指示事务状态的一致性协议增强的制作方法
本发明总体上涉及请求及响应协议,且更具体言之,涉及指示事务状态的一致性协议增强。
芯片上的中央处理单元(CPU)核心的数目及连接至共享存储器的CPU核心的数目持续显著地增长以支持不断增长的工作负载容量需求。合作以处理相同工作负载的CPU的增加数目对软件伸缩性施予显著负担;举例而言,受到传统旗号(semaphore)保护的共享队列或数据结构变为热点且导致次线性n路定标曲线。传统上,此情形已通过在软件中实施较细粒度锁定且借助硬件中的较低延时/较高带宽互连来应对。实施细粒度锁定以改进软件伸缩性可以是非常复杂且易出错的,且在现今的CPU频率下,硬件互连的延时受到芯片及系统的物理尺寸限制且受到光速限制。
已引入硬件事务存储器(HTM,或在此论述中简单地为TM),其中指令组(被称为事务)在存储器中的数据结构上以原子方式操作,如由其他中央处理单元(CPU)及I/O子系统所看到的(原子操作在其他文献中亦被称为块并行或串行化)。事务在不获得锁的情况下乐观地执行,但在执行事务对存储器位置的操作与对同一存储器位置的另一操作相冲突的情况下可能需要中止及重试事务执行。先前,已提议软件事务存储器实施方式以支持软件事务存储器(TM)。
技术实现要素:
各实施例包括一种用于实施一致性协议的方法、系统及计算机程序产品。将针对数据的请求发送至远程处理器。处理器自所述远程处理器接收响应,且所述响应具有所述远程处理器上的远程事务的事务状态。所述处理器将所述远程处理器上的所述远程事务的所述事务状态添加至本地事务干扰追踪表中。
附图说明
当本说明书完结时在权利要求中特定地指出且清楚地要求保护被视为实施例的主题。实施例的前述及其他特征及优点自结合附图而进行的以下详细描述显而易见,在附图中:
图1描绘根据一个实施例的实例多处理器(CPU)/核心事务存储器环境的示意性方块图;
图2描绘说明根据一个实施例的事务处理器的示意性方块图;
图3描绘根据一个实施例的图1及图2所示的事务处理器(CPU)的例示性组件的示意性方块图;
图4描绘用于允许根据一个实施例的硬件事务存储器环境中的请求及响应的具有作为图1至图3所示的多处理器系统的组件的计算机系统的示意性方块图;
图5描绘根据一个实施例的例示性协议请求及响应;
图6描绘根据一个实施例的例示性协议请求;
图7描绘根据一个实施例的由做出针对数据的请求的处理器进行的协议请求产生的流程图;
图8描绘根据一个实施例的由接收请求且发送响应的接收/远程处理器进行的请求处置的流程图;
图9描绘说明根据一个实施例的由处理器进行的事务处置的流程图;
图10描绘根据一个实施例的协议请求及新协议响应;
图11描绘根据一个实施例的协议写入请求及新响应;
图12描绘说明根据一个实施例的由接收请求的接收/远程处理器进行的一致性请求处置的流程图;
图13描绘说明根据一个实施例的由请求处理器进行的协议请求发起及处理的流程图;
图14描绘说明根据一个实施例的由处理器进行的事务处置的流程图;
图15描绘说明根据一个实施例的处理器如何对本地追踪事务干扰存储表中的干扰指示作出响应的流程图;
图16描绘说明根据一个实施例的处理器如何对本地追踪事务干扰存储表中的干扰指示作出响应的流程图;
图17描绘根据一个实施例的用于一致性协议处置的方法;及
图18描绘根据一个实施例的计算机可读介质。
具体实施方式
多处理器系统使用一致性协议以维护分布式共享存储器的系统中的全部高速缓存之间的一致性。当进行来自某一高速缓存的针对数据的请求时,该高速缓存发出所述数据且更新其不再具有所述数据或所述数据不被独占式地保留的状态。如果处理器在事务执行中,且向其高速缓存请求为事务的一部分的数据,则处理器将中止事务,且发送数据。
不提供请求是否已造成另一事务中止的信息。在一些情况下,将需要向原始请求者通知请求是否影响另一事务、提供反馈且允许请求者的发起者改变其执行,例如,检测活锁(livelock)情景且处理其他性能降级情景。
根据实施例,一致性协议被扩展以包括关于事务状态的额外信息。当处理器在事务执行中时,一致性请求能造成其执行中止,例如,这是因为数据为事务读取或写入集合的一部分,且检测到冲突。根据各实施例,一致性协议请求借助其(接收一致性请求的处理器)在事务执行期间中止事务的额外信息而扩展。
“2013年5月22日公开的来自且全文以引用方式并入本文中的Power ISATM版本2.07教导了实例精简指令集计算机(RISC)指令集架构(ISA)”。又,来自且全文以引用方式并入本文中的“z/Architecture Principles of Operation”SA22-7832-09(2012年8月)教导了实例复杂指令集计算机(CISC)指令集架构。
历史上,计算机系统或处理器具有仅单处理器(亦称为处理单元或中央处理单元)。处理器包括指令处理单元(IPU)、分支单元、存储器控制单元及其类似者。此类处理器能够每次执行程序的单个线程。开发出可通过分派待在处理器上执行一时段的程序且接着分派待在所述处理器上执行另一时段的另一程序而在时间上共享所述处理器的操作系统。随着技术演进,常常将存储器子系统高速缓存添加至处理器以及包括转换后备缓冲器(TLB)的复杂动态地址转换。IPU自身常常被称作处理器。随着技术继续演进,可将整个处理器封装于单个半导体芯片或管芯中,此类处理器被称作微处理器。接着开发出合并有多个IPU的处理器,此类处理器常常被称作多处理器。多处理器计算机系统(处理器)的每个此类处理器可包括个体或共享高速缓存、存储器接口、系统总线、地址转换机构及其类似者。虚拟机及指令集架构(ISA)仿真器将软件层添加至处理器,其通过单个硬件处理器中的单个IPU的时间分片使用而向虚拟机提供多个“虚拟处理器”亦称为处理器)。随着技术进一步演进,开发出多线程处理器,从而使具有单个多线程IPU的单个硬件处理器能够提供同时地执行不同程序的线程的能力,因此,多线程处理器的每一线程对于操作系统表现为一个处理器。随着技术进一步演进,有可能将多个处理器(每一者具有一个IPU)放置于单个半导体芯片或管芯上。这些处理器被称为处理器核心或仅称为核心。因此,诸如处理器、中央处理单元、处理单元、微处理器、核心、处理器核心、处理器线程、线程的术语常常可被互换地使用。在不脱离本文中的教导的情况下,可由包括上文所示的处理器的任何或全部处理器实施本文中的实施例的各方面。其中,本文中使用术语“线程”或“处理器线程”,预期可在处理器线程实施方式中具有实施例的特定优点。
在基于的实施例中的事务执行
在2012年2月的全文以引用方式并入本文中的“Architecture Instruction Set Extensions Programming Reference”319433-012A中,第8章部分地教导多线程应用可利用增加数目的CPU核心以获得较高性能。然而,多线程应用的写入需要编程人员理解及考虑在多个线程之间共享的数据。对共享数据的存取通常需要同步机制。这些同步机制用于确保多个线程通过应用于共享数据的串行化操作而常常经由使用受锁保护的关键区段来更新共享数据。因为串行化限制并行性,所以编程人员试图限制归因于同步的开销。
事务同步扩展(TSX)允许处理器动态地判定线程是否需要经由受锁保护的关键区段而串行化,且仅当时需要才执行该串行化。这允许处理器曝露及利用由于不必要的动态同步而隐藏于应用中的并行性。
在使用Intel TSX的情况下,事务性地执行编程人员指定的代码区域(亦被称作“事务区域”或仅仅被称作“事务”)。如果事务执行成功地完成,则在事务区域内执行的全部存储器操作将看起来在自其他处理器进行查看时已瞬时地发生。处理器进行在事务区域内执行的被执行事务的存储器操作,仅当发生成功提交时(亦即,当事务成功地完成执行时)才可为其他处理器所见。此过程常常被称作原子提交。
Intel TSX提供两个软件接口以指定用于事务执行的代码区域。硬件锁省略(Hardware Lock Elision,HLE)为用于指定事务区域的旧版兼容指令集扩展(包括XACQUIRE及XRELEASE前缀)。受限事务存储器(Restricted Transactional Memory,RTM)为供编程人员以比在使用HLE的情况下可能的方式更灵活的方式定义事务区域的新指令集接口(包括XBEGIN、XEND及XABORT指令)。HLE用于喜好常规互斥程序设计模型的回溯兼容性且愿意在旧版硬件上执行具备HLE功能的软件但亦愿意在具有HLE支持的硬件上利用新锁省略能力的编程人员。RTM用于喜好事务执行硬件的灵活接口的编程人员。另外,Intel TSX亦提供XTEST指令。此指令允许软件查询逻辑处理器是否正在由HLE或RTM识别的事务区域中事务地执行。
因为成功事务执行确保原子提交,所以处理器在无显式同步的情况下乐观地执行代码区域。如果同步对于该特定执行是不必要的,则执行能够在无任何跨线程串行化的情况下提交。如果处理器不能原子地提交,则乐观执行失败。当发生此情形时,处理器将回滚执行,其是被称作事务中止的过程。在事务中止时,处理器将丢弃在由事务所使用的存储器区域中执行的全部更新、还原架构状态以看起来好像乐观执行从未发生,且非事务地恢复执行。
处理器可出于众多原因而执行事务中止。中止事务的主要原因归因于事务执行逻辑处理器与另一逻辑处理器之间的冲突存储器存取。此类冲突存储器存取可阻止成功事务执行。自事务区域内读取的存储器地址构成事务区域的读取集合,且写入至事务区域内的地址构成事务区域的写入集合。Intel TSX以高速缓存行的粒度维护读取集合及写入集合。如果另一逻辑处理器读取是事务区域的写入集合的一部分的位置或写入是事务区域的读取集合或写入集合的一部分的位置,则发生冲突存储器存取。冲突存取通常意味着此代码区域需要串行化。因为Intel TSX检测到在高速缓存行的粒度下的数据冲突,所以放置于同一高速缓存行中的无关数据位置将被检测为引起事务中止的冲突。事务中止亦可归因于有限事务资源而发生。举例而言,在所述区域中存取的数据量可超过实施方式特定的容量。另外,一些指令及系统事件可造成事务中止。频繁事务中止引起浪费周期及无效率增加。
硬件锁省略
硬件锁省略(HLE)提供用于使编程人员使用事务执行的旧版兼容指令集接口。HLE提供两个新指令前缀提示:XACQUIRE及XRELEASE。
在使用HLE的情况下,编程人员将XACQUIRE前缀添加至用于获取正保护关键区段的锁的指令前方。处理器将前缀处理为用于省略与锁获取操作相关联的写入的提示。即使锁获取具有对锁的关联写入操作,处理器仍不将锁的地址添加至事务区域的写入集合,其亦不发出对锁的任何写入请求。取而代之,将锁的地址添加至读取集合。逻辑处理器进入事务执行。如果锁在XACQUIRE前缀指令之前可用,则全部其他处理器此后将继续将锁视为可用。因为事务执行逻辑处理器既不将锁的地址添加至其写入集合亦不执行对锁的外部可见写入操作,所以其他逻辑处理器能在不造成数据冲突的情况下读取锁。这允许其他逻辑处理器亦进入且并行地执行受锁保护的关键区段。处理器自动地检测在事务执行期间发生的任何数据冲突且将在必要时执行事务中止。
即使省略处理器(eliding processor)不执行对锁的任何外部写入操作,硬件仍确保对锁的操作的程序次序。如果省略处理器自身读取关键区段中的锁的值,则将看起来好像处理器已获取锁,亦即,读取将返回非省略值(non-elided value)。此行为允许HLE执行在功能上等效于无HLE前缀的执行。
能够将XRELEASE前缀添加于用于释放保护关键区段的锁的指令前方。释放锁涉及对锁的写入。如果指令用于将锁的值还原至锁在对同一锁的XACQUIRE前缀锁获取操作之前所具有的值,则处理器省略与锁的释放相关联的外部写入请求且不将锁的地址添加至写入集合。处理器接着尝试提交事务执行。
在使用HLE的情况下,如果多个线程执行受到同一锁保护的关键区段,但它们不对彼此的数据执行任何冲突操作,则线程能够并行地且在无串行化的情况下执行。即使软件使用对公用锁的锁获取操作,硬件仍识别此情形、省略锁,且在两个线程上在无需经由锁的任何通信的情况下(如果此类通信为动态地不必要的)执行关键区段。
如果处理器不能够事务地执行该区域,则处理器将非事务地且在无省略的情况下执行该区域。具备HLE功能的软件具有与基于底层非HLE锁的执行相同的前向进度保证。为了成功HLE执行,锁及关键区段代码必须遵循某些准则。这些准则仅影响性能;且遵循这些准则的失败将不引起功能失败。无HLE支持的硬件将忽略XACQUIRE及XRELEASE前缀提示且将不执行任何省略,这是因为这些前缀对应于其中XACQUIRE及XRELEASE有效的指令上忽略的REPNE/REPE IA-32前缀。重要地,HLE与现有基于锁的程序设计模型兼容。提示的不当使用将不造成功能错误,但其可曝露已经在代码中的潜在错误。
受限事务存储器(RTM)提供用于事务执行的灵活软件接口。RTM提供三个新指令(XBEGIN、XEND及XABORT)以供编程人员开始、提交及中止事务执行。
编程人员使用XBEGIN指令以指定事务代码区域的开始且使用XEND指令以指定事务代码区域的结束。如果不能成功地事务地执行RTM区域,则XBEGIN指令采取将相对偏移提供至后退(fallback)指令地址的操作数。
处理器可出于许多原因而中止RTM事务执行。在许多情况下,硬件自动地检测事务中止条件且自具有与在XBEGIN指令的开始时存在的架构状态对应的架构状态及被更新以描述中止状态的EAX寄存器的后退指令地址重新开始执行。
XABORT指令允许编程人员显式地中止RTM区域的执行。XABORT指令采取加载至EAX寄存器中的8位直接自变量且因此将在RTM中止之后可用于软件。RTM指令不具有与其相关联的任何数据存储器位置。虽然硬件不提供关于RTM区域是否将永远成功地事务地提交的保证,但遵循建议准则的大多数事务被预期为成功地事务地提交。然而,编程人员必须始终在后退路径中提供替代代码序列以保证前向进度。此情形可与获取锁且非事务地执行指定代码区域一样简单。另外,始终在给定实施方式上中止的事务可在未来实施方式上事务地完成。因此,编程人员必须确保在功能上测试用于事务区域及替代代码序列的代码路径。
HLE支持的检测
如果CPUID.07H.EBX.HLE[bit 4]=1,则处理器支持HLE执行。然而,应用能够在不检查处理器是否支持HLE的情况下使用HLE前缀(XACQUIRE及XRELEASE)。无HLE支持的处理器忽略这些前缀且将在不进入事务执行的情况下执行代码。
RTM支持的检测
如果CPUID.07H.EBX.RTM[bit 11]=1,则处理器支持RTM执行。应用必须检查处理器在其使用RTM指令(XBEGIN、XEND、XABORT)之前是否支持RTM。这些指令将在不支持RTM的处理器上使用时产生#UD异常。
XTEST指令的检测
如果处理器支持HLE或RTM,则其支持XTEST指令。应用必须在使用XTEST指令之前检查这些特征标志中的任一者。此指令将在不支持HLE或RTM的处理器上使用时产生#UD异常。
查询事务执行状态
XTEST指令能够用于判定由HLE或RTM指定的事务区域的事务状态。应注意,虽然在不支持HLE的处理器上忽略HLE前缀,但XTEST指令将在不支持HLE或RTM的处理器上使用时产生#UD异常。
针对HLE锁的要求
对于用于成功地事务地提交的HLE执行,锁必须满足某些属性且对锁的存取必须遵循某些准则。
XRELEASE前缀指令必须将被省略锁的值还原至其在锁获取之前所具有的值。这允许硬件通过不将锁添加至写入集合而安全地省略锁。锁释放(XRELEASE前缀)指令的数据大小及数据地址必须匹配于锁获取(XACQUIRE前缀)的数据大小及数据地址,且锁必须不跨越高速缓存行边界。
软件不应将除了XRELEASE前缀指令以外的任何指令写入至事务HLE区域内部的被省略锁,否则此写入可造成事务中止。另外,递归锁(其中线程在无首先释放锁的情况下多次获取同一锁)亦可造成事务中止。应注意,软件能够观察关键区段内部的被省略锁获取的结果。此类读取操作将写入的值返回给锁。
处理器自动地检测对这些准则的违反,且在无省略的情况下安全地转变至非事务执行。因为Intel TSX检测到在高速缓存行的粒度下的冲突,所以至共置于与被省略锁相同的高速缓存行上的数据的写入可由省略同一锁的其他逻辑处理器检测为数据冲突。
事务嵌套(Transactional Nesting)
HLE及RTM两者支持嵌套式事务区域。然而,事务中止将状态还原至开始事务执行的操作:最外XACQUIRE前缀HLE合格指令或最外XBEGIN指令。处理器将全部嵌套式事务视为一个事务。
HLE嵌套及省略
编程人员能够将HLE区域嵌套直至为MAX_HLE_NEST_COUNT的实施方式特定的深度。每一逻辑处理器在内部追踪嵌套计数,但此计数不可用于软件。XACQUIRE前缀HLE合格指令递增嵌套计数,且XRELEASE前缀HLE合格指令递减嵌套计数。当嵌套计数自0变为1时,逻辑处理器进入事务执行。仅当嵌套计数变为0时,逻辑处理器才尝试提交。如果嵌套计数超过MAX_HLE_NEST_COUNT,则可发生事务中止。
除了支持嵌套式HLE区域以外,处理器亦能够省略多个嵌套锁。处理器追踪用于省略的锁,该锁以用于该锁的XACQUIRE前缀HLE合格指令开始且以用于该同一锁的XRELEASE前缀HLE合格指令结束。处理器能够在任一时间追踪高达MAX_HLE_ELIDED_LOCKS数目个锁。举例而言,如果实施方式支持为2的MAX_HLE_ELIDED_LOCKS值,且如果编程人员嵌套三个HLE识别关键区段(在不对三个相异锁中的任一者执行介入XRELEASE前缀HLE合格指令的情况下通过对所述三个锁执行XACQUIRE前缀HLE合格指令),则将省略前两个锁,但将不省略第三锁(但被添加至事务的写入集合)。然而,执行仍将事务地继续。一旦遇到用于两个省略锁中的一者的XRELEASE,就将省略经由XACQUIRE前缀HLE合格指令而获取的后续锁。
当全部省略的XACQUIRE及XRELEASE对已匹配、嵌套计数变为0且锁已满足要求时,处理器尝试提交HLE执行。如果执行不能被原子地提交,则执行在无省略的情况下转变至非事务执行,就好像第一指令不具有XACQUIRE前缀那样。
RTM嵌套
编程人员能够将RTM区域嵌套直至实施方式特定的MAX_RTM_NEST_COUNT。逻辑处理器在内部追踪嵌套计数,但此计数不可用于软件。XBEGIN指令递增嵌套计数,且XEND指令递减嵌套计数。仅当嵌套计数变为0时,逻辑处理器才尝试提交。如果嵌套计数超过MAX_RTM_NEST_COUNT,则发生事务中止。
嵌套HLE及RTM
HLE及RTM提供至公共事务执行能力的两个替代软件接口。当HLE及RTM嵌套在一起(例如,HLE在RTM内部或RTM在HLE内部)时,事务处理行为是实施方式特定的。然而,在全部状况下,实施方式将维护HLE及RTM语义。实施方式可在用于RTM区域内部时选择忽略HLE提示,且可在RTM指令用于HLE区域内部时造成事务中止。在后一情况中,自事务执行至非事务执行的转变无缝地发生,这是因为处理器将在不实际上进行省略的情况下重新执行HLE区域,且接着执行RTM指令。
中止状态定义
RTM使用EAX寄存器以将中止状态传达给软件。在RTM中止之后,EAX寄存器具有以下定义。
表1
用于RTM的EAX中止状态仅提供中止的原因。对于RTM区域,无论发生中止抑或提交,EAX中止状态自身皆不编码。在RTM中止之后,EAX的值可为0。举例而言,CPUID指令在用于RTM区域内部时造成事务中止,且可不满足用于设定EAX位中的任一者的要求。此情形可引起为0的EAX值。
RTM存储器排序
成功RTM提交造成RTM区域中的全部存储器操作看起来好像原子地执行。由XBEGIN接着由XEND组成的被成功提交的RTM区域(甚至在RTM区域中无存储器操作的情况下)具有与LOCK前缀指令相同的排序语义。
XBEGIN指令不具有栅栏(fencing)语义。然而,如果RTM执行中止,则来自RTM区域内的全部存储器更新被丢弃且不可为任何其他逻辑处理器所见。
具备RTM功能的除错程序支持
默认地,RTM区域内部的任何除错异常将造成事务中止,且将使控制流程重新导向至架构状态被复原且EAX中的位4被设定的后退指令地址。然而,为了允许软件除错程序在除错异常时拦截执行,RTM架构提供额外能力。
如果DR7的位11及IA32_DEBUGCTL_MSR的位15皆为1,则归因于除错异常(#DB)或断点异常(#BP)的任何RTM中止造成执行回滚且自XBEGIN指令而非后退地址重新开始。在此情景下,EAX寄存器亦将还原回至XBEGIN指令的点。
程序设计考虑
典型编程人员识别区域被预期为事务地执行且成功地提交。然而,Intel TSX不提供任何此类保证。事务执行可出于许多原因而中止。为了完全地利用事务能力,编程人员应遵循某些准则以增加其事务执行成功地提交的机率。
此章节论述可造成事务中止的各种事件。架构确保在随后中止执行的事务内执行的更新将永不变得可见。仅已提交的事务执行发起对架构状态的更新。事务中止永不造成功能失败且仅影响性能。
基于指令的考虑
编程人员可安全地在事务(HLE或RTM)内部使用任何指令且可使用处于任何特权层级的事务。然而,一些指令将始终中止事务执行且造成执行无缝地及安全地转变至非事务路径。
Intel TSX允许最常见的指令在不造成中止的情况下用于事务内部。事务内部的以下操作通常不造成中止:
·对指令指针寄存器(通用寄存器(GPR)及状态标志(CF、OF、SF、PF、AF及ZF)的操作;及
·对XMM及YMM寄存器以及MXCSR寄存器的操作。
然而,当在事务区域内部互混SSE操作与AVX操作时,编程人员必须小心。互混存取XMM寄存器的SSE指令与存取YMM寄存器的AVX指令可造成事务中止。编程人员可在事务内部使用REP/REPNE前缀字符串操作。然而,长字符串可造成中止。另外,如果CLD指令及STD指令改变DF标志的值,则CLD指令及STD指令的使用可造成中止。然而,如果DF为1,则STD指令将不造成中止。类似地,如果DF为0,则CLD指令将不造成中止。
此处未被列举为用于事务内部时造成中止的指令通常将不造成事务中止(实例包括但不限于MFENCE、LFENCE、SFENCE、RDTSC、RDTSCP等)。
以下指令将中止任何实施方式上的事务执行:
·XABORT
·CPUID
·PAUSE
另外,在一些实施方式中,以下指令可始终造成事务中止。这些指令不被预期为常用于典型事务区域内部。然而,编程人员必须不依赖于这些指令以迫使事务中止,这是因为其是否造成事务中止是实施方式相关的。
·对X87及MMX架构状态的操作。此情形包括全部MMX及X87指令,包括FXRSTOR及FXSAVE指令。
·对EFLAGS的非状态部分的更新:CLI、STI、POPFD、POPFQ、CLTS。
·更新段寄存器、除错寄存器和/或控制寄存器的指令:MOV至DS/ES/FS/GS/SS、POP DS/ES/FS/GS/SS、LDS、LES、LFS、LGS、LSS、SWAPGS、WRFSBASE、WRGSBASE、LGDT、SGDT、LIDT、SIDT、LLDT、SLDT、LTR、STR、远CALL、远JMP、远RET、IRET、MOV至DRx、MOV至CR0/CR2/CR3/CR4/CR8及LMSW。
·环形转变:SYSENTER、SYSCALL、SYSEXIT,及SYSRET。
·TLB及缓存能力控制:CLFLUSH、INVD、WBINVD、INVLPG、INVPCID,及具有非时间提示的存储器指令(MOVNTDQA、MOVNTDQ、MOVNTI、MOVNTPD、MOVNTPS及MOVNTQ)。
·处理器状态存储:XSAVE、XSAVEOPT及XRSTOR。
·中断:INTn、INTO。
·IO:IN、INS、REP INS、OUT、OUTS、REP OUTS及其变型。
·VMX:VMPTRLD、VMPTRST、VMCLEAR、VMREAD、VMWRITE、VMCALL、VMLAUNCH、VMRESUME、VMXOFF、VMXON、INVEPT及INVVPID。
·SMX:GETSEC。
·UD2、RSM、RDMSR、WRMSR、HLT、MONITOR、MWAIT、XSETBV、VZEROUPPER、MASKMOVQ及V/MASKMOVDQU。
运行时考虑
除了基于指令的考虑以外,运行时事件亦可造成事务执行中止。这些事件可归因于数据存取模式或微架构实施方式特征。以下清单并非全部中止原因的全面论述。
将抑制必须曝露于软件的事务中的任何故障或陷阱。事务执行将中止且执行将转变至非事务执行,就好像故障或陷阱从未发生。如果异常未被屏蔽,则该未屏蔽异常将引起事务中止且状态将看起来好像异常从未发生。
在事务执行期间发生的同步异常事件(#DE、#OF、#NP、#SS、#GP、#BR、#UD、#AC、#XF、#PF、#NM、#TS、#MF、#DB、#BP/INT3)可造成执行不事务地提交,且需要非事务执行。这些事件被抑制,就好像其从未发生。在使用HLE的情况下,因为非事务代码路径与事务代码路径相同,所以这些事件通常将在造成异常的指令非事务地被重新执行时重新出现,从而造成关联同步事件在非事务执行中适当地递送。在事务执行期间发生的异步事件(NMI、SMI、INTR、IPI、PMI等)可造成事务执行中止且转变至非事务执行。在处理事务中止之后,将搁置及处置异步事件。
事务仅支持回写可缓存存储型操作。如果事务包括对任何其他存储器类型的操作,则事务可始终中止。此情形包括对UC存储器类型的指令取回。
事务区域内的存储器存取可需要处理器设定被引用页表表项的已存取标志及已变更(dirty)标志。处理器如何处置此情形的行为是实施方式特定的。即使事务区域随后中止,一些实施方式仍可允许对这些标志的更新变得外部可见。如果这些标志需要被更新,则一些Intel TSX实施方式可选择中止事务执行。另外,处理器的页表遍历可产生对其自身事务写入但未提交的状态的存取。在此类情形下,一些Intel TSX实施方式可选择中止事务区域的执行。无论如何,架构皆确保:如果事务区域中止,则经由诸如TLB的结构的行为将不会使事务写入状态在架构上可见。
事务地执行自修改代码亦可造成事务中止。即使当采用HLE及RTM时,编程人员仍必须继续遵循Intel建议准则以用于写入自修改及交叉修改代码。虽然RTM及HLE的实施方式通常将提供足够资源以用于执行公共事务区域,但用于事务区域的实施方式约束及过度大小可造成事务执行中止且转变至非事务执行。架构不提供可用于进行事务执行的资源量的保证,且不保证事务执行将永远成功。
对事务区域内存取的高速缓存行的冲突请求可防止事务成功地执行。举例而言,如果逻辑处理器P0在事务区域中读取行A,且另一逻辑处理器P1写入行A(在事务区域内部或外部),则逻辑处理器P0可在逻辑处理器P1的写入干扰处理器P0事务地执行的能力的情况下中止。
类似地,如果P0在事务区域中写入行A,且P1读取或写入行A(在事务区域内部或外部),则P0可在P1对行A的存取干扰P0事务地执行的能力的情况下中止。另外,其他一致性业务可有时表现为冲突请求且可造成中止。虽然可发生这些错误冲突,但其被预期为不常见。用于在上述情景下判定P0抑或P1中止的冲突解决策略是实施方式特定的。
通用事务执行实施例:
根据由Austen McDonald在2009年6月为了部分地满足哲学博士学位的要求而提交给斯坦福大学的计算机科学系及研究生委员会的论文“ARCHITECTURES FOR TRANSACTIONAL MEMORY”(其全文以引用方式并入本文中),基本上存在实施原子且隔离的事务区域所需要的三个机制:版本设定、冲突检测,及争用管理。
为了使事务代码区域显得是原子的,必须存储由该事务代码区域执行的全部修改且使其保持与其他事务隔离直至提交时间为止。系统通过实施版本设定策略而执行此情形。存在两个版本设定范例:急切(eager)及缓慢(lazy)。急切版本设定系统在适当位置中存储新产生的事务值且另外在被称为复原日志(undo-log)的日志中存储先前存储器值。缓慢版本设定系统在被称为写入缓冲器的缓冲器中暂时地存储新值,从而仅在提交时将新值复制至存储器。在任一系统中,高速缓存用于优化新版本的存储。
为了确保事务看起来好像被原子地执行,必须检测及解决冲突。两个系统(亦即,急切版本设定系统及缓慢版本设定系统)通过实施冲突检测策略(乐观或悲观)来检测冲突。乐观系统并行地执行事务,从而仅当事务提交时才检查冲突。悲观系统在每一加载及存储时检查冲突。类似于版本设定,冲突检测亦使用高速缓存,从而将每一行标记为读取集合的部分、写入集合的部分,或两者。两个系统通过实施争用管理策略来解决冲突。存在许多争用管理策略,一些策略更适合于乐观冲突检测且一些策略更适合于悲观冲突检测。下文描述一些实例策略。
因为每一事务存储器(TM)系统需要版本设定检测及冲突检测两者,所以这些选项引起四个相异TM设计:急切-悲观(EP)、急切-乐观(EO)、缓慢-悲观(LP)及缓慢-乐观(LO)。表2简要地描述全部四个相异TM设计。
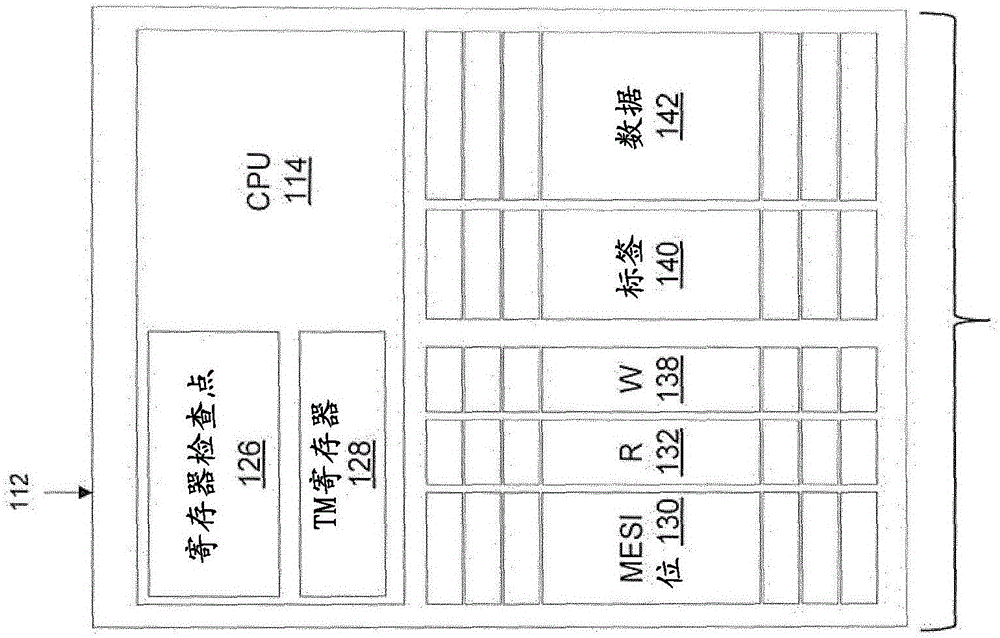
图1及图2描绘多核心TM环境的一个实例。图1示出一个管芯100上的在互连控件120a、120b的管理下与互连122连接的许多具备TM功能的CPU(CPU1 114a、CPU2 114b等)。每一CPU 114a、114b(亦被称为处理器)可具有由用于自存储器缓存待执行指令的指令高速缓存116a、116b及用于缓存待由CPU 114a、114b操作的存储器位置的数据(操作数)的具有TM支持的数据高速缓存118a、118b组成的分割高速缓存(在图1中,每一CPU 114a、114b及其关联高速缓存被引用为112a、112b)。在一实施方式中,多个管芯100的高速缓存被互连以支持多个管芯100的高速缓存之间的高速缓存一致性。在一实施方式中,使用单个高速缓存而非分割高速缓存,从而保留指令及数据两者。在各实施方式中,CPU高速缓存为分层高速缓存结构中的一个缓存级。举例而言,每一管芯100可使用待在管芯100上的全部CPU之间共享的共享高速缓存124。在另一实施方式中,每一管芯可存取在全部管芯100的全部处理器之间共享的共享高速缓存124。
图2示出实例事务CPU 114的细节,包括用于支持TM的添加物。事务CPU(处理器)114可包括用于支持寄存器检查点126及特殊TM寄存器128的硬件。事务CPU高速缓存可具有常规高速缓存的MESI位130、标签140及数据142,而且具有(例如)示出一行已由CPU 114读取同时执行事务的R位132,及示出一行已由CPU 114写入同时执行事务的W位138。
用于任何TM系统中的编程人员的关键细节为非事务存取如何与事务交互。根据设计,使用上述机制将事务存取彼此过滤。然而,仍必须考虑规则非事务加载与含有用于该地址的新值的事务之间的交互。另外,亦必须探索非事务存储与已读取该地址的事务之间的交互。这些情形为数据库概念隔离的问题。
当每一非事务载入及存储就像原子事务时,TM系统被称为实施强隔离,有时被称为强原子性。因此,非事务加载不能看到未提交数据且非事务存储造成已读取该地址的任何事务的原子性违反。并非此状况的系统被称为实施弱隔离,有时被称为弱原子性。
归因于强隔离的概念化及实施的相对简易性,强隔离相比于弱隔离常常更理想。另外,如果编程人员已忘记使用事务来环绕一些共享存储器引用,从而造成错误,则在使用强隔离的情况下,编程人员将常常使用简单除错接口来检测该失察,这是因为编程人员将看到造成原子性违反的非事务区域。又,在一个模型中写入的程序可在另一模型上不同地工作。
另外,强隔离相比于弱隔离常常较易于在硬件TM中支持。在使用强隔离的情况下,因为一致性协议已经管理处理器之间的加载及存储通信,所以事务能够检测非事务加载及存储且适当地起作用。为了在软件事务存储器(TM)中实施强隔离,必须修改非事务代码以包括读取及写入屏障;从而潜在地削弱性能。尽管已花费极大努力以移除许多不需要的屏障,但此类技术常常是复杂的且性能通常远低于HTM的性能。
表2
表2说明事务存储器的基本设计空间(版本设定及冲突检测)。
急切-悲观(EP)
下文所描述的此第一TM设计被称为急切-悲观。EP系统将其写入集合存储“在适当位置中”(因此,名称「急切」),且为了支持回滚,在“复原日志”中存储覆盖行的旧值。处理器使用W 138及R 132高速缓存位以追踪读取及写入集合且当接收到窥探加载请求时检测冲突。或许,已知文献中的EP系统的最值得注意的实例为LogTM及UTM。
在EP系统中开始事务非常类似于在其他系统中开始事务:tm_begin()获取寄存器检查点,且初始化任何状态寄存器。EP系统亦需要初始化复原日志,其细节取决于日志格式,但常常涉及初始化指向预分配线程专用存储器的区域的日志基址指针,及清除日志界限寄存器。
版本设定:在EP中,归因于急切版本设定被设计以起作用的方式,MESI 130状态转变(对应于已修改、独占、共享及无效代码状态的高速缓存行指示符)通常不变。在事务外部,MESI 130状态转变完全地不变。当在事务内部读取一行时,标准一致性转变适用(S(共享)→S,I(无效)→S,或I→E(独占)),从而按需要而发出加载未命中,但亦设定R 132位。同样地,写入一行应用标准转变(S→M,E→I,I→M),从而按需要而发出未命中,但亦设定W 138(写入)位。在第一次写入行时,载入整个行的旧版本,接着写入至复原日志以在当前事务中止的状况下保留旧版本。接着在旧数据上方将新写入数据存储“在适当位置中”。
冲突检测:悲观冲突检测使用在未命中时交换的一致性消息,或升级,以寻找事务之间的冲突。当在事务内发生读取未命中时,其他处理器接收加载请求;但如果其不具有所需行,则其忽略该请求。如果其他处理器非推测式地具有所需行或具有行R 132(读取),则其将该行降级至S,且在某些状况下,如果其具有处于MESI 130的M或E状态的行,则发出高速缓存至高速缓存传输。然而,如果高速缓存具有行W 138,则在两个事务之间检测到冲突且必须采取额外动作(多个)。
类似地,当事务设法将一行自共享升级至已修改(在第一写入时)时,事务发出独占加载请求,其亦用于检测冲突。如果接收高速缓存非推测式地具有该行,则该行失效,且在某些状况下发出高速缓存至高速缓存传送(M或E状态)。但是,如果行为R 132或W 138,则检测到冲突。
验证:因为对每一加载执行冲突检测,所以事务始终具有对其自身写入集合的独占存取。因此,验证无需任何额外工作。
提交:因为急切版本设定在适当位置中存储数据项的新版本,所以提交过程简单地清除W 138及R 132位且丢弃复原日志。
中止:当事务回滚时,必须还原复原日志中的每一高速缓存行的原始版本,其为被称为“展开(unrolling)”或“应用(applying)”日志的过程。这在tm_discard()期间进行,且相对于其他事务必须为原子的。具体言之,写入集合必须仍用于检测冲突:此事务具有其复原日志中的行的唯一正确版本,且请求事务必须等待正确版本自该日志还原。可使用硬件状态机或软件中止处理机来应用此类日志。
急切-悲观具有以下特性:提交为简单的,且因为其在适当位置中,所以非常快速。类似地,验证为无操作(no-op)。悲观冲突检测提早地检测到冲突,藉此缩减“注定(doomed)”事务的数目。举例而言,如果两个事务涉及读取后写入相关性,则在悲观冲突检测中立即检测该相关性。然而,在乐观冲突检测中,在写入器提交以前不检测此类冲突。
急切-悲观亦具有以下特性:如上文所描述,在第一次写入高速缓存行时,必须将旧值写入至日志,从而招致额外高速缓存存取。中止是昂贵的,这是因为其需要复原该日志。对于日志中的每一高速缓存行,必须发出一加载,或许在继续至下一行之前直至主存储器。悲观冲突检测亦防止存在某些可串行化调度。
另外,因为随着发生冲突而处置冲突,所以存在活锁的可能性,且必须使用小心争用管理机制以保证前向进度。
缓慢-乐观(LO)
另一流行TM设计为缓慢-乐观(LO),其将其写入集合存储于“写入缓冲器”或“重做日志”中且在提交时检测冲突(仍使用R 132及W 138位)。
版本设定:正如在EP系统中,在事务外部强制LO设计的MESI协议。一旦在事务内部,读取一行就招致标准MESI转变,而且设定R 132位。同样地,写入一行会设定该行的W 138位,但处置LO设计的MESI转变不同于EP设计的转变。第一,在使用缓慢版本设定的情况下,写入数据的新版本存储于高速缓存分层中直至提交为止,同时其他事务能够存取存储器或其他高速缓存中可提供的旧版本。为了使旧版本可用,当通过事务进行第一次写入时必须驱逐已变更行(M行)。第二,由于乐观冲突检测特征而无需升级未命中:如果事务具有处于S状态的行,则其可简单地写入至该行且将该行升级至M状态而不向其他事务传达改变,这是因为冲突检测是在提交时进行。
冲突检测及验证:为了验证事务且检测冲突,仅当LO准备提交时,LO才将已推测式修改行的地址传达给其他事务。在验证时,处理器发送含有写入集合中的全部地址的一个潜在大的网络分组。数据未被发送,但存留于提交者的高速缓存中且被标记为已变更(M)。为了在不搜寻用于被标记为W的行的高速缓存的情况下构建此分组,使用简单位向量(被称为“存储缓冲器”,其中每高速缓存行具有一个位)以追踪这些推测修改行。其他事务使用此地址分组以检测冲突:如果在高速缓存中找到地址且设定R 132和/或W 138位,则发起冲突。如果找到行,但既不设定R 132亦不设定W 138,则该行简单地失效,其类似于处理独占加载。
为了支持事务原子性,必须原子地处置这些地址分组,亦即,不可同时存在具有相同地址的两个地址分组。在LO系统中,这可通过在发送地址分组之前简单地获取全局提交令牌来实现。然而,可通过首先发送出地址分组、收集响应、强制排序协议(或许首先为最旧事务)且在全部响应令人满意后就提交而使用两阶段提交方案。
提交:一旦已发生验证,提交就无需特殊处理:简单地清除W 138及R 132位以及存储缓冲器。事务的写入已经在高速缓存中被标记为已变更,且这些行的其他高速缓存的复本已经由地址分组而失效。其他处理器能够接着经由规则一致性协议而存取已提交数据。
中止:回滚同等地容易:因为本地高速缓存内含有写入集合,所以这些行可失效,接着清除W 138及R 132位以及存储缓冲器。存储缓冲器允许找到W行以在无需搜寻高速缓存的情况下失效。
缓慢-乐观具有以下特性:中止非常快速,从而无需额外加载或存储且仅进行本地改变。相比于在EP中找到的可串行化调度,可存在更多可串行化调度,这允许LO系统更积极地推测出事务是独立的,其可得到较高性能。最后,冲突的晚检测能够增加前向进度的可能性。
缓慢-乐观亦具有以下特性:验证花费与写入集合的大小成比例的全局通信时间。因为仅在提交时检测冲突,所以注定事务会浪费工作。
缓慢-悲观(LP)
缓慢-悲观(LP)代表第三TM设计选项,位于EP与LO之间的某处:在写入缓冲器中存储新写入行,但基于每一存取而检测冲突。
版本设定:版本设定类似于但不相同于LO的版本设定:读取一行会设定其R位132,写入一行会设定其W位138,且存储缓冲器用于追踪高速缓存中的W行。又,当通过事务进行第一次写入时必须驱逐已变更(M)行,正如在LO中那样。然而,因为冲突检测是悲观的,所以必须在自I,S→M升级事务行时执行加载独占,这不同于LO。
冲突检测:LP的冲突检测操作与EP的冲突检测相同:使用一致性消息以寻找事务之间的冲突。
验证:类似于EP中,悲观冲突检测确保:在任何点处,正在运行的事务不具有与任何其他正在运行的事务的冲突,因此,验证为无操作。
提交:提交无需特殊处理:简单地清除W 138及R 132位以及存储缓冲器,类似于LO中。
中止:回滚亦类似于LO的回滚:使用存储缓冲器而简单地使写入集合失效,且清除W及R位以及存储缓冲器。
急切-乐观(EO)
LP具有以下特性:类似于LO,中止非常快速。类似于EP,悲观冲突检测的使用会缩减“注定”事务的数目。类似于EP,不允许一些可串行化调度,且必须在每一快取未命中时执行冲突检测。
版本设定与冲突检测的最后组合为急切-乐观(EO)。EO可为用于HTM系统的次最佳选择:因为在适当位置中写入新事务版本,所以其他事务无选择,但随着发生冲突(亦即,随着发生快取未命中)而注意冲突。但是,因为EO等待直至提交时为止以检测冲突,所以这些事务变为“僵尸(zombie)”,从而继续执行、浪费资源,又“注定”中止。
EO已被证实为有用于STM中且由Bartok-STM及McRT实施。缓慢版本设定STM需要在每一读取时检查其写入缓冲器以确保其正读取最新值。因为写入缓冲器并非硬件结构,所以这是昂贵的,因此首选在适当位置中写入急切版本设定。另外,因为检查冲突在STM中也是昂贵的,所以乐观冲突检测提供大量执行此操作的优点。
争用管理
上文已描述事务在系统已决定中止该事务后如何回滚,但是,因为冲突涉及两个事务,所以需要探索哪一事务应中止、应如何发起该中止及应何时重试已中止事务的主题。这些主题为通过争用管理(CM)(事务存储器的关键组件)而处理的主题。下文描述关于系统如何发起中止的策略及管理哪些事务应在冲突中中止的各种已建立方法。
争用管理策略
争用管理(CM)策略为判定冲突中涉及的哪一事务应中止且何时应重试中止事务的机制。举例而言,通常为如下状况:立即重试已中止事务不会导致最佳性能。相反地,采用退避机制(其延迟已中止事务的重试)能得到较好性能。STM首先尽力寻找最佳争用管理策略,且下文所概述的许多策略最初被开发用于STM。
CM策略利用数种度量以进行决策,包括事务的年龄、读取及写入集合的大小、先前中止的数目等。用于进行此类决策的度量的组合是无限的,但下文大致按增加复杂性的次序描述某些组合。
为了建立某一命名法,首先应注意,在冲突中存在两方:攻击者及防御者。攻击者为请求对共享存储器位置的存取的事务。在悲观冲突检测中,攻击者为发出加载或加载独占的事务。在乐观中,攻击者为尝试验证的事务。防御者在两种状况下为接收攻击者的请求的事务。
积极CM策略立即且始终重试攻击者或防御者。在LO中,积极意味着攻击者始终获胜,且因此,积极有时被称为提交者获胜。此策略用于最早LO系统。在EP的情况下,积极可为防御者获胜或攻击者获胜。
重新开始将立即经历另一冲突的冲突事务必然浪费工作—即,互连带宽再填充快取未命中。礼貌CM策略在重新开始冲突之前采用指数退避(但亦可使用线性)。为了防止耗尽(过程不具有由调度器分配给其的资源的情形),指数退避在一些n次重试之后极大地增加事务成功的胜算。
冲突解决的另一方法是随机地中止攻击者或防御者(被称为随机化的策略)。可将此策略与随机化退避方案组合以避免不需要的争用。
然而,当选择事务以中止时,进行随机选择可引起中止已完成“大量工作”的事务,这会浪费资源。为了避免此浪费,当判定哪一事务中止时可考虑在事务时完成的工作量。工作的一个度量可为事务的年龄。其他方法包括最旧、块状TM、大小物质、Karma及Polka。最旧为中止冲突中的较年轻事务的简单时间戳方法。块状TM使用此方案。大小物质类似于最旧而非事务年龄,读取/写入字的数目用作优先级,在固定数目次中止之后还原至最旧。Karma是类似的,使用写入集合的大小作为优先级。在退避固定时间量之后,回滚接着进行。已中止事务在中止之后保持其优先级(因此,名称Karma)。Polka的工作类似于Karma而非退避预定时间量,其每次更按指数律成比例地退避。
因为中止浪费工作,所以争论停止攻击者直至防御者已完成其事务为止将导致较好性能是逻辑的。不幸的是,此简单方案容易导致死锁。
死锁避免技术能够用于解决此问题。贪婪使用两个规则以避免死锁。第一规则为:如果第一事务T1相比于第二事务T0具有较低优先级,或如果T1等待另一事务,则T1在与T0冲突时中止。第二规则为:如果T1相比于T0具有较高优先级且不等待,则T0等待直至T1提交、中止或开始等待为止(在此状况下应用第一规则)。贪婪提供关于时间界限的一些保证以用于执行一事务集合。一种EP设计(LogTM)使用类似于贪婪的CM策略以使用保守死锁避免来实现停止。
实例MESI一致性规则提供多处理器高速缓存系统的高速缓存行可驻留的四个可能状态M、E、S及I,其被定义如下:
已修改(M):高速缓存行仅存在于当前高速缓存中,且为已变更;其已自主存储器中的值修改。在准许(不再有效的)主存储器状态的任何其他读取之前,需要高速缓存以在未来的某一时间将数据回写至主存储器。回写将该行改变为独占状态。
独占(E):高速缓存行仅存在于当前高速缓存中,但为未变更(clean);其匹配于主存储器。响应于读取请求,高速缓存行可在任何时间改变为共享状态。替代地,当写入至高速缓存行时,其可改变为已修改状态。
共享(S):指示此高速缓存行可存储于机器的其他高速缓存中且为“未变更”;其匹配于主存储器。可在任何时间丢弃该行(改变为无效状态)。
无效(I):指示此高速缓存行为无效(未使用)。
除了MESI一致性位以外或编码于MESI一致性位中,亦可针对每一高速缓存行提供TM一致性状态指示符(R 132、W 138)。R 132指示符指示已自高速缓存行的数据读取当前事务,且W 138指示符指示已将当前事务写入至高速缓存行的数据。
在TM设计的另一方面中,使用事务存储缓冲器来设计系统。2000年3月31日申请且全文以引用方式并入本文中的名为“Methods and Apparatus for Reordering and Renaming Memory References in a Multiprocessor Computer System”的美国专利第6,349,361号教导一种用于在至少具有第一处理器及第二处理器的多处理器计算机系统中重新排序及重新命名存储器引用的方法。第一处理器具有第一专用高速缓存及第一缓冲器,且第二处理器具有第二专用高速缓存及第二缓冲器。所述方法包括如下操作:对于由第一处理器接收以存储数据的多个选通存储请求中的每一者,由第一专用高速缓存独占地获取含有所述数据的高速缓存行,且在第一缓冲器中存储所述数据。在第一缓冲器自第一处理器接收到对加载特定数据的加载请求后,基于载入及存储操作的按次序序列而将特定数据自存储于第一缓冲器中的数据当中提供至第一处理器。在第一高速缓存自第二高速缓存接收到针对给定数据的加载请求后,指示一错误条件,且当针对给定数据的加载请求对应于存储于第一缓冲器中的数据时,将所述处理器中的至少一者的当前状态重设至较早状态。
一个此类事务存储器工具的主要实施组件为用于保留预事务GR(通用寄存器)内容的事务备份寄存器文件、用于追踪在事务期间存取的高速缓存行的高速缓存目录、用于缓冲存储直至事务结束为止的存储高速缓存,及用于执行各种复杂功能的固件例程。在此章节中描述详细实施方式。
IBM zEnterprise EC12企业服务器实施例
IBM zEnterprise EC12企业服务器在事务存储器中引入事务执行(TX),且部分地描述于可得自IEEE计算机学会会议出版服务(CP)的2012年12月1至5日在MICRO-45处呈现的论文集第25至36页的论文“Transactional Memory Architecture and Implementation for IBM System z”(温哥华、英国哥伦比亚、加拿大)中,该论文的全文以引用方式并入本文中。
表3示出实例事务。并不保证以TBEGIN开始的事务以TEND永远成功地完成,这是因为其可在每一已尝试执行时经历中止条件,例如,归因于与其他CPU的重复冲突。这要求程序(例如)通过使用传统锁定方案来支持后退路径以非事务地执行相同操作。这对程序设计及软件检验团队施予显著负担,尤其是在后退路径未由可靠编译器自动地产生的情况下。
表3
针对已中止事务执行(TX)事务提供后退路径的要求是麻烦的。对共享数据结构操作的许多事务被预期为短的、接触仅几个相异存储器位置,且仅使用简单指令。对于这些事务,IBM zEnterprise EC12引入受约束事务的概念;在正常条件下,尽管是在不对必要重试的数目提供严格限制的情况下,但CPU 114保证受约束事务最终成功地结束。受约束事务以TBEGINC指令开始且以规则TEND结束。将任务实施为受约束或非受约束事务通常会引起非常相当的性能,但受约束事务通过移除针对后退路径的需要而简化软件开发。IBM的事务执行架构进一步描述于2012年9月自IBM公开的第十版SA22-7832-09的z/Architecture,Principles of Operation(其全文以引用方式并入本文)中。
受约束事务以TBEGINC指令开始。以TBEGINC起始的事务必须遵循一系列程序设计约束;否则,程序采取非可过滤约束违反中断。例示性约束可包括但不限于:事务可执行最大32个指令,全部指令文字必须在存储器的256个连续字节内;事务仅含有前向指向相对分支(亦即,无循环或子例程调用);事务可存取存储器的最大4个对准八进制字(八进制字为32个字节);及限定指令集合以排除类似于十进制或浮点运算的复杂指令。约束被选择为使得可执行类似于双重链接列表-插入/删除操作的许多公共操作,包括原子比较及交换以高达4个对准八进制字为目标的非常强大的概念。同时,约束被保守地选择为使得未来CPU实施方式可在无需调整约束的情况下保证事务成功,这是因为这原本将会导致软件不兼容性。
TBEGINC通常作用就像在IBM的zEC12服务器上的TSX或TBEGIN中的XBEGIN,只是不存在浮点寄存器(FPR)控件及程序中断过滤字段且控件被视为0。在事务中止时,将指令地址直接地设定回至TBEGINC而非在反映立即重试及用于受约束事务的中止路径的不存在之后的指令。
在受约束事务内不允许嵌套事务,但如果在非受约束事务内发生TBEGINC,则其被处理为开启新非受约束嵌套层级,正如TBEGIN那样。此情形可(例如)在非受约束事务调用在内部使用受约束事务的子例程的情况下发生。
因为中断过滤隐含地关闭,所以在受约束事务期间的全部异常导致操作系统(OS)的中断。事务的最终成功完成依赖于OS页入通过任何受约束事务而触控的至多4个页的能力。OS亦必须确保时间片段足够长以允许事务完成。
表4
表4示出表3中的代码的受约束事务实施方式,这假定受约束事务不与其他基于锁定的代码交互。因此未示出锁测试,但在受约束事务与基于锁的代码混合的情况下可添加锁测试。
当重复地发生失败时,使用毫代码(millicode)作为系统固件的一部分来执行软件仿真。有利地,受约束事务由于自编程人员移除负担而具有期望属性。
参看图3,IBM zEnterprise EC12处理器引入事务执行工具。该处理器可每时钟周期解码3个指令;将简单指令分派为单个微操作,且将较复杂指令断裂成多个微操作。将微操作(Uop 232b)写入至统一发出队列216中,所述微操作可从该处被无次序地发出。每隔一个周期可执行高达两个定点、一个浮点、两个载入/存储及两个分支指令。全局完成表(GCT)232保留每一微操作及事务嵌套深度(TND)232a。GCT 232在解码时被按次序写入、追踪每一微操作232b的执行状态,且当最旧指令组的全部微操作232b已成功地执行时完成指令。
第1级(L1)数据高速缓存240为具有256个字节高速缓存行及4周期使用延时的96KB(千字节)6路关联性高速缓存,耦合至具有用于L1 240未命中的7周期使用延时损失的专用1MB(兆字节)8路关联性第2级(L2)数据高速缓存268。L1 240高速缓存是最接近于处理器的高速缓存,且Ln高速缓存为在第n缓存级处的高速缓存。L1 240及L2 268高速缓存两者是贯穿存储的(store-through)。每一中央处理器(CP)芯片上的六个核心共享48MB第3级存储内高速缓存,且六个CP芯片连接至片外384MB第4级高速缓存,在玻璃陶瓷多芯片模块(MCM)上封装在一起。高达4个多芯片模块(MCM)可连接至具有高达144个核心(并非全部核心皆可用于执行客户工作负载)的一致对称多处理器(SMP)系统。
一致性以MESI协议的变型而管理。高速缓存行可被拥有为只读(共享)或独占;L1 240及L2 268是贯穿存储的且因此不含有已变更行。L3 272及L4高速缓存(未示出)是存储内的且追踪已变更状态。每一高速缓存包括全部其连接的低级高速缓存。
一致性请求被称为“交叉询问”(XI),且自较高级至较低级高速缓存及在L4之间分层式地发送。当一个核心未命中L1 240及L2 268且从其本地L3 272请求高速缓存行时,L3 272检查其是否拥有该行,且在其将高速缓存行返回至请求者之前在必要时将XI发送至在该L3 272下的当前拥有的L2 268/L1 240以确保一致性。如果请求亦未命中L3 272,则L3 272将请求发送至L4(未图示),此情形通过将XI发送至在该L4下的全部必要L3且发送至相邻L4而强制一致性。接着,L4对将响应转发至L2 268/L1240的请求L3作出响应。
应注意,归因于高速缓存分层的包括性规则,有时归因于由来自请求的关联性溢出导致的在较高级高速缓存上的驱逐而将高速缓存行自低级高速缓存XI至其他高速缓存行。这些XI可被称为“LRU XI”,其中LRU代表最近最少使用。
在引用又一类型的XI请求的情况下,降级XI将高速缓存所有权自独占式转变成只读状态,且独占式XI将高速缓存所有权自独占式转变成无效状态。降级XI及独占式XI需要回至XI发送者的响应。目标高速缓存可“接受”XI,或在其在接受XI之前第一次需要驱逐已变更数据的情况下发送“拒绝”响应。L1 240/L2 268高速缓存是贯穿存储的,但在其具有需要在降级独占式状态之前发送至L3的在其存储队列中的存储的情况下可拒绝降级XI及独占式XI。已拒绝XI将由发送者重复。只读XI被发送至拥有行只读的高速缓存;无需针对此类XI的响应,这是因为其不能被拒绝。SMP协议的细节类似于由P.Mak、C.Walters及G.Strait在2009年IBM研究及开发杂志第53:1卷的“IBM System z10processor cache subsystem microarchitecture”中针对IBM z10所描述的细节,其全文以引用方式并入本文中。
事务指令执行
图3描绘实例CPU环境112的实例组件,包括CPU 114及与其交互的高速缓存/组件(诸如,图1及图2所描绘的高速缓存/组件)。指令解码单元208(IDU)保持追踪当前事务嵌套深度212(TND)。当IDU 208接收到TBEGIN指令时,嵌套深度212递增,且相反地针对TEND指令递减。嵌套深度212针对每一已分派指令而写入至GCT 232中。当TBEGIN或TEND在稍后被清仓的推测式路径上解码时,IDU 208的嵌套深度212自未被清仓的最年轻GCT 232项被刷新。事务状态亦写入至发出队列216中以供执行单元(通常由加载/存储单元(LSU)280)使用,其亦具有包括于LSU280中的有效地址计算器236。如果事务在到达TEND指令之前中止,则TBEGIN指令可指定一事务诊断块(TDB)以用于记录状态信息。
类似于嵌套深度,IDU 208/GCT 232经由事务嵌套而协作地追踪存取寄存器/浮点寄存器(AR/FPR)修改屏蔽;当AR/FPR修改指令被解码且修改屏蔽阻止该情形时,IDU 208可将中止请求放置至GCT 232中。当指令变得接近完成时,完成被阻止且事务中止。其他受限指令被类似地处置,在受约束事务中的同时解码的情况下包括TBEGIN,或超过最大嵌套深度。
最外TBEGIN取决于GR存储屏蔽而断裂成多个微操作;每一微操作232b(包括(例如)uop 0、uop 1及uop 2)将由两个定点单元(FXU)220中的一者执行以将一对GR 228保存至专用事务备份寄存器文件224(其用于在事务中止的状况下稍后还原GR 228内容)中。又,如果指定了1,则TBEGIN繁衍微操作232b以针对TDB执行可存取性测试;地址保存在专用寄存器中以供稍后在中止状况下使用。在最外TBEGIN的解码时,TBEGIN的指令地址及指令文字亦保存在专用寄存器中以供以后进行潜在中止处理。
TEND及NTSTG为单微操作232b指令;NTSTG(非事务存储)类似于正常存储而处置,除了在发出队列216中被标记为非事务以使得LSU 280可对其进行适当处理。TEND在执行时为无操作,当TEND完成时执行事务的结束。
如所提到,在事务内的指令因而被标记于发出队列216中,但以其他方式通常不变地执行;LSU 280执行如下一章节中所描述的隔离追踪。
因为解码是按次序的,且因为IDU 208保持追踪当前事务状态且将其连同来自事务的每一指令一起写入至发出队列216中,所以可无次序地执行在事务之前、之内及之后的TBEGIN、TEND及指令的执行。甚至有可能的是(但未必),首先执行TEND,接着执行整个事务,且最后执行TBEGIN。在完成时经由GCT 232而还原程序次序。事务的长度不受到GCT 232的大小限制,这是因为通用寄存器(GR)228可自备份寄存器文件224被还原。
在执行期间,基于事件抑制控制而过滤程序事件记录(PER)事件,且在启用的情况下检测PER TEND事件。类似地,在事务模式中时,伪随机产生器可在通过事务诊断控制而启用时造成随机中止。
追踪事务隔离
加载/存储单元280追踪在事务执行期间存取的高速缓存行,且在来自另一CPU的XI(或LRU-XI)与占用空间(footprint)冲突的情况下触发中止。如果冲突XI为独占或降级XI,则在期待在L3 272重复XI之前完成事务的情况下,LSU 280将XI拒绝回至L3 272。此“伸直手推开(stiff-arming)”在高度争用事务中非常有效。为了在两个CPU彼此伸直手推开时防止挂起,实施XI拒绝计数器,其在满足阈值时触发事务中止。
L1高速缓存目录240传统上以静态随机存取存储器(SRAM)而实施。对于事务存储器实施方式,目录的有效位244(64列×6路)已移动至正常逻辑锁存器中,且每高速缓存行补充有两个更多位:TX读取248及TX已变更252位。
当解码新的最外TBEGIN(其相对于先前仍搁置事务而互锁)时重设TX读取248位。在执行时由在发出队列中被标记为“事务”的每一加载指令设定TX读取248位。应注意,如果(例如)在错误预测分支路径上执行推测加载,则此情形可导致过度标记。因为多个加载可同时完成,所以在加载完成时设定TX读取248位的替代方案对于硅区而言代价太大,从而需要加载队列上的许多读取端口。
存储以与非事务模式相同的方式执行,但事务标记被放置于存储指令的存储队列(STQ)260项中。在回写时,当来自STQ 260的数据写入至L1240中时,L1目录256中的TX已变更位252被设定用于所写入的高速缓存行。仅在存储指令已完成之后才发生至L1 240中的存储回写,且每周期回写至多一个存储。在完成及回写之前,加载可借助于存储转发而自STQ260存取数据;在回写之后,CPU 114(图2)能存取L1 240中的推测式更新的数据。如果事务成功地结束,则全部高速缓存行的TX已变更位252被清除,且尚未写入的存储的TX标记亦在STQ 260中被清除,从而将搁置存储有效转变成正常存储。
在事务中止时,自STQ 260使全部搁置事务存储失效,即使这些存储已完成亦是如此。通过L1 240中的事务而修改(亦即,使TX已变更位252开启)的全部高速缓存行使其有效位关断,从而瞬时地自L1 240高速缓存有效地移除所述高速缓存行。
架构要求在完成新指令之前保持事务读取集合与写入集合的隔离。当XI搁置时,通过在适当时间停止指令完成而确保此隔离;允许推测式无次序执行,这乐观地假定搁置XI是到不同地址且实际上不造成事务冲突。此设计非常自然地与实施于目前最新系统上以确保架构所需要的强存储器排序的XI-完成互锁配合。
当L1 240接收到XI时,L1 240存取目录以检查L1 240中的已XI地址的有效性,且如果TX读取位248在已XI行上活动且XI未被拒绝,则LSU 280触发中止。当具有活动TX读取位248的高速缓存行是自L1 240被LRU时,特殊LRU扩展向量对于L1 240的64列中的每一者记住TX读取行存在于该列上。因为对于LRU扩展不存在精确地址追踪,所以命中LSU 280的有效扩展列的任何非拒绝XI触发中止。提供LRU扩展会将读取占用空间能力自L1大小有效地增加至L2大小及关联性,前提是相对于非精确LRU扩展追踪的与其他CPU 114(图1)的冲突不造成中止。
存储占用空间受到存储高速缓存大小(下文更详细地论述存储高速缓存)限制且因此隐含地受到L2 268大小及关联性限制。当TX已变更252高速缓存行自L1 240被LRU时,无需执行LRU扩展动作。
存储高速缓存
在目前最新系统中,因为L1 240及L2 268为贯穿存储高速缓存,所以每一存储指令造成L3 272存储存取;在现在每L3 272具有6个核心且每一核心的性能进一步改进的情况下,针对L3 272的存储率(及针对L2 268在较少程度上)对于某些工作负载变得有问题。为了避免存储排队延迟,必须添加搜集存储高速缓存264,其在将相邻地址发送至L3 272之前将存储组合至相邻地址。
对于事务存储器性能,可接受的是在事务中止时使来自L1 240的每一TX已变更252高速缓存行失效,这是因为L2 268高速缓存非常接近(7循环L1 240未命中损失)取回未变更行。然而,对于性能(及用于追踪的硅面积)将不可接受的是使事务存储在事务结束之前写入L2 268且接着在中止时使全部已变更L2 268高速缓存行失效(或在共享L3 272上甚至更坏)。
存储带宽及事务存储器存储处置的两个问题可皆使用搜集存储高速缓存264而解决。高速缓存232是64个项的循环队列,每一项保存具有字节精确有效位的数据的128个字节。在非事务操作中,当自LSU 280接收到存储时,存储高速缓存检查是否存在针对相同地址的项,且如果如此,则将新存储搜集至现有项中。如果不存在项,则将新项写入至队列中,且如果自由项的数目降至低于阈值,则将最旧项回写至L2 268及L3 272高速缓存。
当新的最外事务开始时,存储高速缓存中的全部现有项被标记为关闭,使得无新存储可搜集至其中,且这些项至L2 268及L3 272的驱逐开始。自该点上看,来自LSU 280STQ 260的事务存储分配新项,或搜集至现有事务项中。这些存储至L2 268及L3 272中的回写被阻止,直至事务成功地结束为止;在该点处,后续(后事务)存储能继续搜集至现有项中,直至下一事务再次关闭这些项为止。
在每一独占或降级XI时查询存储高速缓存,且在XI与任何活动项相当的情况下造成XI拒绝。如果在连续地拒绝XI时核心并未完成另外指令,则事务在某一阈值处中止以避免挂起。
当存储高速缓存溢出时,LSU 280请求事务中止。当LSU 280试图发送不能合并至现有项中的新存储时,LSU 280检测此条件,且整个存储高速缓存被填充有来自当前事务的存储。存储高速缓存被管理为L2 268的子集:虽然可自L1 240驱逐事务已变更行,但其必须在整个事务中保持驻留在L2 268中。最大存储占用空间因此限于64×128字节的存储高速缓存大小,且其亦受到L2 268的关联性限制。因为L2 268为8路关联性的且具有512个列,所以其通常足够大以不造成事务中止。
如果事务中止,则通知存储高速缓存且使保留事务数据的全部项失效。存储高速缓存还具有每双字(8字节)一标记,不管项是否由NTSTG指令写入,这些双字在整个事务中止中保持有效。
毫代码实施的功能
传统上,IBM大型主机服务器处理器含有被称为毫代码的固件层,其执行类似于某些CISC指令执行、中断处置、系统同步及RAS的复杂功能。毫代码包括机器相关指令,以及自存储器取回及执行的指令集架构(ISA)的指令,类似于应用程序及操作系统(OS)的指令。固件驻留于客户程序不能存取的主存储器的受限区中。当硬件检测到需要调用毫代码的情形时,指令取回单元204切换成“毫代码模式”且开始在毫代码存储器区中的适当位置处取回。毫代码可以以与指令集架构(ISA)的指令相同的方式被取回及执行,且可包括ISA指令。
对于事务存储器,毫代码涉及各种复杂情形。每一事务中止调用专用毫代码子例程以执行必要中止操作。事务中止毫代码通过读取保存硬件内部中止原因、潜在异常原因及已中止指令地址的专用寄存器(SPR)而开始,如果指定了1,则此毫代码接着用于存储TDB。自SPR加载TBEGIN指令文字以获得GR保存屏蔽,这对于使毫代码知道哪些GR 238将被还原是所需的。
CPU 114(图2)支持特殊仅毫代码指令以读出备份GR 224且将其复制至主GR 228中。亦自SPR加载TBEGIN指令地址以在PSW中设定新指令地址以便一旦在毫代码中止子例程结束后就在TBEGIN之后继续执行。在中止是由非过滤程序中断造成的状况下,该PSW稍后可被存储为程序旧PSW。
TABORT指令可被毫代码实施;当IDU 208解码TABORT时,其指示指令取回单元分支至TABORT的毫代码中,毫代码自其分支至公共中止子例程中。
提取事务嵌套深度(ETND)指令亦可被毫编码,这是因为其并非性能关键的;毫代码自专用硬件寄存器中加载当前嵌套深度且将其放置至GR 228中。PPA指令被毫编码;其基于由软件作为操作数而提供给PPA的当前中止计数且亦基于其他硬件内部状态来执行最佳延迟。
对于受约束事务,毫代码可保持追踪中止的数目。在成功TEND完成时,或如果发生至OS中的中断(因为并不知道OS是否或何时将返回至程序),则将计数器重设至0。取决于当前中止计数,毫代码能够调用某些机制以改进后续事务重试的成功可能性。该机制涉及(例如)连续增加重试之间的随机延迟,及缩减推测执行量以避免遇到由对事务并未实际上使用的数据的推测存取造成的中止。作为最后手段,毫代码可广播至其他CPU 114(图2)以在释放其他CPU 114以继续正常处理之前停止全部冲突工作、重试本地事务。多个CPU 114必须被协调以不造成死锁,因此需要不同CPU114上的毫代码实例之间的某一串行化。
图4说明根据一个实施例的计算机系统300。图4被配置为实施图1至图3及图5至图18中论述的特征。计算机300包括通过分层高速缓存子系统而与存储器310通信的被指定为处理器112a(CPU1)及处理器112b(CPU2)的多处理器(连同未图示的额外处理器),其中由处理器进行的事务加载在分层高速缓存子系统的高速缓存中被监视。图4所示的计算机系统300具有与图1所示的计算机系统100相同的组件及相同标号,但图4中并未示出图1中的每一组件。
计算机系统300可管理呈现给可用于或当前处理事务的一个或多个处理器的请求,例如,中断。在一个实例中,请求处理器(例如,CPU 1(112a))可选择接收/远程处理器(例如,CPU 2(112b))且将一请求发送至选定远程处理器。在一个实例中,计算机系统为事务执行(TX)系统或环境,例如,包括能够执行事务的CPU或处理器。每一事务分别被示出为分别在处理器112a及112b中执行的事务指令320a及320b。每一处理器112a及112b分别具有其自己的寄存器334a及334b。
每一数据高速缓存118a及118b可分别包括其自己的L1及L2高速缓存。计算机存储器一般地由存储器310表示,其可包括在被指定为TX CPU的CPU(亦即,处理器112a及112b)中的较高级高速缓存。每一处理器112a及112b分别具有被指定为表1350a及1350b的其自己的本地事务干扰追踪表。表1350a及1350b可分别存储于数据高速缓存118a、118b、寄存器334a、334b和/或存储器310中。存储器310亦可包括用于存储事务的诊断信息的事务诊断块350,所述诊断信息可包括存储于表1350a及1350b中的事务干扰信息(连同统计),如本文中进一步所论述。
计算机系统300是根据各实施例的发送、接收及处理请求及响应两者的事务(TX)环境的表示。应注意,提供各种实例,其中处理器112a(CPU1)被例示为产生请求且将该请求发送至被例示为接收该请求的接收/远程处理器的处理器112b(CPU2)的请求处理器。应理解,此指定是出于解释目的,这是因为任一处理器可发送及接收针对数据的请求,如本领域技术人员所理解的。
图5说明协议请求及响应实例。所述协议请求可被称作大型机多处理器协议,且协议可经由基于总线或基于交换机的互连。协议可为全部并行信令(总线窥探)、串行分组或它们的组合。
作为一个实例,针对数据的请求505可自CPU 1(112a)发送至CPU 2(112b)。请求505包括告知何种类型的请求正被发送的类型字段506(例如,读取共享或读取独占—或,针对所有权的读取—根据已知MESI一致性协议的请求,或根据其他此类协议的协议请求),及识别发送请求的特定处理器(例如,CPU1)且可选地识别请求正被发送至的接收处理器(例如,CPU 2)及可选地在多个请求可被并行地处理的情况下识别特定请求ID以唯一地识别每一请求的标签字段507。请求505亦包括识别正由请求处理器(CPU1)请求的存取的类型的存取字段508,及地址字段509。地址字段509识别正被请求的高速缓存行或存储器字的存储器地址。请求505协议可包括含有所使用的错误检测和/或校正码(例如,循环冗余校验(CRC)、奇偶校验位或ECC)的错误校正字段510。
响应515可自接收处理器(CPU 2)发送回至请求处理器(CPU 1)。响应515包括指示响应的类型(诸如,读取响应(READRESPONSE))的类型字段516,及标签字段517。标签字段517可为与原始请求505的标签字段507相同的标签,和/或标签字段517可包括高速缓存行的被请求存储器地址。响应515包括是由请求处理器(CPU 1)请求的被请求数据的数据字段518。一些协议响应可不包括数据传送(例如,对将所有权自共享提升至用于行的独占所有权的协议请求),且可仅包括处理已执行的应答。错误校正字段519包括于响应515中。
在一些实施例中,用于协议请求的信令可并行地在多个位线上发生,且任何未使用字段可对应于不具有协议定义值、被设定为默认值或以其他方式不被视为协议消息的一部分的行。在一些实施例中,协议请求可在多个“拍频(beat)”(例如,整体上表示协议消息的连续位组)中传输。在其他实施例中,协议请求可被位串行地传输。在多个拍频中或串行地传输的协议中,一些消息相比于其他协议请求可由更多总线信令周期组成。
图6说明另一协议请求实例。许多协议经由RFO(针对所有权的读取)而获取独占存取或用于写入操作的读取独占请求,而一些其他协议可直接地写入(受限制)。作为一个实例,对写入数据的实例请求605可自CPU 1(112a)被发送至CPU 2(112b)。请求605包括识别正被发送(例如,写入)的请求的类型的类型字段506,及识别发送写入请求的特定处理器(例如,CPU1)且可选地识别请求正被发送至的接收处理器(例如CPU 2)及特定请求的标签字段507。请求605亦包括传输正由请求处理器(CPU 1)写入的数据的数据字段504,及地址字段509。地址字段509识别正被写入到的高速缓存行或地址线的存储器地址。请求605协议可包括含有所使用的错误检测和/或校正码(例如,循环冗余校验(CRC)、奇偶检验位或ECC)的错误校正字段510。
响应于写入请求,通常不存在响应,这是因为没有必要在执行写入之前获得用于独占存取的数据。
图7为根据一个实施例的由做出针对数据的请求的处理器(例如,CPU1(112a))进行的协议请求产生的流程图700。在块705处,处理器(例如,CPU 1)具有针对存储器数据的请求。在块710处,处理器(例如CPU 1(112a))检查被请求数据是否在其自己的本地高速缓存(例如,数据高速缓存118a中的L1高速缓存)中。当在处理器自己的本地高速缓存中可提供数据时,流程进行至块735。当处理器(CPU1)的本地高速缓存中不能提供数据时,在块715处,处理器产生XI请求(交叉询问)以向其他处理器(诸如,CPU 2(112b))请求所要数据。在块720处,请求处理器(CPU1)经由互连122将针对数据的XI请求发送至接收处理器(CPU 2),且在块725处,请求处理器(CPU 1)自接收处理器(CPU 2)接收具有(被请求)数据的XI响应。在块730处,请求处理器(CPU 1)将数据放置于数据高速缓存118a中的其本地高速缓存(例如,L1、L2高速缓存)中。在块735处,请求处理器(CPU 1)经由指令高速缓存116a而自其本地高速缓存118a获得数据。在块740处,请求处理器的指令高速缓存116a将数据提供给CPU 1的电路以供处理。
在一个实施例中,且根据公共高速缓存协议(例如,已知MESI协议),当处理器存取数据以供读取,且数据不可用时,XI被产生用于读取共享,其中数据是以共享方式而获得,使得多个CPU 112a、112b可在高速缓存中具有数据的复本,且其中每一CPU可处理对应于该数据的存储器读取存取。所接收数据放置于高速缓存中且被标记用于共享存取,且处理器可响应于存储器读取操作而执行来自复本的读取存取。当处理器存取用于写入的数据,且数据不可用于独占状态中时,XI被产生用于读取独占,其中数据是以独占式方式而获得,使得仅单个CPU(例如,CPU 112a)可在高速缓存中具有数据的复本。所接收数据放置于高速缓存中且被标记用于独占存取,且处理器可响应于存储器写入操作而更新复本。在一个实施例中,当数据以共享模式而存在,且写入存取被接收时,产生读取独占XI。在至少一个实施例中,这被指示为相异读取独占请求,其中无数据被接收为响应的一部分。在一个实施例中,当已接收到响应时,高速缓存数据被标记用于独占存取。
图8说明根据一个实施例的由接收/远程处理器(例如,CPU 2(112b))接收请求且发送响应而进行的请求处置的实例流程图800。
在块805处,远程处理器(CPU2)自请求处理器(CPU1)接收针对数据的XI请求。在块810处,远程处理器(CPU 2)通过检查远程处理器是否正处理当前需要被请求数据(在远程处理器的本地高速缓存中)的事务而检查是否检测到干扰。当远程处理器(CPU 2(112b))在块810处判定远程处理器当前正使用由请求处理器(CPU 1(112a))请求的数据时,远程处理器判定(是)检测到干扰,且在块815处,远程处理器(CPU 2)中止在远程处理器(CPU 2)处发生的本地事务。一旦在远程处理器(CPU 2)处中止本地事务,在块820处,远程处理器就将具有读取响应(READ RESPONSE)的数据传输至请求处理器(CPU 1)。远程处理器(CPU 2)在块825处改变数据状态且可选地在必要时自其本地高速缓存清除数据。在一个实施例中,高速缓存状态改变可包括当事务已中止时自读取或写入集合中的至少一者释放数据。在一个实施例中,高速缓存状态改变可包括改变高速缓存目录中的高速缓存行的状态,例如,根据诸如已知MESI协议之类的高速缓存协议而将状态设定为共享、独占、无效等中的一者。远程处理器(CPU 1)在块830处发起事务失败处理,且流程结束。当远程处理器(CPU 2(112b))在块810处判定远程处理器当前未使用由请求处理器(CPU 1(112a))请求的数据时,远程处理器判定未检测到干扰,且在块835处,远程处理器(CPU 2)传输具有读取响应(READ RESPONSE)的数据。远程处理器(CPU 2)在块840处改变数据状态且可选地在必要时自本地高速缓存清除数据,且流程结束。
图9为根据一个实施例的说明由处理器进行的事务处置的流程图900。在块905处,事务开始在处理器(例如,CPU 1或CPU 2)上执行。在图9中,应注意,每一处理器(CPU 1及CPU2)可正执行这些动作,亦即,事务可由112a、112b两者处理,等等。在块910处,处理器执行事务内的指令(例如,如图7所论述)。在块915处,处理器响应于事务指令而执行协议动作。在920处,处理器检查是否存在需要处理器中止其事务的干扰(借助使用数据)。当处理器判定(是)存在所检测的干扰时,在块925处,处理器中止其自己的事务(针对该数据),且流程进行至块935。当处理器判定未检测到干扰时,在块930处,处理器完成其事务(的指令)。在块935处,处理器在寄存器中写入事务信息(诸如,事务诊断块(TBD))。
根据多个实施例,一致性协议被扩展以包括关于事务状态的额外信息。图10说明根据多个实施例的协议请求505及新协议响应1005。如图10所示出,请求505的一些字段与图5论述的字段相同。如上文所提及,请求505包括识别何种类型的请求正被发送(例如,READ)的类型字段506,及识别发送请求的特定处理器(例如,CPU 1)(且可选地识别请求正被发送至的接收/远程处理器(例如CPU 2)及请求数目)的标签字段507。请求505亦包括告知正由请求处理器(CPU 1)请求的存取的类型的存取字段508,及告知正被请求的高速缓存行或地址线的存储器地址的地址字段509。请求505协议包括告知所使用的错误码(诸如,循环冗余校验(CRC))的类型的错误校正字段510。
新响应1005包括响应515(在图5中)的字段连同额外事务中止状态字段1010。响应1005可自接收/远程处理器(CPU 2)发送回至请求处理器(CPU1)。响应515包括指示响应的类型(诸如,读取响应(READRESPONSE))的类型字段516,及指示高速缓存行的被请求存储器地址的标签字段517(其可为与原始请求505的标签字段507相同的标签)。响应515包括是由请求处理器(CPU 1)请求的被请求数据的数据字段518。如果数据未以协议响应而传输,则数据字段518为空或不存在。错误检测/校正字段519包括于响应1005中。
另外,新协议响应1005(由远程处理器CPU 2发送至请求处理器CPU1)具有事务中止状态字段1010。事务中止状态字段1010包括关于在中止之前先前在远程/接收处理器(CPU 2)上执行的事务的以下信息中的一者或多者:
1)请求505(来自请求处理器(CPU 1)是否造成和/或不造成回滚(亦即,中止);
2)在中止之前在远程/接收处理器(CPU 2)上执行的此事务的优先级;
3)多少指令、存储器操作和/或工作的其他度量已通过在事务中止之前先前在远程/接收处理器(CPU 2)上执行的事务而执行;
4)识别先前在远程处理器(CPU 2)上执行的事务(例如,令牌、TBEGIN的地址,和/或识别已中止事务的其他方式)。
此外,事务中止状态字段1010告知何种数据是通过必须中止的事务(先前在远程/接收处理器上执行)而获得、告知事务的地址,且告知中止事务的成本(其可能为工作的3个时钟周期或20,000个时钟周期)。
当处理器(例如,在实例情景下为接收处理器CPU 2)在事务执行中时,一致性请求能够造成事务执行中止,例如,这是因为数据为事务读取或写入集合的一部分,且检测到冲突(亦即,干扰)。
根据一个实施例,图11说明图6中对写入数据(自请求处理器CPU 1(112a)发送至接收/远程处理器CPU 2(112b))的(写入)请求605,且新响应1105是自远程处理器CPU 2(112b)发送回至请求处理器CPU 1(112a)。图11为根据一个实施例通过将新协议响应引入至先前无需协议响应的事务而在响应中添加事务信息以便将事务干扰/中止信息传输至请求发起方的协议请求及响应实例。在至少一个实施例中,出于提供事务中止状态的唯一目的而传输的协议响应是可选的,且可在一些模式中、响应于配置位、响应于总线拥塞和/或出于其他原因而受到抑制。在此情景下,当未接收到响应时,不报告对应于尚未接收到响应所针对的请求的事务中止状态。在至少一个实施例中,可报告一个或多个响应的不存在。如上文所提及,请求605包括告知何种类型的请求正被发送(例如,写入)的类型字段506,及识别发送写入请求的特定处理器(例如,CPU 1)(及请求正被发送至的接收处理器(例如,CPU 2))的标签字段507。请求605亦包括告知正由请求处理器(CPU 1)请求的存取的类型的存取字段508,及地址字段509。地址字段509告知正被请求写入至的高速缓存行或地址线的存储器地址。请求605协议可包括具有错误校正/检测码(诸如,奇偶检验位、ECC或循环冗余校验(CRC)码)的错误检测和/或校正字段510。
响应于写入请求605,新响应1105(对写入请求)现在包括本文中论述的事务中止状态字段1010。新响应1105包括响应1005(在图10中)的字段。响应1105可自接收/远程处理器(CPU 2)发送回至请求处理器(CPU 1)。响应1105包括指示响应的类型(诸如,写入响应(WRITERESPONSE))的类型字段516,及指示高速缓存行的被请求存储器地址的标签字段517(其可为与原始请求505的标签字段507相同的标签以识别响应所对应的请求)。响应515可包括是由请求处理器(CPU 1)请求的被请求数据的数据字段518。因为无数据来自接收/远程处理器(CPU 2)的(本地)高速缓存,所以数据字段518为空。错误校正字段519包括于响应1005中。
如本文中所论述,事务中止状态字段1010提供由于写入请求605(来自请求处理器(CPU 1))而中止所需要的事务(先前在接收/远程处理器(CPU2)上执行)的状态。
虽然已在一个例示性实施例中结合将对应于事务中止状态及关联信息的协议字段添加至对读取请求的现有读取响应,且在另一例示性实施例中结合添加与不具有根据目前最新的协议响应的协议写入请求对应的协议响应以便传输对应于事务中止状态及关联信息且识别对应写入请求的至少一个协议字段而描述根据本发明的协议加强,但本领域技术人员能够将本文中含有的教导应用于其他XI格式、协议格式、请求类型、一致性协议等。
根据一个实施例,图12为说明(例如)由自请求处理器CPU 1(112a)接收请求的接收/远程处理器CPU 2(112b)进行的一致性请求处置的流程图1200。图12包括图8的块,连同包括传输事务中止状态(在事务中止字段1010中)作为协议响应的一部分的的新(已修改)块1205及1210。
在图12中,根据一个实施例,由接收/远程处理器(例如,CPU 2(112b))进行的请求处置接收请求。在块805处,远程处理器(CPU 2)自请求处理器(CPU 1)接收针对数据的XI请求(例如,请求505和/或请求605)。在块810处,远程处理器(CPU 2)通过检查远程处理器是否正处理以与所接收请求(例如,请求505及605)不兼容的方式引用数据的事务而检查是否检测到干扰。举例而言,在一个例示性实施例中,读取共享请求与对事务读取集合中的数据的引用兼容,但写入请求并不兼容。另外,读取独占、读取提升(亦即,自共享改变为独占)或写入请求并不与在事务的读取或写入集合中引用的相同数据兼容。当远程处理器(CPU 2(112b))在块810处判定远程处理器(自身)当前正使用由请求处理器(CPU 1(112a))请求的数据时,远程处理器判定(是)检测到干扰,且在块815处,远程处理器(CPU 2)中止在远程处理器(CPU 2)处发生的本地事务。一旦本地事务在远程处理器(CPU 2)处中止,在块1205处,远程处理器就将具有读取响应(READ RESPONSE)的数据连同事务状态字段1010(其通知请求造成事务(先前执行)在远程/接收处理器(CPU 2)处中止以便实现请求)传输至请求处理器(CPU 1)。在另一实施例中,可以以写入响应1105应答所接收写入请求。在目前最新的系统中,无事务状态字段1010将被包括在自远程CPU 2(其先前执行其自己的现在中止的事务)发送回至请求CPU 1(其发送请求505和/或605)的响应(RESPONSE)中。远程处理器(CPU 2)在块825处改变数据状态且可选地在必要时自其本地高速缓存清除数据。远程处理器(CPU 1)在块830处发始事务失败处理,且流程结束。当远程处理器(CPU 2(112b))在块810中判定远程处理器当前未使用由请求处理器(CPU 1(112a))请求的数据时,远程处理器判定未检测到干扰,且在块1210处,远程处理器(CPU 2)连同事务状态字段1010(其指示请求不造成事务中止)一起传输具有读取响应(READ RESPONSE)的数据。远程处理器(CPU 2)在块840处改变数据状态且可选地在必要时自本地高速缓存清除数据,且流程结束。
图13说明根据一个实施例的由请求处理器(CPU 1(112a))进行的协议请求发起及处理的流程图1300。图13包括上文在图7中论述的块,且不重复图7的论述。另外,流程图1300包括新块1305及1310。举例而言,在块1305处,请求处理器(CPU 1)自远程处理器(CPU 2)接收具有数据的XI响应(块725)连同新事务中止状态字段1010。在块730处,请求处理器(CPU 1)将数据放置于本地高速缓存(诸如,L1和/或L2高速缓存)中。在块1310处,请求处理器(CPU 1)将所接收状态(例如,事务状态字段1010中的信息)添加至数据高速缓存118a(和/或存储器310)中的本地事务干扰追踪表1350a。当请求处理器(CPU 1)造成干扰(在远程处理器(CPU 2)处引起事务中止)时,本地事务干扰追踪表1350a可为保持追踪干扰的存储位置,且本地事务干扰追踪表1350a可包括此信息的日志。本地追踪事务干扰(存储)表1350a包括增量统计及当前事务状态。增量统计针对每一事务中止而增加(报告回至接收处理器(CPU 1)),且增量统计可分离成共享/独占(R/W)请求及汇总请求。本地追踪事务干扰存储表1350a可包括针对由请求处理器(CPU 1)造成的每一事务中止及针对每次在请求处理器(CPU 1)处未中止事务而递增的计数器。在一些实施例中,结合块1310而接收的事务中止状态亦可汇总于性能监视单元、运行时插装单元和/或另一性能追踪逻辑中以便使信息可用于动态优化器、适时(JIT)编译器或用于由编程人员进行的性能调谐。信息可通过在存储器中在性能监视时导向的结构中记入和/或通过引发通知(例如,根据Power ISATM的基于PMU事件的分支,或异常)而被记录。报告可包括干扰的性质、干扰和/或被干扰事务的标识、处理器ID、经受此干扰的地址等等。
如本文中所论述,一致性协议使用多个位—地址、数据以及状态和控制位。这些数据用于发出数据请求,且指示其所有权(例如,共享、独占)及状态(例如,已变更、未变更)。额外一个或多个位(用于事务中止状态字段1010)被添加以指示请求造成事务中止和/或可造成事务中止。举例而言,状态位(事务中止状态字段1010)指示当被请求数据由远程处理器(CPU 1)放弃时,该数据造成用于事务执行的冲突。如所提及,对请求的响应可以以事务在进行中且请求造成事务中止的指示而复原。
在一个实施例中,额外度量(诸如,已中止事务中的指令的数目)被在事务中止状态字段1010中传输。在一个实施例中,指示用于判定(例如)在获胜事务稍后变得中止且重新开始的状况下相对于事务的重新开始的失步(holdoff),以避免活锁情景。当请求处理器(CPU 1)判定请求处理器已通过检查本地事务中止状态字段1010而在远程/接收处理器(CPU 2)中造成过多(例如,预定量)的事务中止时,请求处理器(CPU 1)亦能够响应于中止过多的远程事务而节流(缩减)其请求率以增加总系统吞吐量。
在又一实施例中,此类通知(在事务中止状态字段1010中)被搜集于日志中和/或经由通知机制(例如,异常)而向动态再优化组件通知;动态再优化组件能够动态地再优化代码以缩减干扰和/或产生替代代码以使用锁来代替事务。
现在,图9的块包括于图14中,但不重复其论述。图14亦包括对图9的修改。图14为根据一个实施例的说明由处理器进行的事务处置的流程图1400。可假定处理器为请求处理器(CPU 1)。图14包括图9的块,连同块1405。在块1405处,请求处理器(CPU 1)在块1405处将包括事务干扰统计(自新事务中止状态字段1010获得且存储于本地追踪事务干扰存储表1350a中)的事务信息(诸如,事务诊断块(TBD))写入寄存器334、高速缓存118a,和/或存储器310中。在一个实施例中,当事务完成时,事务可包括其是否已造成一个或多个事务中止作为结果码(例如,结果寄存器、结果条件寄存器等(例如,在寄存器334a、334b中))的一部分的指示。在一个实施例中,当事务在一个或多个寄存器(例如,寄存器334a、334b)和/或存储器位置中设定结果状态时,所述一个或多个寄存器(例如,在寄存器334a、334b中)和/或存储器位置(例如,在存储器310、高速缓存118a、118b中)可包括被中止以将数据至提供事务的被干扰事务的数目、干扰的性质(具有写入集合的读取请求,或具有读取或写入的写入请求等)。在一个实施例中,如此存储的信息可包括关于事务中的每一者的特定信息,且包括用于识别发生干扰的处理器的方式、已中止(例如,通过指定事务开始XBEGIN或TBEGIN的地址、令牌、事务ID等)的事务、在中止之前已由该事务执行的工作的度量等。在一个实施例中,当根据本发明而扩展目前最新事务诊断块以具有对应于干扰及事务中止状态的额外字段时,存储至一个或多个存储器位置的信息对应于(例如)根据z/Architecture(以引用方式包括于本文中)的事务诊断块(TDB)的存储器位置,及根据本发明的事务诊断块的字段,所述字段对应于由新引入的协议字段个别地和/或由来自多个此类字段的汇总信息所传输的信息。在另一实施例中,存储于寄存器和/或存储器位置中的信息被提供为相异的、分离的且独立于目前最新TDB。
在块1405处,请求处理器(CPU 1)被配置为经由性能监视单元和/或运行时插装单元而将干扰统计提供给编程人员,且将干扰信息提供给固件、毫代码等。在毫代码中,毫代码可使用干扰统计信息以避免活锁和/或使用干扰统计信息以优化事务重新开始。在应用中,所述应用能够使用干扰统计信息以避免活锁且优化事务重新开始。
根据一个实施例,下文出于解释目的而提供实例代码。
当事务已中止且具体地被优化以避免活锁情景时,以下伪代码(在处理器112a、112b上执行)提供一种执行事务重新开始优化的形式(明显地在毫代码中和/或通过集成在在处理器上运行的应用中的代码)以便重新开始该事务。例示性代码使用以例示性方式而存储于TDB中的信息,然而,本领域技术人员能够使用自包括但不限于存储位置(例如,存储器310)、寄存器334a、334b、状态代码和/或性能监视单元、运行时插装单元等获得的信息:
根据例示性程序代码,事务重新开始代码包括检查其自身是否已中止,及其是否又已中止另一事务。在一个实施例中,立即诊断可能的活锁。在另一实施例中,如果目前事务及被干扰事务为循环干扰图的一部分(亦即,每一事务直接地或间接地中止其他事务),则执行测试(未图示)。在一个实施例中,当诊断到互击落(mutual shootdown)时,采取干扰避免动作。在一个实施例中,当诊断到互击落时,采取活锁避免动作。在一个实施例中,通过调用函数avoid_livelock()而调用干扰避免动作。在一些实施例中,这些动作可包括但不限于以下各者中的一者或多者:目前事务的较低优先级;等待退避时期;使用锁而同步;等等。
在另一例示性实施例中,当事务已中止且具体地被优化以避免活锁情景时,以下伪代码提供一种执行事务重新开始优化的形式(明显地在毫代码中或通过集成在在处理器上运行的应用中的代码)以便重新开始所述事务。例示性代码使用以例示性方式而存储于TDB中的信息;然而,本领域技术人员能够使用自包括但不限于存储位置、寄存器、状态代码或性能监视单元、运行时插装单元等获得的信息。在例示性代码中,当其对应于已超过(可能)互击落的阈值的事务时,事务采取活锁防止操作:
根据例示性代码,事务重新开始代码包括检查事务自身是否已中止,及其是否又已中止另一事务。在一个实施例中,立即诊断可能的活锁。在另一实施例中,如果目前事务及被干扰事务为循环干扰图的一部分(亦即,每一事务直接地或间接地中止其他事务),则执行测试(未图示)。在一个实施例中,当已诊断超过阈值数目个互击落(mutual_shootdown>阈值)时,采取干扰避免动作。在一个实施例中,当已诊断超过阈值数目个互击落(mutual_shootdown>阈值)时,采取活锁避免动作。在一个实施例中,通过调用函数avoid_livelock()而调用干扰避免动作。在一些实施例中,这些动作可包括但不限于以下各者中的一者或多者:目前事务的较低优先级;等待退避时期;使用锁而同步;等等。
重新开始优化(明显地在毫代码中或在应用中):
根据例示性代码,事务重新开始代码包括检查事务自身是否已中止,及其是否又已中止另一事务。在一个实施例中,立即诊断可能的活锁。在一个实施例中,当已被诊断超过阈值数目个互击落(mutual_shootdown>阈值)时,如果目前事务及被干扰事务为(或在另一实施例中可为)循环干扰图的一部分(亦即,每一事务直接地或间接地中止其他事务),则测试被执行live_lock_loop_detected(),其可存取经由响应中止状态消息且可选地结合其他方式而接收的额外信息。如果如此,则采取活锁避免动作。在一个实施例中,通过调用函数avoid_livelock()而调用活锁避免动作。在一些实施例中,这些动作可包括但不限于以下各者中的一者或多者:目前事务的较低优先级;等待退避时段;使用锁定而同步;等等。
根据一个实施例,图15为说明处理器(例如,请求处理器CPU 1)如何根据事务中止状态字段1010中的信息而对干扰指示(例如,在本地追踪事务干扰存储表1350a中存储(及递增/追踪))作出响应的流程图1500。在块1505处,请求处理器(CPU 1)报告干扰统计。报告干扰统计可包括如块1405中所论述而写入事务信息。在块1510处,请求处理器(CPU 1)通过判定干扰成本何时过高而判定额外同步是否有可能避免重复干扰。当请求处理器(CPU 1)重复地中止在接收/远程处理器(CPU 2)上执行的(同一)事务达预定次数(例如,4次)和/或事务在中止之前已完成指令的预定数目个时钟周期(例如,10,000个时钟周期)时,干扰成本过高。
当请求处理器(CPU 1)在块1510中判定额外同步没有可能避免重复干扰(由来自请求处理器(CPU 1)的针对数据的请求造成的在远程处理器(CPU 2)上的重复事务中止)时,在块1515处,请求处理器(CPU 1)检查代码再优化是否为可能的。当请求处理器(CPU 1)判定再优化为可能的时,在块1520处,请求处理器再优化代码。当请求处理器(CPU 1)判定再优化为不可能的时,在块1525处,请求处理器以当前代码(包括诸如退避的耐受性度量)继续。退避是请求处理器判定在做出针对数据的请求之前等待预定时间量,以便使接收/远程处理器(CPU 2)具有用于接收/远程处理器的事务的时间以完成执行(而不必中止)。
当请求处理器(CPU 1)在块1510中判定额外同步有可能避免重复干扰(由来自请求处理器(CPU 1)的针对数据的请求造成的在远程处理器(CPU2)上的重复事务中止)时,在块1530处,请求处理器(CPU 1)利用替代同步。在块1535处,请求处理器(CPU 1)检查(例如)本地追踪事务干扰存储表1350a中的日志以判定(同一事务(亦即,具有相同高速缓存/存储器地址)的)重复干扰何时已在远程/接收处理器(CPU 2)上发生。当不存在重复干扰时,流程进行至块1525。当请求处理器(CPU 1)判定存在重复干扰(对于远程/接收处理器(CPU 2)上的同一已中止事务)时,在块1540处,请求处理器检查代码再优化是否为可能的。当再优化为可能的时,在块1545处,请求处理器(CPU 1)再优化代码。
当请求处理器(CPU 1)判定代码再优化为不可能时,在块1550处,请求处理器(CPU 1)被配置为永久地(和/或历时一预定时期)选择替代同步方法以用于向接收/远程处理器(CPU 2)请求数据的此特定事务(在请求处理器(CPU 1)上执行)。
根据一个实施例,图16为说明处理器(例如,请求处理器CPU 1)如何根据事务中止状态字段1010中的信息而对干扰指示(例如,在本地追踪事务干扰存储表1350a中存储(及递增/追踪))作出响应的流程图1600。图16包括图15的块,除块1605替换块1540以外。不重复图15的块。
当块1535为是时,流程进行至图16中的块1605。在块1605处,请求处理器(CPU 1)检查再优化或替代同步是否为优选的。当块1605中的判定为是时,流程进行至块1545。当块1605中的判定为否时,流程进行至块1550。在图15的块1540中,当代码再优化为可能的时,代码再优化被始终执行。在1605中,计算度量以判定代码再优化或替代同步方法(例如,锁)是否为期望的,且选择一者或另一者。这可基于(例如)将使用替代同步方法的汇总成本与使用再最佳化成本的成本加执行再优化的成本相比较的测试,以判定哪一者为所期望的。其他成本度量是可能的且由本发明涵盖,诸如,(例如)通过将再最佳化成本与阈值相比较而最小化再优化开销的成本。
图17为根据一个实施例的用于实施一致性协议的方法(由处理器112a、112b执行)的流程图1700。
在块1705处,请求处理器112a(CPU1)经由互连122而将针对数据的请求(诸如,请求505、605)发送至远程处理器112b(CPU2)。在块1710处,请求处理器112a(CPU1)自远程处理器112b接收响应(诸如,响应1005、1105),其中该响应包括远程处理器112b上的远程事务(例如,事务320b)的事务状态(例如,事务中止状态1010)。在块1715处,请求处理器112a将远程处理器上的远程事务的事务状态(来自字段1010的信息)添加到本地事务干扰追踪表(例如,表1350a)。
除了上文所描述的特征中的一者或多者以外,或作为替代方案,另外的实施例亦可包括其中将远程事务的事务状态添加至事务诊断块(TBD)(由请求处理器112a)。远程事务在远程处理器112b上执行且基于将针对数据的请求发送至远程处理器而中止执行。该请求是由在发送请求的请求处理器112a上执行的请求事务(例如,事务320a)做出。
除了上文所描述的特征中的一者或多者以外,或作为替代方案,另外的实施例亦可包括其中基于由请求事务进行的请求造成远程事务(例如,事务320b)在远程处理器112b上中止,请求处理器112a将远程事务的事务状态(自字段1010获得)添加至本地事务干扰追踪表1350a且递增已针对远程事务(中止的每一特定事务320b)而发生的事务中止的计数。
除了上文所描述的特征中的一者或多者以外,或作为替代方案,另外的实施例亦可包括其中由请求处理器112a在响应1005、1105中自远程处理器112b接收的远程事务的事务状态指示远程事务(事务320b)必须基于自请求处理器112a接收到请求505、605而中止。
除了上文所描述的特征中的一者或多者以外,或作为替代方案,另外的实施例亦可包括其中本地事务干扰追踪表1350a维护已被干扰且由在请求处理器112a上执行的请求事务320a中止的事务数。本地事务干扰追踪表1350a维护描述远程处理器112b(及其他处理器)上的远程事务320b的信息。描述远程处理器112a上的远程事务320b的信息包括以下各者中的至少一者:由在处理器上执行的请求事务造成的干扰的类型、由请求事务中止的远程事务中的每一者的标识或地址、发生干扰的远程处理器中的每一者的标识、已中止的远程事务中的每一者的地址,和/或在中止之前已由远程事务中的每一者执行的工作的度量。
技术效果及益处包括被扩展以包括关于事务状态的额外信息的一致性协议。当处理器在事务执行中时,一致性请求能够因为检测到冲突而造成接收处理器的事务执行中止。根据各实施例,使用接收处理器已中止其事务执行的额外信息来扩展一致性协议请求。
本文中所用的术语,仅仅是为了描述特定的优选实施例,而不意图限定本发明。本文中所用的单数形式的“一”和“该”,旨在也包括复数形式,除非上下文中明确地另行指出。还要知道,“包含”和/或“包括”在本说明书中使用时,说明存在所指出的特征、整体、步骤、操作、单元和/或组件,但是并不排除存在或增加一个或多个其它特征、整体、步骤、操作、单元和/或组件,以及/或者它们的组合。
以下的权利要求中的对应结构、材料、操作以及所有功能性限定的装置(means)或步骤的等同替换,旨在包括任何用于与在权利要求中具体指出的其它单元相组合地执行该功能的结构、材料或操作。所给出的对本发明的描述其目的在于示意和描述,并非是穷尽性的,也并非是要将本发明限定到所表述的形式。对于所属技术领域的普通技术人员来说,显然可以作出许多修改和变型而不偏离本发明的精神和范围。对实施例的选择和描述,是为了最好地解释本发明的原理和实际应用,使所属技术领域的普通技术人员能够明了,本发明可以有适合所要的特定用途的具有各种改变的各种实施例。
本发明的各种实施例的描述已为达成说明的目的而呈现,但不意欲为穷尽性的或限于所揭示的实施例。在不脱离所描述实施例的范围及精神的情况下,许多修改及变化对于本领域技术人员将显而易见。本文中所使用的术语被选择以最好地解释实施例的原理、实际应用或对市场中找到的技术的技术改进,或使其他本领域技术人员能够理解本文所揭示的实施例。
现在参看图18,大体上示出根据一个实施例的包括计算机可读存储介质1802及程序指令1804的计算机程序产品1800。
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。
计算机可读存储介质可以是可以保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以是但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、静态随机存取存储器(SRAM)、便携式压缩盘只读存储器(CD-ROM)、数字多功能盘(DVD)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。这里所使用的计算机可读存储介质不被解释为瞬时信号本身,诸如无线电波或者其他自由传播的电磁波、通过波导或其他传输媒介传播的电磁波(例如,通过光纤电缆的光脉冲)、或者通过电线传输的电信号。
这里所描述的计算机可读程序指令可以从计算机可读存储介质下载到各个计算/处理设备,或者通过网络、例如因特网、局域网、广域网和/或无线网下载到外部计算机或外部存储设备。网络可以包括铜传输电缆、光纤传输、无线传输、路由器、防火墙、交换机、网关计算机和/或边缘服务器。每个计算/处理设备中的网络适配卡或者网络接口从网络接收计算机可读程序指令,并转发该计算机可读程序指令,以供存储在各个计算/处理设备中的计算机可读存储介质中。
用于执行本发明操作的计算机程序指令可以是汇编指令、指令集架构(ISA)指令、机器指令、机器相关指令、微代码、固件指令、状态设置数据、或者以一种或多种编程语言的任意组合编写的源代码或目标代码,所述编程语言包括面向对象的编程语言—诸如Smalltalk、C++等,以及常规的过程式编程语言—诸如“C”语言或类似的编程语言。计算机可读程序指令可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络—包括局域网(LAN)或广域网(WAN)—连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。在一些实施例中,通过利用计算机可读程序指令的状态信息来个性化定制电子电路,例如可编程逻辑电路、现场可编程门阵列(FPGA)或可编程逻辑阵列(PLA),该电子电路可以执行计算机可读程序指令,从而实现本发明的各个方面。
这里参照根据本发明实施例的方法、装置(系统)和计算机程序产品的流程图和/或框图描述了本发明的各个方面。应当理解,流程图和/或框图的每个方框以及流程图和/或框图中各方框的组合,都可以由计算机可读程序指令实现。
这些计算机可读程序指令可以提供给通用计算机、专用计算机或其它可编程数据处理装置的处理器,从而生产出一种机器,使得这些指令在通过计算机或其它可编程数据处理装置的处理器执行时,产生了实现流程图和/或框图中的一个或多个方框中规定的功能/动作的装置。也可以把这些计算机可读程序指令存储在计算机可读存储介质中,这些指令使得计算机、可编程数据处理装置和/或其他设备以特定方式工作,从而,存储有指令的计算机可读介质则包括一个制造品,其包括实现流程图和/或框图中的一个或多个方框中规定的功能/动作的各个方面的指令。
也可以把计算机可读程序指令加载到计算机、其它可编程数据处理装置、或其它设备上,使得在计算机、其它可编程数据处理装置或其它设备上执行一系列操作步骤,以产生计算机实现的过程,从而使得在计算机、其它可编程数据处理装置、或其它设备上执行的指令实现流程图和/或框图中的一个或多个方框中规定的功能/动作。
附图中的流程图和框图显示了根据本发明的多个实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段或指令的一部分,所述模块、程序段或指令的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或动作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
- 还没有人留言评论。精彩留言会获得点赞!