应用于随机干扰场景下的毫米波雷达动态手势识别方法
本发明属于毫米波雷达手势识别
技术领域:
,涉及雷达信号处理和深度学习技术,具体涉及一种应用于随机干扰场景下的毫米波雷达动态手势识别方法。
背景技术:
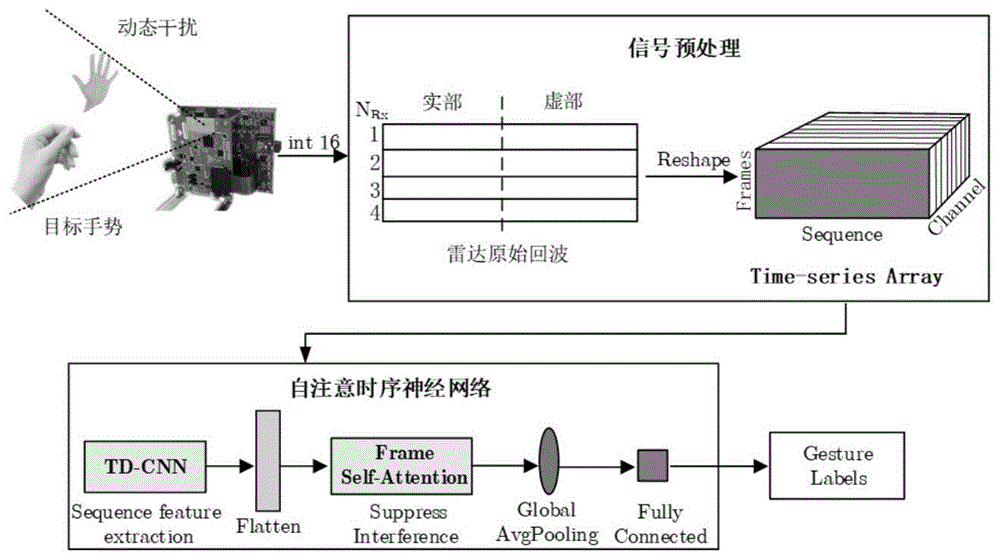
近年来,非接触式的手势识别在智能家居、辅助手语交流、无接触式外科手术等领域得到广泛应用。毫米波雷达具有穿透障碍物和捕获细微动作的能力,可以在无光照环境下工作,通常被选作无接触式手势识别的传感器,如谷歌公司开发的应用于人机交互的ProjectSoli传感器。从毫米波雷达信号中获取目标的特征是识别动态手势的关键。在早期阶段,研究人员主要是利用雷达回波对手势的距离、多普勒和角度等低维特征进行参数估计,从而得到各种手势特征谱图,然后将特征谱图以图片数据集的形式输入支持向量机或卷积神经网络(ConvolutionalNeuralNetworks,CNN)等分类器进行识别。例如,文献“S.Ryu,J.Suh,S.Baek,S.HongandJ.Kim,\"Feature-BasedHandGestureRecognitionUsinganFMCWRadaranditsTemporalFeatureAnalysis,\"inIEEESensorsJournal,vol.18,no.18,pp.7593-7602,15Sept.15,2018.”利用FMCW雷达获取距离-多普勒图(Range-DopplerMap,RDM),通过量子进化算法(quantum-inspiredevolutionaryalgorithm,QEA)进行特征选择,并依靠RDM特征集中提取的特征子集分类动态手势。文献“S.HazraandA.Santra,\"Short-RangeRadar-BasedGestureRecognitionSystemUsing3DCNNWithTripletLoss,\"inIEEEAccess,vol.7,pp.125623-125633,2019.”提出一种基于距离维特征的元学习方法,以3D-CNN模型为框架,采用k最近邻(kNN)算法对已知手势进行分类,距离阈值用于拒绝未知手势,并用聚类法添加新的自定义手势,而无需对模型重新训练。然而,这些方法依靠从时频分布中进行人工选择和提取特征,人为构建的频谱图数据破坏了手势数据的整体性,使识别模型由数据驱动转变成了特征驱动,其性能受特征利用率的影响较大。相比之下,深度学习方法提取的特征是从数据中训练出来的,具有学习高维特征(如特征重要性,时间相关性等)的能力。而且,诸如递归神经网络(RNN)和注意力机制等方法也已被用来开发雷达回波中的时间信息。基于此,文献“S.HazraandA.Santra,\"RobustGestureRecognitionUsingMillimetric-WaveRadarSystem,\"inIEEESensorsLetters,vol.2,no.4,pp.1-4,Dec.2018,Artno.7001804.”针对距离多普勒图像序列建立了一种混合神经网络,设计全卷积神经网络用于提取谱图中的特征,并采用LSTM层进行时间序列建模,最后通过全连接层输出手势分类标签。文献“C.Du,L.Zhang,X.Sun,J.WangandJ.Sheng,\"EnhancedMulti-ChannelFeatureSynthesisforHandGestureRecognitionBasedonCNNWithaChannelandSpatialAttentionMechanism,\"inIEEEAccess,vol.8,pp.144610-144620,2020.”针对复杂环境下的手势识别,提出了一种基于空间多普勒注意机制的神经网络模型。该模型首先通过快速傅里叶变换(FFT)和数字波束形成构建多特征谱图的时间序列,采用基于时间分布的卷积神经网络学习特征,然后通过多普勒注意机制抑制干扰以获得有效手势信息,最后传递到LSTM层进行时间建模和分类。最近,一些研究专注于从原始雷达信号中提取时间相关性和抑制噪声,并且已成功应用于人类活动识别。例如,文献“Chen,H.,andW.Ye.\"ClassificationofHumanActivityBasedonRadarSignalUsing1-DConvolutionalNeuralNetwork.\"IEEEGeoscienceandRemoteSensingLettersPP.99(2019):1-5.”首次提出了一种以雷达原始回波序列为输入的端到端一维CNN,利用一维卷积层替代提取特征的STFT算法,用于识别雷达信号中的人类活动。文献“R.Zhao,X.Ma,X.LiuandF.Li,\"ContinuousHumanMotionRecognitionUsingMicro-DopplerSignaturesintheScenarioWithMicroMotionInterference,\"inIEEESensorsJournal,vol.21,no.4,pp.5022-5034,15Feb.15,2021.”设计了一种信号预处理结构,采用经验模态分解(EmpiricalModeDecomposition,EMD)去除雷达原始信号中的微运动干扰,并通过多窗口时频表示(MultiwindowTime-FrequencyRepresentation,MTFR)进行时频分析,得到高度集中的时频分布(thetime-frequencydistribution,TFD),然后从TFD中识别出连续的人体运动。但是,大多数研究主要集中在无干扰情况下的动态手势识别。在实际应用中往往存在人为干扰的情况,此时有效手势特征是我们关注的对象,因此特征的关联性和重要性将对识别起决定性作用。传统识别方法将动态手势的雷达回波表示到时频域(如TFD或RDM),时频分析等方法仅能对信号进行降噪处理,难以捕捉有效手势的特征关联性。而且,在接收的雷达回波信号中,随机动态干扰信号会与手势信号混合而难以分辨。技术实现要素:发明目的:为了克服现有技术中存在的随机干扰的情况下难以分辨干扰信号和手势信号的问题,提供一种应用于随机干扰场景下的基于自注意时序神经网络(Self-attentionTime-seriesNeuralNetworks,Atten-TsNN)的毫米波雷达动态手势识别方法,实现了随机动态干扰信号和手势信号的有效分辨,提高了对于手势的识别精度。技术方案:为实现上述目的,本发明提供一种应用于随机干扰场景下的毫米波雷达动态手势识别方法,包括如下步骤:S1:通过毫米波雷达捕获手势信息,解析雷达原始回波序列,按雷达原始回波的时域结构构建输入数据块;S2:通过基于时间分布层的包装器、一维卷积与全局池化层和InceptionV3结构搭建卷积神经网络模块;所述InceptionV3结构用于对雷达原始回波预处理;S3:利用卷积神经网络模块的一维时序卷积神经网络对雷达回波进行特征信息提取;S4:通过帧间自注意机制为提取的特征分配权重值,获得序列的帧间相关性并抑制随机干扰;S5:通过全局平均池化层(GlobalAvgPooling)和全连接(FullyConnected,FC)层将前面提取的特征经过非线性变换映射到标签集(Label),并输出识别结果。进一步地,所述步骤S1中雷达原始回波序列的解析方法为:读入采集的雷达原始回波,按接收天线划分序列,设定每个序列长度,并按照实部和虚部分割,再根据帧划分序列,重组后得到结构为帧×序列×通道的输入数据块。进一步地,所述步骤S2中卷积神经网络模块的搭建方法为:采用基于时间分布的一维卷积层(TimeDistributedConv1DLayers,T-Conv1D)和池化层进行计算,采用一维卷积层和全局平均池化层搭建了具有一定宽度的TD-Inception子网组。进一步地,所述步骤S4中帧间自注意机制根据帧序列中底层特征的关联性,计算帧与帧之间的特征距离,并为每一帧序列片段分配权重。进一步地,所述权重的计算和分配方法为:A1:通过全连接层初始化参数矩阵,定义帧序列映射:键(Key)、查询(Query)和值(Value);A2:根据向量点积的几何意义,计算Query与Key之间的帧间相关性,得到注意力得分;A3:通过softmax函数对注意力得分进行归一化处理获得得分权重,并按得分权重对value进行加权求和。进一步地,所述步骤A1中键(Key)、查询(Query)和值(Value)的表达式为:其中,Query为输入帧序列的标准,用Key匹配这个标准得到每一帧的得分,最后将得分按比例分配给Value,WiK表示匹配给第i帧序列得分的参数矩阵,WiQ表示给第i帧序列的标准的参数矩阵,WiV表示分配给第i帧序列Value的参数矩阵,xi为输入的第i帧的序列。进一步地,所述步骤A1中参数矩阵为:dmodel=dQ=dK=320。其中,Rd1×d2表示d1行d2列的实数矩阵,dmodel表示矩阵WiQ、WiK和WiV的行数,dQ、dK和dV分别表示矩阵WiQ、WiK和WiV列数。进一步地,所述步骤A2中根据缩放点积(scaleddot-Product)法计算注意力得分,具体公式为:其中,Qi表示矩阵Q的第i列向量。进一步地,所述步骤A3的公式如下:其中,通过缩放注意力得分QKT以获得更好的泛化能力。在获得权重的同时会以0.2的概率随机丢弃部分权值,防止训练过程过拟合。进一步地,所述步骤S2中卷积神经网络的结构为:该卷积层具有三维结构,通过将维度为(T,d,c)的输入与k个步长为s的卷积核进行卷积和更新参数,生成k个特征序列,其中,T表示帧数,d表示帧序列的长度,c表示输入序列的通道,输出维度为(T,k,cow),其中(补零策略),表示只进行有效卷积,对帧序列边界不处理;全局池化层的结构为:在网络中共使用了两类特殊的池化层,包括基于时间分布的一维最大池化采样层(TimeDistributed1DMaxPoolinglayers,T-MaxPool1D)和全局平局池化采样层(GlobalAve-PoolingLayers,G-AvePool),其中,一维最大池化采样层用于匹配基于时间分布的一维卷积层,保证序列的时间顺序不变,全局平局池化采样层用于替换全连接层,减少参数量;其计算方法与常规的最大池化层相似,对每一帧输入序列按p的倍数向下采样。TD-Inception子网组的获取方法为:以Inceptionv3作为一维卷积神经网络模块的基础结构,搭建串联的TD-Inception子网组,为了保证帧序列的输入顺序在网络模型中保持不变,通过对二维的Inceptionv3改进得到TD-Inception结构,并通过池化层连接得到TD-Inception子网组;按照卷积因子分解的思想,将一维输入分为5个分支,再通过时间分布层的包装,最后得到其一维卷积形式为卷积核尺寸×数量。本发明网络中使用了3个相似的TD-Inception结构。本发明提供了一种基于自注意时序神经网络的毫米波雷达动态手势识别方法,在输入端将雷达原始回波按帧、序列和通道构造时序矩阵,并以时间分布层为包装器搭建一维时序神经网络,实现对每一帧序列的独立特征提取,然后采用自注意机制为并行输入的帧序列分配权重,获得序列的帧间相关性并抑制随机干扰,最后通过全局平均池化层和全连接层完成模块间的衔接并输出手势类别标签。上述方案可以归纳为如下两个步骤:(1)将毫米波雷达回波矩阵作为网络的输入,按回波的时域结构构建数据块(帧×序列×通道),通过基于时间分布层的包装器、一维卷积与全局池化层和InceptionV3结构搭建卷积神经网络模块,学习单帧特征的同时保留了动态手势的时序信息。(2)针对存在随机干扰的情况,在一维卷积神经网络中连接帧间自注意力层,为并行输入的帧序列分配权重,以处理动态手势的帧间相关性,并抑制随机干扰。有益效果:本发明与现有技术相比,针对存在随机干扰情况的动态手势识别问题,将设计的自注意时序神经网络应用到毫米波雷达动态手势识别当中,采用自注意机制为并行输入的帧序列分配权重,获得序列的帧间相关性并抑制随机干扰,实现了随机动态干扰信号和手势信号的有效分辨,提高了对于手势的识别精度,解决了在有人为干扰的应用场景下鲁棒性较差,容易产生错误识别的问题,保证了良好的识别效果。附图说明图1是本发明的流程示意图;图2是雷达回波数据解析流程图;图3是自注意时序神经网络(Atten-SeqNN)结构图;图4是TD-Inception结构图;图5是FrameSelf-Attention结构图;图6是定义的动态手势示意图;图7是不同干扰占比下准确率比较图;图8是可视化的FS-Atten输入输出图;图9是Atten-TsNN混淆矩阵图。具体实施方式下面结合附图和具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。一、本发明提供一种应用于随机干扰场景下的毫米波雷达动态手势识别方法,如图1所示,包括如下步骤:S1:通过毫米波雷达捕获手势信息,解析雷达原始回波序列,按雷达原始回波的时域结构构建输入数据块;S2:通过基于时间分布层的包装器、一维卷积与全局池化层和InceptionV3结构搭建卷积神经网络模块;S3:利用卷积神经网络模块的一维时序卷积神经网络对雷达回波进行特征信息提取;S4:通过帧间自注意机制为提取的特征分配权重值,获得序列的帧间相关性并抑制随机干扰;S5:通过全局平均池化层(GlobalAvgPooling)和全连接(FullyConnected,FC)层将前面提取的特征经过非线性变换映射到标签集(Label),并输出识别结果。如图2所示,步骤S1中雷达原始回波序列的解析方法为:采用77~81GHz毫米波雷达捕获手势信息。该雷达系统有3个发射天线和4个接收天线,发射信号为线性调频连续波(LinearFrequencyModulatedContinuousWave,LFMCW),发射功率为12dBm。通过数据采集卡与终端设备进行通信,终端读取数据并进行解析。首先将采集的雷达原始回波(以ADC_data.bin文件存储)以16位整型(int16)读入,然后按接收天线划分为4个序列,每个序列长度为采样点数(n_samples)和Chirp总数(Num_chirps)乘积的2倍,并按照实部和虚部分割,最后再根据帧划分序列,重组后得到结构为帧×序列×通道的输入数据块。本实施例中采用的接收天线(NRx)个数为4,故重组后的时间序列矩阵有8个通道。其中,每个通道的结构均为(Frames,n_samples*chirps),Frames表示手势采集时长(以帧为单位),chirps表示每一帧的chirp数,Num_chirps=Frames*chirps。参照图3,步骤S2中卷积神经网络模块的搭建方法为:采用基于时间分布的一维卷积层(TimeDistributedConv1DLayers,T-Conv1D)和池化层进行计算。T-Conv1D与传统二维卷积层(Conv2D)具有相似的计算方法,不同之处在于T-Conv1D可以获取每一帧序列中低相关性的特征,同时保留多帧序列的时间顺序。另外,由于时间分布层具有共享特征图权值的特性,使一维卷积层(Conv1D)在不增加算法计算复杂度的同时获得多对多运算的能力。此外,采用T-Conv1D和平均池化层搭建了具有一定宽度的TD-Inception子网组,可以有效提高训练速度和收敛速度。BatchNorm2D(Frames):由于存在随机干扰,未经预处理的雷达原始回波在训练中难以收敛。因此需要对输入的时序矩阵进行标准化处理,本实施例采用BatchNormlization按帧对输入的数据矩阵进行标准化处理。TimeDistributedConv1DLayers(t,ks,k):该卷积层具有三维结构,通过将维度为(T,d,c)的输入与k个步长为s的卷积核进行卷积和更新参数,生成k个特征序列。其中,T表示帧数,d表示帧序列的长度,c表示输入序列的通道。输出维度为(T,k,cow),其中padding=“Valid”(补零策略),表示只进行有效卷积,对帧序列边界不处理。PoolingLayers(t,p):本发明在网络中共使用了两类特殊的池化层,包括基于时间分布的一维最大池化采样层(TimeDistributed1DMaxPoolinglayers,T-MaxPool1D)和全局平局池化采样层(GlobalAve-PoolingLayers,G-AvePool)。T-MaxPool1D用于匹配T-Conv1D层,保证序列的时间顺序不变。G-AvePool用于替换全连接层,减少参数量。其计算方法与常规的最大池化层相似,对每一帧输入序列按p的倍数向下采样。如图4所示,TD-Inception子网组:T-Conv1D在处理手势数据时,本质上仍然是对每一帧序列提取特征,但一维卷积对于多帧序列中的高层特征学习能力不足,需要通过扩展网络结构进一步学习丰富的空间特征。因此,本实施例以Inceptionv3作为一维卷积神经网络模块的基础结构,搭建串联的TD-Inception子网组。为了保证帧序列的输入顺序在网络模型中保持不变,通过对二维的Inceptionv3改进得到TD-Inception结构,并通过池化层连接得到TD-Inception子网组。按照卷积因子分解的思想,将一维输入分为5个分支,再通过时间分布层的包装,最后得到其一维卷积形式为卷积核尺寸×数量。本发明网络中使用了3个相似的TD-Inception结构。参照图5,在实际应用中,随着手势持续的时间变长,TD-CNN模块难以学习多帧序列的关联性。虽然2DCNN可以通过堆叠多个卷积模块来增大感受野,但仍然是在空间和时间上的局部操作,缺乏对序列中前后时间片段的整体分析。因此,本发明借鉴人脑处理大量过载信息的方式,通过引入自注意力机制提高模型处理长序列信息的能力。另外,对于本发明设计的时序分类任务,部分目标手势的原始回波包含不相关的干扰动作,这些无规律的随机动作片段经常会误导神经网络分类器的训练,使网络收敛速度慢或识别率下降。为了分析序列中的关联信息,同时消除手势序列中的随机干扰,本发明设计了一种基于帧序列的自注意机制(FrameSelf-Attention,FS-Atten),具体如图4所示,帧间自注意机制根据帧序列中底层特征的关联性,计算帧与帧之间的特征距离,并为每一帧序列片段分配权重。权重的计算和分配方法为:A1:通过全连接层初始化参数矩阵,定义帧序列映射:键(Key)、查询(Query)和值(Value);键(Key)、查询(Query)和值(Value)的表达式为:其中,Query为输入帧序列的标准,用Key匹配这个标准得到每一帧的得分,最后将得分按比例分配给Value,WiK表示匹配给第i帧序列得分的参数矩阵,WiQ表示给第i帧序列的标准的参数矩阵,WiV表示分配给第i帧序列Value的参数矩阵,xi为输入的第i帧的序列。参数矩阵dmodel=dQ=dk=320;其中,Rd1×d2表示d1行d2列的实数矩阵,dmodel表示矩阵WiQ、WiK和WiV的行数,dQ、dK和dV分别表示矩阵WiQ、WiK和WiV列数。在对参数矩阵尺寸的选取上,将Wv的最后一个维数进行了调整,令dout=32,使最后的输出维度尽可能小。A2:根据向量点积的几何意义,计算Query与Key之间的帧间相关性,得到注意力得分;本实施例中根据缩放点积(scaleddot-Product)法计算注意力得分,具体公式为:其中,Qi表示矩阵Q的第i列向量。A3:通过softmax函数对注意力得分进行归一化处理获得得分权重,并按得分权重对value进行加权求和。公式如下:其中,通过缩放注意力得分QKT以获得更好的泛化能力。在获得权重的同时会以0.2的概率随机丢弃部分权值,防止训练过程过拟合。本发明还提供一种应用于随机干扰场景下的毫米波雷达动态手势识别系统,该系统包括网络接口、存储器和处理器;其中,网络接口,用于在与其他外部网元之间进行收发信息过程中,实现信号的接收和发送;存储器,用于存储能够在所述处理器上运行的计算机程序指令;处理器,用于在运行计算机程序指令时,执行上述共识方法的步骤。本实施例还提供一种计算机存储介质,该计算机存储介质存储有计算机程序,在处理器执行所述计算机程序时可实现以上所描述的方法。所述计算机可读介质可以被认为是有形的且非暂时性的。非暂时性有形计算机可读介质的非限制性示例包括非易失性存储器电路(例如闪存电路、可擦除可编程只读存储器电路或掩膜只读存储器电路)、易失性存储器电路(例如静态随机存取存储器电路或动态随机存取存储器电路)、磁存储介质(例如模拟或数字磁带或硬盘驱动器)和光存储介质(例如CD、DVD或蓝光光盘)等。计算机程序包括存储在至少一个非暂时性有形计算机可读介质上的处理器可执行指令。计算机程序还可以包括或依赖于存储的数据。计算机程序可以包括与专用计算机的硬件交互的基本输入/输出系统(BIOS)、与专用计算机的特定设备交互的设备驱动程序、一个或多个操作系统、用户应用程序、后台服务、后台应用程序等。本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。二、基于上述技术方案,为了验证本发明方法的效果,本实施例进行实验验证,具体如下:采用的实验设备为AWR1443毫米波雷达传感器和DCA1000EVM采集卡。雷达回波通过采集卡传入到PC端,在PyCharm软件上使用numpy库进行数据解析。Atten-TsNN基于TensorFlow2.0深度学习框架,在配置为IntelI7-10700K处理器和NVIDIAGTX3090显卡的服务器上进行训练。具体的实验过程为:步骤1:初始化系统参数给出雷达系统的配置如表1,其中每个手势的采集时间均为60帧(约2.05s)。表1雷达传感器参数参数数量发射天线数量(个)3接收天线数量(个)4采样时间(帧)64帧周期(ms)32Chirp数(个)32带宽(MHz)1798.92采样点数64采样率(MHz)10步骤2:定义动态手势数据集采用AWR1443雷达传感器配套的软件采集原始回波,自建手势原始回波数据集。共设计5种手势,包括顺时针圆形、三角形、折线沙漏、折线字母M和五角星五个运动手势,具体动作如图6所示。每一种手势重复采集数据600次,共3000个雷达原始回波数据。另外,在雷达和有效手势之间引入随机干扰,包括挥手、抛物等随机手势动作,占总数据量的25%。干扰手势在2秒的采集时间内随机出现,并与有效手势处于不同的角度。步骤3:初始化Atten-TsNN模型Atten-TsNN模型主要由基于时间分布的一维卷积和池化层搭建,一维卷积参数初始化情况如表2所示。其中TD-Inception结构的卷积核形式是k×i,k控制该结构的一维滤波器总数,i控制不同尺寸滤波器的分配比例。输入帧序列长度为2048,TD-Inception的i分别取4、6和7。T-Conv1D的卷积核形式为卷积核数量×卷积核尺寸,由于帧通道不参与卷积计算,故第二个通道的输出保持不变。表2一维卷积参数配置类型卷积核+步长参数量输出尺寸Input-0(128,64,2048,8)T-Conv1D-164×48+824640(128,64,251,64)T-Conv1D-2128×9+873856(128,64,31,128)TD-Inception(a)64×4+17248(128,64,31,192)T-MaxPool1D1×4+20(128,64,8,192)TD-Inception(b)64×6+110448(128,64,8,256)T-MaxPool1D1×4+20(128,64,2,256)TD-Inception(c)64×7+113584(128,64,2,320)T-MaxPool1D1×4+20(128,64,1,320)分析T-Conv1D-1滤波器尺寸对测试精度的影响。滤波器的尺寸从32开始测试,以8为增量单位进行最优调参(GridSearch),在保证T-Conv1D-2输出尺寸尽可能小的前提下,滤波器的最优尺寸为48。另外,为了探索FS-Atten模块在模型中的最优输入尺寸,通过调整T-Conv1D的步长使FS-Atten模块获得不同的输入。在设置输入FS-Atten为64×32的条件下,比较了FS-Atten输入尺寸对整个模型大小的影响,结果如表3所示。表3FS-Atten输入尺寸比较FS-Atten输入T-Conv1D步长模型大小准确率(128,64,2048)232.7MB96.69%(128,64,320)81.3MB98.43%步骤4:模型训练与在线验证将数据集划分为训练集、验证集和测试集,以数据集的20%定义验证集和测试集,初始化学习率为3e-4。采用早停法(EarlyStopping)监听验证集的准确率,利用compile和fit函数定义损失,在泛化效果变差时结束模型训练。在训练中发现,当数据含有随机动态干扰的数据占比较少时,模型对含有干扰数据的抑制能力不足,具体表现如图6所示。从图中可以看出,干扰数据占比在5%-10%区间内,验证集和测试准确率呈下降趋势。随着干扰数据比例的提高,训练模型时能较好地拟合这部分数据,得到的验证集准确率均在96%以上,测试准确率也不断提高。考虑到实际情况,在后面的对比实验中将干扰数据占比均调整至25%。为了分析FS-Atten模块对整个网络的贡献,从测试集中抽取5类手势对FS-Atten模块的输入和输出进行了可视化比较。为了便于与FS-Atten的输出(64×32)关联比较,将FS-Atten的输入(64×320)归一化到(0,1)区间,并按照AvePooling层的方法将长度为320的通道平均采样到32,得到维数为64×32的矩阵,如图8所示。从图中可以看出,64帧特征矩阵经过FS-Atten模块输出后得到的矩阵在帧维度上的排布更连贯,特征更加显著,相当于对图像做了锐化处理,使处理后不同手势间更易区分。为了验证本发明所构建的神经网络的在线识别准确率,选取了未参与训练的两组数据作为测试集(包括有干扰和无干扰的两组数据),分析模型对每种手势的识别表现。图9给出了Atten-TsNN模型在测试集上得出的混淆矩阵。从图中可以看出,在有干扰的测试集中,手势2(三角形)和手势3(折线沙漏)的表现较差。在无干扰的测试集中,手势2(三角形)和手势4(折线M)的表现较差。这说明所提模型对这三类手势的辨识度不高,相互间较易混淆,而对于节点最多和最少的两类手势识别效果较好。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1