转录因子VP1在调控作物株高及籽粒淀粉含量中的应用的制作方法
本发明属于农作物的基因工程育种领域,具体地说,涉及一种转录因子vp1在调控作物株高及籽粒淀粉含量中的应用。
背景技术:
淀粉是人类食品和家畜饲料的主要碳水化合物组分,在工业及其他领域也有广泛应用,在国民经济中占有非常重要的地位,随着能源短缺和人口增长,对淀粉的需求日益增加,用遗传改良方法获得高淀粉含量玉米是满足这一条需求的途径。玉米是制造淀粉的重要原料之一,由于玉米具有产量高、适应性强、易于种植等特点,所以作为淀粉加工原料,具有如下特点:玉米淀粉的质量好;在相同的加工设备条件下,出粉率高2%~4%;玉米综合利用的潜力大,加工玉米淀粉后的废料可提取玉米油、玉米蛋白粉、胚芽饼和粗饲料,几乎玉米产品的99%都可得到利用。玉米淀粉约占世界淀粉总产量的81.8%。全世界淀粉产量为1100万吨,而玉米淀粉高达900万吨左右。
淀粉合成的主要场所是淀粉体和叶绿体,整个过程受到一系列酶活性的调控。adp-葡萄糖焦磷酸化酶是在淀粉合成途径中起调控作用的主要的酶,是影响淀粉合成速率的关键因子。在淀粉合成过程中,adp-葡萄糖焦磷酸化酶(agpase)起着关键作用,它催化了淀粉合成反应中的第一步反应,生成有活性的葡糖基供体adp-葡萄糖。在谷物的胚乳中的agpase有85%-95%都是胞质型的,是由两个大亚基和两个小亚基组成的异源四聚体,大小亚基是由不同基因编码的。玉米胚乳中编码该酶大小亚基的基因分别是sh2、bt2。有研究表明,玉米的点突变的agpase基因转入其他作物后,增强了亚基之间的相互作用,并且降低了磷的抑制效应,agpase活力更强,最终增加了种子重量及总的生物量。但是也有证据证明在谷物的胚乳中,这种调节并没有在其它器官如叶子中重要。
高淀粉玉米是指籽粒淀粉含量达70%以上的专用型玉米,而普通玉米淀粉含量只60%~69%。玉米淀粉是各种作物中化学成分最佳的淀粉之一,有纯度高(达99.5%)、提取率高(达93%~96%)的特点,广泛应用于食品、医药、造纸、化学、纺织等工业,据调查,以玉米淀粉为原料生产的工业制品达500余种。因此,发展高淀粉玉米生产,不但可为淀粉工业提供含量高、质量佳、纯度好的淀粉,同时可获得较高的经济效益。高淀粉玉米不仅提高了籽粒中的淀粉含量,其籽粒的物理性状和营养成分也发生了变化。高淀粉玉米的籽粒粒重、胚乳重比普通玉米和高油玉米高,而胚重则较低,胚乳较大,胚/胚乳比值最小。目前生产上推广的高淀粉玉米品种籽粒淀粉含量达73%左右,显著高于普通玉米和高油玉米;淀粉成分中支链淀粉和直链淀粉含量都比普通玉米高,但支链/直链的值相差较小,即混合型高淀粉玉米同时提高了支链淀粉和直链淀粉的含量。
种植高淀粉玉米的经济效益是非常显著的,高淀粉玉米籽粒的淀粉含量在73%以上,出粉率比普通玉米增加2%以上。据庄铁成估算,若种植70万公顷高淀粉玉米,则比相同数量的普通玉米多生产35万吨淀粉,每吨淀粉以1700元计算,可增加效益5.95亿元。
株高是玉米产量性状中一个非常重要的性状,培育株高适度降低的玉米品种,有利于通过增加种植密度提高玉米产量,防止植株倒伏。
植物vp1/abi3家族转录因子最先在玉米中发现。vp1位点突变导致玉米种子胚和糊粉层的成熟过程受阻碍。突变的种子中胚的发育不受抑制,从而导致穗萌现象;另外,在突变种子的糊粉层中花青素的合成也受到抑制。同时,vp1突变降低了胚对aba的敏感性。vp1在拟南芥中的同源基因为abi3,其突变体具有与玉米相似的表型。在玉米中vp1转录因子只在糊粉层和胚中表达,在玉米受到胁迫时也在其它组织中表达。在玉米糊粉层中vp1通过与ryrepeat元件相互作用转录激活c1基因的表达,进而激活花青素合成路径。vp1往往与aba共同作用调控基因的表达,在拟南芥abi3突变体中异源组成过表达vp1激活大量种子特异的基因在其它组织中表达,而其中受aba和vp1共激活的基因的启动子中富含ryrepeat元件。
目前,淀粉合成的路径及相关的酶均已被鉴定,人们试图通过基因工程的方法修饰淀粉合成相关酶,从而提高淀粉含量。其中,agpase作为淀粉合成路径中的限速酶,一直是科学家们研究的热点。stark等(starkdm,timmermankp,barrygf,preissj,kishoregm.1992.regulationoftheamountofstarchinplanttissuesbyadpglucosepyrophosphorylase.science258,287-292.)将大肠杆菌adpg合成酶基因glgc导入土豆中,使得土豆中的淀粉含量增加了35%以上。然而转基因植株的淀粉含量与glgc蛋白量并不存在共相关,在其它glgc基因过表达土豆品种中虽然agpase活性提高了4倍,但淀粉含量却没有增加。将glgc基因导入玉米中发现玉米籽粒粒重增加了13-25%,但并没有观察到淀粉含量发生变化。在玉米中通过修饰胚乳中agpase大亚基基因sh2,使其对pi的抑制不敏感,发现粒重显著增加,但淀粉含量却没有显著变化。这些研究表明增加单个淀粉合成相关基因的表达并不能显著地提高淀粉含量。yang等(yangj,zhangj,wangz,xug,zhuq.2004.activitiesofkeyenzymesinsucrose-to-starchconversioninwheatgrainssubjectedtowaterdeficitduringgrainfilling.plantphysiol135,1621-1629.)对未成熟的小麦籽粒外施aba发现能同时增加多种淀粉合成相关酶的活性,进而显著地提高淀粉的含量;jiang等(jiangl,yux,qix,yuq,dengs,baib,lin,zhanga,zhuc,liub,pangj.2013.multigeneengineeringofstarchbiosynthesisinmaizeendospermincreasesthetotalstarchcontentandtheproportionofamylose.transgenicres22,1133-1142.)通过同时将多个淀粉合成相关基因转化玉米发现籽粒总淀粉含量和直链淀粉比例显著提高。这些研究表明要想提高籽粒的淀粉含量,同时提高多个淀粉合成关键基因的表达才是合理的途径。
技术实现要素:
有鉴于此,本发明针对上述的问题,提供了一种转录因子vp1在调控作物株高及籽粒淀粉含量中的应用,该转录因子vp1突变体能够使其在玉米中过表达降低株高及提高籽粒的淀粉含量。
为了解决上述技术问题,本发明公开了一种转录因子vp1基因在调控作物株高及籽粒淀粉含量中的应用,所述转录因子vp1基因的序列如seqidno.1所示,编码蛋白序列如seqidno.2所示。
进一步地,所述禾本科作物为高粱、水稻或小麦中的一种。
进一步地,将转录因子vp1基因插入到带有植物选择标记基因的植物表达载体中,目标基因由玉米组成型启动子ubiquitin启动,选择标记基因hptii由来自花椰菜花叶病毒的35s启动子启动;通过农杆菌介导的玉米胚愈伤组织的遗传转化,批量获得了转基因植株。
进一步地,包括以下步骤:
1)根据转录因子vp1基因设计pcr扩增引物对,其为5’端引物和3’端引物,其中,5’端引物的核苷酸序列如seqidno.3所示,3’端引物的核苷酸序列如seqidno.4所示;
2)以玉米未成熟种子的mrna为模板,合成玉米籽粒cdna文库采用pcr方法,获得玉米转录因子vp1基因;
3)构建含有vp1基因的植物表达载体pcambia3301-vp1;
4)将植物表达载体pcambia3301-vp1转化农杆菌;
5)通过农杆菌介导的玉米胚愈伤组织的遗传转化,批量获得了转基因植株。
进一步地,构建含有vp1基因的植物表达载体pcambia3301-vp1具体如下:提取玉米基因组dna,设计含hindiii和bamhi酶切位点的特异引物扩增ubiquitin基因启动子序列;提取玉米授粉后15天种子总rna,反转录成cdna,设计含bamhi和saci酶切位点的特异引物扩增vp1基因编码区序列;然后将酶切后的两片段连接入含nos终止子的中间载体pbi221,最后利用hindiii和ecori酶切,获得含ubiquitin启动子、vp1基因和nos终止子的酶切片段;将此酶切片段连接入pcambia3301的hindiii和ecori位点并测序验证,获得植物表达载体pcambia3301-vp1。
进一步地,所述含hindiii和bamhi酶切位点的特异引物的核苷酸序列如seqidno.5和seqidno.6所示;所述的含bamhi和saci酶切位点的特异引物的核苷酸序列如seqidno.3和seqidno.4所示。
进一步地,将植物表达载体pcambia3301-vp1转化农杆菌具体为:制备农杆菌eha105感受态细胞,将1μgpcambia3301-vp1重组质粒加入200ul的农杆菌感受态细胞中,冰上冷却30min;液氮速冻l~2min,然后在37℃水浴锅中融化,然后加入800ul的新鲜yep液体培养基;在28℃,180rpm条件下振荡培养2h-4h;5000rpm离心5min,弃上清;向沉淀中加入200ul的新鲜yep液体培养基悬浮菌体;将菌液涂布在含50mg/l的kan和50mg/l的rif的yep固体培养基上,28℃,暗培养2d-3d。挑克隆到含50mg/l的kan和50mg/l的rif的液体yep培养基中,28℃,180rpm条件下震荡培养12h,做菌液菌液pcr检测,将pcr鉴定正确的菌液按等体积比加入50%的灭菌过的甘油保存于-70℃。
进一步地,通过农杆菌介导的玉米胚愈伤组织的遗传转化具体为:取授粉后10-13d的幼穗,用2.5%次氯酸钠浸泡消毒10min,挑出大约150个幼胚放于2ml的ep管中;将挑取好的幼胚用含有pcambia3301-vp1载体的农杆菌浸染液浸泡5min-10min,用滤纸轻轻吸干浸染液,然后转入共培养基上,注意盾片向下,22℃,3d,暗培养;然后接到恢复培养基上,28℃,7d,暗培养;恢复一周后,转到筛选培养基上筛选两轮,每轮3周,28℃,暗培养;将筛选后的抗性愈伤组织转到分化培养基上,先25℃,7d的暗培养;再在25℃,16h光照,光照强度2000lux、8h黑暗交替循环条件下培养;待苗长到5cm的长度时候转到生根培养基上培养,28℃,光照培养15d;将生根培养后的苗用营养土在小花盆里,28℃,光照培养10d;将幼苗移栽到大田种植,常规田间管理。
本发明还公开了一种含有vp1基因的植物表达载体pcambia3301-vp1。
本发明还公开了一种上述的植物表达载体pcambia3301-vp1在调控作物株高及籽粒淀粉含量中的应用。
与现有技术相比,本发明可以获得包括以下技术效果:
1)现有研究主要通过遗传方法引入突变的矮化基因达到降低作物株高的目的,但这类基因多为隐性基因,育种过程中需将隐性基因导入双亲并纯化,难度较大;且往往与不利性状紧密连锁。本发明利用玉米组成型启动子ubiquitin驱动vp1在玉米中转基因过表达使玉米株高降低,证明该基因可作为一个显性的矮化基因在育种中加以利用。同时vp1在玉米胚乳中过表达增加了多个淀粉关键基因启动子活性,进而增加淀粉含量。
2)由于淀粉含量的增加需要多个淀粉相关基因活性同时提高,现有技术通常采用同时转化多个淀粉相关基因以提高这些基因活性,工作量及难度较大。本发明只需转化一个vp1基因便达到了增加多个淀粉相关基因活性,进而增加淀粉含量的目的。
3)本发明将vp1在玉米中过表达获得集株高降低和淀粉含量增加等优良性状于一身的育种材料。
4)本发明从玉米籽粒cdna文库中克隆出vp1基因并rt-pcr分析表明vp1在转基因玉米胚乳中活跃表达。对转基因后代纯合株系籽粒进行生理生化分析表明,植株株高降低约35%,种子淀粉含量提高到65%以上,比对照株系提高约3%。该方法为改善玉米株型、提高籽粒品质和获得高淀粉玉米开辟了一条新途径。
当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有技术效果。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1是本发明转录因子的vp1基因编码区序列及氨基酸序列;其中,上述序列即为玉米骨干自交系vp1基因编码区序列及氨基酸序列;外加方框的字母为突变的碱基和氨基酸(参照已公布的vp1序列,genbank序列号:nm_001112070);加粗的字母为翻译终止密码;划下划线的字母为vp1的保守功能区域;
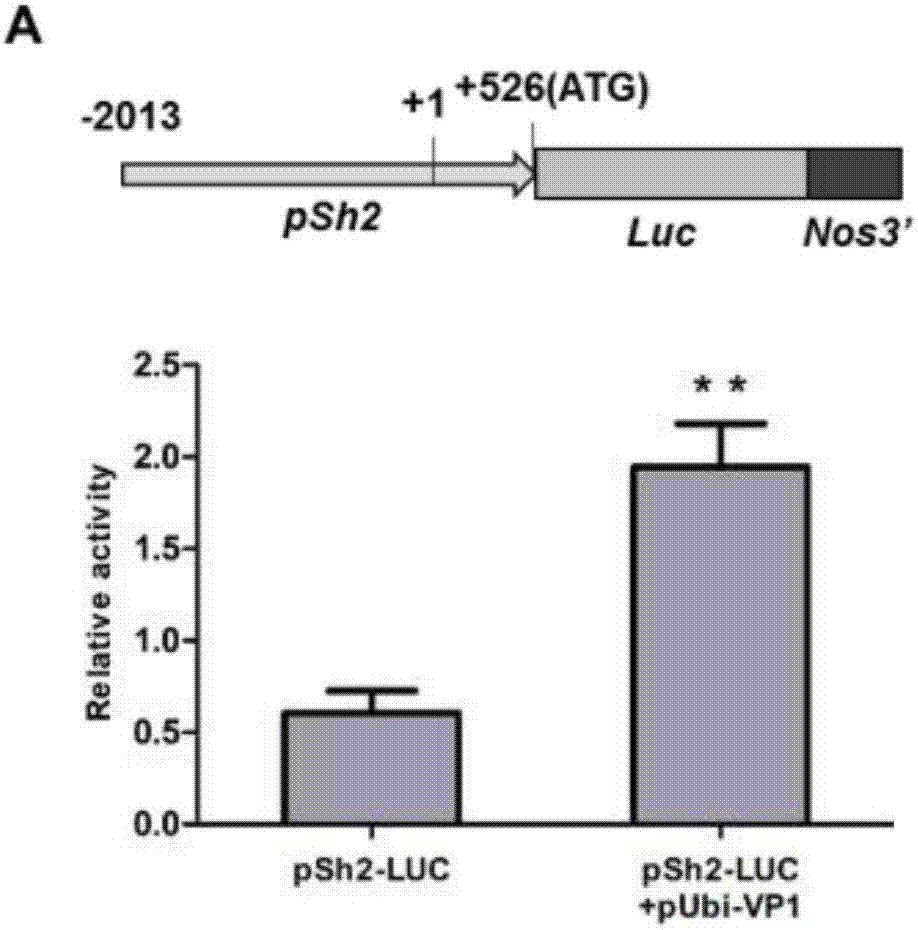
图2是本发明vp1胚乳转基因过表达增加淀粉关键基因sh2启动子活性;
图3是本发明vp1胚乳转基因过表达增加淀粉关键基因bt2启动子活性;
图4是本发明vp1胚乳转基因过表达增加淀粉关键基因ss1启动子活性;
图5是本发明vp1胚乳转基因过表达增加淀粉关键基因du1启动子活性;
图6是本发明vp1胚乳转基因过表达增加淀粉关键基因su1启动子活性;
图7是本发明vp1转基因过表达降低玉米株高;其中,a:转基因植株;b:对照(未转化植株);
图8是本发明vp1胚乳转基因过表达增加淀粉含量,其中,ck为同一个穗上gus染色阴性的籽粒;
图9是本发明转基因过表达载体pcambia3301-vp1示意图;
图10是本发明转基因vp1t0代植株gus染色(a)及pcr检测(b)分析;
图11是本发明转基因vp1t0代植株叶片rt-pcr分析。
具体实施方式
以下将配合实施例来详细说明本发明的实施方式,藉此对本发明如何应用技术手段来解决技术问题并达成技术功效的实现过程能充分理解并据以实施。
实施例1转录因子vp1基因的制备
本发明以玉米未成熟种子的mrna为模板,合成玉米籽粒cdna文库采用pcr方法克隆玉米转录因子vp1基因。以籽粒cdna为模板,用kod酶扩增玉米vp1基因,扩增出一条特异的目的产物带,分子量大小2.1kb左右,与预期值大小一致。vp1基因的pcr产物经纯化后直接与pmd19-t载体连接,从阳性克隆中提取质粒dna并进行限制性内切酶酶切分析,确定pcr法克隆的vp1大小是正确的,dna序列测序肯定了所克隆基因为vp1。用于扩增vp1编码区全长序列的引物序列为:5’端引物5’-ggatccatggaagcctcctccggctc-3’(seqidno.3),3’端引物5’-gagctcagatgctcaccgccatctgg-3’(seqidno.4),在引物5’端加有限制性内切酶位点bamhi和saci(下划线处)。
本发明选取上述鉴定正确的克隆进行全核苷酸序列测定,vp1编码区全序列长为2076bp,其核苷酸序列如seqidno.1所示,具体序列如图1所示,与预期设计的完全相符。将测得的vp1的编码区全序列与genbank中已发表的核苷酸序列(accessionno.nm_001112070)进行比较,同源性为99%,只有4个碱基不同。这4个碱基均位于编码区内,但都没有影响读码框。这4个碱基的突变不会引起氨基酸的改变。为了防止由测序造成的错误,连续测了五个克隆,均为同样的情况,有可能是由于基因供体材料不同造成这样的结果。
根据克隆的vp1基因序列,推导出转录因子vp1基因编码蛋白的氨基酸序列如seqidno.2所示。
实施例2用含有vp1基因的植物表达载体转化玉米骨干自交系
含有vp1基因的植物表达载体构建:本发明选用的植物过表达载体为pcambia3301,首先设计含hindiii和bamhi特异引物(5’端引物:aagcttatcagtggccagcttttgttcta(seqidno.5)和3’端引物:ggatccaagtaacaccaaacaacagggt(seqidno.6)),以玉米基因组dna为模板扩增ubiquitin基因的启动子序列(genbank登录号:u29159.1),再利用实施例1所述的含bamhi和saci的vp1特异引物(5’-ggatccatggaagcctcctccggctc-3’(seqidno.3),5’-gagctcagatgctcaccgccatctgg-3’(seqidno.4)),以玉米cdna文库为模板扩增vp1基因全长序列,然后将酶切后的两片段连接入含nos终止子的中间载体pbi221,最后利用hindiii和ecori酶切,获得含ubiquitin启动子、vp1基因和nos终止子的酶切片段,将此酶切片段连接入pcambia3301的hindiii和ecori位点并测序验证,最终获得含有vp1基因的植物表达载体pcambia3301-vp1(图9)。
植物表达载体pcambia3301-vp1转化农杆菌:制备农杆菌eha105感受态细胞,将1μgpcambia3301-vp1重组质粒加入200ul的农杆菌感受态细胞中,冰上冷却30min。液氮速冻l~2min,然后在37℃水浴锅中融化,然后加入800ul的新鲜yep液体培养基;在28℃,180rpm条件下振荡培养2h-4h。5000rpm离心5min,弃上清;向沉淀中加入200ul的新鲜yep液体培养基悬浮菌体。将菌液涂布在含50mg/l的kan和50mg/l的rif的yep固体培养基上,28℃,暗培养2d-3d。挑克隆到含50mg/l的kan和50mg/l的rif的液体yep培养基中,28℃,180rpm条件下震荡培养12h,做菌液菌液pcr检测,将pcr鉴定正确的菌液按等体积比加入50%的灭菌过的甘油保存于-70℃。
玉米幼胚愈伤组织制备及农杆菌转化:取授粉后10-13d的幼穗,用2.5%次氯酸钠浸泡消毒10min,挑出大约150个幼胚放于2ml的ep管中。将挑取好的幼胚用含有pcambia3301-vp1载体的农杆菌浸染液浸泡5min-10min,用滤纸轻轻吸干浸染液,然后转入共培养基上,注意盾片向下,22℃,3d,暗培养。然后接到恢复培养基上,28℃,7d,暗培养。恢复一周后,转到筛选培养基上筛选两轮,每轮3周左右,28℃,暗培养。将筛选后的抗性愈伤组织转到分化培养基上,先25℃,7d的暗培养;再在25℃,16h光照(光照2000lux)、8h黑暗交替循环条件下培养。待苗长到5cm左右的长度时候转到生根培养基上培养,28℃,光照培养15d。将生根培养后的苗用营养土在小花盆里,28℃,光照培养10d。将幼苗移栽到大田种植,常规田间管理。
实施例3转基因玉米植株的检测及利用
转基因t0代幼苗移栽到大田后,取幼苗叶片用于gus染色,并提取叶片dna,用pcr法检测基因转化情况,将gus染色呈蓝色且pcr有目的条带的幼苗植株作为转基因阳性植株(图10),提取阳性植株叶片rna,反转录cdna后进行rt-pcr分析,检测转基因植株vp1基因表达情况(图11),筛选vp1基因显著过表达的转基因植株,套袋自交或姊妹交结实。
将阳性t0代植株产生的种子进行加代种植,(为防止雌雄发育不同期的问题,分两批种,间隔10天),对三叶期t1代植株进行潮霉素初筛,之后,将抗性好的植株定植入温室大田,长出新叶后,进行gus染色、pcr、rt-pcr分析。转基因t1代植株进行自交和部分杂交,于抽雄期测定转基因阳性植株和对照株株高。果穗单株收获,部分籽粒用于淀粉含量测定。选取株高明显降低且淀粉含量有明显提高的t2、t3代株系进行种植、自交和部分杂交,进行适时定量rt-pcr测定,获得转基因过表达稳定和转基因纯合的株系。
实施例4转基因材料淀粉含量测定
分别取10粒大小均匀的转基因种子和对照种子,去除胚组织,然后充分研磨成粉末,过0.5mm筛(35目);将研磨后样品(准确称量~100mg)加入到试管中(16x120mm),确保全部样品位于试管底部。加入0.2ml乙醇溶液(80%v/v)湿润样品帮助分散,用漩涡混合器混合。立即加入3ml耐热α-淀粉酶(100mm醋酸钠稀释),在沸水浴中孵育6分钟(在孵育2分钟,4分钟,6分钟的时强烈振荡试管)。将试管放置于50℃的水浴锅中,加入0.1ml瓶2成分(淀粉葡糖苷酶,330u在淀粉上)。充分混合,在50℃下孵育30分钟。将全部的溶液转移到100ml的容量瓶中,用洗瓶冲洗试管,并也倒入容量瓶中,然后用蒸馏水调整溶液体积,充分混匀。取部分溶液离心(3,000rpm,10分钟)。取清澈的未稀释的上清用于分析。转移两份稀释的样品溶液(0.1ml)到园底试管中(16x100mm)。加入3.0mlgopod溶液到每一个试管中(包括葡萄糖对照和试剂空白对照),然后在50℃下孵育20分钟。葡萄糖对照包括0.1ml葡萄糖标准溶液(1mg/ml)+3.0mlgopod溶液,试剂空白对照:0.1ml蒸馏水+3.0mlgopod溶液。相对于试剂空白在510nm下测定每一个样品和葡萄糖质控的吸光度。
实验结果表明,vp1过表达转基因植株胚乳中淀粉含量较对照增加约3%(图8)。
上述说明示出并描述了发明的若干优选实施例,但如前所述,应当理解发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述发明构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离发明的精神和范围,则都应在发明所附权利要求的保护范围内。
sequencelisting
<110>四川农业大学
<120>转录因子vp1在调控作物株高及籽粒淀粉含量中的应用
<130>2016
<160>4
<170>patentinversion3.3
<210>1
<211>2076
<212>dna
<213>玉米转录因子vp1基因
<400>1
atggaagcctccgccggctcgtcgccaccgcactcccaagagaacccgccggagcacggt60
ggcgacatgggaggggcccccgcggaggagatcgaaggggaggcggcggatgacttcatg120
ttcgctgaagacacgttcccctccctcccggacttcccttgcctttcgtcgccgtccagc180
tccaccttctcgtccaactcctcgtcaaactcctccagcgcctacaccaacacggcagga240
agagccggcggcgagccctccgagcctgcttcggccggagaagggtttgatgcgctcgat300
gacatcgaccagctcctcgacttcgcgtcgctttccatgccgtgggactccgagccgttc360
ccgggggttagcatgatgctagagaacgccatgtcggcgccgccgcagccggtgggcgac420
ggcatgagtgaagagaaagccgtgccggaagggaccacagggggagaggaggcctgcatg480
gatgcgtcggagggggaggagctgccgcggttcttcatggagtggctcacgagcaaccgc540
gaaaacatctcggccgaggatctccgcgggatccgcctccgccgctccaccatcgaggcc600
gccgccgcccggctcggcggcgggcgccagggcaccatgcagctgctcaagctcatcctc660
acctgggtgcagaaccaccacctccagaggaagcgcccgcgcgacgtgatggaggaggag720
gcgggcctgcacggccagctccccagcccggtcgccaacccaccaggatacgagttcccc780
gccggcggacaggacatggccgcgggcggcggcacatcctggatgccccaccagcaggca840
ttcacgccgcctgctgcgtacggcggcgacgcggtgtacccgagcgcggcaggccaacag900
tactctttccaccagggccccagcacgagcagcgtggtcgtgaacagccaaccgttctcc960
ccgccgcctgtgggcgacatgcacggcgcgaacatggcctggccgcagcagtacgtgccg1020
ttcccaccgcctggggcttccacgggctcttaccctatgccgcagccgttctcccccgga1080
ttcggcgggcagtacgccggcgccggcgctggccacctctcagtggccccccagcgcatg1140
gcaggcgtggaggcctcggcgaccaaggaggcccgcaagaagcgcatggcgagacagcgg1200
cgcctgtcctgcctgcagcagcagcgcagccagcagctgagcctgggccagatccagacc1260
tccgtccacctgcaggagccgtcccctcggtccacgcactccggcccggtcacgccgtca1320
gcaggcggctggggattctggtcgccgagcagccagcagcaggtccagaacccgctctcc1380
aagtccaattcctcaagggcgccgccttcctcgctggaagcggcggcggcggctccacag1440
acaaagcccgcgcctgctggtgctcggcaggacgacattcaccaccgcctcgcagcggct1500
tcagataagcggcagggcgccaaggcggacaagaacctgcggttcctgctgcagaaggtg1560
ctgaagcagagcgacgtcgggagcctcggccgcatcgtgctccccaaaaaggaagcggag1620
gttcacctgccggagctgaagacgagggatggcatctccatccccatggaggacatcgga1680
acgtcgcgcgtgtggaacatgcggtacaggttttggcccaacaacaagagcagaatgtat1740
ctgctggaaaacacaggggaatttgttcgttccaacgagcttcaggagggggatttcata1800
gtgatctactccgatgtcaagtcgggcaaatatctgatacggggcgtgaaggtaaggccc1860
ccgccggcgcaagagcaaggcagtggttccagcgggggaggcaagcacaggcccctctgt1920
ccagcaggtccagagagagccgcagccgccggtgctcctgaagacgccgtcgtcgacggg1980
gtcagcggcgcctgcaaggggaggtctccggaaggcgtgcggcgggttcggcagcaggga2040
gccggcgccatgagccagatggcggtgagcatctga2076
<210>2
<211>691
<212>prt
<213>玉米转录因子vp1基因
<400>2
metglualaseralaglyserserproprohisserglngluasnpro
151015
progluhisglyglyaspmetglyglyalaproalaglugluileglu
202530
glyglualaalaaspaspphemetphealagluaspthrpheproser
354045
leuproasppheprocysleuserserproserserserthrpheser
505560
serasnserserserasnserserseralatyrthrasnthralagly
65707580
argalaglyglygluprosergluproalaseralaglygluglyphe
859095
aspalaleuaspaspileaspglnleuleuaspphealaserleuser
100105110
metprotrpaspserglupropheproglyvalsermetmetleuglu
115120125
asnalametseralaproproglnprovalglyaspglymetserglu
130135140
glulysalavalprogluglythrthrglyglygluglualacysmet
145150155160
aspalasergluglyglugluleuproargphephemetglutrpleu
165170175
thrserasnarggluasnileseralagluaspleuargglyilearg
180185190
leuargargserthrileglualaalaalaalaargleuglyglygly
195200205
argglnglythrmetglnleuleulysleuileleuthrtrpvalgln
210215220
asnhishisleuglnarglysargproargaspvalmetglugluglu
225230235240
alaglyleuhisglyglnleuproserprovalalaasnproprogly
245250255
tyrglupheproalaglyglyglnaspmetalaalaglyglyglythr
260265270
sertrpmetprohisglnglnalaphethrproproalaalatyrgly
275280285
glyaspalavaltyrproseralaalaglyglnglntyrserphehis
290295300
glnglyproserthrserservalvalvalasnserglnpropheser
305310315320
proproprovalglyaspmethisglyalaasnmetalatrpprogln
325330335
glntyrvalpropheproproproglyalaserthrglysertyrpro
340345350
metproglnpropheserproglypheglyglyglntyralaglyala
355360365
glyalaglyhisleuservalalaproglnargmetalaglyvalglu
370375380
alaseralathrlysglualaarglyslysargmetalaargglnarg
385390395400
argleusercysleuglnglnglnargserglnglnleuserleugly
405410415
glnileglnthrservalhisleuglngluproserproargserthr
420425430
hisserglyprovalthrproseralaglyglytrpglyphetrpser
435440445
proserserglnglnglnvalglnasnproleuserlysserasnser
450455460
serargalaproproserserleuglualaalaalaalaalaprogln
465470475480
thrlysproalaproalaglyalaargglnaspaspilehishisarg
485490495
leualaalaalaserasplysargglnglyalalysalaasplysasn
500505510
leuargpheleuleuglnlysvalleulysglnseraspvalglyser
515520525
leuglyargilevalleuprolyslysglualagluvalhisleupro
530535540
gluleulysthrargaspglyileserileprometgluaspilegly
545550555560
thrserargvaltrpasnmetargtyrargphetrpproasnasnlys
565570575
serargmettyrleuleugluasnthrglygluphevalargserasn
580585590
gluleuglngluglyasppheilevaliletyrseraspvallysser
595600605
glylystyrleuileargglyvallysvalargproproproalagln
610615620
gluglnglyserglyserserglyglyglylyshisargproleucys
625630635640
proalaglyprogluargalaalaalaalaglyalaprogluaspala
645650655
valvalaspglyvalserglyalacyslysglyargserproglugly
660665670
valargargvalargglnglnglyalaglyalametserglnmetala
675680685
valserile
690
<210>3
<211>26
<212>dna
<213>人工序列
<400>3
ggatccatggaagcctcctccggctc26
<210>4
<211>26
<212>dna
<213>人工序列
<400>4
gagctcagatgctcaccgccatctgg26
<210>5
<211>29
<212>dna
<213>人工序列
<400>5
aagcttatcagtggccagcttttgttcta29
<210>6
<211>28
<212>dna
<213>人工序列
<400>6
ggatccaagtaacaccaaacaacagggt28
- 还没有人留言评论。精彩留言会获得点赞!