一种抗PDGFRα的单克隆抗体及其制备方法和应用与流程
本发明涉及生物医药领域,具体涉及一种抗pdgfrα的单克隆抗体及其制备方法和应用。
背景技术:
血小板衍生生长因子(platelet-derived-growth-factor,pdgf)是血小板释放出的最主要的生长因子,存在于血管、骨骼等多种人体组织,其在血管生成、胚胎时期原肠形成、细胞分裂与增殖、中枢神经系统和骨骼发展等过程中扮演者十分关键的作用。目前的研究表明,该因子包括5种二聚体配体,即:pdgf-aa、-ab、-bb、-cc和-dd。5种类型的pdgf配体必须与细胞膜上的相应受体结合后才能发挥其生物学效应。
pdgf受体由两种亚单位构成,即pdgfrα和pdgfrβ。当细胞表面的受体与其配体结合形成二聚体后,激活细胞内结构域酪氨酸残基自身磷酸化,或促使激活特殊靶蛋白的酪氨酸残基磷酸化,从而将信号传入细胞内,经级联式放大效应调控细胞的生物功能。
pdgf及pdgfr信号通路的激活参与了神经胶质瘤、脑瘤、肉瘤、白血病、胃癌、卵巢癌等疾病的发生。血管生成在肿瘤形成中的作用非常重要。没有新生血管形成,实体肿瘤便无法生长。因此,抗肿瘤新生血管生成在抗肿瘤生长及转移方面具有重要意义。有研究表明pdgfr受体在nk/t细胞淋巴瘤中过表达并介导细胞存活(lul,etal.platelet-derivedgrowthfactorreceptoralpha(pdgfrα)isoverexpressedinnk/t-celllymphomaandmediatescellsurvival.biochembiophysrescommun.2018;504(2):525-531.)。而且大量研究已经证实了pdgfrα和pdgfrβ在人体内促进血管形成过程中的关键作用,因此以其为靶标开发单克隆抗体类药物是极具吸引力和前景的新药创制项目。
软组织肉瘤(sts)是一种罕见且异质的恶性肿瘤。据文献报道,每年美国大约发生12000例病例,死亡人数约3900例/每年,大约占所有成人癌症诊断的不到1%,儿童恶性肿瘤的15%。在sts中,有超过50种不同的组织学亚型,最常见的sts包括多形性肉瘤、胃肠道间质瘤、脂肪肉瘤、平滑肌肉瘤、滑膜肉瘤和恶性神经鞘瘤等。而且软组织肉瘤的人口统计学、自然病史和临床结果存在较大差异(李舒,等.单中心687例软组织肉瘤临床病理统计分析[j].中华肿瘤外科杂志,2015,7(01):6-8+13.)。虽然目前针对软组织肉瘤局部病灶,主要利用手术切除和放疗等方式治疗,但是化疗的作用仍然存在较大争议;针对转移性sts,全身治疗是主要的治疗方法。对于大多数sts病患而言,一线治疗方案通常是利用蒽环类药物或将其与另外一种化疗药物联合使用,目前亟待开发新的抗体类药物,以满足肿瘤病患的需求。
由美国礼来公司(elililly)研究开发的抗pdgfrα单克隆抗体olaratumab通过阻断pdgf与pdgfrα的结合,抑制肿瘤细胞的生长,已经被批准用于治疗患有无法通过癌症手术或放射治疗的晚期软组织肉瘤的成人,将来还可能用于治疗其它恶性肿瘤。olaratumab(或称为imc-3g3)是一种全人源igg1单克隆抗体,可选择性地与pdgfr受体结合。这种结合能够防止多种血小板衍生生长因子(pdgf)配体,包括例如pdgf-aa、pdgf-bb、pdgf-ab和pdgf-cc与其受体结合,从而阻止受体的活化(davisej,chughr.spotlightonolaratumabinthetreatmentofsoft-tissuesarcoma:design,development,andplaceintherapy.drugdesdevelther.2017;11:3579-3587.)。olaratumab还可以阻止配体诱导的下游信号分子的磷酸化,例如,akt和丝裂原活化蛋白激酶(mapk)等信号分子被磷酸化。2016年olaratumab与阿霉素联合应用的治疗方案获得美国和欧洲批准,作为治疗成人晚期软组织肉瘤患者的一线药物,以改善无进展和总体生存率,然而该药物尚未得到我国药物管理部门的批准。
olaratumab相关的多项临床试验也正在进行中,包括正在进行的多项三期临床试验和其他类型的临床试验,以确定olaratumab临床获益的生物标志物,扩大其效用范围,特别是针对儿科人群的效用。例如,针对胃肠道间质瘤(gist)适应症所展开的临床研究,现有资料表明,大多数gist是由激活kit酪氨酸激酶受体突变驱动的,gist对小分子激酶抑制剂具有敏感性,如伊马替尼,舒尼替尼和瑞格非尼等。在临床前研究中,olaratumab在肉瘤异种移植模型中诱导生长抑制,并导致胶质母细胞瘤异种移植物中,总pdgfr转移和磷酸化水平降低。olaratumab还可以促进细胞表面pdgfr的内化或下调,因此可能具有影响内部激酶结构域生长驱动突变的活性(moroncinig,etal.developmentsinthemanagementofadvancedsoft-tissuesarcoma-olaratumabincontext.oncotargetsther.2018;11:833-842.)。此外,kit突变体gist还表达pdgfrs,反过来可提供抗体定向治疗的靶标和对小分子激酶抑制剂具有抗性的肿瘤潜在治疗方法。
然而,在olaratumab的临床应用过程中,发现该药物存在较高风险。在治疗过程中,产生最严重的副作用是中性粒细胞减少症(中性粒细胞白细胞计数低),约55%患者会发生严重程度为3级或4级的中性粒细胞减少症;约有8%的病人会发生3级或4级的肌肉骨骼疼痛,其余常见的副作用包括恶心、疲劳、粘膜炎、脱发、呕吐、腹泻、食欲下降、腹部疼痛、神经损伤和头痛等症状,还包括输液相关反应和对胚胎-胎儿的危害。
研究表明,在给予olaratumab单抗治疗期间应监测患者的输注相关反应,包括潮红、呼吸急促、支气管痉挛、发烧/发冷、低血压、皮疹以及严重的低血压、过敏性休克或心脏骤停等症状。在一项临床试验中,接受至少一剂olaratumab治疗的485名患者中,有70名患者(14%)出现了输注相关反应。在这70名患者中,68位患者(97%)产生了1-2级输注反应,11位患者(2.3%)发生了3级或更强烈的输注反应,甚至出现了1名患者死亡的情况(0.2%)(pennimanl,etal.olaratumab(lartruvo):aninnovativetreatmentforsofttissuesarcoma.pt.2018;43(5):267-270.)。olaratumab单抗还具有一定的胚胎-胎儿危害性——基于动物试验和药理学,该药物可能导致胎儿伤害,尽管没有关于其在妊娠中使用的确切数据,但是建议育龄妇女在治疗期间和最后一次剂量后三个月内使用避孕措施,以预防怀孕。
而且olaratumab单抗的价格也比较高昂,以美国为例,olaratumab的平均售价可高达2889美元,如果与阿霉素联合使用,其年度治疗费用可能高达十万美元以上。(zuluaga-sanchezs,etal.cost-effectivenessofolaratumabincombinationwithdoxorubicinforpatientswithsofttissuesarcomaintheunitedstates.sarcoma.2018;2018:6703963.)。虽然目前该药物尚未在国内上市,但是可以预测其国内价格也会非常高昂,难以被我国患者承受。
因此,现有抗pdgfrα单克隆抗体药物存在种类较为单一、毒副作用较高以及价格昂贵等缺点。研发新型抗pdgfrα单克隆抗体类药物,使其具有更高的选择性和亲和力、更低的毒副作用以及较为低廉的用药成本,从而为肿瘤患者提供更多的单克隆抗体类药物选择,已经成为亟待解决的问题。
技术实现要素:
本发明所要解决的技术问题是提供一种抗pdgfrα单克隆抗体,其亲和力较高、毒副作用相对较小。
因此,本发明的第一个目的在于提供一种抗pdgfrα单克隆抗体的氨基酸序列。
本发明的第二个目的在于提供编码所述抗pdgfrα单克隆抗体的核苷酸分子。
本发明的第三个目的在于提供包含所述核苷酸分子的表达载体。
本发明的第四个目的在于提供包含所述表达载体的宿主细胞。
本发明的第五个目的在于提供一种所述抗pdgfrα单克隆抗体的制备方法。
本发明的第六个目的在于提供包含所述抗pdgfrα单克隆抗体的组合物。
本发明的第七个目的在于提供所述抗pdgfrα单克隆抗体在制备pdgfrα分子阻滞药物中的应用。
为了实现上述目的,本发明采取了如下技术方案:
本发明采取的技术方案之一为:一种抗pdgfrα的单克隆抗体,该单克隆抗体包含重链可变区和轻链可变区,其所述重链可变区的氨基酸序列如序列表中seqidno:7所示,所述轻链可变区的氨基酸序列如序列表中seqidno:13所示。
本发明所述的抗pdgfrα的单克隆抗体为常规的单克隆抗体,其包括两条抗体重链和两条抗体轻链,其中包括重链可变区和轻链可变区。每一个可变区都包含互补决定区(cdr区),即cdr1、cdr2和cdr3三个结构域。较佳的,本发明所述抗pdgfrα的单克隆抗体的重链可变区氨基酸序列如序列表中seqidno:7所示,较佳地,其重链可变区还包括cdr区,其中cdr1氨基酸序列如序列表中seqidno:8所示,cdr2氨基酸序列如序列表中seqidno:9所示,cdr3氨基酸序列如序列表中seqidno:10所示。其轻链可变区的氨基酸序列如序列表中seqidno:13所示,较佳地,其轻链可变区还包括cdr’区,其中cdr1’氨基酸序列如序列表中seqidno:14所示,cdr2’氨基酸序列如序列表中seqidno:15所示,cdr3’氨基酸序列如序列表中seqidno:16所示。较佳地,所述抗pdgfrα单克隆抗体为人源的。
所述抗pdgfrα单克隆抗体可以是抗体的全长序列,也可以是抗pdgfrα人源抗体的部分片段,所述片段较佳地为fab、fab’、f(ab’)2、fv或scfv等。优选的,所述抗pdgfrα人源抗体是人源的。更优选的,所述抗pdgfrα人源抗体为igg1、igg2或igg4型抗体。
本发明进一步提供所述抗pdgfrα人源抗体的衍生物,所述衍生物为pdgfrα人源抗体的片段、抗体/抗体片段-因子融合蛋白、抗体/抗体片段-化学偶联物;所述抗pdgfrα人源抗体的片段为fab、fab’、f(ab’)2、fv或scfv等。
较佳地,所述抗体/抗体片段-因子融合蛋白具体为抗体-因子融合蛋白、或抗体片段-因子融合蛋白。较佳地,所述抗体/抗体片段-化学偶联物具体为抗体-化学偶联物、或抗体片段-化学偶联物。
本发明所述单克隆抗体可以由本领域常规技术制备,包括杂交瘤技术、噬菌体展示技术、单淋巴细胞基因克隆技术等,较佳地是通过杂交瘤技术从野生型或转基因小鼠制备单克隆抗体。
本发明采取的技术方案之二为:一种分离的核苷酸分子,所述单克隆抗体重链的编码核苷酸序列如序列表中seqidno:5所示,其轻链的编码核苷酸序列如序列表中seqidno:11所示。
所述核苷酸分子的制备方法为本领域常规制备方法,较佳地包括以下制备方法:通过基因克隆技术例如pcr方法等,获得编码所述单克隆抗体的核苷酸分子,或者通过人工全序列合成的方法得到编码上述单克隆抗体的核苷酸分子。
本领域技术人员知晓,编码上述单克隆抗体的氨基酸序列的核苷酸序列可以适当引入替换、缺失、改变、插入或增加来提供一个多聚核苷酸的同系物或其保守型变异序列。本发明中多聚核苷酸的同系物或其保守型变异序列,可以通过对编码该单克隆抗体基因的一个或多个碱基在保持抗体活性范围内进行替换、缺失或增加来制得。
本发明采取的技术方案之三为:一种表达载体,所述表达载体含有如上所述的核苷酸分子。
其中所述表达载体为本领域常规的表达载体,是指包含适当的调控序列,例如启动子序列、终止子序列、多腺苷酰化序列、增强子序列、标记基因和/或序列以及其他适当的序列的表达载体。所述表达载体可以是病毒或质粒,如适当的噬菌体或者噬菌粒,更多技术细节请参见例如sambrook等,molecularcloning:alaboratorymanual,第二版,coldspringharborlaboratorypress,1989。许多用于核酸操作的已知技术和方案请参见currentprotocolsinmolecularbiology,第二版,ausubel等编著。本发明中的表达载体指本领域熟知的细菌质粒、噬菌体、酵母质粒、植物细胞病毒、哺乳动物细胞病毒如腺病毒、逆转录病毒或其他载体。
较佳地,所述表达载体选自phlx101、pee14.4、pcho1.0或pcdna3.1中的一种或多种的组合,更佳地为pcdna3.1。较佳地,所述表达载体包含所述单克隆抗体重链和轻链的编码核苷酸序列,其重链可变区和轻链可变区的编码核苷酸序列,其重链cdr1、cdr2和cdr3以及轻链cdr1’、cdr2’和cdr3’区的编码核苷酸序列等。
本发明采取的技术方案之四为:一种宿主细胞,所述宿主细胞包含如上所述的表达载体。
本发明所述的宿主细胞为本领域常规的各种宿主细胞,只要能满足使上述重组表达载体稳定地自行复制,且所携带所述的核苷酸可被有效表达即可。本发明中的宿主细胞可以是原核细胞,如细菌细胞;或是低等真核细胞,如酵母细胞;或是高等真核细胞,如哺乳动物细胞。所述表达载体较佳地包括:cos、cho(中国仓鼠卵巢,chinesehamsterovary)、hela细胞系、骨髓细胞系如sp2/0细胞系、ns0、sf9、sf21、dh5α、bl21(de3)或e.colitg1、yb2/0细胞系等以及转化的b-细胞或杂交瘤细胞中的一种或多种的组合。更佳地为e.colitg1、bl21细胞(表达单链抗体或fab抗体)或者cho-k1细胞(表达全长igg抗体)。
将前述表达载体转化至宿主细胞中,即可得本发明优选的重组表达转化体。其中所述转化方法为本领域常规转化方法,较佳地为化学转化法,热激法或电转法。
本发明采取的技术方案之五为:抗pdgfrα的单克隆抗体的制备方法,其包括以下步骤:
a)在表达条件下,培养如上所述的宿主细胞,表达抗pdgfrα的单克隆抗体;
b)分离并纯化步骤a)所得抗pdgfrα的单克隆抗体。
本发明所述的宿主细胞的培养方法,所述抗pdgfrα的单克隆的分离和纯化方法为本领域常规方法,具体操作方法请参考相应的细胞培养技术手册以及单克隆抗体分离纯化技术手册。
本发明中所用的宿主细胞均为现有技术,可通过商业途径直接获取,培养中所用的培养基亦为各种常规培养基,本领域技术人员可根据经验选择适用的培养基,在适于宿主细胞生长的条件下进行培养。当宿主细胞生长到适当的细胞密度后,用合适的方法(如温度转换或化学诱导)诱导选择的启动子,将细胞再培养一段时间。在上面的方法中的重组多肽可在细胞内、或在细胞膜上表达、或分泌到细胞外。如果需要,可利用其物理的、化学的和其它特性通过各种分离方法分离和纯化重组的蛋白。这些方法是本领域技术人员所熟知的。这些方法的例子包括但并不限于:常规的复性处理、用蛋白沉淀剂处理(盐析方法)、离心、渗透破菌、超处理、超离心、分子筛层析(凝胶过滤)、吸附层析、离子交换层析、高效液相层析(hplc)和其它各种液相层析技术及这些方法的结合。
本发明从单克隆培养的细胞株中筛选获取目的抗体的基因序列,用以构建真核表达载体,表达后即可重建抗体的活性,获得抗pdgfrα单克隆抗体。
本发明采取的技术方案之六为:一种组合物,其包含有效量的如上所述抗pdgfrα的单克隆抗体和药学上可接受的载体。
本发明的单克隆抗体可以通过本领域任何已知的方式配制药物组合物来使用。这种组合物以所述单克隆抗体为活性成分,加上一种或多种药物可接受的载体、稀释剂、填充剂、结合剂及其它赋形剂,这依赖于给药方式及所设计的剂量形式。本领域枝术人员已知的治疗惰性的无机或有机的载体包括(但不限于)乳糖、玉米淀粉或其衍生物、滑石、植物油、蜡、脂肪、多羚基化合物例如聚乙二醇、水、蔗糖、乙醇、甘油,诸如此类,各种防腐剂、润滑剂、分散剂、矫味剂。保湿剂、抗氧化剂、甜味剂、着色剂、稳定剂、盐、缓冲液诸如此类也可加入其中,这些物质根据需要用于帮助配方的稳定性或有助于提高活性或它的生物有效性,在这种组合物中可以使用抑制剂,可以是其原始化合物本身的形式,或任选地使用其药物学可接受的盐的形式,本发明的单克隆抗体可以单独给药,或以各种组合给药,以及与其它治疗药剂一起结合形式给药。如此配制的组合物根据需要可选择本领域技术人员已知的任何适当的方式对所得单抗进行给药。
本发明提供的抗pdgfrα单克隆抗体,可以和药学上可以接受的载体一起组成药物制剂组合物从而更稳定地发挥疗效,这些制剂可以保证本发明公开的抗pdgfrα单克隆抗体的氨基酸核心序列的构像完整性,同时还保护蛋白质的多官能团防止其降解(包括但不限于凝聚、脱氨或氧化)。通常情况下,对于液体制剂,通常可以在2°c-8°c条件下保存至少稳定一年,对于冻干制剂,在30°c至少六个月保持稳定。所述抗pdgfrα单克隆抗体制剂可为制药领域常用的混悬、水针、冻干等制剂,优选水针或冻干制剂,
对于本发明公开的抗pdgfrα的单克隆抗体的水针或冻干制剂,药学上可以接受的载体较佳地包括但不限于:表面活性剂、溶液稳定剂、等渗调节剂和缓冲液之一或其组合。其中表面活性剂较佳地包括但不限于:非离子型表面活性剂如聚氧乙烯山梨醇脂肪酸酯(吐温20或80);poloxamer(如poloxamer188);triton;十二烷基硫酸钠(sds);月桂硫酸钠;十四烷基、亚油基或十八烷基肌氨酸以及pluronics和monaquattm等,其加入量应使抗pdgfrα单克隆抗体的颗粒化趋势最小。溶液稳定剂较佳地包括但不限于以下列举之一或其组合:糖类,例如,还原性糖和非还原性糖;氨基酸类,例如,谷氨酸单钠或组氨酸;醇类,例如:三元醇、高级糖醇、丙二醇、聚乙二醇等,溶液稳定剂的加入量应该使最后形成的制剂在本领域的技术人员认为达到稳定的时间内保持稳定状态。等渗调节剂较佳地包括但不限于氯化钠、甘露醇之一或其组合。缓冲液较佳地包括但不限于:tris、组氨酸缓冲液、柠檬酸盐、磷酸盐缓冲液之一或其组合。
本发明采取的技术方案之七为:如上所述抗pdgfrα的单克隆抗体在制备pdgfrα分子阻滞药物上的用途。
所述应用更佳地为制备pdgfrα分子阻滞药物上的用途,较佳地,所述制备pdgfrα分子阻滞药物上的用途具体为制备肿瘤治疗或肿瘤诊断类药物上的用途。
本发明所述的药物较佳地为抗肿瘤、治疗自身免疫性疾病、治疗感染性疾病和/或抗移植排斥反应的药物,更佳地为抗肿瘤药物、治疗自身免疫性疾病药物,优选地为抗肿瘤药物。本发明所述抗pdgfrα的单克隆抗体可以单独使用或与其他抗肿瘤药物联合使用。所述其他抗肿瘤药物为本领域常规抗肿瘤药物,包括抗体类药物或小分子抗肿瘤药物。所述抗体类药物为本领域常规抗体类药物,较佳地包括抗pd-1单克隆抗体、伊匹单抗等。所述小分子抗肿瘤药物为本领域常规药物,包括紫杉醇、5-fu嘧啶等。
其中所述抗肿瘤药物所针对的肿瘤较佳地包括但不限于:肺癌、肝癌、卵巢癌、宫颈癌、皮肤癌、结肠癌、神经胶质瘤、膀胱癌、乳腺癌、肾癌、食道癌、胃癌、口腔鳞状细胞癌、尿道上皮细胞癌、胰腺癌和/或头颈肿瘤中的一种或多种。
本发明所称的抗肿瘤药物,指具有抑制和/或治疗肿瘤的药物,可以包括伴随肿瘤相关症状发展的延迟和/或这些症状严重程度的降低,进一步还包括已存在的肿瘤伴随症状的减轻并防止其他症状的出现,还包括减少或防止肿瘤的转移等。
本发明中抗pdgfrα的单克隆抗体及其组合物在对包括人在内的动物给药时,给药剂量因病人的年龄和体重,疾病特性和严重性,以及给药途径而异,可以参考动物实验的结果和种种情况,总给药量不能超过一定范围。具体讲静脉注射的剂量是1-1800mg/天。
在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。
本发明所用试剂和原料均市售可得。
本发明的积极进步效果在于:本发明提供的抗pdgfrα单克隆抗体具有良好的生物活性,具有比对照药更高的亲和力,比对照药物更佳的抑制配体-受体结合能力以及抑制细胞增殖的能力。该单克隆抗体能够单独或与其它抗肿瘤药物联合应用在肿瘤免疫治疗以及诊断和筛查中,能够有效应用于治疗肿瘤、感染性疾病、自身免疫性疾病以及抗免疫排斥等药物的制备中。
附图说明
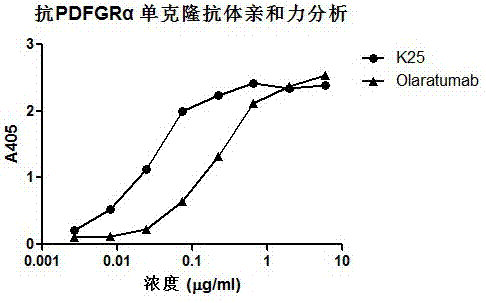
图1为抗pdgfrα抗体的亲和力能力实验结果。
图2为抗pdgfrα抗体的配体-受体结合抑制实验结果。
图3为抗pdgfrα抗体抑制u-118mg细胞增殖的实验结果。
具体实施方式
下面通过实施例的方式进一步说明本发明,但并不因此将本发明限制在所述的实施例范围之中。下列实施例中未注明具体条件的实验方法,按照常规方法和条件,或按照商品说明书选择。实施例中所述的室温为本领域常规的室温,一般为10~30℃。
在进一步描述本发明具体实施方式之前,应理解,本发明的保护范围不局限于下述特定的具体实施方案;还应当理解,本发明实施例中使用的术语是为了描述特定的具体实施方案,而不是为了限制本发明的保护范围;在本发明说明书和权利要求书中,除非文中另外明确指出,单数形式“一个”、“一”和“这个”包括复数形式。
当实施例给出数值范围时,应理解,除非本发明另有说明,每个数值范围的两个端点以及两个端点之间任何一个数值均可选用。除非另外定义,本发明中使用的所有技术和科学术语与本技术领域技术人员通常理解的意义相同。除实施例中使用的具体方法、设备、材料外,根据本技术领域的技术人员对现有技术的掌握及本发明的记载,还可以使用与本发明实施例中所述的方法、设备、材料相似或等同的现有技术的任何方法、设备和材料来实现本发明。
除非另外说明,本发明中所公开的实验方法、检测方法、制备方法均采用本技术领域常规的分子生物学、生物化学、染色质结构和分析、分析化学、细胞培养、重组dna技术及相关领域的常规技术。这些技术在现有文献中已有完善说明,具体可参见sambrook等molecularcloning:alaboratorymanual,secondedition,coldspringharborlaboratorypress,1989andthirdedition,2001;ausubel等,currentprotocolsinmolecularbiology,johnwiley&sons,newyork,1987andperiodicupdates;theseriesmethodsinenzymology,academicpress,sandiego;wolffe,chromatinstructureandfunction,thirdedition,academicpress,sandiego,1998;methodsinenzymology,vol.304,chromatin(p.m.wassarmananda.p.wolffe,eds.),academicpress,sandiego,1999;和methodsinmolecularbiology,vol.119,chromatinprotocols(p.b.becker,ed.)humanapress,totowa,1999等。
实施例1表达人pdgfrα胞外区重组蛋白
合成人pdgfrα-ap融合基因(由南京金斯瑞生物科技有限公司合成),其中pdgfrα基因序列为seqidno:1,ap基因序列为seqidno:2,两段序列连接即为pdgfrα-ap融合基因,设计正向和反向引物分别为:
5’-taacggggccggcaagccgccaccatggggacttcccatccgg-3’(seqidno:3)和5’-tcactacgtatcagtggtggtggtggtggtggcctg-3’(seqidno:4),用于扩增得到编码pdgfrα-ap融合蛋白的基因,在基因的上下游分别引入限制性内切酶位点ngomiv和snabi,pcr条件为95℃10s,60℃10s,72℃60s,35个循环,72℃延伸10min,dna聚合酶为takara公司产品。
pcr产物经琼脂糖凝胶回收(回收试剂盒为omegabio-tek公司产品)纯化后,加入限制性内切酶ngomiv和snabi进行酶切,酶切产物经dna回收试剂(omegabio-tek公司产品)纯化后与用相同限制性内切酶酶切的载体phlx101(由上海复宏汉霖生物技术股份有限公司构建,参见中国专利cn201210211812.1)进行连接反应。连接产物转化到dh5α大肠杆菌,涂布在含有50µg/ml羧苄青霉素的2yt琼脂培养基上。将获得的阳性克隆在含有50µg/ml羧苄青霉素的2yt液体培养基中培养,经过invitrogen公司测序验证后,用质粒大量抽提试剂盒(omegabio-tek公司产品)提取阳性克隆质粒。
采用聚乙烯亚胺(polyethylenimine,pei)的方法将质粒dna转染到293f细胞中(购买自invitrogen公司),转染6个小时后,将细胞离心,更换新鲜的293freestylemedium培养液(gibco公司产品),继续摇床培养。24和48小时后可对细胞进行观察,转染后第3天开始每天对细胞计数,表达时间通常为7-10天,当活细胞密度低于50%时收获细胞培养液上清。
实施例2抗pdgfrα人源抗体真核表达载体的构建和表达
抗体重链(seqidno:5)和轻链(seqidno:11)基因均由南京金斯瑞生物科技有限公司合成。使用pcr反应对上述重链和轻链的编码dna序列进行扩增,在抗体重链和轻链的基因两端引入适当的酶切位点,其中在抗体重链基因5’端及3’端分别引入ngomiv和snabi酶切位点,正向引物序列为:
5’-acctgccggcaagccgccaccatgggttggagcctcatcttgctcttc-3’(seqidno:17)
反向引物序列为:
5’-gctctacgtatcatttacctggagacagggagaggc-3’(seqidno:18),在抗体轻链可变区基因5’端及3’端分别引入ngomiv和snabi,正向引物序列为:
5’-acctgccggcaagccgccaccatgggttggagcctcatcttgctcttc-3’(seqidno:17)
反向引物序列为:
5’-gcatcttacgtattattaacactctcccctgttgaag-3’(seqidno:19)。采用pcr反应,条件为95℃10s,60℃10s,72℃10s,35个循环,72℃延伸10min,dna聚合酶为takara公司产品。pcr扩增后,将pcr产物经琼脂糖凝胶电泳回收纯化。轻链可变区基因加入限制性内切酶ngomiv和snabi进行酶切,重链可变区基因加入限制性内切酶ngomiv和snabi进行酶切,酶切后经dna纯化试剂盒进行纯化,并与相同限制性内切酶消化的载体phlx101。连接产物转化到dh5α大肠杆菌,涂布在含有50µg/ml羧苄青霉素的2yt琼脂培养基上。获得的阳性克隆在含有50µg/ml羧苄青霉素的2yt液体培养基中培养,经过invitrogen公司测序验证后,用质粒大量抽提试剂盒提取阳性克隆质粒。
利用invitrogen公司的neon系统,将线性化的质粒dna转染至cho细胞(购买自invitrogen公司)。转染后的cho细胞进行稀释克隆化培养,在含有50μmol蛋氨酸亚氨基代砜(methioninesulfoximine,msx)的94113培养基(irvinescientific公司产品)中进行筛选,从而获得单克隆细胞系,将其命名为k25。
将获得的单克隆细胞系k25在含有50μmol蛋氨酸亚氨基代砜的94113培养基中进行摇瓶培养,表达时间通常为7-14天,当活细胞密度低于50%时收获细胞培养液上清。利用羊抗人iggfd(meridian公司产品)以及辣根过氧化物酶标记的羊抗人轻链恒定区进行双夹心elisa法检测表达上清中抗体的含量,以未转染上清作为阴性对照,人的igg纯品作为标准品。实验结果显示,表达获得的目的蛋白可以被两个抗体识别,具有人igg抗体特征,并且构建的人源抗体表达量在200~500µg/ml,具有较高的表达水平。采用proteina亲和层析柱从细胞培养上清中分离纯化目的抗体k25。
对照抗体olaratumab根据专利(参见中国专利cn101613409b)中所描述的抗体基因,由南京金斯瑞生物科技有限公司合成,将重链和轻链基因分别构建到phlx101表达载体中。再利用invitrogen公司的neon系统,将线性化的质粒dna转染至cho细胞。转染后的cho细胞进行稀释克隆化培养,在含有50μmol蛋氨酸亚氨基代砜(methioninesulfoximine,msx)的94113培养基(irvinescientific公司产品)中进行筛选,从而获得单克隆细胞系。最后经表达和纯化得到对照抗体olaratumab。
实施例3抗pdgfrα人源抗体亲和力鉴定
将羊抗人iggfd(meridian公司产品)按2µg/ml包被到酶标板中(工作体积30μl),4℃静置过夜。用含有0.05%的tween20的常规磷酸盐缓冲液(pbst)洗3次。用5%的脱脂牛奶室温封闭1小时。用pbst洗3次,将实施例2制备获得的抗体k25和olaratumab分别配制成6µg/ml浓度,并进行3倍梯度稀释,共8个梯度,每孔加入30µl,室温静置1小时。用pbst洗3次,加入30µl实施例1中制备的pdgfrα-ap细胞表达上清,室温静置1小时。用pbst洗6次,加入pnpp显色,用酶标仪在405nm下读数。抗pdgfrα抗体的亲和力能力实验结果如图1所示,从结果可以看出,本发明筛选得到的单克隆抗体k25对pdgfrα受体具有明显的亲和力,其亲和力比对照抗体olaratumab显著提高。
实施例4配体-抗体结合抑制功能鉴定
将pdgf-aa(peprotech公司产品)按1µg/ml包被到酶标板中(工作体积30μl),4℃静置过夜。用pbst洗3次。用含1%的bsa的pbs室温封闭1小时。用pbst洗3次。将实施例2制备获得的抗体k25和olaratumab配制成5µg/ml浓度,并进行3倍梯度稀释,共8个梯度。再将实施例1中制备得到的pdgfrα-ap细胞表达上清,用pbst按1:10稀释,然后与稀释好的抗体按1:1混合,室温静置1.5小时,再加入到封闭好的酶标板中,室温静置1小时。用pbst洗6次。用pnpp显色,用酶标仪在405nm下读数。抗pdgfrα抗体的配体-受体结合抑制实验结果如图2所示,从结果可以看出,本发明筛选所得单克隆抗体k25能有效抑制pdgfrα受体与其配体pdgf-aa的结合,其抑制作用比对照抗体olaratumab更佳,随着单克隆抗体浓度的增加,更早达到最低值。
实施例5抗体对于血管内皮细胞增殖的抑制功能鉴定
u-118mg细胞(atcc,htb-15)用加有10%fbs的dmem培养基进行培养,按每孔4000个细胞/100μl接种到96孔培养板中培养过夜。小心吸去上清,用200μl不含fbs的dmem培养基洗2次,在每孔加入100μl不含fbs的dmem培养基,对细胞进行饥饿培养2天。小心吸去上清。将实施例2制备获得的抗体k25和olaratumab配制成20µg/ml浓度,并进行3倍梯度稀释,共8个梯度,按每孔75μl加到96孔培养板中,将细胞培养板放置于co2培养箱中,37℃,5%co2,孵育30min。将pdgf-aa配制成400ng/ml,按每孔75μl加到96孔培养板中,即pdgf-aa终浓度为200ng/ml,将细胞培养板放置于co2培养箱中,37℃,5%co2,培养4天。每孔加入15μl,5mg/ml的mtt,将细胞培养放置于co2培养箱中,37℃,5%co2,孵育3h。用酶标仪在565nm下读数。抗pdgfrα抗体抑制u-118mg细胞增殖的实验结果如图3所示,从结果可看出,本发明筛选所得单克隆抗体k25对u-118mg细胞具有显著抑制细胞增殖的能力,其抑制能力比对照抗体olaratumab更强,随着抗体浓度的增加,能够更有效的抑制u-118mg细胞增殖。
应理解,在阅读了本发明的上述内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
序列表
<110>上海复宏汉霖生物技术股份有限公司
上海复宏汉霖生物制药有限公司
<120>一种抗pdgfrα的单克隆抗体及其制备方法和应用
<141>2018-11-28
<160>19
<170>siposequencelisting1.0
<210>1
<211>1560
<212>dna
<213>人工序列(artificialsequence)
<400>1
atggggacttcccatccggcgttcctggtcttaggctgtcttctcacagggctgagccta60
atcctctgccagctttcattaccctctatccttccaaatgaaaatgaaaaggttgtgcag120
ctgaattcatccttttctctgagatgctttggggagagtgaagtgagctggcagtacccc180
atgtctgaagaagagagctccgatgtggaaatcagaaatgaagaaaacaacagcggcctt240
tttgtgacggtcttggaagtgagcagtgcctcggcggcccacacagggttgtacacttgc300
tattacaaccacactcagacagaagagaatgagcttgaaggcaggcacatttacatctat360
gtgccagacccagatgtagcctttgtacctctaggaatgacggattatttagtcatcgtg420
gaggatgatgattctgccattataccttgtcgcacaactgatcccgagactcctgtaacc480
ttacacaacagtgagggggtggtacctgcctcctacgacagcagacagggctttaatggg540
accttcactgtagggccctatatctgtgaggccaccgtcaaaggaaagaagttccagacc600
atcccatttaatgtttatgctttaaaagcaacatcagagctggatctagaaatggaagct660
cttaaaaccgtgtataagtcaggggaaacgattgtggtcacctgtgctgtttttaacaat720
gaggtggttgaccttcaatggacttaccctggagaagtgaaaggcaaaggcatcacaatg780
ctggaagaaatcaaagtcccatccatcaaattggtgtacactttgacggtccccgaggcc840
acggtgaaagacagtggagattacgaatgtgctgcccgccaggctaccagggaggtcaaa900
gaaatgaagaaagtcactatttctgtccatgagaaaggtttcattgaaatcaaacccacc960
ttcagccagttggaagctgtcaacctgcatgaagtcaaacattttgttgtagaggtgcgg1020
gcctacccacctcccaggatatcctggctgaaaaacaatctgactctgattgaaaatctc1080
actgagatcaccactgatgtggaaaagattcaggaaataaggtatcgaagcaaattaaag1140
ctgatccgtgctaaggaagaagacagtggccattatactattgtagctcaaaatgaagat1200
gctgtgaagagctatacttttgaactgttaactcaagttccttcatccattctggacttg1260
gtcgatgatcaccatggctcaactgggggacagacggtgaggtgcacagctgaaggcacg1320
ccgcttcctgatattgagtggatgatatgcaaagatattaagaaatgtaataatgaaact1380
tcctggactattttggccaacaatgtctcaaacatcatcacggagatccactcccgagac1440
aggagtaccgtggagggccgtgtgactttcgccaaagtggaggagaccatcgccgtgcga1500
tgcctggctaagaatctccttggagctgagaaccgagagctgaagctggtggctcccacc1560
<210>2
<211>1521
<212>dna
<213>人工序列(artificialsequence)
<400>2
cgaattccttacgtaagatcttccggaatcatcccagttgaggaggagaacccggacttc60
tggaaccgcgaggcagccgaggccctgggtgccgccaagaagctgcagcctgcacagaca120
gccgccaagaacctcatcatcttcctgggcgatgggatgggggtgtctacggtgacagct180
gccaggatcctaaaagggcagaagaaggacaaactggggcctgagatacccctggccatg240
gaccgcttcccatatgtggctctgtccaagacatacaatgtagacaaacatgtgccagac300
agtggagccacagccacggcctacctgtgcggggtcaagggcaacttccagaccattggc360
ttgagtgcagccgcccgctttaaccagtgcaacacgacacgcggcaacgaggtcatctcc420
gtgatgaatcgggccaagaaagcagggaagtcagtgggagtggtaaccaccacacgagtg480
cagcacgcctcgccagccggcacctacgcccacacggtgaaccgcaactggtactcggac540
gccgacgtgcctgcctcggcccgccaggaggggtgccaggacatcgctacgcagctcatc600
tccaacatggacattgacgtgatcctaggtggaggccgaaagtacatgtttcccatggga660
accccagaccctgagtacccagatgactacagccaaggtgggaccaggctggacgggaag720
aatctggtgcaggaatggctggcgaagcgccagggtgcccggtatgtgtggaaccgcact780
gagctcatgcaggcttccctggacccgtctgtgacccatctcatgggtctctttgagcct840
ggagacatgaaatacgagatccaccgagactccacactggacccctccctgatggagatg900
acagaggctgccctgcgcctgctgagcaggaacccccgcggcttcttcctcttcgtggag960
ggtggtcgcatcgaccatggtcatcatgaaagcagggcttaccgggcactgactgagacg1020
atcatgttcgacgacgccattgagagggcgggccagctcaccagcgaggaggacacgctg1080
agcctcgtcactgccgaccactcccacgtcttctccttcggaggctaccccctgcgaggg1140
agctccatcttcgggctggcccctggcaaggcccgggacaggaaggcctacacggtcctc1200
ctatacggaaacggtccaggctatgtgctcaaggacggcgcccggccggatgttaccgag1260
agcgagagcgggagccccgagtatcggcagcagtcagcagtgcccctggacgaagagacc1320
cacgcaggcgaggacgtggcggtgttcgcgcgcggcccgcaggcgcacctggttcacggc1380
gtgcaggagcagaccttcatagcgcacgtcatggccttcgccgcctgcctggagccctac1440
accgcctgcgacctggcgccccccgccggcaccaccgacgccgcgcacccgggttcaggc1500
caccaccaccaccaccactga1521
<210>3
<211>43
<212>dna
<213>人工序列(artificialsequence)
<400>3
taacggggccggcaagccgccaccatggggacttcccatccgg43
<210>4
<211>36
<212>dna
<213>人工序列(artificialsequence)
<400>4
tcactacgtatcagtggtggtggtggtggtggcctg36
<210>5
<211>1404
<212>dna
<213>人工序列(artificialsequence)
<400>5
atgggttggagcctcatcttgctcttccttgtcgctgttgctacgcgtgtccactccgag60
gtgcagctggtgcagtctggggctgaggtgaagaagcctggggcctcagtgaaggtttcc120
tgcaaggcatctggatacaccttcaccagctactatatgcactgggtgcgacaggcccct180
ggacaagggcttgagtggatgggaataatcaaccctagtggtggtagcacaagctacgca240
cagaagttccagggcagagtcaccatgaccagggacacgtccacgagcacagtctacatg300
gagctgagcagcctgagatctggcgacacggccgtgtattactgtgcgagagcccggagt360
ggtcatagttttgactactggggccagggaaccctggtcaccgtctcaagcgctagcacc420
aagggcccatcggtcttccccctggcaccctcctccaagagcacctctgggggcacagcg480
gccctgggctgcctggtcaaggactacttccccgaaccggtgaccgtgtcgtggaactca540
ggcgccctgaccagcggcgtgcacaccttccctgctgtcctacagtcctcaggactctac600
tccctcagcagcgtggtgaccgtgccctccagcagcttgggcacccagacctacatctgc660
aacgtgaatcacaagcccagcaacaccaaggtggacaagaaagcagagcccaaatcttgt720
gacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccatcagtc780
ttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcaca840
tgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggac900
ggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtac960
cgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaag1020
tgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaa1080
gggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaag1140
aaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggag1200
tgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactcc1260
gacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcagggg1320
aacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagc1380
ctctccctgtctccaggtaaatga1404
<210>6
<211>345
<212>dna
<213>人工序列(artificialsequence)
<400>6
gaggtgcagctggtgcagtctggggctgaggtgaagaagcctggggcctcagtgaaggtt60
tcctgcaaggcatctggatacaccttcaccagctactatatgcactgggtgcgacaggcc120
cctggacaagggcttgagtggatgggaataatcaaccctagtggtggtagcacaagctac180
gcacagaagttccagggcagagtcaccatgaccagggacacgtccacgagcacagtctac240
atggagctgagcagcctgagatctggcgacacggccgtgtattactgtgcgagagcccgg300
agtggtcatagttttgactactggggccagggaaccctggtcacc345
<210>7
<211>115
<212>prt
<213>人工序列(artificialsequence)
<400>7
gluvalglnleuvalglnserglyalagluvallyslysproglyala
151015
servallysvalsercyslysalaserglytyrthrphethrsertyr
202530
tyrmethistrpvalargglnalaproglyglnglyleuglutrpmet
354045
glyileileasnproserglyglyserthrsertyralaglnlysphe
505560
glnglyargvalthrmetthrargaspthrserthrserthrvaltyr
65707580
metgluleuserserleuargserglyaspthralavaltyrtyrcys
859095
alaargalaargserglyhisserpheasptyrtrpglyglnglythr
100105110
leuvalthr
115
<210>8
<211>10
<212>prt
<213>人工序列(artificialsequence)
<400>8
glytyrthrphethrsertyrtyrmethis
1510
<210>9
<211>10
<212>prt
<213>人工序列(artificialsequence)
<400>9
ileileasnproserglyglyserthrser
1510
<210>10
<211>9
<212>prt
<213>人工序列(artificialsequence)
<400>10
alaargserglyhisserpheasptyr
15
<210>11
<211>702
<212>dna
<213>人工序列(artificialsequence)
<400>11
atgggttggagcctcatcttgctcttccttgtcgctgttgctacgcgtgtccactccgac60
atccagatgacccagtctccatcctccctgtctgcatctgtaggagacagagtcaccatc120
acttgccgggcaagtcagagcattagcagctatttaaattggtatcagcagaaaccaggg180
aaagcccctaagctcctgatctatgctgcatccagtttgcaaagtggggtcccatcaagg240
ttcagtggcagtggatctgggacagatttcactctcaccatcagcagtctgcaacctgaa300
gattttgcaacttactactgtcaacagagttacagtacccctccgacgttcggccaaggg360
accaaggtggaaatcaaacgaactgtggctgcaccatctgtcttcatcttcccgccatct420
gatgagcagttgaaatctggaactgcctctgttgtgtgcctgctgaataacttctatccc480
agagaggccaaagtacagtggaaggtggataacgccctccaatcgggtaactcccaggag540
agtgtcacagagcaggacagcaaggacagcacctacagcctcagcagcaccctgacgctg600
agcaaagcagactacgagaaacacaaagtctacgcctgcgaagtcacccatcagggcctg660
agctcgcccgtcacaaagagcttcaacaggggagagtgttaa702
<210>12
<211>324
<212>dna
<213>人工序列(artificialsequence)
<400>12
gacatccagatgacccagtctccatcctccctgtctgcatctgtaggagacagagtcacc60
atcacttgccgggcaagtcagagcattagcagctatttaaattggtatcagcagaaacca120
gggaaagcccctaagctcctgatctatgctgcatccagtttgcaaagtggggtcccatca180
aggttcagtggcagtggatctgggacagatttcactctcaccatcagcagtctgcaacct240
gaagattttgcaacttactactgtcaacagagttacagtacccctccgacgttcggccaa300
gggaccaaggtggaaatcaaacga324
<210>13
<211>108
<212>prt
<213>人工序列(artificialsequence)
<400>13
aspileglnmetthrglnserproserserleuseralaservalgly
151015
aspargvalthrilethrcysargalaserglnserilesersertyr
202530
leuasntrptyrglnglnlysproglylysalaprolysleuleuile
354045
tyralaalaserserleuglnserglyvalproserargphesergly
505560
serglyserglythraspphethrleuthrileserserleuglnpro
65707580
gluaspphealathrtyrtyrcysglnglnsertyrserthrpropro
859095
thrpheglyglnglythrlysvalgluilelysarg
100105
<210>14
<211>11
<212>prt
<213>人工序列(artificialsequence)
<400>14
argalaserglnserilesersertyrleuasn
1510
<210>15
<211>7
<212>prt
<213>人工序列(artificialsequence)
<400>15
alaalaserserleuglnser
15
<210>16
<211>9
<212>prt
<213>人工序列(artificialsequence)
<400>16
glnglnsertyrserthrproprothr
15
<210>17
<211>48
<212>dna
<213>人工序列(artificialsequence)
<400>17
acctgccggcaagccgccaccatgggttggagcctcatcttgctcttc48
<210>18
<211>36
<212>dna
<213>人工序列(artificialsequence)
<400>18
gctctacgtatcatttacctggagacagggagaggc36
<210>19
<211>37
<212>dna
<213>人工序列(artificialsequence)
<400>19
gcatcttacgtattattaacactctcccctgttgaag37
- 还没有人留言评论。精彩留言会获得点赞!