合成低聚异麦芽糖的解脂亚罗威酵母菌株及其合成方法与流程
本发明属于食品生物技术领域,涉及一株合成低聚异麦芽糖的解脂亚罗威酵母菌株及其合成方法。
背景技术
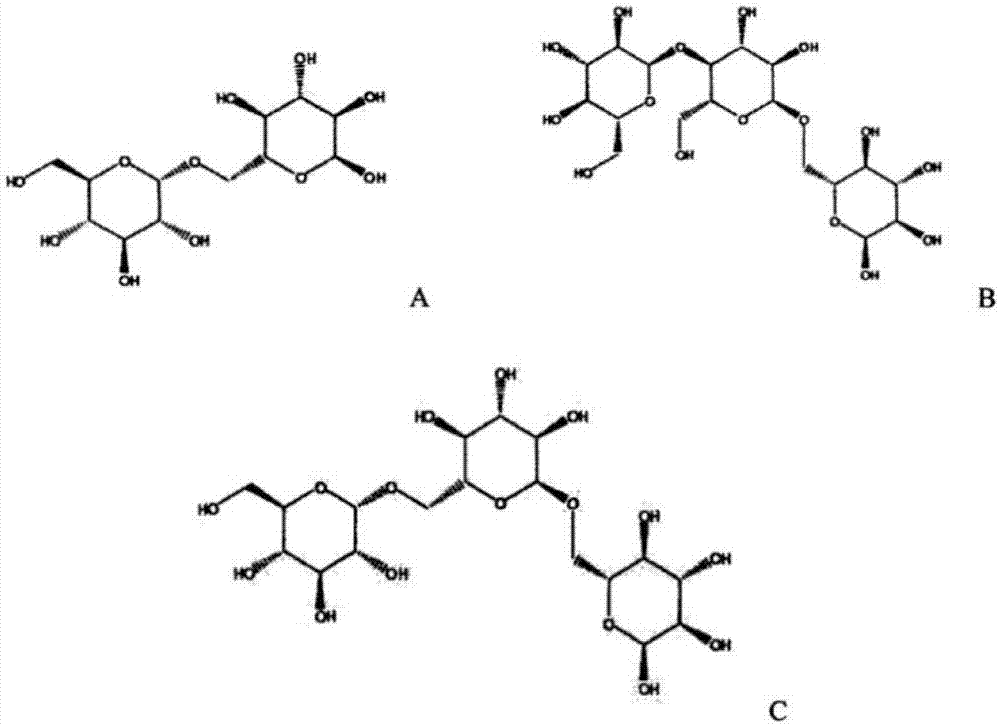
低聚异麦芽糖(isomalto-oligosaccharide,简称imo)是一种重要的功能性低聚糖,一般由2-10个葡萄糖以糖苷键进行连接,这些糖苷键中至少含有一个α-1,6糖苷键,也可能含有极少数的α-1,3糖苷键。低聚异麦芽糖常包含多种组分,如异麦芽糖(ig2)、异麦芽三糖(ig3)、潘糖(p)、异麦芽四糖(ig4),结构式如图1,其中a、b、c分别代表异麦芽糖、潘糖和异麦芽三糖。
目前国家标准根据产品的纯度将低聚异麦芽糖分成了imo-50和imo-90两种,imo-50中ig2+p+ig3含量占35%以上,imo-90中ig2+p+ig3含量达45%以上。目前已知低聚异麦芽糖极少以游离的状态存在于自然界,一般作为多糖或者分支链淀粉的组成部分,在清酒、蜂蜜、酱类及果葡糖浆中才有少量存在。
低聚异麦芽糖具有优异的生理效应。它能促进消化道内多种有益细菌的生长繁殖,是一种优良的益生元(prebiotics)。其主要生理功效如下:
(1)调节人体脂类物质代谢:低聚异麦芽糖基本不含单糖或含量极低,又很难被唾液酶、胃液及小肠中的酶消化利用,不增加血液中糖和胆固醇的含量,且属于非胰岛素依赖性,糖尿病患者可以放心食用;
(2)合成机体必需维生素,并促进矿物质吸收:低聚异麦芽糖是肠道内双歧杆菌的增殖因子,可促进其增殖,增加机体合成b族维生素,促进钙、镁、铁等矿物质元素的吸收,提高机体免疫力;
(3)预防龋齿,抑制牙垢:一般蛀牙主要是由链球菌造成,而低聚异麦芽糖很难被其分解,从而达到预防龋齿的作用,同时在与蔗糖结合时可抑制不溶性葡聚糖合成的产生,可以很好的抑制牙垢的形成;
(4)调节肠道菌群:低聚异麦芽糖促进双歧杆菌和乳酸菌增殖促进食物消化吸收,降低肠道ph,促进肠道蠕动,改善肠道功能;
(5)保护肝功能:如果肝功能发生异常,势必会影响肠道菌群,同样的将肠道菌群向良性调节必有利于肝功能的正常发挥。口服高浓度的低聚异麦芽糖产品可以调节肠道菌群,降低有毒物质含量,大大增加蛋白质耐受性,增加体重。
由于低聚异麦芽糖具有上述优异的生理功能,使得其在食品及医疗保健品中得到非常广泛的应用,市场销量巨大,国内外对生产低聚异麦芽糖的方法进行了大量的研究。
目前在工业上经典的生产低聚异麦芽糖的主要采用的是多酶协同转化法。一般需要利用α-淀粉酶、β-淀粉酶、普鲁兰酶、转苷酶。从淀粉出发经液化(耐高温α-淀粉酶)、糖化(β-淀粉酶、普鲁兰酶)、转苷作用(α-葡萄糖转苷酶)这一多酶协同步骤生产得到低聚异麦芽糖。产物中除了含有低聚异麦芽糖外,还含有40%~50%的葡萄糖、麦芽糖、麦芽三糖以及低聚麦芽糖等以α-1,4糖苷键连接的寡糖。再经过过滤、脱盐、脱色、分离、浓缩、干燥得到低聚异麦芽糖imo-50或高纯度的imo-90,其工艺流程如下图2。该方法存在很多问题,如工序过多、工艺参数难控制、时间过长、难以实现连续化生产等诸多缺点,尤其需要单独制备或者购买比较昂贵的酶制剂,如β-淀粉酶、普鲁兰酶、α-葡萄糖转苷酶。这些都使得规模化生产imo的成本较高。
早在1993年就有报道(kuriki等,anewwayofproducingisomalto-oligosaccharidesyrupbyusingthetransglycosylationreactionofneopullulanase.applenvironmicrobiol,1993,59:953-959),根据新普鲁兰酶(neopullulanase)既有水解酶又有转苷酶的特性,从枯草芽孢杆菌中分离纯化新普鲁兰酶,利用α-淀粉酶先液化淀粉,然后将液化的淀粉加入纯化的新普鲁兰酶,可以得到低聚异麦芽糖的转化液,由淀粉合成低聚异麦芽糖的得率达到45-60%。这种方法虽然不需要经典的多酶协同转化,但是该方法需要制备纯酶新普鲁兰酶,而制备纯酶的过程比较繁多,成本较大,不利于降低规模化生产低聚异麦芽糖的成本。若不制备纯酶,其它来源芽孢杆菌的杂酶会污染产品。
2002年韩国学者lee等报道了利用α-葡糖转移酶与产麦芽糖淀粉酶双酶协同以淀粉合成低聚异麦芽糖的方法(lee等,cooperativeactionofα-glucanotransferaseandmaltogenicamylaseforanimprovedprocessofisomaltooligosaccharideproduction,jagrifoodchem,2002,50:2812-2817)。采用该双酶协同的方法,由淀粉合成imo的得率提高到68%,而且含有相对较长链的imo。该方法需要先制备这两种纯酶,也存在酶制备成本大的缺点,难以实现规模化生产。
最近,丹麦学者sorndech等人报道了一种双酶协同由淀粉合成低聚异麦芽糖的方法(sorndech等,combinationofamylaseandtransferasecatalysistoimproveimocompositionsandproductivity.lwt-foodscitechnol,2017,79:479-486)。同时将特殊的淀粉酶与分支酶加入到淀粉乳化液中,液化淀粉后再加入转苷酶反应得到低聚异麦芽糖。这种方法不用像经典的方法那样逐个加入α-淀粉酶、β-淀粉酶、普鲁兰酶以及转苷酶,而是同时加入特殊的淀粉酶与分支酶,然后再加入转苷酶,具有一定的简便性,但是缺点是同样需要制备多种纯化酶,成本很高。
因此,研究开发一种较多酶协同合成低聚异麦芽糖更简便的方法,对于提高合成效率降低成本具有十分重要的意义。
技术实现要素:
本发明的目的在于克服现有的酶合成低聚异麦芽糖的不足之处,提供了一株直接由淀粉、糊精或者麦芽糖或者其组合物合成低聚异麦芽糖的菌株,及用其合成低聚异麦芽糖的方法。本发明提供的能合成低聚异麦芽糖的解脂亚罗威酵母菌株,该菌株经过培养,即含有能催化淀粉合成低聚异麦芽糖的酶类,而且这些酶类可以分泌到胞外培养基,也可以展示固定在细胞表面,用此酵母细胞或者胞外的酶类作为催化剂,能催化底物(淀粉、糊精、麦芽糖或者其组合物)合成低聚异麦芽糖。
解脂亚罗威酵母属于公认安全的酵母菌株,在食品发酵领域具有重要的应用。有的能高效合成柠檬酸,有的能高效合成赤藓糖醇。同时,该酵母也是常用的异源蛋白表达宿主,用于高效表达具有功能的酶(nicaudetal,proteinexpressionandsecretionintheyeastyarrowialipolytica.femsyeastresearch,2002,2:371-379)。在本发明中,我们以解脂亚罗威酵母为出发菌株(yarrowialipolytica)构建了能够合成低聚异麦芽糖的新菌株解脂亚罗威酵母。
本发明中使用的合成低聚异麦芽糖的酵母菌株是解脂亚罗威酵母(yarrowialipolytica),已经于2018年5月11日保存于中国微生物菌种保藏管理委员会普通微生物中心(北京市朝阳区北辰西路1号,中国科学院微生物研究所),保藏编号为cgmccno.14785。
本发明中使用的解脂亚罗酵母yarrowialipolyticablc13,已经于2013年3月19日保存于中国微生物菌种保藏管理委员会普通微生物中心(北京市朝阳区北辰西路1号,中国科学院微生物研究所),保藏编号为cgmccno.7326。
本发明的目的是通过以下技术方案来实现的:
第一方面,本发明涉及一种代谢工程改良的解脂亚罗威酵母菌株,该菌株含有如下异源基因表达盒中的至少一种:
(1)α-淀粉酶基因表达盒(α-amylasegeneexpressioncassette);
(2)β-淀粉酶基因表达盒(β-amylasegeneexpressioncassette);
(3)新普鲁兰酶基因表达盒(neopullulanasegeneexpressioncassette);
(4)产麦芽糖淀粉酶基因表达盒(maltogenicamylasegeneexpressioncassette);
(5)葡萄糖转苷酶基因表达盒(transglucosidasegeneexpressioncassette);
(6)α-葡萄糖苷酶基因表达盒(α-glucosidasegeneexpressioncassette)。
上述六种酶基因可以来自芽孢杆菌(如枯草芽孢杆菌、地衣芽孢杆菌、嗜热脂肪芽孢杆菌、嗜热细菌或其它芽孢杆菌等)、曲霉菌(如米曲霉、黑曲霉等);还可以来自古菌(如嗜热腾冲菌、嗜热硫化杆菌等)。
优选的,所述菌株包含α-淀粉酶基因表达盒、β-淀粉酶基因表达盒、新普鲁兰酶基因表达盒、产麦芽糖淀粉酶基因表达盒、α-葡萄糖苷酶基因表达盒。
进一步优选的,所述菌株包含α-淀粉酶基因表达盒、β-淀粉酶基因表达盒、产麦芽糖淀粉酶基因表达盒、α-葡萄糖苷酶基因表达盒。
更进一步优选的,所述菌株含有α-淀粉酶基因表达盒、产麦芽糖淀粉酶基因表达盒和α-葡萄糖苷酶基因表达盒。
所述α-淀粉酶基因表达盒包含启动子序列、酶基因序列(seqidno.1)、终止子序列。优选的,启动子序列如seqidno.7所示,终止子序列如seqidno.8所示。
所述产麦芽糖淀粉酶基因表达盒包含启动子序列、酶基因序列(seqidno.3)、终止子序列。优选的,启动子序列如seqidno.9所示,终止子序列如seqidno.10所示。
所述α-葡萄糖苷酶基因表达盒包含启动子序列、酶基因序列(seqidno.5)、终止子序列。优选的,启动子序列如seqidno.11所示,终止子序列如seqidno.12所示。
最优选的,所述菌株含有α-淀粉酶基因表达盒、产麦芽糖淀粉酶基因表达盒和α-葡萄糖苷酶基因表达盒;α-淀粉酶基因基因序列如seqidno.2所示,产麦芽糖淀粉酶基因基因序列如seqidno.4所示,α-葡萄糖苷酶基因序列如seqidno.6所示。
优选的,所述菌株以能合成赤藓糖醇的解脂亚罗威酵母(如yarrowialipolyticablc13,cgmccno.7326)、用于蛋白表达宿主的解脂亚罗威酵母(如yarrowialipolyticapo1d,po1e,po1f系列菌株,该系列菌株在文献j.mol.microbiol.biotechnol,2002,2:207-216中已经公开报道,是常用于异源基因表达的菌株)为出发菌株。
优选的,所述代谢工程菌株能合成低聚异麦芽糖。
优选的,所述代谢工程菌株为解脂亚罗威酵母yarrowialipolyticacgmccno.14785。
第二方面,本发明涉及一种所述的解脂亚罗威酵母菌株在合成低聚异麦芽糖中的用途。
第三方面,本发明涉及一种所述的解脂亚罗威酵母菌株合成低聚异麦芽糖的方法,所述方法包括如下步骤:
s1、将所述解脂亚罗酵母菌株在含碳源、氮源以及无机盐的培养基中进行发酵培养,培养结束后分离得到游离细胞与上清液;
s2、用游离细胞酶催化淀粉、糊精、麦芽糖中的一种或几种的组合生成低聚异麦芽糖;
或者,将游离细胞进行固定化,得到固定化细胞;用固定化细胞酶催化淀粉、糊精、麦芽糖中的一种或几种的组合生成低聚异麦芽糖。
优选的,步骤s1中,所述培养基中,碳源为葡萄糖或甘油的一种或两种,碳源用量为10~400克/升;氮源为蛋白胨、酵母粉、酵母浸膏、玉米浆干粉、玉米浆、磷酸氢二铵、柠檬酸铵、尿素中的一种或几种的混合,氮源的用量为5~25克/升;无机盐为镁、锰、铜、锌离子中的一种或几种,无机盐用量为0~3克/升。更优选碳源用量为50~300克/升。更优选氮源为磷酸氢二铵、酵母粉、玉米浆干粉中的一种或几种,氮源用量为5~25克/升。更优选无机盐用量为0.01~2克/升,最优选为1~2克/升。
优选的,步骤s1中,所述发酵培养可以为含高浓度碳源的发酵培养;该高浓度碳源的发酵培养基为含高浓度碳源、氮源、无机盐以及水的培养基,培养条件为在ph值3~8,优选为ph5-7,温度25~35℃,优选28-32℃下振荡或者搅拌。
所述高浓度碳源为富含葡萄糖或甘油中的一种或多种,折合葡萄糖或甘油含量为200~400克/升;所述氮源为蛋白胨、酵母粉、酵母浸膏、玉米浆干粉、玉米浆、磷酸氢二铵、柠檬酸铵、尿素中的一种或几种的混合,氮源的用量为5~25克/升;所述无机盐为硫酸镁、氯化锰、氯化铜、氯化锌中的一种或几种,无机盐用量为0~3克/升。更优选氮源为磷酸氢二铵、酵母粉、玉米浆干粉中的一种或几种,氮源用量为5~25克/升。更优选无机盐用量为0.01~2克/升,最优选为1~2克/升。
采用高浓度碳源的发酵培养时,菌液分离得到的上清液为含有赤藓糖醇的溶液,用于纯化分离赤藓糖醇,沉淀为解脂亚罗酵母细胞。
优选的,步骤s1中,所述上清液为含有赤藓糖醇溶液,用于分离纯化赤藓糖醇。
优选的,步骤s2中,游离细胞酶催化具体为:在游离细胞中加入加入含淀粉、糊精、麦芽糖中的一种或几种组合的水溶液,在30~80℃,ph3.0~8.0条件下振荡或搅拌,进行转化得到含低聚异麦芽糖的溶液;固定化细胞酶催化具体为在固定化细胞或固定化细胞柱中加入含淀粉、糊精、麦芽糖中的一种或几种组合的水溶液,在30~80℃,ph3.0~8.0条件下振荡或搅拌,进行转化得到含低聚异麦芽糖的溶液。更优选发酵ph值为5.0~7.0。进一步优选发酵温度为28℃~32℃,最优选30℃。
优选的,转化得到含低聚异麦芽糖的溶液后,还包括对低聚异麦芽糖溶液进行纯化精制,得到液体或者粉状低聚异麦芽糖的步骤。
更优选的,所述纯化精制,包括对富含低聚异麦芽糖的溶液进行脱色与脱异味、浓缩、干燥、粉碎得到低聚异麦芽糖粉。也可以直接对富含低聚异麦芽糖的溶液进行脱色与脱异味、浓缩,而不干燥直接得到低聚异麦芽糖浆。还可以对富含低聚异麦芽糖的溶液进行脱色与脱异味、色谱分离、浓缩、干燥得到高纯度的低聚异麦芽糖粉。
上述步骤s2,还包括当转化液中低聚异麦芽糖的含量不再增加时停止转化,进行纯化精制,得到液体或者粉状低聚异麦芽糖。低聚异麦芽糖的含量不再增加是指在连续转化2小时期间,低聚异麦芽糖的含量没有显著的变化,这时可以停止转化。所述纯化精制包括:过滤分离细胞、浓缩、脱色脱异味、离子交换脱盐、纳滤、色谱分离杂糖(指低聚异麦芽糖以外的糖类,如葡萄糖)、干燥等工序。停止转化后,过滤得到的游离细胞或者固定化细胞还可以循环利用。
上述步骤s2中,将游离细胞进行固定化是指将解脂亚罗酵母yarrowialipolyticacgmccno.14785细胞与固定化介质按照一定的比例进行混合,然后凝固制成含细胞的凝胶。固定化介质可以是海藻酸钠(钙)、琼脂糖凝胶、聚丙烯酰胺凝胶等的一种或组合。细胞(指湿重)与固定化介质的比例(重量比)可以是1:100(即1克湿重的细胞与100克固定化介质混合,下面类推),也可以是1:50,也可以是1:10。细胞固定化后,可以装入中空柱中,制成固定化细胞柱。将含淀粉、糊精或者麦芽糖的水溶液通过该固定化细胞柱进行催化反应,柱温控制在30~80℃,优选为40~70℃,最优选为55℃。转化ph值优选为4.0~7.0;更优选为5.5~6.5。也可以直接将含淀粉、糊精或者麦芽糖的水溶液与固定化细胞微球混合进行搅拌催化,温度控制在30~80℃,优选为40~70℃,最优选为55℃。转化ph值优选为4.0~7.0;更优选为5.5~6.5。还可以直接将含淀粉、糊精或者麦芽糖的水溶液与游离的细胞混合进行搅拌催化,温度控制在30~80℃,优选为40~70℃,最优选为55℃。转化ph值优选为4.0~7.0;更优选为5.5~6.5。
与现有合成低聚异麦芽糖的技术相比,本发明具有如下有益效果:
1.本发明采用的解脂亚罗威酵母yarrowialipolyticacgmccno.14785转化方法更加简便,只需要培养得到细胞,用细胞作为酶催化剂,催化淀粉或者液化的淀粉既可以得到低聚异麦芽糖,无需购买酶或者纯化酶,较传统的经典方法更加经济简便。
2.本发明由淀粉合成低聚异麦芽糖的转化率最高可以达到75%,而目前工业上采用多种纯酶协同转化法由淀粉合成低聚异麦芽糖的得率低于50%,因此,本发明提供的方法要显著优越于目前的多酶协同转化法。
3.解脂亚罗威酵母yarrowialipolyticacgmccno.14785细胞可以被固定化循环利用多次,转化淀粉或者糊精或者麦芽糖合成低聚异麦芽糖,而采用游离的酶只能被利用一次,因而显著提高了生产效率与节约了成本。
4.解脂亚罗威酵母yarrowialipolyticacgmccno.14785还可以来自发酵赤藓糖醇后经过过滤得到的酵母细胞,有效提高了生物质资源的利用率。可以先用该菌株其来合成赤藓糖醇,再用得到的酵母细胞用来转化合成低聚异麦芽糖,充分利用了酵母资源。
附图说明
通过阅读参照以下附图,可以对本发明有更详细的了解,本发明的其它特征、目的和优点将会变得更明显:
图1为异麦芽糖、潘糖、异麦芽三糖化学结构示意图;
图2为低聚异麦芽糖工业生产流程图;
图3为本发明中以游离的形式存在于细胞质中的基因表达盒元件组成图;
图4为本发明中以整合的形式存在于细胞核基因组中的基因表达盒元件组成图;
图5为构建本发明yarrowialipolyticacgmccno.14785菌株所使用的表达盒元件图;其中per1,per2,per3分别为来自yarrowialipolytica赤藓糖还原酶基因1,2,3的启动子,tter1,tter2,tter3分别为来自yarrowialipolytica赤藓糖还原酶基因1,2,3的终止子,zeta为长末端重复序列,作为整合同源臂序列,pir1为yarrowialipolytica的锚定蛋白基因,optimizedbsa,optimizedbma以及optimizedangase分别为优化的bsa,bma以及angase基因;
图6为本发明的菌株在含淀粉的基本培养基中滴加碘液后形成的透明圈示意图;
图7为含β-淀粉酶基因表达盒的yarrowialipolytica酵母菌株转化淀粉生成麦芽糖的hplc色谱分析图;其中,a为反应起始时色谱图,为淀粉的峰,b为反应2小时时的色谱图,有麦芽糖产生,c为反应4小时的色谱图,较多麦芽糖产生,d为反应结束时的色谱图,有大量麦芽糖产生,但无低聚异麦芽糖产生;
图8为构建含未优化的bsa,bma以及angase基因yarrowialipolytica菌株所使用的表达盒元件图;其中per1,per2,per3分别为来自yarrowialipolytica赤藓糖还原酶基因1,2,3的启动子,tter1,tter2,tter3分别为来自yarrowialipolytica赤藓糖还原酶基因1,2,3的终止子,zeta为长末端重复序列,作为整合同源臂序列,pir1为yarrowialipolytica的锚定蛋白基因,bsa,bma以及angase分别为原始的未优化的糖化α-淀粉酶基因,产麦芽糖α-淀粉酶基因以及α-糖苷酶基因;
图9为yarrowialipolyticacgmccno.14785酵母菌转化淀粉生成低聚异麦芽糖的hplc色谱分析图,经过计算,淀粉转化为低聚异麦芽糖的转化率为75%;
图10为yarrowialipolyticacgmccno.14785酵母菌催化麦芽糖生成低聚异麦芽糖的hplc色谱分析图;其中,a为反应起始时的色谱图,仅为麦芽糖底物的峰,b为反应结束时的色谱图,含有低聚异麦芽糖的峰。
具体实施方式
以下结合附图和实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,在不脱离本发明权利要求的前提下,发明人还可以做出若干调整和改进,这些都属于本发明的保护范围。
本发明所述的通过代谢工程改良的解脂亚罗威酵母yarrowialipolytica,细胞内可以含有如下基因表达盒中的一种或多种组合:
(1)α-淀粉酶基因表达盒(α-amylasegeneexpressioncassette);
(2)β-淀粉酶基因表达盒(β-amylasegeneexpressioncassette);
(3)新普鲁兰酶基因表达盒(neopullulanasegeneexpressioncassette);
(4)产麦芽糖淀粉酶基因表达盒(maltogenicamylasegeneexpressioncassette);
(5)葡萄糖转苷酶基因表达盒(transglucosidasegeneexpressioncassette);
(6)α-葡萄糖苷酶基因表达盒(α-glucosidasegeneexpressioncassette)。
优选的,本发明所述的通过代谢工程改良的解脂亚罗威酵母yarrowialipolytica菌包含α-淀粉酶基因表达盒、β-淀粉酶基因表达盒、新普鲁兰酶基因表达盒、产麦芽糖淀粉酶基因表达盒、α-葡萄糖苷酶基因表达盒。
更优选的,本发明所述的通过代谢工程改良的解脂亚罗威酵母yarrowialipolytica菌包含α-淀粉酶基因表达盒、β-淀粉酶基因表达盒、产麦芽糖淀粉酶基因表达盒、α-葡萄糖苷酶基因表达盒。
最优选的,本发明所述的通过代谢工程改良的解脂亚罗威酵母yarrowialipolytica菌包含糖化α-淀粉酶基因表达盒、产麦芽糖淀粉酶基因表达盒、α-葡萄糖苷酶基因表达盒。
基因表达盒包括但不限于包括如下基因元件:启动子序列、酶基因序列、终止子序列。其中酶基因序列为上述六种酶基因序列,分别为α-淀粉酶基因、β-淀粉酶基因、新普鲁兰酶基因、产麦芽糖淀粉酶基因、葡萄糖转苷酶基因与α-葡萄糖苷酶基因,这些酶基因序列可以与分泌信号肽序列或者细胞表面锚定蛋白序列进行融合表达。启动子序列是指能启动与其相连的下游酶基因转录的核酸元件(即dna元件),启动子可以是组成型启动子,即任何时候都能具有转录活性的启动子,如来自解脂亚罗威酵母yarrowialipolytica的基因组本身的转录延长因子1的基因启动子(tef1基因启动子)、3-磷酸甘油脱氢酶基因的启动子(gapdh基因启动子)、1,6-二磷酸果糖裂解酶基因启动子(fba基因启动子),还可以是人工杂合启动子,如hp4d启动子,hp8d启动子,还可以是赤藓糖还原酶基因的启动子,该赤藓糖还原酶基因启动子是发明人在本发明首次报道并使用的启动子,具有新颖性。本发明所用的启动子还可以是诱导型启动子,即只有加入特定成分后才能具有转录活性的启动子,比如半乳糖诱导的启动子,l-阿拉伯糖诱导的启动子等。终止子序列为转录终止必需的序列,一般连接在酶基因的下游(即酶基因的3'端)。终止子序列可以是来自解脂亚罗威酵母yarrowialipolytica的基因组本身的一段转录终止子序列,如转录延长因子1的基因转录终止子(tef1基因终止子)、3-磷酸甘油脱氢酶基因的终止子(gapdh基因终止子)、1,6-二磷酸果糖裂解酶基因终止子(fba基因终止子)、ura3基因终止子、leu2基因终止子,还可以是赤藓糖还原酶基因的终止子,该终止子是发明人在本发明首次利用的终止子。
上述酶基因序列除了其上游(5'端)与启动子序列连接,下游(3'端)与终止子序列连接外,其本身还可以与分泌信号肽序列(如y.lipolytica酵母自身的胞外碱性蛋白酶aep基因的信号肽序列)或者细胞表面锚定蛋白序列(如y.lipolytica酵母自身的锚定蛋白pir1基因序列)进行连接,从而与这些信号肽或者锚定蛋白进行融合表达。信号肽一般在酶蛋白的n端,而锚定蛋白可以在酶蛋白的n端也可以位于其c端。
上述基因表达盒可以与其它dna元件组合在一起,以游离的形式存在于细胞质中,或者以整合的形式存在于解脂亚罗威酵母细胞核基因组中。当以游离的形式存在于细胞质中时,其dna元件则含有yarrowialipolytica自主复制的dna元件ars序列(如ars18或者ars68序列等自主复制序列)以及着丝粒附着位点序列cen1。还含有筛选标记序列,如营养缺陷型标记序列如leu2,ura3等。当以整合的形式存在于酵母基因组中时,酶基因表达盒的两侧序列(flankingsequences)分别为整合同源臂序列,如常用的长末端重复序列zeta序列、18s核糖体rdna基因序列、其它生长非必需基因的序列等。
本发明中典型的以游离的形式存在于细胞质中的基因表达盒元件如图3所示,典型的以整合的形式存在于细胞核基因组中的基因表达盒元件如图4所示,但本发明所用的包含基因表达盒的dna元件组成不限于图3或图4所示的dna元件组成。
以游离的形式在细胞质中转录表达的dna元件组成一般包括:y.lipolytica酵母复制起始点序列(ars/cen)、启动子序列、酶基因序列、终止子序列、细菌复制起始点以及细菌抗性筛选标记序列。其中酶基因序列本身还可以与分泌信号肽序列或者细胞表面锚定蛋白序列进行连接,从而与这些信号肽或者锚定蛋白进行融合表达,酶基因序列可以包括上述七种酶基因序列中的一种或者一种以上,若包括一种以上,则形成融合酶基因进行融合表达。
以整合的形式在细胞核基因组中转录表达的dna元件组成一般包括:y.lipolytica酵母左右整合同源臂序列(如zeta序列等)、启动子序列、酶基因序列、终止子序列、细菌复制起始点以及细菌抗性筛选标记序列。其中酶基因序列本身还可以与分泌信号肽dna序列或者细胞表面锚定蛋白dna序列进行连接,从而与这些信号肽或者锚定蛋白进行融合表达。酶基因序列可以包括上述六种酶基因序列中的一种或者一种以上,若包括一种以上,则形成融合酶基因进行融合表达。用限制性内切酶将酶基因的整合表达元件切下,转化y.lipolytica酵母,在含淀粉的基本培养基上筛选。
本发明所用的上述六种酶基因可以来自芽孢杆菌(如枯草芽孢杆菌、地衣芽孢杆菌、嗜热脂肪芽孢杆菌、嗜热细菌或其它芽孢杆菌等)、曲霉菌(如米曲霉、黑曲霉等)。还可以来自古菌(如嗜热腾冲菌、嗜热硫化杆菌等),这些酶基因全序列虽然可以从公开的数据库中检索得到(如ncbi基因库www.ncbi.nih.gov),但是本发明对上述基因进行了优化,以得到最高的表达效果,这些优化是本领域普通技术人员难以想到的;在对上述基因进行优化的同时,本发明还对上述不同基因进行了组合优化,以达到最佳的转化生成低聚异麦芽糖的效果,这些组合优化同样是本领域普通技术人员难以想到的。
以解脂亚罗威酵母yarrowialipolyticacgmccno.14785为例,本发明提供的能合成低聚异麦芽糖的解脂亚罗威酵母yarrowialipolyticacgmccno.14785是通过以下方法设计而获得的:
(1)含有的基因组合。
解脂亚罗威酵母yarrowialipolyticacgmccno.14785含有三种与合成低聚异麦芽糖相关的酶基因组合,分别是来自枯草芽孢杆菌的糖化α-淀粉酶基因(saccharifyingα-amylasegenefromb.subtilis,简称bsa基因)、来自芽孢杆菌的产麦芽糖淀粉酶基因(maltogenicamylasegenefrombacillussp.,简称bma基因)、来自黑曲霉的α-葡糖糖苷酶基因(α-glucosidasegenefroma.niger,简称angase基因)。
(2)上述3种基因的优化。
优化包括:按照出发菌株yarrowialipolyticacgmccno.7326的基因编码偏好性对上述3种基因的密码子进行了碱基替换,对密码子碱基替换后的基因进行了部分序列的截短。然后分别与出发菌株yarrowialipolyticacgmcc7326的锚定蛋白进行融合与表达,经过密码子优化与部分序列截短后表达的酶比不优化不截短的酶具有更好的合成低聚异麦芽糖的效果(详见实施例9与10)。优化后的枯草芽孢杆菌糖化α-淀粉酶基因序列(optimizedsaccharifyingα-amylasegene,optimizedbsa基因)序列如seqidno.2所示;优化后的产麦芽糖淀粉酶基因的序列(maltogenicamylasegene,optimizedbmagene)序列如seqidno.4所示;优化后的黑曲霉α-葡萄糖苷酶基因序列(α-glucosidasegene,optimizedangasegene)序列如seqidno.6所示。
(3)含上述3种优化的酶基因表达盒的设计
优化后的bsa基因与出发菌株yarrowialipolyticacgmccno.7326的锚定蛋白pir1基因融合,融合基因的5'端与赤藓糖还原酶基因1启动子连接,其3'端与赤藓糖还原酶基因1终止子连接,构成优化的bsa基因表达盒。赤藓糖还原酶基因1启动子序列如seqidno.7所示,终止子序列如seqidno.8所示。
优化后的bma基因与出发菌株yarrowialipolyticacgmccno.7326的锚定蛋白pir1基因融合,融合基因的5'端与赤藓糖还原酶基因2启动子连接,其3'端与赤藓糖还原酶基因2终止子连接,构成优化的bma基因表达盒。赤藓糖还原酶基因2启动子序列如seqidno.9所示,终止子序列如seqidno.10所示。
优化后的angase基因与出发菌株yarrowialipolyticacgmccno.7326的锚定蛋白pir1基因融合,融合基因的5'端与赤藓糖还原酶基因3启动子连接,其3'端与赤藓糖还原酶基因3终止子连接,构成优化的angase基因表达盒。赤藓糖还原酶基因3启动子序列如seqidno.11所示,终止子序列如seqidno.12所示。
将上述3种酶基因表达盒进行串联组成新的基因表达盒,串联后两边分别与长末端重复序列zeta序列连接组成整合表达元件,该整合表达元件如图5所示。用该整合表达元件转化yarrowialipolytica出发菌株,在含淀粉为唯一碳源的基本培养基中筛选,只有含有上述酶基因(如淀粉酶基因、糖苷酶基因等)表达盒的酵母转化子才能利用淀粉,将淀粉分解为葡萄糖,并长出单菌落克隆,在含单菌落的基本固体培养基中滴加碘液,能形成明显的透明圈(如图6所示),说明该菌株能水解淀粉。该单菌落克隆能转化淀粉合成低聚异麦芽糖。说明含有上述酶基因表达盒的yarrowialipolytica转化子能水解淀粉。
使用上述3种基因以及其它dna元件来构建yarrowialipolyticacgmccno.14785工程菌株的显而易见的优点是,这3种基因均来自食品级微生物(枯草芽孢杆菌与黑曲霉),使用的dna元件(启动子、终止子、同源臂整合序列zeta、锚定蛋白基因pir1)均来自yarrowialipolytica酵母自身。整个基因表达盒不含抗生素筛选标记,也不含来自非食品级微生物的基因,利用淀粉酶能水解淀粉的特性来获得工程菌株。因而,构建的工程菌株能用于食品低聚异麦芽糖的生产。
获取含有上述3种酶基因表达盒的菌株后,发酵培养该菌株,获得细胞与上清,用细胞作为酶来催化淀粉、糊精或者麦芽糖合成低聚异麦芽糖,上清可以用来纯化其它产物如赤藓糖醇。
本发明所使用的解脂亚罗威酵母yarrowialipolyticacgmccno.14785是采用代谢工程手段而构建的。可以采用能合成赤藓糖醇的出发菌株cgmccno.7326,该出发菌株在本发明人申请的发明专利zl201310282059.x中已经做了描述。还可以使用其它不能合成赤藓糖醇的解脂亚罗威酵母yarrowialipolytica出发菌株(如用于蛋白表达宿主的yarrowialipolytica菌株)。这些yarrowialipolytica菌株不能利用淀粉、麦芽糊精与麦芽糖的特性,不能在含淀粉、麦芽糊精或麦芽糖为唯一碳源的基本培养基上生长(基本培养基成分:酵母氮碱6.7克/升,硫酸铵5克/升,淀粉、麦芽糊精或麦芽糖10克/升,ph6.0)。而本发明所构建的新酵母菌株yarrowialipolyticacgmccno.14785含有淀粉酶、转苷酶等基因,这些基因编码产物有的具有水解淀粉的活性,还具有糖基转移酶活性。能将淀粉或者糊精或者麦芽糖分解为葡萄糖,同时能将分解的葡萄糖以α-1,6糖苷键重新连接合成低聚异麦芽糖。因此构建的新菌株能在含淀粉、麦芽糊精或麦芽糖为唯一碳源的基本培养基中生长,同时又能合成低聚异麦芽糖。因此,本发明使用的yarrowialipolyticacgmccno.14785菌株能催化淀粉、麦芽糊精或麦芽糖合成低聚异麦芽糖。这是第一次报道能够以淀粉、麦芽糊精或麦芽糖为底物合成低聚异麦芽糖的解脂亚罗威yarrowialipolytica酵母菌株。
实施例1、仅含β-淀粉酶基因表达盒的yarrowialipolytica酵母菌株转化淀粉生成的产物测定
按照如下步骤实施:
(1)仅含β-淀粉酶基因表达盒的yarrowialipolytica酵母菌株的构建:将枯草芽孢杆菌β-淀粉酶基因与yarrowialipolyticablc13的锚定蛋白基因pir1融合形成融合基因,融合基因的5'端与hp4d启动子连接,其3'端与ura3基因的终止子连接,构成β-淀粉酶基因表达盒。该表达盒的上下游再分别与同源臂整合序列zeta连接,构成整合基因表达盒。将该表达盒转化yarrowialipolyticablc13酵母,在含淀粉为唯一碳源的基本培养基中培养,长出的克隆能形成透明圈。选取一个克隆进行培养。
(2)在50毫升发酵培养基中接种含β-淀粉酶基因表达盒的解脂亚罗威酵母菌。发酵培养基的成分为(克/升):葡萄糖30,酵母粉2.5,蛋白胨2.0克,磷酸氢二铵0.5,硫酸镁2,ph5.0。
(3)接种后在30℃振荡培养直到葡萄糖残余低于0.5%时即停止培养。
(4)离心保留细胞,获得15.5克湿细胞。将细胞用无菌水洗涤1次,再用50毫升100克/升的淀粉水溶液悬浮细胞,调节ph至5.0,在50℃振荡转化。
(5)每隔2小时取样hplc检测麦芽糖生成的量,在连续4小时期间若麦芽糖的量没有增加(或者略微减少)即停止转化。
(6)离心,菌液分离。此时hplc检测淀粉转化为麦芽糖,而没有低聚异麦芽糖生成。hplc检测图如图7所示,图7中,保留时间为4.1-4.6min的为淀粉,保留时间为7.8min的为麦芽糖。由图7可见,仅含β-淀粉酶基因表达盒的yarrowialipolytica酵母菌株转化淀粉生成麦芽糖,而没有低聚异麦芽糖生成。
实施例2、含α-淀粉酶基因与β-淀粉酶基因表达盒的yarrowialipolytica酵母菌株转化淀粉生成的产物测定
按照如下步骤实施:
(1)含α-淀粉酶基因与β-淀粉酶基因表达盒的yarrowialipolytica酵母菌株的构建:将枯草芽孢杆菌的α-淀粉酶基因与β-淀粉酶基因进行化学合成并融合(注:α-淀粉酶基因的终止密码子taa去除后再与β-淀粉酶基因融合),再与锚定蛋白基因pir1融合形成融合基因,融合基因的5'端与hp4d启动子连接,其3'端与ura3基因的终止子连接,构成α-淀粉酶-β-淀粉酶基因表达盒。该表达盒的上下游再分别与同源臂整合序列zeta连接,构成整合基因表达盒。将该表达盒转化yarrowialipolyticablc13酵母,在含20克/升淀粉为唯一碳源的基本培养基中培养,长出的克隆能形成透明圈。选取一个克隆进行培养。
(2)在50毫升发酵培养基中接种含α-淀粉酶-β-淀粉酶基因表达盒的解脂亚罗威酵母(yarrowialipolytica)。发酵培养基的成分为(克/升):葡萄糖30,酵母粉2.5,蛋白胨2.0克,磷酸氢二铵0.5,硫酸镁2,ph5.0。
(3)接种后在30℃振荡培养直到葡萄糖残余低于0.5%时即停止培养。
(4)离心保留细胞,获得17.5克湿细胞。将细胞用无菌水洗涤1次,再用50毫升100克/升的淀粉水溶液悬浮细胞,调节ph至5.0,在50℃振荡转化。
(5)每隔2小时取样hplc检测是否有低聚异麦芽糖合成。
(6)离心,菌液分离。此时hplc检测淀粉转化为麦芽糖与糊精,而没有低聚异麦芽糖生成。
该结果显示,仅含有α-淀粉酶基因与β-淀粉酶基因表达盒,工程菌株是不能由淀粉生成低聚异麦芽糖的。
实施例3、含α-淀粉酶基因与α-葡萄糖苷酶基因表达盒的yarrowialipolytica酵母菌株转化淀粉生成的产物测定
按照如下步骤实施:
(1)含α-淀粉酶基因与α-葡萄糖苷酶基因表达盒的yarrowialipolytica酵母菌株的构建:将枯草芽孢杆菌的α-淀粉酶基因与黑曲霉的α-葡萄糖苷酶基因进行化学合成并融合(注:α-淀粉酶基因的终止密码子taa去除后再与α-葡萄糖苷酶基因融合),再与锚定蛋白基因pir1融合形成融合基因,融合基因的5'端与hp4d启动子连接,其3'端与ura3基因的终止子连接,构成α-淀粉酶-α-葡萄糖苷酶基因表达盒。该表达盒的上下游再分别与同源臂整合序列zeta连接,构成整合基因表达盒。将该表达盒转化yarrowialipolyticablc13酵母,在含20克/升淀粉为唯一碳源的基本培养基中培养,长出的克隆能形成透明圈。选取一个克隆进行培养。
(2)在50毫升发酵培养基中接种含α-淀粉酶-α-葡萄糖苷酶基因表达盒的解脂亚罗威酵母(yarrowialipolytica)。发酵培养基的成分为(克/升):葡萄糖30,酵母粉2.5,蛋白胨2.0克,磷酸氢二铵0.5,硫酸镁2,ph5.0。
(3)接种后在30℃振荡培养直到葡萄糖残余低于0.5%时即停止培养。
(4)离心保留细胞,获得14.5克湿细胞。将细胞用无菌水洗涤1次,再用50毫升100克/升的淀粉水溶液悬浮细胞,调节ph至5.0,在50℃振荡转化。
(5)每隔2小时取样hplc检测是否有低聚异麦芽糖合成。
(6)离心,菌液分离。此时hplc检测,发现淀粉能合成低聚异麦芽糖,得率为15%,即100克淀粉能合成得到15克低聚异麦芽糖。
该结果显示,含有α-淀粉酶基因与α-葡萄糖苷酶基因表达盒,工程菌株是能由淀粉生成低聚异麦芽糖的,但转化率较低,只有15%。
实施例4、含β-淀粉酶基因与α-葡萄糖苷酶基因表达盒的yarrowialipolytica酵母菌株转化淀粉生成的产物测定
按照如下步骤实施:
(1)含β-淀粉酶基因与α-葡萄糖苷酶基因表达盒的yarrowialipolytica酵母菌株的构建:将枯草芽孢杆菌的β-淀粉酶基因与黑曲霉的α-葡萄糖苷酶基因进行化学合成并融合(注:β-淀粉酶基因的终止密码子taa去除后再与α-葡萄糖苷酶基因融合),再与锚定蛋白基因pir1融合形成融合基因,融合基因的5'端与hp4d启动子连接,其3'端与ura3基因的终止子连接,构成β-淀粉酶-α-葡萄糖苷酶基因表达盒。该表达盒的上下游再分别与同源臂整合序列zeta连接,构成整合基因表达盒。将该表达盒转化yarrowialipolyticablc13酵母,在含20克/升淀粉为唯一碳源的基本培养基中培养,长出的克隆能形成透明圈。选取一个克隆进行培养。
(2)在50毫升发酵培养基中接种含β-淀粉酶-α-葡萄糖苷酶基因表达盒的解脂亚罗威酵母(yarrowialipolytica)。发酵培养基的成分为(克/升):葡萄糖30,酵母粉2.5,蛋白胨2.0克,磷酸氢二铵0.5,硫酸镁2,ph5.0。
(3)接种后在30℃振荡培养直到葡萄糖残余低于0.5%时即停止培养。
(4)离心保留细胞,获得15.5克湿细胞。将细胞用无菌水洗涤1次,再用50毫升100克/升的淀粉水溶液悬浮细胞,调节ph至5.0,在50℃振荡转化。
(5)每隔2小时取样hplc检测是否有低聚异麦芽糖合成。
(6)离心,菌液分离。hplc检测,发现淀粉能合成低聚异麦芽糖,得率为25%,即100克淀粉能合成得到25克低聚异麦芽糖。
该结果显示,含有β-淀粉酶基因与α-葡萄糖苷酶基因表达盒,工程菌株是能由淀粉生成低聚异麦芽糖的,但转化率较低,只有25%。
实施例5、仅含α-葡萄糖苷酶基因表达盒的yarrowialipolytica酵母菌株转化淀粉生成的产物测定
按照如下步骤实施:
(1)含α-葡萄糖苷酶基因表达盒的yarrowialipolytica酵母菌株的构建:将黑曲霉的α-葡萄糖苷酶基因进行化学合成,再与锚定蛋白基因pir1融合形成融合基因,融合基因的5'端与hp4d启动子连接,其3'端与ura3基因的终止子连接,构成α-葡萄糖苷酶基因表达盒。该表达盒的上下游再分别与同源臂整合序列zeta连接,构成整合基因表达盒。将该表达盒转化yarrowialipolyticablc13酵母,在含20克/升淀粉为唯一碳源的基本培养基中培养,长出的克隆能形成透明圈。选取一个克隆进行培养。
(2)在50毫升发酵培养基中接种含α-葡萄糖苷酶基因表达盒的解脂亚罗威酵母(yarrowialipolytica)。发酵培养基的成分为(克/升):葡萄糖30,酵母粉2.5,蛋白胨2.0克,磷酸氢二铵0.5,硫酸镁2,ph5.0。
(3)接种后在30℃振荡培养直到葡萄糖残余低于0.5%时即停止培养。
(4)离心保留细胞,获得15.5克湿细胞。将细胞用无菌水洗涤1次,再用50毫升100克/升的淀粉水溶液悬浮细胞,调节ph至5.0,在50℃振荡转化。
(5)每隔2小时取样hplc检测是否有低聚异麦芽糖合成。
(6)离心,菌液分离。hplc检测,发现淀粉能合成低聚异麦芽糖,得率为6%,即100克淀粉能合成得到6克低聚异麦芽糖。
该结果显示,仅含有α-葡萄糖苷酶基因表达盒,工程菌株是能由淀粉生成低聚异麦芽糖的,但转化率较非常低,只有6%。
实施例6、仅含新普鲁兰酶基因表达盒的yarrowialipolytica酵母菌株转化淀粉生成的产物测定
按照如下步骤实施:
(1)含新普鲁兰酶基因表达盒的yarrowialipolytica酵母菌株的构建:将bacillusstearothermophilus的新普鲁兰酶基因进行化学合成,再与锚定蛋白基因pir1融合形成融合基因,融合基因的5'端与hp4d启动子连接,其3'端与ura3基因的终止子连接,构成新普鲁兰酶基因表达盒。该表达盒的上下游再分别与同源臂整合序列zeta连接,构成整合基因表达盒。将该表达盒转化yarrowialipolyticablc13酵母,在含20克/升淀粉为唯一碳源的基本培养基中培养,长出的克隆能形成透明圈。选取一个克隆进行培养。
(2)在50毫升发酵培养基中接种含新普鲁兰酶基因表达盒的解脂亚罗威酵母(yarrowialipolytica)。发酵培养基的成分为(克/升):葡萄糖30,酵母粉2.5,蛋白胨2.0克,磷酸氢二铵0.5,硫酸镁2,ph5.0。
(3)接种后在30℃振荡培养直到葡萄糖残余低于0.5%时即停止培养。
(4)离心保留细胞,获得16.5克湿细胞。将细胞用无菌水洗涤1次,再用50毫升100克/升的淀粉水溶液悬浮细胞,调节ph至5.0,在50℃振荡转化。
(5)每隔2小时取样hplc检测是否有低聚异麦芽糖合成。
(6)离心,菌液分离。hplc检测,发现能由淀粉合成低聚异麦芽糖,得率为21%,即100克淀粉能合成得到21克低聚异麦芽糖。
该结果显示,仅含有新普鲁兰酶基因表达盒,工程菌株是能由淀粉生成低聚异麦芽糖的,但转化率较低,只有21%。
实施例7、仅含葡萄糖转苷酶基因表达盒的yarrowialipolytica酵母菌株转化淀粉生成的产物测定
按照如下步骤实施:
(1)含葡萄糖转苷酶基因表达盒的yarrowialipolytica酵母菌株的构建:将米曲霉的葡萄糖转苷酶基因进行化学合成,再与锚定蛋白基因pir1融合形成融合基因,融合基因的5'端与hp4d启动子连接,其3'端与ura3基因的终止子连接,构成葡萄糖转苷酶基因表达盒。该表达盒的上下游再分别与同源臂整合序列zeta连接,构成整合基因表达盒。将该表达盒转化yarrowialipolyticablc13酵母,在含20克/升淀粉为唯一碳源的基本培养基中培养,长出的克隆能形成透明圈。选取一个克隆进行培养。
(2)在50毫升发酵培养基中接种含葡萄糖转苷酶基因表达盒的解脂亚罗威酵母(yarrowialipolytica)。发酵培养基的成分为(克/升):葡萄糖30,酵母粉2.5,蛋白胨2.0克,磷酸氢二铵0.5,硫酸镁2,ph5.0。
(3)接种后在30℃振荡培养直到葡萄糖残余低于0.5%时即停止培养。
(4)离心保留细胞,获得13.5克湿细胞。将细胞用无菌水洗涤1次,再用50毫升100克/升的淀粉水溶液悬浮细胞,调节ph至5.0,在50℃振荡转化。
(5)每隔2小时取样hplc检测是否有低聚异麦芽糖合成。
(6)离心,菌液分离。hplc检测,发现能由淀粉合成低聚异麦芽糖,得率为7%,即100克淀粉能合成得到7克低聚异麦芽糖。
该结果显示,仅含有葡萄糖转苷酶基因表达盒,虽然工程菌株能由淀粉生成低聚异麦芽糖,但转化率非常低,只有7%,与只含α-葡萄糖苷酶基因表达盒的工程菌株基本一致(6%的转化率),说明仅含有转苷酶或糖苷酶基因的工程菌株转化率非常低。
实施例8、仅含产麦芽糖淀粉酶基因表达盒的yarrowialipolytica酵母菌株转化淀粉生成的产物测定
按照如下步骤实施:
(1)含产麦芽糖淀粉酶基因表达盒的yarrowialipolytica酵母菌株的构建:将产麦芽糖淀粉酶基因进行化学合成,再与锚定蛋白基因pir1融合形成融合基因,融合基因的5'端与hp4d启动子连接,其3'端与ura3基因的终止子连接,构成产麦芽糖淀粉酶基因表达盒。该表达盒的上下游再分别与同源臂整合序列zeta连接,构成整合基因表达盒。将该表达盒转化yarrowialipolyticablc13酵母,在含20克/升淀粉为唯一碳源的基本培养基中培养,长出的克隆能形成透明圈。选取一个克隆进行培养。
(2)在50毫升发酵培养基中接种含产麦芽糖淀粉酶基因表达盒的解脂亚罗威酵母(yarrowialipolytica)。发酵培养基的成分为(克/升):葡萄糖30,酵母粉2.5,蛋白胨2.0克,磷酸氢二铵0.5,硫酸镁2,ph5.0。
(3)接种后在30℃振荡培养直到葡萄糖残余低于0.5%时即停止培养。
(4)离心保留细胞,获得13.5克湿细胞。将细胞用无菌水洗涤1次,再用50毫升100克/升的淀粉水溶液悬浮细胞,调节ph至5.0,在50℃振荡转化。
(5)每隔2小时取样hplc检测是否有低聚异麦芽糖合成。
(6)离心,菌液分离。hplc检测,发现能由淀粉合成低聚异麦芽糖,得率为25%,即100克淀粉能合成得到25克低聚异麦芽糖。
该结果显示,工程菌株仅含有产麦芽糖淀粉酶基因表达盒即能由淀粉生成低聚异麦芽糖,但转化率较低,只有25%,说明产麦芽糖淀粉酶既有淀粉水解功能又有转苷酶活性。
实施例9、含糖化α-淀粉酶基因(bsa基因)、产麦芽糖α-淀粉酶基因(bma基因)与α-葡萄糖苷酶基因(angase基因)表达盒的yarrowialipolytica酵母菌株转化淀粉生成的产物测定
菌株的构建方法:
上述3种酶基因不进行任何优化,也不进行截短,而是用其原始序列(详见seqidno.1、seqidno.3、seqidno.5)。
bsa基因与出发菌株yarrowialipolyticablc13的锚定蛋白pir1基因融合,融合基因的5'端与赤藓糖还原酶基因1启动子连接,其3'端与赤藓糖还原酶基因1终止子连接,构成bsa基因表达盒。赤藓糖还原酶基因1启动子序列如seqidno.7所示,终止子序列如seqidno.8所示。
bma基因与出发菌株yarrowialipolyticablc13的锚定蛋白pir1基因融合,融合基因的5'端与赤藓糖还原酶基因2启动子连接,其3'端与赤藓糖还原酶基因2终止子连接,构成bma基因表达盒。赤藓糖还原酶基因2启动子序列如seqidno.9所示,终止子序列如seqidno.10所示。
angase基因与出发菌株yarrowialipolyticablc13的锚定蛋白pir1基因融合,融合基因的5'端与赤藓糖还原酶基因3启动子连接,其3'端与赤藓糖还原酶基因3终止子连接,构成angase基因表达盒。赤藓糖还原酶基因3启动子序列如seqidno.11所示,终止子序列如seqidno.12所示。
将上述3种酶基因表达盒进行串联组成新的基因表达盒,串联后两边分别与长末端重复序列zeta序列连接组成整合表达元件,该整合表达元件如图8所示。用该整合表达元件转化yarrowialipolytica出发菌株,在含淀粉为唯一碳源的基本培养基中筛选,只有含有上述酶基因(如淀粉酶基因、葡萄糖苷酶基因等)表达盒的酵母转化子才能利用淀粉,将淀粉分解为葡萄糖,并长出单菌落克隆,在含单菌落的基本固体培养基中滴加碘液,能形成明显的透明圈,说明该菌株能水解淀粉。
培养获得含细胞,然后用游离细胞催化淀粉获得低聚异麦芽糖的方法:
(1)在500毫升发酵培养基中接种解脂亚罗威酵母(yarrowialipolytica)菌。发酵培养基的成分为(克/升):葡萄糖300,酵母粉5.5,蛋白胨2.5,柠檬酸铵2.5,硫酸镁1,ph3.0。
(2)接种后在32℃振荡培养直到葡萄糖残余低于0.5%时即停止培养。
(3)离心保留细胞,获得48克湿细胞与含赤藓糖醇的上清。上清用于分离纯化赤藓糖醇,细胞用作酶源。将细胞用无菌水洗涤1次,再用300毫升200克/升的淀粉水溶液悬浮细胞,调节ph至5.5,在55℃振荡转化。
(4)每隔2小时取样hplc检测低聚异麦芽糖生成的量,若在连续4小时期间若低聚异麦芽糖的量没有增加(或者略微减少)即停止转化。
(5)离心,菌液分离。此时hplc检测淀粉转化为低聚异麦芽糖的转化率为45%。可见,含未优化的糖化α-淀粉酶基因(bsa基因)、产麦芽糖α-淀粉酶基因(bma基因)与α-葡萄糖转苷酶基因(angase基因)表达盒的yarrowialipolytica酵母菌能转化淀粉生成较多的低聚异麦芽糖,转化率达到45%,明显较实施例3-7效果要好,说明该组合极有利于低聚异麦芽糖的合成。但若对上述3种基因进行优化还可能进一步提高转化效率。
实施例10、yarrowialipolyticacgmccno.14785工程菌游离细胞催化淀粉生成低聚异麦芽糖
yarrowialipolyticacgmccno.14785工程菌的制备方法上面已经描述,含有优化的糖化α-淀粉酶、优化的产麦芽糖淀粉酶以及优化的α-葡萄糖苷酶基因表达盒。优化后的枯草芽孢杆菌糖化α-淀粉酶基因序列(optimizedsaccharifyingα-amylasegene,optimizedbsa基因)序列如seqidno.2所示;优化后的产麦芽糖淀粉酶基因的序列(maltogenicamylasegene,optimizedbmagene)序列如seqidno.4所示;优化后的黑曲霉α-葡萄糖苷酶基因序列(α-glucosidasegene,optimizedangasegene)序列如seqidno.6所示。
先培养获得含细胞,然后用游离细胞催化淀粉获得低聚异麦芽糖:
(1)在500毫升发酵培养基中接种解脂亚罗威酵母yarrowialipolyticacgmcc14785菌。发酵培养基的成分为(克/升):葡萄糖300,酵母粉5.5,蛋白胨2.5,柠檬酸铵2.5,硫酸镁1,ph3.0。
(2)接种后在32℃振荡培养直到葡萄糖残余低于0.5%时即停止培养。
(3)离心保留细胞,获得50克湿细胞与含赤藓糖醇的上清。上清用于分离纯化赤藓糖醇,细胞用作酶源。将细胞用无菌水洗涤1次,再用300毫升200克/升的淀粉水溶液悬浮细胞,调节ph至5.5,在55℃振荡转化。
(4)每隔2小时取样hplc检测低聚异麦芽糖生成的量,若在连续4小时期间若低聚异麦芽糖的量没有增加(或者略微减少)即停止转化。
(5)离心,菌液分离。此时hplc检测淀粉转化为低聚异麦芽糖的转化率为75%。hplc检测图如图9所示。由图9可见,yarrowialipolyticacgmcc14785酵母菌转化淀粉能高效生成低聚异麦芽糖,明显要高于实施例8的效果。
实施例11、yarrowialipolyticacgmccno.14785酵母菌催化麦芽糖生成低聚异麦芽糖
按照如下步骤实施,先培养获得含酶细胞,然后用游离细胞催化麦芽糖获得低聚异麦芽糖。
(1)在含500毫升发酵培养基的2升摇瓶中接种解脂亚罗威酵母(yarrowialipolytica)cgmccno.14785菌。发酵培养基的成分为(克/升):葡萄糖50,玉米浆20,柠檬酸铵5,硫酸镁3,ph5.0。
(2)接种后在28℃振荡培养直到葡萄糖残余低于0.5%时即停止培养。
(3)离心保留细胞,获得45克湿细胞。将细胞用无菌水洗涤1次,再用500毫升250克/升的麦芽糖水溶液悬浮细胞,调节ph至5.0,在30℃振荡转化。
(4)每隔1小时取样hplc检测低聚异麦芽糖生成的量,在连续2小时期间若低聚异麦芽糖的量没有增加(或者略微减少)即停止转化。
(5)离心,菌液分离。此时hplc检测麦芽糖转化为低聚异麦芽糖的转化率为65%。hplc检测图如图10所示。图10中,a:转化开始时,7.8min为麦芽糖;b:转化结束时,4.6-7.7min为低聚异麦芽糖,8.6min为葡萄糖;可见,yarrowialipolyticacgmcc14785酵母菌转化麦芽糖能高效生成低聚异麦芽糖。
实施例12、yarrowialipolyticacgmccno.14785酵母菌固定化细胞催化淀粉生成低聚异麦芽糖
按照如下步骤实施,先培养获得含酶细胞,将细胞用介质固定,然后用固定的细胞催化淀粉获得低聚异麦芽糖。
(1)在含1500毫升发酵培养基的发酵罐中接种解脂亚罗威酵母(yarrowialipolytica)cgmccno.14785菌。发酵培养基的成分为(克/升):葡萄糖300,酵母粉7,玉米浆干粉2,柠檬酸铵3,氯化铜0.05,氯化锰0.02,ph5.5。
(2)接种后在33℃发酵培养并流加葡萄糖150克(即总共消耗400克/升的葡萄糖),发酵直到葡萄糖残余低于0.5%时即停止发酵。
(3)离心保留细胞,获得湿细胞与含赤藓糖醇的上清。上清用于分离纯化赤藓糖醇,细胞用作酶源。将细胞用无菌水洗涤1次,与2%的海藻酸钠水混合物5000克充分混合并通过孔径为1mm的孔滴入0.1mol/l的氯化钙水溶液中,制成直径2-3mm的微球,微球固化12小时,用清水清洗2次,将固定化细胞分成两半,一半加入5000毫升50克/升的淀粉水溶液悬浮细胞,调节ph至5.0,在50℃振荡转化。另一半装入直径10cm的塑料柱中,制成固定化细胞柱,将5000毫升50克/升的淀粉水溶液循环通过该柱,柱温用夹套维持在60度。
(4)每隔2小时取样hplc检测低聚异麦芽糖生成的量,若在连续4小时期间若低聚异麦芽糖的量没有增加(或者略微减少)即停止转化。
(5)过滤并离心得到澄清的转化液。此时hplc检测淀粉转化为低聚异麦芽糖的转化率为60%,用固定化柱进行转化的转化率为62%。
实施例13、yarrowialipolyticacgmccno.14785酵母菌固定化细胞催化糊精生成低聚异麦芽糖
(1)在100毫升发酵培养基中接种解脂亚罗威酵母(yarrowialipolytica)cgmcc14785菌。发酵培养基的成分为(克/升):甘油100,酵母粉5,起始ph7。
(2)接种后在30℃发酵培养直到甘油残余低于0.5%时即停止发酵。
(3)离心保留细胞,获得11克湿细胞用作酶源。将细胞用无菌水洗涤1次,与2%的海藻酸钠水混合物400克充分混合,通过注射针头滴入0.1mol/l的氯化钙水溶液中,制成直径2-3mm的微球,微球固化12小时,用清水清洗2次,加入1000毫升100克/升的糊精水溶液悬浮细胞,调节ph至5.0,在50℃振荡转化。
(4)每隔2小时取样hplc检测低聚异麦芽糖生成的量,若在连续4小时期间若低聚异麦芽糖的量没有增加(或者略微减少)即停止转化。
(5)过滤并离心得到澄清的转化液。此时hplc检测糊精转化为低聚异麦芽糖的转化率为62%。
实施例14、yarrowialipolyticacgmccno.14785酵母菌游离细胞催化液化淀粉生成低聚异麦芽糖
(1)在500毫升发酵培养基中接种解脂亚罗威酵母(yarrowialipolytica)cgmcc14785菌。发酵培养基的成分为(克/升):甘油10,酵母粉3,玉米浆1,起始ph8。
(2)接种后在35℃发酵培养直到甘油残余低于0.1%时即停止发酵。
(3)离心保留细胞,获得13克湿细胞用作酶源。将细胞用无菌水洗涤1次,加入200毫升100克/升的液化淀粉溶液悬浮细胞,调节ph至5.0,在80℃振荡转化。液化淀粉的制备方法是在淀粉乳中加入耐高温α-淀粉酶,在95℃下反应10分钟,105℃灭活酶,即得液化淀粉。
(4)每隔2小时取样hplc检测低聚异麦芽糖生成的量,若在连续4小时期间若低聚异麦芽糖的量没有增加(或者略微减少)即停止转化。
(5)过滤并离心得到澄清的转化液。此时hplc检测淀粉转化为低聚异麦芽糖的转化率为72%。
实施例15、先发酵合成赤藓糖醇,再以酵母细胞转化合成低聚异麦芽糖
(1)在含1500毫升培养基的发酵罐中接种解脂亚罗威酵母(yarrowialipolytica)cgmccno.14785。发酵培养基的成分为(克/升):葡萄糖280,酵母浸膏10,玉米浆5克,柠檬酸铵5,硫酸镁1,氯化锰0.005,氯化铜0.002,起始ph6.5。
(2)接种后在30℃,好氧搅拌培养直到葡萄糖全部转化为赤藓糖醇后即停止发酵。
(3)离心,上清经过浓缩、脱色、离子交换、再浓缩、结晶的步骤提取赤藓糖醇,这些提取步骤均为本领域内常用的通识方法。得到细胞沉淀用于转化麦芽糖合成低聚异麦芽糖。获得185.5克湿细胞。将细胞用无菌水洗涤1次,再用2000毫升300克/升的麦芽糖水溶液悬浮细胞,调节ph至6.0,在50℃振荡转化。
(4)每隔2小时取样hplc检测低聚异麦芽糖生成的量,在连续2小时期间若低聚异麦芽糖的量没有增加(或者略微减少)即停止转化。
(5)转化结束后离心,菌液分离。此时hplc检测麦芽糖转化为低聚异麦芽糖的转化率为63.5%。
(6)离心后得到的细胞沉淀再加入2000毫升300克/升的麦芽糖水溶液,悬浮细胞,装入发酵罐,调节ph至6.0,在50℃搅拌转化。每隔2小时取样hplc检测低聚异麦芽糖的合成量,在连续2小时期间若低聚异麦芽糖的量没有增加即停止转化,检测分析,细胞第二次转化率为61.5%。细胞依次重复使用10次。
实施例16、yarrowialipolyticapo1d工程菌游离细胞催化淀粉生成低聚异麦芽糖
yarrowialipolyticapo1d菌株是常见的解脂亚罗威酵母菌,可作为合成产物的出发菌株,但其不能由葡萄糖合成赤藓糖醇。
yarrowialipolyticapo1d工程菌的制备方法:用含有优化的糖化α-淀粉酶、优化的产麦芽糖淀粉酶以及优化的α-葡萄糖苷酶基因表达盒(如图5所示的优化的基因表达盒)转化yarrowialipolyticapo1d菌,在含淀粉为唯一碳源的基本培养基中筛选,只有含有上述酶基因(淀粉酶基因)表达盒的酵母转化子才能利用淀粉,将淀粉分解为葡萄糖,并长出单菌落克隆,在含单菌落的基本固体培养基中滴加碘液,能形成明显的透明圈,说明该菌株能水解淀粉。
先培养获得含细胞,然后用游离细胞催化淀粉获得低聚异麦芽糖:
(1)在500毫升发酵培养基中接种解脂亚罗威酵母(yarrowialipolytica)po1d菌。发酵培养基的成分为(克/升):葡萄糖300,酵母粉5.5,蛋白胨2.5,柠檬酸铵2.5,硫酸镁1,ph3.0。
其余步骤同实施例9。
转化结束后离心,菌液分离,hplc检测淀粉转化为低聚异麦芽糖的转化率为45%。可见,虽然其它的出发菌株yarrowialipolytica酵母也可以用于合成低聚异麦芽糖,但在同样条件下,其转化淀粉生成低聚异麦芽糖的效率远不及本发明采用的出发菌株yarrowialipolyticacgmcc7326的效率(达到75%)。
实施例17、以游离于细胞质中的质粒载体的形式表达优化的优化的糖化α-淀粉酶、优化的产麦芽糖淀粉酶以及优化的α-葡萄糖苷酶基因表达盒的酵母合成低聚异麦芽糖
菌株的制备方法:
优化的糖化α-淀粉酶、优化的产麦芽糖淀粉酶以及优化的α-葡萄糖苷酶基因表达盒的构建同实施例9。
将上述3种酶基因表达盒进行串联组成新的基因表达盒,串联后按照附图3的说明再与酵母自主复制序列ars/cen1连接组成游离质粒表达元件。用该质粒转化yarrowialipolyticablc13,在含淀粉为唯一碳源的基本培养基中筛选,只有含有上述酶基因(如淀粉酶基因等)表达盒的酵母转化子才能利用淀粉,将淀粉分解为葡萄糖,并长出单菌落克隆,在含单菌落的基本固体培养基中滴加碘液,能形成明显的透明圈,说明该菌株能水解淀粉。
该菌株由淀粉合成低聚异麦芽糖的步骤同实施例9。转化结束后hplc检测,该菌株由淀粉合成低聚异麦芽糖的转化率为37%,显著低于实施例9的75%转化率,可能是游离型表达质粒在细胞质中的表达强度低下。由此可见,整合型表达的效果要显而易见的优于游离型的表达效果。
通过上述实施例,可以看出,本发明通过基因表达盒的优化与组合设计,并通过选择良好的出发菌株,构建的工程菌株具有十分优异的效果,新工程菌株除了能合成赤藓糖醇外,还能高效率合成低聚异麦芽糖。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本发明人可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
sequencelisting
<110>上海交通大学
<120>合成低聚异麦芽糖的解脂亚罗威酵母菌株及其合成方法
<130>dag
<160>12
<170>patentinversion3.5
<210>1
<211>1779
<212>dna
<213>saccharifyingα-amylasegene
<400>1
atgtttgcaaaacgattcaaaacctctttactgccgttattcgctggatttttattgctg60
ttttatttggttctggcaggaccggcggctgcgagtgctgaaacggcgaacaaatcgaat120
gagcttacagcaccgtcgatcaaaagcggaaccattcttcatgcatggaattggtcgttc180
aatacgttaaaacacaatatgaaggatattcatgatgcaggatatacagccattcagaca240
tctccgattaaccaagtaaaggaagggaatcaaggagataaaagcatgtcgaactggtac300
tggctgtatcagccgacatcgtatcaaattggcaaccgttacttaggaactgaacaagaa360
tttaaagaaatgtgtgcagccgctgaagaatatggcataaaggtcattgttgacgcggtc420
atcaatcataccacctttgattatgccgcgatttccaatgaggttaagagtattccaaac480
tggacacatggaaacacacaaattaaaaactggtctgatcgatgggatgtcacgcagaat540
tcattgctcgggctgtatgactggaatacacaaaatacacaagtacagtcctatctgaaa600
cggttcttagaaagggcattgaatgacggggcagacggttttcgatttgatgccgccaaa660
catatagagcttccggatgatgggagttacggcagtcaattttggccgaatatcacaaat720
acatctgcagagttccaatacggagaaatcctgcaggatagtgcctccagagatgctgca780
tatgcgaattatatggatgtgacagcgtctaactatgggcattccataaggtccgcttta840
aagaatcgtaatctgggcgtgtcgaatatctcccactatgcatctgatgtgtctgcggac900
aagctagtgacatgggtagagtcgcatgatacgtatgccaatgatgatgaagagtcgaca960
tggatgagcgatgatgatatccgtttaggctggtcggtgatagcttctcgttcaggcagt1020
acgcctcttttcttttccagacctgagggaggcggaaatggtgtgaggttcccggggaaa1080
agccaaataggcgatcgcgggagtgctttatttgaagatcaggctatcactgcggtcaat1140
agatttcacaatgtgatggctggacagcctgaggaactctcgaacccgaatggaaacaac1200
cagatatttatgaatcagcgcggctcacatggcgttgtgctggcaaatgcaggttcatcc1260
tctgtctctatcaatacggcaacaaaattgcctgatggcaggtatgacaataaagctgga1320
gcgggttcatttcaagtgaacgatggtaaactgacaggcacgatcaatgccaggtctgta1380
gctgtgctttatcctgatgatattgcaaaagcgcctcatgttttccttgagaattacaaa1440
acaggtgtaacacattctttcaatgatcaactgacgattaccttgcgtgcagatgcgaat1500
acaacaaaagccgtttatcaaatcaataatggaccagacgacaggcgtttaaggatggag1560
atcaattcacaatcggaaaaggagatccaatttggcaaaacatacaccatcatgttaaaa1620
ggaacgaacagtgatggtgtaacgaggaccgagaaatacagttttgttaaaagagatcca1680
gttgctcaaaaaaatctcggtcagatgttactagcaactcatttacaagaacagcatctt1740
tcctcgtttttcttgtacctgttttttgtgattcaataa1779
<210>2
<211>1662
<212>dna
<213>optimizedsaccharifyingα-amylasegene
<400>2
ggatcccttaccgcaccttcgatcaagagcggaaccattcttcatgcatggaactggtcg60
ttcaacactctcaagcacaacatgaaggatattcatgatgcaggatacaccgccattcag120
acctctcctattaaccaggtgaaggagggtaaccagggagataagagcatgtcgaactgg180
tactggctgtaccagcctacctcgtaccagattggcaaccgttacctcggaactgagcag240
gagtttaaggagatgtgtgcagccgctgaggagtacggcattaaggtcattgttgacgct300
gtcatcaaccataccacctttgattacgccgctatttccaacgaggttaagtctattccc360
aactggacccatggaaacacccagattaagaactggtctgatcgatgggatgtcactcag420
aactccctgctcggtctgtacgactggaacacccagaacacccaggtgcagtcctacctg480
aagcggttcctcgagcgagcactgaacgacggtgcagacggttttcgatttgatgccgcc540
aagcatattgagcttcctgatgatggttcttacggctctcagttttggcctaacatcacc600
aacacctctgcagagttccagtacggagagatcctgcaggattctgcctccagagatgct660
gcatacgctaactacatggatgtgaccgcttctaactacggtcattccattcgatccgct720
ctcaagaaccgtaacctgggcgtgtcgaacatctcccactacgcatctgatgtgtctgct780
gacaagctggtgacctgggtggagtcgcatgatacttacgccaacgatgatgaggagtcg840
acctggatgagcgatgatgatatccgtctcggctggtcggtgattgcttctcgttccggc900
tctactcctcttttcttttccagacctgagggaggcggaaacggtgtgcgattccctggt960
aagagccagattggcgatcgaggttctgctctctttgaggatcaggctatcactgctgtc1020
aacagatttcacaacgtgatggctggacagcctgaggagctctcgaaccctaacggaaac1080
aaccagatttttatgaaccagcgaggctcccatggcgttgtgctggcaaacgcaggttcc1140
tcctctgtctctatcaacactgcaaccaagctgcctgatggccgatacgacaacaaggct1200
ggagctggttcctttcaggtgaacgatggtaagctgaccggcactatcaacgcccgatct1260
gtggctgtgctttaccctgatgatattgcaaaggctcctcatgttttccttgagaactac1320
aagaccggtgtgacccattctttcaacgatcagctgactattaccctgcgtgcagatgct1380
aacaccaccaaggccgtttaccagatcaacaacggacccgacgaccgacgtctccgaatg1440
gagatcaactcccagtcggagaaggagatccagtttggcaagacctacaccatcatgctc1500
aagggaactaactctgatggtgtgactcgaaccgagaagtactcttttgttaagagagat1560
cccgttgctcagaagaacctcggtcagatgctcctggcaactcatctccaggagcagcat1620
ctttcctcgtttttcctgtacctgttttttgtgattcagtaa1662
<210>3
<211>1503
<212>dna
<213>maltogenicamylasegene
<400>3
atggagcttccgcgcgcttatggtctgcttctccaccccacgagcctccccggcccctac60
ggcgtcggcgtcctgggccaggaggcccgggacttcctccgcttcctcaaggaggcaggg120
gggcggtactggcaggtcctccccttgggccccacgggctatggcgactccccctaccag180
tccttcagcgccttcgccggaaacccctacctcatagacctgaggcccctcgcggaaagg240
ggctacgtgcgcctggaggaccccggcttcccccaaggccgggtggactacggcctcctc300
tacgcctggaagtggcccgccctgaaggaggccttccggggcttcaaggaaaaggcctcc360
ccggaggagcgggaggccttcgccgccttccgggagagggaggcctggtggctcgaggac420
tacgccctcttcatggccctgaagggggcgcacggggggcttccctggaaccggtggccc480
cttcccctgcggaagcgggaagagaaggcccttagggaggcgaaaagcgccttggccgag540
gaggtggccttccacgccttcacccagtggctcttcttccgccagtggggggccttgaag600
gcggaggccgaggcgttgggcatccggatcatcggggacatgcccatcttcgtggccgag660
gactccgccgaggtctgggcccaccccgagtggtttcacctggacgaggagggccgcccc720
acggtggtggcgggggtgccccccgactacttctcggagacgggccagcgctggggcaac780
cccctttaccgctgggacgttttggagcgggaggggttctccttctggatccgccgtctg840
gagaaggccctggagctcttccacctggtgcgcatagaccacttccgcggctttgaggcc900
tactgggagatccccgcaagctgccccacggcggtggaggggcgctgggtcaaggccccg960
ggggagaagctcttccagaagatccaggaggtcttcggcgaggtccccgtcctcgccgag1020
gacctgggggtcatcacccccgaggtggaggccctgcgcgaccgcttcggccttcccggg1080
atgaaggtcctgcagttcgcctttgacgacgggatggaaaaccccttcctcccccacaac1140
taccctgcccacggccgggtggtggtctacaccggcacccacgacaacgacaccaccctg1200
ggctggtaccgcacggccaccccccacgagaaggccttcatggcgcggtacctggcggac1260
tgggggatcaccttccgggaagaggaggaggtgccctgggccctgatgcacctggggatg1320
aagtccgtggcccggctcgccgtctacccggtgcaggacgtcctggccctgggcagcgag1380
gcccggatgaactacccgggaaggccctcggggaactgggcctggcggctcctcccgggg1440
gagctttccccggagcacggggcgaggcttagggccatggccgaggccacgggacggctg1500
taa1503
<210>4
<211>1455
<212>dna
<213>optimizedmaltogenicamylasegene
<400>4
ccaggtccatacggtgttggtgttttgggtcaagaagctagagacttcttgagattcttg60
aaggaagctggtggtagatactggcaagttttgccattgggtccaactggttacggtgac120
tctccataccaatctttctctgctttcgctggtaacccatacttgatcgacttgagacca180
ttggctgaaagaggttacgttagattggaagacccaggtttcccacaaggtcgtgttgac240
tacggcttgttgtacgcttggaagtggccagctttgaaggaggcgttccgcggcttcaag300
gaaaaggcgtctccagaagaaagagaagcttttgcggcgttcagagaaagagaggcttgg360
tggttggaagactacgctttgttcatggctttgaagggtgctcacggtggtttgccatgg420
aacagatggccattgccattgagaaagagagaagaaaaggctttgagagaagctaagtct480
gctttggctgaagaagttgctttccacgctttcactcaatggttgttcttcagacaatgg540
ggtgctttgaaggctgaagctgaagctttgggtatcagaatcatcggtgacatgccaatc600
ttcgttgctgaagactctgctgaagtttgggctcacccagaatggttccacttggacgaa660
gaaggtagaccaactgttgttgctggtgttccaccagactacttctctgaaactggtcaa720
agatggggtaacccattgtaccgttgggacgtgctggaaagagaaggctttagcttctgg780
atacgtcgtctcgaaaaggctctcgaattgttccacttggttagaatcgaccacttcaga840
ggtttcgaagcttactgggaaatcccagcttcttgtccaactgctgttgaaggtagatgg900
gttaaggctccaggtgaaaagttgttccaaaagatccaagaagttttcggtgaagttcca960
gttttggctgaagacttgggtgttatcactccagaagttgaagctttgagagacagattc1020
ggtttgccaggtatgaaggttttgcaattcgctttcgacgacggtatggaaaacccattc1080
ttgccacacaactacccagctcacggtcgtgttgttgtgtacacaggtactcacgacaac1140
gacactactttgggttggtacagaactgctactccacacgaaaaggctttcatggctaga1200
tacttggctgactggggtatcactttcagagaagaagaagaagttccatgggctttgatg1260
cacttgggtatgaagtctgttgctcgtctcgctgtgtacccagtgcaagacgttttggct1320
ttgggttctgaagctagaatgaactacccaggtagaccatctggtaactgggcttggaga1380
ttgttgccaggtgaattgtctccagaacacggtgctagattgagagctatggctgaagct1440
actggtagattgtaa1455
<210>5
<211>2958
<212>dna
<213>α-glucosidasegene
<400>5
atggtgaagttgacgcatctccttgccagagcatggcttgtccctctggcttatggagcg60
agccagtcactcttatccaccactgccccttcgcagccgcagtttaccattcctgcttcc120
gcagatgtcggtgcgcagctgattgccaacatcgatgatcctcaggctgccgacgcgcag180
tcggtttgtccgggctacaaggcttcaaaagtgcagcacaattcacgtggattcactgcc240
agtcttcagctcgcgggcaggccatgtaacgtatacggcacagatgttgagtccttgaca300
ctgtctgtggagtaccaggattcggatcgactgaatattcagattctccccactcatgtt360
gactccacaaacgcttcttggtactttctttcggaaaacctggtccccagacccaaggct420
tccctcaatgcatctgtatcccagagcgacctttttgtgtcatggtcaaatgagccgtcg480
ttcaatttcaaggtgatccgaaaggctacaggcgacgcgcttttcagtacagaaggcact540
gtgctcgtatatgagaatcagttcatcgaatttgtgaccgcgctccctgaagaatataac600
ttgtatggccttggggagcatatcacgcaattccgcctccagagaaatgctaatctgacc660
atatatccttcggatgatggaacacctattgaccaaaacctctacggccaacatcccttc720
tatctggatacaagatattacaaaggagataggcagaatgggtcttatattcccgtcaaa780
agcagcgaggctgatgcctcgcaagattatatctccctctctcatggcgtgtttctgagg840
aactctcatggacttgagatactcctccggtctcaaaaattgatctggcggaccctaggt900
ggaggaatcgatctcaccttctactcaggccccgccccggccgatgttaccaggcaatat960
cttaccagcactgtgggattaccggccatgcagcaatacaacactcttggattccaccaa1020
tgtcgttggggctacaacaactggtcggatctggcggacgttgttgcgaactttgagaag1080
tttgagatcccgttggaatatatctggaccgatattgactacatgcacggatatcgcaac1140
tttgacaacgatcaacatcgcttttcctacagtgagggcgatgaatttctcagcaagcta1200
catgagagtggacgctactatgtacccattgttgatgcggcgctctacattcctaatccc1260
gaaaatgcctctgatgcatacgctacgtatgacagaggagctgcggacgacgtcttcctc1320
aagaatcccgatggtagcctctatattggagccgtttggccaggatatacagtcttcccc1380
gattggcatcatcccaaggcagttgacttctgggctaacgagcttgttatctggtcgaag1440
aaagtggcgttcgatggtgtgtggtacgacatgtctgaagtttcatccttctgtgtcggg1500
agctgtggcacaggtaacctgactctgaacccggcacacccatcgtttcttctccccggt1560
gagcctggtgatatcatatatgattacccagaggctttcaatatcaccaacgctacagag1620
gcggcgtcagcttcggcgggagcttccagtcaggctgcagcaaccgcgaccaccacgtcg1680
acttcggtatcatatctgcggacaacgcccacgcctggtgtccgcaatgttgagcaccca1740
ccctatgtgatcaaccatgaccaagaaggccatgatctcagtgtccatgcggtgtcgccg1800
aatgcaacgcatgttgatggtgttgaggagtatgatgtgcacggtctctacggacatcaa1860
ggattgaacgctacctaccaaggtctgcttgaggtctggtctcataagcggcggccattt1920
attattggccgctcaaccttcgctggctctggcaaatgggcaggccactggggcggcgac1980
aactattccaaatggtggtccatgtactactccatctcgcaagccctctccttctcactt2040
ttcggcattccgatgtttggtgcggacacctgtgggtttaacggaaactccgatgaggag2100
ctctgcaaccgatggatgcaactgtccgcattcttcccattctaccgaaaccacaatgag2160
ctctccacaatcccacaggagccttatcggtgggcttctgttattgaagcaaccaagtcc2220
gccatgagaattcggtacgccatcctaccttacttttatacgttgtttgacctggcccac2280
accacgggctccactgtaatgcgcgcactttcctgggaattccctaatgacccaacattg2340
gctgcggttgagactcaattcatggttgggccggccatcatggtggtcccggtattggag2400
cctctggtcaatacggtcaagggcgtattcccaggagttggacatggcgaagtgtggtac2460
gattggtacacccaggctgcagttgatgcgaagcccggggtcaacacgaccatttcggca2520
ccattgggccacatcccagtttatgtacgaggtggaaacatcttgccgatgcaagagccg2580
gcattgaccactcgtgaagcccggcaaaccccgtgggctttgctagctgcactaggaagc2640
aatggaaccgcgtcggggcagctctatctcgatgatggagagagcatctaccccaatgcc2700
accctccatgtggacttcacggcatcgcggtcaagcctgcgctcgtcggctcaaggaaga2760
tggaaagagaggaacccgcttgctaatgtgacggtgctcggagtgaacaaggagccctct2820
gcggtgaccctgaatggacaggccgtatttcccgggtctgtcacgtacaattctacgtcc2880
caggttctctttgttggggggctgcaaaacttgacgaagggcggcgcatgggcggaaaac2940
tgggtattggaatggtag2958
<210>6
<211>2904
<212>dna
<213>optimizedα-glucosidasegene
<400>6
ggagccagccagtccctcctgtccaccactgccccttcgcagcctcagtttaccattcct60
gcttccgccgatgtcggtgcccagctgattgccaacatcgatgatcctcaggctgccgac120
gcccagtcggtttgtcctggctacaaggcttccaaggtgcagcacaactcccgtggattc180
actgcctctcttcagctcgccggccgaccttgtaacgtgtacggcacagatgttgagtcc240
ctgacactgtctgtggagtaccaggattcggatcgactgaacattcagattctccccact300
catgttgactccacaaacgcttcttggtactttctttcggagaacctggtccccagaccc360
aaggcttccctcaacgcctctgtgtcccagagcgacctttttgtgtcctggtccaacgag420
ccttcgttcaacttcaaggtgatccgaaaggctacaggcgacgcccttttctctacagag480
ggcactgtgctcgtgtacgagaaccagttcatcgagtttgtgaccgccctccctgaggag540
tacaacctgtacggccttggtgagcatatcacgcagttccgactccagagaaacgctaac600
ctgaccatttacccttcggatgatggaacacctattgaccagaacctctacggccagcat660
cccttctacctggatacaagatactacaagggagatcgacagaacggttcttacattccc720
gtcaagagcagcgaggctgatgcctcgcaggattacatctccctctctcatggcgtgttt780
ctgcgaaactctcatggacttgagattctcctccggtctcagaagctgatctggcggacc840
ctgggtggaggaatcgatctcaccttctactccggccccgcccctgccgatgttacccga900
cagtaccttaccagcactgtgggactgcctgccatgcagcagtacaacactcttggattc960
caccagtgtcgttggggctacaacaactggtcggatctggccgacgttgttgccaacttt1020
gagaagtttgagatccctctggagtacatctggaccgatattgactacatgcacggatac1080
cgaaactttgacaacgatcagcatcgattttcctactctgagggcgatgagtttctcagc1140
aagctgcatgagtctggacgatactacgtgcccattgttgatgccgccctctacattcct1200
aaccccgagaacgcctctgatgcctacgctacgtacgacagaggagctgccgacgacgtc1260
ttcctcaagaaccccgatggtagcctctacattggagccgtttggcctggatacacagtc1320
ttccccgattggcatcatcccaaggccgttgacttctgggctaacgagcttgttatctgg1380
tcgaagaaggtggccttcgatggtgtgtggtacgacatgtctgaggtttcctccttctgt1440
gtcggtagctgtggcacaggtaacctgactctgaaccctgcccacccttcgtttcttctc1500
cccggtgagcctggtgatatcatttacgattaccctgaggctttcaacatcaccaacgct1560
acagaggccgcctccgcttcggccggagcttcctctcaggctgccgccaccgccaccacc1620
acctcgacttcggtgtcctacctgcggacaacgcccacgcctggtgtccgaaacgttgag1680
caccctccctacgtgatcaaccatgaccaggagggccatgatctctctgtccatgccgtg1740
tcgcctaacgccacgcatgttgatggtgttgaggagtacgatgtgcacggtctctacgga1800
catcagggactgaacgctacctaccagggtctgcttgaggtctggtctcataagcggcgg1860
ccttttattattggccgatccaccttcgctggctctggcaagtgggccggccactggggc1920
ggcgacaactactccaagtggtggtccatgtactactccatctcgcaggccctctccttc1980
tcccttttcggcattcctatgtttggtgccgacacctgtggttttaacggaaactccgat2040
gaggagctgtgcaaccgatggatgcagctgtccgccttcttccctttctaccgaaaccac2100
aacgagctgtccacaatccctcaggagccttaccggtgggcttctgttattgaggccacc2160
aagtccgccatgagaatccggtacgccatcctgccttacttttacacgctgtttgacctg2220
gcccacaccacgggctccactgtgatgcgagccctttcctgggagttccctaacgaccct2280
acactggctgccgttgagactcagttcatggttggtcctgccatcatggtggtccctgtg2340
ctggagcctctggtcaacacggtcaagggcgtgttccctggagttggacatggcgaggtg2400
tggtacgattggtacacccaggctgccgttgatgccaagcccggtgtcaacacgaccatt2460
tcggcccctctgggccacatccctgtttacgtgcgaggtggaaacatcctgcctatgcag2520
gagcctgccctgaccactcgtgaggcccggcagaccccttgggctctgctggctgccctg2580
ggaagcaacggaaccgcctcgggtcagctctacctcgatgatggagagagcatctacccc2640
aacgccaccctccatgtggacttcacggcctcgcggtccagcctgcgatcgtcggctcag2700
ggaagatggaaggagcgaaaccctcttgctaacgtgacggtgctcggagtgaacaaggag2760
ccctctgccgtgaccctgaacggacaggccgtgtttcccggttctgtcacgtacaactct2820
acgtcccaggttctctttgttggtggtctgcagaacctgacgaagggcggcgcctgggcc2880
gagaactgggtgctggagtggtag2904
<210>7
<211>1080
<212>dna
<213>artificialsequence
<220>
<223>per1启动子序列
<400>7
attgagtgcatagcttcagagaatggttcttggcccattcagagcgtatagtacaattgg60
tgagatatgatatataccgtatgttatctttccttcaatagctgttgactagattcacta120
tctgtcccgccattcagtctcttcaagtatgcagggtacatccattttttcaccaccaga180
cacgagcgctcactattagctactgtatgcactcttctccgagacattgctgaaacagtg240
gctagtaacgatctaacgagaaaagtgagggagactcgatggtcaaactgcagaagatgg300
acgtgtagctttgtaacgcccctacatctctgagcgaggtgaaagtgctcgtacaacact360
gtacgtaccaagatgatcttcagccaagtggtggaacatcagacgctgcatcgacagaca420
actattagtatgtacttcttgtacggtagtaattgggtgagaaaaacaactttctcccct480
tgcaaaaccggctaatgtttccttctttctcctccaaaactcgcacttgtagctaccgta540
ctcgtacaagttccctctctccacaatgttcccatgacattccacgaccttcttttcact600
tgcttggtagccactggtgcacgcacagcttacatgcagatgctacacaactacaagaca660
aacaatcgaacgccacatgatccaacggcttgtgcaaagtggatacatggtaaccggctg720
ccgtcaaaagcatgcaatctgtcacatgtcttcccctcgtcttctcctcaaccccaccaa780
cgtctccgaccgctctttgctctcatctctgtctctctcagtgctcgtcactgcacggcc840
ctgcataatcgggggaggccaaggtgaaacgctgcaaggtgtgtcgttgggacctacctt900
tggcagtgccaggatgtacttgtgtctgccgccacaagcgtacattcagtcacagctaca960
gagcaacccgacccaaaccacctacaagtagagtactgctgtcaacgtttcttcttacac1020
tcaattgacccacaattgacacaaactaccagcctatcaacccaaacacaccaattgaac1080
<210>8
<211>429
<212>dna
<213>artificialsequence
<220>
<223>tter1终止子序列
<400>8
gcgtggaaacacggaaacgactggccaaaggttagaagtggacaacgtcctatctataga60
tgtatagcatctggatatgttaacaacatacacagaatatgaagtacattcaacatatta120
tattacgagtcggagagttgactttaccatctgatattagctagctatcgtacattctca180
atgccaaatgccgtatacctcaaccgcatatcaacagcatcccggaagaaaaacttgtgg240
atcaagccatcagttctctagaagcgtgtgtacatactgcaactcatgtcatctacaccc300
aagtgtgatttgtatgtctctgctctgcccatacacgatagtgatacttgtatgtacata360
ctgtagtgtgagtacgaatgtactagacaagccccctcgtagagtatcgatctcccactt420
cttatagag429
<210>9
<211>1202
<212>dna
<213>artificialsequence
<220>
<223>per2启动子序列
<400>9
ttactgtctgaacacaagacgcgcccgaaaacaaaatcagttcatacaggtagaacgagt60
cacccaaagagttggcgagaacattgtagcccaaagtgtcgagaatcacgcagactcctt120
cgacggaaaggtcattcggagcatgggagcagtctgggacttgtttttggtcgtatttgg180
gagctgtcacgaagcgtttctggtcgtatttgggagctatcacgaagcgtttctggatgt240
atttactttggctagactcatggaacttgtgggtgaaactggaggttcaggcgcctgtcc300
ttcatcccttcacgttgttcatgtcggtccttggtcagttggaaaaccaaaaagtcgtag360
tgttgacgacatttctctcgtttgtggatgtctctcgtttgtggatgtctctcgtttgtg420
aatgtttgataatctgtccaaatccacagttgcacacttccgtctccgcatcgcgtgacc480
ggattctcgtatcggatagtggcgtcttccgtaagccgattcgccagcggattgataatc540
tgctcttgaccggctagaagagcgatgagcggtgaagaagttgagcggaattgaaccaat600
tagtgaattgaatggcgaacgaatcgctacagtagtatcagctcacttcacgccctccac660
agtcccacattaccccaccaacagacctagactgcgcttttcccagtctgccagtcccgc720
tgtccctccatcctccgtgtccaattcctccatcctccgtgtccaattcctccatcctcc780
atgtctaatccctccacaaagccgatctaatcacccatcgcaataccaacgccgattgca840
caatctgccgatgacgcaggacggtgcagaatattgcgtgctcgatagcgattagagttg900
tgaaatttcgggggaaaaagcggccttggaggcgctagaacgggcagtttgagagcaatc960
aggaaggggggatcgggaatccgttgctgggggatgcctcagtcgtcgtttcaaatatct1020
ggtcaacaggtggccgattaccccgttttgagactccccaaaatcgccacccacaccccc1080
aagcggcatctcactagtgtgaaactttatttatcagcaacatacatatatatatatata1140
tataggcaccgactccgctgactgcactgaccatctacactgcacttgtacccacgcaca1200
cc1202
<210>10
<211>480
<212>dna
<213>artificialsequence
<220>
<223>tter2终止子序列
<400>10
gcgacttcagtgacctgatcgaattgagatatcaatattgaactagattttctacagcca60
gggttatagaaattgatgatttattgctagtgcgctgcaactgctggagtgccgatatcg120
tacttttagagagaacccatggagttgaggatggatcaaacgaaccacgtgatgggccac180
gtgactggggtcgtatctgcagggagattgtggtaatatggatggaaaggtcagaatcac240
atcttgttggattcgagtgagaaagcggcacgagtgtatgacaactagcacgtacagtgt300
agtgtatgttagtaatcagtaatcatggtaattcacggtaattcacggtaattcacggtc360
acgtgaccccacgtgactttccaatacgatactgcgattgccactgggcataatctagat420
gatcttgttcgggagctcgccagtggctggcgaatagtttgagggaaggttggagagctg480
<210>11
<211>1225
<212>dna
<213>artificialsequence
<220>
<223>per3启动子序列
<400>11
tggttttacctgttcctgttgcagccgtggggggtcaactagagttcaccagggacttgt60
cagccgttaaagagtcacgtttattttgggggtctgtgtctatcatttttggtctggaag120
ctccgtggacggaagaggagcgtgacctgtgacgtacaagcgccgtcgaaaccacagcga180
ttcgcgctggtcaatcgcagccacgttcgccttccccatggctagcgcaattaaccggac240
taagcgcctcaccccacaatgcggagatacggcactactgtagtttgtaagcacgtatat300
gggggatgcagaatgcgcgaaagaggttgtggttgtctgtcccctgctcatgtcggcatt360
gaaattcacgcactagagctcgccattgttcatgtggtagccccttccagcacggctagg420
accagacacatgcccagatacggctgagactcggcctatcagctgtggcgtagttcgttc480
tcgctcgcttaggtcaggtcctgcctgggtcacgtcatggtgcttgtgcaaagttggtgg540
attgccgtggggggtacagtcgaggcacagttattgcatcataggcgtgggaggcgagag600
agggagacgggcccaagacgcacgggtatggtgggtgcaattggcgggtaaatgggcagc660
gggttgtttgtgtgtgttcttcgcctgtgtgggactgtttttggctcttatttaaagcaa720
ttcccaccctcatagcactcctataacccctcttctagcctcttcggtttgctatctgca780
tattgcgattgcgtcaggttgtttgcgaaaagctaatgcgtcattattccgacgtacgac840
ttaattatccgacataccaggcccggtgtgtcacctggtgagaagcaatggagctggcga900
gaatcacaggttgtgagccgtttccatgccaccactttcctggccattgtttaatatctc960
aagggccattgcaacgctctcataatctcttgcaatagtccacctcttctactgagttcc1020
ataacgttaaccttaggcttaggctgggtgtggtgtgctgtggtgggtggatgtacatag1080
cgaggattatatatagaggtggccttcccccttctcttacgacctcatctttcttgttta1140
tagctcaattgtttgtttgcaacaccaattgaacttttaacagacacatcacacacacct1200
acaaccaacccagaagacattcaca1225
<210>12
<211>443
<212>dna
<213>artificialsequence
<220>
<223>tter3终止子序列
<400>12
gtacccagcggtatcagttgagacatctttttatatttgacgatgaatgaattttacgat60
tgtattaaccaaggtccaaattgtagacaacggcagtctgccctagattgacaattagat120
gatacattgaactaacagtaagacgaattagaaccgcaacttggcgcttctcacatgtag180
ataacaggagtgctcgcatatgctgtaattacgatagtattgcatgtattggtgcgatac240
gactactgcacttgtacttgtgtgtcaacctacagtacagtatctatttgagcagataaa300
agtgccccaattcagtcctatgattactcagccaatagcaaagctcgtacatgactaagc360
tgatcacaaatcatacctgaagtgggctatgtatcattagcgaatgcaaccttgcttttt420
ggcgatctgtagagtcaacttgc443
- 还没有人留言评论。精彩留言会获得点赞!