一种适用于伺服控制器的控制算法的制作方法
本发明属于伺服控制器的控制算法技术领域,涉及一种适用于伺服控制器的控制算法。
背景技术:
伺服控制器是现代运动控制的重要组成部分,普遍采用基于矢量控制的电流、速度、位置三闭环控制算法,广泛应用于高精度的定位系统,实现高精度的传动系统定位。伺服控制器要求调节范围宽、定位精度高、有足够的传动刚性和速度稳定性、无超调等特点,而PID控制正好符合了伺服控制器的要求。因为PID控制结构简单、易于实现且鲁棒性强,所以它使用于超过90%的控制系统中。但是,随着工业过程复杂度越来越高,外界环境不确定,对象结构和参数的变化也越来越复杂,传统的PID控制器在复杂工业中变得不适用。随着智能算法如模糊控制、神经网络以及专家算法的普及,如何将先进的预测模型算法和传统经典PID控制算法有效结合起来,更好地服务于大工业生产,成为算法研究的热点。现如今伺服控制器要求反应更加灵敏、控制精度更高、位置定位更加准确,新的复杂的组合式算法逐渐成为算法首选。但是并不是所有的算法组合都能达到事半功倍的效果,比如多种功能相同的算法组合到一块,不仅不能得到满意的效果,还可能造成算法过于冗杂,影响系统性能。而只有让组合结构中各种算法各司其职,才能设计出适合于伺服控制器的算法。
技术实现要素:
本发明的目的是提供一种适用于伺服控制器的控制算法,提出了一种大范围调整+小范围控制+参数优化的模式,既能降低伺服控制器原有结构参数所造成的系统误差,又能减少来自工业现场各种干扰信号对伺服控制系统的影响。
本发明所采用的技术方案是,一种适用于伺服控制器的控制算法,具体包括以下步骤:
步骤1,利用粒子群优化算法求PID控制器的Kp、Ki、Kd;
步骤2,在模糊控制器输入端输入e、ec,按照模糊规则,得出Kp、Ki、Kd的变化值ΔKp、ΔKi、ΔKd;
步骤3,将ΔKp、ΔKi、ΔKd分别与Kp、Ki、Kd相加,作为新的PID控制器的参数,输入给PID控制器,即可进行控制。
本发明的特点还在于,
其中步骤1的具体步骤如下:
步骤1.1,初始化种群粒子规模、迭代次数、监测邻域粒子浓度上限δ,设置粒子速度与空间搜索范围,设置输出量和输入量之间的标准误差e0(t),并对第一代粒子进行PID参数编码;
步骤1.2,计算当前代粒子群适合度值,找到当前粒子的最佳位置Pbestij和种群最佳位置Gbestj;
步骤1.3,将粒子所在的当前代数与步骤1.1初始化代数进行比较,判断粒子所在的当前代数是否达到最大代数,若达到最大代数,则转到步骤1.8步执行;反之,执行步骤1.4;
步骤1.4,根据步骤1.3找到的当前粒子的最佳位置Pbestij和种群最佳位置Gbestj,计算监测邻域中的粒子个数,判断粒子种群是否满足多样性要求:若满足,则跳转至步骤1.6;反之,则执行步骤1.5;
步骤1.5,根据步骤1.2所得的粒子群适合度值,计算粒子被选中变异的概率,根据计算的变异概率确定进行变异的粒子;
步骤1.6,将步骤1.5选取的变异粒子进行变异,更新每一个粒子的位置,代数迭代加1;
步骤1.7,将当代粒子的输出量和输入量之间的误差e(t)与步骤1.1预设的标准误差e0(t)进行比较,当e(t)≤e0(t)时,执行步骤1.8,反之,则返回执行步骤1.2;
步骤1.8,输出PID控制器中的Kp、Ki、Kd参数。
其中步骤1.2的具体过程如下:
步骤1.2.1,据PID的特性以及误差的要求,选取适合度函数f(t)的公式如下:
步骤1.2.2,根据如下公式(2)计算粒子适合度值fitnessi:
fitnessi=f(t)|(b(k,i),b(k-1,i),b(k-2,i),...,b(1,i)) (2);
其中,fitnessi表示第i个粒子的适合度,b(i,j)表示第i个粒子在第j维的位置,j=1,2,3…k,k表示粒子在空间上的最大维数。
其中步骤1.4的具体过程如下:
步骤1.4.1,定义监测邻域φ为:
φ={Pbestij|||Pbestij-Gbestj||2<ε} (3);
其中,||Pbestij-Gbestj||2表示粒子个体i最优位置Pbestij与全局最优位置Gbestj的空间距离,ε为粒子个体i最优位置Pbestij与全局最优位置Gbestj之间的标准距离,ε趋于0,ε表示监测邻域大小;
其中,Q表示寻优空间维数,Pbestij和Gbestj分别是第i个粒子和全局粒子当前所经过的第j维最佳位置;
步骤1.4.2,记Nφ为监测邻域φ中的粒子个数,Nφ开始会被初始化为0,当计算监测邻域φ的粒子数量时,每计算出一个满足公式(3)要求的粒子的时,Nφ加1;
步骤1.4.3,根据如下公式(5)计算种群预设的粒子数量:
Nδ=N×δ (5);
其中:Nδ表示在预设的粒子浓度下,监测邻域应有的粒子数量;N为种群粒子数,即种群粒子规模;
当Nφ≥Nδ成立时,表明监测邻域中粒子浓度过高,种群多样性有损失太多的危险,必须增加种群的多样性,即满足增加种群多样性的要求;
当Nφ<Nδ,则Nφ归0,此种情况不满足增加种群多样性的要求。
其中步骤1.5的具体过程如下:
根据如下公式(6)计算粒子被选中进行变异的概率:
其中,Psi表示第i个粒子被选为变异的概率,其中,i=1.2....Nφ,fitnessj表示第i个粒子在第j维的适合度,粒子的适合度越大,被选为变异的概率越大;
将计算出的从大到小进行排序,并从最大值开始,选取60%Nφ~70%Nφ个粒子,作为进行变异的粒子。
其中步骤1.6中进行变异的具体过程如下:
针对监测邻域φ中的每个粒子产生一个随机数randi,randi∈[0,Psi],此时,由如下公式式子(7)对被选粒子进行随机变异:
Pbestij=aj+(bj-aj)*rand(0,1) (7);
式中,Pbestij是在Nφ个粒子中被选中变异的第i个粒子当前所经过的第j维最好位置;aj,bj分别为粒子第j维寻优范围的下限和上限。
其中步骤2的具体过程如下:
步骤2.1,在模糊控制器输入端输入e、ec,根据参数e、ec、Kp、Ki、Kd对控制系统的影响来制定模糊规则库;
步骤2.2,参数模糊推理器时刻监测e、ec的变化,按照步骤2.1制定的规则库确定Kp、Ki、Kd的输出变化值ΔKp、ΔKi、ΔKd。
本发明的有益效果是,本发明提出的一种适用于伺服控制器的控制算法,采用大范围调整+小范围控制+参数优化模式,这种模式也可适用于其他的一些控制系统,无论e、ec波动多不稳定,根据模糊规则总能输出合理的ΔKp、ΔKi、ΔKd值。采用粒子群优化算法得到PID控制器的Kp、Ki、Kd预设值,减少一些低级误差对系统的影响。采用基于适合度指数定标的概率变异的方式,来减少粒子群在后期陷入局部最优的概率,这种算法结构使伺服控制器的算法简单明了,不仅提供了一种新的设计思路,同时也可以作为一种标准用于评判一种算法的好坏,而且本发明继续沿用了PID的算法,这也充分考虑到了PID性能的优越性,符合现在伺服控制器对快速性、稳定性、准确性以及鲁棒性的要求。
附图说明
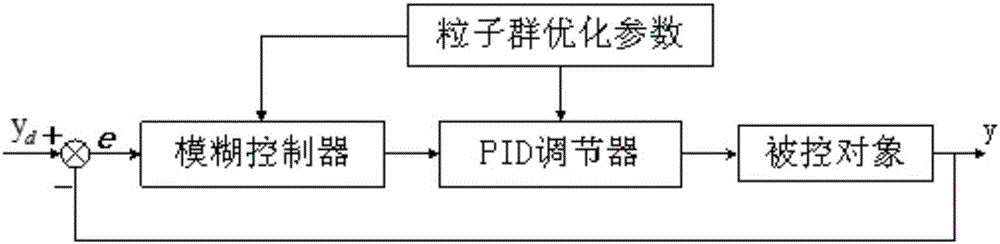
图1是本发明一种适应于伺服控制器的算法的原理框图;
图2是常规PID控制系统结构原理框图;
图3是模糊控制系统结构原理框图;
图4是模糊PID控制系统结构原理框图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明一种适用于伺服控制器的控制算法,本发明提供的算法原理框图如图1所示,具体包括以下步骤:
步骤1,利用粒子群优化算法求PID控制器的Kp、Ki、Kd;
步骤1的具体过程如下:
步骤1.1,初始化种群粒子规模(即种群粒子的个数N)、迭代次数、监测邻域粒子浓度上限δ,设置粒子速度与空间搜索范围,设置输出量和输入量之间的标准误差e0(t),并对第一代粒子进行PID参数编码;
步骤1.2,计算当前代粒子群适合度值,找到当前粒子的最佳位置Pbestij和种群最佳位置Gbestj;
步骤1.2.1,据PID的特性以及误差的要求,选取适合度函数f(t)的公式如下:
步骤1.2.2,根据如下公式(2)计算粒子适合度值fitnessi:
fitnessi=f(t)|(b(k,i),b(k-1,i),b(k-2,i),...,b(1,i)) (2);
其中,fitnessi表示第i个粒子的适合度,b(i,j)表示第i个粒子在第j维的位置,j=1,2,3…k,k表示粒子在空间上的最大维数。
步骤1.3,将粒子所在的当前代数与步骤1.1初始化代数进行比较,判断粒子所在的当前代数是否达到最大代数,若达到最大代数,则转到步骤1.8步执行;反之,执行步骤1.4;
步骤1.4,根据步骤1.3找到的当前粒子的最佳位置Pbestij和种群最佳位置Gbestj,计算监测邻域中的粒子个数,判断粒子种群是否满足多样性要求:若满足,则跳转至步骤1.6;反之,则执行步骤1.5;
步骤1.4.1,定义监测邻域φ为:
φ={Pbestij|||Pbestij-Gbestj||2<ε} (3);
其中,||Pbestij-Gbestj||2表示粒子个体i最优位置Pbestij与全局最优位置Gbestj的空间距离,ε为粒子个体i最优位置Pbestij与全局最优位置Gbestj之间的标准距离,ε趋于0,ε表示监测邻域大小;
其中,Q表示寻优空间维数,Pbestij和Gbestj分别是第i个粒子和全局粒子当前所经过的第j维最佳位置;
步骤1.4.2,记Nφ为监测邻域φ中的粒子个数,Nφ开始会被初始化为0,当计算监测邻域φ的粒子数量时,每计算出一个满足公式(3)要求的粒子的时,Nφ加1;
步骤1.4.3,根据如下公式(5)计算种群预设的粒子数量:
Nδ=N×δ (5);
其中:Nδ表示在预设的粒子浓度下,监测邻域应有的粒子数量;N为步骤1.1初始化的种群粒子数,即种群粒子规模;
当Nφ≥Nδ成立时,表明监测邻域中粒子浓度过高,种群多样性有损失太多的危险,必须增加种群的多样性,即满足增加种群多样性的要求;
当Nφ<Nδ,则Nφ归0,此种情况不满足增加种群多样性的要求。
步骤1.5,根据步骤1.2所得的粒子群适合度值,计算粒子被选中变异的概率,根据计算的变异概率确定进行变异的粒子;
根据如下公式(6)计算粒子被选中进行变异的概率:
其中,Psi表示第i个粒子被选为变异的概率,其中,i=1.2....Nφ,fitnessj表示第i个粒子在第j维的适合度,粒子的适合度越大,被选为变异的概率越大;
将计算出的从大到小进行排序,并从最大值开始,选取60%Nφ~70%Nφ个粒子,作为进行变异的粒子。
步骤1.6,将步骤1.5选取的变异粒子进行变异,更新每一个粒子的位置,代数迭代加1;
对粒子进行变异,指的是对粒子的位置进行改变,让聚集在局部的粒子分散开来,针对监测邻域φ中的每个粒子产生一个随机数randi,randi∈[0,Psi],此时,由如下公式式子(7)对被选粒子进行随机变异:
Pbestij=aj+(bj-aj)*rand(0,1) (7);
式中,Pbestij是在Nφ个粒子中被选中变异的第i个粒子当前所经过的第j维最好位置;aj,bj分别为粒子第j维寻优范围的下限和上限,这里采用随机变异,有利于提高种群的多样性。
步骤1.7,将当代粒子的输出量和输入量之间的误差e(t)与步骤1.1预设的标准误差e0(t)进行比较,当e(t)≤e0(t)时,执行步骤1.8,反之,则返回执行步骤1.2;
步骤1.8,输出PID控制器中的Kp、Ki、Kd参数。
步骤2,在模糊控制器输入端输入e、ec,按照模糊规则,得出Kp、Ki、Kd的变化值ΔKp、ΔKi、ΔKd;
步骤2.1,在模糊控制器输入端输入e、ec,根据参数e、ec、Kp、Ki、Kd对控制系统的影响来制定模糊规则库;
步骤2.2,参数模糊推理器时刻监测e、ec的变化,按照步骤2.1制定的规则库确定Kp、Ki、Kd的输出变化值ΔKp、ΔKi、ΔKd。
步骤3,将ΔKp、ΔKi、ΔKd分别与Kp、Ki、Kd相加,作为新的PID控制器的参数,输入给PID控制器,即可进行控制。
本发明一种适用于伺服控制器的控制算法中采用的几种控制方式如下:
1.常规PID控制
常规PID控制系统主要有模拟PID控制器和被控对象两部分构成,是一种线性控制器。它由预设值和实际输出值之差作为系统的控制输入,而PID中的比例、积分、微分参数都是固定的。其控制规律可以被描述为如下公式:
具体结构如图2所示,主要参数有Kp、Ki、Kd等,作用有:
(1)比例环节Kp:成比例地反映控制系统的偏差信号e(t),偏差一旦产生,控制器立即产生控制作用,减少偏差。
(2)积分环节Ki:主要用于消除静差,提高系统的无差度。积分作用的强弱取决于积分时间常数T1,T1越大,积分作用越弱,反之,则越强。
(3)微分环节Kd:反映偏差信号的变化趋势(变化速率),并能在偏差信号变得太大之前,在系统中引入一个有效的早期修正信号,从而加快系统的动作速度,减少调节时间。
2.模糊PID控制
相比较常规PID,模糊PID有其突出优点:首先,有自动辨识被控过程参数、自动调整控制器参数、能够适应被控过程参数的变化等一系列优点;其次,又具有常规PID控制器结构简单、鲁棒性好、可靠性高、熟知度高等优点。模糊控制结构原理图如图3所示,主要有参数模糊推理器、被控对象构成。模糊PID控制结构原理图如图4所示,主要由参数模糊推理器、PID控制器、被控对象构成。
设定参数:预设值与实际输出之差为e,e的变化率为ec,PID控制器的比例、积分、微分参数分别为Kp、Ki、Kd。
首先,要根据参数e、ec、Kp、Ki、Kd对控制系统的影响来制定模糊规则库。其中,Kp、Ki、Kd对系统的影响在上文已经讨论过;参数e、ec对系统的影响如表1所示。参数模糊推理器时刻监测e、ec的变化,按照规则库确定Kp、Ki、Kd的输出变化值ΔKp、ΔKi、ΔKd。基于伺服控制器的特征,本发明制订了参考模糊规则库,如表2、3、4所示。
表1 e、ec对控制系统的影响
表2参数ΔKp的模糊规则
表3参数ΔKi的模糊规则
表4参数ΔKd的模糊规则
其中,NB、NM、NS、O、PS、PM、PB分别表示负大、负中、负小、不变、正小、正中、正大;e表示输入与实际输出之间的差值,ec表示差值的变化率。
3.改进型粒子群优化算法
根据伺服控制器系统的固有特性,以及模糊PID算法的具体要求,我们首先要给PID控制器的参数Kp、Ki、Kd写入预设参数,为减少预设参数对系统的影响,我们利用改进型粒子群优化算法对输入值进行优化。
粒子群优化算法具有群智能的优点,比如灵活性、稳健性、自组织性等,在智能算法领域中应用极其广泛。但也存在着一些缺点,比如在后期往往因寻优空间维数扩大而容易引起维数灾难、种群陷入局部极值点,速度变慢,寻优结果大打折扣。本发明提出伺服控制器算法中采用了一种改进型粒子群优化算法:优化的每一步都监测粒子群的运动状态,一旦粒子群陷入局部最优,则进行粒子变异,确保种群多样性、健壮性、智能性。
本发明一种适用于伺服控制器的控制算法中,采用粒子群优化算法对伺服控制器的PID控制部分的参数提前优化,减少了系统的原有误差对系统的影响(参数优化);采取模糊控制算法让控制参数在最初以最快速度趋近到最优范围内(大范围调整),这样可以以最快的速度消除来自工业现场的干扰,防止超调,实现系统参数自调整,在线自整定,扩大的伺服控制器的适用范围;然后通过与粒子群优化算法的输出值相结合,得出最优控制参数,最后输出给控制器(小范围控制),以最快的速度得到最精准的控制输出,响应速度快,鲁棒性强。
本发明在利用粒子群优化算法求PID控制器的Kp、Ki、Kd时,根据监测的粒子群最优邻域内粒子的数量来判断粒子是否陷入了局部最优,如果陷入局部最优则根据适合度选取合适的粒子进行变异,提高粒子多样性,能有效地减少粒子群在后期陷入局部极值点的概率。
- 还没有人留言评论。精彩留言会获得点赞!