一种混响条件下的麦克风阵列声源定位装置的制作方法
本发明涉及一种麦克风阵列语音信号处理装置,尤其是涉及一种可适应混响背景的麦克风阵列声源定位装置。
背景技术:
麦克风阵列技术通过组合多个按照一定空间位置排列的麦克风而成,由于采集的多通道语音在时频域的基础上具有空间信息,从而可对声源进行定位,也即估计声源方位信息,从而可为语音增强、语音分离、等算法提供所需的声源方向信息,改善语音信号处理算法性能,因而麦克风阵列声源定位在语音识别、语音追踪、智能家居、视频会议等领域得到了广泛的研究和应用。
在较为安静、理想的背景环境下,目前常用的波束控制、高分辨率谱估计及基于到达时间差(timedifferenceofarrival,tdoa)的麦克风声源定位算法都有较好的声源方位估计性能,其中tdoa方法因计算复杂度低、易于实时实现,得到较多的研究和工程应用。
如:中国专利zl201410424948.x提出一种基于改进phat(相位变换方法,phat)加权时延估计的声源定位方法及其实现系统,该方法通过改进的phat加权广义互相关函数法进行时延估计算法处理,获得时延估计值,再结合放置的麦克风阵列空间位置,利用迭代法解非线性方程组,从而得到声源的相对位置。但由于该方法采用的广义互相关函数方法建立在非混响模型基础上,因而并不适用于有较大混响和有相关噪声的场合。
中国专利zl2009102654269公开一种麦克风阵列降噪控制方法及装置,该装置对麦克风阵列采集的所有声音信号计算入射角度,并根据入射角度进行信号成分的统计,从而根据统计结果中噪声成分所占的比率确定控制参数,对自适应滤波器进行控制,达到消除噪声、提高信噪比的目的。
但是,在麦克风阵列声源定位的实际应用中,结构环境下墙面、天花板、地面等边界形成的语音信号大量反射分量严重降低了常规麦克风阵列声源定位算法的性能,与此同时,汽车、空调外机、音响、家电、机械等背景噪声进一步影响了算法性能,上述影响因素造成常规的麦克风阵列声源定位算法在实际应用中性能往往不能令人满意,成为制约推广应用的一个主要技术瓶颈。因此,研究可适应强烈混响条件的麦克风阵列声源定位算法及装置对于提高语音信号处理系统的稳健性和实用性都起着重要的作用。
中国专利zl201410273464.x公开了一种七元麦克风阵列的声源定位方法,对接收的语音信号进行采集、滤波、加窗、谱减、倒谱处理;再利用相位变换加权广义互相关方法gcc-phat,得各麦克风之间的时间延迟;运用三维空间定位方法与坐标旋转数字式计算机方法,确定声源位置。该发明在混响、噪声等干扰信号存在的室内环境下,能准确确定声源位置。但由于采用倒谱方法进行消除混响处理,要求对语音信号进行傅里叶变换的长度不低于主要混响分量的延迟时间,因此对于存在较为严重混响的会议室、走廊等混响延迟时间较长的场合,该方法性能将受到严重影响。
技术实现要素:
本发明的目的在于提供一种混响条件下的麦克风阵列声源定位装置。
本发明设有5元麦克风阵列、tdoa粗估计模块、等效传输函数实测模块、假设等效传输函数生成模块、自适应迭代模块和比较判决输出模块;
所述5元麦克风阵列用于进行语音信号多通道采集,其中5元麦克风阵列包括4个均匀分布于圆周的定位麦克风采集的语音信号经前置放大、模数转换后通过数据线直接输入tdoa粗估计模块的输入信号通道;位于圆心的参考麦克风采集的语音信号经前置放大、模数转换后通过数据线直接输入tdoa粗估计模块的参考信号通道,tdoa粗估计模块获得参考麦克风与各定位麦克风之间的传输函数输入等效传输函数计算模块;等效传输函数计算模块对各定位麦克风通道与参考麦克风通道传输函数进行叠加,获得实测的等效传输函数;
所述假设传输函数生成模块根据假设的n个声源方向生成n个假设声源方向对应的参考麦克风与各定位麦克风间时延差,并通过叠加生成n个假设声源方向对应的等效传输函数;实测的等效传输函数、假设等效传输函数分别输入n个自适应迭代模块的参考端和信号输入端,通过自适应迭代获得n路迭代误差并输入比较输出模块;比较输出模块对n路迭代误差进行滑动加窗能量计算,获得n个假设声源方向对应的迭代误差,通过比较获得其中最小误差,并输出最小误差所对应的假设声源方向作为声源定位输出。
所述5元麦克风阵列可由均匀分布于圆周的4个定位麦克风和位于圆心的一个参考麦克风组成。
本发明实现混响背景下声源定位功能的步骤包括:5元麦克风阵列、tdoa粗估计、实测传输函数计算、假设传输函数生成、自适应迭代、比较输出。
在tdoa粗估计步骤,对接收到的各定位麦克风信号和参考麦克风信号分别进行tdoa粗估计,获得各定位麦克风与参考麦克风之间的传输函数;
实测传输函数计算步骤,通过加权叠加,使得各定位麦克风与参考麦克风之间的传输函数加权叠加获得等效传输函数;
假设传输函数生成步骤,根据假设的n个声源方向,生成n个假设声源方向对应的参考麦克风与各定位麦克风间时延差,并通过加权叠加生成n个假设声源方向对应的等效传输函数;
自适应迭代步骤,分别将实测等效传输函数和n个假设等效传输函数作为参考端和信号输入端进行自适应迭代,并输出n路迭代误差;
比较输出模块对自适应迭代获得的对应n个假设声源方向的n路迭代误差进行比较,取最小误差所对应的声源方向作为声源方向进行输出。
本发明针对语音识别、语音跟踪、视频会议等智能家居、办公等领域存在的混响背景下麦克风阵列声源定位的困难,本发明提出增加参考麦克风通道结合假设声源方向,并通过各假设声源方向下各定位麦克风通道与参考麦克风通道间时延差关系进行自适应迭代,通过选择个假设声源方向中最小迭代误差对应的声源方向作为声源方向输出,实现混响背景下的麦克风阵列声源定位。
本发明实现适应强烈背景噪声的麦克风阵列语音增强的具体思路为:首先增加一个参考麦克风,通过分配并假设声源方向获得各个假设声源方向下参考麦克风与定位麦克风之间的时延差关系;通过叠加将各个假设声源方向下参考麦克风与定位麦克风之间的时延差关系转换为假设等效传输函数;利用tdoa粗估计获得的参考麦克风与各定位麦克风传输函数的加权叠加获得实测的等效传输函数;在各个假设声源方向下分别对等效传输函数与实测传输函数进行自适应迭代,获得各假设声源方向对应的迭代误差;通过对迭代误差进行最小比较,获得对应的假设声源方向作为当前声源方向,实现混响条件下声源定位。
基于上述考虑,本发明提出的麦克风阵列声源定位方法可对强烈混响背景下对声源方位进行估计,首先通过声源方位进行扇形分区,即将声源可能存在的方向平均分割为等夹角的若干个方向,通过在麦克风阵列中增加一个参考麦克风,阵列中其余的非参考麦克风作为定位麦克风,从而在每个声源可能存在方向下各定位麦克风通道与参考麦克风通道时延差之间具有一一对应的关系,在强烈混响及背景噪声条件下本方法通过有效地利用这种对应关系作为约束进行声源方向检测,以提高定位性能;同时,考虑到混响条件下语音信号的信混比极低,直接对语音信号进行检测处理性能下降,本发明提出采用假设-自适应迭代-比较判决的方式采取对各定位麦克风通道与参考麦克风通道之间的传输函数进行自适应迭代的方式,通过比较不同假设声源方向下的迭代误差进行判决来获取声源方位,从而使本发明方法便于混响条件下的工程实现和推广应用。
与现有的麦克风阵列声源定位方法及装置相比,本发明提出的可适应混响背景的麦克风阵列声源定位装置的突出优点在于:由于采用参考通道形成的时延差约束关系合成等效传输函数,同时结合了对各假设声源方向下迭代误差的比较判决,本发明提出的装置采用对各通道相对参考麦克风的等效传输函数而非接收信号本身进行计算的方式,一方面可避免传统广义相关方法在严重混响条件下处理性能下降的问题;另一方面无需通过倒谱域域处理去混响来保证定位性能所导致的运算复杂度和较长傅里叶变换长度,从而实现语音信号带有强烈混响条件下的声源定位。
附图说明
图1为本发明实施例的麦克风阵列声源定位装置结构图。
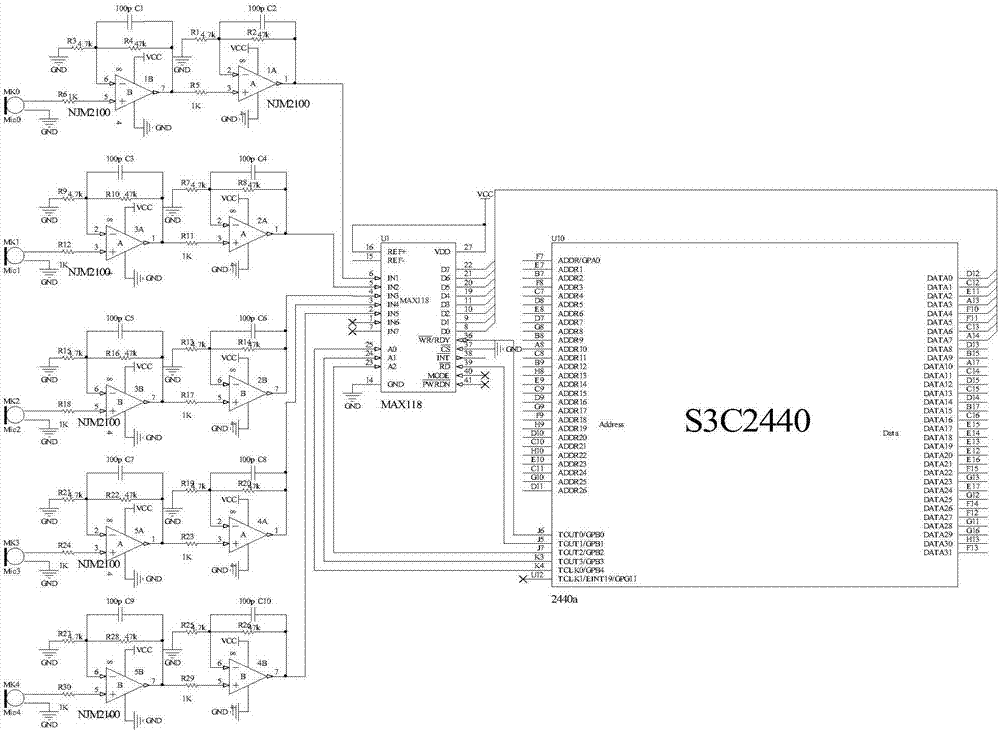
图2为本发明实施例的5元麦克风阵列及其与微处理器连接电路图。
图3为本发明实施例中各定位麦克风到参考麦克风间传输时延原理图。
具体实施方式
为了使本发明的技术内容、特征、优点更加明显易懂,以下以本发明可适应强烈背景噪声的麦克风阵列语音增强装置实施例并结合附图具体说明如下:
参见图1,本发明实施例设有5元麦克风阵列1、tdoa粗估计模块2、等效传输函数实测模块3、假设等效传输函数生成模块4、自适应迭代模块5和比较判决输出模块6;
所述5元麦克风阵列1用于进行语音信号多通道采集,其中5元麦克风阵列1包括4个均匀分布于圆周的定位麦克风11采集的语音信号经前置放大、模数转换后通过数据线直接输入tdoa粗估计模块2的输入信号通道;位于圆心的参考麦克风12采集的语音信号经前置放大、模数转换后通过数据线直接输入tdoa粗估计模块2的参考信号通道,tdoa粗估计模块2获得参考麦克风12与各定位麦克风11之间的传输函数输入等效传输函数计算模块3;等效传输函数计算模块3对各定位麦克风12通道与参考麦克风11通道311~31n传输函数进行叠加3a,获得实测的等效传输函数3b;
所述假设传输函数生成模块4根据假设的n个声源方向生成n个假设声源方向411~41n对应的参考麦克风12与各定位麦克风11间时延差421~42n,并通过叠加生成n个假设声源方向对应的等效传输函数431~43n;实测的等效传输函数、假设等效传输函数分别输入n个自适应迭代模块5的参考端和信号输入端,通过自适应迭代511~51n获得n路迭代误差并输入比较输出模块6;比较输出模块6对n路迭代误差进行滑动加窗能量计算,获得n个假设声源方向对应的迭代误差,通过比较获得其中最小误差,并输出最小误差6a所对应的假设声源方向作为声源定位输出6b。
所述5元麦克风阵列1可由均匀分布于圆周的4个定位麦克风11和位于圆心的一个参考麦克风12组成。
本发明实施例中5元麦克风阵列由4个均匀分布在直径d=20cm圆周的定位麦克风(m0,m2,…m4)和位于圆心的参考麦克风r0组成,通过4个定位麦克风、1个参考麦克风分布获取各定位通道、参考通道的语音信号,并用于作为tdoa粗估计模块的输入进行定位麦克风与参考麦克风间传输函数粗估计。
具体地,4个定位麦克风和1个参考麦克风均由体积小、结构简单、电声性能好的压强式驻极体麦克风mic0,…,mic4,njm2100运算放大器芯片构成的前置放大电路及max118模数转换芯片构成,在本实施例中:圆周半径r=10cm,4个在圆周上均匀分布的定位麦克风两两之间的圆心角为90度。
本实施例中tdoa粗估计模块、实测传输函数计算模块、假设传输函数生成模块、自适应迭代模块、比较输出模块均属于数字信号处理模块,在本实施例中采用arm9s3c2440微处理器进行软件编程实现。
该麦克风阵列语音增强装置中5元麦克风线阵与微处理器的连接方式为:5元麦克风线阵中5个麦克风输出信号经过图2所示运算放大器构成的2级前置放大电路放大后输入多通道模数转换芯片max118,s3c2440微处理器通过io口gpb2,3,4控制max118的输入通道端a1、a2、a3,通过定时器输出脚tout0、tout1控制max118的读出/写入端口wr、rd进行采样频率16ksps的模数转换,通过数据线data0至data7进行8bit模数转换结果到s3c2440微处理器的传送。
该麦克风阵列声源定位装置中多通道语音信号模数转换进入微处理器后,以软件形式运行的各数字信号处理模块间的数据、控制流连接方式如图3所示,具体说明如下:
在本发明实施例中把声源可能存在的360度范围按照20度间隔平均分配为18个角度(即n=18),假设响应生成模块根据假设的18个声源方向,生成18个假设声源方向对应的参考麦克风与各定位麦克风间时延差,并通过叠加生成18个假设声源方向对应的等效传输函数。假设响应生成模块的原理结合图3具体说明如下:在本发明实施例中5元麦克风圆阵如图所示,以5元麦克风线阵圆心的参考麦克风m0位置为坐标原点建立极坐标系,则如图所示但声源处于θj角度时,4个定位麦克风m1,m2,m3,m4与参考麦克风m0之间会产生如下时延(如图3所示):
其中:i为圆阵中各定位麦克风通道的编号;i=1,2,3,4,j代表声源所在方向的空间编号,θj为声源所在空间角度,j=1,2,…,18;θd为1号定位麦克风相对声源0度方向的固定角度;r为圆阵半径,本实施例中r=0.1m;c为空气中的声速(本实施例中取340m/s);fs为麦克风阵列语音信号的采样频率(单位为hz,在本实施例中取16000hz);round()代表取整运算;di,j代表声源方向为θj时,第i通道麦克风阵元相对圆心参考麦克风的时间延迟对应的采样点数,di,j为负代表相对参考麦克风提前,di,j为正代表相对参考麦克风延迟。
则,理想条件下,声源位于θj角度时各定位麦克风到参考麦克风间的传输函数可以写为:
hi,j=δ(n-di,j),i=1,2,3,4;
其中n为采样点的时间刻度。将声源位于θj角度时各定位麦克风到参考麦克风间的理想传输函数进行叠加可以获得声源位于θj角度时的等效传输函数:
相对于理想情况,实际场景中语音信号不可避免受混响干扰,对于麦克风圆形阵列定位麦克风和中心麦克风的实际采集信号,可以采用本领域通用的互相关方法获得的互相关函数近似作为各定位麦克风到参考麦克风间的实测传输函数:
其中:l为互相关运算的处理窗长,本实施例中取值为600,;s为时延的搜索范围,本实施例中取值为300。同样通过叠加各定位麦克风与参考麦克风间的实测传输函数获得实测的等效传输函数:
本发明考虑到存在强烈混响的应用场景,此时语音信号已被混响、噪声严重掩盖,直接对信号进行增强、定位算法处理的性能急剧下降,因此提出通过假设声源方向下各定位麦克风与参考麦克风之间的实测和理想传输函数进行迭代处理,搜索最小误差对应的假设声源方向作为声源方向估计结果,从而避免严重混响、造成带来的信号处理算法性能下降。由于背景噪声强烈且持续存在,噪声源对应的波束稳定存在,而语音只在说话人发生时存在,因此,语音声源对应波束呈现出变化特性。
具体的等效传输函数迭代过程描述如下:
以将声源位于θj角度时进行等效传输函数迭代为例,设定声源角度获得理想等效传输函数hej作为输入信号,利用圆形阵列定位麦克风和参考麦克风获得的语音信号计算获得的实测等效传输函数he’作为训练信号,则等效传输函数迭代的目的是构造一个l阶的校正滤波器系数wθt=[w1w2w3w4……wl],通过自适应算法(本实施例中l=50,采用本领域通用的最小均方误差lms自适应算法)以已知训练信号he’作为目标信号进行系数wθt的自适应迭代学习,迭代学习的准则是最小化误差ej(n)的均方:
wj,n+1=wj,n+μ·ej(n)·rn(1)
n=1,2,...n
rn=hej(n,n+1,...,n+l-1)(3)
其中u为自适应迭代的步长因子,本实施例中取值为0.002。对应各个声源θj角度进行算法迭代,将算法收敛后形成的误差ej(n)进行误差均方值比较,选取最小均方误差对应的角度即为声源的实际角度。
本发明公开的可适应强烈混响的麦克风阵列声源定位装置最大的特点在于:借助对不同声源角度下参考麦克风和定位麦克风之间形成的等效传输函数进行迭代,通过对不同假设方向下的最小迭代误差的搜索来获取声源方向,由于采用的是对等效传输函数计算是方式并结合对不同假设声源方向进行最小迭代误差搜索,从而避免了传统的麦克风阵列声源定位方法直接对接收信号进行计算而受混响、噪声影响严重的缺点,从而可改善存在强烈混响时的麦克风阵列声源定位性能。
同时,本发明公开的可适应强烈混响的麦克风阵列声源定位装置同样可适用于麦克风阵列的其他阵型(如线阵),只需改变本发明中不同阵型下不同的等效传输函数时延进行叠加合成即可。
- 还没有人留言评论。精彩留言会获得点赞!