基于用户搜索日志的兴趣实体获得方法及装置与流程
技术特征:
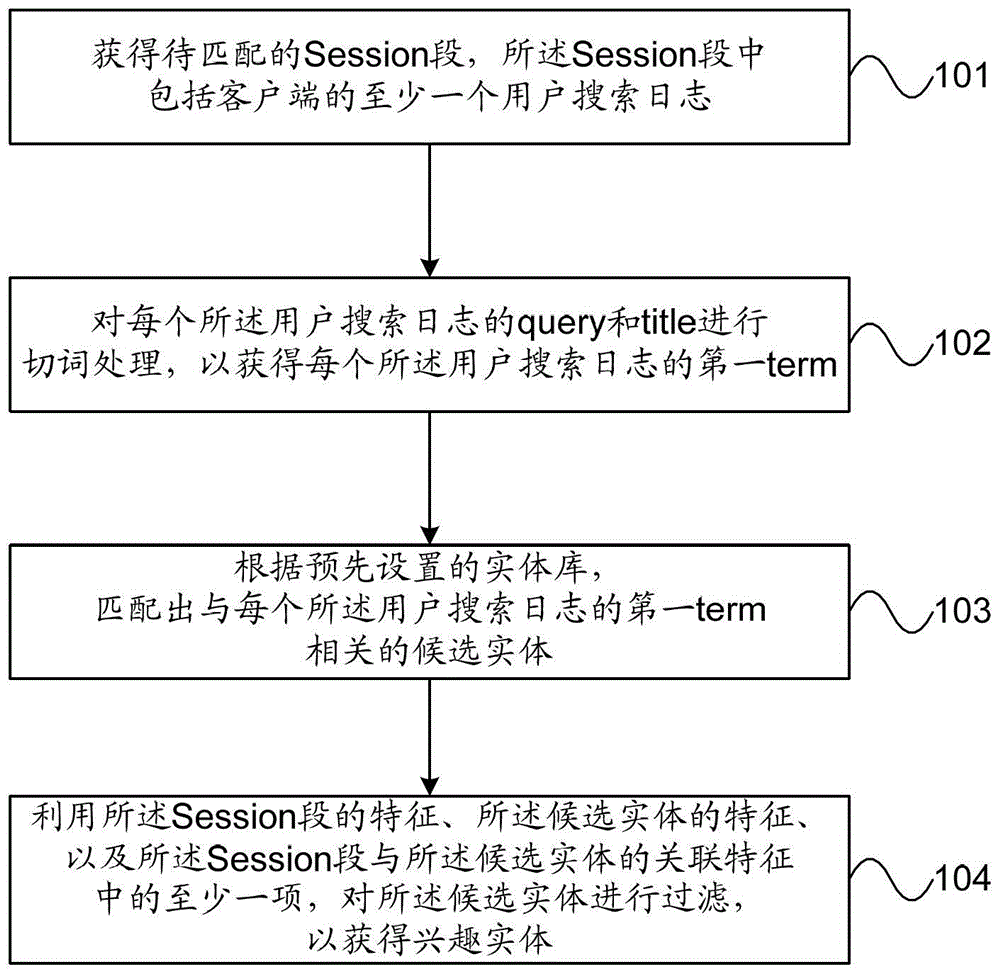
1.一种基于用户搜索日志的兴趣实体获得方法,其特征在于,包括:获得待匹配的Session段,所述Session段中包括客户端的至少一个用户搜索日志;对每个所述用户搜索日志的query和title进行切词处理,以获得每个所述用户搜索日志的第一term;根据预先设置的实体库,匹配出与每个所述用户搜索日志的第一term相关的候选实体;利用所述Session段的特征、所述候选实体的特征、以及所述Session段与所述候选实体的关联特征中的至少一项,对所述候选实体进行过滤,以获得兴趣实体;其中,所述利用所述Session段的特征、所述候选实体的特征、以及所述Session段与所述候选实体的关联特征中的至少一项,对所述候选实体进行过滤,以获得兴趣实体,包括下列中的至少一项:利用所述Session段的特征、所述候选实体的特征、以及所述Session段与所述候选实体的关联特征中的至少一项,作为输入,运行GBDT模型,以获得每个所述候选实体的预测label;若所述候选实体的预测label大于或等于预先设置的label阈值,保留所述候选实体,以作为所述兴趣实体,若所述候选实体的预测label小于预先设置的label阈值,过滤掉所述候选实体;以及根据所述候选实体的预测label、所述候选实体的名称长度、所述候选实体完整匹配的次数、所述候选实体的预设属性是否匹配到所述Session段、以及所述候选实体的所有属性匹配到所述Session段中的个数中的至少一项,获得所述候选实体的排序分数;若所述候选实体的排序分数小于预先设置的第一分数阈值,过滤掉所述候选实体;若所述候选实体的排序分数大于或等于预先设置的第一分数阈值,且小于预先设置的第二分数阈值,若所述候选实体的排序分数大于或等于所述预测label,保留所述候选实体,以作为所述兴趣实体,若所述候选实体的排序分数小于所述预测label,过滤掉所述候选实体;若所述候选实体的排序分数大于或等于预先设置的第二阈值分数,保留所述候选实体,以作为所述兴趣实体;其中,所述第二分数阈值大于所述第一分数阈值。2.根据权利要求1所述的方法,其特征在于,所述根据预先设置的实体库,匹配出与每个所述用户搜索日志的第一term相关的候选实体,包括:根据预先设置的实体库,建立实体的倒排索引;根据所述倒排索引,获得与每个所述用户搜索日志的第一term相关的实体;根据所述实体的term重要性权值覆盖率,对所述实体进行排序;选择所述term重要性权值覆盖率最高的指定数量的所述实体,以作为所述候选实体。3.根据权利要求1~2任一权利要求所述的方法,其特征在于,所述Session段的特征包括下列中的至少一个:所述Session段所包含的所有第一term的长度之和。4.根据权利要求1~2任一权利要求所述的方法,其特征在于,所述候选实体的特征包括下列中的至少一个:所述候选实体的名称长度之和;所述候选实体的名称中所包含的所有第二term的term重要性权值之和;以及所述候选实体的名称中所包含的所有第二term的IDF权值之和;其中,所述第二term为对所述候选实体的名称进行切词处理获得。5.根据权利要求1~2任一权利要求所述的方法,其特征在于,所述Session段与所述候选实体的关联特征包括下列中的至少一个:所述候选实体的名称在所述Session段所包含的所有第一term中出现的所有第二term的长度之和;所述候选实体的名称在所述Session段所包含的所有第一term中出现的所有第二term的长度之和与所述候选实体的名称长度之和的比值;所述候选实体的名称在所述Session段所包含的所有第一term中出现的所有第二term的term重要性权值之和;所述候选实体的名称在所述Session段所包含的所有第一term中出现的所有第二term的term重要性权值之和与所述候选实体的名称中所包含的所有第二term的term重要性权值之和的比值;所述Session段所包含的所有第一term中出现的所述候选实体的名称中所包含的第二term的最大term重要性权值;所述候选实体的名称在所述Session段所包含的所有第一term中出现的所有第二term的IDF权值之和;所述候选实体的名称在所述Session段所包含的所有第一term中出现的所有第二term的IDF权值之和与所述候选实体的名称中所包含的所有第二term的IDF权值之和的比值;所述Session段所包含的所有第一term中出现的所述候选实体的名称中所包含的第二term的最大IDF权值;以及所述Session段所包含的所有第一term中完整匹配所述候选实体的名称的次数;其中,所述第二term为对所述候选实体的名称进行切词处理获得。6.一种基于用户搜索日志的兴趣实体获得装置,其特征在于,包括:获得单元,用于获得待匹配的Session段,所述Session段中包括客户端的至少一个用户搜索日志;切词单元,用于对每个所述用户搜索日志的query和title进行切词处理,以获得每个所述用户搜索日志的第一term;匹配单元,用于根据预先设置的实体库,匹配出与每个所述用户搜索日志的第一term相关的候选实体;过滤单元,用于利用所述Session段的特征、所述候选实体的特征、以及所述Session段与所述候选实体的关联特征中的至少一项,对所述候选实体进行过滤,以获得兴趣实体;其中,所述过滤单元,具体用于执行下列中的至少一项:利用所述Session段的特征、所述候选实体的特征、以及所述Session段与所述候选实体的关联特征中的至少一项,作为输入,运行GBDT模型,以获得每个所述候选实体的预测label;若所述候选实体的预测label大于或等于预先设置的label阈值,保留所述候选实体,以作为所述兴趣实体,若所述候选实体的预测label小于预先设置的label阈值,过滤掉所述候选实体;以及根据所述候选实体的预测label、所述候选实体的名称长度、所述候选实体完整匹配的次数、所述候选实体的预设属性是否匹配到所述Session段、以及所述候选实体的所有属性匹配到所述Session段中的个数中的至少一项,获得所述候选实体的排序分数;若所述候选实体的排序分数小于预先设置的第一分数阈值,过滤掉所述候选实体;若所述候选实体的排序分数大于或等于预先设置的第一分数阈值,且小于预先设置的第二分数阈值,若所述候选实体的排序分数大于或等于所述预测label,保留所述候选实体,以作为所述兴趣实体,若所述候选实体的排序分数小于所述预测label,过滤掉所述候选实体;若所述候选实体的排序分数大于或等于预先设置的第二阈值分数,保留所述候选实体,以作为所述兴趣实体;其中,所述第二分数阈值大于所述第一分数阈值。7.根据权利要求6所述的装置,其特征在于,所述匹配单元,具体用于根据预先设置的实体库,建立实体的倒排索引;根据所述倒排索引,获得与每个所述用户搜索日志的第一term相关的实体;根据所述实体的term重要性权值覆盖率,对所述实体进行排序;选择所述term重要性权值覆盖率最高的指定数量的所述实体,以作为所述候选实体。8.根据权利要求6~7任一权利要求所述的装置,其特征在于,所述Session段的特征包括下列中的至少一个:所述Session段所包含的所有第一term的长度之和。9.根据权利要求6~7任一权利要求所述的装置,其特征在于,所述候选实体的特征包括下列中的至少一个:所述候选实体的名称长度之和;所述候选实体的名称中所包含的所有第二term的term重要性权值之和;以及所述候选实体的名称中所包含的所有第二term的IDF权值之和;其中,所述第二term为对所述候选实体的名称进行切词处理获得。10.根据权利要求6~7任一权利要求所述的装置,其特征在于,所述Session段与所述候选实体的关联特征包括下列中的至少一个:所述候选实体的名称在所述Session段所包含的所有第一term中出现的所有第二term的长度之和;所述候选实体的名称在所述Session段所包含的所有第一term中出现的所有第二term的长度之和与所述候选实体的名称长度之和的比值;所述候选实体的名称在所述Session段所包含的所有第一term中出现的所有第二term的term重要性权值之和;所述候选实体的名称在所述Session段所包含的所有第一term中出现的所有第二term的term重要性权值之和与所述候选实体的名称中所包含的所有第二term的term重要性权值之和的比值;所述Session段所包含的所有第一term中出现的所述候选实体的名称中所包含的第二term的最大term重要性权值;所述候选实体的名称在所述Session段所包含的所有第一term中出现的所有第二term的IDF权值之和;所述候选实体的名称在所述Session段所包含的所有第一term中出现的所有第二term的IDF权值之和与所述候选实体的名称中所包含的所有第二term的IDF权值之和的比值;所述Session段所包含的所有第一term中出现的所述候选实体的名称中所包含的第二term的最大IDF权值;以及所述Session段所包含的所有第一term中完整匹配所述候选实体的名称的次数;其中,所述第二term为对所述候选实体的名称进行切词处理获得。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1