本发明大体上是针对计算系统。更具体来说,本发明是针对统一计算系统内部的计算部件。
背景技术:对使用图形处理单元(GPU)来进行一般计算的渴望在最近由于GPU的示例性每单位功率性能和/或成本而变得更加显著。一般来说,GPU的计算能力已以超过对应中央处理器(CPU)平台的计算能力的速率增长。随着移动计算市场(例如,笔记本计算机、移动智能电话、平板计算机等)和其所必需的支持服务器/企业系统的蓬勃发展,这种增长已被用来提供指定品质的所需用户体验。因此,组合使用CPU和GPU来执行具有数据并行内容的工作量正在成为一项体积技术(volumetechnology)。然而,GPU传统上已在约束程序设计环境中进行操作,其可主要用于图形的加速。这些约束由以下事实而引起:GPU并不具有与CPU一样丰富的程序设计生态系统。因此,它们的使用已主要限于二维(2D)和三维(3D)图形以及少数前沿的多媒体应用,这些多媒体应用已被习惯地用于处理图形和视频应用程序设计接口(API)。随着多厂商支持的和标准API和支持工具的出现,GPU在传统应用中的限制已被扩展到传统图形的范围之外。虽然OpenCL和DirectCompute是有希望的开端,但是在创建允许将CPU和GPU组合来像CPU一样流畅地用于大多数程序设计任务的环境和生态系统方面仍存在着许多障碍。现有的计算系统常常包括多个处理装置。例如,一些计算系统包括在独立芯片上的CPU和GPU(例如,CPU可能位于母板上,而GPU可能位于图形卡上)或在单个芯片封装中的CPU和GPU。然而,这两种布置仍包括与以下各项相关的重大挑战:(i)独立的存储系统、(ii)有效调度、(iii)提供进程之间的服务质量(QoS)保证、(iv)程序设计模型以及(v)编译至多个目标指令集体系结构(ISA)—全部都要同时使功耗降到最小。例如,离散的芯片布置迫使系统和软件体系结构设计者利用芯片间接口来使每一个处理器存取存储器。虽然这些外部接口(例如,芯片间接口)对用于配合异构型处理器的存储器等待时间和功耗具有负效应,但是独立的存储系统(即,独立的地址空间)和驱动器管理的共享存储器产生开销,所述开销对细粒卸荷(finegrainoffload)来说变得不可接受。离散芯片布置和单芯片布置两者都会限制能够发送至GPU来执行的命令的类型。举例来说,常常无法将计算命令(例如,物理或人工智能命令)发送至GPU来执行。存在这个限制是因为CPU可能相对快速地需要由这些计算命令执行的操作的结果。然而,由于当前系统中的向GPU分派工作的高开销以及这些命令可能必须排队等候首先执行其它先前发出的命令的事实,所以将计算命令发送至GPU所引发的等待时间常常是不可接受的。将GPU用于计算卸荷所面临的额外困难在于开发者可用以与GPU形成接口并且提供工作的软件工具。许多现存的软件工具被记住设计成具有GPU的图形能力,并且因此缺乏容易地向GPU提供非图形工作的能力。
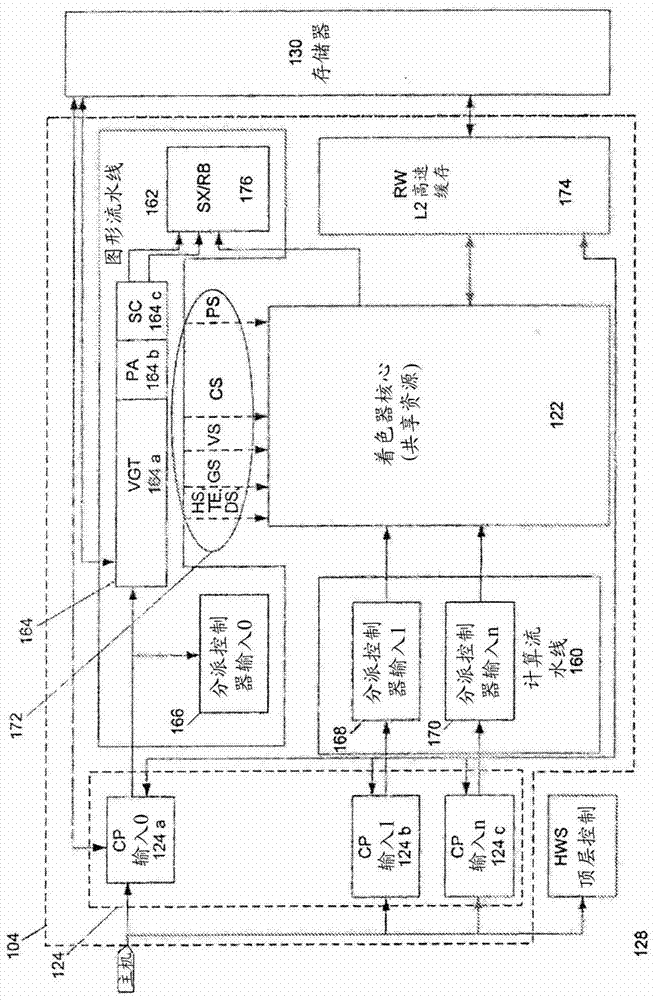
技术实现要素:因此,所需要的是对GPU计算资源的可访问性的改进的支持。虽然GPU、加速处理单元(APU)以及通用用途的图形处理单元(GPGPU)是这个领域中常用的术语,但是表述“加速处理设备(APD)”被认为是更广义的表述。例如,APD是指硬件和/或软件的任何配合集合,与常规CPU、常规GPU、软件和/或其组合相比,所述任何配合集合以加速方式完成与加速图形处理任务、数据并行任务或嵌套数据并行任务相关的那些功能和计算。本发明的各种实施方案包括一种用于经由内核模式驱动器为应用程序分配APD工作队列、为所述应用程序分配计算进程控制块的方法和设备。计算进程控制块包括对工作队列的引用。所述方法和设备还包括由调度器选择计算进程控制块来执行,并且将来自由所述计算进程控制块所引用的工作队列的命令分派给APD。以下参照附图详细地描述本发明的额外特征和优点,连同本发明的各种实施方案的结构和操作。应该指出,本发明不限于本文所描述的具体实施方案。本文所提出的这类实施方案仅用于说明性目的。基于本文所包括的教义,一个或多个相关领域的技术人员将会明白额外的实施方案。附图说明并入本文并且形成本说明书的一部分的附图示出本发明的实施方案,并且与描述一起,进一步用于解释本发明的原理并且用于使相关领域技术人员能够制作并使用本发明。图1A是根据本发明的实施方案的处理系统的说明性方框图。图1B是图1A中所示的APD的说明性方框图。图2是图1B中所示的APD的较详细方框图。图3示出依赖于内核模式驱动器来向APD提交命令的数据流模型。图4示出将图3的数据流模型的概念应用于示例性Windows环境的额外数据流模型。图5示出根据本发明的实施方案的系统堆栈的示例性部件。图6示出根据本发明的实施方案的示例性数据流模型。图7示出根据本发明的实施方案的在运行时的体系结构的系统概观。图8是根据本发明的实施方案的示出对应用程序进行初始化的步骤的流程图。图9是示出应用程序提供命令来由APD执行的步骤的流程图。图10是根据本发明的实施方案的示出调度器调度APD命令的处理的步骤的流程图。图11是根据本发明的实施方案的示出在上下文切换中保存执行状态的步骤的流程图。图12是根据本发明的实施方案的示出基于软件的调度器能够向基于硬件的调度器提供引导的步骤的流程图。下文中参照附图详细地描述本发明的另外特征和优点以及本发明的各种实施方案的结构和操作。应注意,本发明不限于本文所描述的具体实施方案。本文中仅出于说明性目的来呈现这些实施方案。相关领域技术人员将基于本文中所含有的教义而明白额外实施方案。具体实施方式在以下详述中,对“一个实施方案”、“实施方案”、“示例实施方案”等的参考指示所描述的实施方案可以包括具体特征、结构或特点,但是每个实施方案可能并没有必要包括所述具体特征、结构或特点。此外,这类短语没有必要是指同一实施方案。另外,当结合一个实施方案描述具体特征、结构或特点时,所主张的是本领域技术人员知道结合无论是否被明确地描述的其它实施方案来实现这种特征、结构或特点。术语“本发明的实施方案”不要求本发明的所有实施方案都包括所论述的特征、优点或操作模式。在不脱离本发明的范围的情况下,可以设计出替代实施方案,并且可能并未详细描述或可能省略本发明的众所周知的元件,以免模糊本发明的相关细节。另外,本文所使用的术语仅出于描述具体实施方案的目的,而并不意图限制本发明。例如,如本文所使用,单数形式的“一个(种)”以及“所述”也意图包括复数形式,除非上下文另有明确指示。还将进一步理解的是,术语“包括”、“包括了”、“包含”和/或“包含了”在本文中使用时指明所陈述的特征、整体、步骤、操作、元件和/或部件的存在,但是并不排除一个或多个其它特征、整体、步骤、操作、元件、部件和/或其群组的存在或添加。图1A是包括两个处理器(即,CPU102和APD104)的统一计算系统100的示例性图解。CPU102可以包括一个或多个单核或多核CPU。在本发明的一个实施方案中,系统100被形成在单个硅芯片或封装上,组合CPU102和APD104以提供统一的程序设计和执行环境。这个环境使得APD104能够像CPU102一样流畅地用于一些程序设计任务。然而,CPU102和APD104被形成在单个硅芯片上并不是本发明的绝对要求。在一些实施方案中,CPU和APD有可能被单独地形成并且被安装在相同或不同的衬底上。在一个实施例中,系统100还包括存储器106、操作系统108以及通信基础设施109。以下更详细地论述操作系统108和通信基础设施109。系统100还包括内核模式驱动器(KMD)110、软件调度器(SWS)112,以及存储器管理单元116,如输入/输出存储器管理单元(IOMMU)。系统100的部件可以被实施为硬件、固件、软件或其任何组合。本领域技术人员将会理解,除了图1A中所示的实施方案中所示的各项之外,系统100可以包括一个或多个软件、硬件以及固件部件,或与图1A中所示的实施方案中所示的各项不同的一个或多个软件、硬件以及固件部件。在一个实施例中,驱动器(如KMD110)典型地通过计算机总线或通信子系统来与装置进行通信,硬件连接至所述计算机总线或通信子系统。当调用程序调用驱动器中的例程时,所述驱动器向装置发出命令。一旦装置将数据发送回到驱动器,所述驱动器就可以调用原始调用程序中的例程。在一个实施例中,驱动器是与硬件有关的并且是操作系统特定的。所述驱动器常常提供任何必要的异步的时间有关的硬件接口所需要的中断处理。装置驱动器,特别是在现代Microsoft平台上的,能够以内核模式(环0)或以用户模式(环3)进行运行。以用户模式运行驱动器的主要益处是改进的稳定性,因为写入不良的用户模式装置驱动器不会通过盖写内核存储器来使系统崩溃。另一方面,用户/内核模式转换常常强加相当大的性能开销,从而针对短等待时间和高吞吐量要求禁止用户模式驱动器。内核空间可以由用户模块仅通过使用系统调用来存取。最终用户程序,像UNIX操作系统外壳或其它基于GUI的应用程序,是用户空间的一部分。这些应用程序通过内核支持的功能来与硬件进行交互。CPU102可以包括(未图示)控制处理器、现场可编程门阵列(FPGA)、专用集成电路(ASIC)或数字信号处理器(DSP)中的一个或多个。例如,CPU102执行控制计算系统100的操作的控制逻辑,所述控制逻辑包括操作系统108、KMD110、SWS112以及应用程序111。在这个说明性实施方案中,根据一个实施方案,CPU102通过例如以下操作来发起并且控制应用程序111的执行:在CPU102和其它处理资源(如APD104)上分配与那个应用程序相关的处理。尤其是APD104执行用于所选定的功能的命令和程序,所述所选定的功能如图形操作和可能例如特别适用于并行处理的其它操作。一般来说,APD104可以被频繁地用于执行图形流水线操作(如像素操作、几何计算),并且将图像渲染至显示器。在本发明的各种实施方案中,APD104还可以基于从CPU102所接收的命令或指令来执行计算处理操作(例如,与图形无关的那些操作,例如像视频操作、物理模拟、计算流体动力学等)。例如,命令可以被认为是典型地不是定义在指令集体系结构(ISA)中的特殊指令。可以通过特殊处理器(如分派处理器、命令处理器或网络控制器)来执行命令。另一方面,指令可以被认为是例如计算机体系结构内部的处理器的单一操作。在一个实施例中,当使用两个ISA集时,一些指令被用于执行x86程序,而一些指令被用于执行APD计算单元上的内核。在一个说明性实施方案中,CPU102将所选定的命令传输至APD104。这些所选定的命令可以包括图形命令和服从并行执行的其它命令。可以大致上独立于CPU102来执行还可以包括计算处理命令在内的这些所选定的命令。APD104可以包括其自己的计算单元(未图示),如但不限于一个或多个SIMD处理核心。如本文所引用,SIMD是流水线或程序设计模型,其中通过每个处理元件自己的数据和共享的程序计数器,在多个处理元件中的每一个上同时地执行内核。所有处理元件执行一个完全相同的指令集。预测的使用使得工作项目能够参与或不参与每个所发出的命令。在一个实施例中,每个APD104计算单元可以包括一个或多个标量和/或向量浮点单元和/或算术逻辑单元(ALU)。APD计算单元还可以包括专用处理单元(未图示),如反平方根单元和正弦/余弦单元。在一个实施例中,APD计算单元在本文中统称为着色器核心122。一般来说,具有一个或多个SIMD使得APD104理想地适用于数据并行任务(如在图形处理中常见的那些)的执行。一些图形流水线操作(如像素处理)和其它并行计算操作可能要求对输入数据元素的流或集合执行同一命令流或计算内核。同一计算内核的相应实例化可以在着色器核心122中的多个计算单元上同时地执行,以便并行地处理这类数据元素。如本文所引用,例如,计算内核是含有在程序中陈述并且在APD计算单元上执行的指令的功能。这个功能还被称为内核、着色器、着色器程序或程序。在一个说明性实施方案中,每个计算单元(例如,SIMD处理核心)可以执行特定工作项目的相应实例化来处理传入数据。工作项目是由命令在装置上所调用的内核的并行执行的集合中的一个。工作项目可以由一个或多个处理元件执行为在计算单元上执行的工作群组的一部分。工作项目通过其全局ID和局部ID来与所述集合内的其它执行区别开。在一个实施例中,一起同时在SIMD上执行的工作群组中的工作项目子集可以被称为波前136。波前的宽度是计算单元(例如,SIMD处理核心)的硬件的特点。如本文所引用,工作群组是在单一计算单元上执行的相关工作项目的集合。群组中的工作项目执行同一内核并且共享本地存储器和工作群组屏障。在示例性实施方案中,在同一SIMD处理核心上处理来自工作群组的所有波前。一次一个地发出波前上的指令,并且在所有工作项目遵循同一控制流时,每个工作项目执行同一程序。波前还可以被称为弯曲、向量或线程。执行掩码和工作项目预测用于使得发散的控制流能够在一个波前内,其中每个单独的工作项目实际上可以采取通过内核的唯一的代码路径。当工作项目的全集不可在波前开始时间使用时,可以处理部分填充的波前。例如,着色器核心122可以同时执行预定数量的波前136,每个波前136包括多个工作项目。在系统100内,APD104包括其自己的存储器,如图形存储器130(但存储器130不限于仅供图形使用)。图形存储器130提供用于在APD104中进行计算期间使用的本地存储器。着色器核心122内的单独计算单元(未图示)可以具有其自己的本地数据储存器(未图示)。在一个实施方案中,APD104包括存取本地图形存储器130以及存取存储器106。在另一个实施方案中,APD104可以包括存取动态随机存取存储器(DRAM)或直接附接至APD104并且与存储器106分离的其它此类存储器(未图示)。在所示实施例中,APD104还包括一个或“n”数量个命令处理器(CP)124。CP124控制APD104内的处理。CP124还从存储器106中的命令缓冲区125检索待执行的命令,并且对这些命令在APD104上的执行进行协调。在一个实施例中,CPU102将基于应用程序111的命令输入适当的命令缓冲区125中。如本文所引用,应用程序是将在CPU和APD内的计算单元上执行的程序部分的组合。多个命令缓冲区125可以用被调度来在APD104上执行的每个进程来维护。CP124可以用硬件、固件或软件或其组合来实施。在一个实施方案中,CP124被实施为具有用于实施包括调度逻辑在内的逻辑的微代码的精简指令集计算机(RISC)引擎。APD104还包括一个或“n”数量个分派控制器(DC)126。在本申请中,术语“分派”是指由分派控制器执行的命令,所述分派控制器使用上下文状态来为计算单元集合上的工作群组集合发起内核的执行的开始。DC126包括用以发起着色器核心122中的工作群组的逻辑。在一些实施方案中,DC126可以被实施为CP124的一部分。系统100还包括用于从运行列表150选择进程以在APD104上执行的硬件调度器(HWS)128。HWS128可以使用循环法、优先级或基于其它调度策略来从运行列表150选择进程。例如,可以动态地确定优先级。HWS128还可以包括用以管理运行列表150的功能性,例如通过添加新的进程以及通过从运行列表150删除现有进程来管理。HWS128的运行列表管理逻辑有时被称为运行列表控制器(RLC)。在本发明的各种实施方案中,当HWS128发起执行来自运行列表150的进程时,CP124开始从对应的命令缓冲区125检索并且执行命令。在一些情况下,CP124可以生成待在APD104内部执行的一个或多个命令,这些命令对应于从CPU102接收的命令。在一个实施方案中,CP124与其它部件一起对APD104上的命令进行区分优先次序并且调度,其方式为改进或最大化对APD104资源和/或系统100的资源的利用率。APD104可以存取或可以包括中断生成器146。中断生成器146可以由APD104配置来在APD104遇到如页面错误等中断事件时中断操作系统108。例如,APD104可以依赖于IOMMU116内的中断生成逻辑来产生以上所指出的页面错误中断。APD104还可以包括用于抢先取得当前正在着色器核心122内运行的一个进程的抢先和上下文切换逻辑120。例如,上下文切换逻辑120包括用以停止所述进程并且保存其当前状态(例如,着色器核心122状态和CP124状态)的功能性。如本文所引用,术语“状态”可以包括初始状态、中间状态和/或最终状态。初始状态是机器根据程序设计次序处理输入数据集以产生数据输出集合的开始点。存在例如需要在几个点处被存储以使得处理能够向前进的中间状态。这个中间状态有时被存储来允许当由某一其它进程中断时在稍后时间处继续执行。还存在可以被记录为输出数据集的一部分的最终状态。抢先和上下文切换逻辑120还可以包括用以将另一个进程上下文切换至APD104中的逻辑。用以将另一个进程上下文切换成在APD104上运行的功能性可以包括例如通过CP124和DC126来实例化所述进程以在APD104上运行,为这个进程恢复任何先前保存的状态,并且开始其执行。存储器106可以包括非永久性存储器,如DRAM(未图示)。存储器106可以在执行应用程序或其它处理逻辑的若干部分期间存储例如处理逻辑指令、常量值以及变量值。例如,在一个实施方案中,用以在CPU102上执行一个或多个操作的控制逻辑的若干部分可以在由CPU102执行操作的相应部分期间驻留在存储器106内。在执行期间,相应的应用程序、操作系统功能、处理逻辑命令以及系统软件可以驻留在存储器106中。对操作系统108很重要的控制逻辑命令在执行期间通常将驻留在存储器106中。包括例如内核模式驱动器110和软件调度器112在内的其它软件命令在系统100的执行期间也可以驻留在存储器106中。在这个实施例中,存储器106包括由CPU102使用来将命令发送到APD104的命令缓冲区125。存储器106还包括进程列表和进程信息(例如,活动列表152和进程控制块154)。这些列表以及信息由在CPU102上执行的调度软件使用来将调度信息传递至APD104和/或相关调度硬件。存取存储器106可以由耦合到存储器106的存储器控制器140管理。例如,来自CPU102或来自其它装置的对从存储器106读取或写入存储器106的请求由所述存储器控制器140管理。转回参看系统100的其它方面,IOMMU116是一个多上下文存储器管理单元。如本文所使用,上下文可以认为是内核在其中执行的环境和在其中定义同步与存储器管理的领域。上下文包括装置集合、可由这些装置存取的存储器、对应的存储器特性以及用来调度一个或多个内核的执行或在存储器对象上的操作的一个或多个命令队列。转回参看图1A中所示的实施例,IOMMU116包括用以执行用于包括APD104在内的装置的存储器页面存取的虚拟至物理地址翻译的逻辑。IOMMU116还可以包括用以生成中断的逻辑,例如当由如APD104等装置的页面存取导致页面错误时生成中断。IOMMU116还可以包括或能够存取翻译旁视缓冲区(TLB)118。作为实例,TLB118可以在内容可寻址存储器(CAM)中实施,以便应由APD104对存储器106中的数据所做出的请求而加速逻辑(即,虚拟)存储器地址至物理存储器地址的翻译。在所示实施例中,通信基础设施109视需要互连系统100的部件。通信基础设施109可以包括(未图示)外围部件互连(PCI)总线、扩展的PCI(PCI-E)总线、高级微控制器总线体系结构(AMBA)总线、高级图形端口(AGP)或其它此类通信基础设施中的一个或多个。通信基础设施109还可以包括以太网,或类似网络,或满足应用程序的数据传送速率要求的任何适当物理通信基础设施。通信基础设施109包括用以互连包括计算系统100的部件在内的部件的功能性。在这个实施例中,操作系统108包括用以管理系统100的硬件部件以及用以提供常见服务的功能性。在各种实施方案中,操作系统108可以在CPU102上执行,并且提供常见服务。这些常见服务可以包括例如调度用于在CPU102内部执行的应用程序、错误管理、中断服务以及处理其它应用程序的输入和输出。在一些实施方案中,基于由如中断控制器148的中断控制器生成的中断,操作系统108调用适当的中断处理例程。例如,在检测到页面错误中断之后,操作系统108可以即刻调用中断处理程序来起始将相关页面加载到存储器106中,并且更新对应页面表。操作系统108还可以包括用以通过确保以下操作来保护系统100的功能性:存取硬件部件是通过操作系统管理的内核功能性来进行调解。事实上,操作系统108确保了应用程序(如应用程序111)在用户空间中在CPU102上运行。操作系统108还确保了应用程序111调用由操作系统提供的内核功能性,以便存取硬件和/或输入/输出功能性。举例来说,应用程序111包括用以执行用户计算的各种程序或命令,这些用户计算也在CPU102上执行。CPU102能够无缝地发送所选定的命令以用于在APD104上处理。在一个实施例中,KMD110实施应用程序设计接口(API),通过所述应用程序设计接口,CPU102或在CPU102上执行的应用程序或其它逻辑可以调用APD104功能性。例如,KMD110可以使来自CPU102的命令排队到命令缓冲区125,APD104随后将从命令缓冲区检索这些命令。此外,KMD110可以与SWS112一起执行待在APD104上执行的进程的调度。例如,SWS112可以包括用以维护待在APD上执行的进程的已区分优先次序的列表的逻辑。在本发明的其它实施方案中,在CPU102上执行的应用程序可以在对命令进行排队时完全绕过KMD110。在一些实施方案中,SWS112维护待在APD104上执行的进程的在存储器106中的活动列表152。SWS112还在活动列表152中选择进程子集来由硬件中的HWS128管理。关于在APD104上运行每个进程的信息通过进程控制块(PCB)154而从CPU102传递至APD104。用于应用程序、操作系统以及系统软件的处理逻辑可以包括在如C语言的程序设计语言中和/或如Verilog、RTL或网表的硬件描述语言中指定的命令,以便使得能够最终通过掩模作品(maskwork)/光掩模的产生而配置制造过程,从而生产体现本文所描述的本发明的方面的硬件装置。本领域技术人员在阅读本描述后将了解,计算系统100可以包括比图1A中所示更多或更少的部件。例如,计算系统100可以包括一个或多个输入接口、非易失性储存器、一个或多个输出接口、网络接口以及一个或多个显示器或显示器接口。图1B为示出图1A中所示的APD104的更详细的图解的实施方案。在图1B中,CP124可以包括CP流水线124a、124b以及124c。CP124可以被配置来处理命令列表,这些命令列表被提供为来自图1A中所示的命令缓冲区125的输入。在图1B的示例性操作中,CP输入0(124a)负责将命令驱动到图形流水线162中。CP输入1和2(124b和124c)将命令转发到计算流水线160。还提供了用于控制HWS128的操作的控制器机构166。在图1B中,图形流水线162可以包括块集合,本文称为有序流水线164。作为一个实例,有序流水线164包括顶点群组翻译器(VGT)164a、图元汇编器(PA)164b、扫描变换器(SC)164c以及着色器输出后期渲染单元(SX/RB)176。有序流水线164内的每个块可以表示图形流水线162内的不同图形处理级。有序流水线164可以是固定功能硬件流水线。可以使用也将在本发明的精神和范围内的其它实施方式。尽管只有少量数据可以被提供为到图形流水线162的输入,但这些数据将在被提供为从图形流水线162的输出时被放大。图形流水线162还包括用于在从CP流水线124a接收的工作项目群组内的整个范围中进行计数的DC166。通过DC166提交的计算工作与图形流水线162是半同步的。计算流水线160包括着色器DC168和170。所述DC168和170中的每一个被配置来在从CP流水线124b和124c接收的工作群组内的整个计算范围中进行计数。在图1B中示出的DC166、168以及170接收输入范围,将这些范围分解成工作群组,然后将这些工作群组转发到着色器核心122。由于图形流水线162通常是固定功能流水线,因而难以保存并恢复其状态,并且因此,图形流水线162难以进行上下文切换。因此,在大多数情况下,如本文所论述,上下文切换不涉及在图形进程之间进行上下文切换。一个例外是对于在着色器核心122中的图形工作,它可以进行上下文切换。在图形流水线162内部的工作处理已经完成之后,通过后期渲染单元176处理所完成的工作,所述后期渲染单元进行深度和色彩计算,并且然后将其最终结果写入存储器130。着色器核心122可以由图形流水线162和计算流水线160共享。着色器核心122可以是被配置来运行波前的一般处理器。在一个实施例中,在计算流水线160内部的所有工作是在着色器核心122中进行处理的。着色器核心122运行可编程的软件代码,并且包括各种形式的数据,例如状态数据。当所有工作项目都不能够访问APD资源时出现QoS破坏。本发明的实施方案促进有效地并且同时地向APD104内的资源发射两个或更多个任务,从而使得所有工作项目能够访问各种APD资源。在一个实施方案中,APD输入方案通过管理APD的工作负荷来使得所有工作项目能够并行访问APD资源。当APD的工作负荷接近最高水平时(例如...