一种利用光谱数据和化学检测数据建立数据模型的方法与流程
本发明属于物质检测领域,特别是涉及利用光谱检测化学成分的方法,具体是涉及一种利用光谱数据和化学检测数据建立数据模型的方法。
背景技术:
现代近红外光谱仪器的控制及数据处理分析系统是仪器的重要组成部分。一般由仪器控制、采谱和光谱处理分析两个软件系统和相应的硬件设备构成。前者主要功能是控制仪器各部分的工作状态,设定光谱采集的有关参数,如光谱测量方式、扫描次数、设定光谱的扫描范围等,设定检测器的工作状态并接受检测器的光谱信号。光谱处理分析软件主要对检测器所采集的光谱进行处理,实现定性或定量分析。对特定的样品体系,近红外光谱特征峰的差别并不明显,需要通过光谱的处理减少以至消除各方面因素对光谱信息的干扰,再从差别甚微的光谱信息中提取样品的定性或定量信息,这一切都要通过功能强大的光谱数据处理分析软件来实现。
近红外光谱分析技术分析速度快,是因为光谱测量速度很快,计算机计算结果速度也很快的原因。但近红外光谱分析的效率却取决于仪器所配备的模型的数量。比如,测量一张光谱图,如果仅有一个模型,就只能得到一个数据,但是,如果建立了10种性质参数模型,那么,仅凭测量的一张光谱,就可以同时得到10种分析数据。多个性质参数模型的建立,可以大大提高近红外光谱分析的工作效率,充分发挥它的特长。
CN 101556242 B公开了一种用傅立叶红外光谱鉴别微生物的方法,包括培养对照微生物;采集对照微生物的红外图谱;在3000-2300cm-1和1300至700cm-1区间内的一个或多个谱段建立微生物鉴别模型;在上述相同的条件下培养待测微生物,采集待测微生物的红外图谱,将红外图谱代入微生物鉴别模型中确定待测微生物的归属。
目前的方法中,因为模型的建立按照图谱的模式进行的,或者是按照局部数据进行的,或者是在化学计量的基础上进行匹配光谱数据,这些方法都存在建模后调整难度大,基础数据不齐全,导致数据模型的校正和公式的更新和更换难度大。
为解决上述技术问题,本发明提供了一种利用光谱数据和化学检测数据建立数据模型的方法,该方法利用物质的光谱多波长特征信息和多物质信息对应关系的设立运算公式。主要过程是建立完光谱数据和化学检测数据后,输入数据库,进行光谱数据和化学数据的映射,根据映射寻找代表其规律的波长组合信息,并将波长组合信息与物质成分和含量信息建立多套数据公式,然后将多套数学公式嵌入运算服务器,运算服务器与数据库紧密互动,进行新物质检测和数学公式的优化。
具体的,本发明提供了一种利用光谱数据和化学检测数据建立数据模型的方法,其特征在于物体样品的多组光谱数据和多组化学检测数据录入同一数据库,形成数据映射集合,从数据映射集合中,选取2-100个波长的吸光度数值与化学检测数据进行对应,确定2-100个波长吸光度变化与化学检测数据变化具有定性和定量关系的K个公式,将K个公式嵌入运算服务器,物体新样品的光谱数据录入数据库的同时,选取上述确定的2-100个波长录入运算服务器,计算出未进行实际检测的物体新样品化学数据,同时将该化学数据输出到显示端和数据库,并在数据库中与新采集的光谱数据形成测量映射,与已有数据映射形成新的映射集合,其中K≥1。
具体,本发明提供了一种利用光谱数据和化学检测数据建立数据模型的方法,该方法包括如下步骤:
步骤I:用光源照射待检测的物体样品A1,然后收集物体样品A1反射回来的光谱,采用光谱分析设备确定所收集光谱的波长及吸光度,形成物体样品A1的光谱数据;
步骤II:对物体样品A1进行化学分析,分析其T种成分及含量,形成物体样品的化学检测数据;T表示成分的数量,也就是做几种成分的分析,当对物体分析蛋白质和淀粉的时候,则T为2,如果增加可溶性糖,则T为3。T大于等于1,一般情况不对最大数值做限定,只要条件允许,可以对物体的成分做全分析,那样T可能会达到20,甚至30;
步骤III:将物体A1的光谱数据和化学检测数据录入同一数据库,形成数据映射X1;
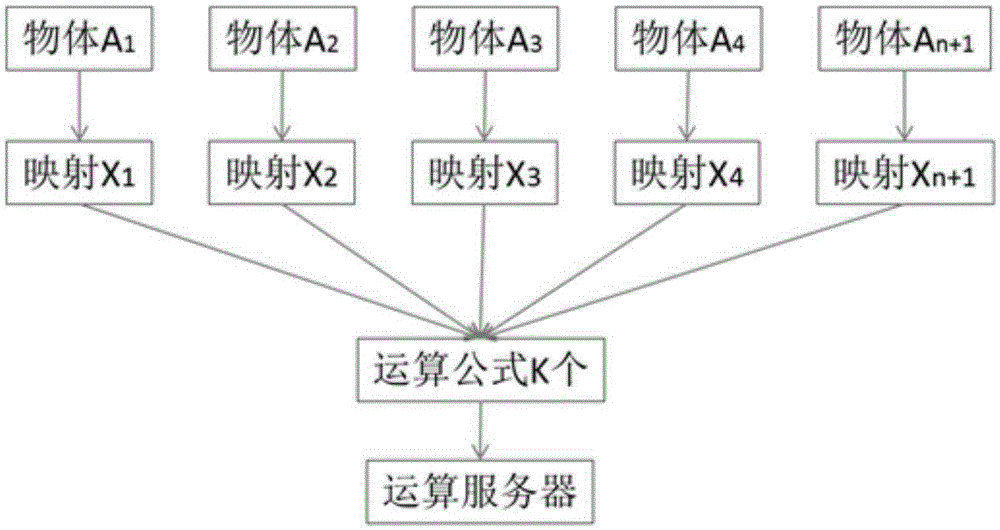
步骤IV:重复上述步骤I、步骤II和步骤III,对物体样品A2至An+1进行n次重复,形成n组光谱数据和对应的n组化学检测数据,将光谱数据和化学检测数据录入同一数据库,形成n组数据映射的数据映射集合;
步骤V:将上述数据库中数据映射集合中的光谱数据选取2-100个波长的吸光度数值与化学检测数据进行对应,确定2-100个波长吸光度变化与化学检测数据变化具有定性和定量 关系的K个公式。K表示公式的数量,一般情况下K≥1,为了单独分析多组分,K值要大于T值,也就是公式的数量一定大于成分的数量,有时为了同时进行多组分分析,需要K值满足如下关系式:
其中C表示组合式的含义。
为了考虑对每个成分或者是多个成分组合的检测准确,需要备用公式,也就是针对异常数据,公式出现无法计算的情况,应对备用公式进行运算,则此时考虑备用公式时,K值则需要满足如下关系式:
其中C表示组合式的含义。
步骤VI:将上述步骤的K个公式嵌入运算服务器,采集物体新样品AX的光谱数据,将其录入数据库的同时,选取步骤V确定的2-100个波长录入运算服务器,计算出未进行实际检测的物体新样品化学数据,同时将该化学数据输出到显示端和数据库,并在数据库中与物体新样品AX的光谱数据形成测量数据映射,该测量数据映射与已有的数据映射形成更新的数据映射集合,作为公式的更新和更换的基础。
步骤VII:根据步骤I至步骤VI所形成的数据库和运算服务器上的K个公式,将数据库和运算服务器相连,同时设置数据库的数据输入端和数据输出端、设置运算服务器的数据输入端和数据输出端,形成物体的光谱数据模型。
优选的,上述方法中,n大于等于30。尤其优选的,n大于等于50,更优选的,n大于等于100。n表示样品检测数量,n值越大,则光谱数据和化学检测数据的数量越大,会使得映射数据集合中的数据更好的支撑公式的建立,此处限定的n值是指建立模型所需的最低样品检测量,最大检测量不受限制,只要条件允许,可以将样品检测量增加到1000以上,甚至是10000以上。
优选的,上述方法中,光谱的波长范围为700-2500nm。优选的,光谱的波长范围为800-1800nm,或光谱的波长范围为1500-2500,或者是700-2500nm内任意范围的波长范围。。
优选的,上述方法中,物体为化学组成成分基本相同但成分含量差异值在20%以内的同类物体,优选的,物体为食物类、农产品类、土壤类等,优选的为农产品类,例如马铃 薯块茎,小麦籽粒,西瓜、叶菜、苹果等等。例如建立马铃薯的数据模型,则上述方法中,物体样品则均为马铃薯样品,而不能选择红薯样品。
优选的,上述方法中,光谱数据为纳米整数级波长的所有波长及吸光度的数据集合。也就是说,光谱数据不仅仅是一个图形或者是几个波长数据,而是所选范围内的所有波长的吸光度,哪怕某些波长的吸光度为零,也要记录入光谱数据中。
优选的,上述方法中,光谱数据为波长为800-1800nm的1001个波长的波长和吸光度的数据集合。
优选的,上述方法中,光谱数据为波长为1500-2500的1001个波长的波长和吸光度的数据集合。
本发明的方法所针对的是建立数据模型的方法,数据模型的建立中的化学测量数据,也成为化学计量数据,是指通过某些物质的国家标准进行测量获得的化学数据。例如马铃薯中的淀粉含量,需要按照国家标准或者是行业标准进行测量,也可以采用满足国标测量精度的仪器进行测量。
有益效果
本发明建立数据模型的方法的有益效果体现在如下三个方面:
1、将光谱数据与化学检测数据输入数据库中,进行映射,避免了目前仅仅将光谱数据录入化学检测数据处理器中导致的数据不独立的缺陷,难以达到公式更新和更换,阻碍了公式的灵活变化。
2、在数据库中的数据映射集合中,选取2-100个波长数据,因为数据库中的波长数据全面,因此选取2-100个波长数据与化学测量数据进行对应和建立公式则更加便捷,2-100个波长数据可以进行变换,摒弃了目前技术中单一波长段的选择,形成不确定分析,对波长的定位不准确。
3、K个公式嵌入服务器中,实现了公式的独立运算,同时也保证了运算结果可以独立的输回数据库中,而且选择波长数据时,没有必要将全部波长数据进行比对,仅仅在服务器中比对2-100个波长数据即可,比对效率高,又不影响原始光谱数据录入到数据库中。
附图说明
图1描述了单个物体样品的数据映射形成过程。
图2描述了多个数据映射形成公式并嵌入服务器中的过程
图3描述了作为新样品光谱数据在数据模型中计算出样品化学数据的过程。
图4描述了数据模型的总体组成结构。
具体实施方式
实施例1马铃薯块茎的数据模型
材料:马铃薯块茎,从马铃薯产品中随机抽取50个马铃薯块茎,横向切割,光源照射和光谱数据收集针对马铃薯横切面。
设备:光源照射装置、光谱收集装置和光谱分析设备为整体设备或分体设备,市场购买得到。
用光源照射马铃薯块茎,然后收集马铃薯块茎反射回来的近红外光谱,光谱范围为800-1800nm,采用近红外光谱分析设备分析光谱吸光度,形成马铃薯块茎的800-1800nm的近红外光谱数据,该光谱数据具有1001个光波吸光度数据。
对马铃薯块茎进行化学分析,分析马铃薯块茎的淀粉含量、维生素C含量、纤维素含量,形成马铃薯块茎的化学检测数据;
将马铃薯块茎的光谱数据和化学检测数据录入同一数据库,形成第1组数据映射;
再抽取马铃薯样品49组,对随机抽取的49组马铃薯块茎按照上述方法独立进行处理,获得49组光谱数据和对应的49组化学检测数据,将光谱数据和化学检测数据录入同一数据库,形成50组数据映射;
在上述数据库中的50组数据映射中,光谱数据选取3个波长的吸光度数值,3个波长的吸光度数值统一与化学检测数据进行对应,确定3个波长吸光度变化与化学检测数据变化具有同步关系的3个公式。
将上述步骤的3个公式嵌入运算服务器,再采集新的马铃薯块茎光谱数据录入数据库,同时选取上述3个波长录入运算服务器,计算出新的马铃薯块茎的淀粉含量、维生素C含量、纤维素含量。同时将马铃薯块茎的淀粉含量、维生素C含量、纤维素含量输出到显示端,并同时输入数据库,并在数据库中与新采集的光谱数据形成测试数据映射。
根据上述步骤确定的数据库和运算服务器上的3个公式,将数据库和运算服务器相连,同时设置数据库的数据输入端和数据输出端、设置运算服务器的数据输入端和数据输出端,形成马铃薯块茎的光谱数据模型。
实施例2小麦的数据模型
材料:小麦,从小麦产品中随机获取100份,每份置于直径10厘米的容器中,高度2cm, 光源照射和光谱数据收集针对容器中小麦堆的上平面。
设备:光源照射装置、光谱收集装置和光谱分析设备为整体设备或分体设备,市场购买得到。
用光源照射小麦,然后收集小麦反射回来的近红外光谱,光谱范围为1500-2500nm,采用近红外光谱分析设备分析光谱吸光度,形成小麦的1500-2500nm的近红外光谱数据,该光谱数据具有1001个光波吸光度数据。
对小麦进行化学分析,分析小麦的淀粉含量、蛋白质含量、纤维素含量,形成小麦的化学检测数据;
将小麦的光谱数据和化学检测数据录入同一数据库,形成第1组数据映射;
再抽取小麦样品99组,对随机抽取的09组小麦按照上述方法独立进行处理,获得99组光谱数据和对应的99组化学检测数据,将光谱数据和化学检测数据录入同一数据库,形成100组数据映射;
在上述数据库中的100组数据映射中,光谱数据选取8个波长的吸光度数值,8个波长的吸光度数值统一与化学检测数据进行对应,确定8个波长吸光度变化与化学检测数据变化具有同步关系的7个公式。
将上述步骤的7个公式嵌入运算服务器,再采集新的小麦光谱数据录入数据库,同时选取上述8个波长录入运算服务器,计算出新的小麦的淀粉含量、蛋白质含量、纤维素含量。同时将小麦的淀粉含量、蛋白质含量、纤维素含量输出到显示端,并同时输入数据库,并在数据库中与新采集的光谱数据形成测试数据映射。
根据上述步骤确定的数据库和运算服务器上的7个公式,将数据库和运算服务器相连,同时设置数据库的数据输入端和数据输出端、设置运算服务器的数据输入端和数据输出端,形成小麦的光谱数据模型。
- 还没有人留言评论。精彩留言会获得点赞!