一种基于CUDA架构加速CT图像重建的方法与流程
本发明涉及医学领域与电子技术领域的交叉,具体涉及X射线CT技术领域中的基于CUDA架构加速CT图像重建的方法。
背景技术:
CT(ComputedTomography)重建尤其是三维重建,计算量大、耗时高,计算复杂度与被重建体数据量、投影视图个数的乘积成正比,比如从360个投影视图重建512张512×512大小的图像(即5123volume)的计算复杂度为360×5123。如何提高重建速度受到越来越多的人重视,在2011年召开的第十一届Fully3D(The11thInternationalMeetingonFullyThree-DimensionalImageReconstruction)会议论文集里有约1/4的文章涉及到三维加速重建,在其他杂志上涉及CT重建加速的文章近年来也很多。GPU的单指令多数据流(SingleInstructionMultipleData,缩写为SIMD)处理模式为可并行地对大规模数据进行同样的操作。由于计算机游戏和工程设计的巨大市场驱动,GPU的发展速度大大超过了CPU的发展速度,图形流水线的高速度和高带宽极大地提高了图形处理能力,近年来发展起来的可编程功能为图形处理之外的通用计算提供了高性价比的运行平台,使得基于GPU的通用计算成为近年来的研究热点之一。FDK重建算法于1984年由Fedlkamp等人首先提出,对CT近似重建有着重大意义,目前广泛应用于锥形束投影重建,而且各个角度的反投影无数据交换,具有高度的并行性,因此特别适于GPU这种单指令多数据(SIMD)的流式计算架构。最早的GPGPU(GeneralPurposeGPU,即通用计算图形处理器)开发直接使用了图形学API编程。这种开发方式要求编程人员将数据打包成纹理,将计算任务映射为对纹理的渲染过程,用汇编或者高级着色器语言(如GLSL、Cg、HLSL)编写shader程序,然后通过图形学API(Direct3D、OpenGL)执行。这种“曲线救国”的方式不仅要求熟悉需要实现的计算和并行算法,还要对图形学硬件和编程接口有深入的了解。由于开发难度大,传统GPGPU没有被广泛应用。CUDA(ComputeUnifiedDeviceArchitecture,统一计算设备架构)的GPU采用了统一处理架构,可以更加有效地利用过去分布在顶点渲染器和像素渲染器的计算资源;而且引入了片内共享存储器,支持随机写入(scatter)和线程间通信。
技术实现要素:
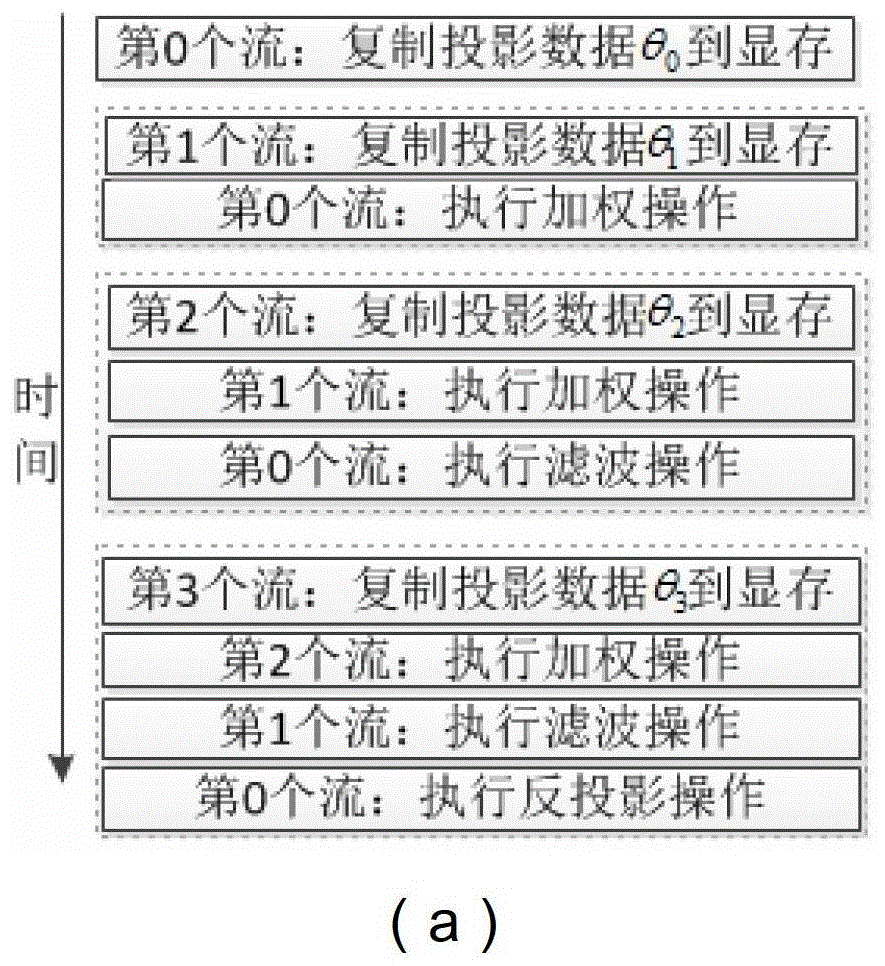
鉴于现有技术的不足,本发明旨在于提供一种快速的CT图像重建的异步并行处理方法,针对目前锥形束重建时数据输入、数据加权、数据滤波及反投影串行执行的瓶颈问题,提出了基于CUDA架构中GPU异步并行处理的重建方法,从而提高重建速度。本发明的技术方案具体是:通过使用两个或者两个以上的流,使应用程序实现任务级的并行化,进一步地说,即GPU在执行核函数的同时,还能在主机与设备之间执行复制操作。为了实现上述目的,本发明采用的技术方案如下:一种基于CUDA架构加速CT图像重建的方法,包括数据输入模块,基于GPU的CT数据加权滤波模块,基于GPU的CT图像重建反投影模块,以及数据输出模块,其特征在于,所述方法包括以下步骤:(1)从扫描的X射线强度数据获得投影数据,经过预处理后,由CPU读入到内存中;(2)应用程序实现任务级的并行化,通过使用两个或两个以上的流,使GPU在执行核函数的同时,能在主机与设备之间执行复制操作。需要说明的是,所述CT数据加权滤波模块在GPU中执行,为每个待加权滤波元素分配至GPU中的单独线程来执行,其中,所述线程分配过程如下:根据GPU的特性设置每个线程块的尺寸;根据补零后投影数据的水平长度和垂直长度设置所述线程块的个数;按照所述线程块设置执行内核程序。需要说明的是,所述CT图像重建反投影模块在GPU中执行,为每个待重建像素分配至GPU中的单独线程来执行,重建所需滤波后的数据存储在GPU的纹理内存中,其中线程分配过程如下:根据GPU的特性设置每个线程块的尺寸;根据待重建图像的尺寸设置所述线程块的个数;按照所述线程块设置执行内核程序。需要说明的是,所述投影数据使用所述基于GPU的CT数据加权滤波模块,以及所述基于GPU的CT反投影模块采用滤波反投影算法获得重建体;其中,所述基于GPU的CT数据滤波模块,将投影数据首先在GPU上进行加权,再通过GPU上FFT变换到频域,频域滤波后通过GPU上的逆FFT获得滤波后的数据。需要说明的是,所述基于GPU的图像重建反投影模块在GPU上实现纹理绑定,将显存中的数据与纹理参照系相关联,并进行纹理拾取操作。作为一种优选的方案,纹理缓存中的数据可以被重复利用,而且一次拾取坐标对于位置附近的几个像元,提高一定局部性的访存效率。需要说明的是,所述两个或两个以上的流处理数据互不影响。需要说明的是,其特征在于,数据从内存复制到显存、GPU上的投影数据加权操作、GPU上的投影数据滤波操作及GPU上的CT图像重建的反投影操作为异步并行执行。需要说明的是,输入数据存储为无符号短整型;GPU的CT加权滤波数据、GPU的CT图像重建反投影数据及CPU的输出数据存储成32位浮点格式。本发明有益效果在于,采用了异步并行的执行方法,明显提高了CT图像的重建速度。附图说明图1为平行探测器锥束扫描几何结构图;图2为本发明的方法流程示意图,其中a为开始部分流程图;b为本循环部分流程图;c为结束部分流程图。具体实施方式下面将结合附图对本发明作进一步的描述。如图1所示,为平板探测器锥束扫描几何结构,射线源到旋转中心的距离为R,射线源到探测器距离为D,扇角为γ,锥角为τ,称射线源到探测器中心且与探测器垂直的射线为中心射线,FDK算法重建公式为:其中gI(u,v,λ)代表投影数据,λ为投影角度。FDK算法实现步骤为:(1)加权滤波:(2)加权反投影:其中,U(x,y,λ)=R+xcosλ+ysinλ需要说明的是,锥形束重建GPU模块主要包括两部分:CT投影数据加权滤波模块和CT图像的反投影模块。假设通过X射线平板探测器获得K个角度的二维投影数据分别为p0p1......pk-1,每一副投影由U×V个像素组成,将从中重建L×W×H的体数据F。1、基于CUDA的CT数据加权滤波模块(1)生成加权函数并保存在显存数组d_weight[U][V]中;(2)利用FFT变换将二维投影数据pn(0≤n≤k-1)转换到频域。由于对投影数据需要进行一维频域滤波,在实现投影数据的滤波之前,需要生成窗函数,并将其做FFT变换。GPU上数据的FFT变换分以下几步实现:第一步,依次复制内存中各个角度的二维投影数据pn(0≤n≤k-1)到显存,记为d_inData[V][U];第二步,对投影数据在水平方向上补零,补零后的数据长度为U′;需要说明的是,此时需要考虑以下三个因素:(a)避免干涉效应,补零的最小数目为探测器长度减1(即:U-1);(b)实现快速FFT变换,补零后的长度应为2的整数次幂;(c)实函数经过FFT变换后在频域上为偶函数。(3)在显存中开辟一个二维数组d_data[V][U′],并将每张投影数据d_inData[V][U]中的每一个元素与d_weight[V][U]中的对应元素相乘,做加权操作,每行的末尾补零。intx=__mul24(blockDim.x,blockIdx.x)+threadIdx.x;inty=__mul24(blockDim.y,blockIdx.y)+threadIdx.y;if(x<U&&y<V)d_data[y][x]=d_inData[y][x]*d_weight[y][x];(4)设置CUDA滤波时参数,主要步骤为:第一步,根据CUDA的特性设置每个线程块(Block)的尺寸;根据补零后投影数据的水平长度U′及垂直长度V设置线程块(Block)的个数。第二步,为FFT变换和逆FFT变换分别创建FFT句柄和一维FFT句柄plan。cufftHandleplanF,planI;cufftPlan1d(&planF,U′,CUFFT_R2C,V);cufftPlan1d(&planI,U′,CUFFT_C2R,V);第三步,将FFT句柄plan与CUDA流相关联cufftSetStream(planF,stream1);cufftSetStream(planI,stream2);(5)将投影数据进行原地(inplace)FFT变换,并与滤波窗函数的频域值在相应位置上进行点乘,得到滤波后的数据。cufftExecR2C(planF,(cufftReal*)d_data,(cufftComplex*d_data)(6)将滤波后的数据进行原地(inplace)逆FFT变换,此时数据的水平大小仍为U′,垂直大小为V,数据仍然存储在d_data[V][U′]中。cufftExecC2R(planI,(cufftComplex*d_data,(cufftReal*)d_data);2、基于GPU的CT数据反投影模块在主机端声明需要绑定到纹理的CUDA数组并设置好纹理参照系,然后将纹理参照系与CUDA数组绑定建立纹理坐标系,之后就可在内核中通过纹理拾取函数访问纹理存储器。具体步骤为:第一步,声明纹理参照系,纹理参照系通过一个作用范围为全文件的texture型变量声明,并且必须在编译前显示声明texture<float,2,cudaReadModeElementType>texRef;第二步,设置运行时纹理参考系属性texRef1.addressMode[0]=cudaAddressModeWrap;texRef1.addressMode[1]=cudaAddressModeWrap;texRef1.filterMode=cudaFilterModeLinear;texRef1.normalized=false;第三步,根据GPU的特性设置每个线程块(Block)的尺寸;根据待重建图像的尺寸设置线程块(Block)的个数;第四步,根据探测器水平大小(U)和垂直大小(V),声明CUDA数组,并分配空间cudaChannelFormatDescchannelDesc=cudaCreateChannelDesc(32,0,0,0,cudaChannelFormatKindFloat);cudaArray*cuArray;cudaMallocArray(&cuArray,&channelDesc,U,V);第五步,将滤波后的投影数据d_data[V][U′]复制到CUDA数组cudaArray中第六步,纹理绑定,将显存中的数据与纹理参照系相关联的操作。cudaBindTextureToArray(texRef,cuArray,channelDesc);第七步,纹理拾取,采用纹理坐标对纹理存储器进行访问,即可得到体数据的值。获取重建体各个像素点的位置:intx=__mul24(blockDim.x,blockIdx.x)+threadIdx.x;inty=__mul24(blockDim.y,blockIdx.y)+threadIdx.y;intz=__mul24(blockDim.z,blockIdx.z)+threadIdx.z;计算各像素点映射到探测器的位置,在此假设水平方向为point_h,垂直方向为point_v。则某个角度的投影数据p在该像素点的贡献值为:tex2D(texRef,point_h+0.5,point_v+0.5);下面结合具体实施例进一步的描述本发明。如图2所示,利用本发明的基于异步并行处理的FDK重建方法进行重建,GPU使用NVIDIA的GeForceGT640。需要说明的是,投影数据大小为512*512*480,待重建体的大小为512*512*512。1、从外部设备(如硬盘)读取投影数据到内存,由于投影数据存储空间远小于内存,待重建体存储空间小于显存的一半,因此投影数据全部读取到内存,并直接生成重建体。如果投影数据过大,可以考虑分块输入;如果重建体过大,可以考虑分块重建。此处假设内存中的投影数据为h_indata。2、初始化四个流对象cudaStream_tstream[4];for(inti=0;i<4;i++)cudaStreamCreate(&steam[i]);3、四个流进行异步并行操作,提高重建速度,其中:(1)第0个流从h_indata取出一张投影数据,并将其复制到显存;(2)在第0个流做加权操作的同时,第1个流从h_indata取出下一张投影数据,并将其复制到显存;(3)在第0个流做滤波操作的同时,第1个流进行加权操作,第2个流从h_indata取出下一张投影数据,并将其复制到显存;(4)在第0个流做反投影操作的同时,在第1个流做滤波操作的同时,第2个流进行加权操作,第3个流从h_indata取出下一张投影数据,并将其复制到显存;重复执行(1)~(4)操作,直到所有投影数据全部被读入。通过使用stream,可以将数据读取时间、加权时间和滤波时间部分隐藏,从而提高程序执行效率。对于本领域的技术人员来说,可根据以上描述的技术方案以及构思,做出其它各种相应的改变以及变形,而所有的这些改变以及变形都应该属于本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1