闭环分数阶PDɑ型迭代学习机器人控制器的设计方法及系统与流程
本发明属于机器人控制领域,尤其涉及一种闭环分数阶PDα型迭代学习机器人控制器的设计方法及系统。
背景技术:
机器人技术是当下全球范围内学术界和工业界的研究热点。随着科学技术发展,机器人已经广泛应用到航天、医疗和军事,甚至日常生活及娱乐教育等各个领域。机器人既是先进制造业的关键支撑装备,也是改善人类生活方式的重要切入点。随着理论和技术的日益成熟,人们对机器人提出了越来越多的要求。
机器人系统是一个典型的高度非线性、强耦合的动力学系统,其高精度控制问题一直是工业自动化领域研究的热点。例如:目前的机器人机械臂的精确控制方法有:变结构控制、滑模控制、鲁棒控制和学习控制等;然而前几种控制方法均为有模型控制,机械臂实际运行过程中存在的摩擦、高频特性、载荷变化以及其它不确定干扰因素势必会对控制品质造成影响。受人类智能行为启发,学习控制以非常简单的方式和需要较少的先验知识处理不确定程度相当高的动态系统,因此得到了广泛的研究和应用。
现有的学习控制方法可以实现机器人对期望轨迹的完全跟踪,然而当系统受环境因素或自身状态变化时,现有控制方法的适应性不强,需要重新学习以达到较好的跟踪效果。另一方面,现有学习控制方法均为整数阶算法,其控制器的可调参数较少,也同样使得控制器的稳定性以及自适应性不强。
技术实现要素:
为了解决现有技术的缺点,本发明的第一目的是提供一种闭环分数阶PDα型迭代学习机器人控制器的设计方法。
本发明的一种闭环分数阶PDα型迭代学习机器人控制器的设计方法,包括:
步骤1:选定机器人的运动机构为分析对象,并构建选定的运动机构的动力学模型;再构建机器人控制器中的闭环分数阶PDα型迭代学习控制律;
其中,闭环分数阶PDα型迭代学习控制律为:机器人运动机构的当前时刻输入量等于前一时刻输入量与两个跟踪误差学习项之和;跟踪误差为机器人运动机构的当前时刻位置与预设机器人运动机构的期望运动轨迹之差,一个跟踪误差学习项等于跟踪误差的Kp倍,另一个跟踪误差学习项等于跟踪误差的α次分数阶微分的Kd倍;Kp、α和Kd均为闭环分数阶PDα型迭代学习控制律的参数,α∈(0,1),Kp和Kd为任意正数;
步骤2:预设机器人运动机构的期望运动轨迹,初始化机器人运动机构的输入量以及机器人控制器中闭环分数阶PDα型迭代学习控制律的参数并作用于机器人的运动机构,获取机器人运动机构的实际运动轨迹;
步骤3:判断机器人运动机构的实际运动轨迹与期望运动轨迹两者的误差是否为零,若误差为零,则实际运动轨迹与期望运动轨迹重合,则闭环分数阶PDα型迭代学习律的当前参数不变,得到机器人控制器的最佳参数,结束;否则,进入下一步;
步骤4:调整闭环分数阶PDα型迭代学习律中的参数来修正输入量并作用于机器人的运动机构,直至完全跟踪期望轨迹,最终得到机器人控制器的最佳参数。
进一步地,所述机器人的运动机构为n自由度机械臂,其中,n为大于或等于2的正整数。其中,该机器人以机械臂运动为主的机器人,比如巡线机器人或用于机械零部件加工机器人。
进一步地,所述机器人为轮式机器人。轮式机器人通过行走轮的运动来使得机器人运动,行走轮通过驱动机构来驱动,驱动机构可选用驱动电机。此时可选定驱动电机为分析对象,则可构建驱动电机的动力学模型。
进一步地,在所述步骤1中,利用拉格朗日-欧拉法,得到选定运动机构的动力学模型。本发明利用拉格朗日-欧拉法,能够准确得到选定运动机构的动力学模型,进而提高了控制器设计的准确性。
本发明的第二目的是提供一种机器人控制器。
本发明的一种机器人控制器,该机器人控制器是采用上述所述的闭环分数阶PDα迭代学习机器人控制器的设计方法而得到的控制器。
本发明的第三目的是提供一种机器人控制系统。
本发明的一种机器人控制系统,该机器人控制系统为上述所述的机器人控制器构成的闭环控制系统。
进一步地,该控制器系统还包括驱动机构,所述驱动机构与机器人控制器相连,在机器人控制器的作用下,所述驱动机构用于驱动机器人的运动机构。
所述驱动机构为驱动电机。
本发明的第四目的是提供一种机器人。
本发明的一种机器人,包括上述所述的机器人控制系统。
其中,机器人的运动机构为n自由度机械臂,其中,n为大于或等于2的正整数。
其中,机器人为轮式机器人,机器人的运动机构为行走轮。
本发明的有益效果为:
(1)本发明提出的闭环分数阶PDα型迭代学习机器人控制器的设计方法,该方法不仅在控制器中分数阶微分算子的引入,增加了控制器的控制律的可调因子,还保证控制器的控制律针对系统出现时变非线性状态时单调收敛性,因此使得控制器的控制律具有更好的稳定性和适应性。
(2)本发明有效地利用了分数阶Dα型学习律较传统迭代学习在调节跟踪学习单调收敛上的独特优势,结合P型学习律以及增加的可调参数分数阶阶次改善跟踪性能,提高了收敛速度,使得机器人能够更快速准确地实现跟踪任务。
附图说明
图1是本发明的一种闭环分数阶PDα型迭代学习机器人控制器的设计方法流程图;
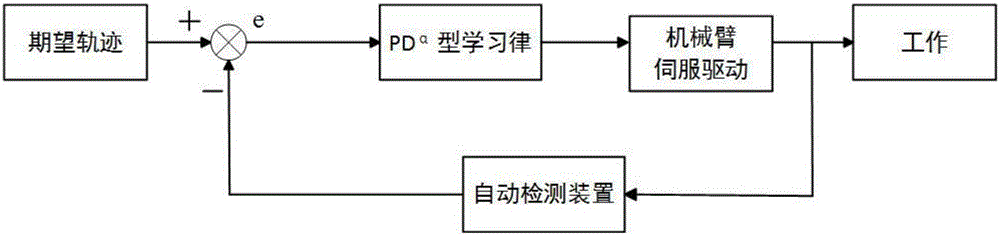
图2是本发明的闭环分数阶PDα型迭代学习控制原理流程图;
图3是两关节机械臂示意图;
图4是随着迭代次数的增加,机械臂各关节跟踪误差曲线图;
图5(a)是迭代30次时的机械臂的第一关节跟踪结果;
图5(b)是迭代30次时的机械臂的第二关节跟踪结果。
具体实施方式
下面结合附图与实施例对本发明做进一步说明:
图1是本发明的一种闭环分数阶PDα型迭代学习机器人控制器的设计方法流程图。
机器人的运动机构以n自由度机械臂为例:其中,n为大于或等于2的正整数。其中,该机器人以机械臂运动为主的机器人,比如巡线机器人或用于机械零部件加工机器人。
如图1所示的闭环分数阶PDα型迭代学习机器人控制器的设计方法,包括:
步骤1:构建n自由度机械臂的动力学模型。
n自由度机械臂包含n个刚性连杆和n个旋转关节,由拉格朗日-欧拉法得,到该n自由度的机械臂的动力学模型为:
式中:分别表示机械臂关节位置、速度和加速度向量;τ表示作用在关节上的广义力矩向量;D(θ)∈Rn×n为惯性矩阵;表示非线性哥氏力和向心力矢量;g(θ)∈Rn为重力项。
再构建机器人控制器中的闭环分数阶PDα型迭代学习控制律。
其中,闭环分数阶PDα型迭代学习控制律为:
其中,uk(t)为n自由度机械臂的当前时刻输入量;uk-1(t)为n自由度机械臂的前一时刻输入量;ek(t)为跟踪误差,其为n自由度机械臂的当前时刻位置与预设n自由度机械臂的期望运动轨迹之差,一个跟踪误差学习项Kpek(t)等于跟踪误差ek(t)的Kp倍,另一个跟踪误差学习项等于跟踪误差的α次分数阶微分的Kd倍;Kp、α和Kd均为闭环分数阶PDα型迭代学习控制律的参数,α∈(0,1),Kp和Kd为任意正数。
步骤2:预设机器人运动机构的期望运动轨迹,初始化n自由度机械臂的输入量以及机器人控制器中闭环分数阶PDα型迭代学习控制律的参数并作用于n自由度机械臂,如图2所示,获取n自由度机械臂的实际运动轨迹。
在具体实施过程中,可以利用图像采集装置来采集n自由度机械臂的实际运动轨迹,然后再传送至机器人控制器内。
步骤3:判断n自由度机械臂的实际运动轨迹与期望运动轨迹两者的误差是否为零,若误差为零,则实际运动轨迹与期望运动轨迹重合,则闭环分数阶PDα型迭代学习律的当前参数不变,得到机器人控制器的最佳参数,结束;否则,进入下一步。
步骤4:调整闭环分数阶PDα型迭代学习律中的参数来修正输入量并作用于机器人的运动机构,直至完全跟踪期望轨迹,最终得到机器人控制器的最佳参数。
仿真验证:
如图3所示,二自由度旋转关节机械臂进行仿真实验该机械臂以平面运动为例,因此忽略重力项,对应系统(1)的系数矩阵分别为:
其中,
mi,li,Ii分别表示第i个连杆的质量,长度和转动惯量;i=1,2。
仿真时取:m1=m2=4kg,l1=2m,l2=1m,I1=I2=1kg·m2,
τ=[τ1,τ2,τ3]T=[21,4,2]T。
机械臂期望的运动轨迹θ1和θ2分别选为时间区间[0,1]s上的q1,d(t)=sint和q2,d(t)=cos t,设系统的初始误差为xk(0)=θk-θd=|0.1,0.1|T。根据算法收敛条件,分别选取学习控制算法中的学习增益为η=20;α=0.95;L=0.95。从图中可以看到随着迭代次数的增加,机械臂不断趋向于期望轨迹。图4是位置跟踪误差,图5(a)和图5(b)分别是第一关节和第二关节迭代第30次的跟踪效果图,从图中可以看出,本发明设计的控制器具有较好的控制性能。
以机械臂在零件加工领域应用为例,,机械臂终端操作零件的部位即为执行机构,机械臂各关节内的电机为驱动机构,通常控制系统为单片机。按照控制系统的信息对执行机构发出指令,实现相应部位规定的运动轨迹。位置检测装置随时将执行机构的实际位置反馈给控制系统,并与设定的位置进行比较,然后通过控制系统进行调整,从而使执行机构以一定的精读达到设定位置。
在另一实施例中,机器人可选用轮式机器人。轮式机器人通过行走轮的运动来使得机器人运动,行走轮通过驱动机构来驱动,驱动机构可选用驱动电机。此时可选定驱动电机为分析对象,则可构建驱动电机的动力学模型。
本发明提出的闭环分数阶PDα型迭代学习机器人控制器的设计方法,该方法不仅在控制器中分数阶微分算子的引入,增加了控制器的控制律的可调因子,还保证控制器的控制律针对系统出现时变非线性状态时单调收敛性,因此使得控制器的控制律具有更好的稳定性和适应性。本发明有效地利用了分数阶Dα型学习律较传统迭代学习在调节跟踪学习单调收敛上的独特优势,结合P型学习律以及增加的可调参数分数阶阶次改善跟踪性能,提高了收敛速度,使得机器人能够更快速准确地实现跟踪任务。
本发明提供的一种机器人控制器,该机器人控制器是采用如图1所示的闭环分数阶PDα型迭代学习机器人控制器的设计方法而得到的控制器,其具体过程将不再累述。
本发明提供的一种机器人控制系统,如图2所示,该机器人控制系统为上述所述的机器人控制器构成的闭环控制系统。
在一个实施例中,机器人的运动机构为n自由度机械臂,其中,n为大于或等于2的正整数。
在另一个实施例中,机器人为轮式机器人,机器人的运动机构为行走轮。
进一步地,该控制器系统还包括驱动机构,所述驱动机构与机器人控制器相连,在机器人控制器的作用下,所述驱动机构用于驱动机器人的运动机构。
其中,驱动机构为驱动电机。驱动电机可选用直流电机。
本发明提供的一种机器人包括上述所述的机器人控制系统。
在一个实施例中,机器人的运动机构为n自由度机械臂,其中,n为大于或等于2的正整数。
在另一个实施例中,机器人为轮式机器人,机器人的运动机构为行走轮。
该机器人的其他结构均为现有结构,此处将不再累述。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!