面向开源社区的软件项目个性化推荐方法与流程
本发明属于软件维护推荐领域,特别涉及面向开源社区的软件项目个性化推荐方法。
背景技术:
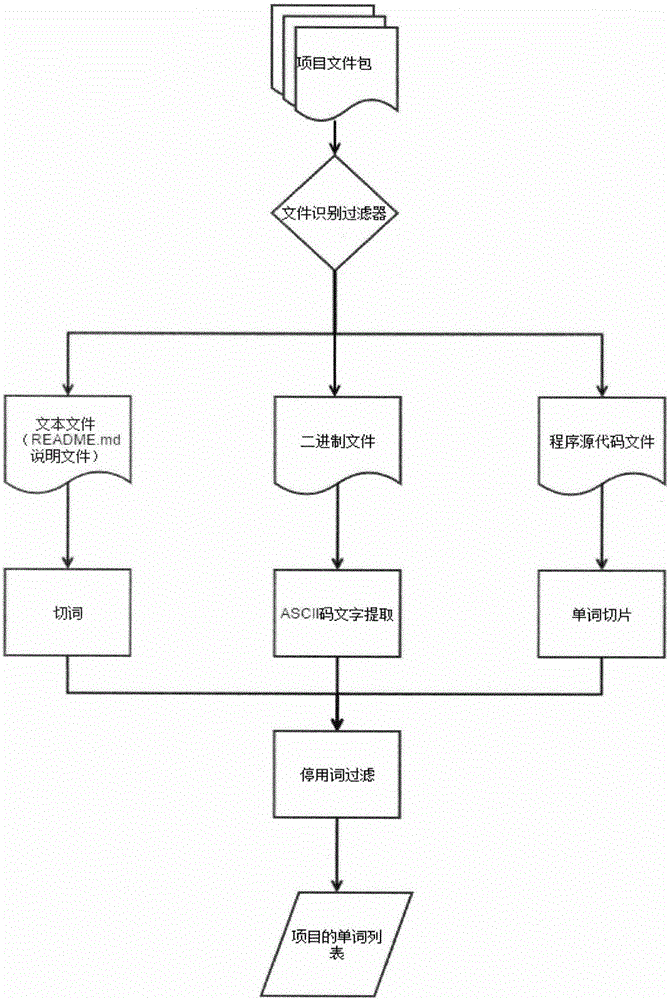
:由于软件项目众多,根据目前最大的开源软件社区--Github统计,截止到2016年,Github已经有超过1400万注册用户和3500万代码仓库。而截至2014年,Github上就有68个仓库stars数超过了10000个,有10个仓库的forks数超过了8000数,forks数大于1的仓库有944872个。可见软件的分布式开发方式已成趋势,开发者个性不同,对项目的需求不一,若没有良好的推荐机制,会出现严重的人力资源浪费等问题。根据用户个性和项目需要推荐相似项目的推荐任务急需要解决。在本发明作出之前,目前的投入使用的推荐技术并不成熟,对于一些热门项目,开源社区只将项目按用户关注度进行排名,并没有考虑到开发者的针对性。而对于一些冷门项目,只将项目按语言,开发者进行分类,之后便直接投放在互联网中。这就使一些有价值的项目没有受关注的机会,因为参与人员较少,无法继续开发,这就造成了大量有价值的项目流失。而在研究领域,大多技术只是对项目描述做语义分析,以此作为基于项目内容推荐的依据,但这一做法并不能完全体现项目特征。一些项目的描述文件只有寥寥几句,要想真正了解项目,还需要分析项目代码。也有的技术可以根据开发者所擅长的语言做个性化推荐。但这一做法粒度不细,在同一语言中,也会分很多种开发方向。同时,若开发者擅长一个开发方向,也很可能会这一开发方向的多种语言。而这种粗粒度的推荐不仅准确率不高,而且还会给开发者留下不信任的印象,进一步加重了人力资源的浪费。因此,不仅要结合项目源代码分析出项目特征,还要根据开发者的行为分析出开发者的隐藏个性,结合两者,将合适的项目推荐出来。技术实现要素:本发明的目的就在于克服上述缺陷,研制面向开源社区的软件项目个性化推荐方法。本发明的技术方案是:面向开源社区的软件项目个性化推荐方法,其主要技术特征在于如下步骤:(1).提取用户行为的特征向量,针对软件协作开发领域中用户产生的标记——star,跟踪——watch,复制——fork和用户正在开发项目的行为进行提取,并对用户的上述行为赋予权重,分别为1-标记、3-跟踪、5-复制、7-正在开发,统一标示并组成用户特征向量;(2).软件项目的内容进行分类过滤处理,由于软件项目中包含许多类型的文件,例如:源代码文件、二进制文件、项目介绍文档,需要分类过滤,针对二进制文件,通过连续的ASCII码提取出文字;针对项目介绍文档,通过分词技术提取出单词;针对源代码文件,通过分词先提炼出单词,再将一些停用词过滤,得到每个项目的所有单词;(3).以步骤2中的过滤结果为输入,进行非结构化的特征处理,即使用词频-逆文档频率TF-IDF方法提取每个项目的关键词作为项目的特征向量,TF-IDF是处理自然语言的一种常用方法,词频TF表现了一个单词在一个项目中出现的频繁程度,每个项目的长短有别,需要对词频标准化,逆文档频率IDF表现了一个单词在一个项目中的重要程度,反应了项目的特性,TF×IDF得出各个单词对每个项目的重要性;(4).根据已有数据进行ALS协同过滤的推荐,以步骤1中用户对项目的评分矩阵作为ALS协同过滤的输入,根据用户对已经评价过的几个项目预测用户对每个项目的需求程度,即通过矩阵分解的方法,将用户-项目评分矩阵X转化为用户-隐因子A与隐因子-项目矩阵B,通过交替最小二乘法ALS完成两个矩阵的填充,同时尽量满足用户-项目评分矩阵X,再由A×B得到用户-项目评分的预测矩阵X′;(5).根据已有数据进行基于项目内容的推荐,即以步骤1所提供的用户数据和步骤3所提供的项目特征作为内容推荐模型的输入,根据用户目前对每一特征的需求程度来判断新项目的需求程度,并将项目中的关键词权重作为项目的特征,在通过项目特征向量通过余弦相似度计算出项目间的相似度,公式为pi表示项目P1的单词表所组成的向量;给用户推荐和他历史上需求的项目内容相似的项目,计算公式为quj=∑i∈N(u)∩S(j,k)wjirui,N(u)是用户需求项目的集合,Sj,k是和项目j最相似的K个项目的集合,rui是用户u对项目i的评价,同步骤1;(6).将步骤4和步骤5的结果做线性组合操作,并结合项目内容推荐的准确性和ALS推荐所体现的个性化的要求,采用公式lui=0.618×pui+0.382×qui,得出最终的用户评分;(7).对步骤6的结果进行过滤和排名,即根据每个项目的得分进行排名,同时滤去用户已知项目,产生Top10推荐;(8).对步骤7的Top10项目进行解释,即根据步骤3中这些项目自身的TF-IDF信息中的前几位结果给项目打上标签,作为最终推荐结果;例如向用户U1推荐项目P1,而单词w1,w3,w6在P1中最具代表性,则将单词w1,w3,w6作为P1的标签。一种面向开源社区的软件项目个性化推荐技术,主要用于对项目内容进行TF-IDF特征抽取,结合用户对已知项目的评价,能够给用户推荐出与用户最感兴趣的项目内容相似、准确的,并符合用户个性,能力,可参与开发的项目。技术方案:本发明的方法是在推荐相关项目时,一方面针对用户个性,通过ALS协同过滤计算候选推荐结果。另一方面,使用词频-逆文本频率计算每个项目特征,按项目特征的相似性计算候选推荐结果。接着将两者推荐结果线性组合,进行过滤和排名,产生推荐结果。最后按词频-逆文本频率作为标签为推荐结果做出合理解释。词频-逆文本频率(TermFrequency-InverseDocumentFrequency,简称TF-IDF)是一种用于资讯检索与文本挖掘的常用加权技术。该模型可以对项目中出现的所有单词做出重要性评价。更全面的反应一个项目的特征。我们将单词组成向量,通过余弦相似性可以计算出项目之间的相似度。ALS(AlternatingLeastSquares)协同过滤是一种通过矩阵来预测一个用户对一个项目的评分的推荐技术。该模型可以将用户-项目矩阵通过机器学习,分解为用户-隐属性、隐属性-项目两个矩阵。我们根据ALS可以预测出用户对其还不了解的项目评分。再结合之前的项目相似的结果,将两结果线性结合,即可做出用户个性和项目需要的推荐。本发明的优点和效果在于从用户对已知项目评分和项目内容角度推荐出针对用户个性和项目内容的相似项目。此方法不仅更准确地推荐出了与用户所在开发的项目类似的项目内容,而且利用用户对已知项目的评分矩阵实现了个性化推荐功能,为用户接下来的参考或重用提供便利,更有效提高了开发人员搜索项目的效率。主要由如下一些优点:(1)覆盖率和准确率。目前的软件推荐方式只能根据项目介绍文档提取关键词,存在着不全面和不准确两个问题。此方法通过TF-IDF模型能够根据项目各类文件提取项目特征并进行项目相似度的计算。为用户提供准确丰富的推荐信息。(2)易用性。整套算法静默式的完成,只对用户的行为进行特征提取。随后就可以利用ALS算法预测用户对每一项目的评价。降低了软件开发的门槛,使没有多少项目开发经验的开发人员也能搜索到对自己有帮助的项目。(3)高效和可拓展性。整套算法除了步骤7,步骤8,其他步骤都可以并行实现,针对拥有大量用户和项目实例的场合,此算法仍然有可靠推荐效果。(4)可解释性。通过对每个项目的TF-IDF关键词提取,可以对推荐结果以标签形式进行解释。也方便用户快速判断和选择自己所需要进一步了解的项目。(5)个性化。ALS协同过滤模型分析了用户行为矩阵,一定程度上反应了用户的个性化行为,而推荐的结果自然就考虑到用户个性化因素。附图说明图1——本发明的流程示意图。图2——本发明的文件过滤流程图图3——本发明的TF-IDF特征提取原理图图4——本发明的ALS协同过滤原理图图5——本发明的基于项目内容原理图具体实施方式本发明的技术思路是:对项目内容进行TF-IDF特征抽取,结合用户对已知项目的评价,给用户推荐结合用户个性和项目需求的相似项目。在推荐相关项目时,一方面针对用户个性,通过ALS协同过滤计算候选推荐结果。另一方面,使用词频-逆文本频率计算每个项目特征,按项目特征的相似性计算候选推荐结果。接着将两者推荐结果线性组合,进行过滤和排名,产生推荐结果。最后按词频-逆文本频率作为标签为推荐结果做出合理解释。如图1所示。词频-逆文本频率(TermFrequency-InverseDocumentFrequency,简称TF-IDF)是一种用于资讯检索与文本挖掘的常用加权技术。该模型可以对项目中出现的所有单词做出重要性评价。更全面的反应一个项目的特征。我们将单词组成向量,通过余弦相似性可以计算出项目之间的相似度。ALS(AlternatingLeastSquares)协同过滤是一种通过矩阵来预测一个用户对一个项目的评分的推荐技术。该模型可以将用户-项目矩阵通过机器学习,分解为用户-隐属性、隐属性-项目两个矩阵。我们根据ALS可以预测出用户对其还不了解的项目评分。再结合之前的项目相似的结果,将两结果线性结合,即可做出用户个性和项目需要的推荐。本发明具体说明如下。步骤(1).提取用户行为的特征向量。针对软件协作开发领域中用户产生的标记——star,跟踪——watch,复制——fork和用户正在开发项目的行为进行提取,并对用户的上述行为赋予权重,分别为1——标记、3——跟踪、5——复制、7——正在开发。统一标示并组成用户特征向量。统一标示并组成用户特征向量。如下表所示。rij表示用户i对项目j的评价。UseridProjectnameBehaviorBehaviorweightU1P1Watchr11U2P2Starr12……………………UnP2Forkrn2步骤(2).软件项目的内容进行分类过滤处理。如图2所示。由于软件项目中包含许多类型的文件,例如:源代码文件、二进制文件、项目介绍文档等。所以需要分类过滤,针对二进制文件,通过连续的ASCII码提取出文字;针对项目介绍文档,通过切词技术提取数单词;针对源代码文件,通过单词切片技术先提炼出单词,再将一些停用词过滤。得到每个项目的所有单词。过滤流程过滤后结果如下表。ProjectnameWordsP1P1Word1,P1Word2,…,P1Wordm…………PnPkWord1,PkWord2,….,PkWordm步骤(3).以步骤(2)中的过滤结果为输入,进行非结构化的特征处理,处理流程如图3所示。即使用TF-IDF(TermFrequency-InverseDocumentFrequency)方法提取每个项目的关键词作为项目的特征向量。TF-IDF是处理自然语言的一种常用方法。词频(TF)表现了一个单词在一个项目中出现的频繁程度。考虑到每个项目的长短有别,需要对词频标准化。逆文档频率(IDF)表现了一个单词在一个项目中的重要程度,反应了项目的特性。TF×IDF得出各个单词对每个项目的重要性。如下表所示。dij表示项目i上单词j的重要性。通过步骤2、步骤3的转化,项目内容的特征可以用单词的TF-IDF向量准确概括。最大程度的保证了项目特征信息的不丢失。保证了步骤5的基于项目内容推荐的准确性。也为推荐内容的解释做准备。Word1Word2……WordmP1d11d12……d1m…………………………Pndn1dn2……dnm步骤(4).根据已有数据进行ALS协同过滤的推荐。以步骤(1)中用户对项目的评分矩阵作为ALS协同过滤的输入,根据用户对已经评价过的几个项目预测用户对每个项目的需求程度。ALS协同过滤原理如图4所示。即通过矩阵分解的方法,将用户-项目评分矩阵X转化为用户-隐因子A与隐因子-项目矩阵B。通过交替最小二乘法(ALS)完成两个矩阵的填充,同时尽量满足用户-项目评分矩阵(X)。再由A×B得到用户-项目评分的预测矩阵X′。如下表所示。puj表示个用户u对项目j的评价。ALS推荐算法中主要体现了用户隐藏的个性化需求。P1P2……PmU1p11p12……p1mU2p21p22……p2m…………………………Unpn1pn2……pnm步骤(5).根据已有数据进行基于项目内容的推荐。如图5所示,以步骤(1)所提供的用户数据和步骤(3)所提供的项目特征作为项目内容的输入,根据用户目前对每一特征的需求程度来判断新项目的需求程度。将项目中的关键词权重作为项目的特征,在通过项目特征向量通过余弦相似度计算出项目间的相似度,公式为pi表示项目P1的单词表所组成的向量。此步骤完全考虑了项目内容的相似性,保证了用户推荐到的项目是用户所需要的。P1P2……PnP11w12……w1nP2w211……w2n…………………………Pnwn1wn2……1给用户推荐和他历史上需求的项目内容相似的项目,计算公式为quj=∑i∈N(u)∩S(j,k)wjirui,N(u)是用户需求项目的集合,Sj,k是和项目j最相似的K个项目的集合,rui是用户u对项目i的评价,同步骤1)。P1P2……PmU1q11q12……q1mU2q21q22……q2m…………………………Unqn1qn2……qnm步骤(6).将步骤(4)和步骤(5)的结果做线性组合操作。结合基于项目内容推荐的准确性和ALS推荐所体现的个性化要求,采用公式lui=0.618×pui+0.382×qui,得出最终的用户评分。P1P2……PmU1l11l12……l1mU2l21l22……l2m…………………………Unln1ln2……lnm步骤(7).对步骤(6)的结果进行过滤和排名。即根据每个项目的得分进行排名,同时滤去用户已知项目,产生Top10推荐。UserTop10U1P1,P5,…,P7U2P3,P8,…,P23…………U3P4,P3,…P2步骤(8).对步骤(7)的Top10项目进行推荐结果的解释。即根据步骤(3)中这些项目自身的TF-IDF信息中的前几位结果给项目打上标签。作为最终推荐结果。用户例如向用户U1推荐项目P1,而单词w1,w3,w6在P1中最具代表性,则将单词w1,w3,w6作为P1的标签。UserTop10U1P1(w1,w3,w6),P5(…),…,P7(…)U2P3(…),P8(…),…,P23(…)…………U3P4(…),P3(…),…P2(…)当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1