一种面向时间序列趋势预测的模糊信息粒化方法与制造工艺
本发明涉及粒度计算技术领域,具体是一种面向时间序列趋势预测的模糊信息粒化方法。
背景技术:
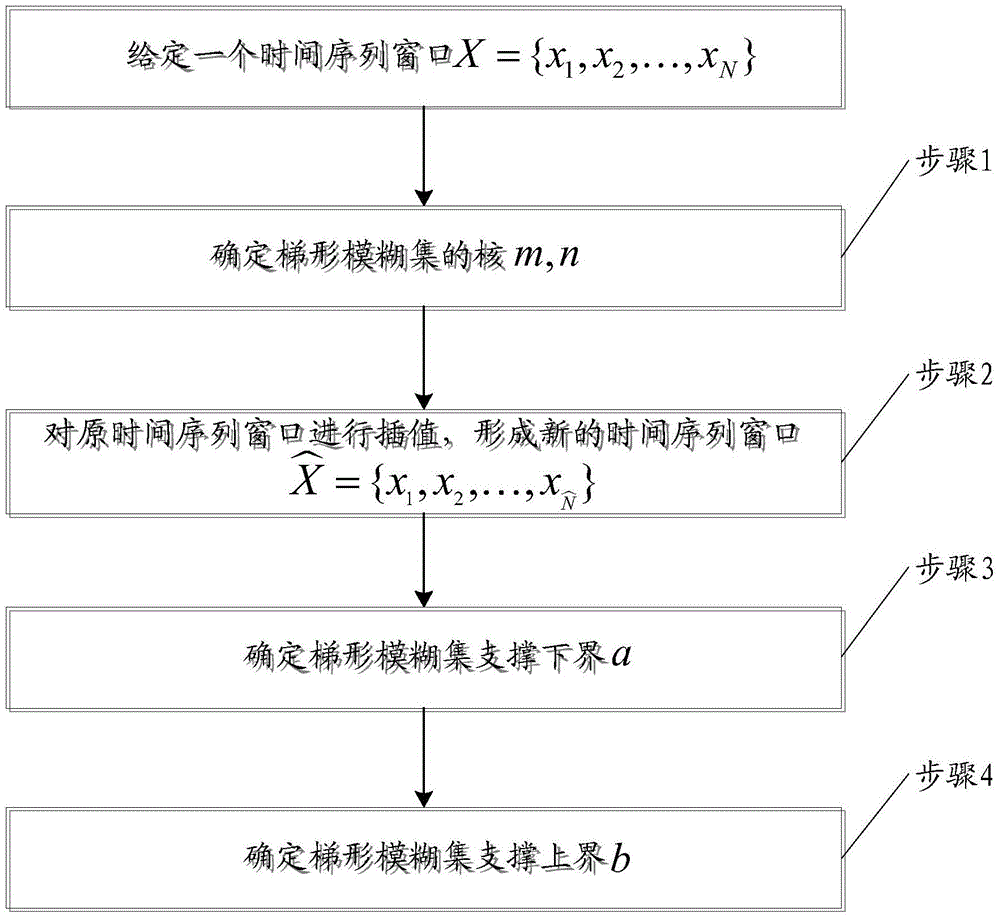
利用模糊集方法对时间序列进行模糊信息粒化主要分为两个步骤:离散化和模糊化。离散化主要目的是将时间序列分成若干子序列,每个子序列的大小称为窗口;模糊化是将离散化产生的窗口进行模糊化,生成时序模糊信息粒。此时生成的新的时间序列称为粒化时间序列。针对粒化时间序列进行预测可以获取原时间序列不能直接获取的高层信息。离散化和模糊化的过程称为模糊信息粒化,记为f-粒化。f-粒化的关键是模糊化,模糊化是指在给定时间子序列上建立一个模糊粒子,即确定一个能够合理描述的模糊集(以为论域的模糊集)。确定了也就确定了模糊例子,即:模糊化的过程就是确定函数的过程,是模糊概念的隶属函数,即。通常,粒化时首先确定概念的基本形式,然后确定具体的隶属函数。模糊粒子的基本形式包括:三角形、梯形、高斯形、抛物型等。其中,本专利主要针对梯形模糊粒子,梯形模糊粒子的隶属函数为:目前,常用的粒化方法包括:W.Pedrycz提出的信息粒化方法以及尘非、董克强对该方法的改进。W.Pedrycz提出的信息粒化方法用于建立的模糊粒子的基本思想是:(1)模糊粒子能够合理的代表原始数据,即最大化;(2)模糊粒子要有一定的特殊性,也就是最小化模糊集的支撑,即最小化,其中和分别是模糊集的支撑边界。通过以上基本思想得到如下优化函数:粒化的目标是使函数取得最大值。对于给定的时间序列粒化窗口,则W.Pedrycz的模糊粒化算法具体步骤为:步骤1、确定梯形模糊集的核,。将按由小到大的顺序排序,不妨设排序后的时间序列仍为,当N是偶数时,,;当N是奇数时,。步骤2、确定梯形模糊集支撑下界。采用数据遍历的方法计算,使取最大值的数据值即为支撑下界,即:使函数取最大值的为的支撑下界,其中为的隶属度。步骤3、确定梯形模糊集支撑上界。采用数据遍历的方法计算,使取最大值的数据值即为支撑上界,即:使函数取最大值的为的支撑下界,其中为的隶属度。经过上述步骤,可以确定梯形模糊信息粒子的4个参数:。通过W.Pedrycz方法可以对任意一个时间序列进行粒化操作,然而该方法得到的模糊集的支撑相对较小,具体表现为过多的数据信息丢失,使所建立的粒子失去了对原始数据的替代意义。造成数据丢失的原因是没有考虑到粒子支撑以外的数据对粒子整体的负面影响,粒子支撑以外的数据的隶属度均为0,针对这种情况,尘非、董克强对该方法的进行了改进,将原始的梯形模糊集的隶属函数改成如下形式:改进的模糊粒化算法具体步骤为:步骤1、确定梯形模糊集的核,。将按由小到大的顺序排序,不妨设排序后的时间序列仍为,当N是偶数时,,;当N是奇数时,。记下和,其中,。步骤2、确定梯形模糊集支撑下界。计算方法为:。步骤3、确定梯形模糊集支撑上界。计算方法为:。该方法较W.Pedrycz方法扩大了对时间序列数据的支撑度,改善了隶属度的适应范围,目前在时间序列模糊信息粒化中使用较为普遍,然而该方法和W.Pedrycz方法一样,确定的支撑上界和支撑下界并不能完全包含窗口内的所有数据,即不能保证:时间序列趋势预测的一个重要评测标准是预测的范围是否能够完全包含未来的测量数据,显然,目前采用现有的模糊信息粒化方法对时间序列进行趋势预测不能较...
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1