一种声品质主观评价及其数据量化的方法与流程
本发明涉及汽车nvh性能,具体涉及一种声品质主观评价及其数据量化的方法。
背景技术:
随着汽车产品的普及及技术的迅速发展,消费者对汽车品质感的追求日益增加。声品质作为汽车品质感中重要的因素之一,包含了人对车内声音的主观感受,受到了研究者和汽车厂商的高度关注。声品质主观评价实验直接反映了人对声音某一主观评价属性(如满意度、烦恼度等)的直观感受,为后续声品质设计、修改提供了目标,是体现声品质意义的重要部分。
目前声品质主观评价实验主要采用四种评价方法:简单排序法、等级评分法、语义细分法以及成对比较法。简单排序法是评价人员听完所有声音样本后,对声音样本进行排序。以声音的主观满意度作为主观评价属性为例,排序序号越靠前,说明评价人员对该声音样本的主观满意度越高。
等级评分法是将声音的某一主观评价属性分为若干等级,评价人员听完单个声音样本后,根据主观感受选择对应的等级,常见的等级划分为1~10级。参见表1,以声音的主观满意度作为主观评价属性。
表1声音主观满意度的10等级划分示例
语义细分法是将一对描述声音的主观反义词进行语义细分,评价人员听完单个声音样本后,根据主观感受选择对应的语义,常见的语义细分等级有5级、7级、9级等。以“不满意的-满意的”作为主观评价属性为例,参见表2。
表2“不满意的-满意的”7级语义细分示例
成对比较法是将声音样本进行两两比较,参见表3,评价人员听完两个样本后,依据主观评价属性,选择对应的声音样本。
表3声音主观满意度的成对比较示例
从以上说明可以看出,简单排序法方便快捷,适合声音样本间的粗略比较,但不能获得声音样本间的优劣尺度信息,并且可同时评价的声音样本总数有限,一般不超过6个声音样本。等级评分法与语义细分法可获得声音样本间的优劣尺度信息,方便快捷,但主要适用于经验丰富的评价人员。若评价人员的评价经验不丰富时(如一般消费者),成对比较法可以得到更为准确的评价结果,但由于声音样本的增加会导致评价时间呈指数级增长,因而成对比较法适于声音样本不超过16个。若声音样本数量过多且评价人员的评价经验不丰富时,上述四种评价方法均具有一定的局限性。
技术实现要素:
本发明的目的是提供一种声品质主观评价及其数据量化的方法,适用于声音样本数量多且评价人员的评价经验不丰富的主观评价试验,能够在较短的时间内获得较准确的主观评价结果,为后续声品质分析提供合理有效的数据支撑。
本发明所述的声品质主观评价及其数据量化的方法,其包括如下步骤。
步骤一,将m个声音样本分为n组,每组4~5个声音样本,各个组内设置两个关联声音样本,组与组通过两个关联声音样本的线性模型进行空间变换,将m个声音样本转换到同一空间中,k名评价人员采用等级评分法分别对组内声音样本相互对比,得到组内各个声音样本的等级分数。
步骤二,采用系统聚类法将对各个组内声音样本主观感受相似的评价人员聚为一类。
步骤三,确定n组内评价人员重合度最高的聚类集合,设第n组内评价人员的聚类子集合数量为qn,则m个声音样本在第n组的空间内存在q1×q2...×qn...×qn种等级分数向量;
所述重合度最高的一种聚类集合的确定具体为:
式中,v*为n组内评价人员重合度最高的聚类集合,(v*)n为v*中第n组内用于线性转换模型建立的聚类子集合,v为q1×q2...×qn...×qn中的一种聚类集合,
步骤四,获取第n组内用于线性转换模型建立的聚类子集合(v*)n后,采用均值法,计算第n组内各个声音样本的等级分数,得到第n组内所有声音样本的等级分数向量sn
步骤五,第n组内所有声音样本的等级分数向量sn通过两个关联声音样本的等级分数的线性模型转换到第n组的空间,得到声品质的主观评价结果。
进一步,所述步骤三中n*的计算式为:
式中,n*∈{1,2,...,n},σ为评价人员的合格率下阈值,其值为σ=0.7。
进一步,所述步骤一中的关联声音样本在各个组内处于中等声品质水准,且不同关联声音样本之间具有明显的声品质差异。
进一步,所述步骤五中的线性模型转换具体为:在第n组和第n组内分别设有两个关联声音样本为l和m,由计算式
式中,sln和smn分别为第n组内所有声音样本相互对比后,声音样本l和m获得的等级分数,sln和smn分别分别为第n组内所有声音样本相互对比后,声音样本l和m获得的等级分数,sn为第n组内所有声音样本的等级分数向量,
进一步,所述步骤一中的等级评分法是将声音样本的某一主观评价属性分为若干等级,评价人员听完单个声音样本后,根据主观感受选择对应的等级分数。
本发明将声音样本分为若干组,组内的声音样本基于等级评分法,通过相互比较后,获得对应的主观评价等级分数,然后通过各组内评价人员的聚类、获取各组内用于线性转换模型的聚类子集合、计算各组内声音样本的等级分数以及建立线性转换模型,得到主观评价结果。该方法适用于声音样本数量多且评价人员的评价经验不丰富的主观评价实验,能在较少的时间内获得较准确的主观评价结果,为后续声品质客观量化、建立主客观分析模型等提供合理有效的数据支撑。
附图说明
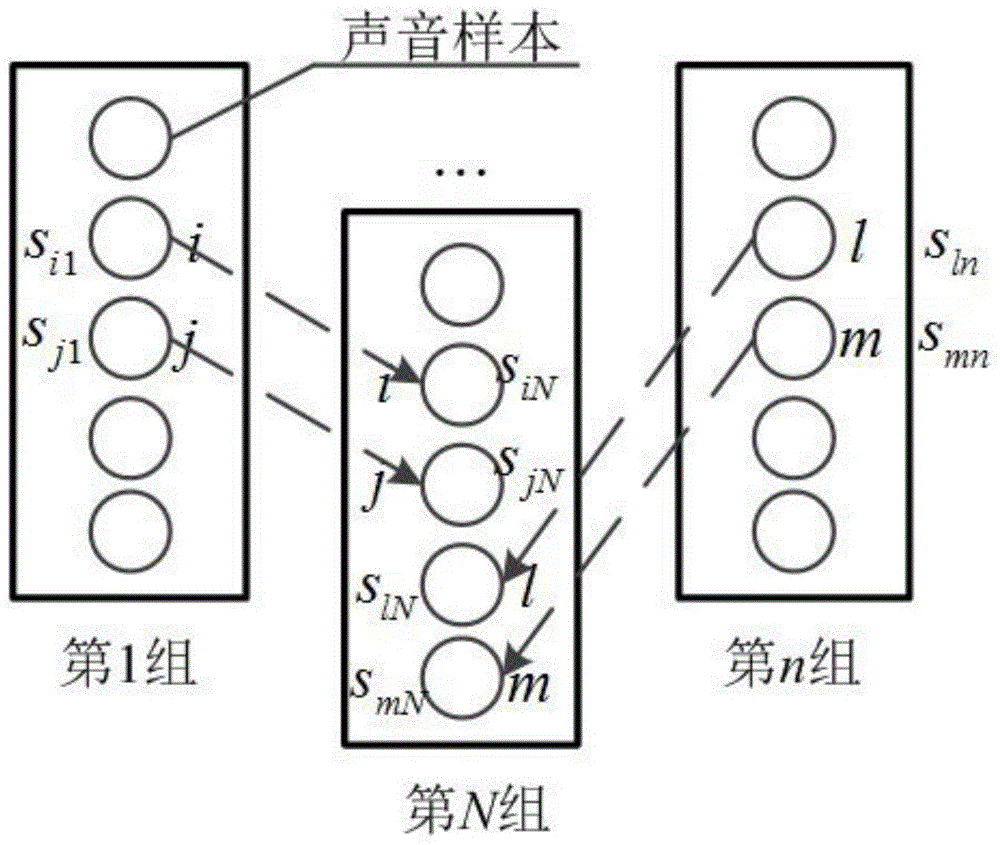
图1是本发明的分组等级比较法示意图;
图2是本发明基于各组内声音样本等级分数的评价人员聚类示意图;
图3本发明实施例中基于等级比较法的加速声主观满意度的评价实验示意图。
具体实施方式
下面结合附图和具体实施例对本发明作详细说明。
实施例一,一种声品质主观评价及其数据量化的方法,其包括如下步骤:
步骤一,将m个声音样本分为n组,每组4~5个声音样本,组内声音样本的主观评价采用等级评分法,组内的声音样本经过互相对比后,根据声音的某一主观评价属性给出组内声音样本的不同等级分数。为了获得组间声音样本的比较等级,各个组内设置两个关联声音样本,组与组通过两个关联声音样本的线性模型进行空间变换,将m个声音样本转换到同一空间中。所述关联声音样本在各个组内处于中等声品质水准,避免选择与其他声音样本的声品质差异大的声音样本作为关联声音样本。并且不同关联声音样本之间具有明显的声品质差异,提高空间线性转换模型的分辨率和正确率。
参见图1,第1组内的声音样本i,j和第n组内的声音样本l,m均为关联声音样本,其中,i,j,l,m∈{1,2,...,m}。si1和sj1分别为第1组内所有声音样本相互对比后,声音样本i和j获得的等级分数。sin和sjn分别为第n组内所有声音样本相互对比后,声音样本i和j获得的等级分数。sln,smn,sln,smn可以此类推,n∈{1,2,...,n}。
第1组内所有声音样本的等级分数通过关联声音样本i和j等级分数的线性模型转换到第n组的空间,转换式为:
式中,s1为第1组内所有声音样本的等级分数向量,
第n组内所有声音样本的等级分数通过关联声音样本l和m等级分数的线性模型转换到第n组的空间,其转换式与第1组的转换式类似。最终实现了m个声音样本在第n组的比对。
步骤二,采用系统聚类法将对各个组内声音样本主观感受相似的评价人员聚为一类,参见图2,根据第1组内声音样本主观感受的相似程度,将k名评价人员分为q1类,qn为第n组内评价人员聚类子集合的数量。(v1)1为第1组内第1类主观评价人员的聚类子集合,(vqn)n为第n组内第qn类主观评价人员的聚类子集合,其他以此类推。第1组内,q1∈{1,2,…,,q…,q1};第n组内,qn∈{1,2,...,qn}。
步骤三,确定n组内评价人员重合度最高的聚类集合,设第n组内评价人员的聚类子集合数量为qn,则m个声音样本在第n组的空间内存在q1×q2...×qn...×qn种等级分数向量。
所述重合度最高的聚类集合的确定具体为:
式中,v*为n组内评价人员重合度最高的聚类集合,(v*)n为v*中第n组内用于线性转换模型建立的聚类子集合,v为q1×q2...×qn...×qn中的一种聚类集合,
所述n*的计算式为:
式中,n*∈{1,2,...,n},σ为评价人员的合格率下阈值,其值为σ=0.7。
步骤四,获取第n组内用于线性转换模型建立的聚类子集合(v*)n,采用均值法,计算第n组内各个声音样本的等级分数,得到第n组内所有声音样本的等级分数向量sn。
步骤五,第n组内所有声音样本的等级分数向量sn通过两个关联声音样本的等级分数的线性模型转换到第n组的空间,具体为:在第n组和第n组内分别设有两个关联声音样本为l和m,由计算式
计算得到m个声音样本在第n组空间的等级分数,即得到声品质的主观评价结果,完成声品质的主观评价。
实施例二,以评价10个加速声音样本的主观满意度为具体实施例,采用分组等级比较法设计主观评价实验,并基于上述数据量化方法,获取主观评价结果,其具体实施过程为。
步骤一,采用分组等级比较法设计的主观评价实验。参见图3,将10个加速声音样本分为3组,第1组内包含声音样本1、2、3、4、5,第2组内包含声音样本6、7、8、9、10,第3组内包含声音样本2、4、8、9。第1组和第3组的关联声音样本为2和4;第2组和第3组的关联声音样本为8和9。总共60位从事非汽车nvh行业的驾驶员参与该加速声主观满意度的评价实验,每组内的声音样本采用等级评分法进行主观评价,评价人员经过互相对比后,得到每组内声音样本相应的主观满意度。
步骤二,基于各组内加速声音样本主观满意度的评价人员聚类,采用系统聚类法对60位评价人员的加速声主观满意度进行聚类分析,评价人员对每组内加速声音样本有着相似主观满意度的,可以归为一类;同时去掉评价人数不超过10的聚类子集合,第1、2、3组内评价人员的聚类结果参见表4。
表4加速声主观满意度的评价试验中评价人员的聚类结果
由表4可得,q1,q2,q3=2。
步骤三,确定各组内用于线性转换模型的聚类子集合,由q1,q2,q3=2可得,10个加速声音样本在第3组的空间内存在8种主观满意度向量。10个加速声音样本的主观评价实验中,n=3。
根据
采用计算式
统计8个聚类集合v中,重合3次的评价人员总数,结果参见表5。
表58个聚类集合里,重合3次的评价人员的总数
由表5确定(v1)1,(v2)2,(v3)3分别为各组内用于线性转换模型的聚类子集合。
步骤四,确定各组内用于线性转换模型的聚类子集合后,采用均值法计算3个组内声音样本的主观满意度,得到s1,s2,s3。
步骤五,基于
为了验证该方法获得的主观满意度的合理性,采用成对比较法获得的10个加速声音样本的主观满意度,结果参见表6。
表6基于分组等级比较法与基于成对比较法的主观评价结果对比
两种方法获得的主观满意度的相关性高达0.980,验证了该主观评价方法的正确性。采用成对比较法完成10个加速声主观满意度的评价实验时,单人需耗费1.5小时,而采用分组等级比较法时,单人仅需耗费0.5小时,主观评价实验的时间大大减少了。综上所述,该主观评价方法适用于声音样本数量多且评价人员的评价经验不丰富的主观评价实验,能在较少的时间内获得较准确的主观评价结果。
- 还没有人留言评论。精彩留言会获得点赞!