实上直到今天,关于情绪是什么,心理学家们也没有一个公认的定义。plutchik估计,在二十世纪,研究者至少提出了90多种情绪的定义。事实上,一句话究竟是哪种情绪,不仅和说话人本身的心理状态相关,还和他/她的生活习惯、表达方式相关,和听众的理解方式和生活背景也有密切关系。例如,对一个喜欢安静的人来说,语调提高一些表示他/她已经很愤怒了,但对于喜欢吵闹的人来说,提高音调本身就是常态。因此,情绪本身具有非常强的主观性和不确定性。对这种本身就具有很大不确定性的语言现象,识别起来必然非常困难。事实上,研究表明人对情绪的识别率也仅有60%左右,让机器来识别人都很难判断的情绪,显然更加困难。
现有技术中,中国专利cn109785863a公开了一种深度信念网络的语音情感识别方法,该方法将所述语音信号特征采用支持向量机进行语音情感的识别分类,虽然可以实现对语音情感进行识别分类,但是该专利中的情感识别分类方法在处理与时间相关的特征序列时容易遗漏部分信息,同时支持向量机更偏向于二分类,因此情感分析的结果可能会产生误差,导致识别精度不高。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种识别精度高、支持多人以及长短句识别的基于中文语音opensmile和双向lstm的端到端情绪识别方法。
本发明的目的可以通过以下技术方案来实现:
一种基于中文语音opensmile和双向lstm的端到端情绪识别方法,包括:
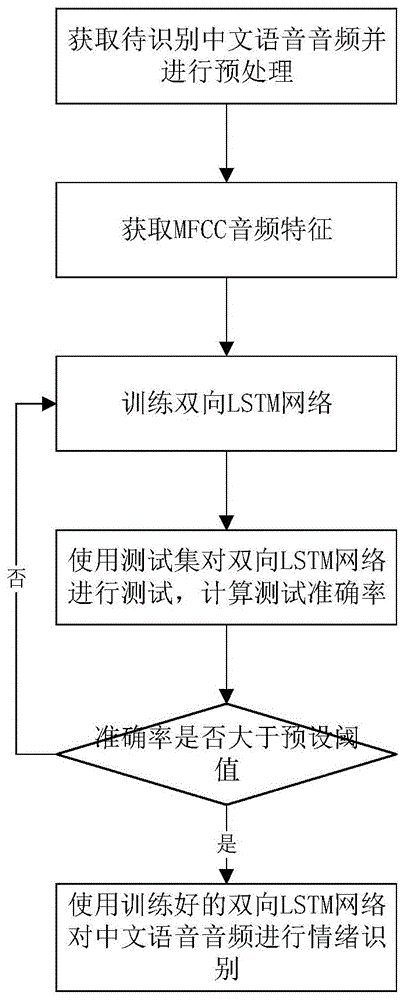
步骤1:获取待识别的中文语音音频,并对音频数据进行预处理;
步骤2:使用opensmile分别提取训练集和测试集语音音频的mfcc音频特征;
步骤3:使用训练集对双向lstm网络进行训练;
步骤4:使用测试集对完成训练的双向lstm网络进行测试,计算测试准确率,判断测试准确率是否大于预设阈值,若是,则执行步骤5,否则,返回步骤3;
步骤5:使用达到预设准确率阈值的双向lstm网络对中文语音音频进行情绪识别。
优选地,所述的步骤1具体为:
获取待识别的中文语音音频集合,将音频按照对应的情感进行分类,并添加对应的数字标签,然后将其分为训练集和测试集。
优选地,所述的步骤2具体为:
使用opensmile的compare特征集提取语音音频的mfcc音频特征,共提取出6373个音频特征,构建音频特征集合。
优选地,所述的双向lstm网络的最后一层结构为softmax全连接层,用于获取分类概率,然后将概率最高的类别作为最终输出的情绪类别。
更加优选地,所述的softmax函数具体为:
其中,zi为双向lstm网络第i个节点的输出值;c为输出节点的个数,即情感分类类别的个数。
更加优选地,所述的情感分类类别包括:愤怒情感、恐惧情感、厌恶情感、惊讶情感、快乐情感、悲伤情感和中性情感。
优选地,所述的双向lstm网络结构的抓包率设置为0.2%。
优选地,所述的步骤5具体为:
将待识别中文语音音频经过opensmile获取特征信息后直接输入训练好的双向lstm网络,获得中文语音音频对应的情绪,完成识别。
优选地,所述的双向lstm网络的损失函数具体为:
其中,y为真实标签合集,pr为分类器预测得到的概率分布,n为样本总数,k为多元分类的k个类别,y为真实值,p为预测值。
优选地,所述双向lstm网络中的forward层和backward层共同连接输出层,设有六个共享权值w1~w6;
在forward层从1时刻到t时刻正向计算依次,得到并保存每个时刻向前隐含层的输出;在backward层沿着时刻t到时刻1反向计算一遍,得到并保存每个时刻向后隐含层的输出;最后在每个时刻结合forward层和backward层的相应时刻输出的结果得到最终的输出,用数学表达式如下:
ht=f(w1xt+w2ht-1)
ht′=f(w3xt+w5h′t+1)
ot=g(w4ht+w6h′t)
其中,ht为隐含层的输出,h′t为forward层的输出,ot为backward层的输出,xt为输入。
与现有技术相比,本发明具有以下有益效果:
一、识别精度高:本发明中的情绪识别方法采用opensmile的compare特征集来获取语音音频特征,最大能够获取6373个音频特征;此外,还采用了双向lstm网络结构对音频进行情感分类,识别精度可达88%。
二、支持多人以及长短句的识别:本发明中的情绪识别方法采用双向lstm网络结构,能够获取时间维度,可以进行多维多步的时间序列预测,获取到的每段时间序列识别情感从而支持多人以及长短句的上下文识别。
附图说明
图1为本发明中情绪识别方法的流程示意图;
图2为本发明实施例中mfcc特征向量计算流程示意图;
图3为本发明实施例中双向lstm网络的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
一种基于中文语音opensmile和双向lstm的端到端情绪识别方法,其流程如图1所示,包括:
步骤1:获取待识别的中文语音音频,并对音频数据进行预处理,具体为:
获取待识别的中文语音音频集合,将音频按照对应的情感进行分类,并添加对应的数字标签,然后将其分为训练集和测试集;
步骤2:使用opensmile分别提取训练集和测试集语音音频的mfcc音频特征,具体为:
使用opensmile的compare特征集提取语音音频的mfcc音频特征,共提取出6373个音频特征,构建音频特征集合;
本实施例中获取mfcc特征向量的流程如图2所示,具体为:
(1)原始语音信号s(n)经过ad转换、预加重、分帧、加窗等处理后,获得每个语音帧的时域信号x′(n),预加重的传递函数为:
h(z)=1-αz-1
α一般取0.97;
窗函数选用汉明窗;
(2)进行傅里叶变换,获取线性频谱;
(3)将线性频谱通过在频率范围内设置若干个具有三角滤波特性的带通滤波器的mel滤波器组以获得mel频谱,求解mel倒谱系数;
(4)求取差分参数和时域能量特征。
步骤3:使用训练集对双向lstm网络进行训练;
本实施例中的双向lstm网络的结构如图3所示,在forward层从1时刻到t时刻正向计算依次,得到并保存每个时刻向前隐含层的输出;在backward层沿着时刻t到时刻1反向计算一遍,得到并保存每个时刻向后隐含层的输出;最后在每个时刻结合forward层和backward层的相应时刻输出的结果得到最终的输出,用数学表达式如下:
ht=f(w1xt+w2ht-1)
ht′=f(w3xt+w5h′t+1)
ot=g(w4ht+w6h′t)
其中,ht为隐含层的输出,h′t为forward层的输出,ot为backward层的输出,xt为输入。
双向lstm网络的最后一层结构为softmax全连接层,用于获取分类概率,然后将概率最高的类别作为最终输出的情绪类别,包括愤怒情感、恐惧情感、厌恶情感、惊讶情感、快乐情感、悲伤情感和中性情感;
softmax函数具体为:
其中,zi为双向lstm网络第i个节点的输出值;c为输出节点的个数,即情感分类类别的个数;
双向lstm网络的抓包率设置为0.2%,可以加快系统的收敛速度。
双向lstm网络的损失函数具体为:
其中,y为真实标签合集,pr为分类器预测得到的概率分布,n为样本总数,k为多元分类的k个类别,y为真实值,p为预测值。
步骤4:使用测试集对完成训练的双向lstm网络进行测试,计算测试准确率,判断测试准确率是否大于预设阈值,若是,则执行步骤5,否则,返回步骤3;
预设阈值可以根据用户实际情况设置。
步骤5:使用达到预设准确率阈值的双向lstm网络对中文语音音频进行情绪识别,具体为:
将待识别中文语音音频经过opensmile获取特征信息后直接输入训练好的双向lstm网络,获得中文语音音频对应的情绪,完成识别。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!