一种MIMU整体动态智能标定补偿方法
一种mimu整体动态智能标定补偿方法
技术领域
1.本发明涉及惯性导航技术领域,特别是一种mimu整体动态智能标定补偿方法。
背景技术:
2.随着半导体技术的发展,mems
‑
imu的精度在逐步提高,已经可以满足战术级制导武器的需求。同时,由于其具有成本低、体积小、功耗低等优点,在军用以及民用等各个领域得到了广泛的应用。
3.随着mems
‑
imu的广泛应用以及其自身输出误差受温度环境以及运动状态影响明显,所以在使用前对mems
‑
imu进行标定对于提高其精度非常有必要。由于传统的标定方法通常是采用静态的数据对标定参数进行解算,但是imu的工作环境通常是在动态环境下,这会造成通过传统标定方法得到的标定参数不能再imu使用中达到理想的效果。另外,由于一般的标定方法大多采用线性误差模型以及多项式误差模型来对惯导进行标定补偿,但是惯导的误差参数通常是非线性的并且是多因素耦合的状态,所以一般的误差模型不能够对惯导输出误差进行充分准确的补偿。
技术实现要素:
4.本发明的目的在于提供一种精度高、适应性强的mimu整体动态智能标定补偿方法。
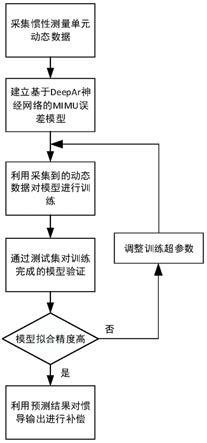
5.实现本发明目的的技术解决方案为:一种mimu整体动态智能标定补偿方法,包括以下步骤:
6.步骤1、采集数据阶段,通过工装将mems
‑
imu固定在转台、离心机这些测试设备上,采集保存imu的输出以及测试设备的输出;
7.步骤2、基于deepar递归神经网络建立mems
‑
imu误差补偿模型,确定神经网络输入输出结构、隐含层数目以及神经元数目;
8.步骤3、将在步骤1采集到惯性测量单元实测数据作为神经网络的输入,测试设备的数据与惯性测量单元的实际输出的差值分别作为神经网络模型的输出,建立训练集与测试集,利用训练集对神经网络模型进行训练;
9.步骤4、利用训练完成的deepar递归神经网络模型结合测试集输入得到模型的输出数据,将输出数据与测试集输出数据进行对比,评价模型性能并对模型参数进行调整优化,进而得到最终的补偿模型。
10.进一步地,步骤1所述的采集数据阶段,通过工装将mems
‑
imu固定在转台、离心机这些测试设备上,采集保存imu的输出以及测试设备的输出,具体如下:
11.将惯导固定在三轴温箱转台上先分别测试单轴的mimu的角速率输出,控制三轴转台每个轴的角速率在
‑
400
°
/s
‑
400
°
/s之间均匀变化,变化速率为1
°
/s,通过分别对单轴采集数据能够学习到单轴的标定补偿模型;进而将三轴设置不同的角加速度从而获得三轴不同角速度的误差耦合数据;转动形式设定为依次从逆时针转动,逐渐减为零,再逐渐顺时针
加速转动;对三轴施加不同的角加速度从而实现对各轴在不同的角速度下的耦合误差进行采集;控制温箱的温度设定为从最高温度到常温再到最低温度循环往复,同时保持上述的转动形式,采集4小时的数据;
12.为了激励惯导加速度计的高阶误差项,通过工装将惯导安装在离心机上,将输入轴安装在离心机工作半径的正方向,测试向心加速度从0g
‑
10g变化,变化速度为10min/g,重新将输入轴安装在离心机工作半径的负方向,测试向心加速度从0g
‑
10g变化,变化速度为10min/g;改变惯导在离心机夹具的安装方位,分别对三轴加速度计进行激励,通过上述数据能够对加速度计的高阶误差模型进行学习;
13.最后,将惯导固定在角振动台上对惯导分别施加幅值为0.5
°
,1
°
,3
°
并且振动频率从0.5hz到100hz的角振动,振动频率每分钟增加0.5hz,改变惯导在夹具上的安装方位分别测试不同轴向的角振动输出并采集数据;
14.上述实验将mems
‑
imu实际输出与转台、离心机这些测试设备的理想输出一同保存,数据均采集两组分为训练集与测试集。
15.进一步地,步骤2所述基于deepar递归神经网络建立mems
‑
imu误差补偿模型,确定神经网络输入输出结构、隐含层数目以及神经元数目,具体如下:
16.建立基于deepar递归神经网络的mems
‑
imu误差补偿模型,该模型的输入为三轴角速度信息、三轴加速度信息、温度信息,输出为三轴角速度误差、三轴加速度误差,模型具体结构如下:
17.需要计算得到的目标值的分布为似然函数的乘积形式,如下:
[0018][0019]
上式即为利用隐含层输出h
i,t
参数化的自回归循环神经网络模型;概率p(z
i,t
∣θ(h
i,t
))服从设定的分布,这个分布的参数由隐含层输出的函数θ(h
i,t
,θ)确定;
[0020]
其中q
θ
为似然函数,为以t0时刻之前的输出以及从1到t时刻的协变量序列为先验信息求得的第i个序列的时刻t的输出;为从1到t0‑
1时刻的输出序列,x
i,1:t
为从1到t时刻的协变量序列,t为当前时刻,t0为预测起始时刻,t为协变量的当前时刻,z
i,t
为t时刻的第i序列的输出,z
i,1:t
‑1表示1到当前时刻的第i输出序列,p表示条件概率;θ(h
i,t
,θ)的形式根据选择的数据分布形式决定,在下面数据分布部分给出了不同分布形式下的函数形式;h
i,t
为隐含层输出;θ表示神经网络参数,包括权值矩阵、阈值矩阵;
[0021]
记z
i,t
‑1为t
‑
1时刻的时间序列i的目标值即为惯性测量单元的测量误差,x
i,t
为t时刻时间序列i的预测协变量即为同时刻与目标值耦合的其他惯性测量单元的测量信息,h
i,t
为t
‑
1时刻时间序列i的隐含层网络输出,
[0022]
h
i,t
=h(h
i,t
‑1,z
i,t
‑1,x
i,t
,θ)
[0023]
其中h表示由lstm神经元构成的多层递归神经网络实现的函数,且lstm神经元由θ参数化;h
i,t
‑1为t
‑
2时刻的隐含层输出,z
i,t
‑1为t
‑
1时刻的第i序列的输出,x
i,t
为t时刻的第i序列的协变量;
[0024]
其中lstm神经元的内部结构由遗忘门、输入门、输出门以及仿射变换神经元构成,其中三个门函数的输出值在0
‑
1之间,表示对信息的控制程度;其中前向传播的流程,首先是计算遗忘门f
t
,遗忘门能够决定记忆信息流c
t
‑1中的内容保留的程度,遗忘门通过以下公式计算:
[0025]
f
t
=σ(w
f
·
[h
t
‑1,x
t
]+b
f
)
[0026]
其中h
t
‑1为t
‑
1时刻的隐含状态,x
t
为t时刻输入,w
f
遗忘为权值矩阵,b
f
为遗忘阈值向量,σ()为激活函数;
[0027]
其次,通过计算输入门控制信息注入记忆信息流,输入门的计算公式为:
[0028][0029]
i
t
=σ(w
i
·
[h
t
‑1,x
t
]+b
i
)
[0030][0031]
其中,i
t
为t时刻的输入门的值,为t时刻的输入门的控制值,e为自然指数,w
i
为输入们权值矩阵,w
c
为控制门权值矩阵,b
c
为控制门阈值向量,b
i
为输入门阈值向量,x
t
为t时刻传递的状态,tanh()为激活函数:
[0032][0033]
最终,t时刻的记忆信息流通过输入门与遗忘门传递的信息求和得到,即为
[0034][0035]
其中c
t
表示t时刻的记忆信息流,c
t
‑1为t
‑
1时刻的记忆信息流;
[0036]
上式等式右侧第一项表述了通过遗忘门留下的信息,第二项表述了新输入记忆信息流的信息;
[0037]
得到当前时刻信息流的值后,计算当前时刻的输出,此时需要考虑输出门的计算,输出门决定了输出信息的量:
[0038]
o
t
=σ(w
o
[h
t
‑1,x
t
]+b
o
)
[0039]
h
t
=o
t
*tanh(c
t
)
[0040]
其中o
t
表示输出门的数值,w
o
为输出门权值矩阵,b
o
为输出门阈值矩阵,h
t
表示传递给下一时刻的当前的系统隐含状态,上式表述了通过输出门o
t
控制信息流c
t
的输出量;
[0041]
此时,即完成一个时刻的lstm神经元的前向传播,反向传播通过依据时间的反向传播算法获得,其中使用了链式法则,通过求导与梯度下降法实现最优化;
[0042]
概率p(z
i,t
∣θ(h
i,t
))为一个固定的概率分布,参数利用下式得到,
[0043]
θ
i,t
=θ(h
i,t
,θ)
[0044]
其中θ
i,t
为似然函数的参数其形式取决于似然函数,h
i,t
为deepar神经网络t时刻隐含层输出,θ为神经网络的连接参数;
[0045]
deepar神经网络的目标是得到一个目标值的条件分布,
[0046][0047]
其中t0代表着目标值未知的
起始时刻,预测协变量x
i,1:t
为全时刻已知的惯性测量单元输出;条件区间的观测信息通过初始状态转移到预测区间中;在该模型中的预测区间与条件区间都选择同样的结构作为编解码模型,同时,编码器与解码器共享权重,因此由式h
i,t
=h(h
i,t
‑1,z
i,t
‑1,x
i,t
,θ)计算,初始状态h
i,0
和z
i,0
设置为零;
[0048]
下一步,给定模型参数θ,即能够通过之前已知的数据得到样本的分布首先通过式h
i,t
=h(h
i,t
‑1,z
i,t
‑1,x
i,t
,θ)计算h
i,t
‑1,t=1,...,t0‑
1;其次为了计算样本预测其中对于t0时刻,令和得到当前时刻的预测目标值的步骤为:利用上时刻的预测目标值上时刻的预测协变量x
i,t
‑1和上时刻的隐含层输出h
i,t
‑1计算当前时刻的隐含层输出h
i,t,
再输入似然函数p(z
i,t
‑1∣θ
i,t
‑1)即得到当前时刻预测目标值
[0049]
deepar神经网络模型中的似然函数根据惯性测量单元的噪声特性确定,在这里选择高斯似然函数作为概率分布模型;高斯似然函数通过均值与方差两个参数来描述为θ=(μ,σ),其中均值是作为神经网络的仿射层的输出,标准差通过仿射变换以及softplus激活函数计算输出,目的是为了保证标准差大于零;
[0050][0051][0052][0053]
其中p
g
代表似然函数,z表示输出数据,μ表示均值,σ表示标准差,π表示圆周率的数值,exp表示e指数,μ表示在该高斯分布的数据分布下的预测均值计算函数,表示deepar神经网络输出预测均值的权值矩阵的转置,b
μ
表示deepar神经网络输出的预测均值的阈值向量,σ表示在高斯分布的数据分布下的预测标准差计算函数,表示deepar神经网络输出预测标准差的权值矩阵的转置,b
σ
表示deepar神经网络输出的预测标准差的阈值向量;
[0054]
上述均值与方差是分别通过了一个仿射变换,不同的是方差通过的仿射变换利用了softplus为激活函数,仿射变换中的权值矩阵与阈值矩阵同样是最优化算法寻优的参数;
[0055]
设置该神经网络的隐含层为四层,每层的神经元数目为50。
[0056]
进一步地,步骤3所述将在步骤1采集到惯性测量单元实测数据作为神经网络的输入,测试设备的数据与惯性测量单元的实际输出的差值分别作为神经网络模型的输出,建立训练集与测试集,利用训练集对神经网络模型进行训练,具体如下:
[0057]
将微惯性测量单元的实际输出数据作为神经网络的输入,具体为惯性测量单元的三轴加速度序列a
x
,a
y
,a
z
,三轴角速度序列ω
x
,ω
y
,ω
z
,以及所在环境的温度序列t;其次deepar神经网络的输出定义为误差序列即利用转台采集到的真实加速度数值减去微惯性
测量单元量测得到的数值得到的序列;将三轴加速度误差序列δa
x
,δa
y
,δa
z
与三轴角速度误差序列δω
x
,δω
y
,δω
z
作为神经网络的输出;
[0058]
根据上述的输入输出定义,利用步骤2采集到的两组数据,分别建立神经网络的训练集与测试集;训练超参数预设值为训练步数1000步,学习率0.0005,使用随机梯度下降优化器,目标精度为0.001;
[0059]
下面进入训练步骤:
[0060]
首先给定数据集{z
i,1:t
}
i=1,...,n
和预测协变量x
i,1:t
,给定模型参数θ,rnn中h(
·
)和θ(
·
)的参数通过最大化下面的似然函数得到
[0061][0062]
其中表示总体的似然函数值,p表示条件概率;θ(h
i,t
)表示神经网络预测的似然函数参数,包括均值、标准差;
[0063]
选择随机梯度下降方法对上述函数进行优化;
[0064]
其次,在进行训练之前还需要进行数据预处理,针对实际数据,将输入数据序列分别除以缩放因子,该缩放因子由下式计算:
[0065][0066]
其中v
i
表示第i序列的缩放因子,t0为预测起始时刻,z
i,t
为当前时刻的第i序列输出值;
[0067]
同时,将预测协变量标准化为均值为零、方差为1的标准正态分布。
[0068]
进一步地,步骤4所述利用训练完成的deepar递归神经网络模型结合测试集输入得到模型的输出数据,将输出数据与测试集输出数据进行对比,评价模型性能并对模型参数进行调整优化,进而得到最终的补偿模型,具体如下:
[0069]
利用步骤3训练完成的deepar神经网络,将微惯性测量单元的实际输出与温度值输入神经网络,再通过将神经网络输出与微惯性测量单元实际输出相加即得到标定补偿后的测量输出;
[0070]
利用步骤3所构建的测试集对deepar模型进行测试,根据测试精度,调整深度神经网络的训练步数、学习率这些超参数并重新训练神经网络。
[0071]
本发明与现有技术相比,其显著优点为:(1)利用deepar深度神经网络的跨时间序列共享信息以及时序数据学习能力,建立多因素影响的时序性误差标定模型,并根据惯性测量单元数据的统计特性以选择合适的概率似然函数,达到了更好的误差补偿性能;(2)可以对难以建模的误差实现标定补偿,并且实现对非线性以及具有时变性误差的标定补偿,标定精度高、适应性强。
附图说明
[0072]
图1是本发明一种mimu整体动态智能标定补偿方法的算法结构流程图。
[0073]
图2是deepar深度神经网络训练步骤内部结构示意图。
[0074]
图3是deepar深度神经网络预测步骤内部结构示意图。
[0075]
图4是本发明中deepar深度神经网络中使用到的lstm神经元的内部结构示意图。
[0076]
图5是本发明中深度神经网络中用到的神经元层中的仿射变换计算示意图。
具体实施方式
[0077]
下面结合附图和实施例对本发明的进行详细的描述。
[0078]
如图1所示,本发明mimu整体动态智能标定补偿方法,包括以下步骤:
[0079]
步骤1、采集数据阶段,通过工装将mems
‑
imu固定在转台、离心机这些测试设备上,采集保存imu的输出以及测试设备的输出;
[0080]
步骤2、基于deepar递归神经网络建立mems
‑
imu误差补偿模型,确定神经网络输入输出结构、隐含层数目以及神经元数目;
[0081]
步骤3、将在步骤1采集到惯性测量单元实测数据作为神经网络的输入,测试设备的数据与惯性测量单元的实际输出的差值分别作为神经网络模型的输出,建立训练集与测试集,利用训练集对神经网络模型进行训练;
[0082]
步骤4、利用训练完成的deepar递归神经网络模型结合测试集输入得到模型的输出数据,将输出数据与测试集输出数据进行对比,评价模型性能并对模型参数进行调整优化,进而得到最终的补偿模型。
[0083]
进一步地,作为一种具体实施方式,步骤1所述采集数据阶段,将mems
‑
imu固定在转台等精密测试设备上采集imu的输出以及测试设备的输出,具体如下:
[0084]
将惯导固定在三轴温箱转台上先分别测试单轴的mimu的角速率输出,控制三轴转台每个轴的角速率在
‑
400
°
/s
‑
400
°
/s之间均匀变化,变化速率为1
°
/s,通过分别对单轴采集数据可以学习到单轴的标定补偿模型。进而将三轴设置不同的角加速度从而获得三轴不同角速度的误差耦合数据。其转动形式设定为依次从逆时针转动,逐渐减为零,再逐渐顺时针加速转动。此处的重点是要对三轴施加不同的角加速度从而实现对各轴在不同的角速度下的耦合误差进行采集。进一步,控制温箱的温度设定为从最高温度到常温再到最低温度循环往复,同时保持上述的转动形式,采集4小时的数据。
[0085]
为了激励惯导加速度计的高阶误差项,通过工装将惯导安装在离心机上,将输入轴安装在离心机工作半径的正方向,测试向心加速度从0g
‑
10g变化,变化速度为10min/g,重新将输入轴安装在离心机工作半径的负方向,测试向心加速度从0g
‑
10g变化,变化速度为10min/g。改变惯导在离心机夹具的安装方位,分别对三轴加速度计进行激励,通过上述数据可以对加速度计的高阶误差模型进行学习。
[0086]
最后,将惯导固定在角振动台上对惯导分别施加幅值为0.5
°
,1
°
,3
°
并且振动频率从0.5hz到100hz的角振动,振动频率每分钟增加0.5hz,改变惯导在夹具上的安装方位分别测试不同轴向的角振动输出并采集数据。上述实验将微惯性测量单元实际输出与转台等设备的理想输出一同保存,数据均采集两组方便分为训练集与测试集。
[0087]
进一步地,作为一种具体实施方式,根据图2、图3可知,步骤2所述deepar神经网络的训练结构以及预测结构,其中隐含层可以由多层神经元构成,通过对实际应用问题的分析选定该神经网络的隐含层数目以及神经元数目分别为四层和五十个神经元。
[0088]
其具体结构为:
[0089]
首先是输入层,输入层由上一时刻的输出以及此时刻的预测协变量以及上一时刻的隐含层输出构成,通过上述输入可以计算此时刻的隐含层输出,再送入似然函数从而得
到此时刻的输出。之前时刻的数据与状态通过上时刻的输出以及上时刻的隐含层输出转移到此时刻用于此时刻的输出。其中隐含层可以为多层结构,其中的神经元由lstm神经元构成。
[0090]
建立基于deepar递归神经网络的mems
‑
imu误差补偿模型,该模型的输入为三轴角速度信息、三轴加速度信息、温度信息,输出为三轴角速度误差、三轴加速度误差,模型具体结构如下:
[0091]
该网络的最终目的是需要计算得到的目标值的分布为似然函数的乘积形式,如下:
[0092][0093]
上式即为利用隐含层输出h
i,t
参数化的自回归循环神经网络模型;概率p(z
i,t
∣θ(h
i,t
))服从设定的分布,这个分布的参数由隐含层输出的函数θ(h
i,t
,θ)确定;
[0094]
其中q
θ
为似然函数,为以t0时刻之前的输出以及从1到t时刻的协变量序列为先验信息求得的第i个序列的时刻t的输出;为从1到t0‑
1时刻的输出序列,x
i,1:t
为从1到t时刻的协变量序列,t为当前时刻,t0为预测起始时刻,t为协变量的当前时刻,z
i,t
为t时刻的第i序列的输出,z
i,1:t
‑1表示1到当前时刻的第i输出序列,p表示条件概率;θ(h
i,t,
θ)的形式根据选择的数据分布形式决定,在下面数据分布部分给出了不同分布形式下的函数形式;h
i,t
为隐含层输出;θ表示神经网络参数,包括权值矩阵、阈值矩阵;
[0095]
记z
i,t
‑1为t
‑
1时刻的时间序列i的目标值即为惯性测量单元的测量误差,x
i,t
为t时刻时间序列i的预测协变量即为同时刻与目标值耦合的其他惯性测量单元的测量信息,h
i,t
为t
‑
1时刻时间序列i的隐含层网络输出,
[0096]
h
i,t
=h(h
i,t
‑
1,
z
i,t
‑
1,
x
i,t,
θ)
[0097]
其中h表示由lstm神经元构成的多层递归神经网络实现的函数,且lstm神经元由θ参数化;h
i,t
‑1为t
‑
2时刻的隐含层输出,z
i,t
‑1为t
‑
1时刻的第i序列的输出,x
i,t
为t时刻的第i序列的协变量;
[0098]
结合图4,其中lstm神经元的内部结构主要由遗忘门、输入门、输出门以及仿射变换神经元构成,其中三个门函数的输出值在0
‑
1之间,表示对信息的控制程度。上述仿射变换由图5所示,其计算即为向量的对应元素相乘再进行求和并于阈值相加。其中前向传播的流程,首先是计算遗忘门f
t
,遗忘门可以决定记忆信息流c
t
‑1中的内容保留的程度,遗忘门通过以下公式计算:
[0099]
f
t
=σ(w
f
·
[h
t
‑1,x
t
]+b
f
)
[0100]
其中h
t
‑1为t
‑
1时刻的隐含状态,x
t
为t时刻输入,w
f
遗忘为权值矩阵,b
f
为遗忘阈值向量,σ()为激活函数;
[0101]
其次,通过计算输入门控制信息注入记忆信息流。输入门的计算公式为:
[0102]
[0103]
i
t
=σ(w
i
·
[h
t
‑1,x
t
]+b
i
)
[0104][0105]
其中,i
t
为t时刻的输入门的值,为t时刻的输入门的控制值,e为自然指数,w
i
为输入们权值矩阵,w
c
为控制门权值矩阵,b
c
为控制门阈值向量,b
i
为输入门阈值向量,x
t
为t时刻传递的状态,tanh()为激活函数:
[0106][0107]
最终,t时刻的记忆信息流通过输入门与遗忘门传递的信息求和得到,即为
[0108][0109]
其中c
t
表示t时刻的记忆信息流,c
t
‑1为t
‑
1时刻的记忆信息流;
[0110]
上式等式右侧第一项表述了通过遗忘门留下的信息,第二项表述了新输入记忆信息流的信息;
[0111]
得到当前时刻信息流的值后,计算当前时刻的输出,此时需要考虑输出门的计算,输出门决定了输出信息的量:
[0112]
ot=σ(w
o
[h
t
‑1,x
t
]+b
o
)
[0113]
h
t
=o
t
*tanh(c
t
)
[0114]
其中o
t
表示输出门的数值,w
o
为输出门权值矩阵,b
o
为输出门阈值矩阵,h
t
表示传递给下一时刻的当前的系统隐含状态,上式表述了通过输出门o
t
控制信息流c
t
的输出量;
[0115]
此时即完成一个时刻的lstm神经元的前向传播,其反向传播通过依据时间的反向传播算法,其中使用了链式法则,通过求导与梯度下降法实现最优化。其相较于传统的rnn神经元主要添加了输入门、输出门与遗忘门,有效避免了随着网络的加深导致的梯度消失、无法感知长时间过去信息的问题。
[0116]
概率p(z
i,t
∣θ(h
i,t
))为一个固定的概率分布,参数利用下式得到,
[0117]
θ
i,t
=θ(h
i,t
,θ)
[0118]
其中θ
i,t
为似然函数的参数其形式取决于似然函数,h
i,t
为deepar神经网络t时刻隐含层输出,θ为神经网络的连接参数;
[0119]
deepar神经网络的目标是得到一个目标值的条件分布,
[0120][0121]
其中t0代表着目标值未知的起始时刻,预测协变量x
i,1:t
为全时刻已知的惯性测量单元输出;条件区间的观测信息通过初始状态转移到预测区间中;在该模型中的预测区间与条件区间都选择同样的结构作为编解码模型,同时,编码器与解码器共享权重,因此由式h
i,t
=h(h
i,t
‑1,z
i,t
‑1,x
i,t
,θ)计算,初始状态h
i,0
和z
i,0
设置为零;
[0122]
下一步,给定模型参数θ,即可通过之前已知的数据得到样本的分布
[0123]
首先通过式h
i,t
=h(h
i,t
‑1,z
i,t
‑1,x
i,t
,θ)计算h
i,t
‑1,t=1,...,t0‑
1;其次为了计算样本预测其中对于t0时刻,令和得到当前时刻的预测目标值的步骤为:利用上时刻的预测目标值上时刻的预测协变量x
i,t
‑1和上时刻的隐含层输出h
i,t
‑1计算当前时刻的隐含层输出h
i,t
,再输入似然函数p(z
i,t
‑1∣θ
i,t
‑1)即得到当前时刻预测目标值
[0124]
deepar神经网络模型中的似然函数根据惯性测量单元的噪声特性确定,在这里选择高斯似然函数作为概率分布模型;高斯似然函数通过均值与方差两个参数来描述为θ=(μ,σ),其中均值是作为神经网络的仿射层的输出,标准差通过仿射变换以及softplus激活函数计算输出,目的是为了保证标准差大于零;
[0125][0126][0127][0128]
其中p
g
代表似然函数,z表示输出数据,μ表示均值,σ表示标准差,π表示圆周率的数值,exp表示e指数,μ表示在该高斯分布的数据分布下的预测均值计算函数,表示deepar神经网络输出预测均值的权值矩阵的转置,b
μ
表示deepar神经网络输出的预测均值的阈值向量,σ表示在高斯分布的数据分布下的预测标准差计算函数,表示deepar神经网络输出预测标准差的权值矩阵的转置,b
σ
表示deepar神经网络输出的预测标准差的阈值向量;
[0129]
上述均值于方差是分别通过了一个仿射变换,不同的是方差通过的仿射变换利用了softplus为激活函数,仿射变换中的权值矩阵与阈值矩阵同样是最优化算法寻优的参数。
[0130]
神经网络的隐含层数目可以说明该网络对复杂模型的学习能力,如果隐含层数目太低会导致网络无法对较为复杂的模型进行拟合,无法很好的对mems
‑
imu的误差模型进行学习,隐含层数目太多可能导致梯度消失或者梯度爆炸以及训练时间长等问题,所以最终设置该神经网络的隐含层为四层,每层的神经元数目为50。
[0131]
进一步地,作为一种具体实施方式,步骤3将在步骤1采集到惯性测量单元实测数据作为神经网络的输入,测试设备的数据与惯性测量单元的实际输出的差值分别作为神经网络模型的输出,建立训练集与测试集,利用训练集对神经网络模型进行训练,具体如下:
[0132]
将微惯性测量单元的实际输出数据作为神经网络的输入,具体为惯性测量单元的三轴加速度序列a
x
,a
y
,a
z
,三轴角速度序列ω
x
,ω
y
,ω
z
,以及所在环境的温度序列t;其次deepar神经网络的输出定义为误差序列即利用转台采集到的真实加速度数值减去微惯性测量单元量测得到的数值得到的序列;将三轴加速度误差序列δa
x
,δa
y
,δa
z
与三轴角速度误差序列δω
x
,δω
y
,δω
z
作为神经网络的输出。
[0133]
根据上述的输入输出定义,利用步骤2采集到的两组数据,分别建立神经网络的训练集与测试集;训练超参数预设值为训练步数1000步,学习率0.0005,使用随机梯度下降优
化器,目标精度为0.001。
[0134]
下面进入训练步骤:
[0135]
首先给定数据集{z
i,1:t
}
i=1,...,n
和预测协变量x
i,1:t
,给定模型参数θ,rnn中h(
·
)和θ(
·
)的参数通过最大化下面的似然函数得到
[0136][0137]
其中表示总体的似然函数值,p表示条件概率;θ(h
i,t
)表示神经网络预测的似然函数参数,包括均值、标准差;
[0138]
可以选择随机梯度下降方法对上述函数进行优化。
[0139]
其次,由于各个序列的数值差异可能较大,在进行训练之前还需要进行数据预处理。针对实际数据,将输入数据序列分别除以其缩放因子,该缩放因子由下式计算:
[0140][0141]
其中v
i
表示第i序列的缩放因子,t0为预测起始时刻,z
i,t
为当前时刻的第i序列输出值;
[0142]
同时,预测协变量需要将其标准化为均值为零,方差为一的标准正态分布。
[0143]
进一步地,作为一种具体实施方式,步骤4所述利用训练完成的deepar递归神经网络模型结合测试集输入得到模型的输出数据,将输出数据与测试集输出数据进行对比,评价模型性能并对模型参数进行调整优化,进而得到最终的补偿模型,具体如下:
[0144]
利用步骤3训练完成的deepar神经网络,将微惯性测量单元的实际输出与温度值输入神经网络,再通过将神经网络输出与微惯性测量单元实际输出相加即得到标定补偿后的测量输出;
[0145]
利用步骤3所构建的测试集对deepar模型进行测试,根据测试精度,调整深度神经网络的训练步数、学习率这些超参数并重新训练神经网络,从而达到更好的误差标定补偿效果,实现对微惯性测量单元难以建模的、时变性强的、高非线性的误差进行拟合的目的。本发明适用于为惯性测量单元的整体动态标定,标定精度高,适应性强。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1