一种电路仿真方法及装置与流程
本发明属于微处理器技术领域,尤其涉及一种电路仿真方法及装置。
背景技术:
在微处理器领域,随着电路器件规模越来越大,电路的仿真工作也面临着巨大的挑战。
这里,面临的挑战主要包括以下两方面:第一、电路器件规模越来越来大,仿真时间也越来越长且仿真结果占用大量硬盘资源;第二、随着工艺尺寸的不断减小,器件和布线的寄生参数的数量远远超过了器件本身的数量,很大程度上增加了后仿真网表的容量。现有技术中,虽然有设计者采用仿真速度更快的仿真器进行电路仿真,但仿真速度远远达不到期望值。
基于此,目前亟需一种新型的仿真方法,以解决上述问题。
技术实现要素:
针对现有技术存在的问题,本发明实施例提供了一种电路仿真方法及装置,用以解决现有技术中对大规模且重复单元多的电路进行仿真时,仿真速度慢且仿真结果占用大量硬盘资源的技术问题。
本发明提供一种电路仿真方法,所述方法包括:
接收所述电路对应的物理拓扑结构图;
根据地址译码信号线、数据读写信号线及地址转换检测(ATD,Address Transition detector)控制信号线在所述物理拓扑结构图中确定仿真路径;
对所述仿真路径对应的储存单元阵列进行处理,获取简化后的所述电路;
通过各数据传输端口DQ接收各模式的仿真激励对所述简化后的电路进行仿真。
上述方案中,根据地址译码信号线、数据读写信号线及地址转换检测ATD控制信号线在所述物理拓扑结构图中确定仿真路径具体包括:
在所述物理拓扑结构图中,确定离中心物理距离最远的一块储存单元阵列;
根据所述地址译码信号线地址译码信号线、所述数据读写信号线及所述ATD控制信号线在物理拓扑结构图中选通一条最长路径的信号路径作为所述仿真路径。
上述方案中,所述仿真路径具体为延时最长的路径。
上述方案中,对所述仿真路径对应的储存单元阵列进行处理具体包括:保留所述仿真路径对应的储存单元阵列中的M行,保留所述对应的储存单元阵列中S-M行的位线负载;其中,所述仿真路径对应的储存单元阵列中共包括S行。
上述方案中,当保留所述对应的储存单元阵列中S-M行的位线负载后,所述方法还包括:删除剩余所有的所述储存单元阵列。
上述方案中,所述物理拓扑结构图包括:第一储存单元阵列、第二储存单元阵列、第三储存单元阵列、第四储存单元阵列、第五储存单元阵列、第六储存单元阵列、第七储存单元阵列及第八储存单元阵列;其中,所述第一储存单元阵列与所述第三储存单元阵列相互对称、所述第二储存单元阵列与所述第四储存单元阵列相互对称、所述第五储存单元阵列与所述第七储存单元阵列相互对称、所述第六储存单元阵列与所述第八储存单元阵列相互对称。
上述方案中,通过各数据传输端口DQ接收各模式的仿真激励对所述电路进行仿真具体包括:
DQ<0>保持“0”不变;
DQ<1>保持“1”不变;
DQ<2>以最快频率从“0”到“1”变化;
DQ<3>以最快频率从“1”到“0”变化;
DQ<4>以最快频率的二分频从“0”到“1”变化;
DQ<5>以最快频率的二分频从“1”到“0”变化;
DQ<6>以最快频率的四分频从“0”到“1”变化;
DQ<7>以最快频率的四分频从“1”到“0”变化。
本发明同时还提供一种电路仿真装置,所述装置包括:
接收单元,用于接收所述电路对应的物理拓扑结构图;
确定单元,用于根据地址译码信号线、数据读写信号线及ATD控制信号线在所述物理拓扑结构图中确定仿真路径;
处理单元,用于对所述仿真路径对应的储存单元阵列进行处理,获取简化后的所述电路;
仿真单元,用于通过各数据传输端口DQ接收各模式的仿真激励对所述电路进行仿真。
上述方案中,所述确定单元具体用于:
在所述物理拓扑结构图中,确定离中心物理距离最远的一块储存单元阵列;
根据所述地址译码信号线地址译码信号线、所述数据读写信号线及所述ATD控制信号线在物理拓扑结构图中选通一条最长路径的信号路径作为所述仿真路径。
上述方案中,所述处理单元具体用于:
保留所述仿真路径对应的储存单元阵列中的M行,保留所述对应的储存单元阵列中S-M行的位线负载;其中,所述仿真路径对应的储存单元阵列中共包括S行。
本发明提供了一种电路仿真方法及装置,所述方法包括:接收所述电路对应的物理拓扑结构图;根据地址译码信号线、数据读写信号线及地址转换检测ATD控制信号线在所述物理拓扑结构图中确定仿真路径;对所述仿真路径对应的储存单元阵列进行处理,获取简化后的所述电路;通过各数据传输端口DQ接收各模式的仿真激励对所述简化后的电路进行仿真;如此,该仿真方法通过确定关键仿真路径,有效减少了电路器件规模或版图网表规模,仿真时只需对该仿真路径对应的信号通路进行仿真即可验证整个电路的性能,这样就提高了仿真速度,降低仿真结果占用的硬盘资源;在对所述仿真路径对应的储存单元阵列进行处理时,还保留有完整的位线负载,确保仿真的精度。
附图说明
图1为本发明实施例一提供的电路仿真方法流程示意图;
图2为本发明实施例一提供的电路对应的物理拓扑结构图;
图3为本发明实施例一提供的对所述仿真路径对应的储存单元阵列进行处理后的结构图;
图4为本发明实施例一提供的储存单元阵列的电路图;
图5为本发明实施例二提供的电路仿真装置整体结构示意图。
具体实施方式
为了对大规模且重复单元多的电路进行仿真时,提高仿真速度慢且降低仿真结果占用的硬盘资源时,本发明提供了一种电路仿真方法及装置,所述方法包括:接收所述电路对应的物理拓扑结构图;根据地址译码信号线、数据读写信号线及地址转换检测ATD控制信号线在所述物理拓扑结构图中确定仿真路径;对所述仿真路径对应的储存单元阵列进行处理,获取简化后的所述电路;通过各数据传输端口DQ接收各模式的仿真激励对所述简化后的电路进行仿真。
下面通过附图及具体实施例对本发明的技术方案做进一步的详细说明。
实施例一
本实施例提供一种电路仿真方法,所述电路具有大规模器件且重复单元多的特点,本实施例以静态随机存储器(SRAM,Static RAM)为例,对SRAM进行仿真时,如图1所示,所述仿真方法包括以下步骤:
步骤110,接收所述电路对应的物理拓扑结构图。
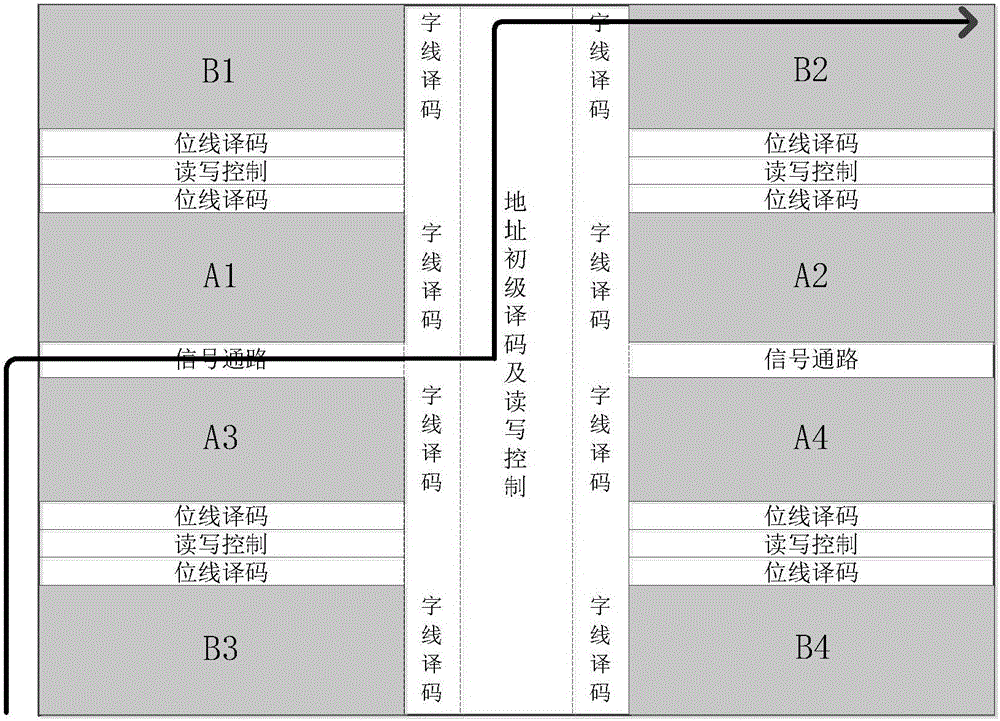
本步骤中,首先仿真软件接收所述SRAM的电路或版图网表对应的物理拓扑结构图,参见图2,所述物理拓扑结构图具体包括:第一储存单元阵列A1、第二储存单元阵列A2、第三储存单元阵列A3、第四储存单元阵列A4、第五储存单元阵列B1、第六储存单元阵列B2、第七储存单元阵列B3及第八储存单元阵列B4;其中,所述第一储存单元阵列A1与所述第三储存单元阵列A3相互对称、所述第二储存单元阵列A2与所述第四储存单元阵列A4相互对称、所述第五储存单元阵列B1与所述第七储存单元阵列B3相互对称、所述第六储存单元阵列B2与所述第八储存单元阵列B4相互对称。其中,各个储存单元阵列之间都布有地址译码信号线(包括位线译码信号线及字线译码信号线)及读写控制信号线;这里,各个储存单元阵列为一个X*Y的阵列。存储器每个周期只能是对其中一个储存单元阵列进行读写。那么就可以根据所述位线译码信号线及读写控制信号线来确定具体的储存单元阵列进行读写。具体地,根据位线译码信号线确定选通的列,根据字线译码信号线确定选通的行;当列和行都确定了,相当于坐标确定了,那么存储单元阵列的位置也就确定了。当存储单元阵列的位置确定之后,根据读写控制信号线来控制每一次的读操作和写操作,所述读写控制信号线决定了读写时的时序约束及控制。
步骤111,根据地址译码信号线、数据读写信号线及ATD控制信号线在所述物理拓扑结构图中确定仿真路径。
本步骤中,将所述物理拓扑结构图确定之后,根据地址译码信号线、数据读写信号线及ATD控制信号线在所述物理拓扑结构图中确定仿真路径。所述仿真路径为延时最长的路径。
具体地,参见图1,在确定仿真路径时,首先确定离中心物理距离最远的一块储存单元阵列,然后根据所述地址译码信号线地址译码信号线、数据读写信号线及ATD控制信号线在物理拓扑结构图中选通一条最长路径的信号路径作为仿真路径。这里,因为该仿真路径是最长路径的信号路径,这条信号通路上的信号延时最大,波形也最不理想。可以称为电路工作的最坏情况。一般来说,如果最坏情况满足时序要求,则其他情况也自然会满足。
步骤112,对所述仿真路径对应的储存单元阵列进行处理,获取简化后的电路。
本步骤中,当仿真路径确定之后,参见图2,所述仿真路径为箭头所指路径,所述仿真路径对应的储存单元阵列为第六储存单元阵列B2,由于第六储存单元阵列B2及第八储存单元阵列B4相互对称,因此将第八储存单元阵列B4删除,并将第一储存单元阵列A1、第二储存单元阵列A2、第三储存单元阵列A3、第四储存单元阵列A4、第五储存单元阵列B1、第七储存单元阵列B3全部删除。如果是版图的话,还需保留相应的电源和地线,防止压降。
由于第六储存单元阵列B2依然存在很多器件,依然会影响仿真速度。因此还需对所述仿真路径对应的储存单元阵列进行处理;具体地,为了提高仿真速度,保留所述第六储存单元阵列B2中的M行,为了确保仿真的精度,还要保留第六储存单元阵列B2中S-M行的位线负载,删除剩余所述储存单元阵列;其中,所述M的值可以根据实际情况确定,优选为2、3或4;所述第六储存单元阵列B2中共包括S行。
参见图3,本实施例中的第六储存单元阵列B2中的M取值为2。
进一步地,参见图4,所述第六储存单元阵列B2为六管存储单元电路,共包括两个PMOS管(P1、P2),四个NMOS管(N1、N2、N3、N4),所述N3、N4为位线负载。
这里,所述六管储存单元电路的工作原理为:当存储单元进行写0操作时,此时,BL为0,BLB为1,当WL为1时,N3和N4打开,这样BL和BLB的电平就传了进去并通过两个反相器(P1N1和P2N2)锁存。
当存储单元进行写1操作时,此时,BL为1,BLB为0,当WL为1时,N3和N4打开,这样BL和BLB的电平就传了进去并通过两个反相器(P1N1和P2N2)锁存。
当存储单元进行读0操作时,此时,BL为0,BLB为1,当WL为1时,N3和N4打开,这样BL和BLB的电平就传出。
当存储单元进行读1操作时,此时,BL为1,BLB为0,当WL为1时,N3和N4打开,这样BL和BLB的电平就传出。
步骤113,通过各数据传输端口DQ接收各模式的仿真激励对所述简化后的电路进行仿真。
本步骤中,当对仿真路径对应的储存单元阵列处理好之后,通过各数据传输端口DQ接收各模式的仿真激励对所述电路进行仿真。具体地,因对SRAM测试的基本模式主要有all“0”(全0图形)、all“1”(全1图形)、checkboard“0”、checkboard“1”、march“0”和march“1”六种,在对电路进行仿真时,需要将不同的仿真激励同时输入至不同的数据传输端口DQ,以能同时提供较为丰富的仿真激励。其中,所述数据传输端口DQ可以包括八个、十六个或三十二个,本实施例以八个为例,具体仿真操作如下:
在DQ<0>输入的仿真激励为:保持“0”不变,让DQ<0>保持“0”不变;
在DQ<1>输入的仿真激励为:保持“1”不变,让DQ<1>保持“1”不变;
在DQ<2>输入的仿真激励为:最快频率从“0”到“1”变化,让DQ<2>最快频率从“0”到“1”变化;
在DQ<3>输入的仿真激励为:最快频率从“1”到“0”变化,让DQ<3>最快频率从“1”到“0”变化;
在DQ<4>输入的仿真激励为:以最快频率的二分频从“0”到“1”变化,让DQ<4>以最快频率的二分频从“0”到“1”变化;
在DQ<5>输入的仿真激励为:最快频率的二分频从“1”到“0”变化,让DQ<5>以最快频率的二分频从“1”到“0”变化;
在DQ<6>输入的仿真激励为:最快频率的四分频从“0”到“1”变化,让DQ<6>以最快频率的四分频从“0”到“1”变化;
在DQ<7>输入的仿真激励为:最快频率的四分频从“1”到“0”变化,让DQ<7>以最快频率的四分频从“1”到“0”变化。
这里,“全0图形”是指从地址为“0”的存储单元地址递增直至所有储存单元全部写“0”,然后按照地址递增顺序从首位地址开始到最大存储单元全部读“0”。
“全0图形”是指从地址为“0”的存储单元地址递增直至所有储存单元全部写“1”,然后按照地址递增顺序从首位地址开始到最大存储单元全部读“1”。
“checkboard”图形具体为:
步骤一:从地址为“0”的存储单元以地址递增的形式直至所有地址的存储单元顺序写入“101010”图形;
步骤二:从地址为“0”的存储单元以地址递增的形式直至所有地址的存储单元顺序读取“101010”图形;
步骤三:从地址为“0”的存储单元以地址递增的形式直至所有地址的存储单元顺序写入“010101”图形;
步骤四:从地址为“0”的存储单元以地址递增的形式直至所有地址的存储单元顺序读取“010101”图形。
“march”图形具体为:
步骤一:从地址为“0”的存储单元以地址递增的形式直至所有地址的存储单元顺序写入“0”图形;
步骤二:在地址为“0”的存储单元读取数据“0”;
步骤三:在此位置写补码,即数据“1”;
步骤四:在此位置读取数据“1”;
步骤五;地址顺序递增;
步骤六:重复步骤二至步骤五直至所有存储单元,此时所有的存储单元内存储的数据均为“1”;
步骤七:在地址为“0”的存储单元读取数据“1”;
步骤八:在此位置写补码,即数据“0”;
步骤九:在此位置读取数据“0”;
步骤十:地址顺序递增;
步骤十一:重复步骤七至步骤十直至所有存储单元,此时所有的存储单元内存储的数据均为“0”。
这样,可以验证all“0”、all“1”及不同频率的checkboard“0”、checkboard“1”这几种模式,因此,在简化电路过程中,保留所有的DQ通路,并且让其端口的激励具有几种不同模式的变化,这样才能仿真的更真实、更全面、更能有效减小仿真时间从而提高整个电路仿真的效率。
本实施例提供的电路仿真方法,通过确定关键仿真路径,有效减少电路器件规模或版图网表规模,提高仿真速度,降低仿真结果占用的硬盘资源;在对所述仿真路径对应的储存单元阵列进行处理时,还保留有完整的位线负载,确保仿真的精度。
实施例二
相应于实施例一,本实施例提供一种电路仿真装置,如图5所示,所述装置包括:接收单元51、确定单元52、处理单元53及仿真单元54;其中,
所述接收单元51用于接收所述电路或版图网表对应的物理拓扑结构图;参见图2,所述物理拓扑结构图具体包括:第一储存单元阵列A1、第二储存单元阵列A2、第三储存单元阵列A3、第四储存单元阵列A4、第五储存单元阵列B1、第六储存单元阵列B2、第七储存单元阵列B3及第八储存单元阵列B4;其中,所述第一储存单元阵列A1与所述第三储存单元阵列A3相互对称、所述第二储存单元阵列A2与所述第四储存单元阵列A4相互对称、所述第五储存单元阵列B1与所述第七储存单元阵列B3相互对称、所述第六储存单元阵列B2与所述第八储存单元阵列B4相互对称。其中,各个储存单元阵列之间都布有地址译码信号线(包括位线译码信号线及字线译码信号线)及读写控制信号线;这里,各个储存单元阵列为一个X*Y的阵列。存储器每个周期只能是对其中一个储存单元阵列进行读写。那么就可以根据所述位线译码信号线及读写控制信号线来确定具体的储存单元阵列进行读写。具体地,根据位线译码信号线确定选通的列,根据字线译码信号线确定选通的行;当列和行都确定了,相当于坐标确定了,那么存储单元阵列的位置也就确定了。当存储单元阵列的位置确定之后,根据读写控制信号线来控制每一次的读操作和写操作,所述读写控制信号线决定了读写时的时序约束及控制。
当接收到物理拓扑结构图后,所述确定单元52用于根据地址译码信号线、数据读写信号线及ATD控制信号线在所述物理拓扑结构图中确定仿真路径;所述仿真路径为延时最长的路径。
具体地,参见图1,在确定仿真路径时,首先确定离中心物理距离最远的一块储存单元阵列,然后根据所述地址译码信号线地址译码信号线、数据读写信号线及ATD控制信号线在物理拓扑结构图中选通一条最长路径的信号路径作为仿真路径。这里,因为该仿真路径是最长路径的信号路径,这条信号通路上的信号延时最大,波形也最不理想。可以称为电路工作的最坏情况。一般来说,如果最坏情况满足时序要求,则其他情况也自然会满足。
当所述仿真路径确定之后,所述处理单元53用于对所述仿真路径对应的储存单元阵列进行处理;具体地,参见图2,所述仿真路径为箭头所指路径,所述仿真路径对应的储存单元阵列为第六储存单元阵列B2,由于第六储存单元阵列B2及第八储存单元阵列B4相互对称,因此将第八储存单元阵列B4删除,并将第一储存单元阵列A1、第二储存单元阵列A2、第三储存单元阵列A3、第四储存单元阵列A4、第五储存单元阵列B1、第七储存单元阵列B3全部删除。如果是版图的话,还需保留相应的电源和地线,防止压降。
由于第六储存单元阵列B2依然存在很多器件,依然会影响仿真速度。因此还需对所述仿真路径对应的储存单元阵列进行处理;具体地,为了提高仿真速度,保留所述第六储存单元阵列B2中的M行,为了确保仿真的精度,还要保留第六储存单元阵列B2中S-M行的位线负载,删除剩余所述储存单元阵列;其中,所述M的值可以根据实际情况确定,优选为2、3或4;所述第六储存单元阵列B2中共包括S行。
参见图3,本实施例中的第六储存单元阵列B2中的M取值为2。
进一步地,参见图4,所述第六储存单元阵列B2为六管存储单元电路,共包括两个PMOS管(P1、P2),四个NMOS管(N1、N2、N3、N4),所述N3、N4为位线负载。
这里,所述六管储存单元电路的工作原理为:当存储单元进行写0操作时,此时,BL为0,BLB为1,当WL为1时,N3和N4打开,这样BL和BLB的电平就传了进去并通过两个反相器(P1N1和P2N2)锁存。
当存储单元进行写1操作时,此时,BL为1,BLB为0,当WL为1时,N3和N4打开,这样BL和BLB的电平就传了进去并通过两个反相器(P1N1和P2N2)锁存。
当存储单元进行读0操作时,此时,BL为0,BLB为1,当WL为1时,N3和N4打开,这样BL和BLB的电平就传出。
当存储单元进行读1操作时,此时,BL为1,BLB为0,当WL为1时,N3和N4打开,这样BL和BLB的电平就传出。
当对仿真路径对应的储存单元阵列处理好之后,所述仿真单元54用于通过各数据端口DQ接收各模式的仿真激励对所述电路进行仿真。具体地,因对SRAM测试的基本模式主要有all“0”(全0图形)、all“1”(全1图形)、checkboard“0”、checkboard“1”、march“0”和march“1”六种,在对电路进行仿真时,需要将不同的仿真激励同时输入至不同的DQ端口,以能同时提供较为丰富的仿真激励。其中,所述DQ端口可以包括八个、十六个或三十二个,本实施例以八个为例,具体仿真操作如下:
在DQ<0>输入的仿真激励为:保持“0”不变,让DQ<0>保持“0”不变;
在DQ<1>输入的仿真激励为:保持“1”不变,让DQ<1>保持“1”不变;
在DQ<3>输入的仿真激励为:最快频率从“0”到“1”变化,让DQ<3>以最快频率从“0”到“1”变化;
在DQ<4>输入的仿真激励为:最快频率从“1”到“0”变化,让DQ<4>以最快频率从“1”到“0”变化;
在DQ<4>输入的仿真激励为:以最快频率的二分频从“0”到“1”变化,让DQ<4>以最快频率的二分频从“0”到“1”变化;
在DQ<5>输入的仿真激励为:最快频率的二分频从“1”到“0”变化,让DQ<5>以最快频率的二分频从“1”到“0”变化;
在DQ<6>输入的仿真激励为:最快频率的四分频从“0”到“1”变化,让DQ<6>以最快频率的四分频从“0”到“1”变化;
在DQ<7>输入的仿真激励为:最快频率的四分频从“1”到“0”变化,让DQ<7>以最快频率的四分频从“1”到“0”变化。
这里,“全0图形”是指从地址为“0”的存储单元地址递增直至所有储存单元全部写“0”,然后按照地址递增顺序从首位地址开始到最大存储单元全部读“0”。
“全0图形”是指从地址为“0”的存储单元地址递增直至所有储存单元全部写“1”,然后按照地址递增顺序从首位地址开始到最大存储单元全部读“1”。
“checkboard”图形具体为:
步骤一:从地址为“0”的存储单元以地址递增的形式直至所有地址的存储单元顺序写入“101010”图形;
步骤二:从地址为“0”的存储单元以地址递增的形式直至所有地址的存储单元顺序读取“101010”图形;
步骤三:从地址为“0”的存储单元以地址递增的形式直至所有地址的存储单元顺序写入“010101”图形;
步骤四:从地址为“0”的存储单元以地址递增的形式直至所有地址的存储单元顺序读取“010101”图形。
“march”图形具体为:
步骤一:从地址为“0”的存储单元以地址递增的形式直至所有地址的存储单元顺序写入“0”图形;
步骤二:在地址为“0”的存储单元读取数据“0”;
步骤三:在此位置写补码,即数据“1”;
步骤四:在此位置读取数据“1”;
步骤五;地址顺序递增;
步骤六:重复步骤二至步骤五直至所有存储单元,此时所有的存储单元内存储的数据均为“1”;
步骤七:在地址为“0”的存储单元读取数据“1”;
步骤八:在此位置写补码,即数据“0”;
步骤九:在此位置读取数据“0”;
步骤十:地址顺序递增;
步骤十一:重复步骤七至步骤十直至所有存储单元,此时所有的存储单元内存储的数据均为“0”。
这样,可以验证all“0”、all“1”及不同频率的checkboard“0”、checkboard“1”这几种模式,因此,在简化电路过程中,保留所有的DQ通路,并且让其端口的激励具有几种不同模式的变化,这样才能仿真的更真实、更全面、更能有效减小仿真时间从而提高整个电路仿真的效率。
实际应用中,所述接收单元51、确定单元52、处理单元53及仿真单元54可以由该装置的本装置的中央处理器(CPU,Central Processing Unit)、数字信号处理器(DSP,Digtal Signal Processor)、可编程逻辑阵列(FPGA,Field Programmable Gate Array)、微控制单元(MCU,Micro Controller Unit)实现。
本实施例提供的电路仿真装置,通过确定关键仿真路径,有效减少电路器件规模或版图网表规模,提高仿真速度,降低仿真结果占用的硬盘资源;在对所述仿真路径对应的储存单元阵列进行处理时,还保留有完整的位线负载,确保仿真的精度。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!