用于靶向核酸编辑的系统、方法和组合物与流程
相关申请及以引用方式并入
本申请要求2017年5月18日提交的美国临时申请号62/508,293、2017年9月21日提交的美国临时申请号62/561,663、2017年10月4日提交的美国临时申请号62/568,133和2017年12月22日提交的美国临时申请号62/609,957的优先权,所述临时申请各自以引用方式整体并入本文。
关于联邦资助研究的声明
本发明是根据由美国国立卫生研究院(nationalinstitutesofhealth)授予的授权号mh100706和mh110049在政府支持下完成的。政府享有本发明的某些权利。
发明领域
本发明总体上涉及用于靶向和编辑核酸,特别地用于目标靶基因座处腺嘌呤的可编程脱氨的系统、方法和组合物。
背景技术:
在基因组测序技术和分析方法中的最新进展显著加速了对与范围广泛的生物功能和疾病相关联的遗传因子进行编目和映射的能力。精确的基因组靶向技术是通过允许个体遗传元件的选择性干扰而使得因果性遗传变异的系统性逆向工程化成为可能、以及推进合成生物学、生物技术应用、和医学应用所需要的。虽然基因组编辑技术,如设计师锌指、转录激活因子样效应子(tale)、或归巢大范围核酸酶(homingmeganuclease)对于产生靶向的基因组干扰是可得的,但是仍然需要采用新颖的策略和分子机制且是负担得起的、易于建立的、可扩展的、并且便于靶向真核基因组内的多个位置的新的基因组工程化技术。这将为基因组工程化和生物技术的新应用提供主要资源。
先前已经报道了胞嘧啶的可编程脱氨,其可用于校正a→g和t→c点突变。例如,komor等人,nature(2016)533:420-424报道了在非靶向dna链中通过apobec1胞嘧啶脱氨酶进行的胞嘧啶脱氨,cas9-指导rna复合物与靶向dna链的结合导致该非靶向dna移位,从而使得胞嘧啶转化为尿嘧啶。另参见kim等人,naturebiotechnology(2017)35:371-376;shimatani等人,naturebiotechnology(2017)doi:10.1038/nbt.3833;zong等人,naturebiotechnology(2017)doi:10.1038/nbt.3811;yangnaturecommunication(2016)doi:10.1038/ncomms13330。
然而,a→g和t→c点突变仅代表已知病原性snp的约12%,而g→a和c→t点突变代表已知病原性snp的约47%,并且不能通过胞嘧啶脱氨来寻址。需要新颖的系统和方法来校正这些点突变和病原性snp。
技术实现要素:
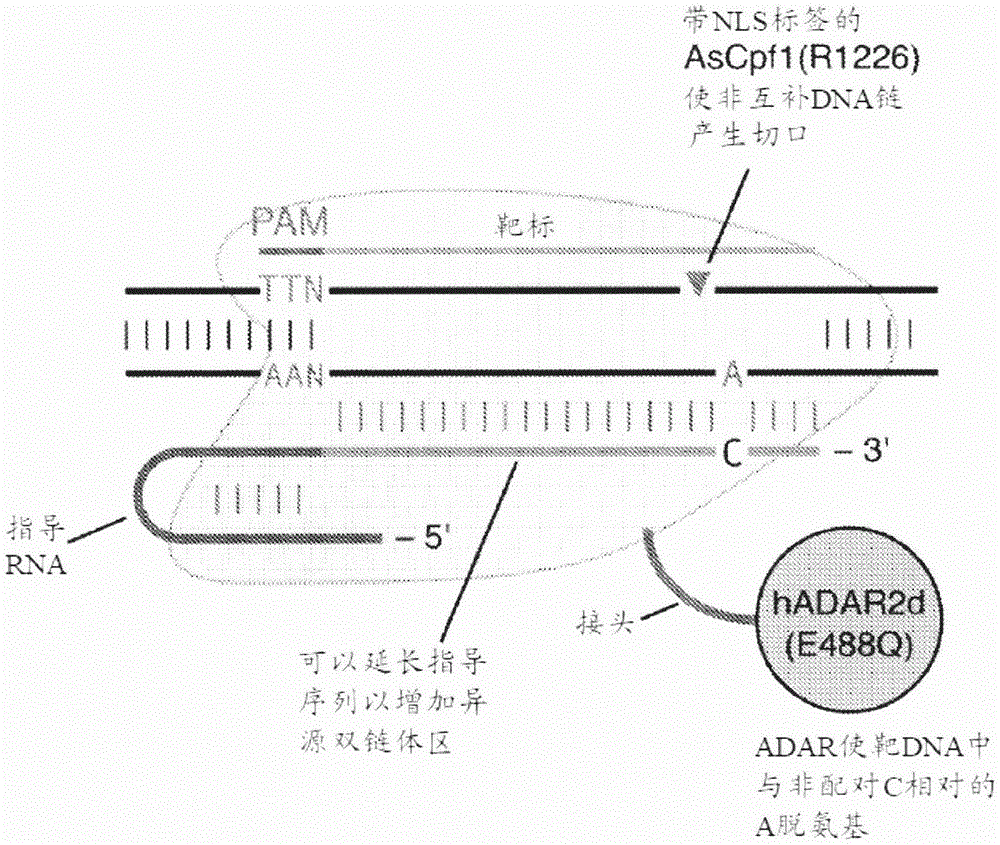
本发明的至少第一方面涉及一种修饰目标靶基因座中的腺嘌呤的方法,所述方法包括向所述基因座递送:(a)cpf1切口酶蛋白;(b)指导分子,所述指导分子包含连接至正向重复序列的指导序列;和(c)腺苷脱氨酶蛋白或其催化结构域;其中所述腺苷脱氨酶蛋白或其催化结构域共价或非共价地连接至所述cpf1切口酶蛋白或所述指导分子,或者适于在递送之后连接至所述cpf1切口酶蛋白或所述指导分子;其中指导分子与所述cpf1切口酶蛋白形成复合物并引导所述复合物结合所述目标靶基因座处的第一dna链,其中所述指导序列能够与所述第一dna链内包含腺嘌呤的靶序列杂交,以形成包含与所述腺嘌呤相对的非配对胞嘧啶的异源双链体;其中所述cpf1切口酶蛋白使因所述异源双链体形成而移位的所述目标靶基因座处的第二dna链产生切口;并且其中所述腺苷脱氨酶蛋白或其催化结构域使所述异源双链体中与所述非配对胞嘧啶相对的腺嘌呤脱氨基。
在一些实施方案中,腺苷脱氨酶蛋白或其催化结构域融合至cpf1切口酶蛋白的n端或c端。在一些实施方案中,腺苷脱氨酶蛋白或其催化结构域通过接头融合至cpf1切口酶蛋白。在一些实施方案中,接头是(ggggs)3-11(seqidno:1-9)、gsg5(seqidno:10)或lepgekpykcpecgksfsqsgaltrhqrthtr(seqidno:11)。
在一些实施方案中,腺苷脱氨酶蛋白或其催化结构域连接至衔接蛋白,并且指导分子或cpf1切口酶蛋白包含能够与衔接蛋白结合的适体序列。在一些实施方案中,衔接序列选自ms2、pp7、qβ、f2、ga、fr、jp501、m12、r17、bz13、jp34、jp500、ku1、m11、mx1、tw18、vk、sp、fi、id2、nl95、tw19、ap205、φcb5、φcb8r、φcb12r、φcb23r、7s和prr1。
在一些实施方案中,腺苷脱氨酶蛋白或其催化结构域插入到cpf1切口酶蛋白的内环中。
在一些实施方案中,cpf1切口酶蛋白是使非靶链,即与包含靶序列并且与指导序列杂交的链互补的链产生切口的切口酶。在一些实施方案中,cpf1切口酶蛋白包含在nuc结构域中的突变。在一些实施方案中,cpf1切口酶蛋白包含对应于ascpf1中的r1226a的突变。
在一些实施方案中,将cpf1切口酶的部分或全部nuc结构域去除。在一个具体实施方案中,将ascpf1的氨基酸1076至1258去除并且替代为接头(例如gsgg或ggsggs接头)。
在一些实施方案中,crispr-cas蛋白是死亡cpf1,其包含在ruvc结构域中的突变。在一些实施方案中,crispr-cas蛋白是死亡cpf1,并且包含对应于ascpf1中的d908a或e993a的突变。在一些实施方案中,将死亡cpf1的部分或全部nuc结构域去除。在一个具体实施方案中,将ascpf1的氨基酸1076至1258去除并且替代为接头(例如gsgg或ggsggs接头)。
在一些实施方案中,指导分子结合至cpf1并且能够与靶序列形成约24nt的异源双链体。在一些实施方案中,指导分子结合至cpf1并且能够与靶序列形成超过24nt的异源双链体。
在一些实施方案中,腺苷脱氨酶是人类、鱿鱼或果蝇腺苷脱氨酶。在一些实施方案中,已对腺苷脱氨酶进行了修饰以增加针对dna-rna异源双链体的活性。在一些实施方案中,腺苷脱氨酶是包含突变e488q的突变hadar2d或包含突变e1008q的突变hadar1d。
在一些实施方案中,所述方法包括确定目标靶序列以及选择最有效地使存在于靶序列中的腺嘌呤脱氨基的腺苷脱氨酶。
在一些实施方案中,cpf1切口酶蛋白来源于选自由以下组成的组的细菌种类:土拉弗朗西斯菌(francisellatularensis)、易北普雷沃氏菌(prevotellaalbensis)、毛螺科菌、解蛋白丁酸弧菌(butyrivibrioproteoclasticus)、异域菌门菌(peregrinibacteriabacterium)、帕库氏菌(parcubacteriabacterium)、史密斯氏菌属种(smithellasp.)、氨基酸球菌属种(acidaminococcussp.)、毛螺科菌、候选白蚁甲烷支原体(candidatusmethanoplasmatermitum)、挑剔真杆菌(eubacteriumeligens)、牛眼莫拉氏菌(moraxellabovoculi)、稻田氏钩端螺旋体(leptospirainadai)、狗口腔卟啉单胞菌(porphyromonascrevioricanis)、解糖胨普雷沃氏菌(prevotelladisiens)和猕猴卟啉单胞菌(porphyromonasmacacae)、溶糊精琥珀酸弧菌(succinivibriodextrinosolvens)、解糖胨普雷沃氏菌、嗜鳃黄杆菌(flavobacteriumbranchiophilum)、孔兹氏创伤球菌(helcococcuskunzii)、真细菌属种(eubacteriumsp.)、微基因组菌(罗兹曼菌)(microgenomates(roizmanbacteria)bacterium)、黄杆菌属种、短普雷沃氏菌(prevotellabrevis)、山羊莫拉氏菌(moraxellacaprae)、口腔拟杆菌(bacteroidetesoral)、犬嘴卟啉单胞菌(porphyromonascansulci)、琼氏互养菌(synergistesjonesii)、布氏普雷沃氏菌(prevotellabryantii)、厌氧弧菌属种(anaerovibriosp.)、溶纤维丁酸弧菌(butyrivibriofibrisolvens)、候选甲烷嗜甲基菌(candidatusmethanomethylophilus)、丁酸弧菌属种(butyrivibriosp.)、口腔无芽孢厌氧菌属种(oribacteriumsp.)、瘤胃假丁酸弧菌(pseudobutyrivibrioruminis)和产丁酸菌(proteocatellasphenisci)。
在一些实施方案中,天然pam序列是ttn,其中n是a/c/g或t,并且crispr-cas蛋白是fncpf1,或者其中pam序列是tttv,其中v是a/c或g,并且crispr-cas蛋白是pacpf1p、lbcpf1或ascpf1。
在一些实施方案中,cpf1切口酶蛋白已被修饰并且识别改变的pam序列。
在一些实施方案中,目标靶基因座在细胞内。在一些实施方案中,细胞是真核细胞。在一些实施方案中,细胞是非人类动物细胞。在一些实施方案中,细胞是人类细胞。在一些实施方案中,细胞是植物细胞。
在一些实施方案中,目标靶基因座在动物体内。在一些实施方案中,目标靶基因座在植物内部。在一些实施方案中,目标靶基因座包含在体外dna分子中。
在一些实施方案中,将组分(a)、组分(b)和组分(c)作为核糖核蛋白复合物递送至细胞。
在一些实施方案中,将组分(a)、组分(b)和组分(c)作为一种或多种多核苷酸分子递送至细胞。在一些实施方案中,所述一种或多种多核苷酸分子包含一种或多种编码组分(a)和/或组分(c)的mrna分子。
在一些实施方案中,所述一种或多种多核苷酸分子包含在一种或多种载体内。在一些实施方案中,所述一种或多种多核苷酸分子包含可操作地配置成表达cpf1切口酶蛋白、指导分子和腺苷脱氨酶蛋白或其催化结构域的一个或多个调控元件,任选地其中所述一个或多个调控元件包括诱导型启动子。
在一些实施方案中,cpf1切口酶蛋白和任选地腺苷脱氨酶蛋白或其催化结构域包含一个或多个异源核定位信号(nls)。
在一些实施方案中,经由粒子、囊泡或一种或多种病毒载体递送所述一种或多种多核苷酸分子或核糖核蛋白复合物。
在一些实施方案中,粒子包含脂质、糖、金属或蛋白质。在一些实施方案中,粒子包含脂质纳米粒子。
在一些实施方案中,囊泡包含外泌体或脂质体。在一些实施方案中,所述一种或多种病毒载体包含一种或多种腺病毒、一种或多种慢病毒、或一种或多种腺相关病毒。
在一些实施方案中,所述方法通过操纵目标基因组基因座处的一个或多个靶序列来修饰细胞、细胞系或生物体。
本发明的至少第二方面涉及一种用于使用本文所述的方法来治疗或预防疾病的方法,其中在目标靶基因座处腺嘌呤的脱氨补救了由g→a或c→t点突变或病原性snp引起的疾病。在一些实施方案中,疾病选自癌症、血友病、β地中海贫血、马凡综合征(marfansyndrome)和成斯科特-奥尔德里奇综合征(wiskott-aldrichsyndrome)。
本发明的至少第三方面涉及一种用于敲除或敲低基因或其调控元件的不合需要的活性的方法,其中在目标靶基因座处的腺嘌呤的脱氨使靶基因座处的靶基因或靶调控元件失活。
本发明的至少第四方面涉及一种从以上所述的方法获得的修饰的细胞或其子代,其中所述细胞与未经历所述方法的相应细胞相比,在目标靶基因座中包含次黄嘌呤或鸟嘌呤而非腺嘌呤。
在一些实施方案中,修饰的细胞是真核细胞。在一些实施方案中,修饰的细胞是动物细胞。在一些实施方案中,修饰的细胞是人类细胞。在一些实施方案中,修饰的细胞是植物细胞。
在一些实施方案中,修饰的细胞是治疗性t细胞。在一些实施方案中,修饰的细胞是产生抗体的b细胞。
本发明的至少第五方面涉及一种包含本文所述的修饰的细胞的非人类动物或植物。
本发明的至少第六方面涉及一种用于细胞疗法的方法,所述方法包括向有需要的患者施用本文所述的修饰的细胞,其中所述修饰的细胞的存在补救了所述患者的疾病。
本发明的至少第七方面涉及一种适用于修饰目标靶基因座中的腺嘌呤的工程化的非天然存在的系统,所述系统包含:包含连接至正向重复序列的指导序列的指导分子,或编码所述指导分子的核苷酸序列;cpf1切口酶蛋白,或编码所述cpf1切口酶蛋白的一个或多个核苷酸序列;腺苷脱氨酶蛋白或其催化结构域,或编码其的一个或多个核苷酸序列;其中所述腺苷脱氨酶蛋白或其催化结构域共价或非共价地连接至所述cpf1切口酶蛋白或所述指导分子,或者适于在递送之后连接至所述cpf1切口酶蛋白或所述指导分子;其中所述指导序列能够与所述靶基因座内第一dna链上包含腺嘌呤的靶序列杂交,但是在对应于所述腺嘌呤的位置处包含胞嘧啶;并且其中所述cpf1切口酶蛋白能够使与所述第一dna链互补的第二dna链中的非靶序列产生切口。因此,本申请提供了药盒,所述药盒包含本文所述的ad官能化的crispr系统或由其组成。
本发明的至少第八方面涉及一种适用于修饰目标靶基因座中的腺嘌呤的工程化的非天然存在的载体系统,所述载体系统包含一种或多种载体,所述一种或多种载体包含:第一调控元件,所述第一调控元件可操作地连接至编码包含连接至正向重复序列的指导序列的指导分子的一个或多个核苷酸序列;第二调控元件,所述第二调控元件可操作地连接至编码cpf1切口酶蛋白的核苷酸序列;和任选地编码腺苷脱氨酶蛋白或其催化结构域的核苷酸序列,所述核苷酸序列受第一调控元件或第二调控元件的控制或者可操作地连接至第三调控元件;其中如果所述编码腺苷脱氨酶蛋白或其催化结构域的核苷酸序列可操作地连接至第三调控元件,则所述腺苷脱氨酶蛋白或其催化结构域适于在表达之后连接至所述指导分子或所述cpf1切口酶蛋白;其中所述指导序列能够与所述靶基因座内第一dna链上包含腺嘌呤的靶序列杂交,但在对应于所述腺嘌呤的位置上包含胞嘧啶;其中组分(a)、组分(b)和组分(c)位于所述系统的相同或不同载体上;并且其中所述cpf1切口酶蛋白能够使与所述第一dna链互补的第二dna链中的非靶序列产生切口。因此,本申请提供了药盒,所述药盒包含编码本文所述的ad官能化的crispr系统的组分的载体或由其组成。
本发明的至少第九方面涉及包含本文所述的工程化的非天然存在的系统或载体系统的体外、离体或体内宿主细胞或细胞系或其子代。
在一些实施方案中,宿主细胞是真核细胞。在一些实施方案中,宿主细胞是动物细胞。在一些实施方案中,宿主细胞是人类细胞。在一些实施方案中,宿主细胞是植物细胞。
附图说明
本发明的新颖特征在所附权利要求中具体阐述。通过参考阐述了其中利用了本发明原理的说明性实施方案的以下详细说明及其附图,将获得对本发明的特征和优点的更好理解:
图1图示了用于目标靶基因座处腺嘌呤的靶向脱氨的本发明的示例性实施方案。
图2示出了cpf1和腺苷脱氨酶的融合蛋白(nls-flag-ascpf1-linker-hadar2d(wt))的示例性实施方案的氨基酸序列。
图3示出了cpf1和腺苷脱氨酶的融合蛋白(nls-flag-ascpf1(r1226a)-linker-hadar2d(e488q))的示例性实施方案的氨基酸序列。
图4示出了cpf1和腺苷脱氨酶的融合蛋白(nls-flag-ascpf1(d908a)-linker-hadar2d(e488q))的示例性实施方案的氨基酸序列。
图5示出了cpf1和腺苷脱氨酶的融合蛋白(nls-flag-ascpf1(e993a)-linker-hadar2d(e488q))的示例性实施方案的氨基酸序列。
图6示出了spcas9和ascpf1与huadar2d的融合物。制备了用于a至g转化的ascpf1的四个构建体和spcas9的四个构建体。ascpf1(r1226a)和spcas9(n863a)的切口酶型式在n端或c端与人类adar2(adar)的脱氨酶结构域融合。另外,通过从spcas9去除hnh结构域或从ascpf1中去除nuc结构域以减少adar的空间位阻,生成了缺失构建体。
图7示出了adar融合物的缺失构建体。ascpf1的氨基酸1076至1258被gsgg接头替代,并且spcas9的氨基酸769至918被ggsggs接头替代。
图8示出了adar融合物在hek细胞中的表达。将hek293t细胞用不同的adar融合构建体或hnh/nuc缺失构建体转染,以确认蛋白质表达。转染两天后收获细胞,并使用ripa缓冲液提取蛋白质。使用针对flag(spcas9)或ha(ascpf1)标签的抗体,将5ul细胞裂解物用于蛋白质印迹。
图9示出了用于hek293细胞中mrna靶标的程序性a至g转化的指导物设计。
图10示出了hek293细胞中mrna靶标的程序性a至g转化的结果。
图11示出了hek293细胞中人类dnmt1的靶向a至g碱基编辑。与wtascpf1和adar2d对照构建体相比,与靶向人类dnmt1基因的指导rna复合的ascpf1(r1226a)-adar2d和ascpf1(δnuc)-adar2d融合构建体各自都显示出可检测水平的靶向a至g碱基编辑。
本文中的附图仅用于说明目的,而不一定按比例绘制。
具体实施方式
在下文中描述各种实施方案。应当指出的是,具体实施方案不旨在作为详尽的描述或作为对本文所论述的更广泛方面的限制。结合特定实施方案描述的一个方面不必限于该实施方案,而是可以与任何其他一个或多个实施方案一起实践。
用于腺嘌呤靶向脱氨的方法
在一方面,本发明提供了用于dna中,更特别地目标基因座中的腺嘌呤的靶向脱氨的方法。根据本发明的方法,通过可以特异性地结合至靶序列的crispr-cas复合物将腺苷脱氨酶(ad)蛋白特异性地募集至目标基因座中的相关腺嘌呤。为了实现这一点,可以将腺苷脱氨酶蛋白共价连接至crispr-cas酶或作为单独的蛋白提供,但是进行调整以确保将其募集至crispr-cas复合物。
在本发明方法的特定实施方案中,通过将腺苷脱氨酶或其催化结构域融合至crispr-cas蛋白(其为cpf1蛋白)来确保将腺苷脱氨酶募集至靶基因座。由两种分离的蛋白质产生融合蛋白的方法在本领域中是已知的,并且通常涉及间隔区或接头的使用。cpf1蛋白可以在其n端或c端融合至腺苷脱氨酶蛋白或其催化结构域。在特定实施方案中,crispr-cas蛋白是cpf1蛋白,其连接至脱氨酶蛋白或其催化结构域的n端。
如关于融合蛋白使用的术语“接头”是指将所述蛋白连接以形成融合蛋白的分子。通常,除了连接蛋白质或保持蛋白质之间的一些最小距离或其他空间关系之外,此类分子不具有特殊的生物活性。然而,在某些实施方案中,可以选择接头以影响接头和/或融合蛋白的某些特性,诸如接头的折叠、净电荷或疏水性。
适用于本发明方法的接头是本领域技术人员所熟知的,并且包括但不限于直链或支链碳接头、杂环碳接头或肽接头。但是,如本文所用,接头还可以是共价键(碳-碳键或碳-杂原子键)。在特定实施方案中,接头用于将crispr-cas蛋白和腺苷脱氨酶分开足以确保每种蛋白保留其所需功能特性的距离。优选的肽接头序列采用柔性的延伸构象,并且不表现出发展有序二级结构的倾向。在某些实施方案中,接头可以是化学部分,其可以是单体、二聚体、多聚体或聚合物。优选地,接头包含氨基酸。柔性接头中的典型氨基酸包括gly、asn和ser。因此,在特定实施方案中,接头包含gly、asn和ser氨基酸中的一种或多种的组合。其他接近中性的氨基酸,诸如thr和ala,也可以用于接头序列中。示例性接头公开于maratea等人(1985),gene40:39-46;murphy等人(1986)proc.nat′l.acad.sci.usa83:8258-62;美国专利号4,935,233;和美国专利号4,751,180中。例如,可以使用glyser接头ggs、gggs或gsg。ggs、gsg、gggs或ggggs接头可以按3个(诸如(ggs)3(seqidno:12)、(ggggs)3)或5、6、7、9甚至12个或更多个的重复使用,以提供合适的长度。在特定实施方案中,在本文中优选使用诸如(ggggs)3(seqidno:13)的接头。可以优选地使用(ggggs)6(seqidno:14)、(ggggs)9(seqidno:15)或(ggggs)12(seqidno:16)作为替代品。其他优选的替代品是(ggggs)1(seqidno:17)、(ggggs)2(seqidno:18)、(ggggs)4(seqidno:19)、(ggggs)5(seqidno:20)、(ggggs)7(seqidno:21)、(ggggs)8(seqidno:22)、(ggggs)10(seqidno:23)或(ggggs)11(seqidno:24)。在又一个实施方案中,使用lepgekpykcpecgksfsqsgaltrhqrthtr(seqidno:25)作为接头。在又另一个实施方案中,接头是xten接头。在特定实施方案中,crispr-cas蛋白是cpf1蛋白,其通过lepgekpykcpecgksfsqsgaltrhqrthtr(seqidno:26)接头连接至脱氨酶蛋白或其催化结构域。在另外的特定实施方案中,cpf1蛋白在c端通过lepgekpykcpecgksfsqsgaltrhqrthtr(seqidno:27)连接至脱氨酶蛋白或其催化结构域的n端。此外,n端和c端的nls也可以充当接头(例如pkkkrkveasspkkrkveas(seqidno:28))。
在本发明方法的特定实施方案中,将腺苷脱氨酶蛋白或其催化结构域作为单独的蛋白递送至细胞或在细胞内表达,但对其进行了修饰以使其能够连接至cpf1蛋白或指导分子。在特定实施方案中,这是通过使用存在于多种多样的噬菌体外壳蛋白中的正交rna结合蛋白或衔接蛋白/适体组合来确保的。此类外壳蛋白的实例包括但不限于:ms2、qβ、f2、ga、fr、jp501、m12、r17、bz13、jp34、jp500、ku1、m11、mx1、tw18、vk、sp、fi、id2、nl95、tw19、ap205、φcb5、φcb8r、φcb12r、φcb23r、7s和prr1。适体可以是通过反复轮次的体外选择或selex(指数富集的配体系统进化)进行工程化以便与特定靶标结合的天然存在的或合成的寡核苷酸。
在本发明的方法和系统的特定实施方案中,指导分子提供有一个或多个可以募集衔接蛋白的不同的rna环或不同的序列。通过插入一个或多个不同的rna环或不同的序列可以扩展指导分子,而不会与cpf1蛋白发生冲突,这些不同的rna环或不同的序列可以募集可以结合至所述不同的rna环或不同的序列的衔接蛋白。konermann(nature2015,517(7536):583-588)中提供了修饰指导物的示例及其在将效应结构域募集至crispr-cas复合物中的用途。在特定实施方案中,适体是选择性地结合哺乳动物细胞中的二聚化ms2噬菌体外壳蛋白的最小发夹适体,并且被引入到指导分子中,诸如茎环和/或四环中。在这些实施方案中,将腺苷脱氨酶蛋白融合至ms2。然后将腺苷脱氨酶蛋白与crispr-cas蛋白和相应的指导rna共同递送。
如本文所用,术语“ad官能化的crispr系统”是指核酸靶向和编辑系统,所述系统包含(a)crispr-cas蛋白,更特别地是无催化活性的cpf1蛋白或切口酶;(b)包含指导序列的指导分子;(c)腺苷脱氨酶蛋白或其催化结构域;其中所述腺苷脱氨酶蛋白或其催化结构域共价或非共价地连接至所述crispr-cas蛋白或所述指导分子,或者适于在递送之后连接至所述crispr-cas蛋白或所述指导分子;其中所述指导序列与靶序列基本上互补,但包含对应于针对脱氨靶向的a的非配对c,导致由所述指导序列和所述靶序列形成的异源双链体中的a-c错配。对于在真核细胞中应用,crispr-cas蛋白和/或腺苷脱氨酶优选地带有nls标签。
在一些实施方案中,将组分(a)、组分(b)和组分(c)作为核糖核蛋白复合物递送至细胞。可以经由一种或多种脂质纳米粒子递送核糖核蛋白复合物。
在一些实施方案中,将组分(a)、组分(b)和组分(c)作为一种或多种rna分子诸如编码crispr-cas蛋白、腺苷脱氨酶蛋白和任选地衔接蛋白的一种或多种指导rna和一种或多种mrna分子递送至细胞。可以经由一种或多种脂质纳米粒子递送rna分子。
在一些实施方案中,将组分(a)、组分(b)和组分(c)作为一种或多种dna分子递送至细胞。在一些实施方案中,一种或多种dna分子包含在一种或多种载体诸如病毒载体(例如aav)中。在一些实施方案中,所述一种或多种dna分子包含可操作地配置成表达crispr-cas蛋白、指导分子和腺苷脱氨酶蛋白或其催化结构域的一个或多个调控元件,任选地其中所述一个或多个调控元件包括诱导型启动子。
在一些实施方案中,crispr-cas蛋白是cpf1切口酶。在一些实施方案中,cpf1切口酶包含在nuc结构域中的突变。在一些实施方案中,cpf1切口酶能够使因靶向dna链与指导分子之间异源双链体形成而移位的目标靶基因座处的非靶向dna链产生切口。本文其他地方提供了有关ad官能化的crispr-cas系统中的crispr-cas蛋白方面的细节。
在一些实施方案中,cpf1切口酶包含对应于ascpf1中的r1226a的突变。
在某些实施方案中,crispr-cas蛋白是死亡cpf1。在一些实施方案中,死亡cpf1包含在ruvc结构域中的突变。在一些实施方案中,死亡cpf1包含对应于ascpf1中的d908a或e993a的突变。
在一些实施方案中,指导分子能够与靶基因座处第一dna链内包含待脱氨基的腺嘌呤的靶序列杂交,以形成包含与所述腺嘌呤相对的非配对胞嘧啶的异源双链体。在形成异源双链体时,指导分子与cpf1蛋白形成复合物,并引导所述复合物结合所述目标靶基因座处的所述第一dna链。下文提供了有关ad官能化的crispr-cas系统中的指导物方面的细节。
在一些实施方案中,使用具有典型长度(例如,对于ascpf1为约24nt)的cpf1指导rna与靶dna形成异源双链体。在一些实施方案中,使用比典型长度(例如,对于ascpf1为>24nt)长的cpf1指导分子与靶dna形成异源双链体,包括在cpf1指导rna-靶dna复合物之外形成异源双链体。在某些示例性实施方案中,指导序列具有能够与所述靶序列形成dna-rna双链体的约20-53nt、或约25-53nt或约29-53nt的长度。在某些其他示例性实施方案中,指导序列具有能够与所述靶序列形成dna-rna双链体双链体的约40-50nt的长度。在某些示例性实施方案中,所述非配对c与所述指导序列的5’端之间的距离为20-30个核苷酸。在某些示例性实施方案中,所述非配对c与所述指导序列的3’端之间的距离为20-30个核苷酸。在特定实施方案中,指导序列包含多于一个对应于靶dna序列中不同腺苷位点的错配,或其中使用了两个指导分子,每个指导分子均包含对应于靶rna序列中不同腺苷位点的错配。
在至少第一设计中,ad官能化的crispr系统包含(a)融合或连接至crispr-cas蛋白的腺苷脱氨酶,其中所述crispr-cas蛋白无催化活性或者是切口酶;和(b)指导分子,其包含被设计来在指导序列与靶序列之间所形成的异源双链体中引入a-c错配的指导序列。在一些实施方案中,crispr-cas蛋白和/或腺苷脱氨酶在n端或c端或这两者上带有nls标签。
在至少第二设计中,ad官能化的crispr系统包含(a)无催化活性或者为切口酶的crispr-cas蛋白;(b)指导分子,其包含被设计来在指导序列与靶序列之间所形成的异源双链体中引入a-c错配的指导序列,和能够结合衔接蛋白(例如ms2外壳蛋白或pp7外壳蛋白)的适体序列(例如ms2rna基序或pp7rna基序);和(c)融合或连接至衔接蛋白的腺苷脱氨酶,其中适体和衔接蛋白的结合将腺苷脱氨酶募集至在指导序列与靶序列之间所形成的异源双链体,以在a-c错配的a处进行靶向脱氨。在一些实施方案中,衔接蛋白和/或腺苷脱氨酶在n端或c端或这两者上带有nls标签。crispr-cas蛋白也可以带有nls标签。
使用不同的适体和相应的衔接蛋白还可以实现正交基因编辑。在结合使用腺苷脱氨酶与胞苷脱氨酶用于正交基因编辑/脱氨的实例中,用不同的rna环修饰靶向不同基因座的sgrna,以分别募集ms2-腺苷脱氨酶和pp7-胞苷脱氨酶(或pp7-腺苷脱氨酶和ms2-胞苷脱氨酶),导致目标靶基因座处的a或c分别发生正交脱氨。pp7是噬菌体假单胞菌的rna结合外壳蛋白。同ms2一样,它结合特定的rna序列和二级结构。pp7rna识别基序与ms2的不同。因此,pp7和ms2可以多路复用,以同时在不同的基因组基因座介导不同的效应。例如,靶向基因座a的sgrna可以用ms2环修饰,从而募集ms2-腺苷脱氨酶;而靶向基因座b的另一sgrna可以用pp7环修饰,从而募集pp7-胞苷脱氨酶。因此,在同一细胞中实现了正交的基因座特异性修饰。可以扩展该原理以并入其他正交rna结合蛋白。
在至少第三设计中,ad官能化的crispr系统包含(a)插入到crispr-cas蛋白的内环或非结构化区中的腺苷脱氨酶,其中所述crispr-cas蛋白无催化活性或者是切口酶;和(b)指导分子,其包含被设计来在指导序列与靶序列之间所形成的异源双链体中引入a-c错配的指导序列。
可以借助晶体结构鉴定适用于腺苷脱氨酶插入的crispr-cas蛋白拆分位点。如果直系同源物与预期的crispr-cas蛋白之间存在相对高程度的同源性,则可以使用直系同源物的晶体结构。
拆分位置可以位于某一区域或环内。优选地,拆分位置在氨基酸序列的中断不会导致结构特征(例如α-螺旋或β-折叠)部分或全部破坏的地方出现。非结构化区(由于结构化程度不足以使其在晶体中“冻结”而未出现在晶体结构中的区域)通常是首选选项。非结构化区或外环内的位置可能不必完全是上面提供的数字,而是可能会变化,例如以上给出的位置任一侧的1个、2个、3个、4个、5个、6个、7个、8个、9个甚至10个氨基酸(取决于环的大小),只要拆分位置仍落在外环的非结构化区内即可。
对于cpf1,已经在cpf1一级结构内预测了非结构化区的若干小的延伸(参见wo2016205711,该专利的内容以引用方式并入本文)。对于拆分而言,不同的cpf1直系同源物内的暴露于溶剂且不保守的非结构化区是优选的侧面。
下表呈现了ascpf1和lbcpf1中的非限制性潜在拆分区域。在这样的区域内的拆分位点可能是适宜的。
对于fn、as和lbcpf1突变体,例如基于序列比对,很容易清楚潜在拆分位点的对应位置是什么。对于非fn、as和lb酶,如果直系同源物与预期的cpf1之间存在相对高程度的同源性,则可以使用直系同源物的晶体结构,或者可以使用计算预测。
本文所述的ad官能化的crispr系统可用于靶向dna序列内的特定腺嘌呤以进行脱氨。例如,指导分子可以与crispr-cas蛋白形成复合物,并引导所述复合物结合所述目标靶基因座处的靶序列。由于指导序列被设计成具有非配对c,因此在指导序列与靶序列之间所形成的异源双链体包含a-c错配,该错配引导腺苷脱氨酶与同非配对c相对的a接触并使其脱氨基,从而将其转化为肌苷(i)。由于肌苷(i)碱基与c配对并且在细胞过程中具发挥类似g的功能,因此本文所述的a的靶向脱氨可用于校正不合需要的g-a和c-t突变,以及获得期望的a-g和t-c突变。
在一些实施方案中,ad官能化的crispr系统是用于体外dna分子中的靶向脱氨。在一些实施方案中,ad官能化的crispr系统是用于细胞内dna分子中的靶向脱氨。细胞可以是真核细胞,诸如动物细胞、哺乳动物细胞、人类细胞或植物细胞。
本发明还涉及一种用于通过使用ad官能化的crispr系统进行靶向脱氨来治疗或预防疾病的方法,其中a的脱氨恢复了目标靶基因座处的健康基因型,从而补救了由g→a或c→t点突变或病原性snp引起的疾病。可以用本发明治疗或预防的疾病的实例包括癌症、血友病、β地中海贫血、马凡综合征和威斯科特-奥尔德里奇综合征。
本发明还涉及一种用于敲除或敲低基因或其调控元件的不合需要的活性的方法,其中在目标靶基因座处的a的脱氨使靶基因座处的靶基因或靶调控元件失活。例如,在一个实施方案中,通过ad官能化的crispr系统进行靶向脱氨可引起无义突变,使得内源性基因中出现提前终止密码子。这可能改变内源性基因的表达,并使得编辑后的细胞具有期望的性状。在另一个实施方案中,通过ad官能化的crispr系统进行靶向脱氨可引起非保守的错义突变,使得内源性基因中出现不同氨基酸残基的密码。这可能改变内源性基因的功能,并使得编辑后的细胞具有期望的性状。
本发明还涉及一种通过使用ad官能化的crispr系统进行靶向脱氨而获得的修饰的细胞或其子代,其中与靶向脱氨之前的相应细胞相比,所述修饰的细胞在目标靶基因座处包含i或g而非a。修饰的细胞可以是真核细胞,诸如动物细胞、植物细胞、哺乳动物细胞或人类细胞。
在一些实施方案中,修饰的细胞是治疗性t细胞,诸如适于car-t疗法的t细胞。修饰可以使得在治疗性t细胞中出现一种或多种期望的性状,包括但不限于免疫检查点受体(例如pda、ctla4)的表达降低、hla蛋白(例如b2m、hla-a)的表达降低以及内源性tcr的表达降低。
在一些实施方案中,修饰的细胞是产生抗体的b细胞。修饰可以使得在b细胞中出现一种或多种期望的性状,包括但不限于抗体产生增强。
本发明还涉及一种修饰的非人类动物或修饰的植物。修饰的非人类动物可以是农场动物。修饰的植物可以是农作物。
本发明还涉及一种用于细胞疗法的方法,所述方法包括向有需要的患者施用本文所述的修饰的细胞,其中所述修饰的细胞的存在补救了所述患者的疾病。在一个实施方案中,用于细胞疗法的修饰的细胞是能够识别和/或攻击肿瘤细胞的car-t细胞。在另一个实施方案中,用于细胞疗法的修饰的细胞是干细胞,诸如神经干细胞、间充质干细胞、造血干细胞或ipsc细胞。
本发明另外涉及一种适用于修饰目标靶基因座中的腺嘌呤的工程化的非天然存在的系统,所述系统包含:包含指导序列的指导分子,或编码所述指导分子的核苷酸序列;crispr-cas蛋白,或编码所述crispr-cas蛋白的一个或多个核苷酸序列;腺苷脱氨酶蛋白或其催化结构域,或编码其的一个或多个核苷酸序列;其中所述腺苷脱氨酶蛋白或其催化结构域共价或非共价地连接至所述crispr-cas蛋白或所述指导分子,或者适于在递送之后连接至所述crispr-cas蛋白或所述指导分子;其中所述指导序列能够与所述靶基因座内包含腺嘌呤的靶序列杂交,但是在对应于所述腺嘌呤的位置处包含胞嘧啶。
本发明另外涉及一种适用于修饰目标靶基因座中的腺嘌呤的工程化的非天然存在的载体系统,所述载体系统包含一种或多种载体,所述一种或多种载体包含:第一调控元件,所述第一调控元件可操作地连接至一个或多个编码包含指导序列的指导分子的核苷酸序列;第二调控元件,所述第二调控元件可操作地连接至编码crispr-cas蛋白的核苷酸序列;和任选地编码腺苷脱氨酶蛋白或其催化结构域的核苷酸序列,所述核苷酸序列受第一调控元件或第二调控元件的控制或者可操作地连接至第三调控元件;其中如果所述编码腺苷脱氨酶蛋白或其催化结构域的核苷酸序列可操作地连接至第三调控元件,则所述腺苷脱氨酶蛋白或其催化结构域适于在表达之后连接至所述指导分子或所述crispr-cas蛋白;其中所述指导序列能够与所述靶基因座内包含腺嘌呤的靶序列杂交,但在对应于所述腺嘌呤的位置上包含胞嘧啶;其中组分(a)、组分(b)和组分(c)位于所述系统的相同或不同载体上。
本发明另外涉及包含本文所述的工程化的非天然存在的系统或载体系统的体外、离体或体内宿主细胞或细胞系或其子代。宿主细胞可以是真核细胞,诸如动物细胞、植物细胞、哺乳动物细胞或人类细胞。
腺苷脱氨酶
如本文所用,术语“腺苷脱氨酶”或“腺苷脱氨酶蛋白”是指能够催化如下所示的将腺嘌呤(或分子的腺嘌呤部分)转化为次黄嘌呤(或分子的次黄嘌呤部分)的水解脱氨反应的蛋白质、多肽或蛋白质或多肽的一个或多个功能结构域。在一些实施方案中,含腺嘌呤的分子是腺苷(a),而含次黄嘌呤的分子是肌苷(i)。含腺嘌呤的分子可以是脱氧核糖核酸(dna)或核糖核酸(rna)。
根据本公开,可以与本公开结合使用的腺苷脱氨酶包括但不限于称为作用于rna的腺苷脱氨酶(adar)的酶家族成员、称为作用于trna的腺苷脱氨酶(adat)的酶家族成员,以及其他含腺苷脱氨酶结构域(adad)的家族成员。根据本公开,腺苷脱氨酶能够靶向rna/dna异源双链体中的腺嘌呤。实际上,zheng等人(nucleicacidsres.2017,45(6):3369-3377)已证明adar可以在rna/dna异源双链体上实现腺苷到肌苷的编辑反应。在特定实施方案中,如下文所详述,已对腺苷脱氨酶进行了修饰以增强其编辑rna/dna异源双链体中的dna的能力。
在一些实施方案中,腺苷脱氨酶来源于一种或多种后生动物种类,包括但不限于哺乳动物、鸟、青蛙、鱿鱼、鱼、蝇和蠕虫。在一些实施方案中,腺苷脱氨酶是人类、鱿鱼或果蝇腺苷脱氨酶。
在一些实施方案中,腺苷脱氨酶是人类adar,包括hadar1、hadar2、hadar3。在一些实施方案中,腺苷脱氨酶是秀丽隐杆线虫(caenorhabditiselegans)adar蛋白,包括adr-1和adr-2。在一些实施方案中,腺苷脱氨酶是果蝇adar蛋白,包括dadar。在一些实施方案中,腺苷脱氨酶是鱿鱼近海长鳍鱿鱼(loligopealeii)adar蛋白,包括sqadar2a和sqadar2b。在一些实施方案中,腺苷脱氨酶是人类adat蛋白。在一些实施方案中,腺苷脱氨酶是果蝇adat蛋白。在一些实施方案中,腺苷脱氨酶是人类adad蛋白,包括tenr(hadad1)和tenrl(hadad2)。
在一些实施方案中,腺苷脱氨酶是tada蛋白,诸如大肠杆菌tada。参见kim等人,biochemistry45:6407-6416(2006);wolf等人,emboj.21:3841-3851(2002)。在一些实施方案中,腺苷脱氨酶是小鼠ada。参见grunebaum等人,curr.opin.allergyclin.immunol.13:630-638(2013)。在一些实施方案中,腺苷脱氨酶是人类adat2。参见fukui等人,j.nucleicacids2010:260512(2010)。
在一些实施方案中,腺苷脱氨酶选自:
在一些实施方案中,腺苷脱氨酶蛋白识别双链核酸底物中的一个或多个靶腺苷残基并将其转化为一个或多个肌苷残基。在一些实施方案中,双链核酸底物是rna-dna杂合双链体。在一些实施方案中,腺苷脱氨酶蛋白识别双链底物上的结合窗口。在一些实施方案中,结合窗口含有至少一个靶腺苷残基。在一些实施方案中,结合窗口在约3bp至约100bp的范围内。在一些实施方案中,结合窗口在约5bp至约50bp的范围内。在一些实施方案中,结合窗口在约10bp至约30bp的范围内。在一些实施方案中,结合窗口为约1bp、2bp、3bp、5bp、7bp、10bp、15bp、20bp、25bp、30bp、40bp、45bp、50bp、55bp、60bp、65bp、70bp、75bp、80bp、85bp、90bp、95bp或100bp。
在一些实施方案中,腺苷脱氨酶蛋白包含一个或多个脱氨酶结构域。不意欲受理论的束缚,预期脱氨酶结构域用于识别双链核酸底物中所含的一个或多个靶腺苷(a)残基并将其转化为一个或多个肌苷(i)残基。在一些实施方案中,脱氨酶结构域包含活性中心。在一些实施方案中,活性中心包含锌离子。在一些实施方案中,在a至i编辑过程中,靶腺苷残基处的碱基配对被破坏,并且靶腺苷残基从双螺旋中“翻转”出来以变得可被腺苷脱氨酶接近。在一些实施方案中,在活性中心内或附近的氨基酸残基与靶腺苷残基5’端的一个或多个核苷酸相互作用。在一些实施方案中,在活性中心内或附近的氨基酸残基与靶腺苷残基3’端的一个或多个核苷酸相互作用。在一些实施方案中,在活性中心内或附近的氨基酸残基进一步与相反链上与靶腺苷残基互补的核苷酸相互作用。在一些实施方案中,氨基酸残基与核苷酸的2’羟基形成氢键。
在一些实施方案中,腺苷脱氨酶包含人类adar2全蛋白(hadar2)或其脱氨酶结构域(hadar2-d)。在一些实施方案中,腺苷脱氨酶是与hadar2或hadar2-d同源的adar家族成员。
特别地,在一些实施方案中,同源adar蛋白是人类adar1(hadar1)或其脱氨酶结构域(hadar1-d)。在一些实施方式中,hadar1-d的甘氨酸1007对应于甘氨酸487hadar2-d,而hadar1-d的谷氨酸1008对应于hadar2-d的谷氨酸488。
在一些实施方案中,腺苷脱氨酶包含hadar2-d的野生型氨基酸序列(参见图2)。在一些实施方案中,腺苷脱氨酶在hadar2-d序列中包含一个或多个突变,这样hadar2-d的编辑效率和/或底物编辑优选性可根据特定需要而改变。
hadar1和hadar2蛋白的某些突变已描述于kuttan等人,procnatlacadsciusa.(2012)109(48):e3295-304;want等人acschembiol.(2015)10(11):2512-9;和zheng等人nucleicacidsres.(2017)45(6):3369-337,所述文献各自以引用方式整体并入本文。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的甘氨酸336处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置336处的甘氨酸残基被天冬氨酸残基替代(g336d)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的甘氨酸487处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置487处的甘氨酸残基被具有相对小的侧链的非极性氨基酸残基替代。例如,在一些实施方案中,位置487处的甘氨酸残基被丙氨酸残基替代(g487a)。在一些实施方案中,位置487处的甘氨酸残基被缬氨酸残基替代(g487v)。在一些实施方案中,位置487处的甘氨酸残基被具有相对大的侧链的氨基酸残基取代。在一些实施方案中,位置487处的甘氨酸残基被精氨酸残基替代(g487r)。在一些实施方案中,位置487处的甘氨酸残基被赖氨酸残基替代(g487k)。在一些实施方案中,位置487处的甘氨酸残基被色氨酸残基替代(g487w)。在一些实施方案中,位置487处的甘氨酸残基被酪氨酸残基替代(g487y)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的谷氨酸488处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置488处的谷氨酸残基被谷氨酰胺残基替代(e488q)。在一些实施方案中,位置488处的谷氨酸残基被组氨酸残基替代(e488h)。在一些实施方案中,位置488处的谷氨酸残基被精氨酸残基替代(e488r)。在一些实施方案中,位置488处的谷氨酸残基被赖氨酸残基替代(e488k)。在一些实施方案中,位置488处的谷氨酸残基被天冬酰胺残基替代(e488n)。在一些实施方案中,位置488处的谷氨酸残基被丙氨酸残基替代(e488a)。在一些实施方案中,位置488处的谷氨酸残基被甲硫氨酸残基替代(e488m)。在一些实施方案中,位置488处的谷氨酸残基被丝氨酸残基替代(e488s)。在一些实施方案中,位置488处的谷氨酸残基被苯丙氨酸残基替代(e488f)。在一些实施方案中,位置488处的谷氨酸残基被赖氨酸残基替代(e488l)。在一些实施方案中,位置488处的谷氨酸残基被色氨酸残基替代(e488w)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的苏氨酸490处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置490处的苏氨酸残基被半胱氨酸残基替代(t490c)。在一些实施方案中,位置490处的苏氨酸残基被丝氨酸残基替代(t490s)。在一些实施方案中,位置490处的苏氨酸残基被丙氨酸残基替代(t490a)。在一些实施方案中,位置490处的苏氨酸残基被苯丙氨酸残基替代(t490f)。在一些实施方案中,位置490处的苏氨酸残基被酪氨酸残基替代(t490y)。在一些实施方案中,位置490处的苏氨酸残基被丝氨酸残基替代(t490r)。在一些实施方案中,位置490处的苏氨酸残基被丙氨酸残基替代(t490k)。在一些实施方案中,位置490处的苏氨酸残基被苯丙氨酸残基替代(t490p)。在一些实施方案中,位置490处的苏氨酸残基被酪氨酸残基替代(t490e)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的缬氨酸493处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置493处的缬氨酸残基被丙氨酸残基替代(v493a)。在一些实施方案中,位置493处的缬氨酸残基被丝氨酸残基替代(v493s)。在一些实施方案中,位置493处的缬氨酸残基被苏氨酸残基替代(v493t)。在一些实施方案中,位置493处的缬氨酸残基被精氨酸残基替代(v493r)。在一些实施方案中,位置493处的缬氨酸残基被天冬氨酸残基替代(v493d)。在一些实施方案中,位置493处的缬氨酸残基被脯氨酸残基替代(v493p)。在一些实施方案中,位置493处的缬氨酸残基被甘氨酸残基替代(v493g)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的丙氨酸589处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置589处的丙氨酸残基被缬氨酸残基替代(a589v)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的天冬酰胺597处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置597处的天冬酰胺残基被赖氨酸残基替代(n597k)。在一些实施方案中,腺苷脱氨酶包含在氨基酸序列的位置597处的突变,在野生型序列中该位置有天冬酰胺残基。在一些实施方案中,位置597处的天冬酰胺残基被精氨酸残基替代(n597r)。在一些实施方案中,腺苷脱氨酶包含在氨基酸序列的位置597处的突变,在野生型序列中该位置有天冬酰胺残基。在一些实施方案中,位置597处的天冬酰胺残基被丙氨酸残基替代(n597a)。在一些实施方案中,腺苷脱氨酶包含在氨基酸序列的位置597处的突变,在野生型序列中该位置有天冬酰胺残基。在一些实施方案中,位置597处的天冬酰胺残基被谷氨酸残基替代(n597e)。在一些实施方案中,腺苷脱氨酶包含在氨基酸序列的位置597处的突变,在野生型序列中该位置有天冬酰胺残基。在一些实施方案中,位置597处的天冬酰胺残基被组氨酸残基替代(n597h)。在一些实施方案中,腺苷脱氨酶包含在氨基酸序列的位置597处的突变,在野生型序列中该位置有天冬酰胺残基。在一些实施方案中,位置597处的天冬酰胺残基被甘氨酸残基替代(n597g)。在一些实施方案中,腺苷脱氨酶包含在氨基酸序列的位置597处的突变,在野生型序列中该位置有天冬酰胺残基。在一些实施方案中,位置597处的天冬酰胺残基被酪氨酸残基替代(n597y)。在一些实施方案中,位置597处的天冬酰胺残基被苯丙氨酸残基替代(n597f)。在一些实施方案中,腺苷脱氨酶包含突变n597i。在一些实施方案中,腺苷脱氨酶包含突变n597l。在一些实施方案中,腺苷脱氨酶包含突变n597v。在一些实施方案中,腺苷脱氨酶包含突变n597m。在一些实施方案中,腺苷脱氨酶包含突变n597c。在一些实施方案中,腺苷脱氨酶包含突变n597p。在一些实施方案中,腺苷脱氨酶包含突变n597t。在一些实施方案中,腺苷脱氨酶包含突变n597s。在一些实施方案中,腺苷脱氨酶包含突变n597w。在一些实施方案中,腺苷脱氨酶包含突变n597q。在一些实施方案中,腺苷脱氨酶包含突变n597d。在某些示例性实施方案中,以上所述的在n597处的突变是在e488q背景的情形下进一步进行的。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的丝氨酸599处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置599处的丝氨酸残基被苏氨酸残基替代(s599t)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的天冬酰胺613处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置613处的天冬酰胺残基被赖氨酸残基替代(n613k)。在一些实施方案中,腺苷脱氨酶包含在氨基酸序列的位置613处的突变,在野生型序列中该位置有天冬酰胺残基。在一些实施方案中,位置613处的天冬酰胺残基被精氨酸残基替代(n613r)。在一些实施方案中,腺苷脱氨酶包含在氨基酸序列的位置613处的突变,在野生型序列中该位置有天冬酰胺残基。在一些实施方案中,位置613处的天冬酰胺残基被丙氨酸残基替代(n613a)。在一些实施方案中,腺苷脱氨酶包含在氨基酸序列的位置613处的突变,在野生型序列中该位置有天冬酰胺残基。在一些实施方案中,位置613处的天冬酰胺残基被谷氨酸残基替代(n613e)。在一些实施方案中,腺苷脱氨酶包含突变n613i。在一些实施方案中,腺苷脱氨酶包含突变n613l。在一些实施方案中,腺苷脱氨酶包含突变n613v。在一些实施方案中,腺苷脱氨酶包含突变n613f。在一些实施方案中,腺苷脱氨酶包含突变n613m。在一些实施方案中,腺苷脱氨酶包含突变n613c。在一些实施方案中,腺苷脱氨酶包含突变n613g。在一些实施方案中,腺苷脱氨酶包含突变n613p。在一些实施方案中,腺苷脱氨酶包含突变n613t。在一些实施方案中,腺苷脱氨酶包含突变n613s。在一些实施方案中,腺苷脱氨酶包含突变n613y。在一些实施方案中,腺苷脱氨酶包含突变n613w。在一些实施方案中,腺苷脱氨酶包含突变n613q。在一些实施方案中,腺苷脱氨酶包含突变n613h。在一些实施方案中,腺苷脱氨酶包含突变n613d。在一些实施方案中,以上所述的在n613处的突变进一步结合e488q突变进行。
在一些实施方案中,为了提高编辑效率,腺苷脱氨酶可包含以下突变中的一个或多个:g336d、g487a、g487v、e488q、e488h、e488r、e488n、e488a、e488s、e488m、t490c、t490s、v493t、v493s、v493a、v493r、v493d、v493p、v493g、n597k、n597r、n597a、n597e、n597h、n597g、n597y、a589v、s599t、n613k、n613r、n613a、n613e(基于hadar2-d中的氨基酸序列位置),以及同源adar蛋白中对应于以上突变的突变。
在一些实施方案中,为了降低编辑效率,腺苷脱氨酶可包含以下突变中的一个或多个:e488f、e488l、e488w、t490a、t490f、t490y、t490r、t490k、t490p、t490e、n597f(基于hadar2-d中的氨基酸序列位置),以及同源adar蛋白中对应于以上突变的突变。在特定实施方案中,可能令人感兴趣的是使用功效降低的腺苷脱氨酶来减少脱靶效应。
术语“编辑特异性”和“编辑优选性”在本文可互换使用,是指在双链底物中特定腺苷位点处a至i编辑的程度。在一些实施方案中,底物编辑优选性是由靶腺苷残基的5’最近邻和/或3’最近邻决定的。在一些实施方案中,腺苷脱氨酶对底物的5’最近邻的优选性排序为u>a>c>g(“>”表示更大的优选性)。在一些实施方案中,腺苷脱氨酶对底物的3’最近邻的优选性排序为g>c~a>u(“>”表示更大的优选性;“~”表示相似的优选性)。在一些实施方案中,腺苷脱氨酶对底物的3’最近邻的优选性排序为g>c>u~a(“>”表示更大的优选性;“~”表示相似的优选性)。在一些实施方案中,腺苷脱氨酶对底物的3’最近邻的优选性排序为g>c>a>u(“>”表示更大的优选性)。在一些实施方案中,腺苷脱氨酶对底物的3’最近邻的优选性排序为c~g~a>u(“>”表示更大的优选性;“~”表示相似的优选性)。在一些实施方案中,腺苷脱氨酶对含有靶腺苷残基的三联体序列的优选性排序为tag>aag>cac>aat>gaa>gac(“>”表示更大的优选性),中心a为靶腺苷残基。
在一些实施方案中,腺苷脱氨酶的底物编辑优选性受腺苷脱氨酶蛋白中是否存在核酸结合结构域影响。在一些实施方案中,为了修改底物编辑优选性,将脱氨酶结构域与双链rna结合结构域(dsrbd)或双链rna结合基序(dsrbm)连接。在一些实施方案中,dsrbd或dsrbm可以来源于adar蛋白,诸如hadar1或hadar2。在一些实施方案中,使用包含至少一个dsrbd和脱氨酶结构域的全长adar蛋白。在一些实施方案中,所述一个或多个dsrbm或dsrbd处于脱氨酶结构域的n端。在其他实施方案中,所述一个或多个dsrbm或dsrbd处于脱氨酶结构域的c端。
在一些实施方案中,腺苷脱氨酶的底物编辑优选性受酶活性中心内或附近的氨基酸残基影响。在一些实施方案中,为了修改底物编辑优选性,腺苷脱氨酶可包含以下突变中的一个或多个:g336d、g487r、g487k、g487w、g487y、e488q、e488n、t490a、v493a、v493t、v493s、n597k、n597r、a589v、s599t、n613k、n613r(基于hadar2-d中的氨基酸序列位置),以及同源adar蛋白中对应于以上突变的突变。
特别地,在一些实施方案中,为了降低编辑特异性,腺苷脱氨酶可包含以下突变中的一个或多个:e488q、v493a、n597k、n613k(基于hadar2-d中的氨基酸序列位置),以及同源adar蛋白中对应于以上突变的突变。在一些实施方案中,为了增加编辑特异性,腺苷脱氨酶可包含突变t490a。
在一些实施方案中,为了增加对具有最接近5’g的靶腺苷(a),诸如包含三联体序列gac(中心a为靶腺苷残基)的底物的编辑优选性,腺苷脱氨酶可包含以下突变中的一个或多个:g336d、e488q、e488n、v493t、v493s、v493a、a589v、n597k、n597r、s599t、n613k、n613r(基于hadar2-d中的氨基酸序列位置),以及同源adar蛋白中对应于以上突变的突变。
特别地,在一些实施方案中,腺苷脱氨酶包含突变e488q或同源adar蛋白中的相应突变,以便编辑包含以下三联体序列的底物:gac、gaa、gau、gag、cau、aau、uac,中心a为靶腺苷残基。
在一些实施方案中,为了减少脱靶效应,腺苷脱氨酶可包含在以下位置处的突变中的一个或多个:r348、v351、t375、k376、e396、c451、r455、n473、r474、k475、r477、r481、s486、e488、t490、s495、r510(基于hadar2-d中的氨基酸序列位置),以及同源adar蛋白中对应于以上突变的突变。在一些实施方案中,腺苷脱氨酶包含在e488和选自r348、v351、t375、k376、e396、c451、r455、n473、r474、k475、r477、r481、s486、t490、s495、r510的一个或多个其他位置处的突变。在一些实施方案中,腺苷脱氨酶包含在t375处,以及任选地在一个或多个其他位置处的突变。在一些实施方案中,腺苷脱氨酶包含在n473处,以及任选地在一个或多个其他位置处的突变。在一些实施方案中,腺苷脱氨酶包含在v351处,以及任选地在一个或多个其他位置处的突变。在一些实施方案中,腺苷脱氨酶包含在e488和t375处,以及任选地在一个或多个其他位置处的突变。在一些实施方案中,腺苷脱氨酶包含在e488和n473处,以及任选地在一个或多个其他位置处的突变。在一些实施方案中,腺苷脱氨酶包含在e488和v351处,以及任选地在一个或多个其他位置处的突变。在一些实施方案中,腺苷脱氨酶包含在e488处以及t375、n473和v351中的一个或多个位置处的突变。
在一些实施方案中,为了减少脱靶效应,腺苷脱氨酶可包含选自以下的突变中的一个或多个:r348e、v351l、t375g、t375s、r455g、r455s、r455e、n473d、r474e、k475q、r477e、r481e、s486t、e488q、t490a、t490s、s495t和r510e(基于hadar2-d中的氨基酸序列位置),以及同源adar蛋白中对应于以上突变的突变。在一些实施方案中,腺苷脱氨酶包含突变e488q和选自r348e、v351l、t375g、t375s、r455g、r455s、r455e、n473d、r474e、k475q、r477e、r481e、s486t、t490a、t490s、s495t和r510e的一个或多个另外的突变。在一些实施方案中,腺苷脱氨酶包含突变t375g或t375s,以及任选地一个或多个另外的突变。在一些实施方案中,腺苷脱氨酶包含突变n473d,以及任选地一个或多个另外的突变。在一些实施方案中,腺苷脱氨酶包含突变v351l,以及任选地一个或多个另外的突变。在一些实施方案中,腺苷脱氨酶包含突变e488q和t375g或t375g,以及任选地一个或多个另外的突变。在一些实施方案中,腺苷脱氨酶包含突变e488q和n473d,以及任选地一个或多个另外的突变。在一些实施方案中,腺苷脱氨酶包含突变e488q和v351l,以及任选地一个或多个另外的突变。在一些实施方案中,腺苷脱氨酶包含突变e488q以及t375g/s、n473d和v351l中的一个或多个。
结合至双链体rna的人类adar2脱氨酶结构域的晶体结构显示出与修饰位点5’侧的rna结合的蛋白质环。该5’结合环是造成adar家族成员之间底物特异性差异的一个原因。参见wang等人,nucleicacidsres.,44(20):9872-9880(2016),该文献的内容以引用方式整体并入本文。另外,在酶活性位点附近识别出adar2特异性rna结合环。参见mathews等人nat.struct.mol.biol.,23(5):426-33(2016),该文献的内容以引用方式整体并入本文。在一些实施方案中,腺苷脱氨酶在rna结合环中包含一个或多个突变以提高编辑特异性和/或效率。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的丙氨酸454处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置454处的丙氨酸残基被丝氨酸残基替代(a454s)。在一些实施方案中,位置454处的丙氨酸残基被半胱氨酸残基替代(a454c)。在一些实施方案中,位置454处的丙氨酸残基被天冬氨酸残基替代(a454d)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的精氨酸455处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置455处的精氨酸残基被丙氨酸残基替代(r455a)。在一些实施方案中,位置455处的精氨酸残基被缬氨酸残基替代(r455v)。在一些实施方案中,位置455处的精氨酸残基被组氨酸残基替代(r455h)。在一些实施方案中,位置455处的精氨酸残基被甘氨酸残基替代(r455g)。在一些实施方案中,位置455处的精氨酸残基被丝氨酸残基替代(r455s)。在一些实施方案中,位置455处的精氨酸残基被谷氨酸残基替代(r455e)。在一些实施方案中,腺苷脱氨酶包含突变r455c。在一些实施方案中,腺苷脱氨酶包含突变r455i。在一些实施方案中,腺苷脱氨酶包含突变r455k。在一些实施方案中,腺苷脱氨酶包含突变r455l。在一些实施方案中,腺苷脱氨酶包含突变r455m。在一些实施方案中,腺苷脱氨酶包含突变r455n。在一些实施方案中,腺苷脱氨酶包含突变r455q。在一些实施方案中,腺苷脱氨酶包含突变r455f。在一些实施方案中,腺苷脱氨酶包含突变r455w。在一些实施方案中,腺苷脱氨酶包含突变r455p。在一些实施方案中,腺苷脱氨酶包含突变r455y。在一些实施方案中,腺苷脱氨酶包含突变r455e。在一些实施方案中,腺苷脱氨酶包含突变r455d。在一些实施方案中,以上所述的在r455处的突变进一步结合e488q突变进行。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的异亮氨酸456处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置456处的异亮氨酸残基被缬氨酸残基替代(i456v)。在一些实施方案中,位置456处的异亮氨酸残基被亮氨酸残基替代(i456l)。在一些实施方案中,位置456处的异亮氨酸残基被天冬氨酸残基替代(i456d)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的苯丙氨酸457处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置457处的苯丙氨酸残基被酪氨酸残基替代(f457y)。在一些实施方案中,位置457处的苯丙氨酸残基被精氨酸残基替代(f457r)。在一些实施方案中,位置457处的苯丙氨酸残基被谷氨酸残基替代(f457e)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的丝氨酸458处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置458处的丝氨酸残基被缬氨酸残基替代(s458v)。在一些实施方案中,位置458处的丝氨酸残基被苯丙氨酸残基替代(s458f)。在一些实施方案中,位置458处的丝氨酸残基被脯氨酸残基替代(s458p)。在一些实施方案中,腺苷脱氨酶包含突变s458i。在一些实施方案中,腺苷脱氨酶包含突变s458l。在一些实施方案中,腺苷脱氨酶包含突变s458m。在一些实施方案中,腺苷脱氨酶包含突变s458c。在一些实施方案中,腺苷脱氨酶包含突变s458a。在一些实施方案中,腺苷脱氨酶包含突变s458g。在一些实施方案中,腺苷脱氨酶包含突变s458t。在一些实施方案中,腺苷脱氨酶包含突变s458y。在一些实施方案中,腺苷脱氨酶包含突变s458w。在一些实施方案中,腺苷脱氨酶包含突变s458q。在一些实施方案中,腺苷脱氨酶包含突变s458n。在一些实施方案中,腺苷脱氨酶包含突变s458h。在一些实施方案中,腺苷脱氨酶包含突变s458e。在一些实施方案中,腺苷脱氨酶包含突变s458d。在一些实施方案中,腺苷脱氨酶包含突变s458k。在一些实施方案中,腺苷脱氨酶包含突变s458r。在一些实施方案中,以上所述的在s458处的突变进一步结合e488q突变进行。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的脯氨酸459处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置459处的脯氨酸残基被半胱氨酸残基替代(p459c)。在一些实施方案中,位置459处的脯氨酸残基被组氨酸残基替代(p459h)。在一些实施方案中,位置459处的脯氨酸残基被色氨酸残基替代(p459w)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的组氨酸460处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置460处的组氨酸残基被精氨酸残基替代(h460r)。在一些实施方案中,位置460处的组氨酸残基被异亮氨酸残基替代(h460i)。在一些实施方案中,位置460处的组氨酸残基被脯氨酸残基替代(h460p)。在一些实施方案中,腺苷脱氨酶包含突变h460l。在一些实施方案中,腺苷脱氨酶包含突变h460v。在一些实施方案中,腺苷脱氨酶包含突变h460f。在一些实施方案中,腺苷脱氨酶包含突变h460m。在一些实施方案中,腺苷脱氨酶包含突变h460c。在一些实施方案中,腺苷脱氨酶包含突变h460a。在一些实施方案中,腺苷脱氨酶包含突变h460g。在一些实施方案中,腺苷脱氨酶包含突变h460t。在一些实施方案中,腺苷脱氨酶包含突变h460s。在一些实施方案中,腺苷脱氨酶包含突变h460y。在一些实施方案中,腺苷脱氨酶包含突变h460w。在一些实施方案中,腺苷脱氨酶包含突变h460q。在一些实施方案中,腺苷脱氨酶包含突变h460n。在一些实施方案中,腺苷脱氨酶包含突变h460e。在一些实施方案中,腺苷脱氨酶包含突变h460d。在一些实施方案中,腺苷脱氨酶包含突变h460k。在一些实施方案中,以上所述的在h460处的突变进一步结合e488q突变进行。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的脯氨酸462处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置462处的脯氨酸残基被丝氨酸残基替代(p462s)。在一些实施方案中,位置462处的脯氨酸残基被色氨酸残基替代(p462w)。在一些实施方案中,位置462处的脯氨酸残基被谷氨酸残基替代(p462e)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的天冬氨酸469处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置469处的天冬氨酸残基被谷氨酰胺残基替代(d469q)。在一些实施方案中,位置469处的天冬氨酸残基被丝氨酸残基替代(d469s)。在一些实施方案中,位置469处的天冬氨酸残基被酪氨酸残基替代(d469y)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的精氨酸470处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置470处的精氨酸残基被丙氨酸残基替代(r470a)。在一些实施方案中,位置470处的精氨酸残基被异亮氨酸残基替代(r470i)。在一些实施方案中,位置470处的精氨酸残基被天冬氨酸残基替代(r470d)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的组氨酸471处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置471处的组氨酸残基被赖氨酸残基替代(h471k)。在一些实施方案中,位置471处的组氨酸残基被苏氨酸残基替代(h471t)。在一些实施方案中,位置471处的组氨酸残基被缬氨酸残基替代(h471v)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的脯氨酸472处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置472处的脯氨酸残基被赖氨酸残基替代(p472k)。在一些实施方案中,位置472处的脯氨酸残基被苏氨酸残基替代(p472t)。在一些实施方案中,位置472处的脯氨酸残基被天冬氨酸残基替代(p472d)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的天冬酰胺473处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置473处的天冬酰胺残基被精氨酸残基替代(n473r)。在一些实施方案中,位置473处的天冬酰胺残基被色氨酸残基替代(n473w)。在一些实施方案中,位置473处的天冬酰胺残基被脯氨酸残基替代(n473p)。在一些实施方案中,位置473处的天冬酰胺残基被天冬氨酸残基替代(n473d)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的精氨酸474处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置474处的精氨酸残基被赖氨酸残基替代(r474k)。在一些实施方案中,位置474处的精氨酸残基被甘氨酸残基替代(r474g)。在一些实施方案中,位置474处的精氨酸残基被天冬氨酸残基替代(r474d)。在一些实施方案中,位置474处的精氨酸残基被谷氨酸残基替代(r474e)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的赖氨酸475处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置475处的赖氨酸残基被谷氨酰胺残基替代(k475q)。在一些实施方案中,位置475处的赖氨酸残基被天冬酰胺残基替代(k475n)。在一些实施方案中,位置475处的赖氨酸残基被天冬氨酸残基替代(k475d)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的丙氨酸476处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置476处的丙氨酸残基被丝氨酸残基替代(a476s)。在一些实施方案中,位置476处的丙氨酸残基被精氨酸残基替代(a476r)。在一些实施方案中,位置476处的丙氨酸残基被谷氨酸残基替代(a476e)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的精氨酸477处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置477处的精氨酸残基被赖氨酸残基替代(r477k)。在一些实施方案中,位置477处的精氨酸残基被苏氨酸残基替代(r477t)。在一些实施方案中,位置477处的精氨酸残基被苯丙氨酸残基替代(r477f)。在一些实施方案中,位置474处的精氨酸残基被谷氨酸残基替代(r477e)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的甘氨酸478处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置478处的甘氨酸残基被丙氨酸残基替代(g478a)。在一些实施方案中,位置478处的甘氨酸残基被精氨酸残基替代(g478r)。在一些实施方案中,位置478处的甘氨酸残基被酪氨酸残基替代(g478y)。在一些实施方案中,腺苷脱氨酶包含突变g478i。在一些实施方案中,腺苷脱氨酶包含突变g478l。在一些实施方案中,腺苷脱氨酶包含突变g478v。在一些实施方案中,腺苷脱氨酶包含突变g478f。在一些实施方案中,腺苷脱氨酶包含突变g478m。在一些实施方案中,腺苷脱氨酶包含突变g478c。在一些实施方案中,腺苷脱氨酶包含突变g478p。在一些实施方案中,腺苷脱氨酶包含突变g478t。在一些实施方案中,腺苷脱氨酶包含突变g478s。在一些实施方案中,腺苷脱氨酶包含突变g478w。在一些实施方案中,腺苷脱氨酶包含突变g478q。在一些实施方案中,腺苷脱氨酶包含突变g478n。在一些实施方案中,腺苷脱氨酶包含突变g478h。在一些实施方案中,腺苷脱氨酶包含突变g478e。在一些实施方案中,腺苷脱氨酶包含突变g478d。在一些实施方案中,腺苷脱氨酶包含突变g478k。在一些实施方案中,以上所述的在g478处的突变进一步结合e488q突变进行。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的谷氨酰胺479处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置479处的谷氨酰胺残基被天冬酰胺残基替代(q479n)。在一些实施方案中,位置479处的谷氨酰胺残基被丝氨酸残基替代(q479s)。在一些实施方案中,位置479处的谷氨酰胺残基被脯氨酸残基替代(q479p)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的精氨酸348处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置348处的精氨酸残基被丙氨酸残基替代(r348a)。在一些实施方案中,位置348处的精氨酸残基被谷氨酸残基替代(r348e)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的缬氨酸351处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置351处的缬氨酸残基被亮氨酸残基替代(v351l)。在一些实施方案中,腺苷脱氨酶包含突变v351y。在一些实施方案中,腺苷脱氨酶包含突变v351m。在一些实施方案中,腺苷脱氨酶包含突变v351t。在一些实施方案中,腺苷脱氨酶包含突变v351g。在一些实施方案中,腺苷脱氨酶包含突变v351a。在一些实施方案中,腺苷脱氨酶包含突变v351f。在一些实施方案中,腺苷脱氨酶包含突变v351e。在一些实施方案中,腺苷脱氨酶包含突变v351i。在一些实施方案中,腺苷脱氨酶包含突变v351c。在一些实施方案中,腺苷脱氨酶包含突变v351h。在一些实施方案中,腺苷脱氨酶包含突变v351p。在一些实施方案中,腺苷脱氨酶包含突变v351s。在一些实施方案中,腺苷脱氨酶包含突变v351k。在一些实施方案中,腺苷脱氨酶包含突变v351n。在一些实施方案中,腺苷脱氨酶包含突变v351w。在一些实施方案中,腺苷脱氨酶包含突变v351q。在一些实施方案中,腺苷脱氨酶包含突变v351d。在一些实施方案中,腺苷脱氨酶包含突变v351r。在一些实施方案中,以上所述的在v351处的突变进一步结合e488q突变进行。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的苏氨酸375处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置375处的苏氨酸残基被甘氨酸残基替代(t375g)。在一些实施方案中,位置375处的苏氨酸残基被丝氨酸残基替代(t375s)。在一些实施方案中,腺苷脱氨酶包含突变t375h。在一些实施方案中,腺苷脱氨酶包含突变t375q。在一些实施方案中,腺苷脱氨酶包含突变t375c。在一些实施方案中,腺苷脱氨酶包含突变t375n。在一些实施方案中,腺苷脱氨酶包含突变t375m。在一些实施方案中,腺苷脱氨酶包含突变t375a。在一些实施方案中,腺苷脱氨酶包含突变t375w。在一些实施方案中,腺苷脱氨酶包含突变t375v。在一些实施方案中,腺苷脱氨酶包含突变t375r。在一些实施方案中,腺苷脱氨酶包含突变t375e。在一些实施方案中,腺苷脱氨酶包含突变t375k。在一些实施方案中,腺苷脱氨酶包含突变t375f。在一些实施方案中,腺苷脱氨酶包含突变t375i。在一些实施方案中,腺苷脱氨酶包含突变t375d。在一些实施方案中,腺苷脱氨酶包含突变t375p。在一些实施方案中,腺苷脱氨酶包含突变t375l。在一些实施方案中,腺苷脱氨酶包含突变t375y。在一些实施方案中,以上所述的在t375y处的突变进一步结合e488q突变进行。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的精氨酸481处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置481处的精氨酸残基被谷氨酸残基替代(r481e)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的丝氨酸486处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置486处的丝氨酸残基被苏氨酸残基替代(s486t)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的苏氨酸490处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置490处的苏氨酸残基被丙氨酸残基替代(t490a)。在一些实施方案中,位置490处的苏氨酸残基被丝氨酸残基替代(t490s)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的丝氨酸495处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置495处的丝氨酸残基被苏氨酸残基替代(s495t)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的精氨酸510处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置510处的精氨酸残基被谷氨酰胺残基替代(r510q)。在一些实施方案中,位置510处的精氨酸残基被丙氨酸残基替代(r510a)。在一些实施方案中,位置510处的精氨酸残基被谷氨酸残基替代(r510e)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的甘氨酸593处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置593处的甘氨酸残基被丙氨酸残基替代(g593a)。在一些实施方案中,位置593处的甘氨酸残基被谷氨酸残基替代(g593e)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的赖氨酸594处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置594处的赖氨酸残基被丙氨酸残基替代(k594a)。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的位置a454、r455、i456、f457、s458、p459、h460、p462、d469、r470、h471、p472、n473、r474、k475、a476、r477、g478、q479、r348、r510、g593、k594中的任何一个或多个位置处的突变,或同源adar蛋白中的相应位置处的突变。
在一些实施方案中,腺苷脱氨酶包含hadar2-d氨基酸序列的突变a454s、a454c、a454d、r455a、r455v、r455h、i456v、i456l、i456d、f457y、f457r、f457e、s458v、s458f、s458p、p459c、p459h、p459w、h460r、h460i、h460p、p462s、p462w、p462e、d469q、d469s、d469y、r470a、r470i、r470d、h471k、h471t、h471v、p472k、p472t、p472d、n473r、n473w、n473p、r474k、r474g、r474d、k475q、k475n、k475d、a476s、a476r、a476e、r477k、r477t、r477f、g478a、g478r、g478y、q479n、q479s、q479p、r348a、r510q、r510a、g593a、g593e、k594a中的任何一个或多个,或同源adar蛋白中的相应位置处的突变。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的位置t375、v351、g478、s458、h460中的任何一个或多个位置处的突变,或同源adar蛋白中的相应位置处的突变,任选地结合e488处的突变。在一些实施方案中,腺苷脱氨酶包含选自t375g、t375c、t375h、t375q、v351m、v351t、v351y、g478r、s458f、h460i的突变中的一个或多个,任选地结合e488q。
在一些实施方案中,腺苷脱氨酶包含选自t375h、t375q、v351m、v351y、h460p的突变中的一个或多个,任选地结合e488q。
在一些实施方案中,腺苷脱氨酶包含突变t375s和s458f,任选地结合e488q。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的位置t375、n473、r474、g478、s458、p459、v351、r455、r455、t490、r348、q479中的两个或更多个位置处的突变,或同源adar蛋白中的相应位置处的突变,任选地结合e488处的突变。在一些实施方案中,腺苷脱氨酶包含选自t375g、t375s、n473d、r474e、g478r、s458f、p459w、v351l、r455g、r455s、t490a、r348e、q479p的突变中的两个或更多个,任选地结合e488q。
在一些实施方案中,腺苷脱氨酶包含突变t375g和v351l。在一些实施方案中,腺苷脱氨酶包含突变t375g和r455g。在一些实施方案中,腺苷脱氨酶包含突变t375g和r455s。在一些实施方案中,腺苷脱氨酶包含突变t375g和t490a。在一些实施方案中,腺苷脱氨酶包含突变t375g和r348e。在一些实施方案中,腺苷脱氨酶包含突变t375s和v351l。在一些实施方案中,腺苷脱氨酶包含突变t375s和r455g。在一些实施方案中,腺苷脱氨酶包含突变t375s和r455s。在一些实施方案中,腺苷脱氨酶包含突变t375s和t490a。在一些实施方案中,腺苷脱氨酶包含突变t375s和r348e。在一些实施方案中,腺苷脱氨酶包含突变n473d和v351l。在一些实施方案中,腺苷脱氨酶包含突变n473d和r455g。在一些实施方案中,腺苷脱氨酶包含突变n473d和r455s。在一些实施方案中,腺苷脱氨酶包含突变n473d和t490a。在一些实施方案中,腺苷脱氨酶包含突变n473d和r348e。在一些实施方案中,腺苷脱氨酶包含突变r474e和v351l。在一些实施方案中,腺苷脱氨酶包含突变r474e和r455g。在一些实施方案中,腺苷脱氨酶包含突变r474e和r455s。在一些实施方案中,腺苷脱氨酶包含突变r474e和t490a。在一些实施方案中,腺苷脱氨酶包含突变r474e和r348e。在一些实施方案中,腺苷脱氨酶包含突变s458f和t375g。在一些实施方案中,腺苷脱氨酶包含突变s458f和t375s。在一些实施方案中,腺苷脱氨酶包含突变s458f和n473d。在一些实施方案中,腺苷脱氨酶包含突变s458f和r474e。在一些实施方案中,腺苷脱氨酶包含突变s458f和g478r。在一些实施方案中,腺苷脱氨酶包含突变g478r和t375g。在一些实施方案中,腺苷脱氨酶包含突变g478r和t375s。在一些实施方案中,腺苷脱氨酶包含突变g478r和n473d。在一些实施方案中,腺苷脱氨酶包含突变g478r和r474e。在一些实施方案中,腺苷脱氨酶包含突变p459w和t375g。在一些实施方案中,腺苷脱氨酶包含突变p459w和t375s。在一些实施方案中,腺苷脱氨酶包含突变p459w和n473d。在一些实施方案中,腺苷脱氨酶包含突变p459w和r474e。在一些实施方案中,腺苷脱氨酶包含突变p459w和g478r。在一些实施方案中,腺苷脱氨酶包含突变p459w和s458f。在一些实施方案中,腺苷脱氨酶包含突变q479p和t375g。在一些实施方案中,腺苷脱氨酶包含突变q479p和t375s。在一些实施方案中,腺苷脱氨酶包含突变q479p和n473d。在一些实施方案中,腺苷脱氨酶包含突变q479p和r474e。在一些实施方案中,腺苷脱氨酶包含突变q479p和g478r。在一些实施方案中,腺苷脱氨酶包含突变q479p和s458f。在一些实施方案中,腺苷脱氨酶包含突变q479p和p459w。本段路中所述的所有突变还可以进一步结合e488q突变进行。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的位置k475、q479、p459、g478、s458中的任何一个或多个位置处的突变,或同源adar蛋白中的相应位置处的突变,任选地结合e488处的突变。在一些实施方案中,腺苷脱氨酶包含选自k475n、q479n、p459w、g478r、s458p、s458f的突变中的一个或多个,任选地结合e488q。
在一些实施方案中,腺苷脱氨酶包含在hadar2-d氨基酸序列的位置t375、v351、r455、h460、a476中的任何一个或多个位置处的突变,或同源adar蛋白中的相应位置处的突变,任选地结合e488处的突变。在一些实施方案中,腺苷脱氨酶包含选自t375g、t375c、t375h、t375q、v351m、v351t、v351y、r455h、h460p、h460i、a476e的突变中的一个或多个,任选地结合e488q。
在某些实施方案中,通过grna的化学修饰实现编辑的改善和脱靶修饰的减少。按照vogel等人(2014),angewcheminted,53:6267-6271,doi:10.1002/anie.201402634(以引用方式整体并入本文)中所例示进行化学修饰的grna降低了脱靶活性并提高了中靶效率。2′-o-甲基和硫代磷酸酯修饰的指导rna通常可提高细胞中的编辑效率。
已证明adar显示出对编辑过的a的任一侧的相邻核苷酸的优选性(www.nature.com/nsmb/journal/v23/n5/full/nsmb.3203.html,matthews等人(2017),naturestructuralmolbiol,23(5):426-433,以引用方式整体并入本文)。因此,在某些实施方案中,选择grna、靶标和/或adar针对基序优选性进行优化。
在体外已证实有意错配允许编辑非优选的基序(https://academic.oup.com/nar/article-lookup/doi/10.1093/nar/gku272;schneider等人(2014),nucleicacidres,42(10):e87);fukuda等人(2017),scienticicreports,7,doi:10.1038/srep41478,以引用方式整体并入本文)。因此,在某些实施方案中,为了提高在非优选的5’或3’相邻碱基上的rna编辑效率,引入了相邻碱基中的有意错配。
adar脱氨酶结构域的靶向窗口中的与c相对的a可先于其他碱基优先被编辑,而靶碱基的几个碱基内与u配对的a可能具有较低的编辑水平。因此,可以通过使待编辑的所有a与c错配来指定cpf1-adar系统的活性窗口中的多个a以进行编辑。因此,在某些实施方案中,活性窗口中的多个a:c错配被设计来创建多个a:i编辑。在某些实施方案中,为了阻遏活性窗口中潜在的脱靶编辑,将非靶a与a或g配对。
在一些实施方案中,腺苷脱氨酶包含hadar1-d的野生型氨基酸序列(例如mgsggggsegapkkkrkvgsslgtgnrcvkgdslslkgetvndchaeiisrrgfirflyselmkynsqtakdsifepakggeklqikktvsfhlyistapcgdgalfdkscsdramestesrhypvfenpkqgklrtkvengqgtipvessdivptwdgirlgerlrtmscsdkilrwnvlglqgallthflqpiylksvtlgylfsqghltraiccrvtrdgsafedglrhpfivnhpkvgrvsiydskrqsgktketsvnwcladgydleildgtrgtvdgprnelsrvskknifllfkklcsfryrrdllrlsygeakkaardyetaknyfkkglkdmgygnwiskpqeeknf*(seqidno:36))。在一些实施方案中,腺苷脱氨酶在hadar1-d序列中包含一个或多个突变,这样hadar1-d的编辑效率和/或底物编辑优选性可根据特定需要而改变。
在一些实施方案中,腺苷脱氨酶包含在hadar1-d氨基酸序列的甘氨酸1007处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置1007处的甘氨酸残基被具有相对小的侧链的非极性氨基酸残基替代。例如,在一些实施方案中,位置1007处的甘氨酸残基被丙氨酸残基替代(g1007a)。在一些实施方案中,位置1007处的甘氨酸残基被缬氨酸残基替代(g1007v)。在一些实施方案中,位置1007处的甘氨酸残基被具有相对大的侧链的氨基酸残基取代。在一些实施方案中,位置1007处的甘氨酸残基被精氨酸残基替代(g1007r)。在一些实施方案中,位置1007处的甘氨酸残基被赖氨酸残基替代(g1007k)。在一些实施方案中,位置1007处的甘氨酸残基被色氨酸残基替代(g1007w)。在一些实施方案中,位置1007处的甘氨酸残基被酪氨酸残基替代(g1007y)。另外,在其他实施方案中,位置1007处的甘氨酸残基被亮氨酸残基替代(g1007l)。在其他实施方案中,位置1007处的甘氨酸残基被苏氨酸残基替代(g1007t)。在其他实施方案中,位置1007处的甘氨酸残基被丝氨酸残基替代(g1007s)。
在一些实施方案中,腺苷脱氨酶包含在hadar1-d氨基酸序列的谷氨酸1008处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,位置1008处的谷氨酸残基被具有相对大的侧链的极性氨基酸残基替代。在一些实施方案中,位置1008处的谷氨酸残基被谷氨酰胺残基替代(e1008q)。在一些实施方案中,位置1008处的谷氨酸残基被组氨酸残基替代(e1008h)。在一些实施方案中,位置1008处的谷氨酸残基被精氨酸残基替代(e1008r)。在一些实施方案中,位置1008处的谷氨酸残基被赖氨酸残基(e1008k)替代。在一些实施方案中,位置1008处的谷氨酸残基被非极性或小极性氨基酸残基替代。在一些实施方案中,位置1008处的谷氨酸残基被苯丙氨酸残基替代(e1008f)。在一些实施方案中,位置1008处的谷氨酸残基被色氨酸残基替代(e1008w)。在一些实施方案中,位置1008处的谷氨酸残基被甘氨酸残基替代(e1008g)。在一些实施方案中,位置1008处的谷氨酸残基被异亮氨酸残基替代(e1008i)。在一些实施方案中,位置1008处的谷氨酸残基被缬氨酸残基替代(e1008v)。在一些实施方案中,位置1008处的谷氨酸残基被脯氨酸残基替代(e1008p)。在一些实施方案中,位置1008处的谷氨酸残基被丝氨酸残基替代(e1008s)。在其他实施方案中,位置1008处的谷氨酸残基被天冬酰胺残基替代(e1008n)。在其他实施方案中,位置1008处的谷氨酸残基被丙氨酸残基替代(e1008a)。在其他实施方案中,位置1008处的谷氨酸残基被甲硫氨酸残基替代(e1008m)。在一些实施方案中,位置1008处的谷氨酸残基被亮氨酸残基替代(e1008l)。
在一些实施方案中,为了提高编辑效率,腺苷脱氨酶可包含以下突变中的一个或多个:e1007s、e1007a、e1007v、e1008q、e1008r、e1008h、e1008m、e1008n、e1008k(基于hadar1-d中的氨基酸序列位置),以及同源adar蛋白中对应于以上突变的突变。
在一些实施方案中,为了降低编辑效率,腺苷脱氨酶可包含以下突变中的一个或多个:e1007r、e1007k、e1007y、e1007l、e1007t、e1008g、e1008i、e1008p、e1008v、e1008f、e1008w、e1008s、e1008n、e1008k(基于hadar1-d中的氨基酸序列位置),以及同源adar蛋白中对应于以上突变的突变。
在一些实施方案中,腺苷脱氨酶的底物编辑优选性、效率和/或选择性受酶活性中心内或附近的氨基酸残基影响。在一些实施方案中,腺苷脱氨酶包含在hadar1-d序列的谷氨酸1008位置处,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,所述突变是e1008r,或同源adar蛋白中的相应突变。在一些实施方案中,e1008r突变体对在相反链上具有错配的g残基的靶腺苷残基具有提高的编辑效率。
在一些实施方案中,腺苷脱氨酶蛋白还包含或连接至一个或多个双链rna(dsrna)结合基序(dsrbm)或结构域(dsrbd),以识别并结合至双链核酸底物。在一些实施方案中,腺苷脱氨酶与双链底物之间的相互作用由一种或多种另外的蛋白质因子(包括crispr/cas蛋白质因子)介导。在一些实施方案中,腺苷脱氨酶与双链底物之间的相互作用进一步由一种或多种核酸组分(包括指导rna)介导。
根据本发明,腺苷脱氨酶的底物是在指导分子与其dna靶标结合后形成的rna/dna异源双链体,该双链体之后与crispr-cas酶形成crispr-cas复合物。rna/dna或dna/rna异源双链体在本文中也称为“rna/dna杂合体”、“dna/rna杂合体”或“双链底物”。指导分子和crispr-cas酶的特殊特征在下文详述。
如本文所用,术语“编辑选择性”是指由腺苷脱氨酶编辑的双链底物上所有位点的分数。不受理论的束缚,预期腺苷脱氨酶的编辑选择性受双链底物的长度和二级结构(诸如错配碱基、凸环和/或内环的存在)影响。
在一些实施方案中,当底物是长于50bp的完全碱基配对的双链体时,腺苷脱氨酶可能能够使双链体内的多个腺苷残基(例如,所有腺苷残基的50%)脱氨基。在一些实施方案中,当底物短于50bp时,腺苷脱氨酶的编辑选择性受靶腺苷位点处错配存在的影响。特别地,在一些实施方案中,在相反链上具有错配的胞苷(c)残基的腺苷(a)残基被高效脱氨基。在一些实施方案中,在相反链上具有错配的鸟苷(g)残基的腺苷(a)残基被跳过而不进行编辑。
具有c至u脱氨活性的修饰的腺苷脱氨酶
在某些示例性实施方案中,定向进化可以用于设计修饰的adar蛋白,除了将腺嘌呤脱氨为次黄嘌呤之外,所述adar蛋白还能够催化另外的反应。例如,修饰的adar蛋白可能能够催化胞嘧啶脱氨为尿嘧啶。尽管不受特定理论的束缚,但是提高c至u活性的突变可以改变结合口袋的形状,使其更适合较小的胞苷碱基。
在一些实施方案中,具有c至u脱氨活性的修饰的腺苷脱氨酶包含在hadar2-d氨基酸序列的位置v351、t375、r455和e488中的任何一个或多个位置处的突变,或同源adar蛋白中的相应位置处的突变。在一些实施方案中,腺苷脱氨酶包含突变e488q。在一些实施方案中,腺苷脱氨酶包含选自以下的突变中的一个或多个:v351i、v351l、v351f、v351m、v351c、v351a、v351g、v351p、v351t、v351s、v351y、v351w、v351q、v351n、v351h、v351e、v351d、v351k、v351r、t375i、t375l、t375v、t375f、t375m、t375c、t375a、t375g、t375p、t375s、t375y、t375w、t375q、t375n、t375h、t375e、t375d、t375k、t375r、r455i、r455l、r455v、r455f、r455m、r455c、r455a、r455g、r455p、r455t、r455s、r455y、r455w、r455q、r455n、r455h、r455e、r455d、r455k。在一些实施方案中,腺苷脱氨酶包含突变e488q,并且还包含选自以下的突变中的一个或多个:v351i、v351l、v351f、v351m、v351c、v351a、v351g、v351p、v351t、v351s、v351y、v351w、v351q、v351n、v351h、v351e、v351d、v351k、v351r、t375i、t375l、t375v、t375f、t375m、t375c、t375a、t375g、t375p、t375s、t375y、t375w、t375q、t375n、t375h、t375e、t375d、t375k、t375r、r455i、r455l、r455v、r455f、r455m、r455c、r455a、r455g、r455p、r455t、r455s、r455y、r455w、r455q、r455n、r455h、r455e、r455d、r455k。
结合具有c至u脱氨活性的前述修饰的adar蛋白,本文所述的发明还涉及一种用于使目标靶基因座中的c脱氨基的方法,所述方法包括向所述目标靶基因座递送:(a)cpf1切口酶蛋白或无催化活性的cpf1蛋白;(b)指导分子,所述指导分子包含连接至正向重复序列的指导序列;和(c)具有c至u脱氨活性的修饰的adar蛋白或其催化结构域;
其中所述修饰的adar蛋白或其催化结构域共价或非共价地连接至所述cpf1蛋白或所述指导分子,或者适于在递送之后连接至所述cpf1蛋白或所述指导分子;
其中指导分子与所述cpf1蛋白形成复合物,并引导所述复合物结合所述目标靶基因座处的第一dna链;
其中所述指导序列能够与所述第一dna链内包含所述c的靶序列杂交以形成异源双链体;
其中任选地,所述指导序列在对应于所述c的位置处包含非配对a或u,导致在所形成的异源双链体中出现错配;
其中任选地,所述cpf1蛋白是使因所述异源双链体形成而移位的所述目标靶基因座处的第二dna链产生切口的cpf1切口酶;并且
其中所述修饰的adar蛋白或其催化结构域使所述rna异源双链体中的所述c脱氨基。
结合具有c至u脱氨活性的前述修饰的adar蛋白,本文所述的发明还涉及一种适用于使目标靶基因座中的c脱氨基的工程化的非天然存在的系统,所述系统包含:(a)包含连接至正向重复序列的指导序列的指导分子,或编码所述指导分子的核苷酸序列;(b)cpf1切口酶蛋白或无催化活性的cpf1蛋白,或编码所述cpf1蛋白的核苷酸序列;(c)具有c至u脱氨活性的修饰的adar蛋白或其催化结构域,或编码所述修饰的adar蛋白或其催化结构域的核苷酸序列;
其中所述修饰的adar蛋白或其催化结构域共价或非共价地连接至所述cpf1蛋白或所述指导分子,或者适于在递送之后连接至所述cpf1蛋白或所述指导分子;
其中所述指导序列能够与所述靶基因座处第一dna链上包含c的靶序列杂交以形成异源双链体;
其中任选地,所述指导序列在对应于所述c的位置处包含非配对a或u,导致在所形成的异源双链体中出现错配;
其中任选地,所述cpf1蛋白是能够使与所述第一dna链互补的第二dna链产生切口的cpf1切口酶;
其中任选地,所述系统是包含一种或多种载体的载体系统,所述一种或多种载体包含:(a)第一调控元件,所述第一调控元件可操作地连接至编码包含所述指导序列的所述指导分子的核苷酸序列;(b)第二调控元件,所述第二调控元件可操作地连接至编码所述cpf1蛋白的核苷酸序列;和(c)编码具有c至u脱氨活性的修饰的adar蛋白或其催化结构域的核苷酸序列,所述核苷酸序列受所述第一调控元件或第二调控元件的控制或者可操作地连接至第三调控元件;
其中如果所述编码修饰的adar蛋白或其催化结构域的核苷酸序列可操作地连接至第三调控元件,则所述修饰的adar蛋白或其催化结构域适于在表达之后连接至所述指导分子或所述cpf1蛋白;
其中组分(a)、组分(b)和组分(c)位于所述系统的相同或不同载体上,任选地其中所述第一调控元件、第二调控元件和/或第三调控元件是诱导型启动子。
crispr-cas蛋白和指导物
在本发明的方法和系统中,使用了crispr-cas蛋白和相应的指导分子。更特别地,crispr-cas蛋白是2类crispr-cas蛋白。在某些实施方案中,所述crispr-cas蛋白cpf1。crispr-cas系统不需要生成靶向特定序列的定制蛋白,而是单个cas蛋白可以通过指导分子进行编程以识别特定核酸靶标,换句话说,可以使用所述指导分子将cas酶蛋白募集至目标靶基因座的特定核酸。
指导分子
2类v型crispr-cas蛋白的指导分子或指导rna包含tracr配对序列(在内源性crispr系统的情形中涵盖“正向重复序列”)和指导序列(在内源性crispr系统的情形中也称为“间隔区”)。实际上,与ii型crispr-cas蛋白成对比,crispr-cascpf1蛋白不依赖于tracr序列的存在。在一些实施方案中,本文所述的crispr-cas系统或复合物不包含和/或不依赖于tracr序列的存在(例如,若cas蛋白是cpf1)。在某些实施方案中,指导分子可以包含融合或连接至指导序列或间隔区序列的正向重复序列,基本上由其组成,或由其组成。
一般来讲,crispr系统由促进在靶序列的位点处crispr复合物形成的元件表征。在形成crispr复合物的情形中,“靶序列”是指指导序列被设计成与其具有互补性的序列,其中靶dna序列与指导序列之间的杂交促进crispr复合物的形成。
术语“指导分子”和“指导rna”在本文可互换使用,是指能够与crispr-cas蛋白形成复合物并且包含与靶核酸序列具有足够的互补性以与靶核酸序列杂交并引导复合物序列特异性地结合至靶核酸序列的指导序列的基于rna的分子。如本文所述,指导分子或指导rna特别涵盖具有一种或多种化学修饰(例如,通过化学连接两个核糖核苷酸或通过用一种或多种脱氧核糖核苷酸替代一种或多种核糖核苷酸)的基于rna的分子。
如本文所用,在crispr-cas系统的情形中,术语“指导序列”包括与靶核酸序列具有足够互补性以与靶核酸序列杂交并且引导核酸靶向复合物序列特异性地结合至靶核酸序列的任何多核苷酸序列。在本发明的情形中,靶核酸序列或靶序列是包含待脱氨基的靶腺苷(在本文中也称为“靶腺苷”)的序列。在一些实施方案中,除预期da-c错配外,当使用合适的比对算法最佳比对时,互补程度为约或大于约50%、60%、75%、80%、85%、90%、95%、97.5%、99%或更大。最佳比对可以借助于用于比对序列的任何合适算法来确定,其非限制性实例包括史密斯-沃特曼算法(smith-watermanalgorithm)、尼德曼-翁施算法(needleman-wunschalgorithm)、基于巴罗斯-维勒变换(burrows-wheelertransform)的算法(例如巴罗斯-维勒比对仪(burrowswheeleraligner))、clustalw、clustalx、blat、novoalign(novocrafttechnologies;在www.novocraft.com上可得)、eland(illumina,sandiego,ca)、soap(在soap.genomics.org.cn上可得)和maq(在maq.sourceforge.net上可得)。指导序列(在核酸靶向指导rna内)引导核酸靶向复合物序列特异性地结合至靶核酸序列的能力可以通过任何合适的测定来评定。举例来说,足以形成核酸靶向复合物的核酸靶向crispr系统的组分,包括有待测试的指导序列,可以提供给具有相应靶核酸序列的宿主细胞,诸如通过用编码核酸靶向复合物的组分的载体转染,继而诸如通过如本文所述的surveyor测定评定靶核酸序列内的优先靶向(例如切割)。类似地,可以在试管中通过提供靶核酸序列、核酸靶向复合物的组分(包括有待测试的指导序列)和不同于测试指导序列的对照指导序列,以及在测试指导序列与对照指导序列反应之间比较靶序列处或附近的结合或切割速率来评估靶核酸序列(或其附近的序列)的切割。其他测定可能存在,并且将为本领域技术人员所想到。可以选择指导序列并且因此选择核酸靶向指导rna以靶向任何靶核酸序列。
在一些实施方案中,指导分子包含被设计成与靶序列具有至少一个错配的指导序列,使得在指导序列与靶序列之间所形成的异源双链体包含在指导序列中的与靶a相对的非配对c,以便于靶序列上的脱氨。在一些实施方案中,除该a-c错配外,当使用合适的比对算法最佳比对时,互补程度为约或大于约50%、60%、75%、80%、85%、90%、95%、97.5%、99%或更大。
在某些实施方案中,指导分子的指导序列或间隔区长度为15至50nt。在某些实施方案中,指导rna的间隔区长度为至少15个核苷酸。在某些实施方案中,间隔区长度为15至17nt,例如15、16或17nt;17至20nt,例如17、18、19或20nt;20至24nt,例如20、21、22、23或24nt;23至25nt,例如23、24或25nt;24至27nt,例如24、25、26或27nt;27-30nt,例如27、28、29或30nt;30-35nt,例如30、31、32、33、34或35nt;或35nt或更长。在某些示例实施方案中,指导序列为15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、3940、41、42、43、44、45、46、4748、49、50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99或100nt。
在一些实施方案中,指导序列是长度为10至50nt之间,但更特别地为约20-30nt,有利地为约20nt、23-25nt或24nt的rna序列。选择指导序列以确保其与包含待脱氨基的腺苷的靶序列杂交。对此将在下文更详细地描述。选择可涵盖进一步的步骤,这些步骤可以提高脱氨的功效和特异性。
在一些实施方案中,指导序列长约20nt至约30nt,并且与靶dna链杂交以形成几乎完美匹配的双链体,除了在靶腺苷位点处具有da-c错配。特别地,在一些实施方案中,da-c错配位于靠近靶序列的中心(并且因此在指导序列与靶序列杂交后的双链体的中心),从而将腺苷脱氨酶限制于狭窄的编辑窗口(例如,约4bp宽)。在一些实施方案中,靶序列可以包含多于一个待脱氨基的靶腺苷。在另外的实施方案中,靶序列可还包含在靶腺苷位点3’端的一个或多个da-c错配。在一些实施方案中,为了避免在靶序列中非预期的腺嘌呤位点处的脱靶编辑,可以将指导序列设计成在对应于所述非预期的腺嘌呤的位置上包含非配对鸟嘌呤以引入da-g错配,对于某些腺苷脱氨酶(诸如adar1和adar2)而言这不具有催化益处。参见wong等人,rna7:846-858(2001),该文献以引用方式整体并入本文。
在一些实施方案中,使用具有典型长度(例如,对于ascpf1为约24nt)的cpf1指导序列与靶dna形成异源双链体。在一些实施方案中,使用比典型长度(例如,对于ascpf1为>24nt)长的cpf1指导分子与靶dna形成异源双链体,包括在cpf1指导rna-靶dna复合物之外形成异源双链体。当有意使给定的一段核苷酸内的多于一个腺嘌呤脱氨基时,这可能是令人感兴趣的。在替代实施方案中,维持典型指导序列长度的限制是令人感兴趣的。在一些实施方案中,指导序列被设计来在cpf1指导物的典型长度之外引入da-c错配,这可以减少cpf1的空间位阻并且增加腺苷脱氨酶与da-c错配之间的接触频率。
在一些实施方案中,错配的核碱基(例如胞苷)的位置是根据pam在dna靶标上的位置计算的。在一些实施方案中,错配的核碱基位于距pam12-21nt处、或距pam13-21nt处、或距pam14-21nt处、或距pam14-20nt处、或距pam15-20nt处、或距pam16-20nt处、或距pam14-19nt处、或距pam15-19nt处、或距pam16-19nt处、或距pam17-19nt处、或距pam约20nt处、或距pam约19nt处、或距pam约18nt处、或距pam约17nt处、或距pam约16nt处、或距pam约15nt处、或距pam约14nt处。在优选的实施方案中,错配的核碱基位于距pam17-19nt或18nt处。
错配距离是cpf1间隔区的3’端与错配的核碱基(例如胞苷)之间的碱基数,其中错配的碱基被包括在内作为错配距离计算的一部分。在一些实施方案中,错配距离为1-10nt、或1-9nt、或1-8nt、或2-8nt、或2-7nt、或2-6nt、或3-8nt、或3-7nt、或3-6nt、或3-5nt、或约2nt、或约3nt、或约4nt、或约5nt、或约6nt、或约7nt、或约8nt。在优选的实施方案中,错配距离为3-5nt或4nt。
在一些实施方案中,本文所述的cpf1-adar系统的编辑窗口距pam12-21nt、或距pam13-21nt、或距pam14-21nt、或距pam14-20nt、或距pam15-20nt、或距pam16-20nt、或距pam14-19nt、或距pam15-19nt、或距pam16-19nt、或距pam17-19nt、或距pam约20nt、或距pam约19nt、或距pam约18nt、或距pam约17nt、或距pam约16nt、或距pam约15nt、或距pam约14nt。在一些实施方案中,本文所述的cpf1-adar系统的编辑窗口距cpf1间隔区的3’端1-10nt、或距cpf1间隔区的3’端1-9nt、或距cpf1间隔区的3’端1-8nt、或距cpf1间隔区的3’端2-8nt、或距cpf1间隔区的3’端2-7nt、或距cpf1间隔区的3’端2-6nt、或距cpf1间隔区的3’端3-8nt、或距cpf1间隔区的3’端3-7nt、或距cpf1间隔区的3’端3-6nt、或距cpf1间隔区的3’端3-5nt、或距cpf1间隔区的3’端约2nt、或距cpf1间隔区的3’端约3nt、或距cpf1间隔区的3’端约4nt、或距cpf1间隔区的3’端约5nt、或距cpf1间隔区的3’端约6nt、或距cpf1间隔区的3’端约7nt、或距cpf1间隔区的3’端约8nt。
在一些实施方案中,选择指导分子的序列(正向重复序列和/或间隔区)以减少指导分子内的二级结构的程度。在一些实施方案中,当最佳折叠时,核酸靶向指导rna的约或小于约75%、50%、40%、30%、25%、20%、15%、10%、5%、1%或更少的核苷酸参与自身互补碱基配对。最佳折叠可以通过任何合适的多核苷酸折叠算法来确定。一些程序是基于计算最小吉布斯自由能(gibbsfreeenergy)。一种此类算法的实例是如zuker和stiegler(nucleicacidsres.9(1981),133-148)所描述的mfold。另一个示例性折叠算法是维也纳大学(universityofvienna)的理论化学研究所(institutefortheoreticalchemistry)开发的使用质心结构预测算法的在线网络服务器rnafold(参见例如a.r.gruber等人,2008,cell106(1):23-24;和pacarr和gmchurch,2009,naturebiotechnology27(12):1151-62)。
在一些实施方案中,降低指导分子对rna切割例如对通过cpf1的切割的易感性是令人感兴趣的。因此,在特定实施方案中,对指导分子进行调整以避免被cpf1或其他rna切割酶切割。
在某些实施方案中,指导分子包含非天然存在的核酸和/或非天然存在的核苷酸和/或核苷酸类似物和/或化学修饰。优选地,这些非天然存在的核酸和非天然存在的核苷酸位于指导序列之外。非天然存在的核酸可包括例如天然和非天然存在的核苷酸的混合物。非天然存在的核苷酸和/或核苷酸类似物可在核糖、磷酸和/或碱基部分被修饰。在本发明的实施方案中,指导核酸包含核糖核苷酸和非核糖核苷酸。在一个这样的实施方案中,指导物包含一种或多种核糖核苷酸和一种或多种脱氧核糖核苷酸。在本发明的实施方案中,指导物包含一种或多种非天然存在的核苷酸或核苷酸类似物,诸如具有硫代磷酸酯键联的核苷酸、包含在核糖环的2’和4’碳原子之间的亚甲基桥的锁定核酸(lna)或桥接核酸(bna)。修饰的核苷酸的其他实例包括2′-o-甲基类似物、2′-脱氧类似物或2′-氟类似物。修饰的碱基的其他实例包括但不限于2-氨基嘌呤、5-溴-尿苷、假尿苷、肌苷、7-甲基鸟苷。指导rna化学修饰的实例包括但不限于在一个或多个末端核苷酸处并入2′-o-甲基(m)、2′-o-甲基3’硫代磷酸酯(ms)、s-约束乙基(cet),或2′-o-甲基3’硫代pace(msp)。此类化学修饰的指导物与未修饰的指导物相比可以包含增加的稳定性和增加的活性,不过中靶对脱靶特异性不可预测。(参见hendel,2015,natbiotechnol.33(9):985-9,doi:10.1038/nbt.3290,2015年6月29日在线发布,ragdarm等人,0215,pnas,e7110-e7111;allerson等人,j.med.chem.2005,48:901-904;bramsen等人,front.genet.,2012,3:154;deng等人,pnas,2015,112:11870-11875;sharma等人,medchemcomm.,2014,5:1454-1471;hendel等人,nat.biotechnol.(2015)33(9):985-989;li等人,naturebiomedicalengineering,2017,1,0066doi:10.1038/s41551-017-0066)。在一些实施方案中,指导rna的5’和/或3’端被包括荧光染料、聚乙二醇、胆固醇、蛋白质或检测标签在内的多种功能性部分修饰。(参见kelly等人,2016,j.biotech.233:74-83)。在某些实施方案中,指导物在结合至靶dna的区域中包含核糖核苷酸,并在结合至cpf1的区域中包含一个或多个脱氧核糖核苷酸和/或核苷酸类似物。在本发明的实施方案中,将脱氧核糖核苷酸和/或核苷酸类似物并入工程化的指导结构(诸如但不限于茎环区和种子区)中。对于cpf1指导物,在某些实施方案中,修饰不在茎环区的5′柄(5’-handle)中。指导物的茎环区的5′柄中的化学修饰可能会废除其功能(参见li等人,naturebiomedicalengineering,2017,1:0066)。在某些实施方案中,指导物的至少1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、17个、18个、19个、20个、21个、22个、23个、24个、25个、26个、27个、28个、29个、30个、35个、40个、45个、50个或75个核苷酸经化学修饰。在一些实施方案中,指导物的3’或5’端的3-5个核苷酸经化学修饰。在一些实施方案中,在种子区中仅引入较小的修饰,诸如2’-f修饰。在某些实施方案中,在指导物的3’端引入2′-f修饰。在某些实施方案中,指导物的5’端和/或3’端的3至5个核苷酸用2′-o-甲基(m)、2′-o-甲基3’硫代磷酸酯(ms)、s-约束乙基(cet)或2′-o-甲基3’硫代pace(msp)化学修饰。这样的修饰可以提高基因组编辑效率(参见hendel等人,nat.biotechnol.(2015)33(9):985-989)。在某些实施方案中,指导物的所有磷酸二酯键被硫代磷酸酯(ps)取代以增强基因破坏的水平。在某些实施方案中,指导物的5’端和/或3’端的多于5个核苷酸用2’-o-me、2’-f或s-约束乙基(cet)化学修饰。这种化学修饰的指导物可以介导增强的基因破坏水平(参见ragdarm等人,0215,pnas,e7110-e7111)。在本发明的一个实施方案中,指导物被修饰成在其3’和/或5’端包含化学部分。这样的部分包括但不限于胺、叠氮化物、炔、硫代基、二苯并环辛炔(dbco)或若丹明。在某些实施方案中,化学部分通过接头诸如烷基链缀合至指导物。在某些实施方案中,修饰的指导物的化学部分可用于将指导物附接至另一分子,诸如dna、rna、蛋白质或纳米粒子。这种化学修饰的指导物可用于识别或富集一般由crispr系统编辑的细胞(参见lee等人,elife,2017,6:e25312,doi:10.7554)。
在一些实施方案中,指导物包括修饰的cpf1crrna,其具有5’柄和指导区段,所述指导区段还包括种子区和3′端。修饰的指导物可以与以下任一种cpf1结合使用:氨基酸球菌属种bv3l6cpf1(ascpf1);土拉弗朗西斯菌新凶手亚种u112cpf1(fncpf1);李斯特氏菌(l.bacterium)mc2017cpf1(lb3cpf1);解蛋白丁酸弧菌cpf1(bpcpf1);帕库氏菌gwc2011_gwc2_44_17cpf1(pbcpf1);异域菌门菌gw2011_gwa_33_10cpf1(pecpf1);稻田氏钩端螺旋体cpf1(licpf1);史密斯氏菌属种sc_k08d17cpf1(sscpf1);李斯特氏菌ma2020cpf1(lb2cpf1);狗口腔卟啉单胞菌cpf1(pccpf1);猕猴卟啉单胞菌cpf1(pmcpf1);候选白蚁甲烷支原体cpf1(cmtcpf1);挑剔真杆菌cpf1(eecpf1);牛眼莫拉氏菌237cpf1(mbcpf1);解糖胨普雷沃氏菌cpf1(pdcpf1);或李斯特氏菌nd2006cpf1(lbcpf1)。
在一些实施方案中,对指导物的修饰是化学修饰、插入、缺失或拆分。在一些实施方案中,化学修饰包括但不限于并入2′-o-甲基(m)类似物、2′-脱氧类似物、2-硫代尿苷类似物,n6-甲基腺苷类似物、2′-氟类似物、2-氨基嘌呤、5-溴-尿苷、假尿苷(ψ)、n1-甲基假尿苷(me1ψ)、5-甲氧基尿苷(5mou)、肌苷、7-甲基鸟苷、2′-o-甲基3’硫代磷酸酯(ms)、s-约束乙基(cet)、硫代磷酸酯(ps)或2′-o-甲基3’硫代pace(msp)。在一些实施方案中,指导物包含一种或多种硫代磷酸酯修饰。在某些实施方案中,指导物的至少1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、17个、18个、19个、20个或25个核苷酸经化学修饰。在某些实施方案中,种子区中的一个或多个核苷酸经化学修饰。在某些实施方案中,在3’端的一个或多个核苷酸经化学修饰。在某些实施方案中,5’柄中的核苷酸均未经化学修饰。在一些实施方案中,种子区中的化学修饰是次要修饰,诸如并入2’-氟类似物。在具体实施方案中,种子区的一个核苷酸被2’-氟类似物替代。在一些实施方案中,在3’端中的5至10个核苷酸经化学修饰。在cpf1crrna的3’端处的此类化学修饰可改善cpf1活性(参见li等人,naturebiomedicalengineering,2017,1:0066)。在具体实施方案中,3’端中的1个、2个、3个、4个、5个、6个、7个、8个、9个或10个核苷酸被2’-氟类似物替代。在具体实施方案中,3’端中的1个、2个、3个、4个、5个、6个、7个、8个、9个或10个核苷酸被2’-o-甲基(m)类似物替代。
在一些实施方案中,指导物的5′柄的环经修饰。在一些实施方案中,指导物的5′柄的环被修饰为具有缺失、插入、拆分或化学修饰。在某些实施方案中,修饰的环包含3个、4个或5个核苷酸。在某些实施方案中,环包含序列ucuu、uuuu、uauu或uguu。
在一些实施方案中,指导分子与单独的非共价连接的序列(其可以是dna或rna)形成茎环。在特定实施方案中,首先使用标准亚磷酰胺合成方案合成形成指导物的序列(herdewijn,p.,编辑,methodsinmolecularbiologycol288,oligonucleotidesynthesis:methodsandapplications,humanapress,newjersey(2012))。在一些实施方案中,可以使用本领域已知的标准方案将这些序列官能化成含有适于连接的官能团(hermanson,g.t.,bioconjugatetechniques,academicpress(2013))。官能团的实例包括但不限于羟基、胺、羧酸、羧酸卤化物、羧酸活性酯、醛、羰基、氯代羰基、咪唑基羰基、肼基、氨基脲、硫代氨基脲、硫醇、马来酰亚胺、卤代烷基、磺酰基、烯丙基、炔丙基、二烯、炔和叠氮化物。一旦该序列被官能化,就可以在该序列与正向重复序列之间形成共价化学键或键联。化学键的实例包括但不限于基于以下的那些:氨基甲酸酯、醚、酯、酰胺、亚胺、脒、氨基三嗪、腙、二硫键、硫醚、硫酯、硫代磷酸酯、二硫代磷酸酯、磺酰胺、磺酸酯、砜(fulfone)、亚砜、脲、硫脲、酰肼、肟、三唑、光不稳定键联、c-c键形成基团(诸如狄尔斯-阿尔德环加成对(diels-aldercyclo-additionpair)或闭环复分解对(ring-closingmetathesispair))以及迈克尔反应对(michaelreactionpair)。
在一些实施方案中,这些茎环形成序列可以经化学合成。在一些实施方案中,化学合成使用自动固相寡核苷酸合成机并利用2’-乙酰氧基乙基原酸酯(2’-ace)(scaringe等人,j.am.chem.soc.(1998)120:11820-11821;scaringe,methodsenzymol.(2000)317:3-18)或2′-硫代氨基甲酸酯(2′-tc)化学品(dellinger等人,j.am.chem.soc.(2011)133:11540-11546;hendel等人,nat.biotechnol.(2015)33:985-989)。
在某些实施方案中,指导分子(能够将cpf1导向至靶基因座)包含(1)能够与靶基因座杂交的指导序列和(2)tracr配对或正向重复序列,其中正向重复序列位于指导序列的上游(即5’)。在特定实施方案中,cpf1指导序列的种子序列(即对于识别靶基因座处的序列和/或与其杂交而言至关重要的序列)大约在指导序列的前10个核苷酸之内。在特定实施方案中,cpf1为fncpf1,并且种子序列大约在指导序列的5’端的前5nt之内。
在特定实施方案中,指导分子包含连接至正向重复序列的指导序列,其中正向重复序列包含一个或多个茎环或优化的二级结构。在特定实施方案中,正向重复序列的最小长度为16nt,并且具有单个茎环。在另外的实施方案中,正向重复序列的长度大于16nt,优选大于17nt,并且具有多于一个茎环或优化的二级结构。在特定实施方案中,指导分子包含连接至全部或部分天然正向重复序列的指导序列或由其组成。典型的v型cpf1指导分子包含(以3’至5’方向):指导序列、第一互补段(“重复序列”)、环(长度通常为4或5个核苷酸)、第二互补段(与重复序列互补的“抗重复序列”),以及polya(通常为rna中的polyu)尾巴(终止子)。在某些实施方案中,正向重复序列保留其天然架构并形成单个茎环。在特定实施方案中,指导物架构的某些方面可以例如通过特征的添加、减去或取代进行修饰,而指导物架构的某些其他方面得以保留。工程化指导分子修饰(包括但不限于插入、缺失和取代)的优选位置包括指导末端和指导分子的在与cpf1蛋白和/或靶标复合时暴露的区域,例如正向重复序列的茎环。
在特定实施方案中,茎含有互补x和y序列,包含至少约4bp,但也涵盖具有更多(例如5个、6个、7个、8个、9个、10个、11个或12个)或更少(例如3个、2个)的碱基对的茎。因此,可以涵盖例如x2-10和y2-10(其中x和y代表任何互补的核苷酸组)。在一方面,由x和y核苷酸组成的茎与环一起将在总体二级结构中形成完整的发夹;并且,这可能是有利的,并且碱基对的数量可以是形成完整发夹的任何数量。在一方面,只要保留整个指导分子的二级结构,就可以容忍任何互补的x:y碱基配对序列(例如,就长度而言)。在一方面,连接由x:y碱基对组成的茎的环,可以是不干扰指导分子的总体二级结构的长度相同(例如4或5个核苷酸)或更长的任何序列。在一方面,茎环可还包含例如ms2适体。在一方面,茎含有互补x和y序列,包含约5-7bp,但也涵盖具有更多或更少的碱基对的茎。在一方面,涵盖非沃森-克里克(watson-crick)碱基配对,这种配对通常以其他方式保留该位置处茎环的架构。
在特定实施方案中,将指导分子的天然发夹或茎环结构延伸或由延伸的茎环替代。已证实茎的延伸可以增强指导分子与crispr-cas蛋白的组装(chen等人cell.(2013);155(7):1479-1491)。在特定实施方案中,茎环的茎延伸了至少1个、2个、3个、4个、5个或更多个互补碱基对(即对应于在指导分子中添加2个、4个、6个、8个、10个或更多个核苷酸)。在特定实施方案中,它们位于茎的端部,邻近茎环的环。
在特定实施方案中,可以通过对指导分子的序列进行不影响其功能的轻微修饰来降低指导分子对rna酶或表达降低的易感性。例如,在特定实施方案中,可以通过修饰指导分子序列中的推定pol-iii终止子(4个连续的u)来消除转录的过早终止,诸如u6pol-iii的过早转录。当在指导分子的茎环中需要这种序列修饰时,优选通过碱基对翻转来确保。
在优选的实施方案中,可以修饰正向重复序列使其包含一个或多个蛋白结合rna适体。在特定实施方案中,可以包括一个或多个适体,诸如优化的二级结构的一部分。此类适体可能能够结合如本文进一步详述的噬菌体外壳蛋白。
在一些实施方案中,指导分子与包含至少一个待编辑的靶腺苷残基的靶dna链形成双链体。指导rna分子与靶dna链杂交后,腺苷脱氨酶结合至双链体并催化dna-rna双链体内包含的一个或多个靶腺苷残基脱氨基。
可以选择指导序列并且因此选择核酸靶向指导rna以靶向任何靶核酸序列。靶序列可以是dna。靶序列可以是基因组dna。靶序列可以是线粒体dna。
在某些实施方案中,靶序列应缔合至pam(原间隔区相邻基序)或pfs(原间隔区侧接序列或位点);即,由crispr复合物识别的短序列。取决于crispr-cas蛋白的性质,应选择靶序列,使得其在dna双链体中的互补序列(在本文中也称为非靶序列)在pam的上游或下游。在crispr-cas蛋白是cpf1蛋白的本发明的实施方案中,中靶序列的互补序列在pam的下游或3’。pam的精确序列和长度要求因所使用的cpf1蛋白而异,但pam通常是与原间隔区(即靶序列)相邻的2-5个碱基对序列。在下文中提供了用于不同cpf1直系同源物的天然pam序列的实例,并且技术人员将能够鉴定与给定cpf1蛋白一起使用的另外的pam序列。
此外,例如,如kleinstiverbp等人engineeredcrispr-cas9nucleaseswithalteredpamspecificities.nature.2015年7月23日;523(7561):481-5.doi:10.1038/nature14592中针对cas9所述,对pam相互作用(pi)结构域的工程化可以允许对pam特异性进行编程,提高靶位点识别的保真度,并提高crispr-cas蛋白的多功能性。如本文进一步详述的,技术人员将理解可以采用类似方式修饰cpf1蛋白。
在特定实施方案中,选择指导序列以确保脱氨酶在待脱氨基的腺嘌呤上的最佳效率。可以考虑靶链中腺嘌呤相对于cpf1切口酶的切割位点的位置。在特定实施方案中,令人感兴趣的是确保切口酶将作用于非靶链上邻近待脱氨基的腺嘌呤的位置处。例如,在特定实施方案中,cpf1切口酶切除非靶向链中在pam下游的17个核苷酸(例如ascpf1、lbcpf1)或pam下游的18个核苷酸(例如fncpf1),并且令人感兴趣的是这样设计指导物:对应于待脱氨基的腺嘌呤的胞嘧啶位于指导序列中,在相应非靶链序列中切口酶切割位点上游或下游10bp内。
在特定实施方案中,指导物是受护航的指导物。“受护航的”是指将cpf1crispr-cas系统或复合物或指导物递送至细胞内的选定时间或位置,从而在空间或时间上控制cpf1crispr-cas系统或复合物或指导物的活性。例如,可以通过对适体配体(诸如细胞表面蛋白或其他局部细胞组分)具有结合亲和力的护航性rna适体序列控制cpf1crispr-cas系统或复合物或指导物的活性和目的地。或者,护航性适体可以例如对细胞上或细胞中的适体效应子作出反应,所述适体效应子诸如有瞬时效应子,诸如在特定时间施加至细胞的外部能源。
受护航的cpf1crispr-cas系统或复合物具有指导分子,其具有被设计来改善指导分子的结构、架构、稳定性、基因表达或它们的任何组合的功能结构。这样的结构可包括适体。
适体是可以例如使用一种称为指数富集的配体系统进化(selex;tuerkc,goldl:“systematicevolutionofligandsbyexponentialenrichment:rnaligandstobacteriophaget4dnapolymerase.”science1990,249:505-510)的技术进行设计或选择以与其他配体紧密结合的生物分子。核酸适体可以例如选自随机序列寡核苷库,它们对大范围的生物医学相关靶具有高结合亲和力和特异性,这揭示了适体的广泛治疗实用性(keefe、anthonyd.、supriyapai和andrewellington.″aptamersastherapeutics.″naturereviewsdrugdiscovery9.7(2010):537-550)。这些特征还揭示了适体作为药物递送媒介物的广泛用途(levy-nissenbaum,etgar等人″nanotechnologyandaptamers:applicationsindrugdelivery.″trendsinbiotechnology26.8(2008):442-449;和hickebj,stephensaw.“escortaptamers:adeliveryservicefordiagnosisandtherapy.”jclininvest2000,106:923-928.)。还可以构建充当分子开关、通过改变特性来响应问询(que)的适体,诸如结合荧光团以模拟绿色荧光蛋白活性的rna适体(paige、jeremys.、kareny.wu和samier.jaffrey.″rnamimicsofgreenfluorescentprotein.″science333.6042(2011):642-646)。先前还已提出适体可以用作靶向的sirna治疗性递送系统的组分,例如靶向细胞表面蛋白(zhou,jiehua和johnj.rossi.″aptamer-targetedcell-specificrnainterference.″silence1.1(2010):4)。
因此,在特定实施方案中,例如通过一种或多种适体对指导分子进行修饰,所述一种或多种适体被设计来改善指导分子的递送,包括递送穿过细胞膜、到达细胞内隔室或进入细胞核。加上所述一种或多种适体或无所述一种或多种适体,这样的结构可包括一个或多个部分,以便使指导分子可递送、可诱导或响应于选定的效应子。因此,本发明包括响应于正常或病理生理条件的指导分子,所述生理条件包括但不限于ph、低氧、o2浓度、温度、蛋白质浓度、酶浓度、脂质结构、曝光、机械破坏(例如超声波)、磁场、电场或电磁辐射。
诱导型系统的光响应性可以经由隐花色素-2和cib1的激活和结合来实现。蓝光刺激诱导隐花色素-2中的激活的构象变化,导致其结合配偶体cib1募集。这种结合是快速且可逆的,在脉冲刺激后的<15秒内达到饱和,并在刺激结束后的<15分钟内恢复至基线。这些快速的结合动力学使得系统暂时仅受转录/翻译和转录物/蛋白质降解的速度限制,而不受诱导剂的吸收和清除的限制。隐花色素-2的激活还是高度敏感的,使得可以使用低光强度刺激并减轻了光毒性的风险。此外,在诸如完整的哺乳动物脑的情形下,可变的光强度可用于控制受激区域的大小,从而获得比单独的载体递送所能提供的精度更高的精度。
本发明考虑了诸如电磁辐射、声能或热能的能源来诱导指导物。有利地,电磁辐射是可见光的组分。在优选的实施方案中,光是波长为约450至约495nm的蓝光。在特别优选的实施方案中,波长为约488nm。在另一个优选的实施方案中,光刺激是经由脉冲实现的。光功率可以在大约0-9mw/cm2的范围内。在优选的实施方案中,每15秒低至0.25秒的刺激范式应该会导致最大的激活。
化学或能量敏感型指导物在由于化学源的结合或能量而被诱导时可能会发生构象变化,使其成为指导物并具有cpf1crispr-cas系统或复合物功能。本发明可涉及施加化学源或能量以具有指导物功能和cpf1crispr-cas系统或复合物功能;并且任选地进一步确定基因组基因座的表达已改变。
此化学诱导型系统有几种不同的设计:1.由脱落酸(aba)可诱导的基于abi-pyl的系统(参见例如http://stke.sciencemag.org/cgi/content/abstract/sigtrans;4/164/rs2);2.由雷帕霉素可诱导的基于fkbp-frb系统(参见例如http://www.nature.com/nmeth/journal/v2/n6/full/nmeth763.html);3.由赤霉素(ga)可诱导的基于gid1-gai的系统(参见例如http://www.nature.com/nchembio/journal/v8/n5/full/nchembio.922.html)。
化学诱导型系统可以是由4-羟基他莫昔芬(4oht)可诱导的基于雌激素受体(er)的系统(参见例如http://www.pnas.org/content/104/3/1027.abstract)。雌激素受体的一种称为ert2的突变配体结合结构域在与4-羟基他莫昔芬结合后易位到细胞的细胞核中。在本发明的另外的实施方案中,任何核受体、甲状腺激素受体、视黄酸受体、雌激素受体、雌激素相关受体、糖皮质激素受体、孕激素受体、雄激素受体的任何天然存在或工程化的衍生物都可以用于与基于er的诱导型系统类似的诱导型系统。
另一种诱导型系统是基于使用由能量、热或无线电波可诱导的基于瞬时受体电位(trp)离子通道的系统进行的设计(参见例如http://www.sciencemag.org/content/336/6081/604)。这些trp家族蛋白响应于不同的刺激,包括光和热。当这种蛋白质被光或热激活时,离子通道将打开并允许诸如钙的离子进入质膜。这种离子涌流将与连接至多肽(包括指导物和cpf1crispr-cas复合物或系统的其他组分)的细胞内离子相互作用配偶体结合,并且该结合将诱导多肽的亚细胞定位发生变化,从而导致整个多肽进入细胞的细胞核。一旦进入细胞核,指导蛋白和cpf1crispr-cas复合物的其他组分就将呈活性状态并调节细胞中的靶基因表达。
尽管光激活可以是有利的实施方案,但是有时对于光可能不穿透皮肤或其他器官的体内应用而言可能是尤为不利的。在这种情况下,可以考虑其他具有类似效果的能量激活方法,特别是电场能和/或超声。
优选地在体内条件下,使用约1v/cm至约10kv/cm的一个或多个电脉冲,基本上如本领域中所述施加电场能。代替脉冲或加上脉冲,可以采用连续方式递送电场。可以施加电脉冲,持续1微秒与500毫秒之间,优选地1微秒与100毫秒之间。可以连续地或以脉冲方式施加电场,持续约5分钟。
如本文所用,“电场能”是细胞暴露于其中的电能。在体内条件下,电场的强度优选为约1v/cm至约10kv/cm或更大(参见wo97/49450)。
如本文所用,术语“电场”包括在可变电容和电压下的一个或多个脉冲,并且包括指数波和/或方形波和/或调制波和/或调制方形波形式。对电场和电的提及应视为包括对细胞环境中电位差的存在的提及。如本领域中已知的,可以通过静电、交流电(ac)、直流电(dc)等来建立这样的环境。电场可以是均匀的、不均匀的或其他方式的,并且可以以时间依赖性方式改变强度和/或方向。
电场的单次或多次施加,以及超声的单次或多次施加也是可能的,可以是任何顺序和任何组合。超声和/或电场可以作为单次或多次连续施加或作为脉冲来递送(脉冲式递送)。
电穿孔已用于体外和体内程序中,以将异物引入活细胞中。在体外应用中,首先将活细胞样品与目标剂混合,接着将它们放置在电极(诸如平行板)之间。接着,电极向细胞/植入物混合物施加电场。执行体外电穿孔的系统的实例包括electrocellmanipulatorecm600产品和electrosquareporatort820,这两者均由genetronics,inc的btx分部制造(参见美国专利号5,869,326)。
已知的电穿孔技术(体外和体内)都通过向位于治疗区域周围的电极施加短暂的高压脉冲来发挥作用。电极之间产生的电场使细胞膜暂时变为多孔的,此时目标剂进入细胞。在已知的电穿孔应用中,此电场包括持续约100微秒的大约1000v/cm的单个方形波脉冲。这样的脉冲可以例如在electrosquareporatort820的已知应用中产生。
在体外条件下,电场的强度优选为约1v/cm至约10kv/cm。因此,电场的强度可以为1v/cm、2v/cm、3v/cm、4v/cm、5v/cm、6v/cm、7v/cm、8v/cm、9v/cm、10v/cm、20v/cm、50v/cm、100v/cm、200v/cm、300v/cm、400v/cm、500v/cm、600v/cm、700v/cm、800v/cm、900v/cm、1kv/cm、2kv/cm、5kv/cm、10kv/cm、20kv/cm、50kv/cm或更大。在体外条件下,更优选为约0.5kv/cm至约4.0kv/cm。在体内条件下,电场的强度优选为约1v/cm至约10kv/cm。然而,当递送至靶位点的脉冲数量增加时,电场强度可能降低。因此,设想以较低的场强脉冲式递送电场。
优选地,采用多个脉冲的形式,诸如具有相同强度和电容的双脉冲或具有变化强度和/或电容的顺序脉冲来施加电场。如本文所用,术语“脉冲”包括在可变电容和电压下的一个或多个电脉冲,并且包括指数波和/或方形波和/或调制波/方形波形式。
优选地,将电脉冲作为选自指数波形式、方形波形式、调制波形式和调制方形波形式的波形递送。
优选的实施方案采用低压直流电。因此,申请人公开了以1v/cm与20v/cm之间的场强向细胞、组织或组织块施加电场,持续时间为100毫秒或更长,优选为15分钟或更长。
有利地,以约0.05w/cm2至约100w/cm2的功率水平施用超声。可以使用诊断性超声或治疗性超声,或它们的组合。
如本文所用,术语“超声”是指一种由机械振动组成的能量形式,所述机械振动的频率特别高以至于超出人类的听觉范围。超声频谱的频率下限通常可以取为约20khz。大多数诊断性超声应用采用1至15mhz’的频率(ultrasonicsinclinicaldiagnosis,p.n.t.wells,编辑,第二版,出版社churchilllivingstone[edinburgh,london&ny,1977])。
在诊断性和治疗性应用中皆已使用超声。当用作诊断性工具(诊断性超声)时,通常在高达约100mw/cm2的能量密度下使用超声(fda推荐),但也使用过高达750mw/cm2的能量密度。在物理疗法中,通常使用高达约3至4w/cm2范围内的超声作为能源(who推荐)。在其他治疗性应用中,可以在短时间内采用更高强度的超声,例如100w/cm至1kw/cm2(或甚至更高)的hifu。在本说明书中使用的术语“超声”旨在涵盖诊断性超声、治疗性超声和聚焦超声。
聚焦超声(fus)允许在不使用侵入式探头的情况下递送热能(参见morocz等人1998,journalofmagneticresonanceimaging,第8卷,第1期,第136-142页。聚焦超声的另一种形式是高强度聚焦超声(hifu),moussatov等人,ultrasonics(1998),第36卷,第8期,第893-900页以及tranhuuhue等人,acustica(1997),第83卷,第6期,第1103-1106页中对此进行了综述。
优选地,采用诊断性超声和治疗性超声的组合。但是,该组合并非旨在进行限制,而是本领域技术人员将理解可以使用超声的任何多种组合。另外,能量密度、超声频率和暴露时间是可以改变的。
优选地,超声能源暴露的功率密度为约0.05至约100wcm-2。甚至更优选地,超声能源暴露的功率密度为约1至约15wcm-2。
优选地,超声能源暴露的频率为约0.015至约10.0mhz。更优选地,超声能源暴露的频率为约0.02至约5.0mhz或约6.0mhz。最优选地,以3mhz的频率施加超声。
优选地,暴露持续约10毫秒至约60分钟的时段。优选地,暴露持续约1秒至约5分钟的时段。更优选地,施加超声持续约2分钟。然而,取决于有待破坏的特定靶细胞,暴露可以持续更长的持续时间,例如持续15分钟。
有利地,将靶组织暴露于超声能源,超声能源的声功率密度为约0.05wcm-2至约10wcm-2,频率在约0.015至约10mhz的范围内(参见wo98/52609)。但是替代方案也是可能的,例如超声能源暴露的声功率密度高于100wcm-2,但持续缩短的时间段,例如1000wcm-2持续毫秒范围或更小的时段。
优选地,超声施加呈多个脉冲的形式;因此,可以采用任何组合的连续波和脉冲波(脉冲式超声递送)。例如,可以施加连续波超声,之后施加脉冲波超声,反之亦然。可以采用任何顺序和组合将其重复任意次数。可以在连续波超声的背景下施加脉冲波超声,并且可以使用任何组数的任何数量的脉冲。
优选地,超声可包括脉冲波超声。在高度优选的实施方案中,以0.7wcm-2或1.25wcm-2的功率密度以连续波形式施加超声。如果使用了脉冲超声波,则可以采用更高的功率密度。
超声的使用是有利的,因为像光一样,超声可以精确地聚焦在靶标上。此外,超声是有利的,因为与光不同,超声可以更深地聚焦到组织中。因此,它更适于完整组织穿透(诸如但不限于肝叶)或完整器官(诸如但不限于整个肝脏或整个肌肉,诸如心脏)疗法。另一个重要的优点是超声是非侵入式刺激,可用于多种多样的诊断性和治疗性应用。举例来说,超声在医学成像技术以及骨科疗法中是众所周知的。此外,适于向受试者脊椎动物施加超声的仪器是广泛可得的,并且它们使用在本领域中是众所周知的。
在特定实施方案中,通过二级结构修饰指导分子以增加crispr-cas系统的特异性,并且所述二级结构可以防御核酸外切酶活性并允许对指导序列进行5’添加(在本文中也称为受保护的指导分子)。
在一方面,本发明提供了将“保护性rna”与指导分子的序列杂交的方法,其中“保护性rna”是与指导分子的3’端互补的rna链,从而产生部分双链的指导rna。在本发明的实施方案中,用完全互补的保护性序列保护错配的碱基(即,指导分子中不形成指导序列的一部分的碱基)降低了靶dna结合至3’端处的错配碱基对的可能性。在本发明的特定实施方案中,在指导分子内还可以存在包含延伸长度的其他序列,使得指导物在指导分子内包含保护性序列。该“保护性序列”确保指导分子除“暴露的序列”(包含与靶序列杂交的指导序列的一部分)之外还包括“受保护的序列”。在特定实施方案中,通过保护性指导物的存在将指导分子修饰为包含二级结构(诸如发夹)。有利地,存在三个或四个至三十个或更多个(例如约10个或更多个)具有与受保护序列、指导序列或两者互补的连续碱基对。有利的是,受保护部分不妨碍crispr-cas系统与其靶相互作用的热力学。通过提供包括部分双链的指导分子在内的这种延伸,指导分子被认为是受保护的并且改善了crispr-cas复合物的特异性结合,同时维持特定活性。
在特定实施方案中,使用了截短的指导物(tru-指导物),即包含相对于典型的指导序列长度,长度被截短的指导序列的指导分子。如nowak等人(nucleicacidsres(2016)44(20):9555-9564)所述,此类指导物可允许催化活性crispr-cas酶结合其靶标,而不切割靶dna。在特定实施方案中,使用了截短的指导物,所述截短的指导物允许靶标的结合,但仅保留了crispr-cas酶的切口酶活性。
crispr-cas酶
在本文提供的方法的某些实施方案中,crispr-cas蛋白具有降低的催化活性或没有催化活性。在crispr-cas蛋白是cpf1蛋白的情况下,突变可包括但不限于催化性ruvc样结构域中的一个或多个突变,诸如d908a或e993a(依据ascpf1中的位置)。
在一些实施方案中,当突变酶的dna切割活性为所述酶的非突变形式的dna切割活性的约不超过25%、10%、5%、1%、0.1%、0.01%或更低时,认为crispr-cas蛋白基本上缺乏所有的dna切割活性;一个实例可以是当突变形式的dna切割活性与非突变形式相比为零或可忽略不计时。在这些实施方案中,将crispr-cas蛋白用作通用dna结合蛋白。突变可以是人工引入的突变或者功能获得或功能丧失突变。
除以上所述的突变外,还可以另外对crispr-cas蛋白进行修饰。如本文所用,关于crispr-cas蛋白的术语“修饰的”通常是指与衍生其的野生型cas蛋白相比,crispr-cas蛋白具有一个或多个修饰或突变(包括点突变、截短、插入、缺失、嵌合体、融合蛋白等)。所谓衍生的,是指在与野生型酶具有高度序列同源性的意义上,衍生酶主要基于野生型酶,但是已经以本领域已知或如本文所述的某种方式对衍生酶进行了突变(修饰)。
对crispr-cas蛋白的另外的修饰可能会或可能不会导致功能改变。举例来说,且特别地就crispr-cas蛋白而言,不导致功能改变的修饰包括例如针对表达到特定宿主中进行密码子优化,或向核酸酶提供特定标记物(例如用于可视化)。可能导致功能改变的修饰还可能包括突变,包括点突变、插入、缺失、截短(包括拆分的核酸酶)等。融合蛋白可包括但不限于例如与异源结构域或功能结构域(例如定位信号、催化结构域等)形成的融合物。在某些实施方案中,可以组合各种不同的修饰(例如,具有催化活性的突变核酸酶进一步融合至功能结构域(例如)以诱导dna甲基化;或另一种核酸修饰,如包括但不限于断裂(例如通过不同的核酸酶(结构域))、突变、缺失、插入、替代、连接、消化、断裂或重组)。如本文所用,“改变的功能性”包括但不限于改变的特异性(例如改变的靶标识别、增加的(例如“增强的”cas蛋白)或降低的特异性,或改变的pam识别)、改变的活性(例如增加的或降低的催化活性,包括无催化活性的核酸酶或切口酶)和/或改变的稳定性(例如与去稳定结构域融合)。合适的异源结构域包括但不限于核酸酶、连接酶、修复蛋白、甲基转移酶、(病毒)整合酶、重组酶、转座酶、argonaute、胞苷脱氨酶、反转录子、ii族内含子、磷酸酶、磷酸化酶、磺酰化酶(sulpfurylase)、激酶、聚合酶、核酸外切酶等。所有这些修饰的实例在本领域中都是已知的。将理解的是,如本文所提及的“修饰的”核酸酶,且特别地“修饰的”cas或“修饰的”crispr-cas系统或复合物优选地仍具有与多核酸相互作用或结合的能力(例如与指导分子复合)。这种修饰的cas蛋白可与如本文所述的脱氨酶蛋白或其活性结构域组合。
在某些实施方案中,crispr-cas蛋白可包含一种或多种使活性和/或特异性增强的修饰,例如包括使靶向或非靶向链稳定的突变残基(例如ecas9;“rationallyengineeredcas9nucleaseswithimprovedspecificity”,slaymaker等人(2016),science,351(6268):84-88,以引用方式整体并入本文)。在某些实施方案中,工程化crispr蛋白的改变或修饰的活性包括增加的靶向效率或减少的脱靶结合。在某些实施方案中,工程化crispr蛋白的改变的活性包括修改的切割活性。在某些实施方案中,改变的活性包括对靶多核苷酸基因座的增加的切割活性。在某些实施方案中,改变的活性包括对靶多核苷酸基因座的降低的切割活性。在某些实施方案中,改变的活性包括对脱靶多核苷酸基因座的降低的切割活性。在某些实施方案中,修饰的核酸酶的改变的或修改的活性包括改变的解旋酶动力学。在某些实施方案中,修饰的核酸酶包含改变蛋白质与包含rna的核酸分子(在cas蛋白的情况下)、或靶多核苷酸基因座的链、或脱靶多核苷酸的链的缔合的修饰。在本发明的一方面,工程化crispr蛋白包含改变crispr复合物的形成的修饰。在某些实施方案中,改变的活性包括对脱靶多核苷酸基因座的增加的切割活性。因此,在某些实施方案中,相较于脱靶多核苷酸基因座,对靶多核苷酸基因座的特异性增加。在其他实施方案中,相较于脱靶多核苷酸基因座,对靶多核苷酸基因座的特异性降低。在某些实施方案中,突变导致脱靶效应(例如切割或结合特性、活性或动力学)降低,诸如在cas蛋白的情况下,例如导致对靶标与指导rna之间的错配的耐受性降低。其他突变可能导致脱靶效应(例如切割或结合特性、活性或动力学)增加。其他突变可能导致中靶效应(例如切割或结合特性、活性或动力学)增加或降低。在某些实施方案中,突变引起改变的(例如增加或降低的)解旋酶活性、功能性核酸酶复合物(例如crispr-cas复合物)的缔合或形成。在某些实施方案中,如上所述,突变导致pam识别改变,即相较于未修饰的cas蛋白,可能(另外地或替代地)识别不同的pam。为了增强特异性,特别优选的突变包括带正电的残基和/或(进化的)保守的残基,诸如保守的带正电残基。在某些实施方案中,此类残基可被突变为不带电荷的残基,诸如丙氨酸。
碱基切除修复抑制剂
在一些实施方案中,ad官能化的crispr系统还包含碱基切除修复(ber)抑制剂。不希望受任何特定理论的束缚,对i:t配对存在的细胞dna修复反应可能导致细胞中核碱基编辑效率的降低。烷基腺嘌呤dna糖基化酶(也称为dna-3-甲基腺嘌呤糖基化酶、3-烷基腺嘌呤dna糖基化酶或n-甲基嘌呤dna糖基化酶)催化细胞dna中次黄嘌呤的去除,这可能启动碱基切除修复,结果i:t配对逆转成a:t配对。
在一些实施方案中,ber抑制剂是烷基腺嘌呤dna糖基化酶的抑制剂。在一些实施方案中,ber抑制剂是人类烷基腺嘌呤dna糖基化酶的抑制剂。在一些实施方案中,ber抑制剂是多肽抑制剂。在一些实施方案中,ber抑制剂是结合次黄嘌呤的蛋白质。在一些实施方案中,ber抑制剂是结合dna中的次黄嘌呤的蛋白质。在一些实施方案中,ber抑制剂是无催化活性的烷基腺嘌呤dna糖基化酶蛋白或其结合结构域。在一些实施方案中,ber抑制剂是不从dna中切除次黄嘌呤的无催化活性的烷基腺嘌呤dna糖基化酶蛋白或其结合结构域。能够抑制(例如,在空间上阻断)烷基腺嘌呤dna糖基化酶碱基切除修复酶的其他蛋白质在本公开的范围之内。另外,阻断或抑制碱基切除修复的任何蛋白质也在本公开的范围之内。
不希望受任何特定理论的束缚,可通过结合编辑链、阻断编辑碱基、抑制烷基腺嘌呤dna糖基化酶、抑制碱基切除修复、保护编辑碱基和/或促进未编辑链固定的分子抑制碱基切除修复。据信,使用本文所述的ber抑制剂可以提高能够催化a至i变化的腺苷脱氨酶的编辑效率。
因此,在以上论述的ad官能化的crispr系统的第一设计中,可以将crispr-cas蛋白或腺苷脱氨酶融合或连接至ber抑制剂(例如烷基腺嘌呤dna糖基化酶的抑制剂)。在一些实施方案中,ber抑制剂可以包含在以下结构之一中(ncpf1=cpf1切口酶;dcpf1=死亡cpf1):
[ad]-[任选的接头]-[ncpf1/dcpf1]-[任选的接头]-[ber抑制剂];
[ad]-[任选的接头]-[ber抑制剂]-[任选的接头]-[ncpf1/dcpf1];
[ber抑制剂]-[任选的接头]-[ad]-[任选的接头]-[ncpf1/dcpf1];
[ber抑制剂]-[任选的接头]-[ncpf1/dcpf1]-[任选的接头]-[ad];
[ncpf1/dcpf1]-[任选的接头]-[ad]-[任选的接头]-[ber抑制剂];
[ncpf1/dcpf1]-[任选的接头]-[ber抑制剂]-[任选的接头]-[ad]。
类似地,在以上论述的ad官能化的crispr系统的第二设计中,可以将crispr-cas蛋白、腺苷脱氨酶或衔接蛋白融合或连接至ber抑制剂(例如烷基腺嘌呤dna糖基化酶的抑制剂)。在一些实施方案中,ber抑制剂可以包含在以下结构之一中(ncpf1=cpf1切口酶;dcpf1=死亡cpf1):
[ncpf1/dcpf1]-[任选的接头]-[ber抑制剂];
[ber抑制剂]-[任选的接头]-[ncpf1/dcpf1];
[ad]-[任选的接头]-[衔接子]-[任选的接头]-[ber抑制剂];
[ad]-[任选的接头]-[ber抑制剂]-[任选的接头]-[衔接子];
[ber抑制剂]-[任选的接头]-[ad]-[任选的接头]-[衔接子];
[ber抑制剂]-[任选的接头]-[衔接子]-[任选的接头]-[ad];
[衔接子]-[任选的接头]-[ad]-[任选的接头]-[ber抑制剂];
[衔接子]-[任选的接头]-[ber抑制剂]-[任选的接头]-[ad]。
在以上论述的ad官能化的crispr系统的第三设计中,可以将ber抑制剂插入crispr-cas蛋白的内环或非结构化区中。
对细胞核的靶向
在一些实施方案中,本发明的方法涉及修饰目标靶基因座中的腺嘌呤,其中所述靶基因座处于细胞内。为了改善在本发明的方法中使用的crispr-cas蛋白和/或腺苷脱氨酶蛋白或其催化结构域对细胞核的靶向,可能有利的是为这些组分之一或两者提供一个或多个核定位序列(nls)。
在优选的实施方案中,在本发明的情形中使用的nls与蛋白质是异源的。nls的非限制性实例包括来源于以下的nls序列:sv40病毒大t抗原的nls,其具有氨基酸序列pkkkrkv(seqidno:37)或pkkkrkveas(seqidno:38);来自核质蛋白的nls(例如核质蛋白两分nls,其具有序列krpaatkkagqakkkk(seqidno:39));c-mycnls,其具有氨基酸序列paakrvkld(seqidno:40)或rqrrnelkrsp(seqidno:41);hrnpa1m9nls,其具有序列nqssnfgpmkggnfggrssgpyggggqyfakprnqggy(seqidno:42);来自输入蛋白-α的ibb结构域的序列rmrizfknkgkdtaelrrrrvevsvelrkakkdeqilkrrnv(seqidno:43);肌瘤t蛋白的序列vsrkrprp(seqidno:44)和ppkkared(seqidno:45);人类p53的序列pqpkkkpl(seqidno:46);小鼠c-abliv的序列salikkkkkmap(seqidno:47);流感病毒ns1的序列drlrr(seqidno:48)和pkqkkrk(seqidno:49);肝炎病毒6抗原的序列rklkkkikkl(seqidno:50);小鼠mx1蛋白的序列rekkkflkrr(seqidno:51);人类聚(adp-核糖)聚合酶的序列krkgdevdgvdevakkkskk(seqidno:52);以及类固醇激素受体(人类)糖皮质激素的序列rkclqagmnlearktkk(seqidno:53)。通常,一个或多个nls具有足够的强度来驱动可检测量的dna靶向cas蛋白在真核细胞的细胞核中的积聚。通常,核定位活性的强度可以源自crispr-cas蛋白中nls的数量、所使用的特定nls或这些因素的组合。可以通过任何合适的技术来检测细胞核中的积聚。例如,(如)结合用于检测细胞核的位置的手段(例如对细胞核具有特异性的染色剂诸如dapi),可以将可检测的标记物融合至核酸靶向蛋白,从而可以可视化细胞内的位置。也可以从细胞中分离细胞核,接着可以通过用于检测蛋白质的任何合适的方法(诸如免疫组织化学、蛋白质印迹或酶活性测定)来分析细胞核的内容。也可以通过针对靶序列处的核酸靶向复合物形成的作用的测定(例如针对脱氨酶活性的测定),或针对受dna靶向复合物形成/或dna靶向影响而改变的基因表达的测定),如与未暴露于crispr-cas蛋白和脱氨酶蛋白的对照物,或暴露于缺少一个或多个nls的crispr-cas和/或脱氨酶蛋白的对照物相比,间接确定细胞核中的积聚。
可以为crispr-cas和/或腺苷脱氨酶蛋白提供1个或多个,诸如2个、3个、4个、5个、6个、7个、8个、9个、10个或更多个异源nls。在一些实施方案中,蛋白质在氨基末端处或附近包含约或多于约1个、2个、3个、4个、5个、6个、7个、8个、9个、10个或更多个nls,在羧基末端处或附近包含约或多于约1个、2个、3个、4个、5个、6个、7个、8个、9个、10个或多个nls,或这些的组合(例如在氨基末端处为零或至少一个或多个nls,或在羧基末端处为零或一个或多个nls)。当存在多于一个nls时,可以彼此独立地选择每个nls,使得单个nls可以多于一个拷贝存在和/或与一个或多个其他nls组合以一个或多个拷贝存在。在一些实施方案中,当nls的最近的氨基酸沿着多肽链距n端或c端约1个、2个、3个、4个、5个、10个、15个、20个、25个、30个、40个、50个或更多个氨基酸内时,认为nls接近n端或c端。在crispr-cas蛋白的优选实施方案中,nls附接至蛋白质的c端。
在本文提供的方法的某些实施方案中,crispr-cas蛋白和脱氨酶蛋白作为单独的蛋白质被递送至细胞或在细胞内表达。在这些实施方案中,crispr-cas和脱氨酶蛋白各自可以被提供有一个或多个如本文所述的nls。在某些实施方案中,crispr-cas和脱氨酶蛋白作为融合蛋白被递送至细胞或在细胞内表达。在这些实施方案中,crispr-cas和脱氨酶蛋白之一或两者都被提供有一个或多个nls。如上所述,当腺苷脱氨酶融合至衔接蛋白(诸如ms2)时,可以在衔接蛋白上提供一个或多个nls,条件是这不干扰适体结合。在特定实施方案中,一个或多个nls序列还可以充当腺苷脱氨酶与crispr-cas蛋白之间的接头序列。
在某些实施方案中,本发明的指导物包含针对衔接蛋白的特异性结合位点(例如适体),所述衔接蛋白可以连接或融合至腺苷脱氨酶或其催化结构域。当这样的指导物形成crispr复合物(即结合至指导物和靶标的crispr-cas蛋白)时,衔接蛋白结合腺苷脱氨酶或其催化结构域,并且与所述衔接蛋白缔合的腺苷脱氨酶或其催化结构域被定位成有利于属性化的功能生效的空间取向。
技术人员将理解,对允许衔接子+腺苷脱氨酶结合但未正确定位衔接子+腺苷脱氨酶(例如由于crispr复合物的三维结构内的空间位阻)的指导物的修饰是未预期的修饰。如本文所述,一种或多种修饰的指导物可在四环、茎环1、茎环2或茎环3处修饰,优选地在四环或茎环2中,且最优选地在四环处环和茎环2两者中修饰。
正交无催化活性的crispr-cas蛋白的用途
在特定实施方案中,将cpf1切口酶与正交无催化活性的crispr-cas蛋白结合使用以提高所述cpf1切口酶的效率(如chen等人2017,naturecommunications8:14958;doi:10.1038/ncomms14958中所述)。更特别地,通过与ad官能化的crispr系统中所用的cpf1切口酶不同的pam识别位点来表征正交无催化活性的crispr-cas蛋白,并且选择相应的指导序列以结合至邻近ad官能化的crispr系统的cpf1切口酶的靶序列的靶序列。如在本发明的情形中使用的正交无催化活性的crispr-cas蛋白不形成ad官能化的crispr系统的一部分,而是仅用于增加所述cpf1切口酶的效率,并且与如在本领域中针对所述crispr-cas蛋白描述的标准指导分子结合使用。在特定实施方案中,所述正交无催化活性的crispr-cas蛋白是死亡crispr-cas蛋白,即包含一种或多种消除所述crispr-cas蛋白的核酸酶活性的突变。在特定实施方案中,无催化活性的正交crispr-cas蛋白被提供有两种或更多种能够与邻近cpf1切口酶的靶序列的靶序列杂交的指导分子。在特定实施方案中,至少两种指导分子用于靶向所述无催化活性的crispr-cas蛋白,其中至少一种指导分子能够与ad官能化的crispr系统的cpf1切口酶的靶序列的5”靶序列杂交并且至少一种指导分子能够与cpf1切口酶的靶序列的3’靶序列杂交,由此所述一个或多个靶序列可以处于与cpf1切口酶的靶序列相同或相反的dna链上。在特定实施方案中,选择正交无催化活性的crispr-cas蛋白的一种或多种指导分子的指导序列,以使靶序列邻近用于ad官能化的crispr的靶向(即cpf1切口酶的靶向)的指导分子的靶序列。在特定实施方案中,正交无催化活性的crispr-cas酶的一个或多个靶序列各自与cpf1切口酶的靶序列分开大于5个但小于450个碱基对。与正交无催化活性的crispr-cas蛋白一起使用的指导物的靶序列与ad官能化的crispr系统的靶序列之间的最佳距离可以由技术人员确定。在特定实施方案中,正交crispr-cas蛋白是ii类ii型crispr蛋白。在特定实施方案中,正交crispr-cas蛋白是ii类v型crispr蛋白。在特定实施方案中,无催化活性的正交crispr-cas蛋白在特定实施方案中,无催化活性的正交crispr-cas蛋白已经如本文别处所述进行了修饰,以改变其pam特异性。在特定实施方案中,cpf1蛋白切口酶是这样的一种切口酶:其本身在人类细胞中活性有限,但与无活性的正交crispr-cas蛋白和一种或多种相应的邻近指导物组合可确保所需的切口酶活性。
crispr开发和使用
可以基于以下文章中所陈述的crispr-cas开发和使用的方面,特别是涉及crispr蛋白复合物的递送以及rna指导的内切核酸酶在细胞和生物体中的使用的方面进一步说明和扩展本发明:
将它们各自以引用方式并入本文,可以在本发明的实践中考虑,并在下文简要论述:
本文提供的方法和工具是针对cpf1示例,cpf1是一种不使用tracrrna的ii型核酸酶。如本文所述,已经在不同的细菌种类中鉴定了cpf1的直系同源物。可以使用本领域中描述的方法鉴定具有类似特性的另外的ii型核酸酶(shmakov等人2015,60:385-397;abudayeh等人2016,science,5;353(6299))。在特定实施方案中,此类用于鉴定新颖crispr效应蛋白的方法可包括以下步骤:从数据库中选择编码种子的序列,所述种子鉴定crisprcas基因座的存在;鉴定位于种子的10kb内、在选定序列中包含开放阅读框(orf)的基因座;从中选择包含多个orf的基因座,其中仅单个orf编码新颖的crispr效应子,所述新颖的crispr效应子具有大于700个氨基酸并且与已知的crispr效应子具有不超过90%的同源性。在特定实施方案中,种子是与crispr-cas系统共用的蛋白质,诸如cas1。在另外的实施方案中,使用crispr阵列作为种子以鉴定新的效应蛋白。
已经证实了本发明的有效性。可以例如通过电穿孔转染包含cpf1和crrna的预组装重组crispr-cpf1复合物,从而产生高突变率且不存在可检测的脱靶突变。hur,j.k.等人,targetedmutagenesisinmicebyelectroporationofcpf1ribonucleoproteins,natbiotechnol.2016年6月6日.doi:10.1038/nbt.3596。全基因组分析显示,cpf1具有高度特异性。根据一种量度,在人类hek293t细胞中确定的cpf1的体外切割位点明显少于spcas9的体外切割位点。kim,d.等人,genome-wideanalysisrevealsspecificitiesofcpf1endonucleasesinhumancells,natbiotechnol.2016年6月6日.doi:10.1038/nbt.3609。在果蝇中已经证明了采用cpf1的有效多重系统,该系统使用了从包含本发明trna的阵列中加工得到的grna。port,f.等人,expansionofthecrisprtoolboxinananimalwithtrna-flankedcas9andcpf1grnas.doi:http://dx.doi.org/10.1101/046417。
另外,“dimericcrisprrna-guidedfokinucleasesforhighlyspecificgenomeediting”,shengdarq.tsai、nicolaswyvekens、cydkhayter、jennifera.foden、vishalthapar、deepakreyon、mathewj.goodwin、martinj.aryee,j.keithjoungnaturebiotechnology32(6):569-77(2014)涉及二聚体rna指导的foki核酸酶,该酶识别扩展序列并且可以在人类细胞中高效编辑内源性基因。
关于crispr/cas系统、其组分、及此类组分的递送(包括方法、材料、递送媒介物、载体、粒子、以及其制造和使用(包括关于量和配制品)),连同表达crispr-cas的真核细胞、表达crispr-cas的真核生物(诸如小鼠)的一般信息,参考以下:美国专利好号8,999,641、8,993,233、8,697,359、8,771,945、8,795,965、8,865,406、8,871,445、8,889,356、8,889,418、8,895,308、8,906,616、8,932,814和8,945,839;美国专利公布us2014-0310830(美国申请序列号14/105,031)、us2014-0287938a1(美国申请序列号14/213,991)、us2014-0273234a1(美国申请序列号14/293,674)、us2014-0273232a1(美国申请序列号14/290,575)、us2014-0273231(美国申请序列号14/259,420)、us2014-0256046a1(美国申请序列号14/226,274)、us2014-0248702a1(美国申请序列号14/258,458)、us2014-0242700a1(美国申请序列号14/222,930)、us2014-0242699a1(美国申请序列号14/183,512)、us2014-0242664a1(美国申请序列号14/104,990)、us2014-0234972a1(美国申请序列号14/183,471)、us2014-0227787a1(美国申请序列号14/256,912)、us2014-0189896a1(美国申请序列号14/105,035)、us2014-0186958(美国申请序列号14/105,017)、us2014-0186919a1(美国申请序列号14/104,977)、us2014-0186843a1(美国申请序列号14/104,900)、us2014-0179770a1(美国申请序列号14/104,837)和us2014-0179006a1(美国申请序列号14/183,486)、us2014-0170753(美国申请序列号14/183,429);us2015-0184139(美国申请序列号14/324,960);14/054,414欧洲专利申请ep2771468(ep13818570.7)、ep2764103(ep13824232.6)和ep2784162(ep14170383.5);以及pct专利公布wo2014/093661(pct/us2013/074743)、wo2014/093694(pct/us2013/074790)、wo2014/093595(pct/us2013/074611)、wo2014/093718(pct/us2013/074825)、wo2014/093709(pct/us2013/074812)、wo2014/093622(pct/us2013/074667)、wo2014/093635(pct/us2013/074691)、wo2014/093655(pct/us2013/074736)、wo2014/093712(pct/us2013/074819)、wo2014/093701(pct/us2013/074800)、wo2014/018423(pct/us2013/051418)、wo2014/204723(pct/us2014/041790)、wo2014/204724(pct/us2014/041800)、wo2014/204725(pct/us2014/041803)、wo2014/204726(pct/us2014/041804)、wo2014/204727(pct/us2014/041806)、wo2014/204728(pct/us2014/041808)、wo2014/204729(pct/us2014/041809)、wo2015/089351(pct/us2014/069897)、wo2015/089354(pct/us2014/069902)、wo2015/089364(pct/us2014/069925)、wo2015/089427(pct/us2014/070068)、wo2015/089462(pct/us2014/070127)、wo2015/089419(pct/us2014/070057)、wo2015/089465(pct/us2014/070135)、wo2015/089486(pct/us2014/070175)、wo2015/058052(pct/us2014/061077)、wo2015/070083(pct/us2014/064663)、wo2015/089354(pct/us2014/069902)、wo2015/089351(pct/us2014/069897)、wo2015/089364(pct/us2014/069925)、wo2015/089427(pct/us2014/070068)、wo2015/089473(pct/us2014/070152)、wo2015/089486(pct/us2014/070175)、wo2016/049258(pct/us2015/051830)、wo2016/094867(pct/us2015/065385)、wo2016/094872(pct/us2015/065393)、wo2016/094874(pct/us2015/065396)、wo2016/106244(pct/us2015/067177)。
还提到了2015年6月17日提交的美国申请62/180,709,受保护的指导rna(protectedguidernas(pgrnas));2014年12月12日提交的美国申请62/091,455,受保护的指导rna(protectedguidernas(pgrnas));2014年12月24日提交的美国申请62/096,708,受保护的指导rna(protectedguidernas(pgrnas));2014年12月12日提交的美国申请62/091,462、2014年12月23日提交的美国申请62/096,324、2015年6月17日提交的美国申请62/180,681和2015年10月5日提交的美国申请62/237,496,crispr转录因子的死亡指导物(deadguidesforcrisprtranscriptionfactors);2014年12月12日提交的美国申请62/091,456和2015年6月17日提交的美国申请62/180,692,用于crispr-cas系统的受护航的和官能化的指导物(escortedandfunctionalizedguidesforcrispr-cassystems);2014年12月12日提交的美国申请62/091,461,用于关于造血干细胞(hsc)的基因组编辑的crispr-cas系统和组合物的递送、用途以及治疗应用(delivery,useandtherapeuticapplicationsofthecrispr-cassystemsandcompositionsforgenomeeditingastohematopoeticstemcells(hscs));2014年12月19日提交的美国申请62/094,903,通过基因组范围的插入捕获测序对双链断裂和基因组重排的无偏鉴定(unbiasedidentificationofdouble-strandbreaksandgenomicrearrangementbygenome-wiseinsertcapturesequencing);2014年12月24日提交的美国申请62/096,761,用于序列操纵的系统、方法及优化的酶以及指导物支架的工程化(engineeringofsystems,methodsandoptimizedenzymeandguidescaffoldsforsequencemanipulation);2014年12月30日提交的美国申请62/098,059、2015年6月18日提交的美国申请62/181,641和2015年6月18日提交的美国申请62/181,667,rna靶向系统(rna-targetingsystem);2014年12月24日提交的美国申请62/096,656和2015年6月17日提交的62/181,151,具有稳定化结构域或与稳定化结构域相关联的crispr(crisprhavingorassociatedwithdestabilizationdomains);2014年12月24日提交的美国申请62/096,697,具有aav或与aav相关联的crispr(crisprhavingorassociatedwithaav);2014年12月30日提交的美国申请62/098,158,工程化crispr复合物插入靶向系统(engineeredcrisprcomplexinsertionaltargetingsystems);2015年4月22日提交的美国申请62/151,052,用于胞外核外报告的细胞靶向(cellulartargetingforextracellularexosomalreporting);2014年9月24日提交的美国申请62/054,490,使用粒子递送组分靶向病症和疾病的crispr-cas系统和组合物的递送、用途以及治疗应用(delivery,useandtherapeuticapplicationsofthecrispr-cassystemsandcompositionsfortargetingdisordersanddiseasesusingparticledeliverycomponents);2014年2月12日提交的美国申请61/939,154,用于用优化的功能性crispr-cas系统进行序列操纵的系统、方法和组合物(systems,methodsandcompositionsforsequencemanipulationwithoptimizedfunctionalcrispr-cassystems);2014年9月25日提交的美国申请62/055,484,用于用优化的功能性crispr-cas系统进行序列操纵的系统、方法和组合物(systems,methodsandcompositionsforsequencemanipulationwithoptimizedfunctionalcrispr-cassystems);2014年12月4日提交的美国申请62/087,537,用于用优化的功能性crispr-cas系统进行序列操纵的系统、方法和组合物(systems,methodsandcompositionsforsequencemanipulationwithoptimizedfunctionalcrispr-cassystems);2014年9月24日提交的美国申请62/054,651,用于对体内多种癌症突变的竞争建模的crispr-cas系统和组合物的递送、用途以及治疗应用(delivery,useandtherapeuticapplicationsofthecrispr-cassystemsandcompositionsformodelingcompetitionofmultiplecancermutationsinvivo);2014年10月23日提交的美国申请62/067,886,用于对体内多种癌症突变的竞争建模的crispr-cas系统和组合物的递送、用途以及治疗应用(delivery,useandtherapeuticapplicationsofthecrispr-cassystemsandcompositionsformodelingcompetitionofmultiplecancermutationsinvivo);2014年9月24日提交的美国申请62/054,675和2015年6月17日提交的美国申请62/181,002,在神经元细胞/组织中crispr-cas系统和组合物的递送、用途以及治疗应用(delivery,useandtherapeuticapplicationsofthecrispr-cassystemsandcompositionsinneuronalcells/tissues);2014年9月24日提交的美国申请62/054,528,在免疫疾病或病症中crispr-cas系统和组合物的递送、用途以及治疗应用(delivery,useandtherapeuticapplicationsofthecrispr-cassystemsandcompositionsinimmunediseasesordisorders);2014年9月25日提交的美国申请62/055,454,用于使用细胞穿透肽(cpp)靶向病症和疾病的crispr-cas系统和组合物的递送、用途以及治疗应用(delivery,useandtherapeuticapplicationsofthecrispr-cassystemsandcompositionsfortargetingdisordersanddiseasesusingcellpenetrationpeptides(cpp));2014年9月25日提交的美国申请62/055,460,多功能性crispr复合物和/或优化的酶连接的功能性crispr复合物(multifunctional-crisprcomplexesand/oroptimizedenzymelinkedfunctional-crisprcomplexes);2014年12月4日提交的美国申请62/087,475和2015年6月18日提交的62/181,690,用优化的功能性crispr-cas系统进行功能性筛选(functionalscreeningwithoptimizedfunctionalcrispr-cassystems);2014年9月25日提交的美国申请62/055,487,用优化的功能性crispr-cas系统进行功能性筛选(functionalscreeningwithoptimizedfunctionalcrispr-cassystems);2014年12月4日提交的美国申请62/087,546和2015年6月18日提交的62/181,687,多功能性crispr复合物和/或优化的酶连接的功能性crispr复合物(multifunctionalcrisprcomplexesand/oroptimizedenzymelinkedfunctional-crisprcomplexes);2014年12月30日提交的美国申请62/098,285,对肿瘤生长和转移的crispr介导的体内建模以及遗传筛选(crisprmediatedinvivomodelingandgeneticscreeningoftumorgrowthandmetastasis)。
提到了2015年6月18日提交的美国申请62/181,659和2015年8月19日提交的美国申请62/207,318,用于序列操纵的cas9直系同源物和变体的系统、方法、酶和指导物支架的工程化和优化(engineeringandoptimizationofsystems,methods,enzymeandguidescaffoldsofcas9orthologsandvariantsforsequencemanipulation)。提到了2015年6月18日提交的美国申请62/181,663和2015年10月22日提交的美国申请62/245,264,新颖的crispr酶和系统(novelcrisprenzymesandsystems);2015年6月18日提交的美国申请62/181,675、2015年10月22日提交的美国申请62/285,349、2016年2月17日提交的62/296,522和2016年4月8日提交的美国申请62/320,231,新颖的crispr酶和系统(novelcrisprenzymesandsystems);2015年9月24日提交的美国申请62/232,067、2015年12月18日提交的美国申请14/975,085、欧洲申请号16150428.7、2015年8月16日提交的美国申请62/205,733、2015年8月5日提交的美国申请62/201,542、2015年7月16日提交的美国申请62/193,507和2015年6月18日提交的美国申请62/181,739,其各自的标题为新颖的crispr酶和系统(novelcrisprenzymesandsystems);以及2015年10月22日提交的美国申请62/245,270,新颖的crispr酶和系统(novelcrisprenzymesandsystems)。还提到了2014年12月12日提交的美国申请61/939,256和2014年12月12日提交的wo2015/089473(pct/us2014/070152),其各自的标题为用于序列操纵的具有新架构的系统、方法和优化的指导物组合物的工程化(engineeringofsystems,methodsandoptimizedguidecompositionswithnewarchitecturesforsequencemanipulation)。还提到了2015年8月15日提交的pct/us2015/045504、2015年6月17日提交的美国申请62/180,699和2014年8月17日提交的美国申请62/038,358,其各自的标题为使用cas9切口酶进行基因组编辑(genomeeditingusingcas9nickases)。
这些专利、专利公布和申请的每一者,以及在其中或在它们的审查程序期间引用的所有文献(“申请引用文献”)以及在这些申请引用文献中引用或参考的所有文献,连同其中提到的或在其中任何文献中提到并以引用方式并入本文的针对任何产品的任何说明书、说明、产品规格和产品表,特此以引用方式并入本文,并且可以在本发明的实践中采用。所有文献(例如这些专利、专利公布和申请以及申请引用文献)在如同每个单独文献被确切地且单独地指明为以引用方式并入的相同程度上以引用方式并入本文。
v型crispr-cas蛋白
本申请描述了使用v型crispr-cas蛋白的方法。本文以cpf1为例,由此鉴定了多种直系同源物或同源物。对于本领域技术人员将显而易见的是,可以鉴定其他直系同源物或同源物,并且本文所述的任何功能物可以被工程化为其他直系同源物,包括包含来自多种直系同源物的片段的嵌合酶。
鉴定新颖的crispr-cas基因座的计算方法描述于ep3009511或us2016208243中,并且可包括以下步骤:检测编码cas1蛋白的所有重叠群;鉴定cas1基因20kb内的所有预测蛋白编码基因;将已鉴定的基因与cas蛋白特异性谱进行比较,并预测crispr阵列;选择含有大于500个氨基酸(>500aa)的蛋白质的未分类候选crispr-cas基因座;使用诸如psi-blast和hhpred的方法分析选定的候选物,以筛选已知的蛋白质结构域,从而鉴定新颖的2类crispr-cas基因座(另参见schmakov等人2015,molcell.60(3):385-97)。除以上提及的步骤之外,还可以通过在宏基因组学数据库中搜索另外的同源物来另外对候选物进行分析。另外地或可替代地,为了将搜索扩展到非自主的crispr-cas系统,可以使用crispr阵列作为种子执行相同的过程。
在一方面,检测编码cas1蛋白的所有重叠群通过genemarks执行,genemarks是一种基因预测程序,其如以下进一步描述:“genemarks:aself-trainingmethodforpredictionofgenestartsinmicrobialgenomes.implicationsforfindingsequencemotifsinregulatoryregions.”johnbesemer,alexandrelomsadzeandmarkborodovsky,nucleicacidsresearch(2001)29,第2607-2618页,以引用方式并入本文。
在一方面,可以通过将已鉴定的基因与cas蛋白特异性谱进行比较并根据ncbi保守结构域数据库(cdd)对其进行注释来鉴定所有预测的蛋白质编码基因,cdd是由针对古代结构域和全长蛋白质的完好注释的多序列比对模型集合组成的蛋白质注释资源。这些可作为位置特异性得分矩阵(pssm)用于经由rps-blast快速鉴定蛋白质序列中的保守结构域。cdd内容物包括ncbi编策的结构域,这些结构域使用3d结构信息来明确地限定结构域边界并为序列/结构/功能关系提供洞见;以及从多个外部来源数据库(pfam、smart、cog、prk、tigrfam)导入的结构域模型。在另一方面,使用piler-cr程序预测crispr阵列,piler-cr程序是用于发现crispr重复序列的公共领域软件,如“piler-cr:fastandaccurateidentificationofcrisprrepeats”,edgar,r.c.,bmcbioinformatics,jan20;8:18(2007)所述,该文献以引用方式并入本文。
在另一方面,使用psi-blast(位置特异性迭代基本局部比对搜索工具)来进行逐例分析。psi-blast使用蛋白质-蛋白质blast从经检测高于给定得分阈值的序列的多序列比对得出位置特异性得分矩阵(pssm)或序型。该pssm用于进一步在数据库中搜索新匹配项,并使用这些新检测到的序列进行更新以进行后续迭代。因此,psi-blast提供了一种检测蛋白质之间远距离关系的手段。
在另一方面,使用hhpred进行逐例分析,hhpred是一种用于序列数据库搜索和结构预测的方法,该方法与blast或psi-blast一样容易使用,同时在发现远同源物方面更加灵敏。实际上,hhpred的灵敏度可与目前可用的功能最强大的结构预测服务器相竞争。hhpred是第一台基于序型隐蔽马尔科夫模型(hmm)的成对比较的服务器。大多数传统的序列搜索方法搜索序列数据库(例如uniprot或nr),而hhpred搜索比对数据库(如pfam或smart)。这大大简化了多个序列簇而非混乱的单一序列的命中物列表。所有主要的公开可得的序型和比对数据库均可通过hhpred获得。hhpred接受单一查询序列或多重比对作为输入。仅在几分钟内,它就以类似于psi-blast的易于阅读的格式返回搜索结果。搜索选项包括局部或全局比对以及对二级结构相似性评分。hhpred可以生成成对的查询模板序列比对、合并的查询模板多重比对(例如用于传递搜索),以及由modeller软件根据hhpred比对计算出的3d结构模型。
cpf1的直系同源物
术语“直系同源物(orthologue)”(在本文中也称为“直系同源物(ortholog)”)和“同源物(homologue)”(本文中也称为“同源物(homolog)”)在本领域中是众所周知的。作为进一步指导,如本文所用的蛋白质的“同源物”是与作为其同源物的蛋白质发挥相同或类似功能的相同种类的蛋白质。同源蛋白质可以是但不需要是结构上相关的,或仅是部分结构上相关的。如本文所用的蛋白质的“直系同源物”是与作为其直系同源物的蛋白质发挥相同或类似功能的不同种类的蛋白质。直系同源蛋白质可以是但不需要是结构上相关的,或仅是部分结构上相关的。同源物和直系同源物可以通过同源建模(参见例如greer,science第228卷(1985)1055和blundell等人eurjbiochemvol172(1988),513)或“结构blast”(deyf,cliffzhangq,petreyd,honigb.towarda″structuralblast″:usingstructuralrelationshipstoinferfunction.proteinsci.2013apr;22(4):359-66.doi:10.1002/pro.2225.)来鉴定。另参见shmakov等人(2015)了解在crispr-cas基因座领域中的申请。同源蛋白质可以是但不需要是结构上相关的,或仅是部分结构上相关的。
cpf1基因存在于若干种不同的细菌基因组中,典型地与cas1、cas2和cas4基因以及crispr盒(例如新凶手弗朗西丝菌(francisellacf.novicida)fx1的fnfx1_1431-fnfx1_1428)在同一基因座中。因此,此推定的新颖crispr-cas系统的布局似乎与ii-b型的布局类似。此外,与cas9类似,cpf1蛋白含有与转座子orf-b同源的易于鉴定的c端区,并且包含活性的ruvc样核酸酶、富含精氨酸的区和zn指(不存在于cas9中)。然而,与cas9不同,cpf1还存在于没有crispr-cas环境的若干种基因组中,并且其与orf-b的相对较高相似性表明其可能是转座子组分。表明如果此是真正的crispr-cas系统并且cpf1是cas9的功能类似物,则其将是新颖crispr-cas类型,即v型(参见annotationandclassificationofcrispr-cassystems.makarovaks,kooninev.methodsmolbiol.2015;1311:47-75)。然而,如本文所述,将cpf1指代为亚型v-a以将其与c2c1p区分,该c2c1p不具有相同的结构域结构并且因此被指代为亚型v-b。
本发明涵盖来源于被指代为亚型v-a的cpf1基因座的cpf1效应蛋白的用途。在本文中,此类效应蛋白也称为“cpf1p”,例如cpf1蛋白(并且这种效应蛋白或cpf1蛋白或来源于cpf1基因座的蛋白也称为“crispr-cas蛋白”)。
在特定实施方案中,效应蛋白是来自包括以下的属的生物体的cpf1效应蛋白:链球菌属(streptococcus)、弯曲杆菌属(campylobacter)、nitratifractor、葡萄球菌属(staphylococcus)、细小棒菌属(parvibaculum)、罗氏菌属(roseburia)、奈瑟氏菌属(neisseria)、葡糖醋杆菌属(gluconacetobacter)、固氮螺菌属(azospirillum)、sphaerochaeta、乳酸杆菌属(lactobacillus)、真细菌属(eubacterium)、棒状杆菌属(corynebacter)、肉杆菌属(carnobacterium)、红细菌属(rhodobacter)、李斯特菌属(listeria)、帕鲁迪菌属(paludibacter)、梭菌属(clostridium)、毛螺旋菌科(lachnospiraceae)、clostridiaridium、纤毛菌属(leptotrichia)、弗朗西丝菌属、军团杆菌属(legionella)、脂环酸芽孢杆菌属(alicyclobacillus)、甲烷嗜甲基菌属(methanomethyophilus)、卟啉单胞菌属(porphyromonas)、普雷沃氏菌属、拟杆菌门(bacteroidetes)、创伤球菌属(helcococcus)、钩端螺旋体属(leptospira)、脱硫弧菌属(desulfovibrio)、脱硫盐碱杆菌属(desulfonatronum)、丰佑菌科(opitutaceae)、肿块芽孢杆菌属(tuberibacillus)、芽孢杆菌属(bacillus)、短芽孢杆菌属(brevibacilus)、甲基杆菌属(methylobacterium)、丁酸弧菌属(butyvibrio)、异域菌门菌属(perigrinibacterium)、副真杆菌属(pareubacterium)、莫拉氏菌属(moraxella)、硫微螺菌属(thiomicrospira)或氨基酸球菌属。在特定实施方案中,cpf1效应蛋白选自选自以下的属的生物体:真细菌属、钩端螺旋体科、纤毛菌属、弗朗西丝菌属、甲烷嗜甲基菌属、卟啉单胞菌属、普雷沃氏菌属、钩端螺旋体属、丁酸弧菌属、异域菌门菌属、副真杆菌属、莫拉氏菌属、硫微螺菌属或氨基酸球菌属。
在另外的特定实施方案中,cpf1效应蛋白来自选自以下的生物体:变异链球菌(s.mutans)、无乳链球菌(s.agalactiae)、似马链球菌(s.equisimilis)、血链球菌(s.sanguinis)、肺炎链球菌;空肠弯曲杆菌(c.jejuni)、大肠弯曲杆菌(c.coli);n.salsuginis、n.tergarcus;耳葡萄球菌(s.auricularis)、肉葡萄球菌(s.carnosus);脑膜炎奈瑟氏菌(n.meningitides)、淋病奈瑟氏菌(n.gonorrhoeae);单核增生李斯特菌(l.monocytogenes)、伊氏李斯特菌(l.ivanovii);肉毒梭菌(c.botulinum)、艰难梭菌(c.difficile)、破伤风梭菌(c.tetani)、索氏梭菌(c.sordellii)、稻田氏钩端螺旋体(l.inadai)、土拉弗朗西斯菌(f.tularensis)1、易北普雷沃氏菌(p.albensis)、毛螺科菌(l.bacterium)、解蛋白丁酸弧菌(b.proteoclasticus)、异域菌门菌(p.bacterium)、狗口腔卟啉单胞菌(p.crevioricanis)、解糖胨普雷沃氏菌(p.disiens)和猕猴卟啉单胞菌(p.macacae)。
效应蛋白可包含嵌合效应蛋白,所述嵌合效应蛋白包含来自第一效应蛋白(例如cpf1)直系同源物的第一片段和来自第二效应蛋白(例如cpf1)直系同源物的第二片段,并且其中第一和第二效应蛋白直系同源物是不同的。第一和第二效应蛋白(例如cpf1)直系同源物中的至少一者可以包含来自包括以下的生物体的效应蛋白(例如cpf1):链球菌属、弯曲杆菌属、nitratifractor、葡萄球菌属、细小棒菌属、罗氏菌属、奈瑟氏菌属、葡糖醋杆菌属、固氮螺菌属、sphaerochaeta、乳酸杆菌属、真细菌属、棒状杆菌属、肉杆菌属、红细菌属、李斯特菌属、帕鲁迪菌属、梭菌属、毛螺旋菌科、clostridiaridium、纤毛菌属、弗朗西丝菌属、军团杆菌属、脂环酸芽孢杆菌属、甲烷嗜甲基菌属、卟啉单胞菌属、普雷沃氏菌属、拟杆菌门、创伤球菌属、钩端螺旋体属、脱硫弧菌属、脱硫盐碱杆菌属、丰佑菌科、肿块芽孢杆菌属、芽孢杆菌属、短芽孢杆菌属、甲基杆菌属、丁酸弧菌属、异域菌门菌属、副真杆菌属、莫拉氏菌属、硫微螺菌属或氨基酸球菌属;例如包含第一片段和第二片段的嵌合效应蛋白,其中第一片段和第二片段各自选自包括以下的生物体的cpf1:链球菌属、弯曲杆菌属、nitratifractor、葡萄球菌属、细小棒菌属、罗氏菌属、奈瑟氏菌属、葡糖醋杆菌属、固氮螺菌属、sphaerochaeta、乳酸杆菌属、真细菌属、棒状杆菌属、肉杆菌属、红细菌属、李斯特菌属、帕鲁迪菌属、梭菌属、毛螺旋菌科、clostridiaridium、纤毛菌属、弗朗西丝菌属、军团杆菌属、脂环酸芽孢杆菌属、甲烷嗜甲基菌属、卟啉单胞菌属、普雷沃氏菌属、拟杆菌门、创伤球菌属、钩端螺旋体属、脱硫弧菌属、脱硫盐碱杆菌属、丰佑菌科、肿块芽孢杆菌属、芽孢杆菌属、短芽孢杆菌属、甲基杆菌属、丁酸弧菌属、异域菌门菌属、副真杆菌属、莫拉氏菌属、硫微螺菌属或氨基酸球菌属,其中第一片段和第二片段并非来自相同细菌;例如,包含第一片段和第二片段的嵌合效应蛋白,其中第一片段和第二片段各自选自包括以下的生物体的cpf1:变异链球菌、无乳链球菌、似马链球菌、血链球菌、肺炎链球菌;空肠弯曲杆菌、大肠弯曲杆菌;n.salsuginis、n.tergarcus;耳葡萄球菌、肉葡萄球菌;脑膜炎奈瑟氏菌、淋病奈瑟氏菌;单核增生李斯特菌、伊氏李斯特菌;肉毒梭菌、艰难梭菌、破伤风梭菌、索氏梭菌;土拉弗朗西斯菌1、易北普雷沃氏菌、毛螺科菌mc20171、解蛋白丁酸弧菌、异域菌门菌gw2011_gwa2_33_10、帕库氏菌gw2011_gwc2_44_17、史密斯氏菌属种scadc、氨基酸球菌属种bv3l6、毛螺科菌ma2020、候选白蚁甲烷枝原体、挑剔真细菌、牛眼莫拉氏菌237、稻田钩端螺旋体、毛螺科菌nd2006、狗口腔卟啉单胞菌3、解糖胨普雷沃氏菌和猕猴卟啉单胞菌,其中第一片段和第二片段并非来自相同细菌。
在更优选的实施方案中,cpf1p来源于选自以下的细菌种类:土拉弗朗西斯菌1、易北普雷沃氏菌、毛螺科菌mc20171、解蛋白丁酸弧菌、异域菌门菌gw2011_gwa2_33_10、帕库氏菌gw2011_gwc2_44_17、史密斯氏菌属种scadc、氨基酸球菌属种bv3l6、毛螺科菌ma2020、候选白蚁甲烷枝原体、挑剔真细菌、牛眼莫拉氏菌237、牛眼莫拉氏菌aax08_00205、牛眼莫拉氏菌aax11_00205、丁酸弧菌属种nc3005、硫微螺菌属种xs5、稻田钩端螺旋体、毛螺科菌nd2006、狗口腔卟啉单胞菌3、解糖胨普雷沃氏菌和猕猴卟啉单胞菌。在某些实施方案中,cpf1p来源于选自氨基酸球菌属种bv3l6、毛螺科菌ma2020的细菌种类。在某些实施方案中,效应蛋白来源于土拉弗朗西斯菌1的亚种,包括但不限于土拉弗朗西斯菌新凶手(novicida)亚种。在某些优选的实施方案中,cpf1p来源于选自以下的细菌种类:氨基酸球菌属种bv3l6、毛螺科菌nd2006、毛螺科菌ma2020、牛眼莫拉氏菌aax08_00205、牛眼莫拉氏菌aax11_00205、丁酸弧菌属种nc3005、硫微螺菌属种xs5。
在特定实施方案中,如本文所提及的cpf1的同源物或直系同源物与cpf1具有至少80%、更优选地至少85%、甚至更优选地至少90%,诸如例如至少95%的序列同源性或同一性。在另外的实施方案中,如本文所提及的cpf1的同源物或直系同源物与野生型cpf1具有至少80%、更优选地至少85%、甚至更优选地至少90%,诸如例如至少95%的序列同一性。在cpf1具有一个或多个突变(是突变的)的情况下,如本文所提及的所述cpf1的同源物或直系同源物与突变的cpf1具有至少80%、更优选地至少85%、甚至更优选地至少90%,诸如例如至少95%的序列同一性。
在一个实施方案中,cpf1蛋白可以是包括但不限于以下的属的生物体的直系同源物:氨基酸球菌属种、毛螺科菌或牛眼莫拉氏菌;在特定实施方案中,v型cas蛋白可以是包括但不限于以下的属的生物体的直系同源物:氨基酸球菌属种bv3l6、毛螺科菌nd2006(lbcpf1)或牛眼莫拉氏菌237。在特定实施方案中,如本文所提及的cpf1的同源物或直系同源物与本文所公开的cpf1序列中的一者或多者具有至少80%、更优选地至少85%、甚至更优选地至少90%,诸如例如至少95%的序列同源性或同一性。在另外的实施方案中,如本文所提及的cpf的同源物或直系同源物与野生型fncpf1、ascpf1或lbcpf1具有至少80%、更优选地至少85%、甚至更优选地至少90%,诸如例如至少95%的序列同一性。
在特定实施方案中,本发明的cpf1蛋白与fncpf1、ascpf1或lbcpf1具有至少60%,更特别地至少70%,诸如至少80%,更优选地至少85%、甚至更优选地至少90%,诸如例如至少95%的序列同源性或同一性。在另外的实施方案中,如本文所提及的cpf1蛋白与野生型ascpf1或lbcpf1具有至少60%,诸如至少70%,更特别地至少80%、更优选地至少85%、甚至更优选地至少90%,诸如例如至少95%的序列同一性。在特定实施方案中,本发明的cpf1蛋白与fncpf1具有少于60%的序列同一性。技术人员将理解,这包括cpf1蛋白的截短形式,由此在截短形式的长度上确定序列同一性。在特定实施方案中,cpf1酶不是fncpf1。
在一些实施方案中,crispr效应蛋白是来源于来自真细菌属的生物体的cpf1蛋白。在一些实施方案中,crispr效应蛋白是来源于来自细菌种类直肠真细菌(eubacteriumrectale)的生物体的cpf1蛋白。在一些实施方案中,cpf1效应蛋白的氨基酸序列对应于ncbi参考序列wp_055225123.1、ncbi参考序列wp_055237260.1、ncbi参考序列wp_055272206.1或genbankidola16049.1。在一些实施方案中,cpf1效应蛋白与ncbi参考序列wp_055225123.1、ncbi参考序列wp_055237260.1、ncbi参考序列wp_055272206.1或genbankidola16049.1具有至少60%,更特别地至少70%,诸如至少80%,更优选地至少85%、甚至更优选地至少90%,诸如例如至少95%的序列同源性或序列同一性。技术人员将理解,这包括cpf1蛋白的截短形式,由此在截短形式的长度上确定序列同一性。在一些实施方案中,cpf1效应子识别tttn或cttn的pam序列。
在一些实施方案中,crispr效应蛋白是来源于来自真细菌属的生物体的cpf1蛋白。在一些实施方案中,crispr效应蛋白是来源于来自细菌种类直肠真细菌的生物体的cpf1蛋白。在一些实施方案中,cpf1效应蛋白的氨基酸序列对应于ncbi参考序列wp_055225123.1、ncbi参考序列wp_055237260.1、ncbi参考序列wp_055272206.1或genbankidola16049.1。在一些实施方案中,cpf1效应蛋白与ncbi参考序列wp_055225123.1、ncbi参考序列wp_055237260.1、ncbi参考序列wp_055272206.1或genbankidola16049.1具有至少60%,更特别地至少70%,诸如至少80%,更优选地至少85%、甚至更优选地至少90%,诸如例如至少95%的序列同源性或序列同一性。技术人员将理解,这包括cpf1蛋白的截短形式,由此在截短形式的长度上确定序列同一性。在一些实施方案中,cpf1效应子识别tttn或cttn的pam序列。
密码子优化的cpf1序列
在效应蛋白有待以核酸形式施用的情况下,本申请设想使用密码子优化的cpf1序列。在这种情况下,密码子优化的序列的实例是对于在真核生物中表达而优化,例如人类(即,对于在人类中表达而优化),或对于在如本文所论述的另一种真核生物、动物或哺乳动物中表达而优化的序列;参见wo2014/093622(pct/us2013/074667)中的作为密码子优化的序列的实例的sacas9人类密码子优化的序列(根据本领域的知识和本公开,密码子优化的编码核酸分子,尤其是关于效应蛋白(例如cpf1)在技术人员的能力范围之内)。虽然这是优选的,但将了解,其他实例可能存在,并且对于除人类以外的宿主种类的密码子优化或对于特定器官的密码子优化是已知的。在一些实施方案中,编码dna/rna-靶向cas蛋白的酶编码序列对于在特定细胞,诸如真核细胞中表达进行密码子优化。真核细胞可以是特定生物体的那些或来源于特定生物体的那些,所述生物体诸如植物或哺乳动物,包括但不限于人类,或如本文所论述的非人类真核生物或动物或哺乳动物,例如小鼠、大鼠、兔、犬、家畜或非人类哺乳动物或灵长类动物。在一些实施方案中,可以排除有可能不会对人或动物带来任何实质性医学益处的修改人类的种系遗传身份的过程和/或修改动物的遗传身份的过程,以及由此类过程产生的动物。一般来讲,密码子优化是指修饰核酸序列用于增强在目标宿主细胞中的表达的过程,这个过程是通过用在宿主细胞的基因中较频繁或最频繁使用的密码子替代原生序列的至少一个密码子(例如约或大于约1个、2个、3个、4个、5个、10个、15个、20个、25个、50个或更多个密码子),同时维持原生氨基酸序列。不同种类对特定氨基酸的某些密码子展现特定偏性。密码子偏性(生物体之间密码子使用的差异)常常与信使rna(mrna)的翻译效率相关,据信所述效率继而尤其取决于所翻译的密码子的特性和特定转移rna(trna)分子的可用性。细胞中所选trna的主导性一般反映了肽合成中最频繁使用的密码子。因此,可以基于密码子优化来调整基因用于给定的生物体中最佳基因表达。密码子使用表可容易得到,例如,在www.kazusa.orjp/codon/上可得的“密码子使用数据库(codonusagedatabase)”中,并且这些表可以按许多方式进行改编。参见nakamura,y.,等人“codonusagetabulatedfromtheinternationaldnasequencedatabases:statusfortheyear2000”nucl.acidsres.28:292(2000)。对于在特定宿主细胞中表达对特定序列进行密码子优化的计算机算法也可得到,诸如geneforge(aptagen;jacobus,pa)也可得到。在一些实施方案中,编码dna/rna-靶向cas蛋白的序列中的一个或多个密码子(例如1个、2个、3个、4个、5个、10个、15个、20个、25个、50个或更多个或所有密码子)对应于对于特定氨基酸最频繁使用的密码子。关于酵母中的密码子使用,参考在http://www.yeastgenome.org/community/codon_usage.shtml上可得的在线酵母基因组数据库(onlineyeastgenomedatabase);或关于酵母中的密码子选择,参考bennetzen和hall,jbiolchem.1982年3月25日;257(6):3026-31。关于包括藻类在内的植物中的密码子使用,参考codonusageinhigherplants,greenalgae,andcyanobacteria,campbellandgowri,plantphysiol.1990年1月;92(1):1-11.;以及关于植物基因中的密码子使用,参考murray等人,nucleicacidsres.1989年1月25日17(2):477-98;或selectiononthecodonbiasofchloroplastandcyanellegenesindifferentplantandalgallineages,mortonbr,jmolevol.1998年4月;46(4):449-59。
在以下某些内容中,cpf1氨基酸后跟核定位信号(nls)(斜体),甘氨酸-丝氨酸(gs)接头(带下划线)和3xha标签(粗体)。在一些实施方案中,cpf1氨基酸序列对应于没有nls、gs接头和3xha标签的序列。
1-土拉弗朗西斯菌新凶手亚种u112(fncpf1)
3-毛螺科菌mc2017(lb3cpf1)
4-解蛋白丁酸弧菌(bpcpf1)
5-异域菌门菌gw2011_gwa_33_10(pecpf1)
6-帕库氏菌gwc2011_gwc2_44_17(pbcpf1)
7-史密斯氏菌属种sc_k08d17(sscpf1)
8-氨基酸球菌属种bv3l6(ascpf1)
9-毛螺科菌ma2020(lb2cpf1)
10-候选白蚁甲烷支原体(cmtcpf1)
11-挑剔真杆菌(eecpf1)
12-牛眼莫拉氏菌237(mbcpf1)
13-稻田氏钩端螺旋体(licpf1)
14-毛螺科菌nd2006(lbcpf1)
15-狗口腔卟啉单胞菌(pccpf1)
16-解糖胨普雷沃氏菌(pdcpf1)
17-猕猴卟啉单胞菌(pmcpf1)
18-硫微螺菌属种xs5(tscpf1)
19-牛眼莫拉氏菌aax08_00205(mb2cpf1)
20-牛眼莫拉氏菌aax11_00205(mb3cpf1)
21-丁酸弧菌属种nc3005(bscpf1)
另外的cpf1直系同源物包括:
ncbiwp_055225123.1
ncbiwp_055237260.1
ncbiwp_055272206.1
genbankola16049.1
修饰的cpf1酶
在特定实施方案中,令人感兴趣的是利用本文所定义的工程化的cpf1蛋白(诸如cpf1),其中所述蛋白与包含rna的核酸分子复合以形成crispr复合物,其中当在crispr复合物中时,所述核酸分子靶向一个或多个靶多核苷酸基因座,所述蛋白与未修饰的cpf1蛋白相比包含至少一种修饰,并且其中包含修饰的蛋白的crispr复合物与包含未修饰的cpf1蛋白的复合物相比具有改变的活性。应当理解,当在本文中提及crispr“蛋白”时,cpf1蛋白质优选地是修饰的crispr-cas蛋白(例如,具有增加的或减少的(或没有)酶活性),如非限制地包括cpf1。术语“crispr蛋白”可以与“crispr-cas蛋白”互换使用,不论所述crispr蛋白与野生型crispr蛋白相比是否具有改变的,如增加的或减少的(或没有)酶活性。
cpf1核酸酶一级结构的计算分析揭示了三个不同的区。第一是c端ruvc样结构域,其是仅功能表征的结构域。第二是n端α-螺旋区并且第三是位于ruvc样结构域与α-螺旋区之间的混合的α区和β区。
预测非结构化区的若干小段在cpf1一级结构之内。对于小的蛋白质序列的拆分和插入而言,不同的cpf1直系同源物内的暴露于溶剂且不保守的非结构化区是优选的侧面。另外,这些侧面可以用于在cpf1直系同源物之间产生嵌合蛋白。
基于以上信息,可以产生突变体,这些突变体使得酶失活或将双链核酸酶修饰为具有切口酶活性。在替代实施方案中,此信息用于开发具有减少的脱靶效应的酶(在本文其他地方描述)。
在以上所述的某些cpf1酶中,酶是通过一个或多个残基(在ruvc结构域中)的突变来修饰的,这些残基包括但不限于参照ascpf1(氨基酸球菌属种bv3l6)的氨基酸位置编号的位置r909、r912、r930、r947、k949、r951、r955、k965、k968、k1000、k1002、r1003、k1009、k1017、k1022、k1029、k1035、k1054、k1072、k1086、r1094、k1095、k1109、k1118、k1142、k1150、k1158、k1159、r1220、r1226、r1242和/或r1252。在某些实施方案中,包含所述一个或多个突变的cpf1酶具有修改的,更优选地增加的对靶标的特异性。
在以上所述的某些非天然存在的crispr-cas蛋白中,酶是通过一个或多个残基(在rad50中)的突变来修饰的,这些残基包括但不限于参照ascpf1(氨基酸球菌属种bv3l6)的氨基酸位置编号的位置k324、k335、k337、r331、k369、k370、r386、r392、r393、k400、k404、k406、k408、k414、k429、k436、k438、k459、k460、k464、r670、k675、r681、k686、k689、r699、k705、r725、k729、k739、k748和/或k752。在某些实施方案中,包含所述一个或多个突变的cpf1酶具有修改的,更优选地增加的对靶标的特异性。
在某些cpf1酶中,酶是通过一个或多个残基的突变来修饰的,这些残基包括但不限于参照ascpf1(氨基酸球菌属种bv3l6)的氨基酸位置编号的位置r912、t923、r947、k949、r951、r955、k965、k968、k1000、r1003、k1009、k1017、k1022、k1029、k1072、k1086、f1103、r1226和/或r1252。在某些实施方案中,包含所述一个或多个突变的cpf1酶具有修改的,更优选地增加的对靶标的特异性。
在某些实施方案中,cpf1酶是通过一个或多个残基的突变来修饰的,这些残基包括但不限于参照lbcpf1(毛螺科菌nd2006)的氨基酸位置编号的位置r833、r836、k847、k879、k881、r883、r887、k897、k900、k932、r935、k940、k948、k953、k960、k984、k1003、k1017、r1033、r1138、r1165和/或r1252。在某些实施方案中,包含所述一个或多个突变的cpf1酶具有修改的,更优选地增加的对靶标的特异性。
在某些实施方案中,cpf1酶是通过一个或多个残基的突变来修饰的,这些残基包括但不限于参照ascpf1(氨基酸球菌属种bv3l6)的氨基酸位置编号的位置k15、r18、k26、q34、r43、k48、k51、r56、r84、k85、k87、n93、r103、n104、t118、k123、k134、r176、k177、r192、k200、k226、k273、k275、t291、r301、k307、k369、s404、v409、k414、k436、k438、k468、d482、k516、r518、k524、k530、k532、k548、k559、k570、r574、k592、d596、k603、k607、k613、c647、r681、k686、h720、k739、k748、k757、t766、k780、r790、p791、k796、k809、k815、t816、k860、r862、r863、k868、k897、r909、r912、t923、r947、k949、r951、r955、k965、k968、k1000、r1003、k1009、k1017、k1022、k1029、a1053、k1072、k1086、f1103、s1209、r1226、r1252、k1273、k1282和/或k1288。在某些实施方案中,包含所述一个或多个突变的cpf1酶具有修改的,更优选地增加的对靶标的特异性。
在某些实施方案中,酶是通过一个或多个残基的突变来修饰的,这些残基包括但不限于参照fncpf1(新凶手弗朗西斯菌u112)的氨基酸位置编号的位置k15、r18、k26、r34、r43、k48、k51、k56、k87、k88、d90、k96、k106、k107、k120、q125、k143、r186、k187、r202、k210、k235、k296、k298、k314、k320、k326、k397、k444、k449、e454、a483、e491、k527、k541、k581、r583、k589、k595、k597、k613、k624、k635、k639、k656、k660、k667、k671、k677、k719、k725、k730、k763、k782、k791、r800、k809、k823、r833、k834、k839、k852、k858、k859、k869、k871、r872、k877、k905、r918、r921、k932、i960、k962、r964、r968、k978、k981、k1013、r1016、k1021、k1029、k1034、k1041、k1065、k1084和/或k1098。在某些实施方案中,包含所述一个或多个突变的cpf1酶具有修改的,更优选地增加的对靶标的特异性。
在某些实施方案中,酶是通过一个或多个残基的突变来修饰的,这些残基包括但不限于参照lbcpf1(毛螺科菌nd2006)的氨基酸位置编号的位置k15、r18、k26、k34、r43、k48、k51、r56、k83、k84、r86、k92、r102、k103、k116、k121、r158、e159、r174、r182、k206、k251、k253、k269、k271、k278、p342、k380、r385、k390、k415、k421、k457、k471、a506、r508、k514、k520、k522、k538、y548、k560、k564、k580、k584、k591、k595、k601、k634、k640、r645、k679、k689、k707、t716、k725、r737、r747、r748、k753、k768、k774、k775、k785、k787、r788、q793、k821、r833、r836、k847、k879、k881、r883、r887、k897、k900、k932、r935、k940、k948、k953、k960、k984、k1003、k1017、r1033、k1121、r1138、r1165、k1190、k1199和/或k1208。在某些实施方案中,包含所述一个或多个突变的cpf1酶具有修改的,更优选地增加的对靶标的特异性。
在某些实施方案中,酶是通过一个或多个残基的突变来修饰的,这些残基包括但不限于参照mbcpf1(牛眼莫拉氏菌237)的氨基酸位置编号的位置k14、r17、r25、k33、m42、q47、k50、d55、k85、n86、k88、k94、r104、k105、k118、k123、k131、r174、k175、r190、r198、i221、k267、q269、k285、k291、k297、k357、k403、k409、k414、k448、k460、k501、k515、k550、r552、k558、k564、k566、k582、k593、k604、k608、k623、k627、k633、k637、e643、k780、y787、k792、k830、q846、k858、k867、k876、k890、r900、k901、m906、k921、k927、k928、k937、k939、r940、k945、q975、r987、r990、k1001、r1034、i1036、r1038、r1042、k1052、k1055、k1087、r1090、k1095、n1103、k1108、k1115、k1139、k1158、r1172、k1188、k1276、r1293、a1319、k1340、k1349和/或k1356。在某些实施方案中,包含所述一个或多个突变的cpf1酶具有修改的,更优选地增加的对靶标的特异性。
在以上所述的某些cpf1酶中,酶是通过一个或多个残基的突变来修饰的,这些残基包括但不限于根据fncpf1蛋白或任何相应的直系同源物的位置d917、e1006、e1028、d1227、d1255a、n1257。在一方面,本发明提供了一种本文所论述的组合物,其中cpf1酶是失活的酶,该酶包含选自由以下组成的组的一个或多个突变:根据fncpf1蛋白的d917a、e1006a、e1028a、d1227a、d1255a、n1257a、d917a、e1006a、e1028a、d1227a、d1255a和n1257a,或cpf1直系同源物中的相应位置的突变。在一方面,本发明提供了一种本文所论述的组合物,其中crispr酶包含根据fncpf1蛋白的d917或e1006和d917或d917和d1255,或cpf1直系同源物中的相应位置。
在一个实施方案中,cpf1蛋白是通过在参照ascpf1的氨基酸位置编号的s1228处的突变(例如s1228a)来修饰的。参见yamano等人,cell165:949-962(2016),该文献以引用方式整体并入本文。
在某些实施方案中,cpf1蛋白已被修饰以识别非天然pam,如识别具有以下序列或包含以下序列的pam:ycn、ycv、ayv、tyv、ryn、rcn、tgyv、nttn、ttn、trtn、tytv、tyct、tycn、trtn、nttn、tact、tycc、trtc、tatv、nttv、ttv、tstg、tvts、tyys、tcys、tbys、tcys、tnys、tyys、tntn、tstg、ttcc、tccc、tatc、tgtg、tctg、tycv或tctc。在特定实施方案中,所述突变的cpf1包含在ascpf1的位置11、12、13、14、15、16、17、34、36、39、40、43、46、47、50、54、57、58、111、126、127、128、129、130、131、132、133、134、135、136、157、158、159、160、161、162、163、164、165、166、167、168、169、170、171、172、173、174、175、176、177、178、532、533、534、535、536、537、538、539、540、541、542、543、544、545、546、547、548、549、550、551、552、553、554、555、556、565、566、567、568、569、570、571、572、573、574、575、592、593、594、595、596、597、598、599、600、601、602、603、604、605、606、607、608、609、610、611、612、613、614、615、616、617、618、619、620、626、627、628、629、630、631、632、633、634、635、636、637、638、642、643、644、645、646、647、648、649、651、652、653、654、655、656、676、679、680、682、683、684、685、686、687、688、689、690、691、692、693、707、711、714、715、716、717、718、719、720、721、722、739、765、768、769、773、777、778、779、780、781、782、783、784、785、786、871、872、873、874、875、876、877、878、879、880、881、882、883、884或1048或在cpf1直系同源物中与其对应的位置处的一个或多个突变的氨基酸残基;优选地包含在位置130、131、132、133、134、135、136、162、163、164、165、166、167、168、169、170、171、172、173、174、175、176、177、536、537、538、539、540、541、542、543、544、545、546、547、548、549、550、551、552、570、571、572、573、595、596、597、598、599、600、601、602、603、604、605、606、607、608、609、610、611、612、613、614、615、630、631、632、646、647、648、649、650、651、652、653、683、684、685、686、687、688、689或690处的一个或多个突变的氨基酸残基;
在某些实施方案中,cpf1蛋白被修饰成具有增加的活性,即更宽的pam特异性。在特定实施方案中,cpf1是通过一个或多个残基的突变来修饰的,这些残基包括但不限于ascpf1的位置539、542、547、548、550、551、552、167、604和/或607或ascpf1直系同源物、同源物或变体的相应位置,优选地在542或542和607处的突变的氨基酸残基,其中所述突变优选地为542r和607r,诸如s542r和k607r;或优选地在位置542和548(且任选地552)处的突变的氨基酸残基,其中所述突变优选地为542r和548v(且任选地552r),诸如s542r和k548v(且任选地n552r);或lbcpf1的位置532、538、542和/或595,或ascpf1直系同源物、同源物或变体的相应位置,优选地在532或532和595处的突变的氨基酸残基,其中所述突变优选地为532r和595r,诸如g532r和k595r;或优选地在位置532和538(且任选地542)处的突变的氨基酸残基,其中所述突变优选地为532r和538v(且任选地542r),诸如g532r和k538v(且任选地y542r),最优选地其中所述突变为ascpf1的s542r和k607r、s542r和k548v,或s542r、k548v和n552r。
灭活/失活的cpf1蛋白
在cpf1蛋白具有核酸酶活性的情况下,cpf1蛋白可以被修饰成具有减弱的核酸酶活性,例如,与野生型酶相比,具有至少70%、至少80%、至少90%、至少95%、至少97%或100%的核酸酶失活;或者换句话说,cpf1酶有利地具有非突变型或野生型cpf1酶或crispr-cas蛋白的核酸酶活性的约0%,或不超过非突变型或野生型cpf1酶的核酸酶活性的约3%或约5%或约10%,这些酶例如是属于非突变型或野生型新凶手弗朗西斯菌u112(fncpf1)、氨基酸球菌属种bv3l6(ascpf1)、毛螺科菌nd2006(lbcpf1)或牛眼莫拉氏菌237(mbcpf1cpf1酶或crispr-cas蛋白)。有可能通过将突变引入到cpf1及其直系同源物的核酸酶结构域中实现此举。
在本发明的优选实施方案中,使用至少一种cpf1蛋白,其为cpf1切口酶。更特别地,使用cpf1切口酶,其不使靶链产生切口而是能够仅使与靶链互补的链,即在本文中也称为与指导序列不互补的链的非靶dna链产生切口。更特别地,cpf1切口酶是cpf1蛋白,其包含来自氨基酸球菌属种的cpf1的nuc结构域中的位置1226a或cpf1直系同源物中的相应位置处的精氨酸突变。在另外的特定实施方案中,该酶包含精氨酸至丙氨酸取代或r1226a突变。本领域技术人员将理解,在酶不是ascpf1的情况下,可以在相应位置的残基处形成突变。在特定实施方案中,cpf1为fncpf1,并且突变是在位置r1218处的精氨酸上。在特定实施方案中,cpf1为lbcpf1,并且突变是在位置r1138处的精氨酸上。在特定实施方案中,cpf1为mbcpf1,并且突变是在位置r1293处的精氨酸上。
在某些实施方案中,另外地或可替代地使用经工程化的并且可以包含降低或消除核酸酶活性的一个或多个突变的crispr-cas蛋白。fncpf1pruvc结构域中的氨基酸位置包括但不限于d917a、e1006a、e1028a、d1227a、d1255a、n1257a、d917a、e1006a、e1028a、d1227a、d1255a和n1257a。申请人还鉴定了与pd-(d/e)xk核酸酶超家族和hincii样内切核酸酶最类似的推定的第二核酸酶结构域。在此推定的核酸酶结构域中产生的大幅度降低核酸酶活性的点突变包括但不限于n580a、n584a、t587a、w609a、d610a、k613a、e614a、d616a、k624a、d625a、k627a和y629a。在优选的实施方案中,fncpf1pruvc结构域中的突变是d917a或e1006a,其中d917a或e1006a突变使fncpf1效应蛋白的dna切割活性完全失活。在另一个实施方案中,fncpf1pruvc结构域中的突变是d1255a,其中突变的fncpf1效应蛋白具有明显降低的核溶解活性。
更特别地,失活的cpf1酶包括在ascpf1的氨基酸位置as908、as993、as1263或cpf1直系同源物中的相应位置突变的酶。另外,失活的cpf1酶包括在lbcpf1的氨基酸位置lb832、925、947或1180或cpf1直系同源物中的相应位置突变的酶。更特别地,失活的cpf1酶包括包含ascpf1的突变asd908a、ase993a、asd1263a或cpf1直系同源物中的相应突变中的一个或多个的酶。另外,失活的cpf1酶包括包含lbcpf1的突变lbd832a、e925a、d947a或d1180a或cpf1直系同源物中的相应突变中的一个或多个的酶。
突变还可以在邻近残基处,例如在靠近以上指出的参与核酸酶活性的那些的氨基酸处形成。在一些实施方案中,仅ruvc结构域是失活的,而在其他实施方案中,另一推定的核酸酶结构域是失活的,其中效应蛋白复合物充当切口酶并且仅切割一条dna链。在一个优选的实施方案中,其他推定的核酸酶结构域是hincii样内切核酸酶结构域。
失活的cpf1或cpf1切口酶可以具有缔合的(例如经由融合蛋白)一个或多个功能结构域,包括例如腺苷脱氨酶或其催化结构域。在一些情况下,有利的是另外提供至少一个异源nls。在一些情况下,将nls定位在n末端处是有利的。一般来讲,一个或多个功能结构域在失活的cpf1或cpf1切口酶上的定位是允许功能结构域的正确空间取向,从而以属性化的功能效应影响靶标的定位。例如,当功能结构域是腺苷脱氨酶其催化结构域时,腺苷脱氨酶催化结构域被定位成允许其接触靶腺嘌呤并使靶腺嘌呤脱氨基的空间取向。此可以包括除cpf1的n端/c端之外的位置。在一些实施方案中,腺苷脱氨酶蛋白或其催化结构域被插入到cpf1的内环中。
pam的测定
如下可以确保pam的测定。此实验与大肠杆菌中的stcas9异源表达的类似工作(sapranauskas,r.等人nucleicacidsres39,9275-9282(2011))极为相似。申请人将含有pam和抗性基因两者的质粒引入到异源大肠杆菌中,接着铺板在相应抗生素上。如果存在质粒的dna切割,则申请人观察不到有活力的菌落。
在进一步细节中,如下针对dna靶标进行测定。在此测定中使用两种大肠杆菌菌株。一种携带编码来自细菌菌株的内源性效应蛋白基因座的质粒。另一种菌株携带空质粒(例如pacyc184,对照菌株)。将所有可能的7或8bppam序列呈递在抗生素抗性质粒(具有氨苄青霉素抗性基因的puc19)上。将pam定位成靠近原间隔区1的序列(内源性效应蛋白基因座中的第一间隔区的dna靶标)。克隆了两个pam文库。一个具有原间隔区的8个随机bp5′(例如总的65536个不同pam序列=复杂度)。另一个文库具有原间隔区的7个随机bp3′(例如总复杂度是16384个不同的pam)。将两个文库克隆成具有平均500个质粒/可能的pam。用5′pam和3′pam文库在单独的转化中转化测试菌株和对照菌株并且将转化的细胞分别铺在氨苄青霉素板上。使用质粒的识别和随后的切割/干扰使得细胞对氨苄青霉素易感并且阻止了生长。转化后大约12小时,收获由测试菌株和对照菌株形成的所有菌落并且分离出质粒dna。使用质粒dna作为用于pcr扩增和随后的深度测序的模板。未转化的文库中的所有pam的表现度显示转化细胞中的pam的预期表现度。对照菌株中发现的所有pam的表现度显示真实的表现度。测试菌株中的所有pam的表现度显示哪个pam未被酶识别并且与对照菌株的比较允许提取出耗尽pam的序列。
对于某些野生型cpf1直系同源物,已鉴定出以下pam:氨基酸球菌属种bv3l6cpf1(ascpf1)、毛螺科菌nd2006cpf1(lbcpf1)和易北普雷沃氏菌(pacpf1)可以切割以tttvpam开头的靶位点,其中v是a/c或g,fncpf1p可以切割以ttn开头的位点,其中n是a/c/g或t。牛眼莫拉氏菌aax08_00205、牛眼莫拉氏菌aax11_00205、丁酸弧菌属种nc3005、硫微螺菌属种xs5或毛螺科菌ma2020pam是5’ttn,其中n是a/c/g或t。天然pam序列是tttv或bttv,其中b是t/c或g,v是a/c或g,并且效应蛋白是腔隙莫拉氏菌(moraxellalacunata)cpf1。
递送
在一些实施方案中,可以将ad官能化的crispr-cas系统的组分以各种形式递送,这些形式诸如有dna/rna或rna/rna或蛋白质rna的组合。例如,可以将cpf1蛋白作为dna编码多核苷酸或rna编码多核苷酸或作为蛋白质递送。可以将指导物作为dna编码多核苷酸或rna递送。设想了所有可能的组合,包括混合的递送形式。
在一些方面,本发明提供了包括以下步骤的方法:向宿主细胞递送一种或多种多核苷酸(诸如本文所述的一种或多种载体)、其一种或多种转录物和/或由其转录的一种或多种蛋白质。
载体
一般来讲,术语“载体”是指能够转运它所连接的另一个核酸的核酸分子。载体是复制子,诸如质粒、噬菌体或粘粒,可以向该复制子中插入另一个dna区段以便使得该插入的区段复制。通常,载体在与适当控制元件缔合时能够复制。载体包括但不限于单链、双链或部分双链的核酸分子;包含一个或多个游离端、不包含游离端(例如环状)的核酸分子;包含dna、rna或两者的核酸分子;以及本领域中已知的多核苷酸的其他种类。一种类型的载体是“质粒”,其是指环状双链dna环,可以诸如通过标准分子克隆技术向该环中插入另外的dna区段。另一种类型的载体是病毒载体,其中病毒来源的dna或rna序列存在于包装到病毒(例如逆转录病毒、复制缺陷型逆转录病毒、腺病毒、复制缺陷型腺病毒和腺相关病毒)中的载体中。病毒载体还包括由转染到宿主细胞中的病毒携带的多核苷酸。某些载体能够在引入它们的宿主细胞中自主复制(例如具有细菌复制起点的细菌载体和附加型哺乳动物载体)。其他载体(例如非附加型哺乳动物载体)在引入到宿主细胞中之后被整合到宿主细胞的基因组中,并且因此随着宿主基因组一起复制。此外,某些载体能够引导它们可操作地连接的基因的表达。此类载体在本文中称为“表达载体”。用于真核细胞并且在真核细胞中产生表达的载体在本文中可以称为“真核表达载体”。在重组dna技术中有效用的常用表达载体常常呈质粒的形式。
重组表达载体可以包含处于适于在宿主细胞中表达核酸的形式的本发明的核酸,这意味着重组表达载体包含一个或多个调控元件,这些调控元件可以基于用于表达的宿主细胞来选择,可操作地连接至有待表达的核酸序列。在重组表达载体内,“可操作地连接”旨在意指目标核苷酸序列以允许核苷酸序列表达(例如,在体外转录/翻译系统中或当该载体被引入到宿主细胞时在宿主细胞中)的方式连接至一个或多个调控元件。有利的载体包括慢病毒和腺伴随病毒并且此类载体类型还可以被选择用于靶向特定细胞类型。
关于重组和克隆方法,提及2004年9月2日以us2004-0171156a1公布的美国专利申请10/815,730,该专利的内容以引用方式整体并入本文。
术语“调控元件”旨在包括启动子、增强子、内部核糖体进入位点(ires)以及其他表达控制元件(例如转录终止信号,诸如多聚腺苷酸化信号和聚u序列)。此类调控元件描述于例如goeddel,geneexpressiontechnology:methodsinenzymology185,academicpress,sandiego,calif.(1990)。调控元件包括引导核苷酸序列在许多类型的宿主细胞中连续表达的那些元件和引导核苷酸序列仅在某些宿主细胞中表达的那些元件(例如组织特异性调控序列)。组织特异性启动子可以引导主要在希望的目标组织诸如肌肉、神经元、骨骼、皮肤、血液、特定器官(例如肝脏、胰脏)、或特定细胞类型(例如淋巴细胞)中的表达。调控元件还可以时间依赖性方式诸如细胞周期依赖性或发育阶段依赖性方式引导表达,这可以是或也可以不是组织特异性或细胞类型特异性的。在一些实施方案中,载体包含一个或多个poliii启动子(例如1个、2个、3个、4个、5个或更多个poliii启动子)、一个或多个polii启动子(例如1个、2个、3个、4个、5个或更多个polii启动子)、一个或多个poli启动子(例如1个、2个、3个、4个、5个或更多个poli启动子)或它们的组合。poliii启动子的实例包括但不限于u6和h1启动子。polii启动子的实例包括但不限于逆转录病毒劳斯氏肉瘤病毒(rsv)ltr启动子(任选地具有rsv增强子)、巨细胞病毒(cmv)启动子(任选地具有cmv增强子)[参见例如boshart等人,cell,41:521-530(1985)]、sv40启动子、二氢叶酸还原酶启动子、β-肌动蛋白启动子、磷酸甘油激酶(pgk)启动子和ef1α启动子。术语“调控元件”还涵盖增强子元件,诸如wpre;cmv增强子;htlv-i的ltr中的r-u5’区段(mol.cell.biol.,第8(1)卷,第466-472页,1988);sv40增强子;以及兔β-球蛋白的外显子2与3之间的内含子序列(proc.natl.acad.sci.usa.,第78(3)卷,第1527-31页,1981)。本领域技术人员将了解的是,表达载体的设计可以取决于诸如有待转化的宿主细胞的选择、所希望的表达水平等因素。载体可以引入到宿主细胞中从而产生由本文所述的核酸编码的转录物、蛋白质或肽,包括融合蛋白或肽(例如,成簇的规律间隔的短回文重复序列(crispr)转录物、蛋白质、酶、其突变体形式、其融合蛋白等)。关于调控序列,提及美国专利申请10/491,026,该专利的内容以引用方式整体并入本文。关于启动子,提及pct公布wo2011/028929和美国申请12/511,940,这些专利的内容以引用方式整体并入本文。
有利的载体包括慢病毒和腺伴随病毒并且此类载体类型还可以被选择用于靶向特定细胞类型。
在特定实施方案中,使用融合至腺苷脱氨酶的指导rna和(任选地修饰或突变的)crispr-cas蛋白的双顺反子载体。融合至腺苷脱氨酶的指导rna和(任选地修饰或突变的)crispr-cas蛋白的双顺反子表达载体是优选的。一般来讲且具体地讲,在此实施方案中,融合至腺苷脱氨酶的(任选地修饰或突变的)crispr-cas蛋白优选地通过cbh启动子驱动。rna可以优选地通过poliii启动子诸如u6启动子驱动。理想的是,将两者结合。
载体可以被设计为在原核细胞或真核细胞中表达crispr转录物(例如核酸转录物、蛋白质或酶)。例如,crispr转录物可以在细菌细胞(诸如大肠杆菌)、昆虫细胞(使用杆状病毒表达载体)、酵母细胞、或哺乳动物细胞中表达。合适的宿主细胞在goeddel,geneexpressiontechnology:methodsinenzymology185,academicpress,sandiego,calif.(1990)中进一步论述。或者,重组表达载体可以例如使用t7启动子调控序列和t7聚合酶来进行体外转录和翻译。
载体可以在原核生物或原核细胞中引入并增殖。在一些实施方案中,使用原核生物扩增有待引入到真核细胞中的载体拷贝或者作为产生有待引入到真核细胞中的载体的中间载体(例如,扩增作为病毒载体包装系统的一部分的质粒)。在一些实施方案中,使用原核生物扩增载体拷贝并表达一种或多种核酸,如以便提供用于递送至宿主细胞或宿主生物体的一种或多种蛋白质来源。原核生物中的蛋白质表达最常在大肠杆菌中利用含有引导融合蛋白或非融合蛋白表达的组成型启动子或诱导型启动子的载体进行。融合载体将许多氨基酸添加到其中编码的蛋白质,诸如添加到重组蛋白的氨基末端。此类融合载体可以用于一种或多种目的,诸如:(i)增加重组蛋白的表达;(ii)增加重组蛋白的溶解度;以及(iii)通过充当亲和纯化中的配体来帮助纯化重组蛋白。通常,在融合表达载体中,蛋白水解切割位点被引入在融合部分与重组蛋白的接点处,以使得重组蛋白能够与融合部分分离,从而随后纯化该融合蛋白。此类酶及其同源识别序列包括因子xa、凝血酶以及肠激酶。示例性融合表达载体包括pgex(pharmaciabiotechinc;smithandjohnson,1988.gene67:31-40)、pmal(newenglandbiolabs,beverly,mass.)以及prit5(pharmacia,piscataway,n.j.),它们分别将谷胱甘肽s-转移酶(gst)、麦芽糖e结合蛋白或蛋白a融合至靶重组蛋白。合适的诱导型非融合大肠杆菌表达载体的实例包括ptrc(amrann等人,(1988)gene69:301-315)和pet11d(studier等人,geneexpressiontechnology:methodsinenzymology185,academicpress,sandiego,calif.(1990)60-89)。在一些实施方案中,载体是酵母表达载体。用于在酵母酿酒酵母中表达的载体的实例包括pyepsec1(baldari等人,1987.emboj.6:229-234)、pmfa(kuijan和herskowitz,1982.cell30:933-943)、pjry88(schultz等人,1987.gene54:113-123)、pyes2(invitrogencorporation,sandiego,calif.)以及picz(invitrogencorp,sandiego,calif.)。在一些实施方案中,载体使用杆状病毒表达载体驱动昆虫细胞中的蛋白质表达。可用于在培养的昆虫细胞(例如sf9细胞)表达蛋白质的杆状病毒载体包括pac系列(smith等人,1983.mol.cell.biol.3:2156-2165)和pvl系列(lucklow和summers,1989.virology170:31-39)。
在一些实施方案中,载体能够使用哺乳动物表达载体驱动一种或多种序列在哺乳动物细胞中的表达。哺乳动物表达载体的实例包括pcdm8(seed,1987.nature329:840)和pmt2pc(kaufman等人,1987.emboj.6:187-195)。当用于哺乳动物细胞时,表达载体的控制功能典型地是由一个或多个调控元件提供的。例如,常用的启动子是来源于多瘤、腺病毒2、巨细胞病毒、猿猴病毒40,以及在此披露和本领域已知的其他来源。对于原核细胞和真核细胞二者的其他合适表达系统,参见例如sambrook等人,molecularcloning:alaboratorymanual.第2版,coldspringharborlaboratory,coldspringharborlaboratorypress,coldspringharbor,n.y.,1989中的第16章和第17章。
在一些实施方案中,重组哺乳动物表达载体能够引导核酸优先在特定细胞类型中表达(例如,组织特异性调控元件用于表达核酸)。组织特异性调控元件在本领域中是已知的。合适的组织特异性启动子的非限制性实例包括白蛋白启动子(肝脏特异性;pinkert等人,1987.genesdev.1:268-277)、淋巴特异性启动子(calame和eaton,1988.adv.immunol.43:235-275)(具体地说t细胞受体(winoto和baltimore,1989.emboj.8:729-733)和免疫球蛋白(baneiji等人,1983.cell33:729-740;queen和baltimore,1983.cell33:741-748)的启动子)、神经元特异性启动子(例如神经丝启动子;byrne和ruddle,1989.proc.natl.acad.sci.usa86:5473-5477)、胰腺特异性启动子(edlund等人,1985.science230:912-916),以及乳腺特异性启动子(例如乳清启动子;美国专利号4,873,316和欧洲申请公布号264,166)。还涵盖发育调节的启动子,例如鼠hox启动子(kessel和gruss,1990.science249:374-379)和α-胎蛋白启动子(campes和tilghman,1989.genesdev.3:537-546)。关于这些原核载体和真核载体,提及美国专利6,750,059,该专利的内容以引用方式整体并入本文。本发明的其他实施方案可以涉及病毒载体的使用,关于此使用提及美国专利申请13/092,085,该专利的内容以引用方式整体并入本文。组织特异性调控元件在本领域中是已知的,并且就这一点而言,提及美国专利7,776,321,该专利的内容以引用方式整体并入本文。在一些实施方案中,调控元件可操作地连接至crispr系统的一个或多个元件,以便驱动该crispr系统的一个或多个元件表达。
在一些实施方案中,驱动核酸靶向系统的一个或多个元件表达的一种或多种载体被引入到宿主细胞中,以使得该核酸靶向系统的这些元件的表达能引导核酸靶向复合物在一个或多个靶位点处形成。例如,核酸靶向效应蛋白和核酸靶向指导rna可以各自可操作地连接至单独载体上的单独调控元件。核酸靶向系统的一种或多种rna可以被递送至转基因核酸靶向效应蛋白动物或哺乳动物,例如组成型地或诱导型地或条件型地表达核酸靶向效应蛋白的动物或哺乳动物;或以其他方式表达核酸靶向效应蛋白或具有含有核酸靶向效应蛋白的细胞的动物或哺乳动物,诸如通过在先向这些动物或哺乳动物施用编码或体内表达核酸靶向效应蛋白的一种或多种载体的方式。或者,从相同或不同调控元件表达的这些元件的两种或更多种可以组合在单一载体中,其中一种或多种另外的载体提供核酸靶向系统在第一载体中不包含的任何组分。组合于单一载体中的核酸靶向系统元件可以布置为任何适合的取向,诸如一个元件位于相对于第二元件的5′(“上游”)或相对于该第二元件的3′(“下游”)。一个元件的编码序列可以位于第二元件的编码序列的相同链或相反链上,并且取向为相同或相反方向。在一些实施方案中,单一启动子驱动编码核酸靶向效应蛋白的转录物和嵌入一个或多个内含子序列之内(例如,各自在不同内含子中、两个或更多个在至少一个内含子中,或所有在单一内含子中)的核酸靶向指导rna的表达。在一些实施方案中,核酸靶向效应蛋白和核酸靶向指导rna可以可操作地连接至同一启动子并且从该同一启动子表达。用于表达核酸靶向系统的一个或多个元件的递送媒介物、载体、粒子、纳米粒子、配制品以及其组分如在前述文献诸如wo2014/093622(pct/us2013/074667)中所使用的。在一些实施方案中,载体包含一个或多个插入位点,诸如限制性内切核酸酶识别序列(也称之为“克隆位点”)。在一些实施方案中,一个或多个插入位点(例如,约或超过约1个、2个、3个、4个、5个、6个、7个、8个、9个、10个或更多个插入位点)位于一种或多种载体的一个或多个序列元件的上游和/或下游。当使用多个不同的指导序列时,可以使用单一表达构建体来使核酸靶向活性靶向细胞内的多个不同的相应靶序列。例如,单一载体可以包含约或超过约1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、15个、20个或更多个指导序列。在一些实施方案中,可以提供约或超过约1个、2个、3个、4个、5个、6个、7个、8个、9个、10个或更多个含有此指导序列的载体,并且任选地将其递送至细胞中。在一些实施方案中,载体包含可操作地连接至编码核酸靶向效应蛋白的酶编码序列的调控元件。可以单独地递送核酸靶向效应蛋白或一种或多种核酸靶向指导rna;并且有利的是经由粒子复合物递送这些中的至少一者。核酸靶向效应蛋白mrna可以在核酸靶向指导rna之前递送,以给出时间以待核酸靶向效应蛋白表达。核酸靶向效应蛋白mrna可以在施用核酸靶向指导rna之前1-12小时(优选约2-6小时)施用。或者,核酸靶向效应蛋白mrna和核酸靶向指导rna可以一起施用。有利地,指导rna的第二加强剂量可以在初始施用核酸靶向效应蛋白mrna+指导rna之后1-12小时(优选约2-6小时)施用。为了实现最有效的基因组修饰水平,核酸靶向效应蛋白mrna和/或指导rna的附加施用可能是有用的。
常规的基于病毒和非病毒的基因转移方法可以用于在哺乳动物细胞或靶组织中引入核酸。此类方法可以用于向培养基或宿主生物体中的细胞施用编码核酸靶向系统的组分的核酸。非病毒载体递送系统包括dna质粒、rna(例如本文所述的载体的转录物)、裸核酸,以及与递送媒介物诸如脂质体复合的核酸。病毒载体递送系统包括dna和rna病毒,这些病毒在递送至细胞后具有附加型基因组或整合型基因组。对于基因疗法程序的综述,参见anderson,science256:808-813(1992);nabel和felgner,tibtech11:211-217(1993);mitani和caskey,tibtech11:162-166(1993);dillon,tibtech11:167-175(1993);miller,nature357:455-460(1992);vanbrunt,biotechnology6(10):1149-1154(1988);vigne,restorativeneurologyandneuroscience8:35-36(1995);kremer和perricaudet,britishmedicalbulletin51(1):31-44(1995);haddada等人,currenttopicsinmicrobiologyandimmunology,doerfler和
非病毒递送核酸的方法包括包括脂质转染、核转染、微注射、基因枪、病毒体、脂质体、免疫脂质体、聚阳离子或脂质:核酸轭缀合物、裸dna、人工病毒体以及剂增强dna摄取。脂质转染描述于例如美国专利号5,049,386、4,946,787;以及4,897,355)并且脂质转染试剂是商业上销售的(例如transfectamtm和lipofectintm)。适于多核苷酸的有效受体识别脂质转染的阳离子脂质和中性脂质包括felgner,wo91/17424;wo91/16024的那些。递送可以是递送至细胞(例如体外或离体施用)或靶组织(例如体内施用)。
质粒递送涉及将指导rna克隆到crispr-cas蛋白表达质粒中,并在细胞培养物中转染dna。质粒主链是商业上可得的,并且不需要特定的设备。它们的优势为是模块化的,能够携带不同尺寸的crispr-cas编码序列(包括编码更大尺寸蛋白质的序列)以及选择标记物。同时质粒的优点是它们可以确保瞬时但持续的表达。然而,质粒的递送不是直接的,使得体内效率通常很低。持续表达也可能是不利的,因为这可以增加脱靶编辑。另外,crispr-cas蛋白的过度积累可能对细胞有毒。最后,质粒总是具有在宿主基因组中随机整合dsdna的风险,更特别地是考虑到产生双链断裂(中靶和脱靶)。
脂质:核酸复合物(包括靶向脂质体,诸如免疫脂质复合物)的制备是本领域技术人员所熟知的(参见例如crystal,science270:404-410(1995);blaese等人,cancergenether.2:291-297(1995);behr等人,bioconjugatechem.5:382-389(1994);remy等人,bioconjugatechem.5:647-654(1994);gao等人,genetherapy2:710-722(1995);ahmad等人,cancerres.52:4817-4820(1992);美国专利4,186,183、4,217,344、4,235,871、4,261,975、4,485,054、4,501,728、4,774,085、4,837,028和4,946,787)。对此将在下文更详细地论述。
使用用于递送核酸的基于rna或dna病毒的系统利用了用于将病毒靶向身体内的特定细胞并且将病毒有效负载运输到核内的高度进化的方法。病毒载体可以直接施用至患者(体内),或者它们可以用于体外处理细胞,并且修饰的细胞可以任选地施用至患者(离体)。常规的基于病毒的系统可以包括用于基因转移的逆转录病毒、慢病毒、腺病毒、腺相关病毒以及单纯疱疹病毒载体。通过逆转录病毒、慢病毒以及腺相关病毒基因转移方法整合在宿主基因组中是可能的,这常常导致插入的转基因长期表达。另外,已经在许多不同的细胞类型和靶组织中观察到高转导效率。
可以通过并入外源包膜蛋白,扩展靶细胞的潜在靶群体而改变逆转录病毒的向性。慢病毒载体是能够转导或感染非分裂细胞并典型地产生较高病毒效价的逆转录病毒载体。因此,逆转录病毒基因转移系统的选择将取决于靶组织。逆转录病毒载体由顺式作用长末端重复序列组成,这些长末端重复序列具有包装多达6-10kb的外源序列的能力。最低量的顺式作用ltr对于载体的复制和包装而言是足够的,然后使用这些载体将治疗基因整合到靶细胞中,以提供永久的转基因表达。广泛使用的逆转录病毒载体包括基于鼠白血病病毒(mulv)、长臂猿白血病病毒(galv)、猴免疫缺陷病毒(siv)、人类免疫缺陷病毒(hiv)以及它们的组合的那些(参见例如buchscher等人,j.virol.66:2731-2739(1992);johann等人,j.virol.66:1635-1640(1992);sommnerfelt等人,virol.176:58-59(1990);wilson等人,j.virol.63:2374-2378(1989);miller等人,j.virol.65:2220-2224(1991);pct/us94/05700)。
在瞬时表达是优选的应用中,可以使用基于腺病毒的系统。基于腺病毒的载体能够在许多细胞类型中具有极高转导效率并且无需细胞分裂。用此类载体,已经获得了较高的效价和表达水平。可以在相对简单的系统中大量地产生此载体。还可以使用腺相关病毒(“aav”)载体转导具有靶核酸的细胞,例如,在体外产生核酸和肽,以及用于体内和离体基因疗法程序(参见例如west等人,virology160:38-47(1987);美国专利号4,797,368;wo93/24641;kotin,humangenetherapy5:793-801(1994);muzyczka,j.clin.invest.94:1351(1994)。重组aav载体的构建描述于许多出版物中,包括美国专利号5,173,414;tratschin等人,mol.cell.biol.5:3251-3260(1985);tratschin等人,mol.cell.biol.4:2072-2081(1984);hermonat和muzyczka,pnas81:6466-6470(1984);以及samulski等人,j.virol.63:03822-3828(1989)。
本发明提供了含有以下各项或基本上由以下各项组成的aav:编码crispr系统的外源性核酸分子,例如包含第一盒或由该第一盒组成的多个盒,该第一盒包含启动子、编码crispr-相关(cas)蛋白(推定的核酸酶或解旋酶蛋白)(例如cpf1)的核酸分子和终止子或基本上由其组成,以及两个或更多个、有利地多至载体的包装尺寸限度,例如总计(包括该第一盒在内)五个包含启动子、编码指导rna(grna)的核酸分子和终止子或基本上由其组成的盒(例如,每个盒示意性地表示为启动子-grna1-终止子、启动子-grna2-终止子...启动子-grna(n)-终止子,其中n是可以插入的数值,该数值是载体包装尺寸限度的上限);或者两个或更多个单独的raav,其各自含有crispr系统的一个或多于一个盒,例如第一raav含有包含启动子、编码cas例如cas(cpf1)的核酸分子和终止子或基本上由其组成的第一盒,并且第二raav含有一个或多个各自包含启动子、编码指导rna(grna)的核酸分子和终止子或基本上由其组成的盒(例如,每个盒示意性地表示为启动子-grna1-终止子、启动子-grna2-终止子...启动子-grna(n)-终止子,其中n是可以插入的数值,该数值是载体包装尺寸限度的上限)。或者,由于cpf1可以处理自己的crrna/grna,因此可以使用单一crrna/grna阵列用于多重基因编辑。因此,raav可以含有单个包含启动子、多个crrna/grna和终止子或基本上由其组成)的表达盒(例如,示意性地表示为启动子-grna1-grna2...grna(n)终止子,其中n是可以插入的数值,该数值是载体包装尺寸限度的上限),而不是包括多个盒来递送grna。参见zetsche等人naturebiotechnology35,31-34(2017),该文献以引用方式整体并入本文。由于raav是dna病毒,因此本文关于aav或raav的论述中的核酸分子有利地是dna。在一些实施方案中,启动子有利地是人类突触蛋白i启动子(hsyn)。用于将核酸递送至细胞的另外的方法是本领域技术人员已知的。参见例如us20030087817,该专利以引用方式并入本文。
在另一个实施方案中,考虑了科卡尔(cocal)水泡病毒包膜假型化逆转录病毒载体粒子(参见例如转让给fredhutchinsoncancerresearchcenter的美国专利公布号20120164118)。科卡尔病毒属于水泡病毒属,并且是哺乳动物水疱性口炎的致病物。科卡尔病毒最初从特立尼达拉岛(trinidad)的螨虫中分离(jonkers等人,am.j.vet.res.25:236-242(1964)),并且在特立尼达拉岛、巴西和阿根廷已经确定了由昆虫、牛和马引起的感染。感染哺乳动物的许多水泡病毒已从天然感染的节肢动物中分离,这表明它们是载体传播(vector-borne)的。水泡病毒抗体在生活于农村地区的人中是常见的,而这些病毒是地方性的并且是实验室采集的;人类的感染通常导致流感样症状。科卡尔病毒包膜糖蛋白与印第安纳vsv-g享有71.5%氨基酸水平的一致性,并且对水泡病毒的包膜基因的系统发育比较显示科卡尔病毒在血清学上不同于水泡病毒内的印第安纳vsv-g株,但与其紧密相关。jonkers等人,am.j.vet.res.25:236-242(1964)以及travassosdarosa等人,am.j.tropicalmed.&hygiene33:999-1006(1984)。科卡尔水泡病毒包膜蛋白假型化逆转录病毒载体粒子可以包括慢病毒、α逆转录病毒、β逆转录病毒、γ逆转录病毒、δ逆转录病毒以及ε逆转录病毒载体粒子,这些载体粒子可以包含逆转录病毒gag、pol,和/或一种或多种辅助蛋白以及科卡尔水泡病毒包膜蛋白。在这些实施方案的某些方面,gag、pol和辅助蛋白是慢病毒和/或γ逆转录病毒。
在一些实施方案中,用本文所述的一种或多种载体瞬时或非瞬时转染宿主细胞。在一些实施方案中,当细胞天然地出现在受试者体内(任选地有待重新引入其中)时将其转染。在一些实施方案中,转染的细胞是从受试者获得。在一些实施方案中,细胞来源于从受试者获得的细胞,诸如细胞系。用于组织培养的多种多样的细胞系在本领域中是已知的。细胞系的实例包括但不限于c8161、ccrf-cem、molt、mimcd-3、nhdf、hela-s3、huh1、huh4、huh7、huvec、hasmc、hekn、heka、miapacell、panc1、pc-3、tf1、ctll-2、c1r、rat6、cv1、rpte、a10、t24、j82、a375、arh-77、calu1、sw480、sw620、skov3、sk-ut、caco2、p388d1、sem-k2、wehi-231、hb56、tib55、jurkat、j45.01、lrmb、bcl-1、bc-3、ic21、dld2、raw264.7、nrk、nrk-52e、mrc5、mef、hepg2、helab、helat4、cos、cos-1、cos-6、cos-m6a、bs-c-1猴肾上皮细胞、balb/3t3小鼠胚成纤维细胞、3t3swiss、3t3-l1、132-d5人类胎儿成纤维细胞;10.1小鼠成纤维细胞、293-t、3t3、721、9l、a2780、a2780adr、a2780cis、a172、a20、a253、a431、a-549、alc、b16、b35、bcp-1cells、beas-2b、bend.3、bhk-21、br293、bxpc3、c3h-10t1/2、c6/36、cal-27、cho、cho-7、cho-ir、cho-k1、cho-k2、cho-t、chodhfr-/-、cor-l23、cor-l23/cpr、cor-l23/5010、cor-l23/r23、cos-7、cov-434、cmlt1、cmt、ct26、d17、dh82、du145、ducap、el4、em2、em3、emt6/ar1、emt6/ar10.0、fm3、h1299、h69、hb54、hb55、hca2、hek-293、hela、hepa1c1c7、hl-60、hmec、ht-29、jurkat、jy细胞、k562细胞、ku812、kcl22、kg1、kyo1、lncap、ma-mel1-48、mc-38、mcf-7、mcf-10a、mda-mb-231、mda-mb-468、mda-mb-435、mdckii、mdckii、mor/0.2r、mono-mac6、mtd-1a、myend、nci-h69/cpr、nci-h69/lx10、nci-h69/lx20、nci-h69/lx4、nih-3t3、nalm-1、nw-145、opcn/opct细胞系、peer、pnt-1a/pnt2、renca、rin-5f、rma/rmas、saos-2细胞、sf-9、skbr3、t2、t-47d、t84、thp1细胞系、u373、u87、u937、vcap、verocells、wm39、wt-49、x63、yac-1、yar,以及它们的转基因品种。细胞系可从本领域技术人员已知的多种来源获得(参见例如美国典型培养物保藏中心(atcc)(manassus,va.))。
在特定实施方案中,ad官能化的crispr系统的一种或多种组分的瞬时表达和/或存在可能是令人感兴趣的,诸如用以减少脱靶效应。在一些实施方案中,用本文所述的一种或多种载体转染的细胞用于建立包含一种或多种载体来源的序列的新细胞系。在一些实施方案中,使用用如本文所述的ad官能化的crispr系统的组分瞬时转染(诸如通过一种或多种载体进行瞬时转染,或用rna进行转染)并且通过crispr复合物的活性修饰的细胞建立细胞系,所述细胞系包含含有修饰但缺少任何其他外源性序列的细胞。在一些实施方案中,用本文所述的一种或多种载体瞬时或非瞬时转染的细胞,或来源于此类细胞的细胞系用于评定一种或多种测试化合物。
在一些实施方案中,设想将rna和/或蛋白质直接引入宿主细胞。例如,可以将crispr-cas蛋白作为编码mrna与体外转录的指导rna一起递送。此类方法可以减少确保crispr-cas蛋白起效的时间,并且进一步防止crispr系统组分的长期表达。
在一些实施方案中,本发明的rna分子以脂质体或转化脂(lipofectin)脂质转染蛋白配制品递送,并且可以通过本领域技术人员所熟知的方法来制备。此类方法描述于例如美国专利5,593,972、5,589,466和5,580,859,这些专利以引用方式并入本文。已开发了特别旨在增强并改善sirna到哺乳动物细胞的递送的递送系统(参见例如shen等人febslet.2003,539:111-114;xia等人,nat.biotech.2002,20:1006-1010;reich等人,mol.vision.2003,9:210-216;sorensen等人,j.mol.biol.2003,327:761-766;lewis等人,nat.gen.2002,32:107-108以及simeoni等人,nar2003,31,11:2717-2724),并且这些递送系统可以适用于本发明。sirna最近已成功用于抑制灵长类动物中的基因表达(参见,例如tolentino等人,retina24(4):660,该文献也可以适用于本发明)。
实际上,rna递送是可用的体内递送方法。有可能使用脂质体或纳米粒子将cpf1、腺苷脱氨酶和指导rna递送至细胞中。因此,crispr-cas蛋白(诸如cpf1)的递送、腺苷脱氨酶(其可以融合至crispr-cas蛋白或衔接蛋白)的递送和/或本发明的rna的递送可以可以呈rna形式并且经由微泡、脂质体或一个粒子或多个粒子来进行。例如,可以将cpf1mrna、腺苷脱氨酶mrna和指导rna包装到脂质体粒子中以进行体内递送。脂质体转染试剂诸如来自lifetechnologies的lipofectamine和市场上的其他试剂可以有效地将rna分子递送至肝脏中。
rna递送手段还优选包括经由粒子的rna递送(cho,s.、goldberg,m.、son,s.、xu,q.、yang,f.、mei,y.、bogatyrev,s.、langer,r.和anderson,d.,lipid-likenanoparticlesforsmallinterferingrnadeliverytoendothelialcells,advancedfunctionalmaterials,19:3112-3118,2010)或经由外泌体的递送(schroeder,a.、levins,c.、cortez,c.、langer,r.和anderson,d.,lipid-basednanotherapeuticsforsirnadelivery,journalofinternalmedicine,267:9-21,2010,pmid:20059641)。实际上,已显示外泌体在递送sirna中特别有用,其为与crispr系统有一些相似之处的系统。例如,el-andaloussis等人(“exosome-mediateddeliveryofsirnainvitroandinvivo.”natprotoc.2012年12月;7(12):2112-26.doi:10.1038/nprot.2012.131.电子版2012年11月15日)描述了外泌体如何成为用于跨不同生物屏障的药物递送的有希望的工具并且可以用于体外和体内递送sirna。他们的方法是通过包含与肽配体融合的外泌体蛋白的表达载体的转染来产生靶向的外泌体。然后将这些外泌体纯化并且由转染的细胞上清液进行表征,然后将rna加载到外泌体中。根据本发明的递送或施用可以使用外泌体进行,特别地但不限于脑。维生素e(α-生育酚)可以与crisprcas缀合并且与高密度脂蛋白(hdl)一起递送至脑,方式为例如与(uno)等人(humangenetherapy22:711-719(2011年6月))完成的用于将短干扰rna(sirna)递送至脑的方式类似。经由填充有磷酸盐缓冲盐水(pbs)或游离tocsibace或toc-sibace/hdl并且与脑灌注试剂盒3(braininfusionkit3)(alzet)连接的微型渗透泵(型号1007d;alzet,cupertino,ca)灌注小鼠。将脑灌注插管置于在正中线的前囱的后方约0.5mm,以便灌注到背侧第三脑室中。uno等人发现,通过相同的icv灌注方法,少至3nmol的toc-sirna与hdl可以诱导相当程度的靶标减少。在本发明中对于人类可以考虑类似剂量的缀合至α-生育酚并且与hdl共同施用靶向脑的crisprcas,例如,可以考虑靶向脑的约3nmol至约3μmol的crisprcas。zou等人((humangenetherapy22:465-475(april2011))描述了靶向pkcγ的短发夹rna的慢病毒介导的递送方法,其用于在大鼠脊髓中的体内基因沉默。zou等人通过鞘内导管施用约10μl的具有1x109个转导单位(tu)/ml的滴度的重组慢病毒。在本发明中对于人类可以考虑类似剂量的靶向脑的在慢病毒载体中表达的crisprcas,例如,可以考虑靶向脑的在具有1x109个转导单位(tu)/ml的滴度的慢病毒中的约10-50ml的crisprcas。
载体的剂型
在一些实施方案中,载体(例如质粒或病毒载体)是例如通过肌内注射递送至目标组织,而有时经由静脉内、经皮、鼻内、经口、粘膜、或其他递送方法进行递送。这种递送可以经由单剂量或多剂量来进行。本领域技术人员理解的是,本文有待递送的实际剂量可以在很大程度上取决于多种因素而变化,诸如载体选择、靶细胞、生物体或组织、有待治疗的受试者的一般状况、所寻求的转化/修饰的程度、施用途径、施用方式、所寻求的转化/修饰的类型等。
这样的剂量还可以含有例如载剂(水、盐水、乙醇、甘油、乳糖、蔗糖、磷酸钙、明胶、葡聚糖、琼脂、果胶、花生油、芝麻油等)、稀释剂、药学上可接受的载剂(例如磷酸盐缓冲盐水)、药学上可接受的赋形剂,和/或本领域已知的其他化合物。该剂型还可以含有一种或多种药学上可接受的盐,诸如例如,矿物酸盐诸如盐酸盐、氢溴酸盐、磷酸盐、硫酸盐等;以及有机酸盐,诸如乙酸盐、丙酸盐、丙二酸盐、苯甲酸盐等。另外,本文也可以存在辅助物质,诸如润湿剂或乳化剂、ph缓冲物质、凝胶或胶凝材料、调味剂、着色剂、微球体、聚合物、悬浮剂等。此外,还可以存在一种或多种其他常规药用成分,诸如防腐剂、保湿剂、悬浮剂、表面活性剂、抗氧化剂、抗结剂、填充剂、螯合剂、包衣剂、化学稳定剂等,尤其是在该剂型呈可重构形式时。合适的示例性成分包括微晶纤维素、羧甲基纤维素钠、聚山梨酯80、苯乙醇、三氯叔丁醇、山梨酸钾、抗坏血酸、二氧化硫、没食子酸丙酯、对羟基苯甲酸酯、乙基香兰素、甘油、苯酚、对氯酚、明胶、白蛋白以及它们的组合。对药学上可接受的赋形剂的彻底论述可获自remington′spharmaceuticalsciences(mackpub.co.,n.j.1991),该文献以引用方式并入本文。
在本文的一个实施方案中,递送是经由腺病毒进行的,其可以是含有至少1x105个腺病毒载体粒子(也称为粒子单位,pu)的单次加强剂量。在本文的一个实施方案中,该剂量优选为腺病毒载体的至少约1x106个粒子(例如约1x106-1x1012个粒子)、更优选至少约1x107个粒子、更优选至少约1x108个粒子(例如约1x108-1x1011个粒子或约1x108-1x1012个粒子)、且最优选至少约1x100个粒子(例如约1x109-1x1010个粒子或约1x109-1x1012个粒子,或甚至至少约1x1010个粒子(例如约1x1010-1x1012个粒子)。或者,该剂量包含不超过约1x1014个粒子、优选不超过约1x1013个粒子、甚至更优选不超过约1x1012个粒子、甚至更优选不超过约1x1011个粒子、且最优选不超过约1x1010个粒子(例如不超过约1x109个粒子)。因此,该剂量可以含有单剂量的腺病毒载体,其具有例如约1x106粒子单位(pu)、约2x106pu、约4x106pu、约1x107pu、约2x107pu、约4x107pu、约1x108pu、约2x108pu、约4x108pu、约1x109pu、约2x109pu、约4x109pu、约1x1010pu、约2x1010pu、约4x1010pu、约1x1011pu、约2x1011pu、约4x1011pu、约1x1012pu、约2x1012pu或约4x1012pu的腺病毒载体。参见,例如,在2013年6月4日授权的授予nabel等人的美国专利号8,454,972b2中的腺病毒载体;该专利通过引用结合在此,以及在其第29栏第36-58行的剂量。在本文的一个实施方案中,腺病毒是经由多剂量递送的。
在本文的一个实施方案中,递送是经由aav进行的。用于针对人类的aav的体内递送的治疗有效剂量被认为处于含有从约1x1010至约1x1010个功能aav/ml溶液的从约20至约50ml的盐水溶液的范围内。可以调整该剂量以便使治疗益处相对于任何副作用平衡。在本文的一个实施方案中,aav剂量大致处于约1x105至1x1050个基因组aav、约1x108至1x1020个基因组aav、约1x1010至约1x1016个基因组,或约1x1011至约1x1016个基因组aav的浓度范围内。人类剂量可以是约1x1013个基因组aav。这样的浓度能以约0.001ml至约100ml、约0.05至约50ml,或约10至约25ml的载剂溶液进行递送。通过建立剂量反应曲线的常规试验,本领域普通技术人员可以容易地确立其他有效剂量。参见,例如,2013年3月26日授权的授予hajjar等人的美国专利号8,404,658b2,在第27栏,第45-60行。
在本文的一个实施方案中,递送是经由质粒进行的。在此类质粒组合物中,该剂量应当是足以引发反应的质粒的量。例如,在质粒组合物中的质粒dna的适当量可以是约0.1至约2mg,或约1μg至约10μg/70kg个体。本发明的质粒将大体上包含(i)启动子;(ii)可操作地连接至所述启动子的编码crispr-cas蛋白的序列;(iii)选择性标记物;(iv)复制起点;以及(v)在(ii)的下游并可操作地连接至(ii)的转录终止子。质粒还可以编码crispr复合物的rna组分,但是这些组分中的一者或多者还可以被编码在不同载体上。
本文的剂量是基于平均70kg的个体。施用频率在医学或兽医学从业者(例如医师、兽医师)或本领域熟练的科学家的范围之内。还应注意的是,实验中使用的小鼠典型地是约20g,根据小鼠实验可以扩展到70kg的个体。
用于本文提供的组合物的剂量包括用于重复施用或重复给药的剂量。在特定实施方案中,在数周、数月或数年的时段内重复施用。可以进行合适的测定以获得最佳剂量方案。重复施用可以允许使用较低的剂量,这可以积极地影响脱靶修饰。
rna递送
在特定实施方案中,使用基于rna的递送。在这些实施方案中,crispr-cas蛋白的mrna、腺苷脱氨酶的mrna(其可以融合至crispr-cas蛋白或衔接子)与体外转录的指导rna一起递送。liang等人描述了使用基于rna的递送的有效基因组编辑(proteincell.2015年5月;6(5):363-372)。在一些实施方案中,可以通过化学方式修饰编码cpf1和/或腺苷脱氨酶的mrna,与质粒编码的cpf1和/或腺苷脱氨酶相比,这可以使活性提高。例如,一个或多个mrna中的尿苷可以被假尿苷(ψ)、n1-甲基假尿苷(me1ψ)、5-甲氧基尿苷(5mou)部分或完全取代。参见li等人,naturebiomedicalengineering1,0066doi:10.1038/s41551-017-0066(2017),该文献以引用方式整体并入本文。
rnp
在特定实施方案中,预复合的指导rna、crispr-cas蛋白和腺苷脱氨酶(其可以融合至crispr-cas蛋白或衔接子)作为核糖核蛋白(rnp)递送。rnp的优势在于,与rna方法相比,它们带来的快速编辑效应更大,因为该过程避免了对转录的需要。一个重要的优点是rnp递送都是瞬时的,从而减少了脱靶效应和毒性问题。以下作者已观察到不同细胞类型中的有效基因组编辑:kim等人(2014,genomeres.24(6):1012-9);paix等人(2015,genetics204(1):47-54);chu等人(2016,bmcbiotechnol.16:4),以及wang等人(2013,cell.9;153(4):910-8)。
在特定实施方案中,以如wo2016161516中所述的基于多肽的穿梭剂的方式递送核糖核蛋白。wo2016161516描述了使用包含内体泄漏结构域(eld)的合成肽对多肽货物的有效转导,所述内体泄漏结构域(eld)可操作地连接至细胞穿透结构域(cpd),连接至富含组氨酸的结构域和cpd。类似地,这些多肽可用于在真核细胞中递送基于crispr效应子的rnp。
粒子
在一些方面或实施方案中,可以使用包含递送粒子配制品的组合物。在一些方面或实施方案中,配制品包含crispr复合物,该复合物包含crispr蛋白和指导物,该指导物引导crispr复合物特异性地结合至靶序列。在一些实施方案中,递送粒子包含基于脂质的粒子,任选地脂质纳米粒子,或阳离子脂质和任选地生物可降解的聚合物。在一些实施方案中,阳离子脂质包括1,2-二油酰基-3-三甲基铵-丙烷(dotap)。在一些实施方案中,亲水性聚合物包括乙二醇或聚乙二醇。在一些实施方案中,递送粒子还包含脂蛋白,优选地胆固醇。在一些实施方案中,递送粒子的直径小于500nm、任选地直径小于250nm、任选地直径小于100nm、任选地直径为约35nm至约60nm。
已知若干类型的粒子递送系统和/或配制品可用于各种各样的生物医学应用。一般来讲,粒子被定义为,就其传输和特性而言表现为整体的小物体。粒子根据直径被进一步分类。粗粒子的覆盖范围在2500与10,000纳米之间。细粒子的尺寸在100与2500纳米之间。超细粒子或纳米粒子的尺寸通常在1与100纳米之间。100nm限制是基于以下事实,即将粒子与块状材料区分开的新颖特性典型地在100nm以下的临界长度尺度上形成。
如本文所用,粒子递送系统/配制品被定义为包含根据本发明的粒子的任何生物递送系统/配制品。根据本发明的粒子是具有小于100微米(μm)的最大尺寸(例如直径)的任何实体。在一些实施方案中,本发明的粒子具有小于10μm的最大尺寸。在一些实施方案中,本发明的粒子具有小于2000纳米(nm)的最大尺寸。在一些实施方案中,本发明的粒子具有小于1000纳米(nm)的最大尺寸。在一些实施方案中,本发明的粒子具有小于900nm、800nm、700nm、600nm、500nm、400nm、300nm、200nm或100nm的最大尺寸。典型地,本发明的粒子具有500nm或更小的最大尺寸(例如直径)。在一些实施方案中,本发明的粒子具有250nm或更小的最大尺寸(例如直径)。在一些实施方案中,本发明的粒子具有200nm或更小的最大尺寸(例如直径)。在一些实施方案中,本发明的粒子具有150nm或更小的最大尺寸(例如直径)。在一些实施方案中,本发明的粒子具有100nm或更小的最大尺寸(例如直径)。在本发明的一些实施方案中使用较小的粒子,例如具有50nm或更小的最大尺寸的粒子。在一些实施方案中,本发明的粒子具有在25nm与200nm之间的最大尺寸。
就本发明而言,优选使用纳米粒子或脂质包膜递送crispr复合物的一种或多种组分,例如crispr-cas蛋白或mrna、或腺苷脱氨酶(其可以融合至crispr-cas蛋白或衔接子)或mrna、或指导rna。其他递送系统或载体可以与本发明的纳米粒子方面结合使用。
一般来讲,“纳米粒子”是指直径小于1000nm的任何粒子。在某些优选的实施方案中,本发明的纳米粒子具有500nm或更小的最大尺寸(例如直径)。在其他优选的实施方案中,本发明的纳米粒子具有在25nm与200nm之间的最大尺寸。在其他优选的实施方案中,本发明的纳米粒子具有100nm或更小的最大尺寸。在其他优选的实施方案中,本发明的纳米粒子具有在35nm与60nm之间的最大尺寸。应当理解,在适当的情况下,本文中对粒子或纳米粒子的提及可以互换。
应当理解,粒子的尺寸将取决于是在加载之前还是加载之后测量而有所不同。因此,在特定实施方案中,术语“纳米粒子”可能仅适用于加载前的粒子。
本发明中涵盖的纳米粒子可以提供为不同的形式,例如为固体纳米粒子(例如金属(诸如银、金、铁、钛)、非金属、基于脂质的固体、聚合物)、纳米粒子的悬浮液,或它们的组合。可以制备金属、绝缘体和半导体纳米粒子,以及杂合结构(例如核-壳纳米粒子)。如果由半导体材料制备的纳米粒子足够小(典型地低于10nm)以至于出现电子能级的量子化,则这些纳米粒子还可以是标记量子点。此类纳米级粒子作为药物载剂或成像剂用于生物医学应用中并且可以适于本发明中的类似目的。
半固体和软纳米粒子以被制造出并且处于本发明的范围之内。半固体性质的原型纳米粒子是脂质体。目前,临床上将各种类型的脂质体纳米粒子用作抗癌药物和疫苗的递送系统。一半亲水并且另一半疏水的粒子称为杰那斯(janus)粒子,并且对于稳定乳液是特别有效的。它们可以在水/油界面处自组装,并且充当固体表面活性剂。
粒子表征(包括例如表征形态、尺寸等)是使用多种不同的技术进行的。常用技术是电子显微术(tem、sem)、原子力显微镜(afm)、动态光散射(dls)、x-射线光电子光谱法(xps)、粉末x-射线衍射(xrd)、傅里叶变换红外光谱法(ftir)、基质辅助激光解吸/电离飞行时间质谱法(maldi-tof)、紫外-可见光谱法、双偏振干涉法以及核磁共振(nmr)。可以针对天然粒子(即加载前)或在加载货物(在本文中货物是指例如crispr-cas系统的一种或多种组分,例如crispr蛋白或mrna、或腺苷脱氨酶(其可以融合至crispr-cas蛋白或衔接子)或mrna、或指导rna或它们的任何组合,并且可以包括另外的载剂和/或赋形剂)之后进行表征(尺寸测量)以便为本发明的任何体外、离体和/或体内应用的递送提供具有最佳尺寸的粒子。在某些优选实施方案中,粒子尺寸(例如直径)表征是基于使用动态激光散射(dls)的测量。关于粒子、其制备和使用方法以及其测量,提及美国专利号8,709,843;美国专利号6,007,845;美国专利号5,855,913;美国专利号5,985,309;美国专利号5,543,158;以及jamese.dahlman和carmenbarnes等人naturenanotechnology(2014)的出版物,2014年5月11日在线公布,doi:10.1038/nnano.2014.84。
本发明范围内的粒子递送系统可以采用任何形式提供,包括但不限于固体、半固体、乳液或胶体粒子。这样,本文所述的任何递送系统,包括但不限于例如基于脂质的系统、脂质体、胶束、微泡、外泌体或基因枪,可以被提供作为本发明范围内的粒子递送系统。
可以使用粒子或脂质包膜同时递送crispr-cas蛋白mrna、腺苷脱氨酶(其可以融合至crispr-cas蛋白或衔接子)或mrna,以及指导rna;例如,本发明的crispr-cas蛋白和rna,例如作为复合物,可以经由如dahlman等人、wo2015089419a2及其中引用的文献中的粒子诸如7c1来递送(参见例如jamese.dahlman和carmenbarnes等人naturenanotechnology(2014),2014年5月11日在线公布,doi:10.1038/nnano.2014.84),例如递送粒子包含脂质或类脂质(lipidoid)和亲水性聚合物,例如阳离子脂质和亲水性聚合物,例如其中阳离子脂质包括1,2-二油酰基-3-三甲基铵-丙烷(dotap)或1,2-二十四酰基-sn-甘油基-3-磷酸胆碱(dmpc)并且/或者其中亲水性聚合物包括乙二醇或聚乙二醇(peg);并且/或者其中粒子还包含胆固醇(例如,来自以下项的粒子:配制品1=dotap100、dmpc0、peg0、胆固醇0;配制品编号2=dotap90、dmpc0、peg10、胆固醇0;配制品编号3=dotap90、dmpc0、peg5、胆固醇5),其中使用有效的多步方法形成粒子,其中第一步,将效应蛋白和rna例如在无菌、不含核酸酶的1xpbs中例如在室温下以例如1∶1的摩尔比在一起混合例如30分钟;并且分开地,将如适用于该配制品的dotap、dmpc、peg和胆固醇溶解于醇(例如100%乙醇)中;并且,将这两种溶液混合在一起以形成含有这些复合物的粒子)。
可以使用粒子或脂质包膜同时递送核酸靶向效应蛋白(例如,v型蛋白诸如cpf1)mrna和指导rna。合适的粒子的实例包括但不限于us9,301,923中描述的那些。
例如,sux、frickej、kavanaghdg、irvinedj(“invitroandinvivomrnadeliveryusinglipid-envelopedph-responsivepolymernanoparticles”molpharm.2011年6月6日;8(3):774-87.doi:10.1021/mp100390w.电子版2011年4月1日)描述了生物可降解的核-壳结构粒子,其具有由磷脂双层壳包封的聚(β-氨基酯)(pbae)核。这些被开发用于体内mrna递送。该ph响应性pbae组分被选择为促进内体破坏,而该脂质表面层被选择为将聚阳离子核的毒性最小化。因此,这些对于递送本发明的rna是优选的。
在一个实施方案中,考虑了基于自组装生物粘附聚合物的粒子/纳米粒子,这些粒子可以适用于肽的经口递送、肽的静脉内递送以及肽的鼻递送,均递送至脑。还考虑了其他实施方案,诸如疏水性药物的经口吸收和眼部递送。分子包膜技术涉及被保护并递送至疾病位点的工程化聚合物包膜(参见例如mazza,m.等人acsnano,2013.7(2):1016-1026;siew,a.等人molpharm,2012.9(1):14-28;lalatsa,a.等人jcontrrel,2012.161(2):523-36;lalatsa,a.等人,molpharm,2012.9(6):1665-80;lalatsa,a.等人molpharm,2012.9(6):1764-74;garrett,n.l.等人jbiophotonics,2012.5(5-6):458-68;garrett,n.l.等人jramanspect,2012.43(5):681-688;ahmad,s.等人jroyalsocinterface2010.7:s423-33;uchegbu,i.f.expertopindrugdeliv,2006.3(5):629-40;qu,x.等人biomacromolecules,2006.7(12):3452-9以及uchegbu,i.f.等人intjpharm,2001.224:185-199)。考虑了约5mg/kg的剂量,取决于靶组织,采用单剂量或多剂量。
可以使用由丹·安德森实验室(dananderson’slab)在mit开发的可以将rna递送至癌细胞以便使肿瘤生长停止的粒子/纳米粒子并且/或者使这些粒子/纳米粒子适于本发明的ad官能化的crispr-cas系统。具体地说,安德森实验室开发了用于新生物材料和纳米配制品的合成、纯化、表征和配制的全自动化组合系统。参见例如alabi等人,procnatlacadsciusa.2013年8月6号;110(32):12881-6;zhang等人,advmater.2013年9月6日;25(33):4641-5;jiang等人,nanolett.2013年3月13日;13(3):1059-64;karagiannis等人,acsnano.2012年10月23日;6(10):8484-7;whitehead等人,acsnano.2012年8月28日;6(8):6922-9和lee等人,natnanotechnol.2012年6月3日;7(6):389-93。
美国专利申请20110293703涉及类脂质化合物,这些化合物在多核苷酸的施用中也是特别有用的,它们可以适用于递送本发明的ad官能化的crispr-cas系统。在一方面,氨基醇类脂质化合物与有待递送至细胞或受试者的剂组合而形成微粒子、纳米粒子、脂质体或胶束。有待通过粒子、脂质体或胶束递送的剂可以呈气体、液体或固体的形式,并且该剂可以是多核苷酸、蛋白质、肽或小分子。氨基醇类脂质化合物可以与其他氨基醇类脂质化合物、聚合物(合成的或天然的)、表面活性剂、胆固醇、碳水化合物、蛋白质、脂质等组合而形成粒子。然后这些粒子可以任选地与药物赋形剂组合而形成药物组合物。
美国专利公布号20110293703也提供了制备氨基醇类脂质化合物的方法。使胺的一种或多种等效物与环氧化物封端化合物的一种或多种等效物在合适条件下反应而形成本发明的氨基醇类脂质化合物。在某些实施方案中,胺的所有氨基基团与环氧化物封端化合物充分反应而形成叔胺。在其他实施方案中,胺的所有氨基基团未与环氧化物封端化合物完全反应形成叔胺,由此生成在氨基醇类脂质化合物中的伯胺或仲胺。将这些伯胺或仲胺照原样留下或者可以使其与另一种亲电体诸如不同的环氧化物封端化合物反应。如本领域技术人员将理解的,使胺与未过量的环氧化物封端化合物反应将产生多种不同的具有不同数目的尾部的氨基醇类脂质化合物。某些胺可以被两个环氧化物衍生的化合物尾部完全官能化,而其他分子不会被环氧化物衍生的化合物尾部完全官能化。例如,二胺或多胺可以包括离开该分子的不同氨基部分的一个、二个、三个、或四个环氧化物衍生的化合物尾部,从而产生伯胺、仲胺和叔胺。在某些实施方案中,并不是所有氨基基团都被完全官能化。在某些实施方案中,使用了两种相同类型的环氧化物封端化合物。在其他实施方案中,使用了两种或更多种不同的环氧化物封端化合物。氨基醇类脂质化合物的合成是用或不用溶剂进行的,并且该合成可以在30℃-100℃的范围内,优选在大约50℃-90℃的较高温度下进行。任选地,可以将制备的氨基醇类脂质化合物纯化。例如,可以将氨基醇类脂质化合物的混合物纯化以产生具有特定数目的环氧化物衍生的化合物尾部的氨基醇类脂质化合物。或者可以将混合物纯化以产生特定的立体异构体或区域异构体。可以使用卤代烷(例如碘甲烷)或其他烷化剂将这些氨基醇类脂质化合物烷化,并且/或者可以将它们酰化。
美国专利公布号20110293703也提供了通过本发明方法制备的氨基醇类脂质化合物的文库。可以使用涉及液体处理器、机器人、微量滴定板、计算机等的高通量技术制备并且/或者筛选这些氨基醇类脂质化合物。在某些实施方案中,筛选了这些氨基醇类脂质化合物的将多核苷酸或其他剂(例如蛋白质、肽、小分子)转染到细胞中的能力。
美国专利公布号20130302401涉及已经使用组合聚合制备的一类聚(β-氨基醇)(pbaa)。本发明的pbaa可以在生物技术和生物医学应用中用作涂层(诸如用于医疗装置或植入物的膜或多层膜的涂层)、添加剂、材料、赋形剂、生物防污剂(non-biofoulingagent)、微图案化剂以及细胞封装剂。当用作表面涂层时,这些pbaa在体外和体内均引发不同水平的炎症,这取决于它们的化学结构。这类材料的巨大化学多样性允许我们鉴定出在体外抑制巨噬细胞激活的聚合物涂层。此外,在羧化聚苯乙烯微粒的皮下移植之后,这些涂层减少了炎症细胞的募集,并且减轻了纤维化。这些聚合物可以用于形成用于细胞封装的聚电解质复合物胶囊。本发明还可以具有许多其他的生物应用,诸如抗微生物涂层、dna或sirna递送,以及干细胞组织工程化。美国专利公布号20130302401的教导内容可以适用于本发明的ad官能化的crispr-cas系统。
可以例如通过电穿孔转染包含cpf1、腺苷脱氨酶(其可以融合至cpf1或衔接蛋白)和指导rna的预组装重组crispr-cas复合物,从而产生高突变率且不存在可检测的脱靶突变。hur,j.k.等人,targetedmutagenesisinmicebyelectroporationofcpf1ribonucleoproteins,natbiotechnol.2016年6月6日.doi:10.1038/nbt.3596。
就局部递送至脑而言,这可以通过多种方式来实现。例如,可以例如通过注射经纹状体内递送材料。注射可以经由颅骨切开术立体定位地进行。
在一些实施方案中,可以使用基于糖的粒子,例如galnac,如本文所述且参考wo2014118272(以引用方式并入本文)以及nair,jk等人,2014,journaloftheamericanchemicalsociety136(49),16958-16961)以及在此的教导内容,除非另外表明,否则特别涉及适用于所有粒子的递送。这可以被认为是基于糖的粒子,并且本文提供了关于其他粒子递送系统和/或配制品的更多细节。galnac因此可以被认为是在本文所述的其他粒子的意义上的粒子,使得一般用途和其他考虑因素(例如所述粒子的递送)也适用于galnac粒子。溶液相缀合策略可以例如用于将作为pfp(五氟苯酚)酯激活的三触角galnac簇(分子量约2000)附接至5′-己基氨基修饰的寡核苷酸上(5′-haaso,分子量约8000da;
纳米线团
此外,可以使用纳米线团来递送ad官能化的crispr系统,例如,如在以下文献中所述的:sunw等人,cocoon-likeself-degradablednananoclewforanticancerdrugdelivery.,jamchemsoc.2014年10月22日;136(42):14722-5.doi:10.1021/ja5088024.电子版2014年10月13日;或sunw等人,self-assembleddnananoclewsfortheefficientdeliveryofcrispr-cas9forgenomeediting.,angewchemintedengl.2015年10月5日;54(41):12029-33.doi:10.1002/anie.201506030.电子版2015年8月27日。
lnp
在一些实施方案中,递送是通过将cpf1蛋白或mrna形式封装在脂质粒子诸如lnp中而进行的。因此,在一些实施方案中,考虑了脂质纳米粒子(lnp)。抗转甲状腺素蛋白小干扰rna已被封装在脂质纳米粒子中并且被递送至人类(参见例如coelho等人,nengljmed2013;369:819-29),并且此系统可以适于并应用于本发明的crisprcas系统。考虑了静脉内施用约0.01至约1mg/kg体重的剂量。考虑了降低输注相关反应的风险的药物,诸如考虑了地塞米松、对乙酰氨基酚、苯海拉明或西替利嗪,以及雷尼替丁。还考虑了约0.3mg/kg的多剂量,每4周一次,五个剂量。
lnp已经显示在将sirna递送至肝脏中是高度有效的(参见例如tabernero等人,cancerdiscovery,2013年4月,第3卷,第4期,第363-470页),并且因此被考虑用于将编码crisprcas的rna递送至肝脏。可以考虑6mg/kg的lnp的约四个剂量的用量,每两周一次。tabernero等人证明,在以0.7mg/kg给予lnp前2个周期之后,观察到肿瘤消退,并且在6个周期结束之后,患者已经实现了部分反应,具有淋巴结转移完全消退以及肝脏肿瘤的显著萎缩。在40个剂量之后在此患者中获得完全反应,此患者在接受经过26个月的剂量之后保持缓解和完全治疗。具有rcc和在用vegf途径抑制剂进行的在先疗法之后进展的包括肾脏、肺以及淋巴结的肝外位点疾病的两位患者在所有位点的疾病都在大约8至12个月内保持稳定,并且一位具有pnet和肝转移的患者继续在18个月(36个剂量)的延伸研究中保持疾病稳定。
然而,必须将lnp的电荷考虑在内。当阳离子脂质与带负电的脂质结合时,诱导促进细胞内递送的非双层结构。因为带电荷的lnp在静脉内注射之后迅速从循环中清除,所以开发了具有低于7的pka值的可电离阳离子脂质(参见例如rosin等人,moleculartherapy,第19卷,第12期,第1286-2200页,2011年12月)。带负电的聚合物诸如rna可以低ph值(例如ph4)加载到lnp中,在此ph时可电离脂质展示出正电荷。然而,在生理学ph值下,lnp表现出与更长的循环时间相容的低表面电荷。已经关注了四种可电离阳离子脂质,即1,2-二亚油酰基-3-二甲基铵-丙烷(dlindap)、1,2-二亚油基氧基-3-n,n-二甲基氨基丙烷(dlindma)、1,2-二亚油基氧基-酮基-n,n-二甲基-3-氨基丙烷(dlinkdma),以及1,2-二亚油基-4-(2-二甲基氨基乙基)-[1,3]-二氧戊环(dlinkc2-dma)。已经显示,含有这些脂质的lnpsirna系统在体内肝细胞中表现出显著不同的基因沉默特性,具有根据采用因子vii基因沉默模型的dlinkc2-dma>dlinkdma>dlindma>>dlindap系列而变化的潜能(参见例如rosin等人,moleculartherapy,第19卷,第12期,第1286-2200页,2011年12月)。可以考虑在lnp中或与lnp相关联的1μg/ml的lnp或crispr-casrna的剂量,尤其是对于含有dlinkc2-dma的配制品而言。
lnp的制备和crisprcas封装可以使用并且/或者调适自rosin等人,moleculartherapy,第19卷,第12期,第1286-2200页,2011年12月)。阳离子脂质1,2-二亚油酰基-3-二甲基铵-丙烷(dlindap)、1,2-二亚油基氧基-3-n,n-二甲基氨基丙烷(dlindma)、1,2-二亚油基氧基酮基-n,n-二甲基-3-氨基丙烷(dlink-dma)、1,2-二亚油基-4-(2-二甲基氨基乙基)-[1,3]-二氧戊环(dlinkc2-dma)、(3-o-[2″-(甲氧基聚乙二醇2000)琥珀酰基]-1,2-二肉豆蔻酰基-sn-乙二醇(peg-s-dmg),以及r-3-[(ω-甲氧基-聚(乙二醇)2000)氨甲酰基]-1,2-二肉豆蔻酰氧基丙基-3-胺(peg-c-domg)可以由tekmirapharmaceuticals(vancouver,canada)提供或合成。胆固醇可购自sigma(stlouis,mo)。特定的crisprcasrna可以封装在含有dlindap、dlindma、dlink-dma和dlinkc2-dma的lnp中(阳离子脂质∶dspc∶chol∶pegs-dmg或peg-c-domg,摩尔比为40∶10∶40∶10)。在必要时,可并入0.2%sp-dioc18(invitrogen,burlington,canada)来评定细胞摄取、细胞内递送和生物分布。可以通过以下方式来进行封装:将由阳离子脂质∶dspc∶胆固醇∶peg-c-domg(40∶10∶40∶10摩尔比)组成的脂质混合物溶解在乙醇中,直至最终脂质浓度为10mmol/l。可以将脂质的此乙醇溶液逐滴添加到ph4.0的50mmol/l柠檬酸盐中以形成多层囊泡,从而产生30%乙醇(体积/体积)的终浓度。在使用挤出机(northernlipids,vancouver,canada)通过两个重叠的80nmnuclepore聚碳酸酯过滤器挤出多层囊泡之后,可以形成大的单层囊泡。可以通过以下方式来实现封装:将溶解在含有30%乙醇(体积/体积)的ph4.0的50mmol/l柠檬酸盐中的2mg/ml的rna逐滴添加到挤出的预成形的大单层囊泡中,并且在31℃下孵育30分钟,伴随持续混合直至最终的rna/脂质重量比为0.06/1(重量/重量)。通过使用spectra/por2再生纤维素透析膜在ph7.4的磷酸盐缓冲盐水(pbs)中透析16小时进行乙醇的去除以及配制缓冲液的中和。可以使用nicomp370型粒径分析仪、囊泡/强度模式以及高斯拟合通过动态光散射测定纳米粒子粒径分布(nicompparticlesizing,santabarbara,ca)。所有三个lnp系统的粒径可能为约70nm。可以通过使用vivapuredminih柱(sartoriusstedimbiotech)从在透析前后收集的样品中去除游离rna来确定rna封装效率。可以从洗脱的纳米粒子中提取封装的rna并且将其在260nm下量化。通过使用来自wakochemicalsusa(richmond,va)的胆固醇e酶测定测量囊泡中的胆固醇含量来确定rna与脂质的比率。结合本文对lnp和peg脂质的论述,peg化的脂质体或lnp同样适用于crispr-cas系统或其组分的递送。
可以在含有50∶10∶38.5摩尔比的dlinkc2-dma、dspc和胆固醇的乙醇中制备脂质预混物溶液(20.4mg/ml总脂质浓度)。可以0.75∶1的摩尔比(乙酸钠∶dlinkc2-dma)将乙酸钠添加到脂质预混物中。随后可以通过将该混合物与1.85倍体积的柠檬酸盐缓冲液(10mmol/l,ph3.0)在剧烈搅拌下合并来使脂质水合,从而使得在含有35%乙醇的水性缓冲液中自发形成脂质体。可以在37℃下孵育该脂质体溶液以允许粒径的时间依赖性增加。可以通过动态光散射(zetasizernanozs,malverninstruments,worcestershire,uk)在孵育过程中的不同时间处去除等分试样来研究脂质体尺寸的变化。一旦实现所希望的粒径,就可以将水性peg脂质溶液(储备溶液=在35%(体积/体积)乙醇中的10mg/mlpeg-dmg)添加到该脂质体混合物中,以产生3.5%总脂质的最终peg摩尔浓度。在添加peg-脂质之后,这些脂质体应该其大小,有效抑制进一步生长。然后可以大约1∶10(重量∶重量)的rna与总脂质比率将rna添加到空脂质体中,然后在37℃下孵育30分钟以形成加载的lnp。随后可以将该混合物在pbs中透析过夜,并且用0.45-μm的注射器式过滤器进行过滤。
球形核酸(snatm)构建体和其他纳米粒子(特别是金纳米粒子)也被考虑作为将crispr-cas系统递送至预期靶标的手段。大量数据表明,基于核酸官能化的金纳米粒子的aurasensetherapeutics′sphericalnucleicacid(snatm)构建体是可用的。
可以与本文的教导内容结合使用的文献包括:cutler等人,j.am.chem.soc.2011133:9254-9257;hao等人,small.20117:3158-3162;zhang等人,acsnano.20115:6962-6970;cutler等人,j.am.chem.soc.2012134:1376-1391;young等人,nanolett.201212:3867-71;zheng等人,proc.natl.acad.sci.usa.2012109:11975-80;mirkin,nanomedicine20127:635-638;zhang等人,j.am.chem.soc.2012134:16488-1691;weintraub,nature2013495:s14-s16,choi等人,proc.natl.acad.sci.usa.2013110(19):7625-7630;jensen等人,sci.transl.med.5,209ra152(2013)以及mirkin等人,small,10:186-192。
具有rna的自组装纳米粒子可以用peg化的聚乙烯亚胺(pei)构建,其中arg-gly-asp(rgd)肽配体附接在聚乙二醇(peg)的远端。例如,这一系统已经被用作靶向表达整合素的肿瘤新血管系统和递送抑制血管内皮生长因子受体2(vegfr2)表达以及由此实现抑制肿瘤血管新生的sirna的手段(参见例如schifferers等人,nucleicacidsresearch,2004,第32卷,第19期)。纳米束(nanoplex)可以通过以下方式来制备:将等体积的阳离子聚合物水溶液和核酸水溶液混合,以产生在2至6范围上的可电离氮(聚合物)相比磷酸盐(核酸)的净摩尔过量。在阳离子聚合物与核酸之间的静电相互作用导致聚复合物的形成,该聚合物具有约100nm的平均粒径分布,此后称为纳米束。设想了crisprcas的约100至200mg的剂量,用于schiffelers等人的自组装纳米粒子中的递送。
bartlett等人(pnas,2007年9月25日,第104卷,第39期)的纳米复合物也可以适用于本发明。bartlett等人的纳米复合物通过以下方式来制备:将等体积的阳离子聚合物水溶液和核酸水溶液混合,以产生在2至6范围上的可电离氮(聚合物)相比磷酸盐(核酸)的净摩尔过量。在阳离子聚合物与核酸之间的静电相互作用导致聚复合物的形成,该聚合物具有约100nm的平均粒径分布,此后称为纳米束。bartlett等人的dota-sirna的合成如下:1,4,7,10-四氮杂环十二烷-1,4,7,10-四乙酸单(n-羟基琥珀酰亚胺酯)(dota-nhs酯)订购自macrocyclics(dallas,tx)。将于碳酸盐缓冲液(ph9)中的具有100倍摩尔过量的dota-nhs-酯的胺修饰的rna有义链添加到微量离心管中。通过在室温下搅拌4小时使这些内容物反应。将dota-rna有义缀合物用乙醇沉淀,重新悬浮在水中,并且退火到未修饰的反义链上以产生dota-sirna。所有液体均用chelex-100(bio-rad,hercules,ca)预处理,以去除痕量金属污染物。可以通过使用含有环糊精的聚阳离子形成tf靶向和非靶向的sirna纳米粒子。典型地,以3(+/-)的进料比和0.5克/升的sirna浓度在水中形成纳米粒子。用tf(金刚烷-peg-tf)修饰在靶向纳米粒子表面上的百分之一的金刚烷-peg分子。将纳米粒子悬浮在用于注射的5%(重量/体积)葡萄糖载剂溶液中。
davis等人(nature,第464卷,2010年4月15日)进行了使用靶向的纳米粒子递送系统的rna临床试验(临床试验登记号nct00689065)。在21天周期的第1、3、8和10天通过30min的静脉内输注向患有标准护理疗法难治的实体癌的患者施用靶向的纳米粒子剂量。纳米粒子由合成递送系统组成,该系统含有:(1)线性的基于环糊精的聚合物(cdp);(2)展示在纳米粒子外部上的用于接合癌细胞表面上的tf受体(tfr)的人类转铁蛋白(tf)靶向配体;(3)亲水性聚合物(用于促进纳米粒子在生物流体中的稳定性的聚乙二醇(peg));以及(4)被设计来降低rrm2(先前在临床中使用的序列指代为sir2b+5)表达的sirna。长久以来已知tfr在恶性细胞中被下调,并且rrm2是一种确立的抗癌靶标。已经显示这些纳米粒子(临床版本指代为calaa-01)在非人类灵长类动物中的多剂量研究中耐受性良好。虽然已经通过脂质体递送向患有慢性粒细胞白血病的单一患者施用了sirna,但是davis等人的临床试验是初期人类试验,该试验用靶向递送系统全身性地递送sirna并且治疗患有实体癌的患者。为了确定该靶向递送系统是否能够将功能性sirna有效递送至人类肿瘤,davis等人研究了来自三个不同的剂量组群的三位患者的活组织检查;患者a、b和c,他们均患有转移性黑素瘤并且分别接受了18、24和30mgm-2sirna的calaa-01剂量。对于本发明的crisprcas系统,还可以考虑类似的剂量。用含有线性的基于环糊精的聚合物(cdp)、展示在纳米粒子外部上的用于接合癌细胞表面上的tf受体(tfr)的人类转铁蛋白(tf)靶向配体和/或亲水性聚合物(例如,用于促进纳米粒子在生物流体中的稳定性的聚乙二醇(peg))的纳米粒子,可以实现本发明的递送。
以引用方式并入本文的美国专利号8,709,843提供了用于将含有治疗剂的粒子靶向递送至组织、细胞和细胞内区室的药物递送系统。本发明提供了包含缀合至表面活性剂、亲水性聚合物或脂质的聚合物的靶向粒子。以引用方式并入本文的美国专利号6,007,845提供了下述粒子:所述粒子具有通过将多官能化合物与一种或多种疏水性聚合物和一种或多种亲水性聚合物共价地连接而形成的多嵌段共聚合物的核,并且含有生物活性材料。以引用方式并入本文的美国专利no.5,855,913提供了下述颗粒组合物:所述颗粒组合物含有具有小于0.4g/cm3振实密度以及介于5μm与30μm之间的平均直径的空气动力学光粒子,在其表面上并入了表面活性剂,以用于向肺部系统的药物递送。以引用方式并入本文的美国专利号5,985,309提供了下述粒子:所述粒子并入了表面活性剂和/或带正电荷或带负电荷的治疗剂或诊断剂和带相反电荷的带电荷分子的亲水性或疏水性复合物,以用于向肺部系统的递送。以引用方式并入本文的美国专利号5,543,158提供了生物可降解的可注射粒子,所述粒子具有生物可降解实心核,该核在其表面上含有生物活性材料和聚(烷撑二醇)部分。以引用方式并入本文的wo2012135025(也以us20120251560公布)描述了缀合的聚乙烯亚胺(pei)聚合物和缀合的氮杂大环(统称为“缀合微质体(lipomer)”或“微质体”)。在某些实施方案中,可以设想的是,此类缀合微质体可以用于crispr-cas系统的情形中以在体外、离体和在体内实现基因组干扰,从而修饰基因表达,包括调节蛋白质表达。
在一个实施方案中,纳米粒子可以是环氧化物修饰的脂质-聚合物,有利地是7c1(参见例如jamese.dahlman和carmenbarnes等人naturenanotechnology(2014),2014年5月11日在线发布,doi:10.1038/nnano.2014.84)。c71是通过使c15环氧化物封端脂质与pei600以14∶1摩尔比反应合成的,并且与c14peg2000一起进行配制以产生纳米粒子(直径介于35与60nm之间),这些纳米粒子在pbs溶液中在至少40天内保持稳定。
环氧化物修饰的脂质-聚合物可以用于将本发明的crispr-cas系统递送至肺部细胞、心血管细胞或肾细胞,然而本领域的技术人员可以调适该系统以递送至其他靶器官。设想了约0.05至约0.6mg/kg的剂量范围。还设想了经数天或数周的剂量,其中总剂量为约2mg/kg。
在一些实施方案中,用于递送rna分子的lnp通过本领域已知的方法来制备,所述方法诸如在例如wo2005/105152(pct/ep2005/004920)、wo2006/069782(pct/ep2005/014074)、wo2007/121947(pct/ep2007/003496)和wo2015/082080(pct/ep2014/003274)中所述的那些方法,这些文献以引用方式并入本文。明确地旨在增强和改善sirna到哺乳动物细胞中的递送的lnp描述于例如aleku等人,cancerres.,68(23):9788-98(2008年12月1日);strumberg等人,int.j.clin.pharmacol.ther.,50(1):76-8(2012年1月);schultheis等人,j.clin.oncol.,32(36):4141-48(2014年12月20日)以及fehring等人,mol.ther.,22(4):811-20(2014年4月22日)(这些文献以引用方式并入本文),并且可以应用于本发明的技术。
在一些实施方案中,lnp包括在wo2005/105152(pct/ep2005/004920)、wo2006/069782(pct/ep2005/014074)、wo2007/121947(pct/ep2007/003496)和wo2015/082080(pct/ep2014/003274)中所公开的任何lnp。
在一些实施方案中,lnp包含至少一种具有式i的脂质:
其中r1和r2各自且独立地选自包括烷基的组,n是1与4之间的任何整数,并且r3是选自包括赖氨酰基、鸟氨酰基、2,4-二氨基丁酰基、组氨酰基和根据式ii的酰基部分的组的酰基:
其中m是1至3的任何整数,并且y-是药学上可接受的阴离子。在一些实施方案中,根据式i的脂质包括至少两个不对称的c原子。在一些实施方案中,式i的对映异构体包括但不限于r-r;s-s;r-s和s-r对映异构体。
在一些实施方案中,r1是月桂基并且r2是肉豆蔻基。在另一个实施方案中,r1是棕榈基并且r2是油基。在一些实施方案中,m是1或2。在一些实施方案中,y-选自卤化物、乙酸盐或三氟乙酸盐。
在一些实施方案中,lnp包含一种或多种选自以下的脂质:
□-精氨酰基-2,3-二氨基丙酸-n-棕榈基-n-油基-酰胺三盐酸盐(式iii):
□-精氨酰基-2,3-二氨基丙酸-n-月桂基-n-肉豆蔻基-酰胺三盐酸盐(式iv):
□-精氨酰基-赖氨酸-n-月桂基-n-肉豆蔻基-酰胺三盐酸盐(式v):
在一些实施方案中,lnp还包含某种成分。举例来说,但不作为限制,在一些实施方案中,所述成分选自肽、蛋白质、寡核苷酸、多核苷酸、核酸或它们的组合。在一些实施方案中,所述成分是抗体,例如单克隆抗体。在一些实施方案中,所述成分是选自例如核酶、适体、镜像异构适配体(spiegelmer)、dna、rna、pna、lna或它们的组合的核酸。在一些实施方案中,核酸是指导rna和/或mrna。
在一些实施方案中,lnp的成分包括编码cripsr-cas蛋白的mrna。在一些实施方案中,lnp的成分包括编码ii型或v型cripsr-cas蛋白的mrna。在一些实施方案中,lnp的成分包括编码腺苷脱氨酶(其可以融合至crispr-cas蛋白或衔接蛋白)的mrna。
在一些实施方案中,lnp的成分还包括一种或多种指导rna。在一些实施方案中,lnp被配置成递送前述mrna并将rna导向至血管内皮。在一些实施方案中,lnp被配置成递送前述mrna并将rna导向至肺内皮。在一些实施方案中,lnp被配置成递送前述mrna并将rna导向至肝脏。在一些实施方案中,lnp被配置成递送前述mrna并将rna导向至肺。在一些实施方案中,lnp被配置成递送前述mrna并将rna导向至心脏。在一些实施方案中,lnp被配置成递送前述mrna并将rna导向至脾。在一些实施方案中,lnp被配置成递送前述mrna并将rna导向至肾脏。在一些实施方案中,lnp被配置成递送前述mrna并将rna导向至胰腺。在一些实施方案中,lnp被配置成递送前述mrna并将rna导向至脑。在一些实施方案中,lnp被配置成递送前述mrna并将rna导向至巨噬细胞。
在一些实施方案中,lnp还包含至少一种辅助脂质。在一些实施方案中,辅助脂质选自磷脂和类固醇。在一些实施方案中,磷脂是磷酸的二酯和/或单酯。在一些实施方案中,磷脂是磷酸甘油酯和/或鞘脂。在一些实施方案中,类固醇是天然存在的和/或基于部分氢化的环戊[a]菲的合成化合物。在一些实施方案中,类固醇含有21至30个c原子。在一些实施方案中,类固醇是胆固醇。在一些实施方案中,辅助脂质选自1,2-二植烷酰基-sn-甘油基-3-磷酸乙醇胺(dphype)、神经酰胺和1,2-二油酰基sn-甘油基-3-磷酸乙醇胺(dope)。
在一些实施方案中,所述至少一种辅助脂质包含选自包括peg部分、heg部分、聚羟乙基淀粉(聚hes)部分和聚丙烯部分的组的部分。在一些实施方案中,所述部分具有在约500至10,000da之间或在约2,000至5,000da之间的分子量。在一些实施方案中,peg部分选自1,2-二硬脂酰基-sn-甘油基-3磷酸乙醇胺、1,2-二烷基-sn-甘油基-3-磷酸乙醇胺和神经酰胺-peg。在一些实施方案中,peg部分具有在约500至10,000da之间或在约2,000至5,000da之间的分子量。在一些实施方案中,peg部分具有2,000da的分子量。
在一些实施方案中,辅助脂质为组合物的总脂质含量的约20摩尔%至80摩尔%。在一些实施方案中,辅助脂质组分为lnp的总脂质含量的约35摩尔%至65摩尔%。在一些实施方案中,lnp包含占lnp的总脂质含量的50摩尔%的脂质和50摩尔%的辅助脂质。
在一些实施方案中,lnp包含□-3-精氨酰基-2,3-二氨基丙酸-n-棕榈基-n-油基-酰胺三盐酸盐、□-精氨酰基-2,3-二氨基丙酸-n-月桂基-n-肉豆蔻基-酰胺三盐酸盐或□-精氨酰基-赖氨酸-n-月桂基-n-肉豆蔻基-酰胺三盐酸盐中的任一者与dphype的组合,其中dphype的含量为lnp的总脂质含量的约80摩尔%、65摩尔%、50摩尔%和35摩尔%。在一些实施方案中,lnp包含□-精氨酰基-2,3-二氨基丙酸-n-棕榈基-n-油基-酰胺三盐酸盐(脂质)和1,2-二植烷酰基-sn-甘油基-3-磷酸乙醇胺(辅助脂质)。在一些实施方案中,lnp包含□-精氨酰基-2,3-二氨基丙酸-n-棕榈基-n-油基-酰胺三盐酸盐(脂质)、1,2-二植烷酰基-sn-甘油基-3-磷酸乙醇胺(第一辅助脂质)和1,2-二硬脂酰基-sn-甘油基-3-磷酸乙醇胺-peg2000(第二辅助脂质)。
在一些实施方案中,第二辅助脂质为总脂质含量的约0.05摩尔%至4.9摩尔%之间或约1摩尔%至3摩尔%之间。在一些实施方案中,lnp包含为总脂质含量的约45摩尔%至50摩尔%之间的脂质、为总脂质含量的约45摩尔%至50摩尔%之间的第一辅助脂质,条件是存在为总脂质含量的约0.1摩尔%至5摩尔%之间、约1摩尔%至4摩尔%之间或约2摩尔%的peg化的第二辅助脂质,其中脂质、第一辅助脂质和第二辅助脂质的含量之和为总脂质含量的100摩尔%,并且其中第一辅助脂质和第二辅助脂质之和为总脂质含量的50摩尔%。在一些实施方案中,lnp包含:(a)50摩尔%的-精氨酰基-2,3-二氨基丙酸-n-棕榈基-n-油基-酰胺三盐酸盐、48摩尔%的1,2-二植烷酰基-sn-甘油基-3-磷酸乙醇胺;以及2摩尔%的1,2-二硬脂酰基-sn-甘油基-3-磷酸乙醇胺-peg2000;或者(b)50摩尔%的□-精氨酰基-2,3-二氨基丙酸-n-棕榈基-n-油基-酰胺三盐酸盐、49摩尔%的1,2-二植烷酰基-sn-甘油基-3-磷酸乙醇胺;以及1摩尔%的n(羰基-甲氧基聚乙二醇-2000)-1,2-二硬脂酰基-sn-甘油基3-磷酸乙醇胺,或其钠盐。
在一些实施方案中,lnp含有核酸,其中核酸骨架磷酸盐与阳离子脂质氮原子的进料比为约1∶1.5-7或约1∶4。
在一些实施方案中,lnp还包含屏蔽化合物,所述屏蔽化合物可以在体内条件下从脂质组合物中去除。在一些实施方案中,屏蔽化合物是生物惰性化合物。在一些实施方案中,屏蔽化合物在其表面或分子本身上不携带任何电荷。在一些实施方案中,屏蔽化合物是聚乙二醇(peg)、基于羟乙基葡萄糖(heg)的聚合物、聚羟乙基淀粉(聚hes)和聚丙烯。在一些实施方案中,peg、heg、聚hes和聚丙烯的重量为约500至10,000da之间或约2000至5000da之间。在一些实施方案中,屏蔽化合物是peg2000或peg5000。
在一些实施方案中,lnp包含至少一种脂质、第一辅助脂质和在体内条件下可以从脂质组合物中去除的屏蔽化合物。在一些实施方案中,lnp还包含第二辅助脂质。在一些实施方案中,第一辅助脂质是神经酰胺。在一些实施方案中,第二辅助脂质是神经酰胺。在一些实施方案中,神经酰胺包含至少一个6至10个碳原子的短碳链取代基。在一些实施方案中,神经酰胺包含8个碳原子。在一些实施方案中,屏蔽化合物附接至神经酰胺。在一些实施方案中,屏蔽化合物附接至神经酰胺。在一些实施方案中,屏蔽化合物共价附接至神经酰胺。在一些实施方案中,屏蔽化合物附接至lnp中的核酸。在一些实施方案中,屏蔽化合物共价附接至核酸。在一些实施方案中,屏蔽化合物通过接头附接至核酸。在一些实施方案中,接头在生理条件下被切割。在一些实施方案中,接头选自ssrna、ssdna、dsrna、dsdna、肽、s-s接头和ph敏感接头。在一些实施方案中,接头部分附接至核酸有义链的3’端。在一些实施方案中,屏蔽化合物包含ph敏感接头或ph敏感部分。在一些实施方案中,ph敏感接头或ph敏感部分是阴离子接头或阴离子部分。在一些实施方案中,在酸性环境中,阴离子接头或阴离子部分带较少的阴离子或为中性的。在一些实施方案中,ph敏感接头或ph敏感部分选自低聚(谷氨酸)、低聚酚盐和二亚乙基三胺五乙酸。
在先前段落中的任何lnp实施方案中,lnp可以具有约50至600mosmole/kg之间、约250至350mosmole/kg之间或约280至320mosmole/kg之间的重量克分子渗透压浓度,并且/或者其中由脂质和/或一种或两种辅助脂质和屏蔽化合物形成的lnp具有约20至200nm之间、约30至100nm之间或约40至80nm之间的粒度。
在一些实施方案中,屏蔽化合物提供了更长的体内循环时间,并且允许含核酸的lnp的更好的生物分布。在一些实施方案中,屏蔽化合物防止lnp与血清化合物或其他体液或细胞质膜(例如,向其施用lnp的脉管系统的内皮层的细胞质膜)的化合物相互作用。另外地或可替代地,在一些实施方案中,屏蔽化合物还防止免疫系统的元件立即与lnp相互作用。另外地或可替代地,在一些实施方案中,屏蔽化合物充当抗调理化合物。不希望受到任何机制或理论的束缚,在一些实施方案中,屏蔽化合物形成覆盖物或外壳,所述覆盖物或外壳减少了lnp可用于与其环境相互作用的表面区域。另外地或可替代地,在一些实施方案中,屏蔽化合物屏蔽lnp的总电荷。
在另一个实施方案中,lnp包含至少一种具有式vi的脂质:
其中n是1、2、3或4,其中m是1、2或3,其中y-是阴离子,其中r1和r2各自单独地且独立地选自由以下组成的组:直链c12-c18烷基和直链c12-c18烯基;固醇化合物,其中所述固醇化合物是选自由胆固醇和豆甾醇组成的组;以及peg化脂质,其中所述peg化脂质包含peg部分,其中所述peg化脂质选自由以下组成的组:
式vii的peg化磷酸乙醇胺:
其中r3和r4单独地且独立地是直链c13-c17烷基,并且p是15至130之间的任何整数;
式viii的peg化神经酰胺:
其中r5是直链c7-c15烷基,并且q是15至130之间的任何数字;以及
式ix的peg化二酰基甘油:
其中r6和r7各自单独地且独立地是直链c11-c17烷基,并且r是15至130的任何整数。
在一些实施方案中,r1和r2彼此不同。在一些实施方案中,r1是棕榈基并且r2是油基。在一些实施方案中,r1是月桂基并且r2是肉豆蔻基。在一些实施方案中,r1和r2是相同的。在一些实施方案中,r1和r2各自单独地且独立地选自由以下组成的组:c12烷基、c14烷基、c16烷基、c18烷基、c12烯基、c14烯基、c16烯基和c18烯基。在一些实施方案中,c12烯基、c14烯基、c16烯基和c18烯基各自包含一个或两个双键。在一些实施方案中,c18烯基是在c9与c10之间具有一个双键的c18烯基。在一些实施方案中,c18烯基是顺式-9-十八烷基。
在一些实施方案中,阳离子脂质是式x的化合物:
在一些实施方案中,固醇化合物是胆固醇。在一些实施方案中,固醇化合物是豆固醇(stigmasterin)。
在一些实施方案中,peg化脂质的peg部分具有约800至5,000da的分子量。在一些实施方案中,peg化脂质的peg部分的分子量为约800da。在一些实施方案中,peg化脂质的peg部分的分子量为约2000da。在一些实施方案中,peg化脂质的peg部分的分子量为约5,000da。在一些实施方案中,peg化脂质是式vii的peg化磷酸乙醇胺,其中r3和r4各自单独地且独立地是直链c13-c17烷基,并且p是18、19或20,或44、45或46,或113、114或115中的任何整数。在一些实施方案中,r3和r4是相同的。在一些实施方案中,r3和r4是不同的。在一些实施方案中,r3和r4各自单独地且独立地选自由以下组成的组:c13烷基、c15烷基和c17烷基。在一些实施方案中,式vii的peg化磷酸乙醇胺是1,2-二硬脂酰基-sn-甘油基-3-磷酸乙醇胺-n-[甲氧基(聚乙二醇)-2000](铵盐):
在先前段落中的任何lnp实施方案中,其中阳离子脂质组合物的含量在约65摩尔%至75摩尔%之间,固醇化合物的含量在约24摩尔%至34摩尔%之间,并且peg化脂质的含量在约0.5摩尔%至1.5摩尔%之间,其中脂质组合物中阳离子脂质、固醇化合物和peg化脂质的含量之和为100摩尔%。在一些实施方案中,阳离子脂质为约70摩尔%,固醇化合物的含量为约29摩尔%,并且peg化脂质的含量为约1摩尔%。在一些实施方案中,lnp为70摩尔%的式iii、29摩尔%的胆固醇和1摩尔%的式xi。
外泌体
外泌体是转运rna和蛋白质的内源性纳米囊泡,并且可以将rna递送至脑和其他靶器官。为了降低免疫原性,alvarez-erviti等人(2011,natbiotechnol29:341)使用了用于外泌体产生的自我衍生的树突细胞。通过将树突细胞工程化为表达lamp2b(一种外泌体膜蛋白,融合至神经元特异性rvg肽)实现对脑的靶向。通过电穿孔使纯化的外泌体加载外源性rna。静脉内注射的rvg靶向的外泌体将gapdhsirna特异性地递送至脑中的神经元、小胶质细胞、少突神经胶质细胞,导致特异性的基因敲低。预暴露于rvg外泌体未减弱敲低,并且在其他组织中未观察到非特异性摄取。通过bace1的强的mrna(60%)和蛋白质(62%)敲低证明了外泌体介导的sirna递送的治疗潜能,bace1是阿尔茨海默病中的治疗靶标。
为了获得免疫惰性的外泌体库,alvarez-erviti等人收获了来自具有均质主要组织相容性复合体(mhc)单倍型的近交c57bl/6小鼠的骨髓。由于未成熟树突细胞产生大量的缺乏t细胞激活物诸如mhc-ii和cd86的外泌体,alvarez-erviti等人选择了具有粒细胞/巨噬细胞集落刺激因子(gm-csf)的树突细胞,持续7天。次日,使用良好建立的超速离心方案从培养上清液中纯化外泌体。产生的外泌体在物理上是均质的,具有直径为80nm的粒径分布峰,正如通过纳米粒子跟踪分析(nta)和电子显微术所测定。alvarez-erviti等人获得了6-12μg的外泌体(基于蛋白质浓度测量的)/106个细胞。
接着,alvarez-erviti等人研究了使用适于纳米级应用的电穿孔方案给修饰的外泌体加载外源性货物的可能性。由于电穿孔对于纳米级的膜粒子尚未良好表征,使用非特异性cy5标记的rna用于电穿孔方案的经验优化。在外泌体超速离心和溶解之后测定了封装的rna量。在400v和125μf下的电穿孔产生rna的最大保留并且用于所有的后续实验。
alvarez-erviti等人向正常c57bl/6小鼠施用被封装在150μg的rvg外泌体中的150μg的每种bace1sirna并且将敲低效率与四只对照小鼠进行比较:未处理的小鼠、仅用rvg外泌体注射的小鼠、用与体内阳离子脂质体试剂复合的bace1sirna注射的小鼠、以及用与rvg-9r复合的bace1sirna注射的小鼠,该rvg肽与静电结合至sirna的9个d-精氨酸缀合。在施用之后3天,分析皮层组织样品,并且在sirna-rvg-9r处理的小鼠和sirnarvg外泌体处理的小鼠中均观察到显著的蛋白质敲低(45%,p<0.05,相对于62%,p<0.01),这是由于bace1mrna水平的显著降低(分别为66%[+或-]15%,p<0.001和61%[+或-]13%,p<0.01)。此外,申请人证明了在rvg外泌体处理的动物中总[β]-淀粉样蛋白1-42水平上的显著降低(55%,p<0.05),该β淀粉样蛋白是在阿尔茨海默病理学中的淀粉样白斑的主要组分。所观察到的降低大于在心室内注射bace1抑制剂之后的正常小鼠中展示的β淀粉样蛋白1-40降低。alvarez-erviti等人在bace1切割产物上进行了5′-cdna末端快速扩增(race),这提供了经由sirna的rnai-介导的敲低的证据。
最后,alvarez-erviti等人通过评定il-6、ip-10、tnfα和ifn-α血清浓度研究了rna-rvg外泌体是否诱导了体内免疫反应。在外泌体处理之后,类似于与强有力地刺激il-6分泌的sirna-rvg-9r成对比的sirna转染试剂处理,登记了在所有细胞因子上的非显著性变化,证实了外泌体处理的免疫惰性属性(profile)。假定外泌体仅封装20%的sirna,用rvg外泌体的递送比rvg-9r递送显得更有效,因为用少五倍的sirna实现了相当的mrna敲低和更好的蛋白质敲低,而没有相应水平的免疫刺激。这个实验证明了rvg外泌体技术的治疗潜力,这种技术潜在地适用于与神经变性疾病相关的基因的长期沉默。alvarez-erviti等人的外泌体递送系统可以适用于将本发明的ad官能化的crispr-cas系统递送至治疗靶标,尤其是神经变性疾病。对于本发明可以考虑封装在约100至1000mg的rvg外泌体中的约100至1000mg的crisprcas的剂量。
el-andaloussi等人(natureprotocols7,2112-2126(2012))公开了可以如何利用来源于培养细胞的外泌体用于体外和体内递送rna。这个方案首先描述了通过转染包含与肽配体融合的外泌体蛋白的表达载体产生靶向的外泌体。接着,el-andaloussi等人解释了如何纯化和表征来自转染的细胞上清液的外泌体。接着,el-andaloussi等人详述了将rna加载到外泌体中的关键步骤。最后,el-andaloussi等人概述了如何使用外泌体有效地在体外递送rna以及体内递送至小鼠脑中。还提供了预期结果的实例,其中外泌体介导的rna递送通过功能测定和成像来评估。整个方案进行约3周。根据本发明的递送或施用可以使用由自我衍生的树突细胞产生的外泌体进行。根据本文的教导内容,这可以用于本发明的实践中。
在另一个实施方案中,考虑了wahlgren等人(nucleicacidsresearch,2012,第40卷,第17期e130)的血浆外泌体。外泌体是由包括树突细胞(dc)、b细胞、t细胞、肥大细胞、上皮细胞和肿瘤细胞的许多细胞类型产生的纳米尺寸的囊泡(30-90nm大小)。这些囊泡通过晚期内体的向内出芽而形成,然后在与质膜融合后释放到细胞外环境。因为外泌体天然地在细胞之间运送rna,所以这种特性在基因疗法中可能有用,并且根据本公开可以用于本发明的实践中。
来自血浆的外泌体可以通过以下方式制备:在900g离心血沉棕黄层持续20分钟以便分离血浆,之后收获细胞上清液,在300g离心10分钟以便消除细胞,并且在16500g离心30分钟,之后通过0.22mm过滤器进行过滤。通过在120000g超速离心70分钟使外泌体沉淀。根据在rnai人类/小鼠启动试剂盒(rnaihuman/mousestarterkit,quiagen,hilden,germany)中的制造商的说明进行sirna到外泌体中的化学转染。sirna以终浓度2mmol/ml添加到100mlpbs中。在加入hiperfect转染试剂之后,将混合物在室温下孵育10分钟。为了去除过量的胶束,使用醛/硫酸盐乳胶珠再分离外泌体。可以类似于sirna进行crisprcas到外泌体中的化学转染。外泌体可以与从健康供体的外周血中分离的单核细胞和淋巴细胞共培养。因此,可以考虑的是,可以将含有crisprcas的外泌体引入到人类的单核细胞和淋巴细胞中并且以自体方式再引入到人类中。因此,可以使用血浆外泌体进行根据本发明的递送或施用。
脂质体
可以用脂质体进行根据本发明的递送或施用。脂质体是球形囊泡结构,其由围绕内部水性区室的单层或多层脂质双层以及相对不可渗透的外部亲脂性磷脂双层构成。脂质体作为药物递送载剂受到了相当的重视,因为它们是生物相容、无毒的,可以递送亲水性和亲脂性药物分子,保护它们的货物免于被血浆酶降解,并且转运它们的负载跨过生物膜和血脑屏障(bbb)(对于评述,参见例如,spuch和navarro,journalofdrugdelivery,第2011卷,文章id469679,第12页,2011.doi:10.1155/2011/469679)。
可以由几种不同类型的脂质制造脂质体;然而,磷脂最常用来产生作为药物载剂的脂质体。虽然当脂质膜与水性溶液混合时脂质体形成是自发的,但是也可以通过使用均质机、超声破碎器或挤出设备通过以振荡的形式施加力使其加速(对于评述,参见例如,spuch和navarro,journalofdrugdelivery,第2011卷,文章id469679,第12页,2011.doi:10.1155/2011/469679)。
可以将几种其他添加剂添加到脂质体中以修改其结构和特性。例如,可以将胆固醇或鞘磷脂添加到脂质体混合物中,以便帮助稳定化脂质体结构并且防止脂质体内部货物的泄漏。此外,脂质体由氢化卵磷脂酰胆碱或卵磷脂酰胆碱、胆固醇和磷酸二鲸蜡脂制备,并且脂质体的平均囊泡尺寸被调整到约50nm和100nm。(对于评述,参见例如,spuch和navarro,journalofdrugdelivery,第2011卷,文章id469679,第12页,2011.doi:10.1155/2011/469679)。
脂质体配制品可以主要由天然磷脂和脂质诸如1,2-二硬脂酰基-sn-甘油基-3-磷脂酰胆碱(dspc)、鞘磷脂、卵磷脂酰胆碱和单唾酸酰神经节苷酯构成。由于这种配制品仅仅由磷脂组成,脂质体配制品已经遇到了许多挑战,其中之一是在血浆中的不稳定性。已经作出战胜这些挑战的若干尝试,特别是在脂质膜的处理方面。这些尝试之一集中于胆固醇的处理。将胆固醇添加到常规配制品中减缓了封装的生物活性化合物到血浆中的迅速释放,或者添加1,2-二油酰基-sn-甘油基-3-磷酸乙醇胺(dope)增加了稳定性(对于评述,参见例如,spuch和navarro,journalofdrugdelivery,第2011卷,文章id469679,第12页,2011.doi:10.1155/2011/469679)。
在一个特别有利的实施方案中,特洛伊木马(trojanhorse)脂质体(也称为分子特洛伊木马)是令人希望的并且方案可见于http://cshprotocols.cshlp.org/content/2010/4/pdb.prot5407.long。这些粒子允许转基因在血管内注射之后递送至整个脑。在不受限制的情况下,据信表面缀合有特异性抗体的中性脂质粒子允许经由胞吞作用跨过血脑屏障。特洛伊木马脂质体可以用于将核酸酶的crispr家族经由血管内注射递送至脑,这将允许全脑转基因动物,而不需要胚胎操纵。对于在脂质体中的体内施用,可以考虑约1-5g的dna或rna。
在另一个实施方案中,ad官能化的crisprcas系统或其组分可以在脂质体中施用,所述脂质体诸如稳定的核酸-脂质粒子(snalp)(参见例如morrissey等人,naturebiotechnology,第23卷,第8期,2005年8月)。考虑每日静脉内注射约1、3或5mg/kg/天的snalp中的被靶向的特异性crisprcas。日治疗可以经过约三天,并且然后每周治疗持续约五周。在另一个实施方案中,还考虑了通过以约1或2.5mg/kg的剂量静脉内注射施用封装有特异性crisprcas的snalp)(参见例如zimmerman等人,natureletters,第441卷,2006年5月4日)。snalp配制品可以含有为2∶40∶10∶48的摩尔百分比的脂质3-n-[(w甲氧基聚(乙二醇)2000)氨甲酰基]-1,2-二肉豆蔻氧基-丙胺(peg-c-dma)、1,2-二亚油基氧基-n,n-二甲基-3-氨基丙烷(dlindma)、1,2-二硬脂酰基-sn-甘油基-3-磷酸胆碱(dspc)和胆固醇(参见例如zimmerman等人,natureletters,第441卷,2006年5月4日)。
在另一个实施方案中,已经证明稳定的核酸-脂质粒子(snalp)将分子有效地递送至高度血管化的hepg2-衍生的肝脏肿瘤,但是不递送至血管化不良的hct-116衍生的肝脏肿瘤(参见例如li,genetherapy(2012)19,775-780)。可以通过以下方式制备snalp脂质体:使用25∶1的脂质/sirna比率和48/40/10/2的胆固醇/d-lin-dma/dspc/peg-c-dma的摩尔比,用二硬脂酰磷脂酰胆碱(dspc)、胆固醇和sirna配制d-lin-dma和peg-c-dma。所得的snalp脂质体的尺寸为约80-100nm。
在又一个实施方案中,snalp可以包含合成胆固醇(sigma-aldrich,stlouis,mo,usa)、二棕榈酰磷脂酰胆碱(avantipolarlipids,alabaster,al,usa)、3-n-[(w-甲氧基聚(乙二醇)2000)氨甲酰基]-1,2-二肉豆蔻氧基丙胺,以及阳离子的1,2-二亚油基氧基-3-n,n二甲基氨基丙烷(参见例如geisbert等人,lancet2010;375:1896-905)。可以考虑例如静脉内推注施用约2mg/kg总crisprcas/剂的剂量。
在又一个实施方案中,snalp可以包含合成胆固醇(sigma-aldrich)、1,2-二硬脂酰基-sn-甘油基-3-磷酸胆碱(dspc;avantipolarlipidsinc.)、peg-cdma,以及1,2-二亚油基氧基-3-(n;n-二甲基)氨基丙烷(dlindma)(参见例如judge,j.clin.invest.119:661-673(2009))。用于体内研究的配制品可以包含约9∶1的最终脂质/rna质量比。
alnylampharmaceuticals的barros和gollob已对rnai纳米药物的安全性进行了评论(参见例如advanceddrugdeliveryreviews64(2012)1730-1737)。稳定的核酸脂质粒子(snalp)由四种不同的脂质构成-在低ph下为阳离子的可电离脂质(dlindma)、中性辅助脂质、胆固醇以及可扩散的聚乙二醇(peg)-脂质。该粒子的直径为大约80nm并且在生理ph下是电中性的。在配制期间,可电离脂质用于在粒子形成期间使脂质与阴离子rna缩合。当在渐增的酸性内体条件下带正电荷时,可电离脂质还介导snalp与内体膜的融合,从而能够将rna释放到细胞质中。peg-脂质在配制期间稳定化粒子并且减少聚集,并且随后提供改善药代动力学特性的中性的亲水性外部。
到目前为止,已经使用具有rna的snalp配制品开始了两个临床项目。tekmirapharmaceuticals最近在具有升高的ldl胆固醇的成年志愿者中完成了snalp-apobi期单剂量研究。apob主要是在肝脏和空肠中表达,并且是为vldl和ldl的组装和分泌所必需的。十七位受试者接受了snalp-apob的单剂量(跨7个剂量水平的剂量递增)。没有肝脏毒性(预期为基于临床前研究的潜在剂量限制性毒性)的证据。处于最高剂量的(两位中的)一位受试者经历了与免疫系统刺激一致的流感样症状,于是做出结束该试验的决定。
alnylampharmaceuticals已经类似地推出了aln-ttr01,其采用以上所述的snalp技术并且靶向突变体和野生型ttr的肝细胞产生,从而治疗ttr淀粉样变性(attr)。已经描述了三种attr综合征:家族性淀粉样变性多神经病(fap)和家族性淀粉样心肌病(fac)-两者均由ttr中的常染色体显性突变引起;以及由野生型ttr引起的老年全身性淀粉样变性(ssa)。最近在患有attr的患者中完成了aln-ttr01的安慰剂对照单剂量递增i期试验。向31位患者(23位用研究药物,8位用安慰剂)在0.01至1.0mg/kg(基于sirna)的剂量范围内以15分钟静脉内输注施用aln-ttr01。治疗耐受性良好,其中在肝功能试验中没有显著增加。在≥0.4mg/kg时在23位患者的3位中注意到输注相关反应;所有患者均对减慢输注速率做出了反应并且所有患者继续参与研究。在处于1mg/kg的最高剂量(如根据临床前和nhp研究预期的)的两位患者中注意到血清细胞因子il-6、ip-10和il-1ra的最小与瞬时升高。在1mg/kg时观察到aln-ttr01的预期药效动力学效应,即血清ttr的降低。
在又一个实施方案中,可以通过将阳离子脂质、dspc、胆固醇以及peg-脂质例如以40∶10∶40∶10的摩尔比分别溶解在例如乙醇中来制备snalp(参见semple等人,natureniotechnology,第28卷,第2期,2010年2月,第172-177页)。将脂质混合物添加到水性缓冲液(50mm柠檬酸盐,ph4)中,混合至最终的乙醇和脂质浓度分别为30%(体积/体积)和6.1mg/ml,并且使得其在22℃下平衡2分钟,然后挤出。使用lipex挤出仪(northernlipids),在22℃下将水合脂质挤出通过两个重叠的80nm孔径大小的过滤器(nuclepore),直到获得如通过动态光散射分析测定的70-90nm直径的囊泡为止。这大致需要1-3次通过。将sirna(溶解在50mm柠檬酸盐中,ph为4的含有30%乙醇的水性溶液)以约5ml/min的速率在混合下添加到预平衡的(35℃)囊泡中。在达到0.06(重量/重量)的最终靶sirna/脂质比率之后,将混合物在35℃下另外孵育30分钟,以允许囊泡重组和sirna的封装。然后去除乙醇并且通过透析或切向流渗滤用pbs(155mmnacl,3mmna2hpo4,1mmkh2po4,ph7.5)替换外部缓冲液。使用受控的逐步稀释法工艺将sirna封装在snalp中。kc2-snalp的脂质构分为以57.1∶7.1∶34.3∶1.4的摩尔比使用的dlin-kc2-dma(阳离子脂质)、二棕榈酰磷脂酰胆碱(dppc;avantipolarlipids)、合成胆固醇(sigma)和peg-c-dma。在形成加载的粒子后,将snalp在pbs中透析并且在使用之前通过0.2μm的过滤器灭菌过滤。平均粒径为75-85nm,并且90%-95%的sirna被封装在脂质粒子之内。用于体内测试的在配制品中的最终sirna/脂质比率为约0.15(重量/重量)。在临使用之前将含有因子viisirna的lnp-sirna系统在无菌pbs中稀释到适当浓度,并且通过侧尾静脉以10ml/kg的总体积静脉内施用配制品。这种方法和这些递送系统可以外推到本发明的ad官能化的crisprcas系统。
其他脂质
其他阳离子脂质,诸如氨基脂质2,2-二亚油基-4-二甲基氨基乙基-[1,3]-二氧戊环(dlin-kc2-dma)可以类似于sirna地用来封装crisprcas或其组分或对其编码的一个或多个核酸分子(参见例如jayaraman,angew.chem.int.ed.2012,51,8529-8533),因此可以用于本发明的实践中。可以考虑具有下列脂质组成的预成型囊泡:分别处于摩尔比40/10/40/10的氨基脂质、二硬脂酰磷脂酰胆碱(dspc)、胆固醇和(r)-2,3-双(十八烷氧基)丙基-1-(甲氧基聚(乙二醇)2000)丙基碳酸酯(peg-脂质),以及大约0.05(w/w)的fviisirna/总脂质比率。为了确保在70-90nm范围内的窄粒径分布以及0.11±0.04(n=56)的低多分散性指数,可以在添加指导rna之前将粒子通过80nm的膜挤出达三次。可以使用含有高度有效的氨基脂质16的粒子,其中四种脂质组分16、dspc、胆固醇和peg-脂质的摩尔比(50/10/38.5/1.5)可以被进一步优化,以增强体内活性。
michaelsdkormann等人(″expressionoftherapeuticproteinsafterdeliveryofchemicallymodifiedmrnainmice:naturebiotechnology,第29卷,第154-157页(2011))描述了脂质包膜用于递送rna的用途。在本发明中,脂质包膜的使用也是优选的。
在另一个实施方案中,脂质可以用本发明的ad官能化的crisprcas系统或其一种或多种组分或对其编码的一个或多个核酸分子一起配制而形成脂质纳米粒子(lnp)。脂质包括但不限于,dlin-kc2-dma4、c12-200和辅助脂质二硬脂酰磷脂酰胆碱、胆固醇和peg-dmg,可以使用自发囊泡形成程序将其与crisprcas而不是sirna一起配制(参见例如novobrantseva,moleculartherapy-nucleicacids(2012)1,e4;doi:10.1038/mtna.2011.3)。组分摩尔比可以是约50/10/38.5/1.5(dlin-kc2-dma或c12-200/二硬脂酰磷脂酰胆碱/胆固醇/peg-dmg)。在dlin-kc2-dma和c12-200脂质纳米粒子(lnp)的情况下,最终脂质:sirna的重量比分别为约12∶1和9∶1。配制品可以具有约80nm的平均粒子直径,具有>90%的包封效率。可以考虑3mg/kg的剂量。
tekmira在美国和国外具有一组针对lnp和lnp配制品的不同方面的大约95个同族专利(参见例如美国专利号7,982,027;7,799,565;8,058,069;8,283,333;7,901,708;7,745,651;7,803,397;8,101,741;8,188,263;7,915,399;8,236,943和7,838,658,以及欧洲专利号1766035;1519714;1781593和1664316),所有这些专利均可用于并且/或者适于本发明。
ad官能化的crisprcas系统或其组分或对其编码的一个或多个核酸分子可以封装在plga微球中进行递送,诸如进一步描述于美国公布申请20130252281和20130245107以及20130244279(转让给modernatherapeutics)中,这些申请涉及包含修饰的核酸分子的组合物的配制品的多个方面,这些核酸分子可以编码蛋白质、蛋白质前体、或该蛋白质或该蛋白质前体的部分或完全加工形式。该配制品可以具有50∶10∶38.5∶1.5-3.0(阳离子脂质∶融合脂质∶胆固醇∶peg脂质)的摩尔比。peg脂质可以选自但不限于peg-c-domg、peg-dmg。融合脂质可以是dspc。另参见schrum等人,deliveryandformulationofengineerednucleicacids,美国公布申请20120251618。
nanomerics的技术着手解决针对广泛治疗学的生物利用度挑战,包括基于低分子量疏水性药物、肽以及核酸的治疗剂(质粒、sirna、mirna)。该技术已经证明了明显优势的特异性的施用途径包括经口途径、跨血脑屏障的转运、向实体瘤的递送,以及向眼部的递送。参见例如mazza等人,2013,acsnano.2013年2月26日;7(2):1016-26;uchegbu和siew,2013,jpharmsci.102(2):305-10以及lalatsa等人,2012,jcontrolrelease.2012年7月20日;161(2):523-36。
美国专利公布号20050019923描述了用于向哺乳动物身体递送生物活性分子诸如多核苷酸分子、肽和多肽和/或药剂的阳离子树状聚合物。树状聚合物适用于将生物活性分子的递送靶向至例如肝脏、脾、肺、肾脏或心脏(或甚至脑)。树状聚合物是由简单的支化单体单元以逐步方式制备的合成性3维大分子,其性质和功能性可以容易地进行控制和改变。树状聚合物经由向多功能核(发散式合成法)或朝向多功能核(收敛式合成法)重复加成结构单元来合成,并且结构单元的3维壳的每次加成使得更高级别的树状聚合物形成。聚丙烯亚胺树状聚合物从二氨基丁烷核开始,通过对伯胺的丙烯腈的双迈克尔加成反应向其上添加两倍数目的氨基基团,然后进行腈的氢化。这导致氨基基团的加倍。聚丙烯亚胺树状聚合物含有100%的可质子化氮以及高达64个末端氨基基团(5级,dab64)。可质子化基团通常是能够在中性ph下接受质子的胺基。树状聚合物作为基因递送剂的用途在很大程度上集中于聚酰胺-胺和含磷化合物的用途,其中胺/酰胺的混合物或n--p(o2)s分别作为缀合单元,没有报道关于更低级别的聚丙烯亚胺树状聚合物用于基因递送的用途的著作。还研究了作为ph敏感的控制释放系统的聚丙烯亚胺树状聚合物,其用于药物递送以及当被外周氨基酸基团化学修饰时用于它们的客体分子的封装。还研究了聚丙烯亚胺树状聚合物的细胞毒性和其与dna的相互作用以及dab64的转染效力。
美国专利公布号20050019923是基于与早期报道相反的观察:阳离子树状聚合物诸如聚丙烯亚胺树状聚合物展示出合适的特性,诸如特异性靶向和低毒性,其用于靶向递送生物活性分子诸如遗传物质。此外,阳离子树状聚合物的衍生物也展示出适用于生物活性分子的靶向递送的特性。另参见,生物活性聚合物(bioactivepolymers),美国公布申请20080267903,其公开了“不同的聚合物,包括阳离子聚胺聚合物和树枝状聚合物显示出具有抗增殖活性,并且因此可用于治疗特征为不希望的细胞增殖的病症,诸如新生物和肿瘤、炎性病症(包括自身免疫性病症)、银屑病和动脉粥样硬化。这些聚合物可以作为活性剂单独使用,或者作为其他治疗剂(诸如药物分子或用于基因疗法的核酸)的递送媒介物。在此类情况下,聚合物的自身固有的抗肿瘤活性可以补足有待递送的剂的活性。”这些专利公布的公开内容可以与本文的教导内容结合使用,以用于递送一种或多种ad官能化的crisprcas系统或其一种或多种组分或对其编码的一个或多个核酸分子。
超电荷蛋白
超电荷蛋白是一类具有非常高的正或负的理论净电荷的工程化或天然存在的蛋白质并且可以用于递送一种或多种ad官能化的crisprcas系统或其一种或多种组分或对其编码的一个或多个核酸分子。超负电荷蛋白和超正电荷蛋白两者都表现出显著的抵抗热诱导或化学诱导的聚集的能力。超正电荷蛋白还能够穿透哺乳动物细胞。使货物诸如质粒dna、rna或其他蛋白质与这些蛋白质缔合可以使得这些大分子到体外和体内的哺乳动物细胞中的功能递送成为可能。在2007年报道了超电荷蛋白的产生和表征(lawrence等人2007,journaloftheamericanchemicalsociety129,10110-10112)。
rna和质粒dna到哺乳动物细胞中的非病毒递送对于研究和治疗应用都是有价值的(akinc等人,2010,nat.biotech.26,561-569)。纯化的+36gfp蛋白(或其他超正电荷蛋白)与rna在适当的无血清培养基中混合并且使得其在添加到细胞中之前复合。在这个阶段包含血清抑制超电荷蛋白-rna复合物的形成并且降低治疗效果。已经发现以下方案对于多种细胞系是有效的(mcnaughton等人,2009,proc.natl.acad.sci.usa106,6111-6116)(然而,应当进行改变蛋白质和rna剂量的预试验来优化用于特定细胞系的程序):(1)在治疗前一天,以1x105个细胞/孔铺在48孔板中。(2)在治疗当天,将纯化的+36gfp蛋白在无血清的培养基中稀释至终浓度200nm。添加rna至50nm的终浓度。涡旋混合并且在室温下孵育10分钟。(3)在孵育期间,从细胞抽出培养基并且用pbs洗涤一次。(4)在孵育+36gfp和rna之后,向细胞添加蛋白质-rna复合物。(5)将细胞与复合物在37℃下孵育4小时。(6)在孵育之后,抽出培养基并且用20u/ml的肝素pbs洗涤三次。用含血清的培养基另外孵育细胞48小时或更长,这取决于用于活性的测定。(7)通过免疫印迹、qpcr、表型测定或其他适当的方法分析细胞。
进一步发现,+36gfp在一系列细胞中是有效的质粒递送试剂。由于质粒dna是一种比sirna大的货物,有效复合质粒需要成比例地更大的+36gfp蛋白。为了有效质粒递送,申请人已经开发了一种带有c端ha2肽标签的+36gfp变体,这种肽是一种已知的来源于流感病毒血凝素蛋白的内体破坏肽。以下方案在多种细胞中是有效的,但是如上所述,建议针对特定细胞系和递送应用优化质粒dna和超电荷蛋白的剂量:(1)在治疗前一天,以1x105/孔铺在48孔板中。(2)在治疗当天,将纯化的
另参见,例如,mcnaughton等人,proc.natl.acad.sci.usa106,6111-6116(2009);cronican等人,acschemicalbiology5,747-752(2010);cronican等人,chemistry&biology18,833-838(2011);thompson等人,methodsinenzymology503,293-319(2012);thompson,d.b.,等人,chemistry&biology19(7),831-843(2012)。超电荷蛋白的这些方法可以用于并且/或者适于本发明的ad官能化的crisprcas系统的递送。这些系统结合本文的教导内容可以用于递送一种或多种ad官能化的crisprcas系统或其一种或多种组分或对其编码的一个或多个核酸分子。
细胞穿透肽(cpp)
在又一个实施方案中,考虑了细胞穿透肽(cpp)用于ad官能化的crisprcas系统的递送。cpp是促进各种分子货物(从纳米级粒子至小化学分子和大的dna片段)的细胞摄取的短肽。如本文所用,术语“货物”包括但不限于由以下组成的组:治疗剂、诊断性探针、肽、核酸、反义寡核苷酸、质粒、蛋白质、粒子(包括纳米粒子)、脂质体、发色团、小分子以及放射性物质。在本发明的方面中,货物还可以包括ad官能化的crisprcas系统的任何组分或整个ad官能化的crisprcas系统。本发明的各方面还提供了用于将所需货物递送至受试者中的方法,所述方法包括:(a)制备包含本发明的细胞穿透肽和所需货物的复合物,以及(b)向受试者经口地、关节内地、腹膜内地、鞘内地、动脉内地(intrarterially)、鼻内地、实质内地(intraparenchymally)、皮下地、肌内地、静脉内地、真皮地、直肠内地或局部地施用复合物。货物通过经由共价键的化学键联或通过非共价的相互作用与肽缔合。
cpp的功能是将货物递送至细胞中,这是一种通常通过胞吞作用发生的过程,其中货物被递送至活哺乳动物细胞的内体。细胞穿透肽具有不同的尺寸、氨基酸序列并且带电荷,但是所有cpp具有一种独特的特征,该特征是易位质膜并且将各种分子货物递送至细胞质或细胞器的能力。cpp易位可以被分类成三种主要的进入机制:直接穿透膜中、胞吞作用介导的进入,以及通过瞬时结构的形成的易位。cpp在医学中发现了许多应用,在治疗不同疾病包括癌症中作为药物递送剂,和病毒抑制剂以及用于细胞标记的造影剂。后者的实例包括充当用于gfp、mri造影剂或量子点的载剂。cpp作为用于研究和医学的体外及体内递送载体具有极大潜力。cpp典型地具有下述的氨基酸组成,该氨基酸组成含有高相对丰度的带正电荷的氨基酸诸如赖氨酸或精氨酸或具有含有极性/带电荷氨基酸和非极性、疏水性氨基酸的交替图案的序列。这两种类型的结构分别称为聚阳离子的或两亲性的。cpp的第三种类别是仅含有非极性残基的疏水性肽,具有低净电荷或具有对于细胞摄取关键的疏水性氨基酸基团。所发现的初始cpp中之一是来自人类免疫缺陷病毒1(hiv-1)的反激活转录激活因子(tat),发现其高效地从周围介质被许多培养中的细胞类型摄取。从此以后,多种已知的cpp得到了相当地扩展并且产生了具有更有效的效应蛋白转导特性的小分子合成类似物。cpp包括但不限于穿透素、tat(48-60)、转运素和(r-ahx-r4)(ahx=氨基己酰基)。
美国专利8,372,951提供了来源于嗜酸性粒细胞阳离子蛋白(ecp)的cpp,该cpp表现出非常高的细胞穿透效率和低毒性。还提供了将带有其货物的cpp递送至脊椎动物受试者中的方面。cpp及其递送的另外方面描述于美国专利8,575,305;8;614,194和8,044,019中。cpp可用于递送ad官能化的crispr-cas系统或其组分。可以用于递送ad官能化的crispr-cas系统或其组分的cpp还被提供于手稿“通过细胞穿透肽介导的cas9蛋白和指导rna的递送进行的基因破坏(genedisruptionbycell-penetratingpeptide-mediateddeliveryofcas9proteinandguiderna)”,sureshramakrishna、abu-bonsrahkwakudad、jagadishbeloor等人genomeres.2014年4月2日,该文献以引用方式并入,其中证实了用cpp缀合的重组cas9蛋白和cpp复合的指导rna的处理导致人类细胞系中的内源性基因破坏。在论文中,cas9蛋白经由硫醚键缀合至cpp,而指导rna与cpp复合,形成了稠合的带正电荷的粒子。已经显示,用修饰的cas9和指导rna同时和顺序地治疗人类细胞,包括胚胎干细胞、真皮成纤维细胞、hek293t细胞、hela细胞和胚胎癌细胞,导致有效的基因破坏,伴随相对于质粒转染而言降低的脱靶突变。
气雾剂递送
对肺病进行治疗的受试者可以在自主呼吸时例如每侧肺部接受药物有效量的支气管递送的雾化的aav载体系统。因此,一般而言,对于aav递送,雾化的递送是优选的。腺病毒或aav粒子可以用于递送。可以将合适的基因构建体克隆到递送载体中,这些基因构建体各自可操作地连接至一个或多个调控序列。
包装和启动子
用于驱动crispr-cas蛋白和腺苷脱氨酶编码核酸分子表达的启动子可以包括aavitr,其可以用作启动子。这对于消除对另外的启动子元件(可能在载体中占用空间)的需要是有利的。空出来的另外的空间可以用于驱动另外的元件(grna等)的表达。另外,itr活性是相对较弱的,因此可以用于降低由于cpf1的过表达所致的潜在毒性。
对于普遍表达,可以使用的启动子包括:cmv、cag、cbh、pgk、sv40、铁蛋白重链或轻链等。对于脑或其他cns表达,可以使用启动子:用于所有神经元的突触蛋白i(synapsini)、用于兴奋性神经元的camkiiα、用于gaba能神经元的gad67或gad65或vgat。对于肝脏表达,可以使用白蛋白启动子。对于肺表达,可以使用sp-b。对于内皮细胞,可以使用icam。对于造血细胞,可以使用ifnβ或cd45。对于成骨细胞,可以使用og-2。
用于驱动指导rna的启动子可以包括poliii启动子,诸如u6或h1,以及使用polii启动子和内含子盒来表达指导rna。
腺相关病毒(aav)
crispr-cas蛋白、腺苷脱氨酶和一种或多种指导rna可以使用腺相关病毒(aav)、慢病毒、腺病毒或其他质粒或病毒载体类型进行递送,特别地,使用来自以下文献的配方和剂量:例如,美国专利号8,454,972(针对腺病毒的配方、剂量)、8,404,658(针对aav的配方、剂量)和5,846,946(针对dna质粒的配方、剂量)以及来自临床试验和关于涉及慢病毒、aav和腺病毒的临床试验的出版物的配方和剂量。例如,对于aav,施用途径、配方和剂量可以如美国专利号8,454,972并且如涉及aav的临床试验。对于腺病毒,施用途径、配方和剂量可以如美国专利号8,404,658并且如涉及腺病毒的临床试验。对于质粒递送,施用途径、配方和剂量可以如美国专利号5,846,946并且如涉及质粒的临床试验。剂量可以基于或外推为平均70kg的个体(例如,男性成人),并且可以针对不同重量和种类的患者、受试者、哺乳动物进行调整。施用频率在医学或兽医学从业者(例如医师、兽医师)的范围之内,其取决于常规因素,包括患者或受试者的年龄、性别、一般健康状况、其他状况以及着手解决的特定病状或症状。可以将病毒载体注射到目标组织中。对于细胞类型特异性基因组修饰,cpf1和腺苷脱氨酶的表达可以由细胞类型特异性启动子驱动。例如,肝脏特异性表达可以使用白蛋白启动子,而神经元特异性表达(例如靶向cns病症)可以使用突触蛋白i启动子。
就体内递送而言,aav相比于其他病毒载体是有利的,这是由于两个原因:低毒性(这可能是由于纯化方法不需要细胞粒子的超速离心所致,而超速离心可能激活免疫反应);以及引起插入诱变的低概率,原因在于它未整合到宿主基因组中。
aav的包装限度为4.5或4.75kb。这意味着cpf1以及启动子和转录终止子必须都适于相同的病毒载体。大于4.5或4.75kb的构建体将导致病毒产生显著减少。spcas9是相当大的,该基因自身超过4.1kb,使其难于包装到aav中。因此本发明的实施方案包括利用更短的cpf1同源物。
关于aav,aav可以是aav1、aav2、aav5或它们的任何组合。可以相对于有待被靶向的细胞从这些aav中选择aav;例如,可以选择用于靶向脑或神经元细胞的aav血清型1、2、5或杂合衣壳aav1、aav2、aav5或它们的任何组合;并且可以选择用于靶向心脏组织的aav4。aav8可用于递送至肝脏。本文的启动子和载体是单独优选的。就这些细胞而论(参见grimm,d.等人,j.virol.82:5887-5911(2008)),某些aav血清型的列表如下:
慢病毒
病毒是复杂的反转录病毒,其具有在有丝分裂细胞和有丝分裂后细胞两者中感染并表达其基因的能力。最为人熟知的慢病毒是人类免疫缺陷病毒(hiv),其使用其他病毒的包膜糖蛋白来靶向广泛范围的细胞类型。
慢病毒可以如下制备。在克隆pcases10(含有慢病毒转移质粒骨架)之后,将处于低传代数(p=5)的hek293ft接种在t-75烧瓶中,以在转染之前的一天在具有10%胎牛血清而没有抗生素的dmem中达到50%汇合。在20小时之后,将培养基更换为optimem(无血清)培养基,并且在4小时后进行转染。将细胞用10μg的慢病毒转移质粒(pcases10)和下列包装质粒转染:5μg的pmd2.g(vsv-g假型)和7.5ug的pspax2(gag/pol/rev/tat)。在具有阳离子脂质递送剂(50ul的lipofectamine2000和100ul的plus试剂)的4mloptimem中进行转染。在6小时之后,将培养基更换为具有10%胎牛血清的无抗生素的dmem。这些方法在细胞培养期间使用血清,但是优选无血清的方法。
慢病毒可以如下纯化。在48小时后收获病毒上清液。首先清除上清液中的碎片,然后通过0.45um低蛋白结合(pvdf)过滤器进行过滤。然后将它们在超速离心机中以24,000rpm旋转2小时。将病毒沉淀重新悬浮在50ul的dmem中,在4c下过夜。然后将它们等分,并且立即在-80℃下冷冻。
在另一个实施方案中,还考虑了基于马感染性贫血病毒(eiav)的最小非灵长类动物慢病毒载体,特别是对于眼部基因疗法而言(参见例如balagaan,jgenemed2006;8:275-285)。在另一个实施方案中,还考虑了一种经由视网膜下注射递送用于治疗湿型年龄相关性黄斑变性的、表达血管生成抑制蛋白(内皮抑素和血管抑素)的基于马感染性贫血病毒的慢病毒基因疗法载体
在另一个实施方案中,自我失活性慢病毒载体可以用于并且/或者适于本发明的ad官能化的crispr-cas系统核,该自我失活性慢病毒载体具有靶向由hivtat/rev共享的共有外显子的sirna、核仁定位tar诱饵和抗ccr5特异性锤头状核酶(参见例如digiusto等人(2010)scitranslmed2:36ra43)。可以收集最少2.5×106个cd34+细胞/每千克患者体重并且以2×106个细胞/ml的密度在x-vivo15培养基(lonza)中预刺激16至20小时,该培养基含有2μmol/l-谷氨酰胺、干细胞因子(100ng/ml)、flt-3配体(flt-3l)(100ng/ml)和促血小板生成素(10ng/ml)(cellgenix)。可以用慢病毒以感染复数5在75-cm2的包覆有纤连蛋白(25mg/cm2)(retronectin,takarabioinc.)的组织培养瓶中转导预刺激的细胞,持续16至24小时。
慢病毒载体已公开于帕金森病的治疗中,参见例如美国专利公布号20120295960以及美国专利号7303910和7351585。慢病毒载体还已公开于眼部疾病的治疗中,参见例如美国专利公布号20060281180、20090007284、us20110117189;us20090017543;us20070054961、us20100317109。还已公开了将慢病毒载体递送至脑,参见例如美国专利公布号us20110293571;us20110293571、us20040013648、us20070025970、us20090111106和美国专利号us7259015。
在非动物生物体中的应用
一种或多种ad官能化的crispr系统(例如,单一或多重)可以与农作物基因组的研究进展结合来使用。本文所述的系统可以用于进行有效且性价比高的植物基因或基因组探询或编辑或操纵-例如,用于快速研究并且/或者选择并且/或者探询并且/或者比较并且/或者操纵并且/或者转化植物基因或基因组;例如,以便为一种或多种植物产生、鉴定、开发、优化或赋予一种或多种性状或一种或多种特征或者以转化植物基因组。因此,可以存在植物、具有新性状或特征组合的新植物或具有增强的性状的新植物的改善的产生方法。关于定点整合(sdi)或基因编辑(ge)或任何近反向育种(nearreversebreeding)(nrb)或反向育种(rb)技术中的植物,可以使用ad官能化的crispr系统。利用本文所述的cpf1效应蛋白系统的方面可能类似于crispr-cas(例如crispr-cas9)系统在植物中的使用,并且提及亚利桑那大学(universityofarizona)网站“crispr-plant”(http://www.genome.arizona.edu/crispr/)(得到宾州州立大学(pennstate)和agi的支持)。本发明的实施方案可以用于在植物中或在先前已使用rnai或类似基因组编辑技术的情况中进行基因组编辑;参见例如,nekrasov,“plantgenomeeditingmadeeasy:targetedmutagenesisinmodelandcropplantsusingthecrispr-cassystem,”plantmethods2013,9:39(doi:10.1186/1746-4811-9-39);brooks,“efficientgeneeditingintomatointhefirstgenerationusingthecrispr-cas9system,”plantphysiology,2014年9月,第114.247577页;shan,“targetedgenomemodificationofcropplantsusingacrispr-cassystem,”naturebiotechnology31,686-688(2013);feng,“efficientgenomeeditinginplantsusingacrispr-cassystem,”cellresearch(2013)23:1229-1232.doi:10.1038/cr.2013.114;2013年8月20日在线公布;xie,“rna-guidedgenomeeditinginplantsusingacrispr-cassystem,”molplant.2013年11月;6(6):1975-83.doi:10.1093/mp/sst119.电子版2013年8月17日;xu,“genetargetingusingtheagrobacteriumtumefaciens-mediatedcrispr-cassysteminrice,”rice2014,7:5(2014);zhou等人,“exploitingsnpsforbialleliccrisprmutationsintheoutcrossingwoodyperennialpopulusreveals4-coumarate:coaligasespecificityandredundancy,”newphytologist(2015)(论坛)1-4(仅在www.newphytologist.com处在线可得);caliando等人,“targeteddnadegradationusingacrisprdevicestablycarriedinthehostgenome,naturecommunications6:6989,doi:10.1038/ncomms7989,www.nature.com/naturecommunicationsdoi:10.1038/ncomms7989;美国专利号6,603,061-土壤杆菌属介导的植物转化方法(agrobacterium-mediatedplanttransformationmethod);美国专利号7,868,149-植物基因组序列及其用途(plantgenomesequencesandusesthereof)以及us2009/0100536-具有增强的农艺性状的转基因植物(transgenicplantswithenhancedagronomictraits),每份文献的所有内容和公开内容均以引用方式整体并入本文。在本发明的实践中,morrell等人“农作物基因组:进展与应用(cropgenomics:advancesandapplications)”,natrevgenet.2011年12月29日;13(2):85-96的内容和公开内容;每份文献以引用方式并入本文,包括关于本文的实施方案如何可以就植物而使用。因此,除非另外表明,否则本文提及动物细胞也可以加上必要的变更应用于植物细胞;并且,本文的具有降低的脱靶效应的酶和采用此类酶的系统可以用于植物应用,包括本文提及的那些。
ad官能化的crispr系统在植物和酵母中的应用
一般来讲,术语“植物”涉及植物界中通过细胞分裂特征性生长、含有叶绿体并具有包含纤维素的细胞壁的任何不同光合作用生物体、真核生物体、单细胞生物体或多细胞生物体。术语植物涵盖单子叶植物和双子叶植物。确切地说,这些植物旨在包括但不限于被子植物和裸子植物,诸如刺槐、苜蓿、苋菜、苹果、杏、朝鲜蓟、白蜡树、芦笋、鳄梨、香蕉、大麦、豆类、甜菜、桦树、山毛榉、黑莓、蓝莓、西兰花、抱子甘蓝、卷心菜、油菜、哈密瓜、胡萝卜、木薯、花椰菜、雪松、谷类、芹菜、栗子、樱桃、大白菜、柑橘、克莱门氏小柑橘、三叶草、咖啡、玉米、棉花、豇豆、黄瓜、柏树、茄子、榆树、菊苣、桉树、茴香、无花果、冷杉、天竺葵、葡萄、葡萄柚、落花生、地樱桃、树胶铁杉、山核桃木、羽衣甘蓝、奇异果、甘蓝、落叶松、莴苣、韭、柠檬、青柠、洋槐、松树、孔雀草、玉米、芒果、枫树、甜瓜、粟、蘑菇、芥菜、坚果、橡树、燕麦、油棕、秋葵、洋葱、橙、观赏植物或花或树木、木瓜、棕榈、荷兰芹、欧洲防风草、豌豆、桃、花生、梨、泥炭(peat)、胡椒、柿子、木豆、松树、菠萝、大蕉、李子、石榴、马铃薯、南瓜、菊苣、萝卜、油菜籽、覆盆子、稻、黑麦、高粱、红花、黄华柳、大豆、菠菜、云杉、南瓜属植物果实、草莓、糖甜菜、甘蔗、向日葵、甘薯、甜玉米、橘子、茶、烟草、番茄、树类、黑小麦、草坪草、芜菁、藤本植物、胡桃、豆瓣菜、西瓜、小麦、山药、紫杉以及西葫芦。术语植物还涵盖藻类,藻类主要是光能自养生物,它们主要一致缺少根、叶以及其他表征高等植物的器官。
用于使用如本文所述的ad官能化的crispr系统进行基因组编辑的方法可以用于对基本上任何植物赋予所需的性状。针对本文所述的所需生理以及农学特征,可以使用本公开的核酸构建体和以上提及的各种转化方法对多种多样的植物和植物细胞系统进行工程化。在优选实施方案中,用于工程化的靶植物和植物细胞包括但不限于那些单子叶植物和双子叶植物,诸如农作物(包括谷类作物(例如小麦、玉米、稻、粟、大麦)、果实作物(例如番茄、苹果、梨、草莓、橙)、饲料作物(例如苜蓿)、根用蔬菜作物(例如胡萝卜、马铃薯、甜菜、山药)、叶类蔬菜作物(例如莴苣、菠菜);开花植物(例如矮牵牛、玫瑰、菊花)、松柏植物以及松树(例如松杉、云杉);植物修复中所使用的植物(例如重金属累积植物);油料作物(例如向日葵、油菜种子)和用于实验目的植物(例如拟南芥属)。因此,这些方法和系统可以用于遍及广泛范围的植物,像例如与属于以下目的双子叶植物:木兰目(magniolales)、八角目(illiciales)、樟目(laurales)、胡椒目(piperales)、马兜铃目(aristochiales)、睡莲目(nymphaeales)、毛茛目(ranunculales)、罂粟目(papeverales)、瓶子草科(sarraceniaceae)、昆栏树目(trochodendrales)、金缕梅目(hamamelidales)、杜仲目(eucomiales)、塞子木目(leitneriales)、杨梅目(myricales)、壳斗目(fagales)、木麻黄目(casuarinales)、石竹目(caryophyllales)、肉穗果目(batales)、寥目(polygonales)、蓝雪目(plumbaginales)、五桠果目(dilleniales)、山茶目(theales)、锦葵目(malvales)、荨麻目(urticales)、玉蕊目(lecythidales)、堇菜目(violales)、杨柳目(salicales)、白花菜目(capparales)、杜鹃花目(ericales)、岩梅目(diapensales)、柿树目(ebenales)、报春花目(primulales)、蔷薇目(rosales)、豆目(fabales)、川草目(podostemales)、小二仙草目(haloragales)、桃金娘目(myrtales)、山茱萸目(cornales)、山龙眼目(proteales)、檀香目(santales)、大花草目(rafflesiales)、卫矛目(celastrales)、大戟目(euphorbiales)、鼠李目(rhamnales)、无患子目(sapindales)、胡桃目(juglandales)、牻牛儿苗目(geraniales)、远志目(polygalales)、伞形目(umbellales)、龙胆目(gentianales)、花葱目(polemoniales)、唇形目(lamiales)、车前草目(plantaginales)、玄参目(scrophulariales)、桔梗目(campanulales)、茜草目(rubiales)、川续断目(dipsacales)以及菊目(asterales);这些方法和crispr-cas系统可以用于单子叶植物,诸如属于以下目的单子叶植物:泽泻目(alismatales)、水鳖目(hydrocharitales)、茨藻目(najadales)、霉草目(triuridales)、鸭跖草目(commelinales)、谷精草目(eriocaulales)、帚灯草目(restionales)、禾本目(poales)、灯芯草目(juncales)、莎草科(cyperales)、香蒲目(typhales)、凤梨目(bromeliales)、姜目(zingiberales)、槟榔目(arecales)、环花目(cyclanthales)、露兜树目(pandanales)、天南星目(arales)、百合目(lilliales)以及兰目(orchidales),或者用于属于裸子植物(gymnospermae)的植物,例如属于松杉目(pinales)、银杏目(ginkgoales)、苏铁目(cycadales)、南洋杉目(araucariales)、柏目(cupressales)以及麻黄目(gnetales)的植物。
本文所述的ad官能化的crispr系统和使用方法可以用于广泛范围的植物种类,这些植物种类包括在下面的双子叶植物、单子叶植物或裸子植物属的非限制性列表中:颠茄属(atropa)、油丹属(alseodaphne)、腰果属(anacardium)、落花生属(arachis)、琼楠属(beilschmiedia)、芸苔属(brassica)、红花属(carthamus)、木防己属(cocculus)、巴豆属(croton)、甜瓜属(cucumis)、柑橘属(citrus)、西瓜属(citrullus)、辣椒属(capsicum)、长春花属(catharanthus)、椰子属(cocos)、咖啡属(coffea)、南瓜属(cucurbita)、胡萝卜属(daucus)、杜氏木属(duguetia)、花菱草属(eschscholzia)、榕属(ficus)、草莓属(fragaria)、海罂粟属(glaucium)、大豆属(glycine)、棉属(gossypium)、向日葵属(helianthus)、橡胶树属(hevea)、天仙子属(hyoscyamus)、莴苣属(lactuca)、卷枝藤属(landolphia)、亚麻属(linum)、木姜子属(litsea)、番茄属(lycopersicon)、羽扇豆属(lupinus)、木薯属(manihot)、马郁兰属(majorana)、苹果属(malus)、苜蓿属(medicago)、烟草属(nicotiana)、木犀榄属(olea)、银胶菊属(parthenium)、罂粟属(papaver)、鳄梨属(persea)、菜豆属(phaseolus)、黄连木属(pistacia)、豌豆属(pisum)、梨属(pyrus)、李属(prunus)、萝卜属(raphanus)、蓖麻属(ricinus)、千里光属(senecio)、防己属(sinomenium)、千金藤属(stephania)、欧白芥属(sinapis)、茄属(solanum)、可可属(theobroma)、三叶草属(trifolium)、胡芦巴属(trigonella)、蚕豆属(vicia)、蔓长春花属(vinca)、葡萄属(vilis)和豇豆属(vigna);以及葱属(allium)、须芒草属(andropogon)、画眉草属(aragrostis)、天门冬属(asparagus)、燕麦属(avena)、狗牙根属(cynodon)、油棕属(elaeis)、羊茅属(festuca)、羊茅黑麦草属(festulolium)、萱草属(heterocallis)、大麦属(hordeum)、浮萍属(lemna)、毒麦属(lolium)、芭蕉属(musa)、稻属(oryza)、黍属(panicum)、狼尾草属(pannesetum)、梯牧草属(phleum)、早熟禾属(poa)、黑麦属(secale)、高粱属(sorghum)、小麦属(triticum)、玉蜀黍属(zea)、冷杉属(abies)、杉木属(cunninghamia)、麻黄属(ephedra)、云杉属(picea)、松属(pinus),以及黄杉属(pseudotsuga)。
ad官能化的crispr系统以及使用方法还可以用于遍及广泛范围的“藻类”或“藻类细胞”;包括例如选自若干真核生物门的藻类,其包括红藻植物门(rhodophyta)(红藻)、绿藻门(chlorophyta)(绿藻)、褐藻门(phaeophyta)(褐藻)、硅藻门(bacillariophyta)(硅藻)、真眼点藻纲(eustigmatophyta)和沟鞭藻类以及原核门蓝藻门(cyanobacteria)(蓝绿藻)。术语“藻类”包括例如选自以下的藻类:双眉藻属(amphora)、鱼腥藻属(anabaena)、纤维藻属(anikstrodesmis)、丛粒藻属(botryococcus)、角毛藻属(chaetoceros)、衣藻属(chlamydomonas)、绿藻属(chlorella)、绿球藻属(chlorococcum)、小环藻属(cyclotella)、筒柱藻属(cylindrotheca)、杜氏藻属(dunaliella)、球石藻属(emiliana)、眼虫属(euglena)、红球藻属(hematococcus)、等鞭金藻属(isochrysis)、单鞭金藻属(monochrysis)、单针藻属(monoraphidium)、微绿球藻属(nannochloris)、拟微绿球藻属(nannnochloropsis)、舟形藻属(navicula)、肾鞭藻属(nephrochloris)、肾爿藻属(nephroselmis)、菱形藻属(nitzschia)、节球藻属(nodularia)、念珠藻属(nostoc)、髓球藻属(oochromonas)、卵囊藻(oocystis)、颤藻属(oscillartoria)、巴夫藻属(pavlova)、褐指藻属(phaeodactylum)、扁藻属(playtmonas)、颗石藻属(pleurochrysis)、紫菜属(porhyra)、假鱼腥藻属(pseudoanabaena)、塔胞藻属(pyramimonas)、裂丝藻属(stichococcus)、聚球藻属(synechococcus)、集胞藻属(synechocystis)、四爿藻属(tetraselmis)、海链藻属(thalassiosira)以及束毛藻属(trichodesmium)。
可以根据本发明的方法处理植物的一部分,即“植物组织”,以产生改良的植物。植物组织还涵盖植物细胞。如本文所用的术语“植物细胞”是指活体植物的个体单元,或者在完整全株中或者为在体外组织培养基中、在培养基或琼脂上、在生长培养基或缓冲液的悬浮液中或作为高等组织单元一部分生长的分离形式,例如像植物组织、植物器官或全株。
“原生质体”是指这样的植物细胞,其保护性细胞壁使用例如机械或酶手段被完全去除或部分去除从而形成活体植物的完整生物化学活性单元,该活性单元在适当生长条件下可以重新形成细胞壁、增殖并再生成全株。
术语“转化”广泛地是指通过借助于土壤杆菌或多种化学或物理方法之一来引入dna从而对植物宿主进行遗传修饰的过程。如本文所用,术语“植物宿主”是指植物,包括植物的任何细胞、组织、器官、或子代。许多合适的植物组织或植物细胞可以被转化,并且包括但不限于原生质体、体细胞胚胎、花粉、叶、幼苗、茎、愈伤组织、匍伏茎、试管块茎、以及胚芽。植物组织还是指这种植物、种子、子代、繁殖体(不管有性还是无性生殖的)、以及这些中任一项的后代(诸如插条或种子)的任何克隆。
如本文所用,术语“转化的”是指已引入外源dna分子诸如构建体的细胞、组织、器官或生物体。所引入的dna分子可以整合到受体细胞、组织、器官或生物体的基因组dna中,以使得引入的dna分子被传递至后续子代。在这些实施方案中,“转化的”或“转基因的”细胞或植物还可以包括细胞或植物的子代以及通过育种程序采用这种转化的植物作为杂交的母体并表现出因引入的dna分子的存在而产生的改变的表型的子代。优选地,转基因植物是能育的并且能够将引入的dna通过有性繁殖传递给子代。
术语“子代”诸如转基因植物的子代是由植物或转基因植物生出的、由其产生的或从其来源的子代。所引入的dna分子还可以被瞬时引入到受体细胞中,使得所引入的dna分子不被后续子代遗传并且因此不被认为是“转基因的”。因此,如本文所用,“非转基因”植物或植物细胞是不含有稳定整合到其基因组中的外源dna的植物。
如本文所用,术语“植物启动子”是能够启动植物细胞转录的启动子,无论其是否来源自植物细胞。示例性的合适植物启动子包括但不限于,那些获得自植物、植物病毒以及细菌(诸如包含在植物细胞中表达的基因的土壤杆菌属或根瘤菌属)的启动子。
如本文所用,“真菌细胞”是指真菌界内的任何类型的真核细胞。真菌界内的门包括子囊菌门(ascomycota)、担子菌门(basidiomycota)、芽枝霉门(blastocladiomycota)、壶菌门(chytridiomycota)、球囊菌门(glomeromycota)、微孢子虫目(microsporidia)以及新美鞭菌门(neocallimastigomycota)。真菌细胞可包括酵母、霉菌和丝状真菌。在一些实施方案中,真菌细胞是酵母细胞。
如本文所用,术语“酵母细胞”是指子囊菌门和担子菌门内的任何真菌细胞。酵母细胞可以包括芽殖酵母细胞、裂殖酵母细胞和霉菌细胞。不限于这些生物体,在实验室和工业环境中使用的许多类型的酵母菌是子囊菌门的部分。在一些实施方案中,酵母细胞是酿酒酵母(s.cerervisiae)、马克思克鲁维酵母(kluyveromycesmarxianus)或东方伊萨酵母(issatchenkiaorientalis)细胞。其他酵母细胞可以包括但不限于假丝酵母属种(candidaspp.)(例如白色念珠菌(candidaalbicans))、亚罗酵母属种(yarrowiaspp.)(例如亚罗解脂酵母(yarrowialipolytica))、毕赤酵母属种(pichiaspp.)(例如巴斯德毕赤酵母(pichiapastoris))、克鲁维酵母菌属种(kluyveromycesspp.)(例如产乳糖酶酵母(kluyveromyceslactis)和马克思克鲁维酵母)、脉孢菌属种(neurosporaspp.)(例如粗糙脉孢菌(neurosporacrassa))、镰刀菌属种(fusariumspp.)(例如尖孢镰刀菌(fusariumoxysporum)),以及伊萨酵母属种(issatchenkiaspp.)(例如东方伊萨酵母,又称为库德里阿兹威毕赤酵母(pichiakudriavzevii)和candidaacidothermophilum)。在一些实施方案中,真菌细胞是丝状真菌细胞。如本文所用,术语“丝状真菌细胞”是指以丝状体(即菌丝或菌丝体)生长的任何类型的真菌细胞。丝状真菌细胞的实例可以包括但不限于曲霉属种(aspergillusspp.)(例如黑曲霉(aspergillusniger))、木霉属种(trichodermaspp.)(例如里氏木霉(trichodermareesei))、根霉属种(rhizopusspp.)(例如米根霉(rhizopusoryzae))以及被孢霉属种(mortierellaspp.)(例如深黄被孢霉(mortierellaisabellina))。
在一些实施方案中,真菌细胞是工业菌株。如本文所用,“工业菌株”是指工业工艺(例如,商业或工业规模的产品生产)中使用的或从中分离的任何真菌细胞菌株。工业菌株可以指代典型地在工业工艺中使用的真菌种类,或者它可以指代还可用于非工业目的(例如,实验室研究)的真菌种类的分离株。工业工艺的实例可以包括发酵(例如,在食品或饮料产品的生产中)、蒸馏、生物燃料生产、化合物生产以及多肽生产。工业菌株的实例可以包括但不限于jay270和atcc4124。
在一些实施方案中,真菌细胞是多倍体细胞。如本文所用,“多倍体”细胞可以指代其基因组以多于一个拷贝存在的任何细胞。多倍体细胞可以指代天然地发现处于多倍体状态的细胞类型,或者它可以指代已被诱导以多倍体状态存在的细胞(例如,通过特异性调节、改变、失活、激活、或者减数分裂、胞质分裂或dna复制的修饰)。多倍体细胞可以指代其整个基因组是多倍体的细胞,或者它可以指代在特定目标基因组基因座中为多倍体的细胞。不希望受理论的束缚,认为与在单倍体细胞中相比指导rna的丰度在多倍体细胞的基因组工程化中可能更经常地是速率限制性组分,并且因此使用本文所述的ad官能化的crispr系统的方法可以利用使用某一真菌细胞类型的优点。
在一些实施方案中,真菌细胞是二倍体细胞。如本文所用,“二倍体”细胞可以指代其基因组以两个拷贝存在的任何细胞。二倍体细胞可以指代天然地发现处于二倍体状态的细胞类型,或者它可以指代已被诱导以二倍体状态存在的细胞(例如,通过特异性调节、改变、失活、激活、或者减数分裂、胞质分裂或dna复制的修饰)。例如,酿酒酵母菌株s228c可以维持处于单倍体或二倍体状态。二倍体细胞可以指代其整个基因组是二倍体的细胞,或者它可以指代在特定目标基因组基因座中为二倍体的细胞。在一些实施方案中,真菌细胞是单倍体细胞。如本文所用,“单倍体”细胞可以指代其基因组以一个拷贝存在的任何细胞。单倍体细胞可以指代天然地发现处于单倍体状态的细胞类型,或者它可以指代已被诱导以单倍体状态存在的细胞(例如,通过特异性调节、改变、失活、激活、或者减数分裂、胞质分裂或dna复制的修饰)。例如,酿酒酵母菌株s228c可以维持处于单倍体或二倍体状态。单倍体细胞可以指代其整个基因组是单倍体的细胞,或者它可以指代在特定目标基因组基因座中为单倍体的细胞。
如本文所用,“酵母表达载体”是指含有编码rna和/或多肽的一个或多个序列的核酸并且还可以含有控制一个或多个核酸表达的任何所需元件,以及使得能够在酵母细胞内复制并维持表达载体的任何元件。许多合适的酵母表达载体及其特征在本领域中是已知的;例如,各种载体和技术示出于yeastprotocols,第2版,xiao,w.,编辑(humanapress,newyork,2007)以及buckholz,r.g.和gleeson,m.a.(1991)biotechnology(ny)9(11):1067-72。酵母载体可以包含但不限于着丝粒(cen)序列、自主复制序列(ars)、可操作地连接至目标序列或基因的启动子(诸如rna聚合酶iii启动子)、终止子(诸如rna聚合酶iii终止子)、复制起点和标记基因(例如,营养缺陷型、抗生素型、或其他选择性标记物)。在酵母菌中使用的表达载体的实例可以包括质粒、酵母人工染色体、2μ质粒、酵母整合型质粒、酵母复制型质粒、穿梭载体以及附加型质粒。
ad官能化的crispr系统组分在植物和植物细胞基因组中的稳定整合
在特定实施方案中,设想的是引入编码ad官能化的crispr系统的组分的多核苷酸,以稳定整合到植物细胞的基因组中。在这些实施方案中,可以依据指导rna和/或腺苷脱氨酶和cpf1的融合蛋白在何时、何处及在何条件下表达,对转化载体或表达系统的设计进行调整。
在特定实施方案中,设想的是将ad官能化的crispr系统的组分稳定地引入植物细胞的基因组dna中。另外地或可替代地,设想的是引入ad官能化的crispr系统的组分,以将其稳定整合到植物细胞器的dna中,诸如但不限于质体、线粒体或叶绿体。
用于稳定整合到植物细胞基因组中的表达系统可以含有以下元件中的一者或多者:可用于在植物细胞中表达指导rna和/或腺苷脱氨酶和cpf1的融合蛋白的启动子元件;增强表达的5’非翻译区;进一步增强在某些细胞(诸如单子叶植物细胞)中表达的内含子元件;为插入编码指导rna和/或腺苷脱氨酶和cpf1的融合蛋白的序列以及其他所需元件提供方便的限制性位点的多克隆位点;以及为所表达的转录物提供有效终止的3’非翻译区。
表达系统的元件可以处于一个或多个表达构建体上,所述一个或多个表达构建体是环状的(诸如质粒或转化载体),或者是非环状的(诸如线性双链dna)。
在特定实施方案中,ad官能化的crispr表达系统至少包含:编码与植物中的靶序列杂交的指导rna(grna)的核苷酸序列,并且其中所述指导rna包含指导序列和同向重复序列;以及编码腺苷脱氨酶和cpf1的融合蛋白的核苷酸序列,其中组分(a)或(b)位于相同或不同构建体上,并且由此不同核苷酸序列可以处于植物细胞内可操作的相同或不同调控元件的控制下。
可以通过多种常规技术将含有ad官能化的crispr系统的组分的一个或多个dna构建体和(在适用情况下)模板序列引入到植物、植物部分或植物细胞的基因组中。所述方法大体上包括以下步骤:选择合适的宿主细胞或宿主组织、将所述一个或多个构建体引入到宿主细胞或宿主组织中,以及由其再生植物细胞或植物。
在特定实施方案中,可以使用诸如但不限于电穿孔、微注射、植物细胞原生质体的雾化束注入的技术将dna构建体引入到植物细胞中,或者可以使用诸如dna粒子轰击的基因枪法直接将这些dna构建体引入到植物组织中(另参见fu等人,transgenicres.2000年2月;9(1):11-9)。粒子轰击的基础是使包覆有目标一种或多种基因的粒子朝向细胞加速,从而导致粒子穿透原生质并且典型地稳定整合到基因组中。(参见例如klein等人,nature(1987),kleinetah,bio/technology(1992),casasetah,proc.natl.acad.sci.usa(1993).)。
在特定实施方案中,可以通过土壤杆菌介导的转化将含有ad官能化的crispr系统的组分的dna构建体引入到植物中。可以将dna构建体与合适的t-dna侧接区组合,并且将它们引入到常规根瘤土壤杆菌(agrobacteriumtumefaciens)宿主载体中。通过感染植物或通过用含有一种或多种ti(肿瘤诱导)质粒的土壤杆菌属细菌培育植物原生质体,可以将外源dna并入植物基因组中。(参见例如fraley等人(1985)、rogers等人(1987)和美国专利号5,563,055)。
植物启动子
为了确保在植物细胞中适当表达,典型地将本文所述的ad官能化的crispr系统的组分置于植物启动子(即在植物细胞中可操作的启动子)的控制下。设想了使用不同类型的启动子。
组成型植物启动子是能够在所有或几乎所有植物组织的所有或几乎所有植物发育阶段表达可读框(orf)的启动子(称为“组成型表达”)。组成型启动子的一个非限制性实例是花椰菜花叶病毒35s启动子。“调节启动子”是指非组成型地、但是以时间和/或空间调节方式指导基因表达的启动子,并且包括组织特异性、组织优选型及诱导型启动子。不同启动子可以指导在不同组织或细胞类型中、或在不同发育阶段、或响应于不同环境条件的基因表达。在特定实施方案中,ad官能化的crispr组分中的一者或多者在组成型启动子(诸如花椰菜花叶病毒35s启动子)的控制下表达,组织优选型启动子可以用于靶向特定植物组织中某些细胞类型,例如叶或根的维管细胞或种子的特定细胞内的增强的表达。用于ad官能化的crispr系统的特定启动子的实例可见于kawamata等人,(1997)plantcellphysiol38:792-803;yamamoto等人,(1997)plantj12:255-65;hire等人,(1992)plantmolbiol20:207-18;kuster等人,(1995)plantmolbiol29:759-72;以及capana等人,(1994)plantmolbiol25:681-91。
在有限的情况下,为了避免脱氨酶的非特异性活性,诱导型启动子可以有利地表达ad官能化的crispr系统组分中的一者或多者。在特定实施方案中,ad官能化的crispr系统的一个或多个元件在诱导型启动子的控制下表达。允许空间时间控制基因编辑或基因表达的诱导型启动子的实例可以使用能量形式。能量形式可以包括但不限于声能、电磁辐射、化学能和/或热能。诱导型系统的实例包括四环素诱导型启动子(tet-on或tet-off)、小分子双杂交转录激活系统(fkbp、aba等)、或光诱导型系统(光敏色素、lov结构域或隐花色素),诸如以序列特异性方式引导转录活性改变的光诱导型转录效应子(lite)。光诱导型系统的组分可以包括腺苷脱氨酶和cpf1的融合蛋白、光反应性细胞色素异源二聚体(例如,来自阿拉伯芥)。诱导型dna结合蛋白及其使用方法的另外的实例提供于us61/736465和us61/721,283中,这些专利以引用方式整体并入本文。
在特定实施方案中,可以通过使用例如化学调节型启动子来实现瞬时表达或诱导型表达,即由此应用外源性化学品诱导基因表达。也可以通过化学阻抑型启动子来获得对基因表达的调节,其中应用化学品阻抑基因表达。化学诱导型启动子包括但不限于:由苯磺酰胺除草剂安全剂激活的玉米ln2-2启动子(deveylder等人,(1997)plantcellphysiol38:568-77)、由用作萌前除草剂的疏水性亲电子化合物激活的玉米gst启动子(gst-ll-27,wo93/01294),以及由水杨酸激活的烟草pr-1a启动子(ono等人,(2004)bioscibiotechnolbiochem68:803-7)。还可以在本文中使用由抗生素调节的启动子,诸如四环素诱导型启动子和四环素阻抑型启动子(gatz等人,(1991)molgengenet227:229-37;美国专利号5,814,618和5,789,156)。
特定植物细胞器中的易位和/表达
表达系统可以包含在特定植物细胞器中易位并且/或者表达的元件。
叶绿体靶向
在特定实施方案中,设想的是将ad官能化的crispr系统用于特异性修饰叶绿体基因或确保在叶绿体中的表达。出于此目的,使用叶绿体转化方法或者将ad官能化的crispr组分区室化至叶绿体的方法。例如,在质粒基因组中引入遗传修饰可以减少生物安全性问题,诸如通过花粉的基因流。
叶绿体转化的方法在本领域中是已知的,并且包括粒子轰击、peg处理和微注射。另外,涉及转化盒从核基因组易位至质粒的方法可以如wo2010061186所述地使用。
或者,设想的是将ad官能化的crispr组分中的一者或多者靶向植物叶绿体。这是通过在表达构建体中结合编码叶绿体转运肽(ctp)或质体转运肽的序列来实现的,该序列可操作地连接至编码腺苷脱氨酶和cpf1的融合蛋白的序列的5’区。在易位到叶绿体中的过程中,在处理步骤中去除ctp。所表达蛋白质的叶绿体靶向是本领域技术人员所熟知的(参见例如proteintransportintochloroplasts,2010,annualreviewofplantbiology,第61卷:157-180)。在此类实施方案中,还期望将指导rna靶向植物叶绿体。例如在us20040142476中描述了可以用于借助于叶绿体定位序列来将指导rna易位到叶绿体中的方法和构建体,该专利以引用方式并入本文。可以将构建体的此类变型并入本发明的表达系统中以有效地使ad官能化的crispr系统组分易位。
在藻类细胞中引入编码ad官能化的crispr系统的多核苷酸.
转基因藻类(或其他植物诸如油菜)可能在植物油或生物燃料诸如醇类(尤其是甲醇和乙醇)或其他产品的生产中特别有用。这些可以被工程化以表达或过表达高水平的油或醇类,以供在油或生物燃料行业中使用。
us8945839描述了一种用于使用cas9工程化微藻(莱茵衣藻(chlamydomonasreinhardtii)细胞)的方法。使用类似的工具,本文所述的ad官能化的crispr系统的方法可以应用于衣藻属种和其他藻类。在特定实施方案中,在藻类中引入crispr-cas蛋白(例如cpf1)、腺苷脱氨酶(其可以融合至crispr-cas蛋白或适体结合衔接蛋白)和指导rna,其使用在组成型启动子诸如hsp70a-rbcs2或β2-微管蛋白的控制下表达腺苷脱氨酶和cpf1的融合蛋白的载体进行表达。指导rna任选地使用含有t7启动子的载体递送。或者,可以将cpf1mrna和体外转录的指导rna递送至藻类细胞。电穿孔方案可由本领域技术人员获得,诸如来自geneart衣藻属工程化试剂盒(geneartchlamydomonasengineeringkit)的标准推荐方案。
在酵母细胞中引入ad官能化的crispr系统组分
在特定实施方案中,本发明涉及ad官能化的crispr系统用于酵母细胞的基因组编辑的用途。可以用于引入编码ad官能化的crispr系统组分的多核苷酸的转化酵母细胞的方法描述于kawai等人,2010,bioengbugs.2010年11月-12月;1(6):395-403)。非限制性实例包括通过醋酸锂处理(其还可以包括运载dna和peg处理)、轰击或通过电穿孔来转化酵母细胞。
在植物和植物细胞中瞬时表达ad官能化的crispr系统组分
在特定实施方案中,设想的是在植物细胞中瞬时表达指导rna和/或crispr-cas基因。在这些实施方案中,仅当细胞中存在指导rna、crispr-cas蛋白(例如cpf1)和腺苷脱氨酶(其可以融合至crispr-cas蛋白或适体结合衔接蛋白)时,ad官能化的crispr系统可以确保靶基因的修饰,这样使得可以进一步控制基因修饰。因为crispr-cas蛋白的表达是瞬时的,自此类植物细胞再生的植物典型地不含外源dna。在特定实施方案中,crispr-cas蛋白由植物细胞稳定表达,并且指导序列被瞬时表达。
在特定实施方案中,可以使用植物病毒载体将ad官能化的crispr系统组分引入植物细胞中(scholthof等人1996,annurevphytopathol.1996;34:299-323)。在另外的特定实施方案中,所述病毒载体是来自dna病毒的载体。例如,双粒病毒组(例如卷心菜曲叶病毒、豆黄矮病毒、小麦矮化病毒、番茄曲叶病毒、玉米条纹病毒、烟草曲叶病毒或番茄金色花叶病毒)或矮缩病毒组(例如蚕豆坏死黄脉病毒)。在其他特定实施方案中,所述病毒载体是来自rna病毒的载体。例如,烟草脆裂病毒组(例如烟草扰乱病毒、烟草花叶病毒)、马铃薯x病毒组(例如马铃薯x病毒),或大麦病毒组(例如,大麦条纹花叶病毒)。植物病毒复制基因组是非整合型载体。
在特定实施方案中,用于瞬时表达ad官能化的crispr系统的载体是例如peaq载体,该载体被专门定制用于在原生质体中进行土壤杆菌介导的瞬时表达(sainsburyf.等人,plantbiotechnolj.2009sep;7(7):682-93)。使用修饰的卷心菜叶曲病毒(calcuv)载体以在表达crispr酶的稳定转基因植物中表达指导rna证明了基因组位置的精确靶向(scientificreports5,文章编号:14926(2015),doi:10.1038/srep14926)。
在特定实施方案中,可以将编码指导rna和/或crispr-cas基因的双链dna片段瞬时导入到植物细胞中。在此类实施方案中,以足够的量提供引入的双链dna片段以修饰细胞,但在预期时间段过去之后或者在一次或多次细胞分裂之后不再持续。用于在植物中进行直接dna转移的方法是技术人员已知的(参见例如davey等人plantmolbiol.1989年9月;13(3):273-85。)
在其他实施方案中,将编码crispr-cas蛋白(例如cpf1)和/或腺苷脱氨酶(其可以融合至crispr-cas蛋白或适体结合衔接蛋白)的rna多核苷酸引入到植物细胞中,然后植物细胞被生成足够量的蛋白质的宿主细胞翻译并加工以修饰该细胞(在至少一种指导rna存在下),该引入在预期时间段过去之后或者在一次或多次细胞分裂之后不再持续。用于将mrna引入植物原生质体以进行瞬时表达的方法是技术人员已知的(参见例如gallie,plantcellreports(1993),13;119-122)。
还设想了以上所述的不同方法的组合。
将ad官能化的crispr系统组分递送至植物细胞
在特定实施方案中,令人感兴趣的是将ad官能化的crispr系统的一种或多种组分直接递送至植物细胞。对于产生非转基因植物,这是尤其令人感兴趣的(参见下文)。在特定实施方案中,在植物或植物细胞外部制备ad官能化的crispr系统组分中的一者或多者并将其传递至细胞。例如,在特定实施方案中,在体外制备crispr-cas蛋白,之后将其引入植物细胞中。可以通过本领域技术人员已知的各种方法来制备crispr-cas蛋白,包括重组生产。在表达之后,将crispr-cas蛋白分离,如果需要的话进行再折叠,进行纯化和任选地进行处理以去除任何纯化标签(诸如his标签)。一旦获得粗的、部分纯化的、或更完全纯化的crispr-cas蛋白,就可以将该蛋白引入植物细胞中。
在特定实施方案中,将crispr-cas蛋白与靶向目标基因的指导rna混合,以形成预组装的核糖核蛋白。
可以经由电穿孔、通过用crispr-cas相关基因产品包覆的粒子的轰击、通过化学转染或通过跨细胞膜转运的一些其他手段,将这些单独的组分或预组装的核糖核蛋白引入到植物细胞中。例如,已证明用预组装crispr核糖核蛋白转染植物原生质体确保了植物基因组的靶向修饰(如woo等人naturebiotechnology,2015;doi:10.1038/nbt.3389)所述。
在特定实施方案中,使用纳米粒子将ad官能化的crispr系统组分引入到植物细胞中。这些组分,无论是蛋白质或核酸或它们的组合,都可以上载到纳米粒子上或包装在纳米粒子中并且适用于这些植物(例如像wo2008042156和us20130185823所述的)。特别地,本发明的实施方案包括上载有或包装有以下各项的纳米粒子:编码crispr-cas蛋白(例如cpf1)的一个或多个dna分子、编码腺苷脱氨酶(其可以融合至crispr-cas蛋白或适体结合衔接蛋白)的一个或多个dna分子,以及编码指导rna的dna分子和/或如wo2015089419中所述的分离的指导rna。
将ad官能化的crispr系统的一种或多种组分引入植物细胞中的其他手段是使用细胞穿透肽(cpp)。因此,在特定实施方案中,本发明包括含有连接至crispr-cas蛋白的细胞穿透肽的组合物。在本发明的特定实施方案中,将crispr-cas蛋白和/或指导rna与一种或多种cpp偶联以有效地将它们转运到植物原生质体内。ramakrishna(genomeres.2014年6月;24(6):1020-7,针对人类细胞中的cas9)。在其他实施方案中,crispr-cas基因和/或指导rna由一个或多个环状或非环状dna分子编码,所述一个或多个环状或非环状dna分子与一个或多个cpp偶联以便进行植物原生质体递送。然后将植物原生质体再生为植物细胞并进一步再生为植物。cpp通常被描述为来源于蛋白质或来源于能够以非受体依赖性方式跨细胞膜转运生物分子的嵌合序列的小于35个氨基酸的短肽。cpp可以是阳离子肽、具有疏水性序列的肽、两亲性肽、具有富含脯氨酸的序列和抗微生物序列的肽,以及嵌合肽或二分肽(pooga和langel2005)。cpp能够穿透生物膜,并且如此触发不同生物分子跨细胞膜移动到细胞质中,并能改善它们的细胞内通路,并且因此促进生物分子与靶标的相互作用。cpp的实例包括:tat(通过hiv1型进行病毒复制所需的核转录激活蛋白)、穿透素、卡波济(kaposi)成纤维细胞增长因子(fgf)信号肽序列、整联蛋白β3信号肽序列;聚精氨酸肽arg序列、富含鸟嘌呤的分子转运体、甜箭头肽(sweetarrowpeptide)等。
使用ad官能化的crispr系统制备遗传修饰的非转基因植物
在特定实施方案中,本文所述的方法用于修饰内源性基因或修饰其表达而不永久性引入到任何外源基因的植物的基因组中,包括编码crispr组分的外源基因,以便避免在植物基因组中存在外源dna。这可能是令人感兴趣的,因为对非转基因植物的规则要求较不严格。
在特定实施方案中,这是通过ad官能化的crispr系统组分的瞬时表达来确保的。在特定实施方案中,一种或多种组分是在一种或多种病毒载体上表达的,所述一种或多种表达载体产生足够的crispr-cas蛋白、腺苷脱氨酶和指导rna,以一致地稳定地确保根据本文所述的方法修饰目标基因。
在特定实施方案中,在植物原生质体中确保ad官能化的crispr系统构建体的瞬时表达并且因此该构建体并未整合到基因组中。有限的表达窗口足以允许ad官能化的crispr系统确保如本文所述的靶基因的修饰。
在特定实施方案中,ad官能化的crispr系统的不同组分借助于如上文所述的粒子递送分子诸如纳米粒子或cpp分子单独地或混合地引入在植物细胞、原生质体或植物组织中。
ad官能化的crispr系统组分的表达可以通过腺苷脱氨酶的脱氨酶活性诱导基因组的靶向修饰。上文所述的不同策略允许crispr介导的靶向基因组编辑,而无需将ad官能化的crispr系统组分引入到植物基因组中。瞬时导入到植物细胞中的组分典型地在杂交后去除。
植物培养和再生
在特定实施方案中,具有修饰基因组并且通过本文所述的任何方法产生或获得的植物细胞可以被培养至再生成具有转化或修饰表型并因此具有所需表型的全株。常规的再生技术是本领域技术人员所熟知的。此类再生技术的特定实例依赖于组织培养生长培养基中某些植物激素的操纵,并且典型地依赖于已与所需核苷酸序列一起引入的杀生物剂和/或除草剂标记物。在另外的特定实施方案中,植物再生是从培养的原生质体、植物愈伤组织、外植体、器官、花粉、胚胎或其部分获得的(参见例如evans等人(1983),handbookofplantcellculture;klee等人(1987)ann.rev.ofplantphys.)。
在特定实施方案中,如本文所述的转化或改良的植物可以自体受精以提供本发明的纯合改良植物(对于dna修饰是纯合的)的种子,或者可以与非转基因植物或不同的改良植物杂交以提供纯合植物的种子。当将重组dna引入到植物细胞中时,这种杂交所产生的植物是对于重组dna分子为杂合的植物。通过与改良植物杂交并包含遗传修饰(可以是重组dna)而获得的此类纯合植物和杂合植物在此被称为“子代”。子代植物是从原始转基因植物传代并且含有通过本文提供的方法引入的基因组修饰或重组dna分子的植物。或者,遗传修饰植物可以是通过以上所述方法之一使用ad官能化的crispr系统来获得的,因此无外源dna并入该基因组中。通过进一步育种获得的此类植物的子代也可以含有遗传修饰。育种是通过常用于不同农作物的任何育种方法来进行(例如allard,principlesofplantbreeding,johnwiley&sons,ny,u.ofca,davis,ca,50-98(1960)。
生成具有增强的农艺性状的植物
本文提供的ad官能化的crispr系统可用于引入靶向的a-g和t-c突变。通过在单一细胞中共表达旨在实现多种修饰的多个靶向rna,可以确保多重基因组修饰。此技术可以用于高度精确工程化植物以使其具有改良的特征,包括增强的营养品质、增加的对疾病的抗性和对生物和非生物胁迫的抗性,以及增加的有商业价值的植物产品或异源化合物的产生。
在特定实施方案中,如本文所述的ad官能化的crispr系统用于引入靶向的a-g和t-c突变。这种突变可以是无义突变(例如,提前终止密码子)或错义突变(例如,编码不同的氨基酸残基)。当某些内源性基因中的a-g和t-c突变可以赋予或促成所需性状时,这是令人感兴趣的。
本文所述的方法通常导致生成“改良植物”,在这点上它们与野生型植物相比具有一种或多种期望的性状。在特定实施方案中,获得的植物、植物细胞或植物部分是包含并入植物的所有或部分细胞的基因组中的外源性dna序列的转基因植物。在特定实施方案中,获得非转基因遗传修饰植物、植物部分或细胞,在这点上没有外源性dna序列并入植物的任何植物细胞的基因组中。在此类实施方案中,改良植物是非转基因的。当仅确保内源性基因的修饰并且在植物基因组中未引入或维持外源基因时,所得遗传修饰农作物不含有外源基因并且因此可以基本上认为是非转基因的。
在特定实施方案中,多核苷酸通过dna病毒(例如双粒病毒组)或rna病毒(例如烟草脆裂病毒组)递送至细胞。在特定实施方案中,引入步骤包括将含有编码crispr-cas蛋白、腺苷脱氨酶和指导rna的一个或多个多核苷酸序列的t-dna递送至植物细胞,其中所述递送是经由土壤杆菌进行的。可以将编码ad官能化的crispr系统的组分的多核苷酸序列可操作地连接至启动子,诸如组成型启动子(例如花椰菜花叶病毒35s启动子)或细胞特异性启动子或诱导型启动子。在特定实施方案中,通过微粒轰击引入多核苷酸。在特定实施方案中,所述方法还包括在引入步骤之后筛选植物细胞,以确定目标基因的表达是否已被修饰。在特定实施方案中,所述方法包括从植物细胞再生植物的步骤。在另外的实施方案中,所述方法包括使植物杂交育种以获得遗传上所需的植物谱系。
在以上所述的方法的特定实施方案中,抗病性农作物是通过靶向突变疾病易感性基因或植物防卫基因中的编码负调节子的基因(例如,mlo基因)来获得的。在特定实施方案中,耐除草剂农作物是通过靶向取代植物基因诸如编码乙酰乳酸合酶(als)和原卟啉原氧化酶(ppo)的基因的特定核苷酸来生成的。在特定实施方案中,通过靶向突变编码负调节子的基因而产生的具有非生物胁迫耐受性的耐干旱和盐农作物、通过靶向突变waxy基因而产生的低直链淀粉谷物、通过靶向突变糊粉层中的主要脂肪酶基因而产生的具有降低的酸败性的稻谷或其他谷物等。在特定实施方案中。编码目标性状的内源性基因的更广泛列表列出在下文中。
使用ad官能化的crispr系统修饰多倍体植物
许多植物都是多倍体的,这意味着它们携带其基因组的复制拷贝-像在小麦中,有时多至六个。根据本发明利用ad官能化的crispr系统的方法可以被“多重化”以影响基因的所有拷贝,或者一次靶向许多基因。例如,在特定实施方案中,本发明的方法用于同时确保不同基因中负责阻遏针对疾病的防卫的功能丧失突变。在特定实施方案中,本发明的方法用于同时阻遏小麦植物细胞内tamlo-al、tamlo-bl和tamlo-dl核酸序列的表达并且由该细胞再生小麦植物,以便确保该小麦植物抵抗白粉病(另参见wo2015109752)。
赋予农艺性状的示例性基因
在特定实施方案中,本发明涵盖在内源性基因及其调控元件中包括靶向a-g和t-c突变的方法,所述内源性基因诸如以下列出的基因:
1.赋予对害虫或疾病的抗性的基因:
植物疾病抗性基因。可以用克隆的抗性基因转化植物以工程化对特定病原体菌株具有抗性的植物。参见例如jones等人,science266:789(1994)(cloningofthetomatocf-9geneforresistancetocladosporiumfulvum);martin等人,science262:1432(1993)(tomatoptogeneforresistancetopseudomonassyringaepv.tomatoencodesaproteinkinase);mindrinos等人,cell78:1089(1994)(arabidopsmaybersp2geneforresistancetopseudomonassyringae)。可以对在病原体感染期间被上调或下调的植物基因进行工程化以获得病原体抗性。参见例如thomazella等人,biorxiv064824;doi:https://doi.org/10.1101/064824epub.2016年7月23日(tomatoplantswithdeletionsinthesldmr6-1whichisnormallyupregulatedduringpathogeninfection)。
赋予对害虫诸如大豆囊胞线虫的抗性的基因。参见例如,pct申请wo96/30517;pct申请wo93/19181。
苏云金芽孢杆菌蛋白,参见例如geiser等人,gene48:109(1986)。
凝集素,参见例如vandamme等人,plantmolec.biol.24:25(1994。
维生素结合蛋白,诸如抗生物素蛋白,参见pct申请us93/06487,该申请教导了抗生物素蛋白和抗生物素蛋白同源物作为针对害虫的杀幼虫剂的用途。
酶抑制剂诸如蛋白酶或朊酶抑制剂或淀粉酶抑制剂。参见例如abe等人,j.biol.chem.262:16793(1987);huub等人,plantmolec.biol.21:985(1993));sumitani等人,biosci.biotech.biochem.57:1243(1993)和美国专利号5,494,813。
昆虫特异性激素或信息素,诸如蜕皮类固醇或保幼激素、或其变体、基于它的模拟物、或其拮抗剂或激动剂。参见例如hammock等人,nature344:458(1990)。
昆虫特异性肽或神经肽,这些肽在表达时破坏受影响害虫的生理。例如regan,j.biol.chem.269:9(1994)和pratt等人,biochem.biophys.res.comm.163:1243(1989)。另参见美国专利号5,266,317。
在自然界中由蛇、黄蜂或任何其他生物体产生的昆虫特异性毒液。例如,参见pang等人,gene116:165(1992)。
引起单萜、倍半萜、甾体、异羟肟酸、苯丙素衍生物或具有杀昆虫活性的另一种非蛋白质分子超积累的酶。
参与生物活性分子修饰(包括翻译后修饰)的酶;例如,糖解酶、蛋白水解酶、脂解酶、核酸酶、环化酶、转氨酶、酯酶、水解酶、磷酸酶、激酶、磷酸化酶、聚合酶、弹性蛋白酶、壳多糖酶以及葡聚糖酶,无论是天然还是合成的。参见pct申请wo93/02197;kramer等人,insectbiochem.molec.biol.23:691(1993)和kawalleck等人,plantmolec.biol.21:673(1993)。
刺激信号转导的分子。例如,参见botella等人,plantmolec.biol.24:757(1994)和griess等人,plantphysiol.104:1467(1994)。
病毒侵入蛋白或源于此的复合物毒素。参见beachy等人,ann.rev.phytopathol.28:451(1990)。
在自然界中由病原体或寄生虫产生的发育阻滞蛋白。参见lamb等人,bio/technology10:1436(1992)和toubart等人,plantj.2:367(1992)。
在自然界中由植物产生的发育阻滞蛋白。例如,logemann等人,bio/technology10:305(1992)。
在植物中,病原体通常是宿主特异性的。例如,一些镰刀菌种类将引起番茄枯萎病但仅攻击番茄,而其他镰刀菌种类仅攻击小麦。植物具有现有和诱导的防卫以抵抗大部分病原体。跨植物各代的突变和重组事件导致引起易感性的遗传变异性,特别是当病原体以比植物更大频率繁殖时。在植物中可以存在非宿主抗性,例如宿主和病原体是不相容的或者可以存在针对所有病原体种族的部分抗性,这些抗性典型地是通过许多基因来控制的,并且/或者也存在对一些病原体种族而不是其他种族的完全抗性。此抗性典型地是通过几种基因控制的。使用多种方法和ad官能化的crispr系统组分,现在存在一种在此预先诱导特异性突变的新工具。因此,可以分析抗性基因来源基因组,并且在具有所需特征或形状的植物中,使用所述多种方法和ad官能化的crispr系统组分来诱导抗性基因增加。本发明系统可以比先前的诱变剂更精确地完成此分析并且因此加速并改善植物育种程序。
2.涉及植物疾病的基因,诸如wo2013046247中列出的基因:
稻谷病害:稻瘟病菌(magnaporthegrise)、宫部旋孢腔菌(cochliobolusmiyabeanus)、立枯丝核菌(rhizoctoniasolani)、藤仓赤霉(gibberellafujikuroi);小麦病害:白粉病菌(erysiphegraminis)、禾谷镰刀菌(fusariumgraminearum)、燕麦镰刀菌(f.avenaceum)、黄色镰刀菌(f.culmorum)、雪霉叶枯菌(microdochiumnivale)、条形柄锈菌(pucciniastriiformis)、禾柄锈菌(p.graminis)、隐匿柄锈菌(p.recondita)、粉红雪腐病菌(micronectriellanivale)、核瑚菌属种(typhulasp.)、小麦黑粉菌(ustilagotritici)、小麦网腥黑穗病菌(tilletiacaries)、小麦基腐病菌(pseudocercosporellaherpotrichoides)、禾生球腔菌(mycosphaerellagraminicola)、小麦壳多孢(stagonosporanodorum)、偃麦草核腔菌(pyrenophoratritici-repentis);大麦病害:白粉病菌、禾谷镰刀菌、燕麦镰刀菌、黄色镰刀菌、雪霉叶枯菌、条形柄锈菌、禾柄锈菌、大麦柄锈菌(p.hordei)、裸黑粉菌(ustilagonuda)、大麦云纹斑病菌(rhynchosporiumsecalis)、圆核腔菌(pyrenophorateres)、禾旋孢腔菌(cochliobolussativus)、麦类核腔菌(pyrenophoragraminea)、立枯丝核菌:玉米病害:玉米黑粉菌(ustilagomaydis)、异旋孢腔菌(cochliobolusheterostrophus)、高粱胶尾孢(gloeocercosporasorghi)、多堆柄锈菌(pucciniapolysora)、玉米灰斑病菌(cercosporazeae-maydis)、立枯丝核菌;
柑橘病害:柑橘间座壳菌(diaporthecitri)、柑橘痂囊腔菌(elsinoefawcetti)、指状青霉菌(penicilliumdigitatum)、桔青霉菌(p.italicum)、寄生疫霉(phytophthoraparasitica)、柑橘褐腐疫霉(phytophthoracitrophthora);苹果病害:苹果链核盘菌(moniliniamali)、苹果树腐烂病菌(valsaceratosperma)、苹果白粉病菌(podosphaeraleucotricha)、互隔交链孢菌苹果致病型(alternariaalternataapplepathotype)、苹果黑星病菌(venturiainaequalis)、尖孢炭疽(colletotrichumacutatum)、恶疫霉(phytophtoracactorum);
梨病害:梨黑星病菌(venturianashicola)、梨黑星菌(v.pirina)、互隔交链孢霉日本梨致病型(alternariaalternatajapanesepearpathotype)、梨胶锈菌(gymnosporangiumharaeanum)、恶疫霉;
桃病害:桃褐腐病菌(moniliniafructicola)、嗜果枝孢菌(cladosporiumcarpophilum)、拟茎点霉属种(phomopsissp.);
葡萄病害:痂囊腔菌(elsinoeampelina)、檬果炭疽病菌(glomerellacingulata)、葡萄白粉菌(uninulanecator)、葡萄锈病菌(phakopsoraampelopsidis)、葡萄球座菌(guignardiabidwellii)、葡萄霜霉菌(plasmoparaviticola);
柿子病害:柿盘长孢菌(gloesporiumkaki)、柿角斑病菌(cercosporakaki)、柿叶球腔菌(mycosphaerelanawae);
瓠果病害:瓜类炭疽菌(colletotrichumlagenarium)、黄瓜白粉病菌(sphaerothecafuliginea)、甜瓜球腔菌(mycosphaerellamelonis)、尖孢镰刀菌、黄瓜霜霉病菌(pseudoperonosporacubensis)、疫霉属种(phytophthorasp.)、腐霉属种(pythiumsp.);
番茄病害:茄链格孢菌(alternariasolani)、番茄叶霉病菌(cladosporiumfulvum)、致病疫霉菌(phytophthorainfestans);番茄丁香假单胞菌(pseudomonassyringaepv.tomato);辣椒疫霉菌(phytophthoracapsici);黄单胞菌(xanthomonas)
茄子病害:茄褐纹病菌(phomopsisvexans)、二孢白粉菌(erysiphecichoracearum);十字花科蔬菜病害:萝卜链格孢菌(alternariajaponica)、白菜白斑病菌(cercosporellabrassicae)、根肿病菌(plasmodiophorabrassicae)、寄生霜霉菌(peronosporaparasitica);
大葱病害:葱柄锈菌(pucciniaallii)、大葱霜霉(peronosporadestructor);
大豆病害:大豆紫斑病菌(cercosporakikuchii)、大豆痂囊腔菌(elsinoeglycines)、莱豆间座壳大豆变种(diaporthephaseolorumvar.sojae)、大豆壳针孢(septoriaglycines)、大豆尾孢(cercosporasojina)、豆薯层锈菌(phakopsorapachyrhizi)、大豆疫霉病菌(phytophthorasojae)、立枯丝核菌、棒抱叶斑病菌(corynesporacasiicola)、核盘菌(sclerotiniasclerotiorum);
芸豆病害:菜豆炭疽病菌(colletrichumlindemthianum);
花生病害:花生黑斑病菌(cercosporapersonata)、花生褐斑病菌(cercosporaarachidicola)、齐整小核菌(sclerotiumrolfsii);
豌豆病害豌豆:豌豆白粉菌(erysiphepisi);
马铃薯病害:茄链格孢菌、致病疫霉菌、马铃薯疫霉绯腐病菌(phytophthoraerythroseptica)、马铃薯粉状疮痂病菌(spongosporasubterranean,f.sp.subterranean);
草莓病害:薄草单丝壳菌(sphaerothecahumuli)、檬果炭疽病菌;
茶病害:茶网饼病菌(exobasidiumreticulatum)、茶白星病菌(elsinoeleucospila)、拟盘多毛孢属种(pestalotiopsissp.)、茶炭疽菌(colletotrichumtheae-sinensis);
烟草病害:烟草赤星病菌(alternarialongipes)、二孢白粉菌、烟草炭疽病菌(colletotrichumtabacum)、烟草霜霉菌(peronosporatabacina)、烟草疫霉菌(phytophthoranicotianae);
油菜籽病害:核盘菌、立枯丝核菌;
棉花病害:立枯丝核菌;
甜菜病害:甜菜尾孢菌(cercosporabeticola)、水稻纹枯病菌(thanatephoruscucumeris)、水稻纹枯病菌、螺壳状丝囊霉(aphanomycescochlioides);
玫瑰病害:蔷薇双壳菌(diplocarponrosae)、蔷薇单丝壳茵(sphaerothecapannosa)、蔷薇霜霉(peronosporasparsa);
菊花和菊科病害:莴苣盘枝霉(bremialactuca)、野菊壳针抱(septoriachrysanthemi-indici)、堀氏菊柄锈菌(pucciniahoriana);
各种植物的病害:瓜果腐霉菌(pythiumaphanidermatum)、德巴利氏腐霉菌(pythiumdebarianum)、禾草腐霉菌(pythiumgraminicola)、畸雌腐霉菌(pythiumirregulare)、终极腐霉菌(pythiumultimum)、灰葡萄孢菌(botrytiscinerea)、核盘菌;
萝卜病害:甘蓝链格孢菌(alternariabrassicicola);
结缕草病害:同果核盘菌(sclerotiniahomeocarpa)、立枯丝核菌;
香蕉病害:香蕉黑条叶斑病菌(mycosphaerellafijiensis)、香蕉黄条叶斑病菌(mycosphaerellamusicola);
向日葵病害:向日葵霜霉病菌(plasmoparahalstedii);
在不同植物生长初期阶段由以下各项引起的种子疾病或病害:曲霉属种、青霉属种(penicilliumspp.)、镰刀菌属种(fusariumspp.)、赤霉菌属种(gibberellaspp.)、木霉属种、根串珠霉属种(thielaviopsisspp.)、根霉属种、毛霉菌属种(mucorspp.)、伏革菌属种(corticiumspp.)、茎点霉属种(rhomaspp.)、丝核菌属种(rhizoctoniaspp.)、色二孢属种(diplodiaspp.)等;
由杆菌属种(polymixaspp.)、油壶菌属种(olpidiumspp.)等介导的各种植物病毒病。
3.赋予对除草剂的抗性的基因的实例:
对抑制生长点或分生组织的除草剂的抗性,该除草剂诸如咪唑啉酮或硫酰脲,例如分别在lee等人,emboj.7:1241(1988)和miki等人,theor.appl.genet.80:449(1990)中所述的。
草甘膦耐受性(分别由例如突变体5-烯醇丙酮莽草酸-3-磷酸合酶(epsp)基因、aroa基因和草甘膦乙酰转移酶(gat)基因赋予的抗性)、或者对于其他膦羧基化合物诸如草铵膦的抗性(由来自链霉菌种类(包括吸水链霉菌(streptomyceshygroscopicus)和绿色产色链霉菌(streptomycesviridichromogenes))的草丁膦乙酰基转移酶(pat)基因赋予)、以及对吡啶氧基或苯氧基丙酸和环异己酮的抗性(由acc酶抑制剂编码基因赋予)。参见例如美国专利号4,940,835和美国专利号6,248,876、美国专利号4,769,061、欧洲专利号0333033和美国专利号4,975,374。另参见欧洲专利号0242246;degreef等人,bio/technology7:61(1989);marshall等人,theor.appl.genet.83:435(1992);castle等人的wo2005012515,以及wo2005107437。
对抑制光合成的除草剂的抗性,该除草剂诸如三嗪(psba和gs+基因)或苯基氰(腈水解酶基因),以及谷胱甘肽s-转移酶,如在przibila等人,plantcell3:169(1991);美国专利号4,810,648和hayes等人,biochem.j.285:173(1992)中所述的。
编码使除草剂去毒的酶或对抑制具有抗性的突变体谷氨酰胺合酶的基因,例如在美国专利申请序列号11/760,602中所述的。或者去毒酶是编码草丁膦乙酰转移酶的酶(诸如来自链霉菌种类的bar或pat蛋白)。草丁膦乙酰转移酶例如描述于美国专利号5,561,236;5,648,477;5,646,024;5,273,894;5,637,489;5,276,268;5,739,082;5,908,810和7,112,665。
羟基苯丙酮酸双氧化酶(hppd)抑制剂,即天然存在的hppd抗性酶,或者编码突变或嵌合hppd酶的基因,如在wo96/38567、wo99/24585和wo99/24586、wo2009/144079、wo2002/046387,或美国专利号6,768,044中所述的。
4.涉及非生物胁迫耐受性的基因的实例:
能够在植物细胞或植物中减少聚(adp-核糖)聚合酶(parp)基因的表达/或活性的转基因,如在wo00/04173或wo/2006/045633中所述的。
能够减少植物或植物细胞的parg编码基因的表达和/或活性的转基因,如例如在wo2004/090140中所述的。
编码烟酰胺腺嘌呤二核苷酸补救合成途径的植物功能酶的转基因,这些酶包括烟酰胺酶、烟酰酸磷酸核糖基转移酶、烟酸单核苷酸腺嘌呤转移酶、烟酰胺腺嘌呤二核苷酸合成酶或烟酰胺磷酸核糖基转移酶,如在例如ep04077624.7、wo2006/133827、pct/ep07/002,433、ep1999263或wo2007/107326中所述的。
涉及碳水化合物生物合成的酶包括在例如ep0571427、wo95/04826、ep0719338、wo96/15248、wo96/19581、wo96/27674、wo97/11188、wo97/26362、wo97/32985、wo97/42328、wo97/44472、wo97/45545、wo98/27212、wo98/40503、wo99/58688、wo99/58690、wo99/58654、wo00/08184、wo00/08185、wo00/08175、wo00/28052、wo00/77229、wo01/12782、wo01/12826、wo02/101059、wo03/071860、wo2004/056999、wo2005/030942、wo2005/030941、wo2005/095632、wo2005/095617、wo2005/095619、wo2005/095618、wo2005/123927、wo2006/018319、wo2006/103107、wo2006/108702、wo2007/009823、wo00/22140、wo2006/063862、wo2006/072603、wo02/034923、ep06090134.5、ep06090228.5、ep06090227.7、ep07090007.1、ep07090009.7、wo01/14569、wo02/79410、wo03/33540、wo2004/078983、wo01/19975、wo95/26407、wo96/34968、wo98/20145、wo99/12950、wo99/66050、wo99/53072、美国专利号6,734,341、wo00/11192、wo98/22604、wo98/32326、wo01/98509、wo01/98509、wo2005/002359、美国专利号5,824,790、美国专利号6,013,861、wo94/04693、wo94/09144、wo94/11520、wo95/35026或wo97/20936中所述的酶;或者如ep0663956、wo96/01904、wo96/21023、wo98/39460和wo99/24593所公开的涉及多聚果糖(尤其是菊粉和果聚糖类型)的产生的酶;如wo95/31553、us2002031826、美国专利号6,284,479、美国专利号5,712,107、wo97/47806、wo97/47807、wo97/47808和wo00/14249所公开的涉及α-1,4-葡聚糖的产生的酶;如wo00/73422所公开的涉及α-1,6分支α-1,4-葡聚糖的产生的酶;如例如wo00/47727、wo00/73422、ep06077301.7、美国专利号5,908,975和ep0728213所公开的涉及交替糖的产生的酶;如例如wo2006/032538、wo2007/039314、wo2007/039315、wo2007/039316、jp2006304779和wo2005/012529所公开的涉及透明质酸的产生的酶。
提高抗旱性的基因。例如,wo2013122472公开了功能性泛素蛋白连接酶蛋白(upl)、更具体地说是upl3的缺乏或水平降低导致所述植物对水的需求减少或者对干旱的抗性提高。具有增加的耐旱性的转基因植物的其他实例公开于例如us2009/0144850、us2007/0266453和wo2002/083911。us2009/0144850描述了一种由于dr02核酸表达的改变而展示耐旱性表型的植物。us2007/0266453描述了一种由于dr03核酸表达的改变而展示耐旱性表型的植物,并且wo2002/083911描述了一种由于在保卫细胞中表达的abc转运体的活性降低而具有增加的对干旱胁迫的耐受性的植物。另一个实例是kasuga和合著者(1999)的著作,他们描述了在正常生长条件下编码dreb1a的cdna在转基因植物中的过表达激活了许多胁迫耐受性基因的表达并且导致对干旱、盐负荷以及寒冷的耐受性提高。然而,在正常生长条件下dreb1a的表达也导致严重的生长迟缓(kasuga(1999)natbiotechnol17(3)287-291)。
在另外的特定实施方案中,可以通过影响特定植物性状来改良农作物植物。例如,通过开发耐杀虫剂植物、提高植物的抗病性、提高植物的昆虫和线虫抗性、提高植物针对寄生杂草的抗性、提高植物的耐旱性、提高植物的营养价值、提高植物的胁迫耐受性、避免自花授粉、提高植物饲料消化率生物量、提高谷物产量等。在下文中提供了若干特定的非限制性实例。
除单一基因的靶向突变之外,ad官能化的crispr系统可以被设计成允许在植物中靶向突变多基因、缺失染色体片段、位点特异性整合转基因、体内定点诱变、以及精确基因替代或等位基因交换。因此,本文描述的方法在基因发现和验证、突变和顺基因育种,以及杂交育种中具有广泛的应用。这些应用有助于产生新一代的具有各种改良的农艺性状的遗传修饰农作物,这些农艺性状诸如除草剂耐受性、抗病性、非生物胁迫耐受性、高产率以及优等品质。
使用ad官能化的crispr系统产生雄性不育植物
杂交植物与自交植物相比典型地具有有利的农艺性状。然而,对于自花授粉植物,杂交体传代可能是有挑战的。在不同植物类型中,已经修饰了对植物能育性,更特别地雄性能育性至关重要的基因。例如,在玉米中,至少鉴定了两种对能育性至关重要的基因(amitabhmohantyinternationalconferenceonnewplantbreedingmoleculartechnologiestechnologydevelopmentandregulation,2014年10月9-10日,jaipur,india;svitashev等人plantphysiol.2015年10月;169(2):931-45;djukanovic等人plantj.2013dec;76(5):888-99)。本文提供的方法和系统可以用于靶向雄性能育性所需要的基因,以便生成雄性不育植物,这些植物可以易于杂交以生成杂交体。在特定实施方案中,本文提供的ad官能化的crispr系统用于靶向诱变细胞色素p450-样基因(ms26)或大范围核酸酶基因(ms45),从而向玉米植物赋予雄性不育性。如此遗传改变的玉米植物可以用于杂交育种程序。
增加植物的能育性阶段
特定实施方案,本文提供的方法和系统用于延长植物诸如稻谷植物的能育性阶段。例如,可以靶向稻谷能育性阶段基因诸如ehd3,以便生成基因中的突变并且可以选择小植物以延长再生植物能育性阶段(如cn104004782中所述的)。
使用ad官能化的crispr系统生成目标农作物的遗传变异
农作物植物中野生种质和遗传变异的可用性是农作物改良程序的关键,但是来自农作物植物的种质的可用多样性是有限的。本发明设想了用于生成目标种质的遗传变异的多样性的方法。在ad官能化的crispr系统的此应用中,提供了靶向植物基因组中的不同位置的指导rna文库并且将该文库与crispr-cas蛋白和腺苷脱氨酶一起引入到植物细胞中。以这种方式,可以生成基因组范围的点突变和基因敲除的集合。在特定实施方案中,所述方法包括由如此获得的细胞生成植物部分或植物以及针对目标性状筛选细胞。靶基因可以包含编码区和非编码区两者。在特定实施方案中,性状是胁迫耐受性,并且所述方法是用于生成胁迫耐受性农作物品种的方法。
使用ad官能化的crispr影响果实催熟
催熟是果实和蔬菜成熟过程中的正常阶段。仅在催熟开始后的几天,催熟致使果实或蔬菜不可食用。这个过程给农民和消费者都造成了重大损失。在特定实施方案中,本发明的方法用于减少乙烯的产生。这是通过确保以下各项中的一者或多者来确保的:a.阻遏acc合酶基因表达。acc(1-氨基环丙烷-1-羧酸)合酶是负责将s-腺苷甲硫氨酸(sam)转化成acc的酶;这是乙烯生物合成中的第二个步骤至最后一个步骤。当合酶基因的反义(“镜像”)或截短的拷贝插入到植物基因组中时会阻碍酶表达;b.插入acc脱氨酶基因。从一种常见的非致病性土壤细菌绿针假单胞菌(pseudomonaschlororaphis)获得编码该酶的基因。它将acc转化为一种不同的化合物,从而减少可用于产生乙烯的acc量;c.插入sam水解酶基因。这种方法类似于acc脱氨酶,其中当乙烯前体代谢物的量减少时乙烯产生受到阻碍;在此情况下,sam被转化为高丝氨酸。从大肠杆菌t3噬菌体获得编码该酶的基因;以及d.阻遏acc氧化酶基因表达。acc氧化酶是催化acc氧化成乙烯的酶,这是乙烯生物合成途径中的最后一个步骤。使用本文所述的方法,下调acc氧化酶基因,导致乙烯产生受到阻遏,从而延迟果实催熟。在特定实施方案中,对于以上所述修饰另外地或可替代地,本文所述的方法用于修饰乙烯受体,以便干扰由果实获得的乙烯信号。在特定实施方案中,修饰,更特别地说阻遏了编码乙烯结合蛋白的etr1基因的表达。在特定实施方案中,对于以上所述修饰另外地或可替代地,本文所述的方法用于修饰编码多聚半乳糖醛酸酶(pg)的基因的表达,所述多聚半乳糖醛酸酶是负责分解果胶(维持植物细胞壁完整性的物质)的酶。果胶分解发生在催熟过程开始时,导致水果软化。因此,在特定实施方案中,本文描述的方法用于在pg基因中引入突变或阻遏pg基因的激活,以便减少所产生的pg酶的量,从而延迟果胶降解。
因此,在特定实施方案中,所述方法包括使用ad官能化的crispr系统来确保如上所述的植物细胞基因组的一种或多种修饰,并且由所述细胞再生植物。在特定实施方案中,植物是番茄植物。
增加植物的保存期限
在特定实施方案中,本发明的方法用于修饰涉及产生影响植物或植物部分的保存期限的化合物的基因。更特别地,修饰是在防止马铃薯块茎中的还原糖积累的基因中。在高温处理时,这些还原糖与游离氨基酸反应,产生棕色苦味产物和高水平的丙烯酰胺,丙烯酰胺是一种潜在的致癌物。在特定实施方案中,本文提供的方法用于减少或抑制液泡转化酶基因(vinv)的表达,所述液泡转化酶基因编码将蔗糖分解为葡萄糖和果糖的蛋白质(clasen等人doi:10.1111/pbi.12370)。
使用ad官能化的crispr系统确保增值的性状
在特定实施方案中,ad官能化的crispr系统用于产生营养提高的农作物。在特定实施方案中,本文提供的方法适于生成“功能性食品”,即可以提供超过它所含有的传统营养物的健康益处的修饰的食品或食品成分,并且/或者适于生成“营养食品”,即可以被视为食品或食品的一部分并且提供健康益处(包括预防和治疗疾病)的物质。在特定实施方案中,营养食品可用于预防并且/或者治疗癌症、糖尿病、心血管疾病以及高血压中的一者或多者。
营养提高的农作物的实例包括(newell-mcgloughlin,plantphysiology,2008年7月,第147卷,第939-953页):
改良的蛋白质品质、含量和/或氨基酸组成,诸如对于以下各项所描述的:百喜草(luciani等人2005,floridageneticsconferenceposter)、油菜(roesler等人,1997,plantphysiol11375-81)、玉米(cromwell等人,1967,1969janimsci261325-1331;o’quin等人2000janimsci782144-2149;yang等人2002,transgenicres1111-20;young等人2004,plantj38910-922)、马铃薯(yuj和ao,1997actabotsin39329-334;chakraborty等人2000,procnatlacadsciusa973724-3729;li等人2001)chinscibull46482-484、稻(katsube等人1999,plantphysiol1201063-1074)、大豆(dinkins等人2001,rapp2002,invitrocelldevbiolplant37742-747)、甘薯(egnin和prakash1997,invitrocelldevbiol3352a)。
必需氨基酸含量,诸如对于以下各项所描述的:油菜(falco等人1995,bio/technology13577-582)、羽扇豆(white等人2001,jscifoodagric81147-154)、玉米(lai和messing,2002,agbios2008gmcropdatabase(march11,2008))、马铃薯(zeh等人2001,plantphysiol127792-802)、高粱(zhao等人2003,kluweracademicpublishers,dordrecht,thenetherlands,第413-416页)、大豆(falco等人1995bio/technology13577-582;galili等人2002critrevplantsci21167-204)。
油类和脂肪酸,诸如对于油菜(dehesh等人(1996)plantj9167-172[pubmed];delvecchio(1996)informinternationalnewsonfats,oilsandrelatedmaterials7230-243;roesler等人(1997)plantphysiol11375-81[pmcfreearticle][pubmed];froman和ursin(2002,2003)abstractsofpapersoftheamericanchemicalsociety223u35;james等人(2003)amjclinnutr771140-1145[pubmed];agbios(2008,above);棉花(chapman等人(2001).jamoilchemsoc78941-947;liu等人(2002)jamcollnutr21205s-211s[pubmed];o′neill(2007)australianlifescientist.http://www.biotechnews.com.au/index.php/id;866694817;fp;4;fpid;2(june17,2008)、亚麻籽(abbadi等人,2004,plantcell16:2734-2748)、玉米(young等人,2004,plantj38910-922)、油棕(jalani等人1997,jamoilchemsoc741451-1455;parveez,2003,agbiotechnet1131-8)、稻(anai等人,2003,plantcellrep21988-992)、大豆(reddy和thomas,1996,natbiotechnol14639-642;kinney和kwolton,1998,blackieacademicandprofessional,london,pp193-213)、向日葵(arcadia,biosciences2008)
碳水化合物,诸如对于以下各项所描述的果聚糖:菊苣(smeekens(1997)trendsplantsci2286-287;sprenger等人(1997)febslett400355-358;sévenier等人(1998)natbiotechnol16843-846)、玉米(caimi等人(1996)plantphysiol110355-363)、马铃薯(hellwege等人,1997plantj121057-1065)、甜菜(smeekens等人1997,同上);菊粉,诸如对于马铃薯所述(hellewege等人2000,procnatlacadsciusa978699-8704);淀粉,诸如对于稻所述的(schwall等人(2000)natbiotechnol18551-554;chiang等人(2005)molbreed15125-143),
维生素和类葫萝卜素,诸如对于以下各项所述的:油菜(shintani和dellapenna(1998)science2822098-2100)、玉米(rocheford等人(2002).jamcollnutr21191s-198s;cahoon等人(2003)natbiotechnol211082-1087;chen等人(2003)procnatlacadsciusa1003525-3530)、芥菜籽(shewmaker等人(1999)plantj20401-412)、马铃薯(ducreux等人,2005,jexpbot5681-89)、稻(ye等人(2000)science287303-305)、草莓(agius等人(2003),natbiotechnol21177-181)、番茄(rosati等人(2000)plantj24413-419;fraser等人(2001)jscifoodagric81822-827;mehta等人(2002)natbiotechnol20613-618;díazdelagarza等人(2004)procnatlacadsciusa10113720-13725;enfissi等人(2005)plantbiotechnolj317-27;dellapenna(2007)procnatlacadsciusa1043675-3676。
功能性次级代谢产物,诸如对于以下各项所述的:苹果(芪类,szankowski等人(2003)plantcellrep22:141-149)、苜蓿(白藜芦醇,hipskind和paiva(2000)molplantmicrobeinteract13551-562)、猕猴桃(白藜芦醇,kobayashi等人(2000)plantcellrep19904-910)、玉米和大豆(类黄酮,yu等人(2000)plantphysiol124781-794)、马铃薯(花青素和生物碱糖苷,lukaszewicz等人(2004)jagricfoodchem521526-1533)、稻(类黄酮和白藜芦醇,stark-lorenzen等人(1997)plantcellrep16668-673;shin等人(2006)plantbiotechnolj4303-315)、番茄(+白藜芦醇、绿原酸、类黄酮、芪;rosati等人(2000)同上;muir等人(2001)nature19470-474;niggeweg等人(2004)natbiotechnol22746-754;giovinazzo等人(2005)plantbiotechnolj357-69)、小麦(咖啡酸和阿魏酸、白藜芦醇;unitedpressinternational(2002));以及
矿物质可用性,诸如对于以下各项所述的:苜蓿(植酸酶,austin-phillips等人(1999)http://www.molecularfarming.com/nonmedical.html)、生菜(lettuse)(铁;goto等人(2000)theorapplgenet100658-664)、稻(铁,lucca等人(2002)jamcollnutr21184s-190s)、玉米、大豆和小麦(植酸酶,drakakaki等人(2005)plantmolbiol59869-880;denbow等人(1998)poultsci77878-881;brinch-pedersen等人(2000)molbreed6195-206)。
在特定实施方案中,增值的性状与存在于植物中的化合物的设想的健康益处相关。例如,在特定实施方案中,通过应用本发明的方法来确保以下化合物中的一者或多者的合成的修改或者诱导/增加它们的合成,以获得增值的农作物:
类葫萝卜素,诸如存在于胡萝卜中的α-胡萝卜素,其中和可引起对细胞的损害的自由基;或者存在于各种果实和蔬菜中的β-胡萝卜素,其中和自由基
存在于绿色蔬菜中的叶黄素,其有助于维持健康视力
存在于番茄和番茄产品中的番茄红素,认为其降低前列腺癌风险
存在于柑橘和玉米中的玉米黄素,其有助于维持健康视力
膳食纤维,诸如存在于麦麸中的不溶性纤维,其可以降低乳腺癌和/或结肠癌风险;以及存在于燕麦中的β葡聚糖;存在于车前子(psylium)和全谷粒中的可溶性纤维,其可以降低心血管疾病(cvd)风险
脂肪酸,诸如ω-3脂肪酸,其可以降低cvd风险并提高心理功能和视功能;缀合亚油酸,其可以改善身体组成,可以减小某些癌症风险;以及gla,其可以降低癌症和cvd的炎症风险,可以改善身体组成
黄酮类,诸如存在于小麦中的羟基苯乙烯,其具有抗氧化剂样活性,可以降低退行性疾病风险;存在于果实和蔬菜中的黄酮醇、儿茶酚和鞣酸,它们中和自由基并且可以降低癌症风险
葡萄糖异硫氰酸酯、吲哚、异硫氰酸酯,诸如存在于十字花科蔬菜(花椰菜、羽衣甘蓝)、辣根中的萝卜硫素,其中和自由基,可以降低癌症风险
酚类,诸如存在于葡萄中的芪类,其可以降低退行性疾病、心脏病和癌症的风险,可以有延年益寿功效;以及存在于蔬菜和柑橘中的咖啡酸和阿魏酸,它们具有抗氧化剂样活性,可以降低退行性疾病、心脏病和眼病的风险;以及存在于可可中的表儿茶素,其具有抗氧化剂样活性,可以降低退行性疾病和心脏病的风险
存在于玉米、大豆、小麦和木制油中的植物甾烷醇/固醇,它们可以通过减低血胆固醇水平来降低冠心病风险
存在于洋姜、胡葱、洋葱粉中的果聚糖、菊糖、低聚果糖,它们可以提高胃肠健康
存在于大豆中的皂苷,其可以减低ldl胆固醇
存在于大豆中的大豆蛋白质,其可以降低心脏病风险
植物雌激素,诸如存在于大豆中的异黄酮,其可以减少绝经期症状(诸如热潮红),可以减少骨质疏松症和cvd;以及存在于亚麻、黑麦和蔬菜中的木脂素,其可以防止心脏病和一些癌症,可以降低ldl胆固醇、总胆固醇。
硫化物和硫醇,诸如存在于洋葱、大蒜、橄榄、韭葱和青葱(scallon)中的二烯丙基硫;以及存在于十字花科蔬菜中的烯丙基甲基三硫、二硫醇硫酮,它们可以降低ldl胆固醇,帮助维持健康免疫系统
鞣酸,诸如存在于蔓越橘、可可中的原花色素,其可以提高泌尿道健康,可以降低cvd和高血压风险。
此外,本发明的方法还设想了修改蛋白质/淀粉功能性、保质期、味道/美学、纤维品质、以及减少过敏原、抗营养素以及毒素的形状。
因此,本发明涵盖了用于产生具有营养增加价值的植物的方法,所述方法包括使用如本文所述的ad官能化的crispr系统将编码涉及产生具有增加的营养价值的组分的酶的基因引入到植物细胞中并且由所述植物细胞再生植物,所述植物的特征在于所述具有增加的营养价值的组分的表达增加。在特定实施方案中,ad官能化的crispr系统用于例如通过修饰控制此化合物代谢的一种或多种转录因子来间接修改这些化合物的内源性合成。上文描述了用于使用ad官能化的crispr系统将目标基因引入到植物细胞中并且/或者修饰内源性基因的方法。
在已修饰为赋予增值性状的植物中的一些具体修饰实例是:具有修饰的脂肪酸代谢的植物,方式为例如用硬脂酰-acp去饱和酶的反义基因转化植物以增加植物硬脂酸含量的。参见knultzon等人,proc.natl.acad.sci.u.s.a.89:2624(1992)。另一个实例涉及例如通过克隆接着再引入与可以负责特征为低水平植酸的玉米突变体的单一等位基因相关联的dna来降低植酸酯含量。参见raboy等人,maydica35:383(1990)。
类似地,在强启动子控制下调节玉米糊粉层中黄酮类的产生的玉米(玉蜀黍)tfsc1和r的表达导致拟南芥属(阿拉伯芥)中的花青素的高积累速率,推测是通过激活整个途径(bruce等人,2000,plantcell12:65-80)。dellapenna(welsch等人,2007annurevplantbiol57:711-738)发现tfrap2.2及其相互作用配偶体sinat2增加拟南芥叶中的胡萝卜素形成作用。在转基因拟南芥中表达tfdoff诱导了编码用于产生碳架、标记性增加氨基酸含量以及减少glc水平的酶的基因的上调(yanagisawa,2004plantcellphysiol45:386-391),并且doftfatdof1.1(obp2)上调了拟南芥的葡萄糖异硫氰酸酯生物合成途径中的所有步骤(skirycz等人,2006plantj47:10-24)。
减少植物中的过敏原
在特定实施方案中,本文提供的方法用于生成具有减少的水平的过敏原的植物,从而使得它们对于消费者而言更安全。在特定实施方案中,所述方法包括修饰负责产生植物过敏原的一种或多种基因的表达。例如,在特定实施方案中,所述方法包括下调植物细胞诸如黑麦草植物细胞中的lolp5基因的表达并且由所述植物细胞再生植物以便减少所述植物的花粉的过敏原性(bhalla等人1999,proc.natl.acad.sci.usa第96卷:11676-11680)。
花生过敏和对豆类过敏总体上是真实而严重的健康问题。本发明的ad官能化的crispr系统可以用于鉴定然后突变编码此类豆类的过敏原性蛋白的基因。不限于此类基因和蛋白质,nicolaou等人鉴定了花生、大豆、扁豆、豌豆、羽扇豆、青豆以及绿豆中的过敏原性蛋白。参见nicolaou等人,currentopinioninallergyandclinicalimmunology2011;11(3):222)。
用于目标内源性基因的筛选方法
本文提供的方法进一步允许鉴定编码涉及产生具有增加的营养价值的组分的酶的有价值基因或者通常是影响跨种类、门和植物界的目标农艺性状的基因。通过使用如本文所述的ad官能化的crispr系统选择性地靶向例如编码植物代谢途径的酶的基因,可以鉴定负责植物某些营养方面的基因。类似地,通过选择性地靶向可以影响所期望的农艺性状的基因,可以鉴定相关基因。因此,本发明涵盖了用于编码涉及产生具有特定营养价值和/或农艺性状的化合物的酶的基因的筛选方法。
ad官能化的crispr系统在植物和酵母中的进一步应用
在生物燃料生产中使用ad官能化的crispr系统
如本文所用,术语“生物燃料”是由植物和植物来源的资源制成的替代燃料。可以从有机物质中提取可再生生物燃料,已通过碳固定方法获得或者通过使用或转化生物质制成有机物质的能量。此生物质可以直接用于生物燃料或者可以通过热转化、化学转化和生物化学转化来转化成含有能量的便利物质。这种生物质转化可以产生固体、液体或气体形式的燃料。存在两种类型的生物燃料:生物乙醇和生物柴油。生物乙醇主要是通过纤维素(淀粉)的糖发酵过程产生的,纤维素大部分来源于玉米和甘蔗。在另一方面,生物柴油主要是由油料作物诸如油菜籽、棕榈和大豆产生的。生物燃料主要用于运输。
增强用于生物燃料生产的植物特性
在特定实施方案中,使用如本文所述的ad官能化的crispr系统的方法用于改变细胞壁的特性,以便促进关键性水解剂进入,从而更有效地释放用于发酵的糖。在特定实施方案中,修改纤维素和/或木质素的生物合成。纤维素是细胞壁的主要组分。纤维素和木质素的生物合成是共调节的。通过减少植物中的木质素比例,可以增加纤维素的比例。在特定实施方案中,本文所述的方法用于下调植物中的木质素生物合成,以便增加可发酵的碳水化合物。更特别地,本文所述的方法用于下调如wo2008064289a2所公开的选自由以下组成的组的至少第一木质素生物合成基因:4-香豆酸酯3-羟化酶(c3h)、苯丙氨酸氨-裂解酶(pal)、肉桂酸酯4-羟化酶(c4h)、羟基肉桂酰转移酶(hct)、咖啡酸o-甲基转移酶(comt)、咖啡酰辅酶a3-o-甲基转移酶(ccoaomt)、阿魏酸酯5-羟化酶(f5h)、肉桂醇脱氢酶(cad)、肉桂酰辅酶a-还原酶(ccr)、4-香豆酸酯辅酶a连接酶(4cl)、单木质醇-木质素-特异性糖基转移酶,以及醛脱氢酶(aldh)。
在特定实施方案中,本文所述的方法用于产生在发酵过程中生成较低水平乙酸的植物生物质(另参见wo2010096488)。更特别地,本文所公开的方法用于生成与casll同源的突变,以减少多糖乙酰化。
修饰用于生物燃料生产的酵母
在特定实施方案中,本文提供的ad官能化的crispr系统用于通过重组微生物进行生物乙醇生产。例如,ad官能化的crispr系统可以用于工程化微生物,诸如酵母,以由可发酵糖生成生物燃料或生物聚合物并且任选地能够降解来源于作为可发酵糖来源的农业废弃物的植物来源的木质纤维素。在一些实施方案中,ad官能化的crispr系统用于修饰与生物燃料生产途径竞争的内源性代谢途径。
因此,在更具体的实施方案中,本文所述的方法用于如下修饰微生物:修饰编码所述宿主细胞的代谢途径中的酶的至少一种核酸,其中所述途径产生除来自丙酮酸酯的乙醛或来自乙醛的乙醇之外的代谢物,并且其中所述修饰导致所述代谢物的产生减少,或者引入编码所述酶的抑制剂的至少一种核酸。
修饰用于植物油或生物燃料生产的藻类和植物
例如,转基因藻类或其他植物诸如油菜可能在植物油或生物燃料诸如醇类(尤其是甲醇和乙醇)的生产中特别有用。这些可以被工程化以表达或过表达高水平的油或醇类,以供在油或生物燃料行业中使用。
根据本发明的特定实施方案,ad官能化的crispr系统用于生成可用于生物燃料生产的富含脂质的硅藻。
在特定实施方案中,设想的是特异性地修饰涉及改变由藻类细胞产生的脂质的量和/或脂质的品质的基因。编码涉及脂肪酸合成途径的酶的基因的实例可以编码具有例如以下酶活性的蛋白质:乙酰辅酶a羧化酶、脂肪酸合酶、3-酮乙基_酰基-运载蛋白合酶iii、甘油-3-磷酸脱氢酶(g3pdh)、烯酰-酰基运载蛋白还原酶(烯酰-acp-还原酶)、甘油-3-磷酸酰基转移酶、溶血磷脂酰基转移酶或二酰甘油酰基转移酶、磷脂:二酰甘油酰基转移酶、磷脂酸磷酸酶、脂肪酸硫酯酶诸如软脂酰蛋白硫酯酶,或苹果酸酶活性。在另外的实施方案中,设想的是生成具有增加的脂质积累的硅藻。这可以通过靶向减少脂质分解代谢的基因来实现。对于用于本发明的方法中特别令人感兴趣的是涉及激活三酰基甘油和游离脂肪酸的基因,以及直接涉及脂肪酸的β氧化的基因,诸如脂酰辅酶a合成酶、3-酮脂酰辅酶a硫解酶、脂酰辅酶a氧化酶活性以及磷酸葡萄糖变位酶。本文所述的ad官能化的crispr系统和方法可以用于特异性地激活硅藻中的此类基因以增加其脂质含量。
诸如微藻的生物被广泛用于合成生物学。stovicek等人(metab.eng.comm.,2015;2:13描述了工业用酵母例如酿酒酵母的基因组编辑,以有效产生用于工业生产的有力菌株。stovicek使用了对于酵母进行密码子优化的crispr-cas9系统来同时破坏内源性基因的两个等位基因并且敲除异源基因。cas9和指导rna由基因组或附加型2μ基载体位置表达。这些作者们还证实基因破坏效率可以通过优化cas9和指导rna表达水平来提高。hlavová等人(biotechnol.adv.2015)论述了使用诸如crispr的技术靶向核基因和叶绿体基因进行插入诱变和筛选来开发微藻种类或菌株。
us8945839描述了一种用于使用cas9工程化微藻(莱茵衣藻细胞)的方法。使用类似的工具,本文所述的ad官能化的crispr系统的方法可以应用于衣藻属种和其他藻类。在特定实施方案中,在藻类中引入crispr-cas蛋白(例如cpf1)、腺苷脱氨酶(其可以融合至crispr-cas蛋白或适体结合衔接蛋白)和指导rna,其使用在组成型启动子诸如hsp70a-rbcs2或β2-微管蛋白的控制下表达crispr-cas蛋白和任选地腺苷脱氨酶的载体进行表达。指导rna将使用含有t7启动子的载体递送。或者,可以将mrna和体外转录的指导rna递送至藻类细胞。电穿孔方法遵循来自geneart衣藻属工程化试剂盒的标准推荐方法。
使用ad官能化的crispr系统生成能够进行脂肪酸生产的微生物
在特定实施方案中,本发明的方法用于生成能够产生脂肪酸酯诸如脂肪酸甲酯(“fame”)和脂肪酸乙酯(“faee”)的遗传工程化微生物。
典型地,宿主细胞可以被工程化以通过表达或过表达编码硫酯酶的基因、编码脂酰辅酶a合酶的基因以及编码酯合酶的基因来由存在于培养基中的碳源诸如醇产生脂肪酸酯。因此,本文提供的方法用于修饰微生物,以便过表达或引入硫酯酶基因、编码脂酰辅酶a合酶的基因以及编码酯合酶的基因。在特定实施方案中,硫酯酶基因选自tesa、′tesa、tesb、fatb、fatb2、fatb3、fatal或fata。在特定实施方案中,编码脂酰辅酶a合酶的基因选自faddjadk、bh3103、pfl-4354、eav15023、fadd1、fadd2、rpc_4074、faddd35、faddd22、faa39,或编码具有相同特性的酶的鉴定的基因。在特定实施方案中,编码酯合酶的基因是编码来自以下各项的合酶/脂酰辅酶a:二酰基甘油酰基转移酶的基因:霍霍巴(simmondsiachinensis)、不动杆菌属种adp、泊库岛食烷菌(alcanivoraxborkumensis)、铜绿假单胞菌(pseudomonasaeruginosa)、亚德海床杆菌(fundibacterjadensis)、阿拉伯芥或真养产碱杆菌(alkaligeneseutrophus),或其变体。另外地或可替代地,本文提供的方法用于减少以下各项中的至少一者在所述微生物中的表达:编码脂酰辅酶a脱氢酶的基因、编码外膜蛋白受体的基因,以及编码脂肪酸生物合成转录调节子的基因。在特定实施方案中,诸如通过引入突变使这些基因中的一者或多者失活。在特定实施方案中,编码脂酰辅酶a脱氢酶的基因是fade。在特定实施方案中,编码脂肪酸生物合成的转录调节子的基因编码dna转录阻抑因子,例如fabr。
另外地或可替代地,所述微生物被修饰为减少以下各项中的至少一者的表达:编码丙酮酸甲酸裂解酶的基因、编码乳酸脱氢酶的基因或二者。在特定实施方案中,编码丙酮酸甲酸裂解酶的基因是pflb。在特定实施方案中,编码乳酸脱氢酶的基因是idha。在特定实施方案中,诸如通过在其中引入突变使这些基因中的一者或多者失活。
在特定实施方案中,微生物埃希菌属(escherichia)、芽孢杆菌属(bacillus)、乳酸杆菌属(lactobacillus)、红球菌属(rhodococcus)、聚球蓝细菌属(synechococcus)、集胞藻属(synechoystis)、假单胞菌属、曲霉属、木霉属、脉孢菌属、镰刀菌属、腐质霉属(humicola)、根毛霉属(rhizomucor)、克鲁维酵母属、毕赤酵母属、毛霉菌属、蚀丝霉属(myceliophtora)、青霉属、平革菌属(phanerochaete)、侧耳属(pleurotus)、栓菌属(trametes)、金孢子菌属(chrysosporium)、酵母菌属(saccharomyces)、寡养单胞菌属(stenotrophamonas)、裂殖酵母属(saccharomyces)、亚罗酵母属或链霉菌属。
使用ad官能化的crispr系统生成能够进行有机酸生产的微生物
本文提供的方法还用于工程化能够更具体地说由戊糖或己糖生产有机酸的微生物。在特定实施方案中,所述方法包括将外源性ldh基因引入到微生物中。在特定实施方案中,所述微生物中的有机酸生产另外地或可替代地通过使编码涉及内源性代谢途径的蛋白质的内源性基因失活来增加,所述代谢途径产生除目标有机酸之外的代谢物,并且/或者其中所述内源性代谢途径消耗有机酸。在特定实施方案中,所述修饰确保减少除目标有机酸之外的代谢物的产生。根据特定实施方案,所述方法用于引入其中消耗有机酸的内源性途径或编码涉及产生除目标有机酸之外的代谢物的内源性途径的产物的基因的至少一种工程化基因缺失和/或失活。在特定实施方案中,所述至少一种工程化基因缺失或失活是在编码选自由以下组成的组的酶的一种或多种基因中:丙酮酸脱羧酶(pdc)、延胡索酸还原酶、醇脱氢酶(adh)、乙醛脱氢酶、磷酸烯醇丙酮酸羧化酶(ppc)、d-乳酸脱氢酶(d-ldh)、l-乳酸脱氢酶(l-ldh)、乳酸2-单加氧酶。在另外的实施方案中,所述至少一种工程化基因缺失和/或失活是在编码丙酮酸脱羧酶(pdc)的内源性基因中。
在另外的实施方案中,微生物被工程化以产生乳酸,并且所述至少一种工程化基因缺失和/或失活是在编码乳酸脱氢酶的内源性基因中。另外地或可替代地,微生物包含编码细胞色素依赖性乳酸脱氢酶诸如细胞色素b2依赖性l-乳酸脱氢酶的内源性基因的至少一种工程化基因缺失或失活。
使用ad官能化的crispr系统生成改良的利用木糖或纤维二糖的酵母菌株
在特定实施方案中,ad官能化的crispr系统可以应用于选择改良的利用木糖或纤维二糖的酵母菌株。易错pcr可以用于扩增涉及木糖利用或纤维二糖利用途径的一种(或多种)基因。涉及木糖利用途径和纤维二糖利用途径的基因的实例可以包括但不限于描述于ha,s.j.等人(2011)proc.natl.acad.sci.usa108(2):504-9以及galazka,j.m.等人(2010)science330(6000):84-6中的那些基因。如wo2015138855所述,各自在这种选择的基因中包含随机突变的双链dna分子的所得文库可以与ad官能化的crispr系统的组分共转化到酵母菌株(例如s288c)中,并且可以选择具有增加的木糖或纤维二糖利用能力的菌株。
使用ad官能化的crispr系统生成用于类异戊二烯生物合成的改良的酵母菌株
tadas
改良的植物和酵母细胞
本发明还提供了通过本文提供的方法可获得并且通过本文提供的方法获得的植物和酵母细胞。通过本文所述的方法获得的改良的植物可以适用于通过表达确保例如对植物害虫、除草剂、干旱、低温或高温、过量水等耐受的基因来进行食品或饲料生产。
通过本文所述的方法获得的改良的植物,尤其是农作物和藻类可以适用于通过表达例如比野生型中通常所见更高的蛋白质、碳水化合物、营养素或维生素水平来进行食品或饲料生产。就这一点而言,改良的植物,尤其是豆类和块茎类是优选的。
改良的藻类或其他植物诸如油菜可能在植物油或生物燃料诸如醇类(尤其是甲醇和乙醇)的生产中特别有用。这些可以被工程化以表达或过表达高水平的油或醇类,以供在油或生物燃料行业中使用。
本发明还提供了改良的植物部分。植物部分包括但不限于叶、茎、根、块茎、种子、胚乳、胚珠以及花粉。如本文所设想的植物部分可以是有活力的、无活力的、可再生的和/或不可再生的。
本文还涵盖的是提供根据本发明的方法生成的植物细胞和植物。在本发明的范围内还包括通过传统育种方法产生的包含遗传修饰的植物的配子、种子、胚胎(合子胚或体细胞胚)、子代或杂交体。此类植物可以含有插入在靶序列处或代替靶序列的异源或外源dna序列。或者,此类植物可以仅含有在一个或多个核苷酸中的改变(突变、缺失、插入、取代)。这样,此类植物与祖代植物的不同之处仅在于特定修饰的存在。
因此,本发明提供了通过本方法产生的植物、动物或细胞或其子代。子代可以是产生的植物或动物的克隆,或者可以由通过与相同种类的其他个体杂交以使另外的期望的性状渗入其后代来进行的有性繁殖产生。在多细胞生物体(特别是动物或植物)的情况下,细胞可以是体内或离体的。
用于使用如本文所述的ad官能化的crispr系统进行基因组编辑的方法可以用于对基本上任何植物、藻类、真菌、酵母等赋予所需的性状。针对本文所述的所需生理以及农艺特征,可以使用本公开的核酸构建体和以上提及的各种转化方法对多种多样的植物、藻类、真菌、酵母等以及植物藻类、真菌、酵母细胞或组织系统系统进行工程化。
在特定实施方案中,本文所述的方法用于修饰内源性基因或修饰其表达而不永久性引入到任何外源基因的植物、藻类、真菌、酵母等的基因组中,包括编码crispr组分的外源基因,以便避免在植物基因组中存在外源dna。这可能是令人感兴趣的,因为对非转基因植物的规则要求较不严格。
本文所述的方法通常导致生成“改良的植物、藻类、真菌、酵母等”,在这点上它们与野生型植物相比具有一种或多种期望的性状。在特定实施方案中,获得非转基因遗传修饰植物、藻类、真菌、酵母等、部分或细胞,在这点上没有外源性dna序列并入植物的任何细胞的基因组中。在此类实施方案中,改良的植物、藻类、真菌、酵母等是非转基因的。当仅确保内源性基因的修饰并且在植物、藻类、真菌、酵母等基因组中未引入或维持外源基因时,所得遗传修饰农作物不含有外源基因并且因此可以基本上认为是非转基因的。ad官能化的crispr系统用于植物、藻类、真菌、酵母等基因组编辑的不同应用包括但不限于:编辑内源性基因以赋予目标农业性状。赋予农艺性状的示例性基因包括但不限于赋予对害虫或疾病的抗性的基因;涉及植物疾病的基因,诸如wo2013046247中列出的基因;赋予对除草剂、杀真菌剂等的抗性的基因;涉及(非生物)胁迫耐受性的基因。crispr-cas系统的用途的其他方面包括但不限于:产生(雄性)不育植物;增加植物/藻类等的能育性阶段;生成目标农作物的遗传变异;影响果实催熟;增加植物/藻类等的保存期限;减少植物/藻类等中的过敏原;确保增值的性状(例如营养提高);用于目标内源性基因的筛选方法;生物燃料、脂肪酸、有机酸等的生产。
ad官能化的crispr系统可以用于非人类生物体
在一方面,本发明提供了一种非人类的真核生物体;优选地是多细胞真核生物体,这些生物体包含根据任何所述实施方案的真核宿主细胞。在其他方面,本发明提供了一种真核生物体;优选地是多细胞真核生物体,这些生物体包含根据任何所述实施方案的真核宿主细胞。在这些方面的一些实施方案中,生物体可以是动物;例如哺乳动物。而且,生物体可以是节肢动物,诸如昆虫。本发明还可以扩展到其他农业应用,例如像农场和生产动物。例如,猪具有许多特征,这些特征使得它们作为生物医学模型是有吸引力的,尤其是在再生医学中。特别地,具有重症联合免疫缺陷(scid)的猪可以提供用于再生医学、异种移植(还在本文别处论述)以及肿瘤发展的有用模型,并且将有助于开发用于人类scid患者的疗法。lee等人(procnatlacadsciusa.2014年5月20日;111(20):7260-5)利用一种报告基因指导的转录激活因子样效应核酸酶(talen)系统,以高效率生成对体细胞中的重组激活基因(rag)2的靶向修饰,包括影响两种等位基因的一些修饰。可以将ad官能化的crispr系统应用于类似的系统。
lee等人的方法(procnatlacadsciusa.2014年5月20日;111(20):7260-5)可以如下类似地应用于本发明。突变的猪是通过靶向修饰胎儿成纤维细胞中的rag2,随后进行scnt和胚胎转移而产生的。将编码crisprcas和报告基因的构建体电穿孔到胎儿来源的成纤维细胞中。在48小时后,表达绿色荧光蛋白的转染细胞以估计每孔单个细胞的稀释度分到96孔板的单个孔中。通过扩增侧接任何crisprcas切割位点的基因组dna片段随后对pcr产物进行测序来筛选rag2的靶向修饰。在筛选并确保不存在位点外突变之后,将携带rag2的靶向修饰的细胞用于scnt。去除极体连同卵母细胞的一部分相邻细胞质(推测含有中期ii板),并且将供体细胞置于卵黄周隙中。然后对重构的胚胎进行电穿孔,以使供体细胞与卵母细胞融合,接着进行化学激活。将激活的胚胎在具有0.5μmscriptaid(s7817;sigma-aldrich)的猪受精卵培养基(porcinezygotemedium)3(pzm3)中孵育14-16小时。接着洗涤胚胎以去除scriptaid并且在pzm3中培养,直到它们转移到代孕猪的输卵管为止。
本发明用于创建对动物的疾病或病症建模的平台,在一些实施方案中所述动物是哺乳动物,在一些实施方案中是人类。在某些实施方案中,此类模型和平台是基于啮齿动物,在非限制性实例中是基于大鼠或小鼠。此类模型和平台可以利用近交啮齿动物品系之间的区别和比较。在某些实施方案中,此类模型和平台是基于灵长类动物、马、牛、绵羊、山羊、猪、狗、猫或鸟,例如以直接对此类动物的疾病和病症建模或产生此类动物的修改和/或改良的品系。有利地,在某些实施方案中,创建基于动物的平台或模型以模拟人类疾病或病症。例如,猪与人类的相似性使猪成为对人类疾病建模的理想平台。与啮齿动物模型相比,猪模型的开发既昂贵又费时。在另一方面,猪和其他动物在遗传、解剖、生理和病理生理上与人类的相似性更高。本发明提供了一种用于靶向基因和基因组编辑、基因和基因组修饰以及基因和基因组调节的高效平台,以便在此类动物平台和模型使用。尽管道德标准阻碍了人类模型的开发,并且在许多情况下阻碍了基于非人类灵长类动物的模型的开发,但是本发明可用于体外系统,包括但不限于细胞培养系统、三维模型和系统,以及用以模拟、建模并研究人类的结构、器官和系统的遗传学、解剖学、生理学和病理生理学的类器官。所述平台和模型提供对单个或多个靶标的操纵。
在某些实施方案中,本发明适用于像schomberg等人(fasebjournal,2016年4月;30(1):增补版571.1)的疾病模型的疾病模型。为了对遗传性疾病1型神经纤维瘤病(ne-1)建模,schomberg使用crispr-cas9通过将crispr/cas9组分胞质性微注射到猪胚胎中而在猪神经纤维蛋白1基因中引入突变。为cas9靶向切割基因内外显子上游和下游的区靶向位点创建了crispr指导rna(grna),并通过特定的单链寡脱氧核苷酸(ssodn)模板介导了修复,从而引入了2500bp的缺失。crispr-cas系统还用于工程化具有特定nf-1突变或突变簇的猪,并且还可以用于工程化特定于或代表给定人类个体的突变。本发明类似地用于开发人类多基因疾病的动物模型,包括但不限于猪模型。根据本发明,使用多重指导物和任选地一个或多个模板同时靶向一个基因或多个基因中的多个遗传基因座。
本发明还适用于修饰其他动物诸如牛的snp。tan等人(procnatlacadsciusa.2013年10月8日;110(41):16526-16531)使用质粒、raav和寡核苷酸模板扩增家畜基因编辑工具包,以包括转录激活因子样(tal)效应核酸酶(talen)-和成簇的规律间隔的短回文重复序列(crispr)/cas9-刺激性同源定向修复(hdr)。根据他们的方法将基因特异性指导rna序列克隆到church实验室指导rna载体(addgeneid:41824)中(malip等人(2013)rna-guidedhumangenomeengineeringviacas9.science339(6121):823-826)。cas9核酸酶通过共转染hcas9质粒(addgeneid:41815)或由rciscript-hcas9合成的mrna来提供。此rciscript-hcas9通过将来自hcas9质粒(涵盖hcas9cdna)的xbai-agei片段亚克隆到rciscript质粒中来构建。
heo等人(stemcellsdev.2015年2月1日;24(3):393-402.doi:10.1089/scd.2014.0278.电子版2014年11月3日)报道了在牛基因组中使用牛多能细胞和成簇的规律间隔的短回文重复序列(crispr)/cas9核酸酶的高效基因靶向。首先,heo等人通过异位表达山中因子(yamanakafactor)并且进行gsk3β和mek抑制剂(2i)处理来由牛体成纤维细胞生成诱导的多能干细胞(ipsc)。heo等人观察到,这些牛ipsc在畸胎瘤的基因表达和发育潜力方面高度类似于天然多能干细胞。此外,对于牛nanog基因座特异的crispr-cas9核酸酶在牛ipsc和胚胎的牛基因组中显示高度有效的编辑。
qingjianzou等人(journalofmolecularcellbiology,在2015年10月12日在线先行公布)证明通过靶向狗肌生成抑制蛋白(mstn)基因(骨骼肌质量的负调节子)的第一外显子可增加狗的肌肉质量。首选,通过将sgrna靶向mstn与cas9载体共转染到犬胚胎成纤维细胞(cef)中来验证sgrna的效率。之后,通过微注射具有正常形态学的胚胎以及cas9mrna和mstnsgrna的混合物并且将受精卵自身移植到同一母狗的输卵管来生成mstnko狗。与其野生型同窝出生母狗相比,敲除小狗在大腿上显示明显的肌肉表型。这也可以使用本文提供的ad官能化的crispr系统来进行。
家畜-猪
在一些实施方案中,家畜中的病毒靶标可以包括例如猪巨噬细胞上的猪cd163。cd163与prrsv(猪繁殖与呼吸综合征病毒,它是一种动脉炎病毒)的感染(认为是通过病毒细胞侵入)相关联。prrsv的感染,尤其是对猪肺泡巨噬细胞(可见于肺中)的感染导致先前不能治愈的猪综合征(“神秘猪病”或“蓝耳病”),使得家猪遭受(包括)繁殖障碍、体重减轻和高死亡率。常常可见机会性感染诸如流行性肺炎、脑膜炎和耳肿胀,这是因为通过巨噬细胞活性丧失会引起免疫缺陷。由于抗生素使用的增加和经济损失(估计每年660百万美元),这也具有重大的经济和环境影响。
如密苏里大学(universityofmissouri)的kristinmwhitworth和randallprather博士等人(naturebiotech3434,2015年12月07日在线公布)与genusplc合作报道的,使用crispr-cas9靶向cd163,当编辑的猪的后代暴露于prrsv时它们是有抗性的。使在cd163的外显子7中均具有突变的一个雄性起始者和一种雌性起始者繁殖产生后代。雄性起始者具有一个等位基因的外显子7中的11-bp的缺失,这导致结构域5中氨基酸45处的移码突变和错义翻译以及氨基酸64处的后一个提前终止密码子。另一个等位基因具有外显子7中的2-bp添加和在前内含子中的377-bp缺失,预测这引起结构域5的前49个氨基酸的表达,随后是在氨基酸85处的提前终止密码子。母猪在一个等位基因中具有7bp添加,预测该添加在翻译时表达结构域5的前48个氨基酸,随后是在氨基酸70处的提前终止密码子。母猪的另一个等位基因是不可扩增的。预测选定的后代是无效动物(cd163-/-),即cd163敲除。
因此,在一些实施方案中,猪肺泡巨噬细胞可以被crispr蛋白靶向。在一些实施方案中,猪cd163可以被crispr蛋白靶向。在一些实施方案中,猪cd163可以通过诱导dsb或通过插入或缺失来敲除,例如外显子7的靶向缺失或修饰,包括以上所述的那些缺失或修饰中的一种或多种,或者在该基因的其他区域中,例如外显子5的缺失或修饰。
还设想了编辑的猪及其子代,例如cd163敲除猪。这可以是出于家畜、育种或建模目的(即,猪模型)。还提供了包含基因敲除的精液。
cd163是富含半胱氨酸清道夫受体(srcr)超家族的成员。基于体外研究,蛋白质的srcr结构域5是负责启封和释放病毒基因组的结构域。这样,也可以靶向srcr超家族的其他成员,以便评定对其他病毒的抗性。prrsv还是哺乳动物动脉炎病毒组的成员,所述病毒组还包括鼠乳酸脱氢酶病毒、猴出血热病毒和马动脉炎病毒。动脉炎病毒享有重要的发病机理特性,包括巨噬细胞向性和引起严重疾病和持续感染二者的能力。因此,可以例如通过猪cd163或其在其他种类中的同源物来提供动脉炎病毒以及特别地鼠乳酸脱氢酶病毒、猴出血热病毒和马动脉炎病毒,并且还提供鼠、猴和马的模型以及敲除。
实际上,此方法可以扩展到引起其他家畜疾病且可以传播到人类的病毒或细菌,诸如猪流感病毒(siv)株,包括丙型流感和称为h1n1、h1n2、h2n1、h3n1、h3n2以及h2n3的甲型流感亚型,以及以上提及的肺炎、脑膜炎和水肿。
在一些实施方案中,本文所述的ad官能化的crispr系统可以用于遗传性修饰猪基因组以使一个或多个猪内源性逆转录病毒(perv)基因座失活,从而促进猪向人类异种移植的临床应用。参见yang等人,science350(6264):1101-1104(2015),该文献以引用方式整体并入本文。在一些实施方案中,本文所述的ad官能化的crispr系统可以用于产生不包含任何活性猪内源性逆转录病毒(perv)基因座的遗传修饰的猪。
使用crispr系统进行的筛查/诊断/治疗
癌症
本发明的方法和组合物可以用于鉴定与药物耐受性和疾病细胞持久性相关联的细胞状态、组分和机制。terai等人(cancerresearch,19-dec-2017,doi:10.1158/0008-5472.can-17-1904)报道了用厄洛替尼+thz1(cdk7/12抑制剂)组合疗法治疗的egfr依赖性肺癌pc9细胞中的全基因组crispr/cas9增强子/阻遏因子筛选,以鉴定增强厄洛替尼/thz1协同作用的多种基因,以及阻遏协同作用的组分和途径。wang等人(cellrep.2017年2月7日;18(6):1543-1557.doi:10.1016/j.celrep.2017.01.031.;krall等人,elife.2017年2月1日;6.pii:e18970.doi:10.7554/elife.18970)报道了使用全基因组crispr功能丧失筛选来鉴定对mapk抑制剂具有抗性的介体。donovan等人(plosone.2017年1月24日;12(1):e0170445.doi:10.1371/journal.pone.0170445.ecollection2017)使用crispr介导的诱变方法来鉴定mapk信号传导途径基因的新颖功能获得和耐药性等位基因。wang等人(cell.2017年2月23日;168(5):890-903.e15.doi:10.1016/j.cell.2017.01.013.电子版2017年2月2日)使用全基因组crispr筛选来鉴定基因网络以及与致癌ras的合成致死相互作用。chow等人(natneurosci.2017年10月;20(10):1329-1341.doi:10.1038/nn.4620.电子版2017年8月14日)开发了在胶质母细胞瘤中的腺相关病毒介导的自发遗传crispr筛选技术,以鉴定胶质母细胞瘤中的功能阻遏因子。xue等人(nature.2014年10月16日;514(7522):380-4.doi:10.1038/nature13589.电子版2014年8月6日)在小鼠肝脏中采用crispr介导的癌症基因直接突变。
chen等人(jclininvest.2017年12月4日pii:90793.doi:10.1172/jci90793.[印刷前电子版])使用基于crispr的筛选来鉴定mycn扩增的神经母细胞瘤对ezh2的依赖性。支持在患有mycn扩增的神经母细胞瘤的患者中进行ezh2抑制剂测试。
vijai等人(cancerdiscov.2016年11月;6(11):1267-1275.电子版2016年9月21日)报道了使用crispr在乳腺上皮细胞系中生成杂合突变以评定乳腺癌风险。
chakraborty等人(scitranslmed.2017年7月12日;9(398).pii:eaal5272.doi:10.1126/scitranslmed.aal5272)使用基于crispr的筛选来鉴定作为治疗透明细胞肾细胞癌的潜在靶标的ezh1
代谢性疾病
本发明的方法和组合物在治疗肝脏遗传性代谢性疾病方面提供优于常规基因治疗方法的优势,所述疾病包括但不限于家族性高胆固醇血症、血友病、鸟氨酸转氨甲酰酶缺乏症、1型遗传性酪氨酸血症和α-1抗胰蛋白酶缺乏症。参见bryson等人,yalej.biol.med.90(4):553-566,2017年12月19日。
bompada等人(intjbiochemcellbiol.2016年12月;81(pta):82-91.doi:10.1016/j.biocel.2016.10.022.电子版2016年10月29日)描述了使用crispr来敲除胰腺β细胞中的组蛋白乙酰转移酶,以证明组蛋白乙酰化是葡萄糖诱导的txnip基因表达增加并且因此是糖毒性诱导的细胞凋亡的关键调节子。
眼
本发明提供了对遗传性和获得性眼病的有效治疗。holmgaard等人(mol.ther.nucleicacids9:89-99,2017年12月15日doi:10.1016/j.omtn.2017.08.016.电子版2017年9月21日)报道了当spcas9由编码靶向vegfa的spcas9的慢病毒载体(lv)递送时,以高频率形成插入缺失,并且在转导细胞中vegfa显著减少。duan等人(jbiolchem.2016年7月29日;291(31):16339-47.doi:10.1074/jbc.m116.729467.电子版2016年5月31日)描述了使用crispr来靶向人类原代视网膜色素上皮细胞中的mdm2基因组基因座。
本发明的方法和组合物类似地适用于眼病的治疗,所述眼病包括年龄相关性黄斑变性。
huang等人(natcommun.2017年7月24日;8(1):112.doi:10.1038/s41467-017-00140-3使用crispr来编辑vegfr2以治疗与血管新生相关联的疾病。
听力
gao等人(nature.2017年12月20日.doi:10.1038/nature25164.[印刷前电子版])报道了使用crispr-cas9进行基因组编辑以靶向小鼠中的tmc1基因并且减少进行性听力丧失和耳聋。
肌肉
provenzano等人(molthernucleicacids.9:337-348.2017年12月15日;.doi:10.1016/j.omtn.2017.10.006.电子版2017年10月14日)报道了来自1型肌强直性营养不良患者的肌原细胞中的crispr/cas9介导的ctg扩增缺失和永久回复至正常表型。本发明的方法和组合物类似地适用于核苷酸重复序列病症,不限于ctg扩增。tabebordbar等人(2016年1月22日;351(6271):407-411.doi:10.1126/science.aad5177.电子版2015年12月31日)报道了使用crispr来编辑dmd外显子23基因座,以校正dmd中的破坏性突变。tabebordbar表明,在新生儿和成年小鼠中可编程crispr复合物可以局部地和全身性地递送至终末分化的骨骼肌纤维和心肌细胞以及肌肉卫星细胞,在细胞中它们介导靶向基因修饰,恢复肌营养不良蛋白表达并且部分地恢复营养不良肌肉的功能缺陷。另参见nelson等人,(science.2016年1月22日;351(6271):403-7.doi:10.1126/science.aad5143.电子版2015年12月31日)。
感染性疾病
sidik等人(cell.2016年9月8日;166(6):1423-1435.e12.doi:10.1016/j.cell.2016.08.019.电子版2016年9月2日)和patel等人(nature.2017年8月31日;548(7669):537-542.doi:10.1038/nature23477.电子版2017年8月7日)描述了弓形虫中的crispr筛选和抗寄生虫干预措施的扩展。
存在若干关于全基因组crispr筛选的报告,旨在鉴定宿主-病原体相互作用的基础组分和过程。实例包括blondel等人(cellhostmicrobe.2016年8月10日;20(2):226-37.doi:10.1016/j.chom.2016.06.010.电子版2016年7月21日);shapiro等人(natmicrobiol.2018年1月;3(1):73-82.doi:10.1038/s41564-017-0043-0.电子版2017年10月23日)和park等人(natgenet.2017年2月;49(2):193-203.doi:10.1038/ng.3741.电子版2016年12月19日)。
ma等人(cellhostmicrobe.2017年5月10日;21(5):580-591.e7.doi:10.1016/j.chom.2017.04.005)采用全基因组crispr功能丧失筛选来鉴定治疗性干预的病毒转化驱动的合成致死靶标。
心血管疾病
crispr系统可以用作鉴定与血管疾病相关联的基因或遗传变体的工具。这对于鉴定潜在的治疗或预防靶标很有用。xu等人(atherosclerosis,2017年9月21日pii:s0021-9150(17)31265-0.doi:10.1016/j.atherosclerosis.2017.08.031.[印刷前电子版])报道了使用crispr来敲除angptl3基因,以确认angptl3在调节ldl-c血浆水平中的作用。gupta等人,(cell.2017年7月27日;170(3):522-533.e15.doi:10.1016/j.cell.2017.06.049)报道了使用crispr来编辑干细胞来源的内皮细胞以鉴定与血管疾病相关联的遗传变体。beaudoin等人,(arteriosclerthrombvascbiol.2015年6月;35(6):1472-1479.doi:10.1161/atvbaha.115.305534.电子版2015年4月2日)报道了使用crispr基因组编辑来破坏转录因子mef2在该基因座处的结合。这为探索血管内皮中的phactr1功能如何影响冠状动脉疾病奠定了基础。pashos等人(cellstemcell.2017年4月6日;20(4):558-570.e10.doi:10.1016/j.stem.2017.03.017.)报道了使用crispr技术来靶向多能干细胞和肝细胞样细胞以鉴定功能性变体和脂质功能性基因。
除了用作鉴定靶标的工具之外,crispr系统还可以直接用于治疗或预防已知靶标的心血管疾病。khera等人(natrevgenet.2017年6月;18(6):331-344.doi:10.1038/nrg.2016.160.电子版2017年3月13日)描述了常见的变体关联研究,这些将大约60个遗传基因座与冠心病风险联系起来,用于促进更好地了解成因风险因素,以及新治疗剂的潜在生物学发展。例如,khera解释到使pcsk9中的突变失活降低了循环ldl胆固醇的水平并且降低了cad风险,这引起了人们对pcsk9抑制剂开发的浓厚兴趣。此外,被设计来模拟apoc3或lpa中的保护性突变的反义寡核苷酸分别显示约70%的甘油三酯水平降低和80%的循环脂蛋白(a)水平降低。此外,wang等人,(arteriosclerthrombvascbiol.2016年5日;36(5):783-6.doi:10.1161/atvbaha.116.307227.电子版2016年3月3日)和ding等人(circres.2014年8月15日;115(5):488-92.doi:10.1161/circresaha.115.304351.电子版2014年6月10日)报道了使用crispr来靶向pcsk9基因以便预防心血管疾病。
本发明提供了用于研究和治疗神经系统疾病和病症的方法和组合物。nakayama等人,(amjhumgenet.2015年5月7日;96(5):709-19.doi:10.1016/j.ajhg.2015.03.003.电子版2015年4月9日)报道了使用crispr来研究pycr2在人类cns发育中的作用,并且鉴定小头畸形和髓鞘形成减少的潜在靶标。swiech等人(natbiotechnol.2015年1月;33(1):102-6.doi:10.1038/nbt.3055.电子版2014年10月19日)报道了使用crispr来在体内靶向成年小鼠脑中的单个(mecp2)以及多个基因(dnmt1、dnmt3a和dnmt3b)。shin等人(hummolgenet.2016年10月15日;25(20):4566-4576.doi:10.1093/hmg/ddw286)描述了使用crispr来使亨廷顿氏病(huntingon’sdisease)突变失活。platt等人(cellrep.2017年4月11日;19(2):335-350.doi:10.1016/j.celrep.2017.03.052)报道了使用crispr敲入小鼠来鉴定chd8在自闭症谱系障碍中的作用。seo等人(jneurosci.2017年10月11日;37(41):9917-9924.doi:10.1523/jneurosci.0621-17.2017.电子版2017年9月14日)描述了使用crispr来生成神经变性病症的模型。petersen等人(neuron.2017年12月6日;96(5):1003-1012.e7.doi:10.1016/j.neuron.2017.10.008.电子版2017年11月2日)展示了crispr敲除少突胶质祖细胞中的激活素a受体i型,以鉴定具有髓鞘再生障碍的疾病的潜在靶标。本发明的方法和组合物是类似地可适用的。
crispr技术的其他应用.
renneville等人(blood.2015年10月15日;126(16):1930-9.doi:10.1182/blood-2015-06-649087.电子版2015年8月28日)报道了使用crispr来研究ehmt1和emht2在胎儿血红蛋白表达中的作用,并且鉴定scd的新颖治疗靶标。
tothova等人(cellstemcell.2017年10月5日;21(4):547-555.e8.doi:10.1016/j.stem.2017.07.015)报道了在造血干细胞和祖细胞中使用crispr以便产生人类骨髓疾病模型。
giani等人(cellstemcell.2016年1月7日;18(1):73-78.doi:10.1016/j.stem.2015.09.015.电子版2015年10月22日)报道说,通过在人类多能干细胞中进行crispr/cas9基因组编辑来使sh2b3失活,可以增强红系细胞的扩增并保持分化。
wakabayashi等人(procnatlacadsciusa.2016年4月19日;113(16):4434-9.doi:10.1073/pnas.1521754113.电子版2016年4月4日)采用crispr来深入了解gata1转录活性,并且研究人类红系病症中非编码变体的病原性。
mandal等人(cellstemcell.2014年11月6日;15(5):643-52.doi:10.1016/j.stem.2014.10.004.电子版2014年11月6日)描述了crispr/cas9靶向原代人类cd4+t细胞和cd34+造血干细胞和祖细胞(hspc)中的两个临床相关基因,即b2m和ccr5。
polfus等人(amjhumgenet.2016年9月1日;99(3):785.doi:10.1016/j.ajhg.2016.08.002.电子版2016年9月1日)在原代人类造血干细胞和祖细胞中使用crispr来编辑造血细胞系并进行后续靶向敲低实验,并且研究gfi1b变体在人类造血中的作用。
najm等人(natbiotechnol.2017年12月18.doi:10.1038/nbt.4048.[印刷前电子版])报道了使用具有一对sacas9和spcas9的crispr复合物来实现双重靶向以生成高复杂度的合并的双敲除文库,从而鉴定跨多种细胞类型的合成致死和缓冲基因对,包括mapk途径基因和凋亡基因。
manguso等人(nature.2017年7月27日;547(7664):413-418.doi:10.1038/nature23270.电子版2017年7月19日.)报道了使用crispr筛选来识别并且/或者确认新的免疫疗法靶标。另参见roland等人(procnatlacadsciusa.2017年6月20日;114(25):6581-6586.doi:10.1073/pnas.1701263114.电子版2017年6月12日.);erb等人(nature.2017年3月9日;543(7644):270-274.doi:10.1038/nature21688.电子版2017年3月1日.);hong等人,(natcommun.2016年6月22日;7:11987.doi:10.1038/ncomms11987);fei等人,(procnatlacadsciusa.2017年6月27日;114(26):e5207-e5215.doi:10.1073/pnas.1617467114.电子版2017年6月13日.);zhang等人,(cancerdiscov.2017年9月29日.doi:10.1158/2159-8290.cd-17-0532.[印刷前电子版])。
joung等人(nature.2017年8月17日;548(7667):343-346.doi:10.1038/nature23451.电子版2017年8月9日.)报道了使用全基因组筛选来分析长的非编码rna(lncrna);另参见zhu等人,(natbiotechnol.2016年12月;34(12):1279-1286.doi:10.1038/nbt.3715.电子版2016年10月31日);sanjana等人,(science.2016年9月30日;353(6307):1545-1549)。
barrow等人(molcell.2016年10月6日;64(1):163-175.doi:10.1016/j.molcel.2016.08.023.电子版2016年9月22日.)报道了使用全基因组crispr筛选来寻找线粒体疾病的治疗靶标。另参见vafai等人,(plosone.2016sep13;11(9):e0162686.doi:10.1371/journal.pone.0162686.ecollection2016)。
guo等人(elife.2017年12月5日;6.pii:e29329.doi:10.7554/elife.29329)报道了使用crispr来靶向人类软骨细胞以阐明人类生长的生物机制。
ramanan等人(scirep.2015年6月2日;5:10833.doi:10.1038/srep10833)报道了使用crispr来靶向并且切割hbv基因组中的保守区。
使用ad官能化的crispr系统进行治疗性靶向
如将显而易见的,设想的是ad官能化的crispr系统可以用于靶向任何目标多核苷酸序列。本发明提供了一种非天然存在的或工程化的组合物、或编码所述组合物的组分的一种或多种多核苷酸、或包含编码所述组合物的组分的一种或多种多核苷酸的载体或递送系统,其用于体内、离体或体外修饰靶细胞,并且所述修饰可以这样一种方式实施:改变细胞,使得一旦被修饰,crispr修饰的细胞的子代或细胞系保留改变的表型。修饰的细胞和子代可以是多细胞生物体的一部分,诸如在将crispr系统离体或体内应用于所需细胞类型的情况下的植物或动物。crispr发明可以是一种治疗性治疗方法。治疗性治疗方法可以包括基因或基因组编辑,或基因疗法。
过继细胞疗法
本发明还考虑使用本文所述的ad官能化的crispr系统来修饰用于过继疗法的细胞。因此,本发明的方面涉及过继性转移对于选定抗原诸如肿瘤相关抗原特异的免疫系统细胞诸如t细胞(参见maus等人,2014,adoptiveimmunotherapyforcancerorviruses,annualreviewofimmunology,第32卷:189-225;rosenberg和restifo,2015,adoptivecelltransferaspersonalizedimmunotherapyforhumancancer,science第348卷,第6230期,第62-68页;以及restifo等人,2015,adoptiveimmunotherapyforcancer:hamessingthetcellresponse.nat.rev.immunol.12(4):269-281;以及jenson和riddell,2014,designandimplementationofadoptivetherapywithchimericantigenreceptor-modifiedtcells.immunolrev.257(1):127-144)。可以例如采用各种策略来通过改变t细胞受体(tcr)的特异性,例如通过引入具有选定的肽特异性的新tcrα和β链来遗传性修饰t细胞(参见美国专利号8,697,854;pct专利公布:wo2003020763、wo2004033685、wo2004044004、wo2005114215、wo2006000830、wo2008038002、wo2008039818、wo2004074322、wo2005113595、wo2006125962、wo2013166321、wo2013039889、wo2014018863、wo2014083173;美国专利号8,088,379)。
作为tcr修饰的替代方案或者除tcr修饰之外,可以使用嵌合抗原受体(car),以便生成对于选定靶标诸如恶性肿瘤细胞特异的免疫反应细胞诸如t细胞,其中已经描述了多种多样的受体嵌合构建体(参见美国专利号5,843,728;5,851,828;5,912,170;6,004,811;6,284,240;6,392,013;6,410,014;6,753,162;8,211,422;以及pct公布wo9215322)。替代car构建体可以被表征为属于连续世代。第一代car典型地由对于抗原特异的抗体单链可变片段组成,例如包括连接至特异性抗体的vh的vl,通过柔性接头连接,例如通过cd8α铰链结构域和cd8α跨膜结构域,连接至cd3ζ或fcrγ的跨膜和细胞内信号传导结构域(scfv-cd3ζ或scfv-fcrγ;参见美国专利号7,741,465;美国专利号5,912,172;美国专利号5,906,936)。第二代car并入一种或多种共刺激分子的细胞内结构域,诸如内结构域内的cd28、ox40(cd134)或4-1bb(cd137)(例如scfv-cd28/ox40/4-1bb-cd3ζ;参见美国专利号8,911,993;8,916,381;8,975,071;9,101,584;9,102,760;9,102,761)。第三代car包括共刺激内结构域的组合,诸如cd3ζ-链、cd97、gdila-cd18、cd2、icos、cd27、cd154、cds、ox40、4-1bb或cd28信号传导结构域(例如scfv-cd28-4-1bb-cd3ζ或scfv-cd28-ox40-cd3ζ;参见美国专利号8,906,682;美国专利号8,399,645;美国专利号5,686,281;pct公布号wo2014134165;pct公布号wo2012079000)。或者,可以通过在抗原特异性t细胞中表达car来协调共刺激,所述抗原特异性t细胞被选择以便在伴随共刺激的情况下例如由专职抗原呈递细胞上的抗原接合其天然αβtcr之后得以激活并扩增。此外,另外的工程化受体可以被提供在免疫反应细胞上,例如以提高t细胞攻击的靶向并且/或者最小化副作用。
可以使用替代技术转化免疫反应靶细胞,所述替代技术诸如原生质体融合、脂转染、转染或电穿孔。可以使用多种多样的载体,诸如逆转录病毒载体、慢病毒载体、腺病毒载体、腺相关病毒载体、质粒或转座子(诸如睡美人易位子)(参见美国专利号6,489,458;7,148,203;7,160,682;7,985,739;8,227,432),这些载体可以用于例如使用通过cd3ζ和cd28或cd137传导信号的第2代抗原特异性car来引入car。病毒载体可以例如包括基于hiv、sv40、ebv、hsv或bpv的载体。
被靶向转化的细胞可以例如包括t细胞、自然杀伤细胞(nk)、细胞毒性t淋巴细胞(ctl)、调节t细胞、人类胚胎干细胞、肿瘤浸润淋巴细胞(til)或淋巴样细胞可以由其分化的多能干细胞。表达所需car的t细胞可以例如通过与γ-辐射激活和增殖细胞(aapc)共培养来选择,这些激活和增殖细胞共表达癌症抗原和共刺激分子。工程化cart细胞可以例如通过在可溶性因子诸如il-2和il-21存在下在aapc上共培养来扩增。可以例如执行此扩增以提供记忆car+t细胞(这些细胞可以例如通过非酶数字阵列和/或多板块(multi-panel)流式细胞术来测定)。以这种方式,可以提供具有针对携带抗原的肿瘤的特异性细胞毒性活性的cart细胞(任选地与所需趋化因子诸如干扰素-γ的产生相结合)。这种类型的cart细胞例如可以用于动物模型中,例如以威慑肿瘤异种移植物。
诸如上述方法的方法可以适于提供例如通过施用有效量的免疫反应细胞来治疗患有诸如瘤形成的疾病的患者并且/或者增加所述患者的存活的方法,所述免疫反应细胞包含结合选定抗原的抗原识别受体,其中所述结合激活免疫反应细胞,从而治疗或预防所述疾病(诸如瘤形成、病原体感染、自身免疫病症或同种异体移植反应)。在具有或不具有淋巴细胞耗尽过程的情况下,例如在使用环磷酰胺的情况下,cart细胞疗法的给药可以例如涉及施用106至109个细胞/kg。
在一个实施方案中,可以向经受免疫阻遏治疗的患者施用所述治疗。细胞或细胞群体可以被制成由于编码至少一种免疫阻遏剂的受体的基因的失活而抵抗此免疫阻遏剂。不受理论的束缚,免疫阻遏治疗应有助于在患者内选择和扩增根据本发明的免疫反应细胞或t细胞。
可以采用任何常规方式执行根据本发明的细胞或细胞群体的施用,这些方式包括通过雾化吸入、注射、摄取、输血、植入或移植。可以向患者皮下、真皮内、瘤内、节点内、髓内、肌内、通过静脉内注射或淋巴管内注射、或者腹膜内施用所述细胞或细胞群体。在一个实施方案中,本发明的细胞组合物优选地通过静脉内注射来施用。
所述细胞或细胞群体的施用可以由104-109个细胞/kg体重、优选地105至106个细胞/kg体重(包括这些范围内细胞数目的所有整数值)的施用组成。在具有或不具有淋巴细胞耗尽过程的情况下,例如在使用环磷酰胺的情况下,cart细胞疗法的给药可以例如涉及施用106至109个细胞/kg。细胞或细胞群体可以按一个或多个剂量施用。在另一个实施方案中,有效量的细胞作为单一剂量施用。在另一个实施方案中,有效量的细胞作为多于一个剂量在一段时间内施用。施用的时间在管理医师的判断内并且取决于患者的临床状况。细胞或细胞群体可以从任何来源诸如血库或供体获得。虽然个体需要不同,但是针对特定疾病或疾患的给定细胞类型的有效量的最佳范围的确定在本领域技术人员技能之内。有效量是指提供治疗或预防益处的量。施用的剂量将取决于接受者的年龄、健康和体重、同期治疗(如果有的话)的类型、治疗的频率以及所需的作用性质。
在另一个实施方案中,肠胃外施用有效量的细胞或包含那些细胞的组合物。施用可以是静脉内施用。可以通过在肿瘤内注射直接进行施用。
为了防止可能的不良反应,可以用转基因安全开关装备工程化的免疫反应细胞,所述转基因安全开关呈致使这些细胞易于暴露于特定信号的转基因形式。例如,单纯疱疹病毒胸苷激酶(tk)可以这种方式使用,例如通过在干细胞移植之后引入到用作供体淋巴细胞输注的同种异体t淋巴细胞中(greco等人,improvingthesafetyofcelltherapywiththetk-suicidegene.front.pharmacol.2015;6:95)。在此类细胞中,施用核苷前药诸如更昔洛韦或阿昔洛韦引起细胞死亡。替代安全开关构建体包括诱导型半胱天冬酶9,其例如通过施用使两个非功能性icasp9分子连接在一起形成活性酶的小分子二聚体来触发。已经描述了用于实施细胞增殖控制的多种多样的替代方法(参见美国专利公布号20130071414;pct专利公布wo2011146862;pct专利公布wo2014011987;pct专利公布wo2013040371;zhou等人blood,2014,123/25:3895-3905;distasi等人,thenewenglandjournalofmedicine2011;365:1673-1683;sadelainm,thenewenglandjournalofmedicine2011;365:1735-173;ramos等人,stemcells28(6):1107-15(2010))。
在过继疗法的另一个改进方案中,如本文所述的ad官能化的crispr-cas系统进行的基因组编辑可以用于使免疫反应细胞适于替代实施方式,例如提供编辑的cart细胞(参见poirot等人,2015,multiplexgenomeeditedt-cellmanufacturingplatformfor″off-the-shelf″adoptivet-cellimmunotherapies,cancerres75(18):3853)。例如,免疫反应细胞可以被编辑为缺失一些或所有类别的hlaii型和/或i型分子的表达,或者敲除可以抑制所需免疫反应的选定基因诸如pd1基因。
可以使用如本文所述的ad官能化的crispr系统来编辑细胞。可以通过本文所述的任何方法将ad官能化的crispr系统递送至免疫细胞。在优选的实施方案中,将细胞离体编辑并转移至有需要的受试者。可以编辑免疫反应细胞、car-t细胞或用于过继细胞转移的任何细胞。可以进行编辑以消除潜在的同种异体反应性t-细胞受体(tcr)、破坏化学治疗剂的靶标、阻断免疫校验点、激活t细胞并且/或者增加功能耗竭或功能障碍的cd8+t-细胞的分化和/或增殖(参见pct专利公布:wo2013176915、wo2014059173、wo2014172606、wo2014184744和wo2014191128)。编辑可以导致基因失活。
t细胞受体(tcr)是响应于抗原呈递而参与激活t细胞的细胞表面受体。tcr通常是由组装形成异源二聚体的两条链α和β形成,并且与cd3-转导亚基缔合形成存在于细胞表面的t细胞受体复合物。tcr的每条α和β链由免疫球蛋白样n端可变区(v)和恒定(c)区、疏水性跨膜结构域以及短胞质区组成。如对于免疫球蛋白分子,α和β链的可变区是通过v(d)j重组而生成,从而在t细胞群体内形成多种抗原特异性。然而,与识别完整抗原的免疫球蛋白相比,t细胞通过与mhc分子缔合的加工肽片段来激活,从而将额外维度引入到由t细胞进行的抗原识别中,这被称为mhc限制。通过t细胞受体识别供体与受体之间的mhc差异导致t细胞增殖和移植物抗宿主疾病(gvhd)的潜在发展。tcrα或tcrβ的失活可以导致tcr从t细胞表面消除,从而阻止了同种抗原的识别并因此产生gvhd。然而,tcr破坏通常导致cd3信号传导组分的消除并且改变另外的t细胞扩增的方式。
同种异体细胞被宿主免疫系统迅速排斥。已证明存在于非辐射血液产品中的同种异体淋巴细胞将持续不超过5至6天(boni,muranski等人2008blood1;112(12):4746-54)。因此,为了防止同种异体细胞排斥,通常必须在一定程度上阻遏宿主的免疫系统。然而,在过继细胞转移的情况下,使用免疫阻遏药物也对引入的治疗性t细胞具有有害作用。因此,为了在这些情况下有效使用过继免疫治疗方法,引入的细胞将需要抵抗免疫阻遏治疗。因此,在特定实施方案中,本发明还包括优选地通过使编码免疫阻遏剂的靶标的至少一种基因失活来修饰t细胞以使其抵抗免疫阻遏剂的步骤。免疫阻遏剂是一种通过若干作用机制之一阻遏免疫功能的物质。免疫阻遏剂可以是但不限于钙调磷酸酶抑制剂、雷帕霉素的靶标、白介素-2受体α-链阻断剂、肌苷单磷酸脱氢酶的抑制剂、二氢叶酸还原酶的抑制剂、皮质类固醇或免疫阻遏抗代谢物。本发明允许通过使t细胞中的免疫阻遏剂的靶标失活来对用于免疫疗法的t细胞赋予免疫阻遏抗性。作为非限制性实例,免疫阻遏剂的靶标可以是免疫阻遏剂的受体,诸如:cd52、糖皮质激素受体(gr)、fkbp家族基因成员以及亲环蛋白家族基因成员。
免疫检验点是减慢或停止免疫反应并且防止因免疫细胞的不受控活性所致的过度组织损害的抑制性途径。在某些实施方案中,所靶向的免疫检查点是程序性死亡-1(pd-1或cd279)基因(pdcd1)。在其他实施方案中,所靶向的免疫检查点是细胞毒性t-淋巴细胞相关抗原(ctla-4)。在其他实施方案中,所靶向的免疫检查点是cd28和ctla4ig超家族的另一个成员,诸如btla、lag3、icos、pdl1或kir。在另外的其他实施方案中,所靶向的免疫检查点是tnfr超家族的成员,诸如cd40、ox40、cd137、gitr、cd27或tim-3。
其他免疫检验点包括含有src同源2结构域的蛋白酪氨酸磷酸酶1(shp-1)(watsonha等人,shp-1:thenextcheckpointtargetforcancerimmunotherapy?biochemsoctrans.2016年4月15日;44(2):356-62)。shp-1是一种广泛表达的抑制性蛋白酪氨酸磷酸酶(ptp)。在t细胞中,它是抗原依赖性激活和增殖的负调节子。它是一种胞质蛋白,并且因此不适于抗体介导的疗法,但是它在激活和增殖中的作用使得它成为过继转移策略中用于遗传操纵的有吸引力的靶标,诸如嵌合抗原受体(car)t细胞。免疫检查点还可以包括具有ig和itim结构域的t细胞免疫受体(tigit/vstm3/wucam/vsig9)和vista(lemercieri等人,(2015)beyondctla-4andpd-1,thegenerationzofnegativecheckpointregulators.front.immunol.6:418)。
wo2014172606涉及使用mt1和/或mt1抑制剂来增加耗竭的cd8+t细胞的增殖和/或活性并且减少cd8+t细胞耗竭(例如,减少功能耗竭或不反应的cd8+免疫细胞)。在某些实施方案中,在过继性转移的t细胞中通过基因编辑靶向金属硫蛋白。
在某些实施方案中,基因编辑的靶标可以是涉及免疫检验点蛋白的表达的至少一个靶向基因座。此类靶标可以包括但不限于ctla4、ppp2ca、ppp2cb、ptpn6、ptpn22、pdcd1、icos(cd278)、pdl1、kir、lag3、havcr2、btla、cd160、tigit、cd96、crtam、lair1、siglec7、siglec9、cd244(2b4)、tnfrsf10b、tnfrsf10a、casp8、casp10、casp3、casp6、casp7、fadd、fas、tgfbrii、tgfrbri、smad2、smad3、smad4、smad10、ski、skil、tgif1、il10ra、il10rb、hmox2、il6r、il6st、eif2ak4、csk、pag1、sit1、foxp3、prdm1、batf、vista、gucy1a2、gucy1a3、gucy1b2、gucy1b3、mt1、mt2、cd40、ox40、cd137、gitr、cd27、shp-1或tim-3。在优选的实施方案中,靶向涉及pd-1或ctla-4基因的表达的基因座。在其他优选的实施方案中,靶向基因的组合,诸如但不限于pd-1和tigit。
在其他实施方案中,编辑至少两种基因。基因对可以包括但不限于pd1和tcrα、pd1和tcrβ、ctla-4和tcrα、ctla-4和tcrβ、lag3和tcrα、lag3和tcrβ、tim3和tcrα、tim3和tcrβ、btla和tcrα、btla和tcrβ、by55和tcrα、by55和tcrβ、tigit和tcrα、tigit和tcrβ、b7h5和tcrα、b7h5和tcrβ、lair1和tcrα、lair1和tcrβ、siglec10和tcrα、siglec10和tcrβ、2b4和tcrα、2b4和tcrβ。
无论是在t细胞的遗传修饰之前还是之后,t细胞都可以通常使用如例如以下文献所述的方法来激活并扩增:美国专利6,352,694;6,534,055;6,905,680;5,858,358;6,887,466;6,905,681;7,144,575;7,232,566;7,175,843;5,883,223;6,905,874;6,797,514;6,867,041;以及7,572,631。t细胞可以在体外或体内扩增。
本发明的实践采用免疫学、生物化学、化学、分子生物学、微生物学、细胞生物学、基因组学以及重组dna领域中已知的技术,这些技术在本领域技能范围之内。参见molecularcloning:alaboratorymanual,第2版(1989)(sambrook、fritsch和maniatis);molecularcloning:alaboratorymanual,第4版(2012)(green和sambrook);currentprotocolsinmolecularbiology(1987)(f.m.ausubel等人编辑);methodsinenzymology系列(academicpress,inc.);pcr2:apracticalapproach(1995)(m.j.macpherson、b.d.hames和g.r.taylor编辑);antibodies,alaboratorymanual(1988)(harlow和lane编辑);antibodiesalaboratorymanual,第2版(2013)(e.a.greenfield编辑);以及animalcellculture(1987)(r.i.freshney编辑)。
疾病相关突变和病原性snp的校正
在一方面,本文所述的发明提供了用于修饰靶基因座处的腺苷残基的方法,目的是补救并且/或者预防由或可能由g至a或c至t点突变或病原性单核苷酸多态性(snp)引起的疾病状况。
影响脑和中枢神经系统的疾病
与影响脑和中枢神经系统的各种疾病相关联的病原性g至a或c至t突变/snp已在clinvar数据库中报告并在表a中公开,这些疾病包括但不限于阿尔茨海默病、帕金森病、自闭症、肌萎缩性侧索硬化症(als)、精神分裂症、肾上腺脑白质营养不良、艾卡尔迪-goutieres综合征(aicardigoutieressyndrome)、法布里病(fabrydisease)、莱施-奈恩综合征(lesch-nyhansyndrome)和门克斯病(menkesdisease)。因此,本发明的一个方面涉及一种用于校正与如以下所论述的这些疾病中的任一种相关联的一种或多种病原性g至a或c至t突变/snp的方法。
阿尔茨海默病
在一些实施方案中,本文所述的方法、系统和组合物用于校正与阿尔茨海默病相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自psen1、psen2和app的至少一种基因中,至少包括以下各项:
nm_000021.3(psen1):c.796g>a(p.gly266ser)
nm_000484.3(app):c.2017g>a(p.ala673thr)
nm_000484.3(app):c.2149g>a(p.val717ile)
nm_000484.3(app):c.2137g>a(p.ala713thr)
nm_000484.3(app):c.2143g>a(p.val715met)
nm_000484.3(app):c.2141c>t(p.thr714ile)
nm_000021.3(psen1):c.438g>a(p.met146ile)
nm_000021.3(psen1):c.1229g>a(p.cys410tyr)
nm_000021.3(psen1):c.487c>t(p.his163tyr)
nm_000021.3(psen1):c.799c>t(p.pro267ser)
nm_000021.3(psen1):c.236c>t(p.ala79val)
nm_000021.3(psen1):c.509c>t(p.ser170phe)
nm_000447.2(psen2):c.1289c>t(p.thr430met)
nm_000447.2(psen2):c.717g>a(p.met239ile)
nm_000447.2(psen2):c.254c>t(p.ala85val)
nm_000021.3(psen1):c.806g>a(p.arg269his)
nm_000484.3(app):c.2018c>t(p.ala673val)。
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自psen1、psen2和app的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防阿尔茨海默病的方法。
帕金森病
在一些实施方案中,本文所述的方法、系统和组合物用于校正与帕金森病相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,在一些实施方案中,病原性突变/snp存在于选自snca、pla2g6、fbxo7、vps35、eif4g1、dnajc6、prkn、synj1、chchd2、pink1、park7、lrrk2、atp13a2和gba的至少一种基因中,至少包括以下各项:
nm_000345.3(snca):c.157g>a(p.ala53thr)
nm_000345.3(snca):c.152g>a(p.gly51asp)
nm_003560.3(pla2g6):c.2222g>a(p.arg741gln)
nm_003560.3(pla2g6):c.2239c>t(p.arg747trp)
nm_003560.3(pla2g6):c.1904g>a(p.arg635gln)
nm_003560.3(pla2g6):c.1354c>t(p.gln452ter)
nm_012179.3(fbxo7):c.1492c>t(p.arg498ter)
nm_012179.3(fbxo7):c.65c>t(p.thr22met)
nm_018206.5(vps35):c.1858g>a(p.asp620asn)
nm_198241.2(eif4g1):c.3614g>a(p.arg1205his)
nm_198241.2(eif4g1):c.1505c>t(p.ala502val)
nm_001256865.1(dnajc6):c.2200c>t(p.gln734ter)
nm_001256865.1(dnajc6):c.2326c>t(p.gln776ter)
nm_004562.2(prkn):c.931c>t(p.gln311ter)
nm_004562.2(prkn):c.1358g>a(p.trp453ter)
nm_004562.2(prkn):c.635g>a(p.cys212tyr)
nm_203446.2(synj1):c.773g>a(p.arg258gln)
nm_001320327.1(chchd2):c.182c>t(p.thr61ile)
nm_001320327.1(chchd2):c.434g>a(p.arg145gln)
nm_001320327.1(chchd2):c.300+5g>a
nm_032409.2(pink1):c.926g>a(p.gly309asp)
nm_032409.2(pink1):c.1311g>a(p.trp437ter)
nm_032409.2(pink1):c.736c>t(p.arg246ter)
nm_032409.2(pink1):c.836g>a(p.arg279his)
nm_032409.2(pink1):c.938c>t(p.thr313met)
nm_032409.2(pink1):c.1366c>t(p.gln456ter)
nm_007262.4(park7):c.78g>a(p.met26ile)
nm_198578.3(lrrk2):c.4321c>t(p.arg1441cys)
nm_198578.3(lrrk2):c.4322g>a(p.arg1441his)
nm_198578.3(lrrk2):c.1256c>t(p.ala419val)
nm_198578.3(lrrk2):c.6055g>a(p.gly2019ser)
nm_022089.3(atp13a2):c.1306+5g>a
nm_022089.3(atp13a2):c.2629g>a(p.gly877arg)
nm_022089.3(atp13a2):c.490c>t(p.arg164trp)
nm_001005741.2(gba):c.1444g>a(p.asp482asn)
m.15950g>a。
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自snca、pla2g6、fbxo7、vps35、eif4g1、dnajc6、prkn、synj1、chchd2、pink1、park7、lrrk2、atp13a2和gba的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防帕金森病的方法。
自闭症
在一些实施方案中,本文所述的方法、系统和组合物用于校正与自闭症相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自mecp2、nlgn3、slc9a9、ehmt1、chd8、nlgn4x、gspt2和pten的至少一种基因中,至少包括以下各项:
nm_001110792.1(mecp2):c.916c>t(p.arg306ter)
nm_004992.3(mecp2):c.473c>t(p.thr158met)
nm_018977.3(nlgn3):c.1351c>t(p.arg451cys)
nm_173653.3(slc9a9):c.1267c>t(p.arg423ter)
nm_024757.4(ehmt1):c.3413g>a(p.trp1138ter)
nm_020920.3(chd8):c.2875c>t(p.gln959ter)
nm_020920.3(chd8):c.3172c>t(p.arg1058ter)
nm_181332.2(nlgn4x):c.301c>t(p.arg101ter)
nm_018094.4(gspt2):c.1021g>a(p.val341ile)
nm_000314.6(pten):c.392c>t(p.thr131ile)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自mecp2、nlgn3、slc9a9、ehmt1、chd8、nlgn4x、gspt2和pten的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防自闭症的方法。
肌萎缩性侧索硬化症(als)
在一些实施方案中,本文所述的方法、系统和组合物用于校正与als相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自sod1、vcp、ubqln2、erbb4、hnrnpa1、tuba4a、sod1、tardbp、fig4、optn、setx、spg11、fus、vapb、ang、chchd10、sqstm1和tbk1的至少一种基因中,至少包括以下各项:
nm_000454.4(sod1):c.289g>a(p.asp97asn)
nm_007126.3(vcp):c.1774g>a(p.asp592asn)
nm_007126.3(vcp):c.464g>a(p.arg155his)
nm_007126.3(vcp):c.572g>a(p.arg191gln)
nm_013444.3(ubqln2):c.1489c>t(p.pro497ser)
nm_013444.3(ubqln2):c.1525c>t(p.pro509ser)
nm_013444.3(ubqln2):c.1573c>t(p.pro525ser)
nm_013444.3(ubqln2):c.1490c>t(p.pro497leu)
nm_005235.2(erbb4):c.2780g>a(p.arg927gln)
nm_005235.2(erbb4):c.3823c>t(p.arg1275trp)
nm_031157.3(hnrnpa1):c.940g>a(p.asp314asn)
nm_006000.2(tuba4a):c.643c>t(p.arg215cys)
nm_006000.2(tuba4a):c.958c>t(p.arg320cys)
nm_006000.2(tuba4a):c.959g>a(p.arg320his)
nm_006000.2(tuba4a):c.1220g>a(p.trp407ter)
nm_006000.2(tuba4a):c.1147g>a(p.ala383thr)
nm_000454.4(sod1):c.112g>a(p.gly38arg)
nm_000454.4(sod1):c.124g>a(p.gly42ser)
nm_000454.4(sod1):c.125g>a(p.gly42asp)
nm_000454.4(sod1):c.14c>t(p.ala5val)
nm_000454.4(sod1):c.13g>a(p.ala5thr)
nm_000454.4(sod1):c.436g>a(p.ala146thr)
nm_000454.4(sod1):c.64g>a(p.glu22lys)
nm_000454.4(sod1):c.404g>a(p.ser135asn)
nm_000454.4(sod1):c.49g>a(p.gly17ser)
nm_000454.4(sod1):c.217g>a(p.gly73ser)
nm_007375.3(tardbp):c.892g>a(p.gly298ser)
nm_007375.3(tardbp):c.943g>a(p.ala315thr)
nm_007375.3(tardbp):c.883g>a(p.gly295ser)
nm_007375.3(tardbp):c.*697g>a
nm_007375.3(tardbp):c.1144g>a(p.ala382thr)
nm_007375.3(tardbp):c.859g>a(p.gly287ser)
nm_014845.5(fig4):c.547c>t(p.arg183ter)
nm_001008211.1(optn):c.1192c>t(p.gln398ter)
nm_015046.5(setx):c.6407g>a(p.arg2136his)
nm_015046.5(setx):c.8c>t(p.thr3ile)
nm_025137.3(spg11):c.118c>t(p.gln40ter)
nm_025137.3(spg11):c.267g>a(p.trp89ter)
nm_025137.3(spg11):c.5974c>t(p.arg1992ter)
nm_004960.3(fus):c.1553g>a(p.arg518lys)
nm_004960.3(fus):c.1561c>t(p.arg521cys)
nm_004960.3(fus):c.1562g>a(p.arg521his)
nm_004960.3(fus):c.1520g>a(p.gly507asp)
nm_004960.3(fus):c.1483c>t(p.arg495ter)
nm_004960.3(fus):c.616g>a(p.gly206ser)
nm_004960.3(fus):c.646c>t(p.arg216cys)
nm_004738.4(vapb):c.166c>t(p.pro56ser)
nm_004738.4(vapb):c.137c>t(p.thr46ile)
nm_001145.4(ang):c.164g>a(p.arg55lys)
nm_001145.4(ang):c.155g>a(p.ser52asn)
nm_001145.4(ang):c.407c>t(p.pro136leu)
nm_001145.4(ang):c.409g>a(p.val137ile)
nm_001301339.1(chchd10):c.239c>t(p.pro80leu)
nm_001301339.1(chchd10):c.176c>t(p.ser59leu)
nm_001142298.1(sqstm1):c.-47-1924c>t
nm_003900.4(sqstm1):c.1160c>t(p.pro387leu)
nm_003900.4(sqstm1):c.1175c>t(p.pro392leu)
nm_013254.3(tbk1):c.1340+1g>a
nm_013254.3(tbk1):c.2086g>a(p.glu696lys)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自sod1、vcp、ubqln2、erbb4、hnrnpa1、tuba4a、sod1、tardbp、fig4、optn、setx、spg11、fus、vapb、ang、chchd10、sqstm1和tbk1的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防als的方法。
精神分裂症
在一些实施方案中,本文所述的方法、系统和组合物用于校正与精神分裂症相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自prodh、setd1a和shank3的至少一种基因中,至少包括以下各项:
nm_016335.4(prodh):c.1292g>a(p.arg431his)
nm_016335.4(prodh):c.1397c>t(p.thr466met)
nm_014712.2(setd1a):c.2209c>t(p.gln737ter)
nm_033517.1(shank3):c.3349c>t(p.arg1117ter)
nm_033517.1(shank3):c.1606c>t(p.arg536trp)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自prodh、setd1a和shank3的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防精神分裂症的方法。
肾上腺脑白质营养不良
在一些实施方案中,本文所述的方法、系统和组合物用于校正与肾上腺脑白质营养不良相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于abcd1基因中,至少包括以下各项:
nm_000033.3(abcd1):c.421g>a(p.ala141thr)
nm_000033.3(abcd1):c.796g>a(p.gly266arg)
nm_000033.3(abcd1):c.1252c>t(p.arg418trp)
nm_000033.3(abcd1):c.1552c>t(p.arg518trp)
nm_000033.3(abcd1):c.1850g>a(p.arg617his)
nm_000033.3(abcd1):c.1396c>t(p.gln466ter)
nm_000033.3(abcd1):c.1553g>a(p.arg518gln)
nm_000033.3(abcd1):c.1679c>t(p.pro560leu)
nm_000033.3(abcd1):c.1771c>t(p.arg591trp)
nm_000033.3(abcd1):c.1802g>a(p.trp601ter)
nm_000033.3(abcd1):c.346g>a(p.gly116arg)
nm_000033.3(abcd1):c.406c>t(p.gln136ter)
nm_000033.3(abcd1):c.1661g>a(p.arg554his)
nm_000033.3(abcd1):c.1825g>a(p.glu609lys)
nm_000033.3(abcd1):c.1288c>t(p.gln430ter)
nm_000033.3(abcd1):c.1781-1g>a
nm_000033.3(abcd1):c.529c>t(p.gln177ter)
nm_000033.3(abcd1):c.1866-10g>a
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地至少存在于abcd1基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防肾上腺脑白质营养不良的方法。
艾卡尔迪-goutieres综合征
在一些实施方案中,本文所述的方法、系统和组合物用于校正与艾卡尔迪-goutieres综合征相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自trex1、rnaseh2c、adar和ifih1的至少一种基因中,至少包括以下各项:
nm_016381.5(trex1):c.794g>a(p.trp265ter)
nm_033629.4(trex1):c.52g>a(p.asp18asn)
nm_033629.4(trex1):c.490c>t(p.arg164ter)
nm_032193.3(rnaseh2c):c.205c>t(p.arg69trp)
nm_001111.4(adar):c.3019g>a(p.gly1007arg)
nm_022168.3(ifih1):c.2336g>a(p.arg779his)
nm_022168.3(ifih1):c.2335c>t(p.arg779cys)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自trex1、rnaseh2c、adar和ifih1的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防艾卡尔迪-goutieres综合征的方法。
法布里病
在一些实施方案中,本文所述的方法、系统和组合物用于校正与法布里病相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于gla基因中,至少包括以下各项:
nm_000169.2(gla):c.1024c>t(p.arg342ter)
nm_000169.2(gla):c.1066c>t(p.arg356trp)
nm_000169.2(gla):c.1025g>a(p.arg342gln)
nm_000169.2(gla):c.281g>a(p.cys94tyr)
nm_000169.2(gla):c.677g>a(p.trp226ter)
nm_000169.2(gla):c.734g>a(p.trp245ter)
nm_000169.2(gla):c.748c>t(p.gln250ter)
nm_000169.2(gla):c.658c>t(p.arg220ter)
nm_000169.2(gla):c.730g>a(p.asp244asn)
nm_000169.2(gla):c.369+1g>a
nm_000169.2(gla):c.335g>a(p.arg112his)
nm_000169.2(gla):c.485g>a(p.trp162ter)
nm_000169.2(gla):c.661c>t(p.gln221ter)
nm_000169.2(gla):c.916c>t(p.gln306ter)
nm_000169.2(gla):c.1072g>a(p.glu358lys)
nm_000169.2(gla):c.1087c>t(p.arg363cys)
nm_000169.2(gla):c.1088g>a(p.arg363his)
nm_000169.2(gla):c.605g>a(p.cys202tyr)
nm_000169.2(gla):c.830g>a(p.trp277ter)
nm_000169.2(gla):c.979c>t(p.gln327ter)
nm_000169.2(gla):c.422c>t(p.thr141ile)
nm_000169.2(gla):c.285g>a(p.trp95ter)
nm_000169.2(gla):c.735g>a(p.trp245ter)
nm_000169.2(gla):c.639+919g>a
nm_000169.2(gla):c.680g>a(p.arg227gln)
nm_000169.2(gla):c.679c>t(p.arg227ter)
nm_000169.2(gla):c.242g>a(p.trp81ter)
nm_000169.2(gla):c.901c>t(p.arg301ter)
nm_000169.2(gla):c.974g>a(p.gly325asp)
nm_000169.2(gla):c.847c>t(p.gln283ter)
nm_000169.2(gla):c.469c>t(p.gln157ter)
nm_000169.2(gla):c.1118g>a(p.gly373asp)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地至少存在于gla基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防法布里病的方法。
莱施-奈恩综合征
在一些实施方案中,本文所述的方法、系统和组合物用于校正与莱施-奈恩综合征相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于hprt1基因中,至少包括以下各项:
nm_000194.2(hprt1):c.151c>t(p.arg51ter)
nm_000194.2(hprt1):c.384+1g>a
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地至少存在于hprt1基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防莱施-奈恩综合征的方法。
门克斯病
在一些实施方案中,本文所述的方法、系统和组合物用于校正与门克斯病相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于atp7a基因中,至少包括以下各项:
nm_000052.6(atp7a):c.601c>t(p.arg201ter)
nm_000052.6(atp7a):c.2938c>t(p.arg980ter)
nm_000052.6(atp7a):c.3056g>a(p.gly1019asp)
nm_000052.6(atp7a):c.598c>t(p.gln200ter)
nm_000052.6(atp7a):c.1225c>t(p.arg409ter)
nm_000052.6(atp7a):c.1544-1g>a
nm_000052.6(atp7a):c.1639c>t(p.arg547ter)
nm_000052.6(atp7a):c.1933c>t(p.arg645ter)
nm_000052.6(atp7a):c.1946+5g>a
nm_000052.6(atp7a):c.1950g>a(p.trp650ter)
nm_000052.6(atp7a):c.2179g>a(p.gly727arg)
nm_000052.6(atp7a):c.2187g>a(p.trp729ter)
nm_000052.6(atp7a):c.2383c>t(p.arg795ter)
nm_000052.6(atp7a):c.2499-1g>a
nm_000052.6(atp7a):c.2555c>t(p.pro852leu)
nm_000052.6(atp7a):c.2956c>t(p.arg986ter)
nm_000052.6(atp7a):c.3112-1g>a
nm_000052.6(atp7a):c.3466c>t(p.gln1156ter)
nm_000052.6(atp7a):c.3502c>t(p.gln1168ter)
nm_000052.6(atp7a):c.3764g>a(p.gly1255glu)
nm_000052.6(atp7a):c.3943g>a(p.gly1315arg)
nm_000052.6(atp7a):c.4123+1g>a
nm_000052.6(atp7a):c.4226+5g>a
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地至少存在于atp7a基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防门克斯病的方法。
眼病
与各种眼部疾病相关联的病原性g至a或c至t突变/snp已在clinvar数据库中报告并在表a中公开,这些疾病包括但不限于斯特格病(stargardtdisease)、巴比二氏综合征(bardet-biedlsyndrome)、锥杆营养不良、先天性静止性夜盲症、乌谢尔综合征(ushersyndrome)、莱伯氏先天性黑蒙症(lebercongenitalamaurosis)、色素性视网膜炎和色盲症。因此,本发明的一个方面涉及一种用于校正与如以下所论述的这些疾病中的任一种相关联的一种或多种病原性g至a或c至t突变/snp的方法。
斯特格病
在一些实施方案中,本文所述的方法、系统和组合物用于校正与斯特格病相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于abca4基因中,至少包括以下各项:
nm_000350.2(abca4):c.4429c>t(p.gln1477ter)
nm_000350.2(abca4):c.6647c>t(p.ala2216val)
nm_000350.2(abca4):c.5312+1g>a
nm_000350.2(abca4):c.5189g>a(p.trp1730ter)
nm_000350.2(abca4):c.4352+1g>a
nm_000350.2(abca4):c.4253+5g>a
nm_000350.2(abca4):c.3871c>t(p.gln1291ter)
nm_000350.2(abca4):c.3813g>a(p.glu1271=)
nm_000350.2(abca4):c.1293g>a(p.trp431ter)
nm_000350.2(abca4):c.206g>a(p.trp69ter)
nm_000350.2(abca4):c.3322c>t(p.arg1108cys)
nm_000350.2(abca4):c.1804c>t(p.arg602trp)
nm_000350.2(abca4):c.1937+1g>a
nm_000350.2(abca4):c.2564g>a(p.trp855ter)
nm_000350.2(abca4):c.4234c>t(p.gln1412ter)
nm_000350.2(abca4):c.4457c>t(p.pro1486leu)
nm_000350.2(abca4):c.4594g>a(p.asp1532asn)
nm_000350.2(abca4):c.4919g>a(p.arg1640gln)
nm_000350.2(abca4):c.5196+1g>a
nm_000350.2(abca4):c.6316c>t(p.arg2106cys)
nm_000350.2(abca4):c.3056c>t(p.thr1019met)
nm_000350.2(abca4):c.52c>t(p.arg18trp)
nm_000350.2(abca4):c.122g>a(p.trp41ter)
nm_000350.2(abca4):c.1903c>t(p.gln635ter)
nm_000350.2(abca4):c.194g>a(p.gly65glu)
nm_000350.2(abca4):c.3085c>t(p.gln1029ter)
nm_000350.2(abca4):c.4195g>a(p.glu1399lys)
nm_000350.2(abca4):c.454c>t(p.arg152ter)
nm_000350.2(abca4):c.45g>a(p.trp15ter)
nm_000350.2(abca4):c.4610c>t(p.thr1537met)
nm_000350.2(abca4):c.6112c>t(p.arg2038trp)
nm_000350.2(abca4):c.6118c>t(p.arg2040ter)
nm_000350.2(abca4):c.6342g>a(p.val2114=)
nm_000350.2(abca4):c.6658c>t(p.gln2220ter)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于abca4基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防斯特格病的方法。
巴比二氏综合征
在一些实施方案中,本文所述的方法、系统和组合物用于校正与巴比二氏综合征相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自bbs1、bbs2、bbs7、bbs9、bbs10、bbs12、lztfl1和trim32的至少一种基因中,至少包括以下各项:
nm_024649.4(bbs1):c.416g>a(p.trp139ter)
nm_024649.4(bbs1):c.871c>t(p.gln291ter)
nm_198428.2(bbs9):c.263+1g>a
nm_001178007.1(bbs12):c.1704g>a(p.trp568ter)
nm_001276378.1(lztfl1):c.271c>t(p.arg91ter)
nm_031885.3(bbs2):c.1864c>t(p.arg622ter)
nm_198428.2(bbs9):c.1759c>t(p.arg587ter)
nm_198428.2(bbs9):c.1789+1g>a
nm_024649.4(bbs1):c.432+1g>a
nm_176824.2(bbs7):c.632c>t(p.thr211ile)
nm_012210.3(trim32):c.388c>t(p.pro130ser)
nm_031885.3(bbs2):c.823c>t(p.arg275ter)
nm_024685.3(bbs10):c.145c>t(p.arg49trp)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自bbs1、bbs2、bbs7、bbs9、bbs10、bbs12、lztfl1和trim32的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防巴比二氏综合征的方法。
锥杆营养不良
在一些实施方案中,本文所述的方法、系统和组合物用于校正与锥杆营养不良相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自rpgrip1、dram2、abca4、adam9和cacna1f的至少一种基因中,至少包括以下各项:
nm_020366.3(rpgrip1):c.154c>t(p.arg52ter)
nm_178454.5(dram2):c.494g>a(p.trp165ter)
nm_178454.5(dram2):c.131g>a(p.ser44asn)
nm_000350.2(abca4):c.161g>a(p.cys54tyr)
nm_000350.2(abca4):c.5714+5g>a
nm_000350.2(abca4):c.880c>t(p.gln294ter)
nm_000350.2(abca4):c.6079c>t(p.leu2027phe)
nm_000350.2(abca4):c.3113c>t(p.ala1038val)
nm_000350.2(abca4):c.634c>t(p.arg212cys)
nm_003816.2(adam9):c.490c>t(p.arg164ter)
nm_005183.3(cacna1f):c.244c>t(p.arg82ter)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自rpgrip1、dram2、abca4、adam9和cacna1f的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防锥杆营养不良的方法。
先天性静止性夜盲症
在一些实施方案中,本文所述的方法、系统和组合物用于校正与先天性静止性夜盲症相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自grm6、trpm1、gpr179和cacna1f的至少一种基因中,至少包括以下各项:
nm_000843.3(grm6):c.1462c>t(p.gln488ter)
nm_002420.5(trpm1):c.2998c>t(p.arg1000ter)
nm_001004334.3(gpr179):c.673c>t(p.gln225ter)
nm_005183.3(cacna1f):c.2576+1g>a
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自grm6、trpm1、gpr179和cacna1f的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防先天性静止性夜盲症的方法。
乌谢尔综合征
在一些实施方案中,本文所述的方法、系统和组合物用于校正与乌谢尔综合征相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自myo7a、ush1c、cdh23、pcdh15、ush2a、adgrv1、whrn和clrn1的至少一种基因中,至少包括以下各项:
nm_000260.3(myo7a):c.640g>a(p.gly214arg)
nm_000260.3(myo7a):c.1200+1g>a
nm_000260.3(myo7a):c.141g>a(p.trp47ter)
nm_000260.3(myo7a):c.1556g>a(p.gly519asp)
nm_000260.3(myo7a):c.1900c>t(p.arg634ter)
nm_000260.3(myo7a):c.1963c>t(p.gln655ter)
nm_000260.3(myo7a):c.2094+1g>a
nm_000260.3(myo7a):c.4293g>a(p.trp1431ter)
nm_000260.3(myo7a):c.5101c>t(p.arg1701ter)
nm_000260.3(myo7a):c.5617c>t(p.arg1873trp)
nm_000260.3(myo7a):c.5660c>t(p.pro1887leu)
nm_000260.3(myo7a):c.6070c>t(p.arg2024ter)
nm_000260.3(myo7a):c.470+1g>a
nm_000260.3(myo7a):c.5968c>t(p.gln1990ter)
nm_000260.3(myo7a):c.3719g>a(p.arg1240gln)
nm_000260.3(myo7a):c.494c>t(p.thr165met)
nm_000260.3(myo7a):c.5392c>t(p.gln1798ter)
nm_000260.3(myo7a):c.5648g>a(p.arg1883gln)
nm_000260.3(myo7a):c.448c>t(p.arg150ter)
nm_000260.3(myo7a):c.700c>t(p.gln234ter)
nm_000260.3(myo7a):c.635g>a(p.arg212his)
nm_000260.3(myo7a):c.1996c>t(p.arg666ter)
nm_005709.3(ush1c):c.216g>a(p.val72=)
nm_022124.5(cdh23):c.7362+5g>a
nm_022124.5(cdh23):c.3481c>t(p.arg1161ter)
nm_022124.5(cdh23):c.3628c>t(p.gln1210ter)
nm_022124.5(cdh23):c.5272c>t(p.gln1758ter)
nm_022124.5(cdh23):c.5712+1g>a
nm_022124.5(cdh23):c.5712g>a(p.thr1904=)
nm_022124.5(cdh23):c.5923+1g>a
nm_022124.5(cdh23):c.6049+1g>a
nm_022124.5(cdh23):c.7776g>a(p.trp2592ter)
nm_022124.5(cdh23):c.9556c>t(p.arg3186ter)
nm_022124.5(cdh23):c.3706c>t(p.arg1236ter)
nm_022124.5(cdh23):c.4309c>t(p.arg1437ter)
nm_022124.5(cdh23):c.6050-9g>a
nm_033056.3(pcdh15):c.3316c>t(p.arg1106ter)
nm_033056.3(pcdh15):c.7c>t(p.arg3ter)
nm_033056.3(pcdh15):c.1927c>t(p.arg643ter)
nm_001142772.1(pcdh15):c.400c>t(p.arg134ter)
nm_033056.3(pcdh15):c.3358c>t(p.arg1120ter)
nm_206933.2(ush2a):c.11048-1g>a
nm_206933.2(ush2a):c.1143+1g>a
nm_206933.2(ush2a):c.11954g>a(p.trp3985ter)
nm_206933.2(ush2a):c.12868c>t(p.gln4290ter)
nm_206933.2(ush2a):c.14180g>a(p.trp4727ter)
nm_206933.2(ush2a):c.14911c>t(p.arg4971ter)
nm_206933.2(ush2a):c.5788c>t(p.arg1930ter)
nm_206933.2(ush2a):c.5858-1g>a
nm_206933.2(ush2a):c.6224g>a(p.trp2075ter)
nm_206933.2(ush2a):c.820c>t(p.arg274ter)
nm_206933.2(ush2a):c.8981g>a(p.trp2994ter)
nm_206933.2(ush2a):c.9304c>t(p.gln3102ter)
nm_206933.2(ush2a):c.13010c>t(p.thr4337met)
nm_206933.2(ush2a):c.14248c>t(p.gln4750ter)
nm_206933.2(ush2a):c.6398g>a(p.trp2133ter)
nm_206933.2(ush2a):c.632g>a(p.trp211ter)
nm_206933.2(ush2a):c.6601c>t(p.gln2201ter)
nm_206933.2(ush2a):c.13316c>t(p.thr4439ile)
nm_206933.2(ush2a):c.4405c>t(p.gln1469ter)
nm_206933.2(ush2a):c.9570+1g>a
nm_206933.2(ush2a):c.8740c>t(p.arg2914ter)
nm_206933.2(ush2a):c.8681+1g>a
nm_206933.2(ush2a):c.1000c>t(p.arg334trp)
nm_206933.2(ush2a):c.14175g>a(p.trp4725ter)
nm_206933.2(ush2a):c.9390g>a(p.trp3130ter)
nm_206933.2(ush2a):c.908g>a(p.arg303his)
nm_206933.2(ush2a):c.5776+1g>a
nm_206933.2(ush2a):c.11156g>a(p.arg3719his)
nm_032119.3(adgrv1):c.2398c>t(p.arg800ter)
nm_032119.3(adgrv1):c.7406g>a(p.trp2469ter)
nm_032119.3(adgrv1):c.12631c>t(p.arg4211ter)
nm_032119.3(adgrv1):c.7129c>t(p.arg2377ter)
nm_032119.3(adgrv1):c.14885g>a(p.trp4962ter)
nm_015404.3(whrn):c.1267c>t(p.arg423ter)
nm_174878.2(clrn1):c.619c>t(p.arg207ter)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自myo7a、ush1c、cdh23、pcdh15、ush2a、adgrv1、whrn和clrn1的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防增强型乌谢尔综合征的方法。
莱伯氏先天性黑蒙症
在一些实施方案中,本文所述的方法、系统和组合物用于校正与莱伯氏先天性黑蒙症相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自tulp1、rpe65、spata7、aipl1、crb1、nmnat1和pex1的至少一种基因中,至少包括以下各项:
nm_003322.5(tulp1):c.1495+1g>a
nm_000329.2(rpe65):c.11+5g>a
nm_018418.4(spata7):c.322c>t(p.arg108ter)
nm_014336.4(aipl1):c.784g>a(p.gly262ser)
nm_201253.2(crb1):c.1576c>t(p.arg526ter)
nm_201253.2(crb1):c.3307g>a(p.gly1103arg)
nm_201253.2(crb1):c.2843g>a(p.cys948tyr)
nm_022787.3(nmnat1):c.769g>a(p.glu257lys)
nm_000466.2(pex1):c.2528g>a(p.gly843asp)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自tulp1、rpe65、spata7、aipl1、crb1、nmnat1和pex1的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防莱伯氏先天性黑蒙症的方法。
色素性视网膜炎
在一些实施方案中,本文所述的方法、系统和组合物用于校正与色素性视网膜炎相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自crb1、ift140、rp1、impdh1、prpf31、rpgr、abca4、rpe65、eys、nrl、fam161a、nr2e3、ush2a、rho、pde6b、klhl7、pde6a、cngb1、best1、c2orf71、prph2、ca4、cerkl、rpe65、pde6b和adgrv1的至少一种基因中,至少包括以下各项:
nm_001257965.1(crb1):c.2711g>a(p.cys904tyr)
nm_014714.3(ift140):c.3827g>a(p.gly1276glu)
nm_006269.1(rp1):c.2029c>t(p.arg677ter)
nm_000883.3(impdh1):c.931g>a(p.asp311asn)
nm_015629.3(prpf31):c.1273c>t(p.gln425ter)
nm_015629.3(prpf31):c.1073+1g>a
nm_000328.2(rpgr):c.1387c>t(p.gln463ter)
nm_000350.2(abca4):c.4577c>t(p.thr1526met)
nm_000350.2(abca4):c.6229c>t(p.arg2077trp)
nm_000329.2(rpe65):c.271c>t(p.arg91trp)
nm_001142800.1(eys):c.2194c>t(p.gln732ter)
nm_001142800.1(eys):c.490c>t(p.arg164ter)
nm_006177.3(nrl):c.151c>t(p.pro51ser)
nm_001201543.1(fam161a):c.1567c>t(p.arg523ter)
nm_014249.3(nr2e3):c.166g>a(p.gly56arg)
nm_206933.2(ush2a):c.2209c>t(p.arg737ter)
nm_206933.2(ush2a):c.14803c>t(p.arg4935ter)
nm_206933.2(ush2a):c.10073g>a(p.cys3358tyr)
nm_000539.3(rho):c.541g>a(p.glu181lys)
nm_000283.3(pde6b):c.892c>t(p.gln298ter)
nm_001031710.2(klhl7):c.458c>t(p.ala153val)
nm_000440.2(pde6a):c.1926+1g>a
nm_001297.4(cngb1):c.2128c>t(p.gln710ter)
nm_001297.4(cngb1):c.952c>t(p.gln318ter)
nm_004183.3(best1):c.682g>a(p.asp228asn)
nm_001029883.2(c2orf71):c.1828c>t(p.gln610ter)
nm_000322.4(prph2):c.647c>t(p.pro216leu)
nm_000717.4(ca4):c.40c>t(p.arg14trp)
nm_201548.4(cerkl):c.769c>t(p.arg257ter)
nm_000329.2(rpe65):c.118g>a(p.gly40ser)
nm_000322.4(prph2):c.499g>a(p.gly167ser)
nm_000539.3(rho):c.403c>t(p.arg135trp)
nm_000283.3(pde6b):c.2193+1g>a
nm_032119.3(adgrv1):c.6901c>t(p.gln2301ter)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自crb1、ift140、rp1、impdh1、prpf31、rpgr、abca4、rpe65、eys、nrl、fam161a、nr2e3、ush2a、rho、pde6b、klhl7、pde6a、cngb1、best1、c2orf71、prph2、ca4、cerkl、rpe65、pde6b和adgrv1的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防色素性视网膜炎的方法。
色盲症
在一些实施方案中,本文所述的方法、系统和组合物用于校正与色盲症相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自cnga3、cngb3和atf6的至少一种基因中,至少包括以下各项:
nm_001298.2(cnga3):c.847c>t(p.arg283trp)
nm_001298.2(cnga3):c.101+1g>a
nm_001298.2(cnga3):c.1585g>a(p.val529met)
nm_019098.4(cngb3):c.1578+1g>a
nm_019098.4(cngb3):c.607c>t(p.arg203ter)
nm_019098.4(cngb3):c.1119g>a(p.trp373ter)
nm_007348.3(atf6):c.970c>t(p.arg324cys)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自cnga3、cngb3和atf6的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防色盲症的方法。
影响听力的疾病
与影响听力的各种疾病相关联的病原性g至a或c至t突变/snp已在clinvar数据库中报告并在表a中公开,这些疾病包括但不限于耳聋和非综合征性听力丧失。因此,本发明的一个方面涉及一种用于校正与如以下所论述的这些疾病中的任一种相关联的一种或多种病原性g至a或c至t突变/snp的方法。
耳聋
在一些实施方案中,本文所述的方法、系统和组合物用于校正与耳聋相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自fgf3、myo7a、strc、actg1、slc17a8、tmc1、gjb2、myh14、coch、cdh23、ush1c、gjb2、myo7a、pcdh15、myo15a、myo3a、whrn、dfnb59、tmc1、loxhd1、tmprss3、otogl、otof、jag1和marveld2的至少一种基因中,至少包括以下各项:
nm_005247.2(fgf3):c.283c>t(p.arg95trp)
nm_000260.3(myo7a):c.652g>a(p.asp218asn)
nm_000260.3(myo7a):c.689c>t(p.ala230val)
nm_153700.2(strc):c.4057c>t(p.gln1353ter)
nm_001614.3(actg1):c.721g>a(p.glu241lys)
nm_139319.2(slc17a8):c.632c>t(p.ala211val)
nm_138691.2(tmc1):c.1714g>a(p.asp572asn)
nm_004004.5(gjb2):c.598g>a(p.gly200arg)
nm_004004.5(gjb2):c.71g>a(p.trp24ter)
nm_004004.5(gjb2):c.416g>a(p.ser139asn)
nm_004004.5(gjb2):c.224g>a(p.arg75gln)
nm_004004.5(gjb2):c.95g>a(p.arg32his)
nm_004004.5(gjb2):c.250g>a(p.val84met)
nm_004004.5(gjb2):c.428g>a(p.arg143gln)
nm_004004.5(gjb2):c.551g>a(p.arg184gln)
nm_004004.5(gjb2):c.223c>t(p.arg75trp)
nm_024729.3(myh14):c.359c>t(p.ser120leu)
nm_004086.2(coch):c.151c>t(p.pro51ser)
nm_022124.5(cdh23):c.4021g>a(p.asp1341asn)
nm_153700.2(strc):c.4701+1g>a
nm_153676.3(ush1c):c.496+1g>a
nm_004004.5(gjb2):c.131g>a(p.trp44ter)
nm_004004.5(gjb2):c.283g>a(p.val95met)
nm_004004.5(gjb2):c.298c>t(p.his100tyr)
nm_004004.5(gjb2):c.427c>t(p.arg143trp)
nm_004004.5(gjb2):c.109g>a(p.val37ile)
nm_004004.5(gjb2):c.-23+1g>a
nm_004004.5(gjb2):c.148g>a(p.asp50asn)
nm_004004.5(gjb2):c.134g>a(p.gly45glu)
nm_004004.5(gjb2):c.370c>t(p.gln124ter)
nm_004004.5(gjb2):c.230g>a(p.trp77ter)
nm_004004.5(gjb2):c.231g>a(p.trp77ter)
nm_000260.3(myo7a):c.5899c>t(p.arg1967ter)
nm_000260.3(myo7a):c.2005c>t(p.arg669ter)
nm_033056.3(pcdh15):c.733c>t(p.arg245ter)
nm_016239.3(myo15a):c.3866+1g>a
nm_016239.3(myo15a):c.6178-1g>a
nm_016239.3(myo15a):c.8714-1g>a
nm_017433.4(myo3a):c.2506-1g>a
nm_015404.3(whrn):c.1417-1g>a
nm_001042702.3(dfnb59):c.499c>t(p.arg167ter)
nm_138691.2(tmc1):c.100c>t(p.arg34ter)
nm_138691.2(tmc1):c.1165c>t(p.arg389ter)
nm_144612.6(loxhd1):c.2008c>t(p.arg670ter)
nm_144612.6(loxhd1):c.4714c>t(p.arg1572ter)
nm_144612.6(loxhd1):c.4480c>t(p.arg1494ter)
nm_024022.2(tmprss3):c.325c>t(p.arg109trp)
nm_173591.3(otogl):c.3076c>t(p.gln1026ter)
nm_194248.2(otof):c.4483c>t(p.arg1495ter)
nm_194248.2(otof):c.2122c>t(p.arg708ter)
nm_194248.2(otof):c.2485c>t(p.gln829ter)
nm_001038603.2(marveld2):c.1498c>t(p.arg500ter)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自fgf3、myo7a、strc、actg1、slc17a8、tmc1、gjb2、myh14、coch、cdh23、ush1c、gjb2、myo7a、pcdh15、myo15a、myo3a、whrn、dfnb59、tmc1、loxhd1、tmprss3、otogl、otof、jag1和marveld2的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防耳聋的方法。
非综合征性听力丧失
在一些实施方案中,本文所述的方法、系统和组合物用于校正与非综合征性听力丧失相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自gjb2、pou3f4、myo15a、tmprss3、loxhd1、otof、myo6、otoa、strc、triobp、marveld2、tmc1、tecta、otogl和gipc3的至少一种基因中,至少包括以下各项:
nm_004004.5(gjb2):c.169c>t(p.gln57ter)
nm_000307.4(pou3f4):c.499c>t(p.arg167ter)
nm_016239.3(myo15a):c.8767c>t(p.arg2923ter)
nm_024022.2(tmprss3):c.323-6g>a
nm_024022.2(tmprss3):c.916g>a(p.ala306thr)
nm_144612.6(loxhd1):c.2497c>t(p.arg833ter)
nm_194248.2(otof):c.2153g>a(p.trp718ter)
nm_194248.2(otof):c.2818c>t(p.gln940ter)
nm_194248.2(otof):c.4799+1g>a
nm_004999.3(myo6):c.826c>t(p.arg276ter)
nm_144672.3(otoa):c.1880+1g>a
nm_153700.2(strc):c.5188c>t(p.arg1730ter)
nm_153700.2(strc):c.3670c>t(p.arg1224ter)
nm_153700.2(strc):c.4402c>t(p.arg1468ter)
nm_024022.2(tmprss3):c.1192c>t(p.gln398ter)
nm_001039141.2(triobp):c.6598c>t(p.arg2200ter)
nm_016239.3(myo15a):c.7893+1g>a
nm_016239.3(myo15a):c.5531+1g>a
nm_016239.3(myo15a):c.6046+1g>a
nm_144612.6(loxhd1):c.3169c>t(p.arg1057ter)
nm_001038603.2(marveld2):c.1331+1g>a
nm_138691.2(tmc1):c.1676g>a(p.trp559ter)
nm_138691.2(tmc1):c.1677g>a(p.trp559ter)
nm_005422.2(tecta):c.5977c>t(p.arg1993ter)
nm_173591.3(otogl):c.4987c>t(p.arg1663ter)
nm_153700.2(strc):c.3493c>t(p.gln1165ter)
nm_153700.2(strc):c.3217c>t(p.arg1073ter)
nm_016239.3(myo15a):c.5896c>t(p.arg1966ter)
nm_133261.2(gipc3):c.411+1g>a
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自gjb2、pou3f4、myo15a、tmprss3、loxhd1、otof、myo6、otoa、strc、triobp、marveld2、tmc1、tecta、otogl和gipc3的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防非综合征性听力丧失的方法。
血液病症
与各种血液病症相关联的病原性g至a或c至t突变/snp已在clinvar数据库中报告并在表a中公开,这些疾病包括但不限于β地中海贫血、甲型血友病、乙型血友病、丙型血友病和威斯科特-奥尔德里奇综合征。因此,本发明的一个方面涉及一种用于校正与如以下所论述的这些疾病中的任一种相关联的一种或多种病原性g至a或c至t突变/snp的方法。
β地中海贫血
在一些实施方案中,本文所述的方法、系统和组合物用于校正与β地中海贫血相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于hbb基因中,至少包括以下各项:
nm_000518.4(hbb):c.-137c>t
nm_000518.4(hbb):c.-50-88c>t
nm_000518.4(hbb):c.-140c>t
nm_000518.4(hbb):c.316-197c>t
nm_000518.4(hbb):c.93-21g>a
nm_000518.4(hbb):c.114g>a(p.trp38ter)
nm_000518.4(hbb):c.118c>t(p.gln40ter)
nm_000518.4(hbb):c.92+1g>a
nm_000518.4(hbb):c.315+1g>a
nm_000518.4(hbb):c.92+5g>a
nm_000518.4(hbb):c.-50-101c>t
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于hbb基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防β地中海贫血的方法。
甲型血友病
在一些实施方案中,本文所述的方法、系统和组合物用于校正与甲型血友病相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于f8基因中,至少包括以下各项:
nm_000132.3(f8):c.3169g>a(p.glu1057lys)
nm_000132.3(f8):c.902g>a(p.arg301his)
nm_000132.3(f8):c.1834c>t(p.arg612cys)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于f8基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防甲型血友病的方法。
乙型血友病
在一些实施方案中,本文所述的方法、系统和组合物用于校正与乙型血友病相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于f9基因中,至少包括以下各项:
nm_000133.3(f9):c.835g>a(p.ala279thr)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于f9基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防乙型血友病的方法。
丙型血友病
在一些实施方案中,本文所述的方法、系统和组合物用于校正与丙型血友病相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于f11基因中,至少包括以下各项:
nm_000128.3(f11):c.400c>t(p.gln134ter)
nm_000128.3(f11):c.1432g>a(p.gly478arg)
nm_000128.3(f11):c.1288g>a(p.ala430thr)
nm_000128.3(f11):c.326-1g>a
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于f11基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防丙型血友病的方法。
威斯科特-奥尔德里奇综合征
在一些实施方案中,本文所述的方法、系统和组合物用于校正与威斯科特-奥尔德里奇综合征相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于was基因中,至少包括以下各项:
nm_000377.2(was):c.37c>t(p.arg13ter)
nm_000377.2(was):c.257g>a(p.arg86his)
nm_000377.2(was):c.777+1g>a
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于was基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防威斯科特-奥尔德里奇综合征的方法。
肝脏疾病
与各种肝脏疾病相关联的病原性g至a或c至t突变/snp已在clinvar数据库中报告并在表a中公开,这些疾病包括但不限于运甲状腺素蛋白淀粉样变性、α-1抗胰蛋白酶缺乏症、威尔逊氏病(wilson’sdisease)和苯丙酮尿症。因此,本发明的一个方面涉及一种用于校正与如以下所论述的这些疾病中的任一种相关联的一种或多种病原性g至a或c至t突变/snp的方法。
运甲状腺素蛋白淀粉样变性
在一些实施方案中,本文所述的方法、系统和组合物用于校正与运甲状腺素蛋白淀粉样变性相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于ttr基因中,至少包括以下各项:
nm_000371.3(ttr):c.424g>a(p.val142ile)
nm_000371.3(ttr):c.148g>a(p.val50met)
nm_000371.3(ttr):c.118g>a(p.val40ile)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于ttr基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防运甲状腺素蛋白淀粉样变性的方法。
α-1-抗胰蛋白酶缺乏症
在一些实施方案中,本文所述的方法、系统和组合物用于校正与α1-抗胰蛋白酶缺乏症相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于serpina1基因中,至少包括以下各项:
nm_000295.4(serpina1):c.538c>t(p.gln180ter)
nm_001127701.1(serpina1):c.1178c>t(p.pro393leu)
nm_001127701.1(serpina1):c.230c>t(p.ser77phe)
nm_001127701.1(serpina1):c.1096g>a(p.glu366lys)
nm_000295.4(serpina1):c.1177c>t(p.pro393ser)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于serpina1基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防α1-抗胰蛋白酶缺乏症的方法。
威尔逊氏病
在一些实施方案中,本文所述的方法、系统和组合物用于校正与威尔逊氏病相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于atp7b基因中,至少包括以下各项:
nm_000053.3(atp7b):c.2293g>a(p.asp765asn)
nm_000053.3(atp7b):c.3955c>t(p.arg1319ter)
nm_000053.3(atp7b):c.2865+1g>a
nm_000053.3(atp7b):c.3796g>a(p.gly1266arg)
nm_000053.3(atp7b):c.2621c>t(p.ala874val)
nm_000053.3(atp7b):c.2071g>a(p.gly691arg)
nm_000053.3(atp7b):c.2128g>a(p.gly710ser)
nm_000053.3(atp7b):c.2336g>a(p.trp779ter)
nm_000053.3(atp7b):c.4021g>a(p.gly1341ser)
nm_000053.3(atp7b):c.3182g>a(p.gly1061glu)
nm_000053.3(atp7b):c.4114c>t(p.gln1372ter)
nm_000053.3(atp7b):c.1708-1g>a
nm_000053.3(atp7b):c.865c>t(p.gln289ter)
nm_000053.3(atp7b):c.2930c>t(p.thr977met)
nm_000053.3(atp7b):c.3659c>t(p.thr1220met)
nm_000053.3(atp7b):c.2605g>a(p.gly869arg)
nm_000053.3(atp7b):c.2975c>t(p.pro992leu)
nm_000053.3(atp7b):c.2519c>t(p.pro840leu)
nm_000053.3(atp7b):c.2906g>a(p.arg969gln)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于atp7b基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防威尔逊氏病的方法。
苯丙酮尿症
在一些实施方案中,本文所述的方法、系统和组合物用于校正与苯丙酮尿症相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于pah基因中,至少包括以下各项:
nm_000277.1(pah):c.1315+1g>a
nm_000277.1(pah):c.1222c>t(p.arg408trp)
nm_000277.1(pah):c.838g>a(p.glu280lys)
nm_000277.1(pah):c.331c>t(p.arg111ter)
nm_000277.1(pah):c.782g>a(p.arg261gln)
nm_000277.1(pah):c.754c>t(p.arg252trp)
nm_000277.1(pah):c.473g>a(p.arg158gln)
nm_000277.1(pah):c.727c>t(p.arg243ter)
nm_000277.1(pah):c.842c>t(p.pro281leu)
nm_000277.1(pah):c.728g>a(p.arg243gln)
nm_000277.1(pah):c.1066-11g>a
nm_000277.1(pah):c.781c>t(p.arg261ter)
nm_000277.1(pah):c.1223g>a(p.arg408gln)
nm_000277.1(pah):c.1162g>a(p.val388met)
nm_000277.1(pah):c.1066-3c>t
nm_000277.1(pah):c.1208c>t(p.ala403val)
nm_000277.1(pah):c.890g>a(p.arg297his)
nm_000277.1(pah):c.926c>t(p.ala309val)
nm_000277.1(pah):c.441+1g>a
nm_000277.1(pah):c.526c>t(p.arg176ter)
nm_000277.1(pah):c.688g>a(p.val230ile)
nm_000277.1(pah):c.721c>t(p.arg241cys)
nm_000277.1(pah):c.745c>t(p.leu249phe)
nm_000277.1(pah):c.442-1g>a
nm_000277.1(pah):c.842+1g>a
nm_000277.1(pah):c.776c>t(p.ala259val)
nm_000277.1(pah):c.1200-1g>a
nm_000277.1(pah):c.912+1g>a
nm_000277.1(pah):c.1065+1g>a
nm_000277.1(pah):c.472c>t(p.arg158trp)
nm_000277.1(pah):c.755g>a(p.arg252gln)
nm_000277.1(pah):c.809g>a(p.arg270lys)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于pah基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防苯丙酮尿症的方法。
肾脏疾病
与各种肾脏疾病相关联的病原性g至a或c至t突变/snp已在clinvar数据库中报告并在表a中公开,这些疾病包括但不限于常染色体隐性遗传性多囊肾病和肾性肉毒碱转运缺陷。因此,本发明的一个方面涉及一种用于校正与如以下所论述的这些疾病中的任一种相关联的一种或多种病原性g至a或c至t突变/snp的方法。
常染色体隐性遗传性多囊肾病
在一些实施方案中,本文所述的方法、系统和组合物用于校正与常染色体隐性遗传性多囊肾病相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于pkhd1基因中,至少包括以下各项:
nm_138694.3(pkhd1):c.10444c>t(p.arg3482cys)
nm_138694.3(pkhd1):c.9319c>t(p.arg3107ter)
nm_138694.3(pkhd1):c.1480c>t(p.arg494ter)
nm_138694.3(pkhd1):c.707+1g>a
nm_138694.3(pkhd1):c.1486c>t(p.arg496ter)
nm_138694.3(pkhd1):c.8303-1g>a
nm_138694.3(pkhd1):c.2854g>a(p.gly952arg)
nm_138694.3(pkhd1):c.7194g>a(p.trp2398ter)
nm_138694.3(pkhd1):c.10219c>t(p.gln3407ter)
nm_138694.3(pkhd1):c.107c>t(p.thr36met)
nm_138694.3(pkhd1):c.8824c>t(p.arg2942ter)
nm_138694.3(pkhd1):c.982c>t(p.arg328ter)
nm_138694.3(pkhd1):c.4870c>t(p.arg1624trp)
nm_138694.3(pkhd1):c.1602+1g>a
nm_138694.3(pkhd1):c.1694-1g>a
nm_138694.3(pkhd1):c.2341c>t(p.arg781ter)
nm_138694.3(pkhd1):c.2407+1g>a
nm_138694.3(pkhd1):c.2452c>t(p.gln818ter)
nm_138694.3(pkhd1):c.5236+1g>a
nm_138694.3(pkhd1):c.6499c>t(p.gln2167ter)
nm_138694.3(pkhd1):c.2725c>t(p.arg909ter)
nm_138694.3(pkhd1):c.370c>t(p.arg124ter)
nm_138694.3(pkhd1):c.2810g>a(p.trp937ter)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于pkhd1基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防常染色体隐性遗传性多囊肾病的方法。
肾性肉毒碱转运缺陷
在一些实施方案中,本文所述的方法、系统和组合物用于校正与肾性肉毒碱转运缺陷相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于slc22a5基因中,至少包括以下各项:
nm_003060.3(slc22a5):c.760c>t(p.arg254ter)
nm_003060.3(slc22a5):c.396g>a(p.trp132ter)
nm_003060.3(slc22a5):c.844c>t(p.arg282ter)
nm_003060.3(slc22a5):c.505c>t(p.arg169trp)
nm_003060.3(slc22a5):c.1319c>t(p.thr440met)
nm_003060.3(slc22a5):c.1195c>t(p.arg399trp)
nm_003060.3(slc22a5):c.695c>t(p.thr232met)
nm_003060.3(slc22a5):c.845g>a(p.arg282gln)
nm_003060.3(slc22a5):c.1193c>t(p.pro398leu)
nm_003060.3(slc22a5):c.1463g>a(p.arg488his)
nm_003060.3(slc22a5):c.338g>a(p.cys113tyr)
nm_003060.3(slc22a5):c.136c>t(p.pro46ser)
nm_003060.3(slc22a5):c.506g>a(p.arg169gln)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于slc22a5基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防肾性肉毒碱转运缺陷的方法。
肌肉疾病
与各种肌肉疾病相关联的病原性g至a或c至t突变/snp已在clinvar数据库中报告并在表a中公开,这些疾病包括但不限于杜兴氏肌营养不良(duchennemusculardystrophy)、贝克肌营养不良(beckermusculardystrophy)、肢带型肌营养不良、埃-德二氏肌营养不良(emery-dreifussmusculardystrophy)和面肩肱型肌营养不良。因此,本发明的一个方面涉及一种用于校正与如以下所论述的这些疾病中的任一种相关联的一种或多种病原性g至a或c至t突变/snp的方法。
杜兴氏肌营养不良
在一些实施方案中,本文所述的方法、系统和组合物用于校正与杜兴氏肌营养不良相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于dmd基因中,至少包括以下各项:
nm_004006.2(dmd):c.2797c>t(p.gln933ter)
nm_004006.2(dmd):c.4870c>t(p.gln1624ter)
nm_004006.2(dmd):c.5551c>t(p.gln1851ter)
nm_004006.2(dmd):c.3188g>a(p.trp1063ter)
nm_004006.2(dmd):c.8357g>a(p.trp2786ter)
nm_004006.2(dmd):c.7817g>a(p.trp2606ter)
nm_004006.2(dmd):c.7755g>a(p.trp2585ter)
nm_004006.2(dmd):c.5917c>t(p.gln1973ter)
nm_004006.2(dmd):c.5641c>t(p.gln1881ter)
nm_004006.2(dmd):c.5131c>t(p.gln1711ter)
nm_004006.2(dmd):c.4240c>t(p.gln1414ter)
nm_004006.2(dmd):c.3427c>t(p.gln1143ter)
nm_004006.2(dmd):c.2407c>t(p.gln803ter)
nm_004006.2(dmd):c.2368c>t(p.gln790ter)
nm_004006.2(dmd):c.1683g>a(p.trp561ter)
nm_004006.2(dmd):c.1663c>t(p.gln555ter)
nm_004006.2(dmd):c.1388g>a(p.trp463ter)
nm_004006.2(dmd):c.1331+1g>a
nm_004006.2(dmd):c.1324c>t(p.gln442ter)
nm_004006.2(dmd):c.355c>t(p.gln119ter)
nm_004006.2(dmd):c.94-1g>a
nm_004006.2(dmd):c.5506c>t(p.gln1836ter)
nm_004006.2(dmd):c.1504c>t(p.gln502ter)
nm_004006.2(dmd):c.5032c>t(p.gln1678ter)
nm_004006.2(dmd):c.457c>t(p.gln153ter)
nm_004006.2(dmd):c.1594c>t(p.gln532ter)
nm_004006.2(dmd):c.1150-1g>a
nm_004006.2(dmd):c.6223c>t(p.gln2075ter)
nm_004006.2(dmd):c.3747g>a(p.trp1249ter)
nm_004006.2(dmd):c.2861g>a(p.trp954ter)
nm_004006.2(dmd):c.9563+1g>a
nm_004006.2(dmd):c.4483c>t(p.gln1495ter)
nm_004006.2(dmd):c.4312c>t(p.gln1438ter)
nm_004006.2(dmd):c.8209c>t(p.gln2737ter)
nm_004006.2(dmd):c.4071+1g>a
nm_004006.2(dmd):c.2665c>t(p.arg889ter)
nm_004006.2(dmd):c.2202g>a(p.trp734ter)
nm_004006.2(dmd):c.2077c>t(p.gln693ter)
nm_004006.2(dmd):c.1653g>a(p.trp551ter)
nm_004006.2(dmd):c.1061g>a(p.trp354ter)
nm_004006.2(dmd):c.8914c>t(p.gln2972ter)
nm_004006.2(dmd):c.6118-1g>a
nm_004006.2(dmd):c.4729c>t(p.arg1577ter)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于dmd基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防杜兴氏肌营养不良的方法。
贝克肌营养不良
在一些实施方案中,本文所述的方法、系统和组合物用于校正与贝克肌营养不良相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于dmd基因中,至少包括以下各项:
nm_004006.2(dmd):c.3413g>a(p.trp1138ter)
nm_004006.2(dmd):c.358-1g>a
nm_004006.2(dmd):c.10108c>t(p.arg3370ter)
nm_004006.2(dmd):c.6373c>t(p.gln2125ter)
nm_004006.2(dmd):c.9568c>t(p.arg3190ter)
nm_004006.2(dmd):c.8713c>t(p.arg2905ter)
nm_004006.2(dmd):c.1615c>t(p.arg539ter)
nm_004006.2(dmd):c.3151c>t(p.arg1051ter)
nm_004006.2(dmd):c.3432+1g>a
nm_004006.2(dmd):c.5287c>t(p.arg1763ter)
nm_004006.2(dmd):c.5530c>t(p.arg1844ter)
nm_004006.2(dmd):c.8608c>t(p.arg2870ter)
nm_004006.2(dmd):c.8656c>t(p.gln2886ter)
nm_004006.2(dmd):c.8944c>t(p.arg2982ter)
nm_004006.2(dmd):c.5899c>t(p.arg1967ter)
nm_004006.2(dmd):c.10033c>t(p.arg3345ter)
nm_004006.2(dmd):c.10086+1g>a
nm_004019.2(dmd):c.1020g>a(p.thr340=)
nm_004006.2(dmd):c.1261c>t(p.gln421ter)
nm_004006.2(dmd):c.1465c>t(p.gln489ter)
nm_004006.2(dmd):c.1990c>t(p.gln664ter)
nm_004006.2(dmd):c.2032c>t(p.gln678ter)
nm_004006.2(dmd):c.2332c>t(p.gln778ter)
nm_004006.2(dmd):c.2419c>t(p.gln807ter)
nm_004006.2(dmd):c.2650c>t(p.gln884ter)
nm_004006.2(dmd):c.2804-1g>a
nm_004006.2(dmd):c.3276+1g>a
nm_004006.2(dmd):c.3295c>t(p.gln1099ter)
nm_004006.2(dmd):c.336g>a(p.trp112ter)
nm_004006.2(dmd):c.3580c>t(p.gln1194ter)
nm_004006.2(dmd):c.4117c>t(p.gln1373ter)
nm_004006.2(dmd):c.649+1g>a
nm_004006.2(dmd):c.6906g>a(p.trp2302ter)
nm_004006.2(dmd):c.7189c>t(p.gln2397ter)
nm_004006.2(dmd):c.7309+1g>a
nm_004006.2(dmd):c.7657c>t(p.arg2553ter)
nm_004006.2(dmd):c.7682g>a(p.trp2561ter)
nm_004006.2(dmd):c.7683g>a(p.trp2561ter)
nm_004006.2(dmd):c.7894c>t(p.gln2632ter)
nm_004006.2(dmd):c.9361+1g>a
nm_004006.2(dmd):c.9564-1g>a
nm_004006.2(dmd):c.2956c>t(p.gln986ter)
nm_004006.2(dmd):c.883c>t(p.arg295ter)
nm_004006.2(dmd):c.31+36947g>a
nm_004006.2(dmd):c.10279c>t(p.gln3427ter)
nm_004006.2(dmd):c.433c>t(p.arg145ter)
nm_004006.2(dmd):c.9g>a(p.trp3ter)
nm_004006.2(dmd):c.10171c>t(p.arg3391ter)
nm_004006.2(dmd):c.583c>t(p.arg195ter)
nm_004006.2(dmd):c.9337c>t(p.arg3113ter)
nm_004006.2(dmd):c.8038c>t(p.arg2680ter)
nm_004006.2(dmd):c.1812+1g>a
nm_004006.2(dmd):c.1093c>t(p.gln365ter)
nm_004006.2(dmd):c.1704+1g>a
nm_004006.2(dmd):c.1912c>t(p.gln638ter)
nm_004006.2(dmd):c.133c>t(p.gln45ter)
nm_004006.2(dmd):c.5868g>a(p.trp1956ter)
nm_004006.2(dmd):c.565c>t(p.gln189ter)
nm_004006.2(dmd):c.5089c>t(p.gln1697ter)
nm_004006.2(dmd):c.2512c>t(p.gln838ter)
nm_004006.2(dmd):c.10477c>t(p.gln3493ter)
nm_004006.2(dmd):c.93+1g>a
nm_004006.2(dmd):c.4174c>t(p.gln1392ter)
nm_004006.2(dmd):c.3940c>t(p.arg1314ter)参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于dmd基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防贝克肌营养不良的方法。
肢带型肌营养不良
在一些实施方案中,本文所述的方法、系统和组合物用于校正与肢带型肌营养不良相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自sgcb、myot、lmna、capn3、dysf、sgca、ttn、ano5、trappc11、lmna、pomt1和fkrp的至少一种基因中,至少包括以下各项:
nm_000232.4(sgcb):c.31c>t(p.gln11ter)
nm_006790.2(myot):c.164c>t(p.ser55phe)
nm_006790.2(myot):c.170c>t(p.thr57ile)
nm_170707.3(lmna):c.1488+1g>a
nm_170707.3(lmna):c.1609-1g>a
nm_000070.2(capn3):c.1715g>a(p.arg572gln)
nm_000070.2(capn3):c.2243g>a(p.arg748gln)
nm_000070.2(capn3):c.145c>t(p.arg49cys)
nm_000070.2(capn3):c.1319g>a(p.arg440gln)
nm_000070.2(capn3):c.1343g>a(p.arg448his)
nm_000070.2(capn3):c.1465c>t(p.arg489trp)
nm_000070.2(capn3):c.1714c>t(p.arg572trp)
nm_000070.2(capn3):c.2306g>a(p.arg769gln)
nm_000070.2(capn3):c.133g>a(p.ala45thr)
nm_000070.2(capn3):c.499-1g>a
nm_000070.2(capn3):c.439c>t(p.arg147ter)
nm_000070.2(capn3):c.1063c>t(p.arg355trp)
nm_000070.2(capn3):c.1250c>t(p.thr417met)
nm_000070.2(capn3):c.245c>t(p.pro82leu)
nm_000070.2(capn3):c.2242c>t(p.arg748ter)
nm_000070.2(capn3):c.1318c>t(p.arg440trp)
nm_000070.2(capn3):c.1333g>a(p.gly445arg)
nm_000070.2(capn3):c.1957c>t(p.gln653ter)
nm_000070.2(capn3):c.1801-1g>a
nm_000070.2(capn3):c.2263+1g>a
nm_000070.2(capn3):c.956c>t(p.pro319leu)
nm_000070.2(capn3):c.1468c>t(p.arg490trp)
nm_000070.2(capn3):c.802-9g>a
nm_000070.2(capn3):c.1342c>t(p.arg448cys)
nm_000070.2(capn3):c.1303g>a(p.glu435lys)
nm_000070.2(capn3):c.1993-1g>a
nm_003494.3(dysf):c.3113g>a(p.arg1038gln)
nm_001130987.1(dysf):c.5174+1g>a
nm_001130987.1(dysf):c.159g>a(p.trp53ter)
nm_001130987.1(dysf):c.2929c>t(p.arg977trp)
nm_001130987.1(dysf):c.4282c>t(p.gln1428ter)
nm_001130987.1(dysf):c.1577-1g>a
nm_003494.3(dysf):c.5529g>a(p.trp1843ter)
nm_001130987.1(dysf):c.1576+1g>a
nm_001130987.1(dysf):c.4462c>t(p.gln1488ter)
nm_003494.3(dysf):c.5429g>a(p.arg1810lys)
nm_003494.3(dysf):c.5077c>t(p.arg1693trp)
nm_001130978.1(dysf):c.1813c>t(p.gln605ter)
nm_003494.3(dysf):c.3230g>a(p.trg1077ter)
nm_003494.3(dysf):c.265c>t(p.arg89ter)
nm_003494.3(dysf):c.4434g>a(p.trp1478ter)
nm_003494.3(dysf):c.3478c>t(p.gln1160ter)
nm_001130987.1(dysf):c.1372g>a(p.gly458arg)
nm_003494.3(dysf):c.4090c>t(p.gln1364ter)
nm_001130987.1(dysf):c.2409+1g>a
nm_003494.3(dysf):c.1708c>t(p.gln570ter)
nm_003494.3(dysf):c.1956g>a(p.trp652ter)
nm_001130987.1(dysf):c.5004-1g>a
nm_003494.3(dysf):c.331c>t(p.gln111ter)
nm_001130978.1(dysf):c.5776c>t(p.arg1926ter)
nm_003494.3(dysf):c.6124c>t(p.arg2042cys)
nm_003494.3(dysf):c.2643+1g>a
nm_003494.3(dysf):c.4253g>a(p.gly1418asp)
nm_003494.3(dysf):c.610c>t(p.arg204ter)
nm_003494.3(dysf):c.1834c>t(p.gln612ter)
nm_003494.3(dysf):c.5668-7g>a
nm_001130978.1(dysf):c.3137g>a(p.arg1046his)
nm_003494.3(dysf):c.1053+1g>a
nm_003494.3(dysf):c.1398-1g>a
nm_003494.3(dysf):c.1481-1g>a
nm_003494.3(dysf):c.2311c>t(p.gln771ter)
nm_003494.3(dysf):c.2869c>t(p.gln957ter)
nm_003494.3(dysf):c.4756c>t(p.arg1586ter)
nm_003494.3(dysf):c.5509g>a(p.asp1837asn)
nm_003494.3(dysf):c.5644c>t(p.gln1882ter)
nm_003494.3(dysf):c.5946+1g>a
nm_003494.3(dysf):c.937+1g>a
nm_003494.3(dysf):c.5266c>t(p.gln1756ter)
nm_003494.3(dysf):c.3832c>t(p.gln1278ter)
nm_003494.3(dysf):c.5525+1g>a
nm_003494.3(dysf):c.3112c>t(p.arg1038ter)
nm_000023.3(sgca):c.293g>a(p.arg98his)
nm_000023.3(sgca):c.850c>t(p.arg284cys)
nm_000023.3(sgca):c.403c>t(p.gln135ter)
nm_000023.3(sgca):c.409g>a(p.glu137lys)
nm_000023.3(sgca):c.747+1g>a
nm_000023.3(sgca):c.229c>t(p.arg77cys)
nm_000023.3(sgca):c.101g>a(p.arg34his)
nm_000023.3(sgca):c.739g>a(p.val247met)
nm_001256850.1(ttn):c.87394c>t(p.arg29132ter)
nm_213599.2(ano5):c.762+1g>a
nm_213599.2(ano5):c.1213c>t(p.gln405ter)
nm_213599.2(ano5):c.1639c>t(p.arg547ter)
nm_213599.2(ano5):c.1406g>a(p.trp469ter)
nm_213599.2(ano5):c.1210c>t(p.arg404ter)
nm_213599.2(ano5):c.2272c>t(p.arg758cys)
nm_213599.2(ano5):c.41-1g>a
nm_213599.2(ano5):c.172c>t(p.arg58trp)
nm_213599.2(ano5):c.1898+1g>a
nm_021942.5(trappc11):c.1287+5g>a
nm_170707.3(lmna):c.1608+1g>a
nm_007171.3(pomt1):c.1864c>t(p.arg622ter)
nm_024301.4(fkrp):c.313c>t(p.gln105ter)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自sgcb、myot、lmna、capn3、dysf、sgca、ttn、ano5、trappc11、lmna、pomt1和fkrp的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防肢带型肌营养不良的方法。
埃-德二氏肌营养不良
在一些实施方案中,本文所述的方法、系统和组合物用于校正与埃-德二氏肌营养不良相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于emd或syne1基因中,至少包括以下各项:
nm_000117.2(emd):c.3g>a(p.met1ile)
nm_033071.3(syne1):c.11908c>t(p.arg3970ter)
nm_033071.3(syne1):c.21721c>t(p.gln7241ter)
nm_000117.2(emd):c.130c>t(p.gln44ter)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于emd或syne1基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防埃-德二氏肌营养不良的方法。
面肩肱型肌营养不良
在一些实施方案中,本文所述的方法、系统和组合物用于校正与面肩肱型肌营养不良相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于smchd1基因中,至少包括以下各项:
nm_015295.2(smchd1):c.3801+1g>a
nm_015295.2(smchd1):c.1843-1g>a
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于smchd1基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防面肩肱型肌营养不良的方法。
先天性代谢缺损(iem)
与各种iem相关联的病原性g至a或c至t突变/snp已在clinvar数据库中报告并在表a中公开,这些疾病包括但不限于原发性高草酸尿症1型、精氨酸琥珀酸裂解酶缺乏症、鸟氨酸氨甲酰基转移酶缺乏症和枫糖尿病。因此,本发明的一个方面涉及一种用于校正与如以下所论述的这些疾病中的任一种相关联的一种或多种病原性g至a或c至t突变/snp的方法。
原发性高草酸尿症1型
在一些实施方案中,本文所述的方法、系统和组合物用于校正与原发性高草酸尿症1型相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于agxt基因中,至少包括以下各项:
nm_000030.2(agxt):c.245g>a(p.gly82glu)
nm_000030.2(agxt):c.698g>a(p.arg233his)
nm_000030.2(agxt):c.466g>a(p.gly156arg)
nm_000030.2(agxt):c.106c>t(p.arg36cys)
nm_000030.2(agxt):c.346g>a(p.gly116arg)
nm_000030.2(agxt):c.568g>a(p.gly190arg)
nm_000030.2(agxt):c.653c>t(p.ser218leu)
nm_000030.2(agxt):c.737g>a(p.trp246ter)
nm_000030.2(agxt):c.1049g>a(p.gly350asp)
nm_000030.2(agxt):c.473c>t(p.ser158leu)
nm_000030.2(agxt):c.907c>t(p.gln303ter)
nm_000030.2(agxt):c.996g>a(p.trp332ter)
nm_000030.2(agxt):c.508g>a(p.gly170arg)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于agxt基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防原发性高草酸尿症1型的方法。
精氨酸琥珀酸裂解酶缺乏症
在一些实施方案中,本文所述的方法、系统和组合物用于校正与精氨酸琥珀酸裂解酶缺乏症相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于asl基因中,至少包括以下各项:
nm_001024943.1(asl):c.1153c>t(p.arg385cys)
nm_000048.3(asl):c.532g>a(p.val178met)
nm_000048.3(asl):c.545g>a(p.arg182gln)
nm_000048.3(asl):c.175g>a(p.glu59lys)
nm_000048.3(asl):c.718+5g>a
nm_000048.3(asl):c.889c>t(p.arg297trp)
nm_000048.3(asl):c.1360c>t(p.gln454ter)
nm_000048.3(asl):c.1060c>t(p.gln354ter)
nm_000048.3(asl):c.35g>a(p.arg12gln)
nm_000048.3(asl):c.446+1g>a
nm_000048.3(asl):c.544c>t(p.arg182ter)
nm_000048.3(asl):c.1135c>t(p.arg379cys)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于asl基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防面肩肱型肌营养不良的方法。
鸟氨酸氨甲酰基转移酶缺乏症
在一些实施方案中,本文所述的方法、系统和组合物用于校正与鸟氨酸氨甲酰基转移酶缺乏症相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于otc基因中,至少包括以下各项:
nm_000531.5(otc):c.119g>a(p.arg40his)
nm_000531.5(otc):c.422g>a(p.arg141gln)
nm_000531.5(otc):c.829c>t(p.arg277trp)
nm_000531.5(otc):c.674c>t(p.pro225leu)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于otc基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防鸟氨酸氨甲酰基转移酶缺乏症的方法。
枫糖尿病
在一些实施方案中,本文所述的方法、系统和组合物用于校正与枫糖尿病相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自bckdha、bckdhb、dbt和dld的至少一种基因中,至少包括以下各项:
nm_000709.3(bckdha):c.476g>a(p.arg159gln)
nm_183050.3(bckdhb):c.3g>a(p.met1ile)
nm_183050.3(bckdhb):c.554c>t(p.pro185leu)
nm_001918.3(dbt):c.1033g>a(p.gly345arg)
nm_000709.3(bckdha):c.940c>t(p.arg314ter)
nm_000709.3(bckdha):c.793c>t(p.arg265trp)
nm_000709.3(bckdha):c.868g>a(p.gly290arg)
nm_000108.4(dld):c.1123g>a(p.glu375lys)
nm_000709.3(bckdha):c.1234g>a(p.val412met)
nm_000709.3(bckdha):c.288+1g>a
nm_000709.3(bckdha):c.979g>a(p.glu327lys)
nm_001918.3(dbt):c.901c>t(p.arg301cys)
nm_183050.3(bckdhb):c.509g>a(p.arg170his)
nm_183050.3(bckdhb):c.799c>t(p.gln267ter)
nm_183050.3(bckdhb):c.853c>t(p.arg285ter)
nm_183050.3(bckdhb):c.970c>t(p.arg324ter)
nm_183050.3(bckdhb):c.832g>a(p.gly278ser)
nm_000709.3(bckdha):c.1036c>t(p.arg346cys)
nm_000709.3(bckdha):c.288+9c>t
nm_000709.3(bckdha):c.632c>t(p.thr211met)
nm_000709.3(bckdha):c.659c>t(p.ala220val)
nm_000709.3(bckdha):c.964c>t(p.gln322ter)
nm_001918.3(dbt):c.1291c>t(p.arg431ter)
nm_001918.3(dbt):c.251g>a(p.trp84ter)
nm_001918.3(dbt):c.871c>t(p.arg291ter)
nm_000056.4(bckdhb):c.1016c>t(p.ser339leu)
nm_000056.4(bckdhb):c.344-1g>a
nm_000056.4(bckdhb):c.633+1g>a
nm_000056.4(bckdhb):c.952-1g>a
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自bckdha、bckdhb、dbt和dld的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防枫糖尿病的方法。
癌症相关疾病
与各种癌症和癌症相关疾病相关联的病原性g至a或c至t突变/snp已在clinvar数据库中报告并在表a中公开,这些疾病包括但不限于乳腺癌-卵巢癌和林奇综合征(lynchsyndrome)。因此,本发明的一个方面涉及一种用于校正与如以下所论述的这些疾病中的任一种相关联的一种或多种病原性g至a或c至t突变/snp的方法。
乳腺癌-卵巢癌
在一些实施方案中,本文所述的方法、系统和组合物用于校正与乳腺癌-卵巢癌相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于brca1或brca2基因中,至少包括以下各项:
nm_007294.3(brca1):c.5095c>t(p.arg1699trp)
nm_000059.3(brca2):c.7558c>t(p.arg2520ter)
nm_007294.3(brca1):c.2572c>t(p.gln858ter)
nm_007294.3(brca1):c.3607c>t(p.arg1203ter)
nm_007294.3(brca1):c.5503c>t(p.arg1835ter)
nm_007294.3(brca1):c.2059c>t(p.gln687ter)
nm_007294.3(brca1):c.4675+1g>a
nm_007294.3(brca1):c.5251c>t(p.arg1751ter)
nm_007294.3(brca1):c.5444g>a(p.trp1815ter)
nm_000059.3(brca2):c.9318g>a(p.trp3106ter)
nm_000059.3(brca2):c.9382c>t(p.arg3128ter)
nm_000059.3(brca2):c.274c>t(p.gln92ter)
nm_000059.3(brca2):c.6952c>t(p.arg2318ter)
nm_007294.3(brca1):c.1687c>t(p.gln563ter)
nm_007294.3(brca1):c.2599c>t(p.gln867ter)
nm_007294.3(brca1):c.784c>t(p.gln262ter)
nm_007294.3(brca1):c.280c>t(p.gln94ter)
nm_007294.3(brca1):c.5542c>t(p.gln1848ter)
nm_007294.3(brca1):c.5161c>t(p.gln1721ter)
nm_007294.3(brca1):c.4573c>t(p.gln1525ter)
nm_007294.3(brca1):c.4270c>t(p.gln1424ter)
nm_007294.3(brca1):c.4225c>t(p.gln1409ter)
nm_007294.3(brca1):c.4066c>t(p.gln1356ter)
nm_007294.3(brca1):c.3679c>t(p.gln1227ter)
nm_007294.3(brca1):c.1918c>t(p.gln640ter)
nm_007294.3(brca1):c.963g>a(p.trp321ter)
nm_007294.3(brca1):c.718c>t(p.gln240ter)
nm_000059.3(brca2):c.9196c>t(p.gln3066ter)
nm_000059.3(brca2):c.9154c>t(p.arg3052trp)
nm_007294.3(brca1):c.3991c>t(p.gln1331ter)
nm_007294.3(brca1):c.4097-1g>a
nm_007294.3(brca1):c.1059g>a(p.trp353ter)
nm_007294.3(brca1):c.1115g>a(p.trp372ter)
nm_007294.3(brca1):c.1138c>t(p.gln380ter)
nm_007294.3(brca1):c.1612c>t(p.gln538ter)
nm_007294.3(brca1):c.1621c>t(p.gln541ter)
nm_007294.3(brca1):c.1630c>t(p.gln544ter)
nm_007294.3(brca1):c.178c>t(p.gln60ter)
nm_007294.3(brca1):c.1969c>t(p.gln657ter)
nm_007294.3(brca1):c.2275c>t(p.gln759ter)
nm_007294.3(brca1):c.2410c>t(p.gln804ter)
nm_007294.3(brca1):c.2869c>t(p.gln957ter)
nm_007294.3(brca1):c.2923c>t(p.gln975ter)
nm_007294.3(brca1):c.3268c>t(p.gln1090ter)
nm_007294.3(brca1):c.3430c>t(p.gln1144ter)
nm_007294.3(brca1):c.3544c>t(p.gln1182ter)
nm_007294.3(brca1):c.4075c>t(p.gln1359ter)
nm_007294.3(brca1):c.4201c>t(p.gln1401ter)
nm_007294.3(brca1):c.4399c>t(p.gln1467ter)
nm_007294.3(brca1):c.4552c>t(p.gln1518ter)
nm_007294.3(brca1):c.5054c>t(p.thr1685ile)
nm_007294.3(brca1):c.514c>t(p.gln172ter)
nm_007294.3(brca1):c.5239c>t(p.gln1747ter)
nm_007294.3(brca1):c.5266c>t(p.gln1756ter)
nm_007294.3(brca1):c.5335c>t(p.gln1779ter)
nm_007294.3(brca1):c.5345g>a(p.trp1782ter)
nm_007294.3(brca1):c.5511g>a(p.trp1837ter)
nm_007294.3(brca1):c.5536c>t(p.gln1846ter)
nm_007294.3(brca1):c.55c>t(p.gln19ter)
nm_007294.3(brca1):c.949c>t(p.gln317ter)
nm_007294.3(brca1):c.928c>t(p.gln310ter)
nm_007294.3(brca1):c.5117g>a(p.gly1706glu)
nm_007294.3(brca1):c.5136g>a(p.trp1712ter)
nm_007294.3(brca1):c.4327c>t(p.arg1443ter)
nm_007294.3(brca1):c.1471c>t(p.gln491ter)
nm_007294.3(brca1):c.1576c>t(p.gln526ter)
nm_007294.3(brca1):c.160c>t(p.gln54ter)
nm_007294.3(brca1):c.2683c>t(p.gln895ter)
nm_007294.3(brca1):c.2761c>t(p.gln921ter)
nm_007294.3(brca1):c.3895c>t(p.gln1299ter)
nm_007294.3(brca1):c.4339c>t(p.gln1447ter)
nm_007294.3(brca1):c.4372c>t(p.gln1458ter)
nm_007294.3(brca1):c.5153g>a(p.trp1718ter)
nm_007294.3(brca1):c.5445g>a(p.trp1815ter)
nm_007294.3(brca1):c.5510g>a(p.trp1837ter)
nm_007294.3(brca1):c.5346g>a(p.trp1782ter)
nm_007294.3(brca1):c.1116g>a(p.trp372ter)
nm_007294.3(brca1):c.1999c>t(p.gln667ter)
nm_007294.3(brca1):c.4183c>t(p.gln1395ter)
nm_007294.3(brca1):c.4810c>t(p.gln1604ter)
nm_007294.3(brca1):c.850c>t(p.gln284ter)
nm_007294.3(brca1):c.1058g>a(p.trp353ter)
nm_007294.3(brca1):c.131g>a(p.cys44tyr)
nm_007294.3(brca1):c.1600c>t(p.gln534ter)
nm_007294.3(brca1):c.3286c>t(p.gln1096ter)
nm_007294.3(brca1):c.3403c>t(p.gln1135ter)
nm_007294.3(brca1):c.34c>t(p.gln12ter)
nm_007294.3(brca1):c.4258c>t(p.gln1420ter)
nm_007294.3(brca1):c.4609c>t(p.gln1537ter)
nm_007294.3(brca1):c.5154g>a(p.trp1718ter)
nm_007294.3(brca1):c.5431c>t(p.gln1811ter)
nm_007294.3(brca1):c.241c>t(p.gln81ter)
nm_007294.3(brca1):c.3331c>t(p.gln1111ter)
nm_007294.3(brca1):c.3967c>t(p.gln1323ter)
nm_007294.3(brca1):c.415c>t(p.gln139ter)
nm_007294.3(brca1):c.505c>t(p.gln169ter)
nm_007294.3(brca1):c.5194-12g>a
nm_007294.3(brca1):c.5212g>a(p.gly1738arg)
nm_007294.3(brca1):c.5332+1g>a
nm_007294.3(brca1):c.1480c>t(p.gln494ter)
nm_007294.3(brca1):c.2563c>t(p.gln855ter)
nm_007294.3(brca1):c.1066c>t(p.gln356ter)
nm_007294.3(brca1):c.3718c>t(p.gln1240ter)
nm_007294.3(brca1):c.3817c>t(p.gln1273ter)
nm_007294.3(brca1):c.3937c>t(p.gln1313ter)
nm_007294.3(brca1):c.4357+1g>a
nm_007294.3(brca1):c.5074+1g>a
nm_007294.3(brca1):c.5277+1g>a
nm_007294.3(brca1):c.2338c>t(p.gln780ter)
nm_007294.3(brca1):c.3598c>t(p.gln1200ter)
nm_007294.3(brca1):c.3841c>t(p.gln1281ter)
nm_007294.3(brca1):c.4222c>t(p.gln1408ter)
nm_007294.3(brca1):c.4524g>a(p.trp1508ter)
nm_007294.3(brca1):c.5353c>t(p.gln1785ter)
nm_007294.3(brca1):c.962g>a(p.trp321ter)
nm_007294.3(brca1):c.220c>t(p.gln74ter)
nm_007294.3(brca1):c.2713c>t(p.gln905ter)
nm_007294.3(brca1):c.2800c>t(p.gln934ter)
nm_007294.3(brca1):c.4612c>t(p.gln1538ter)
nm_007294.3(brca1):c.3352c>t(p.gln1118ter)
nm_007294.3(brca1):c.4834c>t(p.gln1612ter)
nm_007294.3(brca1):c.4523g>a(p.trp1508ter)
nm_007294.3(brca1):c.5135g>a(p.trp1712ter)
nm_007294.3(brca1):c.1155g>a(p.trp385ter)
nm_007294.3(brca1):c.4987-1g>a
nm_000059.3(brca2):c.9573g>a(p.trp3191ter)
nm_000059.3(brca2):c.1945c>t(p.gln649ter)
nm_000059.3(brca2):c.217c>t(p.gln73ter)
nm_000059.3(brca2):c.523c>t(p.gln175ter)
nm_000059.3(brca2):c.2548c>t(p.gln850ter)
nm_000059.3(brca2):c.2905c>t(p.gln969ter)
nm_000059.3(brca2):c.4689g>a(p.trp1563ter)
nm_000059.3(brca2):c.4972c>t(p.gln1658ter)
nm_000059.3(brca2):c.1184g>a(p.trp395ter)
nm_000059.3(brca2):c.2137c>t(p.gln713ter)
nm_000059.3(brca2):c.3217c>t(p.gln1073ter)
nm_000059.3(brca2):c.3523c>t(p.gln1175ter)
nm_000059.3(brca2):c.4783c>t(p.gln1595ter)
nm_000059.3(brca2):c.5800c>t(p.gln1934ter)
nm_000059.3(brca2):c.6478c>t(p.gln2160ter)
nm_000059.3(brca2):c.7033c>t(p.gln2345ter)
nm_000059.3(brca2):c.7495c>t(p.gln2499ter)
nm_000059.3(brca2):c.7501c>t(p.gln2501ter)
nm_000059.3(brca2):c.7887g>a(p.trp2629ter)
nm_000059.3(brca2):c.8910g>a(p.trp2970ter)
nm_000059.3(brca2):c.9139c>t(p.gln3047ter)
nm_000059.3(brca2):c.9739c>t(p.gln3247ter)
nm_000059.3(brca2):c.582g>a(p.trp194ter)
nm_000059.3(brca2):c.7963c>t(p.gln2655ter)
nm_000059.3(brca2):c.8695c>t(p.gln2899ter)
nm_000059.3(brca2):c.8869c>t(p.gln2957ter)
nm_000059.3(brca2):c.1117c>t(p.gln373ter)
nm_000059.3(brca2):c.1825c>t(p.gln609ter)
nm_000059.3(brca2):c.2455c>t(p.gln819ter)
nm_000059.3(brca2):c.2881c>t(p.gln961ter)
nm_000059.3(brca2):c.3265c>t(p.gln1089ter)
nm_000059.3(brca2):c.3283c>t(p.gln1095ter)
nm_000059.3(brca2):c.3442c>t(p.gln1148ter)
nm_000059.3(brca2):c.3871c>t(p.gln1291ter)
nm_000059.3(brca2):c.439c>t(p.gln147ter)
nm_000059.3(brca2):c.4525c>t(p.gln1509ter)
nm_000059.3(brca2):c.475+1g>a
nm_000059.3(brca2):c.5344c>t(p.gln1782ter)
nm_000059.3(brca2):c.5404c>t(p.gln1802ter)
nm_000059.3(brca2):c.5773c>t(p.gln1925ter)
nm_000059.3(brca2):c.5992c>t(p.gln1998ter)
nm_000059.3(brca2):c.6469c>t(p.gln2157ter)
nm_000059.3(brca2):c.7261c>t(p.gln2421ter)
nm_000059.3(brca2):c.7303c>t(p.gln2435ter)
nm_000059.3(brca2):c.7471c>t(p.gln2491ter)
nm_000059.3(brca2):c.7681c>t(p.gln2561ter)
nm_000059.3(brca2):c.7738c>t(p.gln2580ter)
nm_000059.3(brca2):c.7886g>a(p.trp2629ter)
nm_000059.3(brca2):c.8140c>t(p.gln2714ter)
nm_000059.3(brca2):c.8363g>a(p.trp2788ter)
nm_000059.3(brca2):c.8572c>t(p.gln2858ter)
nm_000059.3(brca2):c.8773c>t(p.gln2925ter)
nm_000059.3(brca2):c.8821c>t(p.gln2941ter)
nm_000059.3(brca2):c.9109c>t(p.gln3037ter)
nm_000059.3(brca2):c.9317g>a(p.trp3106ter)
nm_000059.3(brca2):c.9466c>t(p.gln3156ter)
nm_000059.3(brca2):c.9572g>a(p.trp3191ter)
nm_000059.3(brca2):c.8490g>a(p.trp2830ter)
nm_000059.3(brca2):c.5980c>t(p.gln1994ter)
nm_000059.3(brca2):c.7721g>a(p.trp2574ter)
nm_000059.3(brca2):c.196c>t(p.gln66ter)
nm_000059.3(brca2):c.7618-1g>a
nm_000059.3(brca2):c.8489g>a(p.trp2830ter)
nm_000059.3(brca2):c.7857g>a(p.trp2619ter)
nm_000059.3(brca2):c.1261c>t(p.gln421ter)
nm_000059.3(brca2):c.1456c>t(p.gln486ter)
nm_000059.3(brca2):c.3319c>t(p.gln1107ter)
nm_000059.3(brca2):c.5791c>t(p.gln1931ter)
nm_000059.3(brca2):c.6070c>t(p.gln2024ter)
nm_000059.3(brca2):c.7024c>t(p.gln2342ter)
nm_000059.3(brca2):c.961c>t(p.gln321ter)
nm_000059.3(brca2):c.9380g>a(p.trp3127ter)
nm_000059.3(brca2):c.8364g>a(p.trp2788ter)
nm_000059.3(brca2):c.7758g>a(p.trp2586ter)
nm_000059.3(brca2):c.2224c>t(p.gln742ter)
nm_000059.3(brca2):c.5101c>t(p.gln1701ter)
nm_000059.3(brca2):c.5959c>t(p.gln1987ter)
nm_000059.3(brca2):c.7060c>t(p.gln2354ter)
nm_000059.3(brca2):c.9100c>t(p.gln3034ter)
nm_000059.3(brca2):c.9148c>t(p.gln3050ter)
nm_000059.3(brca2):c.9883c>t(p.gln3295ter)
nm_000059.3(brca2):c.1414c>t(p.gln472ter)
nm_000059.3(brca2):c.1689g>a(p.trp563ter)
nm_000059.3(brca2):c.581g>a(p.trp194ter)
nm_000059.3(brca2):c.6490c>t(p.gln2164ter)
nm_000059.3(brca2):c.7856g>a(p.trp2619ter)
nm_000059.3(brca2):c.8970g>a(p.trp2990ter)
nm_000059.3(brca2):c.92g>a(p.trp31ter)
nm_000059.3(brca2):c.9376c>t(p.gln3126ter)
nm_000059.3(brca2):c.93g>a(p.trp31ter)
nm_000059.3(brca2):c.1189c>t(p.gln397ter)
nm_000059.3(brca2):c.2818c>t(p.gln940ter)
nm_000059.3(brca2):c.2979g>a(p.trp993ter)
nm_000059.3(brca2):c.3166c>t(p.gln1056ter)
nm_000059.3(brca2):c.4285c>t(p.gln1429ter)
nm_000059.3(brca2):c.6025c>t(p.gln2009ter)
nm_000059.3(brca2):c.772c>t(p.gln258ter)
nm_000059.3(brca2):c.7877g>a(p.trp2626ter)
nm_000059.3(brca2):c.3109c>t(p.gln1037ter)
nm_000059.3(brca2):c.4222c>t(p.gln1408ter)
nm_000059.3(brca2):c.7480c>t(p.arg2494ter)
nm_000059.3(brca2):c.7878g>a(p.trp2626ter)
nm_000059.3(brca2):c.9076c>t(p.gln3026ter)
nm_000059.3(brca2):c.1855c>t(p.gln619ter)
nm_000059.3(brca2):c.4111c>t(p.gln1371ter)
nm_000059.3(brca2):c.5656c>t(p.gln1886ter)
nm_000059.3(brca2):c.7757g>a(p.trp2586ter)
nm_000059.3(brca2):c.8243g>a(p.gly2748asp)
nm_000059.3(brca2):c.8878c>t(p.gln2960ter)
nm_000059.3(brca2):c.8487+1g>a
nm_000059.3(brca2):c.8677c>t(p.gln2893ter)
nm_000059.3(brca2):c.250c>t(p.gln84ter)
nm_000059.3(brca2):c.6124c>t(p.gln2042ter)
nm_000059.3(brca2):c.7617+1g>a
nm_000059.3(brca2):c.8575c>t(p.gln2859ter)
nm_000059.3(brca2):c.8174g>a(p.trp2725ter)
nm_000059.3(brca2):c.3187c>t(p.gln1063ter)
nm_000059.3(brca2):c.9381g>a(p.trp3127ter)
nm_000059.3(brca2):c.2095c>t(p.gln699ter)
nm_000059.3(brca2):c.1642c>t(p.gln548ter)
nm_000059.3(brca2):c.8608c>t(p.gln2870ter)
nm_000059.3(brca2):c.3412c>t(p.gln1138ter)
nm_000059.3(brca2):c.4246c>t(p.gln1416ter)
nm_000059.3(brca2):c.6475c>t(p.gln2159ter)
nm_000059.3(brca2):c.7366c>t(p.gln2456ter)
nm_000059.3(brca2):c.7516c>t(p.gln2506ter)
nm_000059.3(brca2):c.8969g>a(p.trp2990ter)
nm_000059.3(brca2):c.6487c>t(p.gln2163ter)
nm_000059.3(brca2):c.2978g>a(p.trp993ter)
nm_000059.3(brca2):c.7615c>t(p.gln2539ter)
nm_000059.3(brca2):c.9106c>t(p.gln3036ter)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于brca1或brca2基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防乳腺癌-卵巢癌的方法。
林奇综合征
在一些实施方案中,本文所述的方法、系统和组合物用于校正与林奇综合征相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自msh6、msh2、epcam、pms2和mlh1的至少一种基因中,至少包括以下各项:
nm_000179.2(msh6):c.1045c>t(p.gln349ter)
nm_000251.2(msh2):c.1384c>t(p.gln462ter)
nm_002354.2(epcam):c.133c>t(p.gln45ter)
nm_002354.2(epcam):c.429g>a(p.trp143ter)
nm_002354.2(epcam):c.523c>t(p.gln175ter)
nm_000179.2(msh6):c.2680c>t(p.gln894ter)
nm_000251.2(msh2):c.350g>a(p.trp117ter)
nm_000179.2(msh6):c.2735g>a(p.trp912ter)
nm_000179.2(msh6):c.3556+1g>a
nm_000251.2(msh2):c.388c>t(p.gln130ter)
nm_000535.6(pms2):c.1912c>t(p.gln638ter)
nm_000535.6(pms2):c.1891c>t(p.gln631ter)
nm_000249.3(mlh1):c.454-1g>a
nm_000251.2(msh2):c.1030c>t(p.gln344ter)
nm_000179.2(msh6):c.2330g>a(p.trp777ter)
nm_000179.2(msh6):c.2191c>t(p.gln731ter)
nm_000179.2(msh6):c.2764c>t(p.arg922ter)
nm_000179.2(msh6):c.2815c>t(p.gln939ter)
nm_000179.2(msh6):c.3020g>a(p.trp1007ter)
nm_000179.2(msh6):c.3436c>t(p.gln1146ter)
nm_000179.2(msh6):c.3647-1g>a
nm_000179.2(msh6):c.3772c>t(p.gln1258ter)
nm_000179.2(msh6):c.3838c>t(p.gln1280ter)
nm_000179.2(msh6):c.706c>t(p.gln236ter)
nm_000179.2(msh6):c.730c>t(p.gln244ter)
nm_000249.3(mlh1):c.1171c>t(p.gln391ter)
nm_000249.3(mlh1):c.1192c>t(p.gln398ter)
nm_000249.3(mlh1):c.1225c>t(p.gln409ter)
nm_000249.3(mlh1):c.1276c>t(p.gln426ter)
nm_000249.3(mlh1):c.1528c>t(p.gln510ter)
nm_000249.3(mlh1):c.1609c>t(p.gln537ter)
nm_000249.3(mlh1):c.1613g>a(p.trp538ter)
nm_000249.3(mlh1):c.1614g>a(p.trp538ter)
nm_000249.3(mlh1):c.1624c>t(p.gln542ter)
nm_000249.3(mlh1):c.1684c>t(p.gln562ter)
nm_000249.3(mlh1):c.1731+1g>a
nm_000249.3(mlh1):c.1731+5g>a
nm_000249.3(mlh1):c.1732-1g>a
nm_000249.3(mlh1):c.1896g>a(p.glu632=)
nm_000249.3(mlh1):c.1989+1g>a
nm_000249.3(mlh1):c.1990-1g>a
nm_000249.3(mlh1):c.1998g>a(p.trp666ter)
nm_000249.3(mlh1):c.208-1g>a
nm_000249.3(mlh1):c.2101c>t(p.gln701ter)
nm_000249.3(mlh1):c.2136g>a(p.trp712ter)
nm_000249.3(mlh1):c.2224c>t(p.gln742ter)
nm_000249.3(mlh1):c.230g>a(p.cys77tyr)
nm_000249.3(mlh1):c.256c>t(p.gln86ter)
nm_000249.3(mlh1):c.436c>t(p.gln146ter)
nm_000249.3(mlh1):c.445c>t(p.gln149ter)
nm_000249.3(mlh1):c.545g>a(p.arg182lys)
nm_000249.3(mlh1):c.731g>a(p.gly244asp)
nm_000249.3(mlh1):c.76c>t(p.gln26ter)
nm_000249.3(mlh1):c.842c>t(p.ala281val)
nm_000249.3(mlh1):c.882c>t(p.leu294=)
nm_000249.3(mlh1):c.901c>t(p.gln301ter)
nm_000251.2(msh2):c.1013g>a(p.gly338glu)
nm_000251.2(msh2):c.1034g>a(p.trp345ter)
nm_000251.2(msh2):c.1129c>t(p.gln377ter)
nm_000251.2(msh2):c.1183c>t(p.gln395ter)
nm_000251.2(msh2):c.1189c>t(p.gln397ter)
nm_000251.2(msh2):c.1204c>t(p.gln402ter)
nm_000251.2(msh2):c.1276+1g>a
nm_000251.2(msh2):c.1528c>t(p.gln510ter)
nm_000251.2(msh2):c.1552c>t(p.gln518ter)
nm_000251.2(msh2):c.1720c>t(p.gln574ter)
nm_000251.2(msh2):c.1777c>t(p.gln593ter)
nm_000251.2(msh2):c.1885c>t(p.gln629ter)
nm_000251.2(msh2):c.2087c>t(p.pro696leu)
nm_000251.2(msh2):c.2251g>a(p.gly751arg)
nm_000251.2(msh2):c.2291g>a(p.trp764ter)
nm_000251.2(msh2):c.2292g>a(p.trp764ter)
nm_000251.2(msh2):c.2446c>t(p.gln816ter)
nm_000251.2(msh2):c.2470c>t(p.gln824ter)
nm_000251.2(msh2):c.2536c>t(p.gln846ter)
nm_000251.2(msh2):c.2581c>t(p.gln861ter)
nm_000251.2(msh2):c.2634g>a(p.glu878=)
nm_000251.2(msh2):c.2635c>t(p.gln879ter)
nm_000251.2(msh2):c.28c>t(p.gln10ter)
nm_000251.2(msh2):c.472c>t(p.gln158ter)
nm_000251.2(msh2):c.478c>t(p.gln160ter)
nm_000251.2(msh2):c.484g>a(p.gly162arg)
nm_000251.2(msh2):c.490g>a(p.gly164arg)
nm_000251.2(msh2):c.547c>t(p.gln183ter)
nm_000251.2(msh2):c.577c>t(p.gln193ter)
nm_000251.2(msh2):c.643c>t(p.gln215ter)
nm_000251.2(msh2):c.645+1g>a
nm_000251.2(msh2):c.652c>t(p.gln218ter)
nm_000251.2(msh2):c.754c>t(p.gln252ter)
nm_000251.2(msh2):c.792+1g>a
nm_000251.2(msh2):c.942g>a(p.gln314=)
nm_000535.6(pms2):c.949c>t(p.gln317ter)
nm_000249.3(mlh1):c.306+1g>a
nm_000249.3(mlh1):c.62c>t(p.ala21val)
nm_000251.2(msh2):c.1865c>t(p.pro622leu)
nm_000179.2(msh6):c.426g>a(p.trp142ter)
nm_000251.2(msh2):c.715c>t(p.gln239ter)
nm_000249.3(mlh1):c.350c>t(p.thr117met)
nm_000251.2(msh2):c.1915c>t(p.his639tyr)
nm_000251.2(msh2):c.289c>t(p.gln97ter)
nm_000251.2(msh2):c.2785c>t(p.arg929ter)
nm_000249.3(mlh1):c.131c>t(p.ser44phe)
nm_000249.3(mlh1):c.1219c>t(p.gln407ter)
nm_000249.3(mlh1):c.306+5g>a
nm_000251.2(msh2):c.1801c>t(p.gln601ter)
nm_000535.6(pms2):c.1144+1g>a
nm_000251.2(msh2):c.1984c>t(p.gln662ter)
nm_000249.3(mlh1):c.381-1g>a
nm_000535.6(pms2):c.631c>t(p.arg211ter)
nm_000251.2(msh2):c.790c>t(p.gln264ter)
nm_000251.2(msh2):c.366+1g>a
nm_000249.3(mlh1):c.298c>t(p.arg100ter)
nm_000179.2(msh6):c.3013c>t(p.arg1005ter)
nm_000179.2(msh6):c.694c>t(p.gln232ter)
nm_000179.2(msh6):c.742c>t(p.arg248ter)
nm_000249.3(mlh1):c.1039-1g>a
nm_000249.3(mlh1):c.142c>t(p.gln48ter)
nm_000249.3(mlh1):c.1790g>a(p.trp597ter)
nm_000249.3(mlh1):c.1961c>t(p.pro654leu)
nm_000249.3(mlh1):c.2103+1g>a
nm_000249.3(mlh1):c.2135g>a(p.trp712ter)
nm_000249.3(mlh1):c.588+5g>a
nm_000249.3(mlh1):c.790+1g>a
nm_000251.2(msh2):c.1035g>a(p.trp345ter)
nm_000251.2(msh2):c.1255c>t(p.gln419ter)
nm_000251.2(msh2):c.1861c>t(p.arg621ter)
nm_000251.2(msh2):c.226c>t(p.gln76ter)
nm_000251.2(msh2):c.2653c>t(p.gln885ter)
nm_000251.2(msh2):c.508c>t(p.gln170ter)
nm_000251.2(msh2):c.862c>t(p.gln288ter)
nm_000251.2(msh2):c.892c>t(p.gln298ter)
nm_000251.2(msh2):c.970c>t(p.gln324ter)
nm_000179.2(msh6):c.4001g>a(p.arg1334gln)
nm_000251.2(msh2):c.1662-1g>a
nm_000535.6(pms2):c.1882c>t(p.arg628ter)
nm_000535.6(pms2):c.2174+1g>a
nm_000535.6(pms2):c.2404c>t(p.arg802ter)
nm_000179.2(msh6):c.3991c>t(p.arg1331ter)
nm_000179.2(msh6):c.2503c>t(p.gln835ter)
nm_000179.2(msh6):c.718c>t(p.arg240ter)
nm_000249.3(mlh1):c.1038g>a(p.gln346=)
nm_000249.3(mlh1):c.245c>t(p.thr82ile)
nm_000249.3(mlh1):c.83c>t(p.pro28leu)
nm_000249.3(mlh1):c.884g>a(p.ser295asn)
nm_000249.3(mlh1):c.982c>t(p.gln328ter)
nm_000251.2(msh2):c.1046c>t(p.pro349leu)
nm_000251.2(msh2):c.1120c>t(p.gln374ter)
nm_000251.2(msh2):c.1285c>t(p.gln429ter)
nm_000251.2(msh2):c.1477c>t(p.gln493ter)
nm_000251.2(msh2):c.2152c>t(p.gln718ter)
nm_000535.6(pms2):c.703c>t(p.gln235ter)
nm_000249.3(mlh1):c.2141g>a(p.trp714ter)
nm_000251.2(msh2):c.1009c>t(p.gln337ter)
nm_000251.2(msh2):c.1216c>t(p.arg406ter)
nm_000179.2(msh6):c.3202c>t(p.arg1068ter)
nm_000251.2(msh2):c.1165c>t(p.arg389ter)
nm_000249.3(mlh1):c.1943c>t(p.pro648leu)
nm_000249.3(mlh1):c.200g>a(p.gly67glu)
nm_000249.3(mlh1):c.793c>t(p.arg265cys)
nm_000249.3(mlh1):c.2059c>t(p.arg687trp)
nm_000249.3(mlh1):c.677g>a(p.arg226gln)
nm_000249.3(mlh1):c.2041g>a(p.a1a681thr)
nm_000249.3(mlh1):c.1942c>t(p.pro648ser)
nm_000249.3(mlh1):c.676c>t(p.arg226ter)
nm_000251.2(msh2):c.2038c>t(p.arg680ter)
nm_000179.2(msh6):c.1483c>t(p.arg495ter)
nm_000179.2(msh6):c.2194c>t(p.arg732ter)
nm_000179.2(msh6):c.3103c>t(p.arg1035ter)
nm_000179.2(msh6):c.892c>t(p.arg298ter)
nm_000249.3(mlh1):c.1459c>t(p.arg487ter)
nm_000249.3(mlh1):c.1731g>a(p.ser577=)
nm_000249.3(mlh1):c.184c>t(p.gln62ter)
nm_000249.3(mlh1):c.1975c>t(p.arg659ter)
nm_000249.3(mlh1):c.199g>a(p.gly67arg)
nm_000251.2(msh2):c.1076+1g>a
nm_000251.2(msh2):c.1147c>t(p.arg383ter)
nm_000251.2(msh2):c.181c>t(p.gln61ter)
nm_000251.2(msh2):c.212-1g>a
nm_000251.2(msh2):c.2131c>t(p.arg711ter)
nm_000535.6(pms2):c.697c>t(p.gln233ter)
nm_000535.6(pms2):c.1261c>t(p.arg421ter)
nm_000251.2(msh2):c.2047g>a(p.gly683arg)
nm_000535.6(pms2):c.400c>t(p.arg134ter)
nm_000535.6(pms2):c.1927c>t(p.gln643ter)
nm_000179.2(msh6):c.1444c>t(p.arg482ter)
nm_000179.2(msh6):c.2731c>t(p.arg911ter)
nm_000535.6(pms2):c.943c>t(p.arg315ter)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自bckdha、bckdhb、dbt和dld的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防林奇综合征的方法。
其他遗传疾病
与其他遗传疾病相关联的病原性g至a或c至t突变/snp已在clinvar数据库中报告并在表a中公开,这些疾病包括但不限于马凡综合征、赫尔勒综合征(hurlersyndrome)、糖原贮积病和囊性纤维化。因此,本发明的一个方面涉及一种用于校正与如以下所论述的这些疾病中的任一种相关联的一种或多种病原性g至a或c至t突变/snp的方法。
马凡综合征
在一些实施方案中,本文所述的方法、系统和组合物用于校正与马凡综合征相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于fbn1基因中,至少包括以下各项:
nm_000138.4(fbn1):c.1879c>t(p.arg627cys)
nm_000138.4(fbn1):c.1051c>t(p.gln351ter)
nm_000138.4(fbn1):c.184c>t(p.arg62cys)
nm_000138.4(fbn1):c.2855-1g>a
nm_000138.4(fbn1):c.3164g>a(p.cys1055tyr)
nm_000138.4(fbn1):c.368g>a(p.cys123tyr)
nm_000138.4(fbn1):c.4955g>a(p.cys1652tyr)
nm_000138.4(fbn1):c.7180c>t(p.arg2394ter)
nm_000138.4(fbn1):c.8267g>a(p.trp2756ter)
nm_000138.4(fbn1):c.1496g>a(p.cys499tyr)
nm_000138.4(fbn1):c.6886c>t(p.gln2296ter)
nm_000138.4(fbn1):c.3373c>t(p.arg1125ter)
nm_000138.4(fbn1):c.640g>a(p.gly214ser)
nm_000138.4(fbn1):c.5038c>t(p.gln1680ter)
nm_000138.4(fbn1):c.434g>a(p.cys145tyr)
nm_000138.4(fbn1):c.2563c>t(p.gln855ter)
nm_000138.4(fbn1):c.7466g>a(p.cys2489tyr)
nm_000138.4(fbn1):c.2089c>t(p.gln697ter)
nm_000138.4(fbn1):c.592c>t(p.gln198ter)
nm_000138.4(fbn1):c.6695g>a(p.cys2232tyr)
nm_000138.4(fbn1):c.6164-1g>a
nm_000138.4(fbn1):c.5627g>a(p.cys1876tyr)
nm_000138.4(fbn1):c.4061g>a(p.trp1354ter)
nm_000138.4(fbn1):c.1982g>a(p.cys661tyr)
nm_000138.4(fbn1):c.6784c>t(p.gln2262ter)
nm_000138.4(fbn1):c.409c>t(p.gln137ter)
nm_000138.4(fbn1):c.364c>t(p.arg122cys)
nm_000138.4(fbn1):c.3217g>a(p.glu1073lys)
nm_000138.4(fbn1):c.4460-8g>a
nm_000138.4(fbn1):c.4786c>t(p.arg1596ter)
nm_000138.4(fbn1):c.7806g>a(p.trp2602ter)
nm_000138.4(fbn1):c.247+1g>a
nm_000138.4(fbn1):c.2495g>a(p.cys832tyr)
nm_000138.4(fbn1):c.493c>t(p.arg165ter)
nm_000138.4(fbn1):c.5504g>a(p.cys1835tyr)
nm_000138.4(fbn1):c.5863c>t(p.gln1955ter)
nm_000138.4(fbn1):c.6658c>t(p.arg2220ter)
nm_000138.4(fbn1):c.7606g>a(p.gly2536arg)
nm_000138.4(fbn1):c.7955g>a(p.cys2652tyr)
nm_000138.4(fbn1):c.3037g>a(p.gly1013arg)
nm_000138.4(fbn1):c.8080c>t(p.arg2694ter)
nm_000138.4(fbn1):c.1633c>t(p.arg545cys)
nm_000138.4(fbn1):c.7205-1g>a
nm_000138.4(fbn1):c.4621c>t(p.arg1541ter)
nm_000138.4(fbn1):c.1090c>t(p.arg364ter)
nm_000138.4(fbn1):c.1585c>t(p.arg529ter)
nm_000138.4(fbn1):c.4781g>a(p.gly1594asp)
nm_000138.4(fbn1):c.643c>t(p.arg215ter)
nm_000138.4(fbn1):c.3668g>a(p.cys1223tyr)
nm_000138.4(fbn1):c.8326c>t(p.arg2776ter)
nm_000138.4(fbn1):c.6354c>t(p.ile2118=)
nm_000138.4(fbn1):c.1468+5g>a
nm_000138.4(fbn1):c.1546c>t(p.arg516ter)
nm_000138.4(fbn1):c.4615c>t(p.arg1539ter)
nm_000138.4(fbn1):c.5368c>t(p.arg1790ter)
nm_000138.4(fbn1):c.1285c>t(p.arg429ter)
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于fbn1基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防马凡综合征的方法。
赫尔勒综合征
在一些实施方案中,本文所述的方法、系统和组合物用于校正与赫尔勒综合征相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp至少存在于idua基因中,至少包括以下各项:
nm_000203.4(idua):c.972+1g>a
nm_000203.4(idua):c.1855c>t(p.arg619ter)
nm_000203.4(idua):c.152g>a(p.gly51asp)
nm_000203.4(idua):c.1205g>a(p.trp402ter)
nm_000203.4(idua):c.208c>t(p.gln70ter)
nm_000203.4(idua):c.1045g>a(p.asp349asn)
nm_000203.4(idua):c.1650+5g>a
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于idua基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防赫尔勒综合征的方法。
糖原贮积病
在一些实施方案中,本文所述的方法、系统和组合物用于校正与糖原贮积病相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于选自gaa、agl、phkb、prkag2、g6pc、pgam2、gbe1、pygm和pfkm的至少一种基因中,至少包括以下各项:
nm_000152.4(gaa):c.1927g>a(p.gly643arg)
nm_000152.4(gaa):c.2173c>t(p.arg725trp)
nm_000642.2(agl):c.3980g>a(p.trp1327ter)
nm_000642.2(agl):c.16c>t(p.gln6ter)
nm_000642.2(agl):c.2039g>a(p.trp680ter)
nm_000293.2(phkb):c.1546c>t(p.gln516ter)
nm_016203.3(prkag2):c.1592g>a(p.arg531gln)
nm_000151.3(g6pc):c.248g>a(p.arg83his)
nm_000151.3(g6pc):c.724c>t(p.gln242ter)
nm_000151.3(g6pc):c.883c>t(p.arg295cys)
nm_000151.3(g6pc):c.247c>t(p.arg83cys)
nm_000151.3(g6pc):c.1039c>t(p.gln347ter)
nm_000152.4(gaa):c.1561g>a(p.glu521lys)
nm_000642.2(agl):c.2590c>t(p.arg864ter)
nm_000642.2(agl):c.3682c>t(p.arg1228ter)
nm_000642.2(agl):c.118c>t(p.gln40ter)
nm_000642.2(agl):c.256c>t(p.gln86ter)
nm_000642.2(agl):c.2681+1g>a
nm_000642.2(agl):c.2158-1g>a
nm_000290.3(pgam2):c.233g>a(p.trp78ter)
nm_000152.4(gaa):c.1548g>a(p.trp516ter)
nm_000152.4(gaa):c.2014c>t(p.arg672trp)
nm_000152.4(gaa):c.546g>a(p.thr182=)
nm_000152.4(gaa):c.1802c>t(p.ser601leu)
nm_000152.4(gaa):c.1754+1g>a
nm_000152.4(gaa):c.1082c>t(p.pro361leu)
nm_000152.4(gaa):c.2560c>t(p.arg854ter)
nm_000152.4(gaa):c.655g>a(p.gly219arg)
nm_000152.4(gaa):c.1933g>a(p.asp645asn)
nm_000152.4(gaa):c.1979g>a(p.arg660his)
nm_000152.4(gaa):c.1465g>a(p.asp489asn)
nm_000152.4(gaa):c.2512c>t(p.gln838ter)
nm_000158.3(gbe1):c.1543c>t(p.arg515cys)
nm_005609.3(pygm):c.1726c>t(p.arg576ter)
nm_005609.3(pygm):c.1827g>a(p.lys609=)
nm_005609.3(pygm):c.148c>t(p.arg50ter)
nm_005609.3(pygm):c.613g>a(p.gly205ser)
nm_005609.3(pygm):c.1366g>a(p.val456met)
nm_005609.3(pygm):c.1768+1g>a
nm_001166686.1(pfkm):c.450+1g>a
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于选自gaa、agl、phkb、prkag2、g6pc、pgam2、gbe1、pygm和pfkm的至少一种基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防糖原贮积病的方法。
囊性纤维化
在一些实施方案中,本文所述的方法、系统和组合物用于校正与囊性纤维化相关联的一种或多种病原性g至a或c至t突变/snp。在一些实施方案中,病原性突变/snp存在于cftr基因中,至少包括以下各项:
nm_000492.3(cftr):c.3712c>t(p.gln1238ter)
nm_000492.3(cftr):c.3484c>t(p.arg1162ter)
nm_000492.3(cftr):c.1766+1g>a
nm_000492.3(cftr):c.1477c>t(p.gln493ter)
nm_000492.3(cftr):c.2538g>a(p.trp846ter)
nm_000492.3(cftr):c.2551c>t(p.arg851ter)
nm_000492.3(cftr):c.3472c>t(p.arg1158ter)
nm_000492.3(cftr):c.1475c>t(p.ser492phe)
nm_000492.3(cftr):c.1679g>a(p.arg560lys)
nm_000492.3(cftr):c.3197g>a(p.arg1066his)
nm_000492.3(cftr):c.3873+1g>a
nm_000492.3(cftr):c.3196c>t(p.arg1066cys)
nm_000492.3(cftr):c.2490+1g>a
nm_000492.3(cftr):c.3718-1g>a
nm_000492.3(cftr):c.171g>a(p.trp57ter)
nm_000492.3(cftr):c.3937c>t(p.gln1313ter)
nm_000492.3(cftr):c.274g>a(p.glu92lys)
nm_000492.3(cftr):c.1013c>t(p.thr338ile)
nm_000492.3(cftr):c.3266g>a(p.trp1089ter)
nm_000492.3(cftr):c.1055g>a(p.arg352gln)
nm_000492.3(cftr):c.1654c>t(p.gln552ter)
nm_000492.3(cftr):c.2668c>t(p.gln890ter)
nm_000492.3(cftr):c.3611g>a(p.trp1204ter)
nm_000492.3(cftr):c.1585-8g>a
nm_000492.3(cftr):c.223c>t(p.arg75ter)
nm_000492.3(cftr):c.1680-1g>a
nm_000492.3(cftr):c.349c>t(p.arg117cys)
nm_000492.3(cftr):c.1203g>a(p.trp401ter)
nm_000492.3(cftr):c.1240c>t(p.gln414ter)
nm_000492.3(cftr):c.1202g>a(p.trp401ter)
nm_000492.3(cftr):c.1209+1g>a
nm_000492.3(cftr):c.115c>t(p.gln39ter)
nm_000492.3(cftr):c.1116+1g>a
nm_000492.3(cftr):c.1393-1g>a
nm_000492.3(cftr):c.1573c>t(p.gln525ter)
nm_000492.3(cftr):c.164+1g>a
nm_000492.3(cftr):c.166g>a(p.glu56lys)
nm_000492.3(cftr):c.170g>a(p.trp57ter)
nm_000492.3(cftr):c.2053c>t(p.gln685ter)
nm_000492.3(cftr):c.2125c>t(p.arg709ter)
nm_000492.3(cftr):c.2290c>t(p.arg764ter)
nm_000492.3(cftr):c.2353c>t(p.arg785ter)
nm_000492.3(cftr):c.2374c>t(p.arg792ter)
nm_000492.3(cftr):c.2537g>a(p.trp846ter)
nm_000492.3(cftr):c.292c>t(p.gln98ter)
nm_000492.3(cftr):c.2989-1g>a
nm_000492.3(cftr):c.3293g>a(p.trp1098ter)
nm_000492.3(cftr):c.4144c>t(p.gln1382ter)
nm_000492.3(cftr):c.4231c>t(p.gln1411ter)
nm_000492.3(cftr):c.4234c>t(p.gln1412ter)
nm_000492.3(cftr):c.579+5g>a
nm_000492.3(cftr):c.595c>t(p.his199tyr)
nm_000492.3(cftr):c.613c>t(p.pro205ser)
nm_000492.3(cftr):c.658c>t(p.gln220ter)
nm_000492.3(cftr):c.1117-1g>a
nm_000492.3(cftr):c.3294g>a(p.trp1098ter)
nm_000492.3(cftr):c.1865g>a(p.gly622asp)
nm_000492.3(cftr):c.743+1g>a
nm_000492.3(cftr):c.1679+1g>a
nm_000492.3(cftr):c.1657c>t(p.arg553ter)
nm_000492.3(cftr):c.1675g>a(p.ala559thr)
nm_000492.3(cftr):c.165-1g>a
nm_000492.3(cftr):c.200c>t(p.pro67leu)
nm_000492.3(cftr):c.2834c>t(p.ser945leu)
nm_000492.3(cftr):c.3846g>a(p.trp1282ter)
nm_000492.3(cftr):c.1652g>a(p.gly551asp)
nm_000492.3(cftr):c.4426c>t(p.gln1476ter)
nm_000492.3:c.3718-2477c>t
nm_000492.3(cftr):c.2988+1g>a
nm_000492.3(cftr):c.2657+5g>a
nm_000492.3(cftr):c.2988g>a(p.gln996=)
nm_000492.3(cftr):c.274-1g>a
nm_000492.3(cftr):c.3612g>a(p.trp1204ter)
nm_000492.3(cftr):c.1646g>a(p.ser549asn)
nm_000492.3(cftr):c.3752g>a(p.ser1251asn)
nm_000492.3(cftr):c.4046g>a(p.gly1349asp)
nm_000492.3(cftr):c.532g>a(p.gly178arg)
nm_000492.3(cftr):c.3731g>a(p.gly1244glu)
nm_000492.3(cftr):c.1651g>a(p.gly551ser)
nm_000492.3(cftr):c.1585-1g>a
nm_000492.3(cftr):c.1000c>t(p.arg334trp)
nm_000492.3(cftr):c.254g>a(p.gly85glu)
nm_000492.3(cftr):c.1040g>a(p.arg347his)
nm_000492.3(cftr):c.273+1g>a
参见表a。因此,本发明的一个方面涉及一种用于通过校正一种或多种病原性g至a或c至t突变/snp、特别地存在于cftr基因中的一种或多种病原性g至a或c至t突变/snp、且更特别地以上所述的一种或多种病原性g至a或c至t突变/snp来治疗或预防囊性纤维化的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性2乳腺癌-卵巢癌相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于brca2基因中(hgvs:u43746.1:n.7829+1g>a)。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防家族性2乳腺癌-卵巢癌的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与遗传因子ix缺乏症相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于f9基因中的grch38:chrx:139537145处,导致arg至gln取代。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防遗传因子ix缺乏症的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与β+地中海贫血、β地中海贫血和重型β地中海贫血相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于hbb基因中的grch38:chr11:5226820处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防β+地中海贫血、β地中海贫血和重型β地中海贫血的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与马凡综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于fbn1基因中(ivs2ds,g-a,+1),如yamamoto等人jhumgenet.2000;45(2):115-8所报道的。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防马凡综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与威斯科特-奥尔德里奇综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于was基因的内含子6的位置-1处(ivs6as,g-a,-1),如kwan等人(1995)所报道的。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防威斯科特-奥尔德里奇综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与囊性纤维化相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于cftr基因中的grch38:chr7:117590440处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防囊性纤维化的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与囊性纤维化和遗传性胰腺炎相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于cftr基因中的grch38:chr7:117606754处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防囊性纤维化和遗传性胰腺炎的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与囊性纤维化相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于cftr基因中的grch38:chr7:117587738处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防囊性纤维化的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与透克综合征(turcotsyndrome)和林奇综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于msh2基因中的grch38:chr2:47470964处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防透克综合征和林奇综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与囊性纤维化相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于cftr基因中的grch38:chr7:117642437处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防囊性纤维化的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与林奇综合征ii和林奇综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于mlh1基因中的grch38:chr3:37001058处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防林奇综合征ii和林奇综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与囊性纤维化相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于cftr基因中的grch38:chr7:117642594处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防囊性纤维化的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与囊性纤维化相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于cftr基因中的grch38:chr7:117592658处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防囊性纤维化的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性1乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征以及遗传性癌症易感综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于brca1基因中的grch38:chr17:43057051处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防家族性1乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征以及遗传性癌症易感综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与二氢嘧啶脱氢酶缺乏症、希尔施普龙病1(hirschsprungdisease1)、氟尿嘧啶反应、嘧啶类似物反应-毒性/adr、卡培他滨反应-毒性/adr、氟尿嘧啶反应-毒性/adr、喃氟啶(tegafur)反应-毒性/adr相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于dpyd基因中的grch38:chr1:97450058处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防二氢嘧啶脱氢酶缺乏症、希尔施普龙病1、氟尿嘧啶反应、嘧啶类似物反应-毒性/adr、卡培他滨反应-毒性/adr、氟尿嘧啶反应-毒性/adr、喃氟啶反应-毒性/adr的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与林奇综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于msh2基因中的grch38:chr2:47478520处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防林奇综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与林奇综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于mlh1基因中的grch38:chr3:37011819处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防林奇综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与林奇综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于mlh1基因中的grch38:chr3:37014545处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防林奇综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与林奇综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于mlh1基因中的grch38:chr3:37011867处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防林奇综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与林奇综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于mlh1基因中的grch38:chr3:37025636处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防林奇综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与林奇综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于mlh1基因中的grch38:chr3:37004475处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防林奇综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与林奇综合征和遗传性癌症易感综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于msh2基因中的grch38:chr2:47416430处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防林奇综合征和遗传性癌症易感综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与林奇综合征和遗传性癌症易感综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于msh2基因中的grch38:chr2:47408400处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防林奇综合征和遗传性癌症易感综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与林奇综合征和遗传性癌症易感综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于mlh1基因中的grch38:chr3:36996710处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防林奇综合征和遗传性癌症易感综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性1乳腺癌-卵巢癌相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于brca1基因中的grch38:chr17:43067696处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防家族性1乳腺癌-卵巢癌的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性2乳腺癌-卵巢癌和遗传性乳腺癌及卵巢癌综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于brca2基因中的grch38:chr13:32356610处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防家族性2乳腺癌-卵巢癌和遗传性乳腺癌及卵巢癌综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与原发性扩张型心肌病和原发性家族性肥厚型心肌病相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于myh7基因中的grch38:chr14:23419993处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防原发性扩张型心肌病和原发性家族性肥厚型心肌病的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与原发性家族性肥厚型心肌病、躯干前曲症(camptocormism)和肥厚型心肌病相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于myh7基因中的grch38:chr14:23415225处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防原发性家族性肥厚型心肌病、躯干前曲症和肥厚型心肌病的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性乳腺癌、家族性2乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征以及遗传性癌症易感综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于brca2基因中的grch38:chr13:32357741处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防家族性乳腺癌、家族性2乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征以及遗传性癌症易感综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与原发性扩张型心肌病、肥厚型心肌病、心肌病和左心室肌致密化不全相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于myh7基因中的grch38:chr14:23431584处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防原发性扩张型心肌病、肥厚型心肌病、心肌病和左心室肌致密化不全的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性1乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征以及遗传性癌症易感综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于brca1基因中的grch38:chr17:43067607处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防家族性1乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征以及遗传性癌症易感综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性1乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征、遗传性癌症易感综合征和乳腺癌相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于brca1基因中的grch38:chr17:43047666处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防家族性1乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征、遗传性癌症易感综合征和乳腺癌的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性2乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征以及遗传性癌症易感综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于brca2基因中的grch38:chr13:32370558处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防家族性2乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征以及遗传性癌症易感综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性1乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征、遗传性癌症易感综合征和乳腺癌相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于brca1基因中的grch38:chr17:43074330处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防家族性1乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征、遗传性癌症易感综合征和乳腺癌的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性1乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征以及遗传性癌症易感综合征相关联的病原性a至g(a>g)突变或snp,其中所述病原性a>g突变或snp位于brca1基因中的grch38:chr17:43082403处。因此,本发明的另一方面涉及一种用于通过校正前述病原性a>g突变或snp来治疗或预防家族性1乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征以及遗传性癌症易感综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与囊性纤维化和遗传性胰腺炎相关联的病原性c至t(c>t)突变或snp,其中所述病原性c>t突变或snp位于cftr基因中的grch38:chr7:117639961处。因此,本发明的另一方面涉及一种用于通过校正前述病原性c>t突变或snp来治疗或预防囊性纤维化和遗传性胰腺炎的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性2乳腺癌-卵巢癌相关联的病原性c至t(c>t)突变或snp,其中所述病原性c>t突变或snp位于brca2基因中的grch38:chr13:32336492处。因此,本发明的另一方面涉及一种用于通过校正前述病原性c>t突变或snp来治疗或预防家族性2乳腺癌-卵巢癌的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性1乳腺癌-卵巢癌相关联的病原性c至t(c>t)突变或snp,其中所述病原性c>t突变或snp位于brca1基因中的grch38:chr17:43063365处。因此,本发明的另一方面涉及一种用于通过校正前述病原性c>t突变或snp来治疗或预防家族性1乳腺癌-卵巢癌的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性1乳腺癌-卵巢癌相关联的病原性c至t(c>t)突变或snp,其中所述病原性c>t突变或snp位于brca1基因中的grch38:chr17:43093613处。因此,本发明的另一方面涉及一种用于通过校正前述病原性c>t突变或snp来治疗或预防家族性1乳腺癌-卵巢癌的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性乳腺癌和家族性1乳腺癌-卵巢癌相关联的病原性c至t(c>t)突变或snp,其中所述病原性c>t突变或snp位于brca1基因中的grch38:chr17:43093931处。因此,本发明的另一方面涉及一种用于通过校正前述病原性c>t突变或snp来治疗或预防家族性乳腺癌和家族性1乳腺癌-卵巢癌的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性肥厚型心肌病1、原发性家族性肥厚型心肌病和肥厚型心肌病相关联的病原性c至t(c>t)突变或snp,其中所述病原性c>t突变或snp位于myh7基因中的grch38:chr14:23429279处。因此,本发明的另一方面涉及一种用于通过校正前述病原性c>t突变或snp来治疗或预防家族性肥厚型心肌病1、原发性家族性肥厚型心肌病和肥厚型心肌病的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性2乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征以及遗传性癌症易感综合征相关联的病原性c至t(c>t)突变或snp,其中所述病原性c>t突变或snp位于brca2基因中的grch38:chr13:32356472处。因此,本发明的另一方面涉及一种用于通过校正前述病原性c>t突变或snp来治疗或预防家族性2乳腺癌-卵巢癌、遗传性乳腺癌及卵巢癌综合征以及遗传性癌症易感综合征的方法。
在一些实施方案中,本文所述的方法、系统和组合物用于校正据信与家族性肥厚型心肌病1、原发性家族性肥厚型心肌病、家族性限制型心肌病和肥厚型心肌病相关联的病原性c至t(c>t)突变或snp,其中所述病原性c>t突变或snp位于myh7基因中的grch38:chr14:23429005处。因此,本发明的另一方面涉及一种用于通过校正前述病原性c>t突变或snp来治疗或预防家族性肥厚型心肌病1、原发性家族性肥厚型心肌病、家族性限制型心肌病和肥厚型心肌病的方法。
另外的病原性a>g突变和snp可见于clinvar数据库中并且在表a中列出。因此,本公开的另一方面涉及使用本文所述的方法、系统和组合物对表a中所列的病原性a>g突变或snp进行校正以治疗或预防与其相关联的疾病或疾患。
另外的病原性c>t突变和snp可见于clinvar数据库中并且也在表a中列出。因此,本公开的另一方面涉及使用本文所述的方法、系统和组合物对表a中所列的病原性c>t突变或snp进行校正以治疗或预防与其相关联的疾病或疾患。
另外的实施方案
实施方案1.一种修饰目标靶基因座中的腺嘌呤的方法,所述方法包括向所述基因座递送:(a)cpf1切口酶蛋白;(b)指导分子,所述指导分子包含连接至正向重复序列的指导序列;和(c)腺苷脱氨酶蛋白或其催化结构域;其中所述腺苷脱氨酶蛋白或其催化结构域共价或非共价地连接至所述cpf1切口酶蛋白或所述指导分子,或者适于在递送之后连接至所述cpf1切口酶蛋白或所述指导分子;其中指导分子与所述cpf1切口酶蛋白形成复合物并引导所述复合物结合所述目标靶基因座处的第一dna链,其中所述指导序列能够与所述第一dna链内包含所述腺嘌呤的靶序列杂交以形成异源双链体,其中所述指导序列在对应于所述腺嘌呤的位置处包含非配对胞嘧啶,导致在所形成的异源双链体中出现a-c错配;其中所述cpf1切口酶蛋白使因所述异源双链体形成而移位的所述目标靶基因座处的第二dna链产生切口;并且其中所述腺苷脱氨酶蛋白或其催化结构域使所述异源双链体中的所述腺嘌呤脱氨基。
实施方案2.如实施方案1所述的方法,其中所述腺苷脱氨酶蛋白或其催化结构域融合至所述cpf1切口酶蛋白的n端或c端。
实施方案3.如实施方案2所述的方法,其中所述腺苷脱氨酶蛋白或其催化结构域通过接头融合至所述cpf1切口酶蛋白。
实施方案4.如实施方案3所述的方法,其中所述接头是(ggggs)3-11(seqidno:1-9)、gsg5(seqidno:10)或lepgekpykcpecgksfsqsgaltrhqrthtr(seqidno:11)。
实施方案5.如实施方案1所述的方法,其中所述腺苷脱氨酶蛋白或其催化结构域连接至衔接蛋白,并且所述指导分子或所述cpf1切口酶蛋白包含能够与所述衔接蛋白结合的适体序列。
实施方案6.如实施方案5所述的方法,其中所述衔接序列选自ms2、pp7、qβ、f2、ga、fr、jp501、m12、r17、bz13、jp34、jp500、ku1、m11、mx1、tw18、vk、sp、fi、id2、nl95、tw19、ap205、φcb5、φcb8r、φcb12r、φcb23r、7s和prr1。
实施方案7.如实施方案1所述的方法,其中所述腺苷脱氨酶蛋白或其催化结构域插入到所述cpf1切口酶蛋白的内环中。
实施方案8.如实施方案1-7中任一项所述的方法,其中所述cpf1切口酶蛋白包含在nuc结构域中的突变。
实施方案9.如实施方案8所述的方法,其中所述cpf1切口酶蛋白包含对应于ascpf1中的r1226a的突变。
实施方案10.如实施方案1-7中任一项所述的方法,其中已将所述cpf1切口酶蛋白的至少部分所述nuc结构域去除。
实施方案11.如实施方案1-10中任一项所述的方法,其中所述指导分子结合至所述cpf1切口酶蛋白并且能够与所述靶序列形成约24nt的所述异源双链体。
实施方案12.如实施方案1-10中任一项所述的方法,其中所述指导分子结合至所述cpf1切口酶蛋白并且能够与所述靶序列形成超过24nt的所述异源双链体。
实施方案13.如前述实施方案中任一项所述的方法,其中所述腺苷脱氨酶蛋白或其催化结构域是人类、鱿鱼或果蝇腺苷脱氨酶蛋白或其催化结构域。
实施方案14.如实施方案13所述的方法,其中已对所述腺苷脱氨酶蛋白或其催化结构域进行了修饰以增加针对dna-rna异源双链体的活性。
实施方案15.如实施方案14所述的方法,其中所述腺苷脱氨酶蛋白或其催化结构域是包含突变e488q的突变hadar2d或包含突变e1008q的突变hadar1d。
实施方案16.如实施方案13所述的方法,其中已对所述腺苷脱氨酶蛋白或其催化结构域进行了修饰以减少脱靶效应。
实施方案17.如实施方案16所述的方法,其中所述腺苷脱氨酶蛋白或其催化结构域是包含突变t375g/s、n473d或两者的突变hadar2d,或包含相应突变的突变hadar1d。
实施方案18.如前述实施方案中任一项所述的方法,其中所述cpf1切口酶蛋白和任选地所述腺苷脱氨酶蛋白或其催化结构域包含一个或多个异源核定位信号(nls)。
实施方案19.如前述实施方案中任一项所述的方法,其中所述方法包括确定所述目标靶序列以及选择最有效地使存在于所述靶序列中的所述腺嘌呤脱氨基的所述腺苷脱氨酶蛋白或其催化结构域。
实施方案20.如前述实施方案中任一项所述的方法,其中所述cpf1切口酶蛋白获自来源于选自由以下组成的组的细菌种类的cpf1核酸酶:土拉弗朗西斯菌、易北普雷沃氏菌、毛螺科菌、解蛋白丁酸弧菌、异域菌门菌、帕库氏菌、史密斯氏菌属种、氨基酸球菌属种、毛螺科菌、候选白蚁甲烷支原体、挑剔真杆菌、牛眼莫拉氏菌、稻田氏钩端螺旋体、狗口腔卟啉单胞菌、解糖胨普雷沃氏菌和猕猴卟啉单胞菌、溶糊精琥珀酸弧菌、解糖胨普雷沃氏菌、嗜鳃黄杆菌、孔兹氏创伤球菌、真细菌属种、微基因组菌(罗兹曼菌)、黄杆菌属种、短普雷沃氏菌、山羊莫拉氏菌、口腔拟杆菌、犬嘴卟啉单胞菌、琼氏互养菌、布氏普雷沃氏菌、厌氧弧菌属种、溶纤维丁酸弧菌、候选甲烷嗜甲基菌、丁酸弧菌属种、口腔无芽孢厌氧菌属种、瘤胃假丁酸弧菌和产丁酸菌。
实施方案21.如实施方案20所述的方法,其中所述cpf1切口酶蛋白是fncpf1切口酶并且识别ttn的pam序列,其中n是a/c/g或t,或者所述cpf1切口酶蛋白是pacpf1p、lbcpf1或ascpf1切口酶并且识别tttv的pam序列,其中v是a/c或g。
实施方案22.如实施方案20所述的方法,其中所述cpf1切口酶蛋白已被修饰并且识别改变的pam序列。
实施方案23.如前述实施方案中任一项所述的方法,其中所述目标靶基因座在细胞内。
实施方案24.如实施方案23所述的方法,其中所述细胞是真核细胞。
实施方案25.如实施方案23所述的方法,其中所述细胞是非人类动物细胞。
实施方案26.如实施方案23所述的方法,其中所述细胞是人类细胞。
实施方案27.如实施方案23所述的方法,其中所述细胞是植物细胞。
实施方案28.如前述实施方案中任一项所述的方法,其中所述目标靶基因座在动物体内。
实施方案29.如前述实施方案中任一项所述的方法,其中所述目标靶基因座在植物内部。
实施方案30.如前述实施方案中任一项所述的方法,其中所述目标靶基因座包含在体外dna分子中。
实施方案31.如前述实施方案中任一项所述的方法,其中将所述组分(a)、组分(b)和组分(c)作为核糖核蛋白复合物递送至所述细胞。
实施方案32.如前述实施方案中任一项所述的方法,其中将所述组分(a)、组分(b)和组分(c)作为一种或多种多核苷酸分子递送至所述细胞。
实施方案33.如实施方案32所述的方法,其中所述一种或多种多核苷酸分子包含一种或多种编码组分(a)和/或组分(c)的mrna分子。
实施方案34.如实施方案32所述的方法,其中所述一种或多种多核苷酸分子包含在一种或多种载体内。
实施方案35.如实施方案34所述的方法,其中所述一种或多种多核苷酸分子包含可操作地配置成表达所述cpf1切口酶蛋白、所述指导分子和所述腺苷脱氨酶蛋白或其催化结构域的一个或多个调控元件,任选地其中所述一个或多个调控元件包括诱导型启动子。
实施方案36.如实施方案31-35中任一项所述的方法,其中经由粒子、囊泡或一种或多种病毒载体递送所述一种或多种多核苷酸分子或所述核糖核蛋白复合物。
实施方案37.如实施方案36所述的方法,其中所述粒子包含脂质、糖、金属或蛋白质。
实施方案38.如实施方案37所述的方法,其中所述粒子包含脂质纳米粒子。
实施方案39.如实施方案36所述的方法,其中所述囊泡包含外泌体或脂质体。
实施方案40.如实施方案36所述的方法,其中所述一种或多种病毒载体包含一种或多种腺病毒、一种或多种慢病毒、或一种或多种腺相关病毒。
实施方案41.如前述实施方案中任一项所述的方法,其中所述方法通过操纵目标基因组基因座处的一个或多个靶序列来修饰细胞、细胞系或生物体。
实施方案42.如实施方案41所述的方法,其中在所述目标靶基因座处所述腺嘌呤的所述脱氨补救了由g→a或c→t点突变或病原性snp引起的疾病。
实施方案43.如实施方案42所述的方法,其中所述疾病选自癌症、血友病、β地中海贫血、马凡综合征和威斯科特-奥尔德里奇综合征。
实施方案44.如实施方案41所述的方法,其中在所述目标靶基因座处所述腺嘌呤的所述脱氨使所述靶基因座处的靶基因失活。
实施方案45.一种从如前述实施方案中任一项所述的方法获得的修饰的细胞或所述修饰的细胞的子代,其中所述细胞与未经历所述方法的相应细胞相比,在所述目标靶基因座中包含次黄嘌呤或鸟嘌呤而非所述腺嘌呤。
实施方案46.如实施方案45所述的修饰的细胞或其子代,其中所述细胞是真核细胞。
实施方案47.如实施方案45所述的修饰的细胞或其子代,其中所述细胞是动物细胞。
实施方案48.如实施方案45所述的修饰的细胞或其子代,其中所述细胞是人类细胞。
实施方案49.如实施方案45所述的修饰的细胞或其子代,其中所述细胞是治疗性t细胞。
实施方案50.如实施方案45所述的修饰的细胞或其子代,其中所述细胞是产生抗体的b细胞。
实施方案51.如实施方案45所述的修饰的细胞或其子代,其中所述细胞是植物细胞。
实施方案52.一种非人类动物,所述非人类动物包含如实施方案47所述的修饰的细胞。
实施方案53.一种植物,所述植物包含如实施方案51所述的修饰的细胞。
实施方案54.一种用于细胞疗法的方法,所述方法包括向有需要的患者施用如实施方案45-50中任一项所述的修饰的细胞,其中所述修饰的细胞的存在补救了所述患者的疾病。
实施方案55.一种适用于修饰目标靶基因座中的腺嘌呤的工程化的非天然存在的系统,所述系统包含:包含连接至正向重复序列的指导序列的指导分子,或编码所述指导分子的核苷酸序列;cpf1切口酶蛋白,或编码所述cpf1切口酶蛋白的核苷酸序列;腺苷脱氨酶蛋白或其催化结构域,或编码所述腺苷脱氨酶蛋白或其催化结构域的核苷酸序列;其中所述腺苷脱氨酶蛋白或其催化结构域共价或非共价地连接至所述cpf1切口酶蛋白或所述指导分子,或者适于在递送之后连接至所述cpf1切口酶蛋白或所述指导分子;其中所述指导序列能够与所述靶基因座处第一dna链上包含腺嘌呤的靶序列杂交以形成异源双链体,其中所述指导序列在对应于所述腺嘌呤的位置处包含非配对胞嘧啶,导致在所形成的异源双链体中出现a-c错配;并且其中所述cpf1切口酶蛋白能够使与所述第一dna链互补的第二dna链产生切口。
实施方案56.一种适用于修饰目标靶基因座中的腺嘌呤的工程化的非天然存在的载体系统,所述载体系统包含如实施方案55所述的a)、b)和c)的核苷酸序列。
实施方案57.如实施方案56所述的工程化的非天然存在的载体系统,所述载体系统包含一种或多种载体,所述一种或多种载体包含:第一调控元件,所述第一调控元件可操作地连接至编码包含所述指导序列的所述指导分子的核苷酸序列;第二调控元件,所述第二调控元件可操作地连接至编码所述cpf1切口酶蛋白的核苷酸序列;和编码腺苷脱氨酶蛋白或其催化结构域的核苷酸序列,所述核苷酸序列受所述第一调控元件或所述第二调控元件的控制或者可操作地连接至第三调控元件;其中如果所述编码腺苷脱氨酶蛋白或其催化结构域的核苷酸序列可操作地连接至所述第三调控元件,则所述腺苷脱氨酶蛋白或其催化结构域适于在表达之后连接至所述指导分子或所述cpf1切口酶蛋白;其中组分(a)、组分(b)和组分(c)位于所述系统的相同或不同载体上。
实施方案58.一种包含如实施方案55-57中任一项所述的系统的体外或离体宿主细胞或其子代或者细胞系或其子代。
实施方案59.如实施方案58所述的宿主细胞或其子代或者细胞系或其子代,其中所述细胞是真核细胞。
实施方案60.如实施方案58所述的宿主细胞或其子代或者细胞系或其子代,其中所述细胞是动物细胞。
实施方案61.如实施方案58所述的宿主细胞或其子代或者细胞系或其子代,其中所述细胞是人类细胞。
实施方案62.如实施方案58所述的宿主细胞或其子代或者细胞系或其子代,其中所述细胞是植物细胞。
工作实施例
实施例1
腺嘌呤脱氨酶(ad)典型地使双链rna中特定位点处的腺嘌呤脱氨基。先前的努力已尝试使ad进化以将其底物优选性从dsrna变为dsdna,使得进化的ad可以融合至cpf1,从而在基因组dna上实现rna指导的腺嘌呤脱氨。
一些ad可以在dna-rna异源双链体上实现腺嘌呤脱氨(例如zheng等人,nucleicacidsresearch2017),这一事实提供了利用在非活性cpf1的rna指导的dna结合期间所形成的r-环中在指导rna与其互补dna靶标之间所形成的异源双链体来开发rna指导的ad的独特机会。通过使用无活性的cpf1来募集ad,ad酶随后将作用于rna-dna异源双链体中的腺嘌呤。
在一个实施方案中,使用以下突变来获得无活性的ascpf1:d908a或e993a。为了提高通过ad进行编辑的效率,切口酶cpf1还可以用于使与指导rna不互补的dna链产生切口。对于ascpf1,突变将是r1226a。
用于将ad募集至特定基因座的设计:
1.带有nls标签的无活性或切口酶cpf1在n端或c端融合至ad。使用多种接头,包括诸如gsg5的柔性接头或诸如lepgekpykcpecgksfsqsgaltrhqrthtr(seqidno:78)的较低柔性接头。
2.用诸如ms2结合位点的适体修饰指导rna支架(例如konermann等人,nature2015)。将带有nls标签的ad-ms2结合蛋白融合物与(带有nls标签的无活性或切口酶cpf1)和相应的指导rna共同引入到靶细胞中。
3.将ad插入带有nls标签的无活性或切口酶cpf1的内环中。
rna指导物的设计:
1.设计正常长度的rna指导物(对于ascpf1为24nt)用于靶向目标基因组基因座。
2.使用比典型长度长的rna指导物以在蛋白质指导rna-靶dna复合物之外形成异源双链体。
对于这些rna指导物设计中的每一个,与dna链上腺嘌呤相对的rna碱基将被指定为c而不是u。
ad的选择和设计:
使用了多种ad,每种ad具有不同的活性水平。这些ad包括:
1.人类adar(hadar1、hadar2、hadar3)
2.鱿鱼近海长鳍鱿鱼adar(sqadar2a、sqadar2b)
3.adat(人类adat、果蝇adat)
还可以使用突变以增加adar针对dna-rna异源双链体反应的活性。例如,对于人类adar基因,使用hadar1d(e1008q)或hadar2d(e488q)突变以增加其针对dna-rna靶标的活性。
每种adar具有不同级别的序列情形要求(sequencecontextrequirement)。例如,对于hadar1d(e1008q),tag和aag位点被有效脱氨基,而aat和cac的编辑效率较低,而gaa和gac的编辑效率甚至更低。然而,情形要求因不同的adar而异。
图1中提供了该系统一种型式的示意图。图2至图5中提供了示例性cpf1-ad融合蛋白的氨基酸序列。
实施例2
图6示出了spcas9和ascpf1与huadar2d的融合物。制备了用于a至g转化的ascpf1的四个构建体和spcas9的四个构建体。ascpf1(r1226a)和spcas9(n863a)的切口酶型式在n端或c端与人类adar2(adar)的脱氨酶结构域融合。另外,通过从spcas9去除hnh结构域或从ascpf1中去除nuc结构域以减少adar的空间位阻,生成了缺失构建体。
图7示出了adar融合物的缺失构建体。ascpf1的氨基酸1076至1258被gsgg接头替代,并且spcas9的氨基酸769至918被ggsggs接头替代。
图8示出了adar融合物在hek细胞中的表达。将hek293t细胞用不同的adar融合构建体或hnh/nuc缺失构建体转染,以确认蛋白质表达。转染两天后收获细胞,并使用ripa缓冲液提取蛋白质。使用针对flag(spcas9)或ha(ascpf1)标签的抗体,将5ul细胞裂解物用于蛋白质印迹。
用三种构建体转染hek293t细胞。一种提供了萤光素酶(cluc)mrna靶标,该靶标在限定的位置处具有uag基序(图9,左)。在20nt区域上拼贴tag基序,产生可能被adar2d或多或少地接近的10种靶标(seqidno:85-94)。对于这10种靶标构建体中的每一者,均提供了含有程序性a至g转化的匹配crrna或sgrna(图9,右)(seqidno:95-104)。
收获细胞,使用这些细胞进行ct方案(joung等人,natprotoc.2017)。通过pcr扩增cdna,并通过ngs测序。针对每种adar融合构建体和指导物/靶标组合,进行三至六次技术重复。
具有c端adar融合物的ascpf1表现最佳,(从dna靶标上的pam开始计数)在核苷酸位置18处有高达30%的a至g转化(靶标/指导物#2)(图10,左)。相比之下,spcas9adar融合物未导致超出用仅adar对照物观察的背景的a至g转化(图10,右)。
此外,在hek293细胞中测试了ascpf1-adar2d构建体对人类dnmt1基因的靶向a至gdna碱基编辑。如图11所示,与靶向人类dnmt1基因的grna复合的ascpf1(r1226a)-adar2d和ascpf1(anuc)-adar2d融合构建体各自表现出可检测水平的靶向a至gdna碱基编辑,而wtascpf1和adar2d对照构建体未导致可检测水平的靶向a至gdna碱基编辑。
在本文说明性地描述的实施方案可以在缺少本文未具体公开的任何一种或多种要素、一种或多种限制的情况下实践。因此,例如术语“包含”、“包括”、“含有”等应当被理解为开放性的,而非限制性的。另外,本文所采用的术语和表达被用作描述性术语而非用于限制,并且无意在使用这些术语和表达时排除所示和所描述的特征的任何等效物或其部分,但是应当认识到在所要求保护的技术的范围内可以进行各种修改。另外,短语“基本上由......组成”将被理解为包括具体叙述的那些要素以及不会实质性影响所要求保护的技术的基本和新颖特征的那些附加要素。短语“由......组成”排除未指定的任何要素。
本公开不限于本申请中所描述的特定实施方案。如对于本领域技术人员将显而易见的,在不脱离本公开的精神和范围的情况下可以进行许多修改和变型。除本文列举的那些方法和组合物之外,根据前述描述在本公开范围内的功能上等效的方法和组合物对于本领域技术人员将是显而易见的。这些修改和变型也旨在落入所附权利要求的范围内。本公开仅由所附权利要求的术语以及这些权利要求所享有的等效物的全部范围来限制。应当理解,本公开不限于特定的方法、试剂、化合物组合物或生物系统,它们当然可以变化。还应理解,本文使用的术语仅用于描述特定实施方案的目的,而并非旨在进行限制。
此外,在以马库什组来描述本公开的特征或方面的情况下,本领域技术人员将认识到,由此也以马库什组的任何单独成员或成员的子组来描述本公开。
如本领域技术人员将理解的,出于任何目的和所有目的,特别是就提供书面描述而言,本文公开的所有范围还涵盖其任何和所有可能的子范围及子范围的组合。所列出的任何范围可以容易地被认为充分描述且使得同一范围能够细分为至少相等的二分之一、三分之一、四分之一、五分之一、十分之一等。作为非限制性实例,本文所论述的每个范围可以容易地细分为下三分之一、中三分之一和上三分之一等。如本领域技术人员还将理解的,所有语言诸如“多至”、“至少”、“大于”、“小于”等包括所叙述的数字并且指代可随后细分为以上论述的子范围的范围。最后,如本领域技术人员将理解的,范围包括每个单独成员。
本说明书中引用的所有公布、专利申请、授权专利和其他文献以引用方式并入本文,如同每个单独公布、专利申请、授权专利或其他文献被确切地且单独地指明为以引用方式整体并入。若以引用方式并入的文本中所含的定义与本公开中的定义相抵触,则将其排除。
其他实施方案在以下权利要求中阐述。
- 还没有人留言评论。精彩留言会获得点赞!