本发明涉及生物技术领域,尤其涉及一种利用脂质生物标志物预测甲状腺癌的方法,能够准确预测甲状腺癌。
背景技术:
甲状腺癌是常见的内分泌恶性肿瘤,传统上分为甲状腺分化性癌、甲状腺未分化癌和甲状腺髓样癌,分化性癌又分为乳头状癌和滤泡型腺癌,甲状腺未分化癌比较少见且预后极差,甲状腺髓样癌来源于甲状腺滤泡旁细胞(c细胞),属于神经内分泌肿瘤中的一种,在多发性2型内分泌瘤中约25%的患者伴有甲状腺髓样癌。近年来,我国甲状腺癌高发,已成为增长速度最快的恶性肿瘤,发病率10年增长了近5倍。甲状腺癌尤其好发于中青年女性,女性和男性比例为3:1,已成近20年来我国癌症谱中女性恶性肿瘤上升速度最快的肿瘤。如今在一、二线城市的女性群体中,该病发病率基本位列三甲,有的甚至已跃居榜首。
目前,确诊甲状腺癌的主要手段主要是甲状腺细胞穿刺、术中病理冰冻及术后石蜡病理切片,甲状腺细胞穿刺虽然能达到确诊的意义,但由于阳性率低而限制了它在临床上的推广,所以临床实际确诊甲状腺癌的方法主要还是依靠术中冰冻或术后石蜡切片。除此之外,在甲状腺癌血清学方面,虽然对甲状腺癌肿瘤标志物的研究进展的很快,但至今还没有一种在临床上得到一致的认可,说明对甲状腺癌肿瘤标志物的研究仍然处于初步阶段,值得进一步发展。
研究表明,脂质代谢与组织病变有非常直接的联系,也包括甲状腺机能紊乱。目前,通过核磁共振,maldi/ms或者gc/ms,已经发现少许与甲状腺癌相关的脂质。其中,对脂肪酸的研究表明,良性甲状腺瘤的患者c14:0,c16:1n7,c18:1n9,c20:1n9,c18:3n3显著降低,c16:0,c20:3n6,c20:4n6,c22:6n3显著升高;恶性肿瘤患者表现出c14:0,c16:0,c18:3n3升高,而c20:3n6降低的趋势。另外,也有研究利用数学模型结合脂质组学,开始寻找肿瘤标志物。他们利用pls-da模型,发现了长醇,胆固醇,胆碱以及27种脂肪酸,在甲状腺癌良性和恶性人群中,体现明显的差异。
但是,目前为止,还没有出现能够利用这些标志物准确预测甲状腺癌的预测模型,尤其是针对中国人群的甲状腺癌预测模型。
技术实现要素:
本发明的一个目的是解决至少上述问题,并提供至少后面将说明的优点。
本发明还有一个目的是提供一种利用脂质生物标志物预测甲状腺癌的方法,能够快捷、准确、高效地预测甲状腺癌。
本发明还有一个目的是提供一种针对中国人群的利用脂质生物标志物预测甲状腺癌的方法。
本发明还有一个目的是提供一组针对中国人群的与甲状腺癌密切相关的化合物。
为了实现根据本发明的这些目的和其它优点,提供了以下技术方案:
一种利用脂质生物标志物预测甲状腺癌的方法,其中,主要包括以下步骤:
步骤1、筛选出正常人组群和甲状腺癌组群之间的差异性化合物r1-r9,分别为:
r1:pg(17:0/14:1);
r2:ps(o-20:0/18:1);
r3:pc(16:0/18:2);
r4:bacteriohopane-,32,33,34-triol-35-cyclitolguanine;
r5:pc(16:0/20:4);
r6:tg(16:0/16:1/20:2);
r7:pc(16:0/18:1);
r8:ps(o-18:0/17:0);
r9:ps(p-18:0/22:2);
步骤2、利用逻辑回归模型3进行计算,得到tc值,所述逻辑回归模型3的计算公式为:
tc=1.8002-2.2815*r1-2.3474*r4+2.8573*r9;
步骤3、根据所得tc值进行判断,tc=0为否;tc=1为是。
优选的是,步骤1中利用opls-da模型对差异性化合物进行筛选,然后将vip>1的排名前9位变量的数据提取出来即得r1-r9。
优选的是,步骤1中筛选的具体方法为:
步骤1.1将样品进行超高效液相色谱和质谱分析,得到脂质组学数据,将正常人组群和甲状腺癌组群分别计为ck及jc;
步骤1.2对脂质组学数据进行标准化操作,利用opls-da模型对ck及jc进行s-plot分布得到s形曲线,并进行强制分组,计算影响ck及jc分组的变量重要性,即得vip值;
步骤1.3按照vip值大于5的标准得到15个化合物,并将该15个化合物作为与甲状腺癌相关度最高的差异性化合物;
步骤1.4将所得15个化合物按照vip值大小从高到低排列,取前9位,即得步骤1中所述差异性化合物ri-r9。
优选的是,步骤2中tc值或者用逻辑回归模型2进行计算,所述逻辑回归模型2的计算公式为:
tc=1.6361-12.5962*r+0.4081*r2-0.962*r3-1.7675*r4+0.7317*r5-7.3848*r6+15.9658*r7+0.494*r8+2.5964*r9。
优选的是,步骤2中tc值或者用逻辑回归模型1进行计算,所述逻辑回归模型1的计算公式为:
tc=1.6054-13.4331*r1-2.4503*r4+0.9397*r5+9.5919*r7+3.3108*r9。
本发明至少包括以下有益效果:
本发明通过筛选,首次发现与甲状腺癌相关的一组化合物,即与甲状腺癌相关的脂质生物标志物,并通过构建逻辑回归模型,得到根据这些脂质标志物预测甲状腺癌的方法,快捷方便,准确度高。通过aic值初步判断,并进行roc曲线绘制,auc值达到0.872。
本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
图1为本发明中所述的opls-da模型的s-plot分布图;
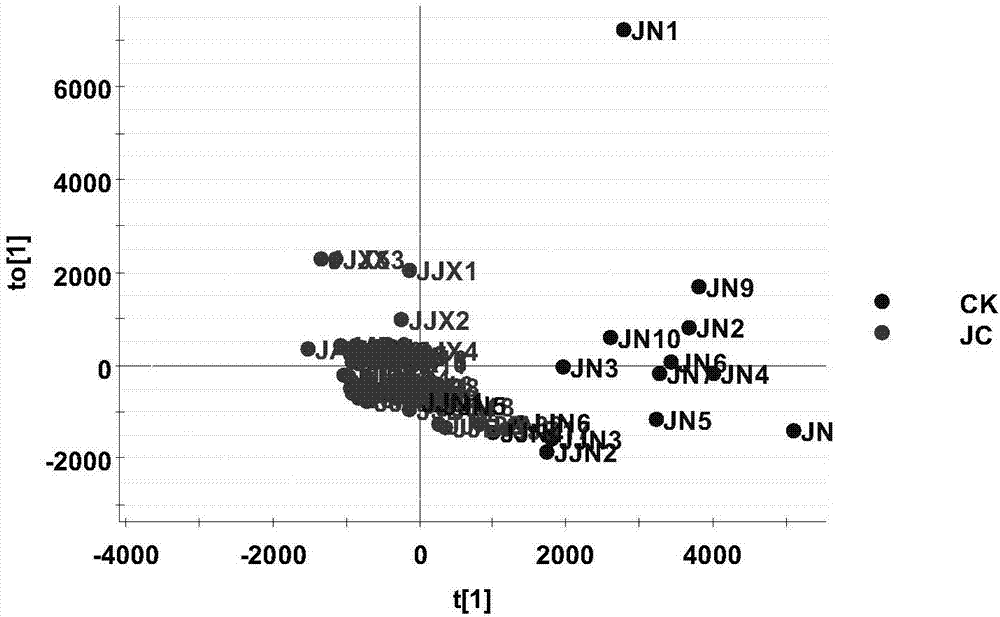
图2为本发明中利用opls-da模型对ck和jc进行强制分组的结果;
图3为本发明中用来考察筛选出的化合物的火山图;
图4为本发明中roc曲线图。
具体实施方式
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
应当理解,本文所使用的诸如“具有”、“包含”以及“包括”术语并不配出一个或多个其它元件或其组合的存在或添加。
一种利用脂质生物标志物预测甲状腺癌的方法,其中,主要包括以下步骤:
步骤1、筛选出正常人组群和甲状腺癌组群之间的差异性化合物r1-r9,分别为:
r1:pg(17:0/14:1);
r2:ps(o-20:0/18:1);
r3:pc(16:0/18:2);
r4:bacteriohopane-,32,33,34-triol-35-cyclitolguanine;
r5:pc(16:0/20:4);
r6:tg(16:0/16:1/20:2);
r7:pc(16:0/18:1);
r8:ps(o-18:0/17:0);
r9:ps(p-18:0/22:2)。
步骤2、利用逻辑回归模型1进行计算,得到tc值,所述逻辑回归模型3的计算公式为:
tc=1.8002-2.2815*r1-2.3474*r4+2.8573*r9;
经过roc曲线绘制,模型3的auc值为0.872,准确度高达87.2%。
步骤3、根据所得tc值进行判断,tc=0为否;tc=1为是。r1-r9均为检测样品中该脂质的含量值。
步骤1中利用opls-da模型对差异性化合物进行筛选,然后将vip>1的排名前9位变量的数据提取出来即得r1-r9。
步骤1中筛选的具体方法为:
步骤1.1将样品进行超高效液相色谱和质谱分析,得到脂质组学数据,将正常人组群和甲状腺癌组群分别计为ck及jc。
步骤1.2对脂质组学数据进行标准化操作,利用opls-da模型对ck及jc进行s-plot分布得到s形曲线,并进行强制分组,计算影响ck及jc分组的变量重要性,即得vip值。
步骤1.3按照vip值大于5的标准得到15个化合物,并将该15个化合物作为与甲状腺癌相关度最高的差异性化合物。
步骤1.4将所得15个化合物按照vip值大小从高到低排列,取前9位,即得步骤1中所述差异性化合物r1-r9。
步骤2中tc值或者用逻辑回归模型2进行计算,所述逻辑回归模型2的计算公式为:tc=1.6361-12.5962*r+0.4081*r2-0.962*r3-1.7675*r4+0.7317*r5-7.3848*r6+15.9658*r7+0.494*r8+2.5964*r9。
经过roc曲线绘制,模型2的auc值为0.864,准确度为86.4%。
步骤2中tc值或者用逻辑回归模型1进行计算,所述逻辑回归模型1的计算公式为:
tc=1.6054-13.4331*r1-2.4503*r4+0.9397*r5+9.5919*r7+3.3108*r9。
经过roc曲线绘制,模型1的auc值为0.866,准确度为86.6%。
实施例1
材料和方法
1.实验对象(均选自中国人):16位正常人,64位甲状腺癌患者,抽取静脉血5ml。准确量取100μl的血液,加入0.9ml的提取液(100%异丙醇),转入2ml离心管(必须是进口离心管,塑料不易溶于有机溶剂中;axygen品牌)中,漩涡振荡10s以上,超声10min,然后在-20度冰箱中冷冻1小时,取出后在室温下漩涡振荡,用冷冻离心机10000rpm离心10min,然后去上清液1ml并过0.22μm的有机相滤膜到玻璃进样品种,保存在冰箱中待测。
2.主要仪器
2.1.1冷冻离心机:型号d3024r,scilogex公司,美国
2.1.2漩涡振荡器:型号mx-s,scilogex公司,美国
2.1.3高分辨质谱仪:esi-qtof/ms;型号:xevog2-sq-tof;厂家:waters
2.1.4超高效液相色谱:uplc;型号:acquityuplci-class系统;厂家:waters
2.1.4数据采集软件:masslynx4.1;厂家:waters
2.1.5分析鉴定软件:progenesisqi;厂家:waters
2.1.6作图软件:ezinfo;hemi;simca-p
3.主要试剂
甲醇、乙腈、甲酸、甲酸铵、亮氨酸脑啡肽、甲酸钠。厂家均为fisher。
4.实验设置
以提取液(100%异丙醇)作为空白对照(blank)样品;从每个样品的进样品种取出100μl混合到新的进样品种作为质控(qc)样品;正式样品按照每组样品间隔进样,例如先是blank1,然后是qc1,然后是w1,然后是w2这个顺序,然后再进行下一轮进样。
液相方法
色谱柱:acquityuplccshc18column,1.7μm,1mmx50mm,1/pkg[186005292];
柱温:55度
流速:0.4ml/min
流动相:a:acn/h2o(60%/40%),含有10mm甲酸铵和0.1%甲酸
b:ipa/acn(90%/10%),含有10mm甲酸铵和0.1%甲酸
(注:acn为乙腈,ipa为异丙醇)
进样体积:0.2μl
洗脱程序:
质谱方法
数据采集方式:mse;分子量扫描范围:50-1500m/z;分辨率模式(轮廓图)。
正负离子模式各采集一次。
离子源:电喷雾电离源(esi)
毛细管电压:3kv
锥孔电压为:25v
碰撞能:15-60v
源温度:120度
脱溶剂温度:500度
锥孔气体速度:50l/h
脱溶剂气体速度:500l/h
扫描时间:0.2s
使用亮氨酸脑啡肽(m/z556.2771,正离子;554.2615,负离子)进行实时校正。使用甲酸钠进行校正。
脂质组学数据分析
progenesisqi软件(waters,massachusetts,usa)用于结果分析,抽提非靶向脂质分子的特征峰,进行比对和筛选。同时,用qc(quantifyingcontrol)和blank(空白)来筛选背景数据。最终的数据,导入ezinfo3.0,并进行principalcomponentanalysis(pca)分析,orthogonalsignalcorrectionpartialleastsquarediscriminationanalysis(opls-da)建模,variableimportanceinprojection(vip)的计算,同时得到火山图(coefficientsvs.vipspots),如图3所示。其中,逻辑回归模型以及roc曲线(如图4)通过r语言进行建设和绘制。
结果描述
正常人群与甲状腺癌人群脂质差异物质的鉴定。
我们首先建立opls-da模型,对正常人(ck)和甲状腺癌(jc)组群进行分类,并研究造成他们出现差异的原因。我们看到在opls-da模型中,利用相关性(correlation)和协方差(covarience)的p值作出的s-plot形成了非常好的s形曲线,如图1所示。利用opls-da将两组数据进行强制分组,结果如图2所示。计算影响ck和jc分组的变量重要性,即vip(variableimportanceinprojection)值。一共筛选到308个化合物,他们的vip值大于1;我们挑选vip>5,贡献率大的15个化合物,如表1所示。
表1.变量重要性投影
我们通过vip>1筛选出来的化合物在s-plot上用红色方框标出,发现他们均匀的分布在两侧。同时,我们利用火山图,来考察筛选出的化合物的分布,如图3所示,发现筛选出来的化合物都分布在火山图的外围。这些结果都说明,借由opls-da模型,我们成功筛选出造成ck和jc差异的化合物。
建立逻辑回归模型以及roc曲线。我们对脂质组学的数据进行标准化操作(rproject:scale)。然后将vip>1的排名前9位变量的数据提取出来,建立逻辑回归模型和roc曲线。
公式中,tc:是否患有肿瘤,0为否,1为是
r1:pg(17:0/14:1)
r2:ps(o-20:0/18:1)
r3:pc(16:0/18:2)
r4:bacteriohopane-,32,33,34-triol-35-cyclitolguanine
r5:pc(16:0/20:4)
r6:tg(16:0/16:1/20:2)
r7:pc(16:0/18:1)
r8:ps(o-18:0/17:0)
r9:ps(p-18:0/22:2)
模型3:tc=1.8002-2.2815*r1-2.3474*r4+2.8573*r9
aic:57.484
signif.codes:‘***’0.001;‘**’0.01;‘*’0.05;‘.’0.1;
模型2:
tc=1.6361-12.5962*r+0.4081*r2-0.962*r3-1.7675*r4+0.7317*r5-7.3848*r6+15.9658*r7+0.494*r8+2.5964*r9
aic:65.973
signif.codes:‘***’0.001;‘**’0.01;‘*’0.05;‘.’0.1;
模型1:
tc=1.6054-13.4331*r1-2.4503*r4+0.9397*r5+9.5919*r7+3.3108*r9
aic:58.782
signif.codes:‘***’0.001;‘**’0.01;‘*’0.05;‘.’0.1;
针对以上三个逻辑回归模型,进行roc曲线绘制,如图4所示,模型1为m1,auc值达到0.866;模型2为m2,auc值为0.864;模型3为m3,auc值达到0.872。我们发现模型3最靠近左上角定点,同时auc值最高,最终,确定模型3为基于脂质指标来预测糖尿病血脂异常较好的预测模型。也可以根据所测样品数据情况,选择模型1或者模型2进行计算预测,或者优先选择模型3进行计算,同时使用1和2模型进行辅助验证,协同分析预测。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。