一种多智能体安全事件触发模型预测控制方法
1.本发明涉及智能协同控制技术领域,尤其是一种多智能体安全事件触发模型预测控制方法。
背景技术:
2.随着互联网的高速发展,多智能体系统更加倾向于依靠网络来进行信息传递,通过网络和系统平台来制定多智能体共同参与的协同任务,从而应对各种各样复杂的工作环境。然而,通过网络来通信具有受到攻击的风险,其中比较常见的是欺骗攻击和dos攻击。dos攻击是通过阻断信道中信号的传播来完成攻击目的。与dos攻击相比,欺骗攻击更隐蔽,对受控系统危害也更大,因此需要重点研究抵抗多智能体系统控制过程中的欺骗攻击。
3.在控制系统中引入网络虽然有许多优点,但也会带来一些具有挑战性的问题,如网络诱导时延和丢包等,这些问题主要是由于通信网络带宽的限制造成的。目前,事件触发方案因其在保持预期系统性能的同时减少网络传输量的优势而备受研究人员的青睐。目前的事件触发方案忽略了网络攻击对系统的负面影响,所以,人们急需一种改进的安全事件触发控制方法来解决上述问题。
技术实现要素:
4.本发明需要解决的技术问题是提供一种多智能体安全事件触发模型预测控制方法,在一致性控制中,考虑欺骗攻击和输入约束对系统性能的影响,通过鲁棒模型预测控制器抵抗欺骗攻击带来的影响,并引入安全事件触发机制降低通信负载和控制器的更新次数,提高系统资源的利用率。
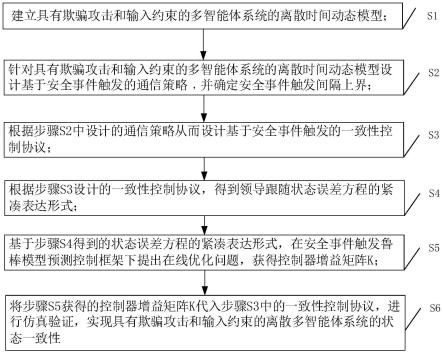
5.为解决上述技术问题,本发明所采用的技术方案是:一种多智能体安全事件触发模型预测控制方法,包括如下步骤:
6.步骤s1、建立具有欺骗攻击和输入约束的多智能体系统的离散时间动态模型;
7.步骤s2、针对具有欺骗攻击和输入约束的多智能体系统的离散时间动态模型设计基于安全事件触发的通信策略,并确定安全事件触发间隔上界;
8.步骤s3、根据步骤s2中设计的通信策略从而设计基于安全事件触发的一致性控制协议;
9.步骤s4、根据步骤s3设计的一致性控制协议,得到领导跟随状态误差方程的紧凑表达形式;
10.步骤s5、基于步骤s4得到的领导跟随状态误差方程的紧凑表达形式,在安全事件触发鲁棒模型预测控制框架下提出在线优化问题,获得控制器增益矩阵k;
11.步骤s6、将步骤s5获得的控制器增益矩阵k代入步骤s3中的一致性控制协议,进行仿真验证,实现具有欺骗攻击和输入约束的离散多智能体系统的状态一致性。
12.本发明技术方案的进一步改进在于:所述步骤s1的具体过程为:
13.建立一个由n个智能体构成的多智能体系统,存在欺骗攻击的第i个智能体的动力
学模型如下:
[0014][0015]
其中,xi(k)∈rn为第i个智能体状态在k时刻的状态,xi(k+1)∈rn为第i个智能体状态在k+1时刻的状态,为带有欺骗攻击信号的控制输入,这里考虑的欺骗攻击类型为替代欺骗攻击,即控制器受到攻击后会使控制信号被替代为相应的攻击信号,ui(k)∈rm为实际的控制输入,|ui(k)|≤u
max
,ξi(k)为欺骗攻击信号,a,b是具有适当维数的矩阵,β(k)是在{0,1}上取值的伯努利分布随机变量,为已知常数:
[0016][0017]
此外,ξi(k)是任意有界能量信号,存在常数使得
[0018][0019]
领导者的动力学模型如下:
[0020]
x0(k+1)=ax0(k),
ꢀꢀ
(4)
[0021]
其中,x0(k)为领导者在k时刻的状态,x0(k+1)为领导者在k+1时刻的状态。
[0022]
本发明技术方案的进一步改进在于:所述步骤s2的具体过程为:
[0023]
定义智能体i当前采样时的状态与最近一次传输时的状态之间的误差如下
[0024][0025]
其中表示智能体i的第m个事件触发时刻;
[0026]
对于第i个智能体,事件触发条件如下:
[0027][0028]
其中σi表示事件触发阈值,φi加权矩阵,yi(k)是和邻居智能体状态、领导者状态有关的函数,表示如下;
[0029][0030]
其中其中是智能体j的最新事件触发时刻,即每个智能体的事件触发条件取决于自身及其邻居的最新事件触发时刻和领导者的当前时刻;
[0031]
第i个智能体的下一个事件触发时间可以表示为:
[0032][0033]
[0034]
是满足条件(9)的最小事件触发间隔,tm表示相邻两个触发时刻之间的最大事件触发间隔。
[0035]
本发明技术方案的进一步改进在于:所述步骤s3中的一致性控制协议如下:
[0036][0037][0038]
其中ki是要通过优化问题设计的控制器增益,a
ij
和bi为系统的邻接矩阵,ui(k+n|k)表示智能体i的控制协议。
[0039]
本发明技术方案的进一步改进在于:所述步骤s4中的状态误差方程紧凑表达形式如下:
[0040][0041]
其中,h是与系统网络拓扑有关的矩阵,表示了状态测量误差,是kronecker积。
[0042]
本发明技术方案的进一步改进在于:所述步骤s5提出在线优化问题如下;
[0043][0044][0045]
其中,r1,r2为正定矩阵。
[0046]
由于采用了上述技术方案,本发明取得的技术进步是:
[0047]
1、本发明解决了具有欺骗攻击和输入约束的离散时间多智能体系统的领导者-跟随者一致性问题,提供了一种针对具有欺骗攻击和输入约束的离散时间多智能体系统实现安全一致性的方法,在一致性控制中,考虑欺骗攻击和输入约束对系统性能的影响,通过鲁棒模型预测控制器抵抗欺骗攻击带来的影响,并引入安全事件触发机制降低通信负载和控制器的更新次数,提高系统资源的利用率。
[0048]
2、本发明与现有技术中多智能体系统需要依赖于实时连续信息交换的一致性控制方式相比,采用本发明中基于事件触发的方法,多智能体之间只需要在发生事件触发时才会发生信息通信,降低了智能体处理器的计算处理负荷和多智能体之间的通信频次,大大减轻了网络传输负载,同时充分考虑了实际工程环境中欺骗攻击和输入约束对多智能体系统的影响,并加以克服,最终实现了多智能体系统的一致性,具有易于操作和实现的特点。
附图说明
[0049]
图1为本发明所述方法流程图;
[0050]
图2是网络化多智能体系统通信拓扑结构图;
[0051]
图3是智能体i的状态分量x
i1
(k),i=0,1,2,3,4,5;
[0052]
图4是智能体i的状态分量x
i2
(k),i=0,1,2,3,4,5;
[0053]
图5是智能体i的误差分量e
i1
(k),i=1,2,3,4,5;
[0054]
图6是智能体i的误差分量e
i2
(k),i=1,2,3,4,5;
[0055]
图7是智能体i的事件触发时刻。
具体实施方式
[0056]
下面结合实施例对本发明做进一步详细说明:
[0057]
如图1所示,一种多智能体安全事件触发模型预测控制方法,包括如下步骤:
[0058]
步骤s1、考虑实际工程环境中欺骗攻击和输入约束对系统一致性的影响,建立具有欺骗攻击和输入约束的多智能体系统的离散时间动态模型,具体过程为:
[0059]
建立一个由n个智能体构成的多智能体系统,存在欺骗攻击的第i个智能体的动力学模型如下:
[0060][0061]
其中,xi(k)∈rn为第i个智能体状态在k时刻的状态,xi(k+1)∈rn为第i个智能体状态在k+1时刻的状态,为带有欺骗攻击信号的控制输入,这里考虑的欺骗攻击类型为替代欺骗攻击,即控制器受到攻击后会使控制信号被替代为相应的攻击信号,ui(k)∈rm为实际的控制输入,|ui(k)|≤u
max
,ξi(k)为欺骗攻击信号,a,b是具有适当维数的矩阵,β(k)是在{0,1}上取值的伯努利分布随机变量,为已知常数:
[0062][0063]
此外,ξi(k)是任意有界能量信号,存在常数使得
[0064][0065]
领导者的动力学模型如下:
[0066]
x0(k+1)=ax0(k),
ꢀꢀ
(4)
[0067]
其中,x0(k)为领导者在k时刻的状态,x0(k+1)为领导者在k+1时刻的状态。
[0068]
步骤s2、针对具有欺骗攻击和输入约束的多智能体系统的离散时间动态模型设计基于安全事件触发的通信策略,并确定安全事件触发间隔上界,具体过程为:
[0069]
定义智能体i当前采样时的状态与最近一次传输时的状态之间的误差如下
[0070][0071]
其中表示智能体i的第m个事件触发时刻;
[0072]
对于第i个智能体,事件触发条件如下:
[0073]
[0074]
其中σi表示事件触发阈值,φi加权矩阵,yi(k)是和邻居智能体状态、领导者状态有关的函数,表示如下;
[0075][0076]
其中其中是智能体j的最新事件触发时刻,即每个智能体的事件触发条件取决于自身及其邻居的最新事件触发时刻和领导者的当前时刻;
[0077]
第i个智能体的下一个事件触发时间可以表示为:
[0078][0079][0080]
是满足条件(9)的最小事件触发间隔,tm表示相邻两个触发时刻之间的最大事件触发间隔。
[0081]
本发明的步骤s2与传统的通信策略低效利用通信资源相比,使用了事件触发策略,有效节约资源,事件触发通信策略的设计中,充分考虑了网络攻击对事件触发通信的影响,引入最大事件触发间隔。
[0082]
步骤s3、根据步骤s2中设计的通信策略从而设计基于安全事件触发的一致性控制协议,一致性控制协议如下:
[0083][0084]
其中ki是要通过优化问题设计的控制器增益,a
ij
和bi为系统的邻接矩阵,ui(k+n|k)表示智能体i的控制协议。
[0085]
步骤s4、根据步骤s3设计的一致性控制协议,得到领导跟随状态误差方程的紧凑表达形式,状态误差方程紧凑表达形式如下:
[0086]
状态误差方程紧凑表达形式如下:
[0087][0088]
其中,h是与系统网络拓扑有关的矩阵,表示了状态测量误差,是kronecker积。
[0089]
步骤s5、基于步骤s4得到的状态误差方程的紧凑表达形式,在安全事件触发鲁棒模型预测控制框架下提出在线优化问题,获得控制器增益矩阵k,在线优化问题如下:
[0090]
[0091][0092]
其中,r1,r2为正定矩阵。
[0093]
步骤s6:将步骤s5获得的控制器增益矩阵k代入步骤s3中的一致性控制协议,进行仿真验证,实现具有欺骗攻击和输入约束的离散多智能体系统的状态一致性。
[0094]
实施例:
[0095]
由通信拓扑图2所示,带有领导跟随的且具有欺骗攻击的离散多智能体系统由6个智能体组成的,6个智能体分别用0、1、2、3、4、5来表示,其中0代表领导者智能体,1、2、3、4、5分别代表跟随者智能体。
[0096]
系统参数:
[0097][0098]
ξ(k)=[1
×
10-3
sin(k)1
×
10-3
sin(k)],
[0099]
系统拉普拉斯矩阵为:
[0100][0101]
领导者与跟随者之间的信息传递β为:
[0102][0103]
(11)中
[0104]
设描述欺骗攻击的伯努利分布随机变量
[0105]
系统的初始状态为:
[0106]
x0=[0.2
ꢀ‑
0.2]
t
,x1=[0.21
ꢀ‑
0.21]
t
,x2=[0.22
ꢀ‑
0.22]
t
,
[0107]
x3=[0.17
ꢀ‑
0.19]
t
,x4=[0.18
ꢀ‑
0.18]
t
,x5=[0.23
ꢀ‑
0.17]
t
[0108]
图3是智能体i的状态分量x
i1
(k),图4是智能体i的状态分量x
i2
(k),图5是智能体i的误差分量e
i1
(k),图6是智能体i的误差分量e
i2
(k),图7是智能体i的事件触发时刻。
[0109]
由图3至图7可见,针对具有欺骗攻击和输入约束的多智能体系统,所发明的一致性控制协议可有效地达到领导跟随一致。
[0110]
本发明解决了具有欺骗攻击和输入约束的离散时间多智能体系统的领导者-跟随者一致性问题,提供了一种针对具有欺骗攻击和输入约束的离散时间多智能体系统实现安全一致性的方法,在一致性控制中,考虑欺骗攻击和输入约束对系统性能的影响,通过鲁棒模型预测控制器抵抗欺骗攻击带来的影响,并引入安全事件触发机制降低通信负载和控制器的更新次数,提高系统资源的利用率。
[0111]
本发明与现有技术中多智能体系统需要依赖于实时连续信息交换的一致性控制
方式相比,采用本发明中基于事件触发的方法,多智能体之间只需要在发生事件触发时才会发生信息通信,降低了智能体处理器的计算处理负荷和多智能体之间的通信频次,大大减轻了网络传输负载,同时充分考虑了实际工程环境中欺骗攻击和输入约束对多智能体系统的影响,并加以克服,最终实现了多智能体系统的一致性,具有易于操作和实现的特点。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1