调节目标蛋白表达的折叠因子及其应用的制作方法
本发明属于生物技术领域,更具体地,本发明涉及调节目标蛋白表达的折叠因子及其应用。
背景技术:
折叠因子(分子伴侣蛋白)可以定义为“一类在序列上没有相关性但有共同功能的蛋白质,它们在细胞内帮助其他含多肽的结构完成正确的组装,而且在组装完毕后与之分离,不构成这些蛋白质结构执行功能时的组份”,如热休克蛋白。还有一类“分子内伴侣”前肽常位于信号肽与成熟多肽之间,是成熟多肽正确折叠所必需的。折叠酶则是催化蛋白质折叠过程共价键的异构化。有的辅助折叠分子即可以是折叠酶又可以是折叠因子。
利用毕赤酵母(pichia pastoris)表达外源蛋白时,常面临蛋白分泌和表达效果不理想的问题。其中一个重要的原因是外源蛋白过表达导致蛋白错误折叠,造成ER(endoplasmic reticulum)压力。而折叠因子(分子伴侣蛋白)具有促进蛋白正确折叠的潜力。因此如能找到适合于调节酵母细胞的外源蛋白表达的折叠因子,则对于表达生产是有利的。
蛋白的重组表达一直是本领域的技术热点,因此,本领域有必要探寻一些新型折叠因子,为有目的地调节蛋白的重组表达提供有效的方式。
技术实现要素:
本发明的目的在于提供调节目标蛋白表达的折叠因子及其应用。
在本发明的第一方面,提供一种调节目标蛋白重组表达或活性的方法,所述方法包括:当目标蛋白在细胞表达的同时,还在细胞内表达折叠因子;所述的折叠因子选自:PDI2蛋白、PDI3蛋白或NEF蛋白。
在一个优选例中,所述的调节目标蛋白重组表达或活性包括:促进目标蛋白的表达或活性或抑制目标蛋白的表达或活性。
在另一优选例中,所述的促进目标蛋白的表达或抑制目标蛋白的表达是:促进目标蛋白的分泌表达或抑制目标蛋白的分泌表达。
在另一优选例中,所述的细胞是酵母细胞;较佳地是毕赤酵母细胞,酿酒酵母细胞。
在另一优选例中,所述的目标蛋白是外源蛋白;较佳地,所述的目标蛋白是适于利用酵母细胞重组表达的蛋白;较佳地,所述的目标蛋白包括(但不限于):结构蛋白,功能性蛋白,酶。
在另一优选例中,所述的目标蛋白包括EGFP蛋白或Gal蛋白,且所述的PDI2蛋白、PDI3蛋白或NEF蛋白抑制目标蛋白的重组表达;或所述的目标蛋白是Gal蛋白,且所述的PDI3可提高Gal蛋白的活性;或所述的目标蛋白是CPC酰化酶,且所述的PDI2蛋白、PDI3蛋白或NEF蛋白促进目标蛋白的重组表达或活性。
在另一优选例中,所述的PDI2蛋白是:(a)如SEQ ID NO:2氨基酸序列的多肽;(b)将SEQ ID NO:2氨基酸序列经过一个或多个(如1-30个;较佳地1-20个;更佳地1-10个;如5个,3个)氨基酸残基的取代、缺失或添加而形成的,且具有(a)多肽功能的由(a)衍生的多肽;或(c)与(a)限定的多肽序列有80%以上(较佳地90%以上,如95%,98%,99%或更高)同源性且具有(a)多肽功能的由(a)衍生的多肽;
所述的PDI3蛋白是:(a’)如SEQ ID NO:4氨基酸序列的多肽;(b’)将SEQ ID NO:4氨基酸序列经过一个或多个(如1-30个;较佳地1-20个;更佳地1-10个;如5个,3个)氨基酸残基的取代、缺失或添加而形成的,且具有(a’)多肽功能的由(a’)衍生的多肽;或(c’)与(a’)限定的多肽序列有80%以上(较佳地90%以上,如95%,98%,99%或更高)同源性且具有(a’)多肽功能的由(a’)衍生的多肽;
所述的NEF蛋白是:(a”)如SEQ ID NO:6氨基酸序列的多肽;(b”)将SEQ ID NO:6氨基酸序列经过一个或多个(如1-30个;较佳地1-20个;更佳地1-10个;如5个,3个)氨基酸残基的取代、缺失或添加而形成的,且具有(a”)多肽功能的由(a”)衍生的多肽;或(c”)与(a”)限定的多肽序列有80%以上(较佳地90%以上,如95%,98%,99%或更高)同源性且具有(a”)多肽功能的由(a”)衍生的多肽。
在另一优选例中,编码所述PDI2蛋白的多核苷酸具有SEQ ID NO:1或其简并的序列;编码所述PDI3蛋白的多核苷酸具有SEQ ID NO:3或其简并的序列;编码所述NEF蛋白的多核苷酸具有SEQ ID NO:5或其简并的序列。
7.折叠因子的用途,用于调节目标蛋白重组表达或活性;其中,所述的折叠因子选自:PDI2蛋白、PDI3蛋白或NEF蛋白。
8.如权利要求7所述的用途,其特征在于,所述的调节目标蛋白重组表达包括:促进目标蛋白的表达或抑制目标蛋白的表达。
在一个优选例中,所述的目标蛋白是外源蛋白;较佳地,所述的目标蛋白是适于利用酵母细胞重组表达的各种蛋白;较佳地,所述的目标蛋白包括(但不限于):结构蛋白,功能性蛋白,酶。
在另一优选例中,所述的目标蛋白包括EGFP蛋白或Gal蛋白,所述的PDI2蛋白、PDI3蛋白或NEF蛋白抑制目标蛋白的重组表达;或所述的目标蛋白是CPC酰化酶,所述的PDI2蛋白、PDI3蛋白或NEF蛋白促进目标蛋白的重组表达。
在本发明的另一方面,提供用于调节目标蛋白的表达的折叠因子集,所述的折叠因子集包括:PDI2蛋白、PDI3蛋白和NEF蛋白。
在本发明的另一方面,提供一种重组表达目标蛋白的方法,所述方法包括:
(1)将目标蛋白的表达盒转入细胞中,分别将权利要求9的折叠因子集中的折叠因子转入细胞中;
(2)观察各折叠因子对于目标蛋白的表达或活性的影响,选择出促进目标蛋白的表达或活性的折叠因子;
(3)将步骤(2)选择出的折叠因子与目标蛋白共表达。
在本发明的另一方面,提供一种表达构建物,所述的表达构建物包括:折叠因子表达盒,和外源蛋白表达盒;其中,所述的折叠因子选自:PDI2蛋白、PDI3蛋白或NEF蛋白。
在另一优选例中,所述的表达构建物是表达载体。
在本发明的另一方面,提供一种宿主细胞,其特征在于,所述宿主细胞包括所述的表达构建物;较佳地,所述的宿主细胞是酵母细胞。
本发明的其它方面由于本文的公开内容,对本领域的技术人员而言是显而易见的。
附图说明
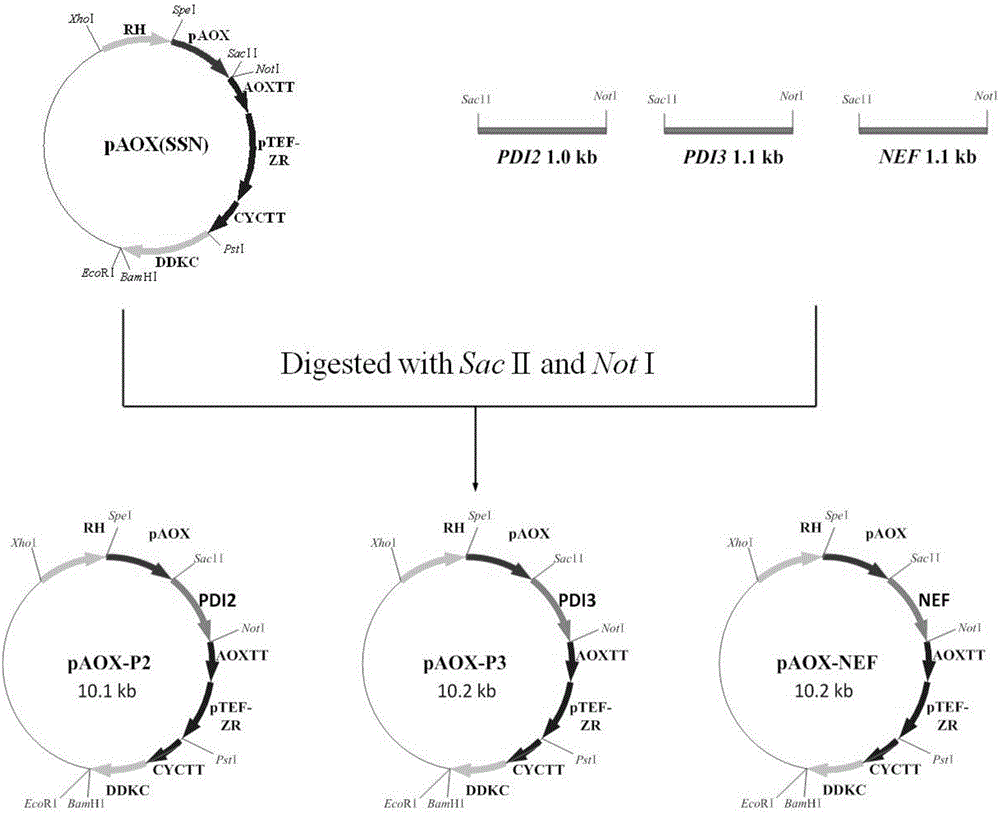
图1、折叠因子的表达质粒构建过程示意图。
图2、PCR扩增目标折叠因子基因。泳道1:以GS115基因组DNA为模板,PDI2F/PDI2R为引物扩增PDI2基因;泳道2:以GS115基因组DNA为模板,PDI3F/PDI3R为引物扩增PDI3基因;泳道3:以GS115基因组DNA为模板,NEF F/NEF R为引物扩增NEF基因。
图3、双酶切验证折叠因子表达质粒。泳道1:pAOX-P3经Xho I和Not I消化;泳道2:pAOX-NEF经Xho I和Not I消化;泳道3:pAOX-P1经Xho I和Not I消化;M:Marker。
图4、外源蛋白分泌表达质粒构建流程。分别以pG1Hg、pG1HL和pMFCA为模板,用引物对GFP F/GFP R、LacZ F/LacZ R和SECA F/SECA R,分别扩增出egfp、LacZ和SECA基因,扩增产物和pPIC9K载体经EcoR I/Not I双酶切消化后连接,通过热击转化大肠杆菌DH5α感受态细胞。
图5、PCR扩增egfp、LacZ和SECA。泳道1:以pG1Hg为模板,GFP F/GFP R为引物,PCR扩增egfp;泳道2:以pG1HL为模板,LacZ F/LacZ R为引物,PCR扩增LacZ;泳道3:以pMFCA为模板,SECA F/SECA R.为引物,PCR扩增LacZ SECA。
图6、pPIC9KG、pPIC9kL和pPIC9kCA双酶切验证。泳道1:pPIC9KG;泳道2:pPIC9kL;泳道3:pPIC9kCA。
图7、PCR验证G/9KG,G/9KL和G/9KCA重组菌。道1:G/9KG;泳道2:G/9KL;泳道3:G/9KCA。以重组菌基因组DNA为模板,以GFP F1/GFP R1,LacZ F/LacZ R和SECA F/SECA R为引物验证重组菌基因型。
图8、PCR验证yEGFP共表达重组菌。泳道1:G/9KGP2为模板;泳道2:G/9KGP3;泳道3:G/9KGNEF。以重组菌基因组DNA为模板,RH F和PAOX R为引物验证重组菌基因型。
图9、折叠因子过表达对yEGFP的分泌表达(A)和转录的影响(B)。
图10、PCR验证Gal共表达重组菌。泳道1:G/9KLP2为模板;泳道2:G/9KLP3;泳道3:G/9KLNEF。以重组菌基因组DNA为模板,RH F和PAOX R为引物验证重组菌基因型。
图11、折叠因子过表达对Gal的分泌表达(A)和转录的影响(B)。
图12、PCR验证CPC酰化酶共表达重组菌。泳道1:G/9KCAP2为模板;泳道2:G/9KCAP3;泳道3:G/9KCANEF。以重组菌基因组DNA为模板,RH F和PAOX R为引物验证重组菌基因型。
图13、折叠因子过表达对CPC酰化酶的分泌表达(A)和转录的影响(B)。
具体实施方式
本发明人经过大量的筛选工作,揭示了一类可用于调节毕赤酵母分泌表达多种异源蛋白的折叠因子。所述的折叠因子可以有效地调节毕赤酵母细胞的外源蛋白的表达,特别是分泌表达。
如本文所用,所述的“目标蛋白”是指感兴趣的、需要利用宿主细胞进行重组表达的蛋白。
如本文所用,如本文所用,所述的“表达盒”或“基因表达盒”是指包含有表达目的多肽(本发明中为折叠因子,或目标蛋白)所需的所有必要元件的基因表达系统,通常其包括以下元件:启动子、编码多肽的基因序列,终止子;此外还可选择性包括信号肽编码序列等;这些元件是操作性相连的。
如本文所用,所述的“构建物”或“表达构建物”是指重组DNA分子,它包含预期的核酸编码序列,其可以包含一个或多个基因表达盒。所述的“构建物”通常被包含在表达载体中;这个DNA分子还包含转录在体外或体内可操作的连接编码序列所必需的或预期的适合的调控元件。“调控元件”在这里指的是可一定程度上控制核酸序列表达的核苷酸序列。可作为典范的调控元件包括增强子,内核糖体进入位点(IRES),复制起点,多腺苷酸化信号,启动子,转录终止序列,以及上游调节区,这些调控元件有助于核酸的复制、转录、转录后修饰等。
如本文所用,所述的“可操作地连接”或“操作性连接”是指两个或多个核酸区域或核酸序列的功能性的空间排列。例如:启动子区被置于相对于目的基因核酸序列的特定位置,使得核酸序列的转录受到该启动子区域的引导,从而,启动子区域被“可操作地连接”到该核酸序列上。
如本文所用,如本文所用,所述的“外源”或“异源”来自不同来源的两条或多条核酸或蛋白质序列之间的关系。例如,如果启动子与目的基因序列的组合通常不是天然存在的,则启动子对于该目的基因来说是“外源”的。特定序列对于其所插入的细胞或生物体来说是“外源”的。
基于本发明人的上述新发现,本发明提供了一种调节目标蛋白重组表达的方法,所述方法包括:当目标蛋白在细胞表达的同时,还在细胞内表达折叠因子;所述的折叠因子选自:PDI2蛋白、PDI3蛋白或NEF蛋白。
本发明所述的折叠因子包括全长的折叠因子或其生物活性片段(或称为活性片段)。经过一个或多个氨基酸残基的取代、缺失或添加而形成的折叠因子的氨基酸序列也包括在本发明中。折叠因子或其生物活性片段包括一部分保守氨基酸的替代序列,所述经氨基酸替换的序列并不影响其活性或保留了其部分的活性。适当替换氨基酸是本领域公知的技术,所述技术可以很容易地被实施,并且确保不改变所得分子的生物活性。这些技术使本领域人员认识到,一般来说,在一种多肽的非必要区域改变单个氨基酸基本上不会改变生物活性。
任何一种本发明的折叠因子的生物活性片段都可以应用到本发明中。在这里,折叠因子的生物活性片段的含义是指作为一种多肽,其仍然能保持全长的折叠因子的全部或部分功能。通常情况下,所述的生物活性片段至少保持70%的全长折叠因子的活性。在更优选的条件下,所述活性片段能够保持全长折叠因子的80%、90%、95%、99%、或100%的活性。
在本发明中,“PDI2蛋白”指具有PDI2蛋白活性的SEQ ID NO:2序列的蛋白。该术语还包括具有与PDI2蛋白相同功能的、SEQ ID NO:2序列的变异形式。这些变异形式包括(但并不限于):若干个(如1-20个;较佳地1-15个;更佳地1-10个;如5个,3个)氨基酸的缺失、插入和/或取代,以及在C末端和/或N末端添加或缺失一个或数个(通常为20个以内,较佳地为10个以内,更佳地为5个以内)氨基酸。例如,在本领域中,用性能相近或相似的氨基酸进行取代时,通常不会改变蛋白质的功能。又比如,在C末端和/或N末端添加或缺失一个或数个氨基酸通常也不会改变蛋白质的功能。PDI2与已知蛋白PDI1的序列同源性仅为:consensus position:17.9%;identity position:13.3%。
在本发明中,“PDI3蛋白”指具有PDI3蛋白活性的SEQ ID NO:4序列的蛋白。该术语还包括具有与PDI3蛋白相同功能的、SEQ ID NO:4序列的变异形式。这些变异形式包括(但并不限于):若干个(如1-20个;较佳地1-15个;更佳地1-10个;如5个,3个)氨基酸的缺失、插入和/或取代,以及在C末端和/或N末端添加或缺失一个或数个(通常为20个以内,较佳地为10个以内,更佳地为5个以内)氨基酸。PDI3与已知蛋白PDI1的序列同源性仅为:consensus position:27.0%;identity position:16.1%。
在本发明中,“NEF蛋白”指具有NEF蛋白活性的SEQ ID NO:6序列的蛋白。该术语还包括具有与NEF蛋白相同功能的、SEQ ID NO:6序列的变异形式。这些变异形式包括(但并不限于):若干个(如1-20个;较佳地1-15个;更佳地1-10个;如5个,3个)氨基酸的缺失、插入和/或取代,以及在C末端和/或N末端添加或缺失一个或数个(通常为20个以内,较佳地为10个以内,更佳地为5个以内)氨基酸。
编码所述折叠因子或其保守性变异蛋白的多核苷酸序列(编码序列)也可以应用到本发明中。编码成熟PDI2蛋白的编码区序列可以与SEQ ID NO:1所示的序列基本上相同或者是简并的变异体。编码成熟PDI3蛋白的编码区序列可以与SEQ ID NO:3所示的序列基本上相同或者是简并的变异体。编码成熟NEF蛋白的编码区序列可以与SEQ ID NO:5所示的序列基本上相同或者是简并的变异体。如本文所用,“简并的变异体”在本发明中是指编码具有SEQ ID NO:2、4或6的蛋白质,但与SEQ ID NO:1、3或5所示的编码区序列有差别的核酸序列。
术语“编码基因”可以是包括编码所述蛋白的多核苷酸,也可以是还包括附加编码和/或非编码序列的多核苷酸。
所述的编码序列通常可以用PCR扩增法、重组法或人工合成的方法获得。对于PCR扩增法,可根据本发明所公开的有关核苷酸序列,尤其是开放阅读框序列来设计引物,并用市售的cDNA库或按本领域技术人员已知的常规方法所制备的cDNA库作为模板,扩增而得有关序列。此外,还可用人工合成的方法来合成有关序列。
包含所述编码序列的载体,以及用所述的载体或折叠因子的编码序列经基因工程产生的宿主细胞也包括在本发明中。本领域的技术人员熟知的方法能用于构建含所述折叠因子编码序列和合适的转录/翻译控制信号的表达载体。这些方法包括体外重组DNA技术、DNA合成技术、体内重组技术等。所述的序列可有效连接到表达载体中的适当启动子上,以指导mRNA合成。包含上述的适当编码序列以及适当启动子或者控制序列的载体,可以用于转化适当的宿主细胞,以使其能够表达蛋白质。
本发明的方法适用于在多种细胞中重组表达外源蛋白,包括在酵母细胞中重组表达外源蛋白,所述的酵母可以是毕赤酵母等。在本发明的优选实施例中,采用了毕赤酵母细胞。
基于本发明的新发现,本发明还涉及表达构建物,所述的表达构建物包括:折叠因子表达盒,和外源蛋白表达盒;其中,所述的折叠因子选自:PDI2蛋白、PDI3蛋白或NEF蛋白。作为本发明的优选方式,所述的表达构建物是表达载体。
并且,本发明还涉及含有所述表达构建物的宿主细胞,或者,基因组中整合有所述的折叠因子表达盒,和外源蛋白表达盒的宿主细胞。
将外源的折叠因子以及外源蛋白的编码基因导入到所述微生物的细胞内的方法是本领域人员熟知的。通常的方法是,获得编码所述的折叠因子的生物活性片段的基因序列,将其连入合适的表达载体,再转入微生物细胞。更具体的步骤是:(i)提供重组表达载体,该重组表达载体含有基因表达盒,所述表达盒含有折叠因子的编码基因,以及基因表达盒,该表达盒含有外源蛋白的编码基因;(ii)将(i)的重组表达载体转化到所述细胞内,从而使得所述细胞内含有所述重组表达载体或者其基因组中整合有所述折叠因子和外源蛋白的编码基因。在本发明的具体实施例中,提供了六个表达质粒,包括三个外源蛋白表达质粒和三个折叠因子表达质粒。
为了对折叠因子进行验证,在本发明的较佳实施例中,选用了三种不同大小、结构复杂度的报告蛋白进行考察和筛选:增强型绿色荧光蛋白yEGFP、β-半乳糖苷酶(Gal)和CPC酰化酶(SECA)。yEGFP分子量小,蛋白结构简单,成功在多种表达系统中的分泌表达。Gal分子量较大,蛋白结构复杂,分泌表达效果较差。SECA分子量介于yEGFP和Gal之间,具有工业化应用前景。折叠因子对易分泌表达的蛋白yEGFP无明显促进作用(secretion ratio)。将三个折叠因子分别与上述蛋白共表达,以出发菌株(只含有报告基因)为对照,考察三个折叠因子的效果。结果显示,折叠因子的表达降低了Gal的表达水平,但PDI2和PDI3的影响最小,且PDI3可提高Gal的extracellular specific activity。折叠因子的表达均提高了SECA的表达水平,其中PDI2效果最好,达1.6倍。NEF对于SECA的分泌表达效果最好,extracellular specific activity提高了3.3倍。本发明所获得的新的折叠因子为优化外源蛋白在毕赤酵母中的分泌表达提供了更多选择的可能。
本发明获得的PDI2蛋白、PDI3蛋白和NEF蛋白具有各自的特点,适用于不同大小、不同表达特点的目标蛋白,因此它们可以构成一个折叠因子集,以方便人们从中选择到合适的调节目标蛋白表达的因子。
综上,本发明提供了一系列新的折叠因子,在本领域中拓宽了可用的折叠因子库;并且,本发明人还论证了它们对于目标蛋白的表达调节作用,具有良好的应用价值。
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。下列实施例中未注明具体条件的实验方法,通常按照常规条件如J.萨姆布鲁克等编著,《分子克隆指南》,第三版,科学出版社,2002中所述的条件,或按照制造厂商所建议的条件。
1.材料与方法
下述实施例中所用方法如无特殊说明,均为常规方法,参照《分子克隆指南》中所述的条件。下述实施例中所用材料、试剂等,如无特殊说明,均可从商业途径得到。
1.1菌株与质粒
本发明的以下实施例中,应用的质粒如表1所示。
表1、质粒
pG1HL和pG1HG参见:秦秀林;构建GAP启动子文库提高重组毕赤酵母S-腺苷甲硫氨酸合成[博士学位论文];上海:华东理工大学大学,2011。
pAOX(SSN)参见:陆俊杰;毕赤酵母合成S-腺苷甲硫氨酸的代谢工程研究[硕士学位论文];上海:华东理工大学大学;2014。
pMFCA参见丁璐妹等,内源信号肽dse4介导头孢菌素c酰化酶在毕赤酵母中的分泌表达;华东理工大学学报:自然科学版,2015,41:449-454。
本发明的以下实施例中,应用的菌株如表2所示。
表2、菌株
1.2引物
根据引物设计原则以及引物设计软件Primer premier 5.0设计实验所需引物,所用到的引物由上海生工生物工程公司合成(表3)。
表3、引物
*下划线标示为限制性酶切位点。
1.3酶与试剂
本发明所用的PCR酶Pfu PCR MasterMix和Taq PCR MasterMix购自天根生化科技有限公司。T4-ligase、限制性内切酶(XhoI、NotI、EcoRI、BamHI、SacII和SalI等)购自大连TaKaRa生物技术有限公司。
常规分子克隆(质粒抽提、DNA凝胶电泳回收、酶切产物纯化、PCR产物纯化和基因组DNA提取)常用试剂盒以及酵母总RNA提取试剂盒(multisource total RNA miniprep kit)购自Axygen公司。RNA反转录成cDNA试剂盒(PrimeScriptTM II High Fidelity RT-PCR Kit和PrimeScriptTMII 1st Strand cDNA Synthesis Kit)购自大连Takara生物技术有限公司。荧光定量PCR试剂盒( Premix DimerEraserTMKit)购自大连Takara生物技术有限公司。
表4、实验试剂
1.4培养基
1、LB液体培养基
5g/L酵母提取物,10g/L胰蛋白胨,10g/L NaCl。
配制LB固体培养基需再加2%(w/w)的琼脂粉,液体和固体培养基均可根据需要加入适当浓度的抗生素。
2、YPD:20g/L葡萄糖,10g/L酵母提取物,20g/L蛋白胨。
配制YPD固体培养基需再加2%(w/w)的琼脂粉,液体和固体培养基均可根据需要加入适当浓度的抗生素。
3、MD固体培养基:13.4g/L YNB,20g/L葡萄糖,0.4mg/L生物素,20g/L琼脂粉。
4、YPG:20g/L甘油,10g/L酵母提取物,20g/L蛋白胨。
5、BMGY(Buffered Glycerol-complex Medium)液体培养基:20g/L胰蛋白胨,10g/L酵母提取物,0.1M磷酸钾缓冲液pH6.0,13.4g/L YNB,生物素4×10-5,10g/L甘油。
6、BMMY(Buffered Methanol-complex Medium)液体培养基:20g/L胰蛋白胨,10g/L酵母提取物,0.1M磷酸钾缓冲液pH 6.0,13.4g/L YNB,生物素4×10-5,0.5%(v/v)甲醇。
7、BMMT(BMMY去除酵母提取物)液体培养基:20g/L胰蛋白胨,0.1M磷酸钾缓冲液pH6.0,13.4g/L YNB,生物素4×10-5,0.5%(v/v)甲醇。
实施例1、折叠因子表达质粒构建
以pAOX(SSN)为载体(AOX1启动子,ZeocinR和His+),利用Sac IΙ和Not I酶切位点,在AOX1启动子和终止子之间插入折叠因子基因,构建辅助折叠因子表达载体pAOX-Chaperone,构建流程见图1。
为了扩增折叠因子基因片段,根据GS115基因组上的PDI2、PDI3和NEF序列信息以及pAOX(SSN)载体的限制性酶切位点,分别设计引物对(表3)PDI2F/PDI2R、PDI3F/PDI3R和NEF F/NEF R。上述所有正向引物带有Sac II酶切位点,反向引物带有Not I酶切位点。
以GS115基因组DNA为模板,分别以PDI2F/PDI2R、PDI3F/PDI3R和NEF F/NEF R为引物,PCR扩增PDI2、PDI3和NEF。PCR扩增产物电泳结果如图2所示,所有电泳条带大小和预期均一致,经测序证实,得到所需要的折叠因子基因。
pAOX(SSN)载体和折叠因子基因分别经Not I/Sac II消化后,纯化连接。连接产物热击转化大肠杆菌DH5α感受态细胞。在含有Zeocin抗生素的LB平板中,筛选阳性克隆。阳性克隆提取质粒双酶切产物结果如图3所示。
各折叠因子表达质粒的酶切产物电泳条带大小和预期一致,质粒经测序,证实得到正确的折叠因子表达质粒。
实施例2、外源蛋白分泌表达质粒构建
分别以pG1Hg,pG1HL和pMFCA为模板,以表3中所列引物为引物,分别扩增egfp、LacZ和SECA三个外源基因。PCR产物测定结果如图5。
通过pPIC9K质粒中的EcoR I和Not I两个酶切位点将egfp、LacZ和SECA三个外源基因分别连接到载体中,构建yEGFP、Gal和CPC酰化酶分泌表达质粒pPIC9KG、pPIC9KL和pPIC9KCA,构建过程见图4。
Zeocin抗生素LB平板中筛选重组大肠杆菌阳性克隆,扩增培养后提取质粒酶切验证。由图6可知,pPIC9KG,pPIC9kL和pPIC9kCA经过双酶切后得到与预期大小一致的片段条带,送往测序公司测序,测序结果和预期结果一致,获得正确的外源蛋白分泌表达质粒。
实施例3、共表达重组菌构建
pPIC9KG、pPIC9kL和pPIC9kCA分别经Sal I酶切,线性化产物纯化后电击转化毕赤酵母GS115感受态细胞,使质粒整合到GS115的基因组中,利用GS115组氨酸缺陷和质粒组氨酸回补的特征,在MD平板中筛选重组菌,待筛选平板中长出单菌落后,分别以GFP F1/GFP R1,LacZ F/LacZ R和SECA F/SECA R为引物,菌落PCR验证阳性克隆。
菌落PCR验证结果如图7。由图可知,yEGFP、Gal和CPC酰化酶分泌表达重组菌G/9KG、G/9KL和G/9KCA构建成功。
实施例4、折叠因子对yEGFP的影响
将重组菌G/9KG做成感受态细胞。构建好的辅助折叠因子表达质粒pAOX-P2、pAOX-P3、pAOX-NEF经Xho I和BamH I双酶切线性化,纯化后分别电击转化G/9KG感受态细胞。在含Zeocin抗生素的YPD平板中筛选P.pastoris重组菌阳性克隆,培养后提基因组DNA,以RH F和PAOX R为引物,PCR验证线性化的质粒是否成功整合,得到大小和预期一致的PCR产物电泳条带,如图8。
PCR产物经测序验证证实,获得正确的重组菌。根据过表达的折叠因子和外源蛋白将菌株分别命名为G/9KGP2、G/9KGP3和G/9KGNEF。
BiP是P.pastoris热休克蛋白家族中的一员,是已知的多功能折叠因子。因此,本发明人将Bip编码序列(Genbank登录号NC_012964.1中第264385~266421位)替换G/9KGP2中的PDI2编码序列,构建获得G/9KGBiP,作为比较。
PDI也是一个已知的多功能折叠因子,本发明人将PDI编码序列(Genbank登录号NC_012966.1中第1588618~1590172位)替换G/9KGP2中的PDI2编码序列,构建获得G/9KGPDI,作为比较。
yEGFP重组表达菌经BMMT甲醇诱导培养后,yEGFP表达量在24h达到最大值,所以用24h的样品来考察各辅助折叠因子对yEGFP分泌表达的影响。一定体积的样品离心后,取50μL上清到96孔酶标板中,用Refolding buffer稀释至200μL。离心后的菌体用4倍原发酵液体积的Refolding buffer重悬,取200μL重悬液到96孔酶标板中。在酶标仪中检测样品的荧光强度,设定激发波长为485nm,发射波长为535nm。
重组菌表达结果如图9A。由图可知,三个折叠因子分别和yEGFP共表达后,对yEGFP的分泌表达无促进效果。
整体来看(图9B),各重组菌的egfp转录水平与蛋白yEGFP表达水平存在较好的相关性,但是不完全一致。G/9KGP3的yEGFP水平和出发菌株相近,对应的基因转录水平也和出发菌株相近。G/9KGNEF的蛋白表达水平低于出发菌株,对应的egfp转录水平也低于出发菌株,而且其蛋白表达水平和基因转录水平的变化倍数也几乎一致。但是,转录水平和蛋白表达水平的变化倍数并不存在严格的线性关系,例如G/9KGP2中,其egfp转录水平超过出发菌株,但蛋白表达水平只有出发菌株的48%。
上述研究说明,对易分泌表达的蛋白yEGFP,所述的折叠因子无明显的促进作用。
实施例5、折叠因子对Gal的影响
将重组菌G/9KL做成感受态细胞。共表达重组菌构建参照yEGFP共表达重组菌的构建过程。PCR验证结果如图10所示。电泳条带结果和预期一致,测序验证后得到的正确的共表达菌株G/9KLP2、G/9KLP3和G/9KLNEF。
与构建G/9KGBiP与G/9KGPDI类似地,本发明人也构建了G/9KLBiP以及G/9KLPDI,用作比较。
Gal重组表达菌经BMMY甲醇诱导培养后,Gal表达水平在培养96h后达到最大值,所以96h取样考察各辅助折叠因子对Gal分泌表达的影响。取1mL发酵液,4℃、12,000rpm离心5min。分别取上清和菌体进行分析。菌体用1mL裂解缓冲液重悬,重悬液转入到10mL离心管中,加1mL直径为0.5mm的玻璃珠,在斡旋振荡器上振荡30s后立刻冰浴30s,重复上述操作10次,将破碎的菌体转入1.5mL离心管,4℃、12,000rpm离心3min,上清作为粗酶液保存。
分别测定培养液上清和所制备粗酶液的Gal活性来考察重组菌胞内外的Gal含量,结果如图11A所示。
结果显示,过表达折叠因子后,Gal的分泌表达水平下降,表明这三个折叠因子不促进Gal的分泌表达。
从Gal表达来看,共表达辅助折叠因子均使蛋白的表达水平下降,其中NEF对Gal的影响最大,过表达NEF后,Gal表达水平仅为出发菌株的0.3%。PDI2和PDI3对Gal表达的抑制效果相对较小,共表达PDI2和PDI3后,Gal表达水平分别为出发菌株的61.7%和78.5%。
从Gal的分泌率来看,除PDI2外,其余辅助折叠因子共表达均能提高Gal的分泌率。其中对Gal分泌率促进效果最为显著的是NEF,分泌率分别是出发菌株的14.9倍。PDI3共表达重组菌的Gal分泌率是出发菌株的1.36倍。PDI2对Gal的分泌率有显著的抑制作用,过表达PDI2后使得Gal分泌率下降了88%。
和出发菌株G/9KL相比(图11B),不同折叠因子共表达均不同程度抑制了LacZ基因的转录,其中PDI2和NEF的抑制作用最明显,转录水平分别下降至对照菌的10.2%和23.4%。总体来看,LacZ的转录水平和Gal的表达水平存在较好的相关性,过表达折叠因子后,重组菌的Gal表达水平均低于出发菌株,对应的LacZ转录水平也低于出发菌株,即LacZ基因转录下降与Gal产量降低相符。但是两者的变化比例并不完全相符。其中最为异常的是PDI2,PDI2的表达使LacZ的转录水平下降为出发菌株的10.2%,但是对应的Gal表达水平却可达到出发菌株的61.7%。
分泌表达后Gal的蛋白酶活测定结果(图11)显示,PDI3能够显著提高Gal的胞外比活的结果。
综上,Gal分子量较大、蛋白结构复杂,自身分泌表达效果较差。折叠因子的表达降低了Gal的表达水平,但PDI2和PDI3的影响最小,且PDI3可提高Gal的胞外比活。
实施例6、折叠因子对CPC酰化酶的影响
将重组菌G/9KCA做成感受态细胞。共表达重组菌构建参照yEGFP共表达重组菌的构建过程。PCR验证结果如图12所示。电泳条带结果和预期一致,测序验证后得到的正确的共表达菌株G/9KCAP2、G/9KCAP3和G/9KCANEF。
与构建G/9KGBiP与G/9KGPDI类似地,本发明人也构建了G/9KCABiP以及G/9KCAPDI,用作比较。
CPC酰化酶重组菌中,表达水平在培养72h后达到最大值,因此在72h取样考察各折叠因子对CPC酰化酶分泌表达的影响。取1mL发酵液,低温离心机4℃条件下,12,000rpm离心5min。将上清与菌体分离,菌体用1mL裂解缓冲液重悬,重悬液转入到10mL离心管中,加1mL直径为0.5mm的玻璃珠,混匀后在斡旋振荡器上振荡30s后立刻冰浴30s,重复上述操作10次,将破碎的菌体转入1.5mL离心管,4℃、12,000rpm离心3min,上清作为粗酶液保存。
分别测定培养上清和所制备粗酶液的酶活来考察重组菌胞内外的CPC酰化酶,结果如图13所示。
由结果可知,所考察的折叠因子均促进了CPC酰化酶的表达,其中PDI2的效果最明显,表达水平提高了60%以上。其次是NEF,过表达NEF后CPC酰化酶表达水平提高了31%。过表达PDI3提高了CPC酰化酶表达水平13%。CPC酰化酶在P.pastoris中难以分泌,出发菌株的分泌率约为0.01。折叠因子对CPC酰化酶的分泌率影响不同。PDI3和NEF均能提高CPC酰化酶的分泌率,其中NEF的效果最为明显,过表达NEF后,CPC酰化酶的分泌率提高了2倍以上。而PDI2过表达使CPC酰化酶的分泌率下降。CPC酰化酶的转录水平和表达水平具有良好的相关性(图13B)。
总结
1.得到了对毕赤酵母分泌表达外源蛋白有促进效果的新的折叠因子
PDI2、PDI3和NEF均对CPC酰化酶的表达具有促进效果,其中PDI2的效果最为显著。共表达后使得CPC酰化酶的表达水平提高了60%以上。因此,本发明人认为PDI2、PDI3和NEF具有促进P.pastoris分泌表达外源蛋白的潜力。可用于提高其它蛋白的表达水平,拓宽了可用折叠因子的选择范围。
2.确定了各辅助折叠因子对不同类型蛋白的分泌表达效果
所筛选到的三个折叠因子对不同外源蛋白的表达具有不同程度的影响。三个折叠因子均促进了CPC酰化酶的表达。和CPC酰化酶相反,辅助折叠因子均使Gal的表达下降,其中NEF和PDI2的影响最显著,蛋白表达水平仅分别为出发菌株的0.3%和1.1%。而对yEGFP的表达,各折叠因子均抑制其表达。表5为过表达各折叠因子后对yEGFP、Gal和CPC酰化酶的相对分泌(sec)和表达水平(Exp)。
表5
*对照菌株(Control,未共表达折叠因子)的分泌和表达水平均设为1。
在本发明提及的所有文献都在本申请中引用作为参考,就如同每一篇文献被单独引用作为参考那样。此外应理解,在阅读了本发明的上述讲授内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
序列表
<110> 华东理工大学
<120> 调节目标蛋白表达的折叠因子及其应用
<130> 167426
<160> 28
<170> PatentIn version 3.3
<210> 1
<211> 897
<212> DNA
<213> 毕赤酵母
<400> 1
atgaagttac tatccttggc acttctggtg tctttggtgt ctgcggatac tttctacact 60
ccaaaggatg atgtaatcca gttgaatgct tataatttca aggatgtcgt tttcaactca 120
aactactctt cggttgtgga attttatgct ccttggtgtg gccattgtca gaacttgaaa 180
aatcccttca agaaggcagc agccgtttcc aaagactacc ttcaggtggc cgcaattgac 240
tgcgatgctg ccgaaaacaa gaagctttgc tctgattacc gtattcaagg atttcctacg 300
atcatggttt tcagaccccc caagtttgat cccacatcaa gcaccaatag aagatctggt 360
gctcatgcta atgaggtata cagtggtgct agagatacta agtcaattgt tgagtttgga 420
gtgtctcgta taaagaacta cgtcaagcga gtgtcaccca ataatattaa ccaaaccctg 480
ggaaattctg agaagaccca gcttctactt gtgacagata aggccaaacc tagtgctctg 540
ataaagtcaa ttgccttaga ctttttgaat gacatagagt ctttttacta tcctttcaac 600
gacaaaacga agaaagcatt gactacacga ttagaggagt atcaacaatc gttttctgga 660
gagagcataa cttcgccttc gattttggtg ctacatgaaa atgaaatcca catttttgat 720
gggaaactgg ataagctgag cattagcaag tttttagccg agttttcaac tcccctggaa 780
ggacctctca gtaagagagg taagtttcta gagcacattc gcaggggaat taaacccgga 840
agaaaagcga agaagggcaa gaagggcaag caaaccaaaa atcacgacga attatag 897
<210> 2
<211> 298
<212> PRT
<213> 毕赤酵母
<400> 2
Met Lys Leu Leu Ser Leu Ala Leu Leu Val Ser Leu Val Ser Ala Asp
1 5 10 15
Thr Phe Tyr Thr Pro Lys Asp Asp Val Ile Gln Leu Asn Ala Tyr Asn
20 25 30
Phe Lys Asp Val Val Phe Asn Ser Asn Tyr Ser Ser Val Val Glu Phe
35 40 45
Tyr Ala Pro Trp Cys Gly His Cys Gln Asn Leu Lys Asn Pro Phe Lys
50 55 60
Lys Ala Ala Ala Val Ser Lys Asp Tyr Leu Gln Val Ala Ala Ile Asp
65 70 75 80
Cys Asp Ala Ala Glu Asn Lys Lys Leu Cys Ser Asp Tyr Arg Ile Gln
85 90 95
Gly Phe Pro Thr Ile Met Val Phe Arg Pro Pro Lys Phe Asp Pro Thr
100 105 110
Ser Ser Thr Asn Arg Arg Ser Gly Ala His Ala Asn Glu Val Tyr Ser
115 120 125
Gly Ala Arg Asp Thr Lys Ser Ile Val Glu Phe Gly Val Ser Arg Ile
130 135 140
Lys Asn Tyr Val Lys Arg Val Ser Pro Asn Asn Ile Asn Gln Thr Leu
145 150 155 160
Gly Asn Ser Glu Lys Thr Gln Leu Leu Leu Val Thr Asp Lys Ala Lys
165 170 175
Pro Ser Ala Leu Ile Lys Ser Ile Ala Leu Asp Phe Leu Asn Asp Ile
180 185 190
Glu Ser Phe Tyr Tyr Pro Phe Asn Asp Lys Thr Lys Lys Ala Leu Thr
195 200 205
Thr Arg Leu Glu Glu Tyr Gln Gln Ser Phe Ser Gly Glu Ser Ile Thr
210 215 220
Ser Pro Ser Ile Leu Val Leu His Glu Asn Glu Ile His Ile Phe Asp
225 230 235 240
Gly Lys Leu Asp Lys Leu Ser Ile Ser Lys Phe Leu Ala Glu Phe Ser
245 250 255
Thr Pro Leu Glu Gly Pro Leu Ser Lys Arg Gly Lys Phe Leu Glu His
260 265 270
Ile Arg Arg Gly Ile Lys Pro Gly Arg Lys Ala Lys Lys Gly Lys Lys
275 280 285
Gly Lys Gln Thr Lys Asn His Asp Glu Leu
290 295
<210> 3
<211> 1110
<212> DNA
<213> 毕赤酵母
<400> 3
atgaaaatat taagtgcatt gcttcttctt tttacgttgg cctttgctga ggtcattgag 60
ctgaccaaca agaactttga tgacgtggtt ctaaagtccg gaaagtacac cttagtgaag 120
ttttatgccg attggtgttc gcattgcaag cgaatgaatc cagagtatga aaagctggcc 180
gaagaactga agccaaagag tgatctgatc cagattgccg ccattgatgc taacaaatac 240
tcaaagtaca tgaaggtgta cgatattgat ggatttccga cgatgaaatt gttcacaccc 300
aaggacatat ctcatccgat cgaattttct ggatcaagag acagtgaaag ctttttgaac 360
tttttggagt caactactgg tttgaagttg aagaagaagg cggaagtaaa tgagccttcg 420
ttagttcaat caattgatga ttcaacaata gatgaccttg ttgggaagga caggtttatt 480
gcagttactg cttcgtggtg tggatattgc aaaagattgc atcctgaatg ggagaagtta 540
gccaaagctt ttggcaatga cgatattgtc atcggaaacg ttgttaccga tgttgtggaa 600
ggtgagaata ttaaggcgaa gtataaagtt caatctttcc cgactatcct gtacttcaca 660
gcaggctcag atgaaccaat aagatatgaa tctccagata gaactgttga aggtttggtt 720
aaatttgtca atgaacaagc tggcttattt cgtgatccag atggaacttt gaatttcaac 780
gccggtctaa ttccaggagt gagtgataaa cttaccaatt acattaagga aaaagaccaa 840
agtttattgg agtcaacgtt agacttgcta agcaaccatg aacatatcaa ggacaaattc 900
agtgtcaaat accacaagaa ggtcatagaa aagttgttga agggagagaa tgaattcctc 960
aacaatgaag ttgagaggct atcaaaaatg ctgaatacaa agctatcggc aaacaattca 1020
gactctgtga ttaaaagact gaatatcttg cgcaatttta ttgaggccaa aactgagtca 1080
aaaccccagt tattacacca agagctataa 1110
<210> 4
<211> 369
<212> PRT
<213> 毕赤酵母
<400> 4
Met Lys Ile Leu Ser Ala Leu Leu Leu Leu Phe Thr Leu Ala Phe Ala
1 5 10 15
Glu Val Ile Glu Leu Thr Asn Lys Asn Phe Asp Asp Val Val Leu Lys
20 25 30
Ser Gly Lys Tyr Thr Leu Val Lys Phe Tyr Ala Asp Trp Cys Ser His
35 40 45
Cys Lys Arg Met Asn Pro Glu Tyr Glu Lys Leu Ala Glu Glu Leu Lys
50 55 60
Pro Lys Ser Asp Leu Ile Gln Ile Ala Ala Ile Asp Ala Asn Lys Tyr
65 70 75 80
Ser Lys Tyr Met Lys Val Tyr Asp Ile Asp Gly Phe Pro Thr Met Lys
85 90 95
Leu Phe Thr Pro Lys Asp Ile Ser His Pro Ile Glu Phe Ser Gly Ser
100 105 110
Arg Asp Ser Glu Ser Phe Leu Asn Phe Leu Glu Ser Thr Thr Gly Leu
115 120 125
Lys Leu Lys Lys Lys Ala Glu Val Asn Glu Pro Ser Leu Val Gln Ser
130 135 140
Ile Asp Asp Ser Thr Ile Asp Asp Leu Val Gly Lys Asp Arg Phe Ile
145 150 155 160
Ala Val Thr Ala Ser Trp Cys Gly Tyr Cys Lys Arg Leu His Pro Glu
165 170 175
Trp Glu Lys Leu Ala Lys Ala Phe Gly Asn Asp Asp Ile Val Ile Gly
180 185 190
Asn Val Val Thr Asp Val Val Glu Gly Glu Asn Ile Lys Ala Lys Tyr
195 200 205
Lys Val Gln Ser Phe Pro Thr Ile Leu Tyr Phe Thr Ala Gly Ser Asp
210 215 220
Glu Pro Ile Arg Tyr Glu Ser Pro Asp Arg Thr Val Glu Gly Leu Val
225 230 235 240
Lys Phe Val Asn Glu Gln Ala Gly Leu Phe Arg Asp Pro Asp Gly Thr
245 250 255
Leu Asn Phe Asn Ala Gly Leu Ile Pro Gly Val Ser Asp Lys Leu Thr
260 265 270
Asn Tyr Ile Lys Glu Lys Asp Gln Ser Leu Leu Glu Ser Thr Leu Asp
275 280 285
Leu Leu Ser Asn His Glu His Ile Lys Asp Lys Phe Ser Val Lys Tyr
290 295 300
His Lys Lys Val Ile Glu Lys Leu Leu Lys Gly Glu Asn Glu Phe Leu
305 310 315 320
Asn Asn Glu Val Glu Arg Leu Ser Lys Met Leu Asn Thr Lys Leu Ser
325 330 335
Ala Asn Asn Ser Asp Ser Val Ile Lys Arg Leu Asn Ile Leu Arg Asn
340 345 350
Phe Ile Glu Ala Lys Thr Glu Ser Lys Pro Gln Leu Leu His Gln Glu
355 360 365
Leu
<210> 5
<211> 1119
<212> DNA
<213> 毕赤酵母
<400> 5
atgaaagtga cattatctgt gttagctatt gcctcccaat tggttagaat cgtttgttcg 60
gaaggagaaa atatctgcat aggtgaccag tgctatccga agaattttga acctgacaag 120
gagtggaaac ctgttcagga aggccagatt atccctccag gatcacacgt aagaatggac 180
tttaatacac accagagaga ggcaaaactg gtggaagaga atgaggatat agacccctca 240
tcattgggag tggctgtagt ggattccacc ggttcgtttg ctgatgatca atctttggaa 300
aagattgagg gactttccat ggaacaacta gatgagaagt tagaagaact gattgagctt 360
tcccatgact acgagtacgg atcagacata atcttgagtg atcagtatat ttttggagta 420
gccgggctag ttcctactaa gacaaagttt acttctgagt tgaaggaaaa ggccttgaga 480
attgtcggat catgcttgag aaacaatgcc gatgcggtag agaaactact gggaactgtt 540
ccaaatacta taaccataca attcatgtca aacctagtgg gtaaagtaaa ttccactgga 600
gagaatgttg actctgttga acagaaacga atcctttcaa ttattggagc tgttattcct 660
ttcaaaattg gaaaggtatt gtttgaagct tgttcgggaa cgcagaagct attactatcc 720
ttggataaac tggaaagttc agttcaactg agaggatacc aaatgttgga cgacttcatt 780
catcaccctg aagaggaact tctctcttca ttgacagcaa aggaacgatt agtaaagcat 840
attgagttga ttcaatcatt ttttgcatca ggaaagcatt ctcttgatat agcaataaat 900
cgtgagttat tcactaggct gattgcctta cgaaccaatt tagaatctgc caatccaaat 960
ctatgtaaac catcaactga ctttttgaac tggctgatcg acgaaattga agctacgaaa 1020
gataccgatc cacacttttc aaaagagctt aaacatttac gttttgaact ttttgggaac 1080
ccattggcat ctaggaaagg tttctccgat gagttatag 1119
<210> 6
<211> 372
<212> PRT
<213> 毕赤酵母
<400> 6
Met Lys Val Thr Leu Ser Val Leu Ala Ile Ala Ser Gln Leu Val Arg
1 5 10 15
Ile Val Cys Ser Glu Gly Glu Asn Ile Cys Ile Gly Asp Gln Cys Tyr
20 25 30
Pro Lys Asn Phe Glu Pro Asp Lys Glu Trp Lys Pro Val Gln Glu Gly
35 40 45
Gln Ile Ile Pro Pro Gly Ser His Val Arg Met Asp Phe Asn Thr His
50 55 60
Gln Arg Glu Ala Lys Leu Val Glu Glu Asn Glu Asp Ile Asp Pro Ser
65 70 75 80
Ser Leu Gly Val Ala Val Val Asp Ser Thr Gly Ser Phe Ala Asp Asp
85 90 95
Gln Ser Leu Glu Lys Ile Glu Gly Leu Ser Met Glu Gln Leu Asp Glu
100 105 110
Lys Leu Glu Glu Leu Ile Glu Leu Ser His Asp Tyr Glu Tyr Gly Ser
115 120 125
Asp Ile Ile Leu Ser Asp Gln Tyr Ile Phe Gly Val Ala Gly Leu Val
130 135 140
Pro Thr Lys Thr Lys Phe Thr Ser Glu Leu Lys Glu Lys Ala Leu Arg
145 150 155 160
Ile Val Gly Ser Cys Leu Arg Asn Asn Ala Asp Ala Val Glu Lys Leu
165 170 175
Leu Gly Thr Val Pro Asn Thr Ile Thr Ile Gln Phe Met Ser Asn Leu
180 185 190
Val Gly Lys Val Asn Ser Thr Gly Glu Asn Val Asp Ser Val Glu Gln
195 200 205
Lys Arg Ile Leu Ser Ile Ile Gly Ala Val Ile Pro Phe Lys Ile Gly
210 215 220
Lys Val Leu Phe Glu Ala Cys Ser Gly Thr Gln Lys Leu Leu Leu Ser
225 230 235 240
Leu Asp Lys Leu Glu Ser Ser Val Gln Leu Arg Gly Tyr Gln Met Leu
245 250 255
Asp Asp Phe Ile His His Pro Glu Glu Glu Leu Leu Ser Ser Leu Thr
260 265 270
Ala Lys Glu Arg Leu Val Lys His Ile Glu Leu Ile Gln Ser Phe Phe
275 280 285
Ala Ser Gly Lys His Ser Leu Asp Ile Ala Ile Asn Arg Glu Leu Phe
290 295 300
Thr Arg Leu Ile Ala Leu Arg Thr Asn Leu Glu Ser Ala Asn Pro Asn
305 310 315 320
Leu Cys Lys Pro Ser Thr Asp Phe Leu Asn Trp Leu Ile Asp Glu Ile
325 330 335
Glu Ala Thr Lys Asp Thr Asp Pro His Phe Ser Lys Glu Leu Lys His
340 345 350
Leu Arg Phe Glu Leu Phe Gly Asn Pro Leu Ala Ser Arg Lys Gly Phe
355 360 365
Ser Asp Glu Leu
370
<210> 7
<211> 29
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 7
tccccgcgga tgaagttact atccttggc 29
<210> 8
<211> 31
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 8
atatgcggcc gcctataatt cgtcgtgatt t 31
<210> 9
<211> 31
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 9
tccccgcgga tgaaaatatt aagtgcattg c 31
<210> 10
<211> 34
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 10
atatgcggcc gcttatagct cttggtgtaa taac 34
<210> 11
<211> 35
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 11
tccccgcgga tgaaagtgac attatctgtg ttagc 35
<210> 12
<211> 37
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 12
atatgcggcc gcctataact catcggagaa acctttc 37
<210> 13
<211> 24
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 13
tcgtacgagc ttgctcctga tcag 24
<210> 14
<211> 23
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 14
aaccaacatc cctgacgtgc aac 23
<210> 15
<211> 24
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 15
cgttgaatgc tagctcaaac ggac 24
<210> 16
<211> 26
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 16
gggttcagaa gcgatagaga gactgc 26
<210> 17
<211> 29
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 17
ccggaattca tgtctaaagg tgaagaatt 29
<210> 18
<211> 32
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 18
atatgcggcc gcttatttgt acaattcatc ca 32
<210> 19
<211> 31
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 19
ccggaattca tggtcgtttt acaacgtcgt g 31
<210> 20
<211> 32
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 20
atatgcggcc gcttattttt gacaccagac ca 32
<210> 21
<211> 38
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 21
ccggaattca tgactatggc tgctaagact gatagaga 38
<210> 22
<211> 31
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 22
atatgcggcc gctcaagctg gaaccaattc t 31
<210> 23
<211> 24
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 23
gctgaagctg tcatcggtta ctca 24
<210> 24
<211> 27
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 24
caacttgaac tgaggaacag tcatgtc 27
<210> 25
<211> 20
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 25
agcctatgcc tacagcatcc 20
<210> 26
<211> 20
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 26
ggcattctga caatcctctt 20
<210> 27
<211> 18
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 27
tgccgaaacg caaatggg 18
<210> 28
<211> 20
<212> DNA
<213> 人工序列
<220>
<221> misc_feature
<223> 引物
<400> 28
cagcacccaa caaaccgtat 20
- 还没有人留言评论。精彩留言会获得点赞!