处理与机器人的对话的方法和系统与流程
本专利涉及数字数据处理领域,更特别地涉及语音合成和交互式对话的处理,尤其是在机器人与人类用户之间的交谈的特定背景下。
背景技术:
陪伴机器人有益地能够与人类建立情感关系。通过语音或对话皮肤的对话的动态适应能够实现丰富的交互。
现有的用于讲话或语音合成的系统大多数被动且无变化:超过比如男人或女性语音选择的几个选项,语言生成引擎的音色相当中性。而且,提供回应缺乏文化参照。工业或大众市场语音回答系统的目标确切地是提供普遍接受的回应,即,被尽可能广泛地理解。这暗指避免任何上下文参照,更不用说文化参照。语音命令通常限于具体的上下文。例如,语音听写软件主要用于独立软件应用(例如,文字处理软件)的上下文中。根据现代操作系统越来越提供的一些可访问性特征,用户能够使用语音命令来执行一些动作(例如,开始应用,复制和粘贴,等等)。这些预定义的动作相当有限。这种视觉或听觉交互模式通常是被动的(例如,用户主动地给予指示,机器执行指示)。即使使用近期的计算机交互模型,诸如那些在例如回答系统中所实现的模型,也会发生从机器到用户的有限交互。
在伴随类人机器人的背景下,当相比于与个人计算机(及其不同的形式)的交互模型时,与人类用户的交互模型显著地变化。与机器人的认知交互基本上不同于与平板PC或智能手机的认知交互。特别地,调制机器人的讲话合成的能力即便对丰富交互不主要也是有益的,这进而能够允许采集相关的数据并且改善机器人或所连接的设备所呈现的服务。
对于尤其在机器人与人类用户之间的交谈的特定背景下处理语音合成(形式)以及相关联的交互对话(实质)的方法和系统存在需求。
技术实现要素:
公开了一种处理机器人与人类用户之间的音频对话的计算机实现的方法,所述方法包括:在所述音频对话期间,接收音频数据并且将所述音频数据转换成文本数据;响应于对所述文本数据的一个或多个对话模式执行规则进行的核验,选择修改后的对话模式;其中对话模式包括一个或多个对话内容以及一个或多个对话语音皮肤;其中对话内容包括预定义句子的集合,所述集合包括问题句子和回答句子;并且其中对话语音皮肤包括语音渲染参数,所述语音渲染参数包括频率、音色、速度和音高。
在发展中,该方法还包括执行所述选择的修改后的对话模式。
在发展中,修改后的对话模式是通过修改当前对话的当前对话内容和/或当前对话语音皮肤来获得的。
在发展中,修改当前对话内容的步骤包括使用所述对话内容的词语的同义词以及应用句法修改,所述句法修改包括所述对话内容的一个或多个词语的插入或置换或替代。
在发展中,修改所述当前对话语音皮肤的步骤包括修改所述当前对话语音皮肤的频率和/或音色和/或速度和/或音高。
在发展中,修改后的对话模式是通过激活预定义对话模式来获得的,所述预定义对话已经由所述一个或多个对话执行规则选定并且所述预定义对话模式包括预定义对话内容和/或预定义对话语音皮肤。
在发展中,对话模式执行规则取决于机器人所感知到的环境。
在发展中,对话模式执行规则包括从包括如下的列表中选出的参数:用户年龄、用户性别、用户的情绪、用户的情感、用户数量、与用户的交互历史、用户偏好、机器人和/或用户的空间放置、机器人和/或用户的姿势或姿势的组合、在机器人的环境中的检测到的事件、本地天气、地理位置、日期、时间及其组合。
在发展中,对话模式执行规则是从因特网动态取回的和/或是用户可配置的。
在发展中,一个或多个对话内容或对其的选择是通过一个或多个过滤器的应用来节制的,所述过滤器包括一个或多个词语的黑名单、一个或多个词语的白名单和/或对话模式执行规则。
在发展中,对话内容和/或对话语音皮肤是通过语音命令或用户请求来选定的。
在发展中,该方法还包括:标识缺失的对话模式,在与用户的对话期间取回所述缺失的对话模式并安装于所述机器人中。在发展中,该方法还包括:在执行选定的对话模式之前,接收用户的确认。在发展中,该方法还包括:在修改的对话模式执行之后,接收用户的反馈。在发展中,该方法的步骤能够迭代(例如,对话模式能进一步被修改)。
公开了一种计算机程序,包括当所述计算机程序在适合的计算机设备或机器人设备上执行时,用于实施所述方法的一个或多个步骤的指令。公开了一种包括适于实施该方法的一个或多个步骤的装置的系统。
陪伴机器人通常是多模态的。沿着与个人计算机及其类似物对比来表征机器人的进展,语音交互构成了与用户的交互的重要部分。用户与机器人之间的对话能够增强或个性化交互且最后改善了用户体验。在实施例中,机器人使其自身通过其对话模式的适应而适应当前感知到的背景。机器人例如可以对外人说“先生”,或者如果过去被允许则可以使用一个人的姓,讲话更加或较不正式,取决于用户和/或上下文。具体的词语同样可以被过滤,取决于用户、历史、反馈、情绪、位置、日期和时间(举例)。当一个人不理解一个句子时,机器人在被请求时或者自己自主地可以慢速重复和/或用同义词重复。机器人还能够学习用户的偏好(使用哪种词汇表讲话更加或较不快速),改善用户的情绪。
有益地,机器人能够实现新语言扩展,渲染每个机器人的独特之处,开始积极情感,以及因此加强机器人与人类的关系。
有益地,根据一些实施例,人机交互是主动的,而不再是被动的:机器人从人类的视角,能够采取一些主动性(例如,机器人能够询问问题,例如,为了澄清的目的)。此外,利用以个性化或其它相关方式表达的适应的对话内容或格式,人机交互得以进一步优化。
有益地,交互的交谈模式允许与用户有更“亲密的”“关系”,至少越来越“自然的”交互。该更佳的用户体验可能导致机器对人类用户的增强的“理解”。通过相关的语音皮肤和/或对话句子暗示和加强的与机器的相关联的“接近度”能够促进来自用户以及关于用户的数据的采集。用户和机器人都可以更“具表达性”。术语“表达力”是指这样的事实:因为人机交互(更加)自然,所以用户将更多的数据传达给机器人,机器人进而能够得知且存储关于用户的更多的数据,在有效的圈内进一步丰富了交互。对于个人计算机,情况并非如此。平板设备可以尝试询问“问题”,例如,为小测验或问卷的形式或者通过讲话合成,但是由于平板设备不被认为是能够(自主地)自我移动、将物体移位或者跟随人类的“陪伴”,所以仍有残存偏差。当与伴随机器人相比时,所能够捕获的数据量较小。伴随机器人能够使用有趣的或其它相关的语音皮肤或对话格式的事实加强了这种捕获数据的能力。
关于用户的主动或被动地采集的信息(例如,用户配置文件或者用户声称的偏好)能够被用作用于开始条件的输入(例如,语音皮肤或对话格式应当仅在用户喜爱“Bienvenue chez les Ch'tis(欢迎来北方)”的情况下才开始。机器学习机制能够被执行:通过系统所开始或执行的语音皮肤或对话格式将根据关于用户所学习到的来演进。
附图说明
现在,将参照附图通过示例的方式来描述本发明的实施例,在附图中相似的标记指代相似的元件,并且在附图中:
图1图示说明了本发明的全局技术环境;
图2详述了方法的实施例的一些方面。
具体实施方式
“对话”包括预制作的句子。对话是预定义句子的集合,包括对问题的回应。对于多个问题的预期回应构成了对话。
“对话模式”包括影响规划的句子的实质(“对话格式”或“对话内容”)和形式(“语音皮肤”或“语音渲染”)的一个或多个修改操作。换言之,“对话模式”与实质性方面(例如,消息所传达的实际内容或信息)相关联以及与形式方面(例如,所讲语言的表达力或情感或音色)相关联。对话模式能够以可下载软件程序的形式来实现,所述程序包括当在适当的机器人设备上执行时使得所述机器人设备执行特定物理动作的指令,物理动作包括执行编程的对话模式(对话内容和/或语音皮肤)。软件程序能够被提供作为“扩展模块”或“插件”或“附加物”。附加的对话模式能够与机器人的缺省对话内容和语音皮肤组合或添加到机器人的缺省对话内容和语音皮肤或替代机器人的缺省对话内容和语音皮肤。在实施例中,对于安装在机器人上的其它软件应用,对话模式可以称为服务。例如,天气应用可以在某上下文中(例如,满月)使用Dark Vador的语音。对话模式和/或相关联的执行规则能够通过网络来访问或者在本地访问。在一些实施例中,通过访问网络和远程知识库来补充或增补对话模式和/或相关联的执行规则。
“对话内容”或“对话格式”或“对话话题”是指预定义句子的集合,所述句子对应于问题和(预期的或期望的或可能的)回答,例如,围绕某主题或话题或感兴趣领域(但是不一定,因为可以构想句子的一般范围)。句法修改可以修改安装在机器人中的现有对话内容的实质(例如,比如“超级”的最高级词的插入,词语的置换,等等)。对话内容或格式能够使得某些词语被审查(例如,无论有二义性或者根据概率或阈值,确定词语的使用会被禁止),一些其它词语能够被允许,或者一些词语的使用能够被鼓励(偏置)。对话内容或格式尤其可以包括(或添加,如果修改)实质性内容和其它文化参照。词语的选择可以取决于上下文并且包括暗指或文化参照。对话可以因此包括一个对话内容(由句子构成的预制作的对话)。例如,不是其唯一的商业名称,游戏应用可被机器人称为“具有鸟和绿色猪的游戏”或者“其中你须将鸟投向目标的游戏”等等。这些由句子、可能的问题和回答构成的元描述构成了对话内容。这些对话内容允许机器人与用户进行交谈。例如,如果用户问到“我愿意和鸟一起玩”,则机器人可进一步问到“你想要和真实的鸟玩还是和虚拟的鸟一起玩?”。如果用户以“和虚拟的鸟”回应,则机器人可以请求确认“那么你想要玩游戏吗?!”。如果用户以“是的”回应,则机器人可更进一步请求确认,例如,“我有一个你须将鸟投向绿色猪的游戏”。
“对话皮肤”或“语音皮肤”是指音频渲染修改。该音频渲染修改影响“形式”(例如,频率、速度、音高和音色)。换言之,对话皮肤的应用能够根本地改变机器人的表达力,而不修改底层的预制作句子。与机器人的讲话交互的修改的影响可以在不同水平下进行评估:以内容的方式(实质)和/或形式(音色等)。语音皮肤可以包括导致模仿某些语音的参数。可以处理多种多样的语音参数来管理讲话合成。语音参数包括频率(判定机器人是否将更严厉或更深切地讲话)、速度(机器人讲话多快或多慢)、音色(例如,如果演员Sylvester Stallone和人物Master Yoda以相同速度和频率讲话,则它们不具有相同的音色)。在实施例中,用户可以要求他的陪伴机器人像Master Yoda或Sylvester Stallone一样讲话。通过用预定义语音参数适当地修改语音参数,能够获得接近的结果。“动态”模仿貌似合理(记录音频摘录、推导参数以及应用相关的修改)并且可允许机器人模仿一个或多个用户。在实施例中,多个语音皮肤能够组合。一些语音皮肤会不兼容组合(相互排斥)。一些其它语音皮肤可以在一定程度上组合。一些其它语音皮肤可以是加性的。
“对话执行规则”是指管控一个或多个语音皮肤和/或对话内容或格式的应用的执行规则。“执行规则”可以包括脚本、程序代码或其它布尔表达或逻辑规则,它们允许适应机器人所能说的措辞(词汇表、一些表达加在句子之前或句子末尾,等等)。每当机器人要对人类用户说某事物时(例如,因为机器人正在尝试回答问题或澄清情形),如果机器人的规划句子确实匹配一个或多个对话执行皮肤规则,则将根据这些规则来修改句子,随后机器人将它说出。在实施例中,一个或多个对话执行规则可应用于一个或多个句子(即,规划以便由机器人说出)。在实施例中,所述规则能够应用于每个句子以便由机器人说出。在实施例中,规则能够应用于句子子集,例如,那些包括预定义词语或表达的句子子集。对话执行规则能够预定义。对话执行规则还能够从因特网动态地取回。一些规则可以是加性的,而一些其它规则可以是互斥的。例如,执行规则可以包括(例如,编码)年龄限制。累加执行规则能够使用或应用。例如,特定的语音皮肤可以在年龄在12以上的用户面前授权和/或根据某些情形(一天中的时间、测得的听众的情感等)来授权。一些执行规则可以是用户能配置的(例如,父母控制)。
作为示例,句子“我现在能跳舞”对应于标准的预定义措辞(写入机器人存储器内)。“我现在能跳hein biloute舞”对应于在应用了称为“Ch'tis”的对话格式后机器人所表达的措辞。音频渲染或语音皮肤“Ch'tis”可以(任选地)还提供适当的声音调制。形式和实质可以进行多样地修改:能够添加具体的口音或语调(例如,形成Northern France),能够丰富机器人所使用的词汇表,能够添加新的交谈话题(例如,问题与回答的模型)。
对话模式(对话内容和/或对话皮肤)能够实现在软件包中,其能够由软件编辑器来定义或编程。该软件可以是可修改的或不可修改。换言之,对话模式(例如,语音皮肤)可以是完全确定的(例如,不可以正式地允许进一步的参数化)。可替代地,对话模式可以仅部分确定。例如,一些(例如,有限数量的)本地参数可以仍在终端用户的控制之下,而大多数设置不会改变(以维持例如语音皮肤的整体完整性)。
换言之,超越了文字含义的软件应用(当在适当的计算机设备上执行时能够执行一个或多个步骤的计算机程序代码)可以(或者关联)对话内容(例如,预定义句子的集合,包括对预期问题的回应)和/或对话皮肤(例如,在对话内容之上编程,即,诸如根据环境、与头部运动同步、灯光(如果有)的激活等的适应的执行规则)及其组合(例如,在跳舞的同时对话)。软件应用可以相互依存。作为多模态输出的结果,软件应用可进一步组合(在输出级或者在较低级,例如,变量或参数或脚本能够在软件应用之间共享或修改)。例如,机器人能够使得所讲结果“外面-10℃度”伴随着将外面冷符号化的姿势的组合。
软件应用有益地能够通过对话接口呈现给用户,即在与用户的(“自然”)对话的动作过程中。换言之,对话系统可以对于用户充当“瓶颈”以便能够开始或执行一个或多个应用。
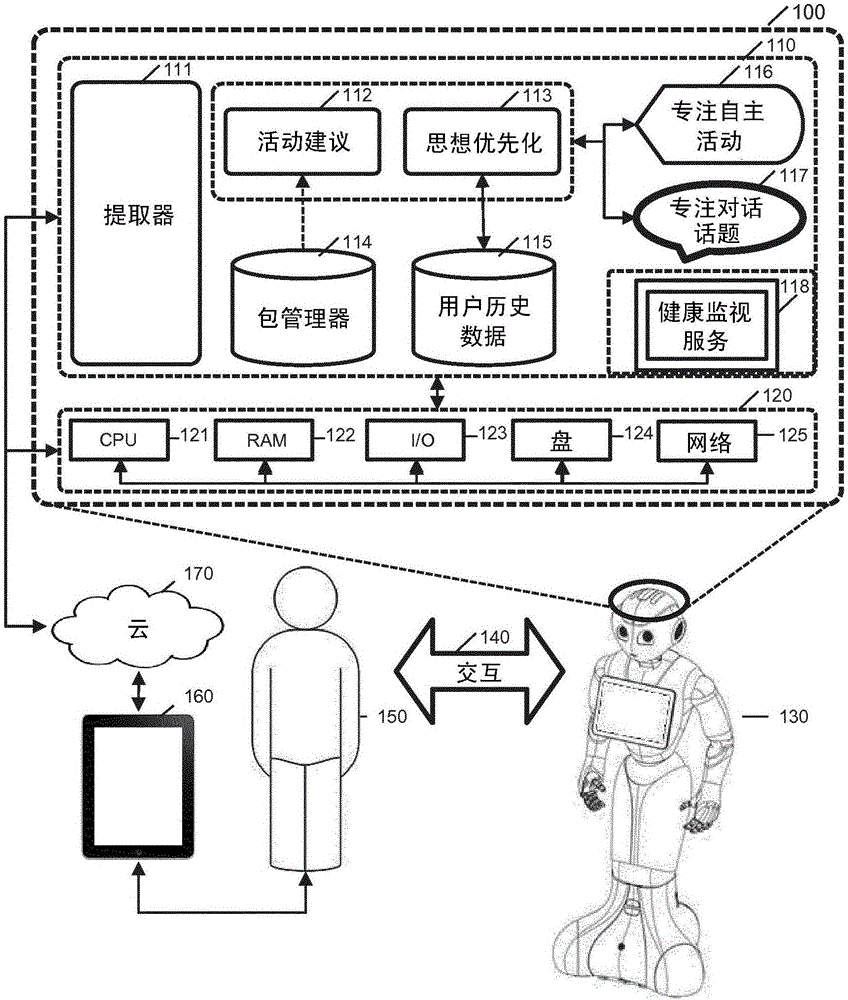
图1示出了本发明的全局与技术环境。机器人130包括传感器和执行器。逻辑或“思想”100实现在机器人中或者与机器人相关联(例如,远程地)并且包括软件组件110和硬件组件120的集合。机器人130正在与一个或多个用户150交互(通过双方或双向通信140,包括一个或多个对话会话)。所述一个或多个用户能够访问其它计算设备160(例如,诸如可佩戴式计算机或智能手机或平板设备的个人计算机),其能够是连接的设备(与服务器云通信和/或与一队其它机器人或连接对象通信,等等)。尤其是,连接设备可以是可佩戴式计算机(例如,手表、眼镜、沉浸式头盔等)。
在图中的具体的机器人130被看作仅仅是能够实现本发明的类人机器人的示例。在图中机器人的下肢没有行走功能,但是能够在其基座上在任意方向上移动,基座在其所在的表面上滚动。本发明能够容易地实现在适合行走的机器人中。
在本发明的一些实施例中,机器人可以包括各种传感器。其中一些传感器用于控制机器人的位置和运动。这是例如位于机器人的躯干中的惯性单元的情况,包括3轴陀螺仪和3轴加速度计。机器人还可以包括在机器人前额(上和下)的两个2D彩色RGB照相机。在机器人的眼睛后面也可以包括3D传感器。机器人还能够任选地包括激光线发生器,例如,在头部和基座中,从而能够感测其与其环境中的对象/人的相对位置。机器人还可以包括能够感测其环境中的声音的麦克风。本发明的机器人还可以包括声纳传感器、可能位于其基座的前部和后部,以测量距其环境中的对象/人类的距离。机器人还可以包括触传感器,在其头部上以及在手部上,以允许与人类交互。机器人还可以包括在其基座上的缓冲器以感测其在路线中所遇到的障碍物。为了转换其情感以及与其环境中的人类沟通,本发明的机器人还可以包括LED,例如,在其眼睛、耳部中以及在其肩部上以及扬声器(例如,位于其耳部中)。机器人能够通过各种网络(3G、4G/LTE、Wifi、BLE、网格等)与基站通信,与其它连接的设备通信,或者与其它机器人通信。机器人包括电池或能源。机器人能够访问适合于其所包含的电池类型的充电站。机器人的位置/运动由其电动机利用算法来控制,算法根据传感器的测量来激活由每个肢部以及限定在每个肢部的端部处的效应器所限定的链。
在具体的实施例中,机器人能够嵌入平板设备,利用该平板设备,机器人能够将消息(音频、视频、网页)传达给其环境,或者通过平板设备的触摸接口接收来自用户的输入。在另一实施例中,机器人不嵌入或呈现屏幕,但是其确实具有视频投影仪,利用该视频投影仪,能够将数据或信息投影到机器人附近的表面上。所述表面可以是平坦的(例如,地板)或不是平坦的(例如,投影表面的变形处可被补偿以获得基本上平坦的投影)。在两个实施例中(利用屏幕和/或利用投影仪),本发明的实施例均保持有效:要求保护的交互模型仅由视觉交互手段来增补或补充。在任意情况下,只要图形装置无序或被有意地去激活,交互的交谈模式保留。
在实施例中,机器人不包括这种图形用户接口装置。现有的类人机器人通常被提供了先进的语言能力,但是通常没有被提供GUI。日益增加的用户的群体可能不使用图形装置(例如,平板设备,智能手机),甚至作为补充,来与机器人通信,通过选择和/或必需(年轻人、功能缺损者,因实际情形,等等)。
软件110的集合(非穷尽地)包括彼此交互的软件模块或对象或软件代码部分,包括“提取器”111、“活动建议”112、“思想优先化”113、“包管理器”114、“用户历史数据”115、“专注自主活动”116和“专注对话话题”117和“健康监视服务”118。
“提取器服务”111通常感应或感知在机器人内或外的某物并且将短期数据提供给机器人的存储器。提取器服务接收来自机器人传感器的输入读数;这些传感器读数经预处理从而提取与机器人的位置、在其环境中的对象/人类的标识、所述对象/人类的距离、人类所讲的词语或其情感有关的相关数据。提取器服务尤其包括:面部识别、人感知、接合区、波动检测、微笑检测、注视检测、情感检测、语音分析、语言识别、声音定位、移动检测、全景罗盘、机器人姿态、机器人健康诊断、电池、QR码处理、家庭自动化、宗族、时间和安排。
“执行器服务”使得机器人130物理地做或执行动作。运动跟踪器、LED、行为管理器是“执行器服务”。
“数据服务”提供长期存储的数据。数据服务的示例是用户会话服务115,其存储用户数据,以及它们已经对机器人和包管理器服务114所做的历史,这利用它们的高级定义、开始条件和标签提供了机器人执行的程序的可扩展存储。“包管理器”尤其提供了活动和对话的可扩展存储,以及展示。“展示”包含了诸如开始条件、标签和高级描述的元数据。
“思想服务”(例如,服务思想优先化113)是在其开始动作时由机器人的中心“思想”控制的服务。“思想服务”与“执行器服务”130、“提取器服务”111和“数据服务”115结合在一起。基本感知是“思想服务”。其订阅“提取器服务”,诸如人感知、运动检测和声音定位,来告知运动服务移动。“思想”113基于该情形来配置基本感知行为。在其它时候,基本感知要么自我作用,要么由运行活动(Running Activity)来配置。
“自主生命”是思想服务。其执行行为活动。基于情形的上下文,思想能够告知自主生命专注何种活动(“专注自主活动”116)。在展示中的元数据将该信息结合思想。任何活动能够访问操作系统API中的一个或多个。活动还可以直接告知自主生命专注于何种活动,或者告知对话服务专注于何种话题。
“对话”服务能够配置为思想服务。其订阅讲话识别提取器并且能够使用“动画讲话执行器服务”来说话。基于情形的上下文,思想能够告知对话专注于何种话题(“对话话题”)。“对话”服务还使其算法来管理交谈并且通常自我起作用。对话服务的一个部件可以是“专注对话话题”服务117。对话话题能够在任何时候编程地告知思想切换注意力于(或者执行或开始)不同的活动或对话话题。确定对话话题的可能的方法的一个示例包括:在对话话题或活动的开始条件变为真或假的时刻,该时刻的全部可能的活动或对话话题的列表送给思想;列表根据活动优先化来过滤;列表次序随机化;列表被分类(或计分)以对“独特的”且已经不太经常启动的活动或对话话题给予优先权;确保该列表中的顶级对话话题或活动的特殊检查不是与先前所执行的活动相同的活动。该列表可以再次根据用户的偏好进行分类和过滤。
机器人能够实现“健康监视”服务118。该服务能够充当守护进程或“看门狗”,以阅览或控制或调节机器人的不同优先级。该服务能够监视(持续地、间断地或者周期性地)机器人的内部组件的状况并且测量或预期或预测或校正硬件故障。在发展中,监视一队(例如,安装的库)机器人。嵌入式服务能够持续地检测出错情况且将它们与“云”服务同步(例如,每分钟一次)。
硬件组件120包括处理器件121、存储器件122、输入/输出I/O器件123、大容量存储器件124和网络访问器件125、所述器件彼此交互(高速缓存、交换、分布式计算、负载平衡等)。处理器件121可以是CPU(多核或许多核)或FPGA。存储器器件122包括闪速存储器或随机存取存储器中的一个或多个。I/O器件123可以包括屏幕(例如,触摸屏)、灯或LED、触觉反馈、虚拟键盘、鼠标、跟踪球、操纵杆或投影仪(包括激光投影仪)中的一个或多个。存储器件124可以包括硬盘驱动器或SSD中的一个或多个。网络访问器件能够提供对诸如3G、4G/LTE、Wifi、BLE或网格网络的一个或多个网络的访问。网络业务量可以被加密(例如,隧道、SSL等)。
在实施例中,计算资源(运算、存储器、I/O器件、存储和连接)能够远程地访问,例如,作为(在机器人自身内可用的)本地资源的补充。例如,另外的CPU单元能够通过用于语音识别计算任务的云来访问。计算资源还能够共享。尤其是,多个机器人能够共享资源。在机器人附近的连接的设备也能够在一定程度上例如经由安全协议来共享资源。还能够共享显示器件。例如,电视能够在机器人经过时被机器人用作另外的显示器。
图2详述了该方法的实施例的一些方面。机器人130正在与人类用户150交互(例如,对话、姿势、命令)。交互的部分是对话140,包括句子(回答、问题、指示、断言、评论等)。机器人通常使用其缺省的标准语音皮肤(形式)并且输出标准的和预定义的对话内容(实质)。例如,机器人说出对话句子141。根据某些参数(用户请求或环境参数),机器人能够切换到另一语音皮肤和/或另一对话内容,例如142。机器人还能够切换回到初始或缺省的语音。在更详细地,以缺省的语音皮肤和对话内容200开始(或者根据初始/修改后的语音皮肤和/或修改后的对话内容),对话执行规则220判定对话是否已经修改以及在何种程度上修改。
对话执行规则220例如由用户请求221和/或由感知到的环境222来影响或确定(例如,通过传感器或机器人确定,通过提取器或者根据关于在机器人思想中实现的逻辑的所描述的实施例来过滤)。例如,环境参数包括:附近的一个或多个用户的年龄组(孩子,成年人)、附近的一个或多个用户的性别、附近的用户总数、当前地点、当前日期和时间、一个或多个用户的当前情绪(例如,微笑、大笑、哭等)。用户请求221对应于新对话模式的激活的“按需”模式(例如,用户可以说“现在模仿Dark Vador”)。通过感知的环境的确定强调了新对话模式的激活的“自动触发”模式。机器人能够前摄地激活或者去激活对话模式的一个或多个参数(减弱或夸大语音皮肤、适应对话内容等)。两种激活(或去激活)模式能够组合,即,新对话模式的触发能够部分地由用户请求确定,部分地由环境确定。例如,在用户请求时,环境参数能够确认或抑制对话模式的变化。可替代地,自动切换可以要求用户的确认或授权来激活。对话模式通常可以在任何时候激活或去激活。在实施例中,有希望是有趣的,机器人能够来回使用多个对话模式。任选地,在变化数量上的限制能够被实现(以避免用户饱和或者给出机器人极其愚蠢的印象)。
对话执行规则220作用于实质和/或形式,实质和/或形式保持独立地处理。规则能够确定新对话内容210的加载(例如,参照剧院电影,通过表达公知的句子),以及控制音频渲染变化230。即使没有选择211对话内容,新语音皮肤能够应用230。新的或修改的对话内容还可以在没有新语音皮肤231的情况下应用。所确定的参数应用于对话模式(或者新的对话模式加载或替代机器人使用的当前对话模式)。例如,应用称为“Ch'tis”对话模式并且讲出句子142。可以观察到,整体地或者部分地,对话内容和/或语音皮肤参数能够从因特网或云223取回。
现在描述对话模式(对话内容以及尤其是语音皮肤)的示例。
在实施例中,“实用”对话模式(例如,对话内容的修改)允许使用一个或多个词典(或词库)以便机器人能够以不同方式说出给定的句子。例如,可以使用同义词。有益地,该实施例避免了机器人重复词语。语言学家(编辑预制作对话句子)能够写很多对话内容或话题,从而使得机器人能够讲出很多事情。同义词的使用增加了机器人的表达的多样性,像人类在使用不同词语时共同完成的。对话模式能够不同地渲染对话句子。例如,不是重复“今天天气很好”,机器人将能够说出“今天天气令人舒服”。
在实施例中,“本地”适应允许定制或个性化对话内容和/或语音皮肤,取决于多个参数,包括地理位置。例如,一些地理区域——例如,机器人将在此商业化——的一些语言特征,能够通过应用适合的语音皮肤来处理。在该实施例中,一些词语的发音能够例如基于地理位置来改动。语音皮肤的触发条件例如可以包括地理位置参数。实际上,在法国南部商业化的机器人能够自动地加载法国南部口音,反之亦然,对于法国北部加载北方口音。还可以应用惯用表达。
在实施例中,能够实现或执行“教育”对话模式。一般而言,由于实质性内容的添加可以是对话模式的应用的部分,所以可以设想一些教育范围。在该模式中,能够实现教育对话模式(例如,利用先决条件、目标的定义、因此的教育内容、同化的核验步骤)。用户可以利用陪伴机器人来学习外语。用户还可以发现他们的母语的方面。例如,不同的语言式样能够教导年轻用户(法国“Soutenu”、法国“Verlan”、法国“argot”等)。对话模式还能够实现具体的专业术语(医疗、律师等)。
在实施例中,能够实现“有趣”对话模式。例如机器人能够模仿或参照近期发布的剧院电影。例如,语音皮肤可以是“Dark Vador”或“Master Yoda”皮肤(Yoda人物经常变换动词和主语,Dark Vador可以将“我是你的父亲”添加到句子末尾并且以噪声呼吸)。
在发展中,电影院的发布与可下载程序相关联,当可下载程序加载到机器人上时会使得所述机器人实现具体的对话模式(根据对话内容和/或语音皮肤表达力)。例如,在电影院发布了比如“Bienvenue chez les Ch'tis”后,对应的对话模式能够供用作“特别吸引人的东西”或衍生产品。在实施例中,能够在DVD外套的背面上或者在电影票上使用的QR码可由图像获取器件来读取并且实现相应的对话模式的它们对应的软件程序能够被下载且进一步安装。任选地,该软件程序的效果的持续时间可以在时间上受限制(例如,两周)。在另一实施例中,著名明星或名人或英雄可以具有他们的数字对话模式对应部分。例如,Claude(法国的著名歌唱家)的爱好者可以在机器人中实现对应的语音皮肤(例如,语音模仿、语调)和/或对话内容(例如,复制品、引用语、会晤确切复制或重构,等)。作为多模态对象,除了所描述的对话模式之外(以及任选地),机器人例如能够编舞或者像Claude一样跳舞或者以歌唱家的过去记录的会晤的真实摘录(关于版权的方面如果适用)排他地回应。
在实施例中,机器人能够从与用户的交互中达到长期同化。例如,个性化的以及持久的对话模型能够逐渐地与给定机器人相关联。长期品质的选择和持续能够帮助定义与机器人相关联的“性格”的独特性。例如,比如“vin de diouss”的某些表达可以呈现出沿某些用户的充分高的可接受性,使得皮肤的特定方面将永久地实现。经过一个又一个皮肤,机器人的“个性”因此能够固定,混合不同对话模式的不同的特别之处,以及尤其是语音皮肤的不同的特别之处。
语言交互能够暗示学习曲线,既针对机器人,又针对用户。该交互可以命名为“社会交互”,即使一个参与者是机器人。鼓励(确认)所强调的重复性以及迭代性的语言交互例如能够促进学习活动。对话交互通常减少了“使用”与“学习”阶段之间的分离度。陪伴机器人能够尝试模仿其“教育者”,例如重新使用人类的口语表达和/或利用相似的音速。更多的与机器人的交互通常意味着更相关的交互,因为知识库得以丰富和交叉检查。
现在描述对话模式的触发的示例(例如,对话内容和/或对话皮肤的激活或去激活,例如利用执行规则)。
对话模式(例如,语音皮肤)能够与一个或多个执行规则相关联。可以根据该执行规则来触发(激活或去激活)对话模式。下文描述不同的实施例。存在多种在人类用户与机器人之间的包括句子的对话期间触发包括对话内容和对话语音皮肤的对话模式的开始或执行的方式。这些不同的触发一个或多个对话模式的开始或执行的方式(尤其所下文所描述的)能够独立并且能够进一步彼此结合。
在实施例中,一个或多个软件应用的开始或执行在与用户的对话(与用户的交互)期间被触发。音频信号被捕获,任选的被过滤和增强,执行讲话-文本操作(在机器人上本地地和/或在云上远程地),所获得的文本被分析,并且利用所述格式来执行一个或多个比较。在一个或多个匹配时,任选地利用阈值,在那些安装到机器人上的对话模式中选定一个或多个对话模式。结果,执行一个或多个对话模式。
在实施例中,对话模式的开始是全自动的,即无需用户同意或确认。在发展中,用户或超级用户(例如,父母)能够中断或暂停或终止或结束对话模式的执行。在另一实施例中,对话模式的开始要求用户的明确确认。机器人能够声明其开始某对话模式的意图,但是将在继续之前等待确认。例如,机器人能够声明“我打算像Dark Vador一样讲话”并且用户仍能够回复“现在不可以”。
在实施例中,能够取决于开始条件或参数执行对话模式。这些条件或参数可以是事实或规则或者两者(关于事实的规则)。这些事实例如包括用户的类型或种类、当前上下文或情形或环境,其特征在于一个环境值(例如,当前本地天气、日期和时间、检测到的情感、用户数量等)。执行规则的范围从简单规则到复杂规则。执行规则可以是有条件的。例如,在实施例中,多个规则必须其它规则中同时满足以授权或允许对话模式的执行。在另一实施例中,多个规则必须顺序地满足(例如,按某次序和/或利用时间限制或阈值)。一些执行规则可以被预定义。一些其它执行规则可以被动态地定义(例如,一些规则可以取自因特网)。
在实施例中,执行规则可以是简单规则。例如,执行规则可以包括(例如,编码)年龄限制。在另一实施例中,多个执行规则可以累加地使用或应用。例如,特定的语音皮肤可以在年龄在12以上的用户面前授权和/或根据某些情形(一天中的时间、测得的听众的情感等)来授权。在实施例中,对话语音皮肤或对话内容的应用由机器人检测到预定义事件时触发,所述事件确定时间标准(日历、一天中的时间等)和空间标准(在附近检测到的用户数量、所述用户的相应的年龄、从所述用户感知到的情感态度,例如微笑与否)的具体组合。
在实施例中,一些执行规则能够是用户可配置的(例如,父母控制)。一些执行规则可以预定义,而其它执行规则可以动态地取回,例如从因特网和/或从其它机器人。在同一对话期间能够激活或去激活对话模式:这些激活或去激活可以是动态的,例如能够以不同方式取决于所感知到的环境。
在实施例中,对话模式(例如,对话内容和/或对话皮肤,独立地)能够根据多种参数来激活或结束,包括“标签”的使用和/或“条件”的使用和/或“先决条件”的使用。
标签是能够与机器人所能说的一个或多个表达相关联的标记。这些标签能够动态地激活或去激活并且能够判定是否能够保存相关联的表达。例如,在机器人询问“你喜欢谈论烹饪吗?”,如果用户回应“不,我对烹饪不感兴趣”(或类似的),标签“烹饪”被去激活。机器人更新与标识的用户相关联的对话话题的列表。机器人未来将避免所述对话话题。
“条件”和“交叉条件”使得能够修改机器人将要说的,其根据预定义变量(例如,用户偏好)。例如,对于机器人问的问题“你的年龄是”,用户可以回应“我12岁”。在该情况下,机器人将值12存储为所标识的用户的值的年龄。后来,机器人可以问“你今晚做什么”。如果用户回应“什么也不做”,则机器人将回应存储为与“晚间活动”相关联的变量。从年龄组和夜晚事务的缺失,机器人的推理后来可以在夜晚推导或提议“你想要和我玩吗?”。
在实施例中,触发(即,对话模式或语音皮肤或对话内容的激活或去激活)能够由上下文(例如,环境、数据、时间、地点等)来驱动。在实施例中,机器人能够监视并记录一个或多个用户表达。在检测到类似“氛围(atmosphere)”的词语时,机器人则可以说“atmosphere,atmosphere,est ce j'ai une gueule d'atmosphere?”。这是文化参照的示例。然而,对话还可以更复杂的事实和规则来触发,例如,通过所谓的“事件”检测。例如,在某年龄组存在的情况下,不允许某些对话模式或皮肤。事实上,机器人例如能够评估至少用户年龄在12以下并且检测到交谈中的词语“法国油炸马铃薯”且随后加载特定的预定义皮肤(“Ch'tis”)。当用户触摸机器人的头时,事件的另一示例发生。在该情况下,可以加载、激活和执行特定的皮肤。事件可以包括诸如空间放置、姿势或姿势的组合、对话内容(关键词或关键表达)、年龄组和或性别的评估、用户偏好的参数。
在实施例中,在对话期间执行一个或多个应用,通过一个或多个执行规则的满足(或核验或满意)而触发该一个或多个应用。人与机器之间的对话被监视并且“格式”(例如)从对话流中持续地提取(“协作对话”模式)。在实施例中,讲话流被接收且持续地分析。提取超越了讲话流中带有或者不带有标记(“好的,Glass,拍照”)的语音命令(例如,关键表达)的唯一提取。尤其是,用户的词语或表达被提取且与预定义条件、标签、标记或交叉条件进行比较或匹配。
在另一实施例中,预定义一个或多个执行规则。软件应用由编辑者或出版者提供,包括包含执行规则列表的文件以便能够或允许或授权所述对话模式的执行。执行规则被测试:如果它们令人满意或允许或核验,则能够选择一个或多个对话模式。一些规则可以是最小满足标准。一些其它规则时间能够定义优选的开始或执行条件。例如,最小执行规则可以是“如果用户年龄在12以下且在22pm之前,则Dark Vador语音皮肤被授权”,优选的规则可以是“如果三个用户位于5m内,并且至少两个用户年龄在12以下,并且至少一个正在微笑且如果没其它相反指示,则提议用Dark Vador的语音来开玩笑”。
现在描述各个实施例。
现在描述反作用循环和相关反馈。在一个实施例中,给定的对话模式(例如,语音皮肤)的整体的成功或失败,从人类用户的视角,能够被接收和/或量化。在发展中,利用细粒度的粒度,机器人的每个语言主动性可以由用户确认或不确认(例如,通过检测明确的许可或者甚至从组合了姿势和语音命令的复杂人类行为得到的隐式的许可)。而且,协作模型能够实现:在用户/机器人的群体之间统计地执行给定表达的验证或无效。例如,如果表达“cha va biloute”接收到关于安装的库的部分的积极反馈超过75%,则所述表达能够在全局规模上被验证。相反,如果表达“à”接收到过少的积极反馈(或者接收到否定反馈),则所述表达可以永久地从具体的对话模式或模型移除。
在发展中,人类提供给“带皮肤的”对话的回应可以被记录以及进一步利用。在实施例中,回应用于衡量机器人干预的质量。在另一实施例中,它们的回应的实质进而能够用于进一步丰富交谈模型。例如,如果一个回应被循环地观察到,则回应进一步重新用于对话模式(即,对话内容)。
关于涉及到技术问题的商业方面,在实施例中,对话模式(例如,语音皮肤)经由电子市场分布。一些皮肤能够自由下载;一些其它皮肤会要求支付。一些皮肤可以时间上、区域上或其它硬件要求上受限制。
即使陪伴机器人理论上能够记录人类所说的每个词语,但是隐私方面阻止这样的记录。通过使用机器学习技术,机器人仍获取高级和非侵入的特征。例如,利用机器学习技术,能够提取循环的格式(词汇表的类型、优选的表达,等等)。同样,从剧院电影有限提取可以从副标题的分析中发生(在Master Yoda的示例中,能够从这些分析确定对话内容)。关于音色和频率的方面,监督学习能够允许机器人模仿某些指定的人。例如,机器人可以开始讲话并且可以进一步被请求修改某些参数(“讲话更严厉点”)。在实施例中,自动化陪伴能够在实现的语音皮肤与真实音频摘录之间执行,从而提供用于改善反馈环的机会。
现在描述对话内容的著作。不同的实体可能编辑对话内容。在实施例中,操作者或机器人平台可以著作对话句子(例如,语言学家编写对话句子)。在实施例中,对话内容由第三方公司(例如,软件开发者)编写和商业化。在实施例中,对话模式由机器人的用户或所有者来编写。例如,软件工具(“DJ-skins”)或网络平台可以促进语音皮肤的创建或修改。用户能够提交新的语音皮肤、在线编辑它们、为流行的语音皮肤投票或评分。版本可以包括混合预定义语音皮肤和/或为用户提供某些创建控件来微调语音皮肤和/或上传并共享声音或记录的句子,或其组合。可用的皮肤可以伴有证书或者没有,免费或者付费。语音皮肤能够由机器人的用户选定,用户例如可以收听不同的语音皮肤的不同应用并且选择或选定一个或多个优选的应用。在另一实施例中,对话由多方共同著作。在实施例中,对话是从机器人的安装的库以及从作为不同机器人的所有者的用户的真正的回应合并的。所述合并可以是对初始对话的补充。在另一实施例中,也是作为补充或替代,对话内容由在因特网内容上进行的提取来编写(例如,监督或非监督方法能够允许标识、提取和使用问题和回答)。有益地,这些实施例允许快速改善对话内容,接收分布式的反馈。所述改进能够迅速地在安装的库之间传播。例如,通过使用闭环机器学习,流行的语音皮肤能够在世界范围内传播。
如果多个实体能够贡献于对话模式的定义(即,提供对话内容和/或语音皮肤和/或相关联的执行规则),则最终的实现能够由机器人的提供者来控制。进一步的控制或调节层能够调制或过滤或减弱或放大或增加或鼓励或减少或抑制或限制或避免或禁止对话模式的使用。尤其是,如所述的,对话模式的使用能够通过执行规则来调节:机器人的制造商或提供者能够支配这些规则,或者部分地支配这些规则。
在实施例中,机器人的提供者能够控制最终音频渲染设备,即在类比复原之前的最新点。换言之,由选定的对话模式或内容或皮肤应用于对话的预制作句子所得到的机器人的规划音频表达能够在有效音频复原之前滤除。
为了确保或合理地确保机器人不会讲出任何差的词语,能够实现授权词语的白名单和禁用词语的黑名单以及灰名单(能够取决于实际上下文而被授权或不被授权的词语或表达)。在该情况下,将语音皮肤应用于对话内容的预制作句子上的结果可以与该名单进行比较。超过名单的使用的复杂的逻辑规则同样可以被使用。在成功时,如果经授权或允许,则句子被讲出(和/或相应地修改)。
另一将一个或多个对话内容和/或语音皮肤应用于机器人所表达的最终对话的调节方法可以包括使用安全启动方法。例如,对特定对话模式编码的每个软件包能够与(例如,二进制形式的程序的)散列值相关联。通过安装在机器人中的软件包的散列值的核验所证明的所述程序的适当的存在能够在成功核验后有条件地授权机器人的启动(或者在功能上进行一些限制)。
作为(通常是安装在机器人中的软件应用的)对话模式的执行的进一步调节,机器人的健康监视服务能够调节执行优先级。尤其是,软件应用的执行可以考虑到该“健康监视”服务。换言之,高级优先级方案能够进一步调节软件应用的执行,包括对话模式。在实施例中,机器人不与用户交互(即,没有与任何人交互)。在该情况下,机器人执行或者能够执行自主任务。在另一实施例中,机器人处于危险中(例如,“防护模式”、电池电量低或者临界、障碍物的存在或者掉落的风险,等等)。在该情况下,机器人的优先级是处理并解决其自身的问题(例如,执行其自身的任务)。例如,如果电池电量临界,则机器人能够中断与用户的对话并且尝试到达能源基地。如果在附近检测到用户和/或如果机器人不处于临界情形(其中机器人可以不执行其基本功能),能够激活对话模式。相反,如果在附近没有检测到用户和/或机器人处于临界情形,则对话模式模块可以被去激活。
公开的方法能够采取完全硬件的实施例(例如,FPGA)、完全软件实施例或者包含硬件元件和软件元件两者的实施例的形式。软件实施例包括但不限于固件、常驻软件、微码等。本发明能够采取计算机程序产品的形式,计算机程序产品能够从提供由计算机或任何指令执行系统使用或者与其相结合的程序代码的计算机可用或计算机可读介质来访问。计算机可用或计算机可读可以是任何能够包含、存储、传达、传播或传送由指令执行系统、装置或设备使用的或者与其相结合的程序的装置。介质可以是电子的、磁的、光的、电磁的、红外的或半导体系统(或装置或设备)或传播介质。
- 还没有人留言评论。精彩留言会获得点赞!