本发明涉及的是基因工程的技术领域,尤其涉及的是一种基于zmmikc2a基因调节玉米籽粒淀粉含量的方法。
背景技术:
玉米在人类的各类生产生活中占据着重要的位置,它不仅是主要的粮食作物,更是各类生产中主要的淀粉来源。我国研究人员在提高玉米产量上做出了重要的贡献,但对改善玉米品质方面的研究较少。淀粉作为植物种子胚乳的主要组成成分,其含量和品质直接影响着种子的品质。因此,研究淀粉合成的调控对于提高种子的品质具有重要意义。
淀粉根据结构不同分为直链淀粉和支链淀粉,淀粉中直链淀粉和支链淀粉的比例以及支链淀粉的分支链结构决定着玉米品质,同时直链淀粉和直链淀粉之间的比例还决定着淀粉的用途,高直链和低支链的淀粉可以用于食品、医药、环保、纺织等领域,而低直链和高支链的淀粉可用在食品行业。直链淀粉生产的可再生、可降解膜应用于农用薄膜加工业和包装工业,可以减少工业废气及减弱温室效应气体的释放,高直链淀粉还是生产光解塑料的最佳原料,用于一次性餐具,是解决日益严重的“白色污染”的有效途径;支链淀粉具有更好的薪性,可增加膨化食品的体积,作为食品添加剂具有不同于直链淀粉的效果,在黏合剂领域具有较多应用。普通玉米中直链淀粉的含量一般约为25%,支链淀粉约为75%,如何调节和改善直链和支链淀粉含量的平衡度,需要深入开展对淀粉生物代谢途径的研究,不仅对完善淀粉代谢途径有重要的理论意义,而且对作物品质的遗传改良,培育具有独特品质或新型淀粉品质的材料具有重要的理论和实践意义。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供了一种基于zmmikc2a基因调节玉米籽粒淀粉含量的方法,以提供一种能够提高或降低玉米籽粒直链淀粉含量及直链淀粉/总淀粉比例的方法。
本发明是通过以下技术方案实现的:
本发明提供了一种基于zmmikc2a基因调节玉米籽粒淀粉含量的方法,包括:
i)构建zmmikc2a基因过量表达载体,将过量表达载体导入目的玉米,得到zmmikc2a基因过量表达植株;或者:
ii)将目的玉米中的zmmikc2a基因敲除,获得zmmikc2a基因缺失植株;
所述zmmikc2a基因过量表达植株的籽粒直链淀粉含量和直链淀粉/总淀粉比例高于目的玉米,所述zmmikc2a基因缺失植株的籽粒直链淀粉含量和直链淀粉/总淀粉比例低于目的玉米;所述zmmikc2a基因为下述i)或ii)的dna分子:
i)核苷酸序列如seqidno.1所示的dna分子;
ii)核苷酸序列与seqidno.1至少具有98%同一性且编码如seqidno.2所示的氨基酸序列的dna分子。
进一步地,所述zmmikc2a基因的获得方法为:提取玉米籽粒胚乳或玉米花丝rna并反转录成cdna,以cdna为模板,以mikc2a-f、mikc2a-r为引物进行pcr克隆;其中,mikc2a-f、mikc2a-r引物序列为:
mikc2a-f:5′-atgggtaggggaaggattga-3′
mikc2a-r:5′-ttagaactgatgatgagggttattg-3′。
进一步地,所述zmmikc2a基因过量表达载体为多克隆位点区域依次连接有35s启动子、zmend1a基因和终止子的pzz00005植物表达载体。
进一步地,所述将目的玉米中的zmmikc2a基因敲除方法包括:物理诱变法、化学诱变法、基因工程法,其中,基因工程法包括rnai技术。
进一步地,采用rnai技术将目的玉米中的zmmikc2a基因敲除,包括以下步骤:
a)根据zmmikc2a基因序列确定zmmikc2a基因的特异性rnai干涉序列,所述rnai干涉序列如seqidno.3所示或与seqidno.3序列具有98%同源性,为部分zmmikc2a基因序列;
b)根据zmmikc2a基因序列设计引物,pcr扩增zmmikc2a基因的rnai干涉序列;
c)构建rnai干涉表达载体,包括依次连接的胚乳特异性启动子、正反向zmmikc2a基因rnai干涉序列和终止子;所述正反向zmmikc2a基因rnai干涉序列为正向-反向连接的zmmikc2a基因rnai干涉序列或反向-正向连接的zmmikc2a基因rnai干涉序列;
d)将rnai干涉表达载体导入目的玉米的基因组中,筛选获得zmmikc2a基因缺失植株。
进一步地,所述rnai干涉序列如seqidno.3所示。
进一步地,所述步骤c)中,正反向zmmikc2a基因rnai干涉序列之间还连接有植物内含子。
本发明相比现有技术具有以下优点:本发明提供了一种基于zmmikc2a基因调节玉米籽粒淀粉含量的方法,该方法利用zmmikc2a基因对玉米籽粒淀粉合成相关基因的正调控作用,通过基因工程的方法提高或降低目的玉米中直链淀粉含量和直链淀粉/总淀粉比例,获得具有高直链淀粉/低支链淀粉或高支链淀粉/低直链淀粉的转基因玉米新品种,对利用基因工程技术开发具有特定功能的转基因玉米新品种具有重要的实践意义。
附图说明
图1为peasy-t1载体图谱
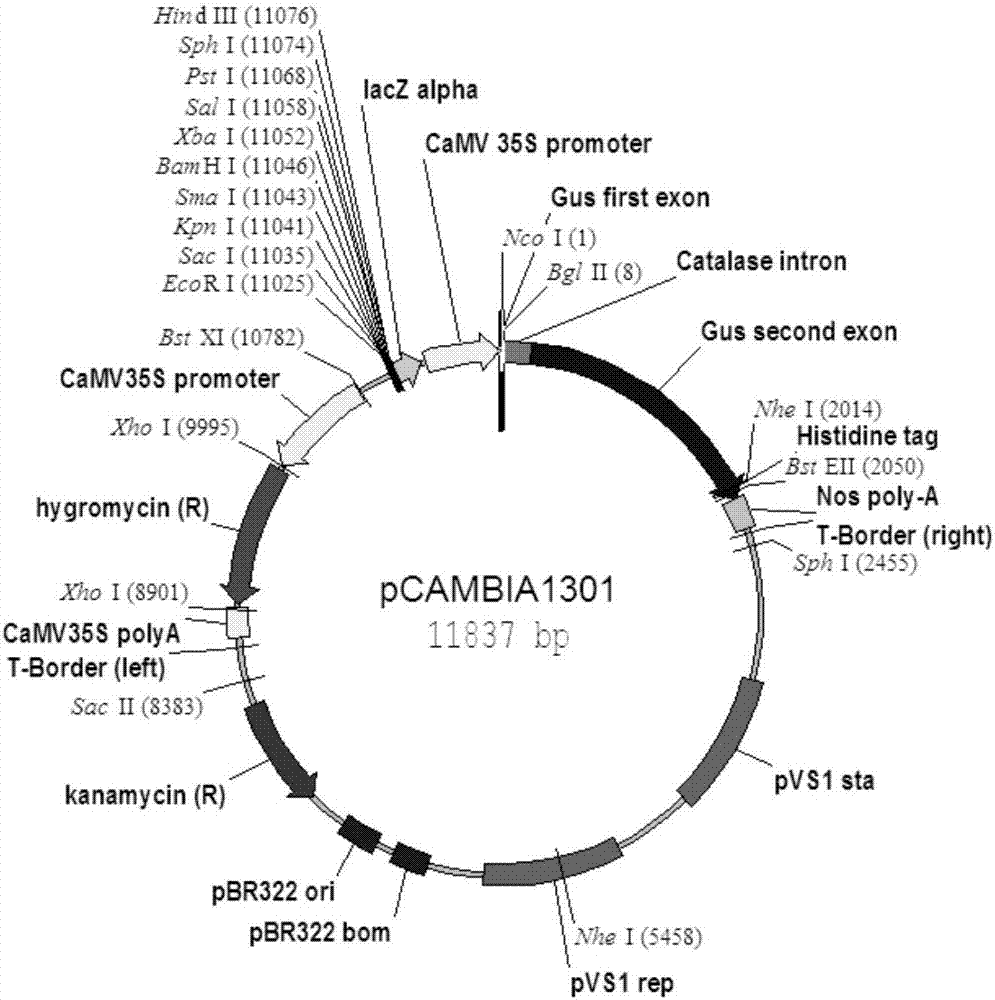
图2为pcambia1301植物表达载体图谱;
图3为pzz00005植物表达载体;
图4为zmmikc2a基因过表达植株和目的玉米籽粒直链淀粉和总淀粉含量柱状图;其中图4a为直链淀粉含量柱状图,图4b为总淀粉含量柱状图;wt为野生型植株,l1、l2、l5、l8为过表达植株;虚线为过表达植株籽粒直链淀粉和总淀粉含量均值;
图5为puccrnai干涉载体图谱;
图6为peasy-t3载体图谱;
图7为cpb载体图谱;
图8为zmmikc2a基因缺失植株和目的玉米籽粒直链淀粉和总淀粉含量柱状图;其中图8a为直链淀粉含量柱状图,图8b为总淀粉含量柱状图;wt为野生型植株,m1、m3、m4、m6为基因缺失植株;虚线为基因缺失植株籽粒直链淀粉和总淀粉含量均值。
具体实施方式
下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
实施例1
本实施例提供了一种提高玉米籽粒直链淀粉含量和直链淀粉/总淀粉比例的方法,包括以下步骤:
(1)zmmikc2a基因的克隆
选取玉米b73品种授粉后16天的籽粒胚乳,提取玉米胚乳rna并反转录成cdna,以玉米胚乳cdna为模板,根据玉米b73基因组数据库公布的基因序列,结合pzz00005植物表达载体(载体图谱如图1所示)的多克隆位点设计引物,进行pcr扩增,获得pcr扩增产物。
引物序列为:
mikc2a-f-1:5′-cgcggatccatgggtaggggaaggattga-3′
mikc2a-r-1:5′-aactgcagttagaactgatgatgagggttattg-3′
pcr反应程序为:98℃,预变性10min;98℃,变性20s;60℃,退火20s;72℃,延伸2min,30个循环;72℃,复性10min;10℃保存。
将pcr扩增产物用质量比为2%的琼脂糖凝胶电泳检测,回收目的片段并连接至peasy-t1载体(购于全式金生物技术有限公司,载体图谱如图1所示),获得连接产物。将连接产物转化到大肠杆菌感受态trans5α细胞中,提取质粒。以提取的质粒做模板,以mikc2a-f-1、mikc2a-r-1为引物进行pcr扩增验证,同时用bamhi和psti双酶切质粒进行检测,筛选阳性克隆子,将阳性克隆子送去华大生物公司进行测序,测序结果使用mega4.0软件比对,结果与预测一致。获得的重组质粒命名为t-mikc2a。
(2)zmmikc2a基因过量表达载体的构建
以pcambia1301(购于上海捷兰生物技术有限公司,载体图谱如图2所示)为原始载体,在其多克隆位点的ecori和saci酶切位点之间连接一个35s启动子,并在sphi和hindiii酶切位点之间加上一段nos终止子,获得改造的载体p1。用bamhi和psti双酶切t-end1a得到小的目的片段,同时用bamhi和psti双酶切p1得到大的目的片段,将上述两片段使用t4连接酶连接,构建获得载体p1-zmmikc2a。
以p1-zmmikc2a为模板,以mikc2a-f-2和mikc2a-r-2为上下游引物进行pcr扩增,得到hindiii-35s+zmend1a+nos-pmei片段,分别用hindiii和pmei双酶切pzz00005基础载体(载体pzz00005购于中国种子集团有限公司,载体图谱如图3所示)和hindiii-35s+zmend1a+nos-pmei片段,将上述两片段使用t4连接酶连接,构建获得载体p2-zmmikc2a。
引物序列为:
mikc2a-f-2:cccaagcttcgacactctcgtctactccaag
mikc2a-r-2:agctttgtttaaaccccgatctagtaacatagatgacac
(3)农杆菌介导的zmmikc2a基因过量表达植株的获得
将p2-zmmikc2a转化农杆菌ag10中,获得重组农杆菌ag10/p2-zmmikc2a,具体参见文献:methodsinmolecularbiology,vol.343:agrobacteriumprotocols,2/e,volume1。
农杆菌介导对目的玉米的转化(玉米原位转化技术):
原位转化液的配制:1/4ms培养基中加2%(质量)蔗糖,0.05%(质量)silwet-77(表面活性剂),2mg/l6-ba,1ng/l2,4-d以及10mg/l乙酰丁香酮。每100ml培养基中加4ml农杆菌ag10/p2-zmmikc2a菌液,于28℃,250rpm培养24小时。
将玉米须剪去,用5ml的注射器将菌液从玉米的下部1/3处直接注入玉米棒中,注入的量以玉米须处有菌液渗出为宜。经过两个月的生长,收获玉米粒。
将玉米粒晒干,播种,待幼苗长到3-4叶期时用配制的0.01%(质量)除草剂basta和quickstixpat/bar蛋白检测试纸条(as013ls)检测表达载体p2-zmmikc2a上所含的bar基因蛋白,筛选阳性转基因植株,获得42株独立转化事件的玉米苗。
(4)zmmikc2a基因过量表达植株的鉴定
上述42株独立转化事件的玉米苗成熟后,以其叶片总dna为模板,使用quickstixpat/bar蛋白检测试纸条(as013ls)检测表达载体p2-zmmikc2a上所含的bar基因蛋白,同时使用zmmikc2a目的基因进行pcr检测(引物为mikc2a-f-1和mikc2a-r-1),鉴定转基因植株,鉴定时,以野生型目的玉米植株为阴性对照。
pcr反应程序为:94℃预变性10min;94℃变性30s,60℃退火20s,72℃延伸2min,30个循环;72℃总延伸10min。
结果,检测出18株阳性玉米植株,即为t0代转基因玉米植株,命名为l1-18。t0代转基因玉米植株成熟后,收获t1代转基因玉米种子,t1代转基因玉米种子自交繁殖得到t2代转基因玉米种子。依次类推,获得zmmikc2a基因过量表达的转基因玉米株系。
(5)zmmikc2a基因过表达植株的籽粒直链淀粉和总淀粉含量的测定
随机取4株独立转化事件转基因株l1、l2、l5、l8的t3代籽粒进行直链淀粉和总淀粉测定,并以野生型目的玉米籽粒做对照,每次实验测定至少重复三次,测定方法如下:
直链淀粉测定时,首先对籽粒中淀粉进行提纯,将烘干去硬壳和胚的玉米种子在室温下用0.4%(质量分数)的naoh溶液浸泡48h,料液(样本比0.4%的naoh溶液)比为1:3,洗涤后再用0.4%的naoh溶液浸泡24h,反复水洗至种子表面不再黏滑为止,沥干水分,用胶体磨粉碎,淀粉乳过筛(200目),离心(3000r/min,20min),取下层白色沉淀,即为淀粉,将淀粉反复漂洗离心,40℃鼓风干燥,粉碎,过筛(200目),即得淀粉纯品,用于直链淀粉的测定。直链淀粉的测定采用爱尔兰megazyme公司生产的直链淀粉/支链淀粉分析试剂盒(货号:k-amyl),测定方法可参见试剂盒说明书,在此不做详细描述。
总淀粉测定时,先将烘干的种子去硬壳和胚,再使用组织研磨仪将其研磨成粉末,40℃过夜烘干,过0.5mm筛(35目)。总淀粉测定采用爱尔兰megazyme公司生产的总淀粉测定试剂盒(货号:k-tsta),具体为:将研磨后样品(准确称量~100mg)加入到试管中(16×120mm),确保全部样品位于试管底部;加入0.2ml乙醇溶液(80%v/v),用漩涡混合器混合;放入搅拌架子,加入2ml的2mol/l的koh至每个试管中,冰水混合浴中搅拌20min左右,重悬粉末和溶解抗性淀粉(注意:不要使用涡旋仪混匀,会使淀粉乳化,确保加入koh时,试管处于剧烈震荡状态。这是为了避免淀粉形成团块难以溶解);当试管在磁力搅拌器上搅拌时,加入8ml的1.2mol/l醋酸钠缓冲液(ph3.8)至每个试管。立即加入0.1ml耐热α-淀粉酶(试剂盒配置溶液)和0.1ml淀粉葡糖苷酶(试剂盒配置溶液),充分混合,在50℃下孵育;孵育30min,间断混匀;样品淀粉含量>10%:将全部的溶液转移到100ml的容量瓶中,用洗瓶冲洗试管,并也倒入容量瓶中,然后用蒸馏水调整溶液体积至100ml,充分混匀。取部分溶液离心(1800rpm,10min);转移两份稀释的样品溶液(0.1ml)到圆底试管中(16×100mm);加入3.0mlgopod溶液(试剂盒配置溶液)到每一个试管中(包括葡萄糖对照和试剂空白对照),然后在50℃下孵育20min;葡萄糖对照包括0.1ml葡萄糖标准溶液(1mg/ml)+3.0mlgopod溶液。试剂空白对照:0.1ml蒸馏水+3.0mlgopod溶液;相对于试剂空白在510nm下测定每一个样品和葡萄糖质控的吸光度。计算公式如下:
δa=相对于试剂空白所读取的吸光度;fv=总体积(例如100ml或10ml);0.1=样品分析体积;1/1000=转化从μg至mg;100/w=淀粉作为干粉重量的比例;w=干粉重量;162/180=d葡萄糖转化为脱氢葡萄糖;淀粉%(占干物质比重)=淀粉%×100/100-水分含量(%)。
结果如图4所示,图中可以看出,zmmikc2a基因过表达植株的籽粒总淀粉含量几乎不变(图4a),而直链淀粉明显提高,提高幅度在3.93%-11.42%(图4b),直链淀粉/总淀粉比例显著上调。
实施例2
本实施例提供了一种降低玉米籽粒直链淀粉含量和直链淀粉/总淀粉比例的方法,包括以下步骤:
(1)zmmikc2a基因rnai干涉序列mikc2a-rnai的克隆
以玉米b73品种授粉后16天的籽粒胚乳为原料,克隆zmmikc2a基因,并连接至t载体,获得重组质粒t-mikc2a,具体步骤参见实施例1的步骤(1)。
以t-mikc2a为模板,根据zmmikc2a基因序列,结合puccrnai干涉载体(载体图谱如图3所示)的多克隆位点设计引物,进行pcr扩增,获得pcr扩增产物。
引物序列为:
mikc2a-rnai-f:gctctagagtcgcctctacgagtatgccaaca
mikc2a-rnai-r:ggactagttgacaggtttcccacggaatcac
pcr反应程序为:98℃,预变性10min;98℃,变性20s;65℃,退火30s;72℃,延伸30s,30个循环;72℃,复性10min;10℃保存。
克隆得到如seqidno.3所示的rnai干涉序列,命名为zmmikc2ai。
(2)rnai干涉载体的构建
将zmmikc2ai用xhoⅰ和pstⅰ双酶切,回收zmmikc2ai小片段;同时使用xhoⅰ和pstⅰ双酶切puccrnai载体,回收puccrnai大片段;将zmmikc2ai小片段和puccrnai大片段在t4连接酶的作用下连接,得到载体puccrnai-zmmikc2ai。用xbaⅰ和salⅰ双酶切puccrnai-zmmikc2ai,回收puccrnai-zmmikc2ai大片段;将zmmikc2ai小片段和puccrnai-zmmikc2ai大片段在t4连接酶的作用下连接,得到载体puccrnai-2zmmikc2ai。
用pstⅰ单酶切中间载体puccrnai-2zmmikc2ai,回收2zmmikc2ai小片段;同时使用pstⅰ单酶切载体peasy-t3(载体图谱如图6所示),回收片段;再将上述两片段使用t4连接酶连接,得到中间载体peasy-t3-2zmmikc2ai。
用speⅰ和sacⅰ双酶切中间载体peasy-t3-2zmmikc2ai;同时使用xbaⅰ和sacⅰ双酶切载体cpb(图7),回收大片段;将上述两片段使用t4连接酶连接,构建获得含有正反向zmmikc2a基因rnai干涉序列的rnai干涉载体,命名为zmmikc2ar。
(3)农杆菌介导的zmmikc2a基因缺失植株的获得
将zmmikc2ar转化农杆菌ag10中,获得重组农杆菌ag10/zmmikc2ar,具体参见文献:methodsinmolecularbiology,vol.343:agrobacteriumprotocols,2/e,volume1。
农杆菌介导对目的玉米的转化(玉米原位转化技术),同实施例1的步骤(3),获得21株独立转化事件的玉米苗。
(4)zmmikc2a基因缺失植株的鉴定
上述21株独立转化事件的玉米苗成熟后,以其叶片总dna为模板,用cpb载体上所含的camv35s启动子序列中的一段为检测对象,设计引物,鉴定转基因植株,同时以野生型目的玉米为隐形对照。
用于检测camv35s启动子的引物为:
35s-f:5’-catgggatccgcttcatggagtcaaagattcaaa-3’
35s-r:5’-catgtctagagtcaagagtcccccgtgttc-3’
pcr反应条件为:94℃预变性5min;94℃变性30s,59℃退火30s,72℃延伸30s,34个循环;72℃总延伸10min。
结果,21株玉米植株有20株扩增出目的片段,阴性对照未扩增出目的片段,即共获得20株t0代基因缺失植株,命名为m1-20。t0代转基因玉米植株成熟后,收获t1代转基因玉米种子,t1代转基因玉米种子自交繁殖得到t2代转基因玉米种子。依次类推,获得zmmikc2a基因缺失的转基因玉米株系。
(5)zmmikc2a基因缺失植株的籽粒直链淀粉和总淀粉含量的测定
取4株独立转化事件转基因株m1、m3、m4、m6的t3代籽粒进行直链淀粉和总淀粉测定,并以野生型目的玉米做对照,每次实验测定至少重复三次,测定方法同实施例1的步骤(5)。
结果如图8所示,图中可以看出,zmmikc2a基因缺失植株的籽粒中总淀粉含量变化不大(图8a),但直链淀粉有所降低,降低幅度在10.22%-19.21%(图8b),说明zmmikc2a基因缺失降低了玉米直链淀粉/总淀粉比例。
结论:本发明利用基因工程技术获得了zmmikc2a基因过表达植株和zmmikc2a基因缺失植株,其中zmmikc2a基因过表达植株籽粒直链淀粉含量和直链淀粉/总淀粉比例相比较目的玉米显著提高,zmmikc2a基因缺失植株籽粒直链淀粉含量和直链淀粉/总淀粉比例相比较目的玉米显著降低,说明zmmikc2a基因对玉米淀粉合成具有正调控作用,这对完善淀粉代谢途径提供了新的证据,对作物品质的遗传改良,培育具有独特品质或新型淀粉品质的材料具有重要的理论和实践意义。
以上为本发明一种详细的实施方式和具体的操作过程,是以本发明技术方案为前提下进行实施,但本发明的保护范围不限于上述的实施例。
sequencelisting
<110>安徽省农业科学院烟草研究所
<120>一种基于zmmikc2a基因调节玉米籽粒淀粉含量的方法
<130>/
<160>3
<170>patentinversion3.3
<210>1
<211>810
<212>dna
<213>zeamays
<400>1
atgggtaggggaaggattgagatcaagaggatcgagaacaacacgagccggcaggtcacc60
ttctgcaagcgccgcaatgggctcctcaagaaggcgtatgagctctccgtcctctgcgac120
gctgaggtggccctcatcgtcttctctagccgtggtcgcctctacgagtatgccaacaac180
agtgtcaaggctactattgagaggtacaagaaggcacacaccgttggctcttcctctggg240
ccaccgctcctagagcacaatgcccagcaattctaccagcaagaatcagcaaaactgcgc300
aaccagatccagatgctgcaaaacactaacaggcacttggttggtgattccgtgggaaac360
ctgtcactcaaggagctgaagcagctggagagccgccttgagaaaggcatctctaagatc420
agggccaggaagagtgagctgctggctgcggagatcagttacatggccaaaagggagact480
gagcttcagaatgaccacatgaccctcaggaccaagattgaggagggagagcaacagctg540
cagcaggtgaccgtggcacggtcagttgcagcagcagcagcagctgccaccaacttggag600
ctgaacccattcttagagatggataccaaatgcttcttcactggcggccccttcgcaacg660
ctggacatgaagtgctttctccccggcagcttgcagcagatgctggaggcacagcagcgc720
cagatgctcgccaccgagctgaacctcggctaccaactggcgccgcctggttctgacgct780
gccgacaataaccctcatcatcagttctaa810
<210>2
<211>269
<212>prt
<213>zeamays
<400>2
metglyargglyargilegluilelysargilegluasnasnthrser
151015
argglnvalthrphecyslysargargasnglyleuleulyslysala
202530
tyrgluleuservalleucysaspalagluvalalaleuilevalphe
354045
serserargglyargleutyrglutyralaasnasnservallysala
505560
thrilegluargtyrlyslysalahisthrvalglysersersergly
65707580
proproleuleugluhisasnalaglnglnphetyrglnglngluser
859095
alalysleuargasnglnileglnmetleuglnasnthrasnarghis
100105110
leuvalglyaspservalglyasnleuserleulysgluleulysgln
115120125
leugluserargleuglulysglyileserlysileargalaarglys
130135140
sergluleuleualaalagluilesertyrmetalalysarggluthr
145150155160
gluleuglnasnasphismetthrleuargthrlysilegluglugly
165170175
gluglnglnleuglnglnvalthrvalalaargservalalaalaala
180185190
alaalaalaalathrasnleugluleuasnpropheleuglumetasp
195200205
thrlyscysphephethrglyglyprophealathrleuaspmetlys
210215220
cyspheleuproglyserleuglnglnmetleuglualaglnglnarg
225230235240
glnmetleualathrgluleuasnleuglytyrglnleualapropro
245250255
glyseraspalaalaaspasnasnprohishisglnphe
260265
<210>3
<211>212
<212>dna
<213>zeamays
<400>3
gtcgcctctacgagtatgccaacaacagtgtcaaggctactattgagaggtacaagaagg60
cacacaccgttggctcttcctctgggccaccgctcctagagcacaatgcccagcaattct120
accagcaagaatcagcaaaactgcgcaaccagatccagatgctgcaaaacactaacaggc180
acttggttggtgattccgtgggaaacctgtca212