用于预测对食物的反应的方法和装置与流程
在一些实施方案中,本发明涉及营养学,并更具体地但不只是涉及用于预测个体对一种或多种食物的反应的方法和装置。
在过去30年间,肥胖症在成人、儿童和青少年中的患病率急剧增加并持续上升。肥胖症的传统定义是基于体脂百分比,或最近以来是基于体重指数(BMI),其定义为体重(Kg)除以身高(米)的平方所得的比率。
超重和肥胖症与增大发生许多慢性老年疾病的风险相关。此类合并症包括:2型糖尿病、高血压、冠心病和血脂异常、胆结石和胆囊切除、骨关节炎、癌症(乳腺癌、结肠癌、子宫内膜癌、前列腺癌和胆囊)和睡眠呼吸暂停。已经认识到,降低这些疾病的严重程度的关键在于有效地减肥。尽管约30%至40%的人声称试图减肥或保持体重,现有疗法似乎不起作用。除了控制饮食以外,药物治疗以及(在极端情况下)外科手术,是批准用于治疗超重和肥胖患者的辅助疗法。药物有副作用,而手术虽然有效,却是极端措施,因而专用于病态肥胖。
Morris 等人[“Identification of Differential Responses to an Oral Glucose Tolerance Test in Healthy Adults,” 2013, PLoS ONE 8(8): e72890]识别出了针对口服葡萄糖耐受测试(OGTT)的差异反应者。发现了针对OGTT的四种不同的代谢反应,并通过不同水平的BMI、体脂和最大耗氧量表征。
国际公布No.WO2002100266公开了采用参考人类因素的数据库的饮食技术。计算机接收用户的人类因素数据并根据用户数据和测得的血液特征预测所选定的该用户的血液特征,以生成预测模型。然后根据输入的人类因素数据查询所述预测模型以生成并显示预测的血液特征。还公开了包含针对选定的血液特征的预测模型的数据库的用途,所述选定的血液特征是人类因素的函数。
国际公布No.WO2006079124公开了对食品和/或锻炼以能量单位的表征,其中与摄入食品相关的以线性单位表示的能量数量与所得的吸收到1型糖尿病患者血液中的血糖直接成正比。还公开了对锻炼以线性单位的表征,使得人在锻炼时消耗的以线性单位表示的能量数量与所得的其血糖水平的降低直接成正比。
发明概述
根据本发明的一些实施方案的一个方面,提供了预测个体对食物的反应的方法。该方法包括:选择食物,其中所述个体对其的反应是未知的;访问第一数据库,其含有描述所述个体但不描述其对所选食物的反应的数据;访问第二数据库,其含有关于其它个体对食物的反应的数据;以及基于所选食物分析这些数据库以估计所述个体对所选食物的反应。
根据本发明的一些实施方案,所述第一数据库包含关于所述个体对食物的反应的数据,这些食物均不同于所选食物。
根据本发明的一些实施方案的一个方面,提供了预测个体对食物的反应的方法。该方法包括:选择食物和食物摄入背景,其中所述个体对其的反应是未知的;访问第一数据库,其含有描述所述个体但不描述其对所选食物在所选食物摄入背景下的反应的数据;访问第二数据库,其含有关于其它个体对食物的反应(其包括至少一名其它个体对所选食物的反应)的数据;以及基于所选食物分析这些数据库以估计所述个体对所选食物在所选食物摄入背景下的反应。
根据本发明的一些实施方案,所述第一数据库包含关于所述个体对食物在相应食物摄入背景下的反应的数据,这些食物在所选食物摄入背景下均不同于所选食物。
根据本发明的一些实施方案,所述食物摄入背景选自:食物量、日时间、睡前或睡后的时间、锻炼前或锻炼后的时间、精神或生理状态以及环境状况。
根据本发明的一些实施方案,所述其它个体的反应包括至少一名其它个体对所选食物的反应。
根据本发明的一些实施方案,所述第二数据库缺乏任何其它个体对所选食物的任何反应。
根据本发明的一些实施方案,所述分析包括执行机器学习程序。
根据本发明的一些实施方案,所述第二数据库包含根据预定的分类组群分类的数据,其中所述分析包括根据所述分类组群将所述个体分类以提供特异于所述个体的分类组,并且其中基于对应于所述分类组的所述第二数据库中的反应估计所述个体对所选食物的反应。
根据本发明的一些实施方案,所述第一和所述第二数据库中的至少一个包含一个或多个多维条目,其中每个条目具有至少三个维度。根据本发明的一些实施方案,所述第一和所述第二数据库中的至少一个包含一个或多个多维条目,其中每个条目具有至少四个维度。根据本发明的一些实施方案,所述第一和所述第二数据库中的至少一个包含一个或多个多维条目,其中每个条目具有至少五个维度。
根据本发明的一些实施方案,所述第一和所述第二数据库中的至少一个包含一个或多个多维条目,其中每个条目分别对应于一名个体并包含该个体所食用的食物并至少包含该个体对所述食物的升糖反应。
根据本发明的一些实施方案,所述第一和所述第二数据库中的至少一个包含一个或多个多维条目,其中每个条目分别对应于一名个体,该个体在相应数据库中通过至少所述个体的部分微生物组概况表征。
根据本发明的一些实施方案,所述第一和所述第二数据库中的至少一个包含一个或多个多维条目,其中每个条目分别对应于一名个体并包含该个体所食用的食物并至少包含与所述食物相关的独特摄入频率。
根据本发明的一些实施方案,所述第一和所述第二数据库中的至少一个包含一个或多个多维条目,其中每个条目分别对应于一名个体并包含该个体所食用的食物并至少包含所述食物的部分化学组成。
根据本发明的一些实施方案,所述第一和所述第二数据库中的至少一个包含一个或多个多维条目,其中每个条目分别对应于一名个体,该个体在相应数据库中通过至少所述个体的部分血液化学表征。
根据本发明的一些实施方案,所述第一和所述第二数据库中的至少一个包含一个或多个多维条目,其中每个条目分别对应于一名个体,该个体在相应数据库中通过至少所述个体的遗传学概况表征。
根据本发明的一些实施方案,所述第一和所述第二数据库中的至少一个包含一个或多个多维条目,其中每个条目分别对应于一名个体,该个体在相应数据库中通过至少与所述个体相关的代谢组学数据表征。
根据本发明的一些实施方案,所述第一和所述第二数据库中的至少一个包含一个或多个多维条目,其中每个条目分别对应于一名个体,该个体在相应数据库中通过至少所述个体的身体状况表征。
根据本发明的一些实施方案,所述第一和所述第二数据库中的至少一个包含一个或多个多维条目,其中每个条目分别对应于一名个体,该个体在相应数据库中通过至少所述个体的食物摄入习惯表征。
根据本发明的一些实施方案,所述第一和所述第二数据库中的至少一个包含一个或多个多维条目,其中每个条目分别对应于一名个体并包含该个体在一定时间内所进行的活动的列表。
根据本发明的一些实施方案的一个方面,提供了计算机软件产品,该产品包括计算机可读介质,其中存储了程序指令,当通过数据处理器读取所述指令时,所述指令造成所述数据处理器接收食物(其中个体对所述食物的反应是未知的)并执行如上所述并任选地如下详述的方法。
根据本发明的一些实施方案的一个方面,提供了用于预测个体对食物的反应的装置。该装置包括:用户界面,其被配置成接收食物,其中所述个体对所述食物的反应是未知的;和数据处理器,其具有存储所述计算机软件产品的计算机可读介质。
根据本发明的一些实施方案的一个方面,提供了构建数据库的方法。该方法包括,针对一组个体中的每名个体:监测该个体在至少数天的时间内的血糖水平;监测该个体在所述时间内所食用的食物;分析所监测的血糖水平和所监测的食物以将升糖反应与所食用的食物的至少一部分中的每种食物关联起来;以及在至少一个数据库中制作关于所述关联的数据库记录。
根据本发明的一些实施方案,所述方法中的所述至少一个数据库包含对应于所述个体组中所有个体的组数据库。
根据本发明的一些实施方案,针对至少一名个体,所述至少一个数据库还包含对应于所述个体的个体特异性数据库。
根据本发明的一些实施方案,所述方法包括获得关于所述个体和/或所述食物的额外数据,并在所述至少一个数据库中制作所述额外数据的记录。
根据本发明的一些实施方案,所述方法包括使用多维分析程序处理所述至少一个数据库,并响应于所述分析更新所述至少一个数据库。
根据本发明的一些实施方案,所述多维分析程序包括执行机器学习程序。
根据本发明的一些实施方案,所述机器学习程序包含监督学习程序。
根据本发明的一些实施方案,所述机器学习程序包含选自以下的至少一种程序:分类、回归、聚类、支持向量机、线性建模、k-最近邻分析、决策树学习、集成学习程序、神经网络、概率模型、图形模型、贝叶斯网络和关联规则学习。
根据本发明的一些实施方案,所述额外数据包含所述个体的至少部分微生物组概况。
根据本发明的一些实施方案,所述额外数据包含与所述食物相关的独特摄入频率。
根据本发明的一些实施方案,所述额外数据包含所述食物的至少部分化学组成。
根据本发明的一些实施方案,所述额外数据包含所述个体的至少部分血液化学。
根据本发明的一些实施方案,所述额外数据包含所述个体的至少遗传学概况。
根据本发明的一些实施方案,所述额外数据包含与所述个体相关的代谢组学数据。
根据本发明的一些实施方案,所述额外数据包含所述个体的身体状况。
根据本发明的一些实施方案,所述额外数据包含所述个体的食物摄入习惯。
根据本发明的一些实施方案,所述额外数据包含所述个体在一定时间内所进行的活动的列表。
根据本发明的一些实施方案,所述食物是食物产品。
根据本发明的一些实施方案,所述食物是食物类型。
根据本发明的一些实施方案,所述食物是食物类型家族。
根据本发明的一些实施方案,所述食物是多种食物的组合,所述多种食物中的每种食物分别选自食物产品、食物类型和食物类型家族。
根据本发明的一些实施方案,所述方法、产品或装置是用于预防、控制和/或治疗身体状况,如与肥胖症、代谢综合征、糖尿病以及肝脏疾病或失调直接相关的状况。
除非另行定义,否则本文中所用的全部技术和/或科学术语具有与本发明所属领域普通技术人员通常所理解的相同的含义。尽管与本文所述那些类似或等同的方法和材料可用于实践或测试本发明的实施方案,但仍然在下文中描述了示例性方法和/或材料。在冲突的情况下,以本专利说明书(包括定义在内)为准。另外,所述材料、方法和实施例仅为说明性的而非旨在必要限制。
本发明的实施方案的方法和/或装置的实施可涉及以手动、自动或其组合的方式执行或完成所选任务。此外,根据本发明的方法和/或装置的实施方案的实际仪器和设备,若干选定的任务可以通过硬件、通过软件或通过固件或通过其组合使用操作系统实施。
例如,用于执行根据本发明的实施方案的所选任务的硬件可以芯片或电路的形式实施。至于软件,根据本发明的实施方案的所选任务可以多个软件指令的形式实施,所述多个软件指令通过计算机使用任何合适的操作系统执行。在本发明的示例性实施方案中,根据如本文所述的方法和/或装置的示例性实施方案的一项或多项任务通过数据处理器(如用于执行多个指令的计算平台)执行。任选地,所述数据处理器包括易失性存储器,用于存储指令和/或数据,和/或非易失性存储(例如,硬磁盘和/或可移动介质),用于存储指令和/或数据。任选地,也提供了网络连接。任选地也提供了显示器和/或用户输入设备(如键盘或鼠标)。
附图的若干视图的简要说明
本文仅以举例的方式,结合附图描述了本发明的一些实施方案。现在具体结合附图的细节,强调所示具体内容是以举例的方式并出于说明讨论本发明的实施方案的目的。就此而言,附图说明使得如何实践本发明的实施方案对于本领域技术人员变得显而易见。
在附图中:
图1是根据本发明的一些实施方案的适用于预测个体对食物的反应的方法的流程图;
图2A和2B是根据本发明的一些实施方案的个体特异性数据库(图2A)和组数据库(图2B)的代表性图解;
图3是根据本发明的一些实施方案的适用于构建数据库的方法的流程图;
图4示出了根据本发明的一些实施方案进行的研究的参与者的原始血糖测量结果的实例;
图5A-F示出了根据本发明的一些实施方案进行的研究的参与者的血糖反应的柱状图;
图5G示出了如根据本发明的一些实施方案进行的实验中所测量的不同个体对葡萄糖、面包和面包加黄油的反应的聚类;
图6A-C示出了如根据本发明的一些实施方案进行的研究过程中获得的葡萄糖(图6A)、面包(图6B)和面包加黄油(图6C)的两组重复测量结果的血糖反应的比较;
图7A-E示出了如根据本发明的一些实施方案进行的研究过程中,所有研究参与者的餐食中的碳水化合物量与升糖反应间的相关性柱状图(图7A)、在碳水化合物量与升糖反应间具有低相关性的两名参与者的实例(图7B和7C)和具有高的此类相关性的两名参与者的实例(图7D和7E);
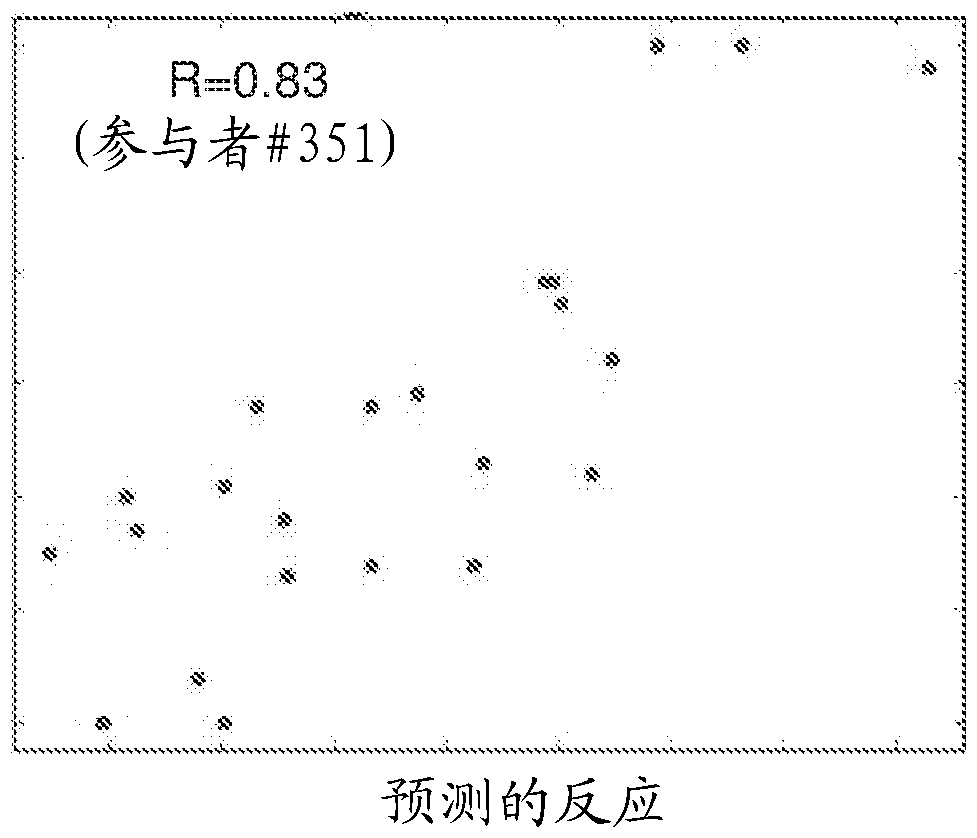
图8A-D 示出了如根据本发明的一些实施方案进行的研究过程中获得的 升糖反应的预测结果;
图9A-G示出了根据本发明的一些实施方案通过分析所获得的结果,所述分析包括使用决策树的随机梯度boosting;
图10A-B示出了根据本发明的一些实施方案使用组数据库(包含其它个体对食物的反应)和个体特异性数据库(包含描述该个体的数据但不包含对任何食物的任何反应)获得的血糖水平预测;
图11是条形图,其表明:相比不良周,在良好周的平均升糖反应更低。在良好周(绿色)和不良周(红色),16名参与者的平均iAUCmed水平。iAUCmed是相对于进餐前15分钟的中值血糖水平,在进餐后的头两个小时内,曲线下方面积(AUC)的增量。参与者的iAUCmed水平是其所有早餐、午餐和晚餐的平均iAUCmed。在x轴上,IG代表血糖受损的参与者,而H代表健康的参与者。符号IG/H后方括号内的第一个数字是6天实验的平均起床血糖水平,而方括号内的第二个数字是实验开始时的HbA1C;
图12是坐标图,其表明:对餐食的升糖反应遵循昼夜变化规律,其中早餐具有最低反应,然后是午餐,而晚餐具有最高反应。每个点均代表:相比良好周(y轴),不良周(x轴)的餐食的平均iAUCmed。大多数点位于x=y线的下方,意味着:平均而言,相比良好周,不良周的AUC更高。示出了早餐(红色)、午餐(绿色)和晚餐(蓝色)的iAUCmed水平。实心点对应血糖受损的参与者,而空心点对应健康的个体。相比午餐(绿线)然后是晚餐(绿线),血糖受损的参与者的所有早餐(红线)的线性拟合的斜率是最高的。虚线对应健康的参与者,而实线对应血糖受损的参与者;
图13A-B是曲线图,其表明:在通过餐食卡路里和碳水化合物水平的归一化之后,进餐后的AUC显示出昼夜变化规律。图13A示出了通过餐食卡路里含量归一化的iAUCmed,而图13B示出了通过餐食碳水化合物含量归一化的iAUCmed。
发明的具体实施方式
在一些实施方案中,本发明涉及营养学,并更具体地但不只是涉及用于预测个体对一种或多种食物的反应的方法和装置。
在详细阐释本发明的至少一个实施方案之前,应当理解,本发明不一定受限于其在以下说明中提及的和/或在附图和/或实施例中示出的部件和/或方法的具体构造和布置方式中的应用。本发明可以有其他的实施例或以各种方式实施或使用。
本实施方案采用计算方法用于预测个体对食物的反应的目的,以及任选地但非必须地,用于解读微生物群对此类反应的贡献。那些其对食物的反应是根据本发明的一些实施方案而预测的个体,在下文中被称为分析个体。本实施方案优选地探究先前收集的有关不同于分析个体的多名个体对食物的反应的理解。此多名个体在下文中被称为“其它个体”。
在本发明的各种示例性实施方案中,预测的反应包括预测的在个体食用食物之后立刻或短时间后将发生的血糖水平变化。个体对食物的反应任选地和优选地是针对这样的食物进行预测的:该个体对所述食物的反应是未知的。例如,本实施方案可以预测个体对以下的反应:其从未食用过的食物、过去食用过的但没有确定对其的反应的食物、或过去已知该个体对其的反应但怀疑由于该个体的条件(例如,健康状况、生长、微生物组含量)变化而发生了改变的食物。本实施方案可以预测这样的个体对食物的反应:所述反应在特定的食物摄入背景下是已知的,但在另一个食物摄入背景下是未知的。食物摄入背景可以包括但不限于:进食量、在一天中的什么时间进食、在睡前或睡后的什么时间进食、在锻炼前或锻炼后的什么时间进食、在食物摄入期间个体的精神或生理状态(例如,压力水平、疲劳程度、心情、疼痛、姿势)、食物摄入期间的环境状况(例如,温度、进食地点、共同进食的个体数量)等。因此,例如,对于个体在早晨对其的反应是已知的食物而言,本实施方案可以预测该个体在中午或之后对该食物的反应。
在本发明的一些实施方案中,所述食物是食物产品(例如,由特定生产商或由生产相同食物产品的两个或更多个生产商销售的特定食物产品)。在本发明的一些实施方案中,所述食物是食物类型(例如,具有不同改变形式的食物,例如,白米,其可具有不同种类,但都称为“白米”,或全麦面包,其可能回溯自各种混合物,等等)。在本发明的一些实施方案中,所述食物是食物类型家族。所述家族可以根据食物类型的主要成分而分类,例如,甜食、乳制品、水果、香草(herb)、蔬菜、鱼类、肉类等。在本发明的一些实施方案中,所述食物类型家族是食物组,如但不限于:碳水化合物,其是涵盖了富含碳水化合物的食物类型的家族;蛋白质,其是涵盖了富含蛋白质的食物类型的家族;和脂肪,其是涵盖了富含脂肪的食物类型的家族;矿物质,其是涵盖了富含矿物质的食物类型的家族;维生素,其是涵盖了富含维生素的食物类型的家族,等等。在本发明的一些实施方案中,所述食物是食物组合,其包括了多种不同食物产品和/或不同食物类型和/或不同食物家族。此类组合被称为“复合餐食”。所述复合餐食可以作为构成所述组合的食物产品、食物类型和/或食物类型家族的列表而提供。所述列表可能包括或不包括组合中各种食物产品、食物类型和/或食物类型家族的具体的量。
本文所述的任何方法均可以多种形式体现。例如,其可以体现在有形介质(如计算机)上用于进行所述方法操作。其可以体现在计算机可读介质(包含计算机可读指令)上用于进行所述方法操作。其也可以体现在具有数字计算机能力的电子装置上,所述数字计算机能力被布置成在有形介质上运行计算机程序或在计算机可读介质上执行指令。
实施本实施方案的方法的计算机程序通常可以在传播介质(如但不限于CD-ROM或闪存介质)上被传播给用户。从传播介质,所述计算机程序可以被复制到硬盘或类似的中间存储介质上。在本发明的一些实施方案中,实施本实施方案的方法的计算机程序可以通过允许用户经由通信网络(例如,互联网)远程下载程序而被传播给用户。所述计算机程序可以通过如下运行:从其传播介质或其中间存储介质加载计算机指令至计算机执行内存,配置计算机以根据本发明的方法运作。所有这些操作均是计算机系统领域技术人员所熟知的。
现在参见附图,图1是根据本发明的一些实施方案的适用于预测个体对食物的反应的方法的流程图。应当理解,除非另行定义,否则下文所述的操作可以多种执行组合或顺序同时或依序执行。具体地讲,该流程图的顺序不被视为限制性的。例如,在以下描述中或流程图中以特定顺序出现的两个或更多个操作,可以不同顺序(例如,反序)或基本上同时执行。另外,下述若干操作是任选的并且可以不执行。
所述方法从10开始并继续到11,在该处选定食物,其中个体对所述食物的反应是未知的。食物产品可以选自食物列表,所述列表可通过例如用户界面装置或组件(如触摸屏或显示装置和键盘)而被提供给个体或其它用户。任选地,可以向用户提供主要食物类型家族的列表以供选择。根据食物类型家族的选择,如果需要,可以任选地提供属于该家族的食物类型列表以供选择。根据食物类型的选择,如果需要,可以任选地提供食物产品列表,用户可以从中选择食物。还设想了这样的实施方案,其中个体或其它用户使用键盘输入食物。任选地,当用户输入时,采用补全算法(例如,文字补全),如本领域中已知的。食物的选择可以任选地并优选地伴随针对所选食物的选择食物摄入背景。例如,可以向用户提供食物摄入背景的列表以供选择。
所述方法继续至12,在此处, 访问个体特异性数据库 。所述个体特异性数据库以计算机可读形式存储在计算机可读介质上,并且任选地并优选地通过数据处理器(如通用计算机或专用电路)访问。
所述个体特异性数据库包含描述该个体的数据。在本发明的一些实施方案中,所述 个体特异性数据库 包含关于该个体对食物的反应的数据。在图2A中提供了根据本发明的一些实施方案的个体特异性数据库22的代表性图解。
所述个体特异性数据库的数据可以被布置为构成该个体对相应食物组的一组反应。在所述个体特异性数据库中的食物的数量优选地为至少10或至少20或至少30或更多。当以组的形式定义食物和反应时,食物的数量可以被定义为所述组的大小(各组中要素的数量)。
在本发明的各种示例性实施方案中,所述个体特异性数据库包含关于该个体对食物的反应的数据,但不包含该个体对所选食物的反应。换句话讲,在这些实施方案中,食物组中没有食物是在11所选择的食物。与所选食物具有一些相似性的食物可能存在于所述个体特异性数据库中。例如,如果选择了一种食物产品,那么所述个体特异性数据库优选地不包含该特定食物产品,但可能任选地并优选地包含与所选食物产品属于相同类型或相同类型家族的食物产品。例如,如果选择了一种食物类型,那么所述个体特异性数据库优选地不包含该食物类型,但可能任选地并优选地包含与所选食物类型属于相同类型家族的食物类型。在其中还选择了食物摄入背景的实施方案中,所述个体特异性数据库可能任选地包含该个体对所选食物的反应,但优选地在不同于所选背景的背景下。
虽然对上述实施方案的描述中特别强调了个体特异性数据库包含关于个体对食物的反应的数据,但应当理解,所述个体特异性数据库可能缺乏该个体对食物的任何反应。所述个体特异性数据库可以包含描述该个体的任何数据。不同于对食物的反应的数据类型的代表性实例包括但不限于:微生物组概况、部分微生物组概况、个体的血液化学、个体的部分血液化学、个体的遗传学概况、与个体相关的代谢组学数据、个体的身体状况、个体的食物摄入习惯等。这些和其它数据类型更详细地描述于下。
所述方法继续至13,在此处,访问组数据库。所述组数据库以计算机可读形式存储在计算机可读介质上,并且任选地并优选地通过数据处理器(如通用计算机或专用电路)访问。两种数据库均可以存储在相同介质上并任选地和优选地通过相同的数据处理器访问。
在图2B中提供了根据本发明的一些实施方案的组数据库24的代表性图解。所述组数据库包含关于其它个体对食物的反应的数据。然而,不同于可能任选地仅包含分析个体对食物的反应的个体特异性数据库,组数据库的反应包括其它个体对食物的反应。所述组数据库的数据可以被布置为构成对相应食物组的一组反应。
在图2A示出的个体特异性数据库中,每个条目均可以元组(F, R)的形式描述,其中F表示数据库中的特定食物,而R表示该个体对F的反应。因此,该示例性图解是二维数据库,其中所有要素均可以通过食物和相应反应张成的二维空间中的向量描述。在图2B示出的组数据库中,每个条目均可以元组(S, F, R)的形式描述,其中S表示组数据库中的特定个体,F表示特定食物,而R表示个体S对食物F的反应。因此,该示例性图解是三维数据库,其中所有要素均可以通过个体、食物和相应反应张成的三维空间中的向量描述。本发明的一些实施方案设想了使用具有更高维度的数据库。此类数据库在下文中有述。
所述组数据库可能任选地并优选地还包含所述个体特异性数据库的一个或多个、更优选全部的条目。在其中组数据库包含所述个体特异性数据库的全部条目的实施方案中,不必使用两个单独的数据库,因为整个数据集都被包含在一个包容性数据库中。此类包容性数据库还任选地并优选地以这样的方式注释:其允许区分所述包容性数据库中与分析个体相关的的部分和所述包容性数据库中仅与其它个体相关的部分。在本公开的上下文中,所述包容性数据库中与分析个体相关的部分被称为个体特异性数据库,即使当其并未以单独的数据库的形式提供时。类似地,所述包容性数据库中仅与其它个体相关的部分被称为组数据库,即使当其并未以单独的数据库的形式提供时。
在本发明的一些实施方案中,所述组数据库包含在11选择的食物和一名或多名其它个体对所选食物的反应,但不包含分析个体对所选食物的反应。因此,在本发明的一些实施方案中,分析个体对在11选择的食物的反应既不在所述个体特异性数据库中,也不在所述组数据库中。
组数据库优选包含许多个体(例如,至少10名个体或至少100名个体,例如,500名个体或更多)对食物的反应。在组数据库中的不同食物的数量任选地并优选地大于在个体特异性数据库中的不同食物的数量。两种数据库均可包含相同数量的不同食物类型和/或不同食物类型家族。然而,这并不是必须的,因为这两种数据库之间不同食物类型的数量和/或不同食物类型家族的数量可能不同。
由于组数据库包含关于多名个体的数据,所以该数据库中的食物组可能包含重复要素。例如,简单起见,考虑三名个体(标注为S1、S2和S3)以及四种食物(标注为F1、F2、F3和F4)。假设该组数据库包含关于这三名个体和这些食物的数据,其中所述组数据库包含个体S1和S2分别对全部四种食物的反应,以及个体S3对食物F1、F2和F3但没有对F4的反应(注意,在不丧失一般性的同时,这符合其中S3是分析个体而F4是所选食物的情况)。在此实例中,食物F1、F2和F3可能在所述组数据库中各出现三次,而食物F4可能在所述组数据库中出现两次。在数学上,用Rij指代第i名个体对第j种食物的反应,组数据库的反应组可以是{R11、R12、R13、R14、R21、R22、R23、R24、R31、R32、R33},而组数据库的食物组可以是{F1、F2、F3、F4、F1、F2、F3、F4、F1、F2、F3}。
应当理解,虽然本文所述的数据库可以组的形式布置,但在本发明的一些实施方案中也设想了其它类型的数据结构。数据库中的至少一些数据还可以如上所示被布置成组的形式。
一旦数据库被访问,则所述方法继续至14,此处,基于所选食物分析所述数据库以估计该个体对所选食物的反应。此分析可以不止一种方式执行。在下文中提供了适用于分析根据本发明的一些实施方案的数据库的示例性技术。
所述方法任选地并优选地继续至15,此处,将估计的反应至少暂时地存储在计算机可读介质中,从中可以根据需要提取或显示所述反应。在一些实施方案中,所述方法继续至16,此处,使用所估计的反应更新所述数据库之一或两者。
所述方法在17结束。
在提供用于预测个体对食物的反应的方法的进一步详细说明之前,如上所述并根据本发明的一些实施方案,将要关注于优点及其提供的潜在应用。
本发明人证实了本实施方案的方法提供个体反应(例如葡萄糖、胆固醇、钠、钾、钙)的个人预测的能力,这些个人预测切合该个体的各种收集的参数。本实施方案因此提供了基于个人的营养学,这是对传统上基于经验的营养学的显著改善。本实施方案可以用作主要预防或减少正常和易感个体的例如高血糖风险的手段。本实施方案提供了生物和计算工具箱,其结合了个体的饮食习惯并任选地还有遗传学和/或微生物群,以预测他/她对各种未测试食物的反应(例如,升糖反应)。
本实施方案可用于提供个体特异性饮食干预的个体化预测,例如,出于一级和/或二级预防和/或治疗和/或控制身体状况的目的,所述身体状况如与肥胖症、代谢综合征、糖尿病和肝脏疾病或失调直接相关的状况。
一般来讲,术语“预防”、“控制”和“治疗”涵盖了:预防个体中疾病或症状的发展,该个体可能具有所述疾病或所述症状的易感体质但尚未诊断出患有所述疾病或所述症状;抑制疾病的症状,即,抑制或延迟其进展;以及缓解疾病的症状,即,所述疾病或所述症状消退,或所述症状的进展逆转。
可根据本发明的一些实施方案控制或治疗所有类型的肥胖症,包括但不限于:内源性肥胖、外源性肥胖、胰岛功能亢进性肥胖、增生性肥大性肥胖、肥大性肥胖、甲状腺功能减退性肥胖和病态肥胖。例如,本实施方案可以用于减慢、停止或逆转体重增长,特别是体脂增长,导致体重保持或下降。体重或体脂下降可通过降低血压、总胆固醇、LDL胆固醇和甘油三酯而防止心血管疾病,并可缓解与慢性疾病(如高血压、冠心病、2型糖尿病、高脂血症、骨关节炎、睡眠呼吸暂停和退行性关节疾病)相关的症状。
代谢综合征或综合征X,是伴随有各种异常(包括高血压、高甘油三酯血症、高血糖、低水平的HDL-C和腹型肥胖)的复杂的多因素疾病。具有这些特征的个体通常表现出血栓前和促炎症反应状态。现有数据表明代谢综合征确实是一种综合征(一种风险因素分组)。
根据世界卫生组织(WHO)指导原则,如果个体表现出:a)高血压(>140 mm Hg 收缩压 或 >90 mm Hg 舒张压);b) 血脂异常,定义为升高的血浆甘油三酯(150 mg/dL)和/或低高密度脂蛋白(HDL)胆固醇(<35 mg/dL 男性,<39 mg/dL 女性);c)内脏型肥胖,定义为高体重指数(BMI)(30 kg/m2)和/或高腰臀比(>0.90 男性,>0.85 女性);和 d) 微量白蛋白尿(尿白蛋白排泄率:20 g/min),则存在代谢综合征。参见WHO-国际高血压学会高血压管理指南(International Society of Hypertension Guidelines for the Management of Hypertension)。指导委员会(Guidelines Subcommittee)。J. Hypertens.17:151-183, 1999。
根据全美胆固醇教育计划(NCEP ATP III 研究),如果存在下列五(5)项风险因素中的三(3)项或更多项,则诊断为代谢综合征:1)腰围 >102 cm (40 in) 男性 或 >88 cm (37 in) 女性;2)甘油三酯水平:150 mg/dL;3)HDL胆固醇水平 <40 mg/dL 男性 或 <50 mg/dL 女性;4)血压 >130/85 mm Hg;或5)空腹血糖 >110 mg/dL。JAMA 285: 2486-2497, 2001。
与代谢综合征相关的各项失调自身就是风险因素,并且可以促发动脉粥样硬化、心血管疾病、脑卒中、全身性微血管和大血管并发症以及其它不良健康后果。然而,当同时存在时,这些因素对增加的心血管疾病、脑卒中以及全身性微血管和大血管并发症的风险具有预测性。
本实施方案可以降低代谢综合征的症状的严重程度和/或数量,如在分析个体中所示。此类症状可包括:血糖升高、葡萄糖耐受不良、胰岛素抵抗、甘油三酯升高、LDL胆固醇升高、低高密度脂蛋白(HDL)胆固醇、血压升高、腹型肥胖、促炎症反应状态和血栓前状态。本实施方案还可以降低发展相关疾病的风险,和/或推迟此类疾病的发作。此类相关疾病包括:心血管疾病、冠心病和其它与动脉壁斑块有关的疾病以及糖尿病。
糖尿病包括:例如,1型糖尿病、2型糖尿病、妊娠期糖尿病、糖尿病前期、缓慢发作的自身免疫性1型糖尿病(LADA)、高血糖和代谢综合征。所述糖尿病可能是显性的、确诊的糖尿病,例如,2型糖尿病,或是糖尿病前期状况。
糖尿病(diabetes mellitus)(本文中一般称为“糖尿病(diabetes)”)是以血糖调节受损为特征的疾病。糖尿病是当胰腺无法产生足够的胰岛素或当身体无法有效利用所产生的胰岛素时而发生的慢性疾病,其导致血液中葡萄糖浓度升高(高血糖)。糖尿病可分为1型糖尿病(胰岛素依赖型、青少年或儿童期发作的糖尿病)、2型糖尿病(非胰岛素依赖型或成年期发作的糖尿病)、LADA糖尿病(成年晚期自身免疫性糖尿病)或妊娠期糖尿病。另外,中间状况(如葡萄糖耐受性异常和空腹血糖异常)被认为是表明发展出2型糖尿病的高风险的状况。
在1型糖尿病中,由于胰腺β细胞的自身免疫性破坏而缺乏胰岛素生产。所述自身免疫性破坏具有若干可在体液和组织中检测到的标记物,包括:胰岛细胞自身抗体、胰岛素自身抗体、谷氨酸脱羧酶自身抗体和酪氨酸磷酸酶ICA512/IA-2自身抗体。在2型糖尿病(占世界上糖尿病的90%)中,胰岛素分泌可能不足,但据信,外周组织胰岛素抵抗才是主要缺陷。2型糖尿病通常(尽管并非总是)与肥胖症(胰岛素抵抗的成因之一)相关。
2型糖尿病之前通常具有糖尿病前期,其中血糖水平高于正常但尚未高到足以被诊断为糖尿病。
术语“糖尿病前期”,如本文所用,可与术语“葡萄糖耐受性异常”或“空腹血糖异常”互换使用,这些都是涉及用于测量血糖水平的测试的术语。
糖尿病中的慢性高血糖与影响微血管和/或大血管的多种(主要是血管)并发症相关。这些远期并发症包括:视网膜病变(导致焦距模糊、视网膜脱离以及部分或全部视力丧失)、肾脏病变(导致肾功能衰竭)、神经病变(导致疼痛、麻木以及四肢失去知觉,并可能会导致足部溃疡和/或截肢),心脏病变(导致心力衰竭)和感染风险增加。2型糖尿病或非胰岛素依赖型糖尿病(NIDDM)与利用葡萄糖的组织(如脂肪组织、肌肉和肝脏)对胰岛素的生理作用的抵抗有关。与NIDDM相关的长期高血糖可以导致引起衰弱的并发症,包括:肾脏病变(通常必须透析或肾移植);周围神经病变;视网膜病变(导致失明);下肢溃疡和坏死(导致截肢);脂肪肝(可能发展为肝硬化);以及易发冠心病和心肌梗死。本实施方案可以用于降低发展糖尿病的风险,或推迟此类疾病的发作。本实施方案可以用于降低发展相关并发症的风险,和/或推迟此类并发症的发作。
糖尿病的状况可以使用本领域已知的多种测定法中的任一种进行诊断或监测。用于将个体诊断或分类为糖尿病或糖尿病前期或监测所述个体的测定法的实例包括但不限于:糖化血红蛋白(HbA1c)测试、连接肽(C-肽)测试、空腹血糖(FPG)测试、口服葡萄糖耐受测试(OGTT)以及非正式的血糖测试。
HbA1c是生物标记物,其测量血液中糖化血红蛋白的量。HbA1c代表了血红蛋白的稳定的轻微糖基化的亚部分。其反映了在过去6-8周内的平均血糖水平,并且以总血红蛋白的百分数(%)表示。作为另外一种选择,糖尿病或糖尿病前期可以通过测量血糖水平来诊断,例如,使用血糖监测仪或本领域已知的数种测试中的任一种,包括但不限于,空腹血糖测试或口服葡萄糖耐受测试。当使用空腹血糖(FPG)测试时,如果患者的阈值FPG大于125 mg/dl,则该患者被归类为糖尿病人,而如果患者的阈值FPG大于100 mg/dl但小于或等于125 mg/dl,则该患者被归类为糖尿病前期。当使用口服葡萄糖耐受测试(OGTT)时,如果患者的阈值2小时OGTT葡萄糖水平大于200 mg/dl,则该患者被分类为糖尿病。如果患者的阈值2小时OGTT葡萄糖水平大于140 mg/dl但小于200 mg/dl,则该患者被分类为糖尿病前期。
由胰岛素原分子产生的C-肽,自胰岛细胞以与胰岛素的等摩尔比例分泌到血液中,并用作β-细胞功能和胰岛素分泌的生物标记物。大于2.0 ng/ml的空腹C-肽测量结果表明高水平的胰岛素,而小于0.5 ng/ml空腹C-肽测量结果表明胰岛素产量不足。
已被分类为具有糖尿病状况并且根据本发明的一些实施方案进行了分析的个体,可通过测量血糖来监测治疗的功效,例如,使用血糖监测仪和/或通过测量生物标记物指标(包括但不限于:糖化血红蛋白水平、C-肽水平、空腹血糖水平以及口服葡萄糖耐受测试(OGTT)水平)。
本发明的一些实施方案可以用于预防、治疗和/或控制血脂过多(也称为高脂蛋白血症或高脂血症),其涉及血液中任何或所有脂质和/或脂蛋白的异常高水平。其是血脂异常(其包括任何异常的脂质水平)的最常见的形式。血脂过多也根据升高的脂质的类型来分类,即高胆固醇血症、高甘油三酯血症或二者并存的混合型高脂血症。升高水平的脂蛋白也被归类为血脂过多的形式。根据本术语还包括:I型高脂蛋白血症、II型高脂蛋白血症、III型高脂蛋白血症、IV型高脂蛋白血症和V型高脂蛋白血症,以及未分类的家族型和获得型高脂血症。
本发明的一些实施方案可以用于预防、治疗和/或控制肝脏疾病和失调,包括肝炎、肝硬化、非酒精性脂肪性肝炎(NASH)(也被称为非酒精性脂肪肝-NAFLD)、肝中毒和慢性肝脏疾病。
术语“肝脏疾病”适用于许多疾病和失调,其引起肝功能异常或功能停止,而这种肝功能的丧失指示肝脏疾病。因此,肝功能测试经常用于诊断肝脏疾病。此类测试的实例包括但不限于下列:(1) 测定血清酶(如乳酸脱氢酶(LDH)、碱性磷酸酶(ALP)、天冬氨酸转氨酶(AST)和丙氨酸转氨酶(ALT))水平的测定法,其中酶水平的升高指示肝脏疾病。本领域技术人员将适当理解,这些酶测定法仅仅表明肝脏已受损。其并不评估肝脏的功能。其它测试可以用于测定肝脏的功能;(2) 测定血清胆红素水平的测定法。血清胆红素水平以总胆红素和直接胆红素的形式报告。总血清胆红素的正常值为0.1-1.0 mgdl(例如,约2-18 mmol/L)。直接胆红素的正常值为0.0-0.2 mg/dl(0-4 mmol/L)。血清胆红素的升高指示肝脏疾病。(3) 测定血清蛋白质水平,例如,血清白蛋白和球蛋白(例如,α、β、γ)的测定法。总血清蛋白质的正常值为6.0-8.0 g/dl(60-80 g/L)。血清白蛋白的降低指示肝脏疾病。球蛋白的升高指示肝脏疾病。
其它测试包括:凝血酶原时间、国际标准化比值、活化凝血时间(ACT)、部分凝血活酶时间(PTT)、凝血酶原消耗时间(PCT)、纤维蛋白原、凝血因子、甲胎蛋白和甲胎蛋白-L3(百分比)。
肝脏疾病的一种类型是肝炎。肝炎是肝脏炎症,其可由病毒(例如甲肝病毒、乙肝病毒和丙肝病毒(分别为HAV、HBV和HCV))、化学物质、药物、酒精、遗传病或患者自身免疫系统(自体免疫肝炎)引起。这种炎症可以是急性的并在数周至数月内消退,或者是慢性的并持续多年。慢性肝炎在引发显著症状(如肝硬化(瘢痕形成和丧失功能)、肝癌或死亡)前可以持续几十年。术语“肝脏疾病”所涵盖的并根据本发明的一些实施方案适于治疗或预防或控制的不同疾病和失调的其它实例包括但不限于:阿米巴性肝脓肿、胆道闭锁、肝纤维化、肝硬化、球孢子菌病、D型肝炎病毒、肝细胞癌(HCC)、酒精性肝病、原发性胆汁性肝硬化、化脓性肝脓肿、瑞氏综合征、硬化性胆管炎、威尔逊氏病。本发明的一些实施方案可用于治疗以肝实质细胞的损耗或损坏为特征的肝脏疾病。在一些方面,其病因可以是局部或全身性炎症反应。
当肝脏的大部分被损坏时,发生肝衰竭,而肝脏不再能够发挥其正常的生理功能。在一些方面,肝衰竭可以使用上述肝功能测定法或通过个体症状来诊断。与肝衰竭有关的症状包括,例如,以下一种或多种:恶心、食欲不振、疲劳、腹泻、黄疸、异常/出血过多(如凝血病)、腹部肿大、精神迷失或困惑(如肝性脑病)、嗜睡和昏迷。
慢性肝衰竭发生在数月至数年中并且最常由病毒(例如,HBV和HCV)、长期/过量饮酒、肝硬化、血色素沉着症和营养不良引起。急性肝衰竭是肝脏疾病的初期体征(例如,黄疸)后的严重并发症的表观并且包括多种状况,所有这些状况均涉及严重的肝细胞损伤或坏死。本发明的一些实施方案可用于治疗超急性、急性和亚急性肝衰竭、暴发性肝衰竭和晚发性暴发性肝衰竭,所有这些在本文中均被称为“急性肝衰竭”。急性肝衰竭的常见诱因包括,例如,病毒性肝炎、暴露于某些药物和毒素(例如,氟化烃(例如,三氯乙烯和四氯乙烷)、鹅膏蕈(例如,常见的“死帽菇”)、醋氨酚(扑热息痛)、卤乙烷、磺胺类、苯妥英)、心脏相关的肝缺血(例如,心肌梗死、心脏骤停、心肌病和肺栓塞)、肾功能衰竭、肝静脉流出道阻塞(例如,Budd-Chiari综合征)、威尔逊氏病、妊娠急性脂肪肝、阿米巴脓肿和播散性结核。
术语“肝炎”用于描述肝脏状况,其意味着肝脏损伤,特征在于器官组织中存在炎症细胞。该状况可以是自限性的、自愈的,或可以进展为肝脏瘢痕形成。当肝炎持续短于六个月,则其为急性的,而当持续长于六个月,则其为慢性的。被称为肝炎病毒的病毒类别引发全世界大多数肝脏损坏的病例。肝炎也可以是由于毒素(值得注意的是酒精)、其它感染引起或来自自体免疫过程。肝炎包括下列来源的肝炎:病毒感染,包括甲型肝炎至戊型肝炎(A、B、C、D和E--占超过95%的病毒诱因)、单纯疱疹病毒、巨细胞病毒、爱泼斯坦-巴尔病毒、黄热病病毒、腺病毒;非病毒感染,包括弓形虫、钩端螺旋体、Q热、落矶山斑点热、酒精、毒素(包括鹅膏毒蘑菇、四氯化碳、阿魏等等)、药物(包括对乙酰氨基酚、羟氨苄青霉素、抗结核药、米诺环素及如本文所述的其它药物);缺血性肝炎(循环不足);妊娠;自身免疫性疾病,包括系统性红斑狼疮(SLE);和非酒精性脂肪性肝炎。
“无菌性炎症”用于描述这样的肝脏炎症,其由从已经失去其质膜完整性的濒死细胞释放的细胞内分子所触发。此炎症发生时不存在致病因子如病毒或细菌和酒精。已经识别出多种细胞内分子,其可刺激其它细胞产生促炎症反应细胞因子和趋化因子。此类促炎症反应细胞分子被认为是通过接合产生细胞因子的细胞上的受体而发挥作用。如果放任而不治疗,无菌性炎症可能进展为非酒精性脂肪肝(NAFLD)、非酒精性脂肪性肝炎(NASH)或肝硬化。
“非酒精性脂肪性肝炎”或“NASH”是这样一种肝脏状况,其中炎症是由肝脏内脂肪积聚而引起的。NASH是一类肝脏疾病中的一部分,被称为非酒精性脂肪肝,其中脂肪在肝脏内积聚并且有时引起随时间推移而恶化的肝脏损坏(进行性肝脏损坏)。“非酒精性脂肪肝”(NAFLD)是肝脏的脂肪性炎症,其不是由于过量饮酒引起的。其与胰岛素抵抗和代谢综合征、肥胖症、高胆固醇和甘油三酯以及糖尿病有关,并且可能响应于最初针对其它胰岛素抵抗状态(例如,2型糖尿病)而开发的治疗,如减重、二甲双胍和噻唑烷二酮类药物。非酒精性脂肪性肝炎(NASH)是NAFLD的最极端形式,其被视为成因未知的肝脏的硬化的主要诱因。
已知的促成NASH的其它因素包括:缩肠手术、缩胃手术或二者皆有,如空肠旁路手术或胆胰分流;长期使用饲管或接收营养的其它方法;某些药物,包括胺碘酮、糖皮质素、合成雌激素和他莫昔芬。
NASH是可能随时间推移而恶化的状况(称为进行性状况)并可以引起肝脏瘢痕形成(肝纤维化),而导致肝硬化。“肝硬化”描述了这样的状况,其中肝脏细胞已经被瘢痕组织所替换。术语“肝脏的硬化”或“肝硬化”用于描述慢性肝脏疾病,其特征在于肝脏组织被纤维化瘢痕组织以及再生性结节所替换,导致肝功能的进行性丧失。肝硬化最常由脂肪肝(包括NASH以及酗酒和乙型肝炎和丙型肝炎)引起,但也可能具有未知成因。肝硬化的可能危及生命的并发症是肝性脑病(混乱和昏迷)和食管静脉曲张破裂出血。肝硬化历来被认为是一旦发生即一般不可逆的,并且传统治疗着重于防止进展和并发症。在肝硬化晚期,肝脏移植是唯一的选择。本发明的一些实施方案可以用于限制、抑制、降低可能性或治疗肝脏的硬化而无论其病因。
本发明的一些实施方案可以用于治疗、预防或控制化学性肝脏损伤和肝中毒。“化学性损伤”或“急性化学性损伤”指代患者在短时间内发生的严重损伤,其是化学中毒(包括药物诱发的中毒或损伤)的结果。药物诱发的急性肝脏损伤,包括醋氨酚诱发的急性肝脏损伤,是急性肝脏损伤,其发生是暴露于药物(例如,药物过量)(尤其是醋氨酚中毒)的结果。
肝中毒是肝脏毒性剂或诱发肝中毒的生物活性剂造成的化学性肝脏损伤。术语“肝脏毒性剂”和“诱发肝中毒的生物活性剂”在上下文中同义使用以描述在被施用此类试剂的患者体内经常产生肝中毒的化合物。肝脏毒性剂的实例包括,例如,麻醉剂、抗病毒剂、抗逆转录病毒剂(核苷逆转录酶抑制剂和非核苷逆转录酶抑制剂),尤其是抗艾滋病剂、抗肿瘤剂、器官移植药物(环孢素、他克莫司、OKT3)、抗微生物剂(抗结核、抗真菌、抗生素)、抗糖尿病药物、维生素A衍生物、甾体药剂(特别是包括口服避孕药、类固醇、雄激素)、非甾体类抗炎剂、抗抑郁药(尤其是三环类抗抑郁药)、糖皮质素、天然产物和草药以及替代疗法(尤其是包括圣约翰草)。
肝中毒可能表现为甘油三酯积聚,其导致小滴(微泡)或大滴(大泡)脂肪肝。存在单独类型的脂肪变性,其中磷脂积聚导致与具有遗传性磷脂代谢缺陷的疾病(例如,泰-萨克斯病)类似的特征。
本发明的一些实施方案可以用于治疗、预防或控制慢性肝脏疾病。慢性肝脏疾病以随时间推移而逐渐破坏肝脏组织为标志。数种肝脏疾病落入此类别,包括肝硬化和肝纤维化,其中后者常常是肝硬化的前身。肝硬化是急性和慢性肝脏疾病的结果,并且其特征在于肝脏组织被纤维化瘢痕组织和再生性结节所替换,导致肝功能的进行性丧失。肝纤维化和结节再生导致肝脏的正常微观小叶结构的丧失。肝纤维化表示由例如感染、炎症、损伤和甚至愈合造成的瘢痕组织的生长。随时间推移,纤维化瘢痕组织慢慢地替换正常作用的肝脏组织,导致流入肝脏的血量减少,使得肝脏不能充分处理血液中存在的营养物质、激素、药物和毒素。肝硬化的更常见的诱因包括酗酒、丙肝病毒感染、摄入毒素以及脂肪肝,但也存在许多其它可能的诱因。慢性丙肝病毒(HCV)感染和非酒精性脂肪性肝炎(NASH)是美国慢性肝脏疾病的两个主要诱因,据估计影响3-5百万人。让人担忧的是患有肥胖症和代谢综合征并同时患有非酒精性脂肪肝(NAFLD)的美国公民数目(目前数目为3千多万)持续升高,其中大约10%将最终发展为NASH。其它身体的并发症是肝功能丧失的结果。肝硬化的最常见的并发症是被称为腹水的状况,液体在腹膜腔内积聚,其可导致自发性细菌性腹膜炎的风险增加,可能造成患者过早死亡。
例如,根据本发明的一些实施方案预测对食物的升糖反应可以用于构建分析个体的个体化饮食。此类饮食可以包括例如保持相对低的血糖水平的食物清单,从而预防、降低发展风险、控制和/或治疗以上综合征或疾病中的一种或多种。
本文实施方案的方法也可以用于针对普通大众中的健康个体从市场上现有的饮食之一或通过设计新的饮食来私人定制减重或维持重量的饮食。使用本文实施方案的数据库,本文实施方案的方法可以任选地并优选地预测:健康或易患病个体可能被置于我们先进的个体集群之一中,允许准确预测其对未在研究期间食用的食物的反应。在一些实施方案中,所述方法可以用于甚至仅仅基于数据的一部分而将人置于集群中。
以下是对根据本发明的一些实施方案的方法更详细的说明。
本文实施方案设想了个体特异性数据库和组数据库,其包含食物和相应反应之外的额外的数据。在一些实施方案中,所述数据库中的至少一个包含一个或多个(例如,复数个)多维条目,其中每个条目均具有至少三个纬度,在一些实施方案中,所述数据库中的至少一个包含一个或多个(例如,复数个)多维条目,其中每个条目均具有至少四个纬度,在一些实施方案中,所述数据库中的至少一个包含一个或多个(例如,复数个)多维条目,其中每个条目均具有至少五个纬度,而在一些实施方案中,所述数据库中的至少一个包含一个或多个(例如,复数个)多维条目,其中每个条目均具有大于五个纬度。
所述数据库的额外的维度提供了关于分析个体的、关于其它个体的和/或关于相应个体所食用的食物的额外的信息。在下文中,“个体”总体指代这样的个体,其可以是分析个体或来自组数据库的另一名个体。
在本发明的一些实施方案中,所述额外的信息属于该个体的微生物组概况或部分微生物组概况。
通常,个体的微生物组从该个体的粪便样本中测定。
如本文所用,术语“微生物组”指代在确定环境中微生物(细菌、真菌、原生生物)、其遗传成分(基因组)的总体。
本文实施方案涵盖了认识到微生物标记可以倚为微生物组组成和/或活性的代替物。微生物标记包括指示微生物组组成和/或活性的数据点。因此,根据本发明,可以通过检测微生物标记的一项或多项特征来检测和/或分析微生物组的变化。
在一些实施方案中,微生物标记包括涉及一种或多种类型微生物和/或其产物的绝对量的信息。在一些实施方案中,微生物标记包括涉及五种、十种、二十种或更多种类型微生物和/或其产物的相对量的信息。
在一些实施方案中,微生物标记包括涉及至少十种类型微生物的存在、水平和/或活性的信息。在一些实施方案中,微生物标记包括涉及5种至100种类型微生物的存在、水平和/或活性的信息。在一些实施方案中,微生物标记包括涉及100种至1000种或更多种类型微生物的存在、水平和/或活性的信息。在一些实施方案中,微生物标记包括涉及该微生物组内基本上所有类型微生物的存在、水平和/或活性的信息。
在一些实施方案中,微生物标记包括至少五种或至少十种或更多种类型微生物或其组分或产物的水平或水平组。在一些实施方案中,微生物标记包括至少五种或至少十种或更多种DNA序列的水平或水平组。在一些实施方案中,微生物标记包括十种或更多种16S rRNA基因序列的水平或水平组。在一些实施方案中,微生物标记包括18S rRNA基因序列的水平或水平组。在一些实施方案中,微生物标记包括至少五种或至少十种或更多种RNA转录物的水平或水平组。在一些实施方案中,微生物标记包括至少五种或至少十种或更多种蛋白质的水平或水平组。在一些实施方案中,微生物标记包括至少五种或至少十种或更多种代谢物的水平或水平组。
16S和18S rRNA基因序列分别编码原核生物和真核生物核糖体的小的亚单元组分。rRNA基因对于区分微生物类型尤其有用,因为尽管这些基因的序列在微生物物种间有所不同,但是这些基因具有用于引物结合的高度保守的区域。保守引物结合区域间的这种特异性允许用单组引物扩增许多不同类型微生物的rRNA基因并随后通过扩增序列进行区分。
优选地,分析个体的微生物组概况被包括在个体特异性数据库中,而一名或多名(更优选所有)其它个体的微生物组概况被包括在组数据库中。当个体特异性数据库包括微生物组概况时,该微生物组概况可以作为单独的条目被收录。当组数据库包括微生物组概况时,该微生物组概况任选地并优选地针对每名个体收录。因此,例如,组数据库条目可以由元组(S,F,R,{M})描述,其中S、F和R已在之前介绍,而{M}是个体S的微生物组概况。
微生物组概况{M}任选地并优选地包含多个值,其中每个值表示特定微生物的丰度。特定微生物的丰度可以例如通过对该微生物组的核酸进行测序而测定。然后可以通过已知的软件分析此测序数据以测定该个体的特定微生物的丰度。
本发明人发现,相比苗条的人,肥胖个体的微生物组不够多样化。因此,对包括微生物组概况的数据库的分析是有利的,因为其提供了关于分析个体与其它个体间的相似性的额外的信息,从而增加了预测能力的准确性。本发明人还发现,微生物组概况通过胰岛素抵抗和肠道微生物群间的关联而关系到血糖水平。胰岛素抵抗是这样的状态,其中身体细胞对胰腺产生的胰岛素没有反应。因此,身体无法降低血液中的葡萄糖水平。例如,2型糖尿病与微生物组概况间存在已知关联[Qin 等人, 2012, Nature, 490(7418):55-60]。
在本发明的一些实施方案中,所述额外的信息属于个体的至少部分血液化学。
如本文所用的“血液化学”指代血液中溶解的或包含的任何和所有物质的浓度。此类物质的代表性实例包括但不限于:白蛋白、淀粉酶、碱性磷酸酶、碳酸氢盐、总胆红素、BUN、C-反应性蛋白、钙、氯、LDL、HDL、总胆固醇、肌酐、CPK、γ-GT、葡萄糖、LDH、无机磷、脂肪酶、总蛋白质、AST、ALT、钠、甘油三酯、尿酸和VLDL。
优选地,个体的血液化学被包括在个体特异性数据库中,而一名或多名(更优选所有)其它个体的血液化学被包括在组数据库中。当个体特异性数据库包括血液化学时,该血液化学可以作为单独的条目被收录。当组数据库包括血液化学时,该血液化学任选地并优选地针对每名个体收录。因此,例如,组数据库条目可以由元组(S,F,R,{C})描述,其中S、F和R已在之前介绍,而{C}是个体S的血液化学。
本发明人发现,对包括血液化学的数据库的分析是有利的,因为其提供了关于分析个体与其它个体间的相似性的额外的信息,从而增加了预测能力的准确性。
在本发明的一些实施方案中,所述额外的信息属于个体的遗传学概况。
如本文所用的“遗传学概况”指代对大量不同基因的分析。遗传学概况可以涵盖该个体的整个基因组中的基因,或其可以涵盖特定的基因亚组。遗传学概况可包括基因组学概况、蛋白质组学概况、表观基因组学概况和/或转录物组学概况。
优选地,分析个体的遗传学概况被包括在个体特异性数据库中,而一名或多名(更优选所有)其它个体的遗传学概况被包括在组数据库中。当个体特异性数据库包括遗传学概况时,该遗传学概况可以作为单独的条目被收录。当组数据库包括遗传学概况时,该遗传学概况任选地并优选地针对每名个体收录。因此,例如,组数据库条目可以由元组(S,F,R,{G})描述,其中S、F和R已在之前介绍,而{G}是个体S的遗传学概况。
本发明人发现,对包括遗传学概况的数据库的分析是有利的,因为其提供了关于分析个体与其它个体间的相似性的额外的信息,从而增加了预测能力的准确性。
在本发明的一些实施方案中,所述额外的信息属于与个体相关的代谢组学数据。
如本文所用,术语“代谢组”指代个体内存在的代谢物的集合。人类代谢组涵盖了天然小分子(可天然生物合成的、非聚合的化合物),其参与一般代谢反应并且是细胞的保持、生长和正常功能所需的。通常,代谢物是小分子化合物,如代谢途径中酶的底物、此类途径的中间体或由代谢途径获得的产物。
根据本发明的一些实施方案所设想的代谢途径的代表性实例至少包括但不限于:柠檬酸循环、呼吸链、光合成、光呼吸、糖酵解、糖异生、磷酸己糖途径、氧化磷酸戊糖途径、脂肪酸的产生和β-氧化、尿素循环、氨基酸生物合成途径、蛋白质降解途径(如蛋白酶体降解、氨基酸降解途径)、下列物质的生物合成或降解:脂类、聚酮类化合物(包括,例如,黄酮和异黄酮)、类异戊二烯(包括,例如,萜类、甾醇、甾体类、类胡萝卜素、叶黄素)、糖类、苯丙素及衍生物、生物碱、苯类、吲哚、吲哚-硫化合物、卟啉类、花青素、激素、维生素、辅因子(如辅基或电子载体、木质素、芥子油苷、嘌呤、嘧啶、核苷、核苷酸及相关分子(如tRNA、微RNA(miRNA)或mRNA)。
因此,代谢组是对细胞生理状态的直接观测,并因而可以用于确定分析个体和其它个体间的相似性。代谢组学数据可以是代谢组或其部分,即,包含个体内存在的一些但并非全部代谢物的数据。
优选地,分析个体的代谢组学数据被包括在个体特异性数据库中,而一名或多名(更优选所有)其它个体的代谢组学数据被包括在组数据库中。当个体特异性数据库包括代谢组学数据时,该代谢组学数据可以作为单独的条目被收录。当组数据库包括代谢组学数据时,该代谢组学数据任选地并优选地针对每名个体收录。因此,例如,组数据库条目可以由元组(S,F,R,{B})描述,其中S、F和R已在之前介绍,而{B}是个体S的代谢组学数据。
在本发明的一些实施方案中,所述额外的信息属于个体的身体状况。身体状况任选地并优选地包括该个体正在经受或在过去曾经经受的疾病或综合征(如果存在)的列表。身体状况可以例如在构建或更新数据库期间通过对相应个体进行问卷而获得。
优选地,分析个体的身体状况被包括在个体特异性数据库中,而一名或多名(更优选所有)其它个体的身体状况被包括在组数据库中。当个体特异性数据库包括身体状况时,该身体状况可以作为单独的条目被收录。当组数据库包括身体状况时,该身体状况任选地并优选地针对每名个体收录。因此,例如,组数据库条目可以由元组(S,F,R,{D})描述,其中S、F和R已在之前介绍,而{D}是个体S的身体状况。
在本发明的一些实施方案中,所述额外的信息属于个体的食物摄入习惯。食物摄入习惯可以包括该个体经常食用的食物的清单,任选地连同对应的摄入频率。摄入频率表示该个体在一定时间段(例如,24小时、周,等)内习惯食用该食物的次数或体积或重量的估计数值。食物摄入习惯也可以通过问卷获得。由于食物摄入习惯通过问卷获得,所以食物摄入习惯中的食物清单可任选地包括这样的食物,该个体对该食物的反应是未知的。
优选地,分析个体的食物摄入习惯被包括在个体特异性数据库中,而一名或多名(更优选所有)其它个体的食物摄入习惯被包括在组数据库中。当个体特异性数据库包括食物摄入习惯时,该食物摄入习惯可以作为单独的条目被收录。当组数据库包括食物摄入习惯时,该食物摄入习惯任选地并优选地针对每名个体收录。因此,例如,组数据库条目可以由元组(S,F,R,{I})描述,其中S、F和R已在之前介绍,而{I}是个体S的食物摄入习惯。
在本发明的一些实施方案中,所述额外的信息属于个体在一定时间段内所进行的活动。此信息可以该个体在一定时间段内所进行的分立活动(睡觉、锻炼、坐、休息,等)列表的形式提供。这些活动任选地并优选地被提供为与在所述活动期间所食用的食物和/或在所述活动期间所测量的对食物的反应(例如,血糖水平)有关。
优选地,分析个体的分立活动列表被包括在个体特异性数据库中,而一名或多名(更优选所有)其它个体的分立活动列表被包括在组数据库中。这些活动任选地并优选地针对数据库中每个反应条目而被收录。因此,例如,组数据库条目可以由元组(S,F,R,{A})描述,其中S、F和R已在之前介绍,而{A}是个体S在反应R期间所进行的活动。类似的,个体特异性数据库条目可以由元组(F,R,{A})描述。数据库还可以包含这样的条目,其包括个体所进行的与特定食物无关的活动。这是因为对于一些测得的血糖水平而言,尚不清楚这些水平是否是该个体对特定食物的反应。因此,一些组数据库条目也可以由元组(S,R,{A})描述,而一些个体特异性数据库条目可以由元组(R,{A})描述。
在本发明的一些实施方案中,所述额外的信息属于与相应个体所食用的相应食物相关的特征性摄入频率。不同于以上所定义的食物摄入习惯,特征性摄入频率是针对个体对其的反应是已知的食物而提供的,而因此任选地并优选地针对数据库中每个食物条目而提供。因此,个体特异性数据库条目中的一个或多个可以元组(F,R,f)表示,组数据库条目中的一个或多个可以元组(S,F,R,f)表示,其中S、F和R已在之前介绍,而f是与食物F相关的摄入频率。所述摄入频率表示个体在一定时间段(例如,24小时、周,等)内食用该食物的次数或体积或重量的数值。
在本发明的一些实施方案中,所述额外的信息属于食物的至少部分化学组成。在这些实施方案中,个体特异性数据库条目中的一个或多个可以元组(F,R,{L})表示,而组数据库条目中的一个或多个可以元组(S,F,R, {L})表示,其中S、F和R已在之前介绍,而{L}是食物F的化学组成或部分化学组成。
应当理解,虽然分别描述了以上类型的额外信息,但本文实施方案设想了针对数据库的两种或多种类型的信息的任意组合。例如,组数据库条目中的一个或多个可以元组(S,F,R,{X})表示,其中{X}表示这样的数据结构,其包含下列中的两项或多项:微生物组概况、血液化学、遗传学概况、代谢组学数据、身体状况、食物摄入习惯、活动和化学组成,如上所述。类似地,以上信息类型中的两种或多种可以单独条目的形式或以补充个体特异性数据库的元组(F,R)的额外维度的形式被收录。
对个体特异性数据库和组数据库的基于所选食物的分析任选地并优选地包括:遍历数据库或其一些选定部分,并搜索个体特异性数据库中的数据对象与组数据库中的数据对象之间的相似性。然后将所述相似性用于限定组数据库的一部分,其窄于所搜索的数据库或其部分。然后可以从该收窄的组数据库部分提取对所选食物的反应。
如果组数据库中存在对所选食物的若干种反应,则可任选地并优选地执行似然比检验从而提取具有更高似然性的反应作为分析个体的反应。作为另外一种选择,可以将平均化程序应用于所找到的反应。仍作为另外一种选择,可以重复搜索相似性从而限定组数据库的一部分,其窄于先前所限定的部分。此过程可以迭代重复直到可以提取其它个体对所选食物的反应。
本文实施方案也设想了针对下述情况的分析程序,其中组数据库中不存在对所选食物的反应。在此情况下,组数据库任选地并优选地包含一名或多名其它个体对与所选食物类似的食物的反应,而该方法可以从组数据库中选择与所选食物类似的一种或多种食物。然后该方法可以进行以上程序中的一种或多种,就好像那些食物是在11处所选。
食物间的相似性可以基于例如食物组,其中含有相似的相同食物组的相对量的两种食物可被视为是相似的。因此,在这些实施方案中,组数据库包含一名或多名其它个体对含有一种或多种(例如,2、3、4、5或更多种)食物组的食物的反应,所述食物组也任选地并优选地以相同或大致相同(例如,在10%以内)的相对量被包含在所选组中。例如,当所选食物含有食物组G的某个相对量P而组数据库不含所选食物时,该方法可以从组数据库中选择一种或多种食物,其食物组G的量与P相似(例如,在10%以内),并且进行以上程序中的一种或多种,就好像那些食物是在11处所选。食物组G可以是上述食物组(例如,碳水化合物、蛋白质、脂肪、矿物质、维生素等)中的任一种。应当认识到,可以使用不止一种食物组用于确定相似性。例如,当所选食物含有相应的食物组G1、G2、...、GN的相对量P1、P2、...、PN而组数据库不含所选食物时,该方法可以从组数据库中选择一种或多种食物,其食物组G1的量与P1相似(例如,在10%以内)、食物组G2的量与P2相似(例如,在10%以内),以此类推。
在本发明的一些实施方案中,组数据库包含根据预定的分类组群进行分类的数据。所述分类可以基于如上所述的数据的任何维度。在这些实施方案中,所述分析包括根据相同的分类组群对个体进行分类。然后可以基于组数据库中的反应估计个体对所选食物的反应,所述组数据库中的反应对应于该个体所划归的分类组。
根据本发明的一些实施方案的数据库分析包括执行机器学习程序。
如本文所用,术语“机器学习”指代这样的程序,其体现为计算机程序,被配置为从先前收集的数据中归纳出模式、规律或规则从而将合适的反应形成未来的数据,或以某种有意义的方式描述该数据。
当数据库包含多维条目时,使用机器学习具有特别但并非专属的优势。
组数据库和个体特异性数据库可以用作训练组,机器学习程序可以从中提取能最佳描述该数据集的参数。一旦提取了参数,即可以将其用于预测对所选食物的反应。
在机器学习中,信息可以通过监督学习或无监督学习来采集。根据本发明的一些实施方案,所述机器学习程序包含或就是监督学习程序。在监督学习中,全局或局部目标功能被用于优化学习系统的结构。换句话讲,在监督学习中,存在期望的反应,系统将其用于指导学习。
根据本发明的一些实施方案,所述机器学习程序包含或就是无监督学习程序。在无监督学习中,通常不存在目标功能。具体地讲,没有为学习系统提供一套规则。根据本发明的一些实施方案的无监督学习的一种形式是无监督聚类,其中数据对象没有被先验地进行类别标记。
适于本文实施方案的“机器学习”程序的代表性实例包括但不限于:聚类、关联规则算法、特征评价算法、子集选择算法、支持向量机、分类规则、成本敏感的分类器、投票算法、堆栈算法、贝叶斯网络、决策树、神经网络、基于实例的算法、线性建模算法、K-最近邻分析、集成学习算法、概率模型、图形模型、回归分析法、梯度上升法、奇异值分解法和主成分分析。在神经网络模型中,自组织映射和自适应共振理论是常用的无监督学习算法。自适应共振理论模型允许集群的数目随问题的大小而变化并且让用户通过用户定义的常数(称为警戒参数)控制相同集群中成员间的相似程度。
以下是适于本文实施方案的一些机器学习程序的概述。
关联规则算法是用于提取特征间有意义的关联模式的技术。
术语“关联”,在机器学习的语境中,指代特征间的任何相互关系,而不仅仅是预测特定类别或数值的那些。关联包括但不限于:寻找关联规则、寻找模式、进行特征评价、进行特征子集选择、开发预测模型和理解特征间的相互作用。
术语“关联规则”指代在数据库内频繁共现的要素。其包括但不限于:关联模式、判别模式、频繁模式、闭合模式和巨型模式。
关联规则算法的惯常主要步骤是寻找在所有观测结果中最频繁的一组项目或特征。一旦获得该列表,即可以从其中提取规则。
上述自组织映射是常用于高维数据的可视化和分析的无监督学习技术。典型的应用聚焦在对映射上的数据内的中心依赖性的可视化。该算法所生成的映射可以用于加快其它算法对关联规则的识别。该算法通常包括处理单元(被称为“神经元”)的网格。每个神经元均与特征向量(被称为观测结果)相关。所述映射试图使用一组限定的模型以最佳的准确性来表示所有可用的观测结果。同时,所述模型在网格上变得有序,使得相似的模型彼此靠近而相异的模型彼此远离。此程序使得能够对数据中特征间的依赖性或关联进行识别以及可视化。
特征评价算法涉及特征排序或涉及在排序后基于特征对分析个体对所选食物的反应的影响来选择特征。
术语“特征”在机器学习的语境中指代一个或多个原始输入变量、一个或多个经处理的变量、或其它变量(包括原始变量和经处理的变量)的一种或多种数学组合。特征可能是连续的或离散的。
信息增益是适于特征评价的机器学习方法中的一种。定义信息增益需要定义熵,其是对训练实例的集合中杂质的测量。通过知晓某项特征的值而发生的靶特征的熵减被称为信息增益。信息增益可用作参数以确定特征在解释分析个体对所选食物的反应上的有效性。根据本发明的一些实施方案,对称不确定性是可以被特征选择算法使用的算法。对称不确定性通过将特征规一化到[0,1]的范围来补偿信息增益对具有更高价值的特征的偏向。
子集选择算法依赖于评价算法和搜索算法的组合。类似于特征评价算法,子集选择算法对特征子集进行排序。然而,不同于特征评价算法,适于本文实施方案的子集选择算法的目标在于选择针对分析个体对所选食物的反应具有最高影响的特征子集,同时考虑到该子集所包含特征间的冗余度。特征子集选择的好处包括:便于数据的可视化和理解、减少测量和存储的要求、缩短训练和利用的时间、以及消除干扰特征以改善分类。
子集选择算法的两种基本方法是向工作子集中添加特征的过程(前向选择)和从当前子集中删除特征的过程(后向消除)。在机器学习中,前向选择的完成与具有相同名字的统计程序是不同的。在机器学习中,通过使用交叉验证来评价一个新特征对当前子集表现的增强,从而找到待加入当前子集中的特征。在前向选择中,通过将各个剩余特征依次加入到当前子集中来构建子集,并同时使用交叉验证评价所期望的各个新子集的表现。在被加入到当前子集后带来最佳表现的特征被保留下来,而该过程继续。当剩余可用的特征中无一能提高当前子集的预测能力时,搜索结束。此过程找出特征的局部最优集。
后向消除以类似方式实现。在后向消除中,当特征集的进一步消减无法提高子集的预测能力时,搜索结束。本文实施方案设想了前向、后向或在两个方向上搜索的搜索算法。适于本文实施方案的搜索算法的代表性实例包括但不限于:穷举搜索、贪婪爬山、子集随机扰动、封装算法、概率比赛搜索、图式搜索、排序比赛搜索和贝叶斯分类器。
决策树是决策支持算法,其形成在考虑输入时所涉及步骤的逻辑路径以做出决策。
术语“决策树”指代任何类型的基于树的学习算法,包括但不限于,模型树、分类树和回归树。
决策树可以用于将数据库或其关系分层归类。决策树具有树状结构,其包括分支节点和叶结点。每个分支节点指定一项属性(分裂属性)和一项基于该分裂属性的值而进行的测试(分裂测试),并针对该分裂测试的所有可能结果分支出其它节点。作为决策树的根的分支节点被称为根节点。每个叶结点可以表示一个分类(例如,组数据库的特定部分是否与个体特异性数据库的特定部分匹配)或一个值(例如,分析个体对所选食物的预测反应)。叶结点还可以包含关于所代表分类的额外信息,如置信度分数,其测量所代表分类的置信度(即,该分类为准确的可能性)。例如,置信度分数可以是0到1的连续值,其中0分指示非常低的置信度(例如,所代表分类的指示价值非常低)而1分指示非常高的置信度(例如,所代表分类几乎肯定是准确的)。个体对所选食物的反应可以通过如下分类:基于路径上分支节点的分裂测试的结果向下遍历决策树直至到达叶结点,该叶结点提供个体对所选食物的反应。
支持向量机是基于统计学习理论的算法。根据本发明的一些实施方案的支持向量机(SVM)可以用于分类目的和/或用于数值预测。用于分类的支持向量机在本文中被称为“支持向量分类器”,用于数值预测的支持向量机在本文中被称为“支持向量回归”。
SVM的特征通常在于核函数,对核函数的选择决定了所得SVM是否提供分类、回归或其它功能。通过应用核函数,SVM将输入向量映射到高维特征空间中,其中可以构建决策超曲面(也称为分离器)以提供分类、回归或其它决策功能。在最简单的情况下,该曲面是超平面(也称为线性分离器),但还可以想到更复杂的分离器并可以使用核函数而应用。限定该超曲面的数据点被称为支持向量。
支持向量分类器选择这样的分离器,其中该分离器距最近的数据点的距离尽可能的大,从而将与给定类别中的对象相关的特征向量点从与该类别外的对象相关的特征向量点分离开来。对于支持向量回归,构建具有可接受误差半径的高维管,其使数据集的误差最小化,并同时使相关曲线或函数的平面度最大化。换句话讲,该管是围绕拟合曲线的包层,由最靠近该曲线或曲面的数据点的集合所限定。
支持向量机的优点在于:一旦识别出支持向量,则可以从计算结果中移除剩余的观测结果,因而极大地降低该问题的计算复杂性。SVM通常以两个阶段工作:训练阶段和测试阶段。在训练阶段,生成一组支持向量用于执行决策规则。在测试阶段,使用该决策规则做出决策。支持向量算法是用于训练SVM的方法。通过执行该算法,生成参数训练组,其包含表征SVM的支持向量。适于本文实施方案的支持向量算法的代表性实例包括但不限于序列最小优化。
最少绝对收缩和选择算子(LASSO)算法是用于线性回归的收缩和/或选择算法。LASSO算法可通过正则化而使平方误差的一般和最小化,其可以是L1范数正则化(系数的绝对值之和的界限)、L2范数正则化(系数的平方之和的界限),等等。LASSO算法可与小波系数的软阈值化、前向逐步回归和boosting方法相关联。LASSO算法在下列文献中有述:Tibshirani, R, Regression Shrinkage and Selection via the Lasso, J. Royal.Statist.Soc B., 第58卷, No. 1, 1996, 第267-288页,其公开内容通过引用并入本文中。
贝叶斯网络是表示变量以及变量间的条件相互依存关系的模型。在贝叶斯网络中,变量由节点表示,而节点可以通过一个或多个连接彼此相连。连接指示两个节点间存在关联。节点通常具有对应的条件概率表,其用于当与该节点相连的其它节点的状态给定时,确定该节点处于某一状态的概率。在一些实施方案中,采用贝叶斯最优分类器算法以将后验假设的最大值应用于新纪录上,从而预测其分类的概率,以及从得自训练组的其它假设中的每一者计算概率并且使用这些概率作为加权因子用于对食物的反应的未来预测。适于搜索最佳贝叶斯网络的算法包括但不限于基于全局分数量度的算法。在构建该网络的替代方法中,可以采用马尔科夫毯。马尔科夫毯隔离节点使之不受在其边界外的任何节点影响,所述边界由该节点的亲代、其子代以及其子代的亲代构成。
基于实例的算法针对每个实例生成新模型,而不是将预测基于从训练组生成(一次)的树或网络。
术语“实例”,在机器学习的语境中,指代来自数据库的实例。
基于实例的算法通常将整个数据库存储在存储器中并从与那些正在测试的类似的纪录的组中构建模型。此相似性可以例如通过最近邻或局部加权法(例如,使用欧氏距离)来评价。一旦选定了纪录组,即可以使用若干种不同算法(如朴素贝叶斯)构建最终模型。
现在参考图3,其是根据本发明的一些实施方案的适用于构建数据库的方法的流程图。
数据库可以从收集自单个个体或一组个体的数据来构建。当数据收集自单个个体时,所构建的数据库可以用作上文中方法10的个体特异性数据库(例如,数据库22)。当数据收集自一组个体时,所构建的数据库可以用作上文中方法10的组数据库(例如,数据库24)。
该方法从30开始并继续到31,在该处于至少数天的时间内(例如,一周)监测个体体内至少一种物质的水平。该物质可以是葡萄糖、胆固醇、钠、钾、钙中的一种或多种。在本发明的一些实施方案中,该物质包括至少葡萄糖,而在本发明的一些示例性实施方案中,该物质是葡萄糖。所述监测可以是连续的或在多个时间点(例如,每10分钟或每5分钟或每2分钟或每1分钟或每30秒)。优选地,所述水平是血液水平,例如,血糖水平。所述监测可以通过在整个监测期间连接至该个体(例如,与该个体的血管连通)的测量装置进行。
该方法继续到32,在此处监测该个体在一定时间内所食用的食物。监测所食用食物的时间段任选地并优选地与监测水平的时间段相同。
该方法继续到33,在此处分析所监测的水平和所监测的食物以与反应(例如,对所食用的食物的至少一部分中的每种食物的升糖反应)相关联。所述分析可以例如通过如下进行:对所食用的食物和水平在相同时间轴上作图,并搜索可能响应于食物摄入而出现的水平变化的模式。为此,可以采用机器学习程序,如以上算法中的一种或多种。
该方法继续到34,在此处于一个或多个数据库(例如,组数据库或个体特异性数据库)中制作属于关联的数据库记录。
在35处,该方法任选地并优选地获得属于个体和/或食物的额外数据,并在至少一个数据库中制作额外数据的记录。所述额外数据可以描述任何上述类型的额外信息,包括但不限于:微生物组概况、血液化学、遗传学概况、代谢组学数据、身体状况、食物摄入习惯、活动和化学组成。该方法任选地并优选地继续到36,在此处于一个或多个数据库(例如,组数据库或个体特异性数据库)中制作属于所述额外数据的数据库记录。优选地,将36和34应用于相同的数据库。因此,操作36得到包含多维条目的数据库,如上文中所进一步详述的。该方法可以从34或36(如果执行)环回到31,而可以对另一名个体进行操作31-36中的一项或多项。当想要构建组数据库时,则执行此回路。
在本发明的各种示例性实施方案中,该方法继续到37,在此处任选地并优选地使用多维分析程序处理数据库记录,并继续到38,在此处响应于所述分析而更新数据库。当数据库被用作个体特异性数据库时,优选地在收集单个个体的数据之后开始操作37,而当数据库被用作组数据库时,优选地在收集多名个体的数据之后开始操作37。
所述多维分析程序任选地并优选地包括机器学习程序,如上述程序中的一种或多种。所述分析的目的在于确定数据中的模式,其允许找出数据库中不同条目间的相似性。例如,所述分析可以包括:定义可以将数据库条目划归其中的分类组,并根据该分类组将数据库条目分类。随后,可以根据其分类对条目进行标记。所述多维分析可以额外地或可替换地包括构建决策树。随后,可以更新数据库以包含所构建的决策树。所述多维分析可以额外地或可替换地包括提取数据库中特征间的关联模式和/或关联规则。随后,可以更新数据库以包含所述关联模式和/或关联规则。所述多维分析可以额外地或可替换地包括例如使用特征评价算法对数据库中的特征进行排序。随后,可以更新数据库以包含所述排序。所述多维分析可以额外地或可替换地包括从数据库的至少一部分数据构建贝叶斯网络。随后,可以更新数据库以包含所构建的贝叶斯网络。还设想了其它类型的分析。
数据库的处理和更新可以重复一次或多次。在这些实施方案中,该方法可以从38环回到37。
所述方法在39结束。
如本文所用,术语“约”指代 ± 10 %。
词语“示例性”在本文中用于意指“用作示例、实例或举例说明”。任何被描述为“示例性”的实施方案不一定被理解为优选的或优于其它实施方案和/或不一定排除结合来自其它实施方案的特征。
词语“任选地”在本文中用于意指“在一些实施方案中提供而并不在其它实施方案中提供”。本发明的任何特定实施方案可包含多个“任选的”特征,除非此类特征相互冲突。
术语“包含/包括”(“comprises”、“comprising”、“includes”、“including”)、“具有”(“having”)及其动词变化形式意指“包含/包括但不限于”。
术语“由…组成”意指“包括但不限于”。
术语“主要由…组成”意指组合物、方法或结构可包括额外的成分、步骤和/或部分,但仅限于所述成分、步骤和/或部分不会实质性地改变所要求保护的组合物、方法或结构的基础和新颖特性。
如本文所用,单数形式“一个/种”和“所述”包括复数指代物,除非上下文另外清楚地指明。例如,术语“化合物”或“至少一种化合物”可包括多种化合物,包括其混合物。
在整个本申请中,本发明的各种实施方案可以范围格式呈现。应当理解,范围格式的描述仅仅是为了方便和简洁,而不应当被理解为对本发明范围的硬性限制。因此,对范围的描述应当被视为已经具体公开了所有可能的子范围以及该范围内的单个数值。例如,对范围(如1至6)的描述应当被视为已经具体公开了子范围(如1至3、1至4、1至5、2至4、2至6、3至6等)以及该范围内的单个数值(例如,1、2、3、4、5和6)。无论范围的宽度如何,这均适用。
只要本文中指定了数值范围,则其意味着包含该指定范围内任何引用的数值(分数或整数)。短语“范围在/在第一指定数值和第二指定数值间的范围内”以及“范围在/在第一指定数值“至”第二指定数值间的范围内”在本文中可以互换使用并意味着包含所述第一和第二制定数值以及其间所有的分数和整数数值。
应当认识到,本发明的某些特征(其出于清楚的目的而在单独的实施方案的上下文中分别描述)也可在单个实施方案中以组合形式提供。相反地,本发明的各种特征(其出于简洁的目的而在单个实施方案的上下文中描述)也可分别提供或以任何合适的子组合提供或作为适于本发明的任何其它所述实施方案的形式提供。在各种实施方案的上下文中所述的某些特征不应当被视为那些实施方案的必要特征,除非该实施方案在缺乏那些要素的情况下无法实现。
如上所述并在以下权利要求书部分中要求保护的本发明的各种实施方案和方面将在下列实施例中找到实验支持。
实施例
现在参考下列实施例,其与以上描述一起以非限制性方式说明了本发明的一些实施方案。
实施例1
在普通人群中,血糖水平正在迅速升高,导致糖尿病前期和葡萄糖耐受性异常的患病率急剧上升,并最终发展为II型糖尿病。饮食摄入和食物组成被视为血糖水平的核心决定因素,并很关键地涉及到血糖正常个体和糖尿病前期个体等的血糖稳态。糖尿病前期的饮食调整确实可以导致高血糖及其远期并发症的完全逆转。然而,食物摄入在升糖反应上的个体化效应尚不清楚,因而极大地限制了通过饮食干预来有效诱导升糖控制的能力。这一主要障碍的根源在于对食物的升糖反应中的个体差异缺乏基本了解。饮食相关差异的一个关键但研究较少的决定因素是肠道微生物群的组成和功能。
本实施例提供了实验与计算相结合的研究,其包括血糖正常个体和糖尿病前期个体对食物的血糖反应的大规模前瞻性分析,并解读了微生物群对该反应的贡献。已经表征了微生物群和数百名个体对食物摄入的升糖反应以及不同类型的升糖反应模式。已经设计出个人化的机器学习算法用于预测对食物摄入的个体化升糖反应。
方法
在特拉维夫Sourasky医疗中心召募了217名健康志愿者。其中,182名完成了整个研究并且针对他们中的每一者,已经获得了多维概况并记录在组数据库中。所述概况包括:(1) 一般生活方式和健康问卷;(2) 食物频率问卷(FFQ);(3)宽泛的血液化学状况;(4) 一般身体参数(例如,体重、身高、腰围、血压);(5) 综合宿主遗传学概况;(6) 完整的微生物组分析(由16s rDNA分析和鸟枪宏基因组测序二者组成);(7) 一整周的血糖测量结果,使用连续血糖监测仪(CGM);(8) 样本的综合代谢组学分析;和(9) 一整周的记录,包括食物摄入的次数和内容、身体活动、睡眠时间以及压力和饥饿水平;(10) 对七种预定的测试食物的血糖反应。
通过计算机软件分析数据库,其目标在于:表征个体间存在的不同类型的升糖反应模式,并预测个体对食物摄入的升糖反应。
收集综合的代谢、遗传和微生物群概况
参与者到达特拉维夫Sourasky医疗中心。每名参与者签署同意书,并获得信息/样本。以下所有的数据和样本被冠以独特的参与者标识符(不允许识别出参与者)而分别匿名存储在数据库和文库中。
从每名参与者获得下列信息和样本:
1)由每名参与者填写的一般生活方式和健康问卷,包括有关过去和现在的身体状况和生活方式习惯(例如,锻炼和吸烟习惯)的一组综合问题。
2)由每名参与者填写的食物频率问卷(FFQ),包括有关饮食习惯和各种食物种类的日常食用的一组综合问题。
3)宽泛的血液化学状况(例如,胆固醇水平、全血细胞计数、HbA1c),由我们从每名参与者所抽取的血液测量。
4)由我们测量的一般身体参数(例如,体重、身高、腰围、血压)。
5)综合宿主遗传学概况,通过Illumina阵列获得,应用于从参与者在刚抵达中心时所抽取的血液中提取的DNA上,测量了约700,000种不同的单核苷酸多态性(SNP)。
6)综合的微生物群分析,通过对从每名参与者在他/她刚抵达中心时提供的粪便样品中提取的DNA同时进行16S和宏基因组分析而获得。
7)一整周的连续血糖测量结果,通过使每名参与者在一整周中与iPro2连续血糖监测仪(CGM)(其每五分钟测量一次血糖水平)相连而测得。一名参与者的一个测量日的实例示于图4中。图4中所示的是一名研究参与者在七个连接日期间的原始血糖测量结果的实例。用箭头标明了进餐次数;还标明了睡眠时间。
8)样本的完整代谢组学分析,通过对所收集的粪便和血液样品应用LC-MS和GC-MS质谱分析而进行。
9)一整周的活动记录,包括每名参与者在连接周内所进行的并且可能影响他/她血糖水平的活动的全部次数和类型(例如,全部食物摄入的内容和次数、身体活动的次数和强度、睡眠次数、以及压力和饥饿水平)。
10)对七种预定的测试食物的血糖反应。每天早晨,每名参与者食用由工作人员提供的七种测试餐食(纯白面包食用两次、纯白面包加30g黄油食用两次、50g葡萄糖加250g水食用两次、以及50g果糖加250g水食用一次)中的一种,其包含精确的50g可用碳水化合物。
结果
对相同食物的血糖反应的个体间偏差
检查了不同个体对相同食物具有的不同反应的程度。为此,比较了个体对他们每人在研究中的每天早晨被要求食用并由工作人员供应的七种预定的测试食物的血糖反应。对于所检查的全部类型的测试食物,个体对相同食物的反应均存在差异。对于50g可用碳水化合物(甚至对于纯葡萄糖)的食物激发,一些个体几乎不表现出升糖反应,而其它个体则表现出非常明显的反应。
图5A-F示出了研究参与者对葡萄糖(图5A)、面包(图5B)和面包加黄油(图5C)的血糖反应的柱状图,其中所食用的每种食物的量被设定为总碳水化合物含量为50克。还示出了三名具有高血糖反应的个体和三名具有低血糖反应的个体对葡萄糖(图5D)、面包(图5E)和面包加黄油(图5F)的饭后反应的实例。注意到,平均而言,黄油降低了升糖反应,但这仅仅是针对该个体子集的情况。
本发明人令人惊奇地发现,不同个体间对食物的反应的差异相当大。不同个体间的差异示于图5G中,其示出了不同个体对葡萄糖、面包和面包加黄油的反应的聚类。图5G中的每一行对应一名个体,而彩色条目表示对每种食物激发的升糖反应的强度(红色表明更高的反应,而绿色表明更低的反应)。如图所示,在每个集群内存在具有相似反应的个体的集群,在这些个体中,约10%对面包加黄油反应最强烈,约30%对面包反应最强烈,而约60%对纯葡萄糖反应最强烈。
经验证,所述差异不是由于连续血糖测量结果的不准确性,因为:(1) 在整个群体中测得的平均血糖反应与这些食物的公布的升糖反应(其也是按群体平均计算)非常吻合,并且(2) 通过比较两个重复测量结果(其各自被要求针对三种不同类型的预定的测试食物进行),发现在这些个体内其对相同食物的反应具有高度可重复性。图6A-C示出了如根据本发明的一些实施方案进行的研究过程中获得的葡萄糖(图6A)、面包(图6B)和面包加黄油(图6C)的血糖反应的柱状图,其中所食用的每种食物的量被设定为总碳水化合物含量为50克。每个点表示一名研究参与者。对于所述三种不同类型的测试食物,重复间的相关性为0.76-0.78。
预测个体对食物的个人反应
为了评估预测未见过的餐食的能力,采用了交叉验证方案。将约8,000种餐食(获得针对其的血糖反应测量结果)随机分入10个大小相等的组。使用模型(其参数仅使用其它9个餐食组中的餐食而习得)预测各组中餐食的血糖反应。因此,在模型学习阶段期间不会观测到其预测被评估的每种餐食,从而代表了对本文实施方案的预测能力的真实评估。
比较了三种不同的模型,如下:
1)普适(One size fits all)的仅基于碳水化合物的模型。此模型仅使用各餐食中的一项特征,即该餐食中含有的碳水化合物的量,其原理是:碳水化合物是升糖反应的主要已知决定因素。
2)普适(One size fits all)的多项餐食特征模型。此模型扩大了仅基于碳水化合物的模型以包含10项额外的参数,其组成如下:餐食的重量、卡路里数、蛋白质的量、脂肪的量、餐食的碳水化合物分数、餐食的蛋白质分数、餐食的脂肪分数、碳水化合物对蛋白质的对数比、碳水化合物对脂肪的对数比、以及餐食中食物组分的数目。
3)个人化模型。此模型使用模型2的参数,但还另外包含:
a)三项个人临床参数,由年龄、血液中糖化血红蛋白的水平(HbA1c)和血液中磷的水平组成。
b)来自先前餐食(在过去10小时内食用的餐食)的四项参数,由先前餐食中的卡路里量、碳水化合物量、碳水化合物对脂肪的比率以及先前餐食后所过去的时间本身组成。
仅基于训练数据(即,用于构建预测因子的餐食,而非被预测的单列出的餐食)而将研究个体聚类到三个不同的组中。然后针对所述三个不同人群组中的每一者构建单独的模型。这些组是基于每个人所具有的餐食中碳水化合物的量与他/她的血糖反应之间的相关性而定义的。本发明人注意到碳水化合物的量与血糖反应间的这种关系在个体间变化很大,并因而试图使用此特征来针对各个子群体或集群分别构建单独的预测因子。图7A-E展示了此模型的原理,其中可以清楚看到在碳水化合物的量与血糖反应之间的关系中人群间的高度差异。图7A-E中所示的是所有研究参与者的餐食中的碳水化合物量与升糖反应间的相关性柱状图(图7A)、在碳水化合物量与升糖反应间具有低相关性的两名参与者的实例(图7B和7C)和具有高的此类相关性的两名参与者的实例(图7D和7E)。
这些模型是使用L1(绝对值之和)正则化的LASSO算法的线性模型而习得的。在所有被预测的餐食中(回想一下,每种餐食均使用基于将其排除在外的餐食而习得的模型来预测),模型1、2和3分别达到0.35、0.36和0.44的预测相关性。所有模型的预测值均为正值,这证明了使用本文实施方案的组数据库来预测对未见过的餐食的升糖反应的效力。使用模型3带来预测准确性的提升,这证明利用个体的个人参数私人定制的预测因子可以导致性能的极大提升。在具有最高的碳水化合物含量与血糖反应间相关性的两个个体集群上,该模型预测了单列的未见过的餐食,其中集群1和2的相关性分别为0.50和0.51。这些集群统共占全部个体的几乎50%,证明对于几乎半数的研究参与者(事先确定的),所述预测因子实现了非常好的预测。
这些结果汇总于图8A-D中,其示出了个体升糖反应的私人定制的预测因子。图8A示出了使用餐食的一般参数(模型1和2)或还使用个体的个人参数(模型3)的三种模型之间预测单列的未见过的餐食的相关性的比较。还示出了针对用于模型3中的个体集群中的每一者的预测。图8B-D示出了对三个个体集群的得自私人定制的模型(模型3)的预测,所述三个个体集群是基于各集群中个体所表现出的其餐食中碳水化合物的量与其血糖反应间的关系而定义的。注意到个体集群1和2中0.5和0.51的高相关性,所述个体集群表现出餐食中碳水化合物含量与血糖反应间的高相关性。
结论
本实施例证明了本文实施方案的方法在预测个体对食物摄入的升糖反应上的实用性。本实施例显示,针对个体参数私人定制的预测因子可以实现性能改善。本实施例显示,对于由大致半数人口组成的并且其身份可以事先确定的个体子集而言,所述预测更加准确。这些个体具有这样的特质:(相比人口中的其它个体)其表现出餐食中碳水化合物的量与血糖反应间的高度相关性。
实施例2
使用决策树通过随机boosting重新分析上文实施例1中收集的数据。结果示于图9A-G中。
图9A示出了对应于5个不同的血糖水平预测中每一者的实际测得的血糖反应的箱线图。中心线是中值,而顶部和底部的横杠分别表示75和25百分位数。还指明了全部餐食的总体相关性(R=0.56)。
图9B示出了根据本发明的一些实施方案所预测的全部7072种餐食。示出的是预测的血糖反应(横坐标)和所测得的反应(纵坐标)之间的比较。还示出的是总体相关性(R=0.56)和指示出移动窗口平均值(100个连续预测)的线。
图9C示出了不同相关性预测水平的参与者数目的柱状图。
图9D-G示出了来自典型预测的两名参与者的预测反应和测得反应的比较(图9D和9E),以及两名最佳预测的参与者的预测反应和测得反应的比较(图9F和9G)。
实施例3
本实施例证明了根据本文所述的实施方案的数据库预测个体对食物的反应的能力,其使用组数据库(包含其它个体对食物的反应)和个体特异性数据库(包含描述该个体的数据但不包含对任何食物的任何反应)。数据和在学习阶段对所收集数据的分析与实施例2中是相同的。在预测阶段,将分析个体的血糖水平数据从数据库中移除。所述个体特异性数据库包含描述以下的数据:生活方式、健康、血液化学和食物摄入习惯(包括该个体惯常食用的食物的清单连同对应的摄入频率)。所述生活方式、健康和食物摄入习惯通过问卷收集。
图10A示出了对应于5个不同的血糖水平预测中每一者的测得的血糖反应的箱线图。注释和标记与
图9A中相同。如图所示,全部餐食的总体相关性为R=0.46。
图10B示出了根据本发明的一些实施方案所预测的全部7072种餐食。注释和标记与
图9B中相同。
实施例4
本实施例说明了可以如何使用数据库预测个体对食物的升糖反应。
材料和方法
16名升糖反应异常的参与者和健康参与者参加了为期三周的饮食干预实验。第一周是分析周,其中计算了两种个人化的测试饮食:(1) 一整周的个人化饮食,其预测具有“好的”(低)饭后血糖反应;和(2) 一整周的个人化饮食,其预测具有“不好的”(高)饭后血糖反应。本发明人评价了相比在所述“不好的”周给予的个人化饮食,所述“好的”周的个人化饮食是否确实引发了更低的血糖反应。
在实验前,膳食学家制定了为期6天的私人定制的饮食,如下:每名参与者决定他/她在一天中吃几餐和摄入多少卡路里。6天中所有的餐食都是不同的,并且每天食用相同数量的餐食和卡路里,其中餐食之间的间隔为至少3小时。餐食的内容由参与者决定以符合其口味和正常饮食。例如,参与者可能选择一天食用5种餐食类别,如下:300卡路里的早餐、200卡路里的早午餐、500卡路里的午餐、200卡路里的零食和800卡路里的晚餐。该参与者针对每种餐食类别(所述实例中的5种餐食类别:早餐、早午餐、午餐、零食和晚餐)在膳食学家的帮助下就6种不同的选择作出决定,以确保所有的早餐都是等卡路里的,其最大偏差为10%。
实验从对该参与者采集血样并进行人体测量开始,将该参与者连接至连续血糖监测仪并开始所述6天饮食,同时记录在研究期间所有食用的餐食。在实验的第7天,该参与者进行标准(50g)口服葡萄糖耐受测试,其后他在那一整天中正常摄食。被称为“混合周”的第一周将该参与者暴露于各种食物,此做法随后将确定哪种餐食相对“好”和“不好”,即哪种餐食分别导致低和高血糖反应。使用连续血糖监测仪(Medtronic iPro2)以密集的5分钟时间间隔监测血糖水平。测量了每种餐食的血糖上升以及血糖增量的曲线下面积(AUC)。按从低到高的反应选择餐食,其中选择了每个餐食类别中最好和最差的两种餐食并标记为好的餐食和不好的餐食。
在选定好的和不好的餐食之后,该参与者继续进行实验的另外两周,即测试周。“好的周”仅由好的餐食构成,而“不好的周”则仅由经预测会引发“不好的”(高)血糖反应的餐食构成。一周包括6天的饮食和一天的50克葡萄糖耐受测试,如上所述。周的次序是随机选择的,并且参与者和膳食学家均不知晓周的次序。三周后,比较各周之间的血糖水平。
到目前为止,16名个体完成了实验,其中10名具有升糖反应异常,而6名是健康的。
结果
“好的”和“不好的”餐食被正确地归类:据发现,在所述两个测试周中所测试的餐食中的绝大多数显示出与预测(低/高)相符的血糖反应。
相比“不好的”周,在“好的”周中的餐食之后观察到了平均AUC的显著改善。此结果对于健康个体和葡萄糖耐受性异常个体均成立,其中在后者组中,“好的”周与“不好的”周之间的差别更大(图11)。
该结果还显示,餐后的血糖反应显示出昼夜变化规律(图12)。当通过一个类别中所有餐食的平均AUC反应进行线性拟合时,可以看到早餐AUC趋势相对低,然后是午餐,而晚餐具有最高的AUC趋势。在通过餐食中的碳水化合物或卡路里规一化后,此趋势依然保持(图13A-B)。
参考文献
1.Danaei, G. 等人,National, regional, and global trends in fasting plasma glucose and diabetes prevalence since 1980: systematic analysis of health examination surveys and epidemiological studies with 370 country-years and 2.7 million participants.Lancet 378, 31-40, doi:10.1016/S0140-6736(11)60679-X (2011).
2.Li, G. 等人,The long-term effect of lifestyle interventions to prevent diabetes in the China Da Qing Diabetes Prevention Study: a 20-year follow-up study.Lancet 371, 1783-1789, doi:10.1016/S0140-6736(08)60766-7 (2008).
3.Gerstein, H. C. 等人,Annual incidence and relative risk of diabetes in people with various categories of dysglycemia: a systematic overview and meta-analysis of prospective studies.Diabetes research and clinical practice 78, 305-312, doi:10.1016/j.diabres.2007.05.004 (2007).
4.Tabak, A. G. 等人,Trajectories of glycaemia, insulin sensitivity, and insulin secretion before diagnosis of type 2 diabetes: an analysis from the Whitehall II study.Lancet 373, 2215-2221, doi:10.1016/S0140-6736(09)60619-X (2009).
5.Is fasting glucose sufficient to define diabetes: Epidemiological data from 20 European studies.The DECODE-study group.European Diabetes Epidemiology Group.Diabetes Epidemiology: Collaborative analysis of Diagnostic Criteria in Europe.Diabetologia 42, 647-654 (1999).
6.Gong, Q. 等人,Long-term effects of a randomised trial of a 6-year lifestyle intervention in impaired glucose tolerance on diabetes-related microvascular complications: the China Da Qing Diabetes Prevention Outcome Study.Diabetologia 54, 300-307, doi:10.1007/s00125-010-1948-9 (2011).
7.Meyer, K. A. 等人,Carbohydrates, dietary fiber, and incident type 2 diabetes in older women.The American journal of clinical nutrition 71, 921-930 (2000).
8.Lau, C. 等人,Dietary glycemic index, glycemic load, fiber, simple sugars, and insulin resistance: the Inter99 study.Diabetes care 28, 1397-1403 (2005).
9.Vega-Lopez, S., Ausman, L. M., Griffith, J. L. & Lichtenstein, A. H. Interindividual variability and intra-individual reproducibility of glycemic index values for commercial white bread.Diabetes care 30, 1412-1417, doi:10.2337/dc06-1598 (2007).
10.Wolever, T. M. 等人,Determination of the glycaemic index of foods: interlaboratory study.European journal of clinical nutrition 57, 475-482, doi:10.1038/sj.ejcn.1601551 (2003).
11.Williams, S. M. 等人,Another approach to estimating the reliability of glycaemic index.The British journal of nutrition 100, 364-372, doi:10.1017/S0007114507894311 (2008).
12.Shulzhenko, N. 等人,Crosstalk between B lymphocytes, microbiota and the intestinal epithelium governs immunity versus metabolism in the gut.Nature medicine 17, 1585-1593, doi:10.1038/nm.2505 (2011).
13.Everard, A. 等人,Responses of gut microbiota and glucose and lipid metabolism to prebiotics in genetic obese and diet-induced leptin-resistant mice.Diabetes 60, 2775-2786, doi:10.2337/db11-0227 (2011).
14.Musso, G., Gambino, R. & Cassader, M. Interactions between gut microbiota and host metabolism predisposing to obesity and diabetes.Annual review of medicine 62, 361-380, doi:10.1146/annurev-med-012510-175505 (2011).
15.Turnbaugh, P. J. 等人,A core gut microbiome in obese and lean twins.Nature 457, 480-484, doi:10.1038/nature07540 (2009).
16.Turnbaugh, P. J. 等人An obesity-associated gut microbiome with increased capacity for energy harvest.Nature 444, 1027-1031, doi:10.1038/nature05414 (2006).
17.Claesson, M. J. 等人,Gut microbiota composition correlates with diet and health in the elderly.Nature 488, 178-184, 10.1038/nature11319 (2012)。
尽管本发明已经结合其具体实施方案进行了描述,但显然许多替代形式、修改形式和变型形式对于本领域技术人员将是显而易见的。因此,其旨在包含落入所附权利要求书的精神和宽广范围内的所有此类替代形式、修改形式和变型形式。
本说明书中提及的所有出版物、专利和专利申请均全文引入本说明书作为参考,其程度如同每个单独的出版物、专利或专利申请被专门并单独指明并入本文作为参考。另外,本申请中对任何参考文献的引用或确认不应解释为承认:这样的参考文献可作为本发明的现有技术。就节标题的使用程度而言,其不应理解为一定是限制性的。
- 还没有人留言评论。精彩留言会获得点赞!