粮粒和粮粒测试样本的柔性粮食品质检测方法与流程
本发明涉及人工智能及其应用、粮食品质检测技术领域,特别是涉及一种粮粒和粮粒测试样本的柔性粮食品质检测方法。
背景技术:
当前的粮食品质检测中,采用确定性的量化标准,被检粮食样品中不同的籽粒品质可能分属于不同的品质级别;即使同一个籽粒,由于属性值测量结果存在一定的随机误差,不同次结果可能归属于不同品质级别。现有方法根据既有量化指标对粮食品质进行刚性分类,无法有效处理这些不确定性,无法有效判断被检样本是否奇异。
近年来,利用嵌入式、计算机视觉、人工智能、模式识别等现代技术手段,从粮食的一些物理特性、几何特征、纹理等属性入手,进行粮食品质的自动、快速检测,得到了越来越多的关注。在人工智能领域,人们提出了许多分类方法,如决策树、贝叶斯、人工神经网络、k-近邻、支持向量机、规则学习、粗糙集、模糊逻辑,等等。为了优化分类器性能,还引入了蚁群、粒子群等优化算法。贝叶斯方法、模糊逻辑、D-S证据理论还被专门用于不确定性推理。这些分类方法在应用于具体领域时能取得优异的分类效果。不过,这些分类器的输出是刚性的。对相同输入取得唯一确定的分类结果。这是由于分类器在本质上属于精确方法。如贝叶斯推理中的概率密度函数、模糊推理的隶属度函数、D-S证据理论的信任度函数一经确定,都是具有精确输出、可重复的结果。且一些方法依赖于人的主观经验。显然这些分类方法不能处理粮食品质类的边界不确定性问题。
粮食是典型的散粒体。粮食籽粒携带了丰富的信息。即使是同一品种的粮食,其不同籽粒无论在几何外形、色泽、重量、硬度、含水量、各品质指标、各种物理、化学性能等属性,都存在随机差异。这在本质上决定了粮食品质类别从各个属性维上不能一刀切划分。包括粮食品质在内,不确定性才是真实世界的辩证反映。粮食品质检测在本质上是一个分类问题。即按一个或多个属性将被检划分为如合格、不合格、合格的X等级等类别(下文称粮食品质类,或简称品质类)。按照明确的量化标准,被检粮食样品中不同的籽粒品质可能分属于不同的类别;即使同一个籽粒,由于属性值测量结果存在一定的随机误差,不同次结果可能归属于不同类别。由此可见,粮食品质类之间并不存在清晰的界限。该如何处理粮食品质检测中的不确定性?
技术实现要素:
针对这些问题,本发明提出一种基于粮食品质属性分布特征的柔性粮食品质检测方法,提取粮食品质属性的分布规律,以定性概念的表示方法表示粮食品质的模糊性、随机性,对粮粒品质进行柔性分类,并根据粮食品质属性的分布规律判断被检样本是否奇异。在样本正常时,将被检归属于出现数量多且确定度大的粮粒所属品质类别。
本发明通过以下技术方案实现:
一种粮粒的柔性粮食品质检测方法,包括如下步骤:
步骤1,选取粮粒的m个基于图像的品质属性特征,建立m维云模型,m为大于1的整数;
步骤2,选取若干粮粒训练样本,每种粮粒训练样本包含粮粒数量≥N,采用机器视觉方法提取训练样本中N粒粮粒的m维品质属性特征值;
步骤3,对获取的训练样本属性值,运用逆向云算法,估计粮食样本品质的多维云模型数字特征,建立K个粮食品质多维云模型;
步骤4,对被测的粮粒,利用机器视觉提取品质属性特征值,针对K个品质概念分别计算确定度μ,将被测的粮粒归属于使确定度μ取得最大值的品质概念。
所述步骤1中品质属性特征包括粮粒长轴长、短轴长、长短轴比、纹理和色泽。
所述步骤3中逆向云算法使用权重估计各样本品质多维云模型参数,建立多维加权云模型。
所述步骤4中计算粮粒的确定度方法为:
记第j个粮粒的属性值为xj={xji|i=1,2,…,m},j=1,2,…,n;对K个品质云模型,分别利用公式(1)和公式(2)计算粮粒的K个确定度μ(xj)={μ(xjk)|k=1,2,…,K}:
Enki’=Norm(Enki,Heki2) (2)
Norm表示正态分布,Exki,Enki和Heki分别为第k个品质云模型第i个属性特征的期望、熵和超熵。
一种粮粒测试样本的柔性粮食品质检测方法,包括如下步骤:
步骤1,选取粮粒的m个基于图像的品质属性特征,建立m维云模型,m为大于1的整数;
步骤2,选取若干粮粒训练样本,每种粮粒训练样本包含粮粒数量≥N,采用机器视觉方法提取训练样本中N粒粮粒的m维品质属性特征值;
步骤3,对获取的训练样本属性值,运用逆向云算法,估计粮食样本品质的多维云模型数字特征,建立K个粮食品质多维云模型;
步骤4,若测试样本的粮粒数量为n,分别对测试样本的每个粮粒利用机器视觉提取品质属性特征值,针对K个品质概念分别计算确定度μ,将每个粮粒归属于使μ取得最大值的品质概念;
步骤5,按照公式(3)计算异类粮粒占比r,
r=(n-nmax)/n(3),式中nmax为归属于同一品质概念最多的粮粒数量;
步骤6,设定阈值r0,当r≤r0时,认为样本正常,将测试样本归属于nmax个粮粒所归属的品质概念;否则认为样本奇异,拒绝判定其品质。
所述步骤1中品质属性特征包括粮粒长轴长、短轴长、长短轴比、纹理和色泽。
所述步骤3中逆向云算法使用权重估计各样本品质多维云模型参数,建立多维加权云模型。
本发明与现有技术相比,具有以下明显优点:
(1)将粮食品质视为定性概念,各品质间不必存在清晰的界限
由于粮食品质通过大量粮粒综合体现,而品质属性在各个粮粒的实现具有随机差异。因此,相对于传统按照既定量化指标刚性界定粮食品质的方法,将其视为具有不确定性的定性概念更为合适。本发明将粮食品质视为定性概念,根据粮粒样本估计粮食品质概念的不确定性特征,使用云模型刻画它的模糊性、随机性,使用粮粒品质确定度指示粮粒品质可代表粮食品质的程度。粮食品质概念之间不存在清晰界限,能客观描述粮食品质的属性分布特征。
(2)粮粒品质分类器具有柔性输出
基于粮粒品质确定度设计粮粒品质归属方法。将粮粒归属于品质云空间中使其取得最大确定度值的粮食品质。由于确定度是具有稳定倾向的随机数,因此其分类结果不是确定性的。即使对同一粒粮食,不同次运用云滴归属算法,将取得不同的分类结果。粮粒依概率归属于粮食品质空间的若干个概念。因此,粮粒品质分类器的输出具有柔性。尤其适合处理边界区域的品质值。这个特点并不影响样本整体品质的判定结果。相反,如果边界区域异类数量增加,反而能够判别样本的奇异性,起到增强粮食品质判别信息的作用。
附图说明
图1为本发明的柔性粮食品质检测方法示意图。
图2为本发明的小麦品质云示例图。
图3为本发明的云滴归属概率分布结果平面示例图。
具体实施方式
图1为本发明公布的粮食品质检测中的柔性品质分类方法总体结构示意图。主要内容详述如下。
(1)将粮食品质视为定性概念。
粮食品质属性值在各个粮粒的分布具有差异性。不同粮粒可能分属于不同品质,同一粮粒的不同次检测结果也可能被划分为不同品质。粮食品质间不存在清晰界限,在本质上属于定性概念。其不确定性包括模糊性和随机性。各粮粒品质属性值之间的差异越小,则品质概念越清晰;反之则越模糊。随机性刻画了粮粒品质属性在论域内的分布。
(2)以正态云模型为定性概念的基本研究工具
云模型能够将定性概念的模糊性与随机性统一量化描述。粮食品质可视为定性概念。粮粒品质是粮食品质的随机实现,可视为云滴。因此,用云模型表示粮食品质最合适不过。云模型C(Ex,En,He)的参数来自样本估计,具有客观性。
(3)以粮粒几何特征、纹理、色泽等属性作为品质属性集
以粮粒长轴长、短轴长、长短轴比、纹理、色泽,作为粮粒品质候选属性集。
(4)选取粮粒样本,采用机器视觉方法,分别抽取属性特征值
以小麦为例。选取10种以上常见小麦品种。每个样本麦粒不低于500个,作为训练样本。利用机器视觉技术手段分别获取各样本粮粒属性值。
(5)运用逆向云算法,估计粮食样本品质的多维云模型数字特征,建立粮食品质多维正态云模型
对获取的训练样本属性值,分别运用逆向云算法,并考虑是否使用权重,估计各样本品质多维云模型参数,建立它们的多维云模型或多维加权云模型。
(6)设计基于确定度μ的粮粒品质柔性归属算法,考察粮粒归属于不同品质的概率特征
云滴确定度μ是有稳定倾向的随机数。利用这一特征可实现粮粒品质的柔性分类。
算法设计基本思想:对测试样本的粮粒,利用机器视觉提取品质属性特征值,分别计算它们在全体品质概念空间的各属性维的联合确定度μ,将它归属于使μ取得最大值的品质概念。由于μ的随机性,分类结果具有不确定性。云滴依概率归属于多个概念。
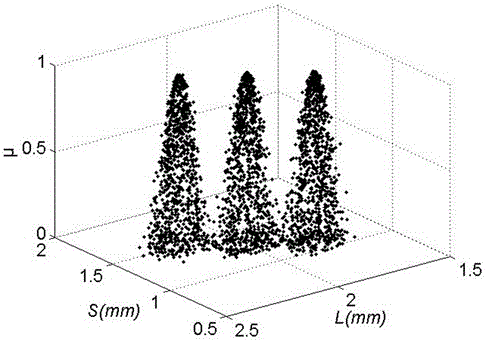
对任意测试样本的全部粮粒,重复运用算法,考察粮粒归属于各品质的概率分布特征。图3是云滴归属概率沿L-S=0.7mm平面截取的一个分布结果示例图。图3中,P为估计的归属于某个云模型的概率,L为麦粒长轴长(单位:毫米),S为麦粒短轴长(单位:毫米)。C1、C2、C3分别对应C{(1.8,0.05,0.02),(1.1,0.05,0.02)}、C{(2.0,0.05,0.02),(1.3,0.05,0.02)}、C{(2.2,0.05,0.02),(1.5,0.05,0.02)}。
(7)基于粮粒品质属性分布规律,设计测试样本的整体品质融合方法
按照上述分类方法,边界区域的粮粒可以归属于多个品质概念。根据粮粒品质分布规律,越远离品质概念的期望,品质值可代表该品质概念的确定度越低。其出现的概率也应越小。根据这一原则,设计粮粒品质分类的奇异性判别方法。对正常样本,将其品质归属于出现次数多、且确定度大的粮粒所属品质。
例如,以小麦品质检测为研究对象。
(1)小麦品质的量化表示
记基于图像的小麦品质属性特征有m个,可以用m维云模型C(X1,X2,…,Xm)表示小麦品质。即:C{(Exi,Eni,Hei)|i=1,2,…,m},其中Exi,Eni,Hei估计自训练样本,分别为第i个属性特征的期望、熵和超熵。选取不同品质的样本,可建立相应的小麦品质云模型。假定建立的小麦品质云模型为K个。则K个小麦品质云记为Ck{(Exki,Enki,Heki)|i=1,2,…,m},k=1,2,…,K。小麦品质云示例如图2所示,图2中,μ为确定度,L为麦粒长轴长(单位:毫米),S为麦粒短轴长(单位:毫米)。三个麦粒长轴长—短轴长二维云模型的参数分别为C{(1.8,0.05,0.02),(1.1,0.05,0.02)}、C{(2.0,0.05,0.02),(1.3,0.05,0.02)}、C{(2.2,0.05,0.02),(1.5,0.05,0.02)},从图2可以看出不同品质之间并不存在清晰界限。
(2)麦粒品质的柔性归属算法
对被检样本的n粒麦粒,利用机器视觉提取每粒麦粒的m维属性特征值。第j粒麦粒的属性值记为xj={xji|i=1,2,…,m},j=1,2,…,n。对K个品质云模型,分别利用下式计算xi归属于它们的确定度:
Enki’=Norm(Enki,Heki2) (2)
上式中Norm表示正态分布。可得到K个确定度μ(xj)={μ(xjk)|k=1,2,…,K}。若μI=max{μ(xjk)|k=1,2,…,K},即为K个确定度中的最大值,则将云滴xj归属于品质云I,I为K个确定度中的最大的确定度的下标k值。
从式(1)和(2)可以看出,由于Enki’符合正态分布,μ(xjk)也是随机的。因此对云滴xj,每次的计算结果可能使得它归属于不同的品质概念。但μ(xjk)有稳定倾向。由此,云滴xj将依概率归属于若干小麦品质云概念,而不再是刚性的被划分到某个品质等级。麦粒品质归属于不同品质云的概率分布示例如图(3)。
(3)被检样本奇异性判别方法
上述麦粒可归属于不同品质概念的柔性分类算法,似乎为被检样本的整体品质判定造成冲突。实际上,本方法不仅不会引起矛盾,反而能起到信息增强的作用。从图2可以看出,远离期望的品质值,它能代表该品质的确定度越小,且出现的次数也越低。根据此规律,可以判断样本是否奇异。如果分属于不同品质的麦粒数量接近,则说明该样本是奇异的。而只有归属于某一品质的麦粒数量远大于归属于异类品质的麦粒数量时,才能说明样本是正常的。据此原理,对有n个麦粒的样本,定义异类麦粒占比
r=(n-nmax)/n (3)
式中nmax为归属于同一品质概念最多的麦粒数量。设定阈值r0。当r≤r0时,认为样本正常。否则认为样本奇异。
(4)被检小麦样本品质判定
对奇异样本,拒绝判定其品质。当样本正常时,将其品质判定为nmax个麦粒所共同归属的那个品质概念。
粮食品质的各属性表现为大量粮粒相应属性的综合。反过来看,每个籽粒都是该粮食的一个随机实现,每个籽粒的属性值都是其粮食品质相应属性的一个随机实现。即使是整体属性相近的品种,其在各个籽粒上实现的属性值分布特征可能不同。由于粮食品质在各个粮粒的分布差异,它具有模糊性和随机性特征。模糊性表征了品质属性值在论域内的集中程度。粮粒属性值越集中,整体品质越清晰;反之则越模糊。随机性则表征了各个粮粒品质属性值的差异程度。因此,粮食品质在本质上属于定性概念。从粮食属性在各个籽粒的分布特征入手,按照定性概念的表示和分类方法处理粮食品质检测中的不确定性问题,能够取得更合理的结果。
粮食品质在各个粮粒实现的差异性决定了它属于定性概念。每个粮粒的品质属性值是粮食品质相应属性的一个随机实现。它的确定度μ指示了它能够代表该整体品质属性的程度。由于μ的稳定倾向和随机性,基于它涉及分类器,能够实现粮食品质类别的柔性划分。
本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!