一种适用于分散式风电场的组合风电功率预测方法与流程
本发明涉及一种基于人工智能技术的数据建模及预测方法,尤其涉及一种适合于分散式风电场的基于径向基神经网络的风速预测方法以及基于改进微粒群优化的BP神经网络的功率预测方法。
背景技术:
风电作为一种变化性电源,大规模风电开发势必受到电网消纳随机性电量能力的限制。由于风电场建设周期短,电网建设相对复杂,难以与风电场的建设同时完成,以及电网对风电装备技术条件要求提升,风电并网开始从物理“并网难”向技术“并网难”转化。同时“弃风”成为了风电发展的新难题。随着“建设大基地,融入大电网”的风电开发战略的有力推进,“三北”地区等风资源富集地区风电机组并网容量迅速增加,渐渐达到电网的消纳极限。陆上集中式开发、陆上分散式开发和海上风电并举,成了当前新的风电开发战略。分散式风电开发以就地消纳为目的,接入配电网,距离居民较近,具有开发和并网接入等难点。2011年,国家能源主管部门出台了相应的管理办法。在风能资源欠丰富的和靠近负荷中心的地风速地区及高原低密度和复杂地形区,分散建设风电场,当地消纳。对中东部省份一些地区风能资源较弱,土地资源有限,可以选择风电分散式开发,就近接入电网。中国分布式风电开发到2015年的装机目标是30GW。可以预见,内陆地区分散式开发的风电场将占有越来越大的比重。这也是中国风电开发不断走向成熟的必然趋势。由于分散式风电位于用电负荷中心附近,就近接入配电网,风电的间歇性、波动性对于接入对配电网的安全、稳定运行以及保证电能质量带来了严峻挑战。若能对风场的风速和发电功率做出比较准确的预测,则可有效减轻风电对整个电网的影响。通过风电功率预测将有助于电网调度部门及时制定合理的运行方式并准确地调整调度计划,从而保证电力系统的可靠、优质、经济运行。我国2015年和2020年前,研发和应用风电功率预测的重点是充分应用各种成熟的统计预报技术,重点是开发应用适用于陆地风电成的超短气预报(4h以内)和短期预报(48h以内)系统。协调电网调度机构、气象部门、风电场共同建立集中式与分散式相结合的风电功率系统,为风电调度提供有效支持。2011年,国家提出建立风功率预测系统的要求,2012年6月建成并完善,目前已部分完成。但已建成的风电场风功率预测系统精确度不高,误差常在20%左右。国内风电功率预测理论与系统开发研究及其应用还需要一段时间的积累,现实的情况主要表现在:1、预测的风速普遍为风电场的平均风速,未考虑风电场地形地貌对风速的影响,预测的不是风电机组处的风速,不能准确定位,且预测的推算一般基于指数函数关系进行切变分析,预测精度差,可置信度欠佳。2、目前风功率预测系统统计算法多采用单神经网络模型,输入为预测风速,输出为预测功率。在基于神经网络方法的建模过程中,如果对网络的规模不加限制,有充足的训练数据,理沦上基于神经网络的单模型结构总能得到一个令人满意的模型结构,但在实际风电场中常常要面对有限的过程数据,且囿于实时性的要求,网络结构也不能任意增加,因此一般依赖于网络的泛化能力,通常不能取得良好的建模效果。3、大量风电场区还缺少具有详查功能的原始测风数据,无法有效发挥风电功率预测系统的功能,即使是较好的风能预报软件也需要一个资料积累的过程。4、由于目前国内较大的风电场是经过多年发展形成的,采用的机型较多。风电功率预测系统与不同类型的风电机组信息交互较困难,这也制约了其应用。目前风电功率的预测方法多为统计方法,其实质是利用有效的历史数据(如数值天气预报数据、历史统计风电功率数据)进行预测。常见的相关方法有持续预测法、空间平滑法、时间序列法、卡尔曼滤波法、灰色预测法、人工神经网络法、小波分析法、支持向量机回归法、最小二乘法、模糊逻辑法等。国内已有预测系统多采用基于自回归线性模型的时间序列法,由于模型本身是线性,依此预测精度往往不够理想。人工神经网络和支持向量机的相关研究是现在主要应用的方法,而现有的采用单一神经网络法通常需要较多的训练样本,一方面计算消耗过大,另一方面无法保证较好的泛化能力,同时在样本信息不充分时又无法取得较好的预测精度。支持向量机的参数选择对模型预测精度有较大影响。
技术实现要素:
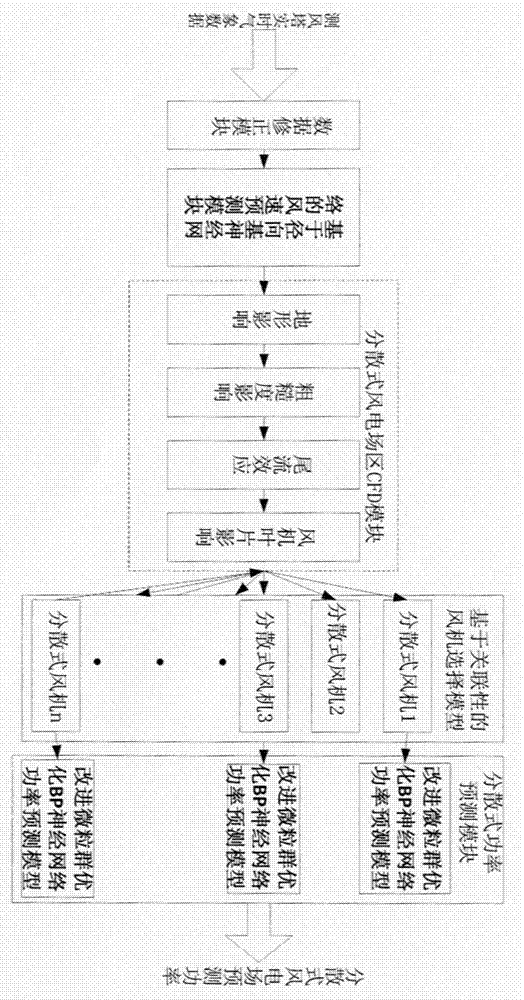
发明目的:本发明在于克服现有技术的缺陷,提出一种适用于分散式接入的组合风电功率预测方法,其目的为解决以往的方法中所存在的预测精度不理想的问题。该方法结合历史测风塔气象数据和风机输出功率,建立双层神经网络模型——基于径向基神经网络的风速预测和基于改进微粒群优化的BP神经网络的功率预测,分别预测分散式风机点的风速和功率。分散式风电场输出功率的影响因素主要有风速、风向、气温、气压、湿度及地表粗糙度等。因此从测风塔得到的风速、风向、气温、气压、湿度等数据都是风速预测模型的必要输入。根据风电场数字化模型,考虑地形、障碍物、粗糙度及风机间尾流效应对风电场输出功率的影响,建立CFD插件表,将测风塔位置的风速外推至每台风机轮毂高度处的风速,结合功率预测模型,结合关联系数和外推系数,计算得到整个风电场的输出功率。为实现上述发明目的,本发明一种适用于分散式接入的组合风电功率预测方法,其特征在于,包括以下步骤:步骤1,通过收集测风塔点的历史气象数据,根据数据和现场需要,对数据进行预处理,统计单位时间(如10min)的平均值,形成可用于风功率预测的数据样本集。对数据分段,根据实际情况,分为3份。前2/3用于预测训练的样本集,后1/3作为测试和订正预测模型的测试集。本方法设计如下公式把数据归一化到[0.05,0.95]区间,以便使网络输出有足够的增长空间。式中为归一化后的输入样本;为原始输入样本。步骤2,数据的获取和预处理:风速预测系统从测风塔数据库及数值天气预报数据库获得指定时间段内的数据,包括风速、风向、温度、湿度、大气压强等。并用两组数据进行关联性分析及相互修正,由此得到训练集和仿真集。其中将t-1时刻的风速、风向、温度、湿度、大气压强等作为输入向量X,输出向量Y为t、t+1时刻的风速。步骤3,分散式风电场区CFD模型通过分散式风电场的地形、大气热稳定度、粗糙度、风切变、尾流效应等因素进行建模。继而通过订正方法不断优化参数和结构,直到模型与实际区域风速分布误差满足要求停止。订正方法有两种:(1)、塔间修正。首先收集两个测风塔的气象数据将处理后的数据通过物理CFD方法外推到另外测风塔,将得到的外推气象数据与实际气象数据进行比对,通过误差最小的约束条件不断循环订正,直到满足条件为止。(2)、测风塔—气象预报订正。通过获取附近气象站或者气象部门提供的当地区域气象数据为基础,外推到测风塔,并与真实数据进行对比修正。本方法拟定均方误差<=20为约束条件。外推方法:首先:采集测风塔的实时数据,预处理后输入到已建立好的地理模型。其次,对本地地形区域划分网格,根据不同区域设置不同的网格,通过CFD方法计算出各台分散式风电机组处网格的预测风速v_((t)n)和下一时刻风速v_(t+1)n。步骤4,风机功率预测模块a)首先采集分散式风场SCADA系统风机功率数据,并进行预处理。其次,结合外推风机处历史气象数据和历史输出功率对采用异步、双馈、永磁直驱三种发电机的风电机组进行建模,并结合风机厂商提供的标准功率曲线数据进行订正。b)建立基于改进微粒群优化的BP神经网络的功率预测模型,本方法采用3层神经网络结构,即输入层、输出层和一个隐含层。输入层的节点有t、t+1时刻的每个分散点的预测风速及t-1时刻的风机的输出功率。输出层为t时刻的预测功率。本方法采用试验法确定隐含层节点个数,分别改变,用同一样本训练,从中确定网络误差最小时所对应的隐含层节点数,其中l为隐含层节点数,n为输入层节点数,m为输出层节点数,a为1-10之间的调节常数。c)用改进的微粒群算法优化BP神经网络的权值与阈值,包括如下步骤:适应度函数:式中,mse为网络的均方误差;为训练样本总数;Y为网络输出;y为样本实际输出;当F在一定程度上接近1时,即被认为达到网络的精度要求。d)淘汰操作淘汰操作是基于适应度比例的选择策略,每个个体i的选择概率Pi为:=式中,Fi为个体i的适应度值,由于适应度值越小越好,所以在个体选择前对适应度值求倒数;K为系数;N为种群个体数目。e)蜕变操作按照一定的概率进行蜕变操作:假设选定微粒i进行蜕变,将该微粒的当前最好位置用当前全局最好位置代替,即,而该微粒所具有的位置速度属性不改变,继续进化。f)变异操作:为了保持微粒飞行后期的多样性,每个微粒在同一速度方向上,以大小不同的幅值飞行。vij(t+1)=vij(t)+c1r1j(t)(pij(t)-xij(t))+c2r2j(t)(gbest(t)-xij(t))xij(t+1)=xij(t)+vij(t+1)式中,分别为微粒所允许的最大速度与最小速度,T为最大进化次数。若vij(t+1)>vmax则搜索速度变小;若vij(t+1)<vmin则搜索速度变大;若vmax>vij(0)>vmin速度合适时,搜索速度vij(0)在两边变大和变小。检验是否符合条件,如果当前全局最佳位置满足预定的要求或是进化次数达到给定次数时,则停止迭代,输出神经网络的最优解。步骤5,通过关联系数,对异步、双馈、永磁直驱三种发电机的风电机组进行分群建模,利用外推系数得到分散式风场预测功率。a)根据各个风电机组实测出力与区域实际出力的关联系数选择基准风电机组并确定所选基准风电机组的个数,关联系数采用下述公式计算;其中:为第i个风电机组出力与区域出力之间的关联系数;n为分散式风电场功率测量点的个数;为第k个测量点与平均值的功率偏差值;为第k个测量点与平均值的出力偏差值;为第k个测量点的实测功率;为n个测量点的平均值;为该区域第k个测量点对应的区域实际出力;为该区域n个测量点的平均出力;b)按照计算后的关联系数大小进行排序,选择关联系数大的风电机组为基准风电机组,并使各个基准风电机组出力之和达到区域额定功率的70%;设i=1,2...L依次为关联系数较大的前L个风电机组的编号,且满足其中:为第i个风电机组的额定出力;为该区域的额定出力。则所选的基准风电机组为编号1.2...L的风电机组,共计L个。c)各象限扩大系数计算方法如下:通过分散式风电机组功率计算模型计算出风电场内每台风机的出力,同时参考风电场至少一年的实际运行资料,选择其中具有代表性的风机作为基准代表点,整个风电场的出力(即所有风机出力之和)与该代表点的出力的比值,为全象限外推系数,按风向分16象限,每个象限内整个风电场的出力与该代表点的出力的比值,则为各象限的外推系数。选定编号为m的风机为代表点,第i象限m风机对风电场的的外推系数可按下式计算。其中:x指风机的出力;y指风机容量;n指风电场风机总台数;J指风机编号,为1……n;m指选定代表点的风机编号i象限编号,为1......16本发明的有益效果是:1、首次提出双层组合神经网络分别对风速和功率进行预测。适合实际风场中有限的过程数据,且囿于实时性的要求,网络结构也不能任意增加,过分依赖于网络的泛化能力的情况。并将加入“改进”“变异”“淘汰”思想的改进微粒群算法对神经网络进行优化,可以有效提高建模的速度和精度。2、在业内普遍采用单神经网络和物理CFD建模的情况下,常规的神经网络不能很好的拟合风速极端变化的情况,而物理方法对于一个风场来讲,地形、湍流以及尾流效应等不确定性因素常用一个值来代替,很难做到精确建模。本发明创新性地应用物理CFD模型对单机进行建模,减小了整个风场的集中效应影响,并结合改进的神经网络,使模型具备了稳定和不稳定两种状态下的建模准确性,为精确地功率预测奠定了基础。3、独特的功率预测模块设计。现有的风功率系统只使用厂家提供的功率曲线进行简单映射来获得预测风速,而分散式风机常运行在恶劣的环境(高海拔、低温),实际环境与实验室不同,导致实际的功率曲线偏离标准功率曲线。本方法采用的输入数据为预测风速、变化趋势以及历史输出功率。由于风电机组对于风速的时变性会产生诸如变桨或偏航的动作,会直接影响风机输出的动态功率,增加下一时刻的风速和历史功率可以有效反映风电机组的动态输出状态,得到的模型比现有的实际运行的风机模型更加准确,特别适合风机数量少、风速时变、间歇性强的情况。4、将删选出的风机根据发电机的类型分为异步、双馈、永磁直驱三类。由于不同类型发电机的功率特性会随着转速的波动产生性能差异,比如...
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1