一种基于改进DBN的近红外光谱分析纺织品棉含量的方法与流程
本发明涉及红外无损检测技术领域,尤其涉及一种基于改进dbn的近红外光谱分析纺织品棉含量的方法。
背景技术:
纺织品与人们的生活息息相关,随着生活水平的提高,纺织品的质量逐渐受到人们的重视。有关纺织品和服装质量问题的日益突出,诸如成分及含量标识不清、以次充好等,欺骗消费者,不仅影响人们的日常生活,而且扰乱了市场秩序。因此,为了防止纺织品含量混淆不清的情况,应加强纺织品的质量监测,其在纺织品检测项目中有着重要的地位。
常用的传统检测方法操作复杂、费时费力、成本高,无法满足纺织品质量检测的需要。近红外光谱技术以其快速、无损等优点,在纺织品质量检测方面有较好的应用前景,其原理为对有机物中的含氢集团x-h的倍频合频的吸收,通过化学计量方法测得有机物的理化指标,用有效的数学算法将理化值与光谱数据建立函数关系,实现对未知的定性或定量分析。近几年来,近红外光谱分析技术在纺织品领域也得到了广泛的应用。目前存在的基于近红外光谱法的纺织品棉含量的预测方法,主要为单隐层网络和支持向量回归等浅层学习方法,些网络的共同特点是,它们都使用不超过三层的结构将原始输入信号变换到一个特征空间。毋庸置疑,浅层学习对于解决简单的问题非常有效,但是在解决复杂实际应用问题时,往往出现函数表达能力不足等问题,从而会导致结果会出现较大的误差等问题,进而会导致预测结果不准确。而此时深度学习网络则仅需要相对较少的计算单元,即在表达同样的复杂函数时,与浅层网络相比,深度学习网络可能仅需要较少的节点和较少的参数。这意味着,在节点数相同的情况下,深度学习网络通常较浅层网络的函数表达能力更强。对此情况,本发明设计一种基于改进dbn的纺织品棉含量的预测方法,以提高预测的准确度和可靠性。
技术实现要素:
本发明的目的在于提出一种基于改进dbn的近红外光谱分析纺织品棉含量的测定方法,旨在解决现有技术中棉涤纺织品棉含量预测准确度和可靠性较低的问题。
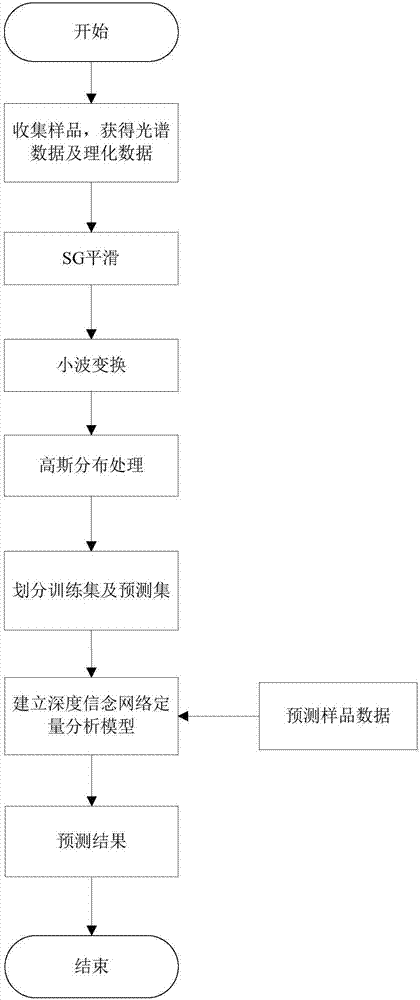
本发明所采用的技术方案是:一种基于改进dbn的近红外光谱分析纺织品棉含量的方法,其特征在于,具体包括以下步骤:
(1)收集样品,采集样品的近红外光谱以及样品的理化数据;
(2)对获取的光谱数据进行预处理,得到预处理后的数据;
(3)使用改进dbn方法,建立定量分析模型,通过全局学习算法对网络进行调整,从而获得最优纺织品棉含量定量分析模型;
(4)将预测数据导入所述最优纺织品棉含量定量分析模型进行纺织品棉含量的预测分析。
进一步的,所述步骤(1)具体实现如下:使用近红外光谱仪以及相关漫反射部件对纺织品布料进行正反两面采集光谱数据,得到正反两面的平均样品光谱,并且按定量化学分析方法——硫酸溶解法对纺织品中棉含量进行测定,得到样品棉含量的理化分析值。
进一步的,所述步骤(2)具体实现如下:
(2.1)对步骤(1)获得的光谱数据进行sg平滑处理;
(2.2)对步骤(2.1)sg平滑处理后的光谱数据进行小波变换方法对光谱数据进行压缩,得到压缩后的近红外光谱数据矩阵;
(2.3)对步骤(2.2)经小波变换处理后的数据进行高斯分布处理,得到规范化后的数据;
(2.4)使用spxy样品集划分方法将步骤(2.3)处理后的样品数据划分训练集及预测集。
进一步的,所述步骤(2.1)中的sg平滑处理具体如下:
(2.1.1)利用最小二乘拟合系数建立数字滤波函数,对移动窗口内的波长点数据进行多项式最小二乘拟合,其表达式如下:
式中,m是多项式的次数;q是平滑窗口点数的中心点;p为平滑窗口点数;
(2.1.2)采用最小二乘法求解待定二项方程式系数,最小二乘拟合的残差ε如下所示:
令
进一步的,所述步骤(2.2)具体实现如下:将sg平滑处理后的光谱数据进行小波变换处理,小波变换选择小波母函数为dbn,n为消失矩,得到压缩后的近红外光谱数据矩阵。
进一步的,所述步骤(2.3)具体实现如下:将小波变换处理后的光谱进行高斯分布处理;其公式为:
进一步的,所述步骤(3)具体实现如下:将预处理后的近红外光谱数据以及其对应的理化分析数据作为改进dbn定量分析模型的输入,建立定量分析模型,改进dbn由多层稀疏高斯受限玻尔兹曼机(spare-grbm)的堆叠和bp神经网络构成,建立定量分析模型的过程如下:
(3.1)将处理后的近红外光谱数据矩阵作为网络的输入;
(3.2)从上而下,采用对比散度算法训练得到高斯受限玻尔兹曼机参数,继续向上逐层对高斯受限玻尔兹曼机进行训练,并结合随机隐匿算法来隐藏部分隐含层节点数,即高斯受限玻尔兹曼机的部分输出置0,对网络模型进行稀疏化处理,直到最顶层结束,得到稀疏后的dbn模型;直到最顶层结束;该模型对应的能量函数为:
其中,e(v,h)为能量模型函数,v为可见层,h为隐含层,vi为输入层第i个节点的值,ci为输入层第i个节点的偏置,σi为第i维输入的标准差向量,wi,j为第i个输入层节点与第j个隐含层节点的连接权重,hj为隐含层的第j个节点的值,bj为隐含层第j个节点的偏置;
相对应的条件概率分布为:
其中,sigmoid=1/(1+e-x),n代表高斯分布;
(3.3)以步骤(3.2)得到的参数{ci,bj,wi,j}作为初始值,使用bp算法对整个网络进行全局训练,得到最终的网络参数,从而获得最优的棉涤纺织品棉含量定量分析模型。
本发明的有益效果是:该改进dbn模型中由高斯分布输入层来代替传统深度信念网络中二进制可视节点,减少了原始光谱数据输入的遗漏。该网络由多层稀疏高斯受限玻尔兹曼机组成,采用逐层无监督贪心算法训练参数,并结合随机隐匿算法来隐藏部分隐含层节点数,对网络模型进行稀疏化处理,从而优化网络的权值,得到稀疏后的dbn架构,从而提高网络的训练速率,然后利用bp算法对整个网络进行全局训练,得到最终的网络参数,完成整个模型的训练。与传统神经网络预测模型对比,该模型克服了传统神经网络容易陷入局部最优、训练时间长及预测准确度低等问题,提高了预测的准确度和可靠性。本方法在纺织品质量监测等方面具有良好的应用前景。
附图说明
图1为本发明预测方法流程图;
图2为本发明样品原始光谱图;
图3为本发明棉涤纺织品棉含量预测值与真实值的拟合曲线图。
具体实施方法
本发明的具体实施方式提出了一种基于改进dbn的近红外光谱分析纺织品棉含量的方法,下面结合附及实施例对本发明进一步详细说明。所描述的实施例为解释本发明,并非用于限定本发明。
实施例:
(1)收集样品,采集样品的近红外光谱以及样品的理化数据;具体为:从市场上收集混纺样品308个,样品状态繁多,颜色有深有浅,有染色也有印花,面料有厚也有薄,有平纹也有斜纹,具有一定的代表性。使用supnir-1100近红外光谱仪对涤棉纺织品的光谱数据进行采集,具体步骤如下:确定布样后对布样进行折叠,依据布料厚度进行z字型折叠,可保证布料内外表面不在同一个面上,便于检测布料的正反两面;将折叠后的布样压平;采集参比光谱后,开始采集样品漫反射光谱,对布料正反两面光谱进行采集,从而得到308个样品正反两面的平均样品光谱,并将其用于后续分析,谱区采集范围:1000-1800nm,实验均在室温下进行。并且按定量化学分析方法——硫酸溶解法对涤棉纺织品中棉含量进行测定,得到样品棉含量的理化分析值。
(2)对获取的光谱数据进行预处理,得到预处理后的数据;具体为:
(2.1)对步骤(1)获得的光谱数据进行sg平滑处理;具体为:选用sg平滑窗口点数13对光谱数据进行降噪处理,得到降噪后的光谱数据矩阵。为了压缩光谱数据,并去除光谱噪声,保留了光谱的主要信息且大大减小了数据量。
(2.2)对步骤(2.1)sg平滑处理后的光谱数据进行小波变换方法对光谱数据进行压缩,得到压缩后的近红外光谱数据矩阵;具体为:选择小波母函数为dbn,n为消失矩,消失矩选取2,分解层数为3层,得到压缩后的近红外光谱数据矩阵,压缩后的矩阵数据量缩减为原始数据量的23%,能量保留率达到99%,压缩后的数据将提高建模速率。
(2.3)对步骤(2.2)经小波变换处理后的数据进行高斯分布处理,得到规范化后的数据;具体为:将上一步处理后的光谱进行高斯分布处理,其公式为:
(2.4)使用spxy(samplesetpartitioningbasedonjointx-ydistance)样品集划分方法将步骤(2.3)处理后的样品数据划分训练集及预测集。具体为:将308个样品按3:1数量比划分为训练集及预测集,训练集样品数为231个,预测集样品数为77个,训练集样品用于模型的建立,预测集样品用于验证模型。
(3)使用改进的深度信念网络方法,建立定量分析模型,通过全局学习算法对网络进行调整,从而获得最优纺织品棉含量定量分析模型;具体为:
将预处理后的近红外光谱数据以及其对应的理化分析数据作为改进dbn定量分析模型的输入,建立定量分析模型,改进dbn由多层稀疏高斯受限玻尔兹曼机(spare-grbm)的堆叠和bp神经网络构成,建立定量分析模型的过程如下:
(3.1)将处理后的近红外光谱数据矩阵作为网络的输入;
(3.2)从上而下,采用对比散度算法训练得到高斯受限玻尔兹曼机参数,继续向上逐层对高斯受限玻尔兹曼机进行训练,并结合随机隐匿算法来隐藏部分隐含层节点数,对网络进行稀疏化处理,设置随机隐匿算法中的参数为0.6,随机隐藏60%隐含层节点数,即60%输出置零,从而优化网络的权值,直到最顶层结束,得到稀疏后的网络模型;该模型对应的能量函数为:
其中,σi为第i维输入的标准差,vi为输入层第i个节点的值,hj为隐含层的第j个节点的值,wi,j为第i个输入层节点与第j个隐含层节点的连接权重,ci为输入层第i个节点的偏置,bj为隐含层第j个节点的偏置;相对应的条件概率分布为:
其中,sigmoid=1/(1+e-x),n代表高斯分布。
(3.3)以上一步得到的参数作为初始值,使用bp算法对整个网络进行全局训练,得到最终的网络参数。从而获得最优的棉涤纺织品棉含量定量分析模型。经过对比多次实验结果,当网络结构取[102,50,25,1]时,模型的稳定性较好,从而获得最优的棉涤纺织品棉含量定量分析模型。
(4)将预测数据导入所述最优纺织品棉含量定量分析模型进行纺织品棉含量的预测分析。具体为:将预测集样品的77条光谱导入最优棉涤纺织品棉含量定量分析模型,对涤棉纺织品棉含量进行预测,经验证,预测结果和真实值有很好的线性关系,其拟合曲线如附图3所示。图中横坐标表示预测值,纵坐标代表真实值,并引入相关系数r指标,r表示预测值与真实值之间的拟合程度,当r越大说明预测值与真实值之间的拟合程度越高。网络预测分析评价标准预测标准差rmsep,其值越小代表模型的预测能力越高。实验结果r=0.9957,rmsep=0.0253,结果表明所构建改进dbn模型具有较高的预测精度及可靠性。
(5)实验结果对比。具体为:使用bp神经网络对上述纺织品样品数据进行建模预测,其网络预测结果为相关系数r=0.9321,预测标准差rmsep=0.2362,对比本发明结果可以得出:所构建的改进dbn模型较bp神经网络模型具有较好的预测精度及可靠性,其对纺织品的质量检测等方面具有一定的实际意义。
- 还没有人留言评论。精彩留言会获得点赞!