智能网联混合动力汽车的鲁棒能量管理方法及系统与流程
本发明涉及汽车动力技术领域,尤其涉及智能网联混合动力汽车的鲁棒能量管理方法及系统。
背景技术:
近年来,基于深度强化学习的混合动力能量管理策略获得了广泛研究,并与基于规则和最优控制理论的策略进行对比,证明了其优越性。该策略通过大量训练,并结合智能网联信息,能够实现较优的燃油经济性和排放性能。
基于深度强化学习的混合动力能量管理策略,目前仍停留在理论阶段,主要原因在于鲁棒性问题。由于实际工况的复杂性和不确定性,离线标定和训练过程难以体现全部真实工况;同时,训练模型中存在未建模的动态特征,因此其实际控制过程中往往存在导致电池过充、过放电,造成系统崩溃的现象,因此尚不具备工业应用的可行性。如何保证深度强化学习能量管理策略的系统鲁棒性,是该研究领域亟待突破的核心技术。
技术实现要素:
本发明提供智能网联混合动力汽车的鲁棒能量管理方法及系统,用以解决现有技术中存在的缺陷。
第一方面,本发明提供智能网联混合动力汽车的鲁棒能量管理方法,包括:
获取基于人机协同的节能驾驶决策和基于智能网联的全局和实时工况更新;
基于所述节能驾驶决策和所述全局和实时工况更新,执行基于深度强化学习的能量管理策略;
对所述基于深度强化学习的能量管理策略采用策略鲁棒性修正,得到修正后的鲁棒控制策略;
将所述修正后的鲁棒控制策略应用于混合动力汽车,得到所述混合动力汽车的能量分配结果。
进一步地,所述获取基于人机协同的节能驾驶决策和基于智能网联的全局和实时工况更新,具体包括:
获取驾驶员驾驶意图,根据所述驾驶员驾驶意图判断开启的驾驶模式,由所述驾驶模式获取速度需求和转矩需求,基于所述速度需求和所述转矩需求得到车辆速度给定和车辆加速度给定;
基于智能网联数据,预测车辆从出发地到目的地的全程工况以及短期实时工况;采用动态规划算法求解所述全程工况的最优soc参考轨迹,并采用滚动时域定时更新所述最优soc参考轨迹;将所述短期实时工况采用0和1的逻辑进行描述,0代表前方路况拥堵,1代表前方路况畅通。将定时更新的soc参考轨迹以及定时更新的短期实时工况输出给所述基于深度强化学习的能量管理策略。
进一步地,所述基于所述节能驾驶决策和所述全局和实时工况更新,执行基于深度强化学习的能量管理策略,具体包括:
获取所述车辆速度给定、所述车辆加速度给定、所述定时更新的soc参考轨迹、所述定时更新的短期实时工况、soc实际值反馈和发动机工作点与高效区的偏离程度;
将所述车辆速度给定、所述车辆加速度给定、所述短期实时工况、所述soc参考轨迹与soc实际值反馈的差值以及所述发动机工作点与高效区的偏离程度作为状态变量;
将发动机输出功率给定作为动作变量;
将第一预设倍数的燃油消耗量加上第二预设倍数的所述soc参考轨迹和soc实际值反馈的差值的平方,作为奖励函数;
基于所述状态变量、所述动作变量和所述奖励函数对深度q网络模型进行训练,获得所述基于深度强化学习的能量管理策略。
进一步地,所述对所述基于深度强化学习的能量管理策略采用策略鲁棒性修正,得到修正后的鲁棒控制策略,具体包括:
采用基于模型预测的策略鲁棒性修正方法,并基于动力电池组sop估计得到的发动机功率约束条件,对所述基于深度强化学习的能量管理策略进行修正,其中,所述基于模型预测的策略鲁棒性修正方法包括在神经网络外部进行修正,或在神经网络内部进行修正;
或基于强化学习的策略鲁棒性修正方法,对所述基于深度强化学习的能量管理策略进行修正。
进一步地,所述在神经网络外部进行修正,具体包括:
若判断获知所述鲁棒能量管理策略满足所述发动机功率约束条件,则直接输出所述鲁棒能量管理策略;
若判断获知所述鲁棒能量管理策略不满足所述发动机功率约束条件,则进行约束条件边界判断,当所述鲁棒能量管理策略给出的发动机输出功率超过所述发动机功率约束条件的上边界,则取值为所述上边界,否则取值为所述发动机功率约束条件的下边界。
进一步地,所述在神经网络内部进行修正,具体包括:
在深度q网络模型的隐藏层之后,输出层softmax之前的位置加入deactivation约束矩阵;
基于所述发动机功率约束条件,实时更新所述deactivation约束矩阵,将神经网络中的部分神经元失活,从而将不满足所述发动机功率约束条件的发动机功率输出动作进行剔除。
进一步地,所述动力电池组sop估计,具体包括:
获取采用预设数量的rc元件串联欧姆电阻的等效电路模型;
基于所述等效电路模型获得预设时间段内的电池充电电压、电池放电电压、极限充电电流和极限放电电流;
由所述电池充电电压乘以所述极限充电电流得到最大充电功率,由所述电池放电电压乘以所述极限放电电流得到最大放电功率。
进一步地,所述基于强化学习的策略鲁棒性修正方法,对所述基于深度强化学习的能量管理策略进行修正,具体包括:
基于有限状态机方法,获取若干车辆能量管理模式,制定基于逻辑规则的能量管理方法,得到基于有限状态机的规则逻辑策略;
将基于深度强化学习的智能控制策略与所述基于有限状态机的规则逻辑策略进行结合,采用q学习的方法进行两种策略的切换。
第二方面,本发明还提供智能网联混合动力汽车的鲁棒能量管理系统,包括:
获取模块,用于获取基于人机协同的节能驾驶决策和基于智能网联的全局和实时工况更新;
策略模块,用于基于所述节能驾驶决策和所述全局和实时工况更新,执行基于深度强化学习的能量管理策略;
修正模块,用于对所述基于深度强化学习的能量管理策略采用策略鲁棒性修正,得到修正后的鲁棒控制策略;
分配模块,用于将所述修正后的鲁棒控制策略应用于混合动力汽车,得到所述混合动力汽车的能量分配结果。
第三方面,本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述智能网联混合动力汽车的鲁棒能量管理方法的步骤。
第四方面,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述智能网联混合动力汽车的鲁棒能量管理方法的步骤。
本发明提供的智能网联混合动力汽车的鲁棒能量管理方法及系统,通过提出的智能网联混合动力汽车的鲁棒能量管理方法,有效解决了深度强化学习能量管理策略的鲁棒性问题,并提升了网联环境下混合动力汽车的节能效果,具有较好的工程应用价值。
附图说明
为了更清楚地说明本发明或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
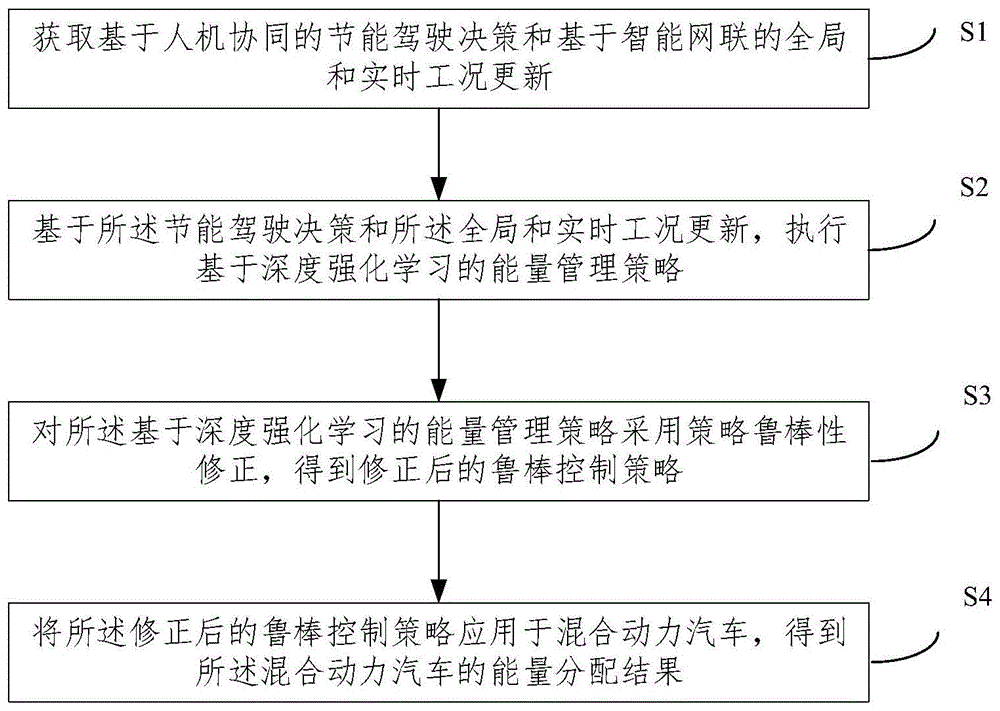
图1是本发明提供的智能网联混合动力汽车的鲁棒能量管理方法的流程示意图;
图2是本发明提供的系统整体框架示意图;
图3是本发明提供的人机协同的节能驾驶模块示意图;
图4是本发明提供的基于深度强化学习的能量管理策略框架示意图;
图5是本发明提供的基于dqn的能量管理策略训练流程示意图;
图6是本发明提供的神经网络外部修正实施例示意图;
图7是本发明提供的神经网络内部修正实施例示意图;
图8是本发明提供的神经网络的内部修正结构示意图;
图9是本发明提供的用于sop估计的一阶rc等效电路图;
图10是本发明提供的基于强化学习的鲁棒能量管理策略实施例示意图:
图11是本发明提供的在插电式混合动力汽车上的应用效果图;
图12是本发明提供的智能网联混合动力汽车的鲁棒能量管理系统的结构示意图;
图13是本发明提供的电子设备的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明针对现有技术中针对深度强化学习控制策略鲁棒性不足的问题,提出了一种智能网联混合动力汽车的鲁棒能量管理方法,如图1所示,包括:
s1,获取基于人机协同的节能驾驶决策和基于智能网联的全局和实时工况更新;
s2,基于所述节能驾驶决策和所述全局和实时工况更新,执行基于深度强化学习的能量管理策略;
s3,对所述基于深度强化学习的能量管理策略采用策略鲁棒性修正,得到修正后的鲁棒控制策略;
s4,将所述修正后的鲁棒控制策略应用于混合动力汽车,得到所述混合动力汽车的能量分配结果。
具体地,如图2的整体框架流程示意,包括人机协同的节能驾驶决策,基于该决策获得速度、转矩需求,结合基于智能网联的全局和实时soc规划以及混合动力汽车的状态反馈,构建状态变量;基于深度强化学习的能量管理策略根据当前的状态选择动作,经过策略鲁棒性修正环节,输出鲁棒控制策略进行混合动力汽车的能量流分配;最后给出了基于模型预测的,以及基于强化学习的两种策略鲁棒性修正方法。
此处,各个子策略的关系和算法流程具体为:第一步,基于人机协同的节能驾驶决策以及车辆状态反馈,获得速度、转矩需求,基于此可以计算车辆速度给定、加速度给定;根据智能网联的全局和实时工况预测,利用动态规划算法求解最优的soc参考轨迹,并将短期实时工况采用数学逻辑进行描述;结合混合动力汽车的状态反馈,获得发动机转速和转矩(进而根据发动机map得到当前发动机bsfc或效率)以及电池实际soc。
第二步,将整车作为环境,训练基于深度强化学习算法(如dqn、ddpg、a3c和ppo等)的能量管理智能体,具体包括:状态变量的定义为:车辆速度给定、加速度给定、短期实时工况、soc参考轨迹与电池实际soc的差值、发动机工作点与高效区的偏离程度;动作变量的定义为:发动机输出功率给定;奖励函数定义为:a倍的燃油消耗量+b倍的soc参考轨迹与电池实际soc差值的平方,即reward=-(a(fuel_con)+b(soc-soc_ref)2)。
第三步,将基于深度强化学习训练好的能量管理智能体(神经网络)用于混合动力汽车的能量管理控制,即把实时的状态变量作为智能体(神经网络)的输入,智能体根据当前状态选择动作,给定发动机的输出功率。
第四步,由于基于深度强化学习获得的智能体(神经网络)控制策略的鲁棒性不足,本发明提出了策略的鲁棒性修正环节,即对发动机输出功率的修正,以保证动力电池不会出现过冲、过放电的情况,后续实施例将给出基于模型预测的,以及基于强化学习的两种策略鲁棒性修正方法。
最后,将修正后获得的鲁棒控制策略,用于混合动力汽车的能量管理,重复上述过程,直至抵达目的地。
本发明通过提出的智能网联混合动力汽车的鲁棒能量管理方法,有效解决了深度强化学习能量管理策略的鲁棒性问题,并提升了网联环境下混合动力汽车的节能效果,具有较好的工程应用价值。
基于上述实施例,该方法中步骤s1具体包括:
获取驾驶员驾驶意图,根据所述驾驶员驾驶意图判断开启的驾驶模式,由所述驾驶模式获取速度需求和转矩需求,基于所述速度需求和所述转矩需求得到车辆速度给定和车辆加速度给定;
基于智能网联数据,预测车辆从出发地到目的地的全程工况以及短期实时工况;采用动态规划算法求解所述全程工况的最优soc参考轨迹,并采用滚动时域定时更新所述最优soc参考轨迹;将所述短期实时工况采用0和1的逻辑进行描述,0代表前方路况拥堵,1代表前方路况畅通,将定时更新的soc参考轨迹以及定时更新的短期实时工况输出给所述基于深度强化学习的能量管理策略。
具体地,如图3所示,程序一开始,首先进行驾驶员意图判断,判断驾驶员是否希望启动辅助节能驾驶模式。如果判断是,则基于车载摄像头、毫米波雷达、激光雷达等设备采集短期实时路况信息,基于端到端的深度学习方法对路况信息进行处理,输出经济性最优的驾驶行为,即对驾驶员油门踏板给定进行修正,输出经济性最优的转矩给定;如果判断否,即表明驾驶员追求激进的驾驶模式,则直接依据油门踏板信号进行转矩查表,输出驾驶员给定的需求转矩。根据车辆反馈的车速,结合转矩给定,最终该人机协同的节能驾驶决策模块的输出为速度和转矩需求。
进一步地,智能网联信息处理(基于智能网联的全局和实时工况定时更新)流程如下:基于车联网数据、交通灯信号、车载gps高精度地图、gis地理信息系统、充电站位置(对于插电式混合动力),预测出车辆从出发地到目的地的全程工况(速度曲线)以及短期实时工况。利用动态规划算法求解最优的soc参考轨迹,以上过程采用滚动时域进行计算,每180s(或其它)将更新的soc参考轨迹输出给基于深度强化学习的能量管理策略。将短期实时工况采用0,1逻辑进行描述,0代表前方路况拥堵,1代表前方路况畅通,以上过程同样采用滚动时域进行计算,每15s(或其它)将更新的短期实时工况信息输出给基于深度强化学习的能量管理策略。
本发明采用的人机协同的节能驾驶决策部分,具有一定的灵活性;基于智能网联的全局和实时工况定时更新,实现了对智能网联全局和实时信息的利用。
基于上述任一实施例,该方法中步骤s2具体包括:
获取所述车辆速度给定、所述车辆加速度给定、所述定时更新的短期实时工况、所述定时更新的soc参考轨迹、soc实际值反馈和发动机工作点与高效区的偏离程度;
将所述车辆速度给定、所述车辆加速度给定、所述定时更新的短期实时工况、所述soc参考轨迹和soc实际值反馈的差值以及所述发动机工作点与高效区的偏离程度作为状态变量;
将发动机输出功率给定作为动作变量;
将第一预设倍数的燃油消耗量加上第二预设倍数的所述soc参考轨迹和soc实际值反馈的差值的平方,作为奖励函数;
基于所述状态变量、所述动作变量和所述奖励函数对深度q网络模型进行训练,获得所述基于深度强化学习的能量管理策略。
具体地,在前述实施例的基础上,如图4所示,基于深度强化学习的能量管理策略流程如下:输入包括基于人机协同的节能驾驶决策模块输出的车辆速度给定、加速度给定,基于智能网联的全局和实时工况更新模块输出的短期实时工况定时更新、soc参考轨迹定时更新,以及混合动力汽车的soc实际值反馈、发动机工作点与高效区的偏离程度。将速度给定、加速度给定、所述定时更新的短期实时工况、soc参考与实际值之差、发动机工作点与高效区的偏离程度,作为状态变量。输入到深度q网络中,输出动作为发动机输出功率给定。该能量管理策略(智能体)的训练方法如下:将整车作为环境,训练基于深度强化学习算法(如dqn、ddpg、a3c、ppo等)的能量管理智能体。其中状态变量的定义为:车辆速度给定、加速度给定、所述定时更新的短期实时工况、soc参考轨迹与电池实际soc的差值、发动机工作点与高效区的偏离程度;动作变量的定义为:发动机输出功率给定;奖励函数定义为:a倍的燃油消耗量+b倍的soc参考轨迹与电池实际soc差值的平方,即reward=-(a(fuel_con)+b(soc-soc_ref)2)。其中dqn算法实施例的框架如下,也可采用其他算法框架,如ddpg、a3c、ppo等:
首先是建立dqn框架,本发明的dqn算法采用了两个神经网络,分别是当前值q网络和目标值
式中:q为智能体动作at的期望价值函数,即在状态st下执行at动作预计获得的价值,rt为实际价值,t为时间步,α为学习率,γ为对未来潜在奖励的衰减率。
dqn的损失函数定义为当前值q网络和目标值
在不损失经验多样性的前提下优先使用具有较大回报的经验,进一步提高经验数据的利用率,引入了排序优先经验回放算法。定义时序误差δ(t)、经验优先级pt和采样概率p(t)如下:
pt=1/rank(t)(4)
式中:rank(t)为时序误差按绝对值由大到小排序后的序号。n为记忆存储空间的大小,β为控制优先采样的程度,取值为[0,1],当β=0时表示均匀采样。
混合动力系统作为环境,与能量管理智能体进行交互,反馈给智能体的状态信息包括电池soc实际值与参考值之差soc_diff、车辆加速度acc、车速v以及发动机工况点与高效区的偏离程度σ。由此定义混合动力系统模型的状态空间,如式(6)所示:
s=[soc_difft,acct,vt,σt](6)
其中,soc_difft定义如式(7)所示,σt的定义如式(8)所示,bsfct为t时刻的燃油消耗率,bsfcmin为发动机最小燃油消耗率:
soc_difft=soc_realt-soc_reft(7)
σt=(bsfct-bsfcmin)/bsfcmin(8)
能量管理策略核心是对发动机输出功率的优化。当智能体收到环境的状态反馈时,需在动作空间a中选择一个动作,即对发动机的功率pice进行调整。其中,对输出功率调整被定义为每秒功率的变化量,并进行了离散化。其中输出功率增量的上、下限分别设为5kw/s和-10kw/s(也可为其他值),以减小对系统的冲击。能量管理策略的动作空间如式(9)所示:
a=[δpice](9)
式中:pice表示对发动机输出功率的调整,单位为kw,其定义分别如式(10)所示:
δpice={0,±1,±2,±5,-10}(10)
能量管理的初衷是提高燃油经济性,因此油耗被纳入奖励函数中。此外,还需要维持电池soc与全局最优的soc参考轨迹一致,因此在奖励函数中加入了电池soc实际值与其参考值之差soc_diff的平方项。由于以上两者均为对系统产生不利影响的指标,因此在定义奖励函数时,均设置为惩罚系数,即设为负值,惩罚权重分别用a、b表示,如式(11)所示:
r=-(a(fuel_cont)+b(soc_difft)2)(11)
式中:r为奖励,fuel_cont为动作at持续时间内的燃油消耗量,soc_diff为电池soc实际值与参考值之差。
整体的算法流程如图5所示,提出了基于dqn算法的混合动力能量管理策略,完整的算法如表1(dqn算法伪代码)所示。
表1
本发明对于基于深度强化学习的能量管理策略,引入状态空间、动作空间和奖励函数进行模型训练,特别是对车辆速度给定、加速度给定、所述定时更新的短期实时工况、soc参考轨迹与电池实际soc的差值和发动机工作点与高效区的偏离程度的状态变量的应用,输出为能量管理策略,实现对发动机、电池输出功率的分配,结合混合动力汽车的动态协调控制达到节能减排效果。
基于上述任一实施例,该方法中步骤s3具体包括:
采用基于模型预测的策略鲁棒性修正方法,并基于动力电池组sop估计得到的发动机功率约束条件,对所述基于深度强化学习的能量管理策略进行修正,其中,所述基于模型预测的策略鲁棒性修正方法包括在神经网络外部进行修正,或在神经网络内部进行修正;
或基于强化学习的策略鲁棒性修正方法,对所述鲁棒能量管理策略进行修正。
其中,所述在神经网络外部进行修正,具体包括:
若判断获知所述鲁棒能量管理策略满足所述发动机功率约束条件,则直接输出所述鲁棒能量管理策略;
若判断获知所述鲁棒能量管理策略不满足所述发动机功率约束条件,则进行约束条件边界判断,当所述鲁棒能量管理策略给出的发动机输出功率超过所述发动机功率约束条件的上边界,则取值为所述上边界,否则取值为所述发动机功率约束条件的下边界。
其中,所述在神经网络内部进行修正,具体包括:
在深度q网络模型的隐藏层之后,输出层softmax之前的位置加入deactivation约束矩阵;
基于所述发动机功率约束条件,实时更新所述deactivation约束矩阵,将神经网络中的部分神经元失活,从而将不满足所述发动机功率约束条件的发动机功率输出动作进行剔除。
其中,所述动力电池组sop估计,具体包括:
获取采用预设数量的rc元件串联欧姆电阻的等效电路模型;
基于所述等效电路模型获得预设时间段内的电池充电电压、电池放电电压、极限充电电流和极限放电电流;
由所述电池充电电压乘以所述极限充电电流得到最大充电功率,由所述电池放电电压乘以所述极限放电电流得到最大放电功率。
其中,所述基于强化学习的策略鲁棒性修正方法,对所述基于深度强化学习的能量管理策略进行修正,具体包括:
基于有限状态机方法,获取若干车辆能量管理模式,制定基于逻辑规则的能量管理方法,得到基于有限状态机的规则逻辑策略;
将基于深度强化学习的智能控制策略与所述基于有限状态机的规则逻辑策略进行结合,采用q学习的方法进行两种策略的切换。
具体地,为了解决能量管理策略鲁棒性差的问题,需对深度q网络能量管理策略输出的动作进行修正。
本发明采用两种修正方法,一种是基于模型预测的修正方法,另一种是基于强化学习的修正方法,具体如下:
对于基于模型预测的策略鲁棒性修正方法,其核心是基于对动力电池组的sop估计,即对最大充电功率pcharge和最大放电功率pdischarge的预测,由此计算发动机需提供的功率范围。将此作为深度q网络能量管理策略所输出动作(发动机输出功率)的约束条件,对策略输出的发动机功率进行修正。此处,分为在神经网络外部进行修正和在神经网络内部进行修正两种方法:
如图6所示的在神经网络外部进行修正方法,如果策略输出的动作满足约束条件,则直接输出原策略;如果策略输出的动作不满足上述发动机功率约束条件,则进行进一步判断,若策略给出的发动机输出功率超出约束条件的上边界,则取上边界,否则取约束条件的下边界。经上述约束条件修正后所输出的动作,就是鲁棒能量管理策略。将其作为发动机功率给定,用于混合动力汽车动力系统的动态协调控制。
如图7所示的在神经网络内部进行修正方法,在神经网络隐藏层之后,输出层softmax之前的位置,加入一个deactivation约束矩阵。该矩阵是一个由0,1组成的系数矩阵,能够将神经网络中的部分神经元失活,从而将不满足约束条件的发动机功率输出值剔除。依据由sop估计获得的发动机功率约束条件,实时更新deactivation约束矩阵,将不满足约束条件的发动机功率输出动作剔除,实现在神经网络内部对输出动作值的修正。经上述deactivation矩阵修正后所输出的策略,即为鲁棒能量管理策略。将其作为发动机功率给定,用于混合动力汽车动力系统的动态协调控制。神经网络的内部修正结构如图8所示。
进一步地,对于动力电池组sop的估计,即对最大充电功率pcharge和最大放电功率pdischarge的预测方法:是将soc的反馈值作为输入,利用低阶rc等效电路并结合截止电压进行判断。其预测具体流程如下:锂离子电池的可用功率(充、放电功率)需要考虑电池电压、soc以及电流的限制,对于采用有限数目rc元件串联欧姆电阻的等效电路模型,本发明采用一阶rc等效电路,如图9所示,其具体预测步骤如下:
某一时间段δt的电池充电电压vcharge(δt)和放电电压vdischarge(δt)可通过下式(12)、(13)获得:
其中,vcharge(δt)和vdischarge(δt)均由四部分组成:第一部分δvr0(t)为r0的电压变化;第二部分
其中,r0为线性电阻,表示电池的电解质、电极与电流收集器等组件的电阻贡献。r0主要取决于温度以及电池的寿命;τ1为rc元件的时间常数;rct(ir)为随ir大小变化的电阻,其阻值可由下式(14)确定:
其中,rct,0为可变电阻的初始阻值;ir为流入电极的电流,可由下式(15)确定:
其中,i0为交换电流密度;n为反应中涉及的电子数,对于锂离子电池而言,n=1;t为电池的热力学温标;f为法拉第常数;r为理想气体常数。
除了上述方程,要确定电池电压上限vmax所决定的极限充电电流icharge,volt,电池电压下限vmin所决定的极限放电电流idischarge,volt,还必须求解式(16)、(17):
电池socmax决定的极限充电电流icharge,soc和电池socmin决定的极限放电电流idischarge,soc可由下两式(18)、(19)求得:
其中,soc(t)为t时刻电池的soc;socmax和socmin为允许的最大和最小soc;cactual为实际充电倍率。
电池的极限充电电流icharge,max可通过取规定的极限充电电流icharge,lim、vmax所决定的极限充电电流icharge,volt和socmax决定的极限充电电流icharge,soc的最小值获得:
icharge,max=min(icharge,lim,icharge,volt,icharge,soc(20)
电池的极限放电电流idischarge,max可通过取规定的极限放电电流idischarge,lim、vmin所决定的极限放电电流idischarge,volt和socmin决定的极限放电电流idischarge,soc的最小值获得:
idischarge,max=min(idischarge,lim,idischarge,volt,idischarge,soc(21)
最后,可以通过下式求得锂离子电池的sop,即最大充电功率pcharge和最大放电功率pdischarge如下:
pcharge=vcharge(δt)·icharge,max(22)
pdischarge=vdischarge(δt)·idischarge,max(23)
本发明采用的基于模型预测修正的思路是将电池soc作为输出变量,利用电池低阶rc模型并结合电池截止电压,预测在不损害动力电池性能和寿命前提下的最大充、放电功率,pcharge和pdischarge。该过程同样采用滚动时域,由于计算量小,可以实现每5s更新一次。基于电池功率范围计算发动机功率范围,以此作为约束条件,修正能量管理策略输出的发动机给定功率。
对于基于强化学习的策略鲁棒性修正方法,如图10所示,首先根据输出的速度、转矩需求,以及soc实际值,基于有限状态机方法,制定基于逻辑规则的能量管理方法,具体地,可将车辆能量管理模式分为1)纯电动驱动模式、2)纯发动机驱动模式、3)混合驱动模式、4)行车充电模式、5)减速/制动能量回馈模式、6)怠速/停车模式等。
各模式的设置如下,1)纯电动驱动模式:当电池的荷电状态soc不小于soc下限阈值时,且当前整车处于小功率驱动工况,则发动机熄火,可选地将发动机与传动系统之间通过离合器切断,发动机不输出动力,由动力电池提供汽车的全部行驶能量。2)纯发动机驱动模式:在正常行驶工况下车辆克服路面阻力运行所需的动力较小,一般情况下主要由发动机提供动力。3)行车充电模式:当动力电池的电量比较低时,为了使发动机工作于高效率区,发动机除了要提供克服路面阻力所需的动力外,还要提供多余的动力驱动发电机发电,将部分机械能转换成电能储存在动力电池中,以备其他工况使用。4)混合驱动模式:在加速行驶或爬坡等大负荷工况下,当车辆行驶所需的功率超过电池sop(可用的输出功率),同时也超过了发动机的经济油耗区,则发动机和动力电池同时输出能量,为车辆驱动提供动力。5)减速/制动能量回馈模式:混合动力汽车在减速/制动工况时通常有两种工作模式:一种是只通过电机的反拖使车速缓慢下降并回收部分制动能量;另一种模式是既通过电机反拖使车速迅速下降并回收大量的制动能量,同时机械制动系统也参与制动过程。6)怠速/车模式:在怠速/停车模式下混合动力传动系统中没有能量流动,通常情况下发动机和电动机均处于停机状态,但当动力电池soc比较低时,发电机需工作于经济工作区为动力电池充电,即驻车充电。
以上基于有限状态机实现的规则逻辑策略,其输出同样是发动机功率给定,但该能量管理策略的节能效果远落后于基于深度强化学习的智能控制策略。因此,需要将两种策略结合起来,既具有深度强化学习的能效优势,又能够利用逻辑规则满足鲁棒性。
此处采用q学习的方法实现两种策略的切换,将基于深度q网络能量管理策略的动作输出记为动作1,将基于有限状态机的能量管理策略输出的动作记为动作2。将基于q学习训练好的q表作为动作选择器,其输入为:动作1、动作2和soc实际值;其输出为:动作1或动作2。由q表所输出的动作,就是鲁棒能量管理策略,作为发动机功率给定,用于混合动力汽车的动态协调控制。其训练过程可参考能量管理策略的训练流程,仅是把dqn算法换成q-learning算法。
本发明采用的基于强化学习修正的思路是,利用q表(通过q学习进行训练得到)在逻辑规则控制策略和深度强化学习控制策略之间选择一个作为输出,q表的输入为两者的动作1和动作2,以及当前soc,既能够避免电池过冲、过放提高策略鲁棒性,又不会因长时间使用规则策略而损害能量管理算法的优化性能和节能潜力,算法的实现效果参见图11。
下面对本发明提供的智能网联混合动力汽车的鲁棒能量管理系统进行描述,下文描述的智能网联混合动力汽车的鲁棒能量管理系统与上文描述的智能网联混合动力汽车的鲁棒能量管理方法可相互对应参照。
图12是本发明提供的智能网联混合动力汽车的鲁棒能量管理系统的结构示意图,如图12所示,包括:获取模块1201、策略模块1202、修正模块1203和分配模块1204;其中:
获取模块1201用于获取基于人机协同的节能驾驶决策和基于智能网联的全局和实时工况更新;策略模块1202用于基于所述节能驾驶决策和所述全局和实时工况更新,获得基于深度强化学习的能量管理策略;修正模块1203用于对所述基于深度强化学习的能量管理策略采用策略鲁棒性修正,得到修正后的鲁棒控制策略;分配模块1204用于将所述修正后的鲁棒控制策略应用于混合动力汽车,得到所述混合动力汽车的能量分配结果。
本发明通过提出的智能网联混合动力汽车的鲁棒能量管理方法,有效解决了基于深度强化学习的能量管理策略的鲁棒性差问题,并提升了网联环境下混合动力汽车的节能效果,具有较好的工程应用价值。
图13示例了一种电子设备的实体结构示意图,如图13所示,该电子设备可以包括:处理器(processor)1310、通信接口(communicationsinterface)1320、存储器(memory)1330和通信总线1340,其中,处理器1310,通信接口1320,存储器1330通过通信总线1340完成相互间的通信。处理器1310可以调用存储器1330中的逻辑指令,以执行智能网联混合动力汽车的鲁棒能量管理方法,该方法包括:获取基于人机协同的节能驾驶决策和基于智能网联的全局和实时工况更新;基于所述节能驾驶决策和所述全局和实时工况更新,获得基于深度强化学习的能量管理策略;对所述基于深度强化学习的能量管理策略采用策略鲁棒性修正,得到修正后的鲁棒控制策略;将所述修正后的鲁棒控制策略应用于混合动力汽车,得到所述混合动力汽车的能量分配结果。
此外,上述的存储器1330中的逻辑指令可以通过软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。
基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
另一方面,本发明还提供一种计算机程序产品,所述计算机程序产品包括存储在非暂态计算机可读存储介质上的计算机程序,所述计算机程序包括程序指令,当所述程序指令被计算机执行时,计算机能够执行上述各方法所提供的智能网联混合动力汽车的鲁棒能量管理方法,该方法包括:获取基于人机协同的节能驾驶决策和基于智能网联的全局和实时工况更新;基于所述节能驾驶决策和所述全局和实时工况更新,获得基于深度强化学习的能量管理策略;对所述基于深度强化学习的能量管理策略采用策略鲁棒性修正,得到修正后的鲁棒控制策略;将所述修正后的鲁棒控制策略应用于混合动力汽车,得到所述混合动力汽车的能量分配结果。
又一方面,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现以执行上述各提供的智能网联混合动力汽车的鲁棒能量管理方法,该方法包括:获取基于人机协同的节能驾驶决策和基于智能网联的全局和实时工况更新;基于所述节能驾驶决策和所述全局和实时工况更新,获得基于深度强化学习的能量管理策略;对所述基于深度强化学习的能量管理策略采用策略鲁棒性修正,得到修正后的鲁棒控制策略;将所述修正后的鲁棒控制策略应用于混合动力汽车,得到所述混合动力汽车的能量分配结果。
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
- 还没有人留言评论。精彩留言会获得点赞!