基于改进多尺度模糊熵的滚动轴承故障诊断方法与流程
本发明涉及一种故障诊断技术,特别涉及一种基于改进多尺度模糊熵的滚动轴承故障诊断方法。
背景技术:
滚动轴承是旋转机械中关键的部件之一,其运行状态往往决定着整台机器的性能。因此,滚动轴承的故障诊断有重要的意义。在各种轴承故障诊断方法中,基于振动信号的诊断是最常用、最有效的方法之一。而滚动轴承在运行过程中难免会受到摩擦、间隙和非线性刚度等非线性因素的影响,所采集的振动信号往往呈现出很强的非线性、非稳态特征。因此,传统的基于线性系统的时域和时频域信号分析方法很难准确地提取轴承的故障特征信息。随着非线性动力学的发展,出现了一些非线性动力学分析技术,为分析轴承复杂的非线性动力学行为提供了一种很好的选择。这其中近似熵、样本熵、多尺度熵和多尺度模糊熵等都被引入到滚动轴承的故障诊断中,并取得了很好的诊断效果。近似熵是对时间序列复杂度的一种度量,样本熵是对近似熵的一种改进,减少了对序列长度依赖的同时克服了近似熵自身匹配的缺点。模糊熵是把模糊集的概念引入到样本熵的计算中,其对参数的依赖性更小、相对一致性更强且抗噪能力更好。多尺度模糊熵是定义在不同尺度下的模糊熵,用来衡量时间序列在不同尺度下的复杂性,比单一尺度的模糊熵能更全面的衡量信号的复杂度。
然而,模糊熵在构建计算所需的向量时减去了一个局部均值,这使得在计算熵值时忽略了信号的整体趋势。而对于滚动轴承的故障诊断而言,只有全面考虑振动信号所包含的特征,才能提取可以更加全面地反映轴承运行状态的故障特征信息。
技术实现要素:
本发明是针对传统的多尺度模糊熵算法在提取轴承状态信息时存在局限的问题,提出了一种基于改进多尺度模糊熵的滚动轴承故障诊断方法,对模糊熵算法进行改进,用一个总体均值代替的传统模糊熵计算中的局部均值,计算不同尺度下的改进模糊熵。改进后的多尺度模糊熵能更全面地反映信号的特征,从而更准确地评估轴承的运行状态。
本发明的技术方案为:一种基于改进多尺度模糊熵的滚动轴承故障诊断方法,具体包括如下步骤:
1)、测量滚动轴承的振动信号;
2)、计算轴承振动信号的改进多尺度模糊熵:
对测量得到的轴承振动信号进行粗粒化;针对模糊熵计算过程中存在的局限性,对模糊熵算法进行改进;计算不同尺度因子下粗粒序列的改进模糊熵,改进模糊熵算法点为利用总体均值
其中,
3)、选取前八个尺度上的改进模糊熵作为轴承故障特征向量;
4)、将得到的轴承故障特征分为训练样本和测试样本;
5)、利用训练样本对支持向量机进行训练得到预测模型;
6)、利用得到的预测模型对测试样本进行预测;
7)、根据预测结果识别滚动轴承的工作状态与故障类型。
本发明的有益效果在于:本发明基于改进多尺度模糊熵的滚动轴承故障诊断方法,改进传统的模糊熵算法,能够提取更加丰富的轴承状态信息,在故障模式识别过程中有更高的识别率。
附图说明
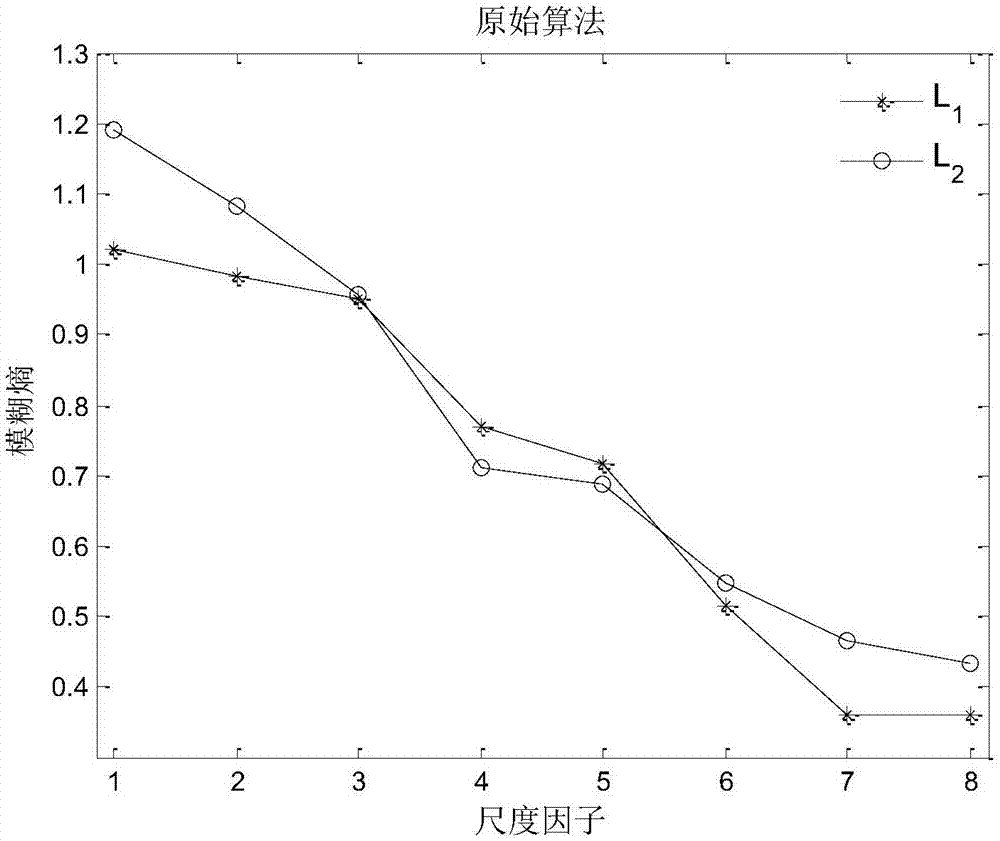
图1为模拟信号原始算法的多尺度熵分析图;
图2为本发明模拟信号改进算法的多尺度熵分析图;
图3为本发明十种不同轴承故障在八个不同尺度上的改进模糊熵图;
图4为本发明基于改进多尺度模糊熵和支持向量机的滚动轴承故障诊断流程图;
图5为本发明基于改进多尺度模糊熵和svm的识别结果图;
图6为基于原始多尺度模糊熵和svm的识别结果图。
具体实施方式
本发明为了克服传统的模糊熵在计算时忽略信号的整体趋势这一局限,同时为了提高故障诊断效率,减少人为因素对诊断结果的干扰,提供了一种基于改进的多尺度模糊熵和支持向量机的滚动轴承故障诊断方法,具体采用以下技术方案:
1.改进的多尺度熵算法
1.1多尺度模糊熵
近似熵和样本熵都是基于heaviside函数(单位阶跃函数)来定义向量的相似性的,导致了传统的二值分类的结果,而现实世界中类的边界是模糊的,很难直接确定一个待定模式是否完全属于某一类。模糊熵引入了模糊集的概念,利用指数函数作为模糊函数来计算向量的相似性。
模糊熵的定义如下:
(1)对于一个n点时间序列{u(i):1≤i≤n},构建一个m维向量
其中,
其中
(2)定义
(3)利用模糊函数定义
r为相似容限,即相似度
(4)对每一个
(5)定义函数
(6)类似地,对m+1维,重复上面的步骤得
(7)定义模糊熵为
(8)当n为有限值时,(8)式可以表示为
fuzzyen(m,r,n)=lnφm(r)-lnφm+1(r)(9)
模糊熵最初选择作为模糊函数的指数函数为
为了使指数函数有更明确的物理意义,式(10)进行了如下改进
本文使用(11)式来计算模糊熵。
模糊熵和样本熵一样,都是对时间序列复杂度在单一尺度上的度量,熵值越大,序列的复杂度越高。为了衡量时间序列在不同尺度下的复杂性和自相似性,构造原始时间序列的粗粒化序列如下:
其中,τ代表尺度因子,1<<j<<n/τ。实际上,当τ=1时,
1.2改进的多尺度模糊熵
然而,模糊熵在构建计算相似性的向量时,减去了一个均值,这样设计的目的是为了能更准确地描述短暂生理电信号中发生的局部相似性,但这却忽略了信号的整体趋势。而对于滚动轴承的性能退化评估而言,只有全面考虑振动信号所包含的特征,才能更加全面地反映轴承运行的状态。基于上面的分析,本文在计算时利用总体均值
其中,
然后用(13)式计算模糊熵,并用改进后的模糊熵算法和多尺度分析相结合计算轴承振动信号,进行改进的多尺度模糊熵分析。模拟信号以及实际轴承疲劳寿命加速试验数据验证了改进后的多尺度模糊熵的有效性和优越性。
1.3参数的选择
根据模糊熵的定义,模糊熵值的计算取决于嵌入维数m、相似容限r、序列长度n以及模糊函数的梯度n。嵌入维数m表示比较窗口的长度,r代表相似容限的宽度。m值越大,重构系统的发展过程就越细致,然而大的m值需要足够的数据长度(n=10m~30m),或者相似容限足够大。但是相似容限过大会导致丢掉很多统计信息,反过来相似容限过小又会增加计算结果对噪声的敏感性。一般r的取值范围是0.1~0.25sd(sd为原始序列的标准差)。综合考虑,本发明取m=2,r=0.2sd,n=2048。与样本熵相比,模糊熵的计算还多了一个参数n,它决定着相似容限边界的梯度。n在计算向量相似性过程中起着权重的作用,当n>1时,更多地计入较近的向量对其相似度的贡献,而更少地计入较远的向量的相似度贡献;当n<1时,效果则相反。过大的n会丧失细节信息,当n为无穷大时,指数函数退化为heaviside函数,此时会丧失边缘的全部细节信息。因此,为了获取尽量多的细节信息,n取较小的整数值,如2或3等,本发明取n=2。
2.模拟信号的分析
利用模拟信号初步验证原始算法与改进后算法对不同复杂度信号的分辨能力,模拟信号由一个逻辑序列l、一个正弦信号s和一个随机信号r组成:
lj=l+aj×(s+r)
式中a表示s与l的幅值比,l代表由下式生产的逻辑序列:
x(n+1)=ω×x(n)×(1-x(n))
ω是决定序列复杂度的常数,改变不同的a和ω可以得到不同复杂度的模拟信号。当取a1=a2=0.1,ω1=3.7,ω2=3.8时可知,其对应信号的复杂度满足这样的关系:l1<l2。图1是原始算法的多尺度熵分析,计算了前八个尺度的模糊熵,由图可知,l2在一些尺度上(τ=1,2,3,6,7,8)的熵值大于l1,但是在τ=4和5时,熵值小于l1,这在进行l1和l2的复杂度分析时会造成混乱。作为对比,图2是改进算法的多尺度熵分析,从图中可以看到,l2在8个尺度上的熵值都大于l1。因此,与原始算法相比,改进的多尺度模糊熵对信号复杂度具有更好的区分能力。
3.实例验证
为了进一步说明改进多尺度模糊熵在提取滚动轴承故障特征的有效性,对实际的轴承试验数据进行了分析。同时,为了实现故障诊断的智能化并降低人为因素对故障识别结果的影响,建立了基于支持向量机的多故障分类器来实现不同轴承故障的自动诊断。支持向量机算法简单,泛化能力强,在小样本分类中表现优异,被广泛应用于故障诊断领域。
3.1试验数据
本文采用的试验数据来自于美国凯斯西储大学的轴承数据中心,测试轴承型号为skf6205-2rsjem深沟球轴承,利用电火花加工技术布置故障尺寸不同的单点故障。轴承转速为1797r/min,采样频率为12khz,包含正常状态、内圈故障、外圈故障和滚动体故障以及不同故障尺寸共10种故障类型,每个数据长度为2048点,具体如表1所示试验数据集。
表1
3.2试验结果与分析
利用改进的多尺度模糊熵分析上述十种不同滚动轴承状态下振动数据,结果如图3所示。从图中可以看出,正常状态下信号在不同尺度上的改进模糊熵变化趋势与故障信号不同,故障状态下信号的熵值随着尺度的增大呈现明显的下降趋势,而正常信号随着尺度的增加先增大然后逐渐趋于平稳,在大部分尺度上的熵值都比故障信号大,说明正常状态下信号的复杂度比故障信号高。这是因为当正常运行在健康状态下时,振动是随机的、不规则的,主要来自于机械零部件之间的相互作用、耦合以及环境噪声,因此,正常信号有比较低的自相似度,高的复杂度。相对地,当轴承出现故障时,由故障引起的冲击会带来很多确定性的冲击成分,从而增加了故障信号的自相似性,降低了其复杂度。从图3还可以看出,虽然不同故障状态下的信号在不同尺度下有相似的变化趋势,但是不同的故障状态在不同尺度上的熵值大小不同,说明不同的故障状态下信号的复杂度不同,因此,改进后的多尺度模糊熵是一种有效的反映和区分滚动轴承故障特征的方法。
为了降低人为因素对故障识别结果的影响,并且验证改进的多尺度模糊熵相对于原始算法的多尺度模糊熵在提取轴承状态信息时的优越性,支持向量机被用来实现滚动轴承故障的自动诊断。由于进行多类分类,本发明采用一对一的方法建立多分类支持向量机。核函数选用径向基核函数,利用交叉验证和网格搜索的方法寻找最优的惩罚参数和核函数参数。利用改进多尺度模糊熵和支持向量机的滚动轴承故障诊断步骤如图4所示。具体包括如下步骤:
步骤(1)、测量滚动轴承的振动信号;
步骤(2)、计算轴承振动信号的改进多尺度模糊熵:
对测量得到的轴承振动信号进行粗粒化;针对模糊熵计算过程中存在的局限性,对模糊熵算法进行改进;计算不同尺度因子下粗粒序列的改进模糊熵,计算模糊熵采用上述公式(13)和(14);
步骤(3)、选取前八个尺度上的改进模糊熵作为轴承故障特征向量;
步骤(4)、将得到的轴承故障特征分为训练样本和测试样本;
步骤(5)、利用训练样本对支持向量机进行训练得到预测模型;
步骤(6)、利用得到的预测模型对测试样本进行预测;
步骤(7)、根据预测结果识别滚动轴承的工作状态与故障类型。
十种轴承状态每种状态选取50组数据,考虑实际中故障样本很难得到,其中10组用于训练,其余40组用来测试,一共500组数据。把训练样本输入支持向量机进行训练,用训练好的模型预测测试数据,所有的训练样本都被正确识别,测试样本的识别结果如图5所示,400组测试样本只有3个被错分,预测准确率为99.25%。为了突出改进多尺度熵算法的优越性,计算了上述数据的原始多尺度熵,利用同样的步骤训练并建立支持向量机预测模型,然后对测试数据进行分类识别。所有的训练样本都被正确识别,测试样本的识别结果见图6,400组测试样本一共有14个被错分,分类准确率为96.5%。这一对比结果也说明了改进后的多尺度模糊熵比原始算法能够更有效地提取隐含在轴承振动信号里的状态信息,因而能更准确地识别不同的轴承故障状态。
- 还没有人留言评论。精彩留言会获得点赞!