本发明涉及口语自然语言理解领域,尤其涉及一种高鲁棒性口语语义解析系统及方法。
背景技术:
口语语音识别涉及语音学、语言学、数学信号处理、模式识别等多学科领域。随着智能设备的普及,人与智能设备之间如何更直接友好的交互成为重要问题。由于口语自然语言对于用户天然的友好性和便捷性,基于口语自然语言的人机交互成为趋势,受到工业界越来越多的重视。口语自然语言交互的关键技术在于口语语义理解,即对用户的口语句子进行解析,得到用户想要表达的意图及相应的关键词。一般地,实现口语语义理解的方法是人工搜集或撰写相应的语义句式,然后将待解析的句子与句式匹配从而得到解析结果。在现有的口语语义解析方法中,大都是基于某种文法的匹配,比如正则文法、上下文无关文法,这要求待解析口语句子要与语义句式完全一致,才能解析成功;这使得语义理解系统的构造人员需要耗费大量的时间搜集语义句式;由于前端语音识别等模块存在识别不准确的现象,从而造成语义理解的解析失败;并且由于待解析句式需要与大量的语义句式进行匹配,会造成解析时间长、效率低的问题。
技术实现要素:
针对现有的口语语义解析方法存在的上述问题,现提供一种旨在实现可在大规模语义句式库中能够快速准确的查找到与待解析口语句子相似句子,并给出准确的结果的口语语义解析系统及方法。
具体技术方案如下:
一种口语语义解析系统,用于对预设领域的口语语义进行解析,包括:
一存储单元,用于存储所述预设领域的语义句式,每个所述语义句式对应一地址,所述语义句式包括字和关键词,每个所述关键词对应一标签,所述存储单元中预设有一词表,用以存储每个所述字所在的所述语义句式的地址和/或每个所述标签所在的所述语义句式的地址;
一获取单元,用于获取待解析口语句子;
一索引单元,分别连接所述存储单元和所述获取单元,用于根据所述待解析口语句子对所述存储单元中的所述语义句式进行检索,获取与所述待解析口语句子相符的候选语义句式,及相应的候选顺序;
一解析单元,连接所述索引单元,用于根据排序后的所述候选语义句式采用模糊匹配算法对所述待解析口语句子进行解析,获取解析结果。
优选的,所述索引单元包括:
一提取模块,用于提取所述待解析口语句子中与所述存储单元中相同的所述关键词,并获取所述关键词对应的标签;
一替换模块,连接所述提取模块,用于将所述待解析口语句子中的所述关键词采用与所述关键词对应的标签替换,形成替换式口语句子;
一索引模块,连接所述替换模块,用于根据所述替换式口语句子中的字和所述标签,在所述存储单元中的所述词表中进行检索,获取与所述字匹配的所述语义句式的地址,和/或所述标签匹配的所述语义句式的地址;
一排序模块,连接所述索引模块,用于采用与所述替换式口语句子的相似度比较的方式对与所述替换式口语句子中的所述字匹配的所述语义句式和/或所述标签匹配的所述语义句式进行排序,获取经排序后的所述候选语义句式。
优选的,所述排序模块采用得分公式获取所述候选语义句式与所述替换式口语句子的相似度的分数;
所述得分公式为:
S=(S1+S2)/2,
其中,S表示所述候选语义句式与所述替换式口语句子的相似度的分数,S1表示所述候选语义句式中的所述字和/或所述标签占所述替换式口语句子的比例;S2表示所述候选语义句式中的所述字和/或所述标签占所述候选语义句式的比例。
优选的,所述解析单元根据排序后的所述候选语义句式采用模糊匹配算法对所述待解析口语句子进行解析的具体过程为:
对每个所述候选语义句式建立有限状态自动机网络,根据所述有限状态自动机网络对所述待解析口语句子进行打分,比较所述待解析口语句子的分数,将最高分数的所述待解析口语句子作为所述待解析口语句子的解析结果。
优选的,所述词表采用哈希表表示。
一种口语语义解析方法,应用于所述口语语义解析系统,包括下述步骤:
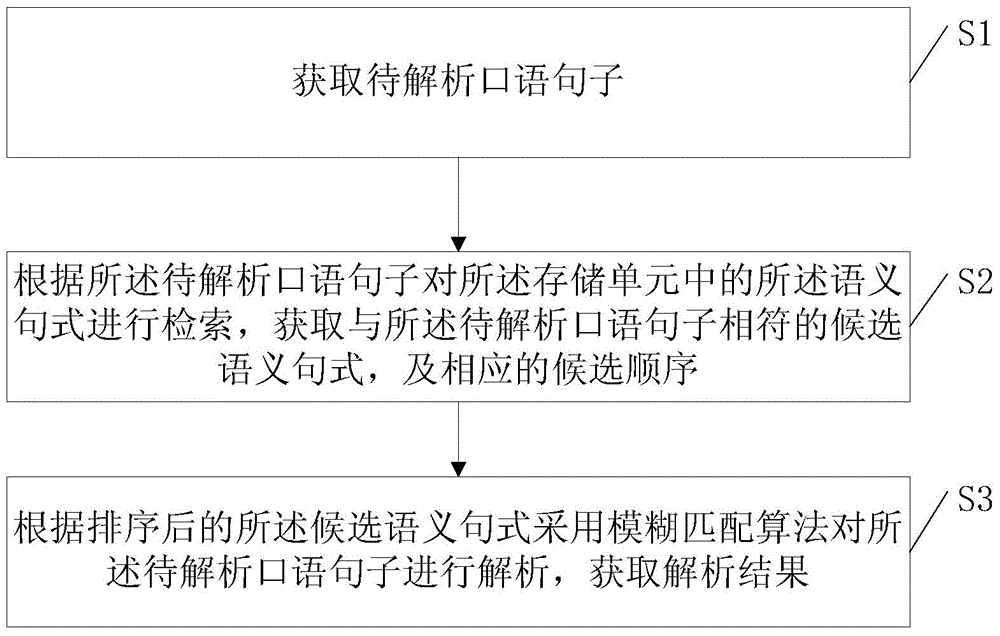
S1.获取待解析口语句子;
S2.根据所述待解析口语句子对所述存储单元中的所述语义句式进行检索,获取与所述待解析口语句子相符的候选语义句式,及相应的候选顺序;
S3.根据排序后的所述候选语义句式采用模糊匹配算法对所述待解析口语句子进行解析,获取解析结果。
优选的,所述步骤S2的具体过程为:
S21.提取所述待解析口语句子中与所述存储单元中相同的所述关键词,并获取所述关键词对应的标签;
S22.将所述待解析口语句子中的所述关键词采用与所述关键词对应的标签替换,形成替换式口语句子;
S23.根据所述替换式口语句子中的字和所述标签,在所述存储单元中的所述词表中进行检索,获取与所述字匹配的所述语义句式的地址,和/或所述标签匹配的所述语义句式的地址;
S24.采用与所述替换式口语句子的相似度比较的方式对与所述替换式口语句子中的所述字匹配的所述语义句式和/或所述标签匹配的所述语义句式进行排序,获取经排序后的所述候选语义句式。
优选的,所述步骤S24采用得分公式获取所述候选语义句式与所述替换式口语句子的相似度的分数;
所述得分公式为:
S=(S1+S2)/2,
其中,S表示所述候选语义句式与所述替换式口语句子的相似度的分数,S1表示所述候选语义句式中的所述字和/或所述标签占所述替换式口语句子 的比例;S2表示所述候选语义句式中的所述字和/或所述标签占所述候选语义句式的比例。
优选的,所述步骤S3的具体过程为:
S31.对每个所述候选语义句式建立有限状态自动机网络;
S32.根据所述有限状态自动机网络对所述待解析口语句子进行打分;
S33.比较所述待解析口语句子的分数,将最高分数的所述待解析口语句子作为所述待解析口语句子的解析结果。
优选的,所述词表采用哈希表表示。
上述技术方案的有益效果:
在本技术方案中,在口语语义解析系统中通过索引单元可快速检索出与待解析口语句子相关的句式,以提高匹配的效率;采用的模糊匹配算法可在对待解析口语句子进行解析时,允许待解析口语句子和候选语义句式之间可存在不一致的部分,具有一定的容错性,从而提高了系统的鲁棒性。在口语语义解析方法中可快速检索出与待解析口语句子相关的句式,以提高匹配的效率,以使在大规模语义句式库中能够快速准确的查找到与待解析口语句子相似的句式,并输出准确的结果。
附图说明
图1为本发明所述口语语义解析系统的一种实施例的模块图;
图2为本发明所述口语语义解析方法的一种实施例的方法流程图;
图3为本发明对所述存储单元中的所述语义句式进行检索的方法流程图;
图4为本发明对所述待解析口语句子进行解析的方法流程图;
图5为本发明句式倒排索引示意图;
图6为本发明句式对应的有限状态自动机示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
如图1所示,一种口语语义解析系统,用于对预设领域的口语语义进行解析,包括:
一存储单元1,用于存储预设领域的语义句式,每个语义句式对应一地址,语义句式包括字和关键词,每个关键词对应一标签,存储单元1中预设有一词表,用以存储每个字所在的语义句式的地址和/或每个标签所在的语义句式的地址;
一获取单元2,用于获取待解析口语句子;
一索引单元3,分别连接存储单元1和获取单元2,用于根据待解析口语句子对存储单元1中的语义句式进行检索,获取与待解析口语句子相符的候 选语义句式,及相应的候选顺序;
一解析单元4,连接索引单元3,用于根据排序后的候选语义句式采用模糊匹配算法对待解析口语句子进行解析,获取解析结果。
在本实施例中,通过索引单元3可快速检索出与待解析口语句子相关的句式,以提高匹配的效率;采用的模糊匹配算法可在对待解析口语句子进行解析时,允许待解析口语句子和候选语义句式之间可存在不一致的部分,且可使得口语语义解析系统的构建人员不需要撰写大量的差异很小的句式;同时对语音识别前端的错误具有一定的容错性,从而提高了系统的鲁棒性。
在优选的实施例中,索引单元3包括:
一提取模块31,用于提取待解析口语句子中与存储单元1中相同的关键词,并获取关键词对应的标签;
一替换模块32,连接提取模块31,用于将待解析口语句子中的关键词采用与关键词对应的标签替换,形成替换式口语句子;
一索引模块34,连接替换模块32,用于根据替换式口语句子中的字和标签,在存储单元1中的词表中进行检索,获取与字匹配的语义句式的地址,和/或标签匹配的语义句式的地址;
一排序模块33,连接索引模块34,用于采用与替换式口语句子的相似度比较的方式对与替换式口语句子中的字匹配的语义句式和/或标签匹配的语义句式进行排序,获取经排序后的候选语义句式。
在本实施例中,索引单元3用于在给定待解析口语句子时,根据索引快速检索到与待解析口语句子相近的候选语义句式。
具体地,获取待解析口语句子后,提取待解析口语句子中关键词;通过 词表进行检测:遍历待解析口语句子中所有可能的词,查找词表中是否存在该词或字,若存在则记下该词在待解析口语句子中的位置;通过统计模型进行检测,可以选择条件随机场(Conditional Radom Fields,CRF)训练统计模型,并进行检测;将待解析口语句子中的关键词替换为相应的标签。将待解析口语句子中的标签以及未做替换的字在索引中检索。在本实施例中,将每个字或标签在词表中检索,都可得到其所出现的语义句式的地址(ID)。可记录每个语义句式与待检索句式中匹配了多少个字或标签。对检索结果根据相似度得分进行排序,取得分高的句式作为候选语义句式。
在优选的实施例中,排序模块33采用得分公式获取候选语义句式与替换式口语句子的相似度的分数;
得分公式为:
S=(S1+S2)/2,
其中,S表示候选语义句式与替换式口语句子的相似度的分数,S1表示候选语义句式中的字和/或标签占替换式口语句子的比例;S2表示候选语义句式中的字和/或标签占候选语义句式的比例。
在优选的实施例中,解析单元4根据排序后的候选语义句式采用模糊匹配算法对待解析口语句子进行解析的具体过程为:
对每个候选语义句式建立有限状态自动机网络,根据有限状态自动机网络对待解析口语句子进行打分,比较待解析口语句子的分数,将最高分数的待解析口语句子作为待解析口语句子的解析结果。
在本实施例中,解析单元4可对每个候选语义句式建立有限状态自动机网络。每个字或标签作为有限状态自动机上的一个弧。如图6所示表示一个 句式所对应的有限状态自动机网络示意图;根据有限状态机网络对待解析口语句子进行解析和打分,具体地,根据关键词检测的结果将待解析口语句子中的关键词用相应标签替换。假设待解析口语句子中有n个关键词检测结果,则存在2n个标签的可能组合。在这些可能组合中去掉标签的位置冲突的组合,即可得到候选的待检测标签替换句子;将替换式口语句子与每个句式生成的有限状态机网络进行模糊匹配,进行匹配的方法有更多,如《Error-tolerant Finite-state Recognition with Applications to Morphological Analysis and Spelling Correction》中的方法,由于该匹配方法为现有技术故此处不再赘述,该匹配方法通过动态规划算法可以快速计算两个句子之间的匹配程度;根据打分获取最优的句式及其相应的解析结果。
进一步地,解析和打分过程允许待解析口语句子和口语语义句式之间存在插入和/或删除和/或替换的操作;并且插入和/或删除和/或替换的操作的个数受预设阈值的限制,当个数小于预设阈值时,则待解析句子符合相应的语义句式,反之则不符合。
在优选的实施例中,词表采用哈希表表示。
如图2所示,一种口语语义解析方法,应用于口语语义解析系统,包括下述步骤:
S1.获取待解析口语句子;
S2.根据待解析口语句子对存储单元1中的语义句式进行检索,获取与待解析口语句子相符的候选语义句式,及相应的候选顺序;
S3.根据排序后的候选语义句式采用模糊匹配算法对待解析口语句子进行解析,获取解析结果。
在本实施例中,在口语语义解析方法中可快速检索出与待解析口语句子相关的句式,以提高匹配的效率,以使在大规模语义句式库中能够快速准确的查找到与待解析口语句子相似的句式,并输出准确的结果。
如图3所示,在优选的实施例中,步骤S2的具体过程为:
S21.提取待解析口语句子中与存储单元1中相同的关键词,并获取关键词对应的标签;
S22.将待解析口语句子中的关键词采用与关键词对应的标签替换,形成替换式口语句子;
S23.根据替换式口语句子中的字和标签,在存储单元1中的词表中进行检索,获取与字匹配的语义句式的地址,和/或标签匹配的语义句式的地址;
S24.采用与替换式口语句子的相似度比较的方式对与替换式口语句子中的字匹配的语义句式和/或标签匹配的语义句式进行排序,获取经排序后的候选语义句式。
在本实施例中,口语语义解析方法可包括离线阶段和在线阶段两部分,其中离线阶段包括:根据定义的领域需求,收集和整理相应领域的语义句式。其中的语义句式,包括:符合口语规范,并且该语义句式需要解析的关键词用标签表示。例如打电话领域的一条可能的句子为“打电话给张三”,由于“张三”是要解析的名称关键词,将需要解析的关键词用标签替代,如:“张三”替换为“$name”,那么通过该查询句子改写后的句式为“打电话给$name”。对每个领域的语义句式建立索引:对语义句式中的字和标签共同建立索引,其中标签作为一个字进行索引。本实施例采用哈希倒排索引,其示意图如图5所示。哈希表中存放的是所有语义句式中出现过的字和标签,每个字或标 签后跟一个列表,列表中的每个元素存放该字或标签所在句式的地址(ID号)。
在线阶段包括:在给定待解析口语句子时,根据索引快速检索到与待解析句子相近的候选语义句式。其具体步骤如下:
获取待解析口语句子后,提取待解析口语句子中关键词;通过词表进行检测:对词表中的每个词建立哈希索引,给定待解析口语句子,遍历待解析口语句子中所有可能的词,查找哈希表中是否存在该词,若存在则记下该词在待解析句子中的位置;通过统计模型进行检测,可以选择条件随机场训练统计模型,进行检测;将待解析口语句子中的关键词替换为相应的标签。该替换与离线阶段的替换一致;将待解析口语句子中的标签以及未做替换的字在索引中检索。在本实施例中,将每个字或标签在哈希倒排索引中检索,都可得到其所出现的语义句式的地址(ID)。记录每个语义句式与待检索句式中匹配了多少个字或标签。将检索结果根据相似度的得分进行排序,取得分高的句式作为候选语义句式。
在优选的实施例中,步骤S24采用得分公式获取候选语义句式与替换式口语句子的相似度的分数;
得分公式为:
S=(S1+S2)/2,
其中,S表示候选语义句式与替换式口语句子的相似度的分数,S1表示候选语义句式中的字和/或标签占替换式口语句子的比例;S2表示候选语义句式中的字和/或标签占候选语义句式的比例。
如图4所示,在优选的实施例中,步骤S3的具体过程为:
S31.对每个候选语义句式建立有限状态自动机网络;
S32.根据有限状态自动机网络对待解析口语句子进行打分;
S33.比较待解析口语句子的分数,将最高分数的待解析口语句子作为待解析口语句子的解析结果。
在本实施例中,可对每个候选语义句式建立有限状态自动机网络。每个字或标签作为有限状态自动机上的一个弧。如图6所示表示一个句式所对应的有限状态自动机网络示意图;根据有限状态机网络对待解析口语句子进行解析和打分,具体地,根据关键词检测的结果将待解析口语句子中的关键词用相应标签替换。假设待解析口语句子中有n个关键词检测结果,则存在2n个标签的可能组合。在这些可能组合中去掉标签的位置冲突的组合,即可得到候选的待检测标签替换句子;将替换式口语句子与每个句式生成的有限状态机网络进行模糊匹配,进行匹配的方法有更多,如《Error-tolerant Finite-state Recognition with Applications to Morphological Analysis and Spelling Correction》中的方法,由于该匹配方法为现有技术故此处不再赘述,该匹配方法通过动态规划算法可以快速计算两个句子之间的匹配程度;根据打分获取最优的句式及其相应的解析结果。
进一步地,解析和打分过程允许待解析口语句子和口语语义句式之间存在插入和/或删除和/或替换的操作;并且插入和/或删除和/或替换的操作的个数受预设阈值的限制,当个数小于预设阈值时,则待解析句子符合相应的语义句式,反之则不符合。
以上所述仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书及图示内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。