利用脂质生物标志物预测肥胖的方法与流程
本发明涉及生物技术领域,尤其涉及一种利用脂质生物标志物预测肥胖的方法,能够准确预测肥胖。
背景技术:
据"国际肥胖问题工作组"公布的数据显示,地球上每4人中就有1人过于肥胖。具体而言,全球3.12亿人体重超标,17亿人应该减肥。报告指出,全世界肥胖人口已超过饥饿人口,肥胖已经成为困扰发达国家和发展中国家的一个重大社会问题。
全球每年有300多万人死于与肥胖有关的ⅱ型糖尿病。据世界卫生组织预测,未来25年内,这一数字还可能翻一番。肥胖可能加重心脏病隐患。世卫组织数据显示,全球总共有1700万人死于心脏病和其他循环系统疾病,占总死亡人数三分之一。在大多数国家和地区,心脏病致死案例在达到工作年龄的成年人群中更为普遍。
中国的肥胖症患病率近年来也呈迅速上升趋势,中国成年人估计有2亿人超重,6000多万人肥胖。在大城市中超重率为30%,肥胖率已经达到13%,这意味着在我国大城市里已有接近一半的人口在"体重"方面存在问题。另外,在城市中儿童的肥胖问题也十分严重,并预计今后肥胖率还将呈持续增长趋势。
肥胖的主要危害包括以下多方面:
易患冠心病及高血压。
肥胖者脂肪组织增多,耗氧量加大,心脏做功量大,使心肌肥厚,尤其左心室负担加重,久之易诱发高血压。脂质沉积在动脉壁内,致使管腔狭窄,硬化,易发生冠心病、心绞痛、中风和猝死。
易患内分泌及代谢性疾病。
伴随肥胖所致的代谢、内分泌异常,常可引起多种疾病。糖代谢异常可引起糖尿病,脂肪代谢异常可引起高脂血症,核酸代谢异常可引起高尿酸血症等。肥胖女性因卵巢机能障碍可引起月经不调。
肥胖易导致肺血管阻塞。
医学研究表明,肥胖和致命的突发性肺部动脉血管阻塞有密切的关系。这种阻塞肺部动脉血管的血栓常常是随血流从大腿部向肺部转移的。研究人员通过对20年来的医院医疗记录的调查分析发现,肥胖的病人发生突发性肺部动脉血管阻塞而导致死亡的几率比一般人高25倍。这种风险在40岁以下的人群中的发生率更高。突发性肺部动脉血管阻塞是紧随心肌梗塞和脑溢血之后的第三大致命的心血管疾病。
肥胖可损害心血管系统。
心脏和血管就是这样共同维持血液在人体内不停息地循环运转的。健康的动脉管壁光滑而富有弹性,可以保证血液在其中畅通流动。然而,当动脉复生粥样硬化改变时,血液中的一些成分就容易在动脉内壁形成斑块,降低管壁弹性,使血管通路变窄,血流受阻,甚至被切断。超重或肥胖的人比体重正常的人更容易发生动脉粥样硬化。因为肥胖降低了人体对胰岛素的敏感性,胰腺只好拼命地分泌更多的胰岛素来满足身体的需要。胰腺超负荷运转导致血液中胰岛素快速增加,损伤动脉内壁,促使动脉粥样硬化发生。
肥胖会使大脑受损。
瑞典医学人员经研究指出,肥胖会对大脑造成不良影响。成年期肥胖的女性更有可能导致脑部组织损失,这种被称为脑部萎缩的现象会造成脑部功能受损和痴呆。
肥胖易患脂肪肝。
正常情况下,肝脏里只含有少量脂肪,若脂肪含量超过30%,就称为轻度脂肪肝;超过50%,则为中度脂肪肝;超过75%,则为重度脂肪肝。肥胖是引起脂肪肝的重要因素之一,尤其是腹部肥胖。腹部的脂肪比较容易分解,并可通过门静脉直接进入肝脏。大量脂肪以甘油三酯的形式涌入肝脏等待处理,超过肝脏的负荷力时,多余的甘油三酯则沉积于肝细胞内,从而导致脂肪肝。
肥胖易导致老年痴呆症。
老年痴呆症是一种因脑部退化而形成的疾病。其症状包括失忆、判断力欠佳及语言能力逐渐衰退等。导致该病的原因很多,但主要可分为三大类:阿尔兹海默氏病;中风引起的血管破裂,脑供血不足,以至脑功能下降;其他原因,包括情绪忧郁、营养不良、药物中毒、酗酒等。根据目前的研究显示,肥胖导致老年痴呆虽然只发生在老年妇女中,但这并不意味着男性就可掉以轻心。专家认为,控制体重能避免痴呆,提高老年人的生活质量。老年人在70岁以后,bmi每增加一个点,患病的危险就会增加36%。
预防肥胖,以及对肥胖的早期预测,是非常重要的工作。目前有许多工作开始了对肥胖预测的标志物的寻找。通过对单卵双生的双胞胎血清进行脂质组学的研究,发现获得性肥胖与溶血性磷脂酰胆碱的含量升高,同时醚磷脂出现下降有密切的关系(pietila¨inenetal.,2007)。paul通过尿液代谢组学,发现尿糖蛋白,乙酰神经氨酸,二甲胺,三甲胺,甲苯基硫酸盐,苯乙酰谷氨酰胺,2-羟基异丁酸,琥珀酸,柠檬酸,酮亮氨酸和酮亮氨酸/亮氨酸,乙醇胺和3-甲基组氨酸,与bmi有直接的关系(2015)。类似地,steven利用血液代谢组学的方法,也发现了100种代谢物与bmi有p<0.05的相关性,从中发现了18种前人没有报道过的代谢标志物,包括组氨酸、神经递质、丁酰肉碱等(2014)。
但是,目前为止,还没有出现针对中国人的肥胖标志物寻找的研究。因为人具有异质性,东西方人的人种差异很大,所以,目前已经报道的肥胖标志物,不适合于中国人群。也缺乏能够通过通过脂质组学准确、快捷预测肥胖预测模型。
技术实现要素:
本发明的一个目的是解决至少上述问题,并提供至少后面将说明的优点。
本发明还有一个目的是提供一种利用脂质生物标志物预测肥胖的方法,能够快捷、准确、高效地预测肥胖。
本发明还有一个目的是提供一种针对中国人群的利用脂质生物标志物预测肥胖的方法。
本发明还有一个目的是提供一组针对中国人群的与肥胖密切相关的化合物。
为了实现根据本发明的这些目的和其它优点,提供了以下技术方案:
一种利用脂质生物标志物预测肥胖的方法,其中,主要包括以下步骤:
步骤1、筛选出正常人组群和肥胖组群之间vip值大于1的排名前8位的差异性化合物r1-r8,分别为:
r1:sm(d18:1/26:1(17z));
r2:tg(18:4(6z,9z,12z,15z)/19:1(9z)/20:5(5z,8z,11z,14z,17z))[iso6];
r3:phenolicphthiocerol;
r4:pe(22:1(11z)/22:6(4z,7z,10z,13z,16z,19z));
r5:mayolene-19;
r6:dg(o-16:0/18:1(9z));
r7:25-methyl-24-isopropenyl-22e-dehydrocholesterol;
r8:dg(16:0/20:3(8z,11z,14z)/0:0)[iso2];
步骤2、利用逻辑回归模型1进行计算,得到tc值,所述逻辑回归模型1的计算公式为:
tc=-1.675+16.031*r1-6.476*r2-35.888*r3+2.823*r4+20.2*r5-21.951*r6+15.726*r7+18.845*r8;
步骤3、根据所得tc值进行判断,tc=0为否;tc=1为是。
优选的是,步骤1中利用opls-da模型对差异性化合物进行筛选,筛选条件vip>1。
优选的是,步骤1中筛选的具体方法为:
步骤1.1将样品进行超高效液相色谱和质谱分析,得到脂质组学数据,将正常人组群和肥胖组群分别计为nc及ow;
步骤1.2对脂质组学数据进行标准化操作,利用opls-da模型对nc及ow进行s-plot分布得到s形曲线,并进行强制分组,计算影响nc及ow分组的变量重要性,即得vip值;
步骤1.3按照vip值大于1的标准得到63个化合物,并将该63个化合物作为与肥胖相关度最高的差异性化合物;
步骤1.4将所得63个化合物按照vip值大小从高到低排列,取前8位,即得步骤1中所述差异性化合物。
优选的是,步骤2中tc值或者用逻辑回归模型2进行计算,所述逻辑回归模型2的计算公式为:
tc=-1.331+6.255*r1-8.419*r3+1.827*r4-13.914*r6+8.808*r7+11.369*r8。
优选的是,步骤2中tc值或者用逻辑回归模型3进行计算,所述逻辑回归模型3的计算公式为:
tc=-0.693+4.059*r1-6.954*r3-13.299*r6+9.063*r7+10.011*r8。
本发明至少包括以下有益效果:
本发明通过脂质组学方法,检测血液中所有的脂质,从而有针对性地筛选出和肥胖密切相关的脂质化合物,并将其作为预测人体肥胖的脂质标志物,并通过构建逻辑回归模型,得到根据这些脂质标志物预测肥胖的方法,快捷方便,准确度高达96.4%。能够通过提前发现变化的脂质来进行肥胖的预测,从而进行一定的干预和预防措施。
本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
图1为本发明中所述的opls-da模型的s-plot分布图;
图2为本发明中利用opls-da模型对nc和ow进行强制分组的结果;
图3为本发明中用来考察筛选出的化合物的火山图;
图4为本发明中roc曲线图。
具体实施方式
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
应当理解,本文所使用的诸如“具有”、“包含”以及“包括”术语并不配出一个或多个其它元件或其组合的存在或添加。
一种利用脂质生物标志物预测肥胖的方法,其中,主要包括以下步骤:
步骤1、筛选出正常人组群和肥胖组群之间vip值大于1的排名前8位的差异性化合物r1-r8,分别为:
r1:sm(d18:1/26:1(17z))
r2:tg(18:4(6z,9z,12z,15z)/19:1(9z)/20:5(5z,8z,11z,14z,17z))[iso6];
r3:phenolicphthiocerol;
r4:pe(22:1(11z)/22:6(4z,7z,10z,13z,16z,19z));
r5:mayolene-19;
r6:dg(o-16:0/18:1(9z));
r7:25-methyl-24-isopropenyl-22e-dehydrocholesterol;
r8:dg(16:0/20:3(8z,11z,14z)/0:0)[iso2];
步骤2、利用逻辑回归模型1进行计算,得到tc值,所述逻辑回归模型1的计算公式为:
tc=-1.675+16.031*r1-6.476*r2-35.888*r3+2.823*r4+20.2*r5-21.951*r6+15.726*r7+18.845*r8;经过roc曲线绘制,模型1的auc值为0.964,准确度高达96.4%。
步骤3、根据所得tc值进行判断,tc=0为否;tc=1为是。
一个优选方案中,步骤1中利用opls-da模型对差异性化合物进行筛选,筛选条件vip>1。
一个优选方案中,步骤1中筛选的具体方法为:
步骤1.1将样品进行超高效液相色谱和质谱分析,得到脂质组学数据,将正常人组群和肥胖组群分别计为nc及ow;
步骤1.2对脂质组学数据进行标准化操作,利用opls-da模型对nc及ow进行s-plot分布得到s形曲线,并进行强制分组,计算影响nc及ow分组的变量重要性,即得vip值;
步骤1.3按照vip值大于1的标准得到63个化合物,并将该63个化合物作为与肥胖相关度最高的差异性化合物;
步骤1.4将所得63个化合物按照vip值大小从高到低排列,取前8位,即得步骤1中所述差异性化合物。
一个优选方案中,步骤2中tc值或者用逻辑回归模型2进行计算,所述逻辑回归模型2的计算公式为:
tc=-1.331+6.255*r1-8.419*r3+1.827*r4-13.914*r6+8.808*r7+11.369*r8。
经过roc曲线绘制,模型2的auc值为0.943,准确度为94.3%。
一个优选方案中,步骤2中tc值或者用逻辑回归模型3进行计算,所述逻辑回归模型3的计算公式为:
tc=-0.693+4.059*r1-6.954*r3-13.299*r6+9.063*r7+10.011*r8。
经过roc曲线绘制,模型3的auc值为0.904,准确度为90.4%.
优先选择模型1进行分析,也可以根据所测样品数据情况,选择模型2或者模型3进行计算预测,或者优先选择模型1进行计算,同时使用2和3模型进行辅助验证,协同分析预测。
本发明通过筛选,首次发现与肥胖相关的一组化合物,即与肥胖相关的脂质生物标志物,并通过构建逻辑回归模型,得到根据这些脂质标志物预测肥胖的方法,快捷方便,准确度高。通过aic值初步判断,并进行roc曲线绘制,准确度高达96.4%。
实施例1
材料和方法
1.实验对象(均选自中国人):28位正常人(bmi<24),22位肥胖(bmi>25),抽取静脉血5ml,离心后取上清液即为血清,然后准确量取100μl的血清,加入900μl的提取液(100%异丙醇),转入2ml离心管中,漩涡振荡10s以上,超声10min,然后在-20度冰箱中冷冻1小时,取出后在室温下漩涡振荡,用冷冻离心机10000rpm离心10min,然后去上清液800μl至玻璃进样瓶中,保存在冰箱中待测。
2.主要仪器和软件
2.1冷冻离心机:型号d3024r,scilogex公司
2.2漩涡振荡器:型号mx-s,scilogex公司
2.3高分辨质谱仪:esi-qtof/ms;型号:xevog2-sq-tof;厂家:waters
2.4超高效液相色谱:uplc;型号:acquityuplci-class系统;厂家:waters
2.5数据采集软件:masslynx4.1;厂家:waters
2.6分析鉴定软件:progenesisqi;厂家:waters;
2.7作图软件:ezinfo;r语言
3.主要试剂
甲醇、乙腈、甲酸、甲酸氨、亮氨酸脑啡肽、甲酸钠。厂家均为fisher。
4.实验设置
液相方法
无色谱柱,直接进样
流速:0.04ml/min
流动相:
a:acn/h2o(60%/40%),含有10mm甲酸铵和0.1%甲酸
b:ipa/acn(90%/10%),含有10mm甲酸铵和0.1%甲酸
(注:acn为乙腈,ipa为异丙醇)
进样体积:2μl
洗脱程序:
质谱方法
数据采集方式:mse;分子量扫描范围:50-1500m/z;分辨率模式(轮廓图)。
正负离子模式各采集一次。
离子源:电喷雾电离源(esi)
毛细管电压:3kv
锥孔电压为:25v
碰撞能:15-60v
源温度:120度
脱溶剂温度:400度
锥孔气体速度:50l/h
脱溶剂气体速度:500l/h
扫描时间:0.2s
使用亮氨酸脑啡肽(m/z556.2771,正离子;554.2615,负离子)进行实时校正。使用甲酸钠进行校正。
脂质组学数据分析
progenesisqi软件(waters,massachusetts,usa)用于结果分析,抽提非靶向脂质分子的特征峰,进行比对和筛选。同时,用qc(quantifyingcontrol)和blank(空白)来筛选背景数据。最终的数据,导入ezinfo3.0,并进行principalcomponentanalysis(pca)分析,orthogonalsignalcorrectionpartialleastsquarediscriminationanalysis(opls-da)建模,variableimportanceinprojection(vip)的计算,同时得到火山图(coefficientsvs.vipspots)。其中,逻辑回归模型以及roc曲线通过r语言进行建设和绘制。
结果描述
正常人群与肥胖人群具有不同的脂质组成。
通过对正常和肥胖人群的血液脂质组学的分析,一共鉴定到540种化合物。将这些化合物进行分类,发现无论正常还是肥胖人群,脂质最大的组分是甘油磷脂(glycerophospholipids),其次是鞘脂(sphingolipids),然后是甘油脂(glycerolipid),甾醇(sterollipid)和脂肪酸(fattyacyls)。但是,与正常人相比,肥胖人群甘油磷脂百分比降低而甘油脂和脂肪酸升高。
正常人群与肥胖人群脂质差异物质的鉴定。
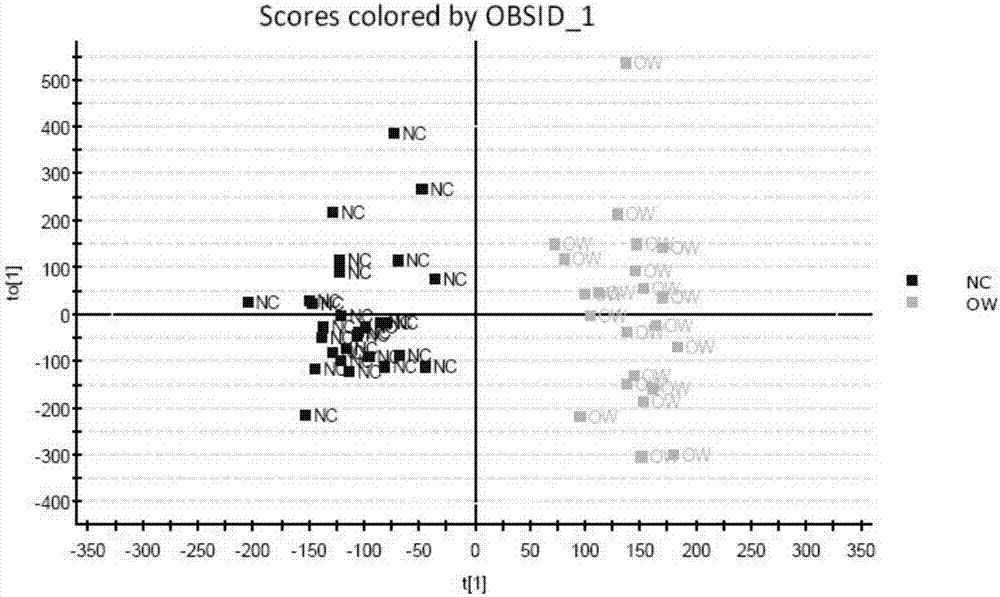
首先进行pca分析。结果发现:nc(normalcontrol)人群与ow(overweighted)人群没有办法完全分开。因此,建立opls-da模型,对nc和ow组群进行分类,并研究造成他们出现差异的原因。
在opls-da模型中,利用相关性(correlation)和协方差(covarience)的p值作出的s-plot形成了非常好的s形曲线,如图1所示。
利用opls-da将两组数据进行强制分组,分组结果如图2所示。
计算影响nc和ow分组的变量重要性,即vip(variableimportanceinprojection)值。一共筛选到63个化合物,他们的vip值大于1,如表1所示。
表1.变量重要性投影
通过vip筛选出来的化合物在s-plot上用红色方框标出,发现他们均匀的分布在两侧。同时,利用火山图,来考察筛选出的化合物的分布,如图3所示,发现筛选出来的化合物都分布在火山图的外围。这些结果都说明,借由opls-da模型,成功筛选出造成ow和nc差异的化合物。
建立逻辑回归模型以及roc曲线。
对脂质组学的数据进行标准化操作(rproject:scale)。然后将vip>1的排名前10位变量的数据提取出来,建立逻辑回归模型和roc曲线。
公式中,tc:是否肥胖0为否,1为是。
模型1:
tc=-1.675+16.031*r1-6.476*r2-35.888*r3+2.823*r4+20.2*r5-21.951*r6+15.726*r7+18.845*r8
aic:40.24
模型2:
tc=-1.331+6.255*r1-8.419*r3+1.827*r4-13.914*r6+8.808*r7+11.369*r8
aic:43.12
模型3:
tc=-0.693+4.059*r1-6.954*r3-13.299*r6+9.063*r7+10.011*r8
aic:50.26
通过aic值初步判断,模型1优于模型2,同时模型2优于模型3。
针对以上三个逻辑回归模型,进行roc曲线绘制,如图4所示,模型1为m1,auc值达到0.964;模型2为m2,auc值为0.904;模型3为m3,auc值达到0.943。我们发现模型1最靠近左上角定点,同时auc值最高,最终,确定模型1为基于脂质指标来预测糖尿病血脂异常较好的预测模型。也可以根据所测样品数据情况,选择模型2或者模型3进行计算预测,或者优先选择模型1进行计算,同时使用2和3模型进行辅助验证,协同分析预测。
本发明第一次利用shotgun的脂质组学方法,快速进行肥胖脂质组学的研究。通过脂质分类发现,肥胖人群中甘油磷脂比例下降2%,甘油酯比例升高1%,脂肪酸比例升高1%。利用opls-da模型,首次发现与肥胖相关的63个biomarker。利用逻辑回归模型以及roc曲线,首次提出了基于脂质指标的肥胖预测模型,其中8个脂质是作为模型预测的关键分子:sm(44:2),tg(57:10),pe(44:7),dg(34:2),dg(336:3),tg(57:11),tg(59:11),pc(42:0),这些物质在肥胖人群中显著升高,该模型的预测准确性为96.4%。
通过模型分析,发现碳链为18-22的脂肪酸(fa),碳链为56以上的心磷脂(cl),碳链为32以上的二酰甘油(dg),碳链为30以上的磷脂(pa,pc,pe,pg,pi,ps),碳链为40以上的鞘脂(sm),碳链为50以上的三酰甘油(tg)是预测肥胖发生的关键物质。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
- 还没有人留言评论。精彩留言会获得点赞!