一种基于演化聚类学习的液氢加注系统安全性评估方法与流程
本发明实施涉及安全性评估技术,尤其涉及一种基于演化聚类学习的液氢加注系统安全性评估方法。
背景技术:
21世纪人类将全面走向空间、探索空间、开发空间和利用空间,航天发射,作为评判一个国家综合国力的重要标志,具有重要的战略意义。航天发射是一个典型的涉及多人、多机、多环境的大规模复杂工程系统,由航天器、运载火箭和发射设施等组成,在发射过程中,任何安全隐患、人员误操作以及系统故障都可能导致运行事故甚至灾祸,其探索性、试验性、危险性和社会性决定了航天发射的安全具有非常重要的地位。
随着科学技术的不断发展,航天发射系统和设备组成趋于系统网络化,使得异常行为与系统部件呈现多对多关联,影响着系统的安全运行。测试、指挥、运行、控制等任务中涉及多人、多操作以及遥操作等,故障和人为差错构成系统运行的重大安全隐患。发射系统运行于恶劣的自然环境(如高温、高盐、高湿,或严寒、风沙等),在发射任务过程中受到复杂的物理-化学-力学综合作用(如低温推进剂对管路系统的物理影响,火箭发射对系统的声波、力学冲击以及高温喷出燃料的化学腐蚀等)。反复的阶段性间歇运行对系统设备、器件的性能产生强烈的劣化作用,导致各子系统出现设备隐患,呈现出不同的系统或设备故障。因此,如何分析航天发射系统在外部干扰、应力变化以及操作错误下的系统运行规律和动态行为,研究航天发射系统阶段性间歇运行下“危险因素-安全事故”的演化,揭示系统中设备性能劣化趋势、系统故障传播以及事故发生机理,是航天发射系统运行安全实时评估的关键问题。
以液氢加注为例,将液氢推进剂的燃料和氧化剂从地面储箱输送至运载火箭的燃料箱中,如图1所示。液氢加注是低温液体推进剂组合,以液氢做燃料,液氧做氧化剂,这两类物质沸点极低,容易挥发,需要在高压力下灌注,才能使之保持液态,对低温推进剂的加注时间精度要求非常高。长征系列运载火箭每发任务加注常规燃料数百吨,具有很强的腐蚀性和毒性。而低温推进剂液氢液氧具有易挥发和蒸发特性,液氢的爆炸极限是4.0%~75.6%(体积浓度),即在空气中的体积浓度在4%~75.6%之间时,遇到火源就引发爆炸。因此,在航天发射过程中保证高安全性是首要的。
为保障系统安全可靠运行,需要对航天发射液氢加注系统进行运行参数采集、多次射前模拟飞行和测试总检查等,使得发射系统运行过程中产生的数据量不断积累,结合数据分析、挖掘和处理,克服过程的非线性和各种不确定干扰对过程系统安全可靠运行的影响,有着重要的意义。然而,液氢加注系统失效模式相当复杂、影响安全性的诱因多、难以预测;以至于在整个液氢加注过程中存在着大量的未知规律,使得该过程具有很大的不确定性。因此,通过测试数据事后判读分析排除系统运行异常和故障保证发射安全,亟需研究在任务过程中运行安全性实时评估理论和方法。
航天发射液氢加注系统运行安全实时评估问题,是保证航天发射安全运行的基础。目前,各类复杂工程系统运行的安全评估理论和方法主要包括:
(1)基于定性分析的运行安全评估方法,包括故障树分析方法、风险评价指数法、安全检查表、预先危险分析、故障模式与影响分析、危险可操作性分析等方法。
(2)基于定量分析的运行安全评估方法,包括事件树法、马尔可夫法、事件序列图法、逻辑分析方法、模拟仿真方法等。
(3)综合评估方法,包括风险协调评审和概率风险评估方法等。
可见,现有的安全性评估方法,在系统/设备的工艺参数超限、故障以及误操作等危险因素的影响下,未充分考虑系统的大规模和子系统间的强耦合使得系统运行事故的发生机理和演化规律随时间序列呈现出复杂性和不确定性。因此,在不同时间序列与不同工况下,如何有效表征过程参数和状态行为的特征变化,以及建立危险因素作用下“过程参数-安全事故”之间的演化模型,是亟待解决的关键科学问题。
技术实现要素:
有鉴于此,本发明所要解决的技术问题是提供一种基于演化聚类学习的液氢加注系统安全性评估方法,将演化聚类学习引入安全性评估理论框架中,刻画数据驱动下演化聚类字典的学习与更新机制,构造安全性评估指标,实现航天发射液氢加注系统的安全性实时评估。
本发明的基于演化聚类学习的液氢加注系统安全性评估的大致流程如图2所示,其具体实现步骤如下:
S1:选取训练样本。从液氢加注系统的历史感知数据中选取训练样本;
S2:分块处理。根据液氢加注系统时间序列下运行工况、系统运动规律等先验知识,对训练样本进行分块处理;
S3:块相似性度量。通过非局部操作算子、联合操作算法,以及l2范数距离测度块相似性度量;
S4:求解组结构稀疏系数。通过块坐标松弛算法求解组稀疏系数;
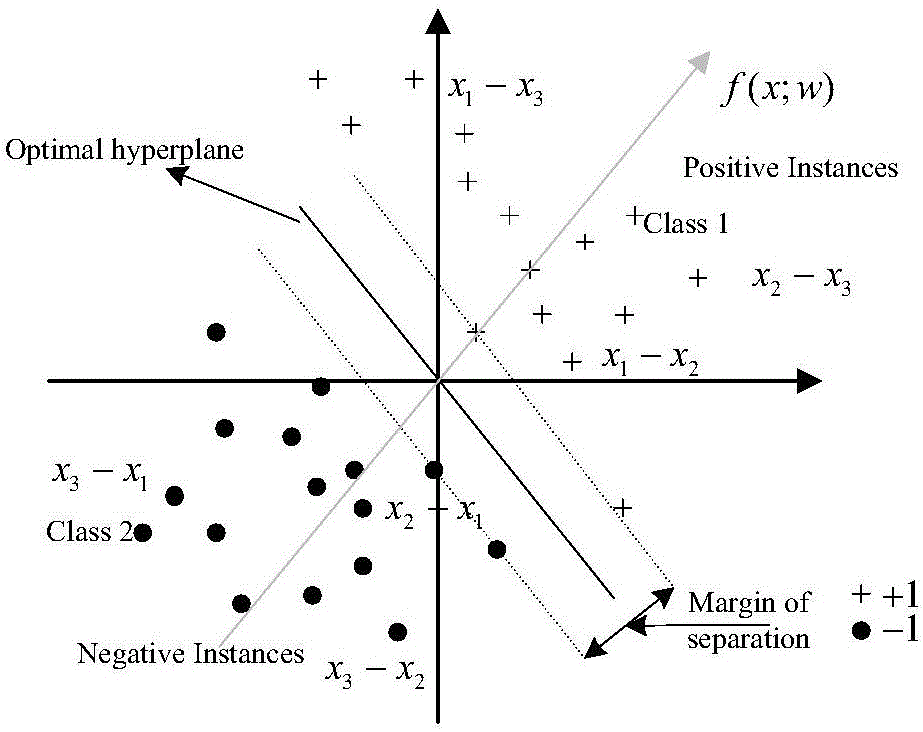
S5:确定支持向量机模型(Support Vector Machines,SVM)的参数,更新演化聚类块字典。确定支持向量机分类器的参数,并根据历史标签及时更新字典;
S6:液氢加注系统安全度及其度量标准的构建;结合系统的运动规律和状态行为的运动规律,定量分析液氢加注系统的安全度及其度量标准、概率风险评估;
S7:刻画系统的安全性等级。构造液氢加注系统的安全性评估指标,自适应调整危险因素权重,给出系统的安全性等级,验证历史运行数据下系统安全性等级;
S8:在线实时安全性评估。
进一步,所述步骤S3中的块相似性度量,如图3所示,具体步骤如下:
S31:利用块的非局部相似性的先验信息,通过非局部操作算子和联合操作算子,获取块的稀疏表示。
S32通过参考块与候选块的l2范数距离相似性度量,获取相似块的聚类。
进一步,所述步骤S5中的确定支持向量机模型的参数,更新演化聚类块字典,具体步骤如下:
S51:根据过程参数与其对应系统安全状态行为标签的先验信息,对l2-SVM分类器模型进行训练,获取其最优参数,如图5所示。
S52:针对测试信息或在线感知信息,通过分类预测结果与真实结果相对比,构建演化聚类字典的更新机制。
进一步,所述步骤S6中的液氢加注系统安全度及其度量标准的构建,具体步骤如下:
S61:通过故障树分析,获取可能事故下液氢加注系统的结构逻辑框图,利用最小割集上限与最小路径下限方法,来逼近系统的状态行为,并分割为独立的基本事件,如图6所示。
S62:通过故障的分类正确率与基本事件的发生概率,定义液氢加注系统安全性评估的安全度。
进一步,所述步骤S8中的在线实时安全性评估,具体步骤如下:
S81:重复上述S2至S7步骤,实现液氢加注系统安全性实时评估。
S82:特别的是,重复步骤S4与S5时,故障预测分类与字典的更新平行处理:首先,字典更新原则--通过与实际系统安全状态相比较,进而更新学习字典;其次,在线运行时,故障的特征提取、分类与预测不考虑字典的更新,仅仅考虑上一时刻的字典。
本发明的优点在于:将演化聚类学习引入安全性评估理论框架中,刻画数据驱动下字典学习与更新机制,构造安全性评估指标,实现液氢加注系统安全性评估。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明做进一步的详细描述,其中
图1为某液体火箭低温助推剂液氢加注系统;
图2为基于演化聚类学习的安全性评估理论框架;
图3为相似块聚类;
图4为信号聚类与分组
图5为支持向量机基本原理图;
图6为故障树结构示意图。
图1中,1-放气阀门;2-三级火箭氦热交换器;3-气态氦;4-三级氢箱;5-塔架的放气管路;6-加注阀门;7-过滤器;8-主加注阀门;9-气氦口;10-燃料焚烧池;11-二级氦热交换器;12-二级氢箱;13-放气阀门;14-加注管放气;15-气氦口;16-蒸发器;17-液氢贮存容器;18-滤水池。
图3中,(a)-原始信号;(b)-块聚类;(c)-组维数。
图4中,(a)-实际信号及其搜索区域;(b)-参考块及其相似块;(c)-信号组。
具体实施方式
以下将结合附图,对本发明的优选实施例进行详细的描述;应当理解,优选实施例仅为了说明本发明,而不是为了限制本发明的保护范围。
本发明,基于演化聚类学习的液氢加注系统安全性评估方法的大致流程如图2所示,具体步骤如下:
S1:选取训练样本。从液氢加注系统的历史运行感知数据中,选取尽可能多的训练数据,减少数据采集、传输、存储等过程中噪声的干扰。
S2:分块处理。根据液氢加注系统时间序列下运行工况、系统运动规律等先验知识,对训练样本进行分块处理;
S3:块的相似性度量。通过非局部操作算子、联合操作算法,以及l2范数距离测度块相似性度量。
S31:通过基于块的非局部操作算子与联合操算子来有效地表征信号,分块处理的流程如图3所示。对于给定的信号X∈RN,利用固定大小(L×1)的块分割信号,非局部操作算子定义为:
式中,vj为信号块分组的索引;为第vj组的信号块;D2-dimension为二维变换。为了有效获取信号块的稀疏表征,优化的组稀疏可以表示为:
zj=Ajxi (2)
其中,联合操作算子且满足从而确保每块都能分配到一个组中。
S32:利用l2范数距离来度量相似性。为了有效地分组信号块,如图4所示,给定搜索区域Ω和参考块T,参考块与候选块的相似性的度量定义为:
S4:求解组结构稀疏系数。利用KSVD训练获取聚类字典,并通过块坐标松弛算法求解组结构稀疏系数,具体过程描述如下:
考虑感知信息获取模型:
X=DZ+ε (4)
典型的求解目标函数为:
其中,X∈RN为离散信号;Z∈RC为获取的k-特征空间;D∈RM×N为字典;ε为噪声向量;λ为正则化参数。式(5)中,第一项为重构误差,用来测量表征信号的特征空间的有效性;第二项为特征空间的稀疏性。
在实际应用中,给定信号由块组成X={x1,…,xi,…}。其中块xi可以表征为xi=zidi,则组结构稀疏表示的目标函数可以表示为
通过KSVD字典学习与块坐标松弛算法的迭代优化逼近,获取最优的组结构稀疏字典,以及逼近原始信号的稀疏系数。
S5:确定SVM的参数,更新演化聚类块字典。其具体过程描述如下:
S51:根据过程参数与其对应系统安全状态行为标签的先验信息,对l2-SVM分类器模型进行训练,获取其最优参数,如图5所示。
S52:针对测试信息或在线感知信息,通过分类预测结果与真实结果相对比,构建演化聚类字典的更新机制。
S6:液氢加注系统安全度及其度量标准的构建。结合系统的运动规律和状态行为的运动规律,定量分析液氢加注系统的安全度及其度量标准、概率风险评估。其具体过程如下:
S61:通过故障树分析,获取可能事故下液氢加注系统的结构逻辑框图,利用最小割集上限与最小路径下限方法,来逼近系统的状态行为,并分割为独立的基本事件,如图6所示。
S62:通过故障的分类正确率与基本事件的发生概率定义液氢加注系统安全性评估的安全度。液氢加注系统运行事故(Top-event)的安全度可定义为
S7:刻画液氢加注系统的安全性等级。结合不同时间序列、不同工况下关键因素影响的不同,建立过程参数与安全事故的关联关系,合理分配关键因素的权重;通过专家知识与关键因素权重,构造液氢加注系统的安全性评估指标,给出系统的安全性等级,验证历史运行数据下系统安全性等级。
S8:在线实时安全性评估。其具体过程如下:
S81:重复上述S2至S7步骤,建立关键危险因素在不同时间序列、不同工况下“关键因素(感知数据)--安全事故”的关联关系,实现液氢加注系统安全性实时评估。
S82:特别的是,重复步骤S4与S5时,故障预测分类与字典的更新平行处理:首先,字典更新原则--通过与实际系统安全状态相比较,进而更新学习字典;其次,在线运行时,故障的特征提取、分类与预测不考虑字典的更新,仅仅考虑上一时刻的字典。
以上所述仅为本发明的优选实施例,并不用于限制本发明,显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!