一种基于强化学习的AUV三维路径规划方法与流程
本发明属于auv技术领域,具体涉及一种基于强化学习的auv三维路径规划方法。
背景技术:
由于河流海洋资源开发以及对水文环境监测的迫切需要,水下领域在国家经济发展格局和对外开放中的作用显得愈加重要,在国家生态文明建设中的角色更加显著,在维护国家主权、安全、发展利益中的地位更加突出,在国际政治、经济、军事、科技竞争中的战略地位也明显上升。目前各国不断发展更新水下作业任务系统,越来越多高效经济的方法和装置逐渐被采用,auv作为海洋环境探测和资源调查监测的重要手段之一越来越受重视。auv是一种能在水下代替人类完成某一特定任务的装置,它可以搭载不同类型的设备进行水下高效率工作。现代auv的发展迅速,种类和型号都较多,依据不同的标准可以对其进行了不同的划分,如可将auv分成载人潜水器、遥控潜水器、拖曳式潜水器和爬行式潜水器四大类。从控制技术的角度可以把auv分成三类:载人、无人、载人无人两用auv三类,而无人auv又可以根据其是否具有电缆进行划分,具体包括了缆控水下机器人remotelyoperatedvehicle,即rov和无缆水下机器人autonomousunderwatervehicle,即auv。其中根据各种实际情况或作业需要又有不同的种类区分。21世纪以来,随着一些技术问题的不断解决,auv技术已经越来越广泛的运用在商业领域,此外auv也有着重要的军事用途。
路径规划是auv领域的重要技术之一,贯穿了auv水下航行的始终,是其完成水下作业任务的基础。auv的工作环境与陆地差异很大,这也导致auv的运动控制特性较为特殊。具体表现在:流体的密度和粘性影响着auv在水下的运动;auv航速较慢;海流对auv的运动也存在不确定性的干扰。这些都增加了auv的控制难度,所以其控制系统的设计需具备较强的自适应能力以及抗干扰能力等。auv控制系统主要包括运动控制体系结构、软硬件系统以及运动控制算法。而其中的一大研究难点就是如何精确地控制auv的运动,由于水下工作环境的特殊性,一个良好的路径规划系统可以保证auv航行路径的经济性,又能保证其水下航行的安全。
强化学习算法具有良好的在线自适应性和对非线性系统的学习能力,在人工智能、机器学习和自动控制领域中得到了广泛的研究;将强化学习方法应用于auv的控制系统中实现auv路径规划功能以提高其环境的自适应性,另外强化学习还可以改善其它规划方法的维数灾、规划时间长、精度低等问题,对auv的水下安全航行具有重要的实际意义。
技术实现要素:
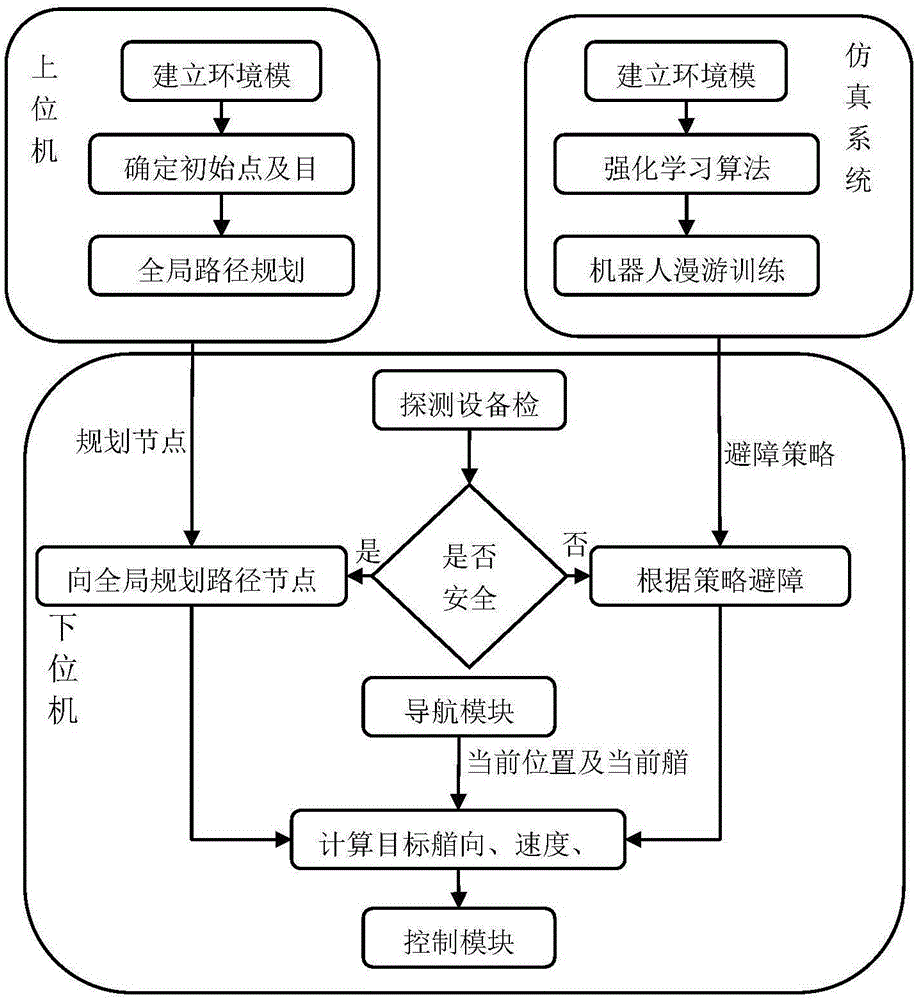
本发明为一种基于强化学习的auv三维路径规划方法,具体包括基于q学习的auv全局路径规划上位机模块、基于自组织竞争神经网络改进q学习方法的auv避障训练仿真模块以及基于避障策略的auv局部路径规划下位机模块;所述的上位机模块为机器人操控台,下位机模块为执行命令的auv,仿真训练模块为机器人仿真系统,三个模块之间通过传输数据实现auv的路径规划功能;所述的基于强化学习的auv三维路径规划方法具体包括如下步骤:
(1)建立模型:根据已知信息或提前探测得到的信息在上位机模块的界面及仿真系统模块中建立auv工作环境三维模型并建立q学习模型:
其中式中,r(st,a)为当前状态所对应动作的奖励值,q(st,a)为当前状态所对应动作的累计强化值,γ为学习率,q(st+1,a)为下一状态所对应动作的q值;
(2)全局规划:基于步骤(1)建立的q学习模型在上位机控制台中实现auv全局路径规划,将规划节点通过无线电发送给下位机模块;
(3)仿真训练:基于自组织竞争神经网络改进q学习的方法在仿真系统中对auv进行避障训练,将所得策略通过无线网络写入下位机模块;
(4)局部规划:下位机模块下水,接受上位机模块的全局规划节点并向规划节点航行,同时利用其搭载的探测设备检测周围环境,遇到突发事件时根据训练学习得到的避障策略实现auv局部路径规划。
所述的步骤(1)具体包括:
(1.1)以auv所搭载探测设备的位置为传感器模型建立机器人传感器模型,并将其与障碍物的距离及相对位置作为输出传递给学习系统;
(1.2)建立水下环境三维模型:在仿真系统及机器人的上位机界面中确定auv工作的经纬度范围,在机器人上位机界面中加载真实航行区域海图,栅格化海图模型,根据已知障碍物位置及大小添加障碍物模型,定义栅格属性;在仿真系统中加载海图并栅格化,设置多种不同的障碍物并加入海流模型以训练机器人得到完备的避障策略;
(1.3)利用奖惩函数模型、动作模型和迭代函数模型建立q学习模型:
奖惩函数为:
r=g[δf(t)]-kδs-100*h|sinα|;
其中h为比例系数,可将g、k、h三个数的和为10;δf(t)为相邻时刻受力之差,
动作模型a为机器人所在状态的可航行状态,包括前1、后2、左3、右4、上5、下6;
迭代函数模型为:
式中,r(st,a)为当前状态所对应动作的奖励值,q(st,a)为当前状态所对应动作的累计强化值,γ为学习率,q(st+1,a)为下一状态所对应动作的q值。
所述的步骤(2)具体包括:
(2.1)设计参数γ的值,建立环境奖励值r矩阵;
(2.2)初始化q值矩阵为0;
(2.3)设置初始位置为当前状态,目标位置为目标状态;
(2.4)若当前状态为目标状态,转(2.8),若当前状态不是目标状态,转(2.5);
(2.5)对当前状态的所有可能动作中,随机选择一个动作,到达下一个状态;
(2.6)对下一个状态,基于所有可能的动作,获得最大的q值,计算公式如下:
(2.7)设置下一个状态为当前状态,转(2.4);
(2.8)判断q值是否收敛,若是,结束,否则,转(2.3)。
所述的步骤(3)中的避障的训练具体包括:
(3.1)初始化:选择机器人起始点和目标点,对网络随机赋值;
(3.2)得到t时刻的环境状态和奖励值;
(3.3)计算每个动作的q值,根据q值随机选择命令输出动作a;
(3.4)执行命令a得到新的状态及奖惩函数;
(3.5)计算公式:
(3.6)调整网络的权值使误差δq最小:
所述的自组织竞争神经网络的输入为状态,神经网络的输出为将q值,相邻动作的反
应强度为:
式中i为当前网络节点序号,j为其相邻节点序号;
网络的目标函数为:
(3.7)判断是否满足结束条件,若是,结束训练,否则,返回(3.2)。
所述的步骤(4)具体包括:
(4.1)将仿真训练所获得的策略写入到auv的规划控制系统中;
(4.2)auv开启规划模式,将上位机全局规划路径节点发送给机器人;
(4.3)判断机器人是否达到目标节点,若是,转(4.7),否则转(4.4);
(4.4)auv规划系统计算目标艏向及目标深度,所用公式如下:
根据上位机下达的全局规划节点计算其目标艏向角公式如下:
式中,β为目标艏向,β’为当前艏向,(x1,y1)为机器人当前位置坐标,(x2,y2)为机器人第一个节点坐标;机器人到达第一个节点后,利用如下公式计算其目标艏向角:
式中,ec为机器人当前位置与上一节点和当前目标节点连线的距离,η为上一节点和当前目标节点连线与水平轴的夹角;
(4.5)auv使用其所搭载的探测设备探测周围海洋环境,若检测到突发障碍或者横向水流,根据避障策略更新目标艏向及目标深度,否则转(4.6);
(4.6)规划系统发送给机器人控制系统以控制机器人按照目标指令航行,转(4.3);
(4.7)判断当前节点是否为最终节点,若是,结束,否则,将下一节点设为当前节点,转(4.4)。
该方法与现有技术相比有如下优势:
1)目前多数auv路径规划系统都是靠人工在上位机点击选取路径节点的方法规划全局路径,该系统利用q学习算法在上位机模块进行全局路径规划较之于上述方法不需要人为参与并能够保证路径的最优性,同时该方法可以适用于复杂的水下环境,将上位机全局路径规划的节点通过无线电下发至下位机,auv按照全局规划路径节点并通过直线路径计算艏向的方法输出目标艏向航行,可以保证机器人航行路径的经济性;
2)在仿真系统模块中对auv进行避障训练避免了机器人的碰撞损坏,并且通过仿真训练得到的避障策略可以应用于实际的机器人,将训练好的避障策略通过无线网络写入下位机模块,提高了机器人的安全性;较之于目前auv常规的经验避障策略,通过训练所得到的策略更加完善;
3)使用基于自组织竞争神经网络改进q学习方法训练auv可以降低系统学习时间,提高学习效率,提高机器人环境自适应性,该方法可应用于多种复杂水下环境;
4)建立学习模型中奖惩函数模型时同时考虑了障碍物、目标点及海流的因素,可以训练机器人避障并抵达目标点的同时考虑海流的影响,将距目标点距离的比例系数调为最大可以保证机器人优先考虑到达目标点。
说明书附图
图1为基于强化学习的auv路径规划系统流程图;
图2为神经网络示意图;
图3为全局路径规划流程图;
图4为仿真训练流程图。
具体实施方式
下面结合附图进行详细说明。
如图1所示,本发明所设计的auv路径规划系统主要包括3个模块:基于q学习的auv全局路径规划上位机模块、基于自组织竞争神经网络改进q学习方法的auv避障训练仿真模块以及基于避障策略的auv局部路径规划下位机模块;其中上位机模块是机器人操控台负责给机器人发送命令,下位机模块为auv本身负责执行命令,仿真训练模块为机器人仿真系统负责训练机器人避障策略及调整控制参数;其运行过程为:在上位机模块的界面及仿真系统模块中建立环境模型,基于q学习方法在上位机控制台中实现auv全局路径规划,将规划节点通过无线电发送给下位机模块;基于自组织竞争神经网络改进q学习的方法在仿真系统中对auv进行避障训练,将所得策略通过无线网络写入下位机模块;下位机模块下水,接受上位机模块的全局规划节点并向规划节点航行,同时利用其搭载的探测设备检测周围环境,遇到突发事件时根据训练学习得到的避障策略实现auv局部路径规划。本发明将一种强化学习方法应用于auv路径规划系统以实现其三维路径规划功能,具体包括如下步骤:
(1)水下环境三维模型及规划算法的数学模型建立;
(2)基于q学习的auv全局路径规划实现;
(3)基于自组织竞争神经网络改进q学习方法的auv避障训练;
(4)基于全局规划节点及训练学习经验的auv局部路径规划实现。
进一步的,所述步骤(1)的具体包括如下内容:
建立模型包括:建立机器人传感器模型、建立环境模型、建立学习模型。
(1.1)以auv所搭载探测设备的位置为传感器模型,其主要功能是探测周围障碍物信息及海流信息,并将其与障碍物的距离及相对位置作为输出传递给学习系统。
(1.2)需在仿真系统及机器人的上位机界面中建立水下环境三维模型:确定auv工作的经纬度范围,在机器人上位机界面中加载真实航行区域海图,栅格化海图模型,根据已知障碍物位置及大小添加障碍物模型,定义栅格属性。在仿真系统中加载海图并栅格化,设置多种不同的障碍物并加入海流模型以训练机器人得到完备的避障策略。
(1.3)学习模型包括:奖惩函数模型、动作模型和迭代函数模型。
在上位机程序中,奖惩函数设计为:
动作模型,设为a,为机器人所在状态的可航行状态,包括:前1、后2、左3、右4、上5、下6。
迭代函数模型为:
式中,r(st,a)为当前状态所对应动作的奖励值,q(st,a)为当前状态所对应动作的累计强化值,γ为学习率(根据情况其值在0到1之间取值,如果γ接近0,机器人趋于考虑即时奖励;如果γ接近1,机器人会更加考虑未来的累计奖励;为了使机器人更快抵达目标点,在本例中,可将γ设为0.8),q(st+1,a)为下一状态所对应动作的q值。
在仿真系统中,主要是训练机器人的避障能力,所以采用势场法模拟障碍物对机器人的斥力,将斥力的合力表示为:
其中n为探测声纳个数,ki为比例系数,di为第i个声纳的探测距离,d0为安全距离,dmi为最大探测距离;θi为声纳i与大地坐标系的夹角。
其表示机器人的运动趋势,δf(t)<0表明机器人远离障碍物,得到奖励,δf(t)>0表示机器人走近障碍物,得到惩罚;另外,机器人靠近目标点应得到奖励,远离目标点应得到惩罚,所以奖惩函数设计为:
r=g[δf(t)]-kδs(5)
其中g、k为比例系数,δs为机器人到目标点的距离,考虑海流的影响,机器人尽量不与海流成90度夹角,将公式(5)变化为:
r=g[δf(t)]-kδs-100*h|sinα|(6)
其中h为比例系数,可将g、k、h三个数的和设为10,g、h值不应过大以免机器人为了获得更大的奖励而累计避障不向目标点靠近,g值可取3,h值可取2,k值可取5,α为海流与机器人航行方向的夹角。
在局部规划系统中,将auv的动作设计为9个离散动作,即旋转动作0°,±10°,±20°,±30°及上浮下潜动作±5m。
基础数学模型仍为q函数的迭代模型,如公式(2)所示。在学习过程中公式(2)等号并不成立,误差信号为:
根据自组织竞争神经网络,将状态s作为网络的输入,网络正向传播产生相应的输出q(s,aj),随机选择动作,假设动作ai被选中在q学习中
根据竞争学习思想,令qmax=1。
通过调整网络的权值使误差尽可能的小。根据自组织竞争神经网络的思想,对同一种输入有多个动作反应,其反应程度不同,采用正态分布的形式,来确认相邻动作的反应强度:
式中i为当前网络节点序号,j为其相邻节点序号,每次学习时会产生多个节点误差,网络的目标函数为:
利用误差反向传播算法来进行网络的权值调整。
进一步的,所述步骤(2)的详细内容为:根据模型(1)建立r值矩阵并初始化q值矩阵为0,在上位机中编写基于q学习算法的全局路径规划程序,选择机器人的初始点及目标点,根据模型(2)训练q值矩阵,根据训练好的q矩阵,选择当前状态所对应最大q值的动作规划路径以得到auv的全局最优路径,将全局路径的节点下发至下位机,机器人将按照全局路径的节点进行航行。
进一步的,所述步骤(3)的详细内容为:根据模型(6)建立r值矩阵并初始化q值为0,在仿真系统中采用基于自组织竞争神经网络的深度强化学习方法训练auv的避障策略,如图2所示,将状态值作为神经网络的输入,q值作为神经网络的输出,训练神经网络直至目标函数收敛,保存训练得到的避障策略,将训练得到的避障策略通过无线网络写入下位机程序。
如图3所示为全局路径规划流程图,进一步的,所述步骤(4)的详细内容为:机器人下水后调整到规划模式,根据上位机下达的全局规划节点,利用公式(11)计算其目标艏向角:
式中,β为目标艏向,β’为当前艏向,(x1,y1)为机器人当前位置坐标,(x2,y2)为机器人第一个节点坐标;当机器人到达第一个节点后,以直线路径计算艏向的方法利用公式(12)计算其目标艏向角以保证机器人直线航行:
式中,ec为机器人当前位置与上一节点和当前目标节点连线的距离,η为上一节点和当前目标节点连线与水平轴的夹角;机器人将计算得到的目标艏向发送给控制系统控制机器人按照规划艏向前进;同时,在机器人航行的过程中,利用避障声纳实时检测其周围障碍物信息,多普勒声速剖面流速仪adcp检测水流信息,机器人遇到突发障碍物时或横向水流时以避障策略给出规划动作即目标艏向及目标深度以进行局部路径规划。
本发明设计的auv路径规划方法的具体实现包含三个部分:全局规划、仿真训练和局部规划。
1.全局规划
在上位机界面中建立完成环境模型后,编写q学习路径规划算法如下:
(1)设计参数γ的值,建立环境奖励值r矩阵;
(2)初始化q值矩阵为0;
(3)设置初始位置为当前状态,目标位置为目标状态;
(4)若当前状态为目标状态,转(8),若当前状态不是目标状态,转(5);
(5)对当前状态的所有可能动作中,随机选择一个动作,到达下一个状态;
(6)对下一个状态,基于所有可能的动作,获得最大的q值,计算公式:
(7)设置下一个状态为当前状态,转(4);
(8)判断q值是否收敛,若是,结束,否则,转(3)。
基于训练好的q值矩阵,选择当前状态所对应的最大q值的动作进行全局规划得到全局最优路径。
2.仿真训练
在仿真系统模块中,为使机器人尽快学习到完善的避碰能力,让机器人在比较复杂的环境中运动,当机器人与障碍物相碰时,回到起点重新开始学习,即在上次学习结果的基础上重新进行权值的调整。用机器人漫游所经过的路径来衡量学习效果的好坏,机器人所航行的路径越长则表明机器人避碰能力越强。算法流程如下:
(1)初始化:选择机器人起始点和目标点,对网络随机赋值;
(2)得到t时刻的环境状态和奖励值;
(3)计算每个动作的q值,根据q值随机选择命令输出动作a;
(4)执行命令a得到新的状态及奖惩函数;
(5)计算公式:
(6)调整网络的权值使误差δq最小;
(7)判断是否满足结束条件,若是,结束训练,否则,返回(2)。
3.局部规划
局部路径规划按照如下步骤实现:
(1)将仿真训练所获得的策略写入到auv的规划控制系统中;
(2)auv开启规划模式,将上位机全局规划路径节点发送给机器人;
(4)判断机器人是否达到目标节点,若是,转(7),否则转(4);
(5)auv规划系统利用公式(11)或(12)计算目标艏向及目标深度;
(6)auv使用其所搭载的探测设备探测周围海洋环境,若检测到突发障碍或者横向水流,根据避障策略更新目标艏向及目标深度,否则转(6);
(7)规划系统发送给机器人控制系统以控制机器人按照目标指令航行,转(3);
(8)判断当前节点是否为最终节点,若是,结束,否则,将下一节点设为当前节点,转(4)。
- 还没有人留言评论。精彩留言会获得点赞!