一种遍在染色质开放表达元件、重组表达载体、表达系统及其制备方法、应用与流程
本发明涉及一种遍在染色质开放表达元件、重组表达载体、表达系统及其制备方法、应用,属于生物技术领域。
背景技术:
随着基因工程技术的发展,利用基因工程生产的重组蛋白质类的数量和种类不断的增加,并已经成为医药工业的重要部分。哺乳动物细胞由于具备类似于人类细胞的翻译后加工修饰(post-translationalmodifications,ptms)的功能,因此,哺乳动物细胞表达系统是目前药物重组蛋白生产的重要平台。中国仓鼠卵巢(chinesehamsterovary,cho)细胞表达系统和hek293细胞是目前应用最为广泛的一类动物细胞表达系统,其中近70%批准上市的重组药物蛋白、重组抗体是采用cho细胞和hek293细胞生产的。但是哺乳动物细胞表达系统存在重组蛋白表达水平低、高产稳定细胞筛选周期长、细胞培养成本高等缺陷,严重制约着重组蛋白药物的生产。而影响重组蛋白在哺乳动物细胞中表达的因素复杂,表达载体就是其中一个重要因素。
遍在染色质开放元件(ubiquitously-actingchromatinopeningelement,ucoe)是具有组织非特异性显性染色质重塑功能的dna结构域,能使dna不依赖于染色体插入位点,处于转录活性的“开放”状态。第一个ucoe是在tata结合蛋白-蛋白酶体亚单位c5编码蛋白(tata-bindingprotein-proteasomalsubunitc5-encodingprotein,tbp-psmb1)基因的染色体位点中被鉴定的,随后在异质核糖核蛋白a2/b1-异染色质蛋白1hs-γ(heterogeneousnuclearribonucleoproteina2/b1-heterochromatinprotein1hs-gamma,hnrpa2b1-cx3)也发现了ucoe序列。自从ucoe发现以来,已经得到了广泛应用,研究证实在表达载体的启动子之前插入ucoe可以显著提高转基因转录的水平和稳定性,并且有效地保护启动子免受表观遗传沉默。hnrpa2b1-cx3序列为2.6kb无甲基化的cpg片段,另外1.5kb、4.0kb、8.0kb不同大小的ucoe片段都能提高cho细胞中目的蛋白表达(nevillejj,orlandoj,mannk,mccloskeyb,antonioumn.2017.ubiquitouschromatin-openingelements(ucoes):applicationsinbiomanufacturingandgenetherapy.biotechnoladv,35:557~564)。
公布号为cn101260384a的中国发明专利申请公开了具有遍在染色质开放表达元件(ucoe)的聚核苷酸;公布号为cn104531699a的中国发明专利申请公开了一种增强外源基因表达的猪的ucoe调控元件片段。但两项公开的中国发明专利申请中ucoe序列来源于天然的ucoe序列,缺乏对有功能ucoe序列的特征分析,另一方面常用的ucoe元件较大,增加了载体构建难度,另外质粒的转染效率会随着载体的大小的增加而降低,从而限制了ucoe元件在哺乳动物细胞表达系统中的应用。此外,由于缺乏对有功能ucoe序列的分析,导致ucoe元件中没有功能或者有副作用的元件存在,导致ucoe的功能减弱或者增强作用被抵消。
技术实现要素:
本发明的目的是提供一种遍在染色质开放表达元件,该序列可增强哺乳动物表达系统转基因的表达,实现重组蛋白在宿主细胞的高表达。
本发明还提供了上述遍在染色质开放表达元件在提高哺乳动物表达系统中重组蛋白表达水平方面的应用。
本发明还提供了包含上述遍在染色质开放表达元件的重组表达载体及其制备方法。
本发明还提供了包含上述重组表达载体的哺乳动物表达系统及其制备方法。
本发明还提供了上述重组表达载体、哺乳动物表达系统在表达重组蛋白的应用。
为了实现上述目的,本发明所采用的技术方案是:
一种遍在染色质开放表达元件,其核苷酸序列如seqidno.3所示。
本发明中的遍在染色质开放表达元件(ucoe序列)是在分析人ucoe序列(genbankaccessionno.d28877.1)的基础上,删除了hnrpa2b1启动子序列,形成672bp序列,并发现672bp序列存在隐蔽拼接位点,将456、494隐蔽拼接位点进行突变设计合成了一种新型的ucoe元件。与天然ucoe序列相比,本发明的ucoe序列在提高哺乳动物细胞转基因表达水平上效果更为显著。
上述的遍在染色质开放表达元件的应用,所述遍在染色质开放表达元件在提高哺乳动物细胞表达系统中重组蛋白表达水平方面的应用。
优选的,所述哺乳动物细胞表达系统中宿主细胞为cho或hek293细胞。
本发明中的遍在染色质开放表达元件在用于外源蛋白的表达时,外源蛋白的表达量与不含有ucoe片段的系统相比可提高4倍以上,与天然的ucoe序列相比,可以提高1.5倍以上。
重组表达载体,包含上述的遍在染色质开放表达元件;所述遍在染色质开放表达元件位于哺乳动物表达载体表达框的启动子上游。
优选的,所述哺乳动物表达载体为pires-neo载体。
优选的,所述启动子为cmv、sv40、ef-1α、cag中的任意一种。
本发明中的将上述ucoe序列插入哺乳动物细胞表达载体中,将表达载体转染至哺乳动物宿主细胞中,培养哺乳动物细胞,即可得到表达的目的蛋白。
上述的重组表达载体的制备方法,包括:
1)人工合成或pcr扩增获得如seqidno.3所示序列,并引入酶切位点,获得含酶切位点遍在染色质开放表达元件;
2)使用与步骤1)中酶切位点相应的酶酶切哺乳动物表达载体,获得载体骨架片段;
3)将步骤1)的含酶切位点遍在染色质开放表达元件和步骤2)载体骨架片段使用连接酶进行连接,即得。
本发明中的制备方法能够简便、快速的获得包含上述ucoe序列的哺乳动物细胞表达载体。
哺乳动物细胞表达系统,所述哺乳动物细胞表达系统中包含上述的重组表达载体。
上述的哺乳动物细胞表达系统的制备方法,将所述的重组表达载体转染至哺乳动物细胞系中,即得;所述哺乳动物细胞系为cho或hek293细胞。
上述的重组表达载体在表达重组蛋白方面的应用。上述的哺乳动物细胞表达系统在表达重组蛋白方面的应用。
本发明中将上述ucoe序列插入哺乳动物细胞表达载体启动子上游;在ucoe序列插入之前或之后将外源基因克隆插入到表达载体中;将表达载体转染至哺乳动物宿主细胞中,培养哺乳动物细胞,即可得到表达的目的蛋白。
本发明在分析人天然的ucoe序列的基础上,将隐蔽拼接位点进行突变设计合成一种新型ucoe序列,通过构建表达载体,测定该ucoe序列对egfp以及西妥昔抗体表达的影响,表明本发明的ucoe序列可增强哺乳动物表达系统转基因的表达,加有本发明提供的ucoe序列的表达载体在cho细胞中,稳定细胞株的细胞池外源蛋白的表达量能提高4倍以上,能实现重组蛋白在宿主细胞的高效表达。
附图说明
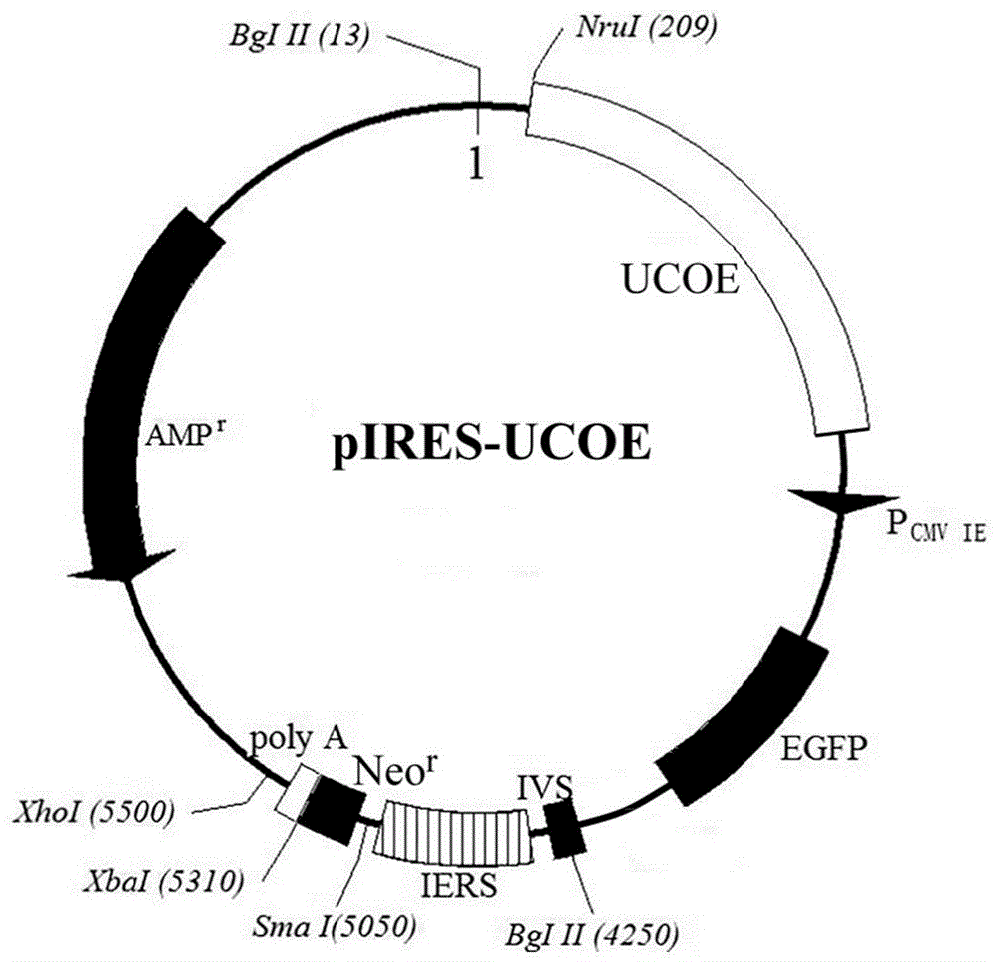
图1为本发明中构建得到的含有ucoe序列的pires-neo质粒结构图;
图2为本发明中试验例1中各组cho细胞池egfp表达水平对比图;
图3为本发明中试验例1中各组hek293细胞池egfp表达水平对比图;
图4为本发明中试验例2中各组cho细胞池西妥昔抗体表达水平对比图;
图5为本发明中试验例2中各组hek293细胞池西妥昔抗体表达水平对比图。
具体实施方式
下述实施例仅对本发明作进一步详细说明,但不构成对本发明的任何限制。实施例及试验例中所用的各类培养基、试剂、大肠杆菌(e.colijm109)pires-neo质粒、细胞系试剂、工具酶等均为市售商品。pires-neo、pegfp-c1质粒购自clontech生物公司。
遍在染色质开放表达元件的实施例1
本实施例中的遍在染色质开放表达元件的序列如seqidno.3所示。
1.5kb(如seqidno.1所示)的a2ucoe序列含有hnrpa2b1启动子,具有双向启动子活性,可能反向启动基因转录,对邻近基因表达产生影响;因此本发明中删除了1.5kb的a2ucoe序列中hnrpa2b1启动子序列,形成672bp序列,如seqidno.2所示,包含cb3基因的2个外显子和1个内含子;如下所示,下划线为第一外显子,斜体为第二外显子,方框内为隐蔽拼接位点。
本发明中通过(http://www.fruitfly.org/seq_tools/other.html)分析表明,在672bp序列存在隐蔽拼接位点,即456~457位置存在供体剪接位点gt,494~495位置存在受体剪接位点序列ag。隐蔽拼接位点影响基因表达,因此本发明进行了隐蔽拼接位点突变,即将seqidno.2所示ucoe序列的456位置序列g突变为t,形成tt;494位置序列a突变为t,形成tg;得到新的序列,如seqidno.3所示。
遍在染色质开放表达元件的应用的实施例1
本实施例中遍在染色质开放表达元件的应用包括:
将上述隐蔽拼接位点突变672bpucoe序列插入哺乳动物细胞表达载体启动子上游;在ucoe序列插入之前或之后将外源基因克隆插入到表达载体中;将表达载体转染至哺乳动物宿主细胞中,培养哺乳动物细胞,即可得到表达的目的蛋白。
重组表达载体及其制备方法的实施例1
cmv启动子上游含有1.5kbucoe序列(如seqidno.1所示)、0.67kb天然ucoe序列(如seqidno.2所示)、隐蔽拼接位点突变0.67kb的ucoe片段(如seqidno.3所示)表达载体的构建。
根据报道的序列(genbankaccessionno.d28877.1),人工合成1.5kbucoe序列(如seqidno.1所示)、0.67kb天然ucoe序列(如seqidno.2所示)、隐蔽拼接位点突变0.67kb的ucoe片段(如seqidno.3所示);5′端和3′端分别引入nrui、mlui酶切位点;具体由通用生物基因(安徽)有限公司完成。
用nrui/mlui分别双酶切合成的ucoe序列序列,同时用nrui/mlui双酶切pires-neo质粒dna载体。琼脂糖凝胶电泳鉴定酶切结果,凝胶回收酶切后的mar序列片段和pires-neo线形质粒dna。
ucoe序列的双酶切体系为:ucoe序列10μl(1μg/μl),10×nebuffer3.13μl,nrui/mlui(10u/μl)各1.0μl,补足水至30μl;酶切条件为:37℃,酶切3min。
pires-neo质粒的双酶切体系为:pires-neo质粒5μl(1μg/μl),10×nebuffer3.12μl,nrui/mlui(10u/μl)各0.5μl,补足水至20μl;酶切条件为:37℃,酶切3min。
取酶切后的ucoe序列片段和pires-neo线形质粒dna(摩尔比5:1),使用neb公司tm的连接试剂盒,25℃连接5min。将连接产物加入到大肠杆菌(e.coli)jm109菌株感受态细胞悬液中转化,取150μl转化菌液接种到含有氨苄青霉素的lb平板上,37℃培养过夜,挑取单菌落继代培养。提取重组质粒并进行双酶切(nrui/mlui)验证,取酶切验证正确的质粒进行测序验证,构建正确的质粒分别命名为pires-ucoe-1.5(包含如seqidno.1所示序列)、pires-ucoe-0.6w(包含如seqidno.2所示序列)、pires-ucoe-0.6m(包含如seqidno.3所示序列)。
重组表达载体的应用的实施例1
本实施例中重组表达载体的应用包括:在ucoe序列插入之前或之后将外源基因克隆插入到上述的重组表达载体中;将重组表达载体转染至哺乳动物宿主细胞中,培养哺乳动物细胞,即可得到表达的目的蛋白。
哺乳动物表达系统及其制备方法的实施例1
本实施例中的哺乳动物表达载体由包括如下步骤的方法制得:
将外源基因克隆插入到上述的表达载体pires-ucoe-0.6m中;将含目的基因的表达载体转染至哺乳动物宿主细胞中,即得。培养哺乳动物细胞,即可得到表达的目的蛋白。
哺乳动物表达系统的应用的实施例1
本实施例中哺乳动物表达系统的应用包括:将含目的基因的表达载体转染至哺乳动物宿主细胞中,培养哺乳动物细胞,即可得到表达的目的蛋白。
试验例1
本试验例中研究ucoe序列对egfp表达的影响
1、含egfp的表达载体的构建
(1)egfp基因扩增
参照pegfp-c1载体的enhancedgreenfluorescentprotein(egfp)基因序列(genbank:u55763.1,第613~1332位碱基)设计引物p1和p2(用于扩增720bp的egfp基因dna),引物的5′端分别引入ecori、bamhi酶切位点,引物序列如下所示(下划线处为酶切位点):
p1:5′-ccggaattcatggtgagcaagggcgaggag-3′(如seqidno.4所示);
p2:5′-ctaggatccggacttgtacagctcgtccatgc-3′(如seqidno.5所示)。
以pegfp-c1质粒(购自美国clontech公司)为模板,使用引物p1、p2扩增egfp基因。pcr反应体系如下表1所示。
表1pcr反应体系
反应程序:95℃3min,94℃40s,56~60℃30s,72℃40s,每个退火温度4个循环,最后55℃1min,30个循环,72℃3min。
琼脂糖凝胶电泳回收pcr扩增产物,纯化后送生物公司测序验证。结果表明,扩增出的dna片段与genbank公开的egfp序列完全一致。
(2)构建含egfp序列的表达载体
用ecori、bamhi双酶切egfp的pcr扩增产物(经测序验证正确的序列),同时用ecori、bamhi双酶切pires-neo2及上述的含1.5kbucoe、0.67kbucoe、突变的0.67kb的ucoe片段的质粒dna。用琼脂糖凝胶电泳鉴定酶切结果,凝胶回收酶切后的egfp序列片段和含mar的线性质粒dna。
egfp序列的酶切体系为:10×mbuffer2μl,10u/μlecori、10u/μlbamhi酶各0.5μl,1.289μg/μlegfp扩增产物0.78μl,补足水至20μl。充分混匀后,37℃孵育6h。
质粒的酶切体系为:10×mbuffer2μl,10u/μlecori、bamhi酶各0.5μl,0.81μg/μl质粒dna1.23μl,补足水至20μl。充分混匀后,37℃孵育3h。
取酶切后的egfp序列片段和线性质粒dna,用t4连接酶进行连接。
连接体系为:2×quickligationbuffer10μl,pires-neo2线性质粒dna200ng,酶切后的egfp序列片段87.2ng,350u/μl的t4连接酶1μl,补足水至20μl,16℃连接过夜。
将连接产物加入大肠杆菌(e.coli)jm109感受态细菌悬液中转化,取100μl转化菌液接种在含有氨苄青霉素的lb固体培养板上,37℃培养过夜,挑取单菌落摇菌继代培养。提取细菌质粒并进行重组质粒的酶切验证,选取酶切鉴定正确的质粒(质粒图谱如图1所示),进行测序验证。
(3)ucoe对转染cho细胞egfp表达的作用
cho细胞于37℃、5%co2条件下,在含10%灭活胎牛血清的dmem/f12培养基中培养。在6孔板内接种cho细胞(3×106/孔)。铺板培养24小时后细胞达到约90%融合度。以lip3000(
试验共分为4组:①对照组-转染不含ucoe的对照载体pires-egfp;②转染含合成1.5kbucoe序列的载体pires-ucoe-1.5;③转染含0.67kbucoe序列的载体pires-ucoe-0.6w;④转染含突变的0.67kb的ucoe序列的载体pires-ucoe-0.6m。48h后在转染孔中加入800μg/ml的g418药物,从第五天开始细胞大量死亡。筛选两周后将g418浓度调整到维持浓度400μg/ml继续培养,用筛选获得的多克隆cho细胞(细胞池)培养30天后,收集各试验组细胞进行流式细胞检测。
结果见图2,由图2可知,与不含ucoe的对照载体pires-egfp相比,含1.5kbucoe序列、0.67kbucoe序列、突变的0.6kb的ucoe的表达载体均能稳定提高egfp基因的稳定表达水平,与不含ucoe相比,egfp表达量分别提高倍数达2.63、3.02、4.65(p<0.05)。
(4)ucoe对转染hek293细胞egfp表达的作用
hek293细胞于37℃、5%co2条件下,在含10%灭活胎牛血清的dmem/f12培养基中培养。选择生长状态良好的hek293细胞接种到6孔培养板上,待铺板密度达到约80%进行转染。具体操作步骤如下:10μllipofectamine2000+240μl无血清freestyletm293expressionmedium,在37℃孵箱中静置5min,将无血清培养基与250μl(5μg)表达载体混合,37℃孵箱中静置20min;同时用pbs将6孔培养板上的细胞清洗三遍,加入2ml无血清细胞培养基;然后将脂质体与质粒dna的混合液逐滴轻滴入孔中,尽快轻轻摇晃培养平板使其混匀;放入5%co2细胞培养箱中。
试验共分为4组:①对照组-转染不含ucoe的对照载体pires-egfp;②转染含合成1.5kbucoe序列的载体pires-ucoe-1.5;③转染含0.67kbucoe序列的载体pires-ucoe-0.6w;④转染含突变的0.67kb的ucoe序列的载体pires-ucoe-0.6m。转染48h后细胞加入600μg/ml的g418药物,每48h换成新鲜完整无血清培养基,从第五天开始细胞大量死亡。筛选两周后将g418浓度调整到维持浓度300μg/ml继续培养。用筛选获得的多克隆hek293细胞(细胞池)培养30天后,收集各试验组细胞进行流式细胞检测。
结果见图3,由图3可知,与不含ucoe的对照载体pires-egfp相比,含1.5kbucoe序列、0.67kbucoe序列、突变的0.67kb的ucoe序列的表达载体均能稳定提高egfp基因的稳定表达水平,egfp表达量分别提高倍数达2.41、2.98、4.12(p<0.05)。
试验例2
本试验例中研究ucoe序列对西妥昔抗体基因表达的影响
1、含西妥昔抗体外源基因表达载体的构建
(1)合成西妥昔抗体基因序列
根据公开号为cn101466404a的中国发明专利申请:抗-egfr的抗体的冻干制剂提供的西妥昔抗体基因序列,人工合成西妥昔抗体基因序列(包含kozak序列和信号肽序列),重链如seqidno.6所示,轻链如seqidno.7所示,5′端和3′端分别引入ecori、bamhi酶切位点,具体由通用生物基因(安徽)有限公司完成。
(2)构建含西妥昔抗体基因序列的表达载体
用ecori/bamhi双酶切引物人工合成的西妥昔抗体重链、轻链基因序列,同时用ecori/bamhi双酶切pires-neo2及上述的含1.5kbucoe序列、0.67kbucoe序列、突变的0.67kb的ucoe序列的质粒dna。
西妥昔序列的双酶切体系为:西妥昔抗体重链基因序列片段或西妥昔抗体轻链基因序列片段10μl(1μg/μl),10×nebuffer2.13μl,ecori/bamhi酶(10u/μl)各1.0μl,补足水至30μl;酶切条件为:37℃,酶切3min。
质粒的双酶切体系为:质粒5μl(1μg/μl),10×nebuffer2.12μl,ecori/bamhi(10u/μl)各0.5μl,补足水至20μl;酶切条件为:37℃,酶切3min。
琼脂糖凝胶电泳鉴定酶切结果,凝胶回收酶切后的西妥昔序列片段和线形质粒dna。
取酶切后的西妥昔抗体重链、轻链基因序列分别和线形质粒dna(摩尔比5:1),使用neb公司tm的连接试剂盒,25℃连接5min。将连接产物加入到大肠杆菌(e.coli)jm109菌株感受态细胞悬液中转化,取150μl转化菌液接种到含有氨苄青霉素的lb平板上,37℃培养过夜,挑取单菌落继代培养。提取重组质粒并进行双酶切(ecori/bamhi)验证,取酶切验证正确的质粒进行测序验证,获得含有西妥昔抗体重链基因序列的质粒和含有西妥昔抗体轻链基因序列的质粒。
(3)ucoe对cho细胞西妥昔抗体表达的作用
cho细胞培养、转染及稳定转染细胞株筛选同试验例1,转染时每组中将含有西妥昔抗体重链基因序列的质粒和含有西妥昔抗体轻链基因序列的质粒同时转染细胞。药物筛选完成后,约两个星期细胞形成稳定细胞池(cellpool),换成无血清的培养基(cdoptichotmmedium,购自gibco公司)继续悬浮培养六天后取细胞上清做elisa检测。
结果如图4所示,利用本发明表达系统的西妥昔表达水平明显高于传统的表达系统,表达载体1.5kbucoe序列、0.67kbucoe序列、突变的0.67kb的ucoe序列质粒dna转染的cho细胞的西妥昔表达量平均为406.34mg/l、509.12mg/l、608.12mg/l,而pires-neo2表达系统的西妥昔表达量仅为136.26mg/l。
(4)ucoe对hek293细胞西妥昔抗体表达的作用
hek293细胞培养、转染及稳定转染细胞株筛选同试验例1,转染时每组中将含有西妥昔抗体重链基因序列的质粒和含有西妥昔抗体轻链基因序列的质粒同时转染细胞。药物筛选完成后,约两个星期细胞形成稳定细胞池(cellpool),换成无血清的培养基(cdoptichotmmedium,购自gibco公司)继续悬浮培养六天后取细胞上清做elisa检测。
结果如图5所示,利用本发明表达系统的西妥昔表达水平明显高于传统的表达系统,表达载体1.5kbucoe序列、0.67kbucoe序列、突变的0.67kb的ucoe序列质粒dna转染的cho细胞的西妥昔表达量平均为507.23mg/l、607.32mg/l、709.23mg/l,而pires-neo2表达系统的西妥昔表达量仅为189.31mg/l。
<110>新乡医学院
<120>一种遍在染色质开放表达元件、重组表达载体、表达系统及其制备方法、应用
<160>7
<170>siposequencelisting1.0
<211>1565
<212>dna
<213>人
<221>1.5kba2ucoe序列
<400>1
ggcgcgcccggccgtccgaggagacgccgtggcccccgaagcagcgtgctttagaaaggg60
aataagaagtcccgcctccgcgccccactttcaccccagcggggcagcgtccgccatgtg120
aaagctccccatcccccacccccagtgaagggaaatggcgccgggaggctgagggtgggg180
aagctgtttgtacgctcaggcctccgctcaagaccccgttcataaaccttaagccccact240
gctactgaattggtccgatttcctgcctctctcccacggaggcggctggccgacttccac300
tgaggcgccaacggcctcgccatgcccttttcaataactcattgatttcaaacccgttac360
ctccatcgcggactcagtcgcttcagcccgatttcccgcagccgagcgagatgagagaga420
tctccgcggacgaacacgaaccggactcgtcctggcgctgtagtgagaactgccgctgct480
ggagaaacaactctgcgaggagcacctccgcacgggacccggcgctgctgctactgccgc540
tagagccgctgccgccgcttttctagaaccttcccccccactaaggcgtcttccgctacg600
tcaggccgtcgcgtaaacgccctatccgccgccaatggcgggaaggctctacgccccacc660
ttacgccaaatgcgtactcctcccacccttgcggccagagacagtacccgacgttacttc720
cgtaaatgcgctcaatgaattgcggaaggctagagtcctgctagttactacctcttggaa780
tagggtcccggcccctgccttggcgaaggcaggtgagaaacgtcgcgcagtttgaaatta840
acgccgacgggaggggcttaatccgcagcctggagatccagccccctcaacccgggaggt900
ggtccctgcagttacgccaatgataacccccgccagaaaaatcttagtagccttcccttt960
ttgttttccgtgccccaactcggcggattgactcggccccttccggaaacacccgaatca1020
acttctagtcaaattattgttcacgccgcaatgacccacccctggcccgcgtctgtggaa1080
ctgacccctggtgtacaggagagttcgctgctgaaagtggtcccaaaggggtactagttt1140
ttaagctcccaactccccctcccccagcgtctggaggattccacaccctcgcaccggcgg1200
gcgaggaagtgggcggagtccggttttggcgccagccgctgaggctgccaagcagaaaag1260
ccaccgctgaggagactccggtcactgtcctcgccccgcctcccccttccctccccttgg1320
ggaccaccgggcgccacgccgcgaacggtaagtgccgcggtcgtcggcgcctccgccctc1380
cccctagggccccaattcccagcgggcgcggcgccggcccctccccccgccgcgcgcgcg1440
cccgctgccccgcccttcgtggccgcccggcgtgggcggtgccacccctccccccggcgg1500
ccccgcgcgcagctcccggctccctcccccttcggatgtggcttgagctgtaggcgcgga1560
gggcc1565
<211>672
<212>dna
<213>人工序列
<221>0.6kbucoe序列
<400>2
gggaggtggtccctgcagttacgccaatgataacccccgccagaaaaatcttagtagcct60
tccctttttgttttccgtgccccaactcggcggattgactcggccccttccggaaacacc120
cgaatcaacttctagtcaaattattgttcacgccgcaatgacccacccctggcccgcgtc180
tgtggaactgacccctggtgtacaggagagttcgctgctgaaagtggtcccaaaggggta240
ctagtttttaagctcccaactccccctcccccagcgtctggaggattccacaccctcgca300
ccggcgggcgaggaagtgggcggagtccggttttggcgccagccgctgaggctgccaagc360
agaaaagccaccgctgaggagactccggtcactgtcctcgccccgcctcccccttccctc420
cccttggggaccaccgggcgccacgccgcgaacgttaagtgccgcggtcgtcggcgcctc480
cgccctcccccttgggccccaattcccagcgggcgcggcgccggcccctccccccgccgc540
gcgcgcgcccgctgccccgcccttcgtggccgcccggcgtgggcggtgccacccctcccc600
ccggcggccccgcgcgcagctcccggctccctcccccttcggatgtggcttgagctgtag660
gcgcggagggcc672
<211>672
<212>dna
<213>人工序列
<221>隐蔽拼接位点突变ucoe序列
<400>3
gggaggtggtccctgcagttacgccaatgataacccccgccagaaaaatcttagtagcct60
tccctttttgttttccgtgccccaactcggcggattgactcggccccttccggaaacacc120
cgaatcaacttctagtcaaattattgttcacgccgcaatgacccacccctggcccgcgtc180
tgtggaactgacccctggtgtacaggagagttcgctgctgaaagtggtcccaaaggggta240
ctagtttttaagctcccaactccccctcccccagcgtctggaggattccacaccctcgca300
ccggcgggcgaggaagtgggcggagtccggttttggcgccagccgctgaggctgccaagc360
agaaaagccaccgctgaggagactccggtcactgtcctcgccccgcctcccccttccctc420
cccttggggaccaccgggcgccacgccgcgaacggtaagtgccgcggtcgtcggcgcctc480
cgccctccccctagggccccaattcccagcgggcgcggcgccggcccctccccccgccgc540
gcgcgcgcccgctgccccgcccttcgtggccgcccggcgtgggcggtgccacccctcccc600
ccggcggccccgcgcgcagctcccggctccctcccccttcggatgtggcttgagctgtag660
gcgcggagggcc672
<211>30
<212>dna
<213>人工序列
<221>p1
<400>4
ccggaattcatggtgagcaagggcgaggag30
<211>32
<212>dna
<213>人工序列
<221>p2
<400>5
ctaggatccggacttgtacagctcgtccatgc32
<211>1431
<212>dna
<213>人工序列
<221>西妥昔抗体重链基因序列
<400>6
gaattcgccgccaccatggattttcaggtgcagattttcagcttcctgctaatcagtgcc60
tcagtcataatatccagaggacaggtgcagctgaagcagtcaggacctggcctagtgcag120
ccctcacagagcctgtccatcacctgcacagtctctggtttctcattaactaactatggt180
gtacactgggttcgccagtctccaggaaagggtctggagtggctgggagtgatatggagt240
ggtggaaacacagactataatacacctttcacatccagactgagcatcaacaaggacaat300
tccaagagccaagttttctttaaaatgaacagtctgcaatctaatgacacagccatatat360
tactgtgccagagccctcacctactatgattacgagtttgcttactggggccaagggact420
ctggtcactgtctctgcagctagcaccaagggcccatcggtcttccccctggcaccctcc480
tccaagagcacctctgggggcacagcggccctgggctgcctggtcaaggactacttcccc540
gaaccggtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccg600
gctgtcctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagc660
agcttgggcacccagacctacatctgcaacgtgaatcacaagcccagcaacaccaaggtg720
gacaagagagttgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagca780
cctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctc840
atgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccct900
gaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccg960
cgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccag1020
gactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagccccc1080
atcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctg1140
cccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggc1200
ttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactac1260
aagaccacgcctcccgtgctggactccgacggctccttcttcctctatagcaagctcacc1320
gtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggct1380
ctgcacaaccactacacgcagaagagcctctccctgtccccgggtaaatga1431
<211>726
<212>dna
<213>人工序列
<221>西妥昔抗体轻链基因序列
<400>7
gaattcgccgccaccatggattttcaggtgcagattttcagcttcctgctaatcagtgcc60
tcagtcataatatccagaggagacatcttgctgactcagtctccagtcatcctgtctgtg120
agtccaggagaaagagtcagtttctcctgcagggccagtcagagtattggcacaaacata180
cactggtatcagcaaagaacaaatggttctccaaggcttctcataaagtatgcttctgag240
tctatctctgggatcccttccaggtttagtggcagtggatcagggacagattttactctt300
agcatcaacagtgtggagtctgaagatattgcagattattactgtcaacaaaataataac360
tggccaaccacgttcggtgctgggaccaagctggagctgaaacgaactgtggctgcacca420
tctgtcttcatcttcccgccatctgatgagcagttgaaatctggaactgcctctgttgtg480
tgcctgctgaataacttctatcccagagaggccaaagtacagtggaaggtggataacgcc540
ctccaatcgggtaactcccaggagagtgtcacagagcaggacagcaaggacagcacctac600
agcctcagcagcaccctgacgctgagcaaagcagactacgagaaacacaaagtctacgcc660
tgcgaagtcacccatcagggcctgagctcgcccgtcacaaagagcttcaacaggggagag720
tgttag726
- 还没有人留言评论。精彩留言会获得点赞!