基于自适应控制器的建筑物节能系统、控制方法及仿真与流程
本发明属于建筑节能技术领域,尤其涉及基于自适应控制器的建筑物节能系统、自适应控制器的控制方法及自适应控制器的仿真方法。
背景技术:
自20世纪70年代后期,在一些西方国家开始出现:室内空气质量(indoor air quality,IAQ)的说法,其发展是近十年以来国际环保界最关注的课题之一。有研究表明,现代人平均花90%的时间在室内度过,因此室内空气质量的好坏会直接影响现代人的身体健康。由此可见IAQ理应作为建筑物设计标准的重要部分和建筑物评估过程中重视的问题。二氧化碳(carbon dioxide,CO2)浓度是IAQ中的一个重要指标,当CO2浓度低时对人体无害,但其超过一定浓度时会影响到人类的呼吸:CO2在大气中含量超过1%时,人就会有轻度头晕反应;当超过3%时,开始出现呼吸困难;超过6%时,就会重度缺氧窒息甚至死亡。
纵观近几十年建筑领域的发展,建筑结构设计与设备管理方面,特别是涉及到生态控制和能源消耗的领域上,都有很显著的进步和变化。一个明显的转折点是在七十年代石油危机爆发之后,提出封闭的建筑物以最小化建筑物的能源消耗这一概念,但是这导致室内空气质量直线下降和全世界范围的健康问题。这就直接造成了研究确保人类舒适度的前提下,同时联系光照、温湿度和空气质量等其他因素的研究趋势。
在现有的能耗研究中,建筑物能耗占世界范围内总基础能耗的45%,这是在总能源消耗中占比例最高的一项。全球范围的建筑能耗,包括民用住宅和商业建筑,在发达国家每年的增长速率已达到20%-40%。然而在一项调查中,商业建筑物的年均耗能大约是70-300kWh/m2,这个数据是民用住宅的10到20倍。人口的增长、建筑服务压力的提升和舒适标准的提高都增大了建筑物的能源消耗,这些预示着未来仍然会持续能源需求的增长趋势。正是因为上述原因,建筑节能已然成为当今所有国家和国际水平在能源政策上重视的首要目标。建筑物的能源消耗问题已经得到越来越多的关注,毕竟建筑物是与人类生活工作息息相关的,也是现代化发展中必不可少的一个环节。
由此可见,研发出一种满足实际需要的可对室内温度和二氧化碳浓度等指标进行监控,并有效实现建筑物节能的系统显得尤为紧迫和必要。现有技术中,已经有类似的建筑物节能系统的报道。但现有的建筑物节能系统的组成比较复杂,不够智能化,使用不便。不能满足实际需要。
此外,控制器是实现建筑节能必不可少的重要组成部分。神经网络、模糊系统、预测控制和它们之间的组合是现有在建筑领域的主流控制器研发的方向。Dounis AI等人在文献“Design of a fuzzyset environmentcomfort system”中提出一种Fuzzy-PD的控制器,用模糊的比例微分方法来控制建筑领域内的相关设备,从而进行监测能耗和控制稳定性。但是在该方法中,使用Fuzzy-PD的控制器的方法控制建筑领域内的相关设备,具有收敛速度慢和稳定性差的缺点。目前已经提出的控制器方法几乎都有类似的缺点,因此,在控制器的收敛速度和收敛之后的稳定性都有待提升和改进。
技术实现要素:
本发明解决的技术问题是提供一种基于自适应控制器的建筑物节能系统,该系统结构简化、便于安装和使用,满足实际需求。
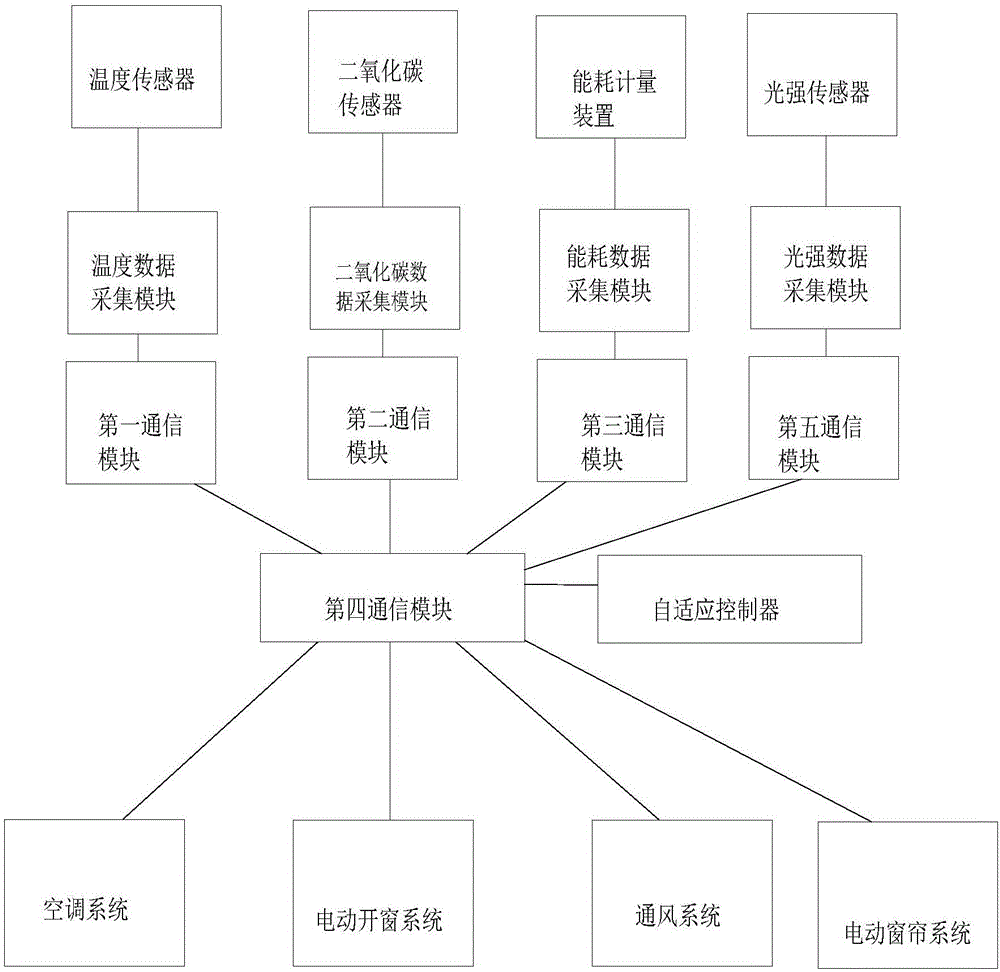
本发明解决其技术问题所采用的技术方案是:基于自适应控制器的建筑物节能系统,包括空调系统、电动开窗系统和通风系统,还包括主控器、用于检测室内温度的温度传感器、用于检测室内二氧化碳浓度的二氧化碳传感器和用于检测能耗的能耗计量装置;
所述温度传感器与温度从控器相连,所述温度从控器包括与温度传感器相连的温度数据采集模块以及与温度数据采集模块相连的第一通信模块;
所述二氧化碳传感器与二氧化碳从控器相连,所述二氧化碳从控器包括与二氧化碳传感器相连的二氧化碳数据采集模块以及与二氧化碳数据采集模块相连的第二通信模块;
所述能耗计量装置与能耗从控器相连,所述能耗从控器包括与能耗计量装置相连的能耗数据采集模块以及与能耗数据采集模块相连的第三通信模块;
所述主控器包括自适应控制器以及与自适应控制器相连的第四通信模块,所述第一通信模块、第二通信模块以及第三通信模块分别与第四通信模块无线连接,所述空调系统、电动开窗系统和通风系统分别与第四通信模块无线连接。
空调系统、电动开窗系统和通风系统的主控器可通过无线模块与第四通信模块相连,进而可通过自适应控制器来控制各个系统的行为动作。
进一步的是,还包括电动窗帘系统以及光强传感器,所述光强传感器与光强数据采集模块相连,所述光强数据采集模块与第五通信模块相连,所述第五通信模块与第四通信模块无线连接,所述电动窗帘系统与第四通信模块无线连接。
本发明还公开了建筑物节能领域的自适应控制器的控制方法,该方法收敛速度快,收敛后状态稳定。
建筑物节能领域的自适应控制器的控制方法包括:
步骤1:建立奖惩反馈模型和评价行为值函数Q(st,at);
步骤2:初始化评价行为值函数Q(s,a)、学习率α,折扣因素γ,其中,s表示状态因素,a表示行为因素,γ是一个0≤γ≤1的参数,可以是0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8或0.9等,状态因素是由室内温度T、室内二氧化碳浓度ρ和空调设置温度setT构成,行为因素是由空调系统行为、电动开窗系统行为和通风系统行为构成;
步骤3:运行片段,每个片段包括N个单位时间步,
初始化,令时刻t=0,通过温度传感器、二氧化碳传感器得到初始状态因素st的室内温度T和二氧化碳浓度ρ,确定空调设置温度setT;
步骤3-1:每个单位时间步的运行包括:
对当前状态因素st,根据贪心选择策略h(st)计算确定出当前状态因素st在时刻t的行为因素at,a∈h(st),
根据行为因素at对空调系统、电动开窗系统和通风系统进行调节,使状态因素变迁到下一状态因素st+1,并测出st+1的室内温度T和二氧化碳浓度ρ,
根据奖惩反馈模型计算得出在状态因素st和行为因素at下的奖惩rt,
更新当前评价行为值函数Q(st,at):
更新学习率α,t=t+1;
步骤4:进行判断,具体为:
若st+1对应的状态不符合状态结束条件,则返回到步骤3-1,进行下一单位时间步的运行;
若st+1对应的状态符合状态结束条件,则监测所有状态因素下的评价行为值函数是否满足预定的精度要求,若有评价行为值函数不满足精度要求,则返回到步骤3进行新的片段的运行,若评价行为值函数都满足精度要求,则结束循环。
进一步的是,所述步骤1中的奖惩反馈模型为:
rt=-w1(T_penalty)
-w2(indoor_air_quality_penalty)
-w3(E_penalty),
indoor_air_quality_penalty=|ρt-350|/500,
其中T0是室内初始温度,Tt是t时刻的室内温度,setT是空调设置温度;Et是t时刻的空调系统、电动开窗系统和通风系统的能耗值,可通过能耗计量装置测量得到;Emax是一个片段的空调系统、电动开窗系统和通风系统的最大能耗,可通过能耗计量装置预先测得;ρt是t时刻的室内CO2浓度;T_penalty是室内温度参数;indoor_air_quality_penalty是室内空气质量参数;E_penalty是能耗参数;w1、w2和w3分别是权重参数,设置为:w1=0.7,w2=0.25,w3=0.05。
进一步的是,步骤4中,若st+1对应的状态不符合状态结束条件是指:若st+1对应的单位时间步的步数小于循环设置的最大步数N;若st+1对应的状态符合状态结束条件是指:若st+1对应的单位时间步的步数等于循环设置的最大步数N。当然,状态结束条件也可以设置为其它的状态因素结束条件。
进一步的是,步骤4中,结束循环后,将获得的空调系统、电动开窗系统和通风系统的行为因素作为一个自适应动作策略储存进入策略库。
本发明还提供了一种可对自适应控制器进行仿真的方法,通过该方法可验证上述控制方法下的收敛速度和收敛后的稳定性。
建筑物节能领域的自适应控制器的仿真方法包括:
步骤1:建立状态变迁模型、奖惩反馈模型和评价行为值函数Q(st,at);
步骤2:初始化评价行为值函数Q(s,a)、学习率α,折扣因素γ,其中,s表示状态因素,a表示行为因素,γ是一个0≤γ≤1的参数,状态因素是由室内温度T、室内二氧化碳浓度ρ和空调设置温度setT构成,行为因素是由空调系统行为、电动开窗系统行为和通风系统行为构成;
步骤3:运行片段,每个片段包括N个单位时间步,
令时刻t=0,初始化初始状态因素s0,也就是确定0时刻的T、ρ和setT,
步骤3-1:每个单位时间步的运行包括:对当前状态因素st,根据贪心选择策略h(st)计算确定出当前状态因素st在时刻t的行为因素at,a∈h(st),
采取这个行为因素at,根据建立的状态变迁模型计算状态因素的变迁,状态因素变迁到下一状态因素st+1,
根据建立的奖惩反馈模型计算得出在状态因素st和行为因素at下的奖惩rt,
更新当前评价行为值函数Q(st,at):
更新学习率α,t=t+1;
步骤4:进行判断,具体为:
若st+1对应的状态不符合状态结束条件,则返回到步骤3-1,进行下一单位时间步的运行;
若st+1对应的状态符合状态结束条件,则监测所有状态因素下的评价行为值函数是否满足预定的精度要求,若有评价行为值函数不满足精度要求,则返回到步骤3进行新的片段的运行,若评价行为值函数都满足精度要求,则结束循环。
进一步的是,所述步骤1中:
状态变迁模型为:
Tt+1=Tt-[(-1)kongtiao_fig%2×T_changerate
×(1-0.1×tongfong_fig)],
ρt+1=ρt-0.1×windows_fig+0.2×tongfeng_fig,
Et+1=Et+kongtiao_fig+tongfeng_fig,
奖惩反馈模型为:
rt=-w1(T_penalty)
-w2(indoor_air_quality_penalty)
-w3(E_penalty),
indoor_air_quality_penalty=|ρt-350|/500,
全部行为因素建模为64×3的矩阵,其横向量是一个三维的向量,表示一个行为;行为向量第一位kongtiao_fig表示空调系统行为:1表示取暖小风,2表示制冷小风,3表示取暖大风,4表示制冷大风;第二位windows_fig表示电动开窗系统行为:0为关闭,1为微张,2为半张,3为全开;最后一位tongfeng_fig表示通风系统行为:0是关闭,1是小档,2是中档,3是大档;
其中,T_changerate表示温度变化速率,T0是室内初始温度,setT是空调设置温度;E是实时能耗,可根据行为因素模型的相关系统行为对应的数值累加得到,Emax是最大能耗,可根据片段中的单位时间步的总步数N计算得到,也就是Emax=7N;ρ是室内CO2浓度;T_penalty是室内温度参数,indoor_air_quality_penalty是室内空气质量参数,E_penalty是能耗参数,w1、w2、w3分别是其权重参数,室内温度稳定在设置温度是首要目的,同样也要考虑CO2浓度和能耗因素,参数的设置为:w1=0.7,w2=0.25,w3=0.05。
进一步的是,初始状态因素s0对应的初始状态室内温度T的范围为0至40摄氏度,室内二氧化碳浓度ρ的范围为200至1000ppm。
进一步的是,步骤4中,若st+1对应的状态不符合状态结束条件是指:若st+1对应的单位时间步的步数小于循环设置的最大步数N;若st+1对应的状态符合状态结束条件是指:若st+1对应的单位时间步的步数等于循环设置的最大步数N。当然,状态结束条件也可以设置为其它的状态因素结束条件。
本发明的有益效果是:
本发明的基于自适应控制器的建筑物节能系统,可对室内温度、二氧化碳浓度和能耗等因素进行实时监控,并采取相应行为动作实现节能,同时还保证了使用者的舒适度。该节能系统结构简单,方便安装和维护,充分满足了实际需要。
本发明的仿真方法,其建立建筑节能中动态自适应控制器中的状态变迁模型、奖惩反馈模型;建立状态因素变量和行为因素变量的模型,通过循环迭代计算出评价行为值函数;基于评价行为值函数得出相应状态因素下的优选行为因素。该仿真方法可对上述控制方法进行仿真,通过实验结果表明,与Fuzzy-PD控制器的控制方法相比较,本发明提供的控制方法有更快的收敛速度,收敛之后更加稳定。
r值作为模型最终评价标准,是室内温度参数、室内空气质量参数与能耗参数的加权值,设置r为一个负值,如公式所示,当三个相关参数越小时,r的值就越大,模型需要的就是尽可能大的r值。也就是说,当室内温度越接近设置温度,室内CO2浓度越低,能耗值越低时,模型获得的r值就越大,这也就是控制器要达到的最终目的——在不影响人的舒适度的条件下达到节能的目的。
附图说明
图1为基于自适应控制器的建筑物节能系统的第一种实施方式示意图;
图2为基于自适应控制器的建筑物节能系统的第二种实施方式示意图;
图3为实验一总回报收敛图;
图4为实验一每个情节收敛步数示意图;
图5为实验一收敛后室内温度变化图;
图6为实验一收敛后CO2浓度变化图;
图7为实验二总回报收敛图;
图8为实验二每个情节收敛步数示意图;
图9为实验二收敛后室内温度变化图;
图10为实验二收敛后CO2浓度变化图;
图11为实验三总回报收敛图;
图12为实验三每个情节收敛步数示意图;
图13为实验三收敛后室内温度变化图;
图14为实验三收敛后CO2浓度变化图;
图15为实验四总回报收敛图;
图16为实验四每个情节收敛步数示意图;
图17为实验四收敛后室内温度变化图;
图18为实验四收敛后CO2浓度变化图;
图19为实验五总回报收敛图;
图20为实验五每个情节收敛步数示意图;
图21为实验五收敛后室内温度变化图;
图22为实验五收敛后CO2浓度变化图。
具体实施方式
下面结合附图和具体实施方式对本发明进一步说明。
本发明的基于自适应控制器的建筑物节能系统可参考图1所示,其包括空调系统、电动开窗系统和通风系统,上述各个系统都是现有技术中建筑物内已经安装使用的系统,在此基础上,还包括主控器、用于检测室内温度的温度传感器、用于检测室内二氧化碳浓度的二氧化碳传感器和用于检测能耗的能耗计量装置,温度传感器和二氧化碳浓度传感器可安装在室内,能耗计量装置可安装在总闸处用于检测各个系统的能耗值,所述温度传感器与温度从控器相连,所述温度从控器包括与温度传感器相连的温度数据采集模块以及与温度数据采集模块相连的第一通信模块,所述二氧化碳传感器与二氧化碳从控器相连,所述二氧化碳从控器包括与二氧化碳传感器相连的二氧化碳数据采集模块以及与二氧化碳数据采集模块相连的第二通信模块,所述能耗计量装置与能耗从控器相连,所述能耗从控器包括与能耗计量装置相连的能耗数据采集模块以及与能耗数据采集模块相连的第三通信模块,所述主控器包括自适应控制器以及与自适应控制器相连的第四通信模块,所述第一通信模块、第二通信模块以及第三通信模块分别与第四通信模块无线连接,所述空调系统、电动开窗系统和通风系统分别与第四通信模块无线连接。其中,空调系统、电动开窗系统和通风系统的主控器可分别与第四通信模块无线连接,以实现信号的传送。
上述系统使用时,所述温度数据采集模块将温度传感器采集得到的室内温度数据通过第一通信模块和第四通信模块传送给自适应控制器;所述二氧化碳数据采集模块将二氧化碳传感器采集得到的室内二氧化碳浓度数据通过第二通信模块和第四通信模块传送给自适应控制器;所述能耗数据采集模块将能耗计量装置得到的能耗数据通过第三通信模块和第四通信模块传送给自适应控制器。自适应控制器一般包括建模模块和决策模块,建模模块用于对环境状态建立相应的模型,决策模块用于确定各个系统设备的行为动作,该行为动作会对环境状态产生影响并给建模模块一个反馈,进而通过决策模块和建模模块的共同作用找出各个系统设备的最优的行为策略。在不影响人的舒适度的条件下达到节能的目的。
在上述基础上,如图2所示,还包括电动窗帘系统以及光强传感器,电动窗帘系统是现有技术中建筑物内已经使用比较成熟的一种可自动控制窗帘开启和闭合的系统,电动窗帘系统的主控器可与第四通信模块无线连接,所述光强传感器与光强数据采集模块相连,所述光强数据采集模块与第五通信模块相连,所述第五通信模块与第四通信模块无线连接,所述电动窗帘系统与第四通信模块无线连接。光强数据采集模块可将光强传感器采集到的光强数据通过第五通信模块和第四通信模块传送给自适应控制器。相应的,上述能耗计量装置检测得到的能耗值也包括上述电动窗帘系统的能耗值。自适应控制器进而可根据相关数据进行决策。
以下将介绍相关元器件的具体设置情况,可参考图1和图2。
图1中,所述自适应控制器可为Arduino UNO控制器,所述第四通信模块为Esp8266-01无线模块。所述温度传感器为DS18B20温度传感器,所述温度数据采集模块为Arduino UNO控制器,所述第一通信模块为Esp8266-01无线模块。所述二氧化碳传感器为VS08二氧化碳传感器,所述二氧化碳数据采集模块为Arduino UNO控制器,所述第二通信模块为Esp8266-01无线模块。所述能耗计量装置为MSP430AFE2xx微控制器,所述能耗数据采集模块为Arduino UNO控制器,所述第三通信模块为Esp8266-01无线模块。
图2是在图1的基础上,添加了光强传感器,光强数据采集模块和第五通信模块以及电动窗帘系统,所述光强传感器可为TSL2561光强传感器,所述光强数据采集模块为Arduino UNO控制器,所述第五通信模块为Esp8266-01无线模块。
本发明还提供了建筑物节能领域的自适应控制器的控制方法,其包括:
步骤1:建立奖惩反馈模型和评价行为值函数Q(st,at);
步骤2:初始化评价行为值函数Q(s,a)、学习率α,折扣因素γ,其中,s表示状态因素,a表示行为因素,γ是一个0≤γ≤1的参数,状态因素是由室内温度T、室内二氧化碳浓度ρ和空调设置温度setT构成,行为因素是由空调系统行为、电动开窗系统行为和通风系统行为构成;
步骤3:运行片段,每个片段包括N个单位时间步,
初始化,令时刻t=0,通过温度传感器、二氧化碳传感器得到初始状态因素st的室内温度T和二氧化碳浓度ρ,确定空调设置温度setT;
步骤3-1:每个单位时间步的运行包括:
对当前状态因素st,根据贪心选择策略h(st)计算确定出当前状态因素st在时刻t的行为因素at,a∈h(st),各个系统的行为动作可根据系统设备的自身情况进行定义,比如空调系统的行为动作可分为:制冷小风、制冷大风、取暖小风、取暖大风等等,电动开窗系统的行为动作可分为:关闭、半开窗、全开窗等等,通风系统的动作行为可分为:关闭、小档、中档、大档等等。
根据行为因素at对空调系统、电动开窗系统和通风系统进行调节,使状态因素变迁到下一状态因素st+1,并测出st+1的室内温度T和二氧化碳浓度ρ,
根据奖惩反馈模型计算得出在状态因素st和行为因素at下的奖惩rt,
更新当前评价行为值函数Q(st,at):
更新学习率α,t=t+1;
步骤4:进行判断,具体为:
若st+1对应的状态不符合状态结束条件,则返回到步骤3-1,进行下一单位时间步的运行;
若st+1对应的状态符合状态结束条件,则监测所有状态因素下的评价行为值函数是否满足预定的精度要求,若有评价行为值函数不满足精度要求,则返回到步骤3进行新的片段的运行,若评价行为值函数都满足精度要求,则结束循环。
上述奖惩反馈模型可根据现有技术中的奖惩反馈模型进行设定。本发明提供了一种奖惩反馈模型,该模型充分考虑了室内温度、二氧化碳浓度和能耗,对其影响给予了不同的权重,这样更有利于节能和维持人体的舒适度。具体为:
所述步骤1中的奖惩反馈模型为:
rt=-w1(T_penalty)
-w2(indoor_air_quality_penalty)
-w3(E_penalty),
indoor_air_quality_penalty=|ρt-350|/500,
其中T0是室内初始温度,Tt是t时刻的室内温度,setT是空调设置温度;Et是t时刻的空调系统、电动开窗系统和通风系统的能耗值,该值是一个累加能耗,每个单位时间步的能耗的累加值,可通过能耗计量装置检测到的当前的能耗值减去上一时刻检测到的能耗值得到当前单位时间步的能耗值;Emax是一个片段的空调系统、电动开窗系统和通风系统的最大能耗,可通过能耗计量装置预先测得,也就是可在总时长内通过将各个系统设备完全开启来测量最大能耗值,并将该值作为一个定值使用,可多次测量,最后取一个平均值,也可根据以往经验确定;ρt是t时刻的室内CO2浓度;T_penalty是室内温度参数;indoor_air_quality_penalty是室内空气质量参数;E_penalty是能耗参数;w1、w2和w3分别是权重参数,设置为:w1=0.7,w2=0.25,w3=0.05。上述权重的设定依据是:室内温度稳定在设置温度是首要目的,同样也要考虑CO2浓度和能耗因素。
进一步的是,步骤4中,若st+1对应的状态不符合状态结束条件是指:若st+1对应的单位时间步的步数小于循环设置的最大步数N;若st+1对应的状态符合状态结束条件是指:若st+1对应的单位时间步的步数等于循环设置的最大步数N。当然,状态结束条件也可根据具体情况来设定,这里通过最大步数来设定,在实际应用时比较直观和方便。比如,设定最大步数N为5000步,若st+1对应的单位时间步的步数为4000步,则小于5000步,不符合状态结束条件。若st+1对应的单位时间步的步数为5000步,则符合状态结束条件。
在上述基础上,步骤4中,结束循环后,将获得的空调系统、电动开窗系统和通风系统的行为因素作为一个自适应动作策略储存进入策略库。通过对不同室内情况的调节可获得多个自适应动作策略,从而可丰富整个策略库。进而在后续遇到类似室内状态下,可通过调用该策略库以最快速率将各个系统调整到位。
为了验证本发明上述方法收敛速率和稳定性,本发明还提供了建筑物节能领域的自适应控制器的仿真方法,其包括:
步骤1:建立状态变迁模型、奖惩反馈模型和评价行为值函数Q(st,at);
步骤2:初始化评价行为值函数Q(s,a)、学习率α,折扣因素γ,其中,s表示状态因素,a表示行为因素,γ是一个0≤γ≤1的参数,状态因素是由室内温度T、室内二氧化碳浓度ρ和空调设置温度setT构成,行为因素是由空调系统行为、电动开窗系统行为和通风系统行为构成;
步骤3:运行片段,每个片段包括N个单位时间步,
令时刻t=0,初始化初始状态因素s0,也就是确定0时刻的T、ρ和setT,
步骤3-1:每个单位时间步的运行包括:对当前状态因素st,根据贪心选择策略h(st)计算确定出当前状态因素st在时刻t的行为因素at,a∈h(st),
采取这个行为因素at,根据建立的状态变迁模型计算状态因素的变迁,状态因素变迁到下一状态因素st+1,
根据建立的奖惩反馈模型计算得出在状态因素st和行为因素at下的奖惩rt,
更新当前评价行为值函数Q(st,at):
更新学习率α,t=t+1;
步骤4:进行判断,具体为:
若st+1对应的状态不符合状态结束条件,则返回到步骤3-1,进行下一单位时间步的运行;
若st+1对应的状态符合状态结束条件,则监测所有状态因素下的评价行为值函数是否满足预定的精度要求,若有评价行为值函数不满足精度要求,则返回到步骤3进行新的片段的运行,若评价行为值函数都满足精度要求,则结束循环。
步骤4中,若st+1对应的状态不符合状态结束条件是指:若st+1对应的单位时间步的步数小于循环设置的最大步数N;若st+1对应的状态符合状态结束条件是指:若st+1对应的单位时间步的步数等于循环设置的最大步数N。当然,状态结束条件也可根据具体情况来设定,这里通过最大步数来设定,在实际应用时比较直观和方便。比如,设定最大步数N为5000步,若st+1对应的单位时间步的步数为4000步,则小于5000步,不符合状态结束条件。若st+1对应的单位时间步的步数为5000步,则符合状态结束条件。
上述方法中,状态变迁模型和奖惩反馈模型可根据现有技术中的相应模型设定。这里给出本发明的相应模型,该模型更符合大多数建筑物内的实际情况。具体为:
所述步骤1中:
状态变迁模型为:
ρt+1=ρt-0.1×windows_fig+0.2×tongfeng_fig (2)
Et+1=Et+kongtiao_fig+tongfeng_fig (3)
在公式(1)中,在开启空调系统的同时,采取通风系统和开窗行为,会在一定程度上减弱空调系统的作用,所以设定减弱参数为0.1;在公式(2)中,模型中二氧化碳浓度与开窗行为和通风系统有关,影响因子设为1:2。在公式(3)中,与空调和通风系统相比,电动开窗系统能耗非常低,而且,有时候窗户不需要频繁调整,所以此处就不统计电动开窗系统的能耗。
奖惩反馈模型为:
indoor_air_quality_penalty=|ρt-350|/500 (7)
全部行为因素建模为64×3的矩阵,其横向量是一个三维的向量,表示一个行为;行为向量第一位kongtiao_fig表示空调系统行为:1表示取暖小风,2表示制冷小风,3表示取暖大风,4表示制冷大风;第二位windows_fig表示电动开窗系统行为:0为关闭,1为微张,2为半张,3为全开;最后一位tongfeng_fig表示通风系统行为:0是关闭,1是小档,2是中档,3是大档;
其中,T_changerate表示温度变化速率,T0是室内初始温度,setT是空调设置温度;E是实时能耗,可根据行为因素模型的相关系统行为对应的数值累加得到,Emax是最大能耗,可根据片段中的单位时间步的总步数N计算得到,也就是Emax=7N,7是空调系统最大能耗4和通风系统最大能耗3之和,也就是可根据上述行为因素模型中的相应数值来模拟能耗;ρ是室内CO2浓度;T_penalty是室内温度参数,indoor_air_quality_penalty是室内空气质量参数,E_penalty是能耗参数,w1、w2、w3分别是其权重参数,室内温度稳定在设置温度是首要目的,同样也要考虑CO2浓度和能耗因素,参数的设置为:w1=0.7,w2=0.25,w3=0.05。
在仿真模拟中,上述初始状态因素s0对应的初始状态室内温度T的范围可以为[0,40],单位是摄氏度,室内二氧化碳浓度ρ的范围为[200,1000],单位是ppm。
以下将给出具体的仿真模拟方案和仿真结果。
实施以及验证如下:
为了验证本发明的建筑节能中的动态自适应控制器的控制方法的有效性,将仿真实验在Pytho2.7环境中进行,采用的编辑器为Sublime Text3。定义片段的总奖惩为r为奖惩,折扣因素γ。
实验一
图3是设置温度setT=26,室内温度T=30,室内CO2浓度为850ppm的情况下,总奖惩与片段数的收敛情况,该图数据为20次实验数据取平均得到。实验中设置一共有160个片段,每个片段是5000步,总步数为800000步。
由图3可看出,动态自适应控制器模型在实验开始阶段表现很不稳定,每个片段的总奖惩值上下波动超过了±2000,平均到每一步的奖惩波动超过±0.4,这是因为这个阶段是刚开始训练的阶段,在探索与利用之间找到平衡。经过约30个片段训练与学习,模型的总奖惩值波动值缩小到±500左右,平均到每一步的奖惩波动幅度约为±0.1;最后模型经过60个片段之后基本收敛,每个片段的总回报值上下波动不超过±70,平均到每一步的奖惩上下波动不超过±0.014,基本可以确定模型收敛。可以从图中看到,模型的学习速率是很快的,基本在三十万步(60个片段)就能收敛,总的实验时间为0:34:57,收敛时间约为0:13:00。
图4是动态自适应控制器模型在每一个片段的收敛步数,由图中可看出:实验设置每个片段为5000步,刚开始实验模型不能再5000步内收敛;0-50个片段内收敛步数一直在2500步-4400步的范围里震荡,这个阶段是的训练阶段;50个片段之后收敛步数有个明显下降的趋势,直到60个片段基本稳定收敛在1400步,说明在60个片段之后找到了最优策略,使得系统在每个片段内都能在1400步左右达到稳定。
将本发明的建筑节能中的动态自适应控制器与Dounis AI等人在文献“Design of a fuzzyset environmentcomfort system”中提出的Fuzzy-PD的控制器方法进行比较,实验结果如表1所示。从表中我们可以看出,本发明的建筑节能中的动态自适应控制器,编号为RL-DAC,实验结果好于传统Fuzzy-PD方法。
表1 动态自适应控制器与Fuzzy-PD方法比较表
图5是在每个片段总回报值基本收敛之后,随机取出其中一个片段,在5000步内室内温度T的变化情况,每200步采样一次。由图可知,0-1400步阶段,动态自适应控制器模型在探索训练阶段,温度变化很不稳定。但在1400步之后本发明方法基本稳定,室内温度T保持在设置温度26℃左右。由此可得出结论,动态自适应控制器模型可满足空调系统维持室内温度等于设置温度的要求。Fuzzy-PD方法在2000步左右才收敛到设置温度26℃。由图5可得出,本发明的动态自适应控制器的方法比传统Fuzzy-PD方法效果更好,在更少的步数内就能收敛达到稳定。
图6是在总回报值基本收敛之后,随机取出其中一个情节,每200步采样一次,在5000步内室内CO2浓度的变化情况。由图4和表1可知,0-1200步阶段,本发明方法在探索学习阶段,CO2浓度没有达到要求的低于450ppm。但在1200步之后本文模型基本稳定,室内CO2浓度保持在与室外CO2浓度380ppm左右。而Fuzzy-PD方法在1800步之后才到达稳定值400。由图可知本发明方法可以满足室内通风的效果,比Fuzzy-PD方法在更少的步数内收敛,并且稳定值最低,通风效果最好。
实验二
图7是设置温度setT=26,室内温度T=30,室内CO2浓度为770ppm的情况下,总奖惩与片段数的收敛情况,该图数据为20次实验数据取平均得到。实验中设置一共有160个片段,每个片段是5000步,总步数为800000步。
由图7可看出,动态自适应控制器模型在实验开始阶段表现很不稳定,每个片段的总奖惩值上下波动超过了±2000,平均到每一步的奖惩波动超过±0.4,这是因为这个阶段是刚开始训练的阶段,在探索与利用之间找到平衡。经过约30个片段训练与学习,模型的总奖惩值波动值缩小到±700左右,平均到每一步的奖惩波动幅度约为±0.1;最后模型经过80个片段之后基本收敛,每个片段的总回报值上下波动不超过±70,平均到每一步的奖惩上下波动不超过±0.014,基本可以确定模型收敛。可以从图中看到,模型的学习速率是很快的,基本在四十万步(80个片段)就能收敛,总的实验时间为0:33:26,收敛时间约为0:14:59。
图8是动态自适应控制器模型在每一个片段的收敛步数,由图中可看出:实验设置每个片段为5000步,刚开始实验模型不能在5000步内收敛;0-60个片段内收敛步数一直在2000步-4000步的范围里震荡,这个阶段是的训练阶段;60个片段之后收敛步数有个明显下降的趋势,直到80个片段基本稳定收敛在1400步,说明在80个片段之后找到了最优策略,使得系统在每个片段内都能在1400步左右达到稳定。
图9是在每个片段总回报值基本收敛之后,随机取出其中一个片段,在5000步内室内温度T的变化情况,每200步采样一次。由图可知,0-1500步阶段,动态自适应控制器模型在探索训练阶段,温度变化很不稳定。但在1500步之后本发明方法基本稳定,室内温度T保持在设置温度26℃左右。由此可得出结论,动态自适应控制器模型可满足空调系统维持室内温度等于设置温度的要求。Fuzzy-PD方法在2600步左右才收敛到设置温度26℃。由图9可得出,本发明的动态自适应控制器的方法比传统Fuzzy-PD方法效果更好,在更少的步数内就能收敛达到稳定。
图10是在总回报值基本收敛之后,随机取出其中一个情节,每200步采样一次,在5000步内室内CO2浓度的变化情况。由图10和表1可知,0-1300步阶段,本发明方法在探索学习阶段,CO2浓度没有达到要求的低于450ppm。但在1300步之后本文模型基本稳定,室内CO2浓度保持在与室外CO2浓度300ppm左右。而Fuzzy-PD方法在1700步之后才到达稳定值400。由图可知本发明方法可以满足室内通风的效果,比Fuzzy-PD方法在更少的步数内收敛,并且稳定值最低,通风效果最好。
实验三
图11是设置温度setT=26,室内温度T=16,室内CO2浓度为770ppm的情况下,总奖惩与片段数的收敛情况,该图数据为20次实验数据取平均得到。实验中设置一共有160个片段,每个片段是5000步,总步数为800000步。
由图11可看出,动态自适应控制器模型在实验开始阶段表现很不稳定,每个片段的总奖惩值上下波动超过了±2000,平均到每一步的奖惩波动超过±0.4,这是因为这个阶段是刚开始训练的阶段,在探索与利用之间找到平衡。经过约30个片段训练与学习,模型的总奖惩值波动值缩小到±500左右,平均到每一步的奖惩波动幅度约为±0.1;最后模型经过95个片段之后基本收敛,每个片段的总回报值上下波动不超过±70,平均到每一步的奖惩上下波动不超过±0.014,基本可以确定模型收敛。可以从图中看到,模型的学习速率是很快的,基本在四十七万步(95个片段)就能收敛,总的实验时间为0:34:08,收敛时间约为0:14:49。
图12是动态自适应控制器模型在每一个片段的收敛步数,由图中可看出:实验设置每个片段为5000步,刚开始实验模型不能在5000步内收敛;0-60个片段内收敛步数一直在2000步-4000步的范围里震荡,这个阶段是的训练阶段;60个片段之后收敛步数有个明显下降的趋势,直到100个片段基本稳定收敛在1500步,说明在100个片段之后找到了最优策略,使得系统在每个片段内都能在1500步左右达到稳定。
图13是在每个片段总回报值基本收敛之后,随机取出其中一个片段,在5000步内室内温度T的变化情况,每200步采样一次。由图可知,0-2500步阶段,动态自适应控制器模型在探索训练阶段,温度变化很不稳定。但在2500步之后本发明方法基本稳定,室内温度T保持在设置温度26℃左右。由此可得出结论,动态自适应控制器模型可满足空调系统维持室内温度等于设置温度的要求。Fuzzy-PD方法在3200步左右才收敛到设置温度26℃。由图13可得出,本发明的动态自适应控制器的方法比传统Fuzzy-PD方法效果更好,在更少的步数内就能收敛达到稳定。
图14是在总回报值基本收敛之后,随机取出其中一个情节,每200步采样一次,在5000步内室内CO2浓度的变化情况。由图14和表1可知,0-1300步阶段,本发明方法在探索学习阶段,CO2浓度没有达到要求的低于450ppm。但在1300步之后本文模型基本稳定,室内CO2浓度保持在与室外CO2浓度300ppm左右。而Fuzzy-PD方法在1600步之后才到达稳定值400ppm。由图可知本发明方法可以满足室内通风的效果,比Fuzzy-PD方法在更少的步数内收敛,并且稳定值最低,通风效果最好。
实验四
图15是设置温度setT=20,室内温度T=30,室内CO2浓度为850ppm的情况下,总奖惩与片段数的收敛情况,该图数据为20次实验数据取平均得到。实验中设置一共有160个片段,每个片段是5000步,总步数为800000步。
由图15可看出,动态自适应控制器模型在实验开始阶段表现很不稳定,每个片段的总奖惩值上下波动超过了±2000,平均到每一步的奖惩波动超过±0.4,这是因为这个阶段是刚开始训练的阶段,在探索与利用之间找到平衡。经过约30个片段训练与学习,模型的总奖惩值波动值缩小到±500左右,平均到每一步的奖惩波动幅度约为±0.1;最后模型经过100个片段之后基本收敛,每个片段的总回报值上下波动不超过±70,平均到每一步的奖惩上下波动不超过±0.014,基本可以确定模型收敛。可以从图中看到,模型的学习速率是很快的,基本在五十万步(100个片段)就能收敛,总的实验时间为0:14:04。
图16是动态自适应控制器模型在每一个片段的收敛步数,由图中可看出:实验设置每个片段为5000步,刚开始实验模型不能在5000步内收敛;0-60个片段内收敛步数一直在2000步-4000步的范围里震荡,这个阶段是的训练阶段;60个片段之后收敛步数有个明显下降的趋势,直到100个片段基本稳定收敛在1500步,说明在100个片段之后找到了最优策略,使得系统在每个片段内都能在1500步左右达到稳定。
图17是在每个片段总回报值基本收敛之后,随机取出其中一个片段,在5000步内室内温度T的变化情况,每200步采样一次。由图可知,0-1500步阶段,动态自适应控制器模型在探索训练阶段,温度变化很不稳定。但在1500步之后本发明方法基本稳定,室内温度T保持在设置温度20℃左右。由此可得出结论,动态自适应控制器模型可满足空调系统维持室内温度等于设置温度的要求。Fuzzy-PD方法在2400步左右才收敛到设置温度20℃。由图17可得出,本发明的动态自适应控制器的方法比传统Fuzzy-PD方法效果更好,在更少的步数内就能收敛达到稳定。
图18是在总回报值基本收敛之后,随机取出其中一个情节,每200步采样一次,在5000步内室内CO2浓度的变化情况。由图10和表1可知,0-1500步阶段,本发明方法在探索学习阶段,CO2浓度没有达到要求的低于450ppm。但在1500步之后本文模型基本稳定,室内CO2浓度保持在与室外CO2浓度300ppm左右。而Fuzzy-PD方法在2000步之后才到达稳定值400ppm。由图可知本发明方法可以满足室内通风的效果,比Fuzzy-PD方法在更少的步数内收敛,并且稳定值最低,通风效果最好。
实验五
图19是设置温度setT=30,室内温度T=8,室内CO2浓度为850ppm的情况下,总奖惩与片段数的收敛情况,该图数据为20次实验数据取平均得到。实验中设置一共有160个片段,每个片段是5000步,总步数为800000步。
由图19可看出,动态自适应控制器模型在实验开始阶段表现很不稳定,每个片段的总奖惩值上下波动超过了±2000,平均到每一步的奖惩波动超过±0.4,这是因为这个阶段是刚开始训练的阶段,在探索与利用之间找到平衡。经过约30个片段训练与学习,模型的总奖惩值波动值缩小到±500左右,平均到每一步的奖惩波动幅度约为±0.1;最后模型经过120个片段之后基本收敛,每个片段的总回报值上下波动不超过±70,平均到每一步的奖惩上下波动不超过±0.014,基本可以确定模型收敛。可以从图中看到,模型的学习速率是很快的,基本在六十万步(120个片段)就能收敛,总的实验时间为0:14:04。
图20是动态自适应控制器模型在每一个片段的收敛步数,由图中可看出:实验设置每个片段为5000步,刚开始实验模型不能在5000步内收敛;0-60个片段内收敛步数一直在2000步-4000步的范围里震荡,这个阶段是的训练阶段;60个片段之后收敛步数有个明显下降的趋势,直到120个片段基本稳定收敛在1500步,说明在120个片段之后找到了最优策略,使得系统在每个片段内都能在1500步左右达到稳定。
图21是在每个片段总回报值基本收敛之后,随机取出其中一个片段,在5000步内室内温度T的变化情况,每200步采样一次。由图可知,0-1500步阶段,动态自适应控制器模型在探索训练阶段,温度变化很不稳定。但在2100步之后本发明方法基本稳定,室内温度T保持在设置温度30℃左右。由此可得出结论,动态自适应控制器模型可满足空调系统维持室内温度等于设置温度的要求。Fuzzy-PD方法在2800步左右才收敛到设置温度30℃。由图21可得出,本发明的动态自适应控制器的方法比传统Fuzzy-PD方法效果更好,在更少的步数内就能收敛达到稳定。
图22是在总回报值基本收敛之后,随机取出其中一个情节,每200步采样一次,在5000步内室内CO2浓度的变化情况。由图22和表1可知,0-1400步阶段,本发明方法在探索学习阶段,CO2浓度没有达到要求的低于450ppm。但在1400步之后本文模型基本稳定,室内CO2浓度保持在与室外CO2浓度300ppm左右。而Fuzzy-PD方法在2000步之后才到达稳定值400ppm。由图可知本发明方法可以满足室内通风的效果,比Fuzzy-PD方法在更少的步数内收敛,并且稳定值最低,通风效果最好。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!