本发明涉及旋转机械状态监测与故障诊断领域,具体涉及一种旋转机械的ELMD和有理样条平滑包络分析方法。
背景技术:
包络分析技术广泛应用于齿轮和滚动轴承的故障诊断中。现有的包络分析技术有下面三个缺陷:①现有的包络分析技术或者是直接对原始信号进行分析,或者是仅对原始信号进行简单的滤波后再进行分析,因此现有的方法容易受到噪声、趋势及其它成分的干扰,从而导致现有技术的分析精度较低;②现有的包络分析技术是以Hilbert变换为基础,而Hilbert变换要求被分析的信号必须是单分量的窄带信号,否则信号的频率调制部分将要污染信号的幅值包络分析结果,但是目前待分析的信号都不严格满足单分量且窄带的条件,这样就会导致现有技术因精度不高而容易出现误判问题;③由传统方法得到的包络谱存在端点效应。
技术实现要素:
本发明要解决的问题是针对以上不足,提出一种旋转机械的ELMD和有理样条平滑包络分析方法,采用本发明的包络分析方法后,具有分析结果准确度和精确度高,并能准确地检测出旋转机械故障类型的优点。
为解决以上技术问题,本发明采取的技术方案如下:一种旋转机械的ELMD和有理样条平滑包络分析方法,其特征在于,包括以下步骤:
步骤1:利用加速度传感器以采样频率fs测取旋转机械的振动信号x(k), (k=1, 2, …,N),N为采样信号的长度;
步骤2:采用集合局部均值分解(Ensemble Local Mean Decomposition, ELMD)算法将信号x(k)分解成n个分量和一个趋势项之和,即,其中,ci(k)代表由ELMD算法得到的第i个分量,rn(k)代表由ELMD算法得到的趋势项;
步骤3:对ci(k)执行重排操作和替代操作,经重排操作得到的数据用cishuffle(k)表示,替代操作后得到数据用ciFTran(k)表示;
步骤4:对ci(k)、cishuffle(k)和ciFTran(k)分别执行多重分形去趋势波动分析(Multifractal Detrended Fluctuation Analysis, MFDFA),得到广义Hurst指数曲线,ci(k)的广义Hurst指数曲线用Hi(q)表示;cishuffle(k)的广义Hurst指数曲线用Hishuffle(q)表示;ciFTran(k)的广义Hurst指数曲线用HiFTran(q)表示;
步骤5:如果Hi(q) 与Hishuffle(q)或Hi(q) 与HiFTran(q)之间的相对误差小于5%,或者Hi(q) 、Hishuffle(q) 和HiFTran(q)三者都不随q而变化,则抛弃对应的ci(k)分量;
步骤6:对剩余的ci(k)分量求和,将该和记为信号经重排和替代滤波后的结果xf1(k);
步骤7:对xf1(k)执行谱峭度分析,求出信号峭度最大处所对应的中心频率f0和带宽B;
步骤8: 根据中心频率f0和带宽B对xf1(k)进行带通滤波,得到xf2(k);
步骤9:对信号xf2(k)执行有理样条迭代平滑包络分析,得到信号包络eov(k);
步骤10:对得到的信号包络eov(k)执行离散傅里叶变换得到包络谱,根据包络谱特征频率判断机器的故障类型。
一种优化方案,所述步骤2中集合局部均值分解算法包括以下步骤:
(1)向数据x0(k)添加白噪声序列产生一个新数据xj(k) :
Std[x0(k)]代表数据x0(k)的标准差,wnj(k)代表wnj中的第k个数据,wnj代表第j个随机产生的白噪声序列,wnj幅值为1,1≤j≤K;x0(k)代表权利要求1所述步骤2中x(k);本例中,K=100;
(2)对xj(k)执行局部均值分解,得到n个分量和一个趋势项
cij(k)代表对xj(k)执行局部均值分解得到的第i个分量,rnj(k)代表对xj(k)执行局部均值分解得到的趋势项;
(3)计算K次分解结果的平均值
ci(k)表示对x0(k)进行集合局部均值分解得到的第i个分量,rn(k)表示对x0(k)进行集合局部均值分解得到的趋势项。
进一步地,所述步骤3中数据重排操作包括以下步骤:
随机打乱分量ci(k)的排列顺序。
进一步地,所述步骤3中数据替代操作包括以下步骤:
1) 对分量ci(k)执行离散傅里叶变换,获得分量ci(k)的相位;
2) 用一组位于(-π,π)区间内的伪独立同分布数来代替分量ci(k)的原始相位;
3) 对经过相位替代后的频域数据执行离散傅里叶逆变换得到数据ciIFFT(k),求取数据ciIFFT(k)的实部。
进一步地,所述步骤4中MFDFA方法包括以下步骤:
1)构造x(k)(k=1,2,…,N)的轮廓Y(i):
x(k)代表权利要求1所述步骤4中的ci(k)或cishuffle(k)或ciFTran(k);
2)将信号轮廓Y(i)分成不重叠的NS段长度为s的数据,由于数据长度N通常不能整除s,所以会剩余一段数据不能利用;
为了充分利用数据的长度,再从数据的反方向以相同的长度分段,这样一共得到2NS段数据;
3)利用最小二乘法拟合每段数据的多项式趋势,然后计算每段数据的方差:
yv(i)为拟合的第v段数据的趋势,若拟合的多项式趋势为m阶,则记该去趋势过程为(MF-)DFAm;本例中,m=1;
4) 计算第q阶波动函数的平均值:
;
5)如果x(k)存在自相似特征,则第q阶波动函数的平均值Fq(s)和时间尺度s之间存在幂律关系:
当q=0时,步骤4)中的公式发散,这时H(0)通过下式所定义的对数平均过程来确定:
6)对步骤5)中的公式两边取对数可得ln[Fq(s)]=H(q)ln(s)+c(c为常数),由此可以获得直线的斜率H(q)。
进一步地,所述步骤7中的谱峭度方法包括以下步骤:
1)构造一个截止频率为fc=0.125+ε的低通滤波器h(n);ε>0,本例中fc=0.3;
2)基于h(n)构造通频带为[0, 0.25]的准低通滤波器h0(n)和通频带为[0.25, 0.5]的准高通滤波器h1(n),
;
3)信号cik(n)经 h0(n)、 h1(n)滤波并降采样后分解成低频部分c2ik+1(n)和高频部分c2i+1k+1(n),降采样的因子为2,再经多次迭代滤波后形成滤波器树,第k层有2k个频带,其中cik(n)表示滤波器树中第k层上的第i个滤波器的输出信号,i=0,…, 2k-1,0≤k≤K-1,本例中K=8;c0 (n)代表权利要求1所述步骤7中xf1(k);
4)分解树中第k层上的第i个滤波器的中心频率fki和带宽Bk分别为
;
5)计算每一个滤波器结果cik(n)( i=0,…, 2k-1) 的峭度;
6)将所有的谱峭度汇总,得到信号总的谱峭度。
进一步地,所述步骤9中的有理样条迭代平滑包络分析方法包括以下步骤:
1)计算信号z(k)的绝对值∣z(k)∣的局部极值;在第1次迭代中,z(k)代表权利要求1所述步骤9中xf2(k);
2)采用有理样条曲线拟合局部极值点得到包络线eov1(k);
3)对z(k)进行归一化处理得到;
4)第2次迭代:把z1(k)重新作为新数据,重复执行上述步骤1)~3),得到;
5)第i次迭代:把zi-1(k) 重新作为新数据,重复执行上述步骤1)~3),得到;
6) 如果第n 次迭代得到的zn(k)的幅值小于或等于1,则迭代过程停止,最后得到信号z(k)的包络为。
进一步地,所述步骤(2)中局部均值分解算法包括以下步骤:
1)计算局部均值函数:确定原始信号x(k)所有的局部极值点ni,计算相邻两个极值点ni和ni+1的平均值mi,即
将所有相邻两个极值点的平均值mi用折线连接,然后采用移动平均方法进行平滑处理,得到局部均值函数m11(k);本例中,移动平均方法中的平滑步长设置为5;在第1次迭代中,x(k)代表权利要求2所述步骤(2)中xj(k);
2)估计信号的包络值:采用局部极值点ni计算包络估计值ai
同样,将所有相邻两个包络估计值ai用折线连接,然后采用移动平均方法进行平滑处理,得到包络估计函数a11(k);
3)将局部均值函数m11(k)从原始信号x(k)中分离出来, 得到
4)用h11(k) 除以包络估计函数a11(k)从而对h11(k)进行解调,得到
理想地,s11(k)是一个纯调频信号,即它的包络估计函数a12(k)满足a12(k)=1;
如果s11(k)不满足该条件,则将s11(k)作为新数据重复以上迭代过程m次,直到得到一个纯调频信号s1m(k),即s1m(k)满足-1≤s1m(k) ≤1,它的包络估计函数a1(m+1)(k)满足a1(m+1)(k)=1;
因此,有
式中
迭代终止的条件为
在实际应用中,可以设定一个变动量Δ,当满足1-Δ≤a1m(k) ≤1+Δ时,迭代终止;本例中变动量Δ=0.01;
5)把迭代过程中产生的所有包络估计函数相乘便可以得到包络信号
6)将包络信号a1(k) 和纯调频信号s1m(k)相乘便可以得到原始信号的第1个分量
;
7)将第1个分量c1(k) 从原始信号x(k)中分离出来,得到一个新的信号r1(k),将r1(k)作为新数据重复以上步骤,循环n次,直到rn(k) 为一个单调函数为止
至此,将原始信号x(k)分解为n个分量和一个单调函数rn(k)之和,即
本发明采用以上技术方案,与现有技术相比,本发明具有以下优点:
1)利用集合局部均值分解(ELMD)对原始信号进行分解,然后利用数据的重排和替代操作排除其中的噪声和趋势分量,仅仅保留信号分量中的有用成分,从而避免了噪声和趋势分量对包络分析结果的影响,分析结果准确度和精确度高。
2)利用有理样条迭代平滑包络分析方法将信号包络与频率调制部分完全分离,能够避免频率调制部分对信号包络分析结果的影响,从而提高包络分析的精度。
3) 能够准确地检测出旋转机械的故障类型。
4) 由传统方法得到的包络谱存在端点效应,而由本发明得到的包络谱能够避免端点效应。
下面结合附图和实施例对本发明做进一步说明。
附图说明
附图1为本发明实施例中包络分析方法的流程图;
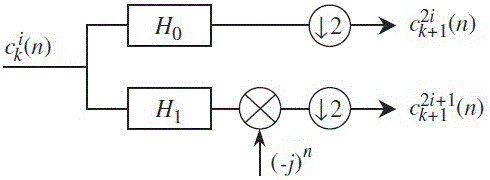
附图2为本发明实施例中采用低通和高通滤波器对信号进行初步分解的示意图;
附图3为本发明实施例中采用树状滤波器结构快速计算谱峭度的示意图;
附图4为本发明实施例中具有内圈故障的滚动轴承振动信号;
附图5为本发明实施例中采用传统包络分析方法对内圈故障滚动轴承振动信号的分析结果;
附图6为本发明实施例中采用本发明包络分析方法对内圈故障滚动轴承振动信号的分析结果;
附图7为本发明实施例中具有外圈故障的滚动轴承振动信号;
附图8为本发明实施例中采用传统包络分析方法对外圈故障滚动轴承振动信号的分析结果;
附图9为本发明实施例中采用本发明包络分析方法对外圈故障滚动轴承振动信号的分析结果。
具体实施方式
实施例,如图1、图2、图3所示,一种旋转机械的ELMD和有理样条平滑包络分析方法,包括以下步骤:
步骤1:利用加速度传感器以采样频率fs测取旋转机械的振动信号x(k), (k=1, 2, …,N),N为采样信号的长度;
步骤2:采用集合局部均值分解(Ensemble Local Mean Decomposition, ELMD)算法将信号x(k)分解成n个分量和一个趋势项之和,即 ,其中,ci(k)代表由ELMD算法得到的第i个分量,rn(k)代表由ELMD算法得到的趋势项;
步骤3:对ci(k)执行重排操作和替代操作,经重排操作得到的数据用cishuffle(k)表示,替代操作后得到数据用ciFTran(k)表示;
步骤4:对ci(k)、cishuffle(k)和ciFTran(k)分别执行多重分形去趋势波动分析(Multifractal Detrended Fluctuation Analysis, MFDFA),得到广义Hurst指数曲线,ci(k)的广义Hurst指数曲线用Hi(q)表示;cishuffle(k)的广义Hurst指数曲线用Hishuffle(q)表示;ciFTran(k)的广义Hurst指数曲线用HiFTran(q)表示;
步骤5:如果Hi(q) 与Hishuffle(q)或Hi(q) 与HiFTran(q)之间的相对误差小于5%,或者Hi(q) 、Hishuffle(q) 和HiFTran(q)三者都不随q而变化,则抛弃对应的ci(k)分量;
步骤6:对剩余的ci(k)分量求和,将该和记为信号经重排和替代滤波后的结果xf1(k);
步骤7:对xf1(k)执行谱峭度分析,求出信号峭度最大处所对应的中心频率f0和带宽B;
步骤8: 根据中心频率f0和带宽B对xf1(k)进行带通滤波,得到xf2(k);
步骤9:对信号xf2(k)执行有理样条迭代平滑包络分析,得到信号包络eov(k);
步骤10:对得到的信号包络eov(k)执行离散傅里叶变换得到包络谱,根据包络谱特征频率判断机器的故障类型。
步骤2中集合局部均值分解算法包括以下步骤:
(1)向数据x0(k)添加白噪声序列产生一个新数据xj(k) :
Std[x0(k)]代表数据x0(k)的标准差,wnj(k)代表wnj中的第k个数据,wnj代表第j个随机产生的白噪声序列,wnj幅值为1,1≤j≤K;x0(k)代表权利要求1所述步骤2中x(k);本例中,K=100;
(2)对xj(k)执行局部均值分解,得到n个分量和一个趋势项
cij(k)代表对xj(k)执行局部均值分解得到的第i个分量,rnj(k)代表对xj(k)执行局部均值分解得到的趋势项;
(3)计算K次分解结果的平均值
ci(k)表示对x0(k)进行集合局部均值分解得到的第i个分量,rn(k)表示对x0(k)进行集合局部均值分解得到的趋势项。
步骤3中数据重排操作包括以下步骤:
随机打乱分量ci(k)的排列顺序。
步骤3中数据替代操作包括以下步骤:
1) 对分量ci(k)执行离散傅里叶变换,获得分量ci(k)的相位;
2) 用一组位于(-π,π)区间内的伪独立同分布数来代替分量ci(k)的原始相位;
3) 对经过相位替代后的频域数据执行离散傅里叶逆变换得到数据ciIFFT(k),求取数据ciIFFT(k)的实部。
步骤4中MFDFA方法包括以下步骤:
1)构造x(k)(k=1,2,…,N)的轮廓Y(i):
x(k)代表权利要求1所述步骤4中的ci(k)或cishuffle(k)或ciFTran(k);
2)将信号轮廓Y(i)分成不重叠的NS段长度为s的数据,由于数据长度N通常不能整除s,所以会剩余一段数据不能利用;
为了充分利用数据的长度,再从数据的反方向以相同的长度分段,这样一共得到2NS段数据;
3)利用最小二乘法拟合每段数据的多项式趋势,然后计算每段数据的方差:
yv(i)为拟合的第v段数据的趋势,若拟合的多项式趋势为m阶,则记该去趋势过程为(MF-)DFAm;本例中,m=1;
4) 计算第q阶波动函数的平均值:
;
5)如果x(k)存在自相似特征,则第q阶波动函数的平均值Fq(s)和时间尺度s之间存在幂律关系:
当q=0时,步骤4)中的公式发散,这时H(0)通过下式所定义的对数平均过程来确定:
6)对步骤5)中的公式两边取对数可得ln[Fq(s)]=H(q)ln(s)+c(c为常数),由此可以获得直线的斜率H(q)。
步骤7中的谱峭度方法包括以下步骤:
1)构造一个截止频率为fc=0.125+ε的低通滤波器h(n);ε>0,本例中fc=0.3;
2)基于h(n)构造通频带为[0, 0.25]的准低通滤波器h0(n)和通频带为[0.25, 0.5]的准高通滤波器h1(n),
;
3)信号cik(n)经 h0(n)、 h1(n)滤波并降采样后分解成低频部分c2ik+1(n)和高频部分c2i+1k+1(n),降采样的因子为2,再经多次迭代滤波后形成滤波器树,第k层有2k个频带,其中cik(n)表示滤波器树中第k层上的第i个滤波器的输出信号,i=0,…, 2k-1,0≤k≤K-1,本例中K=8;c0 (n)代表权利要求1所述步骤7中xf1(k);
4)分解树中第k层上的第i个滤波器的中心频率fki和带宽Bk分别为
;
5)计算每一个滤波器结果cik(n)( i=0,…, 2k-1) 的峭度;
6)将所有的谱峭度汇总,得到信号总的谱峭度。
步骤9中的有理样条迭代平滑包络分析方法包括以下步骤:
1)计算信号z(k)的绝对值∣z(k)∣的局部极值;在第1次迭代中,z(k)代表权利要求1所述步骤9中xf2(k);
2)采用有理样条曲线拟合局部极值点得到包络线eov1(k);
3)对z(k)进行归一化处理得到;
4)第2次迭代:把z1(k)重新作为新数据,重复执行上述步骤1)~3),得到;
5)第i次迭代:把zi-1(k) 重新作为新数据,重复执行上述步骤1)~3),得到;
6) 如果第n 次迭代得到的zn(k)的幅值小于或等于1,则迭代过程停止,最后得到信号z(k)的包络为。
步骤(2)中局部均值分解算法包括以下步骤:
1)计算局部均值函数:确定原始信号x(k)所有的局部极值点ni,计算相邻两个极值点ni和ni+1的平均值mi,即
将所有相邻两个极值点的平均值mi用折线连接,然后采用移动平均方法进行平滑处理,得到局部均值函数m11(k);本例中,移动平均方法中的平滑步长设置为5;在第1次迭代中,x(k)代表权利要求2所述步骤(2)中xj(k);
2)估计信号的包络值:采用局部极值点ni计算包络估计值ai
同样,将所有相邻两个包络估计值ai用折线连接,然后采用移动平均方法进行平滑处理,得到包络估计函数a11(k);
3)将局部均值函数m11(k)从原始信号x(k)中分离出来, 得到
4)用h11(k) 除以包络估计函数a11(k)从而对h11(k)进行解调,得到
理想地,s11(k)是一个纯调频信号,即它的包络估计函数a12(k)满足a12(k)=1;
如果s11(k)不满足该条件,则将s11(k)作为新数据重复以上迭代过程m次,直到得到一个纯调频信号s1m(k),即s1m(k)满足-1≤s1m(k) ≤1,它的包络估计函数a1(m+1)(k)满足a1(m+1)(k)=1;
因此,有
式中
迭代终止的条件为
在实际应用中,可以设定一个变动量Δ,当满足1-Δ≤a1m(k) ≤1+Δ时,迭代终止;本例中变动量Δ=0.01;
5)把迭代过程中产生的所有包络估计函数相乘便可以得到包络信号
6)将包络信号a1(k) 和纯调频信号s1m(k)相乘便可以得到原始信号的第1个分量
;
7)将第1个分量c1(k) 从原始信号x(k)中分离出来,得到一个新的信号r1(k),将r1(k)作为新数据重复以上步骤,循环n次,直到rn(k) 为一个单调函数为止
至此,将原始信号x(k)分解为n个分量和一个单调函数rn(k)之和,即
试验1,利用具有内圈故障的滚动轴承振动数据对本发明所述算法的性能进行验证。
实验所用轴承为6205-2RS JEM SKF,利用电火花加工方法在轴承内圈上加工深度为0.2794mm、宽度为0.3556mm的凹槽来模拟轴承内圈故障,本实验负载约为0.7457kW,驱动电机转频约为29.5Hz,轴承内圈故障特征频率约为160Hz,采样频率为4.8KHz,信号采样时长为1s。
采集到的内圈故障信号如图4所示。
首先采用传统的包络分析方法对图4所示的信号进行分析,得到的分析结果如图5所示。从图5可以看出,轴承的故障特征完全被掩盖,因此传统的包络分析方法不能有效地提取轴承的故障特征;此外,从图5可以看出,包络谱的左端点存在异常高值,这说明由传统方法得到的包络谱存在端点效应。
采用本发明所提出的方法对图4所示的信号进行分析,得到的分析结果如图6所示。从图6可以看出,160Hz和320Hz所对应的谱线明显高于其它谱线,这两个频率分别对应轴承内圈故障特征频率的1倍频和2倍频,据此可以判断轴承具有内圈故障;从图6可以看出,由本发明得到的包络谱没有端点效应。
经多次实验表明,在负载和故障尺寸深度不变的情况下,本发明能够可靠识别的最小内圈故障尺寸宽度约为0.18mm,而传统方法能够可靠识别的最小内圈故障尺寸宽度约为0.53mm,精度提高66.0%。
试验2,利用具有外圈故障的滚动轴承振动数据对本发明所述算法的性能进行验证。
实验所用轴承为6205-2RS JEM SKF,利用电火花加工方法在轴承外圈上加工深度为0.2794mm、宽度为0.5334mm的凹槽来模拟轴承外圈故障,本实验负载约为2.237 kW,驱动电机转频约为28.7Hz,轴承外圈故障特征频率约为103Hz,采样频率为4.8KHz,信号采样时长为1s。
采集到的外圈故障信号如图7所示。
首先采用传统的包络分析方法对图7所示的信号进行分析,得到的分析结果如图8所示。从图8可以看出,轴承的故障特征完全被掩盖,因此传统的包络分析方法不能有效地提取轴承的故障特征;此外,从图8可以看出,包络谱的左端点存在异常高值,这说明由传统方法得到的包络谱存在端点效应。
采用本发明所提出的方法对图7所示的信号进行分析,得到的分析结果如图9所示。从图9可以看出,103Hz和206Hz所对应的谱线明显高于其它谱线,这两个频率分别对应轴承外圈故障特征频率的1倍频和2倍频,据此可以判断轴承具有外圈故障;从图9可以看出,由本发明得到的包络谱没有端点效应。。
经多次实验表明,在负载和故障尺寸深度不变的情况下,本发明能够可靠识别的最小外圈故障尺寸宽度约为0.27mm,而传统方法能够可靠识别的最小外圈故障尺寸宽度约为0.68mm,精度提高60.3%。
根据试验结果,分析后认为:
1) 传统的包络分析方法直接对原始信号进行包络分析,或者对仅经过简单处理后的原始信号进行包络分析,与传统的包络分析方法不同,本发明首先利用ELMD对原始信号进行分解,然后利用数据的重排和替代操作排除其中的噪声和趋势分量,仅仅保留信号分量中的有用成分,从而避免了噪声和趋势分量对包络分析结果的影响,提高了准确度和精确度。
2) 传统的包络分析方法以Hilbert变换为基础,而Hilbert变换要求被分析的信号必须是单分量的窄带信号,否则信号的频率调制部分将要污染信号的包络分析结果,但是目前待分析的信号都不严格满足单分量且窄带的条件,这样就会导致现有技术因精度不高而容易出现误判问题,与传统包络分析方法不同,本发明利用有理样条迭代平滑包络分析方法将信号包络与频率调制部分完全分离,能够避免频率调制部分对信号包络分析结果的影响,从而提高包络分析的精度。
3)能够准确地检测出旋转机械的故障类型。
4) 由传统方法得到的包络谱存在端点效应,而由本发明得到的包络谱能够避免端点效应。
5)各步骤作用:
第1)步:采集振动信号;
第2)步:将原始信号分解成不同分量和的形式,其中有些分量对应噪声和趋势项,有些分量对应有用信号;
第3)~5)步:对上述分解得到的信号执行重排操作和替代操作,剔除其中的噪声分量和趋势项,只保留有用信号;
第6)步:将剩余的有用信号求和,将该和作为信号经重排和替代滤波后的结果xf1(k);
第7)步:对滤波后的信号xf1(k)执行谱峭度分析,求出信号最大峭度处对应的中心频率f0和带宽B;
第8)步:根据中心频率f0和带宽B对xf1(k)进行带通滤波,得到信号xf2(k);
第9)步:计算信号xf2(k)的包络eov(k);
第10)步:对eov(k)执行离散傅里叶变换得到包络谱,根据包络谱判断轴承的故障类型。
本领域技术人员应该认识到,上述的具体实施方式只是示例性的,是为了使本领域技术人员能够更好的理解本发明内容,不应理解为是对本发明保护范围的限制,只要是根据本发明技术方案所作的改进,均落入本发明的保护范围。