一种变电站巡检机器人路径规划系统的制作方法
本发明涉及巡检机器人导航领域,具体涉及一种变电站巡检机器人路径规划系统。
背景技术:
在电力系统中,电能最基本特点是不能大规模地存储,并且电能的生产、输送、分配、使用都是连续的。整个电力系统实现网络化互联,并引入市场化的机制,给人们带来巨大利益,但同时系统的安全稳定运行却面临巨大的挑战。电力变电站系统是整个电力系统中生产、输送以及分配三大核心系统之一,对整个电力系统的安全起着重要的作用。目前对变电站的巡检方式主要有人工巡检和机器人巡检。智能巡检机器人主要通过远程控制或者自主控制方式,对变电站室外设备进行巡视检测,可代替人工进行一些重复、繁杂、高危险性的巡检,并能够完成更准确的常规化的巡检任务。
变电站巡检机器人是移动机器人中的一种。国外对于移动机器人的研究,不仅起步较早,而且发展也较快。相对于国外,国内对移动机器人的研究开始时间较晚,距离世界前沿技术水平还相对较远。但国内正在加快移动机器人的探究步伐。在国家"863计划"项目的支持下,清华大学、哈尔滨工业大学、中国科学院等研究机构均开始对智能移动机器人的研究,并取得一定成果。我国对变电站智能巡检机器人的研究开始于2002年PSI,受到了国家“863”计划的支持。2005年10月,我国第一台变电站设备巡检机器人在长清投入运行,它是由山东电力科学院自主研发的。2012年2月,中国第一台轨道式巡检机器人投入试运行,这标志着中国变电站实体化机器人正处在飞快发展中,在发展自主移动机器人技术水平的同时,也有力地提高了电网系统的智能化水平。目前巡检机器人在我国得到广泛应用并将在今后国家电网智能化巡检工程中得到持续应用。截止到2014年,全国至少有27个省、市、自治区、直辖市采用了变电站巡检机器人进行巡检,覆盖了南方电网、华北电网、华东电网以及西北电网。由此,有必要对变电站巡检机器人进行功能上的改进或完善。
变电站巡检机器人巡检方式可分为正常巡检和特殊巡检作业。正常巡检作业即变电站巡检机器人巡视全部变电站设备;特殊巡检作业即在特殊情况下对某些指定的变电站设备进行巡视,一般指在高温天气、大负荷运行、新设备投入运行以及冰雹、雷电等恶劣环境下,对变电站特别设备进行特殊巡检。在变电站巡检机器人进行特殊巡检时,若采用目前常见的磁轨道等巡检机器人则不具有灵活性。基于行为的变电站巡检机器人路径规划实质就是传感器感知的环境状态到执行器动作的映射。采用这种技术的巡检机器人能够对外界环境变化做出响应,具有实时、快速的优点。因此路径规划性能的优劣将直接影响巡检机器人巡检工作的效率。强化学习是机器学习重要分支之一,在近几年重新受到越来越多的关注,也得到越发广泛和复杂的实际应用。它通过试错的方式与环境进行交互以完成学习。如果环境对其动作评价为积极的则选择该动作趋势加强,否则便会减弱。Agent在不断训练的过程中得到最优策略。因此强化学习具有自主学习和在线学习的特点,通过训练可用于机器人路径规划中,目前也已广泛地应用于移动机器人的路径规划问题当中。
虽然强化学习有着诸多优点以及值得期待的应用前景,但强化学习也存在着收敛速度慢、“维数灾难”、平衡探索与利用、时间信度分配等问题。强化学习收敛速度慢的原因之一是没有教师信号,只能通过探索并依靠环境评价逐渐改进以获得最优动作策略。为进一步加快强化学习收敛速度,启发式强化学习通过给强化学习注入一定的先验知识,有效提高强化学习的收敛速度。Torrey等通过迁移学习为强化学习算法注入先验经验以提高收敛速度;但是迁移学习所注入的先验知识是固定的,即使有不合理规则也无法在训练过程中在线修正。Bianchi等通过给传统强化学习算法添加启发函数,在训练过程中结合使用值函数和启发函数来选择动作,提出了启发式强化学习(Heuristically Accelerated Reinforcement Learning,HARL)算法模型。启发式强化学习最重要的特点是在线更新启发函数,以不断增强表现更好的动作的启发函数。方敏等在启发式强化学习算法基础上提出一种基于状态回溯的启发式强化学习方法,通过引入代价函数描述重复动作的重要性,结合动作奖赏及动作代价提出一种新的启发函数定义以进一步提高收敛速度;但是该方法只是针对重复性动作的重要性进行评估。
技术实现要素:
为解决上述问题,本发明提供了一种变电站巡检机器人路径规划系统。
为实现上述目的,本发明采取的技术方案为:
一种变电站巡检机器人路径规划系统,基于信息强度引导启发式Q学习,包括中控模块、距离传感器模块、RFID模块和运动控制模块,所述距离传感器模块由7个距离传感器组成,用于将所测得的距离数据传送给中控模块用于巡检机器人的避障;RFID模块由定点分布的RFID标签和巡检机器人上的RFID读写器组成,用于将RFID地标数据和目标地点位置数据传送给中控模块用于巡检机器人的位置标定和目标位置确定;运动控制模块接受来自中控模块的命令确定运动方向;中控模块为巡检机器人的Agent,用于接收其他模块传出来的数据确定行动策略,并向运动控制模块传送命令以规划路径。
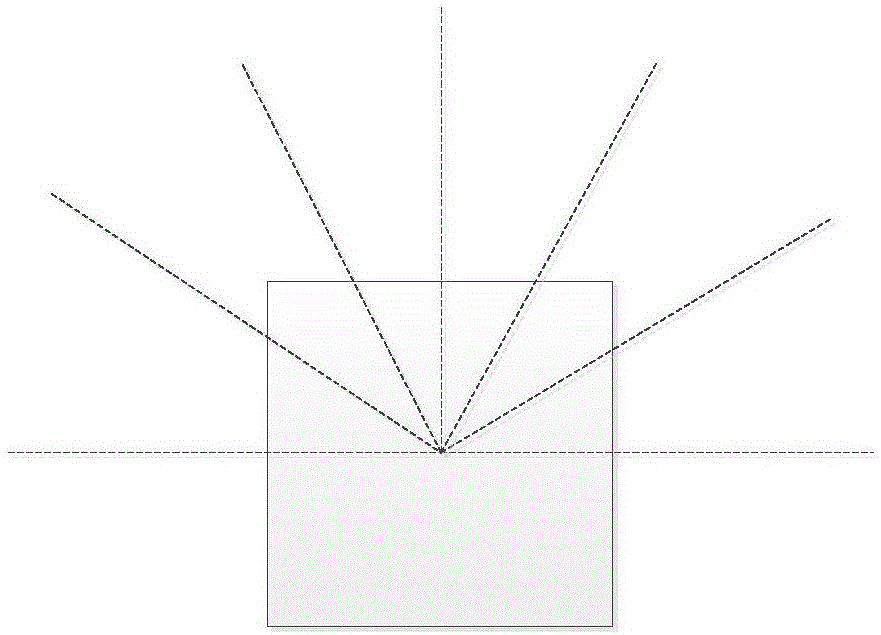
其中,以巡检机器人正前方为零度线,七个距离传感器依次以-90°、-60°、-30°、0°、30°、60°、90°装配在巡检机器人体侧。
其中,通过以下步骤完成巡检机器人奖惩机制的建立:
步骤1:设定移动奖惩机制:为鼓励机器人以尽可能少的步数移动到目标点,每次执行一个动作都会产生一个惩罚回报值;同时为鼓励机器人提前做出判断,在非必要情况下尽量避免大角度移动,大角度移动的惩罚回报值更大一些。具体设置为:在动作属于{-30°,0°,30°}时,惩罚回报值为-0.2;动作属于{-60°,60°}时,惩罚回报值为-0.5;
步骤2:设定目标地点奖惩机制:采用RFID标定巡检机器人与目标设备的位置;在巡检机器人每一步动作后,计算当前位置与目标地点之间的距离d,将-d(即令所计算的距离值取反)作为此时的目标回报值;同时,将移动到目标地点的回报值设置为+100;
步骤3:设置巡检机器人避障回报值:采用两级避障回报值等级:当七个距离传感器有任何一个测量结果小于0.1米时,认定机器人已经撞到障碍物(包括设备和墙壁等),此时惩罚回报值为-100,并将此作为终止状态退出当前episode进入下一个episode的学习;当七个距离传感器有任何一个测量结果大于0.1并且小于半个机器人车身长时,为鼓励机器人及早避障,设置此时的惩罚回报值为-2。
其中,所述中控模块基于以下步骤完成巡检机器人路径的规划:
步骤1:初始化Agent
初始化状态-动作值函数、启发函数;确定目标设备位置和巡检所在位置;
步骤2:设计表H记录信息强度
将表H定义为四元组<si,ai,p(si,ai),fmax>;其中,si为需要更新信息强度的信息状态;ai为需要更新信息强度的信息动作;p(si,ai)为更新后的信息强度,信息强度为与适应度呈正比的标量;fmax为此前记录的信息状态si适应度最大值;
步骤3:更新状态-动作值函数
Q学习状态-动作值函数的更新规则如下所示:
步骤4:更新适应度最大值
将适应度值定义为每幕(episode)训练中Agent从初始状态移动到目标状态的折扣累计回报;其定义方式为其中,β为适应度折扣因子,R为Agent每次移动所获的回报;当Agent完成一幕训练所获得的适应度值大于表H中的最大适应度时,则进行适应度最大值的更新;
步骤5:更新信息强度
若适应度最大值更新,则相应地更新信息强度,信息强度p(si,ai)的更新规则如下:
其中,at表示Agent最新情节的学习中在状态si采用的动作,ai表示表H中的信息动作,fmax表示表H中的适应度最大值;
步骤6:确定基于信息强度的启发函数
为使所获得的信息强度大小直接反映在动作选择上,将信息强度融入到启发函数;通过设置影响量级参数来控制信息强度对动作选择的影响程度;启发函数更新方式定义如下:
其中,πp(st)为在信息强度启发下的最优动作;是通过最大信息强度与信息强度总和比重来表示的该动作的重要性,记为h;U是信息强度对动作选择的影响量级参数,U越大则信息强度的影响越大;
在以上更新规则中,只有信息强度启发下最优动作的启发函数进行更新,作用于动作策略的选择,非信息素强度启发下最优动作的启发函数都被设为0;当信息素强度启发下最优动作的值函数小于另一动作时,通过叠加启发函数使动作选择更加倾向于信息素强度较大的动作,而不是在不完全探索情况下选择值函数较大的动作;
步骤7:在启发函数和值函数作用下确定策略
信息强度引导的启发式Q学习的动作选择策略采用Boltzmann机制,其更新方式规则如下:
当采用Boltzmann机制时,若当前最大动作值函数下的动作不是信息素强度下最优动作,则通过Q(st,a)+H(st,a),加大信息素强度下最优动作的选择概率;同时使用Boltzmann机制,在不同动作信息素强度差距不大的情况下,使得最大动作值函数下的动作和信息素强度下最优动作的概率相近,从而避免陷入信息素强度下的局部最优;在信息素强度差距较大的情况下,使得动作选择概率偏向于信息素强度下最优动作,从而有助于算法收敛。
本发明具有以下有益效果:
采用强化学习的路径规划系统完成特殊天气等条件下对重点指定设备进行特殊巡检任务,避免磁轨道等路径规划方法的轨道维护工作;提出可在线更新的信息强度引导的启发式Q学习算法,该算法在启发式强化学习算法的基础上引入依据每次训练回报进行在线更新的信息强度,通过结合强弱程度不同的动作信息强度和状态-动作值函数来确定策略,从而提高算法收敛速度。
附图说明
图1为本发明实施例一种变电站巡检机器人路径规划系统的系统框图。
图2为本发明实施例中7个距离传感器的安装示意图。
图3为本发明实施例中中控模块规划路径的流程图。
图4为本发明实施例中变电站仿真实验图。
图5为本发明实施例中累计成功率结果图。
图6为本发明实施例中算法平均步数结果图。
图7为本发明实施例中算法平均累计回报结果图。
具体实施方式
为了使本发明的目的及优点更加清楚明白,以下结合实施例对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图1所示,本发明实施例提供了一种变电站巡检机器人路径规划系统,基于信息强度引导启发式Q学习,包括中控模块、距离传感器模块、RFID模块和运动控制模块,所述距离传感器模块由7个距离传感器组成,用于将所测得的距离数据传送给中控模块用于巡检机器人的避障;RFID模块由定点分布的RFID标签和巡检机器人上的RFID读写器组成,用于将RFID地标数据和目标地点位置数据传送给中控模块用于巡检机器人的位置标定和目标位置确定;运动控制模块接受来自中控模块的命令确定运动方向;中控模块为巡检机器人的Agent,用于接收其他模块传出来的数据确定行动策略,并向运动控制模块传送命令以规划路径。
如图2所示,以巡检机器人正前方为零度线,七个距离传感器依次以-90°、-60°、-30°、0°、30°、60°、90°装配在巡检机器人体侧,相应地,机器人运动模式设定为向-60°、-30°、0°、30°、60°方向移动。
其中,通过以下步骤完成巡检机器人奖惩机制的建立:
步骤1:设定移动奖惩机制:为鼓励机器人以尽可能少的步数移动到目标点,每次执行一个动作都会产生一个惩罚回报值;同时为鼓励机器人提前做出判断,在非必要情况下尽量避免大角度移动,大角度移动的惩罚回报值更大一些。具体设置为:在动作属于{-30°,0°,30°}时,惩罚回报值为-0.2;动作属于{-60°,60°}时,惩罚回报值为-0.5;
步骤2:设定目标地点奖惩机制:采用RFID标定巡检机器人与目标设备的位置;在巡检机器人每一步动作后,计算当前位置与目标地点之间的距离d,将-d(即令所计算的距离值取反)作为此时的目标回报值;同时,将移动到目标地点的回报值设置为+100;
步骤3:设置巡检机器人避障回报值:采用两级避障回报值等级:当七个距离传感器有任何一个测量结果小于0.1米时,认定机器人已经撞到障碍物(包括设备和墙壁等),此时惩罚回报值为-100,并将此作为终止状态退出当前episode进入下一个episode的学习;当七个距离传感器有任何一个测量结果大于0.1并且小于半个机器人车身长时,为鼓励机器人及早避障,设置此时的惩罚回报值为-2。
如图3所示,所述中控模块基于以下步骤完成巡检机器人路径的规划:
步骤1:初始化Agent
初始化状态-动作值函数、启发函数;确定目标设备位置和巡检所在位置;
步骤2:设计表H记录信息强度
将表H定义为四元组<si,ai,p(si,ai),fmax>;其中,si为需要更新信息强度的信息状态;ai为需要更新信息强度的信息动作;p(si,ai)为更新后的信息强度,信息强度为与适应度呈正比的标量;fmax为此前记录的信息状态si适应度最大值;
步骤3:更新状态-动作值函数
Q学习状态-动作值函数的更新规则如下所示:
步骤4:更新适应度最大值
将适应度值定义为每幕(episode)训练中Agent从初始状态移动到目标状态的折扣累计回报;其定义方式为其中,β为适应度折扣因子,R为Agent每次移动所获的回报;当Agent完成一幕训练所获得的适应度值大于表H中的最大适应度时,则进行适应度最大值的更新;
步骤5:更新信息强度
若适应度最大值更新,则相应地更新信息强度,信息强度p(si,ai)的更新规则如下:
其中,at表示Agent最新情节的学习中在状态si采用的动作,ai表示表H中的信息动作,fmax表示表H中的适应度最大值;
通过以上更新规则,使信息强度p(si,ai)由适应度f与表H中适应度最大值fmax的差值程度所决定;当f大于表H中储存的fmax时,信息强度则需要更新,即表H需要更新;基于上述更新规则,该算法在保留此前信息强度的同时,使按照适应度差值程度更新的信息强度体现出不同信息动作的重要性;
假设ai∈{a1,a2…aN},且在训练过程中执行am时获得最大适应度f1,表H中适应度最大值在更新前为fmax=f0;则按照上式更新结果如下:(I)若ai=am,则p(si,am)=1;(II)若ai≠am:(1)当p(si,am)=0时,更新后的p(si,am)仍为0;(2)当p(si,am)=1时,更新后的(3)当时,更新后的
步骤6:确定基于信息强度的启发函数
为使所获得的信息强度大小直接反映在动作选择上,将信息强度融入到启发函数;通过设置影响量级参数来控制信息强度对动作选择的影响程度;启发函数更新方式定义如下:
其中,πp(st)为在信息强度启发下的最优动作;是通过最大信息强度与信息强度总和比重来表示的该动作的重要性,记为h;U是信息强度对动作选择的影响量级参数,U越大则信息强度的影响越大;
在以上更新规则中,只有信息强度启发下最优动作的启发函数进行更新,作用于动作策略的选择,非信息素强度启发下最优动作的启发函数都被设为0。当信息素强度启发下最优动作的值函数小于另一动作时,通过叠加启发函数使动作选择更加倾向于信息素强度较大的动作,而不是在不完全探索情况下选择值函数较大的动作。注意,如上式所示,启发函数并不是直接作用于动作值函数,使动作值函数发生变化;而是进行叠加操作,将叠加函数用于决定动作选择策略,继而此情节学习的回报作用于动作值函数的更新。
步骤7:在启发函数和值函数作用下确定策略
信息强度引导的启发式Q学习的动作选择策略采用Boltzmann机制,其更新方式规则如下:
当采用Boltzmann机制时,若当前最大动作值函数下的动作不是信息素强度下最优动作,则通过Q(st,a)+H(st,a),加大信息素强度下最优动作的选择概率;同时使用Boltzmann机制,在不同动作信息素强度差距不大的情况下,使得最大动作值函数下的动作和信息素强度下最优动作的概率相近,从而避免陷入信息素强度下的局部最优;在信息素强度差距较大的情况下,使得动作选择概率偏向于信息素强度下最优动作,从而有助于算法收敛。此外,Boltzmann机制使得其他动作也有一定概率被选择,从而促进算法进行探索。
以变电站环境作为背景设置仿真环境:如图4所示,实心红色区域代表以设备为主的障碍物,四周代表墙壁障碍。起点位置设置为(1,1),目标位置设置为(18,17);目标位置回报值为100,其余位置回报值均按照该位置与目标位置的距离差的大小分布在[0,2]的范围内,距离差越小则回报值越大;为鼓励Agent以最少步数找到目标位置,Agent每执行一个动作,会得到一个-1的回报值;Agent动作空间为{1,2,3,4},分别代表向上、向下、向左、向右;若Agent撞到障碍物或者墙壁,则退回起点,并得到-10的惩罚。
在采用不同方法进行仿真实验时,均设置为相同参数,如表1所示。为尽可能保证实验结果准确,对每种方法分别进行20次实验,每次实验的episode设置为3000,取该20次实验的数据均值作为实验结果进行分析。其中,PSG-HAQL的信息强度影响量级参数设置为1.5;HAQL为文献[8]中的启发式Q学习,H-HAQL、L-HAQL的η分别设置为1.5、0.1,用以与PSG-HAQL作对比实验。
表1仿真实验参数设置
实验结果及分析
采用上述仿真环境以及参数设置,分别采用PSG-HAQL算法、H-HAQL算法、L-HAQL算法、Standard-QL算法进行仿真实验。
本文给出以下3个参数描述实验结果:
学习过程累计成功率:到达目标位置的学习情节数与学习情节总数的比值;
每情节学习所用步数:该情节学习找到目标位置所用的步数;如果没有到达目标地点则步数为0;
每情节学习所获得累计回报值:该情节学习从起始状态到达终止状态(障碍物或者目标位置)所获得的累计回报值。
为对四种算法性能忧虑有一个总体的认识,首先观察学习过程累计成功率曲线,如图5所示,横轴表示学习情节数episode,纵轴表示成功率。由图5,PSG-HAQL、H-HAQL的曲线明显优于L-HAQL、Standard-QL的成功率曲线,印证了文献[8]中启发函数可以加快强化学习算法的学习速度。此外,PSG-HAQL的成功率曲线最早开始上升,且曲线初始阶段斜率最大,说明在训练初期PSG-HAQL到达目标位置的频率最高;在总成功率上,PSG-HAQL也均高于其他三种算法。
成功率曲线只是总体上针对每情节学习是否到达目标位置进行统计,并不能直接由此判定每情节学习四种算法效果。为此统计每情节学习所用步数,曲线如图6所示,横轴表示学习情节数,纵轴表示每情节学习所用的步数。尽管在20次实验均值的数据统计结果中,PSG-HAQL最先寻找到目标位置;但在实验中发现,在某一次实验中四种算法第一次寻找到目标位置所用步数大小排序并不能确定,即四种算法均有可能最先找到目标位置,这是由于四种算法起始探索方向是随机的。在图6中,PSG-HAQL算法由于采用启发函数,其策略根据适应度情况选择动作,所以步数整体比其他三种都要少;H-HAQL算法虽然也有一个较大的启发函数,但较易陷入局部,所以步数总体情况不如PSG-HAQL;而L-HAQL由于启发函数强度不大,所以和Standard-QL类似,虽然偶尔步数达到最少,但有较大波动。总体结果上,PSG-HAQL可最快得到稳定的步数最少的动作选择策略。
Agent可通过不同路径到达目标位置,不同路径所需步数大多不同;但也有可能不同路径的步数相同。为此设置每情节学习所获得累计回报值结果参数,如图7所示,横轴表示学习情节数,纵轴表示每情节学习所获得累计回报值结果参数。在图7中,每情节学习所获得累计回报值整体情况和每情节学习所用步数曲线相类似。PSG-HAQL大概在情节数为400时达到稳定,H-HAQL大概在情节数为1100时稳定,而L-HAQL和Standard-QL则依然波动较大,且并未达到最优动作。结果表明,PSG-HAQL能更快速的得到累计回报值较高的动作策略,其他算法在该时间内还无法得到稳定的等同回报程度的策略,从而表明PSG-HAQL可有效提高动作选择策略的收敛速度。
PSG-HAQL算法将蜂群信息传递的思想结合到启发式Q学习方法:Agent在训练过程中不断获得不同策略的适应度以在线更新该策略信息强度,将信息强度作为Q学习启发函数,使Agent有更高概率去选择信息强度高的策略。所以,信息强度引导的启发式Q学习(PSG-HAQL)算法能够更高效的寻找到最优策略,从而进一步缩减训练时间。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!