确定地理范围内兴趣区域、兴趣点的方法和装置与流程
本发明涉及电子地图的数据处理领域,具体涉及确定地理范围内兴趣区域、兴趣点的方法和装置。
背景技术:
电子地图数据中通常会标出地理范围,用户可以根据电子地图识别出诸如省、市、区县等地理范围,但是现有的地理范围较大,地理范围内通常还包括多个更具体的区域,例如对于北京市西城区而言,西城区的范围可以根据地图数据进行识别,但西城区中还包括诸如西单地区等更具体的区域,用户无法确定此类区域的范围。
目前兴趣区域划分方法是以地图数据中的某一个对象(例如一条道路、一个信息点)为基础,向该对象周边扩散一定的距离作为兴趣区域,或者按照预设范围(例如预设网格)将地图划分为多个区域,每一个预设区域均可以是兴趣区域,上述两种方式适合应用于信息点较少的地区或者偏远地区,对于城市等信息点较多、排布情况复杂的地区,现有的兴趣区域划分方法准确性较差。
并且,上述信息点筛选方法缺乏区域性分析,通常是在地理范围内,直接根据信息点的热度进行筛选,这会使得在非热门区域的信息点缺失, 筛选效率较低。
技术实现要素:
鉴于此,本发明提供一种确定地理范围内兴趣区域的方法,该方法包括:获取地理范围内的信息点;从上述信息点中选取包含同一关键词且数量大于第一预设阈值的多个信息点;对所述多个信息点间的距离计算,确定出一个位于中心位置的信息点,记为a,并通过所述距离计算的结果确定与该信息点a间的距离值最大的信息点b;对信息点a和信息点b间的距离值进行分段,筛选出每个段内数量大于第二预设阈值的信息点c;计算上述筛选出的各信息点c周围包含所述同一关键词的信息点的数量,并保留数量大于等于第三预设阈值的信息点c;根据上述保留的数量大于等于第三预设阈值的信息点c确定兴趣区域。
相应地,本发明提供一种确定地理范围内兴趣区域的装置,包括:获取单元,用于获取地理范围内的信息点;选取单元,用于从上述信息点中选取包含同一关键词且数量大于第一预设阈值的多个信息点;信息点确定单元,用于对所述多个信息点间的距离计算,确定出一个位于中心位置的信息点,记为a,并通过所述距离计算的结果确定与该信息点a间的距离值最大的信息点b;第一筛选单元,用于对信息点a和信息点b间的距离值进行分段,筛选出每个段内数量大于第二预设阈值的信息点c;第二筛选单元,用于计算上述筛选出的各信息点c周围包含所述同一关键词的信息点的数量,并保留数量大于等于第三预设阈值的信息点c;区域确定单元,用于根据上述保留的数量大于等于第三预设阈值的信息点c确定兴趣区域。
另外,本发明提供一种兴趣点筛选方法,该方法包括:利用上述确定地理范围内兴趣区域的方法确定出兴趣区域;在所述兴趣区域内根据信息点所包含的信息筛选出至少一个信息点,该筛选出的至少一个信息点为兴趣点。
相应地,本发明还提供一种兴趣点筛选装置,包括:兴趣区域确定单元,用于利用上述确定地理范围内兴趣区域的方法确定出兴趣区域;筛选单元,用于在所述兴趣区域内根据信息点所包含的信息筛选出至少一个信息点,该筛选出的至少一个信息点为兴趣点。
本发明实施例提供的确定地理范围内兴趣区域、兴趣点的方法和装置可以将地图数据划分为多个感兴趣区域,然后在兴趣区域中筛选出特征相对明显、知名度相对较高的信息点,该信息点可以作为兴趣区域内的地标性建筑,筛选出的信息点可以应用于多种场景,例如可以在某些服务类应用程序中作为标准信息点,或者在地图数据中进行突出显示,使用户可以更方便的查找信息点。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是根据本发明实施例提供的确定地理范围内兴趣区域的方法的流程图;
图2是选取的多个信息点的排布情况示意图;
图3是对图2所示信息点进行处理的示意图;
图4是对图3所示处理结果进行进一步处理的示意图;
图5是对图4所示信息点进行处理后确定的兴趣区域示意图;
图6是根据本发明实施例提供的兴趣点筛选方法的流程图;
图7是根据本发明实施例提供的确定地理范围内兴趣区域的装置的结构图;
图8是根据本发明实施例提供的兴趣点筛选装置的结构图。
具体实施方式
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为了描述上的简洁和直观,下文通过描述若干代表性的实施例来对本发明的方案进行阐述。实施例中大量的细节仅用于帮助理解本发明的方案。但是很明显,本发明的技术方案实现时可以不局限于这些细节。为了避免不必要地模糊了本发明的方案,一些实施方式没有进行细致地描述,而是仅给出了框架。下文中,“包括”是指“包括但不限于”,“根据……”是指“至少根据……,但不限于仅根据……”。下文中没有特别指出一个成分的数量时,意味着该成分可以是一个也可以是多个,或可理解为至少 一个。
本发明实施例中的确定地理范围内兴趣区域的方法、信息点筛选方法和装置可以由一个能够实现本发明实施例的各种方法和软件系统的计算设备实现。该计算设备可以是能够实现本发明实施例提供的方法和软件系统的计算设备。该计算设备可以是个人电脑或便携设备,例如笔记本电脑、平板电脑、手机或智能手机等。该计算设备还可以是与上述设备通过网络相连的服务器。
所述计算设备可以具有不同的性能和特征。各种可能的实现方式都在本文的保护范围内。例如,计算设备可以包括按键区/键盘,还可以包括一个显示器,如液晶显示器(LCRD),或者具有高级功能的显示器,例如触摸感应2RD或3RD显示器。一个例子中,一个具有web功能的计算设备可以包括一个或多个物理键盘或虚拟键盘,以及大容量存储装置。
计算设备也可以包括或允许各种操作系统、包括或运行各种应用程序,例如编码/解码应用。应用程序能够通过网络与其它设备进行加密通信。
此外,计算设备还可以包括一个或多个处理器可读的非易失性存储介质和一个或多个与存储介质通信的处理器。例如,处理器可读的非易失性存储介质可以是RAM、闪存、ROM、EPROM、EEPROM、寄存器、硬盘、移动硬盘、CRD-ROM,或其它各种形式的非易失性存储介质。存储介质可以存储一系列指令或包含指令的单元和/或模块,用于完成本发明各种实施例的操作。处理器可以执行上述指令,完成各种实施例中的操作。
本发明实施例提供一种确定地理范围内兴趣区域的方法,如图1所示,该方法包括如下步骤:
S1,获取地理范围内的信息点。地理范围可以是行政区划,例如北京市朝阳区、海淀区,也可以是州、镇等已知边界的区域。信息点数据为现有的且对外开放的数据,每一条信息点数据至少包括名称、类别、经度纬度、附近的其他信息点等信息(引用信息),某些信息点还具有富信息,例如对于酒店信息点,其中包括酒店的等级信息(例如0-5星级),又如对于住宅区信息点,其包括住户数量、房产价格等信息。
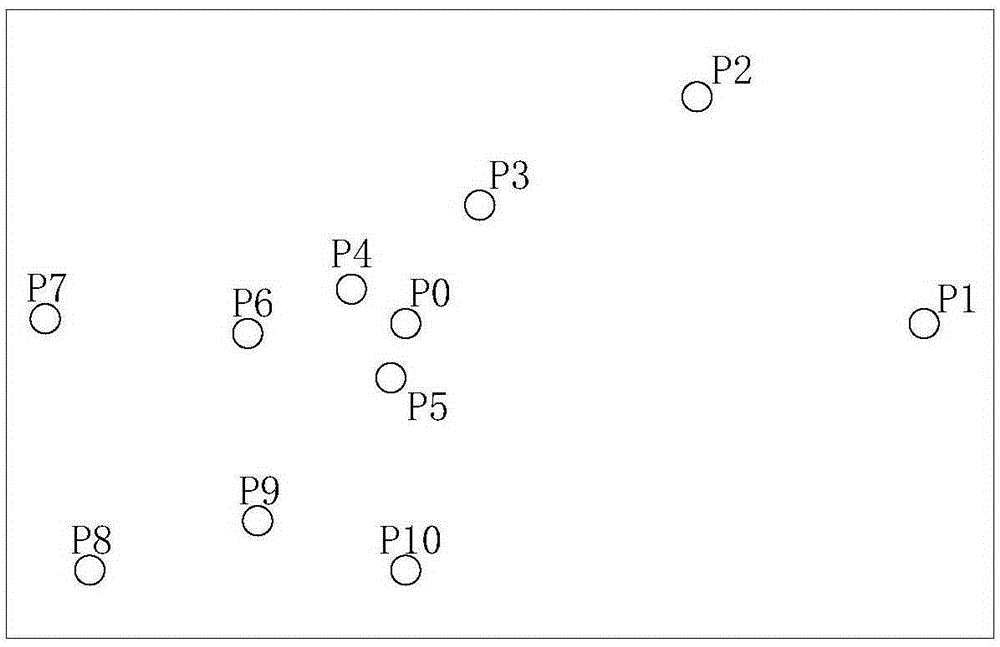
S2,从上述信息点中选取包含同一关键词且数量大于第一预设阈值的多个信息点。具体可以利用词汇识别技术,分别从信息点的名称、地址中识别出关键词,然后确定哪些信息点包含同一关键词。关键词可以是不存在具体边界的地域的名称,例如北京市西城区内的“西单”、东城区内的“东单”等。针对某一个地理范围通常会筛选出多组信息点,每一组信息点均包括同一关键词,但是某些组内的信息点数量可能较少,此情况表示该组信息点包括的关键词的认知度不够高,因此应当选取数量较多的信息点进行后续处理。以地理范围-北京市“西城区”为例,假设包含关键词“西单”的信息点数量大于预设阈值,根据包含关键词“西单”的信息点的在地图中的排布情况可知某些信息点相对集中,某些信息点可能相对分散。假设经过步骤S2的处理后,选取了如图2所示的多个信息点,直观地根据图2中的信息点排布情况可以发现,信息点P1和信息点P2是比较分散的信息点。
排布分散的信息点将会影响最终的区域划分结果,因此需要从上述多个信息点中找出并去除位置分散的信息点。本领域技术人员可以理解,确定多个点相互之间是否集中或分散的方法有多种,例如可以根据每两个点 之间的距离,去除掉距离值较大的点。下面结合图3和图4详细介绍去除分散信息点的过程。
S3,对所述多个信息点间的距离计算,确定出一个位于中心位置的信息点,记为a,并通过所述距离计算的结果确定与该信息点a间的距离值最大的信息点b,信息点a即为所有信息点的中位点。本领域技术人员可以理解,在位置固定的多个点中寻找中位点的方法有多种,通过计算各点之间的距离值即可找出中位点。对于图3所示情况而言,信息点P0即位于中心位置的信息点,将其记为a;信息点P1距离信息点P0最远,因此信息点P1与该信息点a间的距离值最大的信息点,将其记为b。,
S4,对信息点a和信息点b间的距离值进行分段,筛选出每个段内数量大于第二预设阈值的信息点c。如图3所示,本实施例将信息点a和信息点b的距离值Rmax分为5段,分段后即确定了5个距离值区间,然后则计算每个区间内的信息点数量并进行判断,如果数量大于第二预设值则保留,否则去除。假设第二预设阈值为2,则可以判断出信息点b所在的区间中只有其1个信息点,其他区间中的信息点数量均大于或等于2,由此确定信息点b被去除,即去除图3中的P1,其他信息点P0、P2、P3、P4、P5、P6、P7、P8、P9、P10暂时保留,将保留的信息点记为c。
S5,计算上述筛选出的各信息点c周围包含所述同一关键词的信息点的数量,如果数量较少,则表示该信息点周围同样包含该关键词的信息点较少,该信息点排布比较分散,反之则表示该信息点排布集中,由此,可以并保留数量大于等于第三预设阈值的信息点c。上述“周围”是一个范围值,例如可以是半径,实际使用时可以设定一个范围值,然后在该范围内 判断包含上述关键词的数量。如图4所示,假设范围值取N*Rd、第三预设阈值取值为1,则只有信息点P2周围的信息点数量为0,所以进一步去除信息点P2,保留其他符合条件的信息点P0、P3、P4、P5、P6、P7、P8、P9、P10。
S6,根据上述保留的数量大于等于第三预设阈值的信息点c确定兴趣区域。通过上述步骤S2-S5,信息点P1和信息点P2已被去除,然后例如可以根据凸包算法利用保留的信息点P0、P3、P4、P5、P6、P7、P8、P9、P10构造最小外接凸边行区域,图5示出了根据本方法确定的兴趣区域,该兴趣区域中有排布密集的多个信息点。
根据本发明实施例提供的确定地理范围内兴趣区域的方法,通过获取地理范围内所有信息点并筛选出包含同一关键词的多个信息点,可以确定出含有相同关键词的多个信息点,然后对数量是否大于预设阈值的信息点进行处理,去除其中位置分散的信息点,最终根据保留的多个信息点确定兴趣区域,可以在地理范围中进一步确定出更具体的兴趣区域,兴趣区域内均为包括同一关键词的信息点,由此可以提高地兴趣区域范围的准确性。
作为一种优选实施方式,上述步骤S3可以包括如下子步骤:
S31,分别计算每个信息点与除自身之外的所有信息点的距离之和(优选为直线距离,但也可以是地图中的路线距离,下文均以直线距离为例),并确定距离之和最小的信息点a。
S32,分别计算除信息点a外的信息点与信息点a的距离,并确定具有最大距离值的信息点b;如图3所示,最大距离为Rmax(信息点P0与信息点P1之间的距离)。
上述优选方案通过计算每个信息点与除自身之外的所有信息点的距离之和,可以更准确地在多个信息点中找到中位点,并找到距离中位点最远的信息点。
作为一种优选实施方式,上述步骤S4可以包括如下子步骤:
S41,对最大距离Rmax进行分段,优选采用等分的方法,确定分段数量N,将Rmax分为N段,Ri=i/N Rmax,本领域技术人员可以理解,采用其他的分段方法,例如黄金分割都是可行的。
S42,分别计算每一段内的信息点的数量,即计算距离在[0,R1]之间的信息点的数量x1、[R1,R2]之间的信息点的数量x2、[R2,R3]之间的信息点的数量x3,直至计算出[Rn,Rmax]之间的信息点的数量xn,上述各个区间可以表示为[Rmax/N*(n-1),Rmax/N*(n)],其中n为正整数,取值范围是[1,n]且n≤N,N为大于1的正整数,例如上述N取值为5,即可得到[0,Rmax/5]的信息点的数量X1、[Rmax/5,Rmax/5*2]的信息点的数量X2、[Rmax/5*2,Rmax/5*3]的信息点的数量X2、[Rmax/5*3,Rmax/5*4]的信息点的数量X3、[Rmax/5*4,Rmax]的信息点的数量X4;
S43,筛选出数量大于第二预设阈值的段内的信息点。例如分别判断X1-X4是否大于预设阈值,假设第二预设阈值取值为2,则根据判定结果可以确定信息点P1被去除,其他信息点均被保留,即保留距离为[0,Rmax/5*4]之间的信息点,去除距离为[Rmax/5*4,Rmax]的信息点。
上述优选方案对最大距离值进行分段,并依次判断每一分段内的信息点的数量,而保留数量大于预设阈值的信息点,由此可以去除掉分布相对分散的信息点。
作为一种优选实施方式,上述步骤S5可以包括如下子步骤:
S51,计算筛选出的信息点之间的平均距离Rd;
S52,分别计算筛选出的信息点周围N*Rd范围内包含所述同一关键词的信息点的数量,如果个数较少,则表示该信息点周围同样包含该关键词的信息点较少,该信息点排布比较分散,反之则表示该信息点排布集中;
S53,去除周围N*Rd范围内包含所述同一关键词的信息点的数量小于第三预设阈值的信息点,如图4所示,例如预设阈值取值为1,则只有信息点P2周围N*Rd范围内的信息点数量为0,所以去除信息点P2,保留其他符合条件的信息点。
上述优选方案首先计算出信息点之间的平均距离Rd,然后以平均距离Rd和系数N为依据来判断各个信息点N*Rd范围内是否存在足够多的信息点,由此可以进一步去除掉排布分散的信息点,使最终保留下的信息点排布密度足够高。
本发明另一实施例提供了一种兴趣点筛选方法,如图6所示该方法包括如下步骤:
S’1,采用前一实施例中的确定地理范围内兴趣区域的方法确定兴趣区域,兴趣区域中通常存在较多的信息点;
S’2,在所述兴趣区域内根据信息点所包含的信息筛选出至少一个信息点,该筛选出的至少一个信息点为兴趣点(Point of Interest,POI),该兴趣点相比兴趣区域中的其他信息点,具有更高的知名度或更明显的特征。本领域技术人员可以理解,筛选信息点的方法有多种,例如可以根据 信息点的热度(在各种应用系统中被用户查询、选择、提交的次数)进行排序,选择热度较高的信息点。
根据本发明实施例提供的兴趣点筛选方法,可以将地图数据划分为多个感兴趣区域,然后在兴趣区域中筛选出特征相对明显、知名度相对较高的信息点,筛选出的信息点可以作为兴趣区域内的地标性建筑,或称为兴趣点,筛选出的信息点可以应用于多种场景,例如可以在某些服务类应用程序中作为标准信息点,或者在地图数据中进行突出显示,使用户可以更方便的查找信息点。
作为一个优选的实施方式,本实施例中的步骤S’2具体可以包括:
S’21,确定所述兴趣区域内的所有信息点的特征值,本领域技术人员可以理解,确定信息点的特征值的方法有多种,例如可以根据信息点的受重视度等因素来确定,现有的特征值计算方法都是可行的;
S’22,利用支持向量机分类模型,以所述信息点的特征值为输入值对信息点进行筛选。支持向量机(SVM,Support Vector Machine)是与相关的学习算法有关的监督学习模型,可以分析数据,识别模式,用于分类和回归分析。支持向量机模型可以通过给定的样本数据进行训练得到,本发明中的样本数据可归为两类,一类为符合条件的目标样本,另一类是不符合条件的非目标样本。利用经过训练得到的支持向量机模型即可以判断出给定的信息点是否为目标信息点。
本实施例优选使用多个特征值对信息点进行筛选,即信息点的特征值包括第一特征值、第二特征值和第三特征值,其中第一特征值的计算方法包括:
根据信息点的地址信息计算信息点被引用的类型和次数,为每一种类型赋予权重,然后根据引用类型权重和引用次数计算信息点的第一特征值。优选地,上述引用类型至少包括三类:
第一类是被地理位置不相同的另一信息点所引用。例如有两个信息点:信息点1-海淀桥、信息点2-中国技术交易大厦,信息点2的地址信息包括“海淀桥东中国技术交易大厦”,则信息点1-海淀桥被信息点2-中国技术交易大厦引用一次,该引用可以称为外部引用;
第二类是被公交类信息点所引用。例如信息点1-海淀桥,信息点2-海淀桥东公交站,则信息点1-海淀桥被信息点2-海淀桥东公交站引用一次,该引用可以称为公交引用;
第三类是被地理位置相同的另一信息点所引用。例如有两个信息点:信息点1-中国技术交易大厦、信息点2-贝塔咖啡厅,信息点2的地址信息包括“中国技术交易大厦B1层贝塔咖啡”,信息点1-中国技术交易大厦被信息点2-贝塔咖啡厅引用一次,该引用可以称为内部引用。
各个信息点被引用的类型和次数可能均不相同,并且某些信息点可能同时属于多类引用,因此可以使用下列公式来计算第一特征值:
Y1=信息点AX1+BX2+CX3,
其中Y1为第一特征值,信息点A、B、C为三种引用类型的权重,X1、X2、X3为相应引用类型的引用次数,信息点A、B、C可以取任意值,该权重用于体现引用类型的重要性,例如可以是信息点A>B>C、或者信息点A=B=C。本领域技术人员可以理解,上述公式只是为了说明第一特征值的物理含义而举出的一个具体实施方式,实际应用时,还可以通过更简单或更 复杂的算法利用引用类型权重和次数这两个信息计算出信息点的第一特征值。
上述第二特征值的计算方法包括:
根据信息点所包含的数值信息以及最大预设数值和最小预设数值计算信息点的第二特征值,本领域技术人员可以理解,信息点中,除名称信息、地址信息、引用信息以外,还具有富信息,各类信息点的富信息均不相同,如酒店类、医院类、景区类、政府机关等都有相应的等级信息,住宅类有居住户数、价格等信息,餐饮类有点评数量或点评分值等信息,上述富信息均为数值信息,实际应用时可以抽取信息点中的数值信息,然后根据信息点的类型,确定该类信息点的数值信息的最大值和最小值。例如对于酒店类信息点而言,其最大值可以取5,最小值可以取0,然后可以根据该酒店信息点的实际等级信息与最大值、最小值的比例来确定第二特征值。对于其他类型的信息点也可按照此方式进行计算。本领域技术人员可以理解,上述第二特征值的计算方式只是为了说明第二特征值的物理含义而举出的一个具体实施方式,实际应用时还可以使用更简单或更复杂的方式进行计算。
上述第三特征值的计算方法包括:
根据用户使用不同应用程序对信息点的选定操作,确定用户所使用的应用程序及相应的选定次数,为每一种应用程序赋予权值,然后根据权值和选定次数计算信息点的第三特征值。例如对于某一个信息点,用户使用应用程序1选定该信息点X1次,用户使用应用程序2选定该信息点X2次……用户使用应用程序n选定该信息点Xn次,由此,第三特征值可以按 照下式进行计算:
Y3=信息点AX1+BX2+……+NXn,
其中Y3为第三特征值,信息点A、B……N为n种应用程序的权重,上述权重可以任意取值,并可以为特定的应用程序赋予较高的权重等。本领域技术人员可以理解,上述公式只是为了说明第三特征值的物理含义而举出的一个具体实施方式,实际应用时,还可以通过更简单或更复杂的算法利用应用程序类型权重和次数这两个信息计算出信息点的第三特征值。
上述优选方案以信息点被引用的情况、用户提交情况和信息点的富信息为依据,并利用机器学习模型对信息点进行筛选,由此可以使筛选方式更有针对性,并提高筛选效率。
本领域技术人员可以理解,支持向量机分类模型是利用大量的样本数据不断训练而得到的。为了提高支持向量机分类模型的分类性能,作为所述支持向量机分类模型的目标信息点训练样本的特征值(第一特征值、第二特征值和第三特征值)均大于预设特征阈值,该预设特征阈值包括该兴趣区域内的所有信息点的平均特征阈值和/或该兴趣区域内的同一类别信息点的平均特征阈值。
由于一个兴趣区域内可能包括很多知名度较高的信息点,例如西单区域内有很多商场类信息点,很多商场在使用上述模型筛选时都可能被判定为目标信息点,但是这不符合用户对知名度的直观感受。在某个区域,用户对某一个类别的信息点通常只能记住前几名,所以局部区域内某个类别的目标信息点过多是不合理的,为了进一步对目标信息点进行筛选,本方法还可以包括如下步骤:
S’3,选取类型相同的多个信息点;
S’4,根据上述特征值对类型相同的多个信息点进行从高到低的排序,然后保留前N个同一类型的目标信息点,由此可以使筛选出的信息点的识别度更高,提高用户的体验。
本发明的另一个实施例还提供一种确定地理范围内兴趣区域的装置,如图7所示,该装置包括:
获取单元71,用于获取地理范围内的信息点;
选取单元72,用于从上述信息点中选取包含同一关键词且数量大于第一预设阈值的多个信息点;
信息点确定单元73,用于对所述多个信息点间的距离计算,确定出一个位于中心位置的信息点,记为a,并通过所述距离计算的结果确定与该信息点a间的距离值最大的信息点b;
第一筛选单元74,用于对信息点a和信息点b间的距离值进行分段,筛选出每个段内数量大于第二预设阈值的信息点c;
第二筛选单元75,用于计算上述筛选出的各信息点c周围包含所述同一关键词的信息点的数量,并保留数量大于等于第三预设阈值的信息点c;
区域确定单元76,用于根据上述保留的数量大于等于第三预设阈值的信息点c确定兴趣区域。
上述装置通过获取地理范围内所有信息点并筛选出包含同一关键词的多个信息点,可以确定出含有相同关键词的多个信息点,然后对数量是否大于预设阈值的信息点进行处理,去除其中位置分散的信息点,最终根据 保留的多个信息点确定兴趣区域,可以在地理范围中进一步确定出更具体的兴趣区域,兴趣区域内均为包括同一关键词的信息点,由此可以提高地兴趣区域范围的准确性。
优选地,所述信息点确定单元73包括:
中位点确定单元,用于分别计算每个信息点与除自身之外的所有信息点间的距离之和,并确定距离之和最小的信息点a;
最远点确定单元,用于分别计算除信息点a外的信息点与该信息点a间的距离,并确定具有最大距离值的信息点b。
上述优选方案通过计算每个信息点与除自身之外的所有信息点的距离之和,可以更准确地在多个信息点中找到中位点,并找到距离中位点最远的信息点。
优选地,所述第一筛选单元74包括:
分段单元,用于对所述最大距离值进行分段;
第一数量计算单元,用于分别计算每一段内的信息点的数量;
子筛选单元,用于筛选出数量大于第二预设阈值的段内的信息点,记为信息点c。
优选地,所述分段单元包括:
分段数量确定单元,用于确定分段数量;
等分单元,用于根据所述分段数量对所述最大距离值进行等分。
上述优选方案对最大距离值进行分段,并依次判断每一分段内的信息点的数量,而保留数量大于预设阈值的信息点,由此可以去除掉分布相对分散的信息点。
优选地,所述第二筛选单元75包括:
平均距离计算单元,用于计算筛选出的信息点c之间的平均距离Rd;
第二数量计算单元,用于分别计算筛选出的各信息点周围N*Rd范围内包含所述同一关键词的信息点的数量;
去除单元,用于去除周围N*Rd范围内包含所述同一关键词的信息点的数量小于第三预设阈值的信息点c。
上述优选方案首先计算出信息点之间的平均距离Rd,然后以平均距离Rd和系数N为依据来判断各个信息点N*Rd范围内是否存在足够多的信息点,由此可以进一步去除掉排布分散的信息点,使最终保留下的信息点排布密度足够高。
本发明的另一个实施例还提供一种兴趣点筛选装置,如图8所示,该装置包括:
兴趣区域确定单元81,用于利用上述第一个实施例提供的确定地理范围内兴趣区域的方法确定出兴趣区域;
筛选单元82,用于在所述兴趣区域内根据信息点所包含的信息筛选出至少一个信息点,该筛选出的至少一个信息点为兴趣点。
上述兴趣点筛选装置可以将地图数据划分为多个感兴趣区域,然后在兴趣区域中筛选出特征相对明显、知名度相对较高的信息点,该信息点可以作为兴趣区域内的地标性建筑,筛选出的信息点可以应用于多种场景,例如可以在某些服务类应用程序中作为标准信息点,或者在地图数据中进行突出显示,使用户可以更方便的查找信息点。
优选地,上述筛选单元82可以包括:
特征值确定子单元,用于确定所述兴趣区域内的所有信息点的特征值;
分类子单元,用于利用支持向量机分类模型,以所述信息点的特征值为输入值对信息点进行筛选。
优选地,所述特征值包括第一特征、第二特征和第三特征值,其中
所述第一特征值是根据信息点被引用的类型对应的引用权值和引用次数计算得到的;
所述特征值还包括第二特征值,所述第二特征值是根据信息点所包含的数值信息以及最大预设数值和最小预设数值计算得到的;
所述第三特征值是根据用户提交所述信息点所使用的应用程序对应的应用权值和提交次数进行计算得到的。
优选地,所述被引用的类型包括被地理位置不相同的另一信息点所引用、被公交类信息点所引用、被地理位置相同的另一信息点所引用。
上述优选方案以信息点被引用的情况、信息点的富信息、用户在不同场景中选定信息点的情况为依据,并利用机器学习模型对信息点进行筛选,由此可以使筛选方式更有针对性,并提高筛选效率。
优选地,支持向量机分类模型的符合筛选条件的训练样本的信息点的特征值均大于预设特征阈值,预设特征阈值包括兴趣区域内的所有待筛选信息点的平均特征阈值和/或兴趣区域内的同一类别的待筛选信息点的平均特征阈值。上述训练样本可以提高支持向量机分类模型的分类性能。
优选地,上述信息点筛选装置还可以包括:
选取单元83,用于选取类型相同的多个信息点;
去除单元84,用于根据特征值对类型相同的多个信息点进行从高到低 的排序,然后保留排序靠前的至少一个信息点。上述优选方案可以使筛选出的信息点的识别度更高,提高用户的体验。
显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引伸出的显而易见的变化或变动仍处于本发明创造的保护范围之中。
- 还没有人留言评论。精彩留言会获得点赞!