水稻IPA1基因的定点突变系统及其应用的制作方法
本发明涉及生物技术领域,具体涉及一种水稻IPA1基因的定点突变系统及其应用。
背景技术:
基因组编辑技术是一种在基因组水平上对DNA序列进行靶向修饰的遗传操作技术,可对作物基因组进行定点改造,实现作物的遗传改良。TALENs(类转录激活因子效应物核酸酶)技术是一种由序列特异核酸酶介导的基因组编辑技术,由黄单胞杆菌转录激活类效应子TALE和核酸内切酶FokⅠ的DNA切割域组成。其基本原理是TALEN二聚体特异识别并切割靶DNA序列产生双链断裂(double-strand breaks,DSB)),随后DSB会激活细胞的非同源末端连接(NHEJ)或同源重组(HR)修复机制,完成对靶基因的定点改造。目前,该技术已成功地应用于植物的遗传改良和植物功能基因组研究中。
水稻是重要的粮食作物,随着水稻基因组研究的不断深入,越来越多控制水稻重要农艺性状的基因被分离与克隆,为进行水稻分子遗传改良奠定了良好的基础。IPA1是一个调控水稻株型的主效QTL基因,位于水稻第8号染色体上,包括3个外显子。IPA1编码类 Squamosa 启动子结合蛋白 OsSPL14,并受 RNA miR156的调控。IPA1与控制水稻分蘖侧芽生长负调控因子OsTB1的启动子结合,通过促进OsTB1基因的表达进而抑制分蘖;IPA1通过直接正调控水稻株型重要基因DEP1正向调节水稻株高、穗长及枝梗数。研究表明IPA1在其miR156结合位点处发生一个点突变,扰乱了miR156 对IPA1的降解作用,使得IPA1的表达量提高,由于突变后的IPA1仅出现一个氨基酸替换,不影响其正常功能,水稻出现分蘖减少,茎杆变粗,株高、穗粒数和千粒重增加。
利用基因组编辑技术对需改良水稻材料中IPA1基因的miR156结合位点处进行定点突变,不仅可获得如上所述的miR156 结合位点丧失但IPA1功能正常的突变体,还可获得IPA1功能缺失的突变体,为水稻株型改良提供一系列分蘖、株高和穗粒数等农艺性状不同的水稻新材料。
技术实现要素:
本发明的目的在于提供了一种水稻IPA1基因的定点突变系统,为水稻株型改良提供一系列分蘖、株高和穗粒数等农艺性状不同的水稻新材料。
所述的定点突变系统包含一对能特异剪切水稻IPA1基因靶序列的类转录激活因子效应物核酸酶TALENs;所述的靶序列位于IPA1基因第三外显子如SEQ ID NO.1所示,由左侧TALN模块识别序列L、右侧TALN模块识别序列R和其间的间隔序列组成,中间的小写字母为间隔序列(序列为ctgtgctctctctcttc),两侧的大写字母为TALN模块识别序列,分别命名为L靶序列(序列为GCCGCCACCGACTCGAG)和R靶序列(序列为TGTCAACCCAGCCATGGGA)。根据L靶序列设计TALEN-L蛋白,包含TALE和FOK1的融合蛋白,编码该蛋白的核苷酸序列如SEQ ID NO.2所示;根据R靶序列设计TALEN-R蛋白,包含TALE和FOK1的融合蛋白,编码该蛋白的核苷酸序列如SEQ ID NO.3所示。所述类转录激活因子效应物核酸酶TALENs由TALEN-L和 TALEN-R组成,TALEN-L特异识别靶序列L,TALEN-R特异识别靶序列R。
本发明的的另一个目的在于提供了一种获得水稻IPA1基因突变体的方法。包括在水稻中表达上述定点突变系统的所有步骤,具体为根据IPA1基因设计靶序列如SEQ ID NO.1所示,包括中间的间隔序列及两侧的TALN模块识别序列L和R。针对L和R序列合成TALEN-L和TALEN-R蛋白的基因表达盒构建于同一个植物表达载体中,通过农杆菌介导法导入水稻中,可以成功地获得IPA1基因发生突变的水稻突变体,实现对IPA1基因定点突变的实际需求。
本发明的的另一个目的在于提供了一种植物TALENs表达载体,包含表达TALEN-L和 TALEN-R蛋白的基因表达盒,TALEN-L的表达由Ubiquitin启动子驱动,TALEN-R的表达由35S启动子驱动。Ubiquitin启动子序列如SEQ ID NO.4所示,35S启动子序列如SEQ ID NO.5所示。
与现在技术相比,本发明的有益成果在于:
1)利用TALENs基因组编辑技术可以实现IPA1基因的定向突变,克服了传统理化诱变技术具有随机突变及容易携带其不利突变基因的缺陷。
2)利用TALENs基因组编辑技术可以快速地获得不同突变类型的ipa1突变体,为水稻株型改良提供丰富的种质资源。
附图说明
图1. TALENs靶序列在IPA1基因的相对位置。黑色方框表示外显子,白色方框表示5' 和3'非翻译区,TALENs靶序列位于IPA1基因第三外显子的3505-3556bp处。
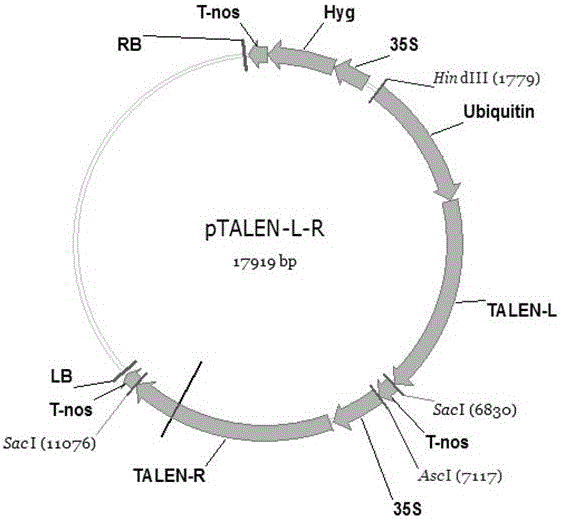
图2. TALENs植物表达载体结构示意图。LB和RB分别为T-DNA的左边界和右边界,35S为烟草花椰菜花叶病毒35S启动子,Hyg为潮霉素抗性基因,Ubiquitin为玉米泛素基因启动子,T-nos为胭脂碱合成酶(nos)基因的终止子,TALEN-L为编码TALEN-L蛋白的基因序列,TALEN-L为编码TALEN-R蛋白的基因序列。
图3. TALENs介导的IPA1基因突变类型。WT为野生型序列,阿拉伯数字表示发生缺失或增加的碱基数(数字前面加“-”表碱基缺失,数字前面加“+”表碱基增加),下划线为TALEN-L和TALEN-R蛋白识别的靶序列L和R。
图4. TALENs介导的IPA1基因突变植株表型。IPA1-CK为杂合突变体后代分离得到野生型植株,IPA1-2为缺失2bp的T2代纯合突变体植株,IPA1-4为缺失4bp的T2代纯合突变体植株,IPA1-16为缺失16p的T2代纯合突变体植株。
具体实施方式
下述实施例中所使用的实验验方法如没有特殊说明,均为常规方法。
下述实施例中所使用的的实验材料如无特别说明均为市售购买产品。
实施例1: TALENs靶序列的设计
利用PCR扩增和测序获得籼稻恢明恢86背景下的IPA1基因序列,比对分析发现明恢86的IPA1基因序列与野生型IPA1基因序列一致。根据TALENs靶序列设计原则,在籼稻明恢86背景下IPA1基因的miRNA156结合位点附近设计TALENs靶序列,序列如下:GCCGCCACCGACTCGAGctgtgctctctctcttcTGTCAACCCAGCCATGGGA(SEQ ID NO.1)。中间小写字母为间隔序列,两侧的大写字母为TALENs模块识别序列,分别命名为靶序列L和靶序列R。
实施例2: TALENs识别模块的合成及植物表达载体的构建
根据DNA碱基与TALE蛋白RVDs区的对应关系,按照上述设计的靶序列L和R合成对应的TALE串联重复区,并分别构建于骨架载体pTALEN-L22和pTALEN-R16中(购于上海斯丹赛生物技术有限公司),经SpeI和BamHI双酶切和测序验证获得重组载体pTALEN-L和pTALEN-R,测序引物序列为305: 5’ CTCCCCTTCAGCTGGACAC 3’和306: 5’ AGCTGGGCCACGATTGAC 3’。pTALEN-L含有表达TALEN-L蛋白的基因表达盒,包含Ubiquitin启动子、TALE蛋白-N端、串联重复区、C端和FokI切割域编码序列;pTALEN-R含有表达TALEN-R蛋白的基因表达盒,包含35S启动子、TALE蛋白-N端、串联重复区、C端和FokI切割域编码序列。
以HindIII 和AscI酶切pTALEN-L,胶回收TALEN-L基因表达盒;以SacI和AscI酶切pTALEN-R,胶回收TALEN-R基因表达盒;以HindIII 和SacI酶切并胶回收改造过的植物表达载体pCAMBIA1301。 通过一步法连接上述三个片段,经SacI酶切和测序验证获得含有TALEN-L和TALEN-R基因表达盒的植物双元表达载体pTALEN-L-R。构建正确的pTALEN-L-R载体经SacI酶切后出现4K和12K两条带,并分回收测序,测序引物序列为305: 5’ CTCCCCTTCAGCTGGACAC 3’和306: 5’ AGCTGGGCCACGATTGAC 3’。其中4K包含TALEN-R基因表达盒,12K包含TALEN-L基因表达盒。
实施例3:pTALEN-L-R植物表达载体的遗传转化
通过农杆菌介导的遗传转化方法将pTALEN-L-R载体导入籼稻明恢86胚性愈伤组织,并经抗性愈伤的筛选、分化和生根获得转化再生植株。具体步骤如下:
1、将成熟的水稻日本晴种子脱壳并消毒后接种于诱导培养基(NB培养基+2,4-D 2 mg·L-1,pH5.8)中, 28℃暗培养7天,切除胚根继续培养7天后将胚性愈伤转移到新的诱导培养基中,每隔14-20天继代一次。继代三次后的自然分散、颜色鲜黄、直径约为2-3mm的颗粒状愈伤可用于农杆菌转化。
2、取少量重组农杆菌菌液划线于YEB固体培养基(含有卡那霉素50 mg·L-1和利福平50 mg·L-1,pH5.8)上,28℃暗培养36~72h进行活化;取活化平板上的单菌落转接划菌,28℃暗培养培养两天,用AAM培养基(含有100µM·L-1乙酰丁香酮,pH5.2)洗菌及重悬菌体,调整菌液浓度至OD600nm=1.5-2.0,静置1h,得到农杆菌悬浮液。
3、将步骤1得到的胚性愈伤浸泡于步骤2的农杆菌悬浮液中,静置30min后于无菌滤纸上晾干愈伤,并接种于共培养基(NB培养基+2,4-D 2 mg·L-1+乙酰丁香酮100µM·L-1,pH5.8)中,25℃暗培养3d。
4、挑取步骤3共培养后的愈伤于广口培养瓶中,用无菌水冲洗3-5次,每次摇动数次,直至水中不见丝状菌体。最后一次用含250 mg·L-1羧卞青霉素的无菌水静置1h,然后置于无菌滤纸上晾干愈伤组织,接种于筛选培养基(NB培养基+2,4-D 2 mg·L-1+羧苄青霉素250mg·L-1 + hygromycin 50mg·L-1,pH5.8)中,28℃暗培养培养,每两周转接1次,约需三周即可见瘤状鲜黄色抗性愈伤从褐化干瘪的愈伤中长出。
5、将步骤4获得的抗性愈伤转移至分化培养基(NB培养基+2,4-D 2 mg·L-1+KT 10 mg·L-1 + NAA 0.4 mg·L-1,pH 5.8)上,2周后愈伤开始转绿,3周后即可长出幼芽,随后根也长出。将幼苗移至生根培养基(1/2 MS培养基,pH 5.8)上,待幼苗生根长成后,洗净根上的培养基,移栽实验基地。
实施例4:ipa突变体的检测及表型分析
提取转化植株基因组DNA,用引物FOK-F(5' TGACCGAGTTCAAGTTCC 3')和NOS-R(5' TTGCGGGACTCTAATCA 3')进行PCR扩增鉴定转基因植株。进一步用引物IPAF(GCAGTGGCGGGATATGGT和IPAR( ATCGTGTTGCTGGTTTGG),PCR扩增上述鉴定的转基因植株基因组DNA,获得带有靶序列的IPA1基因片段,并送往公司测序。对测序结果进行分析,共获得8种类型的IPA1基因突变类型,其中7种突变类型表现为碱基缺失,最小为缺失2bp,最大为缺失180bp。对8种IPA1突变基因编码的蛋白进行预测,发现它们均使IPA1蛋白发生移码突变。
进一步种植突变体植株后代并进行表型调查,为排除环境影响,每种突变体后代只考察种植中间的植株表型。在T1代植株中,考察了缺失2bp、4bp和23bp三种突变体后代的分蘖数和株高,结果显示,与对照(杂合突变体后代分离出的野生型植株)相比,这三种突变体的表型变化一致,即株高变矮、分蘖数增多;进一步考察纯合突变体T2代植株表型,发现突变体性状能稳定遗传,即与对照相比,株高明显降低而分蘖数显著增多。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
SEQUENCE LISTING
<110> 福建省农业科学院生物技术研究所
<120> 水稻IPA1基因的定点突变系统及其应用
<130> 13
<160> 13
<170> PatentIn version 3.3
<210> 1
<211> 53
<212> DNA
<213> TALENs靶序列
<400> 1
GCCGCCACCGACTCGAGctgtgctctctctcttcTGTCAACCCAGCCATGGGA 53
<210> 2
<211> 3018
<212> DNA
<213> 编码TALEN-L蛋白的核苷酸序列
<400> 2
atggactaca aagaccatga cggtgattat aaagatcatg acatcgatta caaggatgac 60
gatgacaaga tggcccccaa gaagaagagg aaggtgggca tccacggggt acccatggta 120
gatttgagaa ctttgggata ttcacagcag cagcaggaaa agatcaagcc caaagtgagg 180
tcgacagtcg cgcagcatca cgaagcgctg gtgggtcatg ggtttacaca tgcccacatc 240
gtagccttgt cgcagcaccc tgcagccctt ggcacggtcg ccgtcaagta ccaggacatg 300
attgcggcgt tgccggaagc cacacatgag gcgatcgtcg gtgtggggaa acagtggagc 360
ggagcccgag cgcttgaggc cctgttgacg gtcgcgggag agctgagagg gcctcccctt 420
cagctggaca cgggccagtt gctgaagatc gcgaagcggg gaggagtcac ggcggtcgag 480
gcggtgcacg cgtggcgcaa tgcgctcacg ggagcacccc tcaacctgac cctgacccca 540
gagcaggtcg tggcaatcgc gagcaataac ggcggaaaac aggctttgga aacggtgcag 600
aggctccttc cagtgctgtg ccaagcgcac ggtttaaccc cagagcaggt cgtggcgatc 660
gcaagccacg acggaggaaa gcaagccttg gaaacagtac agaggctgtt gcctgtgctg 720
tgccaagcgc acggcctcac cccagagcag gtcgtggcga tcgcaagcca cgacggagga 780
aagcaagcct tggaaacagt acagaggctg ttgcctgtgc tttgtcaggc acacggcctc 840
actccggaac aagtggtcgc aatcgcgagc aataacggcg gaaaacaggc tttggaaacg 900
gtgcagaggc tccttccagt gctgtgccaa gcgcacggat taaccccaga gcaggtcgtg 960
gcgatcgcaa gccacgacgg aggaaagcaa gccttggaaa cagtacagag gctgttgcct 1020
gtgctttgtc aggcacacgg cctcactccg gaacaagtgg tcgcgatcgc aagccacgac 1080
ggaggaaagc aagccttgga aacagtacag aggctgttgc ctgtgctgtg ccaagcgcac 1140
ggacttaccc cagagcaggt cgtggcaatc gcctccaaca ttggcgggaa acaggcactc 1200
gagactgtcc agcgcctgct tcccgtgctt tgtcaggcac acggcctcac tccggaacaa 1260
gtggtcgcga tcgcaagcca cgacggagga aagcaagcct tgaaacagta cagaggctgt 1320
gcctgtgctg tgccaagcgc acgggctctt accccagagc aggtcgtggc gatcgcaagc 1380
cacgacggag gaaagcaagc cttggaaaca gtacagaggc tgttgcctgt gctttgtcag 1440
gcacacggcc tcactccgga acaagtggtc gcaatcgcga gcaataacgg cggaaaacag 1500
gctttggaaa cggtgcagag gctccttcca gtgctgtgcc aagcgcacgg actaacccca 1560
gagcaggtcg tggcaatcgc ctccaacatt ggcgggaaac aggcactcga gactgtccag 1620
cgcctgcttc ccgtgctttg tcaggcacac ggcctcactc cggaacaagt ggtcgcgatc 1680
gcaagccacg acggaggaaa gcaagccttg gaaacagtac agaggctgtt gcctgtgctg 1740
tgccaagcgc acgggctcac cccagagcag gtcgtggcca ttgcctcgaa tggagggggc 1800
aaacaggcgt tggaaaccgt acaacgattg ctgccggtgc tttgtcaggc acacggcctc 1860
actccggaac aagtggtcgc gatcgcaagc cacgacggag gaaagcaagc cttggaaaca 1920
gtacagaggc tgttgcctgt gctgtgccaa gcgcacgggc taaccccaga gcaggtcgtg 1980
gcaatcgcga gcaataacgg cggaaaacag gctttggaaa cggtgcagag gctccttcca 2040
gtgctttgtc aggcacacgg cctcactccg gaacaagtgg tcgcaatcgc ctccaacatt 2100
ggcgggaaac aggcactcga gactgtccag cgcctgcttc ccgtgctgtg ccaagcgcac 2160
ggactcacgc ctgagcaggt agtggctatt gcatccaata acgggggcag acccgcactg 2220
gagtcaatcg tggcccagct ttcgaggccg gaccccgcgc tggccgcact cactaatgat 2280
catcttgtag cgctggcctg cctcggcgga cgacccgcct tggatgcggt gaagaagggg 2340
ctcccgcacg cgcctgcatt gattaagcgg accaacagaa ggattcccga gaggacatca 2400
catcgagtgg caggatccca gctggtgaag agcgagctgg aggagaagaa gtccgagctg 2460
cggcacaagc tgaagtacgt gccccacgag tacatcgagc tgatcgagat cgccaggaac 2520
agcacccagg accgcatcct ggagatgaag gtgatggagt tcttcatgaa ggtgtacggc 2580
tacaggggaa agcacctggg cggaagcaga aagcctgacg gcgccatcta tacagtgggc 2640
agccccatcg attacggcgt gatcgtggac acaaaggcct acagcggcgg ctacaatctg 2700
cctatcggcc aggccgacga gatggagaga tacgtggagg agaaccagac ccggaataag 2760
cacctcaacc ccaacgagtg gtggaaggtg taccctagca gcgtgaccga gttcaagttc 2820
ctgttcgtga gcggccactt caagggcaac tacaaggccc agctgaccag gctgaaccac 2880
atcaccaact gcaatggcgc cgtgctgagc gtggaggagc tgctgatcgg cggcgagatg 2940
atcaaagccg gcaccctgac actggaggag gtgcggcgca agttcaacaa cggcgagatc 3000
aacttcagat cttgataa 3018
<210> 3
<211> 3140
<212> DNA
<213> 编码TALEN-R蛋白的核苷酸序列
<400> 3
actagtccag tgtggtggaa ttcgccatgg actacaaaga ccatgacggt gattataaag 60
atcatgacat cgattacaag gatgacgatg acaagatggc ccccaagaag aagaggaagg 120
tgggcatcca cggggtaccc atggtagatt tgagaacttt gggatattca cagcagcagc 180
aggaaaagat caagcccaaa gtgaggtcga cagtcgcgca gcatcacgaa gcgctggtgg 240
gtcatgggtt tacacatgcc cacatcgtag ccttgtcgca gcaccctgca gcccttggca 300
cggtcgccgt caagtaccag gacatgattg cggcgttgcc ggaagccaca catgaggcga 360
tcgtcggtgt ggggaaacag tggagcggag cccgagcgct tgaggccctg ttgacggtcg 420
cgggagagct gagagggcct ccccttcagc tggacacggg ccagttgctg aagatcgcga 480
agcggggagg agtcacggcg gtcgaggcgg tgcacgcgtg gcgcaatgcg ctcacgggag 540
cacccctcaa cctgaccctg accccagagc aggtcgtggc gatcgcaagc cacgacggag 600
gaaagcaagc cttggaaaca gtacagaggc tgttgcctgt gctgtgccaa gcgcacggtt 660
taaccccaga gcaggtcgtg gcgatcgcaa gccacgacgg aggaaagcaa gccttggaaa 720
cagtacagag gctgttgcct gtgctttgtc aggcacacgg cctcactccg gaacaagtgg 780
tcgcgatcgc aagccacgac ggaggaaagc aagccttgga aacagtacag aggctgttgc 840
ctgtgctgtg ccaagcgcac ggcctcaccc cagagcaggt cgtggcaatc gcctccaaca 900
ttggcgggaa acaggcactc gagactgtcc agcgcctgct tcccgtgctt tgtcaggcac 960
acggcctcac tccggaacaa gtggtcgcca ttgcctcgaa tggagggggc aaacaggcgt 1020
tggaaaccgt acaacgattg ctgccggtgc tgtgccaagc gcacggatta accccagagc 1080
aggtcgtggc aatcgcgagc aataacggcg gaaaacaggc tttggaaacg gtgcagaggc 1140
tccttccagt gctttgtcag gcacacggcc tcactccgga acaagtggtc gcaatcgcga 1200
gcaataacgg cggaaaacag gctttggaaa cggtgcagag gctccttcca gtgctgtgcc 1260
aagcgcacgg acttacccca gagcaggtcg tggcgatcgc aagccacgac ggaggaaagc 1320
aagccttgga aacagtacag aggctgttgc ctgtgctttg tcagcacacg gccctcactc 1380
cggaacaagt ggtcgccatt gcctcgaatg gagggggcaa acaggcgttg gaaaccgtac 1440
aacgattgct gccggtgctg tgccaagcgc acgggcttac cccagagcag gtcgtggcaa 1500
tcgcgagcaa taacggcgga aaacaggctt tggaaacggt gcagaggctc cttccagtgc 1560
tttgtcaggc acacggcctc actccggaac aagtggtcgc aatcgcgagc aataacggcg 1620
gaaaacaggc tttggaaacg gtgcagaggc tccttccagt gctgtgccaa gcgcacggac 1680
taaccccaga gcaggtcgtg gcaatcgcga gcaataacgg cggaaaacag gctttggaaa 1740
cggtgcagag gctccttcca gtgctttgtc aggcacacgg cctcactccg gaacaagtgg 1800
tcgccattgc ctcgaatgga gggggcaaac aggcgttgga aaccgtacaa cgattgctgc 1860
cggtgctgtg ccaagcgcac gggctcaccc cagagcaggt cgtggccatt gcctcgaatg 1920
gagggggcaa acaggcgttg gaaaccgtac aacgattgct gccggtgctt tgtcaggcac 1980
acggcctcac tccggaacaa gtggtcgcaa tcgcgagcaa taacggcgga aaacaggctt 2040
tggaaacggt gcagaggctc cttccagtgc tgtgccaagc gcacgggcta accccagagc 2100
aggtcgtggc aatcgcctcc aacattggcg ggaaacaggc actcgagact gtccagcgcc 2160
tgcttcccgt gctttgtcag gcacacggcc tcactccgga acaagtggtc gcgatcgcaa 2220
gccacgacgg aggaaagcaa gccttggaaa cagtacagag gctgttgcct gtgctgtgcc 2280
aagcgcacgg actcacgcct gagcaggtag tggctattgc atccaatgga gggggcagac 2340
ccgcactgga gtcaatcgtg gcccagcttt cgaggccgga ccccgcgctg gccgcactca 2400
ctaatgatca tcttgtagcg ctggcctgcc tcggcggacg acccgccttg gatgcggtga 2460
agaaggggct cccgcacgcg cctgcattga ttaagcggac caacagaagg attcccgaga 2520
ggacatcaca tcgagtggca ggatcccagc tggtgaagag cgagctggag gagaagaagt 2580
ccgagctgcg gcacaagctg aagtacgtgc cccacgagta catcgagctg atcgagatcg 2640
ccaggaacag cacccaggac cgcatcctgg agatgaaggt gatggagttc ttcatgaagg 2700
tgtacggcta caggggaaag cacctgggcg gaagcagaaa gcctgacggc gccatctata 2760
cagtgggcag ccccatcgat tacggcgtga tcgtggacac aaaggcctac agcggcggct 2820
acaatctgcc tatcggccag gccgacgaga tgcagagata cgtgaaggag aaccagaccc 2880
ggaataagca catcaacccc aacgagtggt ggaaggtgta ccctagcagc gtgaccgagt 2940
tcaagttcct gttcgtgagc ggccacttca agggcaacta caaggcccag ctgaccaggc 3000
tgaaccacaa aaccaactgc aatggcgccg tgctgagcgt ggaggagctg ctgatcggcg 3060
gcgagatgat caaagccggc accctgacac tggaggaggt gcggcgcaag ttcaacaacg 3120
gcgagatcaa cttctgataa 3140
<210> 4
<211> 1993
<212> DNA
<213> Ubiquitin启动子
<400> 4
ctgcagtgca gcgtgacccg gtcgtgcccc tctctagaga taatgagcat tgcatgtcta 60
agttataaaa aattaccaca tatttttttt gtcacacttg tttgaagtgc agtttatcta 120
tctttataca tatatttaaa ctttactcta cgaataatat aatctatagt actacaataa 180
tatcagtgtt ttagagaatc atataaatga acagttagac atggtctaaa ggacaattga 240
gtattttgac aacaggactc tacagtttta tctttttagt gtgcatgtgt tctccttttt 300
ttttgcaaat agcttcacct atataatact tcatccattt tattagtaca tccatttagg 360
gtttagggtt aatggttttt atagactaat ttttttagta catctatttt attctatttt 420
agcctctaaa ttaagaaaac taaaactcta ttttagtttt tttatttaat aatttagata 480
taaaatagaa taaaataaag tgactaaaaa ttaaacaaat accctttaag aaattaaaaa 540
aactaaggaa acatttttct tgtttcgagt agataatgcc agcctgttaa acgccgtcga 600
cgagtctaac ggacaccaac cagcgaacca gcagcgtcgc gtcgggccaa gcgaagcaga 660
cggcacggca tctctgtcgc tgcctctgga cccctctcga gagttccgct ccaccgttgg 720
acttgctccg ctgtcggcat ccagaaattg cgtggcggag cggcagacgt gagccggcac 780
ggcaggcggc ctcctcctcc tctcacggca ccggcagcta cgggggattc ctttcccacc 840
gctccttcgc tttcccttcc tcgcccgccg taataaatag acaccccctc cacaccctct 900
ttccccaacc tcgtgttgtt cggagcgcac acacacacaa ccagatctcc cccaaatcca 960
cccgtcggca cctccgcttc aaggtacgcc gctcgtcctc cccccccccc cctctctacc 1020
ttctctagat cggcgttccg gtccatggtt agggcccggt agttctactt ctgttcatgt 1080
ttgtgttaga tccgtgtttg tgttagatcc gtgctgctag cgttcgtaca cggatgcgac 1140
ctgtacgtca gacacgttct gattgctaac ttgccagtgt ttctctttgg ggaatcctgg 1200
gatggctcta gccgttccgc agacgggatc gatttcatga ttttttttgt ttcgttgcat 1260
agggtttggt ttgccctttt cctttatttc aatatatgcc gtgcacttgt ttgtcgggtc 1320
atcttttcat gctttttttt gtcttggttg tgatgatgtg gtctggttgg gcggtcgttc 1380
tagatcggag tagaattctg tttcaaacta cctggtggat ttattaattt tggatctgta 1440
tgtgtgtgcc atacatattc atagttacga attgaagatg atggatggaa atatcgatct 1500
aggataggta tacatgttga tgcgggtttt actgatgcat atacagagat gctttttgtt 1560
cgcttggttg tgatgatgtg gtgtggttgg gcggtcgttc attcgttcta gatcggagta 1620
gaatactgtt tcaaactacc tggtgtattt attaattttg gaactgtatg tgtgtgtcat 1680
acatcttcat agttacgagt ttaagatgga tggaaatatc gatctaggat aggtatacat 1740
gttgatgtgg gttttactga tgcatataca tgatggcata tgcagcatct attcatatgc 1800
tctaaccttg agtacctatc tattataata aacaagtatg ttttataatt attttgatct 1860
tgatatactt ggatgatggc atatgcagca gctatatgtg gattttttta gccctgcctt 1920
catacgctat ttatttgctt ggtactgttt cttttgtcga tgctcaccct gttgtttggt 1980
gttacttctg cag 1993
<210> 5
<211> 780
<212> DNA
<213> 35S启动子
<400> 5
atggtggagc acgacactct cgtctactcc aagaatatca aagatacagt ctcagaagac 60
caaagggcta ttgagacttt tcaacaaagg gtaatatcgg gaaacctcct cggattccat 120
tgcccagcta tctgtcactt catcaaaagg acagtagaaa aggaaggtgg cacctacaaa 180
tgccatcatt gcgataaagg aaaggctatc gttcaagatg cctctgccga cagtggtccc 240
aaagatggac ccccacccac gaggagcatc gtggaaaaag aagacgttcc aaccacgtct 300
tcaaagcaag tggattgatg tgaacatggt ggagcacgac actctcgtct actccaagaa 360
tatcaaagat acagtctcag aagaccaaag ggctattgag acttttcaac aaagggtaat 420
atcgggaaac ctcctcggat tccattgccc agctatctgt cacttcatca aaaggacagt 480
agaaaaggaa ggtggcacct acaaatgcca tcattgcgat aaaggaaagg ctatcgttca 540
agatgcctct gccgacagtg gtcccaaaga tggaccccca cccacgagga gcatcgtgga 600
aaaagaagac gttccaacca cgtcttcaaa gcaagtggat tgatgtgata tctccactga 660
cgtaagggat gacgcacaat cccactatcc ttcgcaagac ccttcctcta tataaggaag 720
ttcatttcat ttggagagga cacgctgaaa tcaccagtct ctctctacaa atctatctct 780
<210> 6
<211> 19
<212> DNA
<213> 人工序列
<400> 6
ctccccttca gctggacac 19
<210> 7
<211> 18
<212> DNA
<213> 人工序列
<400> 7
agctgggcca cgattgac 18
<210> 8
<211> 19
<212> DNA
<213> 人工序列
<400> 8
ctccccttca gctggacac 19
<210> 9
<211> 18
<212> DNA
<213> 人工序列
<400> 9
agctgggcca cgattgac 18
<210> 10
<211> 18
<212> DNA
<213> 人工序列
<400> 10
tgaccgagtt caagttcc 18
<210> 11
<211> 17
<212> DNA
<213> 人工序列
<400> 11
ttgcgggact ctaatca 17
<210> 12
<211> 18
<212> DNA
<213> 人工序列
<400> 12
gcagtggcgg gatatggt 18
<210> 13
<211> 18
<212> DNA
<213> 人工序列
<400> 13
atcgtgttgc tggtttgg 18
- 还没有人留言评论。精彩留言会获得点赞!