DNA条形码、引物、试剂盒、方法和应用与流程
本发明属于物种和菌株鉴定领域,具体涉及dna条形码、引物、试剂盒、方法和应用。
背景技术:
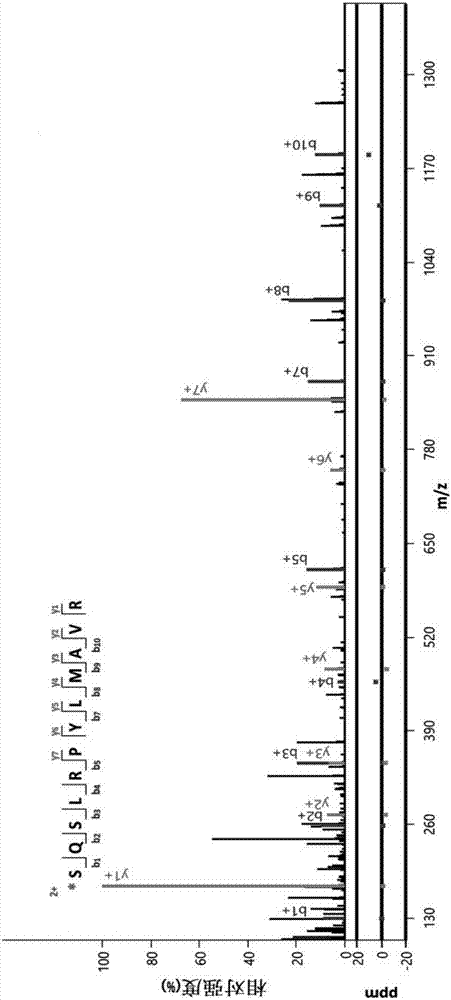
:普洱茶是一种具有云南地理标识的后发酵茶,其采用大叶种晒青毛茶作为原料,经过一系列工艺制作而成。传统的普洱茶制作过程为:采摘的新鲜茶叶经揉捻、晒青、除杂、潮水、渥堆、晾干、筛分、压制成型、包装出厂。在普洱茶的生产中,渥堆发酵过程是普洱茶品质形成的主要因素,在此过程中,茶叶中诸如茶多酚、咖啡因以及一些多糖物质等内含成分发生了巨大变化,成就了普洱茶的特殊风味、口感、品质以及各种保健功效。传统的普洱生产中,湿热的环境激活茶叶本身所含的酶,把茶叶中所含的一部分内含成分转化成微生物能利用的物质,微生物大量滋生,产生丰富的胞内酶和胞外酶,催化茶叶中包含的成分发生一系列转变,再加上湿热等其他因素,逐渐形成不同品质的普洱茶。不同的产地,因为其微生物群落结构的不同,风味及品质也各具特色。普洱茶除了其独特的风味和文化外,其诸如减肥、降血糖血脂、预防和改善心血管疾病、抗衰老、抗癌、消炎、助消化以及养胃等保健功效也备受人们关注。近年来,普洱茶越来越受欢迎,逐渐增加的市场需求拉动了普洱茶产业的发展,促进了云南地区经济增长。然而,普洱茶也面临着一些困境,例如产品质量不稳定、存在一定安全隐患、生产周期长、劳动力投入过高、微生物数量超标和螨虫滋生等。随着人们生活水平的提高,消费者对食品的卫生、安全等问题日益重视。近几年食品质量安全事件频发,茶叶质量的安全问题也日益突出,除了农药的残留问题之外,渥堆发酵过程中微生物也有可能成为影响茶叶质量的重要因素。目前多数厂家的普洱茶生产仍然是半自然人工渥堆的经验式发酵,虽然渥堆过程中以食腺嘌呤节孢酵母(blastobotrysadeninivorans)等优势共性微生物为主的群落相对稳定,但产品的稳定性还存在较大的提升空间。生产过程中也不可避免的存在着一定的安全隐患,为了进一步获得消费者的青睐和市场的认可、突破外贸壁垒、提升普洱茶企业的市场竞争力,必须实现普洱茶生产工艺的人工可控化、清洁化以及高效化,并不断开发新产品、延伸产业链。要做到这些,就必须革新技术,发明一系列安全、清洁、高效、人工可控自动化的普洱茶新工艺,才能确保普洱茶产业的健康发展,给国家和人民带来长远利益。随着普洱茶科研的进一步深入,越来越多的人们开始了人工接种发酵普洱茶的探索,目前已经有许多菌株应用于普洱茶人工可控发酵。近年由于市场需求加大,许多规模较小的厂家对普洱茶缺乏系统深入的研究,大肆滥用许多他人专利进行牟利,比如,按照一些接种发酵普洱茶的专利方法,采用一些菌种进行普洱茶发酵等一系列方法,进行普洱茶加工生产等经营活动,大大损害了一些具有相关专利的普洱茶生产企业的经济利益。为确保普洱茶发酵微生物种质资源得到有效保护,防止滥用普洱茶发酵微生物的侵权行为发生,解决在普洱茶人工可控发酵过程中菌种侵权时难以举证的难题,开发对普洱茶发酵用菌株进行快速精准鉴别的方法势在必行,亟需建立其分子鉴定方法,开发通过dna条形码技术准确鉴别与区分与其相似菌株的方法,以达到通过形态特征与分子数据分析相结合的方法来解决工业生产菌株鉴别和鉴定问题,为普洱茶有控工业发酵工艺开发和资源保护提供理论依据,促进普洱茶产业健康繁荣发展。技术实现要素:为了克服形态学鉴定用于普洱茶发酵生产的食腺嘌呤节孢酵母菌株所存在的不足,本发明提供了一种用于鉴别食腺嘌呤节孢酵母菌株的dna条形码、引物、试剂盒、方法和应用,从而对食腺嘌呤节孢酵母tmcc70007菌株进行快速鉴别和区分,可为普洱茶新发酵工艺提供快速评估,防止发酵过程中其他杂菌的干扰,以及为普洱茶人工可控发酵工艺及菌种非法滥用提供举证方法和依据。为了实现上述目的,本发明采用如下技术方案:(1)一种用于鉴别食腺嘌呤节孢酵母菌株的dna条形码,该dna条形码来源于食腺嘌呤节孢酵母tmcc70007菌株的基因组,并且包含选自如seqidno.1所示的dna序列中的至少600bp的序列,并且该dna条形码的长度为600bp-3000bp,优选为600bp-2200bp,更优选为600bp-1500bp。(2)根据(1)所述的dna条形码,其核苷酸序列如seqidno.1、seqidno.4或seqidno.7所示。(3)一种用于扩增根据(1)所述的dna条形码的引物对。(4)根据(3)所述的引物对,其正向引物的核苷酸序列与食腺嘌呤节孢酵母tmcc70007菌株基因组中的这样的序列相同:该序列为从所述tmcc70007菌株基因组中如seqidno.1所示的核苷酸序列的第1位的上游1000bp到如seqidno.1所示的核苷酸序列的第589位的区域中的序列,并且该正向引物的长度为20-30bp;其反向引物与所述tmcc70007菌株基因组中的这样的序列反向互补:该序列为从所述tmcc70007菌株基因组中如seqidno.1所示的核苷酸序列的第601位到如seqidno.1所示的核苷酸序列的最后一位的下游1000bp的区域中的序列,并且该反向引物的长度为20-30bp。(5)根据(4)所述的引物对,其正向引物和反向引物的核苷酸序列分别如下所示:正向引物:5’-gctcaactgccaatggttca-3’;反向引物:5’-cttgccatggtggtgggata-3’。(6)一种用于鉴别食腺嘌呤节孢酵母菌株的试剂盒,包含根据(3)所述的引物对。(7)一种用于鉴别食腺嘌呤节孢酵母菌株的方法,包括以下步骤:a)提供待测菌株的基因组dna;b)以步骤a)所述的基因组dna为模板,利用根据(3)所述的引物对进行pcr扩增,得到pcr产物;c)电泳检测pcr产物,如果没有目标条带,则判定待测菌株不是食腺嘌呤节孢酵母tmcc70007菌株,如果有目标条带,则进行步骤d);d)对所得pcr产物进行测序,得到待测核苷酸序列;将所述待测核苷酸序列与权利要求1所述的dna条形码的核苷酸序列进行同源性比对,若同源性在97%以上,则判定待测菌株是食腺嘌呤节孢酵母tmcc70007菌株。(8)根据(1)所述的dna条形码在鉴别食腺嘌呤节孢酵母菌株中的应用。(9)根据(3)所述的引物对在鉴别食腺嘌呤节孢酵母菌株中的应用。(10)根据(6)所述的试剂盒在鉴别食腺嘌呤节孢酵母菌株中的应用。本发明与现有技术相比具有以下优点和积极效果:1、本发明采用蛋白质基因组学技术从食腺嘌呤节孢酵母tmcc70007菌株的基因组中发现了一个漏注释编码蛋白,并且发现编码该蛋白的基因的开放阅读框(seqidno.1)为食腺嘌呤节孢酵母tmcc70007菌株的基因组所特有。本发明进一步通过仔细的研究和比较分析,将该特有的dna序列开发为了dna条形码,作为鉴别普洱茶工业发酵生产菌株食腺嘌呤节孢酵母tmcc70007的有效工具。该条形码序列能实现食腺嘌呤节孢酵母种内菌株的快速准确鉴别与区分。2、与现有技术相比,本发明采用蛋白质基因组学技术发现的dna条形码的特异性更好。3、本发明进一步发现,相比于其他基因,arc19基因中的序列(例如seqidno.1)具有通用、易扩增、易比对的特点,其在食腺嘌呤节孢酵母种内不同菌株之间差异明显。4、本发明建立了普洱茶工业发酵生产菌株食腺嘌呤节孢酵母tmcc70007的标准基因序列和样品鉴别方法,相比于传统的形态学鉴定方法,显著提高了鉴定效率。该方法对于样品的完整程度要求低,鉴别指标能够量化,这对于及时判定普洱茶及其种质资源提供了有效的依据。此外,进一步加入了形态学混淆种并运用基于聚类分析的系统发育树法设立鉴定规则进行了鉴定,其鉴定的可靠性和准确性也大大优于常规的分子鉴定方法,弥补了该类普洱发酵茶生产菌株基于dna条形码技术的菌株鉴定的空白。附图说明图1示出新鉴定肽段sqslrpylmavr的质谱谱图。图2示出化学合成肽段sqslrpylmavr的原鉴定肽段质谱图与合成肽段质谱图的对比;所述原鉴定肽段为本发明经过质谱分析并鉴定得到的肽段;图的上方为原鉴定肽段的质谱图,下方为合成肽段的质谱图。图3示出肽段所在区域蛋白质编码框的mrna序列及其编码的蛋白质序列的对应图,灰色背景部分为所鉴定的新肽段。图4示出编码arc19基因所转录的mrna序列及其编码的蛋白质序列的对应图,灰色背景部分为内含子区域。图5示出条形码序列seqidno.1通过ncbi-blastn得到的与之具有同源性的序列比对图,在图5下方的9条短的灰色短线显示出9条同源性序列。图6示出食腺嘌呤节孢酵母的tmcc70007条形码序列seqidno.1与食腺嘌呤节孢酵母ls3菌株同源序列的对比图;图7示出本发明一个实施方案中用于扩增seqidno.1的引物的位置,序列中有下划线的区域即为引物所在区域,加粗字体的atg和taa即为起始和终止位点,所扩增的序列为seqidno.7。图8示出对利用本发明的引物得到的待测菌株pcr扩增产物进行琼脂糖凝胶电泳的结果。图9示出seqidno.1序列与待测菌株pcr扩增序列的对比图。具体实施方式以下通过具体实施方式的描述并参照附图对本发明作进一步说明,但这并非是对本发明的限制,本领域技术人员根据本发明的基本思想,可以做出各种修改或改进,但是只要不脱离本发明的基本思想,均在本发明的范围之内。本发明采用蛋白质基因组学技术从食腺嘌呤节孢酵母tmcc70007菌株的基因组中发现了漏注释的编码蛋白,由于该arc19基因蛋白序列与白地霉(geotrichumcandidum)clib918的arp2/3复合体的arc19亚基(登录号为:cdo53724.1)相似度达91%,因此将其称为arc19蛋白。本发明由该新发现的蛋白序列得到了tmcc70007菌株基因组中的对应基因序列,将其称为arc19基因,并且发现编码该蛋白的基因的开放阅读框(seqidno.1)相对于现有数据库中已经报道的同源基因具有很好的特异性,该特异性dna序列可以用于开发鉴别普洱茶工业发酵生产菌株食腺嘌呤节孢酵母tmcc70007的dna条形码。与现有技术相比,本发明通过上述方法获得的dna条形码的特异性更高。考虑到dna条形码应当具有合适的长度和足够的菌株间特异性,本发明进一步通过仔细的研究和比较分析,基于上述特有的dna序列获得了可准确、有效地鉴别食腺嘌呤节孢酵母tmcc70007菌株的dna条形码。由此,本发明的一个方面提供了一种用于鉴别食腺嘌呤节孢酵母菌株的dna条形码,该dna条形码来源于食腺嘌呤节孢酵母tmcc70007菌株的基因组,并且包含选自如seqidno.1所示的dna序列中的至少600bp的序列,并且该dna条形码的长度为600bp-3000bp,优选为600bp-2200bp,更优选为600bp-1500bp。本发明的条形码序列能实现食腺嘌呤节孢酵母种内菌株的快速准确鉴别与区分。seqidno.1的长度为1189bp,由于seqidno.1为食腺嘌呤节孢酵母tmcc70007菌株基因组所特有,因此该序列本身即可作为鉴别食腺嘌呤节孢酵母tmcc70007菌株的dna条形码。另外,通过理论分析和实验验证,本发明证明包含该序列、长度更长的dna条码的特异性更加得到保证。当dna条形码的长度过长时(例如大于3000bp),对于扩增操作而言较不理想。另一方面,选自该序列中不小于600bp的序列既能够满足特异性的要求,也能够满足易扩增、易比对的操作要求。因此,本发明通过理论分析和实验验证,证明选自如seqidno.1所示的dna序列中的至少600bp的序列能够实现食腺嘌呤节孢酵母种内菌株的快速准确鉴别与区分。在本发明的优选的实施方案中,所述dna条形码序列如seqidno.1、seqidno.4或seqidno.7所示。在本文中,术语“漏注释基因”是指物种完成基因组测序以后,采用基因预测软件(例如genemark、augustus、glimmer等)未能将该基因预测出来,这些基因一般表达量不高、在特定的条件下才表达,所以在研究中难以被发现。术语“dna条形码技术(dnabarcoding)”是指用基因组内一段标准的、短的dna片段来鉴定物种的一项分子鉴定新技术,其可以快速、准确的进行物种鉴定。术语“六框翻译”是蛋白质组学和基因组学中的已知术语,简述其原理为,dna编码蛋白质时,采用三联体密码子编码蛋白质,给定一条dna序列,有3种编码可能性,加上其互补链上的3种编码可能,共有6种编码可能性(+1,+2,+3,-3,-2,-1)。本发明的另一个实施方案提供了一种用于扩增本发明所述的dna条形码的引物对。优选地,其正向引物的核苷酸序列与食腺嘌呤节孢酵母tmcc70007菌株基因组中的这样的序列相同:该序列为从所述tmcc70007菌株基因组中如seqidno.1所示的核苷酸序列的第1位的上游1000bp到如seqidno.1所示的核苷酸序列的第589位的区域中的序列,并且该正向引物的长度为20-30bp;其反向引物与所述tmcc70007菌株基因组中的这样的序列反向互补:该序列为从所述tmcc70007菌株基因组中如seqidno.1所示的核苷酸序列的第601位到如seqidno.1所示的核苷酸序列的最后一位的下游1000bp的区域中的序列,并且该反向引物的长度为20-30bp。在更优选的实施方案中,所述正向引物和反向引物的核苷酸序列分别如下所示:正向引物arc19-f:5’-gctcaactgccaatggttca-3’(seqidno.5);反向引物arc19-r:5’-cttgccatggtggtgggata-3’(seqidno.6)。本发明的引物能实现对所述dna条形码序列的特异性扩增。本发明还提供了一种用于鉴别食腺嘌呤节孢酵母菌株的试剂盒,包含根据本发明所述的引物对。在另一实施方案中,所述试剂盒还包含根据本发明所述的dna条形码。所述dna条形码可存在于记录介质上。该记录介质例如为光盘。所述试剂盒还可以包含用于实验操作的任何工具和试剂。本发明的又一方面提供了一种用于鉴别食腺嘌呤节孢酵母菌株的方法,包括以下步骤:a)提供待测菌株的基因组dna;b)以步骤a)所述的基因组dna为模板,利用根据权利要求3所述的引物对进行pcr扩增,得到pcr产物;c)电泳检测pcr产物,如果没有目标条带,则判定待测菌株不是食腺嘌呤节孢酵母tmcc70007菌株,如果有目标条带,则进行步骤d);d)对所得pcr产物进行测序,得到待测核苷酸序列;将所述待测核苷酸序列与权利要求1所述的dna条形码的核苷酸序列进行同源性比对,若同源性在97%(优选99%)以上,则判定待测菌株是食腺嘌呤节孢酵母tmcc70007菌株。在本发明的一个具体实施方案中,所述pcr扩增的程序为:1)94℃-96℃预变性8分钟;2)94℃-96℃变性45秒,55℃-57℃退火45秒,72℃延伸1分15秒,其中该程序2)进行30-35个循环;3)72℃延伸10分钟。在本发明的又一实施方案中,所述方法还包括将测序结果得到的待测序列与本发明的dna条形码进行聚类分析(例如系统发育树),如果待测序列与dna条形码聚类在一起,则确定待测菌株为食腺嘌呤节孢酵母菌株tmcc70007。在本发明一个具体的实施方案中,利用本发明的引物对对提取自待鉴别的菌株的基因组dna进行pcr扩增,然后进行琼脂糖凝胶电泳检测。基于检测是否存在pcr产物来鉴别菌株:如果待鉴定的菌株没有扩增出相应的目标条带,则说明该菌株不是tmcc70007;如果扩增出相应的目标条带,则证明该菌株可能是tmcc70007。为了进一步进行鉴别,对pcr产物进行测序,将dna测序结果与dna条形码序列进行同源性比对,获得序列间的相似性(即同源性),如果序列同源性小于97%,则判定待测菌株不是食腺嘌呤节孢酵母菌株tmcc70007。如果序列同源性大于或等于97%(优选99%以上),则判定待测菌株是食腺嘌呤节孢酵母菌株tmcc70007。如果进行聚类分析,例如系统发育树,则将所述dna条形码和各待鉴定菌株的dna测序结果(即待测序列)一起应用mega6或paup软件构建nj系统发育树。如果待鉴定菌株的待测序列与食腺嘌呤节孢酵母tmcc70007的dna条形码聚类在一起,则鉴定为食腺嘌呤节孢酵母tmcc70007。在此所使用的术语“聚类”是指经系统发育树分析后,处于同一个分支,且进化距离相同。本发明还提供了本发明所述的dna条形码在鉴别食腺嘌呤节孢酵母菌株中的应用。本发明还提供了本发明所述的引物对在鉴别食腺嘌呤节孢酵母菌株中的应用。实施例下面结合具体的实施例对本发明做进一步说明。实施例中所用方法在未具体说明的情况下,均采用常规方法和已知工具。实施例1:arc19基因和dna条形码的获得该实施例中所用的蛋白质组和基因组分析方法、以及质谱方法均为本领域的已知方法,故具体操作过程不再赘述。1、利用高覆盖蛋白质组技术,采用pfind和panno软件对普洱茶工业发酵菌食腺嘌呤节孢酵母tmcc70007进行了蛋白质组的深度覆盖研究,并对其基因组进行了注释编码基因的验证。具体而言,为了发现新的蛋白编码区,利用系统蛋白质基因组学中的六框翻译(sixframetranslation)策略,获得了食腺嘌呤节孢酵母tmcc70007基因组数据的六框翻译数据库,穷举了基因组的6种编码可能(+1,+2,+3,-1,-2,-3),并且将该核酸序列称为“六框翻译核酸序列”,蛋白序列称为“六框翻译蛋白序列”。通常而言,六框翻译核酸序列是从一个终止子到下一个终止子的序列,在本文中,也将其称为“蛋白编码框”。利用这个六框翻译数据库,采用pfind和panno软件与tmcc70007菌株的全蛋白质谱数据进行比对,从而进行新肽段和新蛋白质的发现和鉴定。经鉴定,发现了一条现有技术中食腺嘌呤节孢酵母tmcc70007注释基因组中未发现的肽段sqslrpylmavr,质谱谱图如图1所示。手工检查质谱谱图结果显示,检测到了肽段sqslrpylmavr的二级质谱谱图(ms2)的几乎所有y离子序列,匹配好,信号强,结果较为可信。为进一步确证这个鉴定结果,按照新鉴定肽段sqslrpylmavr的氨基酸序列化学合成了该肽段,并利用上述sqslrpylmavr的质谱分析条件产生了合成肽段的二级谱图,参见图2。接下来,对合成肽段产生的高能量碰撞ms2进行了核实,一级母离子和二级子离子均符合理论值,表明合成的肽段序列正确(图2)。在此基础上,人工检查了根据大规模蛋白质组数据鉴定到的新肽段序列合成肽段的ms2和大规模鉴定新肽段谱图,两者几乎完全一致,以子离子相似性获得的cosin值高达0.99,由此证明从普洱茶工业发酵菌食腺嘌呤节孢酵母tmcc70007鉴定到的新肽段正确无误。2、根据新肽段所在的位置,以前一个终止密码子和后一个终止密码子包括的区域为界,得到六框翻译核酸序列(蛋白编码框)seqidno.2。seqidno.2序列对应的mrna及其所编码的氨基酸序列如图3所示。3、为了进一步确定编码该蛋白的基因的的编码起始位点和终止位点,将上述蛋白编码框向上游和下游分别扩展1000bp,采用genemark.hmm进行基因预测,参考物种选用粟酒裂殖酵母(schizosaccharomycespombe)。在该区域预测到了该基因,其编码框与上述蛋白编码框序列一致,确定了其编码起始和终止位点,其orf因序列为seqidno.1。seqidno.1的第37-127、455-507和697-1024位为该基因的内含子。该编码基因(arc19)转录的mrna序列和其翻译的蛋白的氨基酸序列的对应关系如图4所示。肽段sqslrpylmavr坐落在该基因的上游。该编码基因(arc19)的核苷酸序列共1189bp,除去内含子区域,共编码232个氨基酸,理论分子量为26.77kda,其理论编码的氨基酸序列如seqidno.3所示。4、以该基因理论编码产物的氨基酸序列(seqidno.3)进行ncbi-blastp分析,其序列具有与arpc4超级家族蛋白类似的结构域,该蛋白家族为几种真核生物arp2/3复合体亚基的组成成分,arp2/3复合体与细胞内肌动蛋白聚合有牵连。所鉴定的arc19蛋白序列与白地霉(geotrichumcandidum)clib918的arp2/3复合体的arc19亚基(登录号为:cdo53724.1)相似度达91%,蛋白blastp序列查询覆盖率为71%。上述blastp比对结果总结在表1中。ncbi-blastp结果表明我们检测到的漏注释蛋白为arc19同源基因产物,其序列有一定的保守性。5、将所鉴定的arc19基因的orf序列(即seqidno.1)进行ncbi-blastn分析,结果见图5(即图7)。blastn结果总结在表2中。结果表明该基因序列仅有一部分序列与偃麦草核腔菌(pyrenophoratritici-repentis)pt-1c-bfp菌株的arp2/3复合体4号亚基的mrna序列的13%具有85%的同源性,该同源区段仅有160bp左右,这表明在食腺嘌呤节孢酵母中检测到的漏注释基因arc19相对于ncbinr数据库中已有序列具有较好的序列特异性,虽然arc19蛋白的氨基酸序列部分区段较为保守,但其dna同源性却很低。这证明了该基因的orf序列可以用于开发普洱茶发酵菌株食腺嘌呤节孢酵母tmcc70007的dna条形码。6、进一步选择了seqidno.1上游1000bp到下游1000bp之间的区域(如seqidno.4所示)。将seqidno.4序列进行ncbi-blastn分析,检索nucleotidecollection(nr/nt)数据库,作为结果,参见下表3,发现其与偃麦草核腔菌pt-1c-bfp菌株,肌动蛋白相关蛋白2/3复合体亚基4mrna序列仅有6%的序列(长约160bp)有85%的同一性,进一步说明该序列具有较好的特异性,可以作为特异性鉴别食腺嘌呤节孢酵母tmcc70007菌株的dna条形码。此外,进一步对seqidno.4序列进行ncbi-blastn分析,检索whole-genomeshotguncontigs(wgs)数据库中食腺嘌呤节孢酵母(分类学id:taxid:409370)的全基因组序列,检索结果总结在表4中。结果发现,seqidno.4与食腺嘌呤节孢酵母ls3菌株全基因组鸟枪法测序序列arad1d染色体重叠群1的相似度为91%,序列查询覆盖率为72%。尽管tmcc70007与ls3菌株为同一物种,但它们在该同源区域内序列差异明显,序列的差异已经足够将两株菌区分开来,说明该序列具有较好的特异性,可以作为特异性鉴别该菌株的dna条形码序列。综上所述,seqidno.1上游1000bp到下游1000bp之间的序列(seqidno.4)可以作为鉴别食腺嘌呤节孢酵母菌株的dna条形码。7、目前,食腺嘌呤节孢酵母物种中,仅有食腺嘌呤节孢酵母ls3菌株的基因组已经被报道。经local-blastn分析后,发现该基因序列seqidno.1在ls3菌株基因组中存在同源序列。经dnaman分析后,两条序列的同源性为78.69%,尽管tmcc70007与ls3菌株为同一个物种(即食腺嘌呤节孢酵母,blastobotrysadeninivorans),但在该dna条形码序列的1189个碱基中,约有30%的位点是不一样的,结果如图6所示。这进一步证明了利用该dna条形码序列可以有效地区别tmcc70007菌株与种内的其他菌株。实施例2.利用dna条形码鉴别菌株依据待测样品的扩增结果和与食腺嘌呤节孢酵母tmcc70007菌株seqidno.1的序列同源性,来判定待测样品是否为普洱茶工业应用菌株食腺嘌呤节孢酵母tmcc70007。(1)基于seqidno.1,采用ncbi引物设计工具在该基因两端设计pcr引物,扩增产物须包括基因的起始和终止位点,得到正反引物序列分别为正向引物序列:arc19-f:5‘-gctcaactgccaatggttca-3’;反向引物序列:arc19-r:5’-cttgccatggtggtgggata-3’。引物的位置见图7。所扩增的序列为seqidno.7。(2)菌株来源表5选用的相关菌株信息样品编号学名菌株号生境1食腺嘌呤节孢酵母tmcc70007普洱茶渥堆,中国2食腺嘌呤节孢酵母cbs8244t土壤,荷兰3食腺嘌呤节孢酵母cbs7350窖贮玉米饲料,荷兰4食腺嘌呤节孢酵母cbs7370土壤,南非5食腺嘌呤节孢酵母cbs8335粘土,意大利6blastobotrysraffinosifermentanscbs6800t未知(3)分别提取菌株dna:采用omegae.z.n.a.tm的yeastdna试剂盒提取酵母基因组dna,并用灭菌的去离子水将样品的dna浓度稀释到0.5μg/μl。(4)扩增dna片段,进行聚合酶链式(pcr)反应,所用引物序列分别为:正向引物序列:arc19-f:5‘-gctcaactgccaatggttca-3’;反向引物序列:arc19-r:5’-cttgccatggtggtgggata-3’。pcr反应体系为50μl,pcr试剂为thermoscientifictm的taqdnapolymerase(重组):ddh2o37.7μl、mgcl25μl,dntps4μl,正向引物1μl,反向引物1μl,taqdna聚合酶0.3μl、dna模板1μl,不含染料。扩增程序为:94℃预变性8分钟;接下来94℃变性45秒,56℃退火45秒,72℃延伸1分15秒,一共进行32-35个循环;最后72℃延伸10分钟。(5)扩增产物检测:用1.0%的琼脂糖凝胶、1×tbe电泳液电泳检测,使用dnamarker检测pcr片段大小。若待测菌株没有扩增条带,说明该菌株不是食腺嘌呤节孢酵母tmcc70007;若出现明显清晰的条带,且无杂带,送生物测序公司进行dna片段测序。(6)该引物仅能在食腺嘌呤节孢酵母tmcc70007中实现扩增,在同物种的食腺嘌呤节孢酵母cbs8244t、cbs7350、cbs7370、cbs8335和blastobotrysraffinosifermentanscbs6800t中则不能实现扩增。结果如图8所示。该pcr引物的理论扩增片段为1380bp,实际扩增结果和预期相符。为了进一步验证扩增的dna的序列,进行了测序和同源序列比较。(7)对于有条带的序列的测序结果,首先用软件chromas检查测序后得到的序列峰图质量,确定峰图质量达到数据分析的要求之后,用dnastar软件包中的seqman进行正反向序列的拼接。将测序结果进行手工校对、序列拼接,如果待测菌株dna片段与食腺嘌呤节孢酵母tmcc70007标准基因序列的同源性在97%以上,即可判断所述的待测菌株可能为食腺嘌呤节孢酵母tmcc70007菌株。例如,经过dnaman,将菌株tmcc70007测序得到序列与dna条形码序列seqidno.1比对后完全一致,进一步证明了这种方法的可靠性。结果如图9所示。sequencelisting<110>勐海茶业有限责任公司<120>dna条形码、引物、试剂盒、方法和应用<130>fi-164052-59:52/c<160>7<170>patentinversion3.5<210>1<211>1189<212>dna<213>食腺嘌呤节孢酵母(blastobotrysadeninivorans)<400>1atgataccccattctatagccgttgaaatggacagggtgacgctcagccacgcttcacca60ctcacaacatggtaggtagagacaagaggcactaaaggatagctggggaaatggtgatac120taactagtctcaatcgctacgcccgtatcttatggcggtgcgccagtcgttgacggcggc180actttgcctggagaactttgcttctcaggtggtggaacgacacaataaccctgaggtgga240gtccagaaagacccccgaagcgctgctcaacccactgactattgctcgaaatgaaaacga300aaaggtgcttatcgagccttctatcaactccgtgcgagtttctatcaagatcaagcaggc360cgatgagattgagaccattctggtgcatcagttcacgcggttcttgaccggacgagccga420gagcttttacattctacgacgaaagcctattgatgtgagttggattggacattgggtgaa480tatgtgttgagagtactaactgtttagggctatgatatttcgtttttgatcacaaacttt540cacactgagcagatgctcaagcataagctagtggactttattattgagtttatggaggag600gttgacaaggagatttcggaaatgaagttgttccttaacgctcgagctcgattcgtggcc660gagtcatatttgacaccggtaagttgattggtctttgacgatttccatacctaggatgct720aacggatagtttgattagaagtgcgggacaagcgctgtacatgtatacatgtattcaatt780agatgacatacgattatagtccttgactagcgttcattagctattaatagtctataattg840atcaaactcgtcggtttctatcccttcaaagagccattgagaaccattccgggggcgtcc900agctcatgttatatcaagaaaaaatcactttttatacaaaactgtttagtgattagactt960gcgagactgtgaaagcccaagtagacattcagactgcttggatatctgtgttctcgaccc1020ttagctcccgagtagtggacgagcgagagatttcccagaagcattgcgtctggacaaatt1080tctgccccaagtagcggatgtattaccatggctcgaagagacagggcttcaactcatggc1140gctcgctctttcccttcgtattgaagaacataatatctgtaagtgttag1189<210>2<211>366<212>dna<213>食腺嘌呤节孢酵母(blastobotrysadeninivorans)<400>2tagtctcaatcgctacgcccgtatcttatggcggtgcgccagtcgttgacggcggcactt60tgcctggagaactttgcttctcaggtggtggaacgacacaataaccctgaggtggagtcc120agaaagacccccgaagcgctgctcaacccactgactattgctcgaaatgaaaacgaaaag180gtgcttatcgagccttctatcaactccgtgcgagtttctatcaagatcaagcaggccgat240gagattgagaccattctggtgcatcagttcacgcggttcttgaccggacgagccgagagc300ttttacattctacgacgaaagcctattgatgtgagttggattggacattgggtgaatatg360tgttga366<210>3<211>232<212>prt<213>食腺嘌呤节孢酵母(blastobotrysadeninivorans)<400>3metileprohisserilealavalglumetaspargserglnserleu151015argprotyrleumetalavalargglnserleuthralaalaleucys202530leugluasnphealaserglnvalvalgluarghisasnasnproglu354045valgluserarglysthrprolysalametleuasnproleuthrile505560alaargasngluasnglulysvalleuilegluproserileasnser65707580valargvalserilelysilelysglnalaaspgluilegluthrile859095leuvalhisglnphethrargpheleuthrglyargalalysserphe100105110tyrileleuargarglysproileaspglytyraspileserpheleu115120125ilethrasnphehisthrgluglnmetleulyshislysleuvalasp130135140pheileilegluphemetglugluvalasplysgluileserglumet145150155160lysleupheleuasnalaargalaargphevalalaglusertyrleu165170175thrproleuproserserglyargalaargasppheproglualaleu180185190argleuasplyspheleuproglnvalalaaspvalleuprotrpleu195200205glugluthrglyleuglnleumetalaleualaleuserleuargile210215220glugluhisasnilecyslyscys225230<210>4<211>2361<212>dna<213>食腺嘌呤节孢酵母(blastobotrysadeninivorans)<400>4tcgtcatccttttggcgtacatagtcgttaaatatttcctgtcggcggactggatcctta60atgacccaatattctggtttggttactaacgctttcatagcatcggtccatgaccaagat120atgtctacccctacctgttcaagcattgctcggtaatcctcaattgcatcttccttggac180ttgtaccatcgctcatgagaaggattgagaaggctttggctagcgaagggatgattttca240gttcctgaaccactgctaaacacatacctttcggatgactgcgctgttgactgagcataa300cctccattggctgacccgggcgcggtaccagtcgaagtctttgagtgctcattgatgatc360cgttcaacttcaggaggggtctcccatactgactgtccagtctgtgagttgtaccagtaa420tggtgtcccccatcggccacgtacttccgccagttgacctccagaaatgcccgctccaaa480tcagtgaaaagctcttccggcttatcccaagtggtttctaacgtctccgtattgtaataa540tacaccgctccattatcctctacctcttgccagggcatggtcgtgccctttgcttatcaa600tcaattagttattgaaaaaggaacaaatatcaccgcaaacttatcttgcaacaattcaat660ggatactgctgctcgatatatttcgagaagaaatcagtactgtaagcgagtcacgtgact720gtacttcttggggaacgtacaggttgctcaactgccaatggttcatggagttttttaggt780caattatagaataaccattatggagttttatttaattataaaaaccgccacttttttatt840gttgtttccccgagaaatgcttcatttttcaacatgataccccattctatagccgttgaa900atggacagggtgacgctcagccacgcttcaccactcacaacatggtaggtagagacaaga960ggcactaaaggatagctggggaaatggtgatactaactagtctcaatcgctacgcccgta1020tcttatggcggtgcgccagtcgttgacggcggcactttgcctggagaactttgcttctca1080ggtggtggaacgacacaataaccctgaggtggagtccagaaagacccccgaagcgctgct1140caacccactgactattgctcgaaatgaaaacgaaaaggtgcttatcgagccttctatcaa1200ctccgtgcgagtttctatcaagatcaagcaggccgatgagattgagaccattctggtgca1260tcagttcacgcggttcttgaccggacgagccgagagcttttacattctacgacgaaagcc1320tattgatgtgagttggattggacattgggtgaatatgtgttgagagtactaactgtttag1380ggctatgatatttcgtttttgatcacaaactttcacactgagcagatgctcaagcataag1440ctagtggactttattattgagtttatggaggaggttgacaaggagatttcggaaatgaag1500ttgttccttaacgctcgagctcgattcgtggccgagtcatatttgacaccggtaagttga1560ttggtctttgacgatttccatacctaggatgctaacggatagtttgattagaagtgcggg1620acaagcgctgtacatgtatacatgtattcaattagatgacatacgattatagtccttgac1680tagcgttcattagctattaatagtctataattgatcaaactcgtcggtttctatcccttc1740aaagagccattgagaaccattccgggggcgtccagctcatgttatatcaagaaaaaatca1800ctttttatacaaaactgtttagtgattagacttgcgagactgtgaaagcccaagtagaca1860ttcagactgcttggatatctgtgttctcgacccttagctcccgagtagtggacgagcgag1920agatttcccagaagcattgcgtctggacaaatttctgccccaagtagcggatgtattacc1980atggctcgaagagacagggcttcaactcatggcgctcgctctttcccttcgtattgaaga2040acataatatctgtaagtgttagataggagcgtacaattgcagcacatatccttatgccag2100cgtgttatcccaccaccatggcaaggtggttatcgatgaaacggtccgcctctctcttca2160gcatcaagatacagctcgatacaacaaacgcctctacagtctgggggtcggtatgcttat2220cttcgttccacatacgcagatcgatgaacaaacggcccccattgccgcctgagtacttct2280tggtgccgggggtacgatactggtcattgcgaatgagatgtgcgacgcgggcgccctttt2340tactgcgtccaccgccgggta2361<210>5<211>20<212>dna<213>人工序列<400>5gctcaactgccaatggttca20<210>6<211>20<212>dna<213>人工序列<400>6cttgccatggtggtgggata20<210>7<211>1380<212>dna<213>食腺嘌呤节孢酵母(blastobotrysadeninivorans)<400>7gctcaactgccaatggttcatggagttttttaggtcaattatagaataaccattatggag60ttttatttaattataaaaaccgccacttttttattgttgtttccccgagaaatgcttcat120ttttcaacatgataccccattctatagccgttgaaatggacagggtgacgctcagccacg180cttcaccactcacaacatggtaggtagagacaagaggcactaaaggatagctggggaaat240ggtgatactaactagtctcaatcgctacgcccgtatcttatggcggtgcgccagtcgttg300acggcggcactttgcctggagaactttgcttctcaggtggtggaacgacacaataaccct360gaggtggagtccagaaagacccccgaagcgctgctcaacccactgactattgctcgaaat420gaaaacgaaaaggtgcttatcgagccttctatcaactccgtgcgagtttctatcaagatc480aagcaggccgatgagattgagaccattctggtgcatcagttcacgcggttcttgaccgga540cgagccgagagcttttacattctacgacgaaagcctattgatgtgagttggattggacat600tgggtgaatatgtgttgagagtactaactgtttagggctatgatatttcgtttttgatca660caaactttcacactgagcagatgctcaagcataagctagtggactttattattgagttta720tggaggaggttgacaaggagatttcggaaatgaagttgttccttaacgctcgagctcgat780tcgtggccgagtcatatttgacaccggtaagttgattggtctttgacgatttccatacct840aggatgctaacggatagtttgattagaagtgcgggacaagcgctgtacatgtatacatgt900attcaattagatgacatacgattatagtccttgactagcgttcattagctattaatagtc960tataattgatcaaactcgtcggtttctatcccttcaaagagccattgagaaccattccgg1020gggcgtccagctcatgttatatcaagaaaaaatcactttttatacaaaactgtttagtga1080ttagacttgcgagactgtgaaagcccaagtagacattcagactgcttggatatctgtgtt1140ctcgacccttagctcccgagtagtggacgagcgagagatttcccagaagcattgcgtctg1200gacaaatttctgccccaagtagcggatgtattaccatggctcgaagagacagggcttcaa1260ctcatggcgctcgctctttcccttcgtattgaagaacataatatctgtaagtgttagata1320ggagcgtacaattgcagcacatatccttatgccagcgtgttatcccaccaccatggcaag1380当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1